7.1 Distribuciones
Una forma sencilla de conocer la distribución de nuestros datos es obtener su gráfica de densidad, que es una representación suavizada de un histograma. Para conocer la distribución del total de población por municipio:
ggplot(data = poblacion, aes(x=pobtot)) +
geom_density()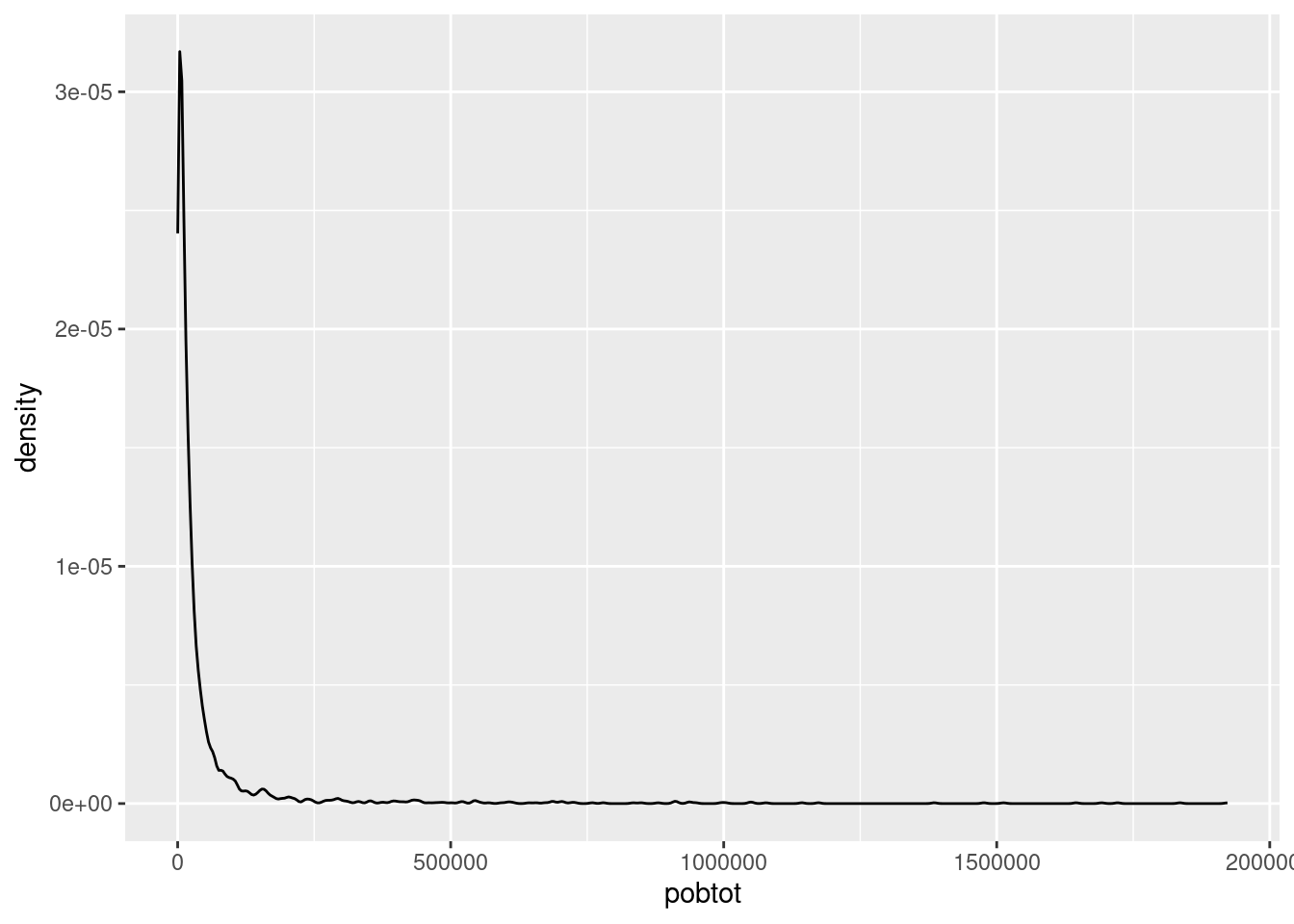
La distribución está altamente sesgada, es decir, hay muchos municipios con pocos habitantes y algunos municipios donde dicha cantidad es muy grande.
Podemos revisar la distribución de población por estado utilizando boxplots. Cambiaremos las
leyendas de los ejes y, para lograr que las etiquetas del eje x puedan leerse, las rotaremos
y las ajustaremos.
ggplot(poblacion, aes(x=nom_ent, y=pobtot)) +
geom_boxplot() +
ylab("Población") +
xlab("") +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust=1))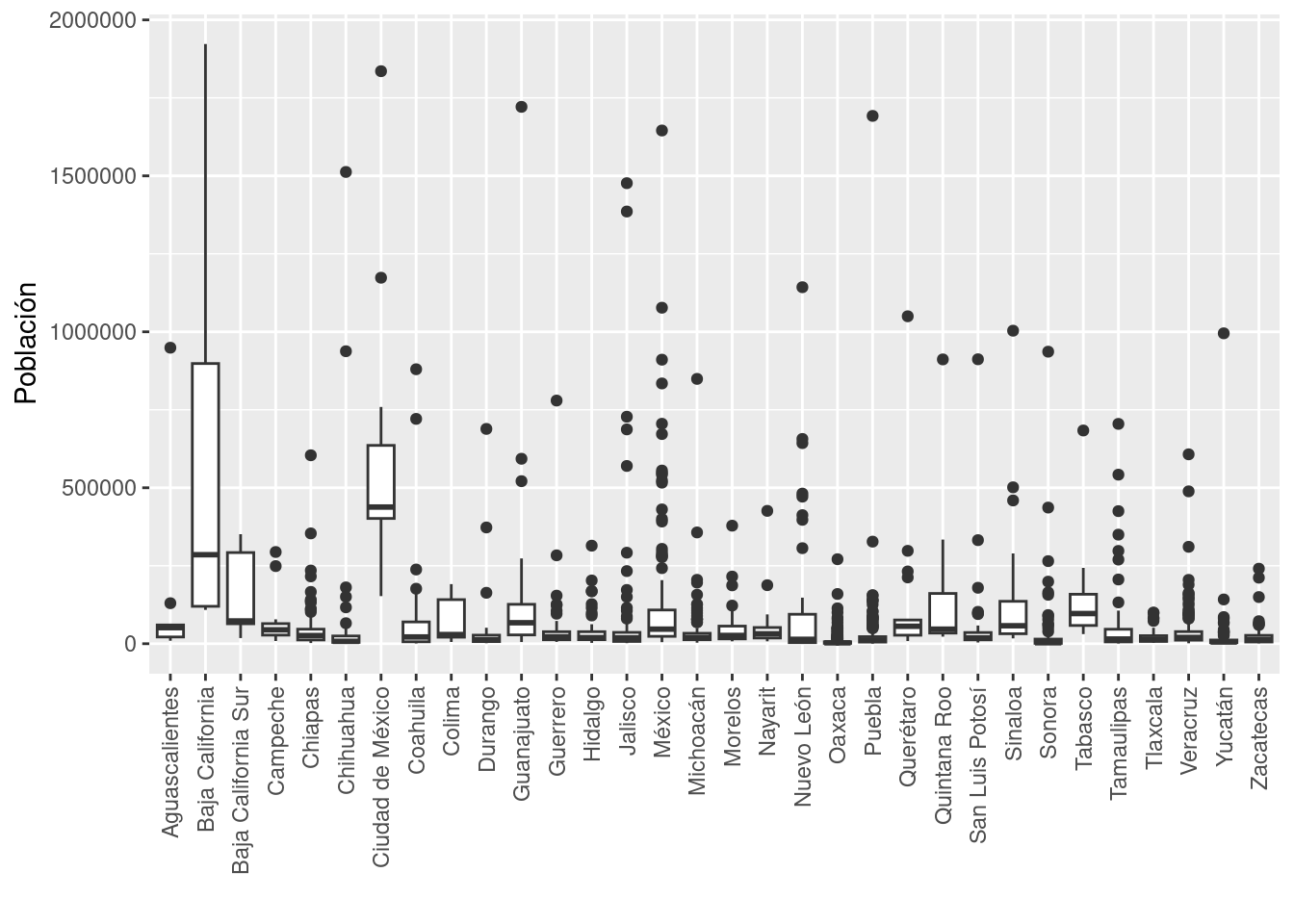 También podemos utilizar un histograma para observar, por ejemplo, la distribución de la población infantil
en los municipios del estado de Veracruz. Ajustamos número de bins para mejorar la resolución de visualización
de los datos. Nuevamente cambiaremos los nombres de los ejes. Además, modificaremos el tema por default
utilizado por ggplot, el tamaño de la fuente y añadiremos una línea vertical para
identificar la media de la distribución. La escala del eje
También podemos utilizar un histograma para observar, por ejemplo, la distribución de la población infantil
en los municipios del estado de Veracruz. Ajustamos número de bins para mejorar la resolución de visualización
de los datos. Nuevamente cambiaremos los nombres de los ejes. Además, modificaremos el tema por default
utilizado por ggplot, el tamaño de la fuente y añadiremos una línea vertical para
identificar la media de la distribución. La escala del eje x ha sido modificada con la función comma del paquete
scales.
poblacion %>%
dplyr::filter(nom_ent == "Veracruz") %>%
ggplot(aes(x=pob0_14)) +
geom_histogram(bins=50, fill="white", color="black") +
geom_vline(aes(xintercept=mean(pob0_14)),
color="blue", linetype="dashed", size=1) +
xlab("Población") +
ylab("Frecuencia") +
scale_x_continuous(label=comma) +
ggtitle("Distribución de la población infantil en Veracruz") +
theme_classic(base_size = 15) ## Warning: Using `size` aesthetic for lines was deprecated in ggplot2
## 3.4.0.
## ℹ Please use `linewidth` instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this
## warning was generated.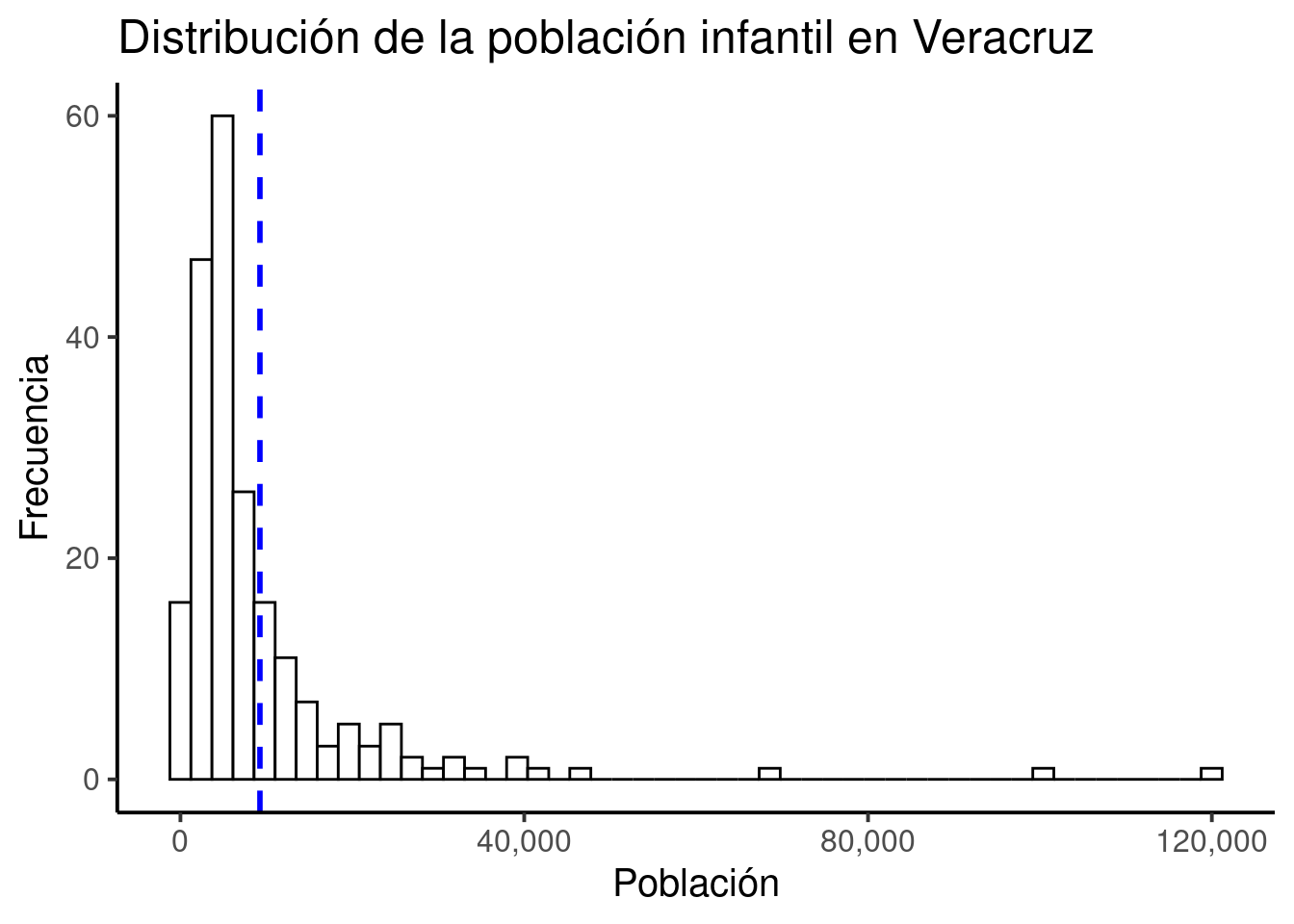 Podemos comparar dos distribuciones. Por ejemplo, los estudiantes de las instituciones de educación superior.
Primero agrupamos por estado para tener menos puntos y obtenemos la media y la desviación estándar
Podemos comparar dos distribuciones. Por ejemplo, los estudiantes de las instituciones de educación superior.
Primero agrupamos por estado para tener menos puntos y obtenemos la media y la desviación estándar
estud_by_mun_sexo <- vroom("data/estud_by_mun_sexo.tsv")
estud_by_est_sexo <- estud_by_mun_sexo %>%
filter(academic_degree %in% c("Maestría", "Doctorado")) %>%
group_by(sex, state) %>%
summarise(total = sum(estudiantes))Podemos comparar las distribuciones con boxplots
ggplot(estud_by_est_sexo, aes(x = sex, y = total)) +
geom_boxplot(width = 0.5, alpha = 0.8, color = "grey") +
geom_jitter(width = 0.1, size = 1, color = "deeppink3") +
xlab("") +
ylab("Estudiantes en Posgrado") +
theme_bw(base_size = 18) +
stat_compare_means(method = "wilcox.test")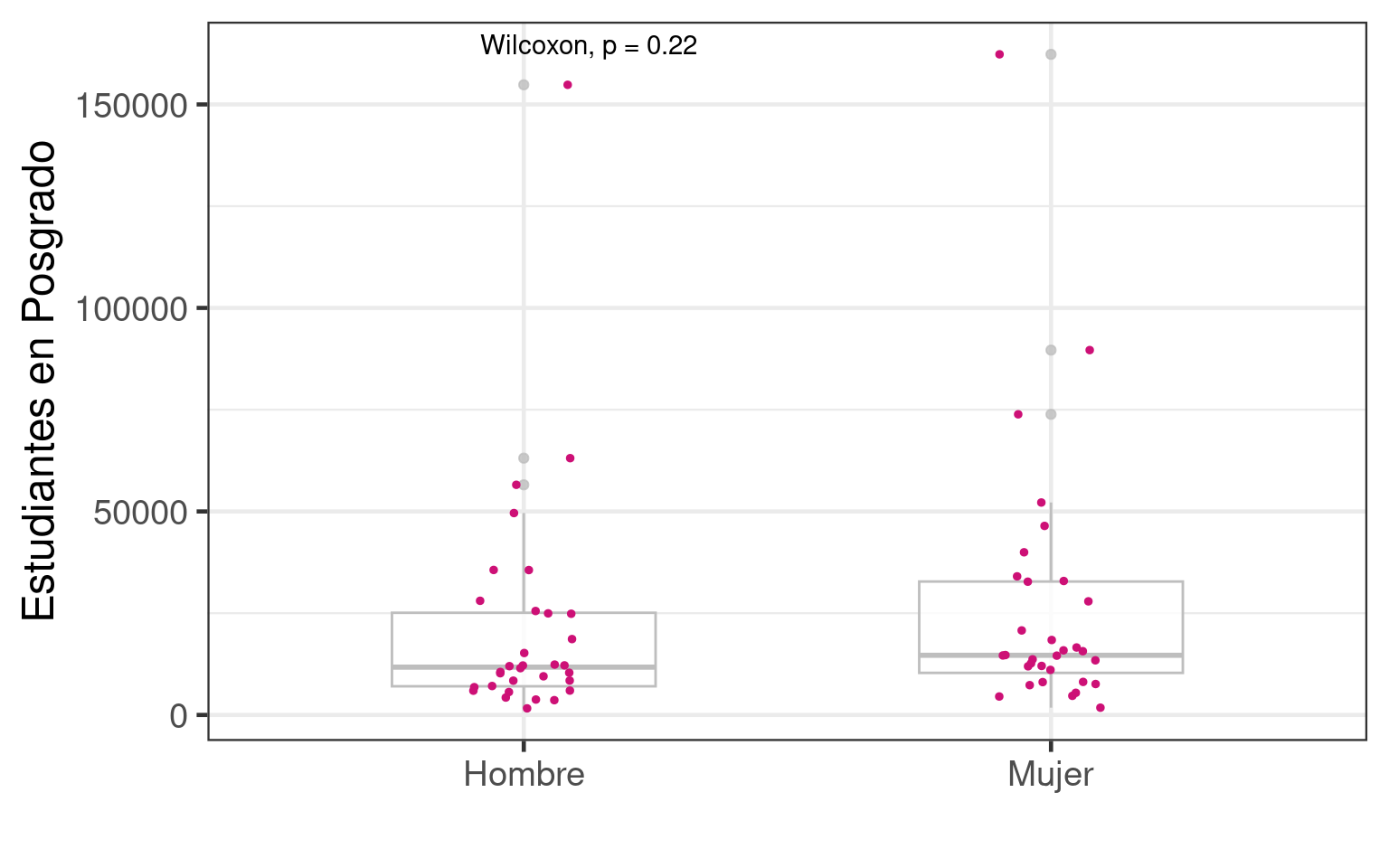
O con violin plots
ggplot(estud_by_est_sexo, aes(x = sex, y = total)) +
geom_violin(width = 0.5, alpha = 0.8, color = "grey") +
geom_jitter(width = 0.1, size = 1, color = "deeppink3") +
xlab("") +
ylab("Estudiantes en Posgrado") +
theme_bw(base_size = 18) +
stat_compare_means(method = "wilcox.test")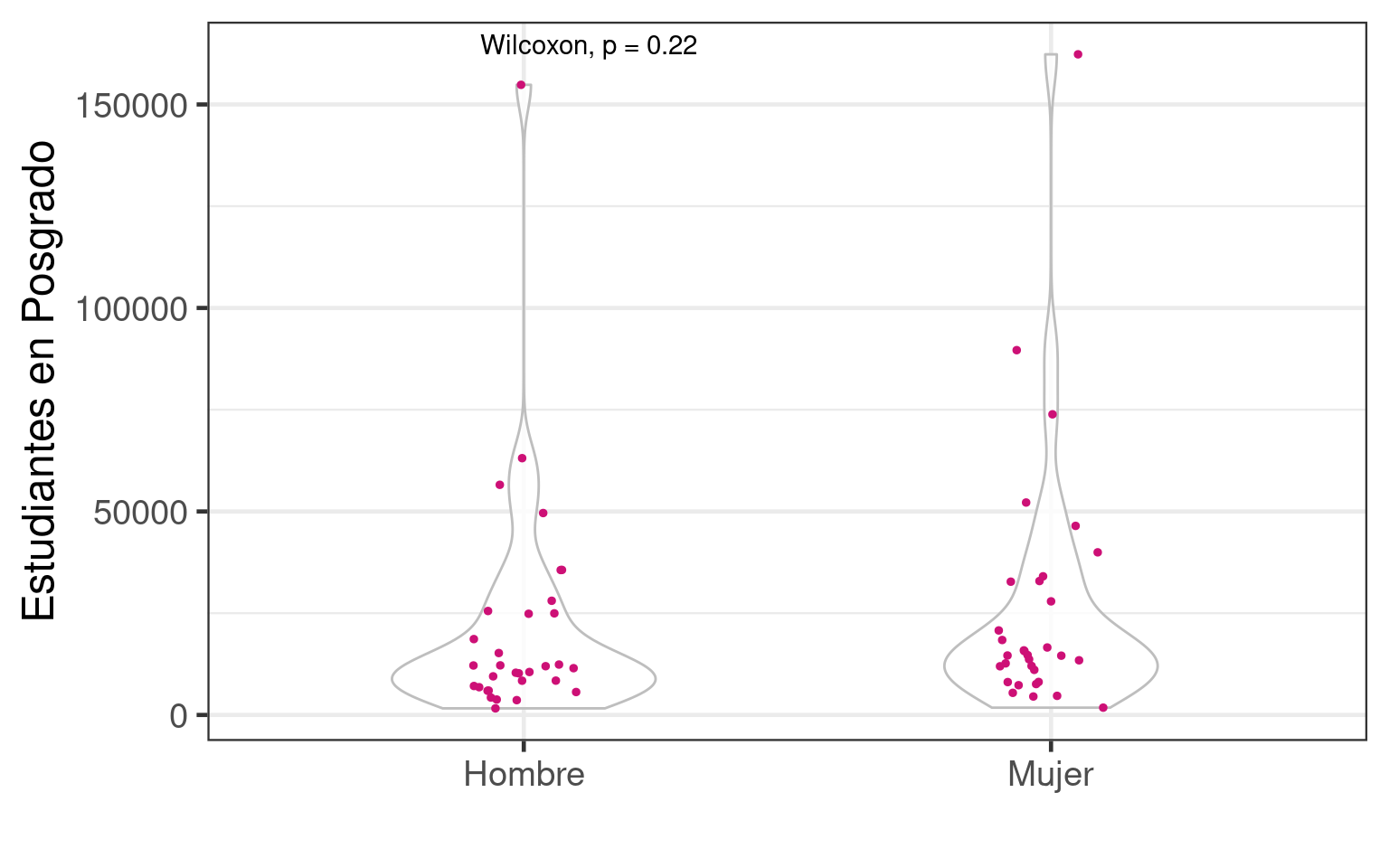
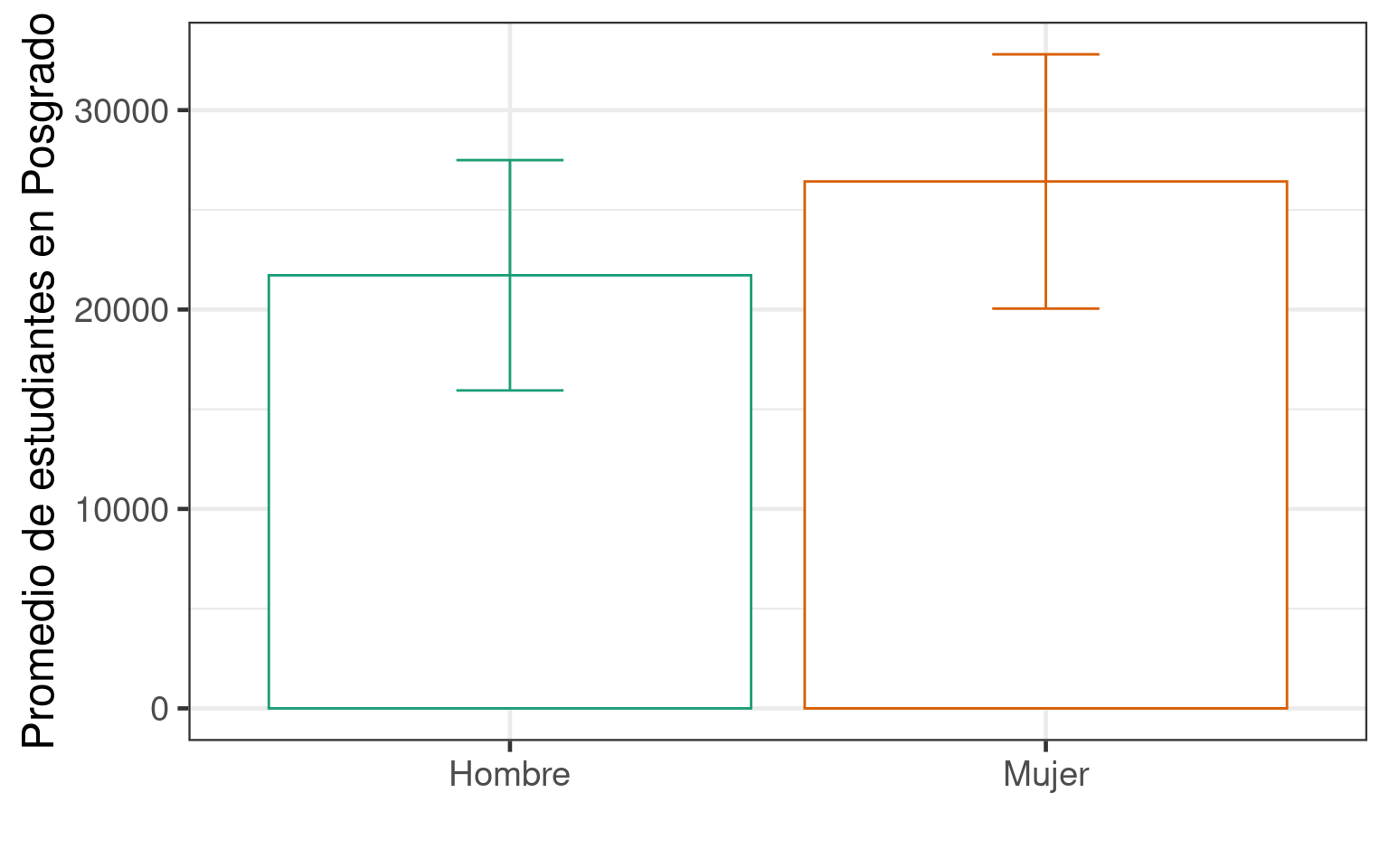
O también graficar las medias y la desviación estándar
est_sexo_sum <- estud_by_est_sexo %>%
group_by(sex) %>%
summarise(mean = mean(total),
sd = sd(total)/5)
ggplot(est_sexo_sum, aes(x = sex, y = mean, color = sex)) +
geom_bar(stat="identity", fill='white') +
geom_errorbar(aes(ymin= mean-sd, ymax=mean+sd), width=.2) +
ylab("Promedio de estudiantes en Posgrado") +
xlab("") +
scale_color_brewer(palette = "Dark2") +
theme_bw(base_size = 18) +
theme(legend.position="none")