Para la visualización de datos univariados en R usaremos el dataset de Iris que esta incorporado en R.
4.2Gráficos univariados
Son aquellos gráficos que se utilizan para mostrar la distribución de una única variable.
Para iniciar cargaremos los paquetes que se usaran lo cuales son ggplot2 y dplyr
library(ggplot2)
Warning: package 'ggplot2' was built under R version 4.3.2
library(dplyr)
Warning: package 'dplyr' was built under R version 4.3.2
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
4.2.1Variables categóricas
Usualmente, este tipo de variables se visualiza con gráficos de barras o de sectores. Si bien su uso es menos frecuente, también pueden utilizarse gráficos de rectángulos o treemap.
4.2.2 Gráfico de barras
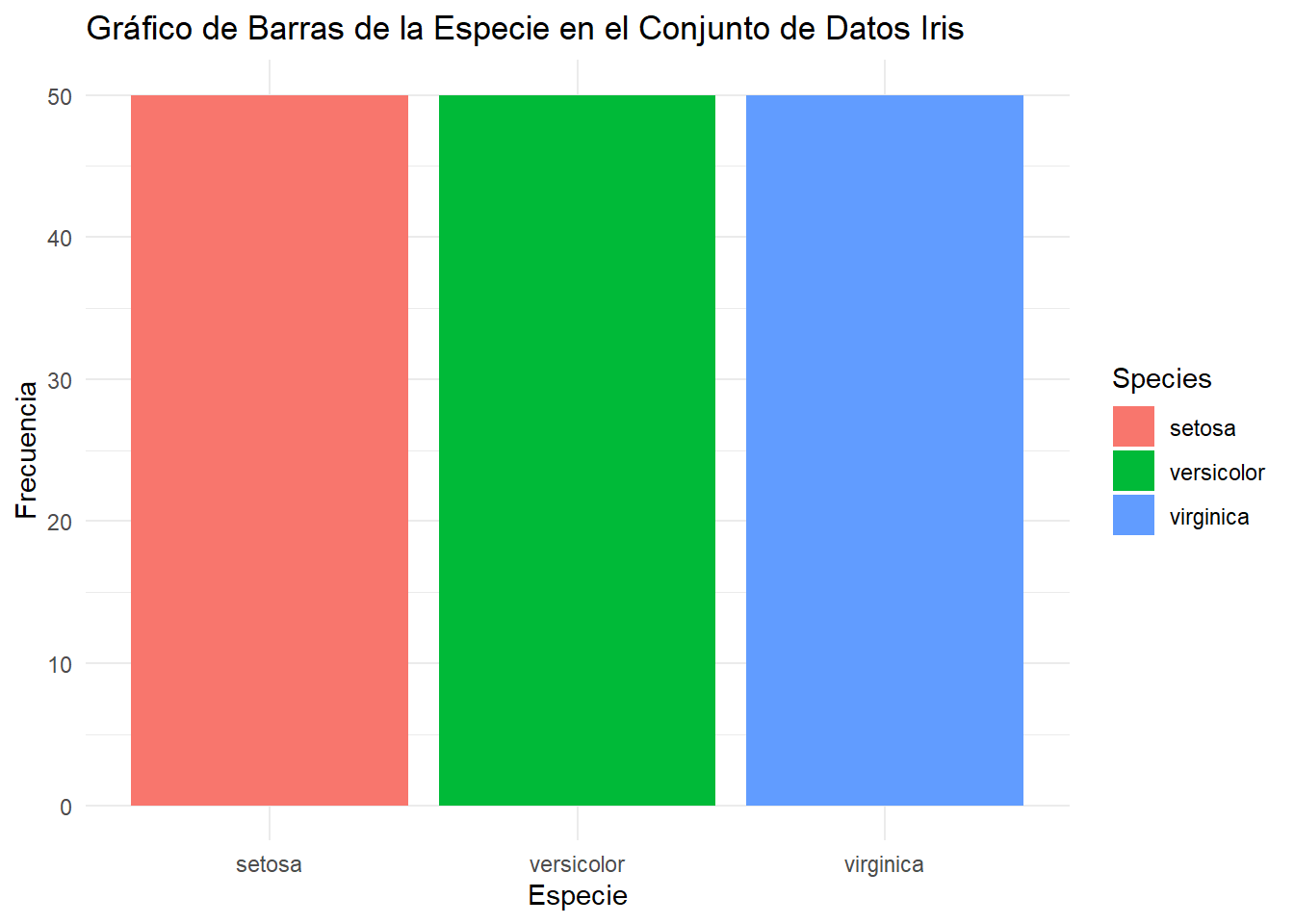
ggplot(iris, aes(x = Species, fill = Species)) +geom_bar() +labs(title ="Gráfico de Barras de la Especie en el Conjunto de Datos Iris", x ="Especie", y ="Frecuencia") +theme_minimal()
En el eje x podemos ver las distintas categorías de la variable “Especie” y en el eje y un conteo de cuántas veces aparece cada categoría en el conjunto de datos, es decir.
Ahora también se puede graficar la proporción o porcentaje en lugar de la frecuencia como el caso anterior.
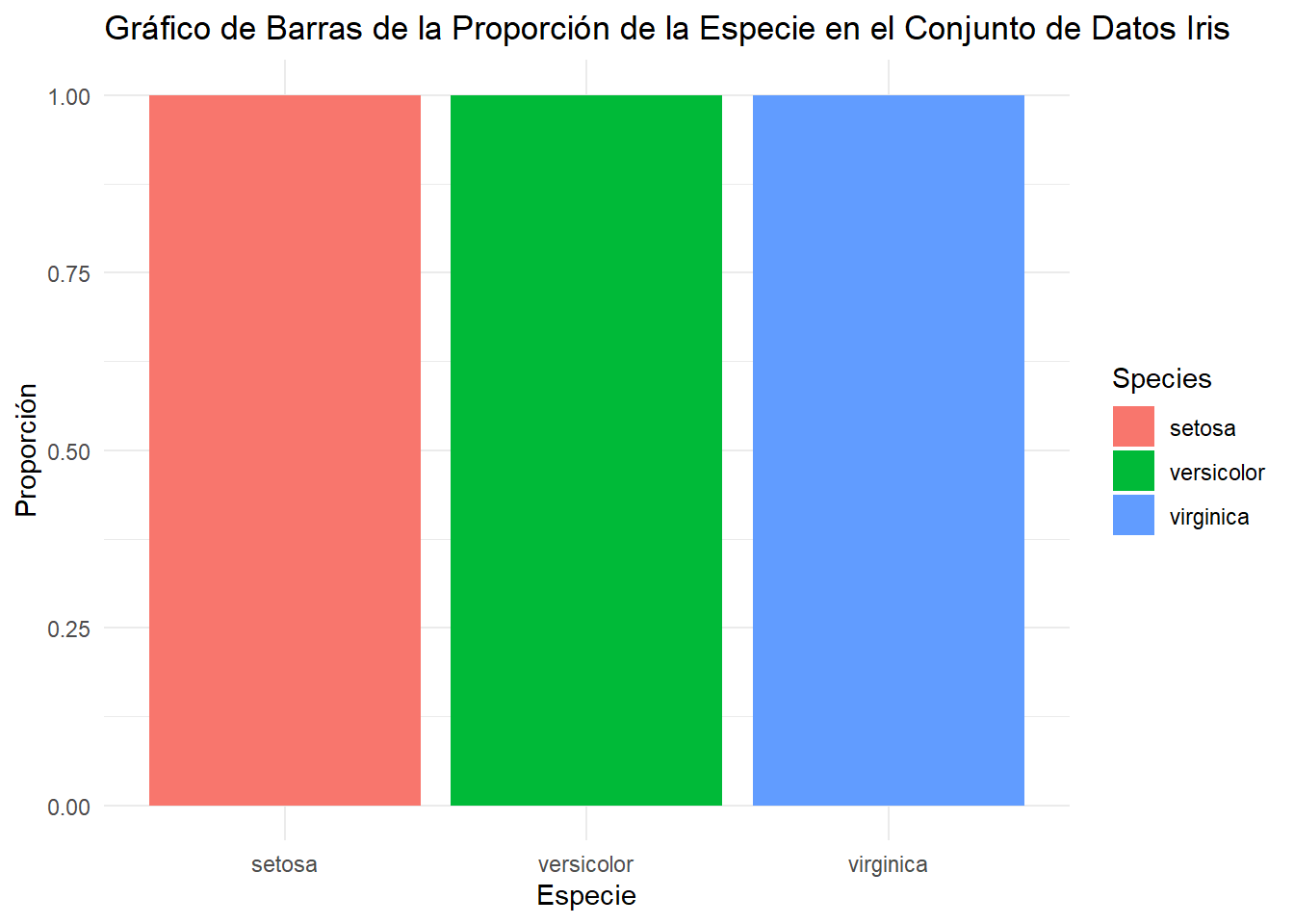
ggplot(iris, aes(x = Species, fill = Species)) +geom_bar(position ="fill") +labs(title ="Gráfico de Barras de la Proporción de la Especie en el Conjunto de Datos Iris", x ="Especie", y ="Proporción") +theme_minimal()
En muchas ocasiones, los porcentajes son más fáciles de interpretar, pero el resultado es el mismo.
4.2.3 Gráfico de sectores
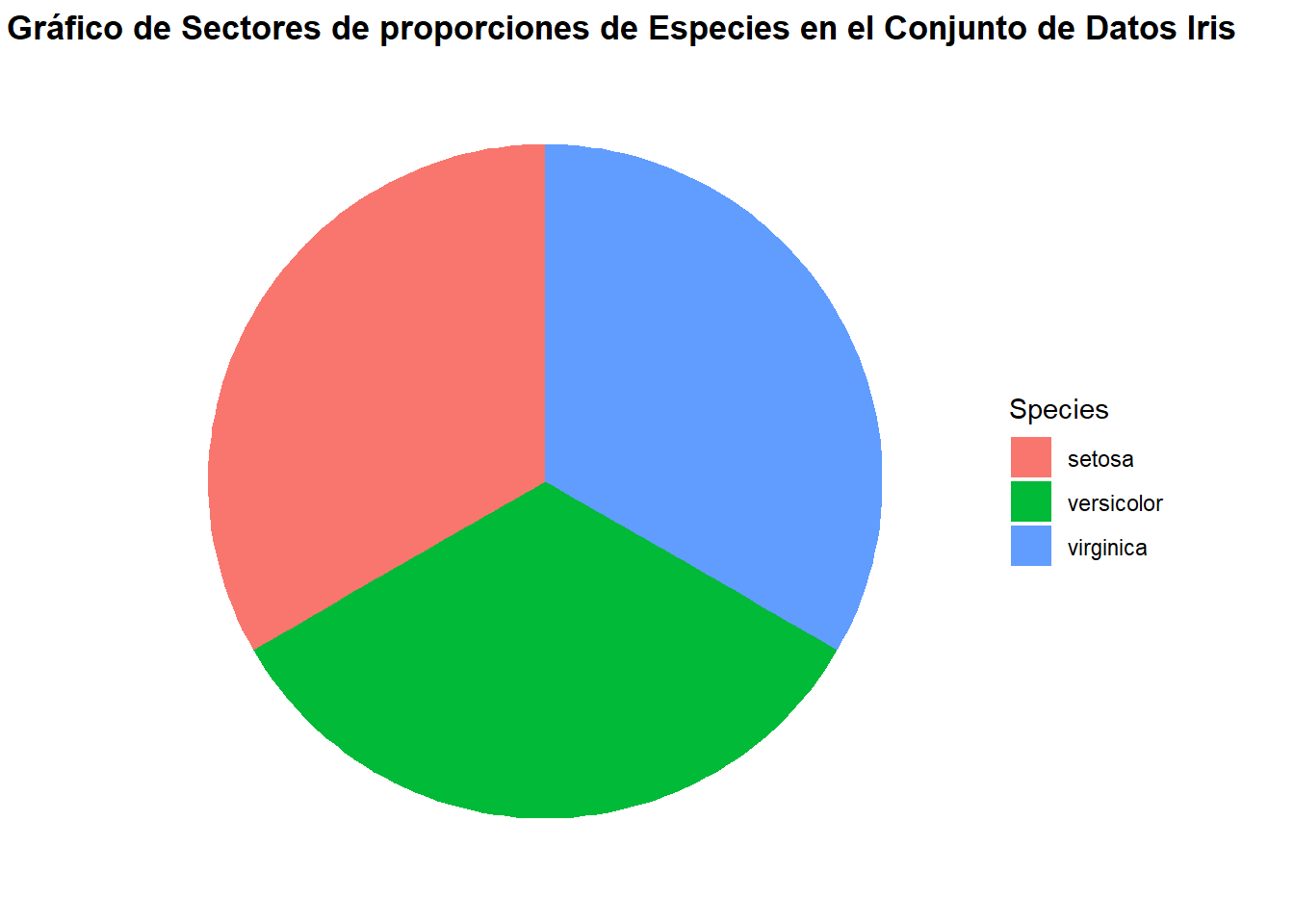
ggplot(iris, aes(x ="", fill = Species)) +geom_bar(width =1) +coord_polar("y") +labs(title ="Gráfico de Sectores de proporciones de Especies en el Conjunto de Datos Iris") +theme_minimal() +theme(axis.text =element_blank(), # Ocultar etiquetas del eje xaxis.title =element_blank(), # Ocultar título del eje ypanel.grid =element_blank(), # Ocultar líneas de la cuadrículaplot.title =element_text(size =13, face ="bold", hjust =0.3) # Ajustes del título )
En el gráfico de sectores, el círculo completo representa el total de las observaciones y cada segmento, la proporción o porcentaje de observaciones que pertenecen a una categoría particular.
Este gráfico muestra que las especies estan proporcionadas de igual forma, entonces podemos decir que hay una igualdad en cuestión de proporción en las especies (setosa, versicolor, virginica).
4.2.4 Variables cuantitativas
Para observar la distribución de los datos en variables cuantitativas, se utilizan principalmente los histogramas y los gráficos de densidad.
4.2.5 Histograma
El histograma es equivalente al gráfico de barras en el caso de variables categóricas, pero como la variable numérica no puede agruparse en categorías se necesita una transformación.
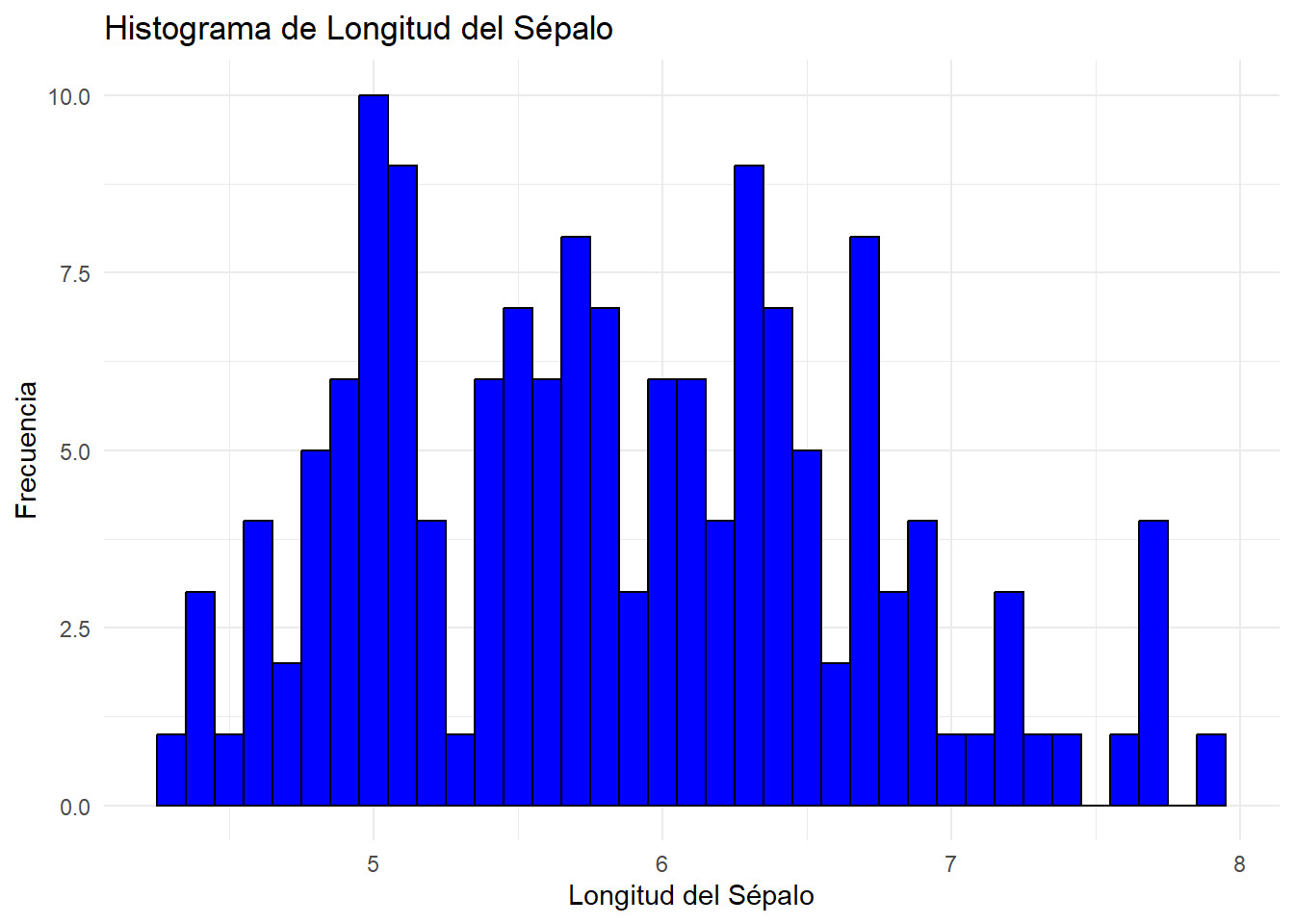
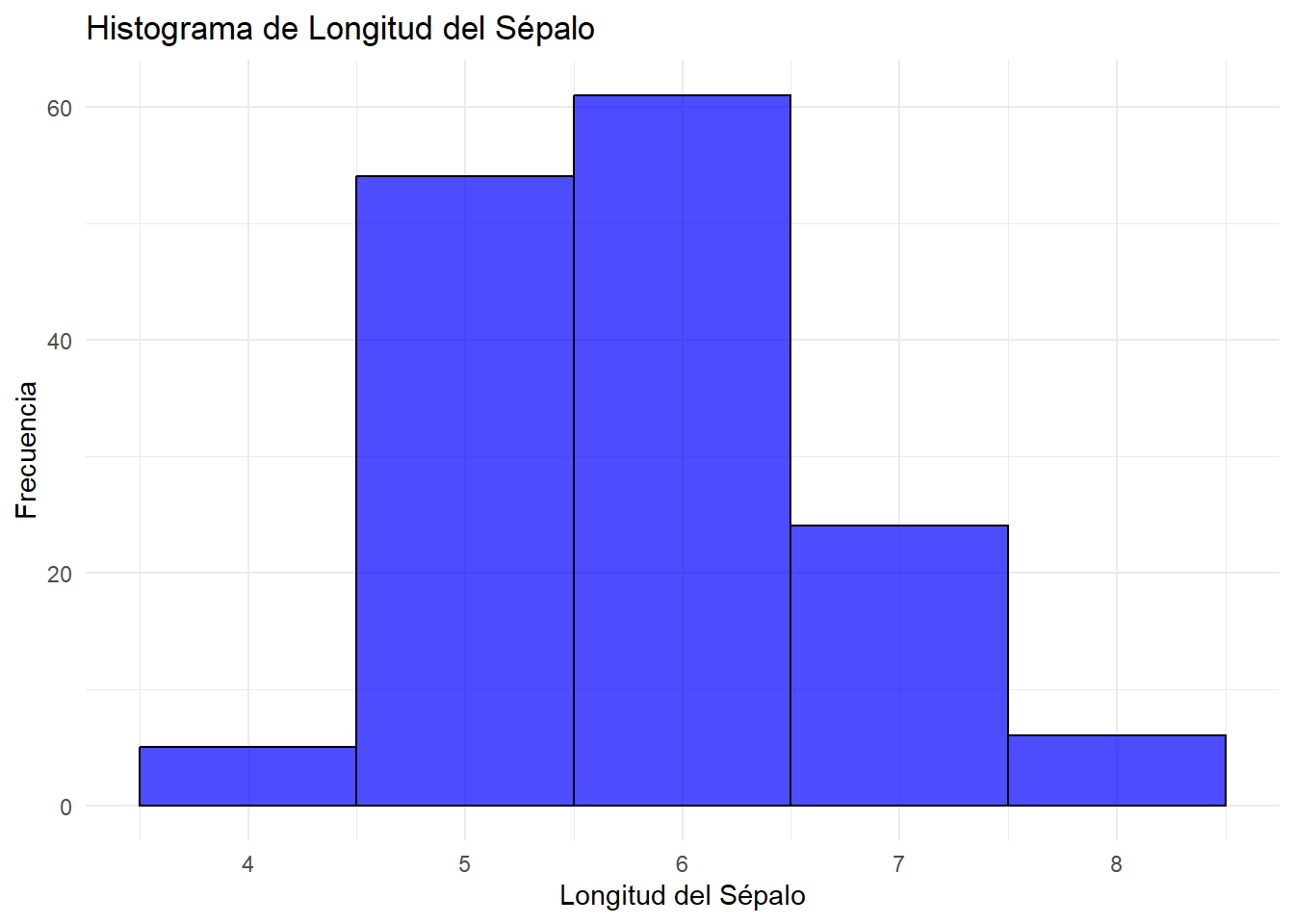
# Crear un histograma para la longitud del sépalo (Sepal.Length)ggplot(iris, aes(x = Sepal.Length)) +geom_histogram(binwidth =0.1, fill ="blue", color ="black", alpha =1.4) +labs(title ="Histograma de Longitud del Sépalo",x ="Longitud del Sépalo",y ="Frecuencia") +theme_minimal()
El gráfico muestra los valores numéricos agrupados en intervalos o “bins” de igual ancho. Cada intervalo se grafica como una barra, y su altura corresponde a la cantidad de observaciones que caen dentro de ese intervalo.
Podemos ver que los valores de longitud del sépalo más frecuentes se encuentran entre 4.9 y 5.1 (la barra más alta).
# Crear un histograma para la longitud del sépalo (Sepal.Length), diferente anchoggplot(iris, aes(x = Sepal.Length)) +geom_histogram(binwidth =1, fill ="blue", color ="black", alpha =0.7) +labs(title ="Histograma de Longitud del Sépalo",x ="Longitud del Sépalo",y ="Frecuencia") +theme_minimal()
En este caso, los intervalos tienen un ancho de 1 punto. La longitud del sépalo mínimo detectado es de 8, por lo que la ultima barra representa cuantos sepalos con longitud mínima estan entre 7 y 9. Aproximadamente 13 sépalos tienen valores dentro de este rango, por lo que la ultima barra en intervalos inferiores es poco visible. El ancho de los intervalos influye sobre la forma que toma el gráfico. Es una buena práctica realizar el histograma con distintos intervalos.
4.2.6 Curvas de densidad
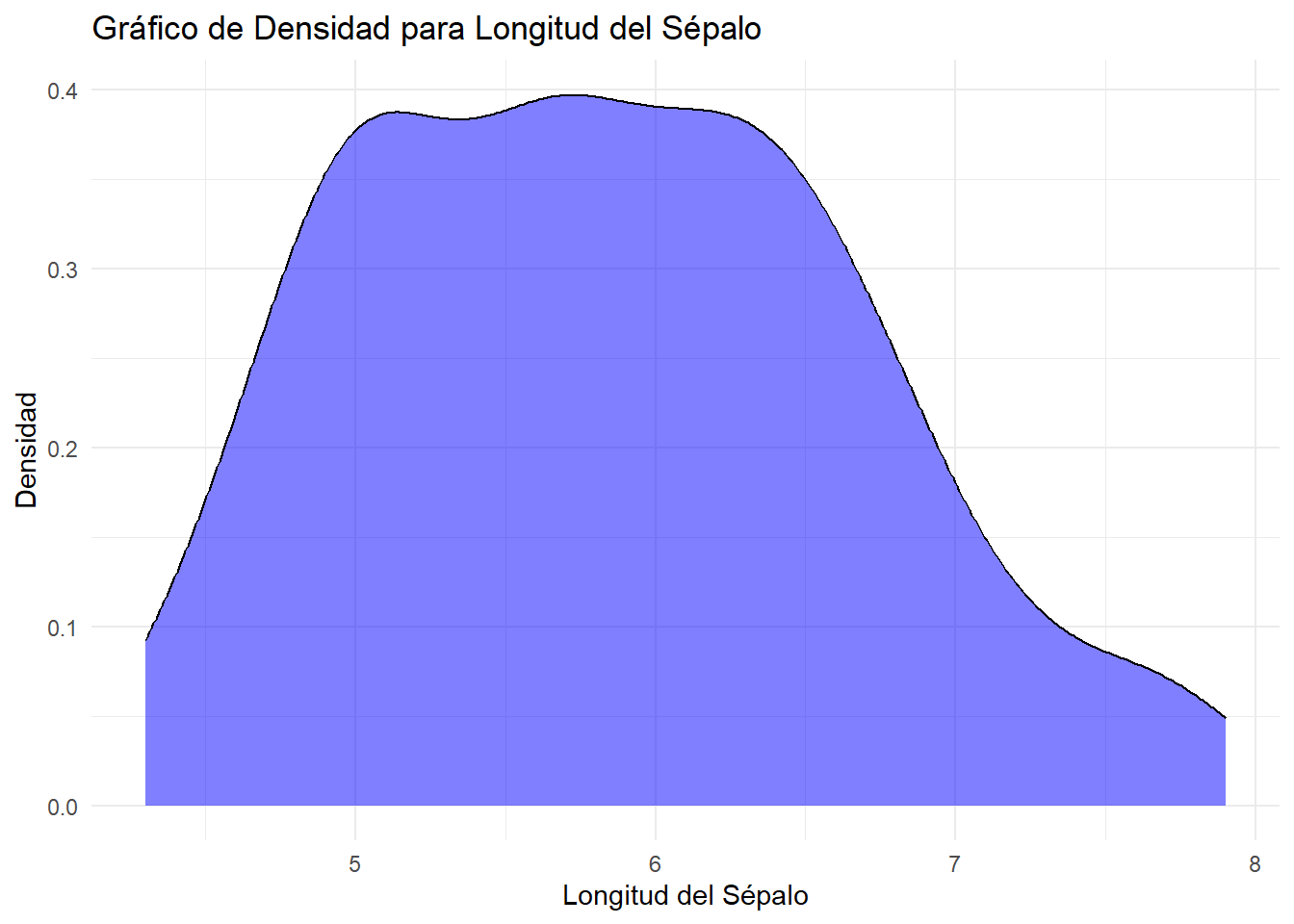
# gráfico de densidad para la longitud del sépalo (Sepal.Length)ggplot(iris, aes(x = Sepal.Length, fill = Species, color = Species)) +geom_density(alpha =0.5, fill ="blue", color ="black") +labs(title ="Gráfico de Densidad para Longitud del Sépalo",x ="Longitud del Sépalo",y ="Densidad") +scale_fill_manual(values ="blue", guide =FALSE) +scale_color_manual(values ="black", guide =FALSE) +theme_minimal()
Warning: The `guide` argument in `scale_*()` cannot be `FALSE`. This was deprecated in
ggplot2 3.3.4.
ℹ Please use "none" instead.
Las curvas de densidad se escalan de manera que el área bajo la curva sea igual a uno (el 100% de las observaciones). Esto hace que la escala del eje y sea confusa, porque depende de las unidades del eje x. En el caso de este gráfico, el eje y toma valores de entre 0 y 0.4.
No es tan claro para ver la cantidad o el porcentaje dentro de un rango específico, pero a veces muestra la distribución de la variable de forma más precisa porque no se ve afectado por el número de intervalos o bins.
4.2.7 Boxplots
# Instalar y cargar la librería ggplot2 si aún no lo has hecho# install.packages("ggplot2")library(ggplot2)# Crear un boxplot para la variable Sepal.Length en irisggplot(iris, aes(y = Sepal.Length)) +geom_boxplot() +labs(title ="Boxplot para Longitud del Sépalo en Iris",y ="Longitud del Sépalo") +theme_minimal()
Al igual que los histogramas o los gráficos de densidad, los boxplots muestran la distribución de una variable cuantitativa. Permiten ver si la misma es simétrica o no, y qué tan dispersos se encuentran los datos alrededor de una medida central.
En general, no se los utiliza tanto como a los otros dos cuando de trata de describir una variable cuantitativa únicamente, pero resultan muy útiles cuando se quiere evaluar la distribución en distintos grupos.
El gráfico se construye en base a cinco medidas: el valor mínimo, el primer cuartil (Q1), la mediana (Q2), el tercer cuartil (Q3) y el valor máximo.
La distancia entre el 1er y 3er cuartil es el rango intercuartil (IQR). El valor mínimo se obtiene restando al 1er cuartil el rango intercuartil multiplicado por 1.5. El valor máximo se obtiene sumando al 3er cuartil el rango intercuartil multiplicado por 1.5.
Entre el 1er y 3er cuartil se ubican el 50% de las observaciones.
Las observaciones por debajo del valor mínimo y por encima del valor máximo pueden ser observaciones extremas o outliers.
4.3 Visualización de datos bivariados
Para la visualización de datos bivariados en R usaremos el dataset de mtcars que esta incorporado en R.
4.4Gráficos bivariados
Son aquellos gráficos que se utilizan para mostrar la asociación entre dos variables.
Para estos gráficos tambien se usará el paquete ggplot2 cargado anteriormente.
4.4.1Asociación entre dos variables categóricas
4.4.2Gráfico de barras agrupadas
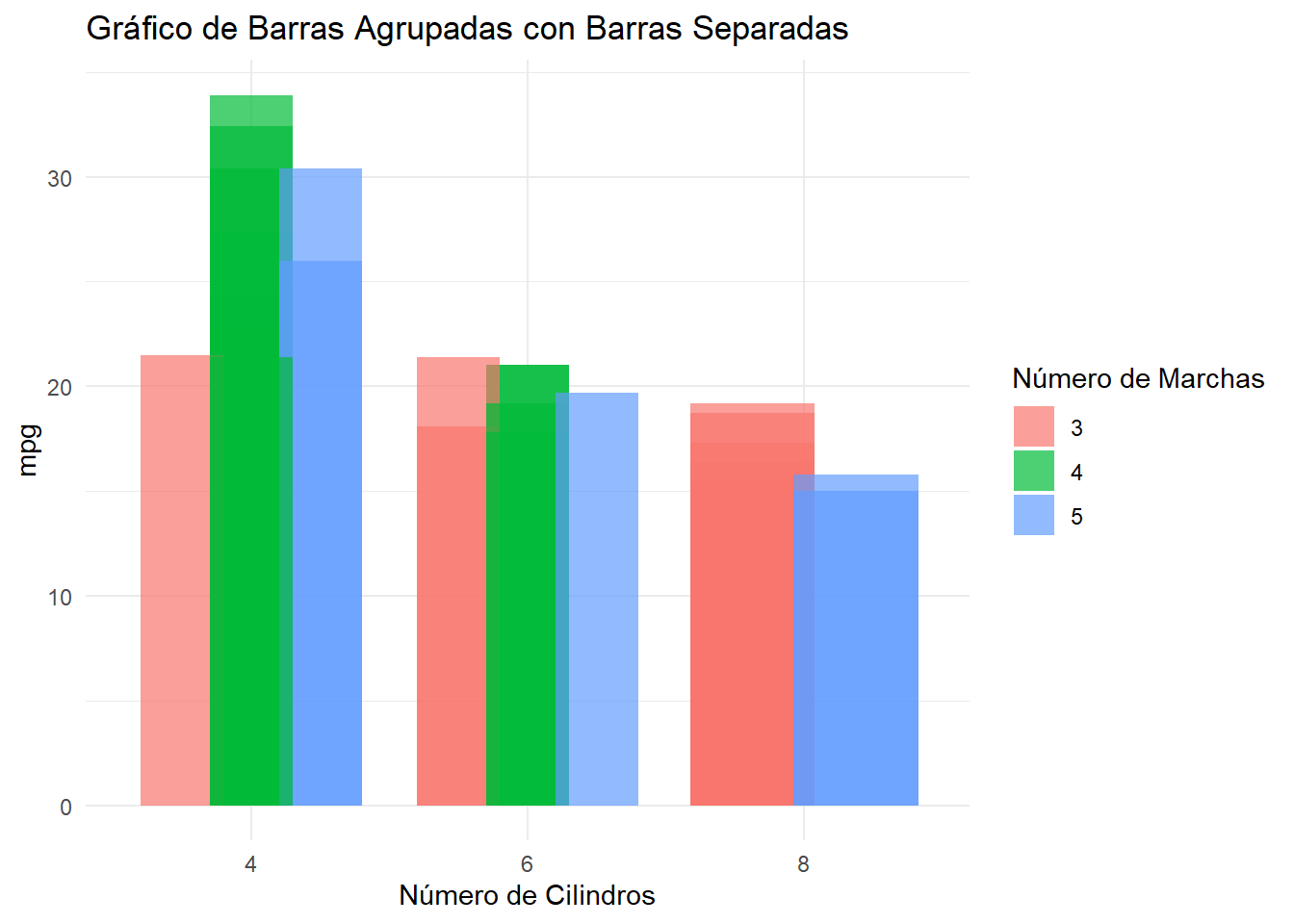
# Gráfico de barras agrupadas con el conjunto de datos mtcarsggplot(mtcars, aes(x =factor(cyl), fill =factor(gear), group = gear)) +geom_bar(aes(y = mpg), position =position_dodge(width =0.75), stat ="identity", alpha =0.7) +labs(title ="Gráfico de Barras Agrupadas con Barras Separadas",x ="Número de Cilindros",y ="mpg",fill ="Número de Marchas") +theme_minimal()
Es equivalente al gráfico de barras univariado, pero con barras y colores adicionales en función de una segunda variable categórica.
4.4.3Gráfico de barras segmentadas
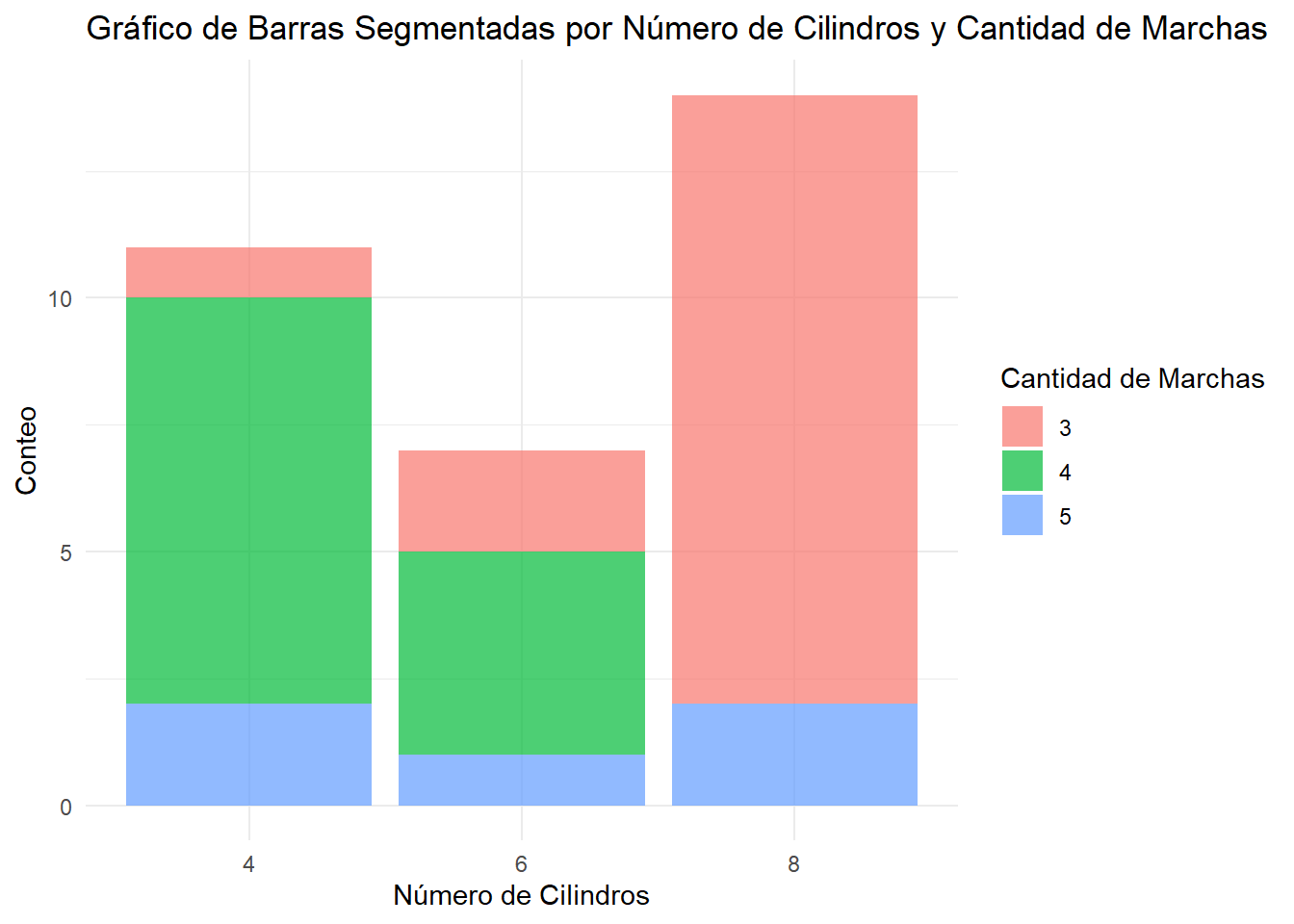
# Gráfico de barras segmentadas con el conjunto de datos mtcarsggplot(mtcars, aes(x =factor(cyl), fill =factor(gear))) +geom_bar(position ="stack", alpha =0.7) +labs(title ="Gráfico de Barras Segmentadas por Número de Cilindros y Cantidad de Marchas",x ="Número de Cilindros",y ="Conteo",fill ="Cantidad de Marchas") +theme_minimal()
En los gráficos de barras segmentadas una barra suma el 100% de las observaciones de una de las categorías. Por ejemplo, la primera barra representa a todos los autos con cuatro cilindros de fuerza.
Luego, la barra se separa en partes que representan el porcentaje de observaciones dentro de esa categoría que caen dentro de un subgrupo de otra categoría. En este caso, los segmentos de la primera barra muestran, del total de autos con cuatro cilindros, el porcentaje de autos con cinco marchas, el porcentaje de autos con cuatro marchas y el porcentaje de autos con tres marchas.
A diferencia del gráfico de barras agrupadas, permite comparar como se distribuyen los valores de la variable resultado en cada categoría de la variable suma.
En base a este gráfico podemos decir que la cantidad de marcha de tres es la que tiene mayor proporción dentro de los autos que tienen ocho cilindros.
Por otro lado, la cantidad de marcha de tres es muy baja en los autos que tienen 4 cilindros.
4.4.4Asociación entre una variable categórica y una cuantitativa
4.4.5Histogramas y gráficos de densidad agrupados
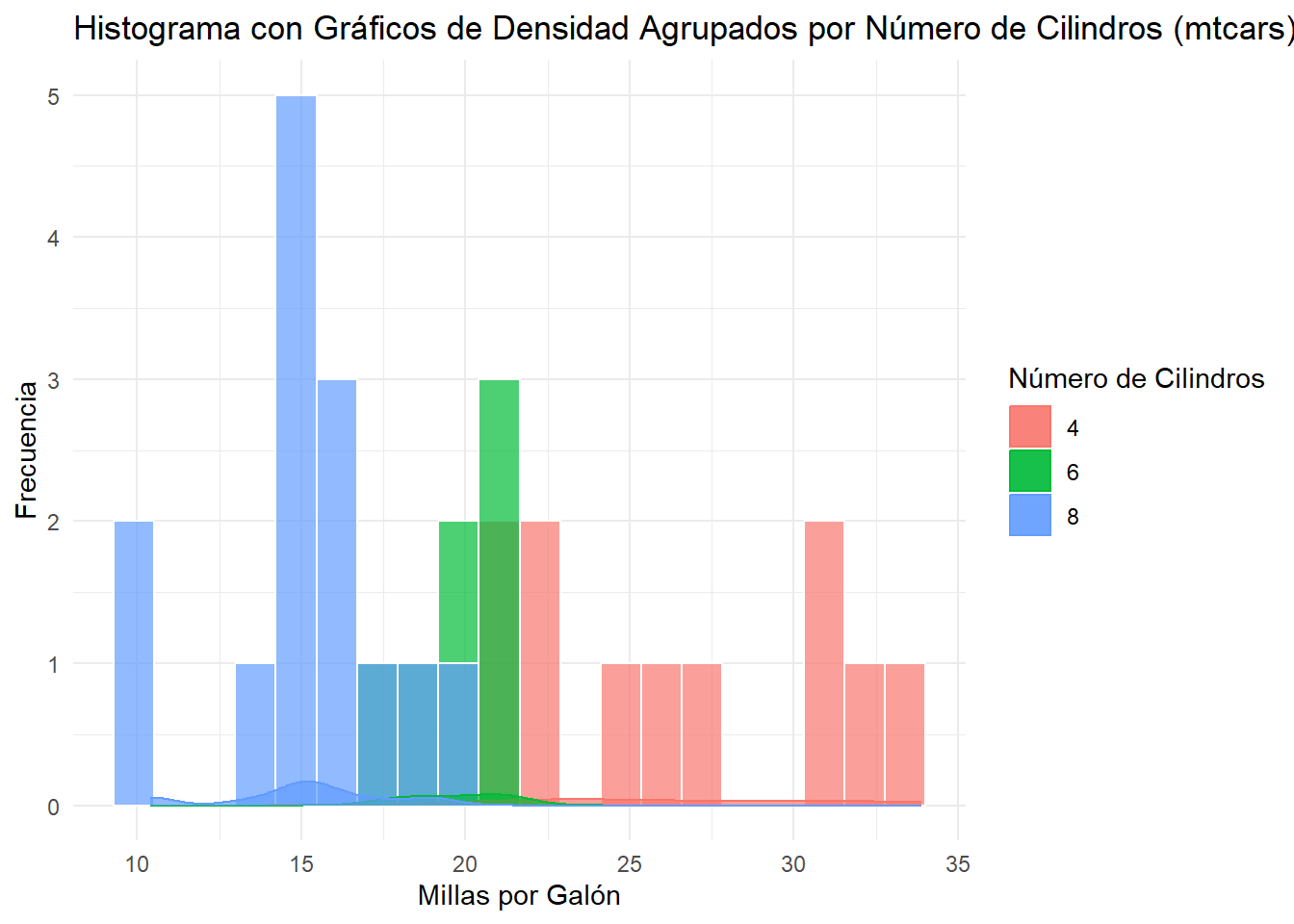
# Instalar y cargar la librería ggplot2 si aún no lo has hecho# install.packages("ggplot2")library(ggplot2)# Crear un histograma con gráficos de densidad agrupados para mpg en mtcarsggplot(mtcars, aes(x = mpg, fill =factor(cyl))) +geom_histogram(alpha =0.7, position ="identity", bins =20, color ="white", width =2) +geom_density(aes(y = ..count.. *0.05, color =factor(cyl)), alpha =0.7) +labs(title ="Histograma con Gráficos de Densidad Agrupados por Número de Cilindros (mtcars)",x ="Millas por Galón",y ="Frecuencia",fill ="Número de Cilindros",color ="Número de Cilindros") +theme_minimal()
Warning: The dot-dot notation (`..count..`) was deprecated in ggplot2 3.4.0.
ℹ Please use `after_stat(count)` instead.
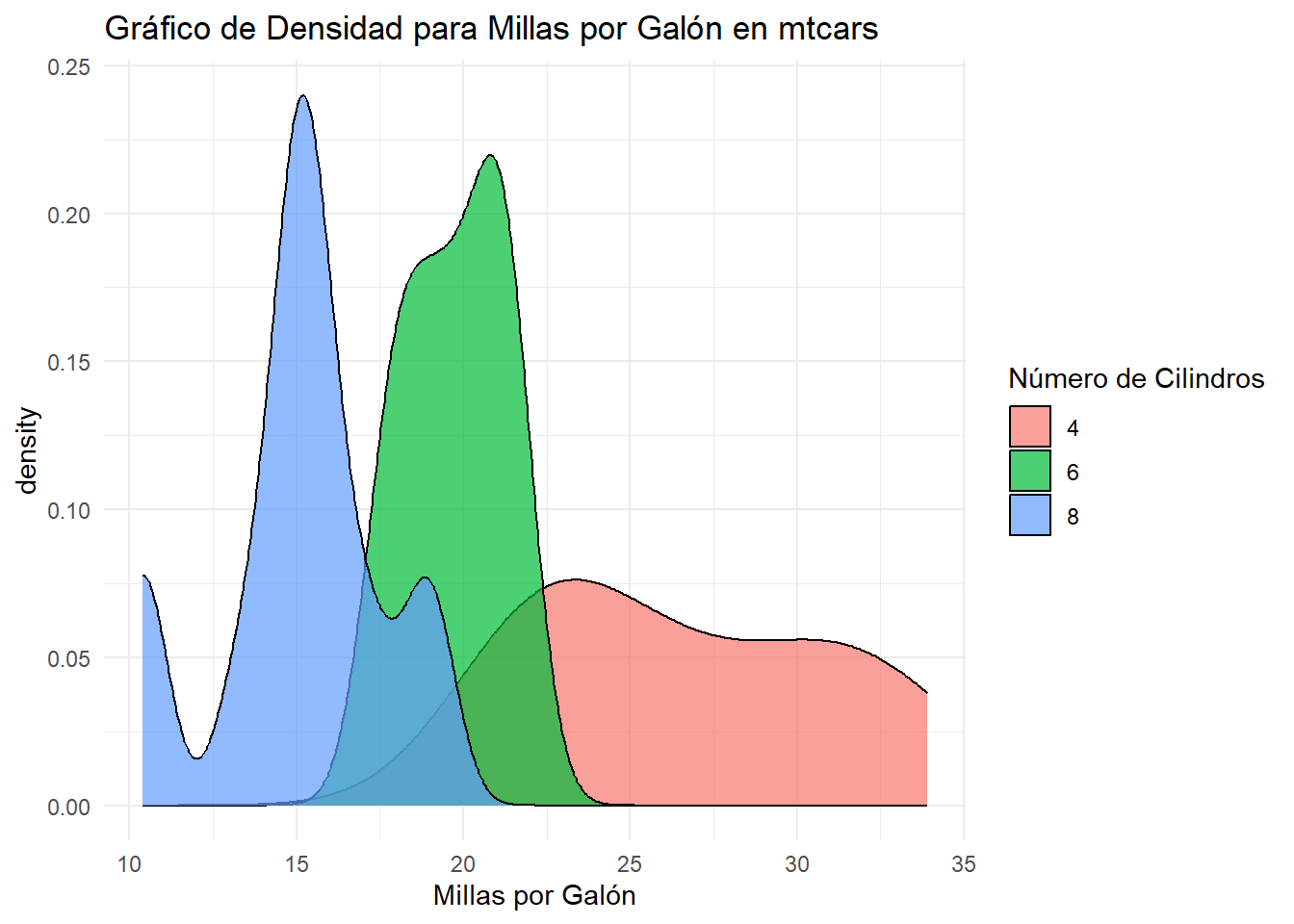
Esto puede resultar más claro en un gráfico de densidad, ya que no depende de la cantidad de observaciones.
# Gráfico de densidad para millas por galón (mpg) en mtcarsggplot(mtcars, aes(x = mpg, fill =factor(cyl))) +geom_density(alpha =0.7) +labs(title ="Gráfico de Densidad para Millas por Galón en mtcars",x ="Millas por Galón",fill ="Número de Cilindros") +theme_minimal()
4.4.6Boxplots
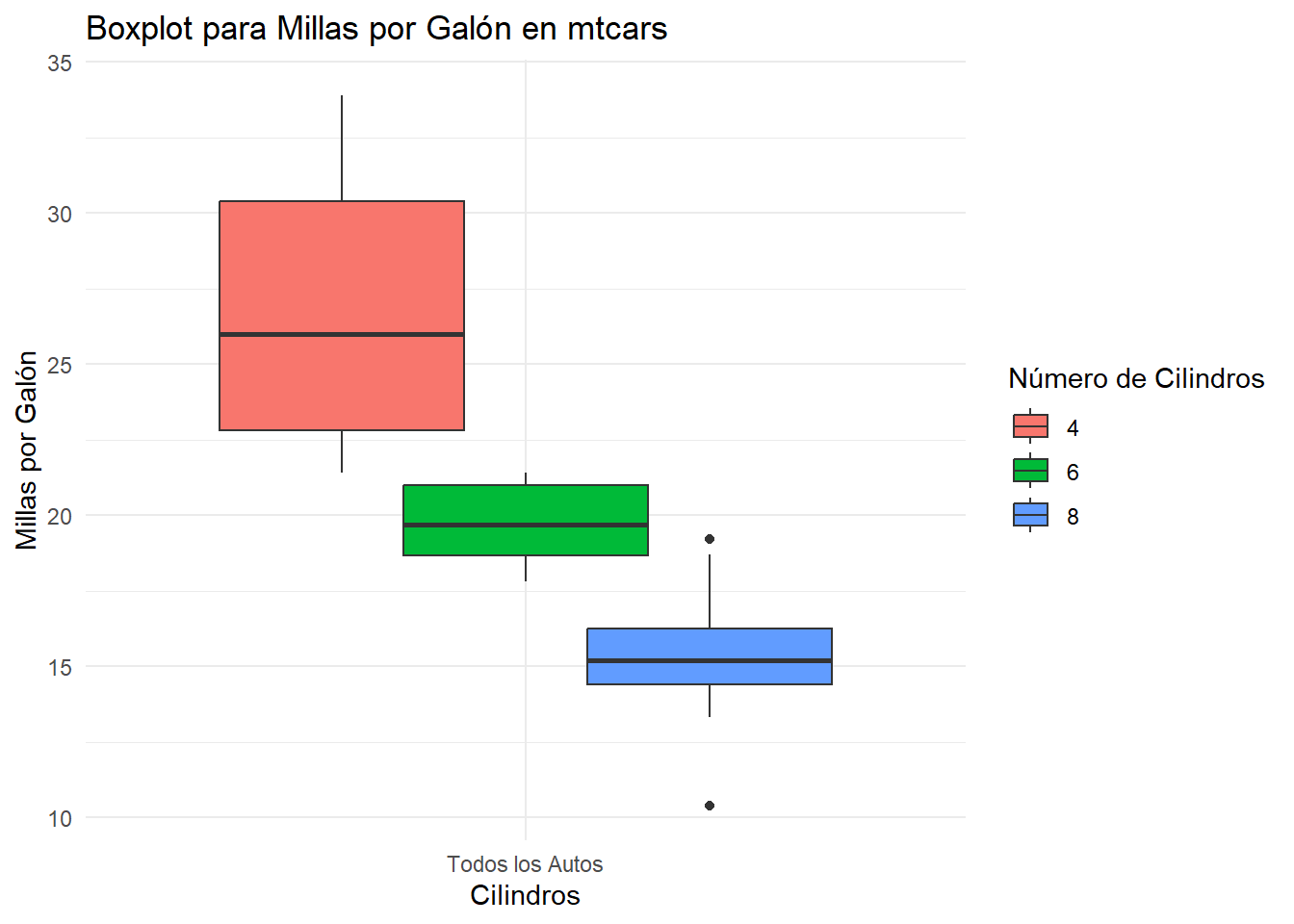
# Gráfico (Boxplot) para millas por galón en mtcarsggplot(mtcars, aes(x ="Todos los Autos", y = mpg, fill =factor(cyl))) +geom_boxplot(width =1, position =position_dodge(width =0.75)) +labs(title ="Boxplot para Millas por Galón en mtcars",x ="Cilindros",y ="Millas por Galón",fill ="Número de Cilindros") +theme_minimal()
Al igual que con los gráficos anteriores, se puede observar que la distribución es similar en los tres grupos. Este gráfico es más útil para visualizar si las medias o medianas difieren entre los grupos.
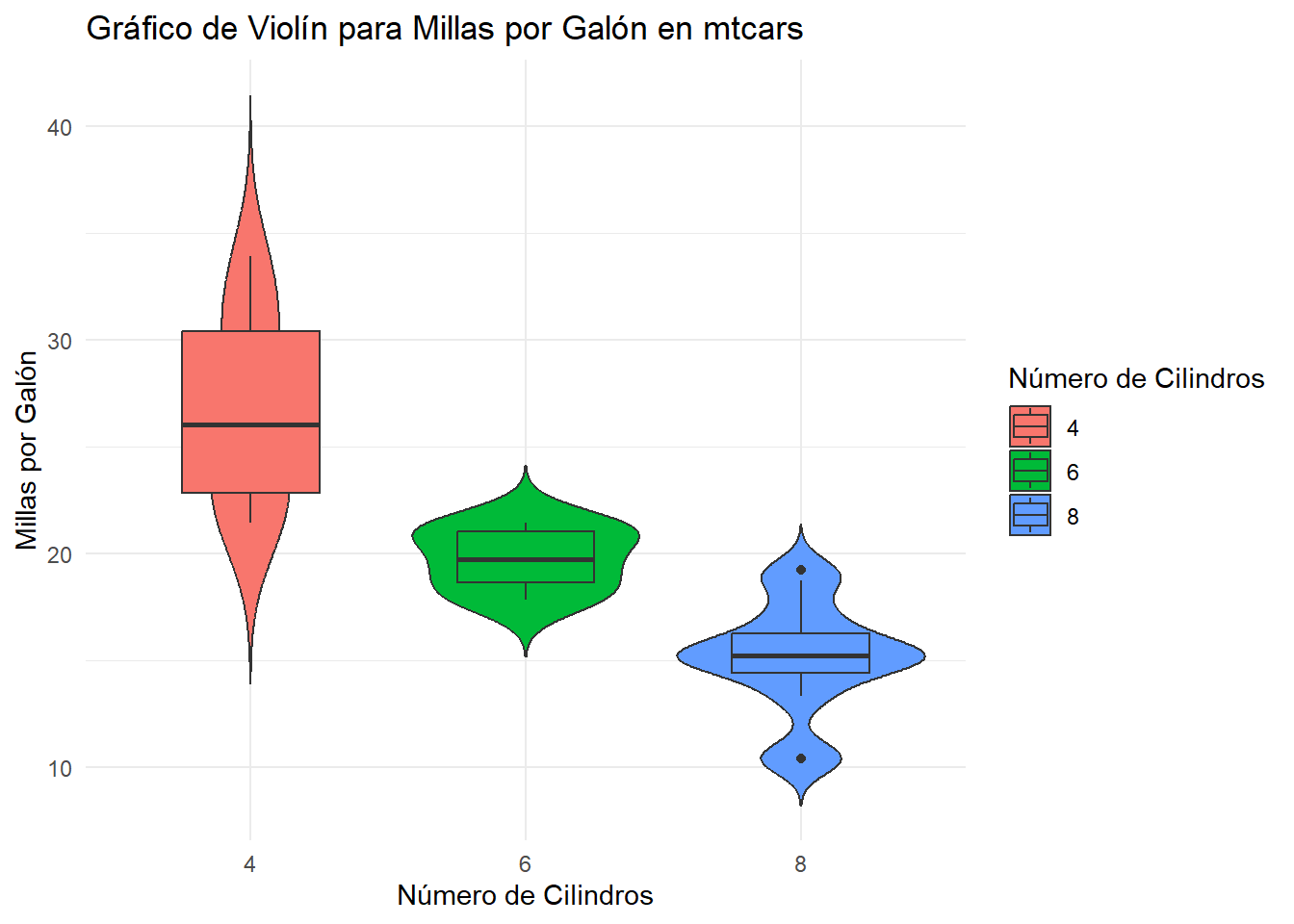
4.4.7Gráficos de violín
Este gráfico es una combinación de un boxplot y bigotes y un gráfico de densidad superpuesto.
# Instalar y cargar la librería ggplot2 si aún no lo has hecho# install.packages("ggplot2")library(ggplot2)# Violin plot para millas por galón (mpg) en mtcarsggplot(mtcars, aes(x =factor(cyl), y = mpg, fill =factor(cyl))) +geom_violin(trim =FALSE) +geom_boxplot(width = .5) +labs(title ="Gráfico de Violín para Millas por Galón en mtcars",x ="Número de Cilindros",y ="Millas por Galón",fill ="Número de Cilindros") +theme_minimal()
4.4.8Asociación entre dos variables cuantitativas
4.4.9Gráfico de dispersión
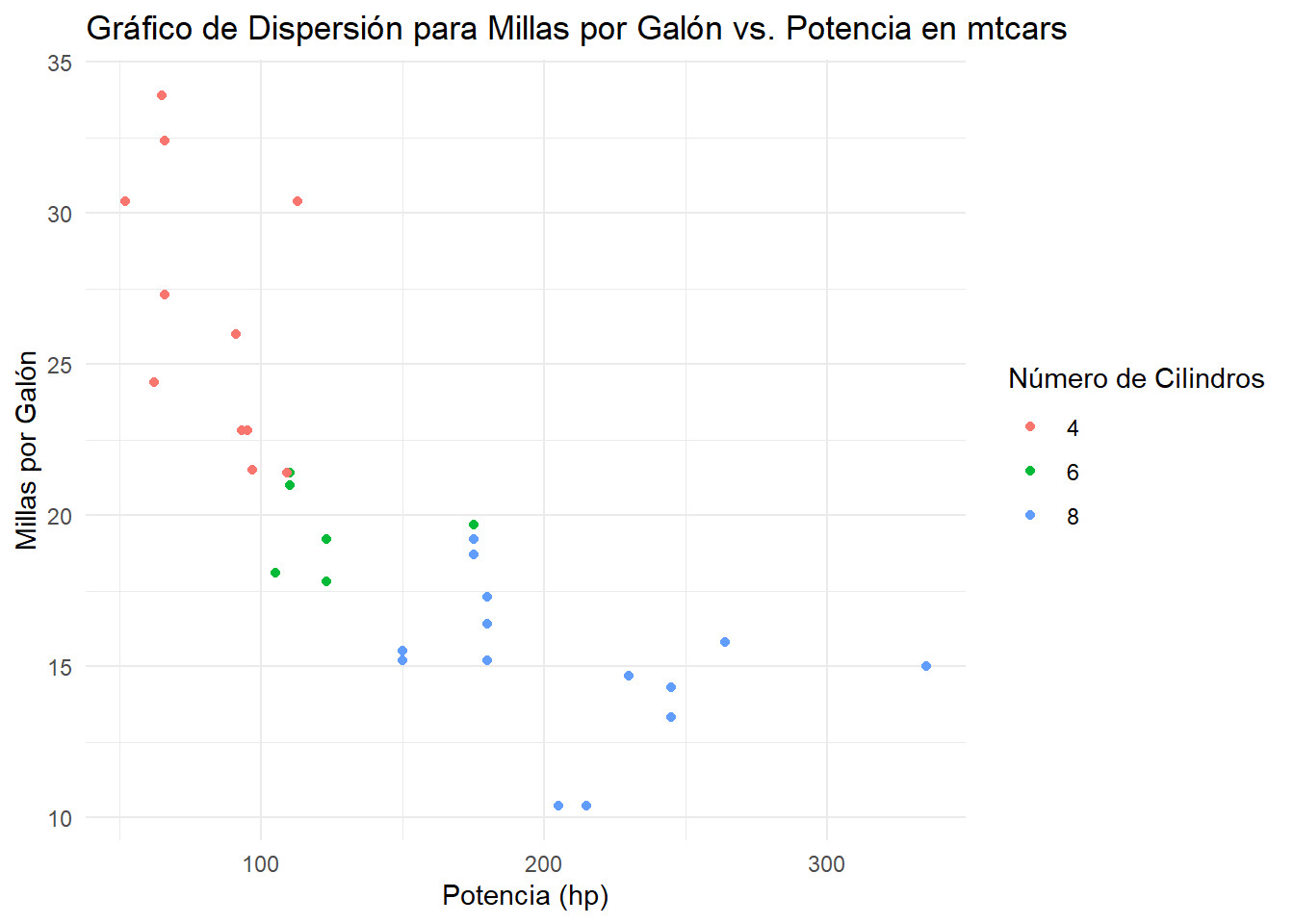
Este gráfico representa a cada observación como un punto. Este punto se ubica en base a los valores que la observación toma en dos variables cuantitativas, una ubicada en el eje x y otra en el eje y.
# Gráfico de dispersión para mpg vs. hp en mtcarsggplot(mtcars, aes(x = hp, y = mpg, color =factor(cyl))) +geom_point() +labs(title ="Gráfico de Dispersión para Millas por Galón vs. Potencia en mtcars",x ="Potencia (hp)",y ="Millas por Galón",color ="Número de Cilindros") +theme_minimal()
Cuando existe una asociación entre las variables, esperamos ver que: - cuando los valores de una de las variables aumentan los de la otra también (asociación positiva). - cuando los valores de una de las variables disminuyen los de la otra aumentan (asociación negativa).
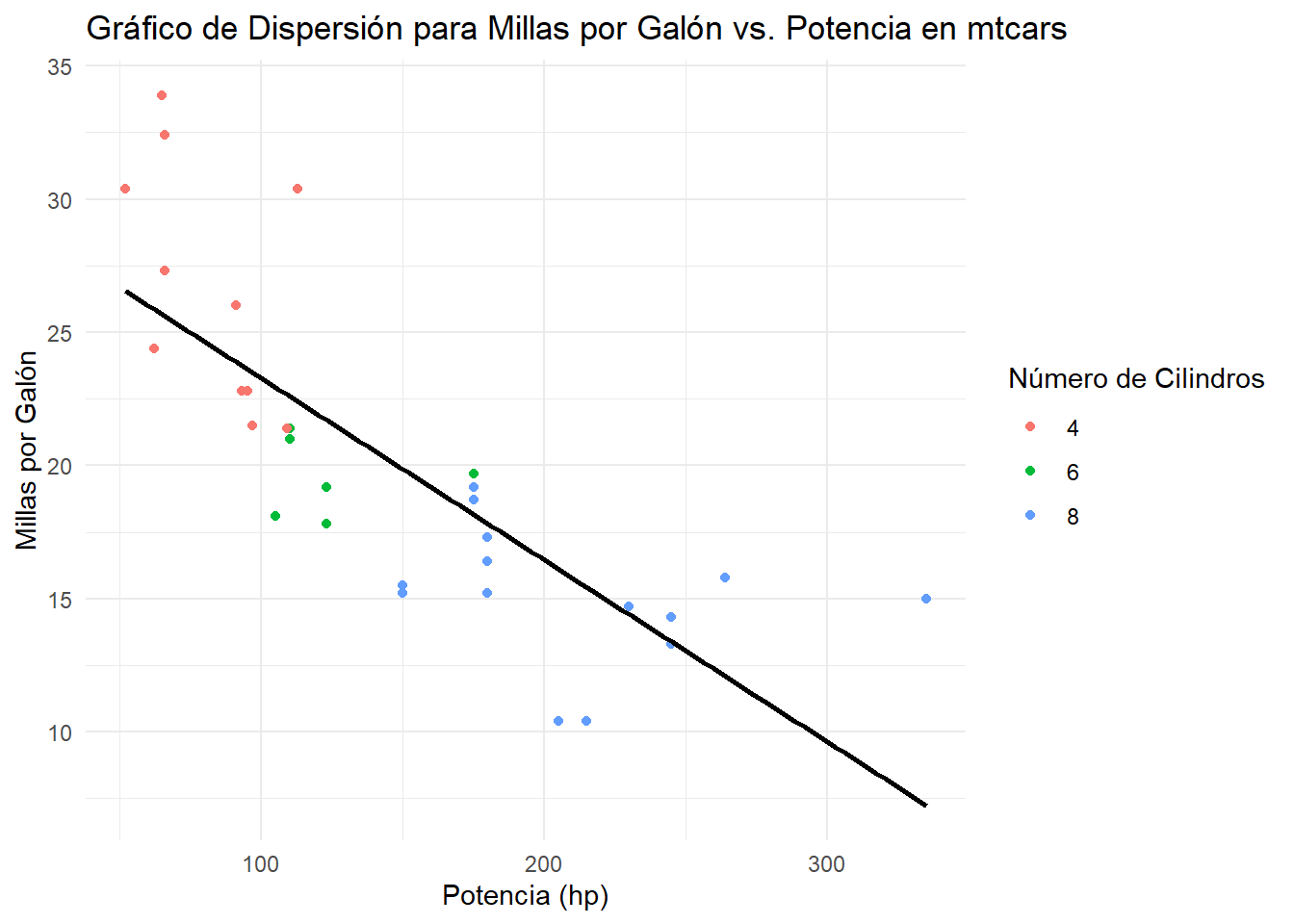
En este caso, no resulta tan claro a simple vista. Podemos agregar una recta de tendencia para ayudarnos.
ggplot(mtcars, aes(x = hp, y = mpg, color =factor(cyl))) +geom_point() +geom_smooth(method ="lm", se =FALSE, color ="black", formula = y ~ x) +labs(title ="Gráfico de Dispersión para Millas por Galón vs. Potencia en mtcars",x ="Potencia (hp)",y ="Millas por Galón",color ="Número de Cilindros") +theme_minimal()
4.5 Visualización de datos bivariados multivariados
Para la visualización de datos bivariados multivariados en R usaremos el dataset de USArrests que esta incorporado en R. Este conjuto de datos o dataset contiene datos sobre los asaltos, asesinatos y arrestos en cada uno de los 50 estados de EE.UU en 1973.
4.6Gráficos bivariados multivariados
Para estos gráficos tambien se usará el paquete ggplot2 cargado anteriormente.
4.6.1 Gráfico de Pares (Pair Plots)
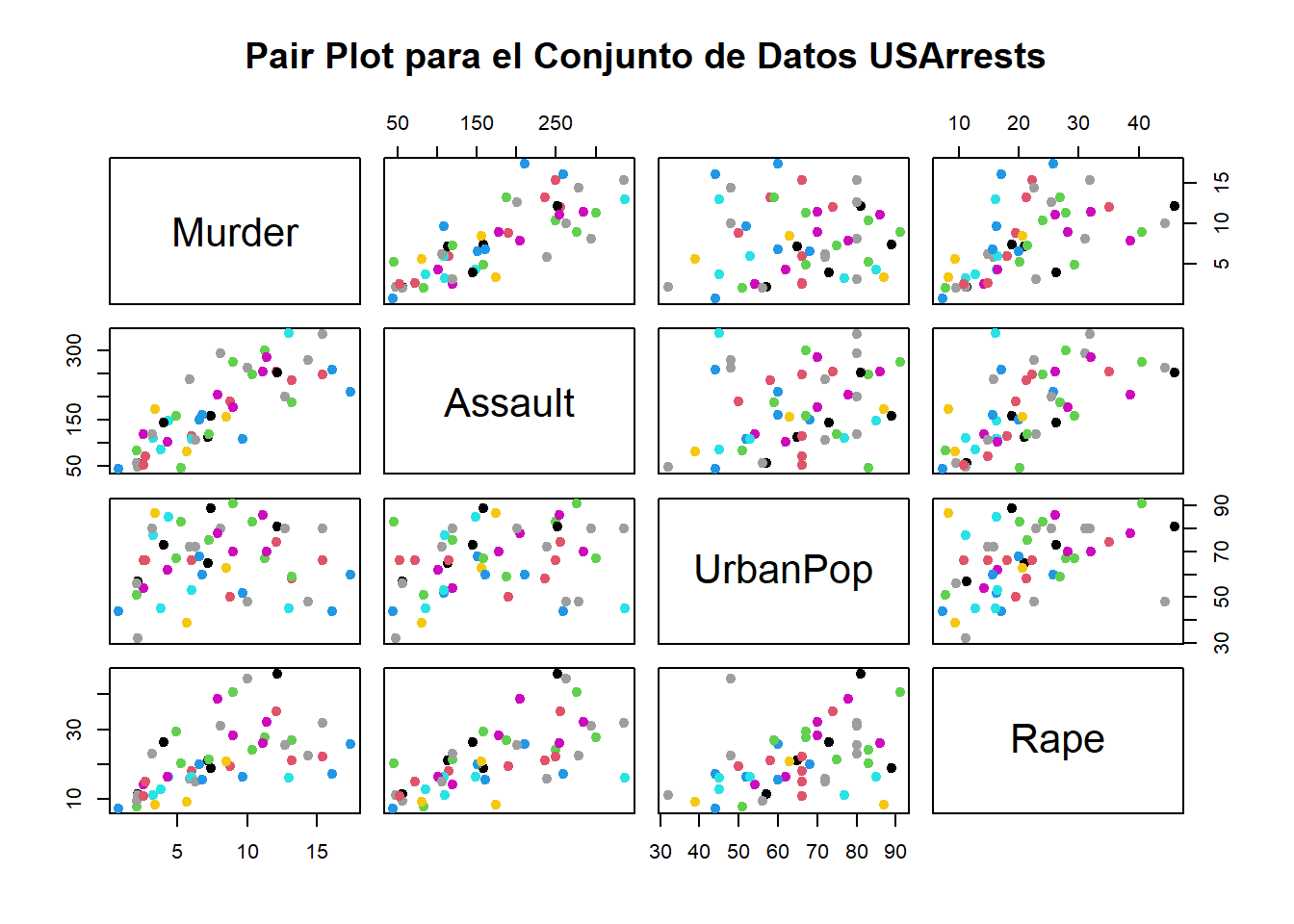
# Crear un gráfico de pares con el conjunto de datos USArrestspairs(USArrests, pch =19, col =as.integer(USArrests$UrbanPop), main ="Pair Plot para el Conjunto de Datos USArrests")
Este gráfico de pares (pair plot) proporciona una visión visual de las relaciones bivariadas multivariadas y las distribuciones marginales de las variables en un conjunto de datos.
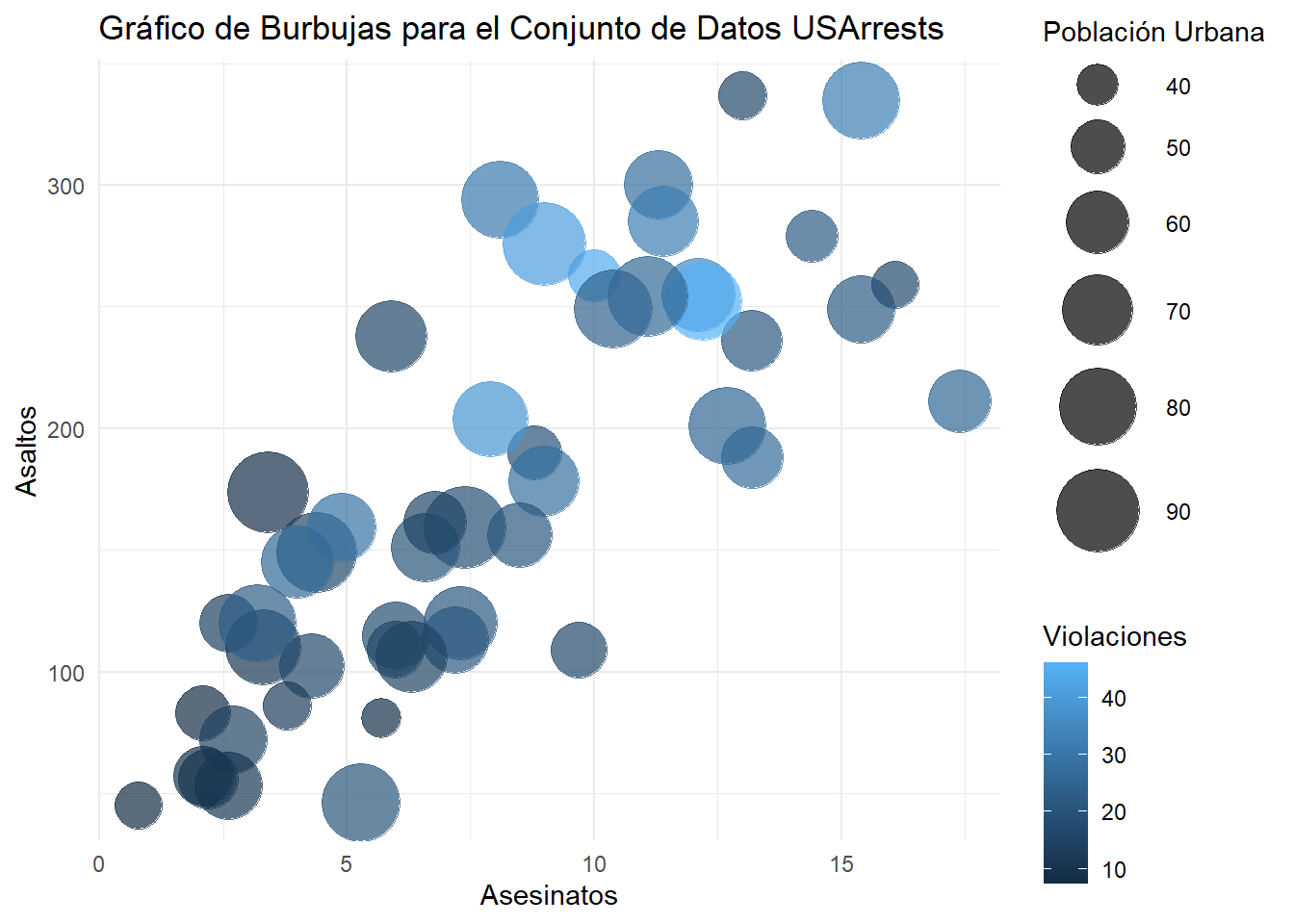
4.6.2 Gráfico de burbujas (bubble plots)
# Gráfico de burbujas con el conjunto de datos USArrestsggplot(USArrests, aes(x = Murder, y = Assault, size = UrbanPop, color = Rape)) +geom_point(alpha =0.7) +scale_size_continuous(range =c(3, 15)) +labs(title ="Gráfico de Burbujas para el Conjunto de Datos USArrests",x ="Asesinatos",y ="Asaltos",size ="Población Urbana",color ="Violaciones") +theme_minimal()
Podemos ver que en este gráfico de burbujas centrado para el conjunto de datos USArrests, las burbujas representan observaciones individuales (en este caso, estados de EE. UU.) y están ubicadas en un espacio bidimensional definido por las variables “Asesinatos” y “Asaltos”, con el tamaño de la burbuja representando la variable “Población Urbana” y el color representando la variable “Violaciones”, todo centrado en torno a cero.
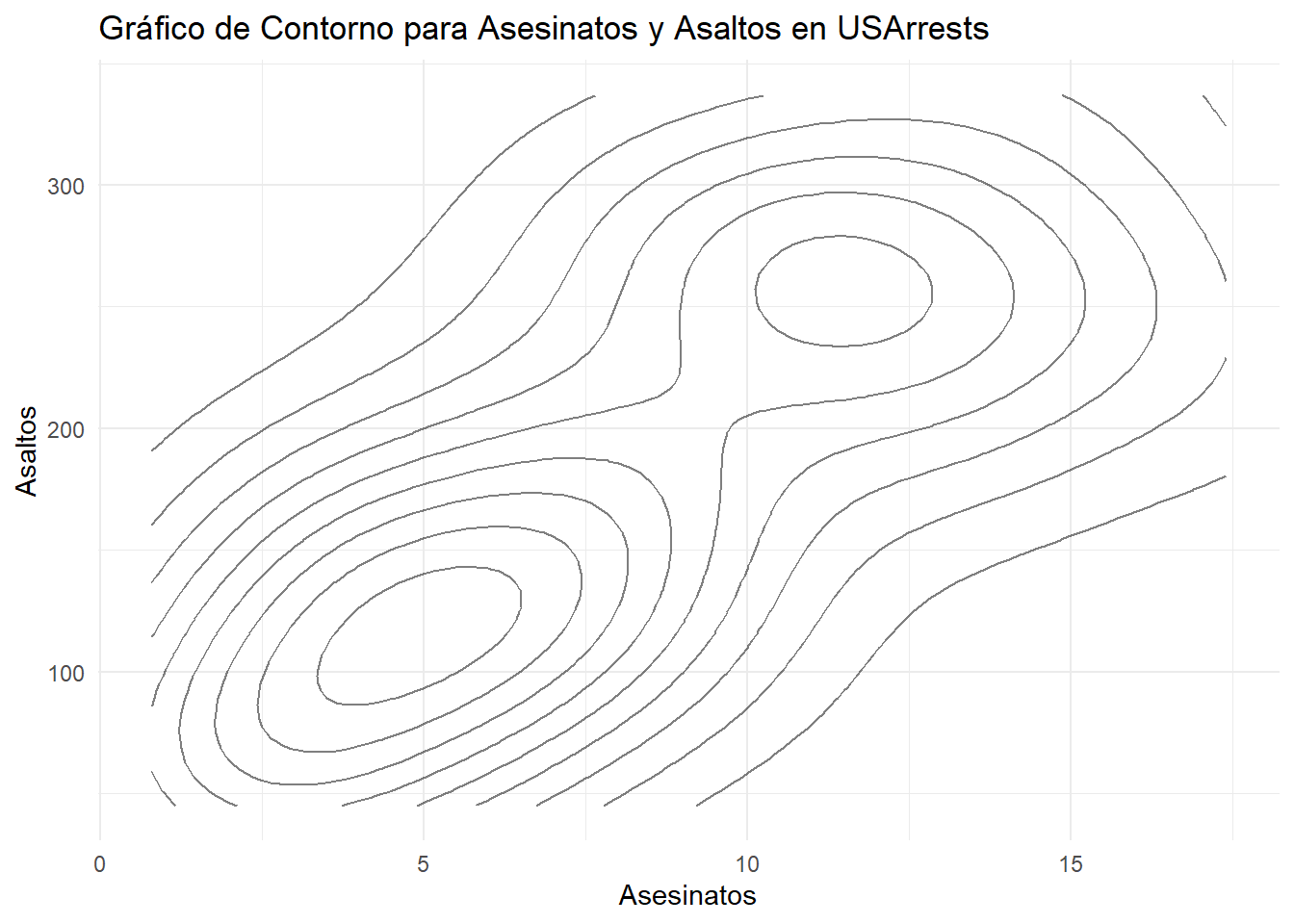
4.6.3 Gráficos de Contorno (Contour Plots)
# Instalar y cargar la librería ggplot2 si aún no lo has hecho# install.packages("ggplot2")library(ggplot2)# Crear un gráfico de contorno con el conjunto de datos USArrestsggplot(USArrests, aes(x = Murder, y = Assault)) +geom_density_2d(color ="black", fill ="blue", alpha =0.5) +labs(title ="Gráfico de Contorno para Asesinatos y Asaltos en USArrests",x ="Asesinatos",y ="Asaltos") +theme_minimal()
Warning in geom_density_2d(color = "black", fill = "blue", alpha = 0.5):
Ignoring unknown parameters: `fill`
Este gráfico de contorno proporciona una representación visual de la densidad de observaciones en el espacio bidimensional de las variables “Asesinatos” y “Asaltos” en el conjunto de datos USArrests.
4.7 Visualización de datos avanzados (imágenes)
La visualización de datos a través de imágenes puede ser una forma poderosa de transmitir información de manera efectiva.
4.7.1 Visualización de Imágenes
Para la visualización de imágenes será necesaria la libreria llamada imager, porque gracias a esta se podra usar la función load.image() que servira para poder cargar, procesar y visualizar la imagen deseada.
La imagen que se usará para ejemplificar será una de Bulbasaur que es un pokemon de la serie “Pokemon” para esto guardaremos la imagen en nuestro espacio de trabajo para que la funcion se cargue exitosamente.
4.7.1.1 Ejemplo
library(imager)
Warning: package 'imager' was built under R version 4.3.2
Loading required package: magrittr
Warning: package 'magrittr' was built under R version 4.3.1
Attaching package: 'imager'
The following object is masked from 'package:magrittr':
add
The following object is masked from 'package:dplyr':
where
The following objects are masked from 'package:stats':
convolve, spectrum
The following object is masked from 'package:graphics':
frame
The following object is masked from 'package:base':
save.image
Para la visualización de mapas se usará la libreria llamada “leaflet”, esta nos permitira visualizar interactivamente un mapa.
4.7.2.1 Ejemplo
library(leaflet)
Warning: package 'leaflet' was built under R version 4.3.2
mapa <-leaflet() %>%addTiles()mapa
4.7.3 Visualización de Datos en 3D
Para la visualización de datos en 3D se usará la libreria “rgl” que su función principal es permitir la visualización interactica de datos en 3D, esta puede ser utilizada para visualizar puntos, líneas y superficies en un espacio tridimensional.
4.7.3.1 Ejemplo
Para este ejemplo sencillo se necesitara 3 puntos que esten en los ejes x,y,z para que sea un espacio tridimensional, por ende creamos los vectores y se les asigna los nombres x, y, z respectivamente y procedemos a usar la función plot3d() para la visualización de datos en 3D.
library(rgl)
Warning: package 'rgl' was built under R version 4.3.2
x <-c(1, 2, 3, 4, 5)y <-c(10, 8, 6, 4, 2)z <-c(3, 6, 9, 12, 15)a<-plot3d(x, y, z, col ="blue", size =3)a