Chapter 5 Workshop: Sequence similarity and alignment
5.1 Handling “next-generation” sequencing (NGS) data: alignments against a reference genome
NGS data from shotgun sequencing of a genome typically generates very large numbers of short sequence reads. Today, we are going to see how we can make some sense of the data, by viewing the reads aligned against a reference genome sequence.

Making sense of short sequence reads is something like piecing together text on scraps of paper from a shredder. There are two main approaches:
- alignment against a reference genome sequence and
- de novo assembly.
Here we will look at the former (alignment).
5.1.1 The data
The sequence data that we are using today comes from the genome (and transcriptome) of the bacterium Mycobacterium tuberculosis, a bacterial pathogen that infects about 2 billion people (a third of the world’s population) and is the causative agent of tuberculosis.
Its genome is small and therefore convenient to work with. The same principles that we learn about today are mostly applicable for larger genomes too but would require more time and computer resource to analyse. Specifically, we will be using genomic sequence data from a survey of tuberculosis transmission in Oxfordshire (Campbell et al. 2018) and a transcriptomic dataset from another as-yet unpublished study.
Both these datasets consist of pairs of short reads, generated using Illumina sequencing. We will also take a look at a genomic sequence dataset generated using PacBio (Pacific Biosciences) longer reads (Philip et al. 2016).
As the reference genome sequence, we will use the completely assembled sequence of strain H37Rv (Cole et al. 1998). In advance, I generated some alignment files for you; the sequence reads were aligned against H37Rv reference genome sequence using a software package called BWA.
| SRA accession number | Genome / transcriptome | Strain of M. tuberculosis | Sequencing method |
|---|---|---|---|
| ERR400344 | Genome | OxTb-6 | Illumina HiSeq |
| ERR400311 | Genome | OxTb-321 | Illumina HiSeq |
| SRR3667790 | Genome | SB24 | PacBio SMRT |
| SRR5061507 | Transcriptome | H37Rv | Illumina HiSeq |
| SRR5061515 | Transcriptome | H37Rv | Illumina HiSeq |
All of the files that you need are available via the “Workshop 3. Link to example data” item on the University of Bristol Blackboard page.
5.1.2 The software: IGV
To interactively browse the genome, and the NGS sequence data aligned against the genome, we are going to us the Integrative Genomics Viewer (IGV) (Thorvaldsdottir, Robinson, and Mesirov 2013). You may need to either download and install the IGV software or you can use the web-based version, which requires no installation; you just access it through your web browser. Under some circumstances this version runs much more smoothly than the locally installed version. The disadvantage is that some of the details of the menus and functions etc. are slightly different than those in the locally installed version; so, you may need to ask for help if you get stuck with this.
5.1.2.1 If you want to find out more:
- An online tutorial for the locally installed IGV is available from here.
- A tutorial video is available here: https://www.youtube.com/watch?v=YpNg0hNUuo8, which uses some human genome data.
- For the web-based version of IGV, help is available at this site, here.
However, by using this document and a bit of trial and error you should be able to quickly learn how to use IGV without needing to access those tutorial materials.
5.1.3 What you need to do
First, download the data from the OneDrive (see link above).Then, you need to follow the steps described below. These will lead you through how to load the reference genome the aligned NGS reads into IGV. You then need to play around with IGV and learn to drive it. Try to answer the questions below.
5.1.4 Loading the reference genome into IGV
When you first start (the locally installed version of) IGV, it will look something like this:
If you are using the web-based version of IGV, it looks sightly different. See the section called “Using the web-based version of IGV” later in this document.
To load the nucleotide sequence of the reference genome, locate the
“Genomes” menu item. Choose “Genomes -> Load genome from file” and
locate the reference genome sequence file that you downloaded earlier.
This file should be called GCA_000195955.2_ASM19595v2_genomic.fna.
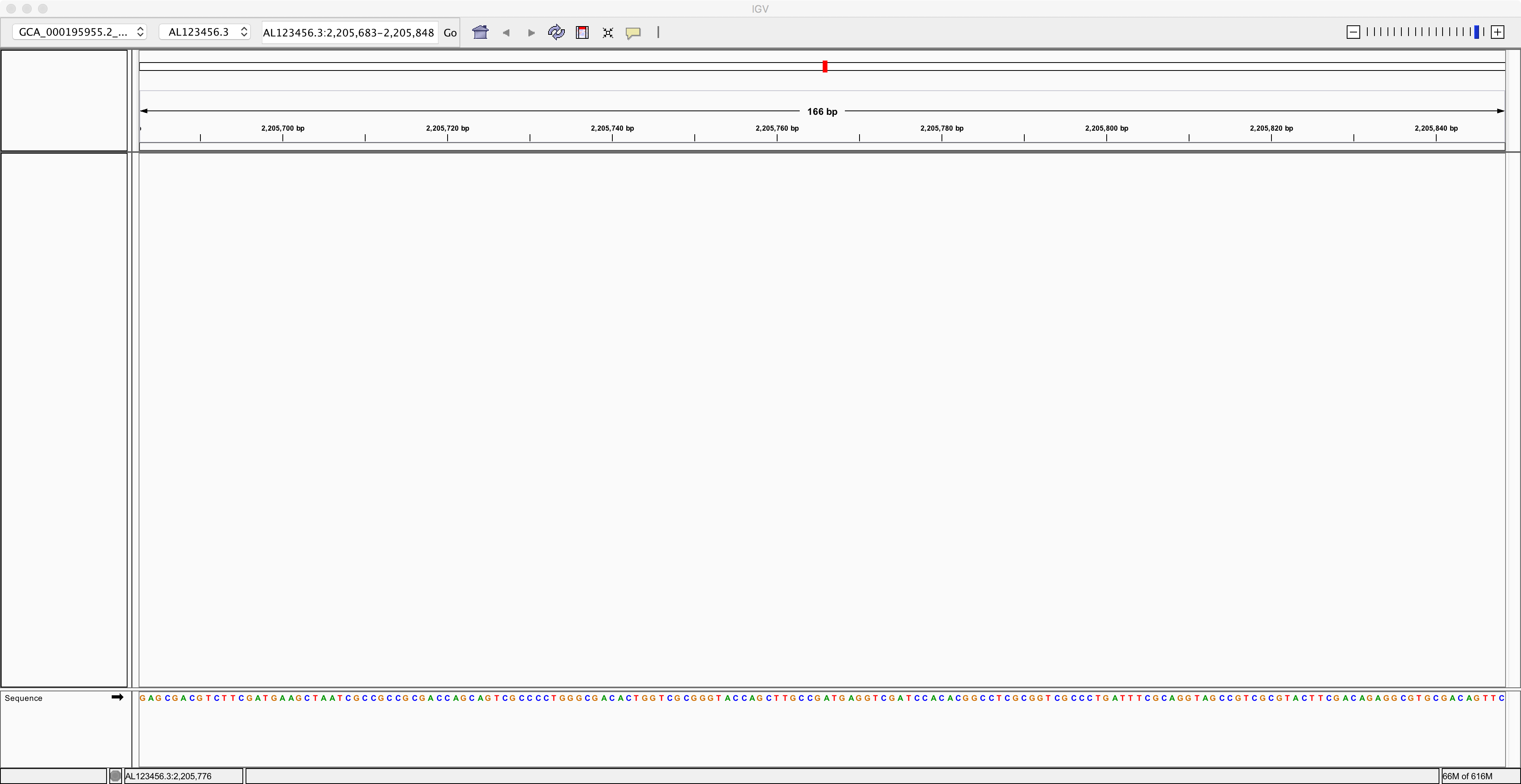
Once you have loaded this reference genome sequence, use the control near the top right corner of the IGV window to zoom in as much as you can. Then you should be able to see the nucleotide sequence of the reference genome along the bottom:
Next, we need to load the genome annotation. Use the menu item
called “File -> Load from file” to select the annotation file that you
downloaded earlier. This should be called
GCA_000195955.2_ASM19595v2_genomic.gff. After loading the annotation
and zooming out a bit, you should see something like this:
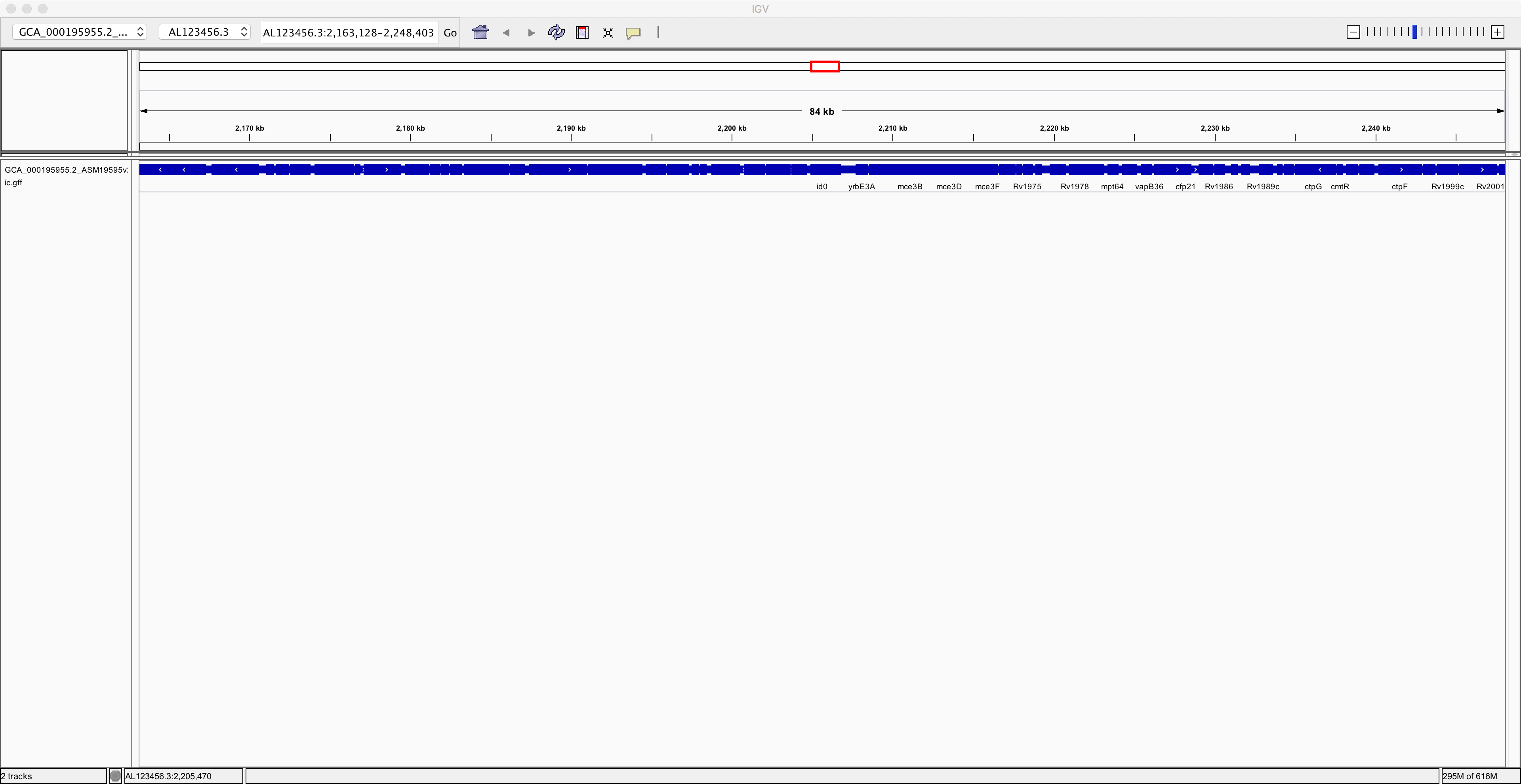
Notice that you have now added an extra track containing the annotation of the genome. Next, to improve clarity, right-click on the annotation track and select the “Expanded” option. Now you can see the individual genes more clearly on the reference genome:
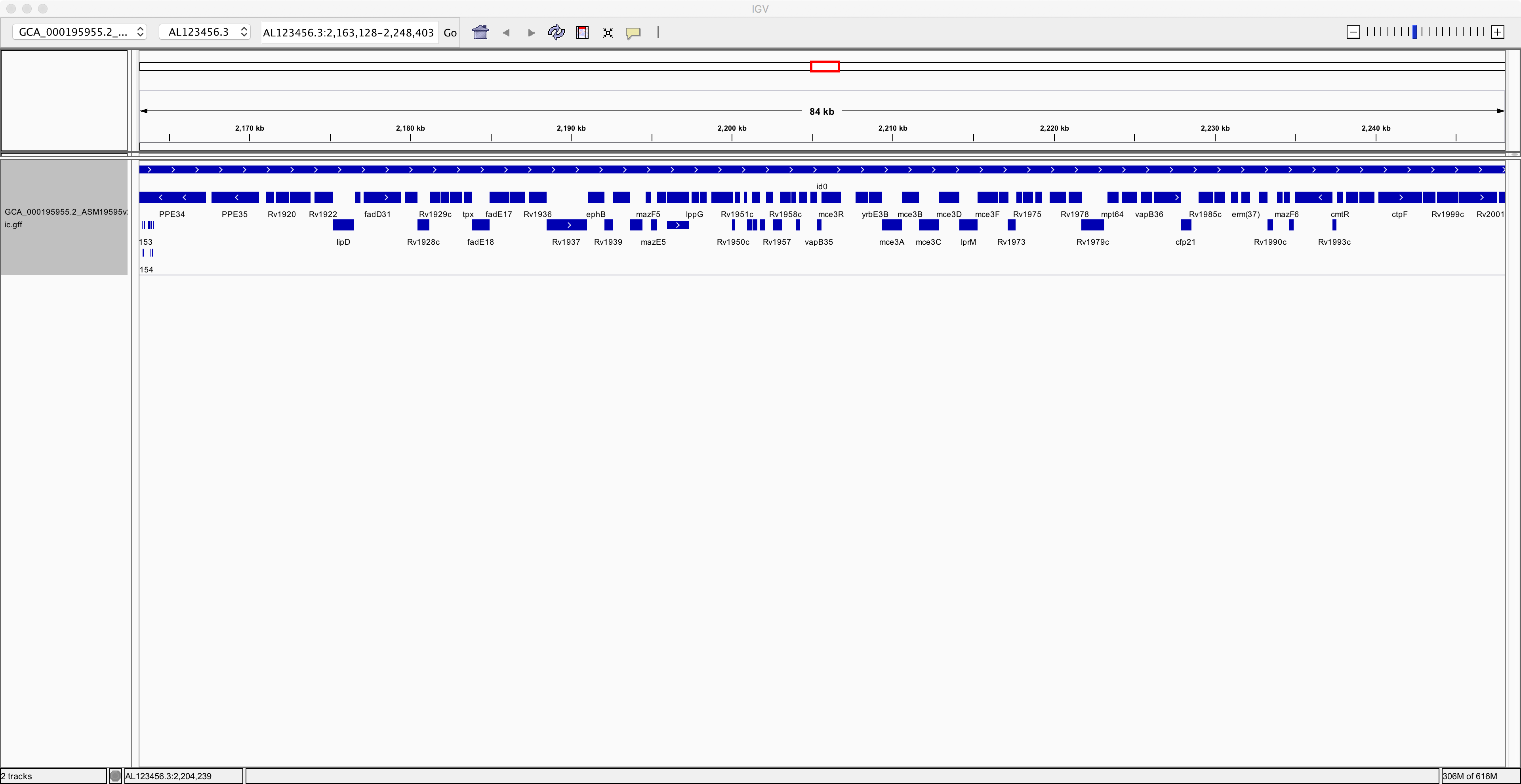
Now spend at least a few minutes learning how to navigate around the genome, zooming in on specific regions and finding information about specific genes:
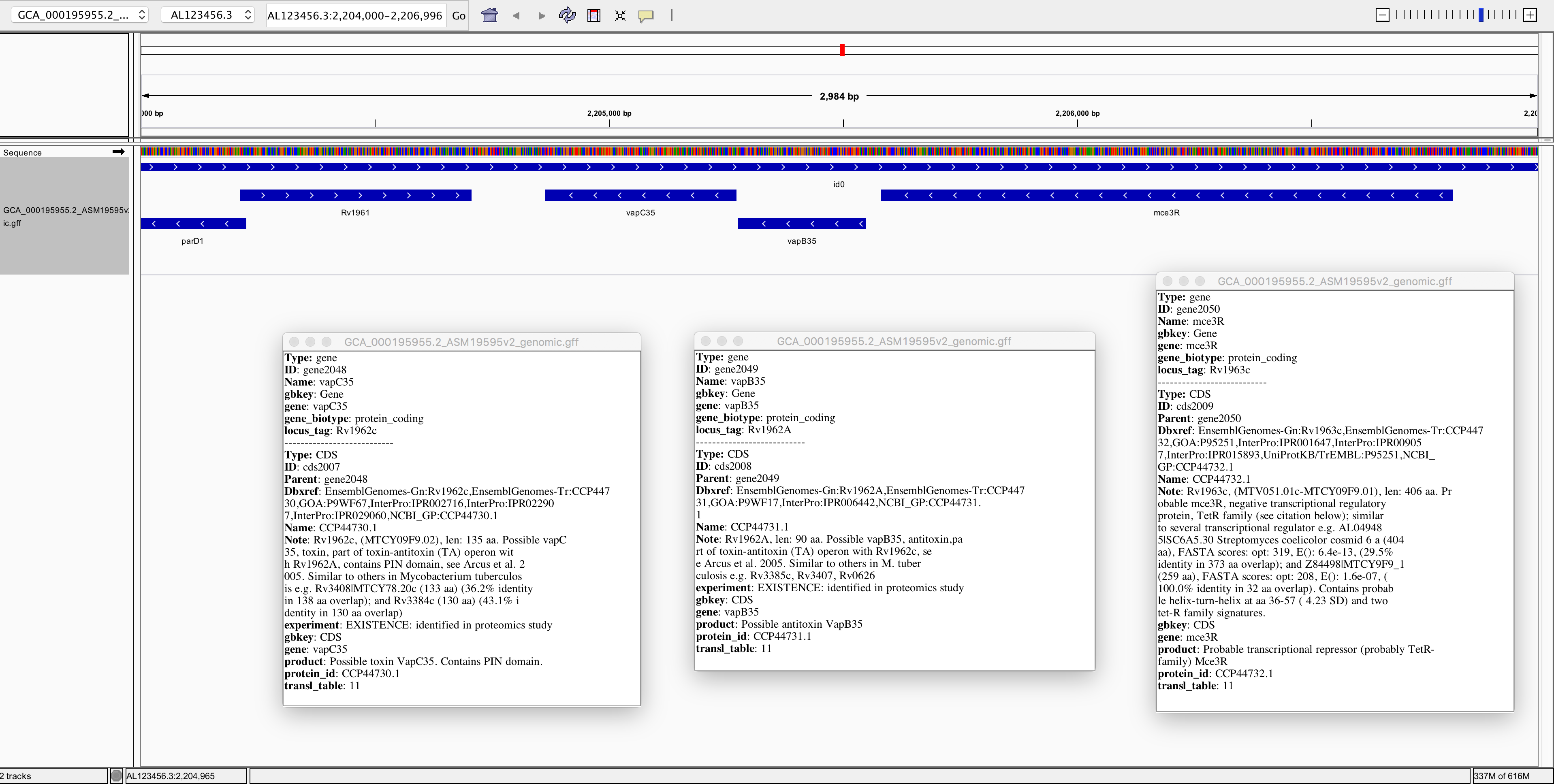
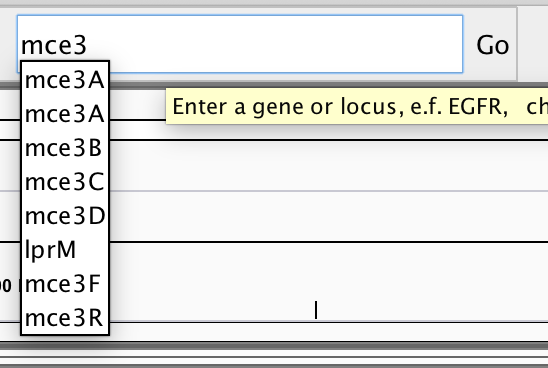
Note that you can navigate to specific sites on the genome or search for specific genes, using the search field near the top:
You might wish to locate genes of particular interest that are involved in virulence of this pathogen, e.g. katG, hspX (acr), erp, hma, pcaA. Once you are confident that you understand what you are looking at and are reasonably adept at navigating around the genome, then please proceed to loading the alignment data into IGV.
5.1.5 Loading the alignments into IGV
Use the “File -> Load from file” menu item to load the alignment files
that you downloaded earlier. The names of these files should end in
.bam. Please note that you also need to have the index files
(.bam.bai) present in the same folder. In the screenshot below, I am
loading two alignment files:
After loading these two alignments of genomic reads, we see something like the following screenshot. Please note that right-clicking on various parts of the window brings up menus that allow you to configure and rename tracks.
What is this ‘alignment data’ that you have added (from the .bam files)? It is the result of aligning each sequence read against this reference genome sequence. Make sure that you understand the following concepts:
- DNA sequencing
- Shotgun DNA sequencing
- A sequence read
- Sequence alignment
- Aligning sequence reads against a reference genome sequence
- Coverage depth
- “Paired-end” DNA sequencing
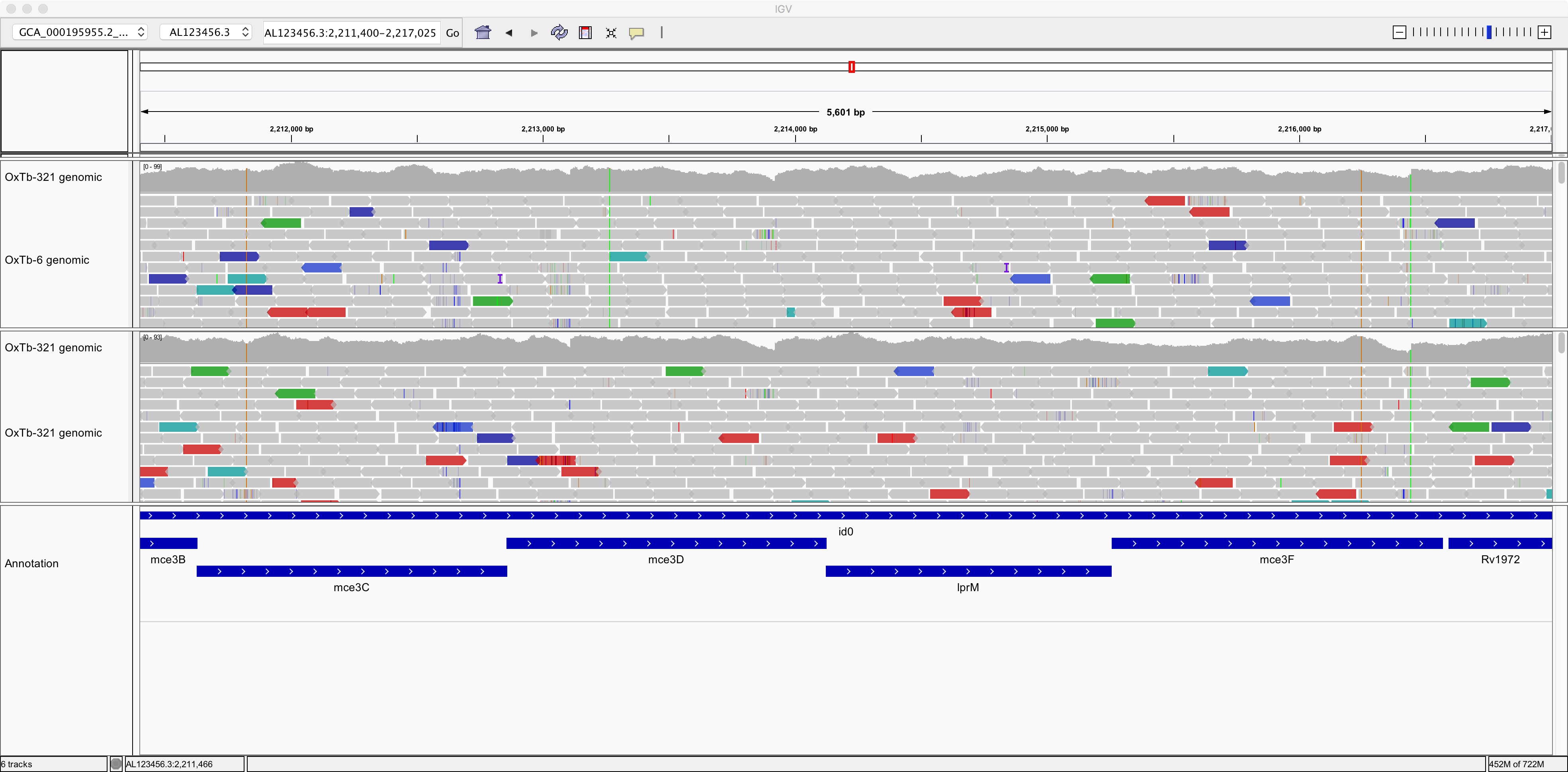
So, now we can see individual sequence reads aligned against the reference genome. We can also see plots of coverage depth.
Now let’s right-click on the tracks and choose the option to “View as pairs”. Now we can see pairs of reads joined by a thin horizontal line. This pairing arises from the fact that sequencing was performed at both ends of the genomic fragments.
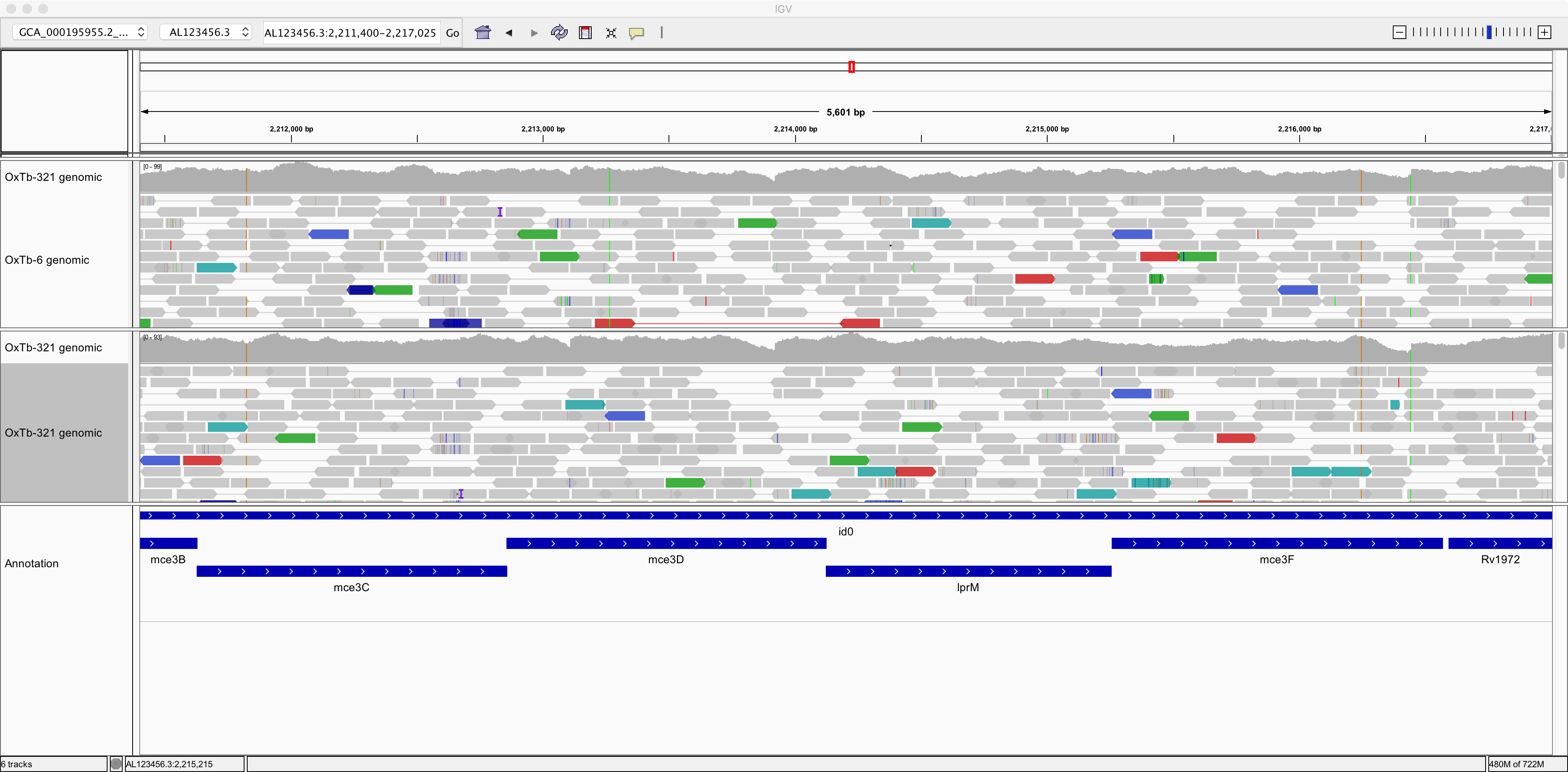
| Question | Answer |
|---|---|
| What size, approximately, were the fragments of genomic DNA in these two samples? | |
| What do you think is denoted by the different colours of the sequence reads? |
Now let’s zoom in on position AL123456.3:2,213,265:
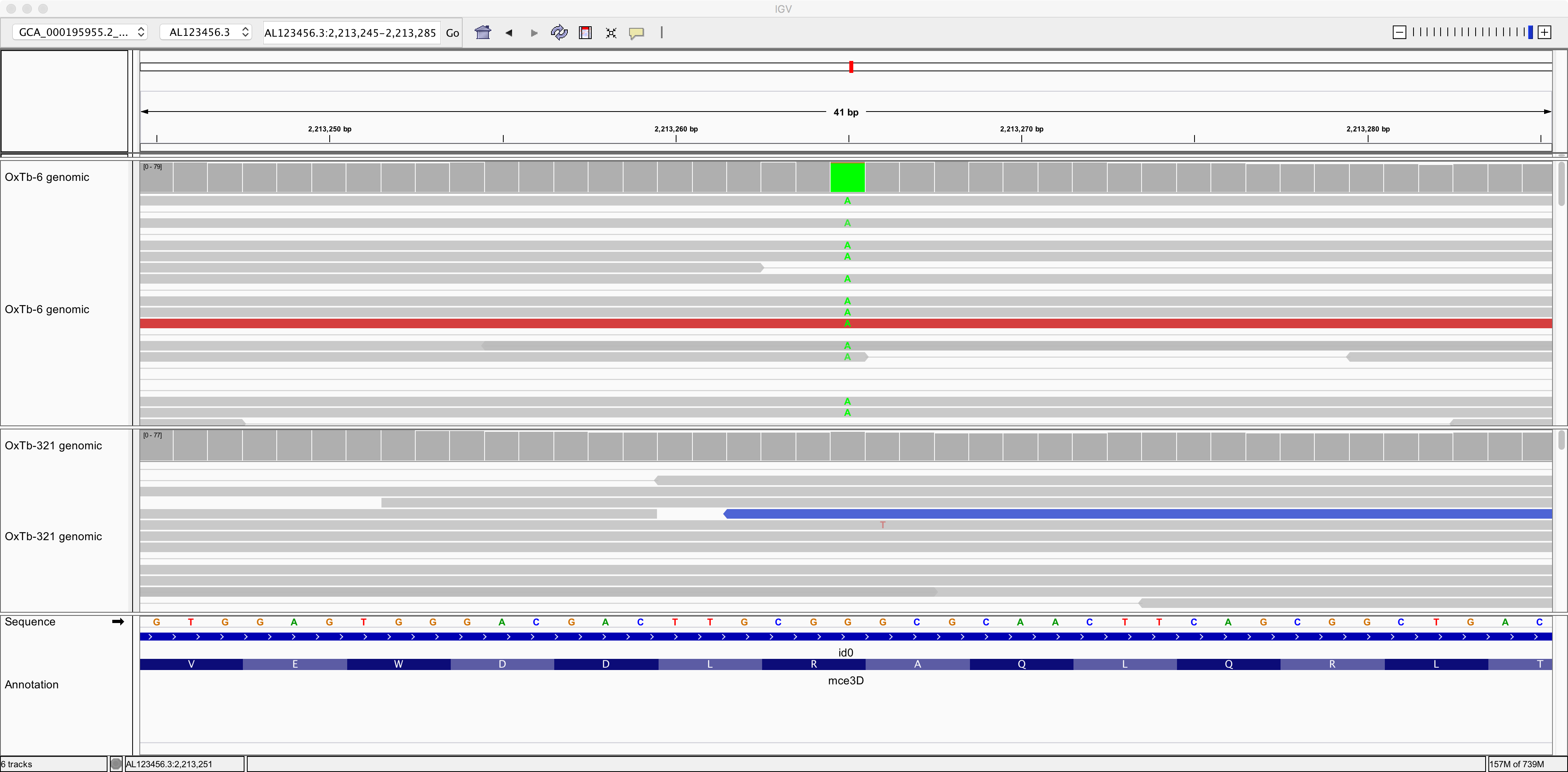
Here we can see a single-nucleotide polymorphism (SNP). Both the reference genome and strain OxTb-321 have a G at this position; but strain OxTb-6 has an A.
Do you think this G/A SNP will have any impact on an encoded protein? Why?
Now, try to find a few more SNPs:
| Genomic position | Reference base | Alternative base | Effect on protein |
|---|---|---|---|
Now, take a look at this genomic region: AL123456.3:2,232,639-2,244,376.
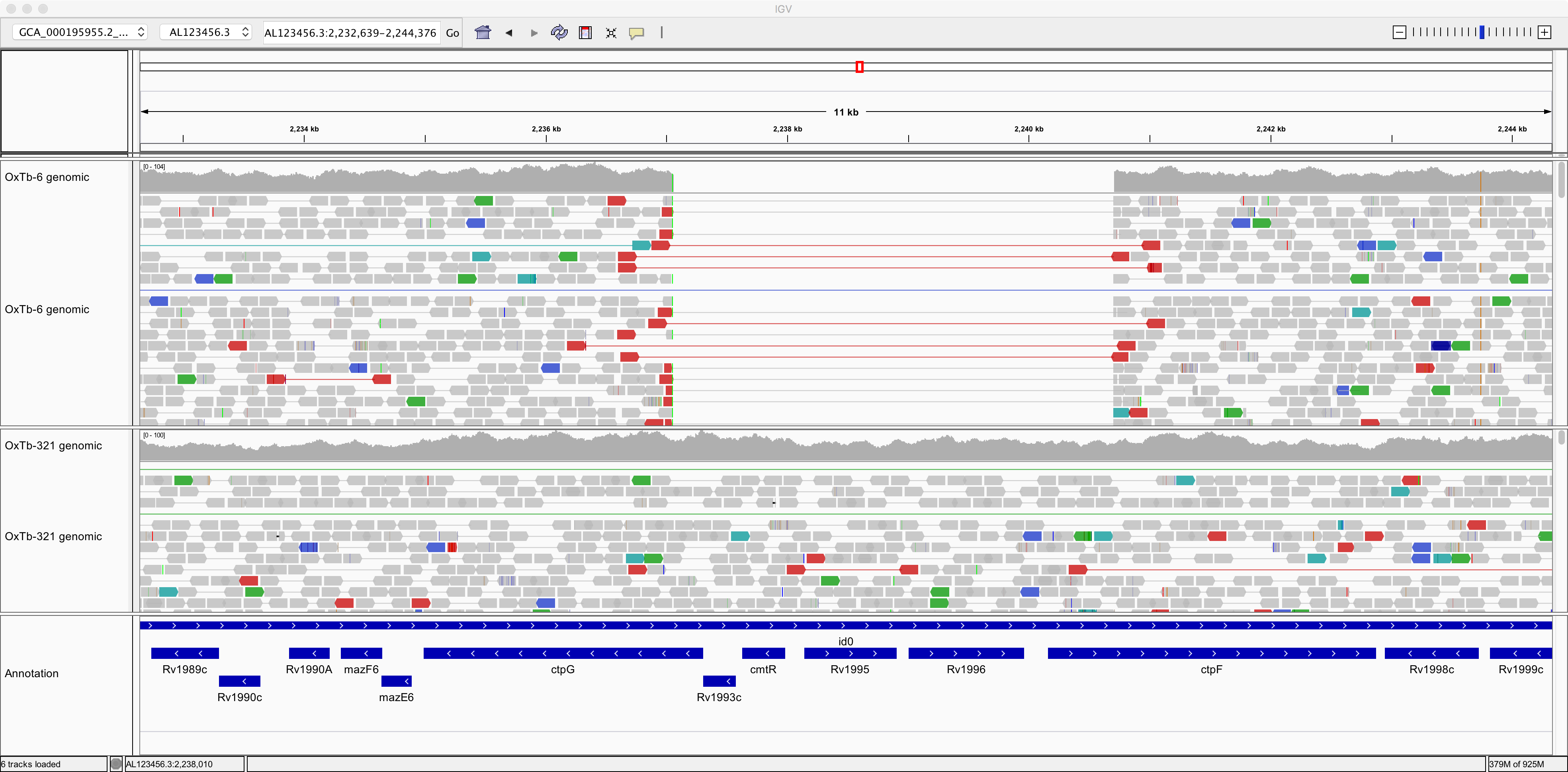
Here, strain OxTb-6 appears to lack a genomic region comprising 4 genes that are present in the reference and in OxTb-321. Notice how the read pairs span across the gap in OxTb-6. Can you find any other genes missing from OxTb-6 and/or OxTb-321?
Now let’s take a look at the genomic data generated using the PacBio method. This is in file
SRR3667790.versus.GCA_000195955.2_ASM19595v2_genomic.aln.sorted.bam.
Notice how the reads are much longer but contain numerous errors:
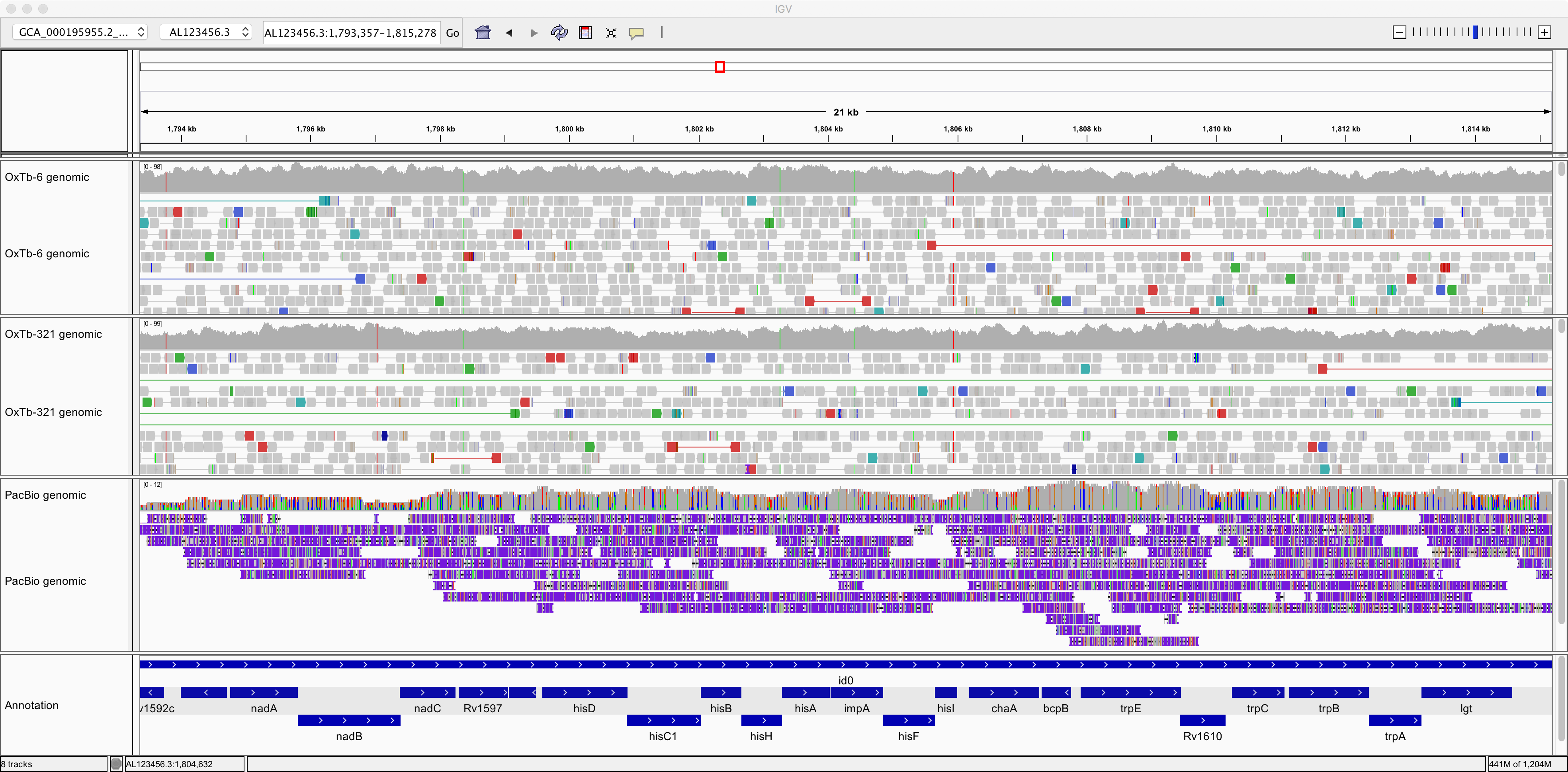
This illustrates the trade-off between read-length and read-accuracy that we are faced with when deciding the best strategy for sequencing a genome. In practice, often researchers have used a combination of Illumina plus PacBio sequencing, using short, accurate Illumina reads to correct the errors in the long, innaccurate reads. (More recently, the accuracy of PacBio sequencing has improved dramatically, such that it is now feasible to use only long PacBio reads; but the databases still contain a lot of poor-quality legacy data).
Now, let’s take a look at some transcriptomic data. Use “File -> Load
from file” to load alignment files
SRR5061507.versus.GCA_000195955.2_ASM19595v2_genomic.aln.sorted.bam
and
SRR5061515.versus.GCA_000195955.2_ASM19595v2_genomic.aln.sorted.bam.
This data consists of Illumina sequencing of fragments of cDNA (i.e. DNA generated in the lab by reverse-transcribing messenger RNA). It therefore presents a survey of the sequences mRNA transcripts present in the cell. The two samples were prepared from the same bacterial strain but under different growth conditions.
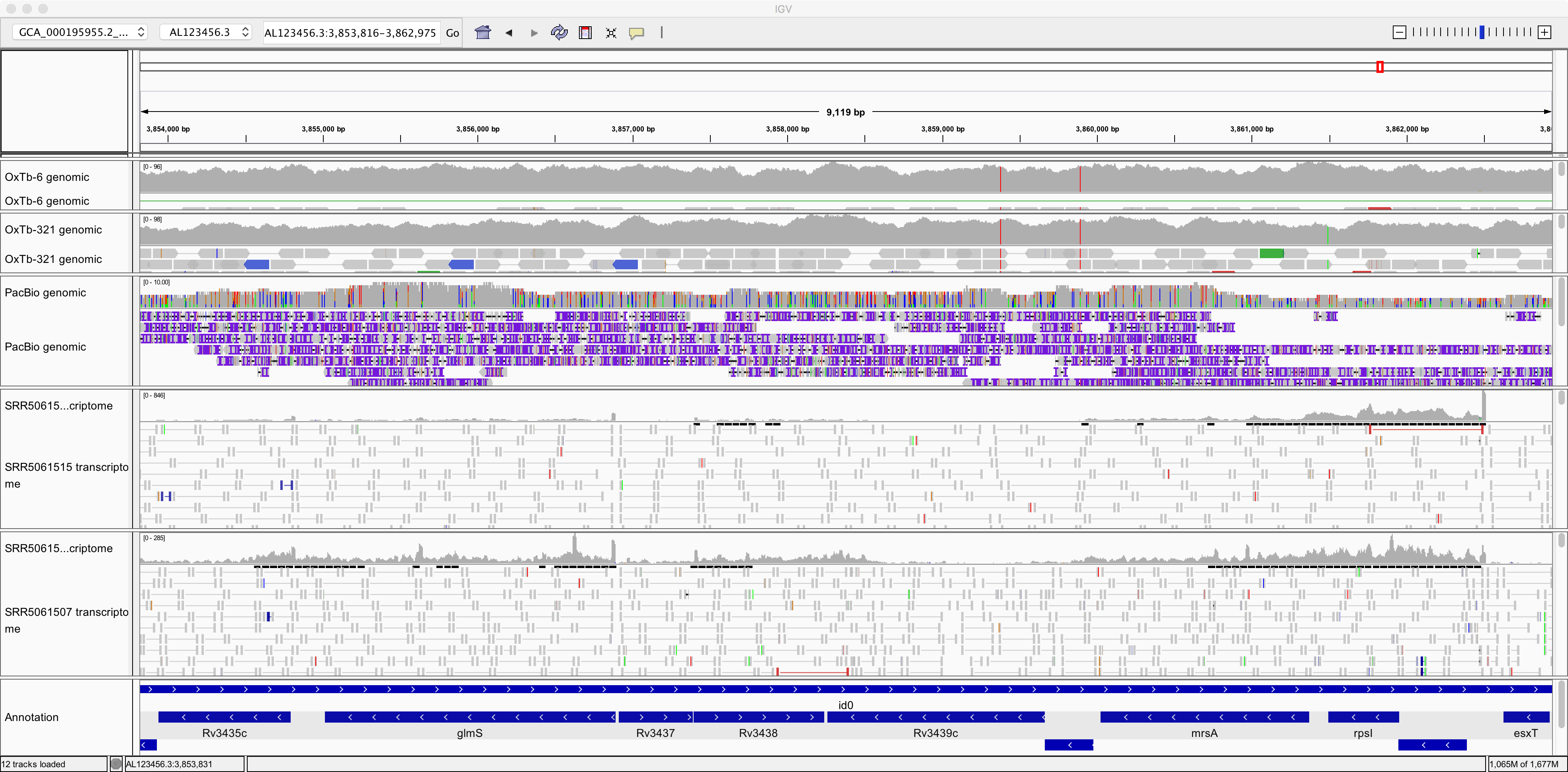
Note that the transcriptomics data looks quite different from the genomic data in a few respects. Make sure you understand the reason for each of these:
The depth of coverage by genomic sequence is more uniform than by transcriptomic sequence.
There are many “gaps” on the reference genome with little or no coverage by transcriptomic sequence.
There tend to be fewer mismatches between the RNA-seq sequences and the reference genome than is the case for these genomic datasets.
Also note in the image above, it seems that gene glmS is significantly more expressed (transcribed) in one sample than in the other. Can you find any more examples of such differentially expressed genes (DGEs)?
5.2 Using the web-based version of IGV
If you encounter problems with the locally installed version of IGV, try the web-based version instead.
First, in your web browser, navigate to https://igv.org/app/ Then use
the Genome -> Local File menu item to load your reference genome:
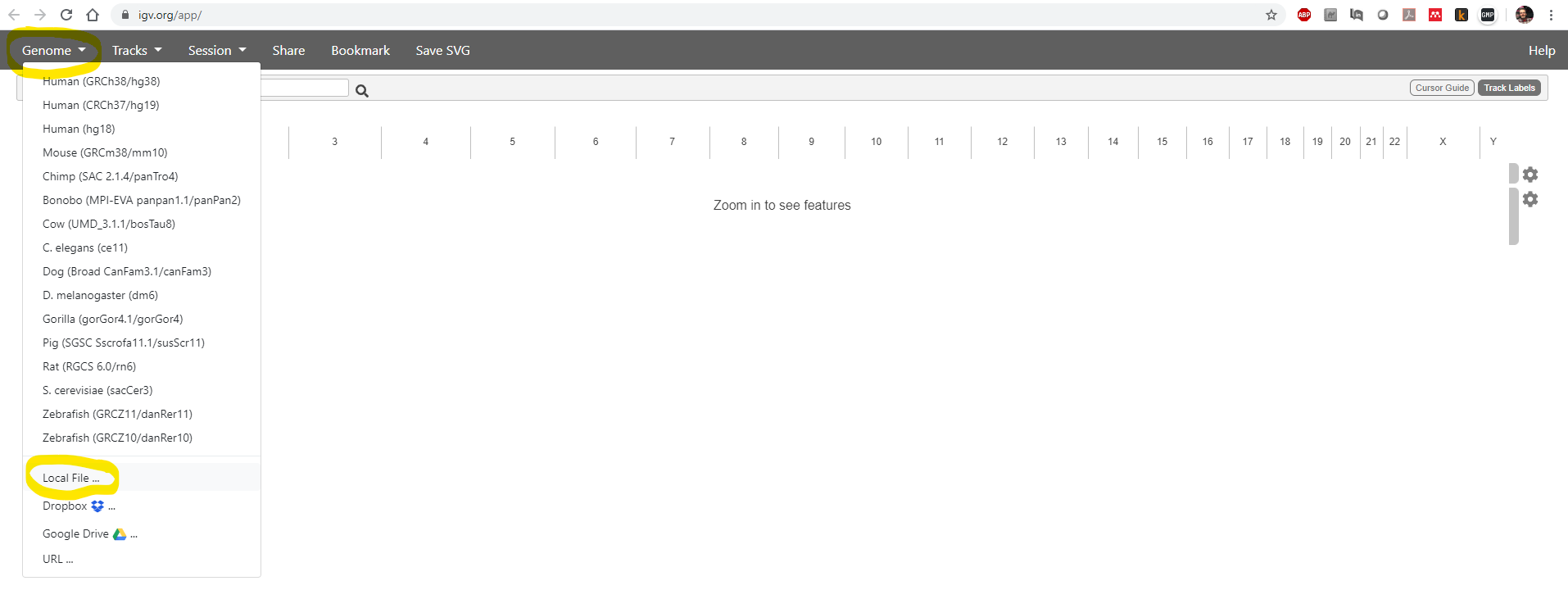
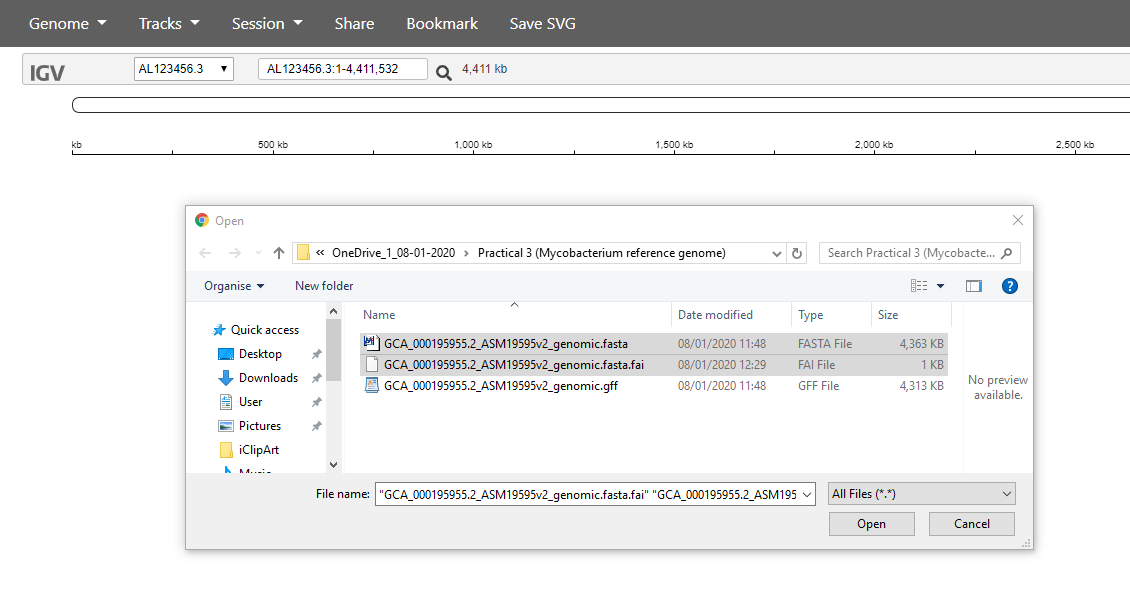
You need to select both of two files: the .fasta sequence file and
the .fasta.fai index file:
Next, use the Tracks -> Local File menu item to load your annotation.
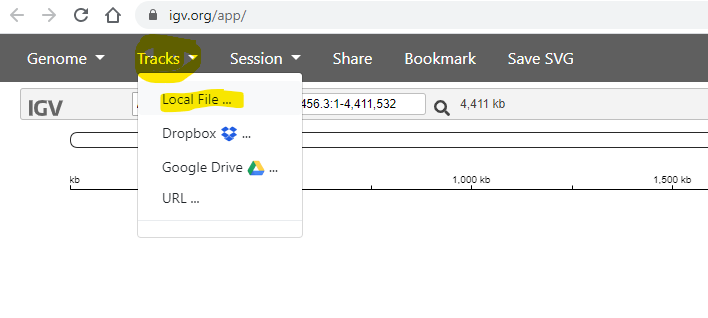
You need to to select the .gff file, which contains the annotation
(positions of genes etc) of the reference genome:
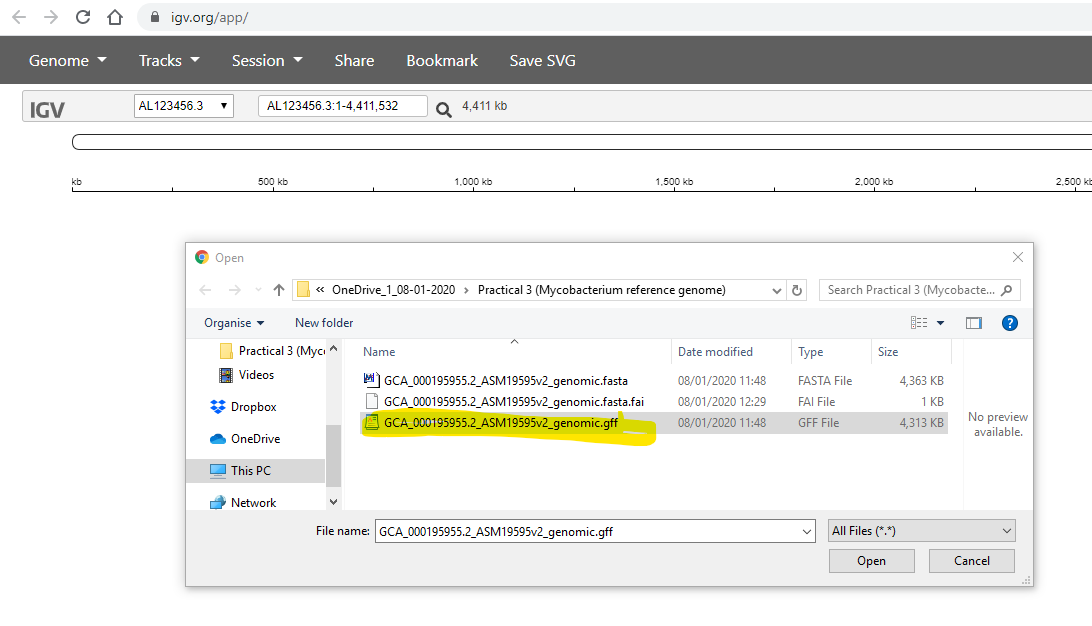
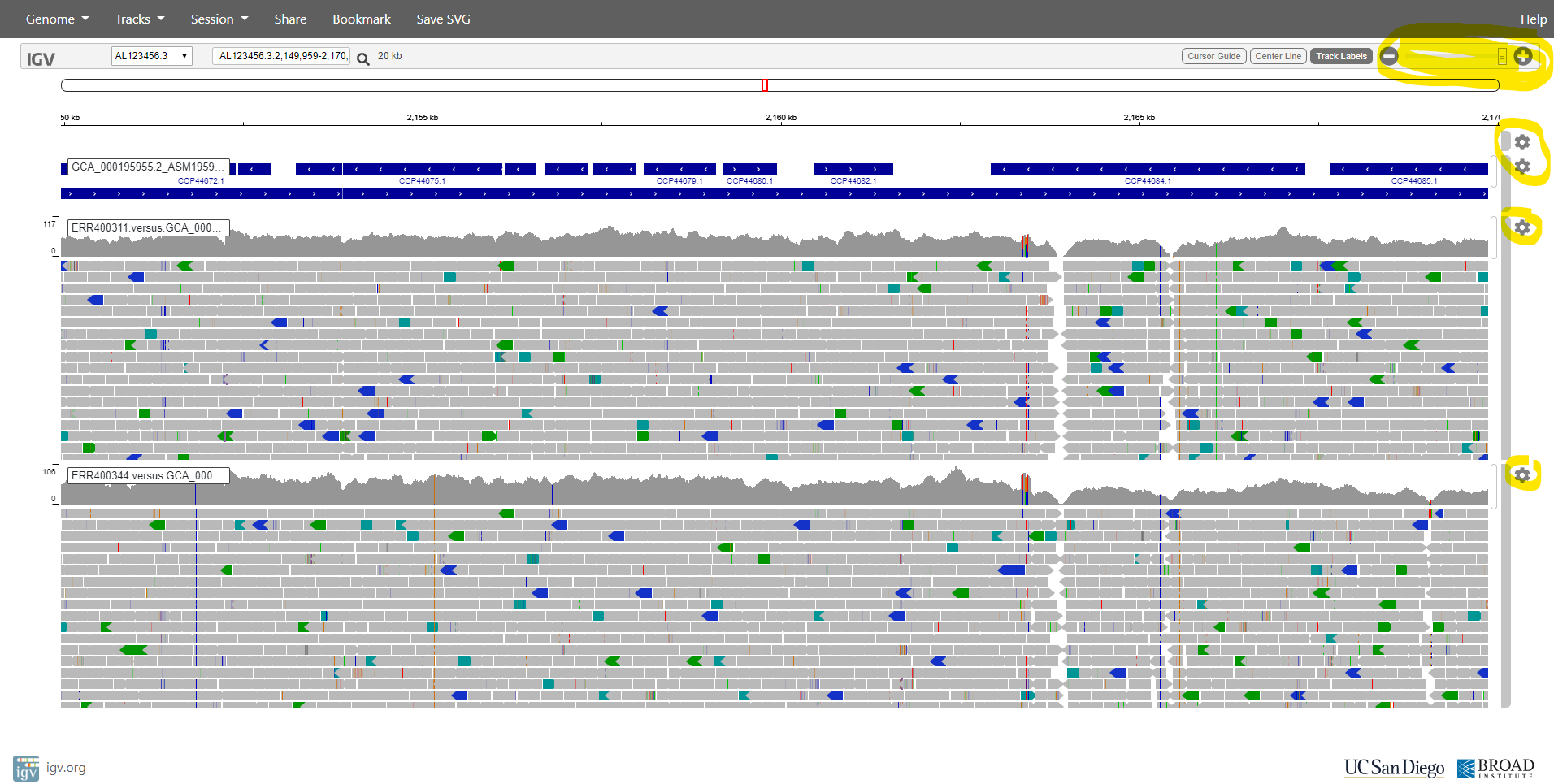
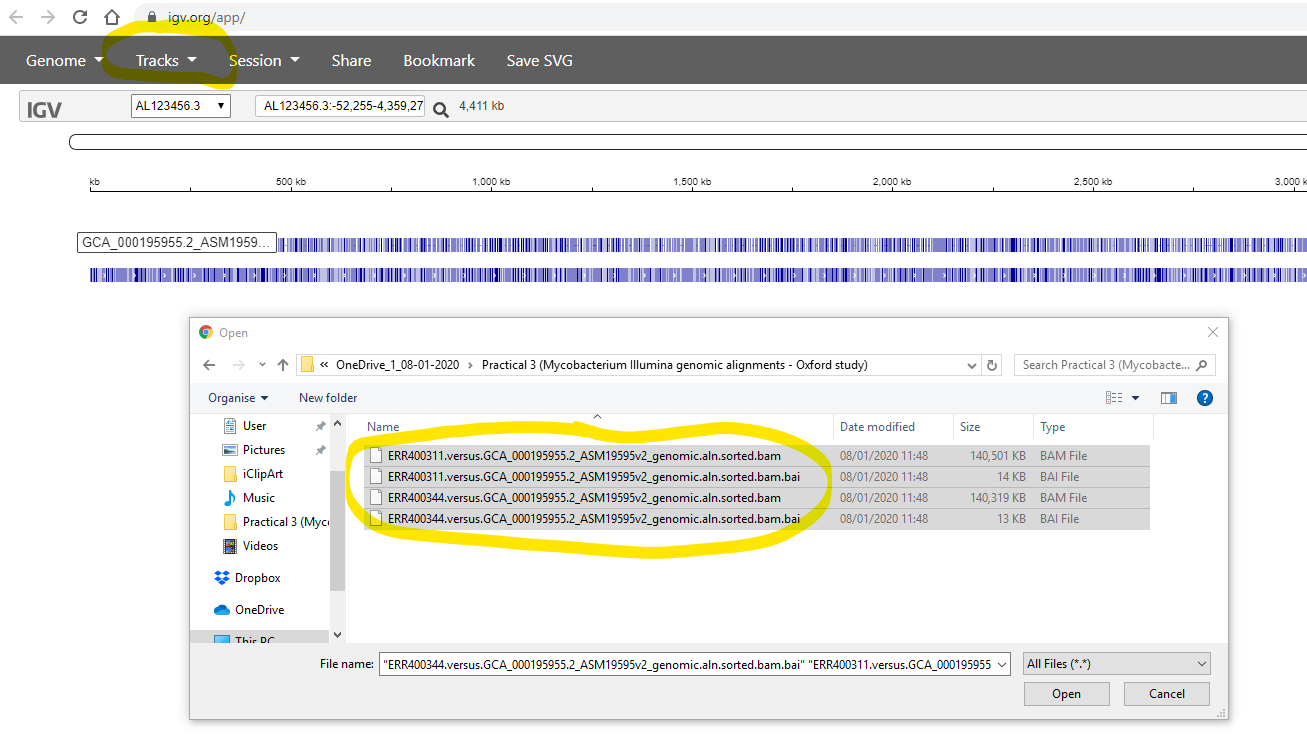
Finally, you use the Tracks -> Local File to select your .bam files.
Simultaneously, you also need to select the corrsponding .bam.bai file
for each of your .bam files:
After zooming-in (using the tool in the top-right), you should see the aligned reads something like the image below. Note that you can configure various aspects of the display by clicking on the widgets at the right side of the window.