Chapter 2 Whether the Treatment and Control Groups Differ in Other Fund Characterisitics?
To answer this question, we need to first define our treatment and control groups.
In our DID framework, we will compare filed funds with non-filed funds. However, since there are several phase-in dates for 6 groups of mutual funds, we follows the multiple DID framework in Gormley and Matsa (2011). To be more specific, for each phase-in date that new funds are filed into SEC, I will construct a cohort of filed and non-filed firms using firm-month observations for the 6 months before and the 6 months after the filing. Funds are not required to be in the sample for the full 12 months around the event. We then pool the data across cohorts with respect to different phase-in dates. The numbers of filed and non-filed funds for each phase-in date are shown in Figure 2.1. Note that 1 indicates funds filed into EDGAR in the corresponding phase-in date, and 0 means other funds that have not been filed into EDGAR before or during the year. Also, we will ignore the 6th phase-in date, because at that time all the funds are filed into EDGAR and therefore we are not able to construnct a control group.
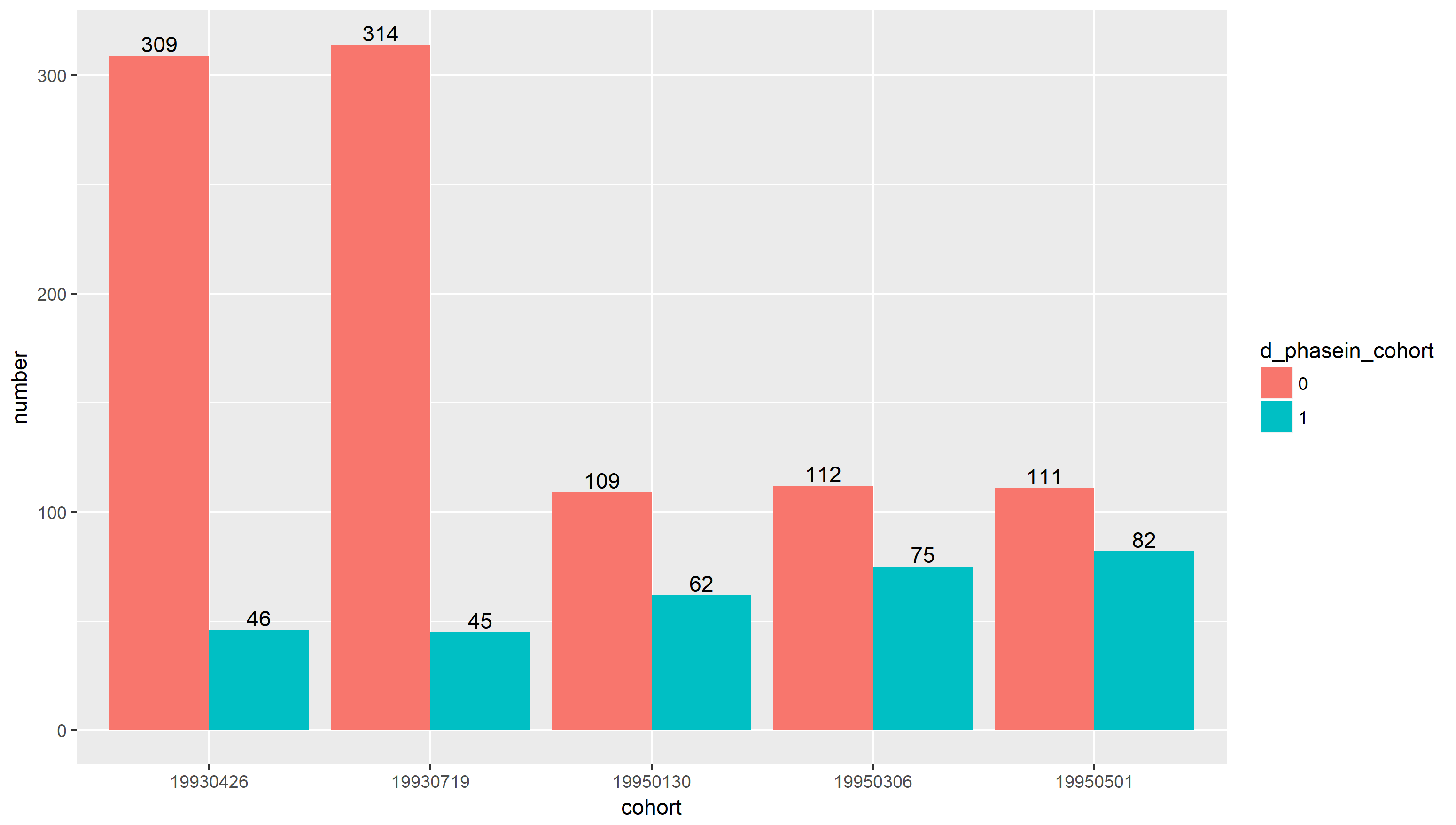
Figure 2.1: Numbers of filed and Non-filed funds in each of cohort
Then we will again compare fund characteristics among filed and non-filed funds for each of 5 cohorts. As shown in Figure 2.2, we found that some fund characteristics are differnt within cohort, before the treatmetn is assigned, that is, before the corresponding phase-in dates. For example, log of fund size and total loads. This could be problematic for DID. To mitigate it, it is appropriate to apply “propensity-score matching” to every sample in treatment group, which will be matched with a similarest sample in the control group. According to 2.2, the matching criterion should include log of fund size and total loads at least.
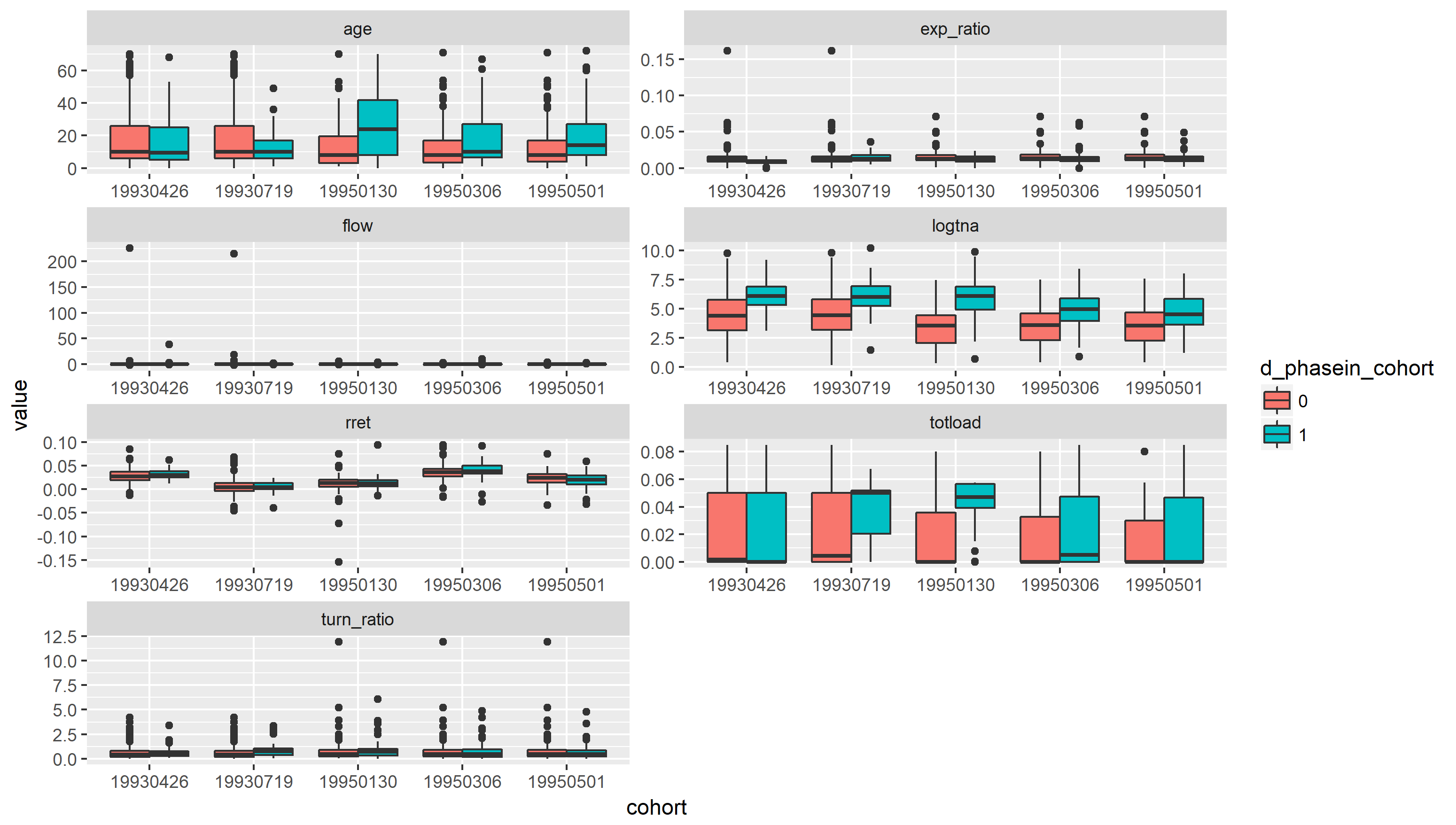
Figure 2.2: Mutual funds characteristics among 6 cohorts
Also, the outlier problem still exist, especially for fund flow and expense ratio. This reinforces our belief to remove those extreme sample in advance in order to get a more unbiased results.