Hoofdstuk 5 Exploratieve analyse van tijdgerelateerde data
5.1 Inleiding
5.1.1 Tijdstippen versus periodes
- We kunnen tijdgerelateerde data in twee categorieën onderverdelen: tijdstippen en periodes.
- Tijdstip.
- Verwijst naar een specifiek moment in de tijd.
- 3 varianten:
- datum (“01-01-2017”) verwijst naar een specifieke dag.
- datum-tijdstip (“01-01-2017 13:54”) verwijst naar een specifiek moment op een specifieke dag.
- tijdstip (“13:54”) verwijst naar een specifiek moment op een ongedefinieerde dag.
- Periode.
- Verwijst naar een periode en wordt typisch uitgedrukt aan de hand van de duur van de periode.
- Bijvoorbeeld: Een periode van “3605 seconden”" of een periode van “2 maanden en 1 dag”.
- Soms wordt een periode specifiek gedefinieerd aan de hand van twee specifieke tijdstippen die het begin en het einde van de periode aangeven.
- Bijvoorbeeld: De periode van 01-01-2017 tot 03-01-2017.
- Verwijst naar een periode en wordt typisch uitgedrukt aan de hand van de duur van de periode.
- Bestudeer hoofdstuk 16 van het boek ‘R for Data Science’ van Grolemund en Wickham !
5.2 Tijdstippen
5.2.1 Creatie van tijdstippen
- Opdat R correct met tijdstippen omgaat, is het belangrijk dat tijdstip-variabelen ook correct als tijdstippen herkend worden.
- Er zijn verschillende manieren om tijdstippen te creëren in R.
- Op basis van het huidige tijdstip.
- Dit is mogelijk met de functies today() en now() om respectievelijk een tijdstip van de huidige dag (datum) of het huidige tijdstip (datum_tijd) aan te maken.
- Op basis van karakterstring. Indien men reeds tijdstippen heeft in de dataset, maar deze zijn gecodeerd als karakterstrings, dan voorziet de lubridate package een aantal handige functies hiervoor:
- ymd(), ydm(), mdy(), myd(), dmy(), dym() voor datum-tijdstippen.
- ymd_hms(), ymd_hm(), ymd_h(), dmy_hms(), dmy_hm(), dmy_h(), mdy_hms(), mdy_hm(), mdy_h(), ydm_hms(), ydm_hm(), ydm_hm() voor datumtijd-tijdstippen.
- Al deze functies omschrijven de structuur van de karakterstring, waarbij y voor jaar staat, de eerste m voor maand, d voor dag, h voor uur, de tweede m voor minuten en s voor seconden.
- Om de karakterstring “2017-21-02 5:15” correct om te zetten naar een tijdstip, moet je dus de functie ydm_hm() gebruiken.
- Op basis van verschillende variabelen die ieder een verschillende component (jaar, maand, dag, uur, minuten, seconden) bevatten.
- Hiervoor kan je de functies ‘make_date()’ of ‘make_datetime()’ gebruiken, afhankelijk of je een datum- of een datumtijd-tijdstip wenst aan te maken.
- Op basis van het huidige tijdstip.
5.2.2 Extractie van tijdstipinformatie
- Eénmaal variabelen in R als tijdstippen gecodeerd zijn, is het eenvoudig om de verschillende componenten hieruit te extraheren.
- De componenten die je onmiddellijk op het oog kunt herkennen in de oorspronkelijke karakterstring zijn te extraheren met de volgende functies:
- year().
- month().
- mday().
- hour().
- minute().
- second().
- Daarnaast zijn er ook andere componenten die je uit een tijdstip kunt extraheren, dewelke niet rechtstreeks af te lezen zijn uit de oorspronkelijke karakterstring.
- week(): De week van het jaar. “5 feb 2017” is bijvoorbeeld de 6de week van het jaar.
- yday(): De dag in het jaar. “5 feb 2017” is bijvoorbeeld de 36ste dag van het jaar.
- wday(): De dag van de week. “5 feb 2017” is bijvoorbeeld de eerste dag van de week. Let wel op dat we hierbij de conventie hanteren dat een week op zondag start.
- wday(…, label=TRUE): De naam van de dag van de week. “5 feb 2017” is bijvoorbeeld zondag.
5.2.3 Afronden van tijdstippen
- Ieder tijdstip heeft een zekere nauwkeurigheid. Sommige tijdstippen zijn tot op de seconde gedefinieerd terwijl andere slechts een nauwkeurigheid hebben van weken of maanden.
- Soms kan het voor visualisaties of analyses zinvol zijn om tijdstippen minder nauwkeurig te maken en deze af te ronden. Hiervoor zijn er drie mogelijke functies, afhankelijk van het soort afronding dat men wenst.
- floor_date(): afronden naar onder toe.
- round_date(): normale afrondingsregels.
- ceiling_date(): afronden naar boven toe.
- Deze drie functies hebben 1 belangrijke parameter (unit) waarmee je het afrondingsniveau kunt bepalen.
5.2.4 Case: NYC Vluchten 2013
- We zullen de concepten omtrent tijdgerelateerde data illustreren aan de hand van een dataset over de vluchten vanuit NYC in 2013.
- Hieronder vind je een samenvatting van de verschillende variabelen die aanwezig zijn in de dataset.
## Observations: 319,809
## Variables: 12
## $ vertrekluchthaven <chr> "EWR", "LGA", "JFK", "LGA", "EWR", "EWR", ...
## $ aankomstluchthaven <chr> "George Bush Intercontinental", "George Bu...
## $ maatschappij <chr> "United Air Lines Inc.", "United Air Lines...
## $ jaar_vertrek <int> 2013, 2013, 2013, 2013, 2013, 2013, 2013, ...
## $ maand_vertrek <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
## $ dag_vertrek <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
## $ uur_vertrek <dbl> 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, ...
## $ minuut_vertrek <dbl> 17, 33, 42, 54, 54, 55, 57, 57, 58, 58, 58...
## $ tijdstip_aankomst <chr> "2013-01-01 08:30:00", "2013-01-01 08:50:0...
## $ vertrek_vertraging <dbl> 2, 4, 2, -6, -4, -5, -3, -3, -2, -2, -2, -...
## $ aankomst_vertraging <dbl> 11, 20, 33, -25, 12, 19, -14, -8, 8, -2, -...
## $ afstand <dbl> 1400, 1416, 1089, 762, 719, 1065, 229, 944...- Allereerst willen we de variabele tijdstip_aankomst omzetten van een karakterstring naar een datumtijd tijdstip.
df %>%
mutate(tijdstip_aankomst = ymd_hms(tijdstip_aankomst)) -> df
glimpse(df)## Observations: 319,809
## Variables: 12
## $ vertrekluchthaven <chr> "EWR", "LGA", "JFK", "LGA", "EWR", "EWR", ...
## $ aankomstluchthaven <chr> "George Bush Intercontinental", "George Bu...
## $ maatschappij <chr> "United Air Lines Inc.", "United Air Lines...
## $ jaar_vertrek <int> 2013, 2013, 2013, 2013, 2013, 2013, 2013, ...
## $ maand_vertrek <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
## $ dag_vertrek <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
## $ uur_vertrek <dbl> 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, ...
## $ minuut_vertrek <dbl> 17, 33, 42, 54, 54, 55, 57, 57, 58, 58, 58...
## $ tijdstip_aankomst <dttm> 2013-01-01 08:30:00, 2013-01-01 08:50:00,...
## $ vertrek_vertraging <dbl> 2, 4, 2, -6, -4, -5, -3, -3, -2, -2, -2, -...
## $ aankomst_vertraging <dbl> 11, 20, 33, -25, 12, 19, -14, -8, 8, -2, -...
## $ afstand <dbl> 1400, 1416, 1089, 762, 719, 1065, 229, 944...- Verder willen we ook een nieuwe variabele tijdstip_vertrek aanmaken op basis van de variabelen jaar_vertrek, maand_vertrek, dag_vertrek, uur_vertrek en minuut_vertrek.
df %>%
mutate(tijdstip_vertrek = make_datetime(jaar_vertrek,
maand_vertrek,
dag_vertrek,
uur_vertrek,
minuut_vertrek)) %>%
select(- jaar_vertrek,
-maand_vertrek,
-dag_vertrek,
-uur_vertrek,
-minuut_vertrek) -> df
glimpse(df)## Observations: 319,809
## Variables: 8
## $ vertrekluchthaven <chr> "EWR", "LGA", "JFK", "LGA", "EWR", "EWR", ...
## $ aankomstluchthaven <chr> "George Bush Intercontinental", "George Bu...
## $ maatschappij <chr> "United Air Lines Inc.", "United Air Lines...
## $ tijdstip_aankomst <dttm> 2013-01-01 08:30:00, 2013-01-01 08:50:00,...
## $ vertrek_vertraging <dbl> 2, 4, 2, -6, -4, -5, -3, -3, -2, -2, -2, -...
## $ aankomst_vertraging <dbl> 11, 20, 33, -25, 12, 19, -14, -8, 8, -2, -...
## $ afstand <dbl> 1400, 1416, 1089, 762, 719, 1065, 229, 944...
## $ tijdstip_vertrek <dttm> 2013-01-01 05:17:00, 2013-01-01 05:33:00,...- Vervolgens willen we graag enkele nieuwe variabelen aanmaken die de volgende informatie bevatten: de weekdag van vertrek (maandag, dinsdag, …), de week van vertrek, de maand van vertrek en de maanddag (1, 2, …, 31) van vertrek.
df %>%
mutate(weekdag_vertrek = wday(tijdstip_vertrek, label = T),
week_vertrek = week(tijdstip_vertrek),
maand_vertrek = month(tijdstip_vertrek),
maanddag_vertrek = mday(tijdstip_vertrek)) -> df
glimpse(df)## Observations: 319,809
## Variables: 12
## $ vertrekluchthaven <chr> "EWR", "LGA", "JFK", "LGA", "EWR", "EWR", ...
## $ aankomstluchthaven <chr> "George Bush Intercontinental", "George Bu...
## $ maatschappij <chr> "United Air Lines Inc.", "United Air Lines...
## $ tijdstip_aankomst <dttm> 2013-01-01 08:30:00, 2013-01-01 08:50:00,...
## $ vertrek_vertraging <dbl> 2, 4, 2, -6, -4, -5, -3, -3, -2, -2, -2, -...
## $ aankomst_vertraging <dbl> 11, 20, 33, -25, 12, 19, -14, -8, 8, -2, -...
## $ afstand <dbl> 1400, 1416, 1089, 762, 719, 1065, 229, 944...
## $ tijdstip_vertrek <dttm> 2013-01-01 05:17:00, 2013-01-01 05:33:00,...
## $ weekdag_vertrek <ord> Tues, Tues, Tues, Tues, Tues, Tues, Tues, ...
## $ week_vertrek <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
## $ maand_vertrek <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
## $ maanddag_vertrek <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...- Tenslotte zullen we een nieuwe variabele maken dewelke het vertrekmoment afrondt tot op de dag nauwkeurig (dus zonder het specifieke uur).
df %>%
mutate(dag_vertrek = floor_date(tijdstip_vertrek, "day")) -> df
glimpse(df)## Observations: 319,809
## Variables: 13
## $ vertrekluchthaven <chr> "EWR", "LGA", "JFK", "LGA", "EWR", "EWR", ...
## $ aankomstluchthaven <chr> "George Bush Intercontinental", "George Bu...
## $ maatschappij <chr> "United Air Lines Inc.", "United Air Lines...
## $ tijdstip_aankomst <dttm> 2013-01-01 08:30:00, 2013-01-01 08:50:00,...
## $ vertrek_vertraging <dbl> 2, 4, 2, -6, -4, -5, -3, -3, -2, -2, -2, -...
## $ aankomst_vertraging <dbl> 11, 20, 33, -25, 12, 19, -14, -8, 8, -2, -...
## $ afstand <dbl> 1400, 1416, 1089, 762, 719, 1065, 229, 944...
## $ tijdstip_vertrek <dttm> 2013-01-01 05:17:00, 2013-01-01 05:33:00,...
## $ weekdag_vertrek <ord> Tues, Tues, Tues, Tues, Tues, Tues, Tues, ...
## $ week_vertrek <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
## $ maand_vertrek <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
## $ maanddag_vertrek <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
## $ dag_vertrek <dttm> 2013-01-01, 2013-01-01, 2013-01-01, 2013-...5.3 Periode-data
- We kunnen 3 soorten van periodes onderscheiden, waarbij het eerste type (interval) naar een specifieke periode tussen 2 tijdstippen verwijst en de 2 andere types (duration en period) naar een periode van een specifieke duur verwijzen maar telkens onafhankelijk van het specifieke tijdstip.
- Om de verschillen duidelijk te illustreren werken we met twee specifieke tijdstippen “1 jan 2016” en “1 jan 2017”.
t1 <- ymd(160101)
t1## [1] "2016-01-01"t2 <- ymd(170101)
t2## [1] "2017-01-01"5.3.1 Interval
- Een interval is een periode die bepaald wordt door twee specifieke tijdstippen.
- Een interval creëer je met behulp van de speciale operator
%--%. - Intervals worden weinig gebruikt om rechtstreeks te analyseren, maar kunnen als tussenstap gebruikt worden om de duurtijd van specifieke periodes te bepalen.
interval_t2t1 <- t1 %--% t2
interval_t2t1## [1] 2016-01-01 UTC--2017-01-01 UTC5.3.2 Duration
- Duration is de duur van een periode uitgedrukt als het exact aantal seconden die feitelijk verstreken zijn tussen twee tijdstippen.
- Tussen ‘26 maart 2017 02:00:00’ en ‘26 maart 2017 03:00:01’ is slechts 1 seconde feitelijk verstreken omdat we van 2u naar 3u zijn overgeschakeld op het zomeruur.
- Durations gebruik je voornamelijk als je de werkelijke tijd tussen twee tijdstippen wenst te berekenen of wanneer je een aantal seconden wenst toe te voegen bij of af te trekken van een specifiek tijdstip.
- Om een duration van een specifieke duur te creëren gebruik je volgende functies:
- dseconds().
- dminutes().
- dhours().
- ddays().
- dweeks().
- dyears().
- Om de duration van een interval te bepalen, gebruik je de functie:
- as.duration().
t1 + dyears(1)## [1] "2016-12-31"interval_t2t1 / dyears(1)## [1] 1.00274as.duration(interval_t2t1)## [1] "31622400s (~1 years)"5.3.3 Period
- De tijd die verstreken ‘lijkt’ te zijn (op een klok) tussen twee tijdstippen.
- Dus tussen ‘26 maart 2017 02:00:00’ en ‘26 maart 2017 03:00:01’ zit een period van 1 uur en 1 seconde.
- Periods gebruik je voornamelijk als je periodes wilt toevoegen aan tijdstippen zonder rekening te moeten houden met onverwachte sprongen in de tijd (zomertijd/wintertijd, schrikkeljaren, …).
- Dus als je bij ieder tijdstip 1 dag (24u) wenst toe te voegen, kan je beter een period gebruiken dan een duration, omdat je anders rekening moet houden met de dag waarop we van zomer- naar winteruur gaan en omgekeerd.
- Belangrijke functies die periods aanmaken zijn:
- seconds().
- minutes().
- hours().
- days().
- months().
- weeks().
- years().
t1 + years(1)## [1] "2017-01-01"interval_t2t1 / years(1)## [1] 1as.period(interval_t2t1)## [1] "1y 0m 0d 0H 0M 0S"5.3.4 Case: NYC vluchten 2013
- Momenteel bevat onze dataset enkel het geplande vertrek- en aankomstmoment. We gaan nu aan de hand van de informatie over de vertrek- en aankomstvertraging de werkelijke vertrek- en aankomstmomenten bepalen.
df %>%
mutate(vertrek_werkelijk = tijdstip_vertrek + dminutes(vertrek_vertraging),
aankomst_werkelijk = tijdstip_aankomst + dminutes(aankomst_vertraging)) %>%
rename(aankomst_gepland = tijdstip_aankomst,
vertrek_gepland = tijdstip_vertrek) %>%
select(vertrekluchthaven, aankomstluchthaven, maatschappij, vertrek_gepland,
vertrek_werkelijk, vertrek_vertraging, aankomst_gepland,
aankomst_werkelijk, aankomst_vertraging, afstand, weekdag_vertrek,
week_vertrek, maand_vertrek, dag_vertrek, maanddag_vertrek) -> df
glimpse(df)## Observations: 319,809
## Variables: 15
## $ vertrekluchthaven <chr> "EWR", "LGA", "JFK", "LGA", "EWR", "EWR", ...
## $ aankomstluchthaven <chr> "George Bush Intercontinental", "George Bu...
## $ maatschappij <chr> "United Air Lines Inc.", "United Air Lines...
## $ vertrek_gepland <dttm> 2013-01-01 05:17:00, 2013-01-01 05:33:00,...
## $ vertrek_werkelijk <dttm> 2013-01-01 05:19:00, 2013-01-01 05:37:00,...
## $ vertrek_vertraging <dbl> 2, 4, 2, -6, -4, -5, -3, -3, -2, -2, -2, -...
## $ aankomst_gepland <dttm> 2013-01-01 08:30:00, 2013-01-01 08:50:00,...
## $ aankomst_werkelijk <dttm> 2013-01-01 08:41:00, 2013-01-01 09:10:00,...
## $ aankomst_vertraging <dbl> 11, 20, 33, -25, 12, 19, -14, -8, 8, -2, -...
## $ afstand <dbl> 1400, 1416, 1089, 762, 719, 1065, 229, 944...
## $ weekdag_vertrek <ord> Tues, Tues, Tues, Tues, Tues, Tues, Tues, ...
## $ week_vertrek <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
## $ maand_vertrek <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
## $ dag_vertrek <dttm> 2013-01-01, 2013-01-01, 2013-01-01, 2013-...
## $ maanddag_vertrek <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...5.4 Analyseren van tijdgerelateerde data
5.4.1 Case: NYC Vluchten 2013
- Een eerste stap om inzicht te krijgen in de tijdgerelateerde data is met behulp van de summary() functie. Het is vooral nuttig om naar de minima en maxima te kijken. Dit geeft vaak aan of de tijdsperiode waarvoor de data verzameld is overeenkomt met de verwachte periode. In onderstaand geval blijkt dit in orde te zijn.
summary(df)## vertrekluchthaven aankomstluchthaven maatschappij
## Length:319809 Length:319809 Length:319809
## Class :character Class :character Class :character
## Mode :character Mode :character Mode :character
##
##
##
##
## vertrek_gepland vertrek_werkelijk
## Min. :2013-01-01 05:17:00 Min. :2013-01-01 05:19:00
## 1st Qu.:2013-04-05 09:07:00 1st Qu.:2013-04-05 09:10:00
## Median :2013-07-04 13:43:00 Median :2013-07-04 13:47:00
## Mean :2013-07-03 21:27:29 Mean :2013-07-03 21:40:07
## 3rd Qu.:2013-10-01 20:37:00 3rd Qu.:2013-10-01 20:39:00
## Max. :2013-12-31 23:32:00 Max. :2014-01-01 00:19:00
##
## vertrek_vertraging aankomst_gepland
## Min. : -43.00 Min. :2013-01-01 07:02:00
## 1st Qu.: -5.00 1st Qu.:2013-04-05 11:22:00
## Median : -2.00 Median :2013-07-04 15:42:00
## Mean : 12.62 Mean :2013-07-03 23:42:08
## 3rd Qu.: 11.00 3rd Qu.:2013-10-01 22:27:00
## Max. :1301.00 Max. :2014-01-01 01:10:00
##
## aankomst_werkelijk aankomst_vertraging afstand
## Min. :2013-01-01 06:55:00 Min. : -86.000 Min. : 80
## 1st Qu.:2013-04-05 11:21:00 1st Qu.: -17.000 1st Qu.: 502
## Median :2013-07-04 15:36:00 Median : -5.000 Median : 828
## Mean :2013-07-03 23:49:08 Mean : 6.987 Mean :1035
## 3rd Qu.:2013-10-01 22:12:00 3rd Qu.: 14.000 3rd Qu.:1372
## Max. :2014-01-01 01:53:00 Max. :1272.000 Max. :4983
##
## weekdag_vertrek week_vertrek maand_vertrek
## Sun :44396 Min. : 1.00 Min. : 1.000
## Mon :48246 1st Qu.:14.00 1st Qu.: 4.000
## Tues :48084 Median :27.00 Median : 7.000
## Wed :47597 Mean :26.77 Mean : 6.569
## Thurs:47378 3rd Qu.:40.00 3rd Qu.:10.000
## Fri :47455 Max. :53.00 Max. :12.000
## Sat :36653
## dag_vertrek maanddag_vertrek
## Min. :2013-01-01 00:00:00 Min. : 1.00
## 1st Qu.:2013-04-05 00:00:00 1st Qu.: 8.00
## Median :2013-07-04 00:00:00 Median :16.00
## Mean :2013-07-03 07:43:47 Mean :15.74
## 3rd Qu.:2013-10-01 00:00:00 3rd Qu.:23.00
## Max. :2013-12-31 00:00:00 Max. :31.00
## 5.4.1.1 Analyse visuele tijdreekspatronen
- Eén van de meest voorkomende exploratieve visuele analysetechnieken voor tijdgerelateerde data is het zoeken naar patronen hoe een variabele doorheen de tijd verandert.
- De eerste stap is hierbij telkens de tijdreekspatronen te visualiseren. Om dit te doen kan je volgend stappenplan toepassen.
- Bepaal over welke tijdsdimensie je patronen wenst te bestuderen. Dit is je X-variabele. De X-variabele bepaalt de granulariteit van je visualisatie. Wens je op niveau van dagen te visualiseren, dan is je tijdsdimensie ‘dag’, en dan ga je gedetailleerder naar de patronen kijken, dan wanneer je op niveau van bijvoorbeeld ‘maand’ naar de data kijkt.
- Bepaal welke variabele je doorheen de tijd wenst te bestuderen. Dit is je Y-variabele.
- Je gaat voor iedere X waarde 1 Y waarde moeten hebben. Vaak betekent dit dat je deze Y-variabele nog moet aanmaken. Mogelijke Y variabelen zijn het aantal observaties per tijdseenheid of de centrummaat (bv. mediaan) van een specifieke variabele.
- Je R-code vertrekt steeds van de oorspronkelijke dataset, groepeert vervolgens op de tijdsdimensie, berekent de gewenste samenvattende statistiek (summarise()) en visualiseert vervolgens via ggplot() + geom_line().
- We willen bijvoorbeeld de evolutie zien van het aantal vluchten per dag. De tijdsdimensie is dus dag_vertrek en de Y-variabele wordt gemaakt door het aantal rijen per dag te tellen.
- De analyse van onderstaande grafiek toont een aantal opvallende zaken:
- Er is een zware en niet-wederkerende daling tussen januari en april. Hier moet iets uitzonderlijks gebeurd zijn.
- We zien een terugkerend patroon, waarbij om de aantal dagen een daling is in het aantal vluchten.
- De schommelingen en met name de daling op het einde van ieder terugkerend patroon wordt groter op het einde van het jaar.
df %>%
group_by(dag_vertrek) %>%
summarise(aantal_vluchten = n()) %>%
ggplot(aes(x=dag_vertrek, y=aantal_vluchten)) +
geom_line()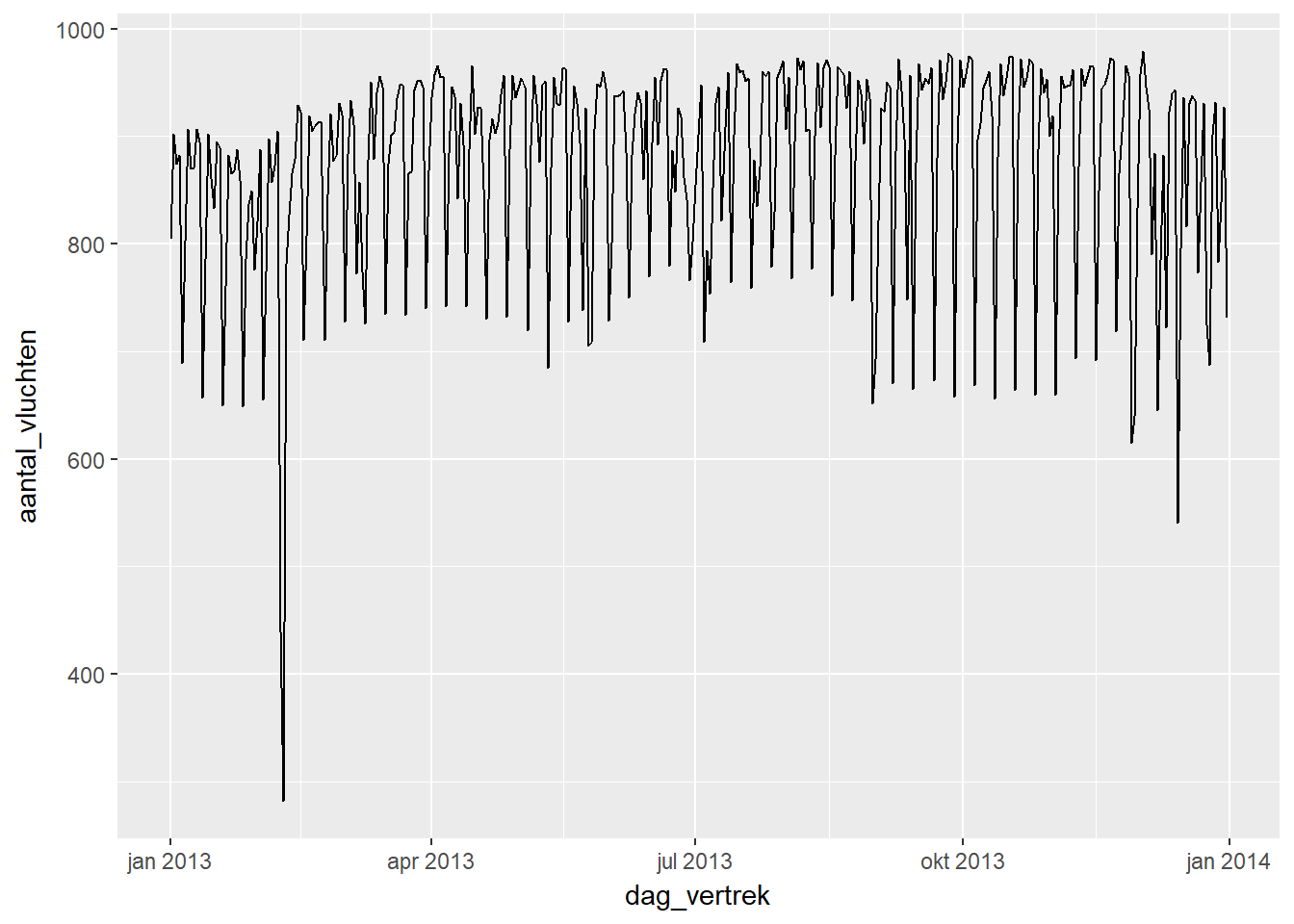
- We kunnen een soortgelijke analyse doen voor de gemiddelde vertrekvertraging.
df %>%
group_by(dag_vertrek) %>%
summarise(gemiddelde_vertrekvertraging = mean(vertrek_vertraging)) %>%
ggplot(aes(x=dag_vertrek, y=gemiddelde_vertrekvertraging)) +
geom_line()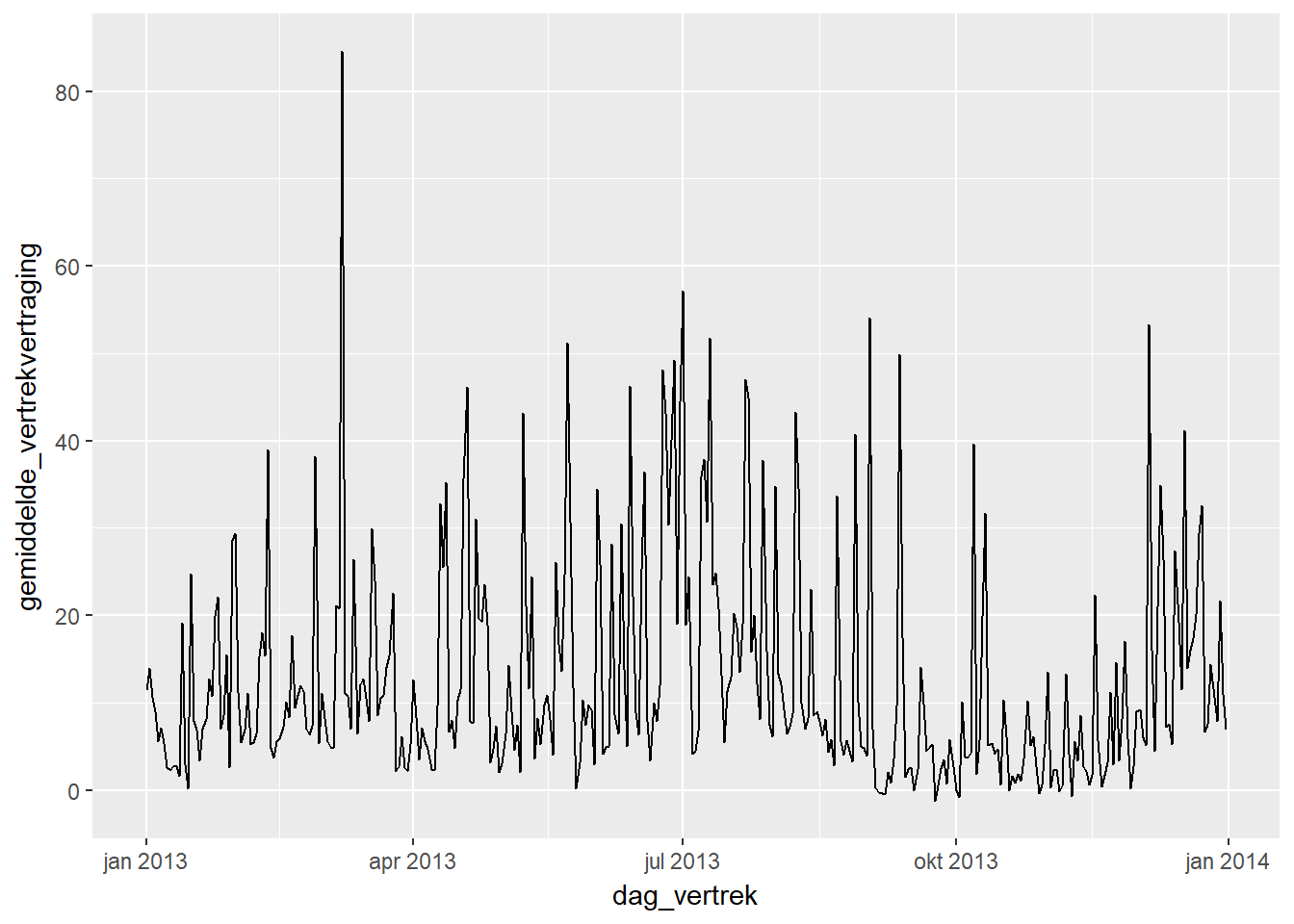
- Een volgende stap is vaak om de tijdreekspatronen apart te visualiseren voor de verschillende waarden van een categorische variabele.
- Dit kan op eenvoudige wijze door in onze R-code deze categorische variabele op te nemen in het group_by() gedeelte en vervolgens aparte plots te creëren met behulp van facet_wrap().
- Laten we de evolutie van het aantal vluchten per dag bijvoorbeeld uitsplitsen per luchthaven.
- Uit onderstaande analyse blijkt dan dat het aantal vluchten vanuit JFK veel minder sterk schommelt dan EWR en LGA. Wel valt op dat alle drie de luchthavens een sterke uitzonderlijke daling kenden in de eerste helft van het jaar.
df %>%
group_by(dag_vertrek, vertrekluchthaven) %>%
summarise(aantal_vluchten = n()) %>%
ggplot(aes(x = dag_vertrek, y = aantal_vluchten, colour=vertrekluchthaven)) +
geom_line() + facet_wrap(~vertrekluchthaven, ncol = 1)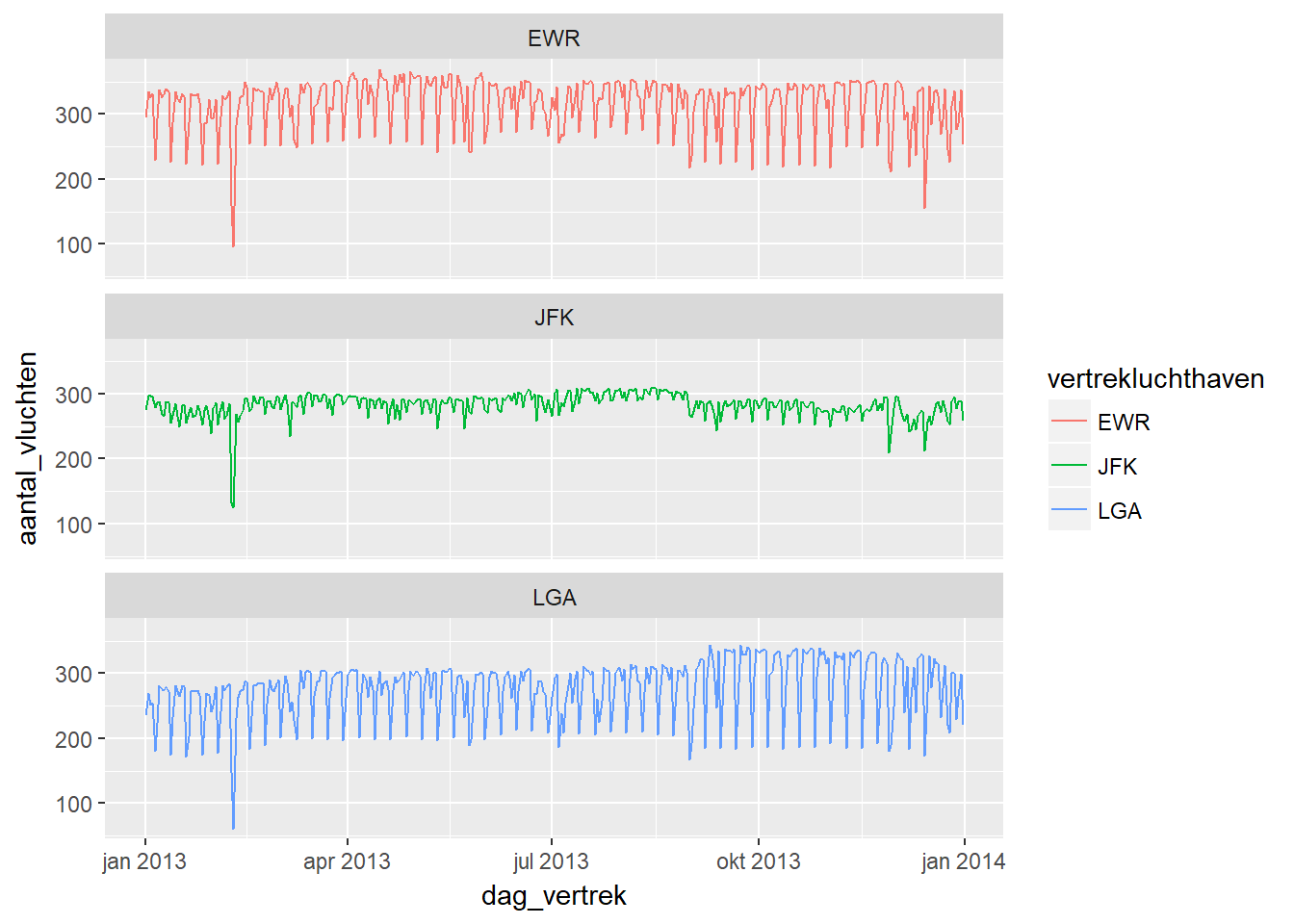
5.4.1.2 Identificeren van opmerkelijke gebeurtenissen in een tijdreeks
- In de evolutie van het aantal vluchten valt op dat er een uitzonderlijke daling plaatsvond in de periode tussen januari en april.
- In zulke gevallen is het best te achterhalen wat hier precies de oorzaak is.
- De eerste stap is dan ook het exacte tijdstip te identificeren.
- We kunnen dit doen door de data te filteren op die dagen dat er zeer weinig vluchten zijn.
df %>%
group_by(dag_vertrek, vertrekluchthaven) %>%
summarise(aantal_vluchten = n()) %>%
filter(aantal_vluchten < 160)## # A tibble: 7 x 3
## # Groups: dag_vertrek [3]
## dag_vertrek vertrekluchthaven aantal_vluchten
## <dttm> <chr> <int>
## 1 2013-02-08 EWR 159
## 2 2013-02-08 JFK 133
## 3 2013-02-08 LGA 148
## 4 2013-02-09 EWR 96
## 5 2013-02-09 JFK 125
## 6 2013-02-09 LGA 61
## 7 2013-12-14 EWR 155- Uit deze analyse blijkt dat de daling plaatsvond op 8 en 9 februari 2013. Na enig opzoekwerk blijkt dat New York toen geteisterd werd door een hevige sneeuwstorm waardoor zeer veel vluchten geannuleerd moesten worden.
- Omdat dit moment niet representatief is voor een normaal jaar, beslissen we om enkel met de tijdgerelateerde data van maart tot en met december verder te gaan.
df %>%
filter(vertrek_gepland >= ymd(130301)) -> df_mardec- We kunnen de tijdreeks van de nieuwe periode opnieuw visualiseren.
df_mardec %>%
group_by(dag_vertrek, vertrekluchthaven) %>%
summarise(aantal_vluchten=n()) %>%
ggplot(aes(x = dag_vertrek, y= aantal_vluchten, colour=vertrekluchthaven)) +
geom_line() + facet_wrap(~ vertrekluchthaven, ncol = 1)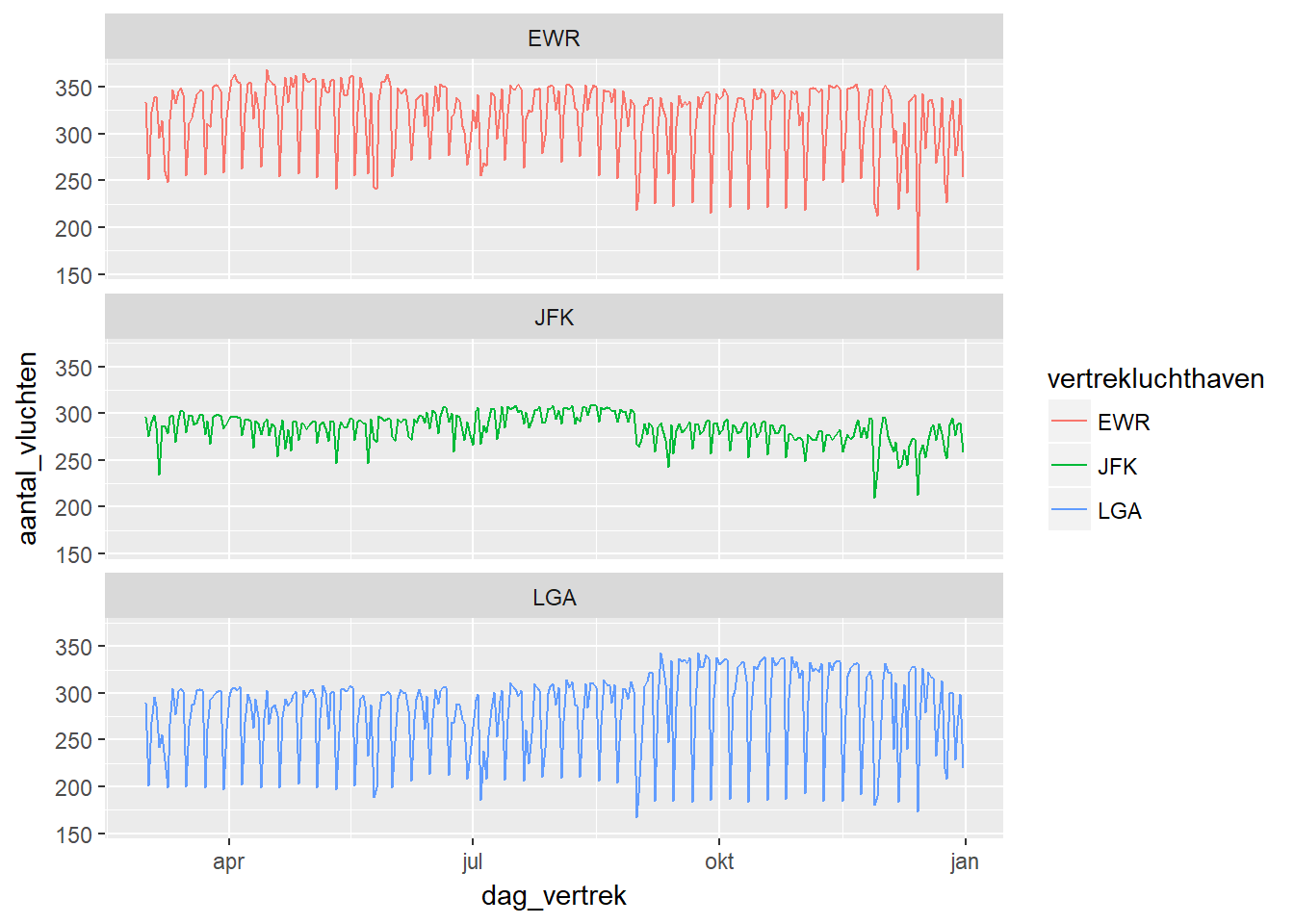
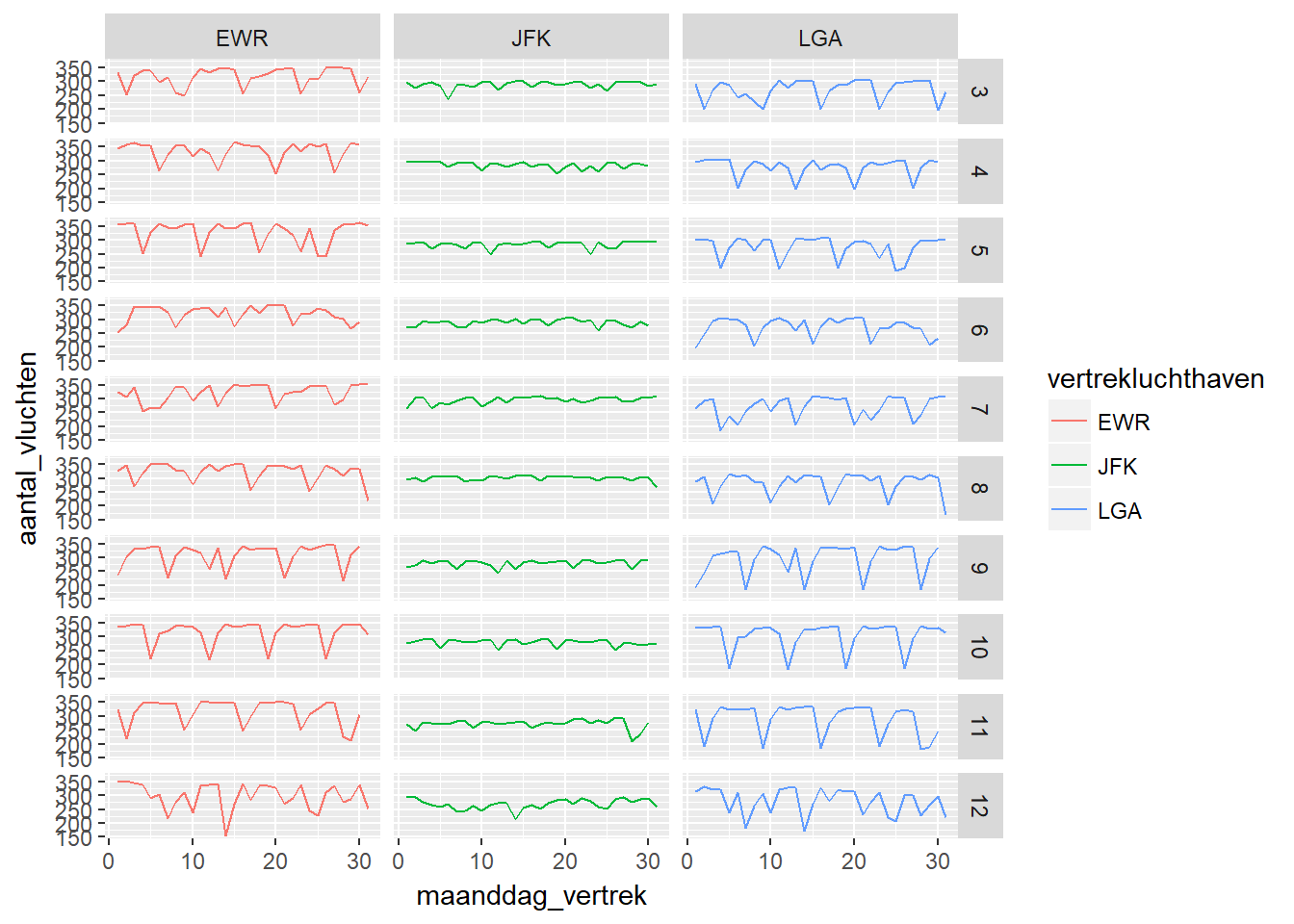
- We kunnen verder inzoomen in de data door naar de tijdreekspatronen te kijken per maand en per luchthaven.
df_mardec %>%
group_by(maanddag_vertrek, maand_vertrek, vertrekluchthaven) %>%
summarise(aantal_vluchten = n()) %>%
ggplot(aes(x=maanddag_vertrek, y=aantal_vluchten, colour=vertrekluchthaven)) +
geom_line() + facet_grid(maand_vertrek ~ vertrekluchthaven)