Chapter 4 基本資料統計
透過dplyr套件統計運輸資料是數據分析的第一步,可瞭解運輸供給與需求的概況,並可將大數據轉換為可理解且有意涵的資訊。
4.1 公車資料統計分析
請先利用 TDX 套件介接公車資料(以新竹市為例):
# 公車路線
bus_route=Bus_Route(access_token, "Hsinchu")
# 公車站牌
bus_stop=Bus_StopOfRoute(access_token, "Hsinchu")
# 公車站間距離
bus_distance=Bus_Distance(access_token, "Hsinchu", bus_route$RouteID)以下藉由各議題展示分析架構與程式碼,針對每一問題先瞭解運輸資料的特性,而後再依據分析邏輯撰寫程式碼。
4.1.1 路線統計分析
公車路線的代碼有兩種,其一為 RouteUID,另一為 SubRouteUID。前者是主路線代碼,後者是子路線代碼,亦即將主路線再依據不同行駛路線(如:延駛、繞駛等)或方向(去程、返程)細部分類不同路線。
§ 統計所有主路線數
先初步觀察bus_route資料可以發現,當中有許多重複的主路線,故不可直接透過資料的列數(row)來判斷主路線數,必須先去除重複的代碼。unique()函式可用以去除一向量中重複的元素,故執行後所回傳的向量僅會是唯一值。若欲計算一向量的總個數,可透過length()回傳長度。程式碼撰寫如下。
## [1] 26試著統計此資料的總子路線數,檢查是否與bus_route總資料筆數相同?
## [1] 54## [1] TRUE由以上結果得知,總子路線數會等於總資料筆數!
§ 統計各主路線擁有的子路線數
由於我們知道一個主路線可能含括多個子路線,若欲統計各主路線擁有的子路線數,可利用group_by() %>% summarise()達成此一目的,程式碼撰寫如下。首先根據 RouteUID 與 RouteName 分組,再統計相同主路線的總資料筆數(n())。
bus_route_sum=group_by(bus_route, RouteUID, RouteName)%>%
summarise(NumSubRoute=n())
# 查看前六筆結果
head(bus_route_sum)## # A tibble: 6 × 3
## # Groups: RouteUID [6]
## RouteUID RouteName NumSubRoute
## <chr> <chr> <int>
## 1 HSZ0007 81 2
## 2 HSZ0008 83 4
## 3 HSZ0010 藍線1區 1
## 4 HSZ0020 2 4
## 5 HSZ0100 10 2
## 6 HSZ0110 11 2由統計結果可知,RouteUID 為 HSZ0007(路線名為 81)者,其子路線數為 2 條,查看原始bus_route資料,可發現其含括子路線 HSZ000701 與 HSZ000702;又 HSZ0008(路線名為 83)的子路線數共計 4 條,其中包含 HSZ000801、HSZ000802、HSZ0008A1、HSZ0008A2。細部觀察原始資料,可發現 HSZ0007 兩條子路線的 Direction 一個為 0;另一為 1,表示方向不同,子路線即不同。而 HSZ0008 除了因方向不同而有不同子路線外,子路線代碼含括「A1」與「A2」者為延駛或繞駛,亦會使子路線不同。上述皆為 TDX 針對公車路線編碼的標準規範。最後 HSZ0010(路線名為 藍線1區)僅一條子路線,乃因該路線為環狀線(注意:藍線1區公車係由火車站至竹中站後立即折返,故屬於環狀線)。
{kind=link}
{kind=link}
{kind=link}
§ 羅列各主路線含括的子路線
前一案例藉由group_by() %>% summarise()計算總數,事實上此一函式的功能繁多,可透過改變summarise()函式內的操作,以達成目的。如欲整理各主路線含括的子路線代碼與名稱,應將 RouteUID 與 RouteName 作為分群的變項,並在summarise()函式中將所有同一分群者,將其子路線代碼以paste()函式相連。其中paste()函式內,須設定collapse=參數,以表達使用特定的符號或字元串接。依上述流程,程式碼撰寫如下。
bus_route_list=group_by(bus_route, RouteUID, RouteName)%>%
summarise(AllSubRoute=paste(SubRouteUID, collapse=", "))
# 查看前六筆結果
head(bus_route_list)## # A tibble: 6 × 3
## # Groups: RouteUID [6]
## RouteUID RouteName AllSubRoute
## <chr> <chr> <chr>
## 1 HSZ0007 81 HSZ000701, HSZ000702
## 2 HSZ0008 83 HSZ000801, HSZ000802, HSZ0008A1, HSZ0008A2
## 3 HSZ0010 藍線1區 HSZ001001
## 4 HSZ0020 2 HSZ002001, HSZ002002, HSZ0020A1, HSZ0020A2
## 5 HSZ0100 10 HSZ010001, HSZ010002
## 6 HSZ0110 11 HSZ0110A1, HSZ0110A2§ 尋找公車支線
在前述的案例中,我們發現有些公車主路線會有多條子路線,除了因為跟方向有關外,其次則是屬於支線之故,形成繞駛或延駛情形。進一步觀察可以發現,新竹市公車的支線中,其名稱會包含「支」一字。若欲擷取所有支線資料,可藉由grepl()函式先尋找該字元是否存在 SubRouteName 的欄位中,所回傳的邏輯判斷值可用以進一步篩選原始資料。程式碼撰寫如下。
# 利用grepl查看SubRouteName中是否含有「支」字
sub_TF=grepl("支", bus_route$SubRouteName)
# 透過sub_TF的邏輯判斷回傳所需資料
bus_route[sub_TF, c("RouteName", "SubRouteUID", "SubRouteName")]## RouteName SubRouteUID SubRouteName
## 5 83 HSZ0008A1 83支A
## 6 83 HSZ0008A2 83支A
## 10 2 HSZ0020A1 2支A
## 11 2 HSZ0020A2 2支A
## 30 20 HSZ0200A1 20支A
## 33 23 HSZ0230A1 23支A
## 34 23 HSZ0230A2 23支A
## 41 52 HSZ0520A1 52支A#---可直接簡化為:---#
# bus_route[grepl("支", bus_route$SubRouteName), c("RouteName", "SubRouteUID", "SubRouteName")]以上的中括號([ , ])內,逗點前表示擷取的橫列(row),逗點後則為擷取的直欄(column),可直接輸入欲回傳的欄列數值或名稱,抑或使用邏輯值(T, F),惟須注意使用邏輯值時,向量長度必須相同!
此外亦可透過filter()函式達成相同結果,程式碼撰寫如下。
4.1.2 站牌統計分析
公車站牌資料中係記錄每一子路線(SubRouteUID)的所有站牌資訊,含括路線名稱、方向、站牌代碼、名稱、站序、經緯度等資訊。
§ 統計各子路線總站牌數
如前述統計各主路線中子路線數量的方法,可利用group_by() %>% summarise()函式達成目的,程式碼撰寫如下。
bus_stop_sum=group_by(bus_stop, SubRouteUID, SubRouteName, Direction)%>%
summarise(StopNum=n())
# 查看前六筆結果
head(bus_stop_sum)## # A tibble: 6 × 4
## # Groups: SubRouteUID, SubRouteName [6]
## SubRouteUID SubRouteName Direction StopNum
## <chr> <chr> <int> <int>
## 1 HSZ000701 81 0 21
## 2 HSZ000702 81 1 20
## 3 HSZ000801 83 0 18
## 4 HSZ000802 83 1 18
## 5 HSZ0008A1 83支A 0 11
## 6 HSZ0008A2 83支A 1 10由以上回傳結果可發現,新竹市 81 公車共有兩條子路線(HSZ000701、HSZ000702),方向分為去程(Direction:0)與返程(Direction:1),而去程站牌數共計 21 個,而返程的站牌數則為 20 個。
§ 整理同一站名的所有路線
分析流程彙整如下:
- Step 1: 從站牌中,先挑出站點名稱(StopName)、子路線名稱(SubRouteName)兩資訊。
- Step 2: 此時,可能會有重複的資料,乃因同一子路線,不同方向的情況下,會存在相同站名(但在此我們不考慮方向性,只單純考慮子路線的名稱)。故必須先行透過
distinct()函式將重複的資料予以去除。
- Step 3: 最後依據站點名稱(StopName)分群,統計各站點擁有的子路線名稱(SubRouteName),及其數量(使用
group_by() %>% summarise()函式)。
- Step 4: 將整理完成的資料依據總子路線數降冪排列(使用
arrange()函式)。
依上述流程,程式碼撰寫如下。
# Step 1
bus_stop_route=select(bus_stop, SubRouteName, StopName)
# Step 2
bus_stop_route=distinct(bus_stop_route)
# Step 3
bus_stop_route=group_by(bus_stop_route, StopName)%>%
summarise(NumSubRoute=n(),
AllSubRoute=paste(SubRouteName, collapse=", "))
# Step 4
bus_stop_route=arrange(bus_stop_route, desc(NumSubRoute))
#---可直接簡化為:---#
# bus_stop_route=select(bus_stop, SubRouteName, StopName)%>%
# distinct()%>%
# group_by(StopName)%>%
# summarise(NumSubRoute=n(),
# AllSubRoute=paste(SubRouteName, collapse=", "))%>%
# arrange(desc(NumSubRoute))
# 查看前六筆資料
head(bus_stop_route)## # A tibble: 6 × 3
## StopName NumSubRoute AllSubRoute
## <chr> <int> <chr>
## 1 火車站 20 藍線1區, 2, 2支A, 10, 11A, 11甲, 12, 藍15區, 藍15區B, 16…
## 2 東門市場 18 藍線1區, 2, 2支A, 10, 11A, 11甲, 12, 藍15區, 藍15區B, 16…
## 3 公園 10 藍線1區, 2, 2支A, 182, 31, 世博5號, 71A, 72, 73, 藍線
## 4 馬偕醫院 10 藍線1區, 2, 2支A, 182, 31, 52, 52支A, 53, 世博5號, 藍線
## 5 文教新村 9 藍線1區, 2, 2支A, 182, 31, 52, 52支A, 世博3號, 藍線
## 6 西門市場 8 10, 11A, 11甲, 20, 20支A, 23支A, 50A, 51A其中 Step 4 的arrange()函式內,設定desc(...)以表示依據指定變數降冪排列,否則預設為升冪排列。
§ 尋找公車環狀線
前文中提及,新竹市公車有些屬於環狀路線,亦即公車的起始站與終點站相同。在公車站牌資料中,可以先萃取各子路線的第一個站點(站序為 1 者)與最後一個站點(同一路線站序為最大者),並檢查起訖站點是否相同。分析邏輯彙整如下:
- Step 1: 先利用
select()函式萃取需要的欄位名稱。
- Step 2: 將公車站牌依據 SubRouteUID 與 SubRouteName 分群,並利用
slice()函式分離出最小站序與最大站序者。
- Step 3: 經過 Step 2 後所得資料僅剩各路線站序為 1 與最大者,在此我們希望兩者能夠並列,以方便比較(使用
dcast()函式可將長資料轉換為寬資料)。 - Step 4: 最後篩選站序為 1 與站序最大之站名為相同者。
# Step 1
bus_route_circle=select(bus_stop, SubRouteUID, SubRouteName, StopSequence, StopName)
# Step 2
bus_route_circle=group_by(bus_route_circle, SubRouteUID, SubRouteName)%>%
slice(which.min(StopSequence),
which.max(StopSequence))
# 初步查看前六筆資料
head(bus_route_circle)## # A tibble: 6 × 4
## # Groups: SubRouteUID, SubRouteName [3]
## SubRouteUID SubRouteName StopSequence StopName
## <chr> <chr> <int> <chr>
## 1 HSZ000701 81 1 古奇峰
## 2 HSZ000701 81 21 新莊車站
## 3 HSZ000702 81 1 新莊車站
## 4 HSZ000702 81 20 古奇峰
## 5 HSZ000801 83 1 成德路
## 6 HSZ000801 83 18 北校門截至 Step 2,可以發現資料中僅剩餘第一站序與最後一站序,其餘皆已刪除,然而接下來我們希望能夠將同一子路線不同站序並排,尚能進一步做分析。首先我們必須針對每一筆資料給定起始站或終點站的標籤,由於起始站的站序必然是 1,故在此我們可以利用簡單的ifelse()函式判斷站序為 1 者為起始站,反之則為終點站,如是即可得到起訖(Stop_O、Stop_D)的標籤。ifelse()函式的參數設定如下:
目前為止,資料型態屬於「長資料(long data)」,亦即資料橫列數比較長的情況。然而我們希望的是將同一路線不同站序展開並排,屬「寬資料(wide data)」,亦即欄位數比較多的情況,此時應利用data.table套件中的dcast()函式達成此一目的。dcast()函式的參數設定如下,如圖4.1之示意圖所示。
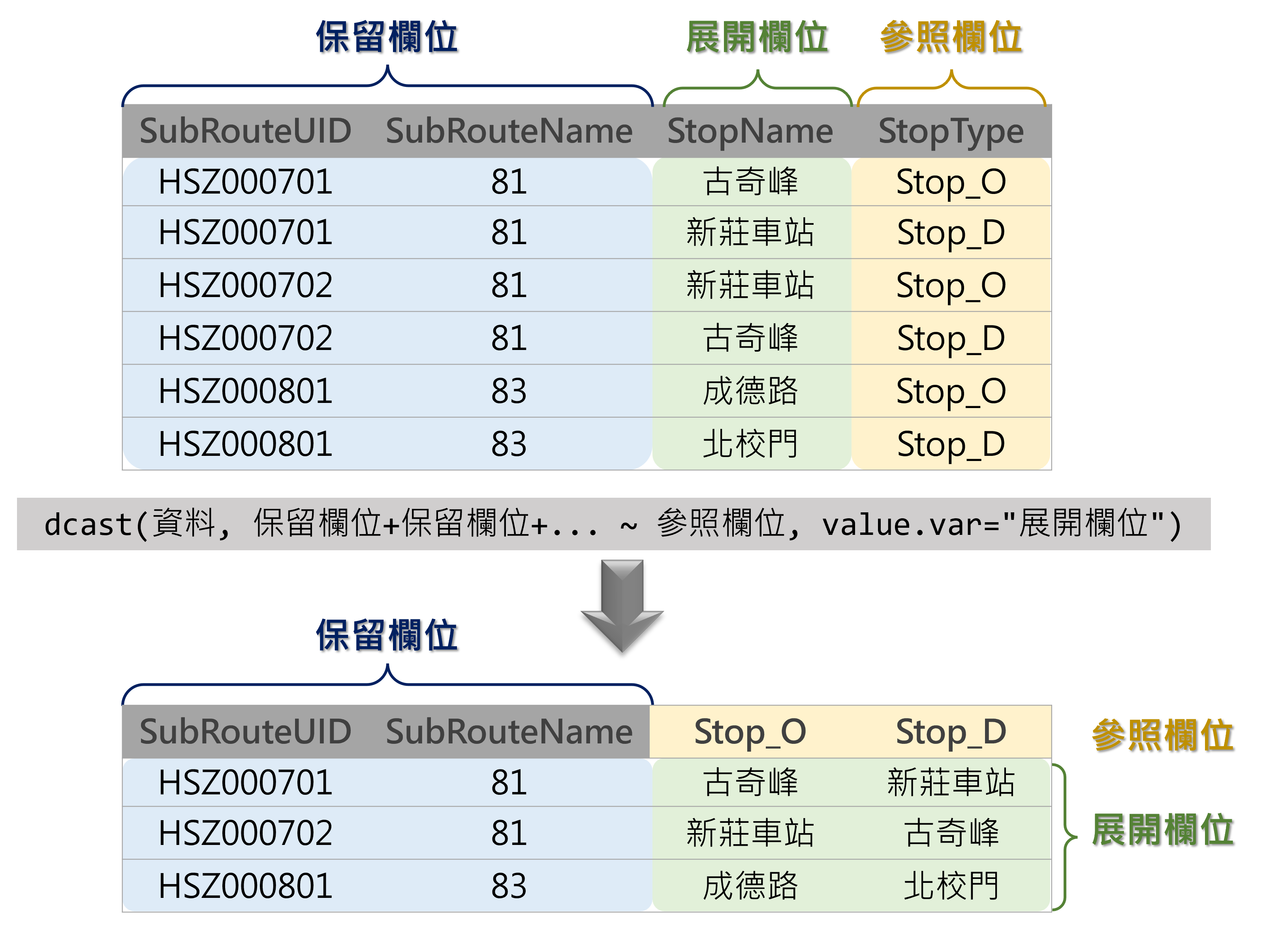
圖 4.1: dcast()函式用法
經過處理成為寬資料後,即可針對起訖相同站名者利用filter()函式予以保留。filter()函式之參數設定如下:
# Step 3
bus_route_circle=mutate(bus_route_circle, StopType=ifelse(StopSequence==1, "Stop_O", "Stop_D"))
bus_route_circle=dcast(bus_route_circle, SubRouteUID+SubRouteName ~ StopType, value.var="StopName")
# Step 4
bus_route_circle=filter(bus_route_circle, Stop_O==Stop_D)
#---可直接簡化為:---#
# bus_route_circle=select(bus_stop, SubRouteUID, SubRouteName, StopSequence, StopName)%>%
# group_by(SubRouteUID, SubRouteName)%>%
# slice(which.min(StopSequence),
# which.max(StopSequence))%>%
# mutate(StopType=ifelse(StopSequence==1, "Stop_O", "Stop_D"))%>%
# dcast(SubRouteUID+SubRouteName ~ StopType, value.var="StopName")%>%
# filter(Stop_O==Stop_D)
# 查看所有環狀線資料
bus_route_circle## SubRouteUID SubRouteName Stop_D Stop_O
## 1 HSZ001001 藍線1區 火車站 火車站
## 2 HSZ027001 27 火車站 火車站
## 3 HSZ0500A1 50A 香山區公所 香山區公所
## 4 HSZ0510A1 51A 香山區公所 香山區公所
## 5 HSZ052001 52 新莊車站 新莊車站
## 6 HSZ0520A1 52支A 新莊車站 新莊車站
## 7 HSZ053001 53 新莊車站 新莊車站
## 8 HSZ057301 世博3號 後站(公園路口) 後站(公園路口)
## 9 HSZ0710A1 71A 北新竹後站 北新竹後站由以上回傳資料可知,新竹市公車共計 9 條路線屬於環狀路線。
4.1.3 站間行駛距離計算
公車站間距離資料中係記錄每一子路線(SubRouteUID)相鄰站點間的路線距離,其中 FromStopID 為起點站代碼,ToStopID 為迄點站代碼,StopSequence 為「迄點站」的站序,Distance 即為兩相鄰站點間距離。
§ 計算任意起迄站間距離
公車站間距離資料係記錄兩相鄰站點距離,而非「任意兩站點間」的距離,故必須經過資料處理尚能透過原始資料計算任意起迄站間距離。在給定的一組站點序號,首先必須回傳所有該起迄區間的資料,例如若要尋找新竹市區 81 公車去程(SubRouteUID: HSZ000701)的「陽明交大光復南門」(StopID: 303819)至「科技生活館」(StopID: 303823)站點,我們必須先知道兩站點的序號,並擷取所有介於這兩序號間的公車站點距離資料,最後將 Distance 欄位相加總後即為該區間的行駛距離。
在公車站間距離之原始資料中,請務必注意,StopSequence 為 1 時,路線距離為 0(原始資料記錄為 NA);StopSequence 為 2 時,路線距離係第 1 站至第 2 站的距離,其他則以此類推。因此若欲計算第 3 站至第 6 站間的距離,必須先行回傳公車站間距離資料中站序為 4 至 6 的資料,如圖4.2之示意圖所示。據上述案例,由第 3 站出發,必須由站序為 4 者始擷取資料,故後續得知起點站序後,務必加 1 以在原始資料中擷取正確區間。
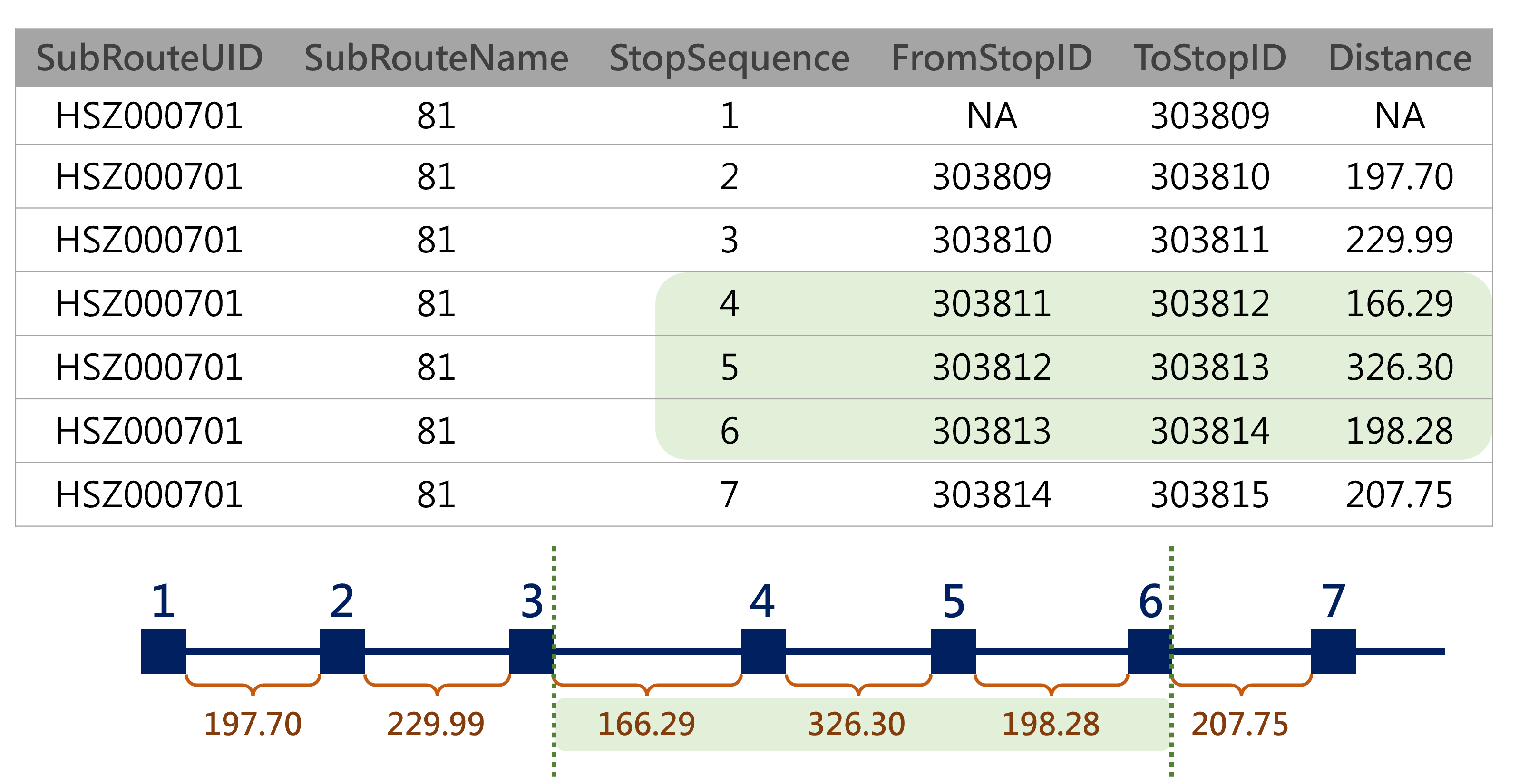
圖 4.2: 公車站間距離資料計算示意圖
回到尋找新竹市區 81 公車去程的「陽明交大光復南門」至「科技生活館」站點之範例,程式碼撰寫如下:
# 先依據路線名稱與站名,尋找起迄站點的站序
sqid_o=filter(bus_stop, SubRouteName=="81", Direction==0, StopName=="陽明交大光復南門")$StopSequence
sqid_d=filter(bus_stop, SubRouteName=="81", Direction==0, StopName=="科技生活館")$StopSequence
# 查看起迄站序
print(c(sqid_o, sqid_d))## [1] 11 15得知站序後,回傳原始資料中該路線且站序介於 sqid_o+1 與 sqid_d 之間者。
# 擷取公車站間距離資料中sqid_o+1至sqid_d的資料
temp=filter(bus_distance, SubRouteName=="81", Direction==0, Sequence>=sqid_o+1, Sequence<=sqid_d)
# 將Distance欄位予以加總
sum(temp$Distance)## [1] 1346.73由上述分析結果得知,81 公車「陽明交大光復南門」至「科技生活館」的路線距離即為 1346.73 公尺。
此外,我們可以將上述的流程打包成一個函式以方便後續查詢,程式碼撰寫如下。
# 建立函式
# 需含括四個參數:子路線名稱(route)、方向(dir)、起點站名(stop_o)、迄點站名(stop_d)
Bus_OD_Dist=function(route, dir, stop_o, stop_d){
sqid_o=filter(bus_stop, SubRouteName==route, Direction==dir, StopName==stop_o)$StopSequence
sqid_d=filter(bus_stop, SubRouteName==route, Direction==dir, StopName==stop_d)$StopSequence
temp=filter(bus_distance, SubRouteName==route, Direction==dir, Sequence>=sqid_o+1, Sequence<=sqid_d)
# 原始資料中少部分資料為NA,為方便概算,在此忽略NA值 (此為資料品質問題!)
dist=sum(temp$Distance, na.rm=T)
return(dist)
}
# 使用函式 (範例1)
Bus_OD_Dist(route="81", dir=0, stop_o="陽明交大光復南門", stop_d="科技生活館")## [1] 1346.73## [1] 1842.72透過上述範例得知,新竹市 81 公車由「清華大學」至「交大光復校區」,路線行駛距離為 1842.72 公尺。