5 Modelación: Regresión Poisson
## 'data.frame': 744 obs. of 11 variables:
## $ country : Factor w/ 2 levels "Mexico","United States": 1 1 1 1 1 1 1 1 1 1 ...
## $ year : Factor w/ 31 levels "1985","1986",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ sex : Factor w/ 2 levels "female","male": 2 2 2 2 2 1 1 1 1 1 ...
## $ age : Factor w/ 6 levels "5-14 years","15-24 years",..: 6 5 3 4 2 2 6 3 4 5 ...
## $ suicides : int 44 145 340 327 375 107 7 61 55 15 ...
## $ population : int 432000 2330000 5679000 5836000 8420000 8211000 563000 5661000 6100000 2651000 ...
## $ no_suicides: int 431956 2329855 5678660 5835673 8419625 8210893 562993 5660939 6099945 2650985 ...
## $ rate : num 0.000102 0.000062 0.00006 0.000056 0.000045 0.000013 0.000012 0.000011 0.000009 0.000006 ...
## $ HDI : num 0.634 0.634 0.634 0.634 0.634 0.634 0.634 0.634 0.634 0.634 ...
## $ GDP_PP : num 2730 2730 2730 2730 2730 2730 2730 2730 2730 2730 ...
## $ generation : Factor w/ 6 levels "G.I. Generation",..: 1 1 3 2 4 4 1 3 2 1 ...En este modelo los coeficientes de cada categoría representan el logaritmo del cociente de las esperanzas de los conteos dada dicha varible entre la categoría basal. Es decir, en este modelo comparamos directamente las respuestas(número esperado de conteos) de cada categoría contra la categoría basal.
Comencemos modelando con una sola variable explicativa
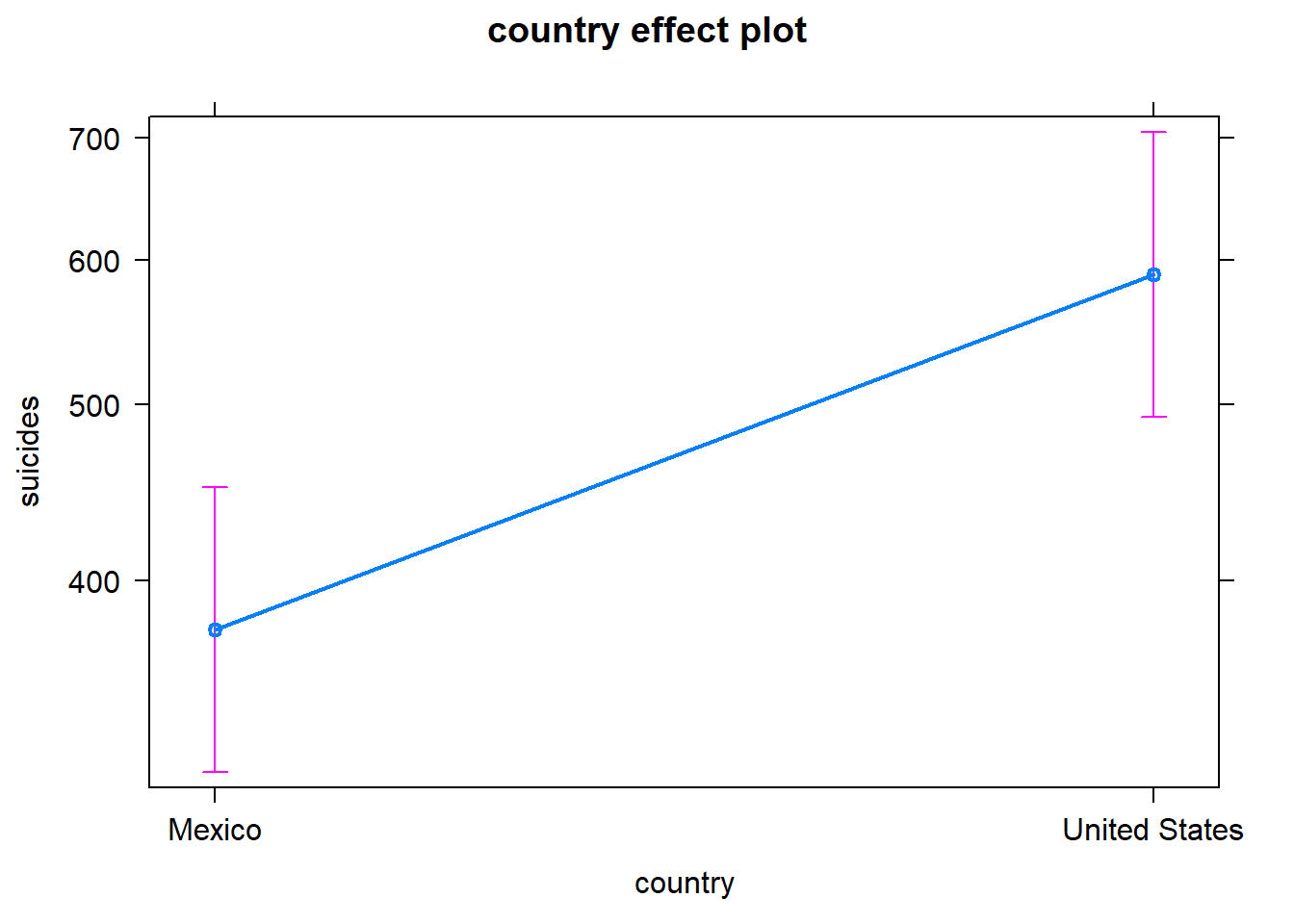
5.1 País
| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -10.124644 | 0.0029996 | -3375.318 | 0 |
| countryUnited States | 1.164164 | 0.0031567 | 368.791 | 0 |
El país resulta muy significativo.
Además, tenemos el coeficiente positivo por lo que parece que en Estados Unidos hay un mayor número de suicidios.
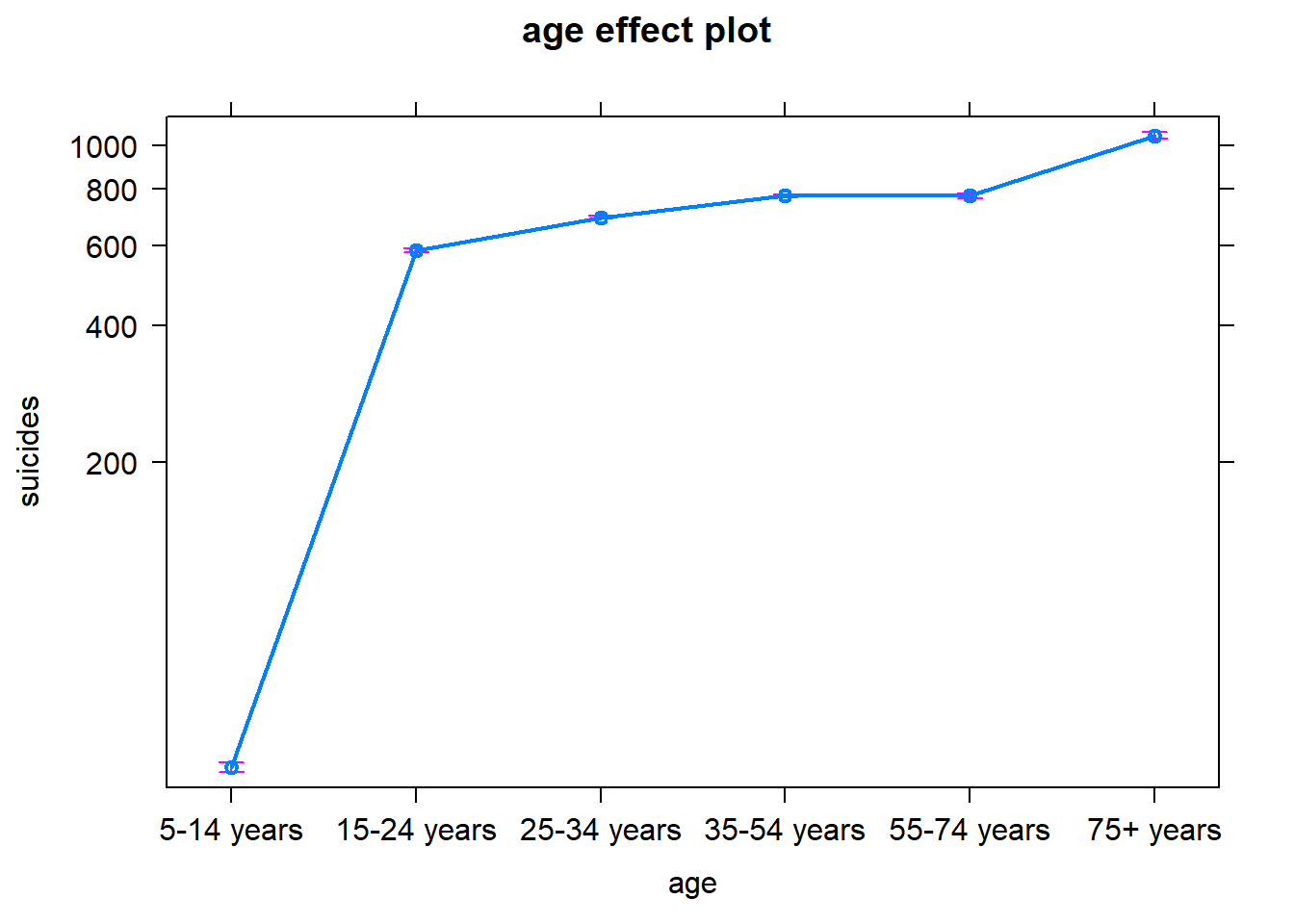
5.2 Edad
| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -11.903246 | 0.0088206 | -1349.4837 | 0 |
| age15-24 years | 2.628727 | 0.0091382 | 287.6649 | 0 |
| age25-34 years | 2.852436 | 0.0090874 | 313.8883 | 0 |
| age35-54 years | 3.009767 | 0.0089575 | 336.0060 | 0 |
| age55-74 years | 3.014433 | 0.0090565 | 332.8464 | 0 |
| age75+ years | 3.265944 | 0.0093720 | 348.4784 | 0 |
La edad también es muy significativa para todos los grupos de edad.
Nuestra categoría basal es el grupo de edad más joven, de 5 a 14 años de edad.
Todos los grupos de edad tienen un número de suicidios esperado mayor a la categoría basal. El grupo que presenta mayor número de suicidios es el de mayores de 75 años.
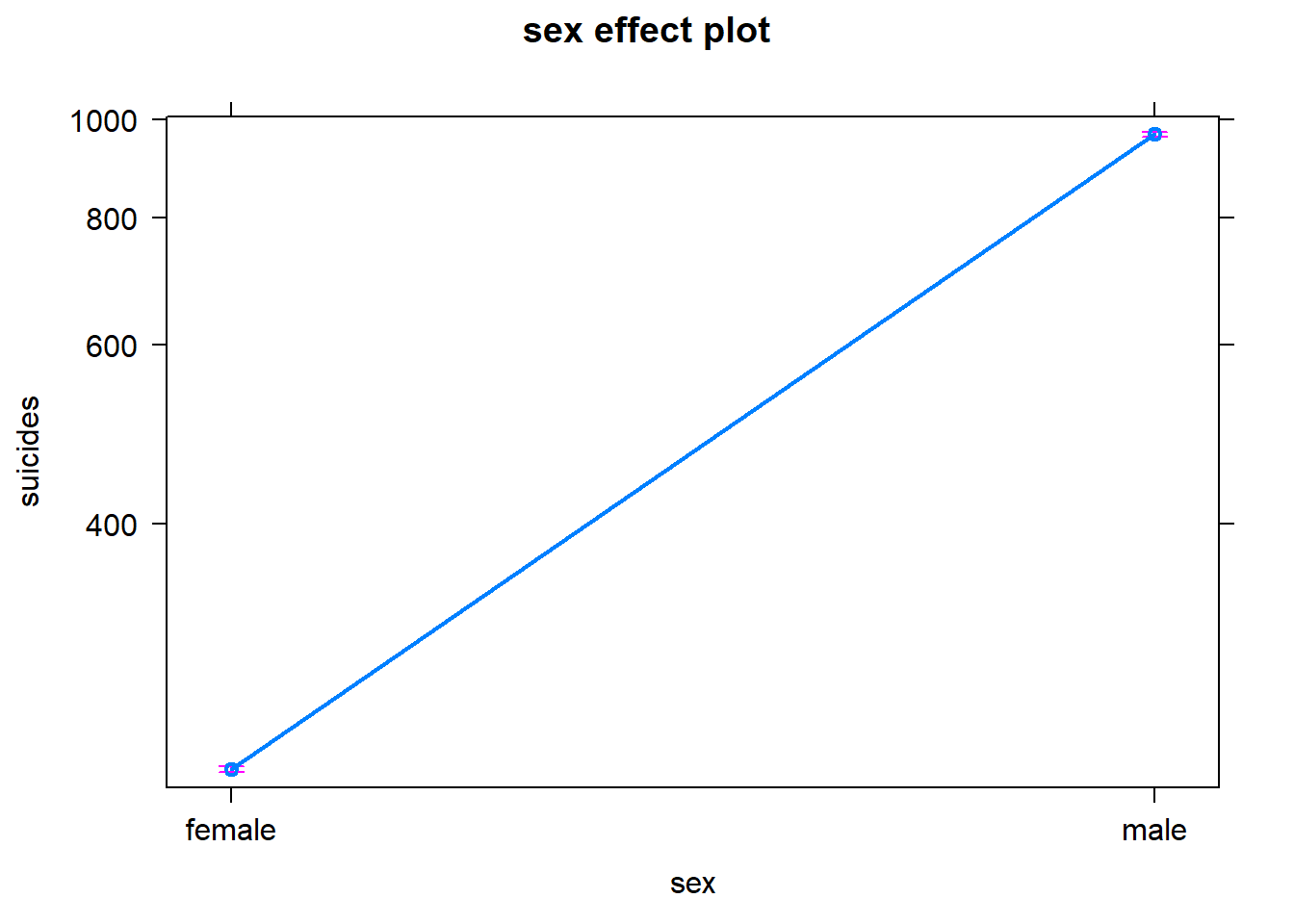
5.3 Sexo
| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -10.070705 | 0.0020711 | -4862.5032 | 0 |
| sexmale | 1.400189 | 0.0023208 | 603.3338 | 0 |
El sexo es muy significativo. Como habíamos dicho antes, los hombres tienen un mayor número esperado de suicidios que las mujeres.
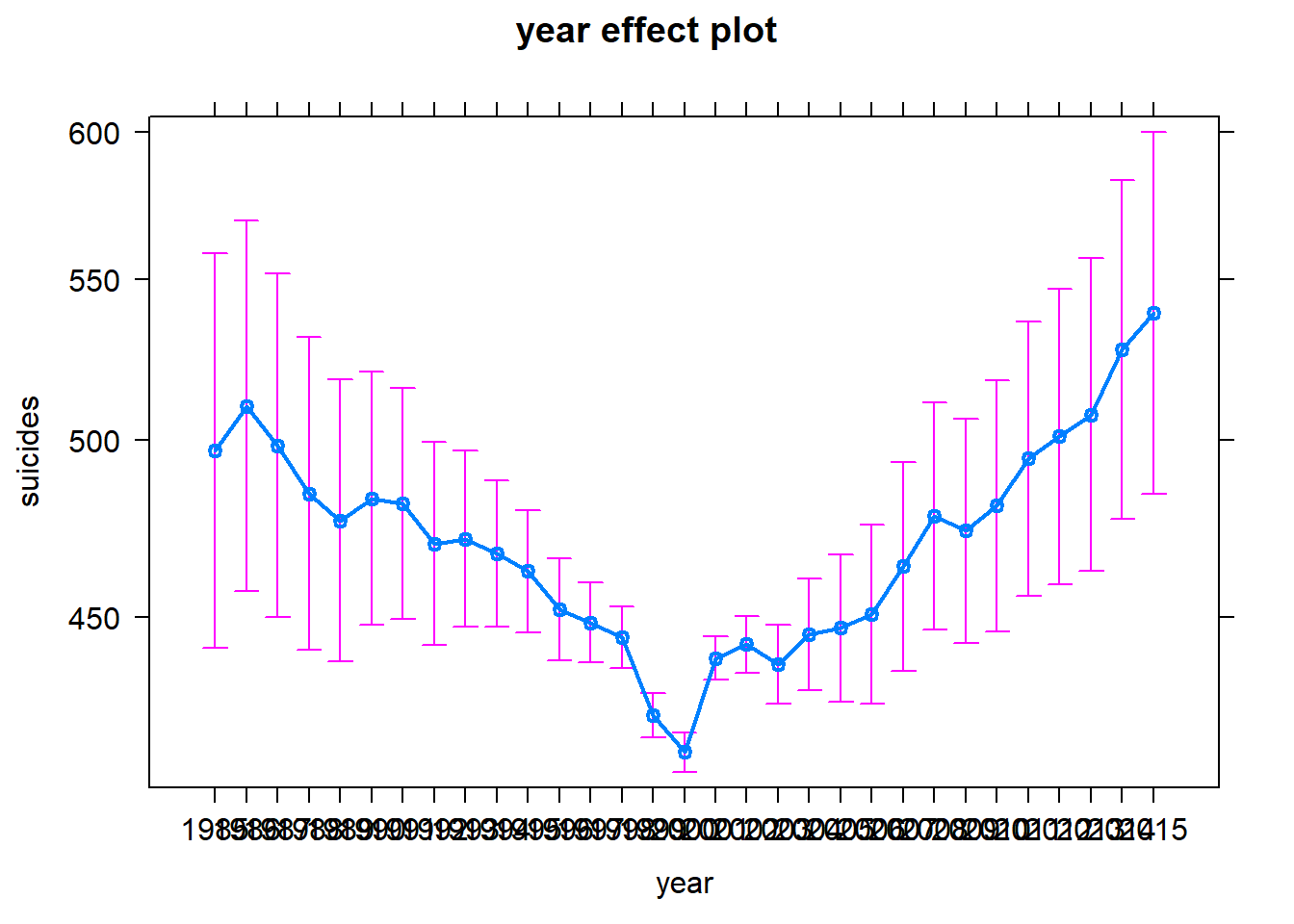
5.4 Año
| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -9.1380542 | 0.0056805 | -1608.6710865 | 0.0000000 |
| year1986 | 0.0377794 | 0.0079333 | 4.7621491 | 0.0000019 |
| year1987 | 0.0305460 | 0.0079405 | 3.8468453 | 0.0001196 |
| year1988 | 0.0051457 | 0.0079642 | 0.6461040 | 0.5182120 |
| year1989 | -0.0079733 | 0.0079647 | -1.0010814 | 0.3167874 |
| year1990 | 0.0075386 | 0.0079206 | 0.9517706 | 0.3412133 |
| year1991 | -0.0057332 | 0.0079164 | -0.7242246 | 0.4689278 |
| year1992 | -0.0213964 | 0.0079272 | -2.6990975 | 0.0069528 |
| year1993 | -0.0126829 | 0.0078857 | -1.6083338 | 0.1077621 |
| year1994 | -0.0170310 | 0.0078697 | -2.1641383 | 0.0304537 |
| year1995 | -0.0169028 | 0.0078455 | -2.1544657 | 0.0312037 |
| year1996 | -0.0451564 | 0.0078599 | -5.7451771 | 0.0000000 |
| year1997 | -0.0578838 | 0.0078610 | -7.3634232 | 0.0000000 |
| year1998 | -0.0706852 | 0.0078608 | -8.9920944 | 0.0000000 |
| year1999 | -0.1230245 | 0.0079390 | -15.4962411 | 0.0000000 |
| year2000 | -0.1427664 | 0.0079219 | -18.0217228 | 0.0000000 |
| year2001 | -0.1088832 | 0.0078336 | -13.8994790 | 0.0000000 |
| year2002 | -0.0902898 | 0.0077756 | -11.6119398 | 0.0000000 |
| year2003 | -0.0981956 | 0.0077717 | -12.6349883 | 0.0000000 |
| year2004 | -0.0830200 | 0.0077251 | -10.7467803 | 0.0000000 |
| year2005 | -0.0825488 | 0.0077049 | -10.7137525 | 0.0000000 |
| year2006 | -0.0782110 | 0.0076759 | -10.1892001 | 0.0000000 |
| year2007 | -0.0518712 | 0.0076149 | -6.8117566 | 0.0000000 |
| year2008 | -0.0161730 | 0.0075402 | -2.1449020 | 0.0319607 |
| year2009 | 0.0020221 | 0.0074914 | 0.2699270 | 0.7872165 |
| year2010 | 0.0209749 | 0.0074435 | 2.8178894 | 0.0048340 |
| year2011 | 0.0520530 | 0.0073795 | 7.0536919 | 0.0000000 |
| year2012 | 0.0615009 | 0.0073497 | 8.3678151 | 0.0000000 |
| year2013 | 0.0700969 | 0.0073219 | 9.5735264 | 0.0000000 |
| year2014 | 0.1038015 | 0.0072594 | 14.2989956 | 0.0000000 |
| year2015 | 0.1238268 | 0.0072181 | 17.1551561 | 0.0000000 |
Para esta variable tenemos algunos años que no son significativos pero la mayoría lo son. Por lo que la podemos tomar como una variable significativa.
Además, notamos que para los siguientes dos años posteriores al año basal (1985) el número de suicidios crece significativamente, después hay algunos años con diferencias no significativas y apartir de 1992 y hasta el 2000 disminuyen los suicidios cada año un poco más, después del 2000, siguen siendo menor al años basal pero en menor medida y a partir del 2009 el número de suicidios empieza a aumentar.
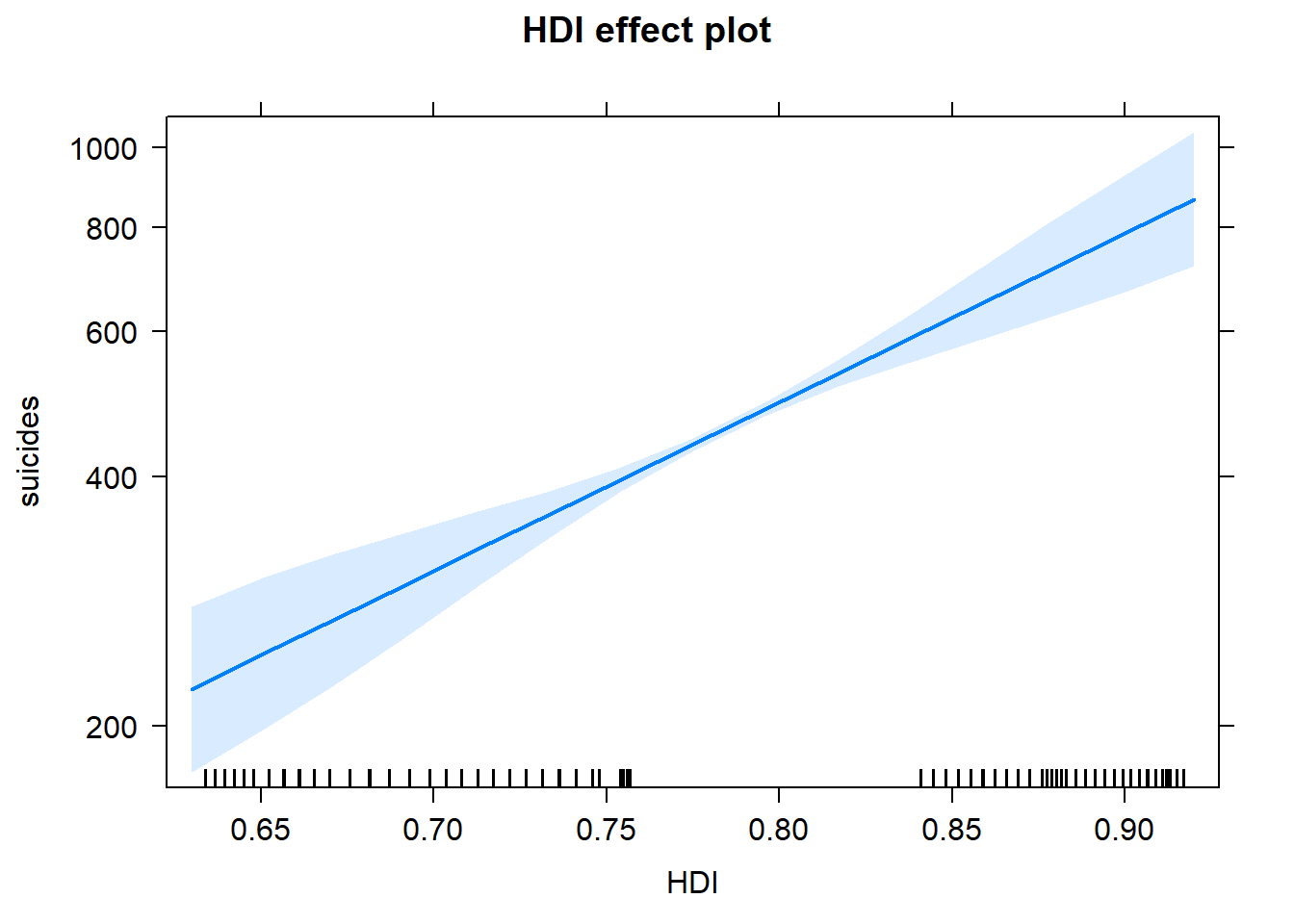
5.5 Índice de Desarrollo Humano
| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -14.043595 | 0.0135578 | -1035.8328 | 0 |
| HDI | 5.713386 | 0.0155631 | 367.1103 | 0 |
Esta variable es muy siginificativa.
Parece que el número de suicidios aumenta conforme el IDH aumenta, recordamos que en nuestra base sólo tenemos a México y Estados Unidos, de los cuáles encontramos más suicidios en E.U. que también es donde es mayor el HDI.
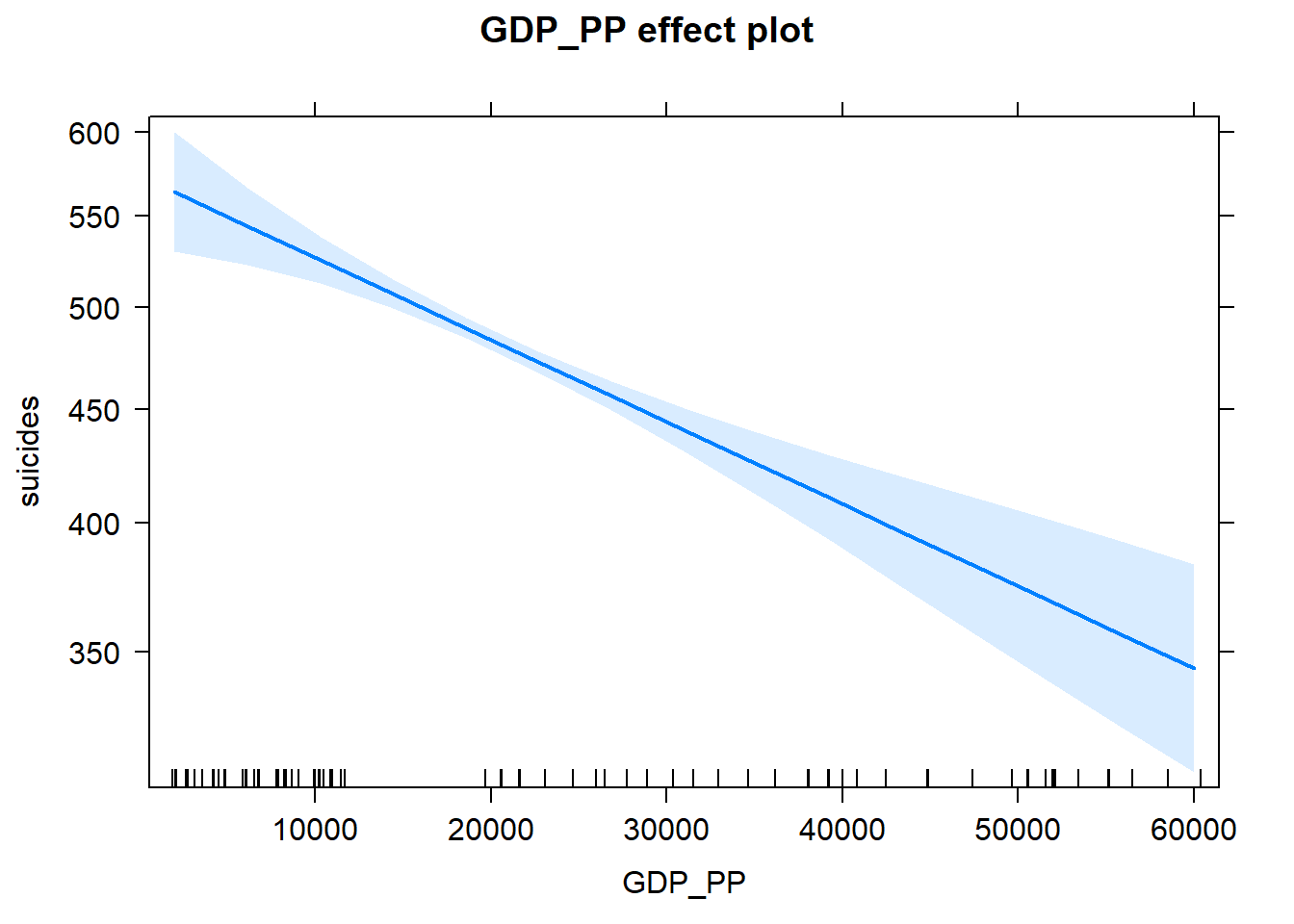
5.6 PIB per cápita
| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -9.7640178 | 0.0022597 | -4320.9063 | 0 |
| GDP_PP | 0.0000175 | 0.0000001 | 318.9235 | 0 |
También el PIB es muy significativo, aunque el coeficiente es muy pequeño, de igual forma el número esperado de suicidios aumenta conforme el PIB per cápita aumenta.
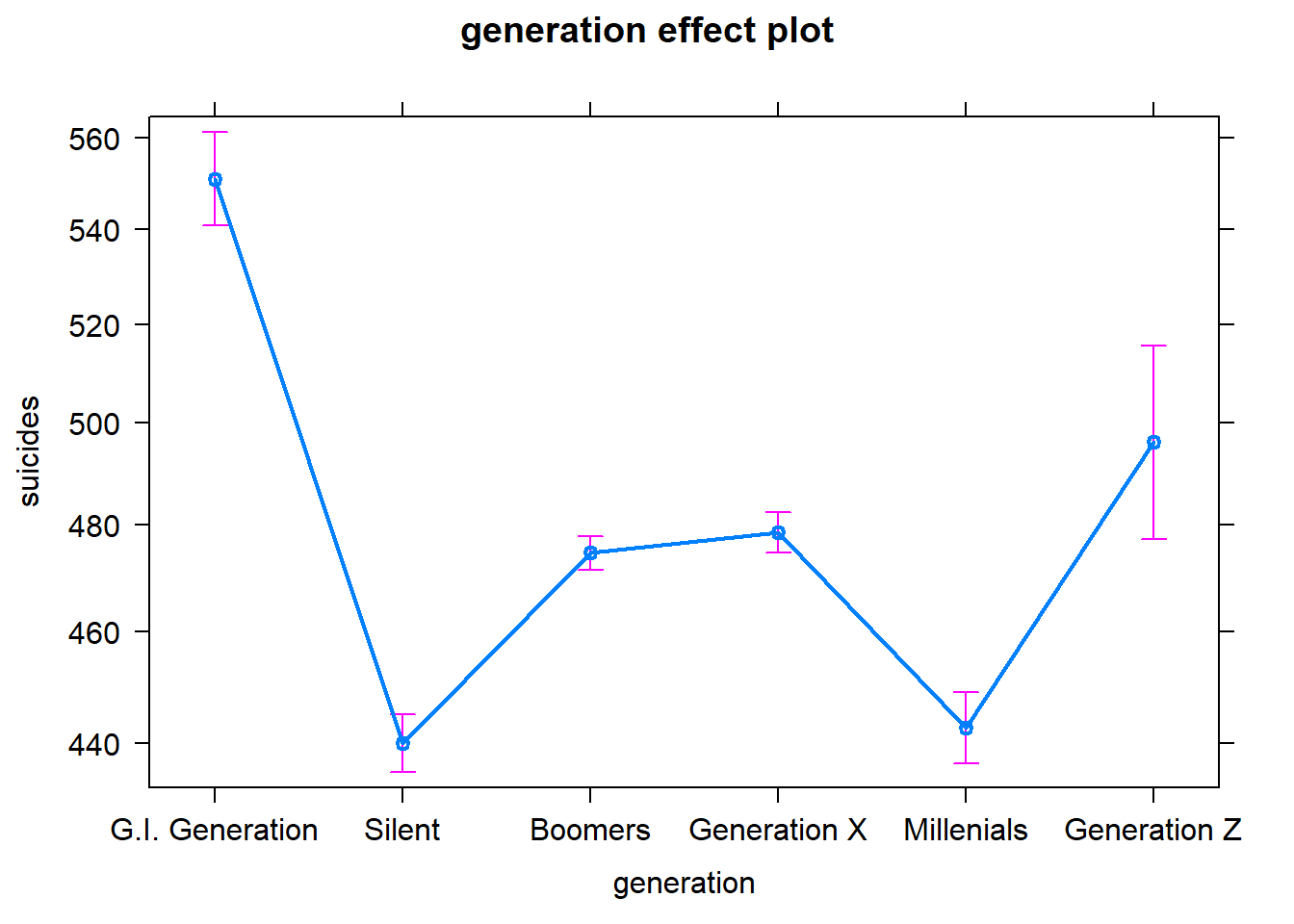
5.7 Generación
| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -8.6235037 | 0.0032855 | -2624.68254 | 0 |
| generationSilent | -0.2985983 | 0.0038637 | -77.28243 | 0 |
| generationBoomers | -0.2872374 | 0.0036641 | -78.39278 | 0 |
| generationGeneration X | -0.5571358 | 0.0037705 | -147.76267 | 0 |
| generationMillenials | -1.1129118 | 0.0042750 | -260.32825 | 0 |
| generationGeneration Z | -3.1345317 | 0.0151720 | -206.59992 | 0 |
La variable generación es muy significativa.
Nuestra categoría basal es la ganeración G.I., nacidos entre 1901 y 1926, quienes vivieron la segunda guerra mundial. Notamos que la esta generación es la que presenta un número esperado de suicidios mayor al de las demás generaciones, cuyos coeficientes son negativos.
Comparamos los modelos con una categoría.
| df | AIC | |
|---|---|---|
| fit1 | 2 | 845407.6 |
| fit2 | 6 | 656753.5 |
| fit3 | 2 | 575387.5 |
| fit4 | 31 | 1025387.5 |
| fit5 | 2 | 856320.9 |
| fit6 | 2 | 924157.7 |
| fit7 | 6 | 829440.2 |
El mejor es fit3 el modelo que tiene como variable explicativa al sexo. Seguido de fit 2, el modelo que tiene como variiable explicativa la edad.
Ya que todas nuestras variables son significativas, parecería adecuado explorar los modelos con las distintas combinaciones de covariables, sin embargo estás son demasiadas, por lo que empezaremos ajustando un modelo con las dos variables que ajustaron los mejores modelos (sexo y edad), e iremos aumentando o disminuyendo variables hasta encontrar nuetro mejor modelo.
5.8 Sexo y edad
| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -12.875069 | 0.0090217 | -1427.1192 | 0 |
| sexmale | 1.438935 | 0.0023250 | 618.8967 | 0 |
| age15-24 years | 2.630663 | 0.0091381 | 287.8783 | 0 |
| age25-34 years | 2.864418 | 0.0090874 | 315.2082 | 0 |
| age35-54 years | 3.030601 | 0.0089575 | 338.3325 | 0 |
| age55-74 years | 3.065654 | 0.0090567 | 338.4965 | 0 |
| age75+ years | 3.437438 | 0.0093744 | 366.6817 | 0 |
Las dos variables siguen siendo muy significativas. Veamos si este modelo es mejor a nuestro mejor modelo anterior.
## Analysis of Deviance Table
##
## Model 1: suicides ~ offset(log(population)) + sex
## Model 2: suicides ~ offset(log(population)) + sex + age
## Resid. Df Resid. Dev Df Deviance Pr(>Chi)
## 1 742 569487
## 2 737 170646 5 398841 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Nustro modelo con dos variables tiene una devianza menor y esta diferencia es significativa, por lo que nuestro modelo con sexo y edad es mejor.
Agreguemos ahora la variable país.
5.9 País, sexo y edad
| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -13.613519 | 0.0093960 | -1448.8668 | 0 |
| countryUnited States | 1.000998 | 0.0031803 | 314.7537 | 0 |
| sexmale | 1.438202 | 0.0023253 | 618.4903 | 0 |
| age15-24 years | 2.607588 | 0.0091382 | 285.3515 | 0 |
| age25-34 years | 2.799227 | 0.0090885 | 307.9953 | 0 |
| age35-54 years | 2.908300 | 0.0089616 | 324.5286 | 0 |
| age55-74 years | 2.904416 | 0.0090636 | 320.4471 | 0 |
| age75+ years | 3.251569 | 0.0093834 | 346.5254 | 0 |
Las tres variables siguen siendo muy siginificativas, comparamos con nuestro moelo anterior.
## Analysis of Deviance Table
##
## Model 1: suicides ~ offset(log(population)) + sex + age
## Model 2: suicides ~ offset(log(population)) + country + sex + age
## Resid. Df Resid. Dev Df Deviance Pr(>Chi)
## 1 737 170646
## 2 736 42567 1 128080 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1La devianza es menos significativamente, por lo que nos quedamos con este modelo con país, sexo y edad.
Agregamos la variable generación
5.9.1 País, sexo, edad y generación
| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -13.6490292 | 0.0129936 | -1050.440214 | 0 |
| countryUnited States | 1.0031640 | 0.0031832 | 315.146227 | 0 |
| sexmale | 1.4388477 | 0.0023256 | 618.703577 | 0 |
| age15-24 years | 2.6776289 | 0.0112683 | 237.625664 | 0 |
| age25-34 years | 2.8913300 | 0.0114088 | 253.428896 | 0 |
| age35-54 years | 3.0486067 | 0.0115820 | 263.218880 | 0 |
| age55-74 years | 3.0960843 | 0.0120153 | 257.677769 | 0 |
| age75+ years | 3.4047366 | 0.0125190 | 271.966592 | 0 |
| generationSilent | -0.2231725 | 0.0041014 | -54.413990 | 0 |
| generationBoomers | -0.1078096 | 0.0049562 | -21.752590 | 0 |
| generationGeneration X | -0.0363467 | 0.0055839 | -6.509169 | 0 |
| generationMillenials | -0.0373800 | 0.0065093 | -5.742518 | 0 |
| generationGeneration Z | 0.1754166 | 0.0194161 | 9.034587 | 0 |
Todas las variables son muy significativas. Comparemos con el modelo anterior.
## Analysis of Deviance Table
##
## Model 1: suicides ~ offset(log(population)) + country + sex + age
## Model 2: suicides ~ offset(log(population)) + country + sex + age + generation
## Resid. Df Resid. Dev Df Deviance Pr(>Chi)
## 1 736 42567
## 2 731 37978 5 4588.4 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1La devianza del modelo agregando la variable generación es menor significativamente por lo que nos quedamos con este último modelo.
Agregamos la variable Índice de Desarrollo Humano.
5.10 País, sexo, edad, generación e IDH
| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -14.6183504 | 0.0423922 | -344.836051 | 0e+00 |
| countryUnited States | 0.6893334 | 0.0134003 | 51.441537 | 0e+00 |
| sexmale | 1.4386518 | 0.0023256 | 618.618311 | 0e+00 |
| age15-24 years | 2.6400939 | 0.0113752 | 232.092524 | 0e+00 |
| age25-34 years | 2.8153754 | 0.0118383 | 237.818806 | 0e+00 |
| age35-54 years | 2.9232642 | 0.0126985 | 230.204816 | 0e+00 |
| age55-74 years | 2.9115193 | 0.0142547 | 204.249205 | 0e+00 |
| age75+ years | 3.1892618 | 0.0153917 | 207.206051 | 0e+00 |
| generationSilent | -0.2887224 | 0.0049248 | -58.625737 | 0e+00 |
| generationBoomers | -0.2295078 | 0.0070868 | -32.385284 | 0e+00 |
| generationGeneration X | -0.2126608 | 0.0092145 | -23.078838 | 0e+00 |
| generationMillenials | -0.2773612 | 0.0119105 | -23.287203 | 0e+00 |
| generationGeneration Z | -0.1208010 | 0.0229865 | -5.255299 | 1e-07 |
| HDI | 1.7295448 | 0.0719055 | 24.053041 | 0e+00 |
Todas las variables siguen siendo muy significativas. Veamos si este modelo es mejor.
## Analysis of Deviance Table
##
## Model 1: suicides ~ offset(log(population)) + country + sex + age + generation
## Model 2: suicides ~ offset(log(population)) + country + sex + age + generation +
## HDI
## Resid. Df Resid. Dev Df Deviance Pr(>Chi)
## 1 731 37978
## 2 730 37399 1 579.36 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1El modelo agregando esta última variable es mejor.
Agregamos la variable año
5.11 País, sexo, edad, generación, IDH y año
| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -19.2172906 | 0.1114625 | -172.4104381 | 0.0000000 |
| countryUnited States | -0.5868616 | 0.0302579 | -19.3953392 | 0.0000000 |
| sexmale | 1.4387116 | 0.0023256 | 618.6412868 | 0.0000000 |
| age15-24 years | 2.6203252 | 0.0114461 | 228.9275001 | 0.0000000 |
| age25-34 years | 2.7846248 | 0.0121409 | 229.3584446 | 0.0000000 |
| age35-54 years | 2.8945350 | 0.0135419 | 213.7465817 | 0.0000000 |
| age55-74 years | 2.8934700 | 0.0160639 | 180.1229613 | 0.0000000 |
| age75+ years | 3.1997835 | 0.0176661 | 181.1261420 | 0.0000000 |
| generationSilent | -0.2254443 | 0.0055648 | -40.5122568 | 0.0000000 |
| generationBoomers | -0.1501932 | 0.0088299 | -17.0096855 | 0.0000000 |
| generationGeneration X | -0.1421728 | 0.0118906 | -11.9567855 | 0.0000000 |
| generationMillenials | -0.2203530 | 0.0154420 | -14.2697500 | 0.0000000 |
| generationGeneration Z | -0.1065486 | 0.0256691 | -4.1508544 | 0.0000331 |
| HDI | 8.7742983 | 0.1672272 | 52.4693236 | 0.0000000 |
| year1986 | 0.0054581 | 0.0079554 | 0.6860863 | 0.4926587 |
| year1987 | -0.0407629 | 0.0080289 | -5.0770161 | 0.0000004 |
| year1988 | -0.0959365 | 0.0081598 | -11.7571987 | 0.0000000 |
| year1989 | -0.1390575 | 0.0083080 | -16.7377746 | 0.0000000 |
| year1990 | -0.1512045 | 0.0084522 | -17.8893776 | 0.0000000 |
| year1991 | -0.1721961 | 0.0089947 | -19.1442750 | 0.0000000 |
| year1992 | -0.2205320 | 0.0092540 | -23.8309896 | 0.0000000 |
| year1993 | -0.2418127 | 0.0094937 | -25.4708344 | 0.0000000 |
| year1994 | -0.2765086 | 0.0097819 | -28.2674409 | 0.0000000 |
| year1995 | -0.3086590 | 0.0102302 | -30.1713858 | 0.0000000 |
| year1996 | -0.3496106 | 0.0103973 | -33.6252300 | 0.0000000 |
| year1997 | -0.3785865 | 0.0105659 | -35.8309483 | 0.0000000 |
| year1998 | -0.4064891 | 0.0107412 | -37.8439143 | 0.0000000 |
| year1999 | -0.4752176 | 0.0109819 | -43.2727498 | 0.0000000 |
| year2000 | -0.5142016 | 0.0111656 | -46.0523820 | 0.0000000 |
| year2001 | -0.4771951 | 0.0116910 | -40.8172668 | 0.0000000 |
| year2002 | -0.4875331 | 0.0119901 | -40.6613831 | 0.0000000 |
| year2003 | -0.5233097 | 0.0123372 | -42.4172016 | 0.0000000 |
| year2004 | -0.5366143 | 0.0126688 | -42.3570377 | 0.0000000 |
| year2005 | -0.5651911 | 0.0130280 | -43.3827474 | 0.0000000 |
| year2006 | -0.5855639 | 0.0133497 | -43.8634505 | 0.0000000 |
| year2007 | -0.5832005 | 0.0136699 | -42.6632051 | 0.0000000 |
| year2008 | -0.5685501 | 0.0139866 | -40.6497153 | 0.0000000 |
| year2009 | -0.5743478 | 0.0143265 | -40.0899383 | 0.0000000 |
| year2010 | -0.5824735 | 0.0150638 | -38.6671450 | 0.0000000 |
| year2011 | -0.5744496 | 0.0158345 | -36.2784661 | 0.0000000 |
| year2012 | -0.5807136 | 0.0160515 | -36.1781683 | 0.0000000 |
| year2013 | -0.5823441 | 0.0161768 | -35.9987691 | 0.0000000 |
| year2014 | -0.5665334 | 0.0164007 | -34.5432536 | 0.0000000 |
| year2015 | -0.5644844 | 0.0166370 | -33.9293956 | 0.0000000 |
Notamos que el año en prescencia de las demás variables, sólo no es significativo para el año 1986 pero para el resto sí lo es, ganó significancia, a cuando sólo considerábamos esta variable por sí sola.
Comparamos este modelo con el anterior.
## Analysis of Deviance Table
##
## Model 1: suicides ~ offset(log(population)) + country + sex + age + generation +
## HDI
## Model 2: suicides ~ offset(log(population)) + country + sex + age + generation +
## HDI + year
## Resid. Df Resid. Dev Df Deviance Pr(>Chi)
## 1 730 37399
## 2 700 31722 30 5677 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1El ajuste es mejor con la variable año.
Sólo nos falta por agregar la variable PIB per cápita
5.12 País, sexo, edad, generación, HDI, año y PIB per cápita
| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -16.6556997 | 0.4610498 | -36.1255974 | 0.0000000 |
| countryUnited States | 0.4481359 | 0.1833289 | 2.4444370 | 0.0145078 |
| sexmale | 1.4387170 | 0.0023256 | 618.6435232 | 0.0000000 |
| age15-24 years | 2.6202726 | 0.0114463 | 228.9180588 | 0.0000000 |
| age25-34 years | 2.7847869 | 0.0121412 | 229.3661704 | 0.0000000 |
| age35-54 years | 2.8949123 | 0.0135425 | 213.7657481 | 0.0000000 |
| age55-74 years | 2.8943485 | 0.0160650 | 180.1644114 | 0.0000000 |
| age75+ years | 3.2009715 | 0.0176671 | 181.1823770 | 0.0000000 |
| generationSilent | -0.2249144 | 0.0055656 | -40.4115624 | 0.0000000 |
| generationBoomers | -0.1491161 | 0.0088319 | -16.8838814 | 0.0000000 |
| generationGeneration X | -0.1408823 | 0.0118926 | -11.8461919 | 0.0000000 |
| generationMillenials | -0.2187157 | 0.0154444 | -14.1615111 | 0.0000000 |
| generationGeneration Z | -0.1049802 | 0.0256709 | -4.0894646 | 0.0000432 |
| HDI | 4.6990815 | 0.7311640 | 6.4268498 | 0.0000000 |
| year1986 | 0.0266060 | 0.0087739 | 3.0323924 | 0.0024262 |
| year1987 | 0.0032438 | 0.0111215 | 0.2916661 | 0.7705420 |
| year1988 | -0.0254336 | 0.0147817 | -1.7206119 | 0.0853213 |
| year1989 | -0.0415001 | 0.0189677 | -2.1879370 | 0.0286742 |
| year1990 | -0.0282399 | 0.0230906 | -1.2230048 | 0.2213279 |
| year1991 | -0.0311078 | 0.0262442 | -1.1853205 | 0.2358908 |
| year1992 | -0.0549938 | 0.0303698 | -1.8108074 | 0.0701707 |
| year1993 | -0.0521903 | 0.0344671 | -1.5142067 | 0.1299734 |
| year1994 | -0.0609146 | 0.0389194 | -1.5651471 | 0.1175484 |
| year1995 | -0.0714292 | 0.0426859 | -1.6733689 | 0.0942547 |
| year1996 | -0.0940997 | 0.0458342 | -2.0530431 | 0.0400684 |
| year1997 | -0.1018983 | 0.0494837 | -2.0592298 | 0.0394722 |
| year1998 | -0.1106329 | 0.0527965 | -2.0954608 | 0.0361300 |
| year1999 | -0.1567306 | 0.0567198 | -2.7632437 | 0.0057230 |
| year2000 | -0.1786367 | 0.0596812 | -2.9931825 | 0.0027608 |
| year2001 | -0.1230923 | 0.0629593 | -1.9551093 | 0.0505702 |
| year2002 | -0.1148820 | 0.0661989 | -1.7354058 | 0.0826689 |
| year2003 | -0.1265220 | 0.0704128 | -1.7968599 | 0.0723579 |
| year2004 | -0.1089463 | 0.0757858 | -1.4375550 | 0.1505604 |
| year2005 | -0.1051253 | 0.0814282 | -1.2910179 | 0.1966975 |
| year2006 | -0.0969002 | 0.0864126 | -1.1213666 | 0.2621319 |
| year2007 | -0.0686381 | 0.0909329 | -0.7548216 | 0.4503560 |
| year2008 | -0.0386615 | 0.0936277 | -0.4129278 | 0.6796595 |
| year2009 | -0.0474718 | 0.0931580 | -0.5095837 | 0.6103431 |
| year2010 | -0.0326547 | 0.0972298 | -0.3358504 | 0.7369837 |
| year2011 | -0.0047312 | 0.1007848 | -0.0469438 | 0.9625580 |
| year2012 | 0.0084959 | 0.1041805 | 0.0815498 | 0.9350047 |
| year2013 | 0.0214981 | 0.1067280 | 0.2014289 | 0.8403632 |
| year2014 | 0.0599923 | 0.1106800 | 0.5420336 | 0.5877953 |
| year2015 | 0.0816702 | 0.1140904 | 0.7158372 | 0.4740919 |
| GDP_PP | -0.0000085 | 0.0000015 | -5.7236489 | 0.0000000 |
El año perdió significancia en muchas entradas, veamos si nuestro modelo mejoró.
## Analysis of Deviance Table
##
## Model 1: suicides ~ offset(log(population)) + country + sex + age + generation +
## HDI + year
## Model 2: suicides ~ offset(log(population)) + country + sex + age + generation +
## HDI + year + GDP_PP
## Resid. Df Resid. Dev Df Deviance Pr(>Chi)
## 1 700 31722
## 2 699 31689 1 32.709 1.071e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Aunque el año perdió significancia, la devianza del modelo con todas las variables es significativamente mejor, por lo que es mejor a nuestro modelo anterior. Sin embargo, puede que el PIB y el año expliquen lo mismo por lo que quitaremos la variable año para ver si nuestro modelo mejora.
5.13 País, sexo, edad, generación, IDH y PIB per cápita
| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -16.4600008 | 0.0615673 | -267.349745 | 0.0000000 |
| countryUnited States | 0.5186118 | 0.0139444 | 37.191528 | 0.0000000 |
| sexmale | 1.4390149 | 0.0023256 | 618.763576 | 0.0000000 |
| age15-24 years | 2.6608324 | 0.0113880 | 233.651731 | 0.0000000 |
| age25-34 years | 2.8581583 | 0.0118861 | 240.462203 | 0.0000000 |
| age35-54 years | 3.0008500 | 0.0128374 | 233.759095 | 0.0000000 |
| age55-74 years | 3.0363540 | 0.0145685 | 208.419821 | 0.0000000 |
| age75+ years | 3.3365358 | 0.0157959 | 211.227393 | 0.0000000 |
| generationSilent | -0.2345718 | 0.0050878 | -46.104462 | 0.0000000 |
| generationBoomers | -0.1334297 | 0.0074459 | -17.919888 | 0.0000000 |
| generationGeneration X | -0.0764717 | 0.0097732 | -7.824671 | 0.0000000 |
| generationMillenials | -0.1022473 | 0.0126248 | -8.098932 | 0.0000000 |
| generationGeneration Z | 0.0832918 | 0.0235083 | 3.543077 | 0.0003955 |
| HDI | 4.1570853 | 0.0929615 | 44.718378 | 0.0000000 |
| GDP_PP | -0.0000078 | 0.0000002 | -42.150066 | 0.0000000 |
Todas las variables son muy significativas. Veamos si es mejor a nuestro modelo con todas las variables.
## Analysis of Deviance Table
##
## Model 1: suicides ~ offset(log(population)) + country + sex + age + generation +
## HDI + GDP_PP
## Model 2: suicides ~ offset(log(population)) + country + sex + age + generation +
## HDI + year + GDP_PP
## Resid. Df Resid. Dev Df Deviance Pr(>Chi)
## 1 729 35609
## 2 699 31689 30 3920.2 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Sigue siendo mejor el modelo con todas nuestras variables por lo que este será nuestro modelo final.
| country | year | sex | age | HDI | GDP_PP | |
|---|---|---|---|---|---|---|
| 80 | Mexico | 1991 | female | 25-34 years | 0.6524 | 4204 |
| 89 | Mexico | 1992 | male | 15-24 years | 0.6568 | 4830 |
| 110 | Mexico | 1994 | male | 55-74 years | 0.6656 | 6735 |
| 134 | Mexico | 1996 | male | 55-74 years | 0.6758 | 4904 |
| 156 | Mexico | 1997 | female | 5-14 years | 0.6816 | 5864 |
| 177 | Mexico | 1999 | female | 75+ years | 0.6932 | 6800 |
| 240 | Mexico | 2004 | female | 5-14 years | 0.7174 | 8217 |
| 596 | United States | 2003 | female | 25-34 years | 0.8914 | 42468 |
| 700 | United States | 2012 | male | 25-34 years | 0.9120 | 55170 |
| 713 | United States | 2013 | male | 15-24 years | 0.9130 | 56520 |
| generation | suicides | rate | ajustados | tasas_ajust | residuos | |
|---|---|---|---|---|---|---|
| 80 | Boomers | 72 | 0.000011 | 109.09713 | 0.0000164 | 37.097135 |
| 89 | Generation X | 554 | 0.000058 | 559.53608 | 0.0000585 | 5.536078 |
| 110 | Silent | 299 | 0.000097 | 220.99507 | 0.0000721 | 78.004933 |
| 134 | Silent | 309 | 0.000092 | 250.12176 | 0.0000743 | 58.878244 |
| 156 | Millenials | 30 | 0.000003 | 10.95100 | 0.0000010 | 19.049000 |
| 177 | G.I. Generation | 9 | 0.000008 | 32.57623 | 0.0000301 | 23.576234 |
| 240 | Millenials | 50 | 0.000004 | 13.02161 | 0.0000011 | 36.978392 |
| 596 | Generation X | 909 | 0.000046 | 1023.69955 | 0.0000521 | 114.699554 |
| 700 | Millenials | 4985 | 0.000237 | 4835.24953 | 0.0002299 | 149.750466 |
| 713 | Millenials | 3903 | 0.000172 | 4462.52674 | 0.0001963 | 559.526735 |
Notamos que el ajuste no es tan bueno, pero tampoco tan malo, en algunas entradas sí ajusta bien.
Verifiquemos la dispersión de nuestro modelo
##
## Overdispersion test
##
## data: fit
## z = 16.492, p-value < 2.2e-16
## alternative hypothesis: true dispersion is greater than 1
## sample estimates:
## dispersion
## 43.46441La prueba nos arroja que nuestro modelo tiene sobredispercion, entonces en estos casos es recomendable, tratar de ajustar un modelo binomial negativo, lo cual se realizará a continuación.
Ajustaremos un modelo binomial negativo dada la variabilidad de los datos para ver si el ajuste mejora.
| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -17.1740708 | 3.8910546 | -4.4137316 | 0.0000102 |
| countryUnited States | 0.3834412 | 1.5392651 | 0.2491067 | 0.8032783 |
| sexmale | 1.5543579 | 0.0269350 | 57.7077119 | 0.0000000 |
| age15-24 years | 2.4024892 | 0.0598616 | 40.1340591 | 0.0000000 |
| age25-34 years | 2.4858681 | 0.0814096 | 30.5353317 | 0.0000000 |
| age35-54 years | 2.5918253 | 0.1175649 | 22.0459144 | 0.0000000 |
| age55-74 years | 2.4857642 | 0.1667491 | 14.9072102 | 0.0000000 |
| age75+ years | 2.6560126 | 0.1909649 | 13.9083836 | 0.0000000 |
| generationSilent | -0.3263373 | 0.0732143 | -4.4572869 | 0.0000083 |
| generationBoomers | -0.2911118 | 0.1237396 | -2.3526170 | 0.0186418 |
| generationGeneration X | -0.2882807 | 0.1650687 | -1.7464289 | 0.0807365 |
| generationMillenials | -0.1881089 | 0.2095196 | -0.8978107 | 0.3692865 |
| generationGeneration Z | 0.1585504 | 0.2534192 | 0.6256447 | 0.5315480 |
| HDI | 5.8426733 | 6.1277764 | 0.9534736 | 0.3403501 |
| year1986 | 0.0082659 | 0.1093544 | 0.0755881 | 0.9397468 |
| year1987 | -0.0213339 | 0.1178133 | -0.1810821 | 0.8563031 |
| year1988 | -0.0336123 | 0.1345607 | -0.2497928 | 0.8027476 |
| year1989 | -0.0363630 | 0.1564873 | -0.2323702 | 0.8162505 |
| year1990 | -0.0365614 | 0.1805072 | -0.2025479 | 0.8394884 |
| year1991 | -0.0003516 | 0.2077094 | -0.0016925 | 0.9986496 |
| year1992 | 0.0222974 | 0.2384412 | 0.0935132 | 0.9254959 |
| year1993 | 0.0164845 | 0.2753418 | 0.0598693 | 0.9522598 |
| year1994 | 0.0441734 | 0.3072972 | 0.1437481 | 0.8856994 |
| year1995 | 0.0339985 | 0.3247537 | 0.1046901 | 0.9166217 |
| year1996 | 0.0013722 | 0.3556533 | 0.0038583 | 0.9969215 |
| year1997 | 0.0184909 | 0.3920212 | 0.0471681 | 0.9623792 |
| year1998 | 0.0086811 | 0.4231744 | 0.0205143 | 0.9836331 |
| year1999 | -0.0578193 | 0.4600542 | -0.1256794 | 0.8999857 |
| year2000 | -0.0505941 | 0.4944097 | -0.1023323 | 0.9184929 |
| year2001 | 0.0697063 | 0.5252797 | 0.1327033 | 0.8944281 |
| year2002 | 0.0430355 | 0.5525888 | 0.0778798 | 0.9379237 |
| year2003 | 0.0218304 | 0.5813056 | 0.0375541 | 0.9700432 |
| year2004 | 0.0405570 | 0.6208987 | 0.0653199 | 0.9479193 |
| year2005 | 0.0438740 | 0.6640154 | 0.0660737 | 0.9473191 |
| year2006 | 0.0304039 | 0.7044856 | 0.0431576 | 0.9655759 |
| year2007 | -0.0320931 | 0.7419895 | -0.0432528 | 0.9655000 |
| year2008 | 0.0265091 | 0.7690903 | 0.0344681 | 0.9725038 |
| year2009 | 0.0229464 | 0.7676326 | 0.0298924 | 0.9761529 |
| year2010 | 0.0029875 | 0.8067810 | 0.0037030 | 0.9970455 |
| year2011 | 0.0780691 | 0.8354387 | 0.0934469 | 0.9255485 |
| year2012 | 0.0426644 | 0.8670690 | 0.0492053 | 0.9607557 |
| year2013 | 0.0683691 | 0.8845063 | 0.0772964 | 0.9383878 |
| year2014 | 0.1631208 | 0.9072604 | 0.1797949 | 0.8573136 |
| year2015 | 0.1669786 | 0.9192707 | 0.1816425 | 0.8558633 |
| GDP_PP | -0.0000136 | 0.0000125 | -1.0857610 | 0.2775848 |
La variable año pierde significancia, por lo que quitaremos esta variable para ver si mejora el ajuste.
| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -17.4416104 | 0.4221359 | -41.3175276 | 0.0000000 |
| countryUnited States | 0.3229737 | 0.1522094 | 2.1219039 | 0.0338458 |
| sexmale | 1.5536646 | 0.0271092 | 57.3112721 | 0.0000000 |
| age15-24 years | 2.4227215 | 0.0588212 | 41.1879166 | 0.0000000 |
| age25-34 years | 2.5270391 | 0.0776518 | 32.5432181 | 0.0000000 |
| age35-54 years | 2.6612277 | 0.1094918 | 24.3052587 | 0.0000000 |
| age55-74 years | 2.5952035 | 0.1517267 | 17.1044602 | 0.0000000 |
| age75+ years | 2.7825955 | 0.1730322 | 16.0813780 | 0.0000000 |
| generationSilent | -0.2960857 | 0.0694307 | -4.2644778 | 0.0000200 |
| generationBoomers | -0.2147482 | 0.1126394 | -1.9065107 | 0.0565840 |
| generationGeneration X | -0.1866428 | 0.1501220 | -1.2432744 | 0.2137667 |
| generationMillenials | -0.0429597 | 0.1881769 | -0.2282944 | 0.8194174 |
| generationGeneration Z | 0.3328724 | 0.2302734 | 1.4455529 | 0.1483026 |
| HDI | 6.0483561 | 0.7573958 | 7.9857269 | 0.0000000 |
| GDP_PP | -0.0000129 | 0.0000022 | -5.7733628 | 0.0000000 |
## Likelihood ratio tests of Negative Binomial Models
##
## Response: suicides
## Model
## 1 offset(log(population)) + country + sex + age + generation + HDI + GDP_PP
## 2 offset(log(population)) + country + sex + age + generation + HDI + year + GDP_PP
## theta Resid. df 2 x log-lik. Test df LR stat. Pr(Chi)
## 1 7.709266 729 -9788.206
## 2 7.814702 699 -9779.695 1 vs 2 30 8.511296 0.9999601Primero notamos que el modelo con el año tiene devianza ligeramente menor, pero como esta diferencia no es significativa, nos quedaremos con el modelo más simple, sin la variable año.
Por otra parte notamos que la variable generación perdió significancia, por lo que la quitaremos y volveremos a comparar.
| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -17.9520948 | 0.4002971 | -44.846926 | 0.0000000 |
| countryUnited States | 0.1906786 | 0.0858580 | 2.220859 | 0.0263605 |
| sexmale | 1.5455322 | 0.0284410 | 54.341696 | 0.0000000 |
| age15-24 years | 2.2439181 | 0.0497091 | 45.140959 | 0.0000000 |
| age25-34 years | 2.2956995 | 0.0497397 | 46.154275 | 0.0000000 |
| age35-54 years | 2.3769839 | 0.0496913 | 47.834997 | 0.0000000 |
| age55-74 years | 2.3115996 | 0.0499032 | 46.321704 | 0.0000000 |
| age75+ years | 2.5950172 | 0.0505784 | 51.306777 | 0.0000000 |
| HDI | 6.8870478 | 0.5838346 | 11.796231 | 0.0000000 |
| GDP_PP | -0.0000138 | 0.0000021 | -6.625719 | 0.0000000 |
## Likelihood ratio tests of Negative Binomial Models
##
## Response: suicides
## Model
## 1 offset(log(population)) + country + sex + age + HDI + GDP_PP
## 2 offset(log(population)) + country + sex + age + generation + HDI + GDP_PP
## theta Resid. df 2 x log-lik. Test df LR stat. Pr(Chi)
## 1 6.970030 734 -9854.207
## 2 7.709266 729 -9788.206 1 vs 2 5 66.00085 6.947776e-13En este último modelo todas las variables son significativa, sin embargo, el modelo que contempla la generación es significativamente mejor.
Nos quedaremos con el modelo binomial negativo que contempla las variables país, sexo,edad, generación, IDH y PIB per cápita, y lo compararemos con el ajuste hecho por el modelo poisson.
| country | year | sex | age | HDI | GDP_PP | |
|---|---|---|---|---|---|---|
| 6 | Mexico | 1985 | female | 15-24 years | 0.6340 | 2730 |
| 59 | Mexico | 1989 | male | 5-14 years | 0.6452 | 3125 |
| 61 | Mexico | 1990 | male | 75+ years | 0.6480 | 3595 |
| 69 | Mexico | 1990 | female | 35-54 years | 0.6480 | 3595 |
| 288 | Mexico | 2008 | female | 5-14 years | 0.7364 | 10864 |
| 367 | Mexico | 2015 | female | 25-34 years | 0.7570 | 10228 |
| 395 | United States | 1986 | male | 5-14 years | 0.8446 | 20588 |
| 470 | United States | 1993 | male | 55-74 years | 0.8692 | 28891 |
| 594 | United States | 2003 | female | 35-54 years | 0.8914 | 42468 |
| 695 | United States | 2011 | male | 5-14 years | 0.9110 | 53452 |
| generation | suicides | rate | ajustados | tasas_ajust | residuos | |
|---|---|---|---|---|---|---|
| 6 | Generation X | 107 | 0.000013 | 110.02278 | 0.0000134 | 3.0227788 |
| 59 | Generation X | 40 | 0.000004 | 43.36102 | 0.0000041 | 3.3610234 |
| 61 | G.I. Generation | 87 | 0.000178 | 58.57526 | 0.0001198 | 28.4247365 |
| 69 | Silent | 58 | 0.000008 | 117.72281 | 0.0000167 | 59.7228112 |
| 288 | Generation Z | 73 | 0.000006 | 16.98247 | 0.0000015 | 56.0175275 |
| 367 | Millenials | 267 | 0.000026 | 267.27283 | 0.0000265 | 0.2728293 |
| 395 | Generation X | 199 | 0.000011 | 264.84000 | 0.0000153 | 65.8399992 |
| 470 | Silent | 4797 | 0.000264 | 4456.63969 | 0.0002454 | 340.3603141 |
| 594 | Boomers | 3058 | 0.000071 | 2480.30730 | 0.0000577 | 577.6926953 |
| 695 | Generation Z | 201 | 0.000009 | 335.87948 | 0.0000159 | 134.8794764 |
Sumaremos los residuos para ver qué modelo logra un mejor ajuste
## [1] 121159.7## [1] 182434.3El modelo presenta un error mayor, por lo que nuestro mejor modelo es el modelo Poisson con todas las variables explicativas.