Chapter 4 Methods
library(tidyverse)
library(lubridate)
library(ggplot2)
load("combined_data.RData")4.1 Study Locations
For this study nine different locations inside the Hayman fire perimeter were chosen for analysis. Three emergent wetlands, three forested/shrub wetlands, and three non-wetlands for a control group (Figure 2). Along with this five transects were established for each study location with one being inside the wetland and the other four outside of the wetland (Figure 3). Each transect consists of a 100-meter by 100-meter area and is continuous from one to the next. Study locations for the wetlands were manually located and selected to ensure that the initial transect was predominately occupied by the wetland. This was to ensure that the NDVI values for the area were more representative of the wetland than the area surrounding it. Similarly, each transect past the first, at 0 meters, progressively moves upslope into areas where burning occurred during the fire. Due to the limited size of many of the wetlands within the Hayman fire perimeter it was appropriate to create an area of 100-meter by 100-meter for each transect. The area for the transect allows for the wetlands to take up almost the entirety of the first transect while also allowing for each transect to have at least two pixels worth of NDVI values, due to the resolution of LANDSAT pixel data being 30 meters by 30 meters. Most of the wetlands in this study did not burn but the transects were established so that the area outside of the wetland were within burn areas.
library(png)
hayman_wetland <- readPNG("Data/Hayman_Wetlands.png")
grid::grid.raster(hayman_wetland)
grid::grid.text("Figure 2: Hayman fire burn severity (MTBS, 2002) and wetland study locations.", x = 0.5, y = 0.02,
gp = grid::gpar(fontsize = 10, fontface = "bold"))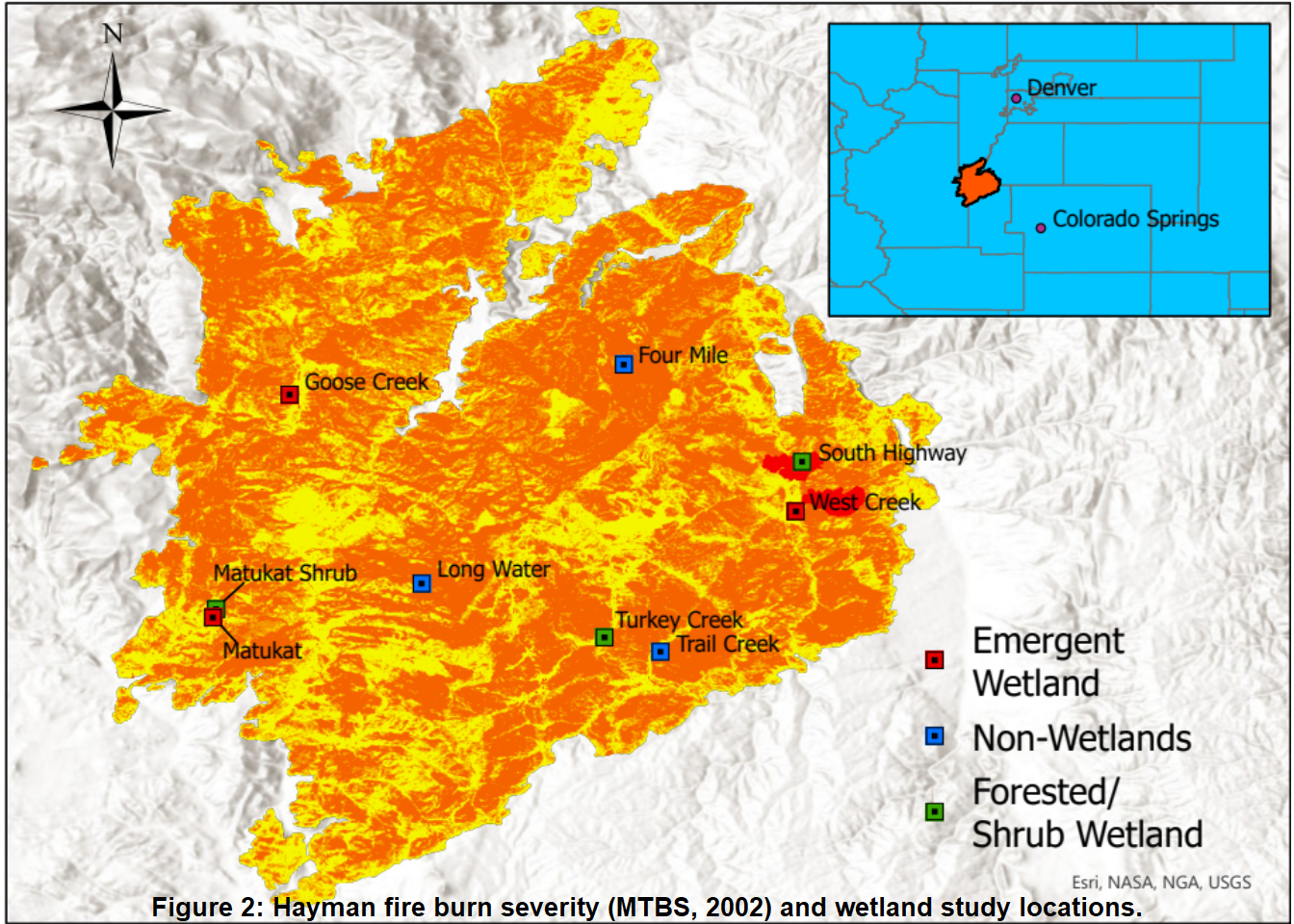
# Now we need to create a graph showing the change in NDVI values over time for each transect
# First we will start with looking at the change in values inside the wetland
# Get a list of the files, including paths
file_list <- list.files(path = "Data/NDVI/Wetlands",
full.names = TRUE)
# Get a list of the files without paths (a little redundant but whatever)
file_list_short <- list.files(path = "Data/NDVI/Wetlands")
# From the list with no paths, extract wetland names and positions
wetland_names <- gsub(
# Find underscores followed by any text
pattern = "_.*",
# Replace it with nothing (i.e., delete)
replacement = "",
# Apply this to the list of filenames
x = file_list_short)
positions <- gsub(
# Upper or lowercase letters followed by underscore OR .csv filetype
pattern = "[a-zA-Z]*_|\\.csv",
replacement = "",
x = file_list_short)
# Example of Wetland transects
transects <- readPNG("Data/Matukat_Transects.png")
grid::grid.raster(transects)
grid::grid.text("Figure 3: Transect locations for the Matukat Freshwater Emergent wetland.", x = 0.5, y = 0.08,
gp = grid::gpar(fontsize = 10, fontface = "bold"))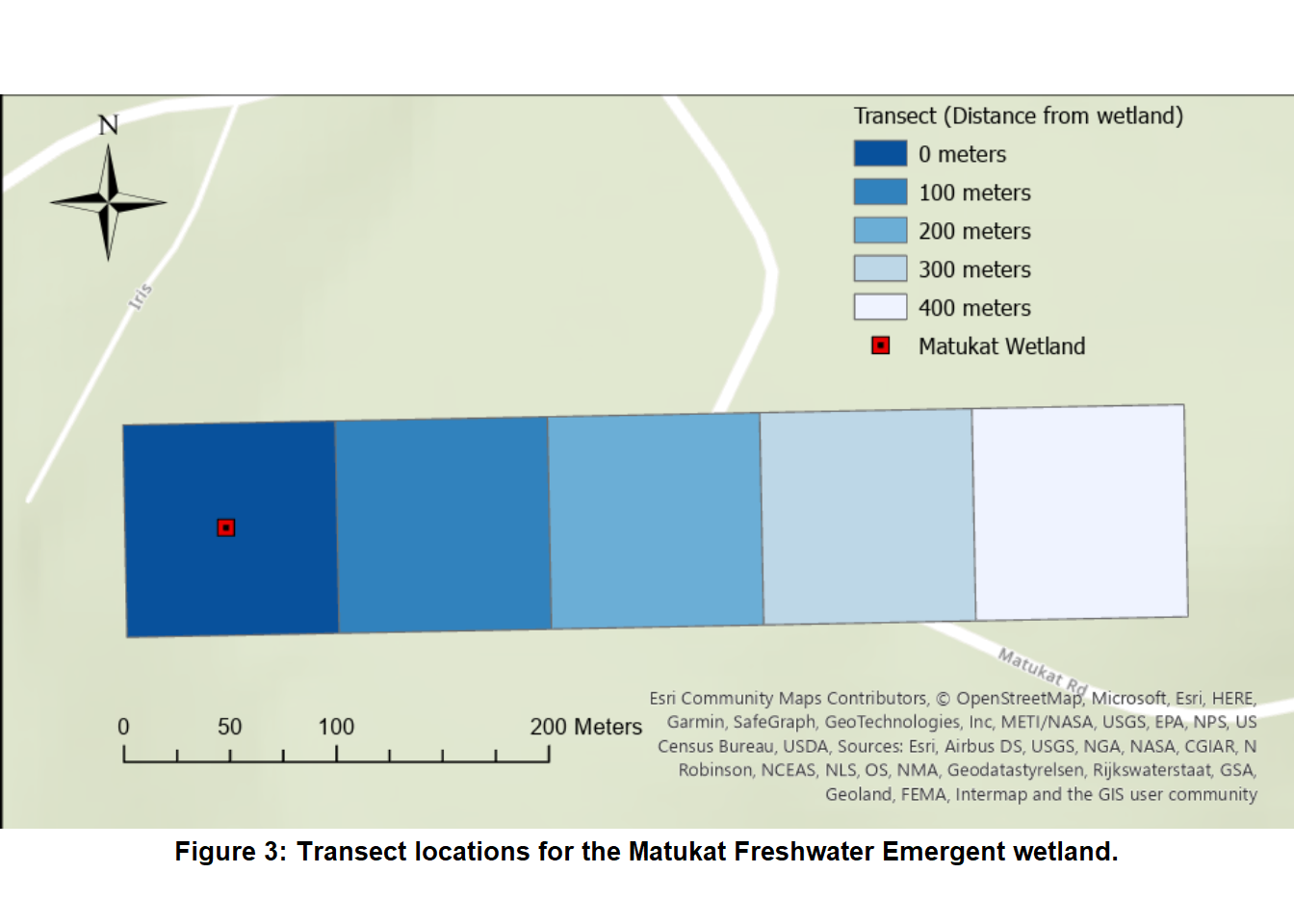
4.2 Data Collection and Use
The NDVI data utilized in this study was sourced from LANDSAT data that was gathered through Climate Engine. Due to the greenness and exposure of the vegetation being essential in this analysis only data for summer months was collected for the period of 1984-2022 and was subsequently cleaned up and utilized in R-Studio. All available NDVI values in the summer months were collected for every transect at all nine study locations. Through R-Studio the data was then averaged for the summer months of every year and then a median value was taken for each summer to allow for better statistical testing. In the statistical testing only the median values after 2002 (post-fire) were analyzed as vegetation recovery is the primary focus in this analysis. Multiple ANOVA tests were used to get an understanding of the variance in vegetation recovery between wetland types and their transects. The ANOVA tests were run on the median values of each wetland type at each transect distance. These ANOVA tests were used to assess the variance in recovery between study location type and their transects post-fire. The variance in NDVI values provides an indication whether there is significant difference between the wetland types and their rates of recovery. Boxplots were also produced to see which study location types varied most from the others since the ANOVA tests would not have an indication of this.
# Now, we should have, all in the same order:
# 1. A vector of file locations
# 2. A vector of wetland names
# 3. A vector of polygon positions relative to wetlands
# Next we'll use these three vectors in a map() statement, which is really just
# a for() loop that's a little less prone to typos, etc.
# Here's an example of how a map() function works:
map(
# .x is a list or vector that you want to iterate over
.x = file_list_short,
# .f is a function or expression that you want to apply to every item in .x separately
# We use a ~ when including ".x" as part of the .f statement, just FYI
.f = ~ paste(.x, "contains wetland data")
)## [[1]]
## [1] "FourMile_0m.csv contains wetland data"
##
## [[2]]
## [1] "FourMile_100m.csv contains wetland data"
##
## [[3]]
## [1] "FourMile_200m.csv contains wetland data"
##
## [[4]]
## [1] "FourMile_300m.csv contains wetland data"
##
## [[5]]
## [1] "FourMile_400m.csv contains wetland data"
##
## [[6]]
## [1] "GooseCreek_0m.csv contains wetland data"
##
## [[7]]
## [1] "GooseCreek_100m.csv contains wetland data"
##
## [[8]]
## [1] "GooseCreek_200m.csv contains wetland data"
##
## [[9]]
## [1] "GooseCreek_300m.csv contains wetland data"
##
## [[10]]
## [1] "GooseCreek_400m.csv contains wetland data"
##
## [[11]]
## [1] "LongWater_0m.csv contains wetland data"
##
## [[12]]
## [1] "LongWater_100m.csv contains wetland data"
##
## [[13]]
## [1] "LongWater_200m.csv contains wetland data"
##
## [[14]]
## [1] "LongWater_300m.csv contains wetland data"
##
## [[15]]
## [1] "LongWater_400m.csv contains wetland data"
##
## [[16]]
## [1] "Matukat_0m.csv contains wetland data"
##
## [[17]]
## [1] "Matukat_100m.csv contains wetland data"
##
## [[18]]
## [1] "Matukat_200m.csv contains wetland data"
##
## [[19]]
## [1] "Matukat_300m.csv contains wetland data"
##
## [[20]]
## [1] "Matukat_400m.csv contains wetland data"
##
## [[21]]
## [1] "MatukatShrub_0m.csv contains wetland data"
##
## [[22]]
## [1] "MatukatShrub_100m.csv contains wetland data"
##
## [[23]]
## [1] "MatukatShrub_200m.csv contains wetland data"
##
## [[24]]
## [1] "MatukatShrub_300m.csv contains wetland data"
##
## [[25]]
## [1] "MatukatShrub_400m.csv contains wetland data"
##
## [[26]]
## [1] "SHighway_0m.csv contains wetland data"
##
## [[27]]
## [1] "SHighway_100m.csv contains wetland data"
##
## [[28]]
## [1] "SHighway_200m.csv contains wetland data"
##
## [[29]]
## [1] "SHighway_300m.csv contains wetland data"
##
## [[30]]
## [1] "SHighway_400m.csv contains wetland data"
##
## [[31]]
## [1] "TrailCreek_0m.csv contains wetland data"
##
## [[32]]
## [1] "TrailCreek_100m.csv contains wetland data"
##
## [[33]]
## [1] "TrailCreek_200m.csv contains wetland data"
##
## [[34]]
## [1] "TrailCreek_300m.csv contains wetland data"
##
## [[35]]
## [1] "TrailCreek_400m.csv contains wetland data"
##
## [[36]]
## [1] "TurkeyCreek_0m.csv contains wetland data"
##
## [[37]]
## [1] "TurkeyCreek_100m.csv contains wetland data"
##
## [[38]]
## [1] "TurkeyCreek_200m.csv contains wetland data"
##
## [[39]]
## [1] "TurkeyCreek_300m.csv contains wetland data"
##
## [[40]]
## [1] "TurkeyCreek_400m.csv contains wetland data"
##
## [[41]]
## [1] "WestCreek_0m.csv contains wetland data"
##
## [[42]]
## [1] "WestCreek_100m.csv contains wetland data"
##
## [[43]]
## [1] "WestCreek_200m.csv contains wetland data"
##
## [[44]]
## [1] "WestCreek_300m.csv contains wetland data"
##
## [[45]]
## [1] "WestCreek_400m.csv contains wetland data"# The above map() function applies paste() to every filename
# We're going to be using a slightly different kind of map() though:
# The pmap() family of functions lets you use MORE than one list (so not just .x)
# The *_dfr() functions row bind, or stack, each iteration on top of the previous one
compiled_data <- pmap_dfr(
# We have .l instead of .x. This time we're providing a named list of all the
# vectors we want to use
.l = list(..1 = file_list, ..2 = wetland_names, ..3 = positions),
# We'll use { } here so that we can have line breaks, multiple <- , etc.
.f = ~{
# Read in data, rename, etc.
temporary_file <- read_csv(..1) %>%
rename(date = 1, ndvi = 2, ndwi = 3) %>%
# This is where the other two lists come in: we're going to add cols for
# wetland name and position. Refer to them by their list names
mutate(wetland = ..2, position = ..3)
# Here you can add in any other steps you want, e.g. formatting dates
temporary_file <- temporary_file %>%
mutate(date = as_date(date, format = "%m/%d/%Y"),
month = month(date), day = day(date), year = year(date)) %>%
filter(month %in% c(5,6,7,8,9))
# Return the final dataframe and R will row bind it to the others
temporary_file
})## New names:
## Rows: 1336 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," dbl
## (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_0 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat 5/7/8/9 SR),... date
## (1): ...1
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1317 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," dbl
## (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_1 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat 5/7/8/9 SR),... date
## (1): ...1
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1312 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," dbl
## (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_2 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat 5/7/8/9 SR),... date
## (1): ...1
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1319 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," dbl
## (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_3 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat 5/7/8/9 SR),... date
## (1): ...1
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1258 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," dbl
## (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_4 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat 5/7/8/9 SR),... date
## (1): ...1
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1261 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_0 ,1984-01-01 to 2023-02-25, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1280 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_1 ,1984-01-01 to 2023-02-25, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1295 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_2 ,1984-01-01 to 2023-02-26, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1293 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_3 ,1984-01-01 to 2023-02-26, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1323 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_4 ,1984-01-01 to 2023-02-26, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1276 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," dbl
## (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_0 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat 5/7/8/9 SR),... date
## (1): ...1
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1271 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," dbl
## (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_1 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat 5/7/8/9 SR),... date
## (1): ...1
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1311 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," dbl
## (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_2 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat 5/7/8/9 SR),... date
## (1): ...1
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1286 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," dbl
## (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_3 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat 5/7/8/9 SR),... date
## (1): ...1
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1245 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," dbl
## (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_4 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat 5/7/8/9 SR),... date
## (1): ...1
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1090 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_0 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1126 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_1 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1101 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_2 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1121 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_3 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1194 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_4 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1091 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_0 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1107 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_1 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1175 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_2 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1167 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_3 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1148 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_4 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1413 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat 5/7/8/9 SR),
## ,1984-...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1353 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_1 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1354 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_2 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1426 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_3 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1444 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_4 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1206 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," dbl
## (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_0 ,1984-01-01 to 2023-02-26, NDWI (NIR/SWIR1) (Landsat 5/7/8/9 SR),... date
## (1): ...1
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1238 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," dbl
## (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_1 ,1984-01-01 to 2023-02-26, NDWI (NIR/SWIR1) (Landsat 5/7/8/9 SR),... date
## (1): ...1
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1225 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," dbl
## (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_2 ,1984-01-01 to 2023-02-26, NDWI (NIR/SWIR1) (Landsat 5/7/8/9 SR),... date
## (1): ...1
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1149 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," dbl
## (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_3 ,1984-01-01 to 2023-02-26, NDWI (NIR/SWIR1) (Landsat 5/7/8/9 SR),... date
## (1): ...1
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1208 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," dbl
## (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_4 ,1984-01-01 to 2023-02-26, NDWI (NIR/SWIR1) (Landsat 5/7/8/9 SR),... date
## (1): ...1
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1212 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_0 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1217 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_1 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1246 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_2 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1245 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_3 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1256 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_4 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1251 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat 5/7/8/9 SR),
## ,1984-...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1266 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_1 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1275 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_2 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1318 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_3 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## New names:
## Rows: 1304 Columns: 3
## ── Column specification
## ────────────────────────────────────────────────────────────────────────────────────────── Delimiter: "," chr
## (1): ...1 dbl (2): NDVI (Landsat 5/7/8/9 SR), CE_ID_4 ,1984-01-01 to 2023-03-07, NDWI (NIR/SWIR1) (Landsat
## 5/7/8/9 SR), ...
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## • `` -> `...1`# Double check:
compiled_data <- compiled_data %>%
mutate(transect = position)
# Compiled Data with wetland type listed
compiled_wetlands <- read.csv("compiled_data.csv")
compiled_wetlands <- compiled_wetlands %>%
mutate(transect = position)
# Make monthly averages of the data
monthly_avg_ndvi <- compiled_wetlands %>%
group_by(wetland, transect, year, month, type) %>%
summarize(avg_ndvi = mean(ndvi))## `summarise()` has grouped output by 'wetland', 'transect', 'year', 'month'. You can override using the `.groups`
## argument.monthly_avg_ndwi <- compiled_wetlands %>%
group_by(wetland, transect, year, month, type) %>%
summarize(avg_ndwi = mean(ndwi))## `summarise()` has grouped output by 'wetland', 'transect', 'year', 'month'. You can override using the `.groups`
## argument.save(compiled_data, compiled_wetlands, monthly_avg_ndvi, monthly_avg_ndwi, file ='combined_data.RData')