Chapter 1 Exploratory Data Analysis
This chapter describes how to load data into R, and explore its properties. The purpose of an exploratory data analysis (EDA) is to learn about the nature of the data, and to become aware of any surprising characteristics or anomalies that might impact our analysis and conclusions. An EDA typically involves calculating summary statistics, and creating graphs and tables that help us explore the data. It does not involve more advanced techniques, such as modeling, but rather helps set the stage for these to be done effectively.
As you explore the data, look for:
- Missing values
- Unusual observations
- Misspecified variable types
We’ll begin by loading the tidyverse package, which can be used to create professional graphics, and wrangle (or manipulate) data into forms that are informative and easy to work with.
library(tidyverse)1.1 Section 1.1: Reading in Data
There are many ways to read data into R. We’ll look at how to read data from common .csv, .txt, and .xlsx files, as well as how to load data that is already part of an R package. Knowing how to read data in these formats is sufficient for this class, however, there are other data formats that can be read into R. If you find yourself working with data in other forms, there are plenty of online resources available.
1.1.1 Read data from a local file on your computer.
If the data are in a .csv, .txt, .xlsx, or .xls file on your computer, make sure that the file is in the same directory as your .Rmd file, and that this is set as your working directory. The easiest way to accomplish this is by using an R Project. Then, read in the data, using read_csv() for .csv files, read_delim for .txt files, or read_excel for .xlsx or .xls files.
The filename goes in quotes inside the read function. The name on the left is the name you will give the dataset. You will use this to refer to the data in all future commands. The <- is called an assignment operator. It assigns the dataset you have read in to the name you are giving it.
1.1.2 Reading Data from a Directory on Your Computer
HollywoodMovies <- read.csv("HollywoodMovies.csv")HollywoodMovies <- read.delim("HollywoodMovies.txt")Reading in excel files requires loading the readxl package.
library(readxl)
HollywoodMovies <- read.excel("HollywoodMovies.xlsx")1.1.3 Read data from the web
If reading data from the web, be sure to specify the entire url.
HollywoodMovies <- read.csv("https://www.lock5stat.com/datapage2e/HollywoodMovies.csv")HollywoodMovies <- read.csv("https://www.lock5stat.com/datapage2e/HollywoodMovies.txt")library(readxl)
HollywoodMovies <- read.csv("https://www.lock5stat.com/datapage2e/HollywoodMovies.xlsx")1.1.4 Load data already included in R package
If the dataset is already available in an R package, load that package and read in the data, using the data command.
library(Lock5Data)
data("HollywoodMovies")1.1.5 R Help File
If your data are part of an R package, you can view the help file, containing information on the dataset using the command ? before the name of the dataset. This should open the description file in the lower right panel of the RStudio window. Even if your data are not part of an R package, it is a good idea to look for this kind of information if it is available.
?HollywoodMovies1.2 Preview the Data
The glimpse() function gives an overview of the information contained in a dataset. We can see the number of observations (rows), and the number of variables, (columns). We also see the name of each variable and its type. Variable types include
Categorical variables, which take on groups or categories, rather than numeric values. In R, these might be coded as logical
<logi>, character<chr>, factor<fct>and ordered factor<ord>.Quantitative variables, which take on meaningful numeric values. These include numeric
<num>, integer<int>, and double<dbl>.
1.2.1 glimpse()
glimpse(HollywoodMovies)## Rows: 970
## Columns: 16
## $ Movie <fct> "Spider-Man 3", "Shrek the Third", "Transformers", "P…
## $ LeadStudio <fct> Sony, Paramount, Paramount, Disney, Warner Bros, Warn…
## $ RottenTomatoes <int> 61, 42, 57, 45, 78, 69, 93, 31, 26, 60, 97, 90, 14, 9…
## $ AudienceScore <int> 54, 57, 89, 74, 82, 69, 91, 72, 73, 90, 84, 78, 72, 8…
## $ Story <fct> Metamorphosis, Quest, Monster Force, Rescue, Quest, Q…
## $ Genre <fct> Action, Animation, Action, Action, Adventure, Thrille…
## $ TheatersOpenWeek <int> 4252, 4122, 4011, 4362, 4285, 3606, 3660, 3832, 3475,…
## $ OpeningWeekend <dbl> 151.1, 121.6, 70.5, 114.7, 77.1, 77.2, 69.3, 44.8, 44…
## $ BOAvgOpenWeekend <int> 35540, 29507, 17577, 26302, 17998, 21411, 18929, 1168…
## $ DomesticGross <dbl> 336.53, 322.72, 319.25, 309.42, 292.00, 256.39, 227.4…
## $ ForeignGross <dbl> 554.34, 476.24, 390.46, 654.00, 647.88, 328.96, 215.3…
## $ WorldGross <dbl> 890.87, 798.96, 709.71, 963.42, 939.89, 585.35, 442.8…
## $ Budget <dbl> 258.0, 160.0, 150.0, 300.0, 150.0, 150.0, 110.0, 130.…
## $ Profitability <dbl> 345.30, 499.35, 473.14, 321.14, 626.59, 390.23, 402.5…
## $ OpenProfit <dbl> 58.57, 76.00, 47.00, 38.23, 51.40, 51.47, 63.00, 34.4…
## $ Year <int> 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007,…A function similar to glimpse() is skim(), which is part of the skimr() package. skim() shows us:
For factor variables, skimr() reports
* number of missing cases (emp)
* proportion of complete cases, i.e. not missing (complete_rate)
* whether or not the categories have an ordering (ordered)
* number of unique categories (n_unique)
* most frequently occurring (top_counts)
For numeric variables, skimr() reports
* number of missing values (n_missing)
* proportion of complete cases, i.e. not missing (complete_rate)
* mean
* standard deviation (sd)
* minimum (p0), 25th percentile (p25), median (p50), 75th percentile (p75), and maximum (p100)
* a histogram of the values (these can be hard to read)
1.2.1.1 summary()
The summary function provides additional information. It can be used for the entire dataset, or individual variables.
summary(HollywoodMovies)## Movie LeadStudio RottenTomatoes AudienceScore
## All About Steve : 2 Independent:133 Min. : 0.00 Min. :19.00
## The Call : 2 Warner Bros:114 1st Qu.:28.00 1st Qu.:49.00
## (500) Days of Summer: 1 Sony : 98 Median :52.00 Median :61.00
## 10,000 B.C. : 1 Fox : 91 Mean :51.71 Mean :61.27
## 12 Rounds : 1 Universal : 85 3rd Qu.:75.00 3rd Qu.:74.00
## 12 years a slave : 1 Paramount : 81 Max. :99.00 Max. :96.00
## (Other) :962 (Other) :368 NA's :57 NA's :63
## Story Genre TheatersOpenWeek OpeningWeekend
## :329 :279 Min. : 1 Min. : 0.01
## Comedy : 80 Comedy :177 1st Qu.:2054 1st Qu.: 5.30
## Love : 64 Action :166 Median :2798 Median : 13.15
## Monster Force: 60 Drama :109 Mean :2495 Mean : 20.62
## Quest : 51 Horror : 52 3rd Qu.:3285 3rd Qu.: 26.20
## Rivalry : 33 Animation: 51 Max. :4468 Max. :207.44
## (Other) :353 (Other) :136 NA's :21 NA's :1
## BOAvgOpenWeekend DomesticGross ForeignGross WorldGross
## Min. : 28 Min. : 0.06 Min. : 0.00 Min. : 0.10
## 1st Qu.: 3528 1st Qu.: 17.57 1st Qu.: 16.67 1st Qu.: 38.36
## Median : 5983 Median : 40.41 Median : 46.66 Median : 88.18
## Mean : 8563 Mean : 68.16 Mean : 101.24 Mean : 169.01
## 3rd Qu.: 9790 3rd Qu.: 89.25 3rd Qu.: 111.91 3rd Qu.: 202.31
## Max. :147262 Max. :760.50 Max. :2021.00 Max. :2781.50
## NA's :25 NA's :94 NA's :56
## Budget Profitability OpenProfit Year
## Min. : 0.00 Min. : 2.3 Min. : 0.16 Min. :2007
## 1st Qu.: 20.00 1st Qu.: 150.0 1st Qu.: 19.50 1st Qu.:2009
## Median : 35.00 Median : 254.8 Median : 34.61 Median :2010
## Mean : 56.12 Mean : 384.6 Mean : 62.22 Mean :2010
## 3rd Qu.: 75.00 3rd Qu.: 418.0 3rd Qu.: 58.38 3rd Qu.:2012
## Max. :300.00 Max. :10175.9 Max. :3373.00 Max. :2013
## NA's :73 NA's :74 NA's :75summary(HollywoodMovies$WorldGross)## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 0.10 38.36 88.18 169.01 202.31 2781.50 56The head() and tail() command allow us the view the first, or last, rows of a dataset.
head(HollywoodMovies)## Movie LeadStudio RottenTomatoes
## 1 Spider-Man 3 Sony 61
## 2 Shrek the Third Paramount 42
## 3 Transformers Paramount 57
## 4 Pirates of the Caribbean: At World's End Disney 45
## 5 Harry Potter and the Order of the Phoenix Warner Bros 78
## 6 I Am Legend Warner Bros 69
## AudienceScore Story Genre TheatersOpenWeek OpeningWeekend
## 1 54 Metamorphosis Action 4252 151.1
## 2 57 Quest Animation 4122 121.6
## 3 89 Monster Force Action 4011 70.5
## 4 74 Rescue Action 4362 114.7
## 5 82 Quest Adventure 4285 77.1
## 6 69 Quest Thriller 3606 77.2
## BOAvgOpenWeekend DomesticGross ForeignGross WorldGross Budget Profitability
## 1 35540 336.53 554.34 890.87 258 345.30
## 2 29507 322.72 476.24 798.96 160 499.35
## 3 17577 319.25 390.46 709.71 150 473.14
## 4 26302 309.42 654.00 963.42 300 321.14
## 5 17998 292.00 647.88 939.89 150 626.59
## 6 21411 256.39 328.96 585.35 150 390.23
## OpenProfit Year
## 1 58.57 2007
## 2 76.00 2007
## 3 47.00 2007
## 4 38.23 2007
## 5 51.40 2007
## 6 51.47 20071.3 Modifying the Data
The Year variable could reasonably be thought of as either categorical or quantitative. We’ll convert it to categorical, and then back.
1.3.1 Converting from quantitative to categorical
HollywoodMovies$Year <- as.factor(HollywoodMovies$Year)1.3.2 Converting from categorical to quantitative
When converting from categorical to quantitative, we must perform the intermediate step of converting to character. Going directly from factor to numeric can lead to unexpected and nonsensical results.
HollywoodMovies$Year <- as.numeric(as.character(HollywoodMovies$Year))We can also create new variables, using the mutate() function.
1.3.3 Adding a new variable with mutate()
In the data description, the variable Profitability is defined as WorldGross as a percentage of Budget. Thus, films for which Profitability exceeds 100 were profitable.
We create a variable to tell whether or not a film was profitable. Note that in R, a variable defined as a condition, such as Profitability>100 will return values of either TRUE or FALSE.
HollywoodMovies <- HollywoodMovies %>% mutate(Profitable = Profitability > 100)summary(HollywoodMovies$Profitable)## Mode FALSE TRUE NA's
## logical 118 778 741.3.4 Selecting Columns
If the dataset contains a large number of variables, narrow down to the ones you are interested in working with. This can be done with the select() command. If there are not very many variables to begin with, or you are interested in all of them, then you may skip this step.
Let’s narrow the dataset down to the variables Movie, RottenTomatoes, AudienceScore, Genre, WorldGross, Budget, “Profitable,” and Year.
MoviesSubset <- HollywoodMovies %>% select(Movie, RottenTomatoes, AudienceScore,
Genre, WorldGross, Budget, Profitable,
Year)1.3.5 Filtering by Row
The filter() command narrows a dataset down to rows that meet a specified condition.
1.3.5.1 Filtering by a Categorical Variable
Let’s filter the data to only include action movies, comedies, dramas, and horror movies.
MoviesSubset1 <- MoviesSubset %>%
filter(Genre %in% c("Action", "Comedy", "Drama", "Horror"))glimpse(MoviesSubset1)## Rows: 504
## Columns: 8
## $ Movie <fct> "Spider-Man 3", "Transformers", "Pirates of the Caribbe…
## $ RottenTomatoes <int> 61, 57, 45, 60, 90, 14, 91, 94, 20, 79, 35, 93, 88, 13,…
## $ AudienceScore <int> 54, 89, 74, 90, 78, 72, 83, 89, 68, 86, 55, 80, 87, 73,…
## $ Genre <fct> Action, Action, Action, Action, Comedy, Comedy, Comedy,…
## $ WorldGross <dbl> 890.87, 709.71, 963.42, 456.07, 527.07, 253.62, 219.08,…
## $ Budget <dbl> 258.0, 150.0, 300.0, 65.0, 75.0, 90.0, 33.0, 7.5, 140.0…
## $ Profitable <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, T…
## $ Year <dbl> 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2…1.3.5.2 Filtering by a Quantitative Variable
Let’s filter the data to only include films whose world gross exceeds 100 million dollars.
MoviesSubset2 <- MoviesSubset %>% filter(WorldGross >100)Now, let’s preview the data again.
glimpse(MoviesSubset2)## Rows: 413
## Columns: 8
## $ Movie <fct> "Spider-Man 3", "Shrek the Third", "Transformers", "Pir…
## $ RottenTomatoes <int> 61, 42, 57, 45, 78, 69, 93, 31, 26, 60, 97, 90, 14, 91,…
## $ AudienceScore <int> 54, 57, 89, 74, 82, 69, 91, 72, 73, 90, 84, 78, 72, 83,…
## $ Genre <fct> Action, Animation, Action, Action, Adventure, Thriller,…
## $ WorldGross <dbl> 890.87, 798.96, 709.71, 963.42, 939.89, 585.35, 442.82,…
## $ Budget <dbl> 258.0, 160.0, 150.0, 300.0, 150.0, 150.0, 110.0, 130.0,…
## $ Profitable <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, T…
## $ Year <dbl> 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2…We’ll use MoviesSubset1 from this point forward.
1.4 Visualize the Data
Next, we’ll create graphics to help us visualize the distributions and relationships between variables. We’ll use the ggplot() function, which is part of the tidyverse package.
1.4.1 Histogram
Histograms are useful for displaying the distribution of a single quantitative variable
1.4.1.1 General Template for Histogram
ggplot(data=DatasetName, aes(x=VariableName)) +
geom_histogram(fill="colorchoice", color="colorchoice") +
ggtitle("Plot Title") +
xlab("x-axis label") +
ylab("y-axis label")1.4.1.2 Histogram of Audience Scores
ggplot(data=MoviesSubset1, aes(x=AudienceScore)) +
geom_histogram(fill="lightblue", color="white") +
ggtitle("Distribution of Audience Scores") +
xlab("Audience Score") +
ylab("Frequency")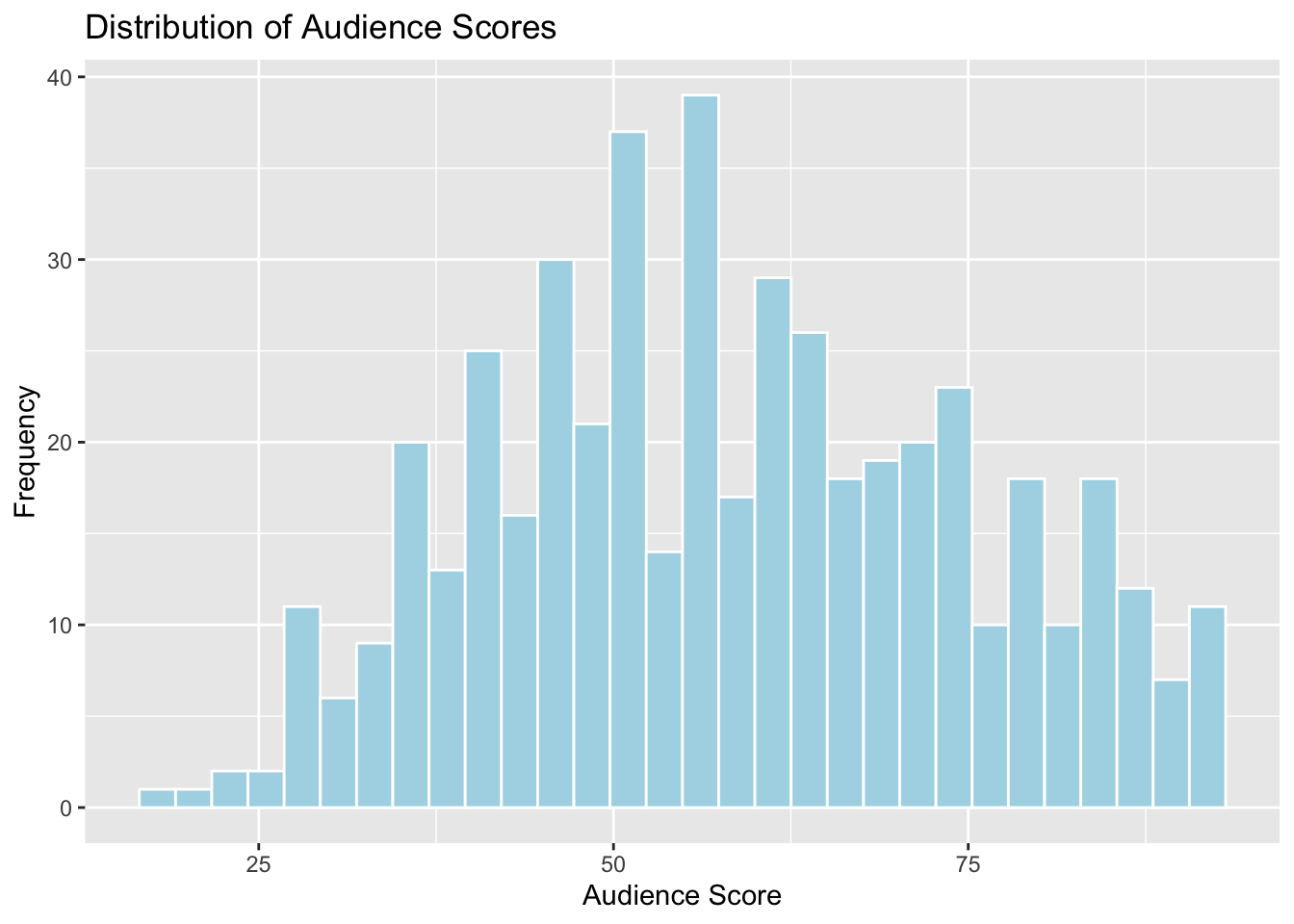
1.4.2 Density Plots
Density plots show the distribution for a quantitative variable like audience score. Scores can be compared across categories, like genre.
1.4.2.1 General Template for Density Plot
ggplot(data=DatasetName, aes(x=QuantitativeVariable,
color=CategoricalVariable, fill=CategoricalVariable)) +
geom_density(alpha=0.2) +
ggtitle("Plot Title") +
xlab("Axis Label") +
ylab("Frequency") alpha, ranging from 0 to 1 dictates transparency.
1.4.2.2 Density Plot of Audience Scores
ggplot(data=MoviesSubset1, aes(x=AudienceScore, color=Genre, fill=Genre)) +
geom_density(alpha=0.2) +
ggtitle("Distribution of Audience Scores") +
xlab("Audience Score") +
ylab("Frequency") 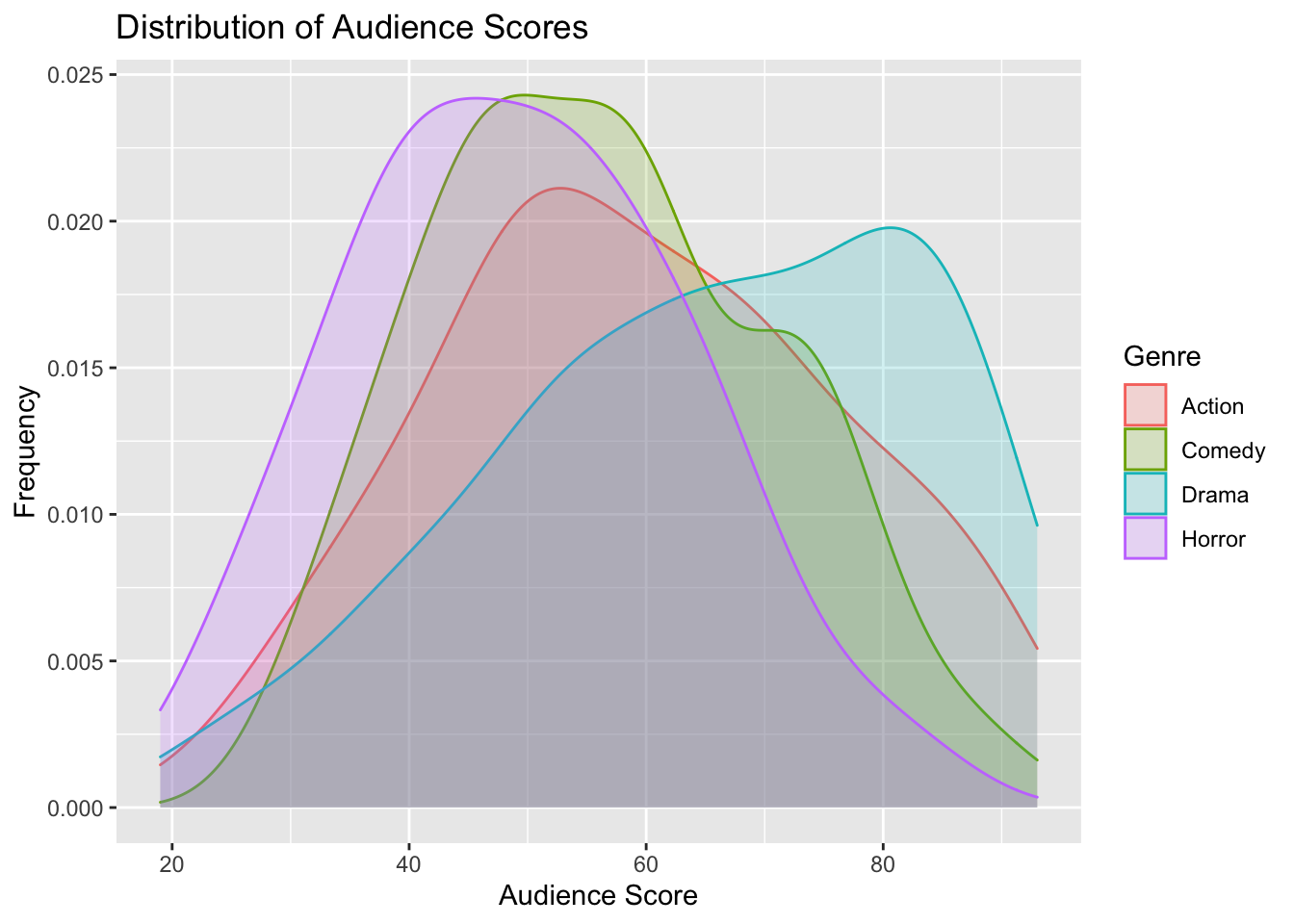
1.4.3 Boxplot
Boxplots can be used to compare a quantitative variable with a categorical variable
1.4.3.1 General Template for Boxplot
ggplot(data=DatasetName, aes(x=CategoricalVariable,
y=QuantitativeVariable)) +
geom_boxplot() +
ggtitle("Plot Title") +
xlab("Variable Name") + ylab("Variable Name") You can make the plot horizontal by adding + coordflip(). You can turn the axis text vertical by adding theme(axis.text.x = element_text(angle = 90)).
1.4.3.2 Boxplot Comparing Scores for Genres
ggplot(data=MoviesSubset1, aes(x=Genre, y=AudienceScore)) + geom_boxplot() +
ggtitle("Audience Score by Genre") +
xlab("Genre") + ylab("Audience Score") +
theme(axis.text.x = element_text(angle = 90))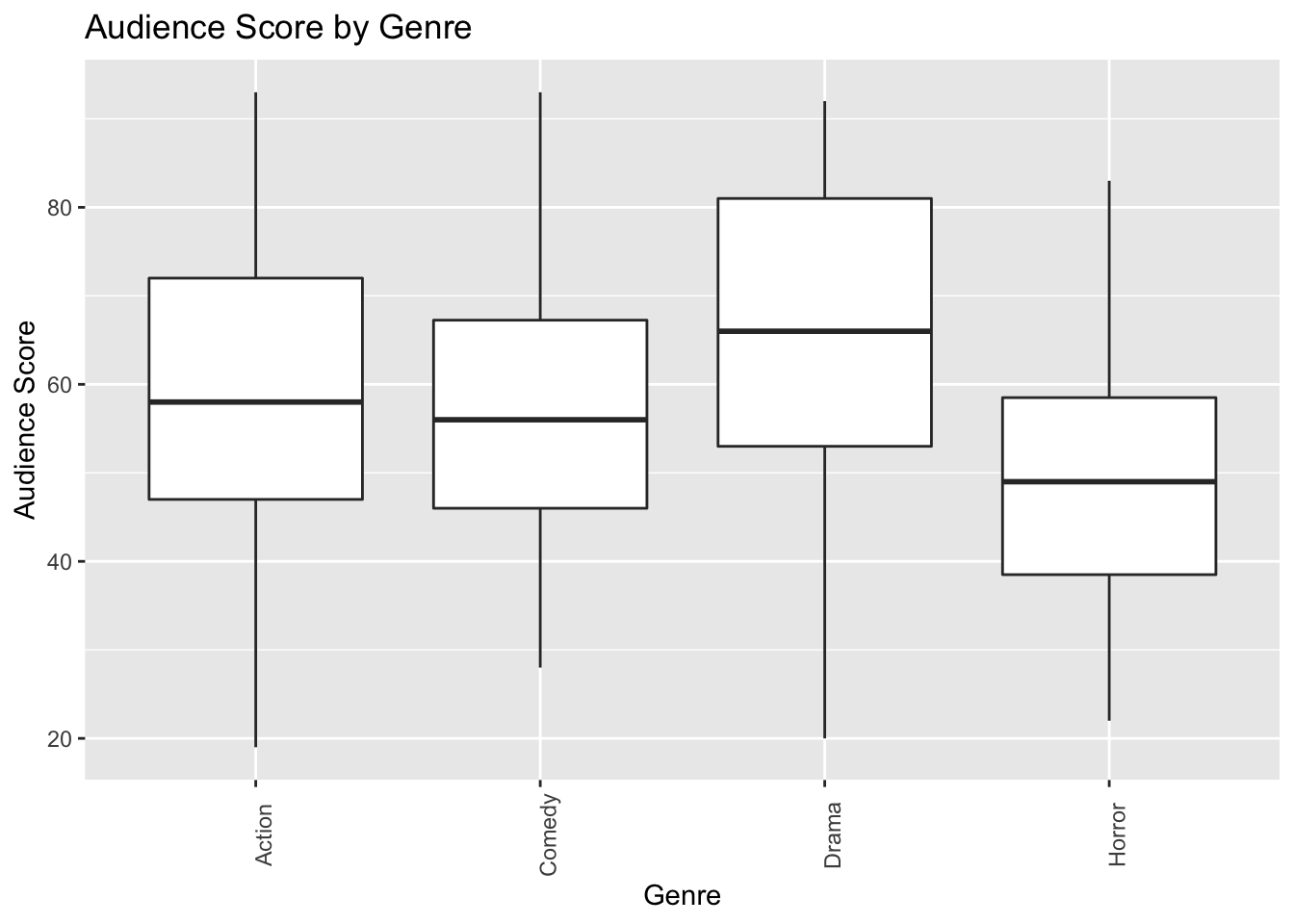
1.4.4 Violin Plot
Violin plots are an alternative to boxplots. The width of the violin tells us the density of observations in a given range.
1.4.4.1 General Template for Violin Plot
ggplot(data=DatasetName, aes(x=CategoricalVariable, y=QuantitativeVariable,
fill=CategoricalVariable)) +
geom_violin() +
ggtitle("Plot Title") +
xlab("Variable Name") + ylab("Variable Name") 1.4.4.2 Violin Plot Comparing Scores for Genres
ggplot(data=MoviesSubset1, aes(x=Genre, y=AudienceScore, fill=Genre)) +
geom_violin() +
ggtitle("Audience Score by Genre") +
xlab("Genre") + ylab("Audience Score") +
theme(axis.text.x = element_text(angle = 90))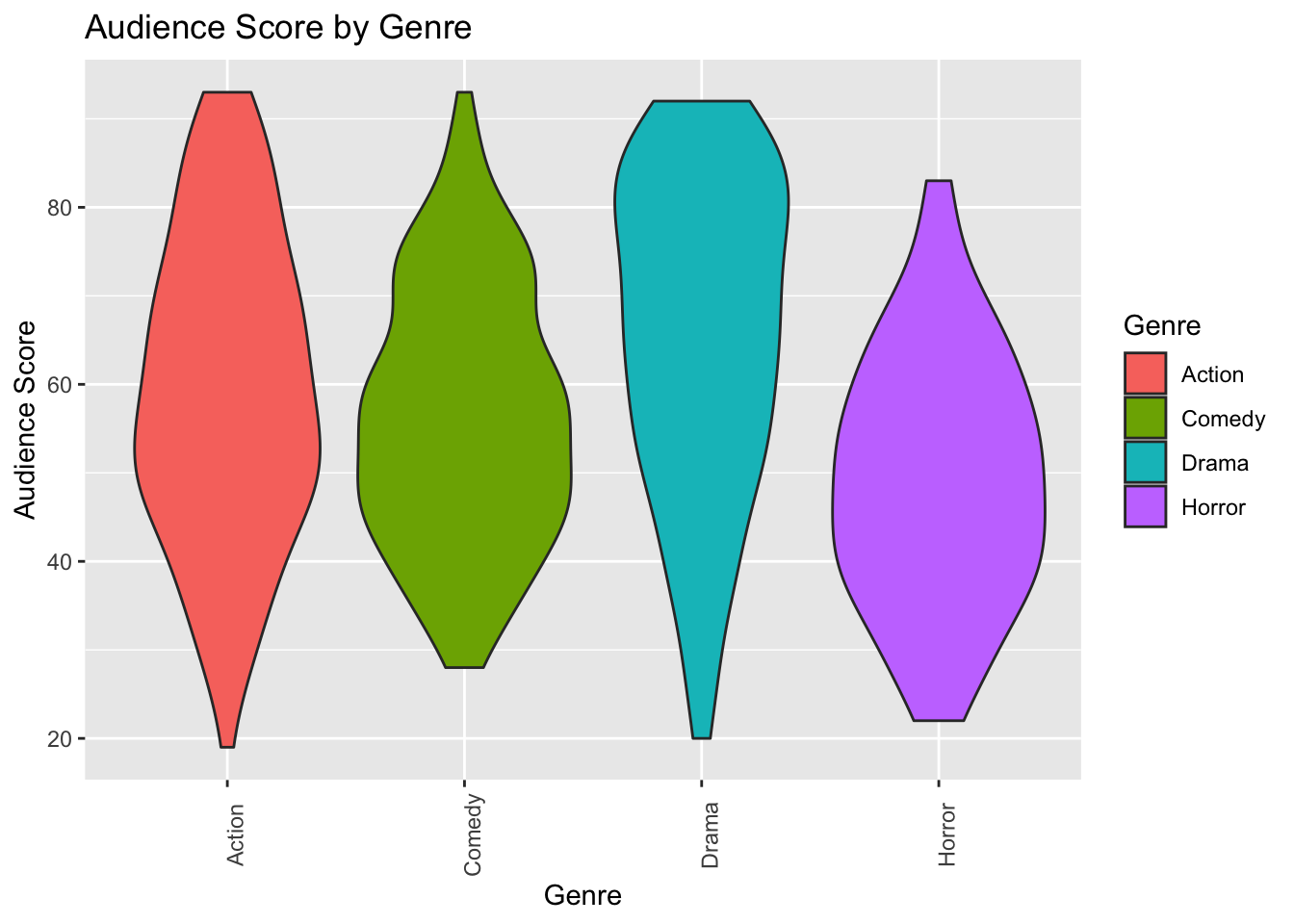
We can view the boxplot and violin plot together.
1.4.5 Scatterplots
Scatterplots are used to visualize the relationship between two quantitative variables.
1.4.5.1 Scatterplot Template
ggplot(data=DatasetName, aes(x=CategoricalVariable, y=QuantitativeVariable)) +
geom_point() +
ggtitle("Plot Title") +
ylab("Axis Label") +
xlab("Axis Label")1.4.5.2 Scatterplot Comparing Audience Score and Rotten Tomatoes Score
ggplot(data=MoviesSubset1, aes(x=RottenTomatoes, y=AudienceScore)) +
geom_point() +
ggtitle("Audience and Critics Ratings") +
ylab("Audience Rating") +
xlab("Critics' Rating")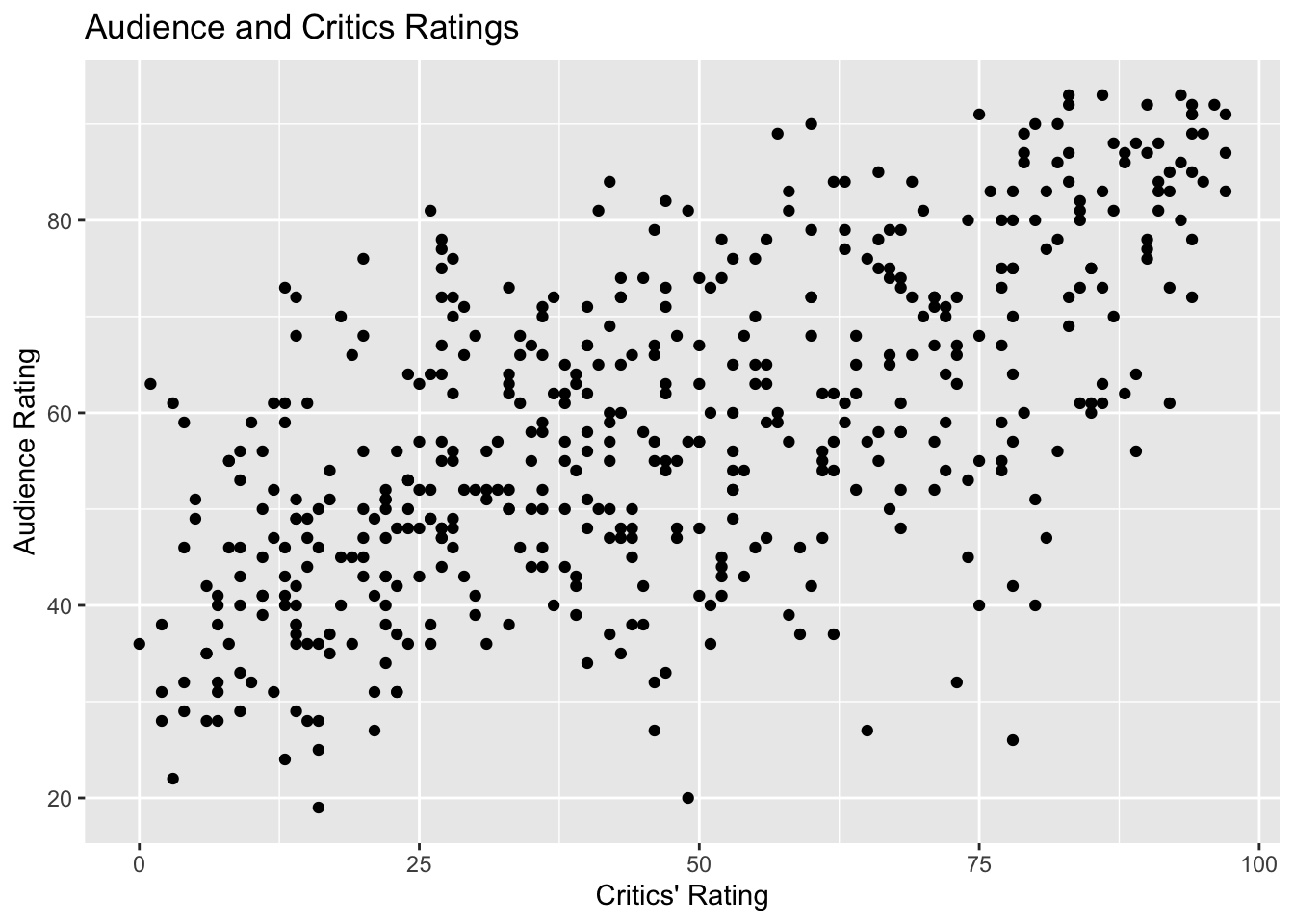
We see that there is an upward trend, indicating a positive association between critics scores (RottenTomatoes), and audience scores. However, there is a lot of variability, and the relationship is moderately strong at best.
We can also add color, size, and shape to the scatterplot to display information about other variables.
ggplot(data=MoviesSubset1,
aes(x=RottenTomatoes, y=AudienceScore, color=Genre, size=WorldGross)) +
geom_point() +
ggtitle("Audience and Critics Ratings") +
ylab("Audience Rating") +
xlab("Critics' Rating")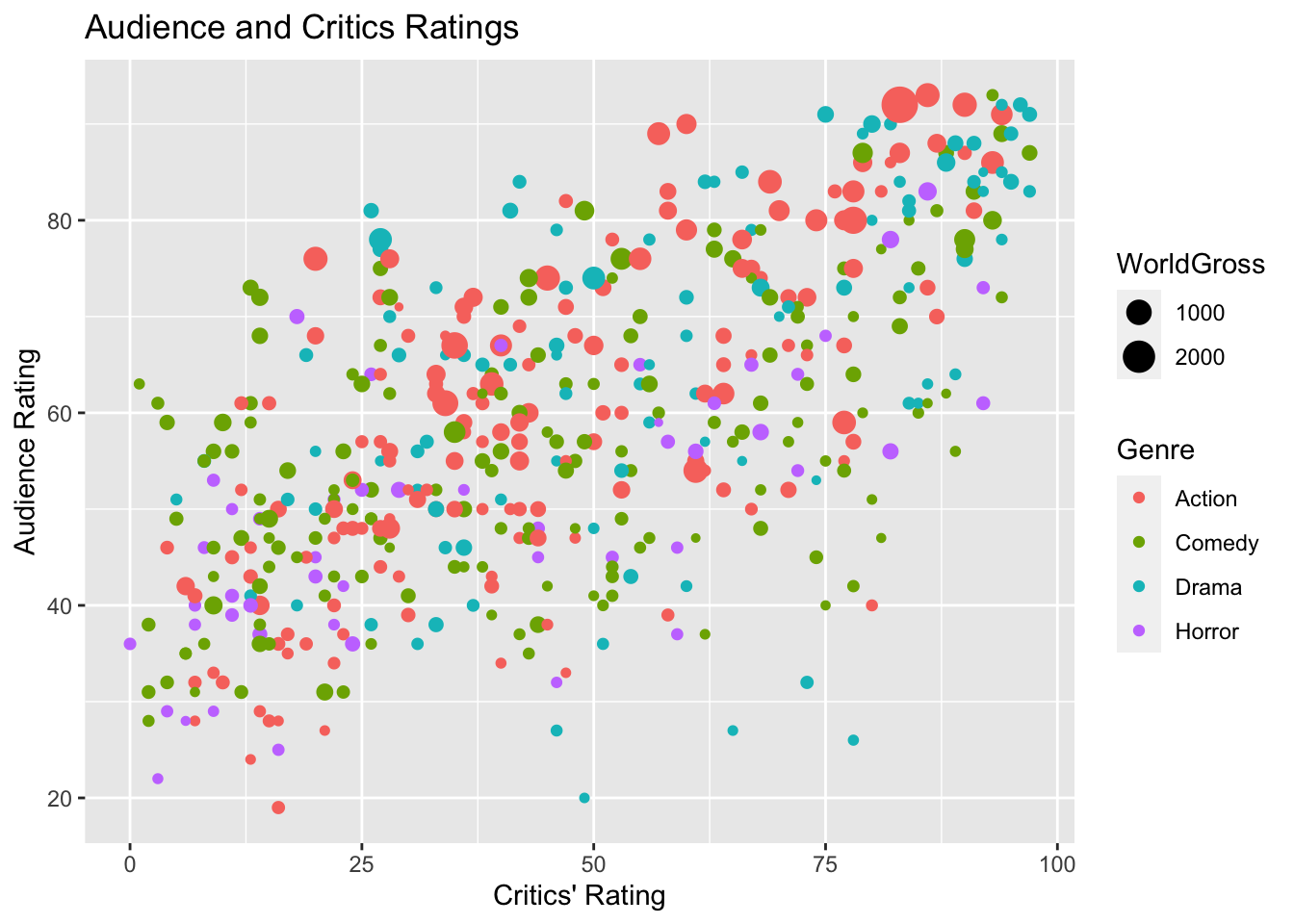
We can add labels for points meeting certain conditions, using geom_text(). This should be done carefully, to avoid overlap.
ggplot(data=MoviesSubset1,
aes(x=RottenTomatoes, y=AudienceScore, color=Genre, size=WorldGross)) +
geom_point() +
ggtitle("Audience and Critics Ratings") +
ylab("Audience Rating") + xlab("Critics' Rating") +
geom_text(data = MoviesSubset1 %>% filter(WorldGross >800), aes(label = Movie),
color="black", check_overlap = TRUE)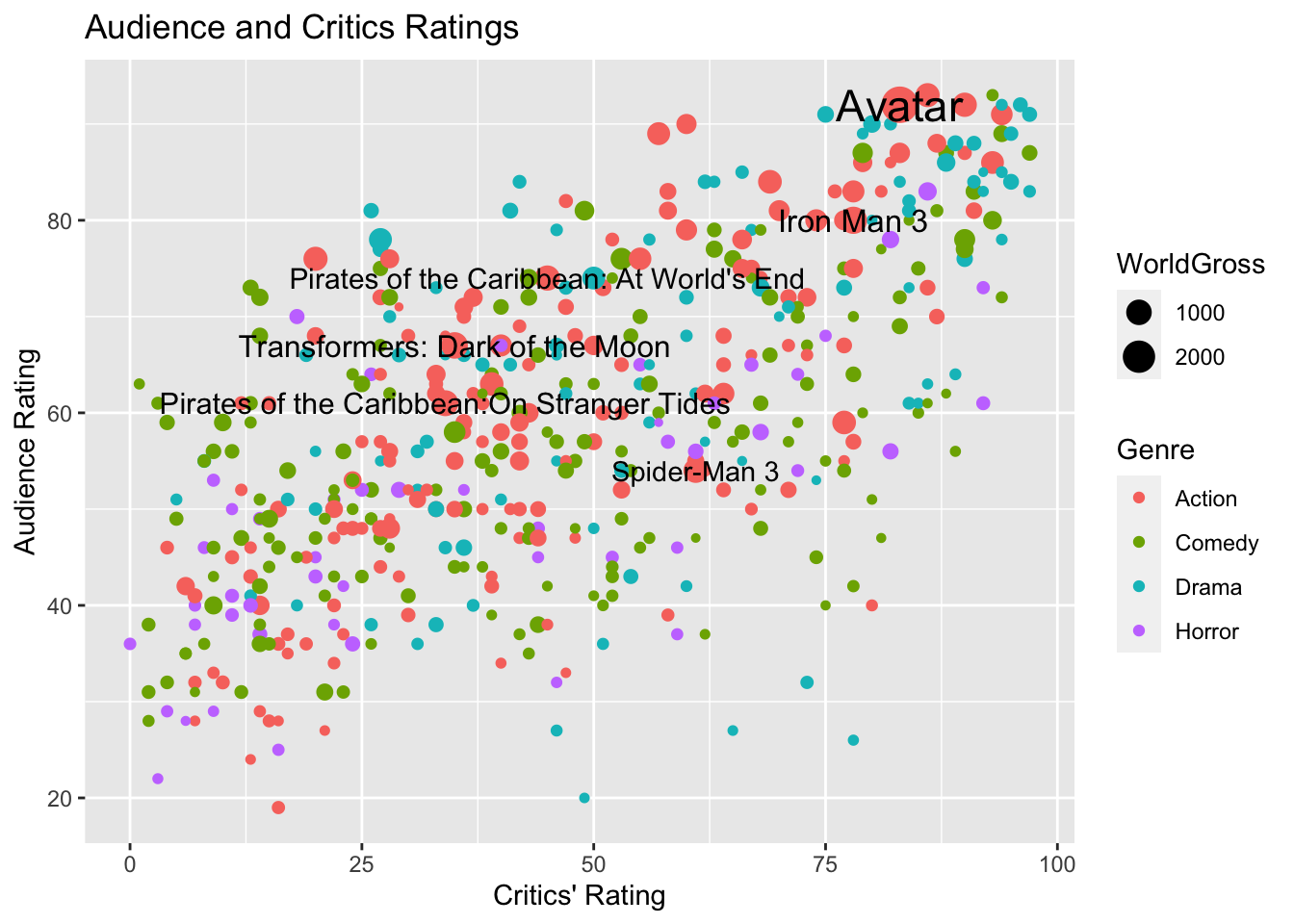
1.4.6 Bar Graphs
Bar graphs can be used to visualize one or more categorical variables
1.4.6.1 Bar Graph Template
ggplot(data=DatasetName, aes(x=CategoricalVariable)) +
geom_bar(fill="colorchoice",color="colorchoice") +
ggtitle("Plot Title") +
xlab("Variable Name") +
ylab("Frequency") 1.4.6.2 Bar Graph by Genre
ggplot(data=MoviesSubset1, aes(x=Genre)) +
geom_bar(fill="lightblue",color="white") +
ggtitle("Number of Films by Genre") +
xlab("Genre") +
ylab("Number of Films") +
theme(axis.text.x = element_text(angle = 90))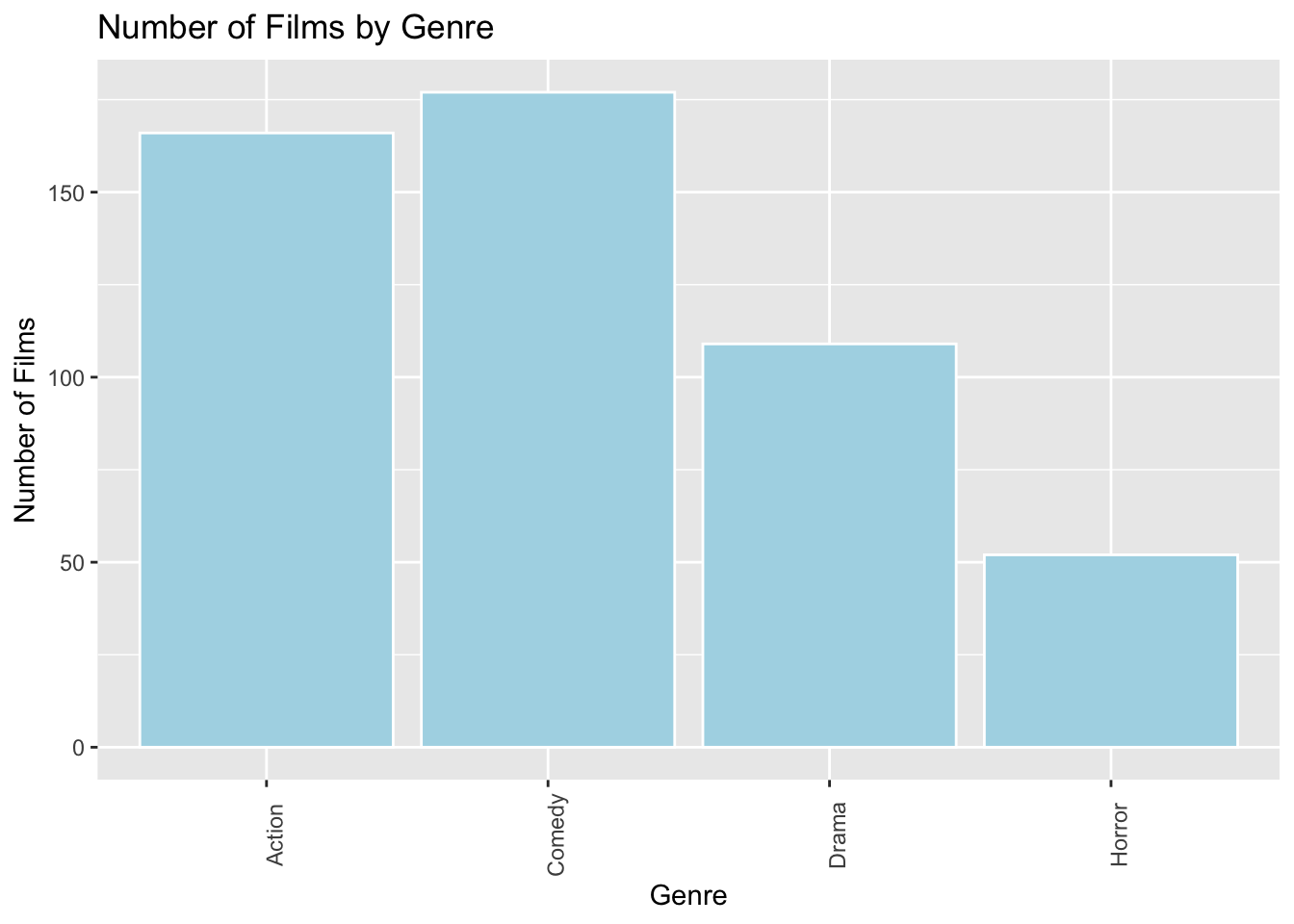
1.4.7 Stacked and Side-by-Side Bar Graphs
1.4.7.1 Stacked Bar Graph Template
ggplot(data = DatasetName, mapping = aes(x = CategoricalVariable1,
fill = CategoricalVariable2)) +
stat_count(position="fill") +
theme_bw() + ggtitle("Plot Title") +
xlab("Variable 1") +
ylab("Proportion of Variable 2") +
theme(axis.text.x = element_text(angle = 90)) 1.4.7.2 Stacked Bar Graph Example
The stat_count(position="fill") command creates a stacked bar graph, comparing two categorical variables. Let’s explore whether certain genres are more profitable than others, using the profitability variable.
ggplot(data = MoviesSubset1, mapping = aes(x = Genre, fill = Profitable)) +
stat_count(position="fill") +
theme_bw() + ggtitle("Profitability by Genre") +
xlab("Genre") +
ylab("Proportion Profitable") +
theme(axis.text.x = element_text(angle = 90)) 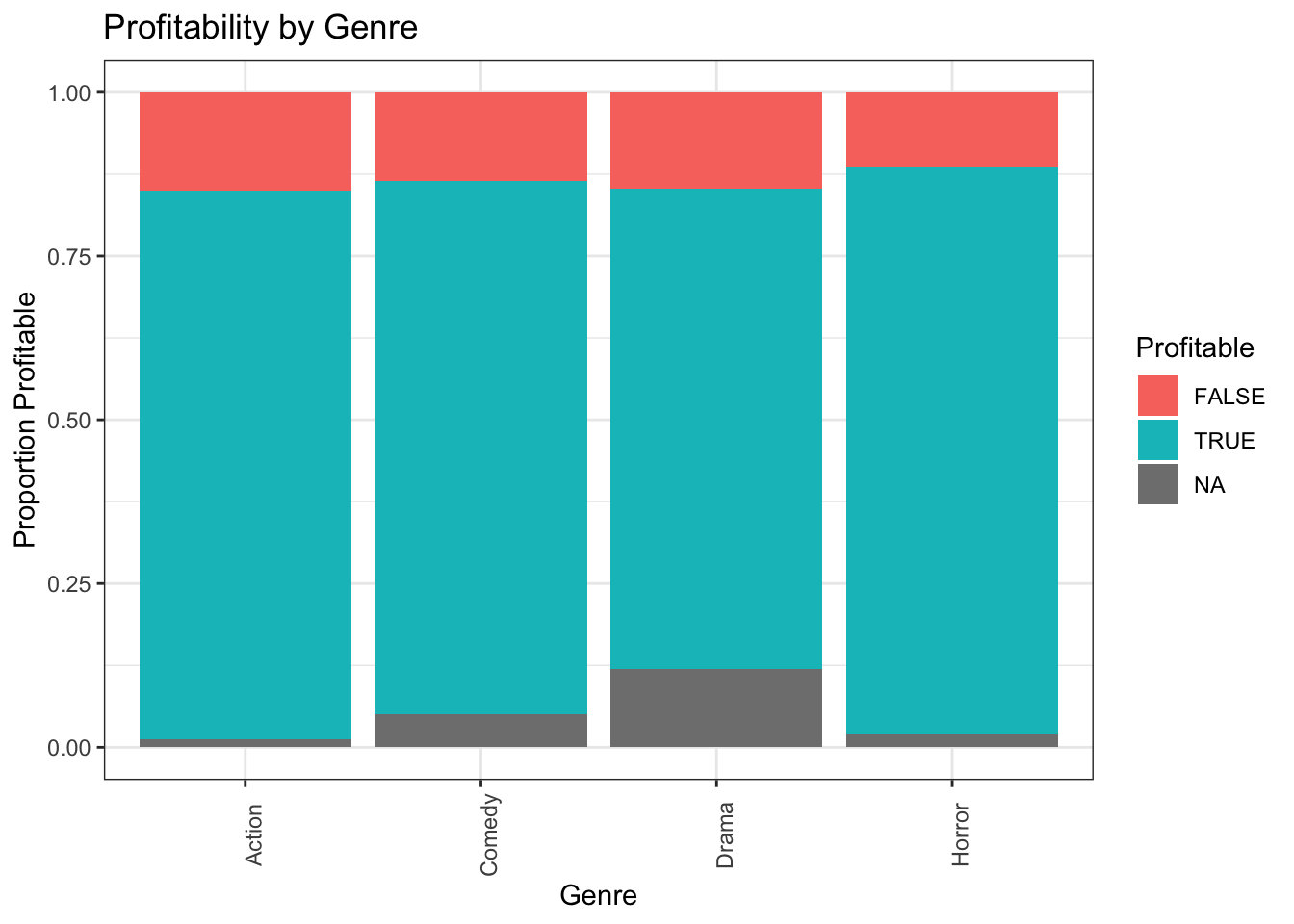
1.4.7.3 Side-by-side Bar Graph Template
We can create a side-by-side bar graph, using position=dodge.
ggplot(data = DatasetName, mapping = aes(x = CategoricalVariable1,
fill = CategoricalVariable2)) +
geom_bar(position = "dodge") +
ggtitle("Plot Title") +
xlab("Genre") +
ylab("Frequency") 1.4.7.4 Side-by-side Bar Graph Example
ggplot(data = MoviesSubset1, mapping = aes(x = Genre, fill = Profitable)) +
geom_bar(position = "dodge") +
ggtitle("Number of Films by Genre") +
xlab("Genre") +
ylab("Number of Films") +
theme(axis.text.x = element_text(angle = 90)) 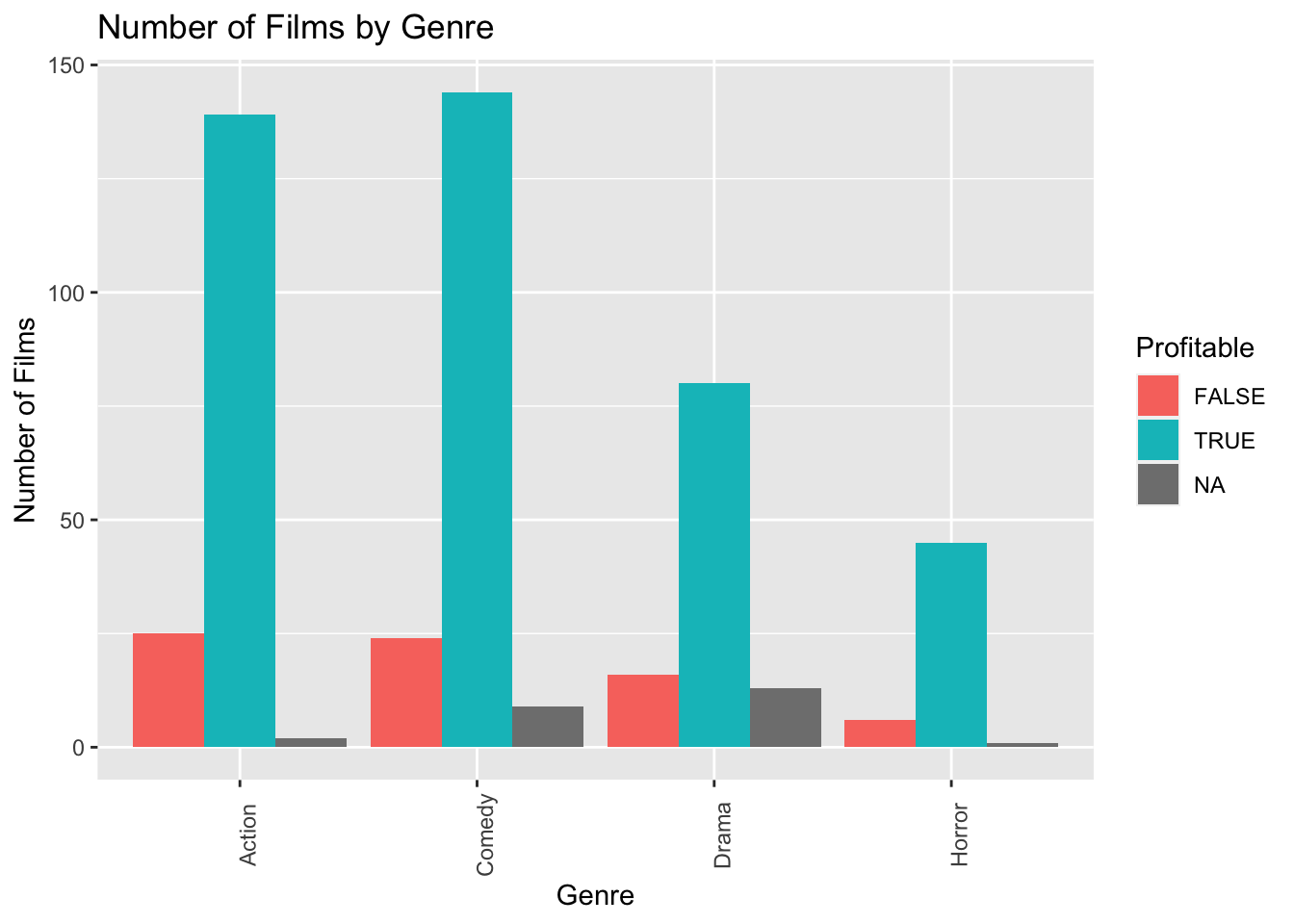
1.4.8 Examining Correlation
Correlation plots can be used to visualize relationships between quantitative variables. These can be helpful when we proceed to modeling. Explanatory variables that are highly correlated with the response are often strong predictors that should be included in a model. However, including two explanatory variables that are highly correlated with one another can create interpretation problems.
The cor() function calculates correlations between quantitative variables. We’ll use select_if to select only numeric variables. The `use=“complete.obs” command tells R to ignore observations with missing data.
1.4.8.1 Correlation Plot
cor(select_if(MoviesSubset1, is.numeric), use="complete.obs")## RottenTomatoes AudienceScore WorldGross Budget Year
## RottenTomatoes 1.000000000 0.64559072 0.15455587 0.005116351 0.13014104
## AudienceScore 0.645590720 1.00000000 0.35437898 0.182867955 0.00460772
## WorldGross 0.154555870 0.35437898 1.00000000 0.727042688 0.04617466
## Budget 0.005116351 0.18286795 0.72704269 1.000000000 0.02140576
## Year 0.130141039 0.00460772 0.04617466 0.021405765 1.00000000The corrplot() function in the corrplot() package provides a visualization of the correlations. Larger, thicker circles indicate stronger correlations.
library(corrplot)
Corr <- cor(select_if(HollywoodMovies, is.numeric), use="complete.obs")
corrplot(Corr)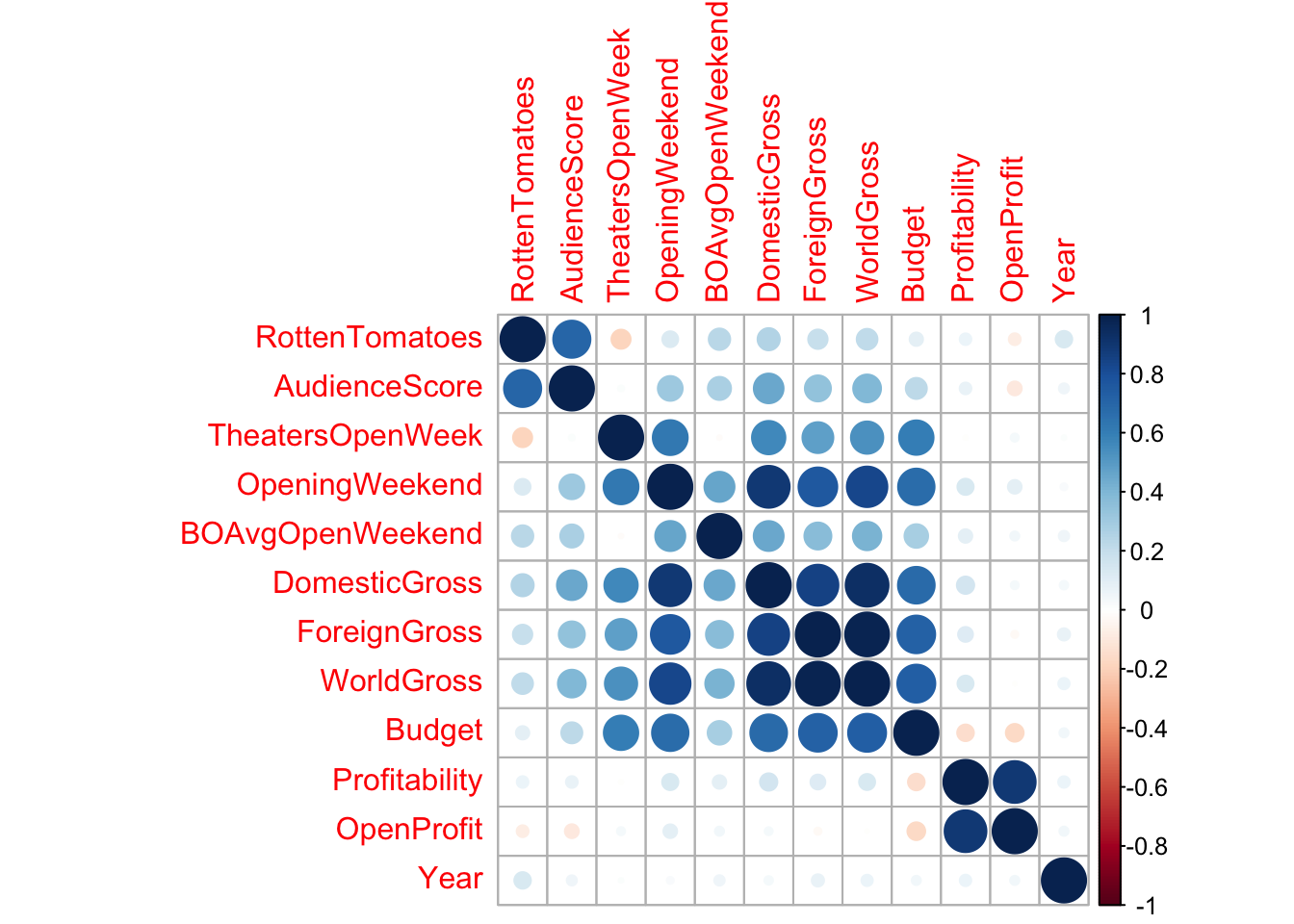
A scatterplot matrix is a grid of plots. It can be created using the ggpairs() function in the GGally package.
The scatterplot matrix shows us:
- Along the diagonal are density plots for quantitative variables, or bar graphs for categorical variables, showing the distribution of each variable.
- Under the diagonal are plots showing the relationships between the variables in the corresponding row and column. Scatterplots are used when both variables are quantitative, bar graphs are used when both variables are categorical, and boxplots are used when one variable is categorical, and the other is quantitative.
- Above the diagonal are correlations between quantitative variables.
We need to remove the column with the movie names. This is done using select.
1.4.8.2 Scatterplot Matrix
library(GGally)
ggpairs(MoviesSubset1 %>% select(-Movie))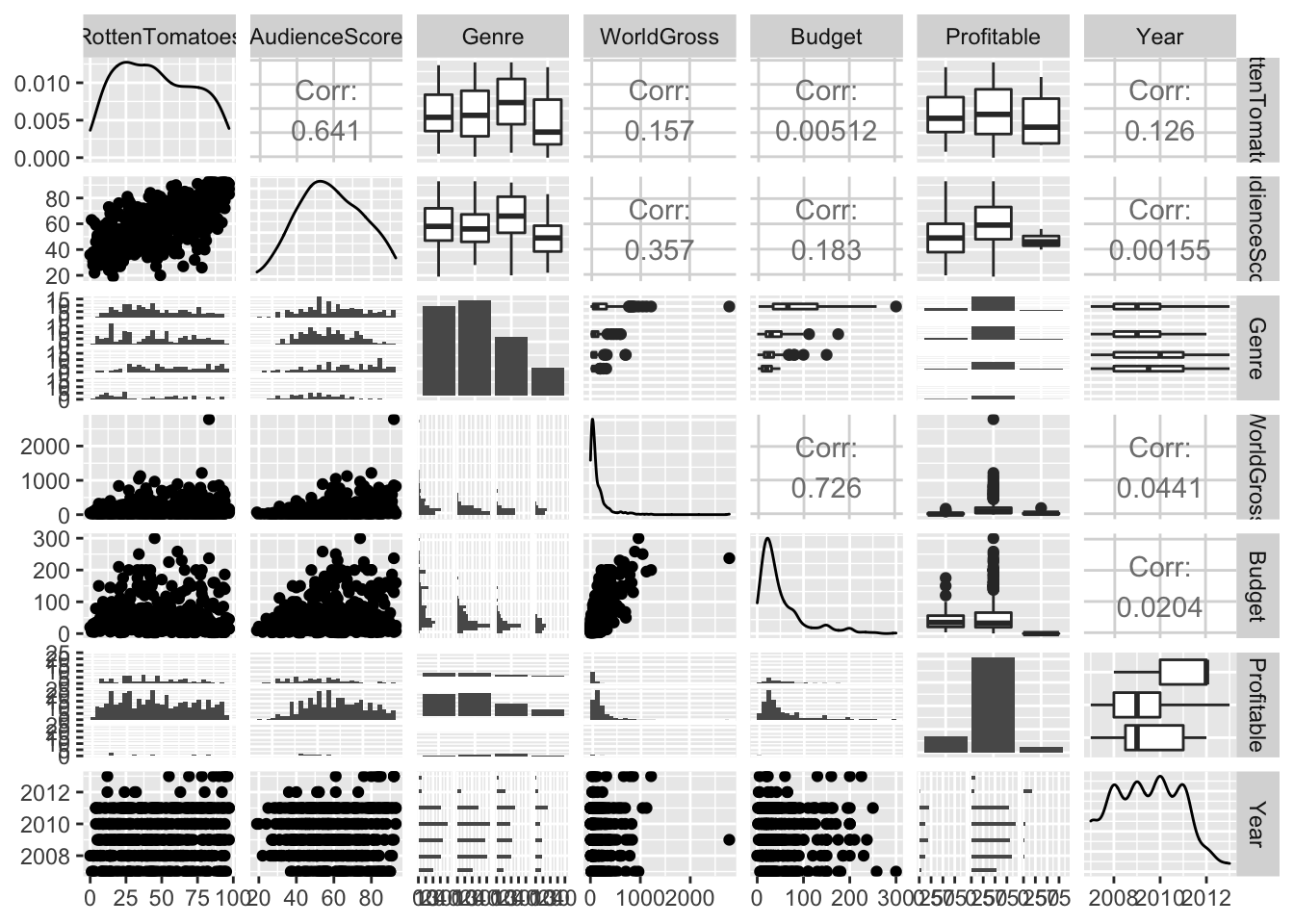
The scatterplot matrix is useful for helping us notice key trends in our data. However, the plot can hard to read as it is quite dense, especially when there are a large number of variables. These can help us look for trends from a distance, but we should then focus in on more specific plots.
1.5 Summary Tables
The group_by() and summarize() commands are useful for breaking categorical variables down by category. For example, let’s calculate number of films in each genre, and the mean, median, and standard deviation in film WorldGross by genre.
Notes:
1. The n() command calculates the number of observations in a category.
2. The na.rm=TRUE command removes missing values, so that summary statistics can be calculated.
3. arrange(desc(Mean_Gross)) arranges the table in descending order of Mean_Gross. To arrange in ascending order, use arrange(Mean_Gross).
MoviesSubset1 %>% group_by(Genre) %>%
summarize(N = n(),
Mean_Gross = mean(WorldGross, na.rm=TRUE),
Median_Gross = median(WorldGross, na.rm=TRUE),
StDev_Gross = sd(WorldGross, na.rm = TRUE)) %>%
arrange(desc(Mean_Gross))## # A tibble: 4 x 5
## Genre N Mean_Gross Median_Gross StDev_Gross
## <fct> <int> <dbl> <dbl> <dbl>
## 1 Action 166 246. 127. 319.
## 2 Comedy 177 104. 70.8 107.
## 3 Drama 109 89.6 55.2 111.
## 4 Horror 52 81.5 64.6 64.4The kable() function in the knitr() package creates tables with professional appearance.
library(knitr)
MoviesTable <- MoviesSubset1 %>% group_by(Genre) %>%
summarize(N = n(),
Mean_Gross = mean(WorldGross, na.rm=TRUE),
Median_Gross = median(WorldGross, na.rm=TRUE),
StDev_Gross = sd(WorldGross, na.rm = TRUE)) %>%
arrange(desc(Mean_Gross))
kable(MoviesTable)| Genre | N | Mean_Gross | Median_Gross | StDev_Gross |
|---|---|---|---|---|
| Action | 166 | 245.50790 | 127.232 | 318.76282 |
| Comedy | 177 | 103.72219 | 70.840 | 106.91791 |
| Drama | 109 | 89.58977 | 55.247 | 111.31833 |
| Horror | 52 | 81.52383 | 64.630 | 64.42613 |