Chapitre 3 : Préparation des métadonnées avec Nesstar Publisher
La préparation des métadonnées est une étape essentielle dans le processus de documentation des données statistiques. Elle garantit la compréhension, la transparence et la réutilisabilité des données collectées. Cette section détaille pas à pas le travail fait à l’aide de Nesstar Publisher, en partant du fichier de données brut jusqu’à l’enregistrement final du projet.
Étape 1 : Lancer Nesstar Publisher et créer un nouveau projet
Téléchargement de l’application Nesstar publisher sur le site officiel du projet Nesstar Publisher ou via le lien : https://ihsn.org/download/NesstarPublisherInstaller_v4.0.10.exe?_ga=2.50181732.333250071.1746483919-1427000134.1745336322
Ouvrir l’application Nesstar Publisher
Aller dans Fichier puis Ajouter une étude
Donner le nom et enregistrer pour créer un squelette du projet tel que présenté sur l’image ci-après :
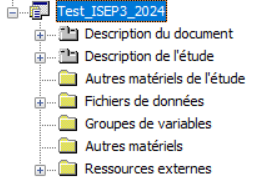
Étape 2 : Définir les métadonnées concernant la Description du document
Cette section regroupe l’ensemble des informations bibliographiques. Elle se compose notamment de trois volets :
Citation – Title Statement : saisissez le titre officiel de l’enquête et son numéro d’identification.
Citation – Responsibility Statement : indiquez le responsable principal de l’étude ainsi que les partenaires et contributeurs à mentionner.
Citation – Production Statement : renseignez la mention de copyright et l’organisation productrice des métadonnées.
Pour chacun de ces champs, une zone grisée « Description du champ » apparaît juste en dessous : elle précise exactement l’information à fournir.
À la fin, une fois tous les champs remplis conformément aux informations du site, le rendu s’affiche ainsi :
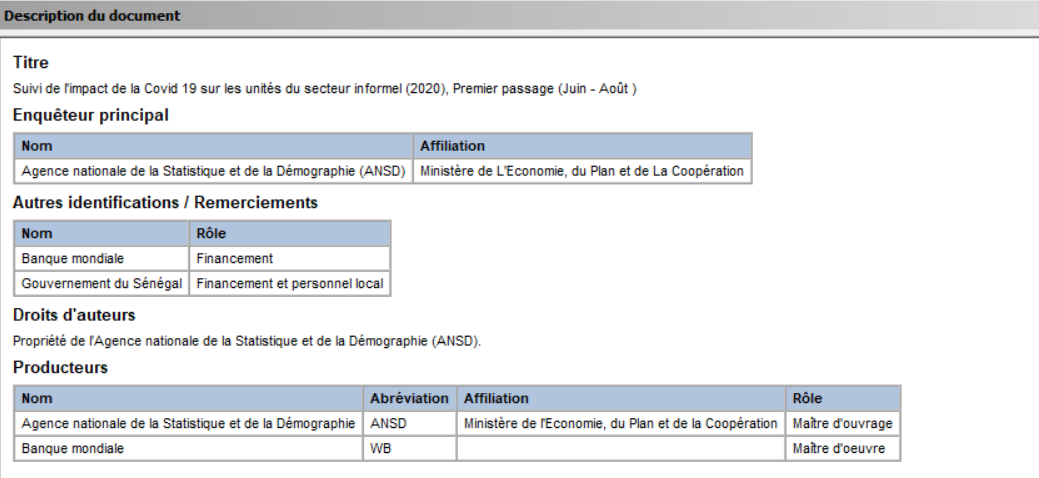
Étape 3 : Définir les métadonnées concernant la Description de l’étude
Cette section présente le contexte, l’objet et la méthodologie de l’enquête. Elle se décline en plusieurs volets :
Citation
Titre, identification & version : titre, numéro de l’étude et version avec date.
Enquêteur principal & Distributeur : nom de l’institution responsable et URL ou nom du portail ANSD.
Production Statement – Funding
- Bailleurs : liste des organismes ayant financé l’étude
Scope – Subject Information
Mots-clés : mots-clés officiels de l’enquête.
Classification du sujet : système de classification utilisé
Résumé : résumé synthétique décrivant l’objectif, la population et la méthode
Scope – Summary Data Description
Pays : pays concerné
Couverture géographique : niveau géographique couvert
Unité d’analyse: unité statistique
Univers : définition précise de la population cible
Methodology – Data Collection
Période : dates de début et de fin de la collecte.
Méthode d’échantillonnage : type et description de l’échantillonnage.
Mode de collecte : CAPI, PAPI, CATI…
Pondération: champ de pondération et formule associée.
Pour chaque champ, la zone grisée “Description du champ” située juste en dessous fournit exactement l’information à saisir. À la fin, une fois tous les champs remplis conformément aux informations du site, le rendu s’affiche ainsi :
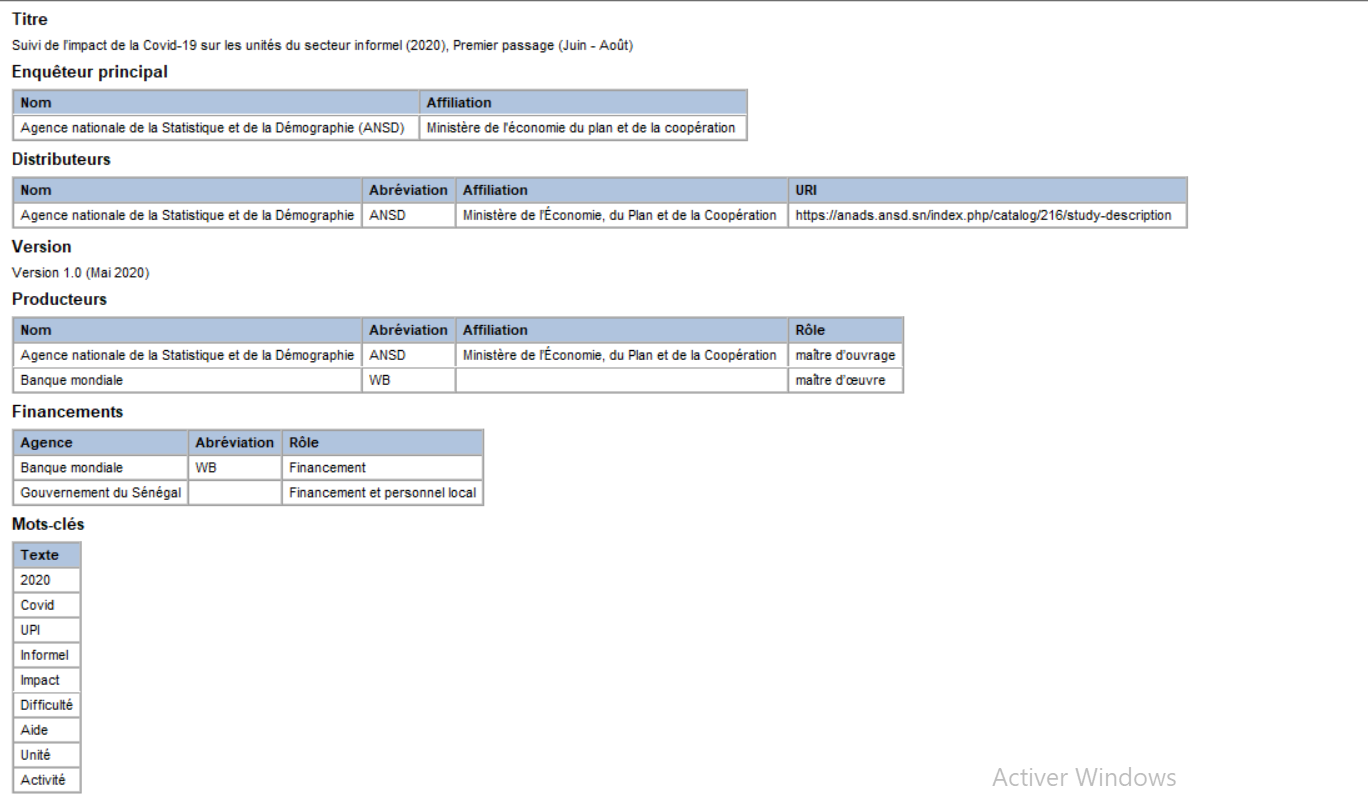


Étape 4 : Remplissage des autres sections
Les sections Autres matériels de l’étude, les Fichiers de données et les Groupes de variables rassemblent tout ce qui permet de comprendre et d’exploiter les données brutes.
D’une part, les documents de support (questionnaires, guides d’enquête, manuels enquêteurs, notes techniques) fournissent le contexte méthodologique et les instructions de collecte.
D’autre part, les jeux de données sont décrits avec précision (nom, format, taille, nombre de variables et d’observations), tandis que chaque variable y est documentée (nom, étiquette, modalités). Pour faciliter l’exploration, les variables sont ensuite organisées en modules thématiques (Démographie, Éducation, Santé, etc.), avec la possibilité de créer, supprimer ou réagencer les groupes selon les besoins analytiques.
Enfin, les Autres matériels et les Ressources externes complètent la documentation. On y retrouve tous les éléments additionnels (rapports, tableaux de résultats, présentations) qui viennent enrichir l’interprétation des données, ainsi que les références hors-fichier (liens vers sites ou études complémentaires, bibliographies, bases de données associées) pour guider l’utilisateur vers des sources externes et contextualiser davantage l’enquête.
Étape 5 : Validation
Accédez au menu Outils, puis exécutez successivement toutes les options de validation disponibles : Validation des métadonnées, Validation des ressources externes, et Validation des relations entre fichiers. Si des messages d’erreur ou d’avertissement apparaissent, apportez les corrections nécessaires. Une fois toutes les validations effectuées avec succès, le projet est prêt à être exporté ou publié sur la plateforme NADA.
Afin de procéder au déploiement via NADA, il est d’abord nécessaire d’exporter le fichier au format DDI et rdf. Pour cela, il faut se rendre dans le menu Documentation, cliquer sur Exporter, puis sélectionner l’option Exporter DDI pour le formar .xml et Exporter vers Dublin Core pour avoir le formar .rdf.