5 Operaciones
Tomado de Lovelace, Nowosad, and Muenchow (2019), capítulo 5.
Librerías usadas:
sf
5.1 Introducción
Usaremos la palabra geometría para denotar las características puramente espaciales, lo que significa que se ignoran los atributos (cualidades, propiedades de algo en una ubicación particular). Con ubicación/locación denotamos un punto, línea, polígono o celda de cuadrícula.
5.2 Unión (st_intersects)
La unión espacial ubica los índices o atributos de un objeto espacial en las ubicaciones de otro. En particular, el método over
devuelve:
- En caso de que
yno tenga atributos: los índices deycorrespondientes a cada característica dex, oNAen caso de que no haya correspondencia; - En caso de que
ytenga atributos: undata.framecon los atributos deycorrespondientes a las ubicaciones dex, o un registroNAen caso de que no haya correspondencia.
Correspondencia significa que dos características se cruzan espacialmente (tocar, superponer, cubrir, incluir, etc.).
st_intersects hace la siguiente operacion gráficamente en conjuntos:
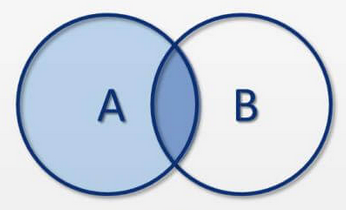
Un uso típico de st_intersects es para seleccionar características de un objeto espacial que están sobre o dentro de otro.
Supongamos que queremos seleccionar todos los puntos en meuse que caen en meuse.grid, podríamos hacer esto de la siguiente manera:
# library(sp)
r1 <- cbind(c(180114, 180553, 181127, 181477, 181294, 181007, 180409,
180162, 180114), c(332349, 332057, 332342, 333250, 333558, 333676,
332618, 332413, 332349))
r2 <- cbind(c(180042, 180545, 180553, 180314, 179955, 179142, 179437,
179524, 179979, 180042), c(332373, 332026, 331426, 330889, 330683,
331133, 331623, 332152, 332357, 332373))
r3 <- cbind(c(179110, 179907, 180433, 180712, 180752, 180329, 179875,
179668, 179572, 179269, 178879, 178600, 178544, 179046, 179110),
c(331086, 330620, 330494, 330265, 330075, 330233, 330336, 330004,
329783, 329665, 329720, 329933, 330478, 331062, 331086))
r4 <- cbind(c(180304, 180403,179632,179420,180304),
c(332791, 333204, 333635, 333058, 332791))
# Paso 1: Crear un poligono:
srdf <- st_multipolygon(list(
r1 = list(matrix(r1,ncol = 2)),
r2 = list(matrix(r2,ncol = 2)),
r3 = list(matrix(r3,ncol = 2)),
r4 = list(matrix(r4,ncol = 2))
))
# Paso 2: convertimos el sfg a sfc:
srdf <- st_sfc(srdf)
# Paso 3: convertimos el sfc a sf:
srdf <- st_sf(geometry = srdf)
# Paso 4: convertimos el sf (MULTIPOLYGON) a sf (POLYGON):
srdf <- st_cast(srdf, "POLYGON")
rm(meuse)
data("meuse",package = "sp")
# coordinates(meuse) = ~x+y
meuse <- st_as_sf(meuse,coords = c(1,2))
plot(st_geometry(meuse))
plot(srdf,add = TRUE)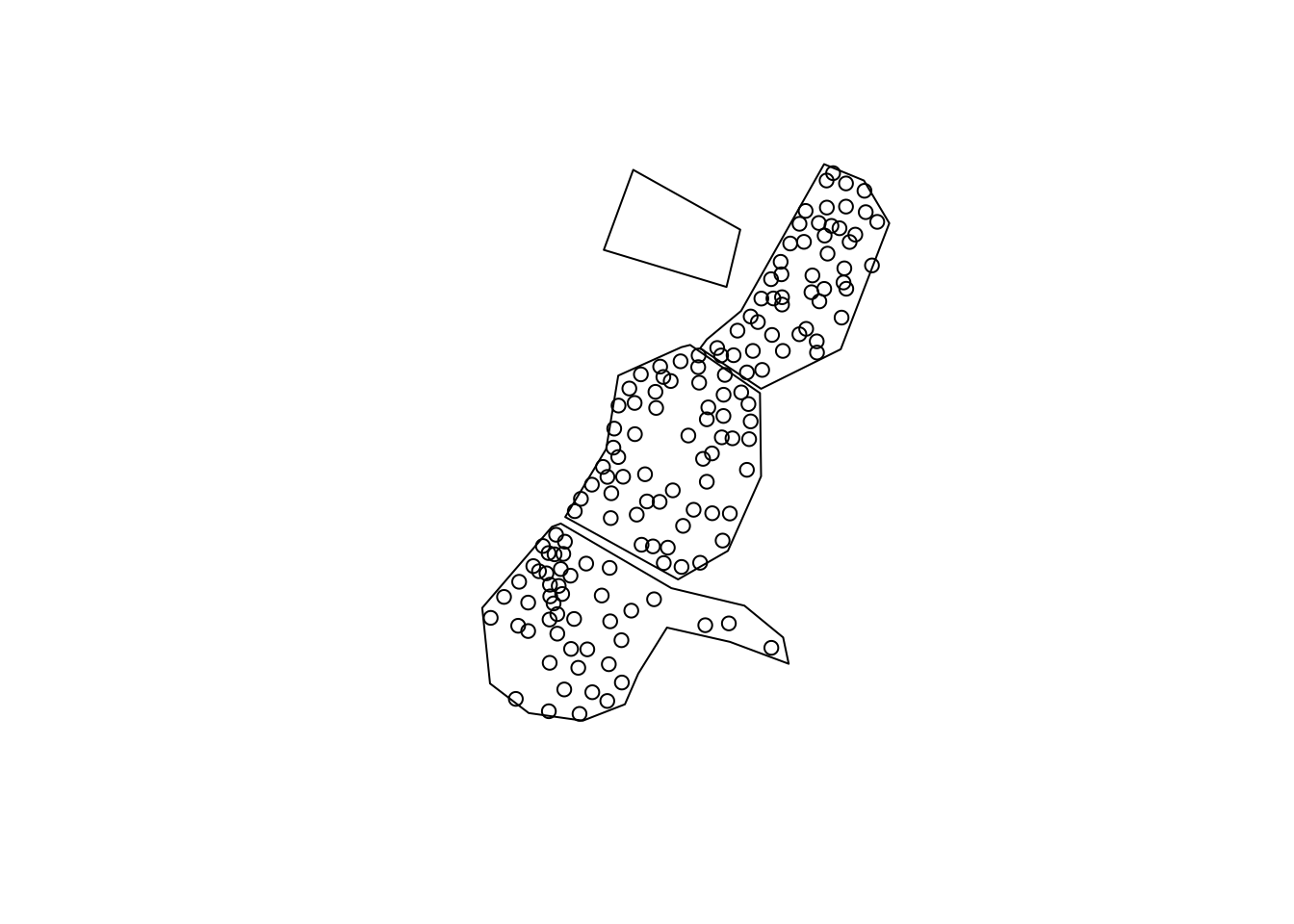
Mediante st_join se selecciona los puntos de meuse que coinciden con (están dentro de) las celdas de srdf. Luego se devuelve las concentraciones medias de metales pesados por polígono:
library(dplyr)
st_join(srdf,meuse,join = st_intersects) %>%
group_by(geometry) %>%
summarise(
cadmium = mean (cadmium,na.rm = TRUE),
copper = mean (copper,na.rm = TRUE),
lead = mean (lead,na.rm = TRUE),
zinc = mean (zinc,na.rm = TRUE)
)## Simple feature collection with 4 features and 4 fields
## Geometry type: POLYGON
## Dimension: XY
## Bounding box: xmin: 178544 ymin: 329665 xmax: 181477 ymax: 333676
## CRS: NA
## # A tibble: 4 × 5
## geometry cadmium copper lead zinc
## <POLYGON> <dbl> <dbl> <dbl> <dbl>
## 1 ((180114 332349, 180553 332057, 181127 332342, 181477 333250… 4.04 44.5 147. 476.
## 2 ((180042 332373, 180545 332026, 180553 331426, 180314 330889… 2.91 40.2 145. 452.
## 3 ((179110 331086, 179907 330620, 180433 330494, 180712 330265… 2.82 36.1 169. 484.
## 4 ((180304 332791, 180403 333204, 179632 333635, 179420 333058… NaN NaN NaN NaNdevuelve el número de puntos en cada polígono n():
## Simple feature collection with 4 features and 1 field
## Geometry type: POLYGON
## Dimension: XY
## Bounding box: xmin: 178544 ymin: 329665 xmax: 181477 ymax: 333676
## CRS: NA
## # A tibble: 4 × 2
## geometry count
## <POLYGON> <int>
## 1 ((180114 332349, 180553 332057, 181127 332342, 181477 333250, 181294 333558, 1810… 50
## 2 ((180042 332373, 180545 332026, 180553 331426, 180314 330889, 179955 330683, 1791… 57
## 3 ((179110 331086, 179907 330620, 180433 330494, 180712 330265, 180752 330075, 1803… 48
## 4 ((180304 332791, 180403 333204, 179632 333635, 179420 333058, 180304 332791)) 15.3 Ejercicios
Importar los datos de Ambato urbano y las emergencias de tránsito reportadas en diciembre 2014. Con esta información:
library(RColorBrewer)
library(classInt)
### Leo el shape:
uu <- "https://github.com/vmoprojs/DataLectures/raw/master/SpatialData/shape_Ambato_urbano.zip"
poligonos <- read_git_shp(uu)
uu <- "https://raw.githubusercontent.com/vmoprojs/DataLectures/master/SpatialData/EmergenciasTransito.txt"
datos <- read.csv(uu, sep ="")
datos <- subset(datos,Month == 12)Contar el número de emergencias por cada parroquia urbana, debe obtener (verifique que el total sume 281):
Generar una variable agregada por polígonos como una columna del
data.frameasociado al polígono espacial.