datos <- read.csv("C:/Users/shari/Downloads/Trabajo final PLE/Trabajo final - PLE/vgsales.csv")2 Trabajo final de PLE
Integrantes:
Porlles Castillo Sharif Snyder
Gutiérrez Huamán Jesús Hernesto
2.1 Manipulación de dataframe
Primero importamos con la data que vamos a trabajar
2.1.1 Funciones, Módulos y Librerías principales en R
En programación utilizamos funciones, también conocidas como subrutinas, procedimientos, métodos, etc., para contener un conjunto de instrucciones que queremos reutilizar, o por su complejidad es mejor mantenerlas independientes de la subrutina y utilizarlas. cuando sea necesario, cuando sean llamados.
En otras palabras, una función es un fragmento de código escrito para realizar una tarea específica. A su vez, pueden aceptar parámetros y posiblemente devolver uno o más valores. De hecho, existen muchas definiciones formales de funciones, desde las matemáticas hasta la informática. En general, sus parámetros forman la entrada y los valores devueltos forman la salida.
Por ejemplo estos son los paquetes que utilizaremos con sus principales funciones:
2.1.1.1 a. Paquete “dplyr”
options(repos = "https://cran.r-project.org")
install.packages('dplyr')Installing package into 'C:/Users/shari/AppData/Local/R/win-library/4.3'
(as 'lib' is unspecified)package 'dplyr' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\shari\AppData\Local\Temp\RtmpghP8HM\downloaded_packageslibrary("dplyr")Warning: package 'dplyr' was built under R version 4.3.2
Attaching package: 'dplyr'The following objects are masked from 'package:stats':
filter, lagThe following objects are masked from 'package:base':
intersect, setdiff, setequal, unionPrincipales funciones:
2.1.1.1.1 1. mutate():
Crea nuevas variables o modifica las existentes.
mutate(df, nueva_variable = expresion)
2.1.1.1.2 2. select():
Selecciona columnas específicas del data frame.
“select(df, columna1, columna2, …)”
2.1.1.1.3 3. select(df, columna1, columna2, …)
“filter(df, condicion)”
2.1.1.1.4 4. arrange():
Ordena filas del data frame.
“arrange(df, columna1, columna2, …)”
2.1.1.1.5 5. summarise() / summarize():
Resumen estadístico de variables.
“summarise(df, mediana = median(x), variance = var(x))”
2.1.1.1.6 6. group_by():
Agrupa el data frame por una o más variables
“group_by(df, columna)”
2.1.1.2 b. Paquete “ggplot2”
options(repos = "https://cran.r-project.org")
install.packages('ggplot2')Installing package into 'C:/Users/shari/AppData/Local/R/win-library/4.3'
(as 'lib' is unspecified)package 'ggplot2' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\shari\AppData\Local\Temp\RtmpghP8HM\downloaded_packageslibrary(ggplot2)Warning: package 'ggplot2' was built under R version 4.3.2Principales funciones:
2.1.1.2.1 1. Graficos de Barras (Barplot)
“ggplot(data = datos, aes(x = )) + geom_bar()”
2.1.1.2.2 2. Histograma (Histogram) y Gráfico de Densidad (Density Plot)
“ggplot(df) + geom_histogram(binwidth = 0.1, aes(x = ), fill = ‘steelblue’) + xlab(”“) + ylab(”Frecuencia”) + ggtitle(“Distribución de la variable x”) + theme_minimal()”
2.1.1.2.3 3. Gráfico de Dispersión (Scatterplot)
“ggplot(data = datos, aes(x = , v = )) + geom_point() + xlab(‘x’) + ylab(‘v’) + ggtitle(‘Relación entre x y v’) + theme_minimal()”
2.1.1.3 c. Funciones para importar datos a R Studio
2.1.1.3.1 Para csv:
“datos <- read.csv(”ruta del archivo”)”
2.1.1.3.2 Para imagen:
“install.packages(”imager”)
library(imager)
imagen <- load.image(“ruta”)”
2.1.1.3.3 Para xslx: install.packages(“readxl”) library(readxl) datos <- read_excel(“ruta”)
2.1.1.3.4 Para sav:
“install.packages(”haven”)
library(haven)
datos <- read_sav(“ruta”)”
2.1.1.3.5 Para txt:
“datos <- readLines(”ruta”)”
2.1.2 Dataframe, Manipulación e Introducción al análisis de datos
La manipulación de datos es una de las actividades que consume más tiempo en la investigación cuantitativa. Manipular datos implica darles la forma deseada o aplicar transformaciones que nos permitan analizarlos como queramos. Este artículo sólo se ocupa de un área de actividad, que podemos llamar transformación. Hay otras dos áreas a considerar: la recopilación y la limpieza de datos, que se tratan en directrices separadas. La recopilación debe tener lugar antes de cualquier acción y no podemos operar sin algún tipo de información. En R, podemos recuperar datos de varias maneras diferentes: recuperando datos directamente en la consola, importando datos de archivos en varios formatos o recuperando datos de recursos en línea. La limpieza de datos se puede realizar al mismo tiempo que la operación, pero hacerlo con antelación puede facilitar la operación.
Analizar los datos requiere colocarlos en nuestro entorno R y darles una estructura que nosotros y las funciones R que queremos usar entendamos. En la práctica, esto significa que las columnas tendrán nombres claros y comprensibles que especifiquen el tipo de datos que contienen: números, factores, caracteres, fechas, etc. ; el conjunto de datos estará libre de ambigüedades y errores de codificación, incluidos errores tipográficos, y los casos faltantes se marcarán claramente como valores NA. Transformar datos no significa cambiarlos de ninguna manera, significa cambiar estrictamente su forma: cambiar su estructura, pero no la información que contienen. Es probable que la conversión también signifique una pérdida de información, pero a cambio ganamos inteligibilidad.
La manipulación de datos de dataframe se resume en 3 operaciones:
Extraer subconjuntos de datos. Ya sea subconjuntos de filas o columnas. En los casos prácticos nunca haremos un análisis sobre la totalidad de los datos.
Transformarlos. Realizar operaciones aritméticas o lógicas sobre los datos. En general cuando una variable es contínua realizamos operaciones aritméticas, cuando es categórica, lógicas.
Transformarlos. Realizar operaciones aritméticas o lógicas sobre los datos. En general cuando una variable es contínua realizamos operaciones aritméticas, cuando es categórica, lógicas.
A continuacion mostraremos ejemplos de una dataframe
colnames(datos) # nombres de cada columna ("estructura") [1] "Rank" "Name" "Platform" "Year" "Genre"
[6] "Publisher" "NA_Sales" "EU_Sales" "JP_Sales" "Other_Sales"
[11] "Global_Sales"str(datos) # estructura del data frame'data.frame': 16598 obs. of 11 variables:
$ Rank : int 1 2 3 4 5 6 7 8 9 10 ...
$ Name : chr "Wii Sports" "Super Mario Bros." "Mario Kart Wii" "Wii Sports Resort" ...
$ Platform : chr "Wii" "NES" "Wii" "Wii" ...
$ Year : chr "2006" "1985" "2008" "2009" ...
$ Genre : chr "Sports" "Platform" "Racing" "Sports" ...
$ Publisher : chr "Nintendo" "Nintendo" "Nintendo" "Nintendo" ...
$ NA_Sales : num 41.5 29.1 15.8 15.8 11.3 ...
$ EU_Sales : num 29.02 3.58 12.88 11.01 8.89 ...
$ JP_Sales : num 3.77 6.81 3.79 3.28 10.22 ...
$ Other_Sales : num 8.46 0.77 3.31 2.96 1 0.58 2.9 2.85 2.26 0.47 ...
$ Global_Sales: num 82.7 40.2 35.8 33 31.4 ...# Eliminar una columna
datos$NA_Sales <- NULL
head(datos) Rank Name Platform Year Genre Publisher EU_Sales
1 1 Wii Sports Wii 2006 Sports Nintendo 29.02
2 2 Super Mario Bros. NES 1985 Platform Nintendo 3.58
3 3 Mario Kart Wii Wii 2008 Racing Nintendo 12.88
4 4 Wii Sports Resort Wii 2009 Sports Nintendo 11.01
5 5 Pokemon Red/Pokemon Blue GB 1996 Role-Playing Nintendo 8.89
6 6 Tetris GB 1989 Puzzle Nintendo 2.26
JP_Sales Other_Sales Global_Sales
1 3.77 8.46 82.74
2 6.81 0.77 40.24
3 3.79 3.31 35.82
4 3.28 2.96 33.00
5 10.22 1.00 31.37
6 4.22 0.58 30.26# Acceso
head(datos$JP_Sales) # selección de columna usando $[1] 3.77 6.81 3.79 3.28 10.22 4.22ToothGrowth[10,1] # usando índices (ToothGrowth es un df que existe en R)[1] 7ToothGrowth[2:3,1][1] 11.5 7.3# Resumen estadístico básico de las columnas numéricas
summary(datos) Rank Name Platform Year
Min. : 1 Length:16598 Length:16598 Length:16598
1st Qu.: 4151 Class :character Class :character Class :character
Median : 8300 Mode :character Mode :character Mode :character
Mean : 8301
3rd Qu.:12450
Max. :16600
Genre Publisher EU_Sales JP_Sales
Length:16598 Length:16598 Min. : 0.0000 Min. : 0.00000
Class :character Class :character 1st Qu.: 0.0000 1st Qu.: 0.00000
Mode :character Mode :character Median : 0.0200 Median : 0.00000
Mean : 0.1467 Mean : 0.07778
3rd Qu.: 0.1100 3rd Qu.: 0.04000
Max. :29.0200 Max. :10.22000
Other_Sales Global_Sales
Min. : 0.00000 Min. : 0.0100
1st Qu.: 0.00000 1st Qu.: 0.0600
Median : 0.01000 Median : 0.1700
Mean : 0.04806 Mean : 0.5374
3rd Qu.: 0.04000 3rd Qu.: 0.4700
Max. :10.57000 Max. :82.7400 # Cambiar nombres de columnas
nuevos_nombres <- c("Nombre", "Plataforma", "Año", "Genero", "Editorial", "NA_Sales", "EU_Sales", "JP_Sales", "Other_Sales", "Global_Sales")
colnames(datos) <- nuevos_nombres
head(nuevos_nombres)[1] "Nombre" "Plataforma" "Año" "Genero" "Editorial"
[6] "NA_Sales" # Acceder a una fila específica, por ejemplo, la segunda fila
fila_2 <- datos[2, ]
head(fila_2) Nombre Plataforma Año Genero Editorial NA_Sales EU_Sales JP_Sales
2 2 Super Mario Bros. NES 1985 Platform Nintendo 3.58 6.81
Other_Sales Global_Sales
2 0.77 40.24# Acceder a la fila 1, columna 2
valor <- datos[1, 2]
head(valor)[1] "Wii Sports"2.1.3 Flujo del proceso de análisis de datos
El flujo de proceso de analisis de datos en R Studio sigue una secuencia estructurada de operaciones para trabajar con datos utilizando el entorno de programacion R. Por ejemplo, importar un conjunto de datos, aplicar funciones para limpiar valores nulos y luego realizar un analisis estadistico utilizando bibliotecas como “dplyr” y “ggplot2” en R Studio.
2.1.3.1 1. dplyr
el paquete dplyr proporciona un conjunto de funciones extremadamente útiles para manipular data frames y así reducir el número de repeticiones , la probabilidad de cometer errores y el número de caracteres que hay que escribir. Como valor extra, puedes encontrar que la gramática de dplyr es más fácil de entender.
2.1.3.1.1 Funcion “select()”
La función select es usada para seleccionar columnas de un data frame que queremos extraer
head(select(datos, NA_Sales, JP_Sales, EU_Sales)) NA_Sales JP_Sales EU_Sales
1 Nintendo 3.77 29.02
2 Nintendo 6.81 3.58
3 Nintendo 3.79 12.88
4 Nintendo 3.28 11.01
5 Nintendo 10.22 8.89
6 Nintendo 4.22 2.262.1.3.1.2 Funcion “arrange()”
La función arrange es usada para reordenar las filas de una data frame según una o más columnas.
head(arrange(datos, NA_Sales)) Nombre Plataforma Año Genero Editorial
1 12351 Panzer Tactics DS 2007 Strategy
2 14132 Boulder Dash: Rocks! DS 2007 Puzzle
3 15709 Pirates: Legend of the Black Buccaneer PS2 2006 Adventure
4 13059 Men of War: Assault Squad PC 2011 Strategy
5 13726 Off-Road Drive PC 2011 Racing
6 16452 King's Bounty: Armored Princess PC 2009 Role-Playing
NA_Sales EU_Sales JP_Sales Other_Sales Global_Sales
1 10TACLE Studios 0.00 0 0.00 0.06
2 10TACLE Studios 0.03 0 0.00 0.03
3 10TACLE Studios 0.01 0 0.00 0.02
4 1C Company 0.03 0 0.01 0.05
5 1C Company 0.03 0 0.01 0.04
6 1C Company 0.01 0 0.00 0.012.1.3.1.3 Funcion “summarise”
Con summarise() podemos agrupar diversos valores y aplicar una función para obtener un resumen que condense los valores.
head(summarise(datos, mediana = median(EU_Sales), variance = var(EU_Sales))) mediana variance
1 0.02 0.25537992.1.3.1.4 Funcion “group_by”
La sentencia group_by identifica una columna seleccionada para utilizarla para agrupar resultados. Divide los datos en grupos por los valores de la columna especificada, y devuelve una fila de resultados para cada grupo
head(group_by(datos, NA_Sales))# A tibble: 6 × 10
# Groups: NA_Sales [1]
Nombre Plataforma Año Genero Editorial NA_Sales EU_Sales JP_Sales
<int> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 1 Wii Sports Wii 2006 Sports Nintendo 29.0 3.77
2 2 Super Mario Bros. NES 1985 Platform Nintendo 3.58 6.81
3 3 Mario Kart Wii Wii 2008 Racing Nintendo 12.9 3.79
4 4 Wii Sports Resort Wii 2009 Sports Nintendo 11.0 3.28
5 5 Pokemon Red/Pokemon … GB 1996 Role-Pla… Nintendo 8.89 10.2
6 6 Tetris GB 1989 Puzzle Nintendo 2.26 4.22
# ℹ 2 more variables: Other_Sales <dbl>, Global_Sales <dbl>2.1.3.2 2. ggplot2
Es un paquete de visualización de datos para el lenguaje R que implementa lo que se conoce como la “Gramática de los Gráficos”, que no es más que una representación esquemática y en capas de lo que se dibuja en dichos gráficos, como lo pueden ser los marcos y los ejes, el texto de los mismos, los títulos, así como, por supuesto, los datos o la información que se grafica, el tipo de gráfico que se utiliza, los colores, los símbolos y tamaños, entre otros.
2.1.3.2.1 Graficos de Barras (Barplot)
Uno de los tipos de gráficos más comunes en el anállisis de datos es el gráfico de barras, en el que simplemente se representa con barras de distintas “alturas” las dimensiones de una cantidad numérica comparada con otra.
ggplot(data = datos, aes(x = Global_Sales)) + geom_bar()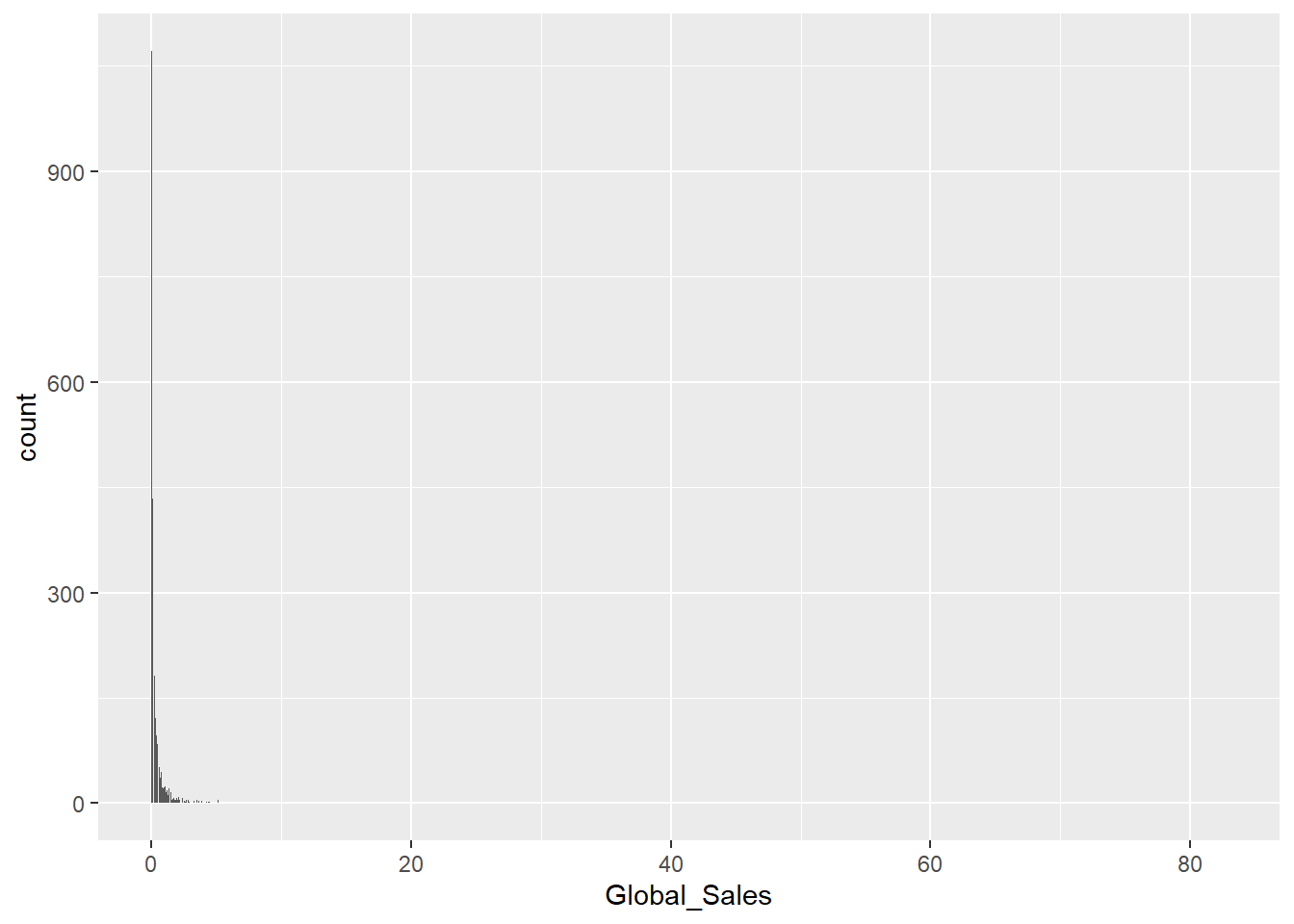
2.1.3.2.2 Histograma (Histogram) y Gráfico de Densidad (Density Plot)
Un histograma es un tipo de gráfico de barras en donde la altura de éstas hacen referencia a la frecuencia con la que aparecen los valores que se representan. Los histogramas son utilizados en la mayoría de las ocasiones para observar la distribución de alguna variable continua, lo que nos permite de una manera sencilla y rápida obtener información como el comportamiento de los datos, tendencias, variabilidad u homogeneidades, entre otros. A efectos de conocer cómo se implementan los histogramas con ggplot2.
ggplot(datos) +
geom_histogram(binwidth = 0.5, aes(x = EU_Sales), fill = 'steelblue') +
xlab("EU_Sales") +
ylab("Frecuencia") +
ggtitle("Distribución de la variable EU_Sales") +
theme_minimal()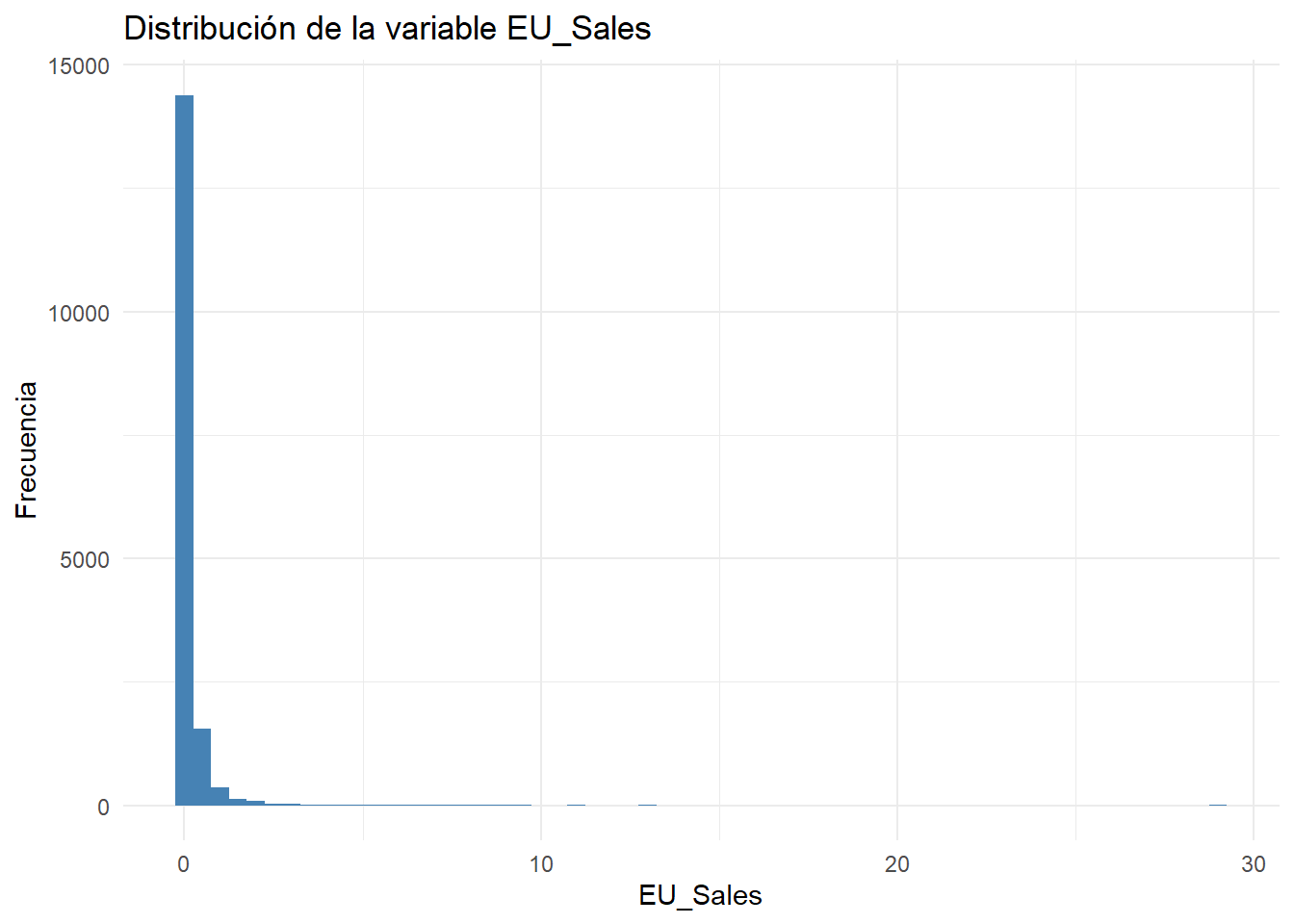
2.1.3.2.3 Gráfico de Dispersión (Scatterplot)
El Gráfico de Dispersión o Scatterplot es tal vez uno de los tipos de gráficos matemáticos más empleados. En él, se representan en un eje cartersiano las relaciones entre dos variables generalmente continuas, en la forma de puntos cuyas posiciones en los ejes horizontal y vertical están asociados al valor de cada variable.
ggplot(data = datos, aes(x = EU_Sales, y = Global_Sales)) +
geom_point() +
xlab('EU_Sales') +
ylab('Global_Sales') +
ggtitle('Relación entre EU_Sales y Global_Sales') +
theme_minimal()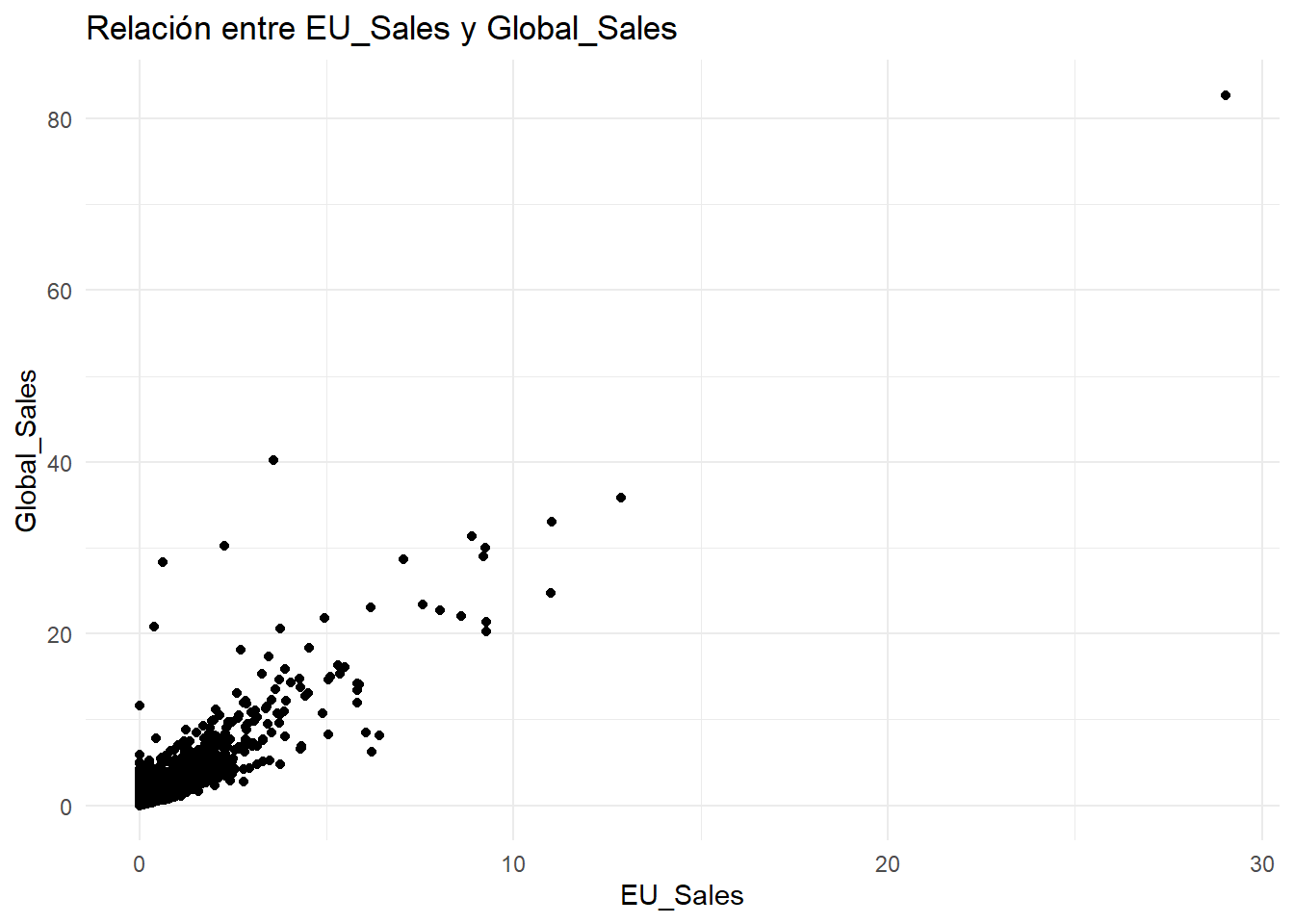
2.1.4 Importación de datos
2.1.4.1 Cargar el archivo CSV desde el enlace directamente en un data frame
url <- "https://www.kaggle.com/datasets/gregorut/videogamesales"
data <- read.csv(url)
head(data) X..DOCTYPE.html.
1 <html lang=en>
2 <head>
3 <title>Video Game Sales | Kaggle</title>
4 <meta charset=utf-8 />
5 <meta name=robots content=index, follow />
6 <meta name=description content=Analyze sales data from more than 16,500 games. />2.1.4.2 Cargar el archivo desde una carpeta en la computadora
datos <- read.csv("C:/Users/shari/Downloads/Trabajo final PLE/Trabajo final - PLE/vgsales.csv")
head(datos) Rank Name Platform Year Genre Publisher NA_Sales
1 1 Wii Sports Wii 2006 Sports Nintendo 41.49
2 2 Super Mario Bros. NES 1985 Platform Nintendo 29.08
3 3 Mario Kart Wii Wii 2008 Racing Nintendo 15.85
4 4 Wii Sports Resort Wii 2009 Sports Nintendo 15.75
5 5 Pokemon Red/Pokemon Blue GB 1996 Role-Playing Nintendo 11.27
6 6 Tetris GB 1989 Puzzle Nintendo 23.20
EU_Sales JP_Sales Other_Sales Global_Sales
1 29.02 3.77 8.46 82.74
2 3.58 6.81 0.77 40.24
3 12.88 3.79 3.31 35.82
4 11.01 3.28 2.96 33.00
5 8.89 10.22 1.00 31.37
6 2.26 4.22 0.58 30.262.2 Manejo de datos
2.2.1 Identificación y manejo de datos missing
La identificación y manejo de datos faltantes (missing data) es crucial en análisis de datos. Se puede hacer identificando los datos faltantes, decidiendo si eliminarlos, imputar valores o usar métodos avanzados como el Multiple Imputation para conservar la integridad de los datos y evitar sesgos en los análisis.
Como estamos trabajando en R Studio, para manejar datos faltantes o “missing data” podemos utilizar las funciones como “is.na()” para identificar los valores faltantes en un conjunto de datos y luego decidir como manejarlos. Luego, para reemplazar los valores faltantes, podemos usar la funcion “na.omit()” y para elimibar filas con valores faltantes o “na.fill()” para rellenarlos con valores especificos.
En R la ausencia de valores se representa por el valor “NA” lo que permite su reconocimiento y consideración en el uso de funciones sobre datos. Las tareas consisten pues en:
. Evaluar la existencia de valores perdidos (exploración). . Excluir los valores ausentes. . Recodificar los valores ausentes (imputación).
2.2.1.1 Funciones “is.na()” y “!is.na()”
Utiliza is.na() para identificar los valores que faltan, o utiliza su opuesto (con ! delante) para identificar los valores que no faltan. Ambos devuelven un valor lógico (TRUE o FALSE).
# Verificar valores faltantes en un dataframe
head(is.na(datos)) Rank Name Platform Year Genre Publisher NA_Sales EU_Sales JP_Sales
[1,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[2,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[3,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[4,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[5,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[6,] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
Other_Sales Global_Sales
[1,] FALSE FALSE
[2,] FALSE FALSE
[3,] FALSE FALSE
[4,] FALSE FALSE
[5,] FALSE FALSE
[6,] FALSE FALSE# Verificar valores no faltantes en un dataframe
head(!is.na(datos)) Rank Name Platform Year Genre Publisher NA_Sales EU_Sales JP_Sales
[1,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[2,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[3,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[4,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[5,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
[6,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
Other_Sales Global_Sales
[1,] TRUE TRUE
[2,] TRUE TRUE
[3,] TRUE TRUE
[4,] TRUE TRUE
[5,] TRUE TRUE
[6,] TRUE TRUE2.2.1.2 Funcion “na.omit()”
Esta función, si se aplica a un dataframe, eliminará las filas con valores faltantes. También es de R base. Si se aplica a un vector, eliminará los valores NA del vector al que se aplica.
head(na.omit(datos)) Rank Name Platform Year Genre Publisher NA_Sales
1 1 Wii Sports Wii 2006 Sports Nintendo 41.49
2 2 Super Mario Bros. NES 1985 Platform Nintendo 29.08
3 3 Mario Kart Wii Wii 2008 Racing Nintendo 15.85
4 4 Wii Sports Resort Wii 2009 Sports Nintendo 15.75
5 5 Pokemon Red/Pokemon Blue GB 1996 Role-Playing Nintendo 11.27
6 6 Tetris GB 1989 Puzzle Nintendo 23.20
EU_Sales JP_Sales Other_Sales Global_Sales
1 29.02 3.77 8.46 82.74
2 3.58 6.81 0.77 40.24
3 12.88 3.79 3.31 35.82
4 11.01 3.28 2.96 33.00
5 8.89 10.22 1.00 31.37
6 2.26 4.22 0.58 30.262.2.2 Identificación y manejo de datos outlier e inconsistentes
Los casos atípicos, outlier o anomalías son observaciones que tienen características diferentes a otras. Este tipo de casos no pueden caracterizarse como útiles o problemáticos, pero deben ser Se deben considerar en el contexto del análisis y se debe evaluar qué información pueden proporcionar. Su principal problema es que son elementos que pueden no ser representativos de la población y pueden distorsionar gravemente el comportamiento de los contrastes estadísticos. Por otro lado, aunque diferente la mayor parte de la muestra puede indicar las características una parte experimentada de la población y, por tanto, un signo de privación representatividad de la muestra.
# Calculamos el IQR para una columna 'columna' en un dataframe 'datos'
Q1 <- quantile(datos$EU_Sales, 0.25)
Q3 <- quantile(datos$EU_Sales, 0.75)
IQR_value <- Q3 - Q1
IQR_value 75%
0.11 # Definimos los límites para identificar outliers
lower_limit <- Q1 - 1.5 * IQR_value
upper_limit <- Q3 + 1.5 * IQR_value
# Identificar outliers
outliers <- datos$EU_Sales[datos$EU_Sales < lower_limit | datos$EU_Sales > upper_limit]head(outliers)[1] 29.02 3.58 12.88 11.01 8.89 2.262.2.3 Limpieza de datos y preparación de datos
La limpieza de datos, también conocida como “Data Cleansing” o “limpieza de datos”, implica varios procesos destinados a mejorar la calidad de los datos. Existen muchas herramientas y prácticas para eliminar los problemas de los conjuntos de datos. Estos procesos se utilizan para corregir o eliminar registros inexactos en una base de datos o conjunto de datos. Generalmente, esto significa identificar y reemplazar datos o registros incompletos, inexactos, corruptos o irrelevantes. Después de una limpieza de datos realizada correctamente, todos los conjuntos de datos deben ser coherentes y estar libres de errores. Esto es necesario para acceder y utilizar la información. Sin purificación, es probable que los resultados del análisis estén distorsionados. De manera similar, un modelo de aprendizaje automático o inteligencia artificial entrenado con datos incorrectos puede ser engañoso o tener un rendimiento deficiente. La limpieza de datos es diferente de la transformación de datos. La limpieza implica convertir datos de una forma a otra, mientras que la transformación (también llamada disputa o procesamiento) implica convertir datos sin procesar en una forma adecuada para el análisis.
2.2.3.1 Ejemplo
Identificamos si tenemos datos faltantes en nuestra “data”
# Identificamos los valores faltantes en un dataframe 'data'
datos %>%
summarise_all(~ sum(is.na(EU_Sales))) Rank Name Platform Year Genre Publisher NA_Sales EU_Sales JP_Sales
1 0 0 0 0 0 0 0 0 0
Other_Sales Global_Sales
1 0 0Luego identificamos la imputacion de los valores faltantes, especificando que columna de nuestra data queremos realizar. Donde la funcion mean() nos ayudara a calcular el promedio o la media aritmetica.
# Imputación de valores faltantes con la media en una columna 'columna'
datos$EU_Sales[is.na(datos$EU_Sales)] <- mean(datos$EU_Sales, na.rm = TRUE)
datos$EU_Sales[is.na(datos$EU_Sales)]numeric(0)# Identificamos y manejamos los outliers en una columna 'Global_Sales'
Q1 <- quantile(datos$Global_Sales, 0.25)
Q3 <- quantile(datos$Global_Sales, 0.75)
IQR_value <- Q3 - Q1
IQR_value 75%
0.41 Para añadir o modificar el nombre de filas y columnas de una matriz se hace uso de las funciones colnames() y rownames().
# Nuevos nombres a las columnas
colnames(datos) <- c("Nomb.", "Plataf.", "Año", "Gen.", "Edit.","NA_S","EU_S", "JP_S", "Other_S", "Global_S")
colnames(datos) [1] "Nomb." "Plataf." "Año" "Gen." "Edit." "NA_S"
[7] "EU_S" "JP_S" "Other_S" "Global_S" NA 2.3 Visualización de datos
datos <- read.csv("C:/Users/shari/Downloads/Trabajo final PLE/Trabajo final - PLE/vgsales.csv")Para visualizar nuestros datos deberemos instalar y cargar las librerias ggplot2, scatterplot3d, plot3d e imager
options(repos = "https://cran.r-project.org")
install.packages("ggplot2")Warning: package 'ggplot2' is in use and will not be installedlibrary(ggplot2)
install.packages("scatterplot3d")Installing package into 'C:/Users/shari/AppData/Local/R/win-library/4.3'
(as 'lib' is unspecified)package 'scatterplot3d' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\shari\AppData\Local\Temp\RtmpghP8HM\downloaded_packageslibrary(scatterplot3d)
install.packages("plot3D")Installing package into 'C:/Users/shari/AppData/Local/R/win-library/4.3'
(as 'lib' is unspecified)package 'plot3D' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\shari\AppData\Local\Temp\RtmpghP8HM\downloaded_packageslibrary(plot3D)Warning: package 'plot3D' was built under R version 4.3.2install.packages("plotrix")Installing package into 'C:/Users/shari/AppData/Local/R/win-library/4.3'
(as 'lib' is unspecified)package 'plotrix' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\shari\AppData\Local\Temp\RtmpghP8HM\downloaded_packageslibrary(plotrix)Warning: package 'plotrix' was built under R version 4.3.2install.packages("imager")Installing package into 'C:/Users/shari/AppData/Local/R/win-library/4.3'
(as 'lib' is unspecified)package 'imager' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\shari\AppData\Local\Temp\RtmpghP8HM\downloaded_packageslibrary(imager)Warning: package 'imager' was built under R version 4.3.2Loading required package: magrittr
Attaching package: 'imager'The following object is masked from 'package:magrittr':
addThe following object is masked from 'package:dplyr':
whereThe following objects are masked from 'package:stats':
convolve, spectrumThe following object is masked from 'package:graphics':
frameThe following object is masked from 'package:base':
save.image2.3.1 Visualización de datos univariados
La visualización de datos univariados implica explorar y representar gráficamente las distribuciones y características de una variable a la vez.
2.3.1.1 Histograma
hist(datos$NA_Sales, main = "Histograma de ventas en Norteamerica", xlab = "Ventas (en millones)")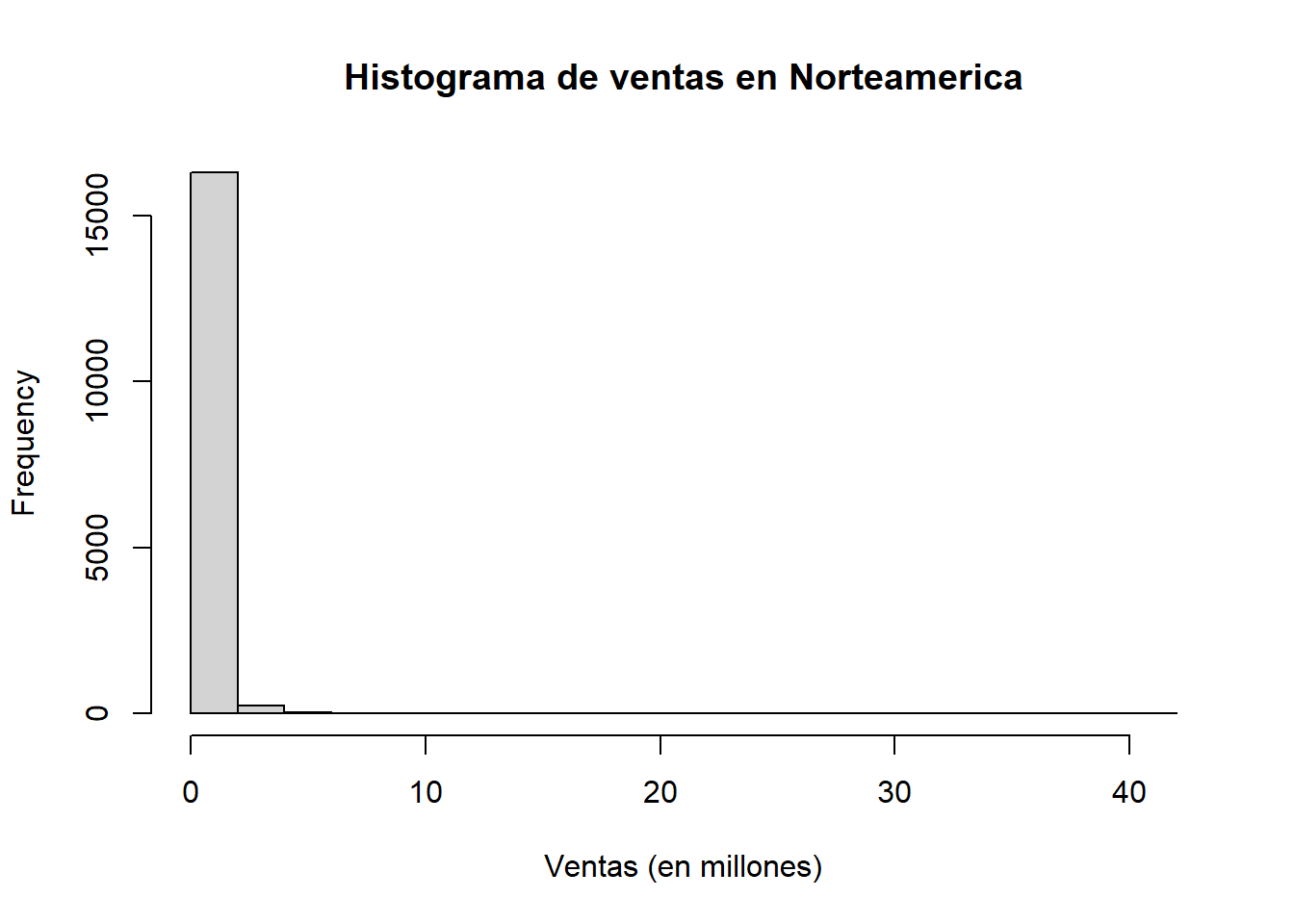
2.3.1.2 Diagrama de cajas
datos$JP_Sales_log <- log(datos$JP_Sales + 1)
#Aqui se agrega + 1 a los datos para evitar errores
boxplot(datos$JP_Sales_log, main = "Diagrama de las ventas en Japon", ylab = "Ventas (en millones)")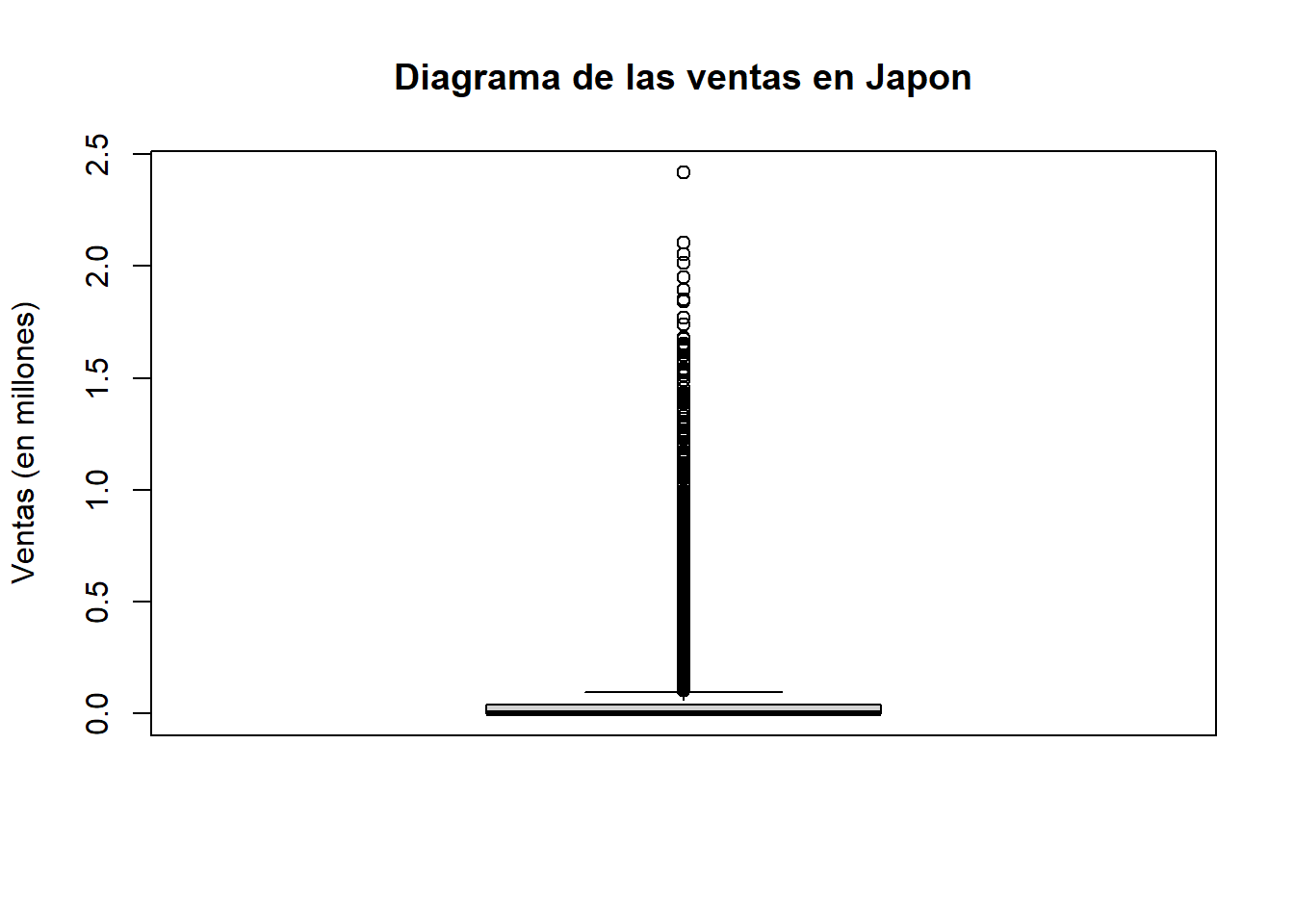
2.3.1.3 Grafico de densidad
plot(density(datos$EU_Sales), main = "Gráfico de Densidad de las ventas en Europa", ylab = "Densidad")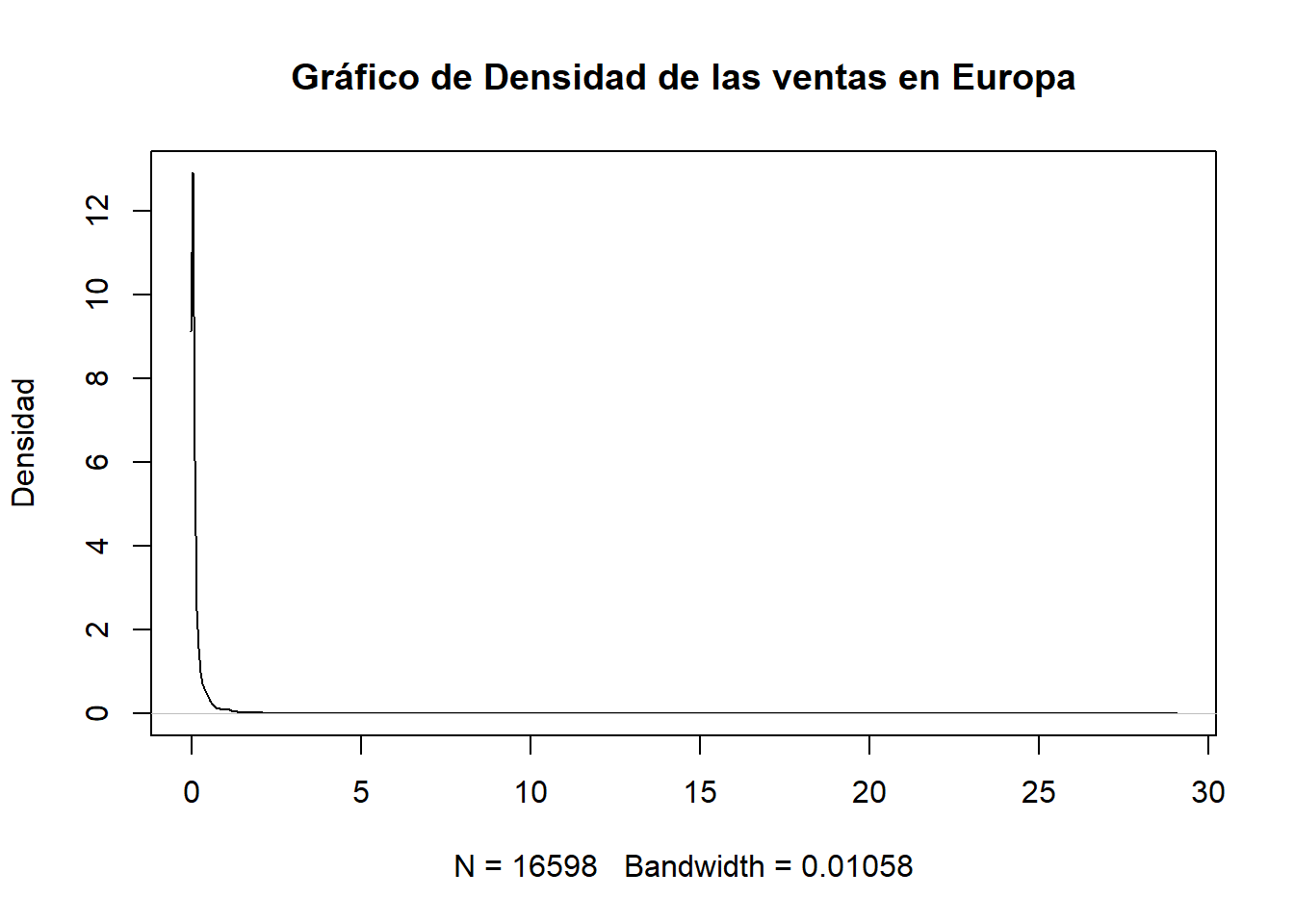
2.3.1.4 Grafico de barras
barplot(table(datos$Genre), main = "Gráfico de Barras de generos de videojuegos", ylab = "Frecuencia")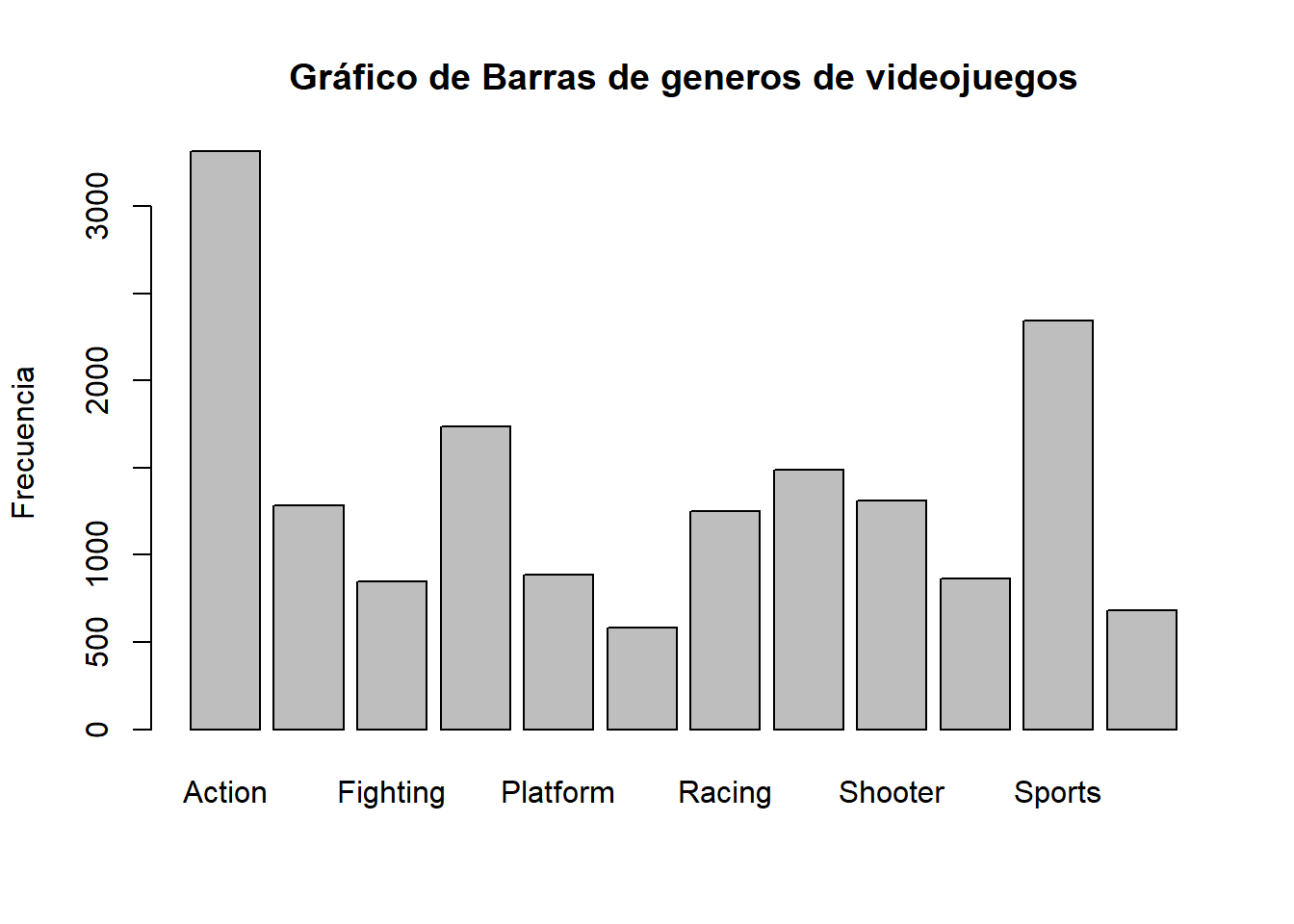
2.3.2 Visualización de datos bivariados
La visualización de datos bivariados implica explorar y visualizar la relación entre dos variables.
2.3.2.1 Diagrama de dispersion
plot(datos$NA_Sales, datos$EU_Sales, main = "Diagrama de Dispersión", xlab = "Ventas NA", ylab = "Ventas EU")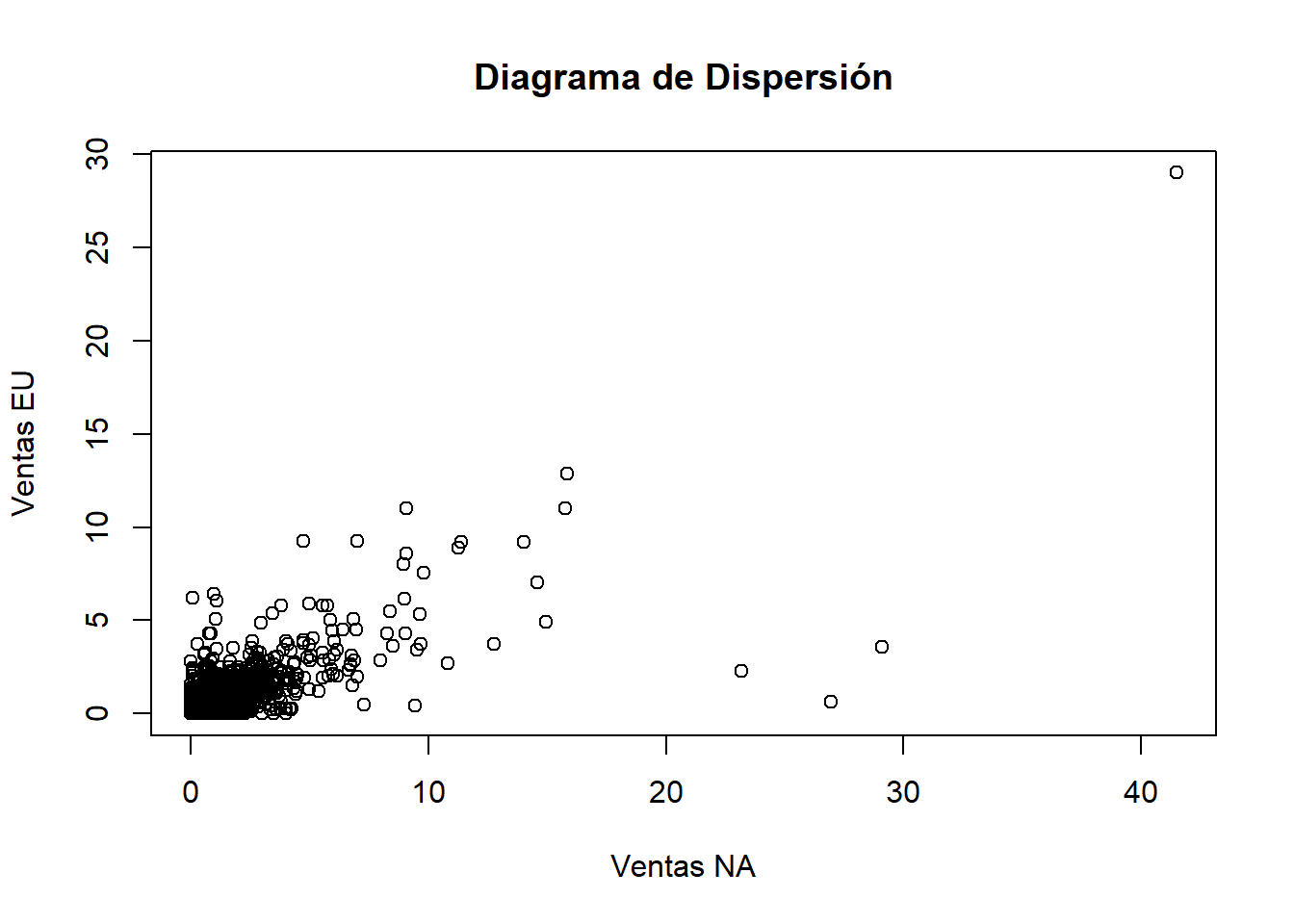
2.3.2.2 Pairs
pairs(datos[, c("NA_Sales", "EU_Sales", "JP_Sales")])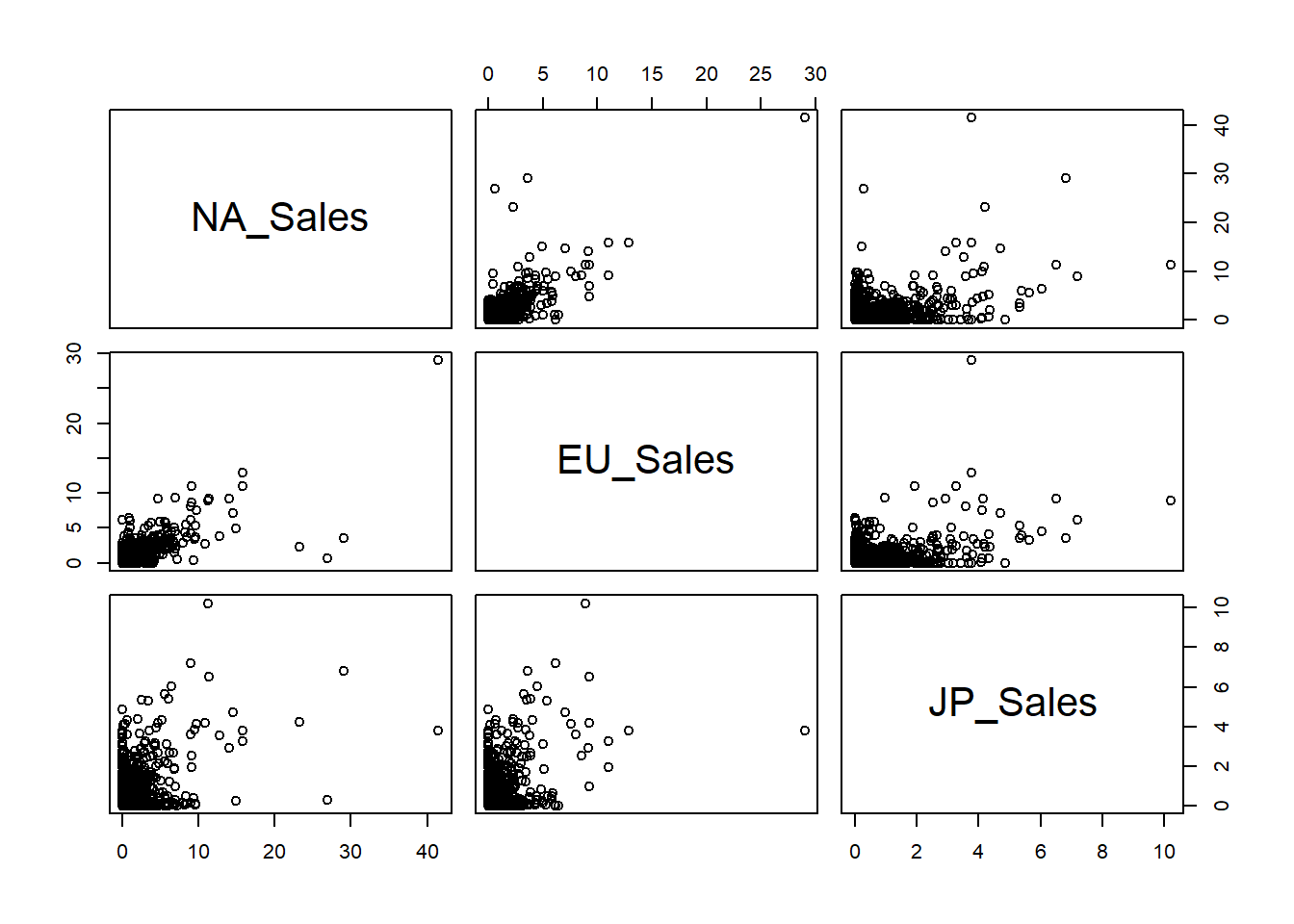
2.3.2.3 Grafico de lineas
plot(datos$NA_Sales ~ datos$JP_Sales, main = "Gráfico de Líneas", xlab = "Ventas en Japon", ylab = "Ventas en Norteamerica")
2.3.2.4 Grafico de barras
barplot(table(datos$JP_Sales, datos$Genre), beside = TRUE)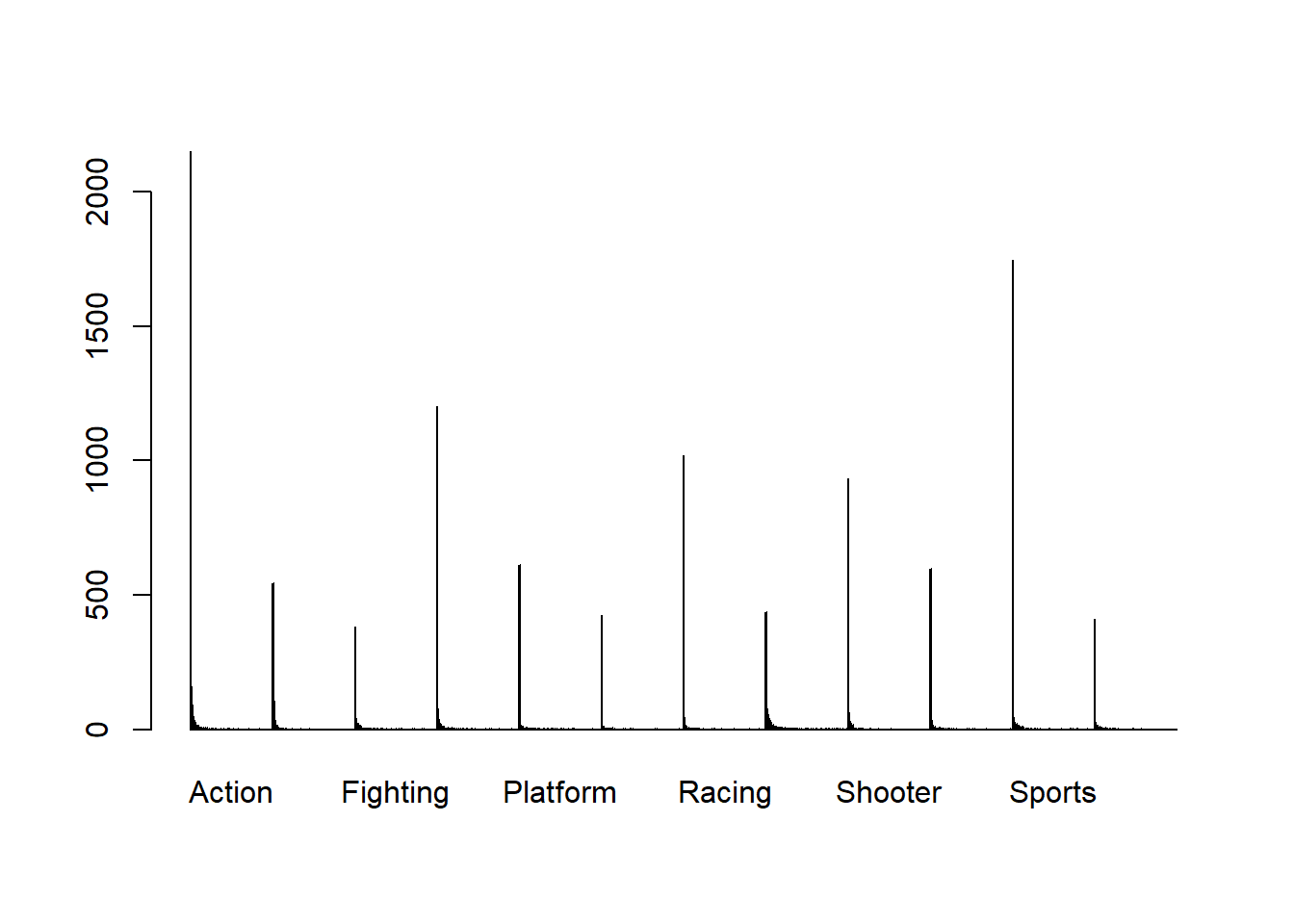
2.3.2.5 Diagrama de cajas
boxplot(datos$EU_Sales ~ datos$Genre, main = "Diagrama de Caja", xlab = "Genero", ylab = "Ventas en Europa")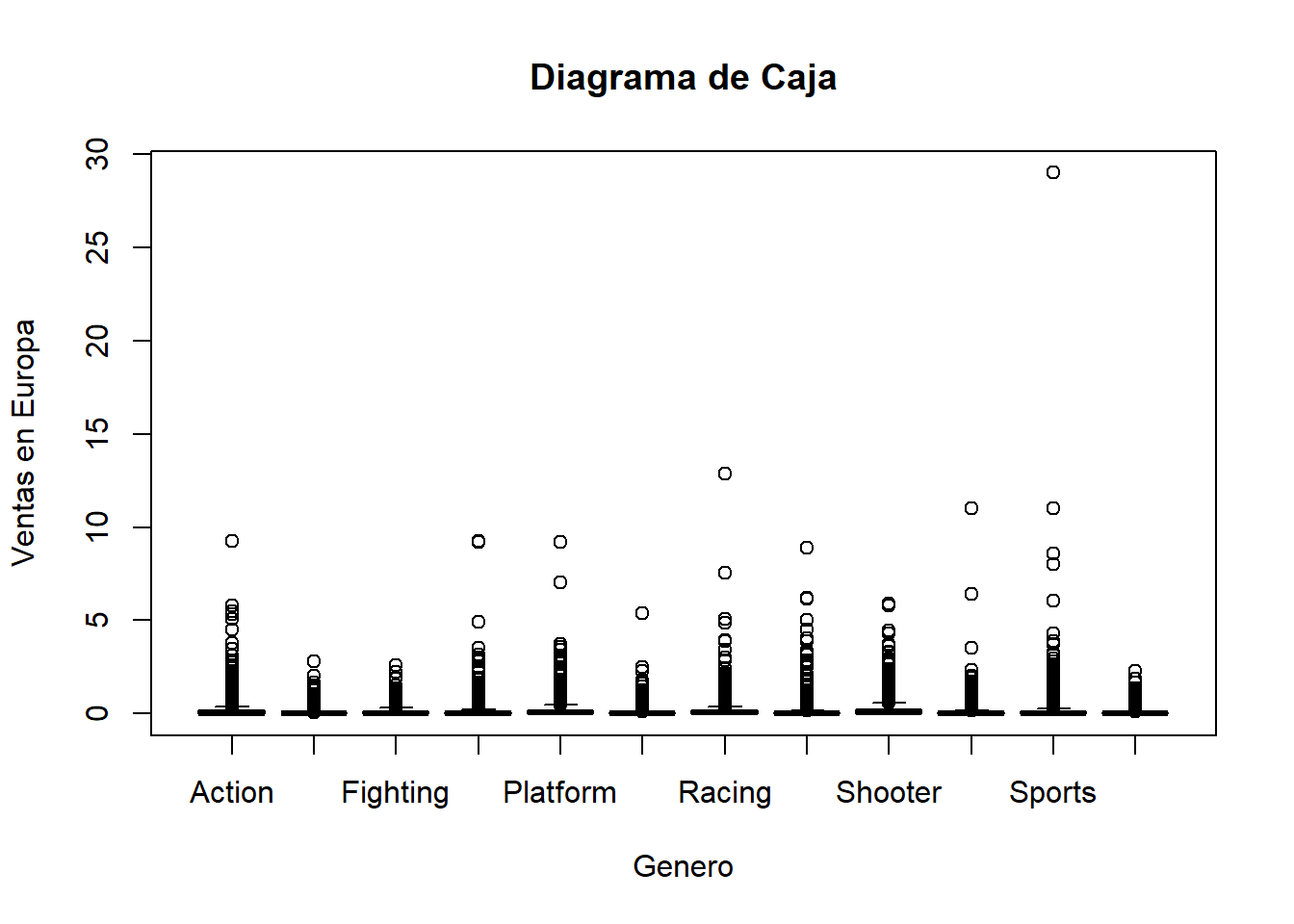
2.3.2.6 Mapa de calor
# Primero es necesario crear una matriz de correlacion
cor_matrix <- cor(datos[, c("EU_Sales", "JP_Sales", "NA_Sales")])
#Se continua creando el mapa de calor
heatmap(cor_matrix, annot = TRUE, main = "Mapa de calor")Warning in plot.window(...): "annot" is not a graphical parameterWarning in plot.xy(xy, type, ...): "annot" is not a graphical parameterWarning in title(...): "annot" is not a graphical parameter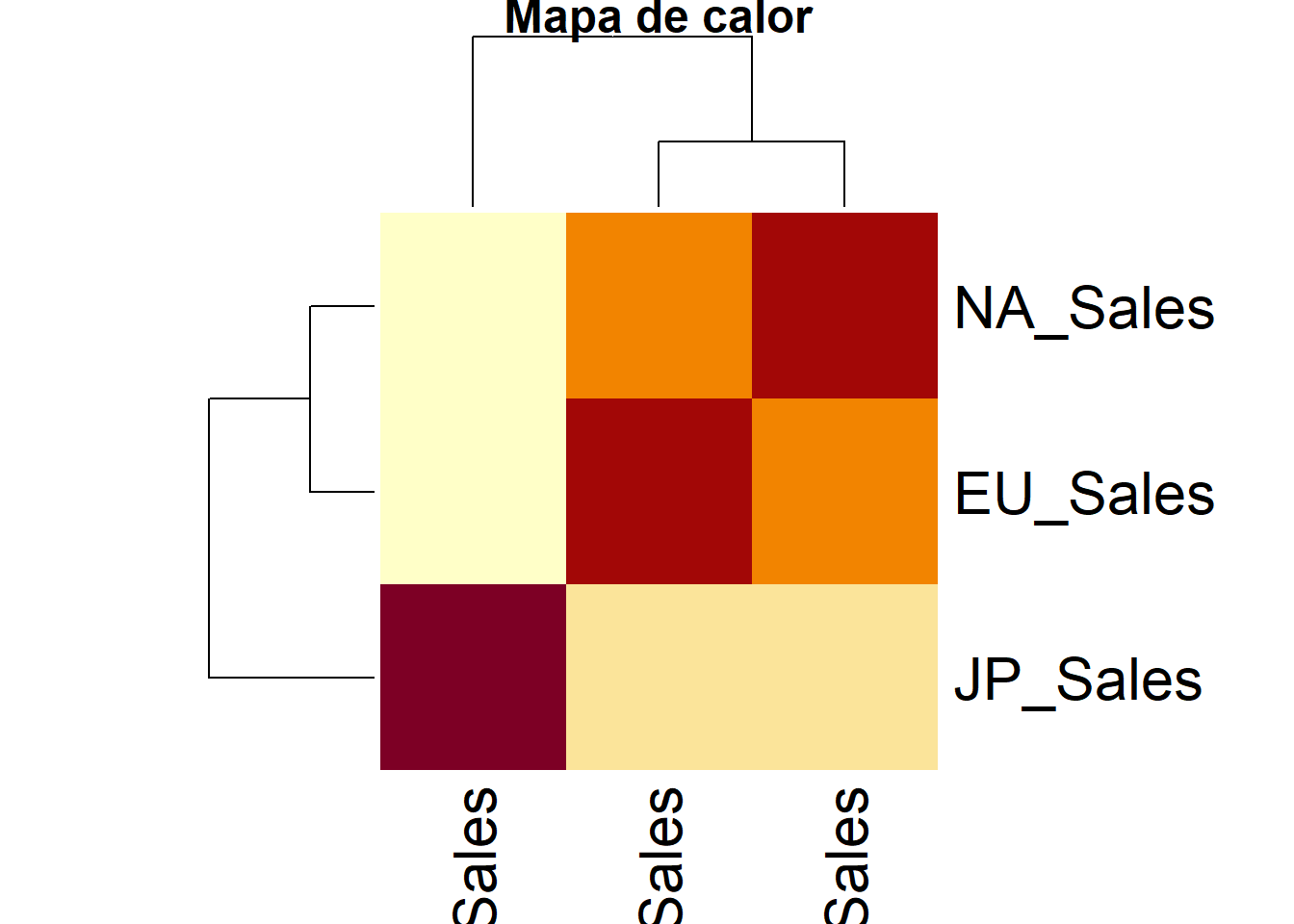
2.3.3 Visualización de datos bivariados multivariados
La visualización de datos bivariados multivariados implica explorar y visualizar las relaciones entre más de dos variables.
2.3.3.1 Pairs
pairs(datos[, c("EU_Sales", "NA_Sales", "JP_Sales", "Other_Sales")])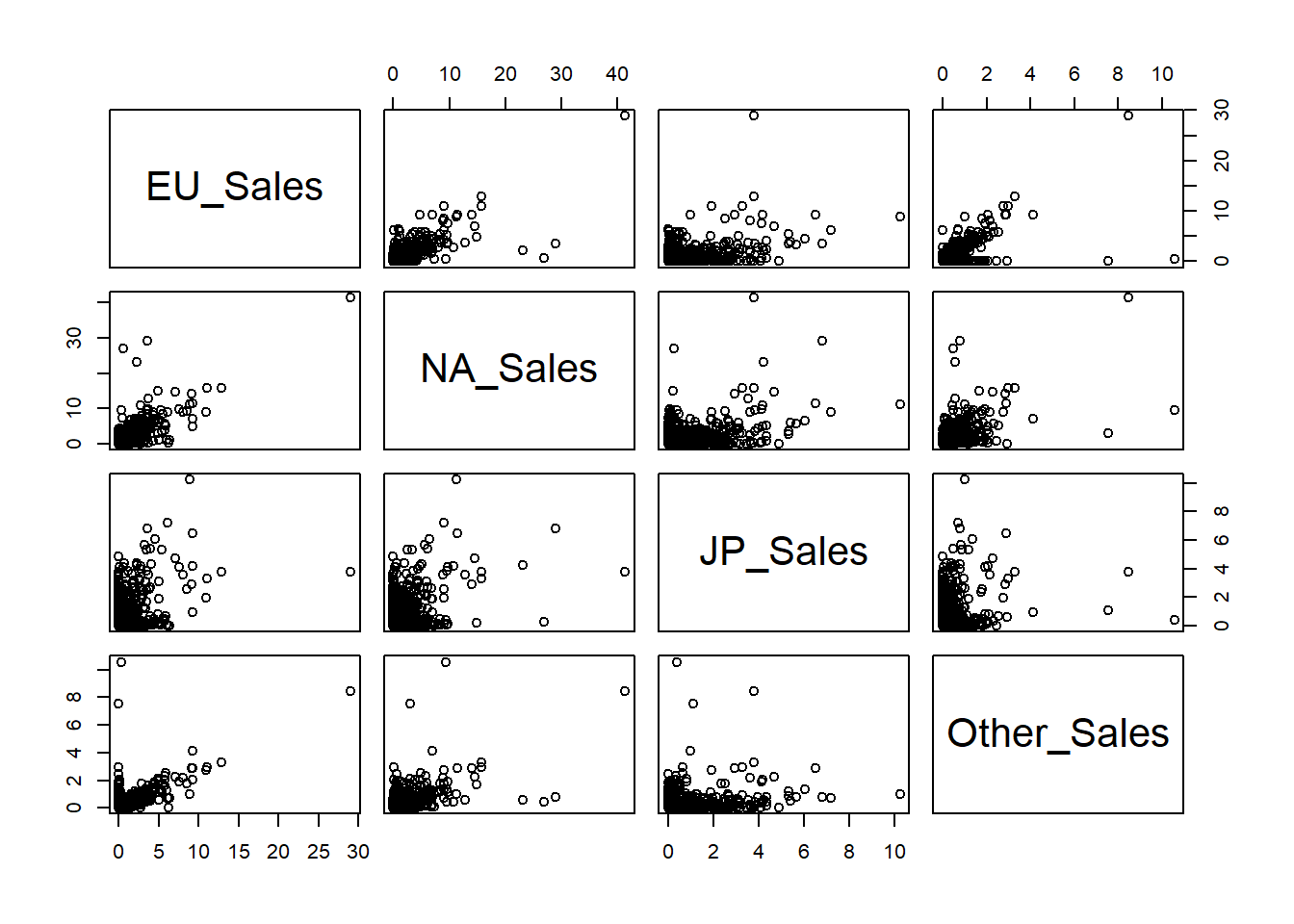
2.3.3.2 Grafico de Burbujas
symbols(datos$EU_Sales, datos$JP_Sales, circles = datos$NA_Sales, inches = 0.2, main = "Gráfico de Burbujas", xlab = "Ventas en Europa", ylab = "Ventas en Japon")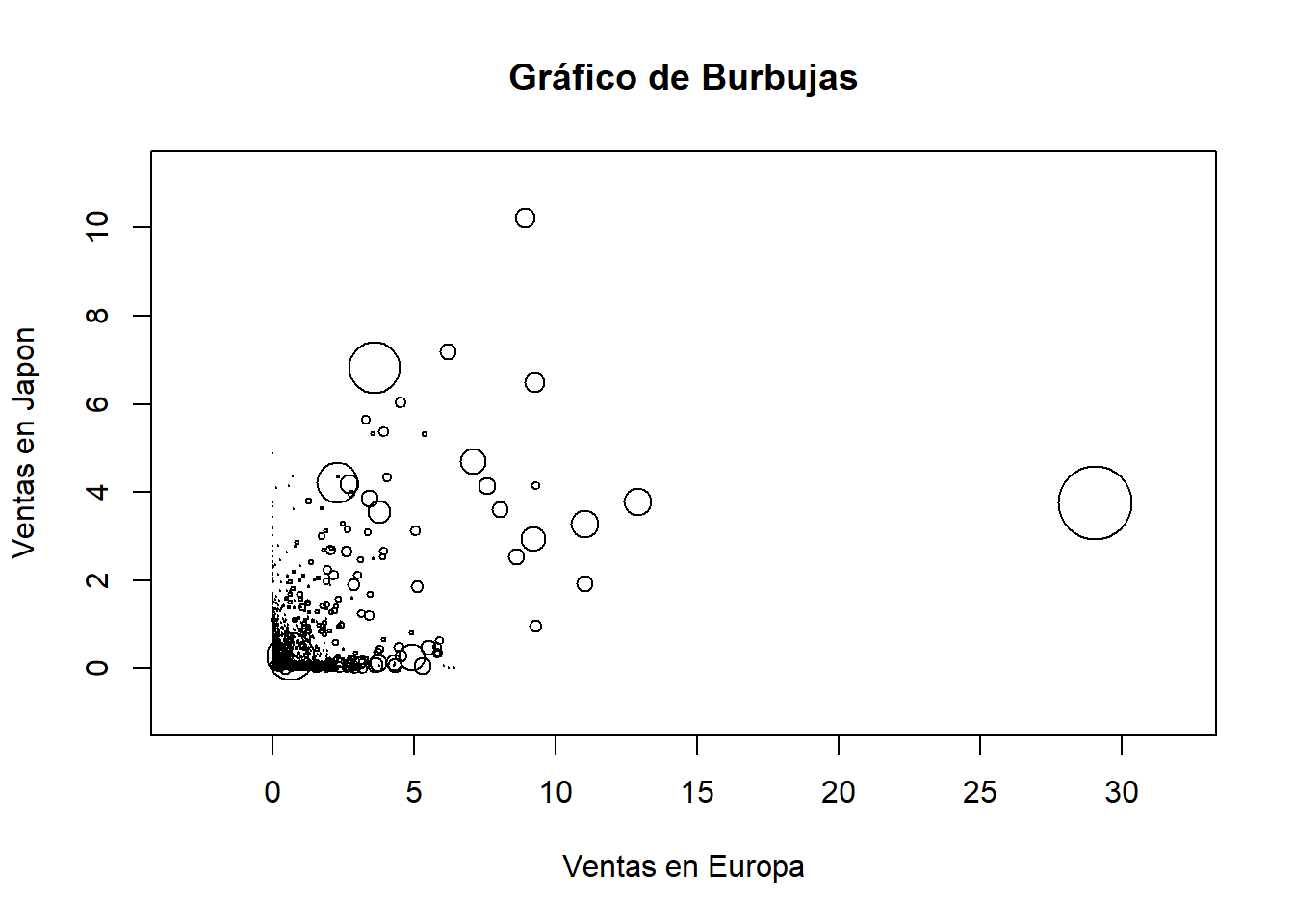
2.3.3.3 Grafico en 3d
scatterplot3d(datos$NA_Sales, datos$JP_Sales, datos$EU_Sales, main = "Gráfico 3D", xlab = "Ventas en Norteamerica", ylab = "Ventas en Japon", zlab = "Ventas en Europa")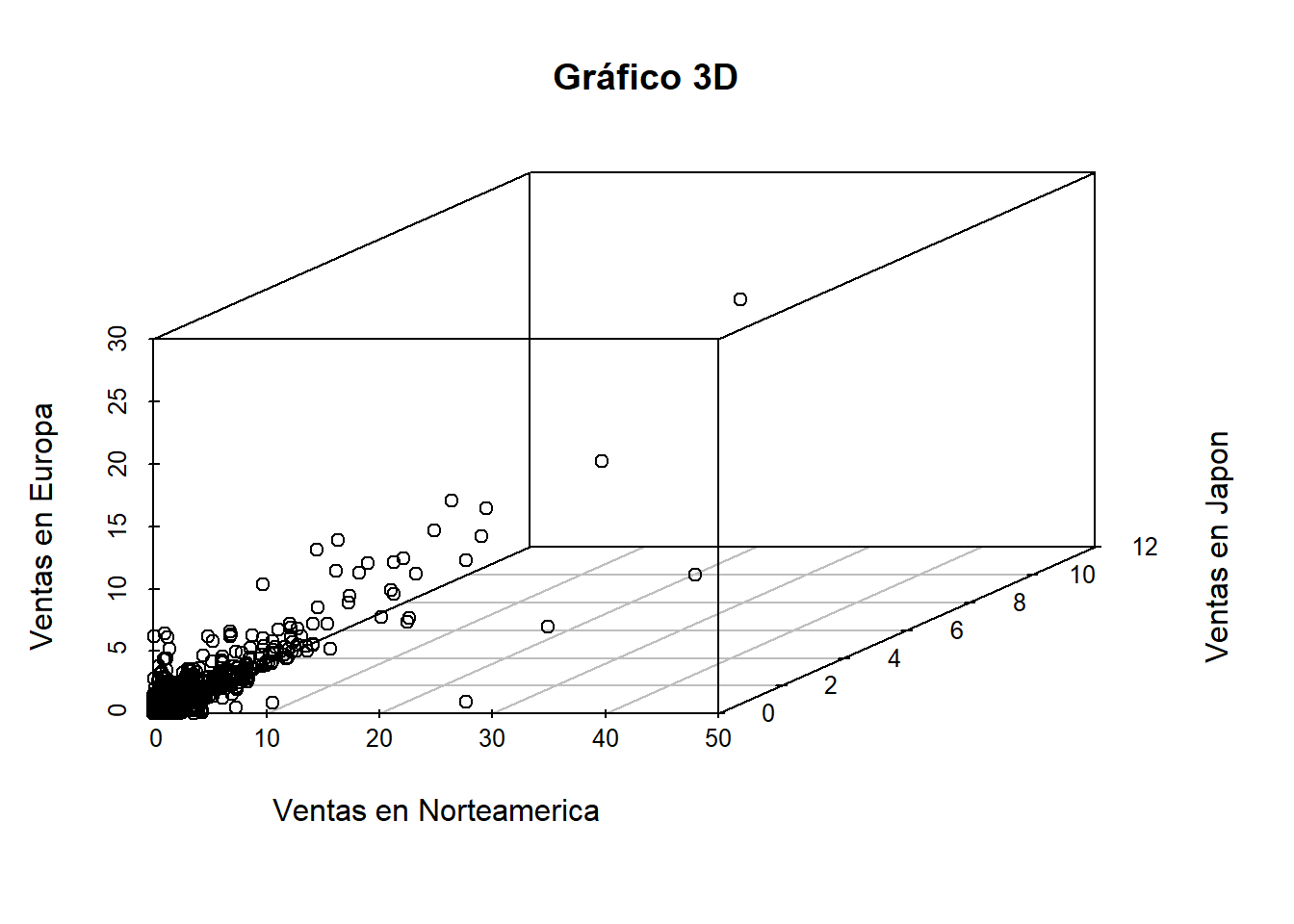
2.3.3.4 Grafico de superficie
scatter3D(datos$JP_Sales, datos$EU_Sales, datos$NA_Sales, colvar = NULL, pch = 19, cex = 2, main = "Gráfico de Superficie")
2.3.4 Visualización de datos avanzados (imágenes)
La visualización de datos avanzados, especialmente imágenes, en R se puede realizar utilizando varios paquetes. Uno de los paquetes más populares y versátiles para trabajar con imágenes en R es imager.
2.3.4.1 Cargar y visualizar una imagen
perro <- load.image("C:/Users/shari/Downloads/Trabajo final PLE/Trabajo final - PLE/perro.jpg")
plot(perro)
2.3.4.2 Convertir la imagen a escala de grises
perro_gris <- grayscale(perro)
plot(perro_gris)
2.3.4.3 Quitar los ejes
plot(perro, axes = FALSE)
2.4 Manipulación de datos no estructurados
La manipulación de datos no estructurados implica trabajar con datos que no están organizados en una estructura tabular típica, como un DataFrame de R o una hoja de cálculo. En lugar de eso, estos datos pueden tomar la forma de texto sin formato, imágenes, audio, video u otros formatos que no se ajusten a una estructura de filas y columnas.
2.4.1 Para texto sin formato (.txt)
texto <- readLines("C:/Users/shari/Downloads/Trabajo final PLE/Trabajo final - PLE/texto.txt")
# Dividir el texto en palabras
palabras <- strsplit(texto, " ")
# Usar grep para que de como resultado la fila en la que se encuentra la palabra deseada
palabra_buscada <- "luna"
matches <- grep(palabra_buscada, palabras)
print(matches)[1] 2 32.4.2 Para imagenes
Se puede usar de ejemplo el manejo realizada a la imagen en la visualizacion de datos avanzados.
2.5 Conclusiones
El manejo de datos mediante las funciones nos permite obtener diversos graficos que ayudan a un rapido analisis estadistico
Pese a que se posean datos no estructurados la versatilidad de R permite que se pueda manipular y trabajar con ellos.