1 Histórico de vencedores absolutos
Buscando información sobre el Descenso Internacional del Sella me encontré con que no está accesible de forma fácil en ningún sitio. La mayor parte de la información está incluida en pdfs que publica la organización cada año. Así que para empezar he ido a una fuente mucho más sencilla de utilizar. Y es que en la página de la Wikipedia dedicada al Descenso Internacional del Sella existe una tabla con todos los vencedores absolutos de la prueba (K2 - Categoría masculina).
Así que si te preguntabas por qué precisamente he empezado por la categoría masculina de K2 la respuesta es muy sencilla y directa: Era lo más fácil.
Y es que en cualquier proyecto de datos, independientemente de su tamaño, dificultad o tipo de problema a solucionar, creo que para empezar lo mejor es empezar por algo sencillo y rápido. Algo que tengas claro que va a tener un resultado concreto y práctico y que tenga asociadas altas probabilidades de éxito. ¡Muerte a la incertidumbre!
Vayamos a ello.
1.1 Obtención de la información
Configuro las opciones de los bloques de código por defecto del documento rmarkdown.
Cargo los paquetes que voy a necesitar para el análisis:
library(tidyverse)
library(rvest)
library(lubridate)
library(kableExtra)
#library(tabulizer)Utilizo las funciones del paquete rvest para importar la información de la wikipedia. Importo toda la entrada de la wikipedia:
#descenso_wiki <- read_html('https://es.wikipedia.org/wiki/Descenso_Internacional_del_Sella')
#save(descenso_wiki, file = "descenso_wiki.Rdata")
#descenso_wiki <- load(file = "descenso_wiki.Rdata") %>%
# as()Localizo las tablas y selecciono la tercera, que es donde están registrados todos los vencedores con sus respectivos tiempos. Asigno el data frame resultante a ‘vencedores_k2_0’ y lo exporto en formato csv para no tener que repetir la tarea de “escrapeo” a la Wikipedia:
#vencedores_k2_0 <- html_nodes(descenso_wiki, "table") %>% .[[3]] %>% html_table(header = #TRUE)
# write_csv(vencedores_k2_0, "final_csvs/vencedores_k2_0.csv")
vencedores_k2_0 <- read_csv("final_csvs/vencedores_k2_0.csv")1.2 Tratamiento de los datos
Echo un vistazo al formato de la tabla:
head(vencedores_k2_0)## # A tibble: 6 x 5
## EXCURSIONES EXCURSIONES_1 EXCURSIONES_2 EXCURSIONES_3 EXCURSIONES_4
## <chr> <chr> <chr> <chr> <chr>
## 1 Edición Año Ganadores Municipio Tiempo
## 2 I 1930 Manés Fdez.- Al~ Infiesto 7 h.
## 3 II 1931 Manés Fdez.- Al~ Infiesto 12 h.
## 4 DESCENSOS P~ DESCENSOS PRO~ DESCENSOS PROVI~ DESCENSOS PRO~ DESCENSOS PR~
## 5 Edición Año Ganadores Municipio Tiempo
## 6 III 1932 César Sánchez L~ Ribadesella 1:53:00Tenemos que arreglar algún detalle de la tabla. Para empezar el nombre de las variables se encuentra en la primera fila de datos, apareciendo como nombres de las columnas el tipo de competición del inicio de la prueba: ‘EXCURSIONES’. Esto último ocurre varias veces a lo largo de la tabla. Cuando cambia el tipo de competición aparece antes una fila con el tipo repetido en cada columna y a continuación otra vez el nombre de las columnas.
Primero modifico los nombres de las columnas (no incluyo ni tildes ni la ñ para evitar problemas).
colnames(vencedores_k2_0) <- c("Edicion", "Ano", "Ganadores", "Municipio", "Tiempo")Y segundo, elimino todas las filas que no recojan los resultados de la prueba. Para ello primero cambio el formato de la variable ‘Año’ a ‘numeric’.
vencedores_k2_0$Ano <- as.numeric(vencedores_k2_0$Ano)Al convertir a formato numérico la variable ‘ano’ R convierte a NA todo lo que no puede convertir en un número. Esto nos puede servir para identificar todas las filas que no nos interesan, quedándonos únicamente con las filas que en la variable ‘Año’ presenta un número.
vencedores_k2_0 <- vencedores_k2_0 %>% filter(!is.na(Ano)) Para recuperar la información del tipo de competición a lo largo de la historia del Descenso creo una nueva variable que la recoja. Utilizo la función ‘cut’ para crear un vector llamado ‘Tipo’ con los tipos de competición para cada rango de años:
Tipo <- cut(vencedores_k2_0$"Ano", breaks = c(1929, 1931, 1934, 1950, Inf), labels = c("Excursión", "Provincial", "Nacional", "Internacional"))Convierto el objeto creado en un data frame y lo uno a la tabla ‘vencedores_k2_0’
Tipo <- as.data.frame(Tipo)
vencedores_k2_1 <- bind_cols(vencedores_k2_0, Tipo)La variable ‘Municipio’ a partir de que la competición se convierte en internacional no recoge el municipio origen de los participantes sino el país.
summary(as.factor(vencedores_k2_1$Municipio))## Alemania Australia Bélgica Cantabria Dinamarca España
## 1 1 3 1 6 48
## Gijón Infiesto Inglaterra Italia Portugal Ribadesella
## 5 2 2 1 1 5
## Sudáfrica Suecia Suiza
## 2 2 1Arreglo esto creando una nueva variable ‘Pais’ donde sólo quede registrado el país y elimino la variable ‘Municipio’
vencedores_k2_1 <- vencedores_k2_1 %>% mutate(Pais = if_else(Ano < 1951, "España", Municipio))
vencedores_k2_1$Municipio <- NULLLa variable “Tiempo” recoge el tiempo empleado por cada ganador en horas, minutos y segundos. Pero antes de poder utilizar esta información hay que realizar alguna modificación a su formato.
Primero, en la tabla de la wikipedia el autor ha incluido un símbolo “®” a la derecha de los tiempos que supusieron un récord en su momento. Eliminamos este símbolo.
vencedores_k2_1$Tiempo <- str_replace(vencedores_k2_1$Tiempo, "®", "" )Los tiempos de los dos primeros años están en otro formato. Sustituimos sus valores por los correspondientes en hh:mm:ss
vencedores_k2_1$Tiempo[[1]] <- "7:00:00"
vencedores_k2_1$Tiempo[[2]] <- "12:00:00"
# Añado el tiempo de la edición de 1943.
vencedores_k2_1$Tiempo[[6]] <- "2:01:10"
# Suprimo el registro con la edición de 1944 ya que en la wikipedia viene sin el tiempo y no he logrado encontrarlo en otros sitios.
vencedores_k2_1 <- vencedores_k2_1 %>%
filter(Ano != "1944")Además hay algún error en el formato del resto de tiempos, en alguna ocasión los “:” son sustituidos por “-” o “.”. Lo solucionamos sustituyendo en esta columna todos los “-” y “.” por “:”.
vencedores_k2_1$Tiempo <- str_replace(vencedores_k2_1$Tiempo, "-", ":" )
vencedores_k2_1$Tiempo <- str_replace(vencedores_k2_1$Tiempo, "\\.", ":" )
vencedores_k2_2 <- vencedores_k2_1Dejamos preparado el código para incluir los datos de los ganadores de 2019.
vencedores_k2_2 <- vencedores_k2_2 %>%
add_row(Edicion = "LXXXIII", Ano = "2019", Ganadores = "Miguel F. Castañón-José Julián Becerro", Tiempo = "1:07:47", Tipo = "Internacional", Pais = "España")Finalmente convertimos la variable de formato “caracter” a formato “hora” con la función “hms” del paquete lubridate. Posteriormente lo convertimos de formato hora a formato “duración”.
vencedores_k2_2$Tiempo <- hms(vencedores_k2_2$Tiempo) %>%
as.duration()Añadimos una columna que identifique como record o no el tiempo de cada edición.
vencedores_k2_2 <- vencedores_k2_2 %>%
mutate(row = row_number(),
minimo = as.duration(cummin(Tiempo)),
Record = if_else(Tiempo == minimo, "1", "0")) %>%
select(-row, -minimo)
#Record = if_else(Tiempo < as.duration(min(Tiempo[1:row_number], na.rm = TRUE)), "1", "0"))
# Vuelvo a añadir el registro de la edición de 1944 que al no tener tiempo registrado daba problemas con la función cummin, que no tiene argumento tipo na.rm.
vencedores_k2_2 <- vencedores_k2_2 %>%
add_row(Edicion = "VII", Ano = "1944", Ganadores = "Armando Menéndez-Melchor Palacios", Tiempo = as.duration(""), Tipo = "Nacional", Pais = "España") %>%
arrange(Ano)
vencedores_k2_2$Ano <- as.numeric(vencedores_k2_2$Ano)
vencedores_k2_2$Pais <- as.factor(vencedores_k2_2$Pais)1.3 Exploración de los datos y visualizaciones
Probamos a hacer un primer gráfico.
#vencedores_k2_3 <- vencedores_k2_2 %>% filter(tipo != "Excursión")
#vencedores_k2_4 <- vencedores_k2_3 %>% mutate(fecha = paste(ano, "-", "08", "-", "01"))
#vencedores_k2_4$fecha <- ymd(vencedores_k2_4$fecha)
breaks <- c(3600, 7200, 10800, 14400, 18000, 21600, 25200, 28800, 32400, 36000, 39600, 43200)
labels <- c( "1h 00m", "2h 00m", "3h 00m", "4h 00m", "5h 00m", "6h 00m", "7h 00m", "8h 00m", "9h 00m", "10h 00m", "11h 00m", "12h 00m")
evolucion_tiempos_0 <- ggplot(data = vencedores_k2_2, aes(x = Ano, y = as.numeric(Tiempo), color = Tipo)) + geom_line() +
labs(title = "Evolución tiempos vencedores K2", y = "Tiempos vencedores K2", x = "Año") +
theme(axis.text.x=element_text(angle=90,hjust=1,vjust=0.5, size = 7)) +
scale_x_continuous(breaks = vencedores_k2_2$Ano) +
scale_y_continuous(
limits = c(3600, 43200),
breaks = breaks,
labels = labels) +
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank()) +
theme(legend.position = c(0.9, 0.8))
evolucion_tiempos_0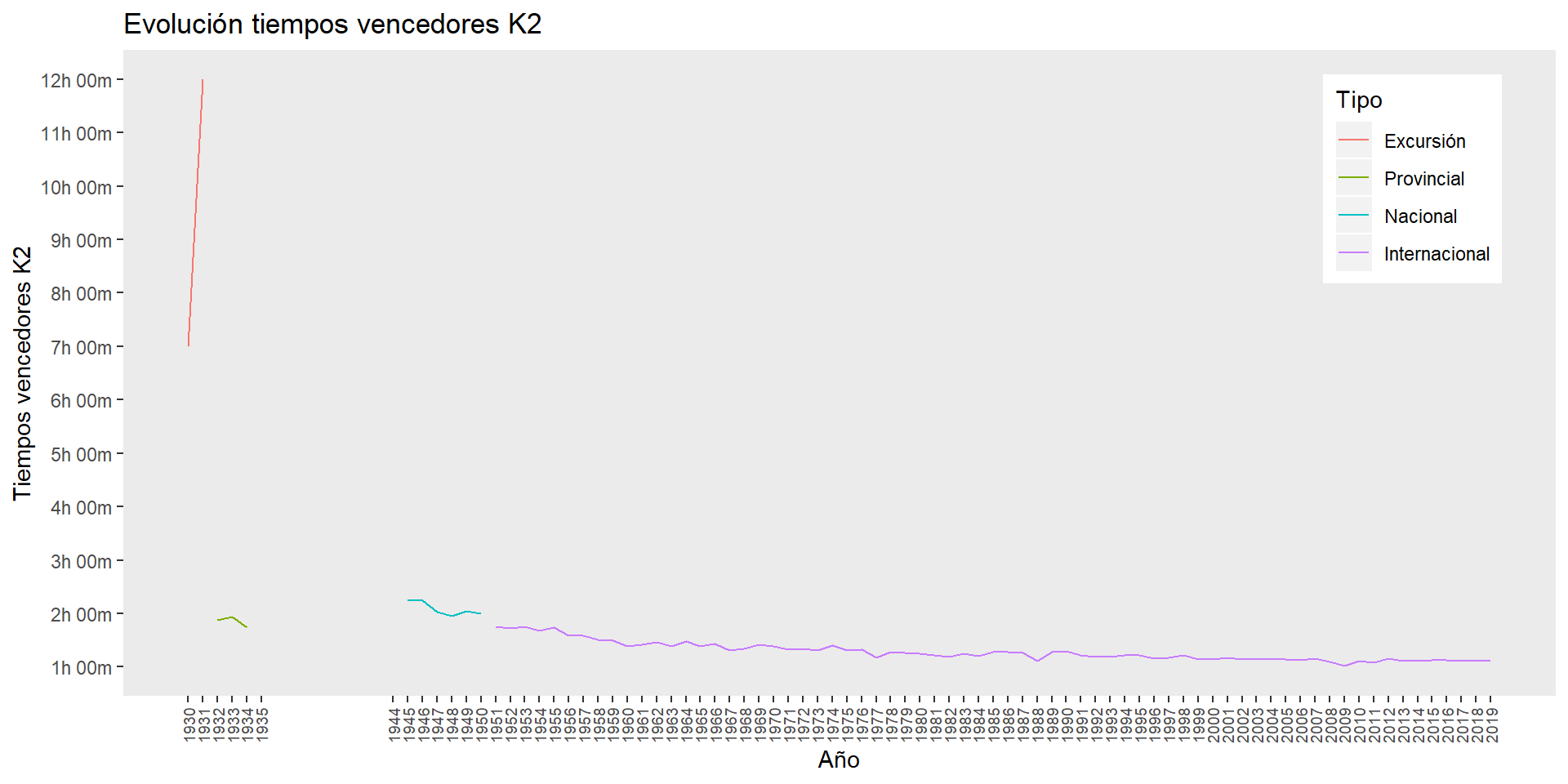
ggsave("plots/evolucion_tiempos_0.png")En este primer gráfico, al incluir los tiempos de las dos primeras ediciones (7 y 12 horas), lejísimos del resto de marcas, es muy difícil observar la evolución de los tiempos históricos. Así, que con perdón del fundador de la prueba, Dionisio Huerta, participante junto a otros dos amigos de estas dos primeras ediciones, eliminamos estos dos primeros años del gráfico.
breaks <- c(3600, 4200, 4800, 5400, 6000, 6600, 7200, 7800, 8400)
labels <- c( "1h 00m", "1h 10m", "1h 20m", "1h 30m","1h 40m", "1h 50m", "2h 00m", "2h 10m", "2h 20m" )
evolucion_tiempos_1 <- ggplot(data = vencedores_k2_2 %>% filter(Tipo != "Excursión"), aes(x = Ano, y = as.numeric(Tiempo), color = Tipo)) + geom_line() +
labs(title = "Evolución tiempos vencedores K2", y = "tiempos vencedores K2", x = "Año") +
theme(axis.text.x=element_text(angle=90,hjust=1,vjust=0.5, size = 7)) +
scale_x_continuous(breaks = vencedores_k2_2$Ano) +
scale_y_continuous(
limits = c(3600, 8400),
breaks = breaks,
labels = labels) +
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank()) +
theme(legend.position = c(0.9, 0.8))
evolucion_tiempos_1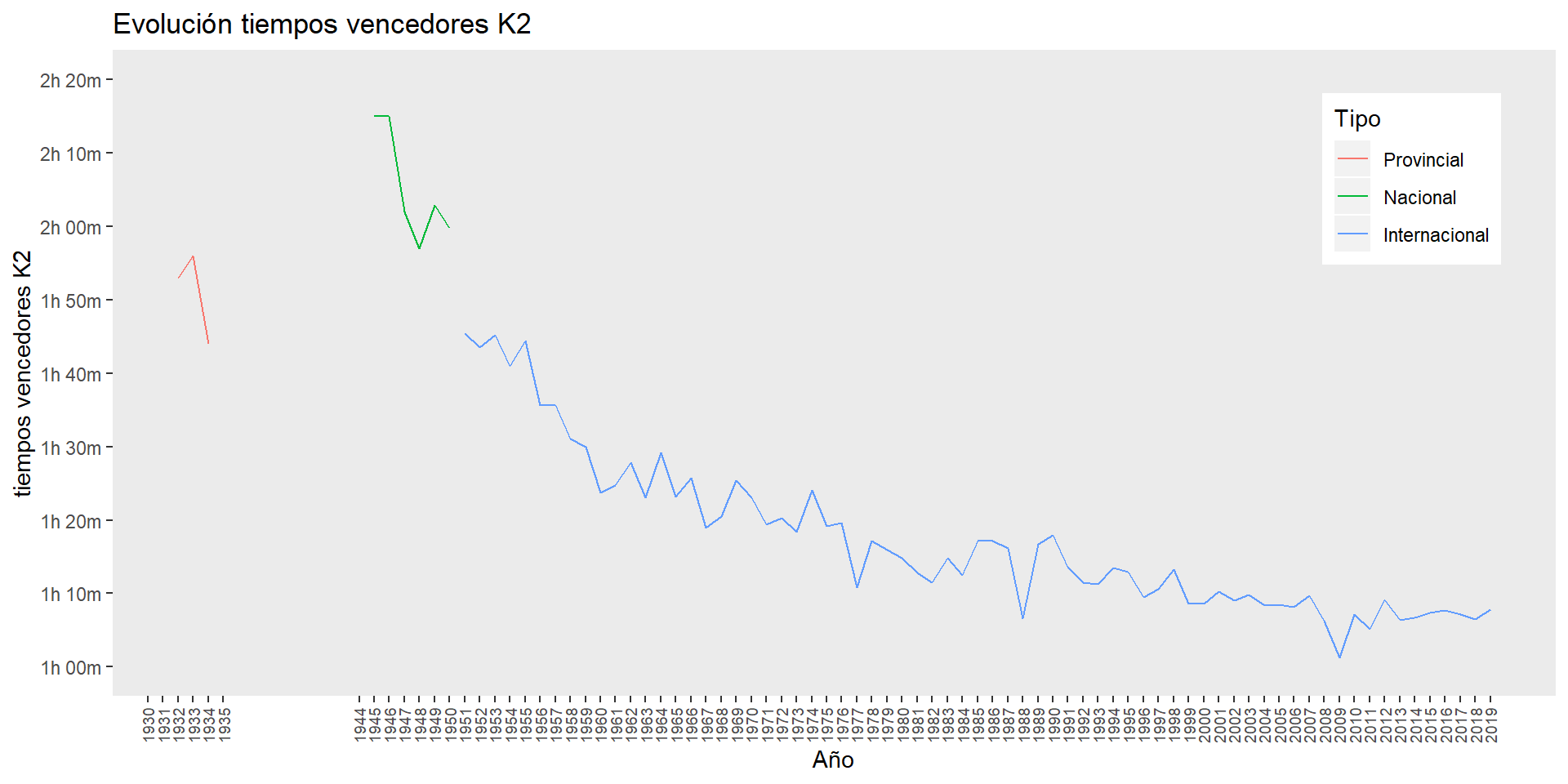
ggsave("plots/evolucion_tiempos_1.png")Al excluir estas dos primeras ediciones ya podemos ver mucho mejor la evolución de los tiempos históricos.
Quizás lo primero que llama la atención es como los tiempos de las ediciones nacionales (línea verde), celebradas después de años de interrupción por la Guerra Civil y comienzo de la dictadura, son peores que los conseguidos por las ediciones iniciales de la prueba, de categoría provincial (línea roja).
Y a partir de convertirse en una competición internacional los tiempos, con sus altibajos, han ido reduciéndose de forma constante año a año. Aunque también aquí se puede observar a simple vista distintos periodos donde esta mejora se ha producido a diferentes ritmos, de forma extremadamente rápida al principio, década de los 50, y reduciéndose ese ritmo de mejora de forma bastante constante hasta aparentemente estancarse en la última década, después del récord absoluto de la prueba de 1 hora, un minuto y 14 segundos, conseguido en 2009 por la pareja conformada por Julio Martínez y Miguel Fernández.
Para observar con más detalle esta evolución generamos otro gráfico, pero esta vez sólo con las ediciones internacionales.
breaks <- c(3600, 3900, 4200, 4500, 4800, 5100, 5400, 6000, 6600)
labels <- c( "1h 00m", "1h 05m", "1h 10m", "1h 15m", "1h 20m", "1h 25m", "1h 30m","1h 40m", "1h 50m")
evolucion_tiempos_2 <- ggplot(data = vencedores_k2_2 %>% filter(Tipo == "Internacional"), aes(x = Ano, y = as.numeric(Tiempo))) + geom_line() +
labs(title = "Evolución tiempos vencedores K2", y = "Tiempos vencedores K2", x = "Año") +
theme(axis.text.x=element_text(angle=90,hjust=1,vjust=0.5, size = 7)) +
scale_x_continuous(breaks = vencedores_k2_2$Ano) +
scale_y_continuous(
limits = c(3600, 6600),
breaks = breaks,
labels = labels) +
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank()) +
theme(legend.position = c(0.9, 0.8))
evolucion_tiempos_2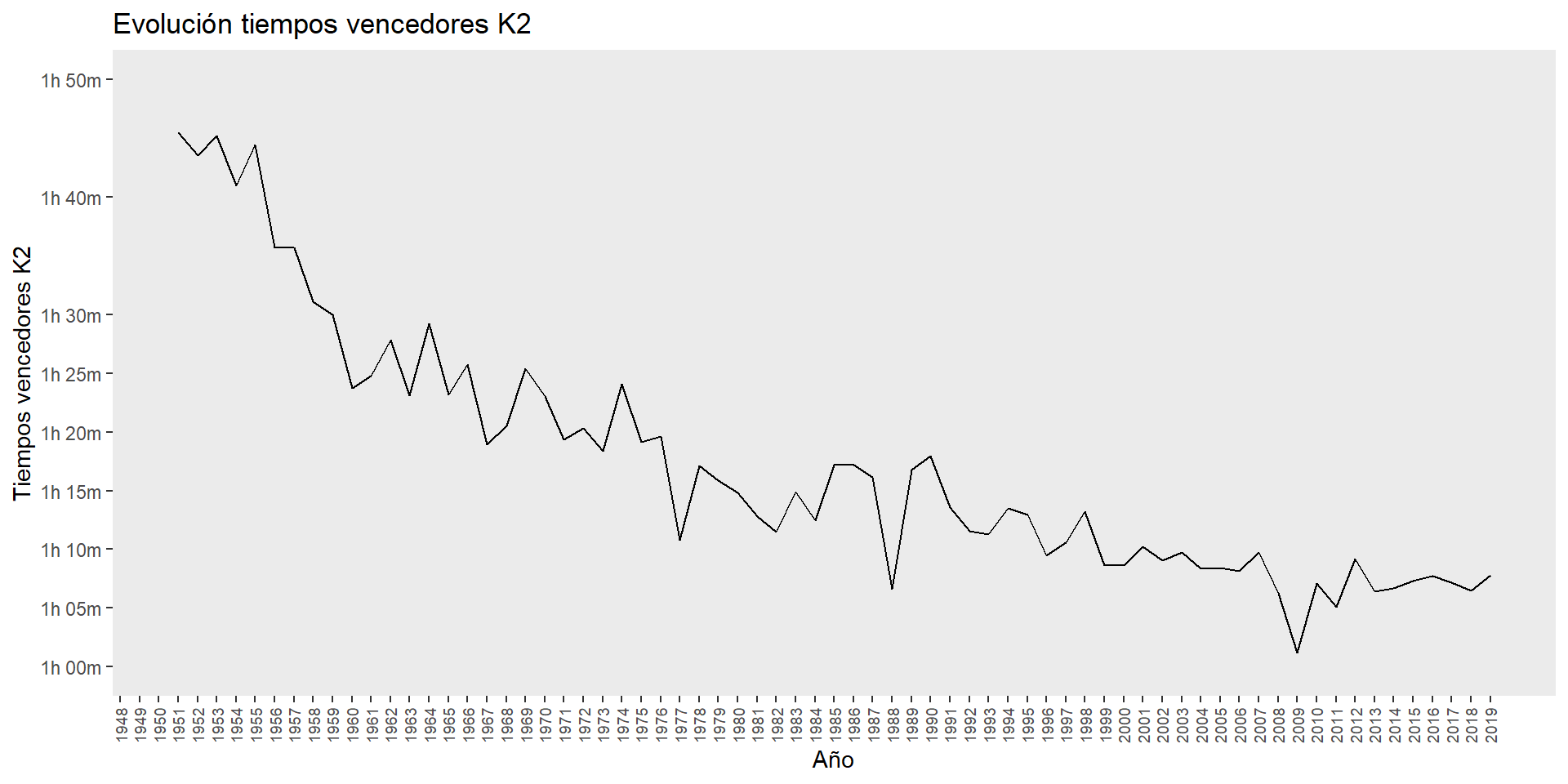
ggsave("plots/evolucion_tiempos_2.png")Pendiente:
- Señalar las distintas pendientes de reducción de tiempos durante las ediciones internacionales:
- 1948-1959: Un primer periodo con una pendiente muy pronunciada en el que poco más de una década se rebaja la marca en unos 22 minutos.
- 1960-2009: Un segundo periodo donde con altibajos se produce una reducción de tiempos que muestra una pendiente más reducida que la anterior. Dentro de estos altibajos destacar los records de 1977, 1988 y 2009, que dentro de su época y contexto destacan de forma muy especial. Sobre todo el último, que parece que va a permanecer por más tiempo incluso que el anterior de 1988, que fue sólo posible por el estado del Sella el día de la prueba, una auténtica riada.
- 2010-2018: Un último periodo donde los tiempos son en general ligeramente mejores que la década anterior, pero parecen haberse estabilizado después del récord absoluto de 2009, que cierra la era de triunfos de Julio Martínez y cia (11 victorias en el periodo 1998-2005) para comenzar la de Walter Bouza y Álvaro Fernández (8 victorias seguidas del 2010 al 2017).
Añadimos una nueva variable para marcar estas dos eras de ganadores.
vencedores_k2_3 <- vencedores_k2_2 %>%
mutate(Eras = if_else(str_detect(vencedores_k2_2$Ganadores, "Walter Bouzán") == TRUE,
"Era Walter Bouzán",
if_else(str_detect(vencedores_k2_2$Ganadores, "Martínez G.,") == TRUE,
"Era Julio Martínez",
if_else(str_detect(vencedores_k2_2$Ganadores, "Hansen") == TRUE,
"Era Stend L. Hansen", "Resto"))))
# Fijo el orden de los niveles
vencedores_k2_3$Eras <- factor(vencedores_k2_3$Eras, levels = c("Era Stend L. Hansen", "Era Julio Martínez", "Era Walter Bouzán", "Resto"))breaks <- c(3600, 3900, 4200, 4500, 4800, 5100, 5400, 6000, 6600)
labels <- c( "1h 00m", "1h 05m", "1h 10m", "1h 15m", "1h 20m", "1h 25m", "1h 30m","1h 40m", "1h 50m")
evolucion_tiempos_2 <- ggplot(data = vencedores_k2_3 %>% filter(Tipo == "Internacional"), aes(x = Ano, y = as.numeric(Tiempo), color = Eras)) + geom_line(aes(group=1)) +
labs(title = "Evolución tiempos vencedores K2", y = "Tiempos vencedores K2", x = "Año") +
theme(axis.text.x=element_text(angle=90,hjust=1,vjust=0.5, size = 7)) +
scale_x_continuous(breaks = vencedores_k2_3$Ano) +
scale_y_continuous(
limits = c(3600, 6600),
breaks = breaks,
labels = labels) +
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank()) +
theme(legend.position = c(0.9, 0.8)) +
geom_point() +
scale_color_manual(values=c("#0000FF", "#CC6666", "#088A29", "#D8D8D8"))
evolucion_tiempos_2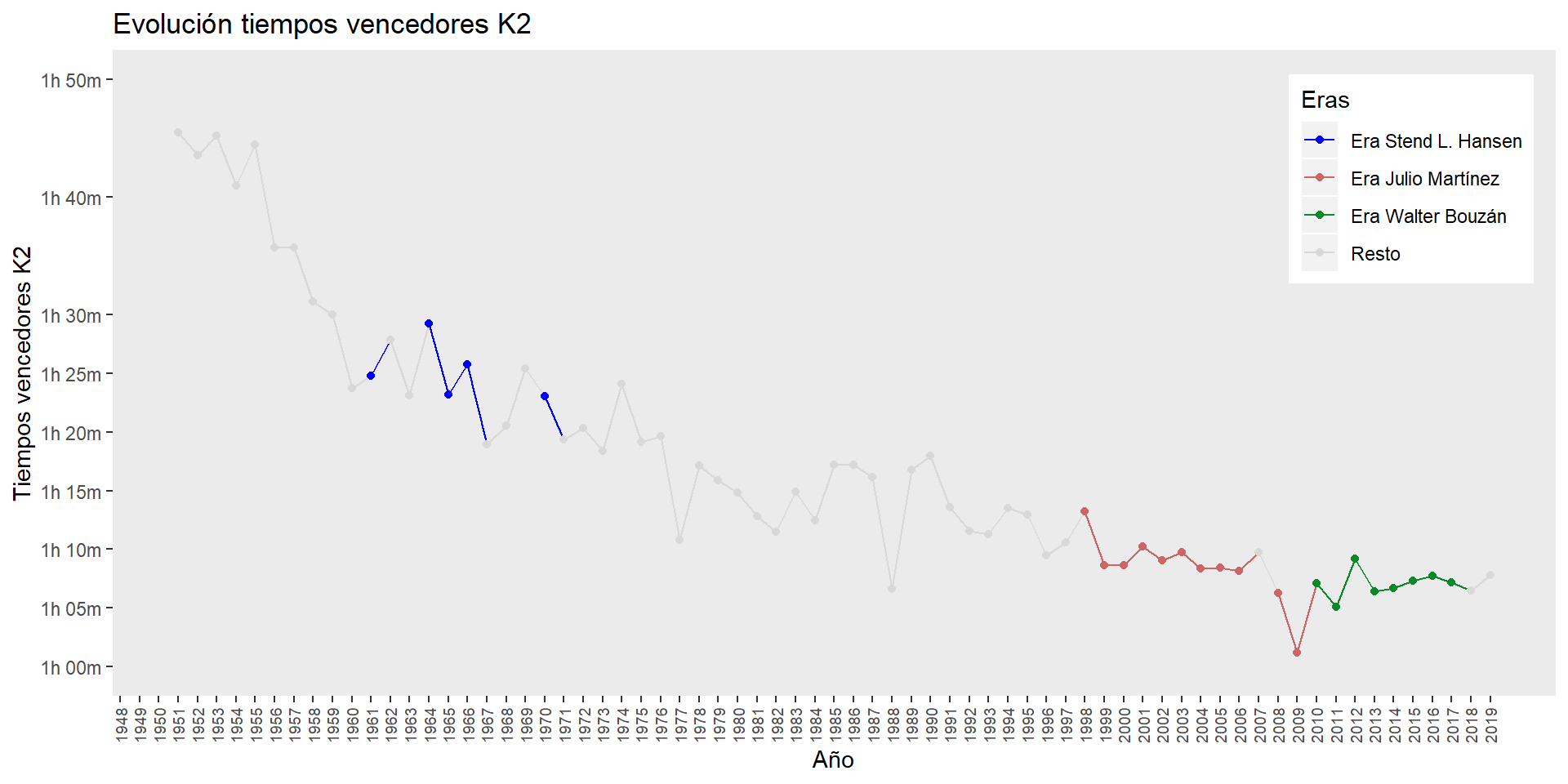
ggsave("plots/evolucion_tiempos_3.png")vencedores_k2_red <- vencedores_k2_1 %>%
select(-Edicion, -Tipo, -Pais) %>%
rename(`Año` = Ano)
era_martinez <- vencedores_k2_red %>%
filter(`Año` >= 1998,
`Año` < 2010)
era_bouzan <- vencedores_k2_red %>%
filter(`Año` > 2009,
`Año` < 2018)kable(era_martinez) %>% kable_styling(position = "float_left")| Año | Ganadores | Tiempo |
|---|---|---|
| 1998 | Martínez G., Julio-Quevedo T., R. | 1:13:14 |
| 1999 | Martínez G., Julio-Quevedo T., R. | 1:08:38 |
| 2000 | Martínez G., Julio-Quevedo T., R. | 1:08:38 |
| 2001 | Martínez G., Julio-Quevedo T., R. | 1:10:16 |
| 2002 | Martínez G., Julio-Busto Fdez., M. | 1:09:04 |
| 2003 | Martínez G., Julio-Merchán A., E. | 1:09:47 |
| 2004 | Martínez G., Julio-Merchán A., E. | 1:08:23 |
| 2005 | Martínez G., Julio-Merchán A., E. | 1:08:27 |
| 2006 | Martínez G., Julio-Merchán A., E. | 1:08:10 |
| 2007 | Alonso, Jorge-Guerrero, Santi | 1:09:46 |
| 2008 | Martínez G., Julio-Hernanz, J. | 1:06:15 |
| 2009 | Martínez G., Julio-Fernández, M. | 1:01:14 |
kable(era_bouzan) %>% kable_styling(position = "float_right")| Año | Ganadores | Tiempo |
|---|---|---|
| 2010 | Walter Bouzán-Álvaro Fernández | 1:07:08 |
| 2011 | Walter Bouzán-Álvaro Fernández | 1:05:08 |
| 2012 | Walter Bouzán-Álvaro Fernández | 1:09:12 |
| 2013 | Walter Bouzán-Álvaro Fernández | 1:06:26 |
| 2014 | Walter Bouzán-Álvaro Fernández | 1:06:43 |
| 2015 | Walter Bouzán-Álvaro Fernández | 1:07:20 |
| 2016 | Walter Bouzán-Álvaro Fernández | 1:07:43 |
| 2017 | Walter Bouzán-Álvaro Fernández | 1:07:13 |