2 Tratamiento archivos .CAT
DESCRIBIR QUÉ ES UN ARCHIVO .CAT. AÑADIR CONTEXTO. PENDIENTE
library(dplyr)
library(stringr)
library(tidyr)
library(purrr)
library(readr)
library(knitr)
library(ggplot2)Importamos el archivo “CAT”. Indicando que es una tabla sin cabecera y no importamos de momento la primera fila, que viene con metadata del archivo. La información de este archivo es correspondiente a la ciudad de Gijón.
# Importa el numero correcto de filas 709.385 (comparado con la importacion con excel). Pero informa de 887 errores de parseo
cat <- read_csv("data/52_24_U_2020-04-24.cat", col_names=FALSE)Importamos también los ficheros con los nombres de las variables (pendiente de acabar, la importación de momento se ejecuta uno a uno; siguiente bloque de código).
De momento lo haremos uno a uno.
tipo11_names <- read_delim("./data/Formato_CAT_tipo11_20071.csv",
delim= ";",
col_types = cols(.default = "c")) %>% names()
tipo13_names <- read_delim("./data/Formato_CAT_tipo13_20071.csv",
delim= ";",
col_types = cols(.default = "c")) %>% names()
tipo14_names <- read_delim("./data/Formato_CAT_tipo14_20071.csv",
delim= ";",
col_types = cols(.default = "c")) %>% names()
tipo15_names <- read_delim("./data/Formato_CAT_tipo15_20071.csv",
delim= ";",
col_types = cols(.default = "c")) %>% names()
tipo17_names <- read_delim("./data/Formato_CAT_tipo17_20071.csv",
delim= ";",
col_types = cols(.default = "c")) %>% names()Echamos un vistazo al formato de la tabla creada
## [1] "01G52 GIJ<d3>N 20200424120302CCATDESCRIPCION DE BIENES (20-11-2009)"
## [2] "11 52024 4851101TP8245S 33ASTURIAS 024024GIJON 00210CL CLAUDIO ALVARGONZALEZ 0014 0000 00000 3320100000000000000000000 000000047100027060002706000000000004580284694750482495565 EPSG:25830"
## [3] "13 52024UR4851101TP8245S0001 33ASTURIAS 024024GIJON 00210CL CLAUDIO ALVARGONZALEZ 0014 0000 00000 1964E000000000000"
## [4] "13 52024UR4851101TP8245S0002 33ASTURIAS 024024GIJON 00210CL CLAUDIO ALVARGONZALEZ 0014 0000 00000 1964E000000000000"
## [5] "13 52024UR4851101TP8245S0003 33ASTURIAS 024024GIJON 00210CL CLAUDIO ALVARGONZALEZ 0014 0000 00000 1964E000000000000"
## [6] "13 52024UR4851101TP8245S0004 33ASTURIAS 024024GIJON 00210CL CLAUDIO ALVARGONZALEZ 0014 0000 00000 1964E000000000000"Creamos una columna con los dos primeros caracteres de cada registro, que en principio tienen que servirnos para identificar el tipo de entidad de información.
cat_1 <- cat
# Eliminamos posibles espacios blancos a la izquierda y a la derecha de la columna V1.
cat_1$X1 <- str_trim(cat_1$X1)
# Creamos la nueva variable (table) con los dos primeros caracteres de la columna V1
cat_1 <- cat_1 %>%
mutate('1_tipo_reg' = str_sub(X1, 1, 2)) %>%
mutate('1_tipo_reg' = as.factor(`1_tipo_reg`)) Echamos un vistazo al contenido de la variable “1_tipo_reg”. Como vemos divide correctamente todos los registros por tipo de registro.
## 01 11 13 14 15 16 17 90
## 1 24922 57563 346781 234079 27992 18046 1Inmuebles
A continuación vemos una descripción gráfica del fichero .CAT. Fuente: Fuente: https://www.idee.es/resources/presentaciones/JIIDE18/JIIDE2018_StatsCATDGC_UPV_RafaSierra.pdf
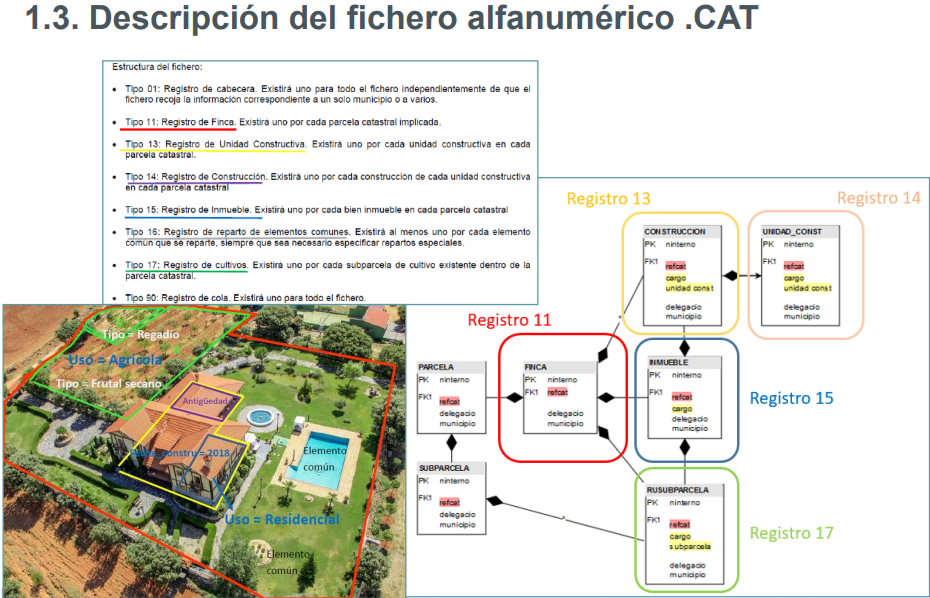
Vamos a tratar los registros “Tipo 15”, que corresponden a los inmuebles.
Creamos una tabla con los registros “Tipo 15” utilizando los nombres de las variables importados anteriormente.
Para dar formato a la tabla seguiremos el documento que el Catastro tiene publicado en su página web Descripción del fichero .CAT.
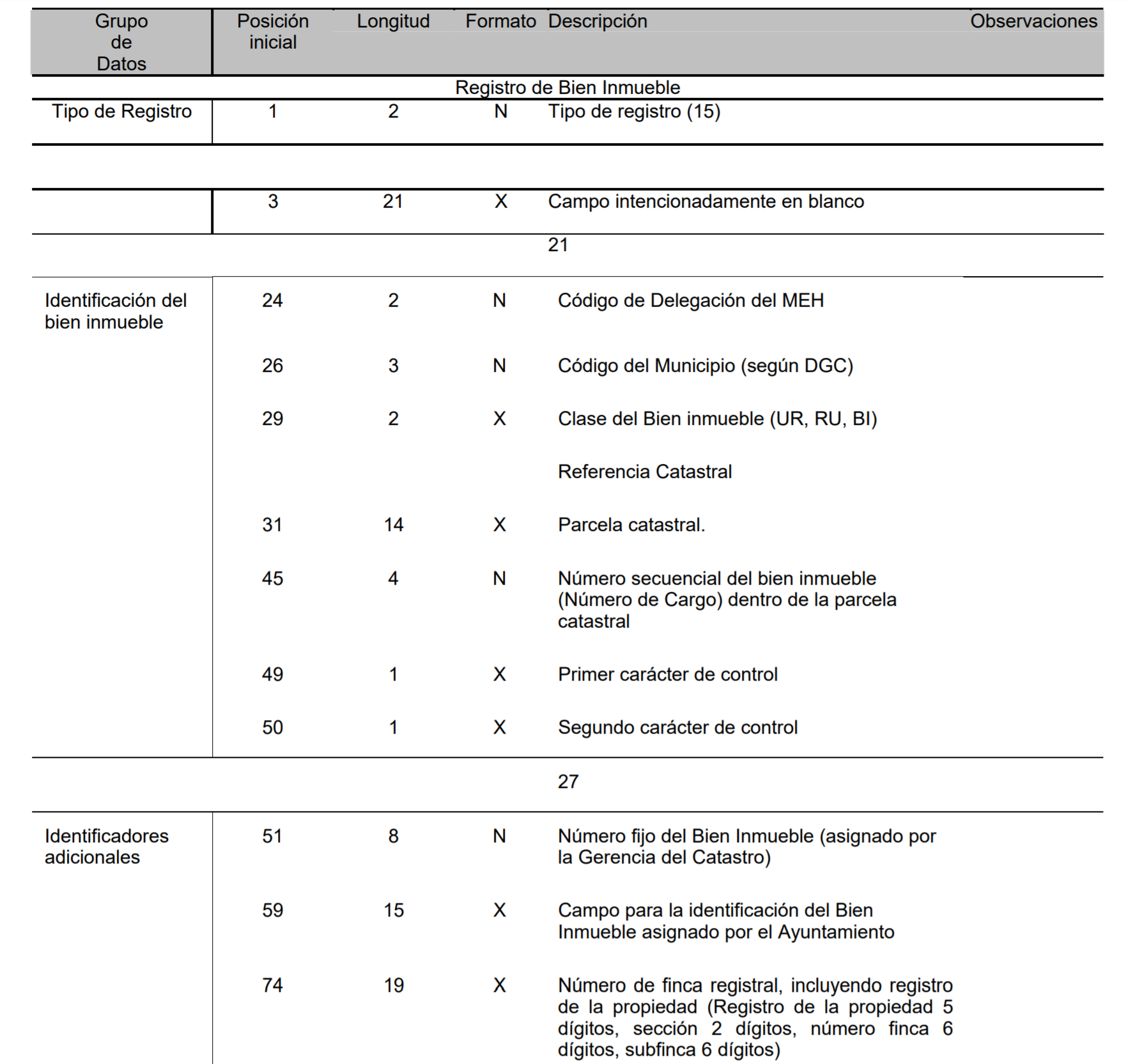
## # A tibble: 10 x 2
## X1 `1_tipo_reg`
## <chr> <fct>
## 1 15 52024UR6143805TP8264S0039PH10331521 ~ 15
## 2 15 52024UR4425608TP8242S0012DX10376932 ~ 15
## 3 15 52024UR3545018TP8234S0088KG10430533 ~ 15
## 4 15 52024UR2734502TP8223S0008EU10408520 ~ 15
## 5 15 52024UR2343114TP8224S0046KR10453640 ~ 15
## 6 15 52024UR5334407TP8253S0004LG10304062 ~ 15
## 7 15 52024UR4537007TP8243N0072DR10399548 ~ 15
## 8 15 52024UR2141104TP8224S0152DP10412785 ~ 15
## 9 15 52024UR5543609TP8254S0001PY10311343 ~ 15
## 10 15 52024UR5049509TP8244N0001UJ10295902 ~ 15En el siguiente código aplico las instrucciones del anterior documento para crear las variables con su contenido correcto.
(Se podría crear una función que hiciese esto de forma automática y generalizable para el resto de tablas del archivo .CAT, ya que en el mismo nombre de cada variable está indicada la posición inicial de cada caracter. Así que para dar referencias a la funcion str_sub solo se necesita el número por el que empieza el nombre de la variable y el número menos 1 del nombre de la siguiente variable. Queda pendiente.)
inmuebles <- inmuebles %>% mutate(`24_cd` = str_sub(X1, 24, 25),
`26_cmc` = str_sub(X1, 26, 28),
`29_cn` = str_sub(X1, 29, 30),
`31_pc` = str_sub(X1, 31, 44),
`45_car` = str_sub(X1, 45, 48),
`49_cc1` = str_sub(X1, 49, 49),
`50_cc2` = str_sub(X1, 50, 50),
`51_nfbi` = str_sub(X1, 51, 58),
`59_iia` = str_sub(X1, 59, 73),
`74_nfv` = str_sub(X1, 74, 92),
`93_cp` = str_sub(X1, 93, 94),
`95_np` = str_sub(X1, 95, 119),
`120_cmc` = str_sub(X1, 120, 122),
`123_cm` = str_sub(X1, 123, 125),
`126_nm` = str_sub(X1, 126, 165),
`166_nem` = str_sub(X1, 166, 195),
`196_cv` = str_sub(X1, 196, 200),
`201_tv` = str_sub(X1, 201, 205),
`206_nv` = str_sub(X1, 206, 230),
`231_pnp` = str_sub(X1, 231, 234),
`235_plp` = str_sub(X1, 235, 235),
`236_snp` = str_sub(X1, 236, 239),
`240_slp` = str_sub(X1, 240, 240),
`241_km` = str_sub(X1, 241, 245),
`246_bl` = str_sub(X1, 246, 249),
`250_es` = str_sub(X1, 250, 251),
`252_pt` = str_sub(X1, 252, 254),
`255_pu` = str_sub(X1, 255, 257),
`258_td` = str_sub(X1, 258, 282),
`283_dp` = str_sub(X1, 283, 287),
`288_dm` = str_sub(X1, 288, 289),
`290_cma` = str_sub(X1, 290, 292),
`293_czc` = str_sub(X1, 293, 294),
`295_cpo` = str_sub(X1, 295, 297),
`298_cpa` = str_sub(X1, 298, 302),
`303_cpaj` = str_sub(X1, 303, 307),
`308_npa` = str_sub(X1, 308, 337),
`368_noe` = str_sub(X1, 368, 371),
`372_ant` = str_sub(X1, 372, 375),
`428_grbice/coduso` = str_sub(X1, 428, 428),
`442_sfc` = str_sub(X1, 442, 451),
`452_sfs` = str_sub(X1, 452, 461),
`462_cpt` = str_sub(X1, 462, 470)) %>%
select(-X1)
# Convierto todas las variables que están en formato string a factor
inmuebles <- inmuebles %>% mutate_if(is.character,as.factor)Hacemos un ranking de calles de Gijón por número de inmuebles.
ranking_inmuebles_calles <- inmuebles %>%
select(`206_nv`) %>%
group_by(`206_nv`) %>%
summarise(n = n()) %>%
arrange(desc(n)) %>%
head(20)
#ranking_inmuebles_calles$`206_nv` <- #str_strim(ranking_inmuebles_calles$`206_nv`)
ggplot(data = ranking_inmuebles_calles, aes(x = reorder(`206_nv`, n), y = n)) +
geom_col() +
ylab("Número de inmuebles") +
xlab("Calle/Vía") +
ggtitle("Ranking de calles de Gijón por número de inmuebles") +
coord_flip() + theme(axis.text.y = element_text(hjust=0))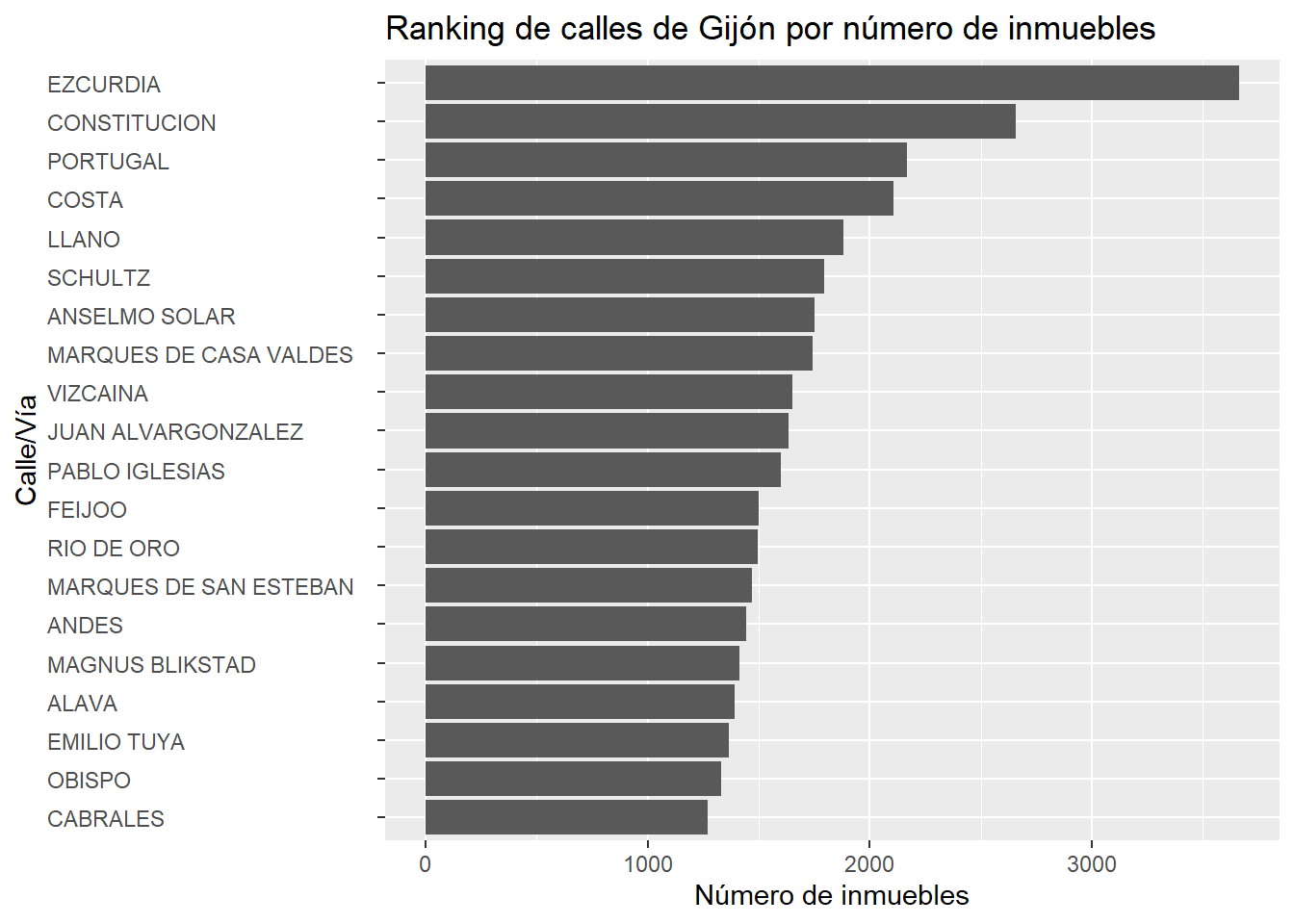
Otras referencias:
http://www.catastro.minhap.es/documentos/formatos_intercambio/catastro_fin_cat_2006.pdf
http://congresoage.unizar.es/eBook/trabajos/031_Mora-Garcia.pdf