5 第四讲:如何清理数据—R语言编程基础
前言
大家解压好我们发在群里的压缩文件,在里面,有几个文件对大家都是有用的。第一个是Rproject,打开它后会自动启动相应的路径,这是上一节课讲过的。有了这个Rproject,我们就不需要再去寻找文件,只要把所有东西都放在这里面,所有的读取和保存文件都可以通过相对路径来解决。在这里面,有一个chap4的网页html文件,它实际上就是我们今晚的PPT。还有一个叫做RMD的文件,里面有代码。大家可以打开它,可能跟我看到的现在看到的应该是一个类似的界面。在右下角的窗口里,有一个chap4 RMD,里面都是关于代码的。大家可能有一些地方不需要自己去抄代码,可以去找一些相关的代码。因为之前有同学会抄PPT上的代码,这样很慢。在这个地方,我们读取数据的代码都在这里面。在自己电脑操作的时候,可以直接点开这个RMD,这样就可以直接进行复制粘贴来完成运行,因为都是相对路径,所以实际上是比较容易,基本上不会出错。

此外,我们还有一个小技巧。在上次课上,我们的助教发现大家都直接在控制台里面写代码,这会导致代码难以查找错误。因此,我们可以使用一个叫做Rscript的脚本来记录我们所有的代码。如何创建Rscript呢?很简单,只需要在RStudio中点击“文件”,然后选择“新建文件”。这个Rscript实际上是一个txt文件,但我们可以在其中记录代码。这将在调试时非常方便。
5.1 R对象的操控
好,那么我们上次课花了一节课帮助大家解决了很小的几个问题,就是知道什么是工作路径、什么是工作目录以及什么是目录、相对路径和绝对路径。然后在理解了这些概念之后,我们第一次读取了一个数据。
这节课我们讲一下在R里面,它到底有哪些数据类型,我们如何得到进行操作。我们上节课很快地讲完了R的数据类型,但大家当时可能听得很懵。如果我们按照讲R语言的方式,它会一直都是很懵。为什么呢?因为它跟我们的数据完全是脱节的。所以这节课我们通过对数据进行操作,进行数据筛选的学习。上次课我们已经读取过数据,这次我们将按照相同的方式再次读取数据。
我们将使用read.csv来读取三个数据,并将它们合并。在这里,我们有三个数据文件,分别是707304、7305和7306。我们的分隔符与上次不同,我们使用空格而不是制表符。在空格中间,有两个引号(““)。我们这次的数据分割方法与上节课不同。上节课我们使用了斜杠和t作为分割符号,但是我们发现使用tab作为分割符号时会出现问题,无法真正进行分割。因此我们进行了尝试,发现使用空格作为分割符号更为合适,空格中间有两个引号,不加任何东西。这与上节课不同。
#实验数据参考读取方法,这里我们随便选择三个被试:
match.data1 <- read.csv("./data/match/data_exp7_rep_match_7304.out",
header = TRUE, sep = "",
stringsAsFactors = FALSE)
match.data2 <- read.csv("./data/match/data_exp7_rep_match_7305.out",
header = TRUE, sep = "",
stringsAsFactors = FALSE)
match.data3 <- read.csv("./data/match/data_exp7_rep_match_7306.out",
header = TRUE, sep = "",
stringsAsFactors = FALSE)我们将每个被试的数据读取到单独的变量名下面。这个符号(<-)是R语言中的一个复制符号,我们通过读取.csv和.out文件,将它们复制到一个变量中,比如match data 1。因为有三个被试,我们将它们变成三个数据。然后我们使用rbind函数,将不同的数据框进行合并,合并它们的列。这个函数很简单,我们有一个新的变量名match_data.all,然后用rbind函数将所有的数据都放到里面去,包括match data 1、match data 2和match data 3。我们刚才的操作就是从这里开始的,先读取单个被试的数据,然后再将它们合并。
我们涉及到了哪些R语言的特性呢?第一个是赋值符号,我们之前已经讲过了。为什么我们需要赋值符号呢?因为它表示将一个值附到一个变量名上,比如将10复制到object中。我们可以对它进行操作。如果我们在object后面加上2,输出就是10 + 2,但是object本身没有变。因此,每当要保存某一个结果的时候,我们一定要把它复制到某一个特定的变量里面去。相当于说,object 只是一个标签,它下面的内容会根据我们的赋值的改变而改变。
## [1] 10## [1] 12## [1] 10在R中,变量名由字母、数字和两个特定的符号(下划线和点)组成,其他符号是不被接受的。我们也不推荐使用中文,因为在不同的电脑上可能会出现编码不一致的问题。为了避免这种情况,我们尽量使用拼音。关于变量命名的可读性,我们应该让变量名称易于理解,一看就知道它代表什么。例如,在我们的课程中,我们有两个数据,一个是match data,另一个是human penguin project的数据,我们可以将它们分别命名为match data和penguin data,这样我们就能够一看到这个名字就知道它代表的是哪个实验的数据。这是关于R对象的复制和变量命名的基础知识。
5.2 函数
刚刚我们使用了R-bind函数将三个对象合并成一个,这涉及到函数的概念,我们在前面已经讲过。数学中的函数实际上就是一种方法,只不过是用代码来实现。数学函数可以表示为y=f(x),或者其他形式,其中括号内是我们输入的变量,它会返回一个结果。在R语言中,函数也基本上是这个意思,就是有一个特定的名称,比如在这里就叫做rbind,然后有一个括号,你在这个括号内输入内容之后,它就会返回一个结果。
函数是用于执行特定任务或计算的代码块,它接受输入参数,执行特定的操作,然后返回结果。函数来源有很多,安装R时,我们一般会安装R-base,这是R开发团队放在R基础包中的所有东西。这个base中已经包含了很多用于统计分析的函数。另外还有R的包,就是我们自己额外安装的包,比如Tidyverse、GGPlot、Nymer、Lmer、Lme4等。还有其他的R源,比如Cray、Microsoft、Stand等。除了这些,还可以在GitHub上直接安装一些包。虽然函数可以自己编写,但这比较复杂,我们会在后面再讲解。
我们经常需要重复执行某个任务,这时可以将其封装成一个函数,以后只需要调用这个函数即可,无需重复编写所有操作。函数是一个重要的知识点,可以用非常简单的两三行代码实现。但是有时候,当我们使用别人提供的函数时,可能不知道它的作用、输入规则和选项。在RStudio中,我们可以通过在函数名前加一个英文问号来查看它的用法。例如,在使用here包时,我们可以在RStudio的右下角看到帮助文件。
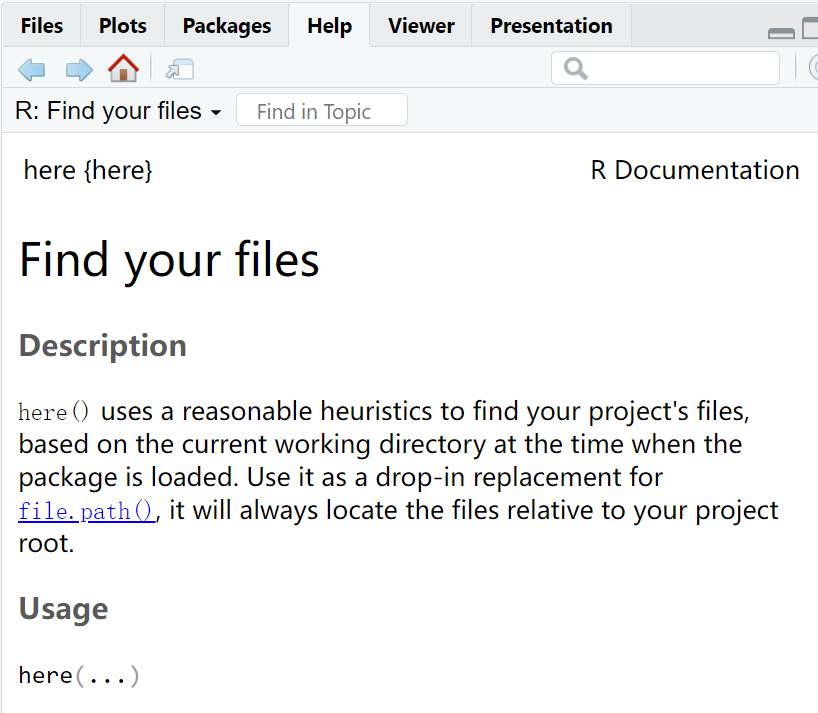
但是有些帮助文件可能并不是很有用,因为开发者有时会有所谓的“知识诅咒”,认为别人都和他一样有基本知识和内容。这时,我们可以在搜索引擎中搜索关键词和R包名,以便找到我们需要的信息。在调用已有的函数 时,我们需要先使用library加载包,然后直接使用函数名和小括号。如果没有加载包,我们可以直接使用R包名和两个冒号加上函数名来调用。个人偏好是将包名加上,因为R的生态系统非常复杂,有很多包都有类似的功能,这样可以避免混淆。
## Warning: package 'here' was built under R version 4.2.3## here() starts at C:/GitHub/R4PsyBook/bookdown_files/Books/Book## [1] "C:/GitHub/R4PsyBook/bookdown_files/Books/Book"5.3 常用函数
我们刚才使用了R中非常常用的函数R bind。现在我们先停一会儿,让大家完成刚才的操作,即通过Match Data完成数据的读取和合并。这个操作在真实的数据中非常常用,当你有不同数据文件或不同数据来源时,你肯定要对它们进行合并。现在我们练习读取三个不同base的数据,将它们合并成为一个数据,并体验一下R bind函数的使用。然后我们再讲下一个知识点。如果大家按照压缩包来打开,应该会很快。我刚才有一个有趣的问题,就是现在Windows系统比较发达,它可以直接读取zip文件,没有解压的过程。但是这个时候你发现,打开R以后,里面的文件是不完整的。所以一定要把那个zip文件右击然后提取成为一个完整的文件夹,这样我才能看到全部的内容。
5.3.1 unique()
我们想看一下这个数据有没有问题。首先,我们想查看这个数据里面的实验条件是不是完整的。如果我们直接看,我们可以点开右边的Match all,然后查看Label这个实验条件。我们想看这个实验条件是不是只有几个独特的值。如果我们的实验条件就是6种条件 的话,那么它就只应该有6个值。这种情况下,我们不可能一个一个地去数。在R语言中,我们可以使用一些简单的函数来查看某一列的唯一数值有多少个。首先,我们可以使用head函数来查看数字的前几行长什么样。然后,我们可以使用unique函数来查看这个列中有多少个唯一的数值。我们可以使用美元符号和列名来选择完整的列。如果我们想要查看一个很大的数据框中的某一列,我们可以使用美元符号和列名来选择每一栏。在这个示例中,我们可以直接输入美元符号和列名来输出这个列的内容。如果我们想要查看这个列中有多少个唯一的数值,我们可以使用unique函数。在这个例子中,我们可以看到这个列中有五个唯一的数值。
## [1] "immoralSelf" "moralSelf" "moralOther" "immoralOther" "moralSelf"
## [6] "moralSelf" "moralSelf" "immoralOther" "moralSelf" "immoralOther"## [1] "immoralSelf" "moralSelf" "moralOther" "immoralOther" "Label"5.3.1.1 filter()
因我们需要使用 filter 功能来筛选我们需要的数据。在本次实验中,我们采用了一个例子,以帮助大家更好地理解数据分析中的 filter 形式及使用方式。
最简单的方法是根据我们所拥有的变量来进行筛选,我们已知其中一个变量可以带来非常明显的效益,即匹配和不匹配的情况。在三个被试中,我们需要进行基本的查看,以确认其匹配和不匹配条件是否相同。为了进行这种分析,我们需要将原始数据分成两部分,即匹配和不匹配。
对于这个 data,我们可以使用 Dplyr 中的 filter 功能,以实现对数据的筛选。filter 的第一个参数是需要操作的数据集,而第二个参数是所需的筛选条件。对于本次实验来说,我们需要使用 filter 函数来提取匹配和不匹配条件相同的数据,即我们需要从 match 数据中提取所有 non-match 或 mismatch 数据。为了保证我们选择的数据正确,我们可以使用 unique 命令来进行检查,如果我们成功完成了筛选,则 unique 命令会返回一个值(即 mismatch)。
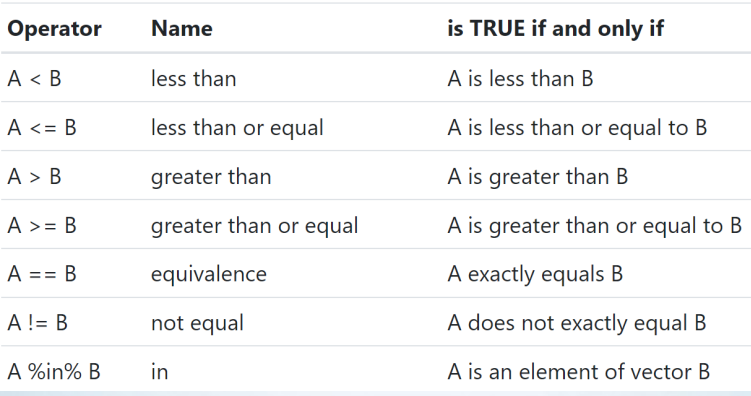
R中有一些用于比较的运算符,例如大于、小于、大于等于、小于等于。这些都是在做基础知识时非常重要的东西,我们可以在这里稍微细致地介绍一下。
在R语言中,我们还有一个特殊的运算符,就是!。我们在命名变量时,不能使用这个!,因为它表示的是不等于。例如a不等于b,实际上是先有一个等于符号,然后再用一个感叹号表示否定,这样它们就不相等了。我们这里使用的是两个等于号,表示完全相等的两个元素。
有人会问,大于小于只能用于数字吗?实际上并不是这样。我们可以使用字符进行比较运算,但是要特别小心。因为有的时候你以为它在做数字运算,但它实际上是基于字符运算的。因此,我们需要在使用时格外注意。
在R语言中,还有一个非常有用的操作符,就是in。它是一个函数,用这个符号代表。它的作用是判断a是否是b中的一个元素。这也是我们在上一节课上讲到的概念,“向量”,它是一个一串的数字,我们需要找到其中的某个值。这时使用in操作符就可以帮助我们查找所有满足条件的值的位置。in操作符在R语言中非常受欢迎,因为它能够快速帮助我们找到一些特定的值。
在比较运算的时候,我们涉及到了“vector”。我们之前讲过,它就是一些数据的类型。但是对于“vector”而言,它有一个特点:里面的所有元素必须是同一个类型的。我们提到的有逻辑型、整型、双精度,字符型等类型。如果要把一些元素放在一起,那么它们应该都属于同一个类型。如果不是同一种类型,我们就可能需要使用其他类型的数据来存放它们。
回到刚才的代码,当我们使用“filter”操作数据时,我们是通过比较数据中的“match”这一列和“mismatch”这个字符串来得到的结果。因为我们需要把它与每一个对象进行比较,所以每个对象都会有一个输出。因此,我们得到了一个逻辑型的“vector”。我们可以把它们连成一个向量。在这个“match”中,我们可以使用“class”函数来查看某一列的数据类型。比如,我们查看一下刚刚的“match”是什么类型的,我们可以发现,它是字符类型的,它的输出结果是“correct”。对于其他类型,我们也可以做类似的查看。当然,字符类型除了“=”操作符外,还有其他方式可以用来确定它是否精确匹配。
#筛选出match.data.all的Match列中所有mismatch的数据
mismatch <- dplyr::filter(match.data.all, match.data.all$Match == "mismatch")
#查看是否成功
unique(mismatch$Match)## [1] "mismatch"## [1] "character"新的DataFrame是根据条件筛选出的子集。在处理DataFrame时,我们可以按步骤来处理。如果没有现成的函数能够直接解决问题,我们可以通过自己的思考,将筛选过程拆成一个个小的步骤,逐步解决问题。首先,我们要提取出一个column,然后将column中的每个元素与条件进行比较。比较结果可以得到一个新的vector。接着,我们可以通过vector中的rowid提取出符合条件的ID,再从原始数据集中提取出对应的子集。如此,我们就完成了整个筛选的过程。再刚刚的过程中机器会自动将我们的需求划分成小的步骤来处理。
除了字符之外,我们也可以对数字进行筛选。首先需要将字符串类型的“acc”转换为数值型的变量。我们可以查看变量类型,如果是字符型,我们可以使用“as.numerical”的函数将其转换为数值型。通过match data.all这个命令,我们可以获取到一个字符型的vector”acc”,将其转换成数值型后,我们将其赋值给另一个名为”acc”的变量。这样,我们就将”acc”变为数值型了。通过查看unique命令,我们可以发现”acc”共有”-1,0,1,2”这几个值。我们可以将大于0的值作为筛选条件,这样筛选过的变量中只保留了0,1,2这几个值,从而完成了数字的筛选过程。
## [1] "character"#通过as.numeric()将其他类型转化为数值型向量
match.data.all$ACC <- as.numeric(match.data.all$ACC)
class(match.data.all$ACC)## [1] "numeric"在看这篇文章时,我们会发现我们需要筛选出0和1的结果,因为-1表示没有按键,2表示按错键。只有0表示错了而1表示做对了。因此,我们需要把结果筛选为0和1。有两种方法可以做到这一点。第一种方法是对结果进行两次筛选,首先做一个大于等于0的筛选,然后再做一个小于2的筛选。第二种方法是使用逻辑运算符adn和all,通过ACC大于等于0和ACC小于2的结果来筛选出0和1。这些逻辑运算符通常是将不同的逻辑连接在一起的常见做法。
#筛选出match.data.all的ACC列中所有大于等于0的数据
mismatch <- dplyr::filter(match.data.all, match.data.all$ACC >=0)
#查看是否成功
unique(mismatch$ACC)## [1] 0 1 2在这个示例中,我们使用了ACC。首先将ACC与0进行比较,使其大于等于0。然后再将ACC与2进行比较,使其小于2。最后得到的两个结果可以使用逻辑运算符AND连接起来。如果前面的结果是True,同时后面的结果也是True,那么它们的AND结果就是True。如果其中一个结果为False,那么AND结果就是False。
或者,我们也可以使用逻辑运算符OR。使用OR时,当前面和后面的结果中至少有一个是True时,它们的OR结果就是True。如果前面和后面的结果都是False,那么它们的OR结果也是False。
总之,我们可以通过使用适当的逻辑符号来筛选结果,使其变得更清晰,更易读。