Chapter 3 Distribution Theory
3.1 Learning Objectives
After finishing this chapter, you should be able to:
- Write definitions of non-normal random variables in the context of an application.
- Identify possible values for each random variable.
- Identify how changing values for a parameter affects the characteristics of the distribution.
- Recognize a form of the probability density function for each distribution.
- Identify the mean and variance for each distribution.
- Match the response for a study to a plausible random variable and provide reasons for ruling out other random variables.
- Match a histogram of sample data to plausible distributions.
- Create a mixture of distributions and evaluate the shape, mean, and variance.
3.2 Introduction
What if it is not plausible that a response is normally distributed? You may want to construct a model to predict whether a prospective student will enroll at a school or model the lifetimes of patients following a particular surgery. In the first case you have a binary response (enrolls (1) or does not enroll (0)), and in the second case you are likely to have very skewed data with many similar values and a few hardy souls with extremely long survival. These responses are not expected to be normally distributed; other distributions will be needed to describe and model binary or lifetime data. Non-normal responses are encountered in a large number of situations. Luckily, there are quite a few possibilities for models. In this chapter we begin with some general definitions, terms, and notation for different types of distributions with some examples of applications. We then create new random variables using combinations of random variables (see Guided Exercises).
3.3 Discrete Random Variables
A discrete random variable has a countable number of possible values; for example, we may want to measure the number of people in a household or the number of crimes committed on a college campus. With discrete random variables, the associated probabilities can be calculated for each possible value using a probability mass function (pmf). A pmf is a function that calculates \(P(Y=y)\), given each variable’s parameters.
3.3.1 Binary Random Variable
Consider the event of flipping a (possibly unfair) coin. If the coin lands heads, let’s consider this a success and record \(Y = 1\). A series of these events is a Bernoulli process, independent trials that take on one of two values (e.g., 0 or 1). These values are often referred to as a failure and a success, and the probability of success is identical for each trial. Suppose we only flip the coin once, so we only have one parameter, the probability of flipping heads, \(p\). If we know this value, we can express \(P(Y=1) = p\) and \(P(Y=0) = 1-p\). In general, if we have a Bernoulli process with only one trial, we have a binary distribution (also called a Bernoulli distribution) where
\[\begin{equation} P(Y = y) = p^y(1-p)^{1-y} \quad \textrm{for} \quad y = 0, 1. \tag{3.1} \end{equation}\] If \(Y \sim \textrm{Binary}(p)\), then \(Y\) has mean \(\operatorname{E}(Y) = p\) and standard deviation \(\operatorname{SD}(Y) = \sqrt{p(1-p)}\).
Example 1: Your playlist of 200 songs has 5 which you cannot stand. What is the probability that when you hit shuffle, a song you tolerate comes on?
Assuming all songs have equal odds of playing, we can calculate \(p = \frac{200-5}{200} = 0.975\), so there is a 97.5% chance of a song you tolerate playing, since \(P(Y=1)=.975^1*(1-.975)^0\).
3.3.2 Binomial Random Variable
We can extend our knowledge of binary random variables. Suppose we flipped an unfair coin \(n\) times and recorded \(Y\), the number of heads after \(n\) flips. If we consider a case where \(p = 0.25\) and \(n = 4\), then here \(P(Y=0)\) represents the probability of no successes in 4 trials, i.e., 4 consecutive failures. The probability of 4 consecutive failures is \(P(Y = 0) = P(TTTT) = (1-p)^4 = 0.75^4\). When we consider \(P(Y = 1)\), we are interested in the probability of exactly 1 success anywhere among the 4 trials. There are \(\binom{4}{1} = 4\) ways to have exactly 1 success in 4 trials, so \(P(Y = 1) = \binom{4}{1}p^1(1-p)^{4-1} = (4)(0.25)(0.75)^3\). In general, if we carry out a sequence of \(n\) Bernoulli trials (with probability of success \(p\)) and record \(Y\), the total number of successes, then \(Y\) follows a binomial distribution, where
\[\begin{equation} P(Y=y) = \binom{n}{y} p^y (1-p)^{n-y} \quad \textrm{for} \quad y = 0, 1, \ldots, n. \tag{3.2} \end{equation}\] If \(Y \sim \textrm{Binomial}(n,p)\), then \(\operatorname{E}(Y) = np\) and \(\operatorname{SD}(Y) = \sqrt{np(1-p)}\). Typical shapes of a binomial distribution are found in Figure 3.1. On the left side \(n\) remains constant. We see that as \(p\) increases, the center of the distribution (\(\operatorname{E}(Y) = np\)) shifts right. On the right, \(p\) is held constant. As \(n\) increases, the distribution becomes less skewed.
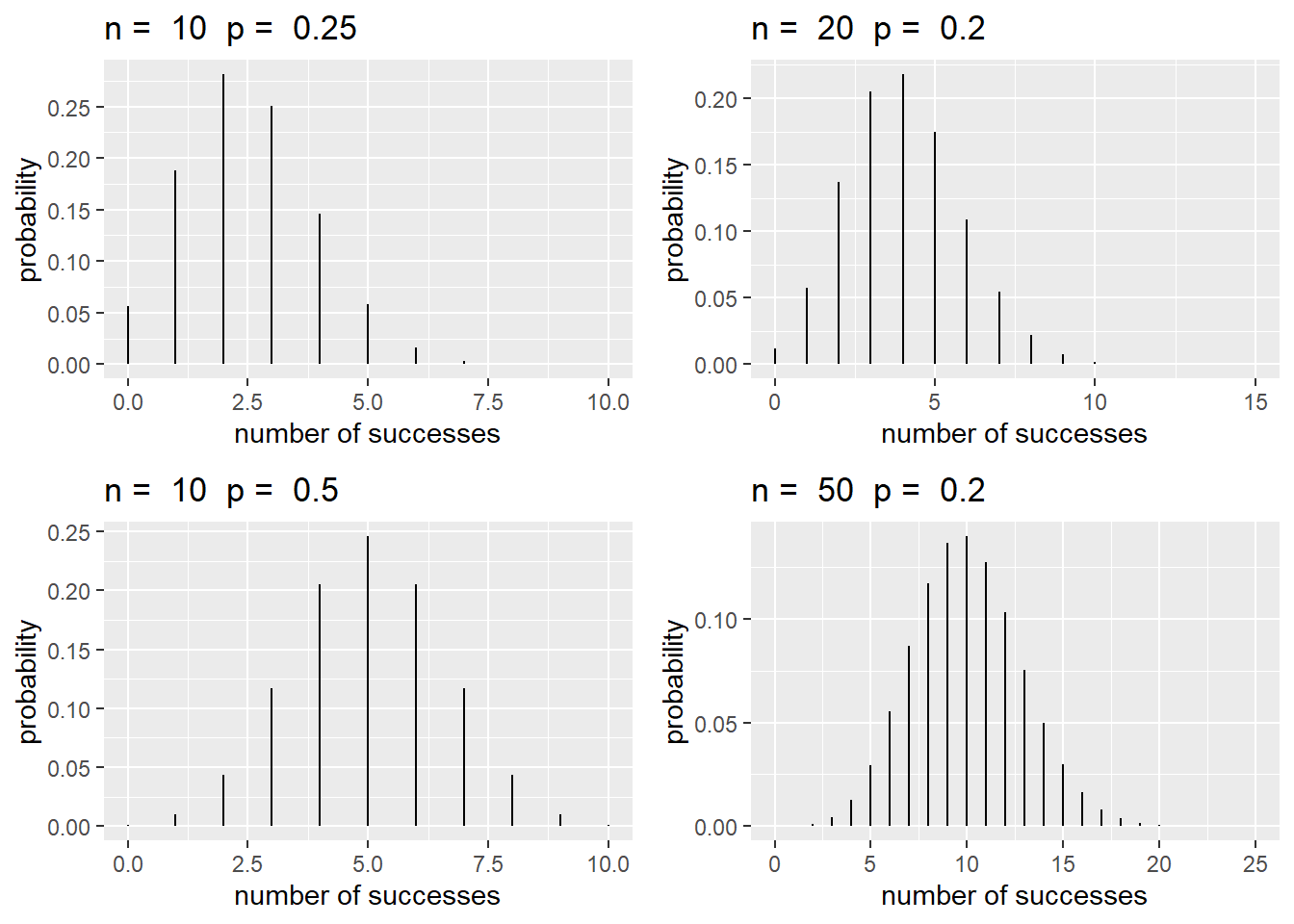
Figure 3.1: Binomial distributions with different values of \(n\) and \(p\).
Note that if \(n=1\),
\[\begin{align*} P(Y=y) &= \binom{1}{y} p^y(1-p)^{1-y} \\ &= p^y(1-p)^{1-y}\quad \textrm{for}\quad y = 0, 1, \end{align*}\] a Bernoulli distribution! In fact, Bernoulli random variables are a special case of binomial random variables where \(n=1\).
In R we can use the function dbinom(y, n, p), which outputs the probability of \(y\) successes given \(n\) trials with probability \(p\), i.e., \(P(Y=y)\) for \(Y \sim \textrm{Binomial}(n,p)\).
Example 2: While taking a multiple choice test, a student encountered 10 problems where she ended up completely guessing, randomly selecting one of the four options. What is the chance that she got exactly 2 of the 10 correct?
Knowing that the student randomly selected her answers, we assume she has a 25% chance of a correct response. Thus, \(P(Y=2) = {10 \choose 2}(.25)^2(.75)^8 = 0.282\). We can use R to verify this:
## [1] 0.2816Therefore, there is a 28% chance of exactly 2 correct answers out of 10.
3.3.3 Geometric Random Variable
Suppose we are to perform independent, identical Bernoulli trials until the first success. If we wish to model \(Y\), the number of failures before the first success, we can consider the following pmf:
\[\begin{equation} P(Y=y) = (1-p)^yp \quad \textrm{for}\quad y = 0, 1, \ldots, \infty. \tag{3.3} \end{equation}\]
We can think about this function as modeling the probability of \(y\) failures, then 1 success. In this case, \(Y\) follows a geometric distribution with \(\operatorname{E}(Y) = \frac{1-p}p\) and \(\operatorname{SD}(Y) = \sqrt{\frac{1-p}{p^2}}\).
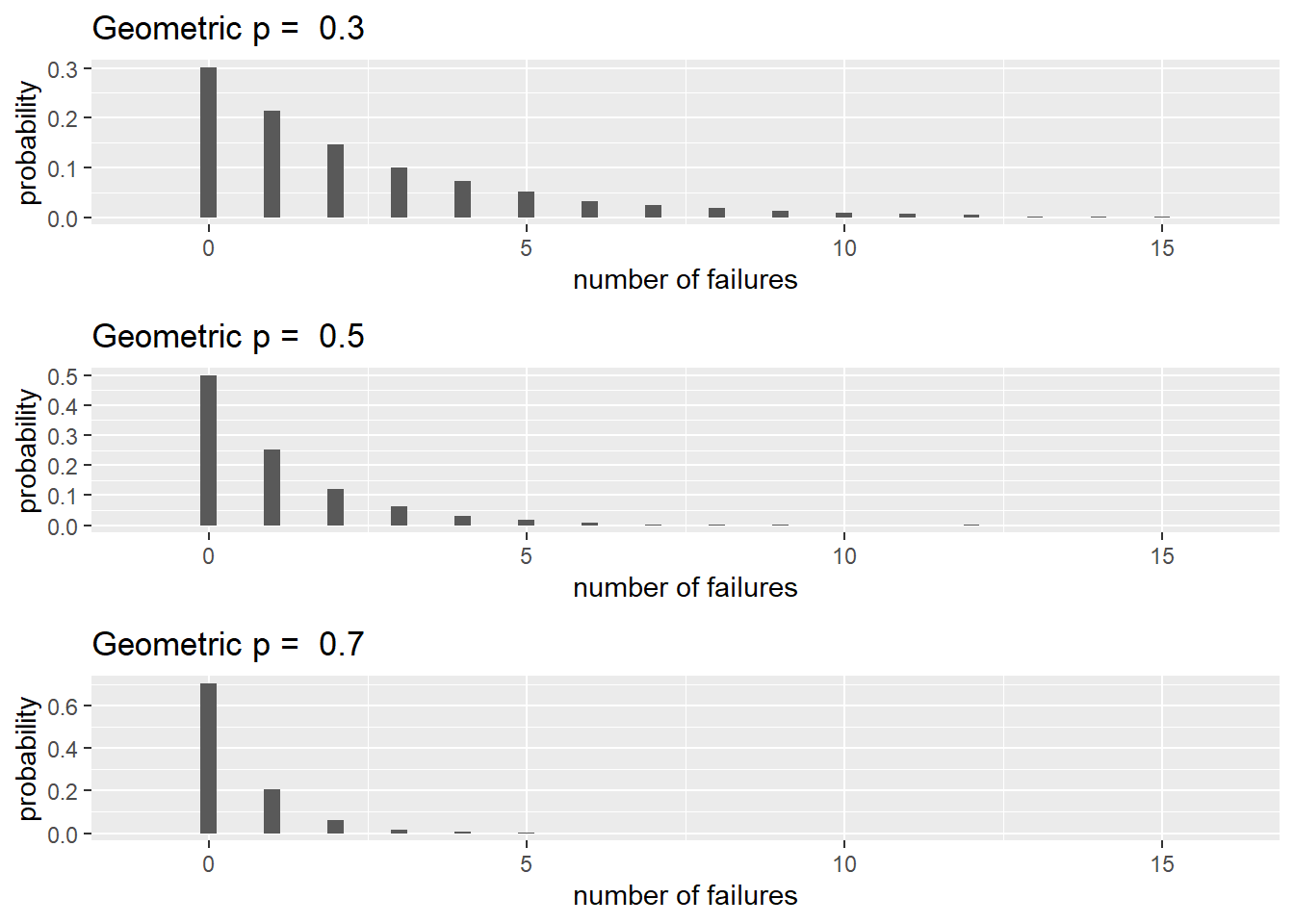
Figure 3.2: Geometric distributions with \(p = 0.3,\ 0.5\) and \(0.7\).
Typical shapes of geometric distributions are shown in Figure 3.2. Notice that as \(p\) increases, the range of plausible values decreases and means shift towards 0.
Once again, we can use R to aid our calculations. The function dgeom(y, p) will output the probability of \(y\) failures before the first success where \(Y \sim \textrm{Geometric}(p)\).
Example 3: Consider rolling a fair, six-sided die until a five appears. What is the probability of rolling the first five on the third roll?
First note that \(p = 1/6\). We are then interested in \(P(Y=2)\), as we would want 2 failures before our success. We know that \(P(Y=2) = (5/6)^2(1/6) = 0.116\). Verifying through R:
## [1] 0.1157Thus, there is a 12% chance of rolling the first five on the third roll.
3.3.4 Negative Binomial Random Variable
What if we were to carry out multiple independent and identical Bernoulli trails until the \(r\)th success occurs? If we model \(Y\), the number of failures before the \(r\)th success, then \(Y\) follows a negative binomial distribution where
\[\begin{equation} P(Y=y) = \binom{y + r - 1}{r-1} (1-p)^{y}(p)^r \quad \textrm{for}\quad y = 0, 1, \ldots, \infty. \tag{3.4} \end{equation}\] If \(Y \sim \textrm{Negative Binomial}(r, p)\) then \(\operatorname{E}(Y) = \frac{r(1-p)}{p}\) and \(\operatorname{SD}(Y) = \sqrt{\frac{r(1-p)}{p^2}}\). Figure 3.3 displays three negative binomial distributions. Notice how centers shift right as \(r\) increases, and left as \(p\) increases.
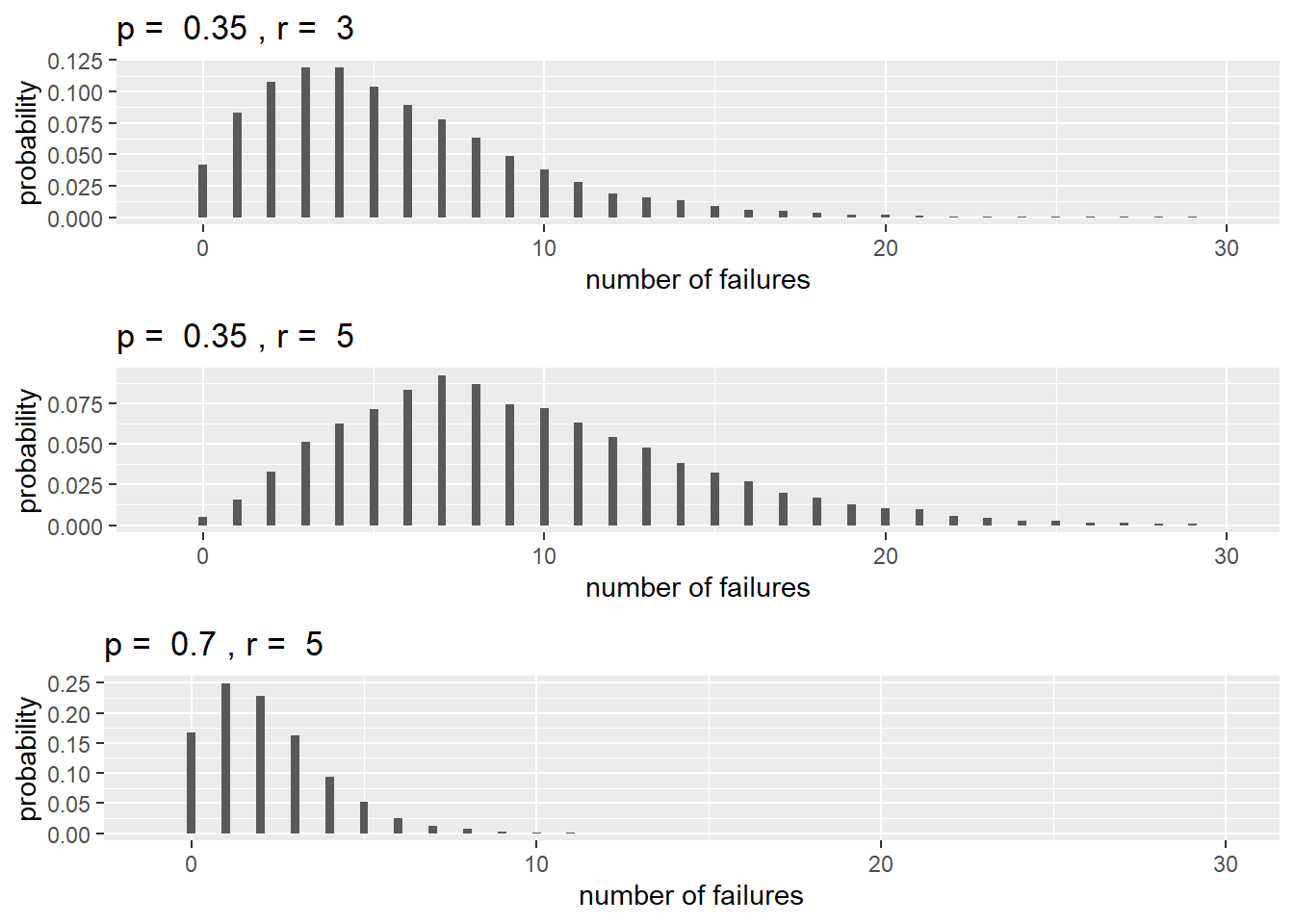
Figure 3.3: Negative binomial distributions with different values of \(p\) and \(r\).
Note that if we set \(r=1\), then
\[\begin{align*} P(Y=y) &= \binom{y}{0} (1-p)^yp \\ &= (1-p)^yp \quad \textrm{for} \quad y = 0, 1, \ldots, \infty, \end{align*}\] which is the probability mass function of a geometric random variable! Thus, a geometric random variable is, in fact, a special case of a negative binomial random variable.
While negative binomial random variables typically are expressed as above using binomial coefficients (expressions such as \(\binom{x}{y}\)), we can generalize our definition to allow non-integer values of \(r\). This will come in handy later when modeling. To do this, we need to first introduce the gamma function. The gamma function is defined as such
\[\begin{equation} \Gamma(x) = \int_0^\infty t^{x-1} e^{-t}dt. \tag{3.5} \end{equation}\] One important property of the gamma function is that for any integer \(n\), \(\Gamma(n) = (n-1)!\). Applying this, we can generalize the pmf of a negative binomial variable such that
\[\begin{align*} P(Y=y) &= \binom{y + r - 1}{r-1} (1-p)^{y}(p)^r \\ &= \frac{(y+r-1)!}{(r-1)!y!} (1-p)^{y}(p)^r \\ &= \frac{\Gamma(y+r)}{\Gamma(r) y!} (1-p)^{y}(p)^r \quad \textrm{for} \quad y = 0, 1, \ldots, \infty. \end{align*}\] With this formulation, \(r\) is no longer restricted to non-negative integers; rather \(r\) can be any non-negative real number.
In R we can use the function dnbinom(y, r, p) for the probability of \(y\) failures before the \(r\)th success given probability \(p\).
Example 4: A contestant on a game show needs to answer 10 questions correctly to win the jackpot. However, if they get 3 incorrect answers, they are kicked off the show. Suppose one contestant consistently has a 90% chance of correctly responding to any question. What is the probability that she will correctly answer 10 questions before 3 incorrect responses?
Letting \(Y\) represent the number of incorrect responses, and setting \(r = 10\), we want
\[\begin{align*} P(Y < 3) &= P(Y=0) + P(Y=1) + P(Y=2) \\ &= \binom{9}{9}(1-0.9)^0 (0.9)^{10} + \binom{10}{9}(1-0.9)^1 (0.9)^{10} \\ & \quad + \binom{11}{9}(1-0.9)^2 (0.9)^{10} \\ &= 0.89 \end{align*}\] Using R:
## [1] 0.8891Thus, there is a 89% chance that she gets 10 correct responses before missing 3.
3.3.5 Hypergeometric Random Variable
In all previous random variables, we considered a Bernoulli process, where the probability of a success remained constant across all trials. What if this probability is dynamic? The hypergeometric random variable helps us address some of these situations. Specifically, what if we wanted to select \(n\) items without replacement from a collection of \(N\) objects, \(m\) of which are considered successes? In that case, the probability of selecting a “success” depends on the previous selections. If we model \(Y\), the number of successes after \(n\) selections, \(Y\) follows a hypergeometric distribution where
\[\begin{equation} P(Y=y) = \frac{\binom{m}{y} \binom{N-m}{n-y}}{\binom{N}{n}} \quad \textrm{for} \quad y = 0, 1, \ldots, \min(m,n). \tag{3.6} \end{equation}\]
If \(Y\) follows a hypergeometric distribution and we define \(p = m/N\), then \(\operatorname{E}(Y) = np\) and \(\operatorname{SD}(Y) = \sqrt{np(1-p)\frac{N-n}{N-1}}\). Figure 3.4 displays several hypergeometric distributions. On the left, \(N\) and \(n\) are held constant. As \(m \rightarrow N/2\), the distribution becomes more and more symmetric. On the right, \(m\) and \(N\) are held constant. Both distributions are displayed on the same scale. We can see that as \(n \rightarrow N\) (or \(n \rightarrow 0\)), the distribution becomes less variable.
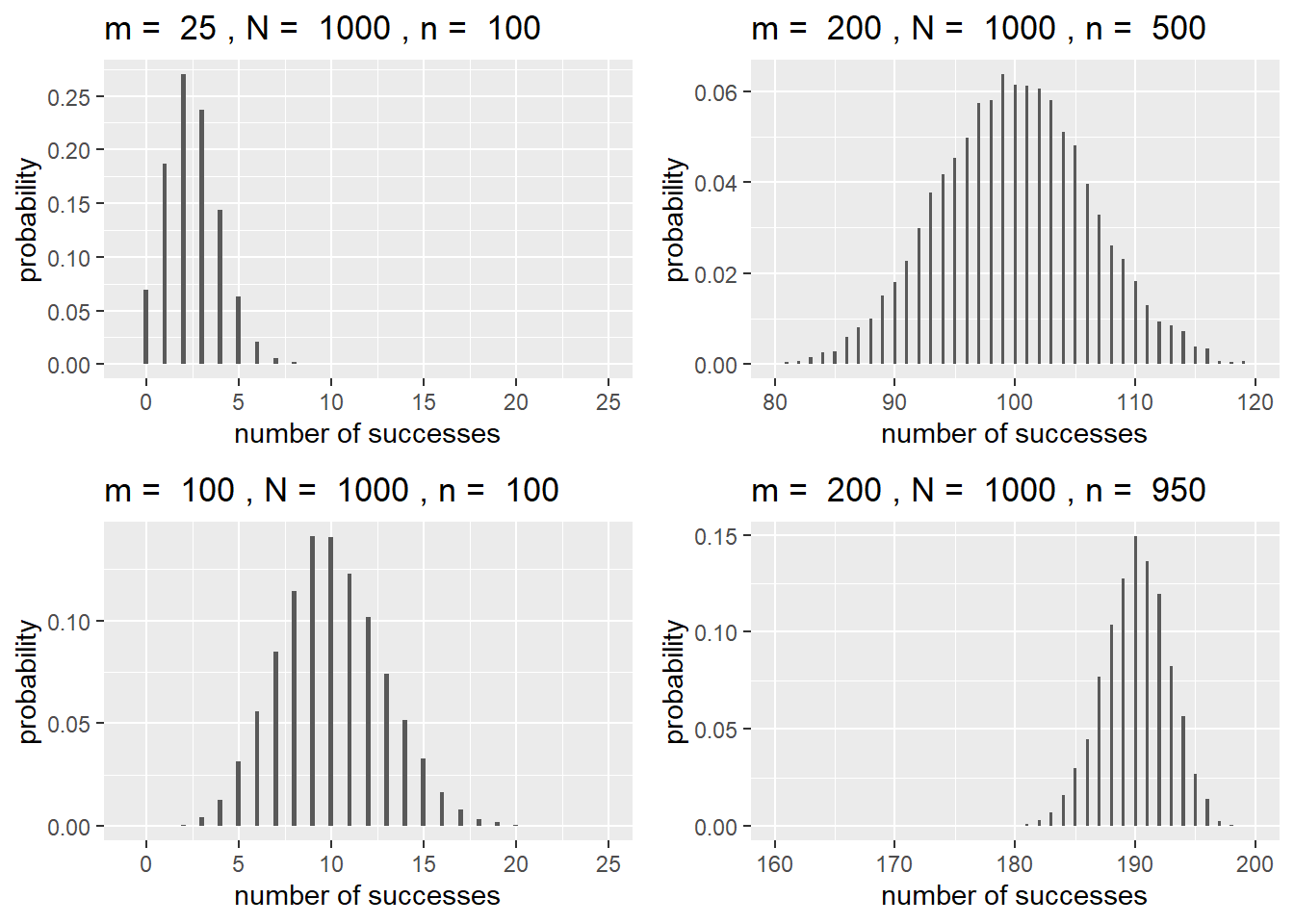
Figure 3.4: Hypergeometric distributions with different values of \(m\), \(N\), and \(n\).
If we wish to calculate probabilities through R, dhyper(y, m, N-m, n) gives \(P(Y=y)\) given \(n\) draws without replacement from \(m\) successes and \(N-m\) failures.
Example 5: Suppose a deck of cards is randomly shuffled. What is the probability that all 4 queens are located within the first 10 cards?
We can model \(Y\), the number of queens in the first 10 cards as a hypergeometric random variable where \(n = 10\), \(m = 4\), and \(N = 52\). Then, \(P(Y=4) = \displaystyle \frac{\binom{4}{4}\binom{48}{6}}{\binom{52}{10}} = 0.0008\). We can avoid this calculation through R, of course:
## [1] 0.0007757So, there is a 0.08% chance of all 4 queens being within the first 10 cards of a randomly shuffled deck of cards.
3.3.6 Poisson Random Variable
Sometimes, random variables are based on a Poisson process. In a Poisson process, we are counting the number of events per unit of time or space and the number of events depends only on the length or size of the interval. We can then model \(Y\), the number of events in one of these sections with the Poisson distribution, where
\[\begin{equation} P(Y=y) = \frac{e^{-\lambda}\lambda^y}{y!} \quad \textrm{for} \quad y = 0, 1, \ldots, \infty, \tag{3.7} \end{equation}\] where \(\lambda\) is the mean or expected count in the unit of time or space of interest. This probability mass function has \(\operatorname{E}(Y) = \lambda\) and \(\operatorname{SD}(Y) = \sqrt{\lambda}\). Three Poisson distributions are displayed in Figure 3.5. Notice how distributions become more symmetric as \(\lambda\) increases.
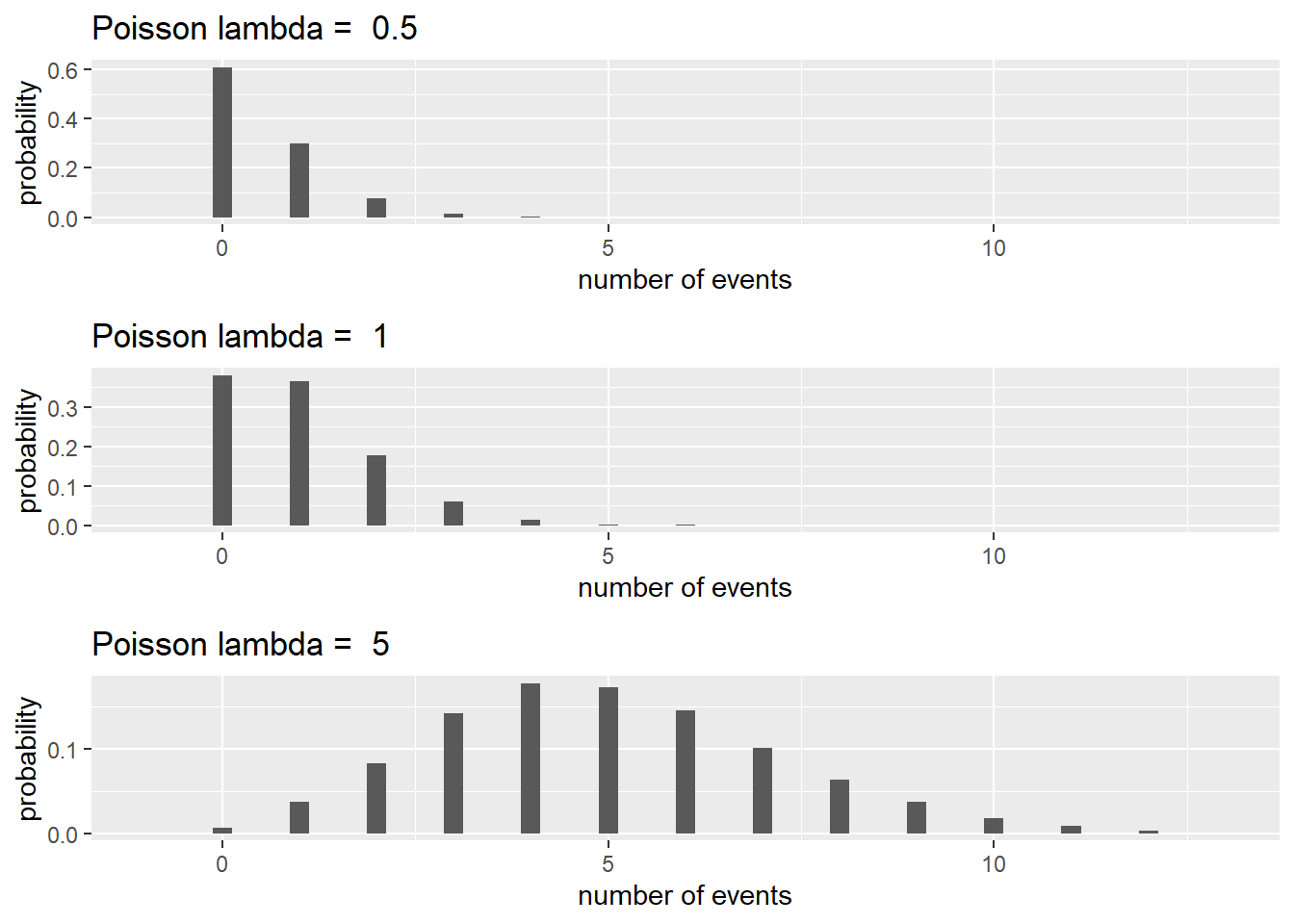
Figure 3.5: Poisson distributions with \(\lambda = 0.5,\ 1\), and \(5\).
If we wish to use R, dpois(y, lambda) outputs the probability of \(y\) events given \(\lambda\).
Example 6: A small town’s police department issues 5 speeding tickets per month on average. Using a Poisson random variable, what is the likelihood that the police department issues 3 or fewer tickets in one month?
First, we note that here \(P(Y \le 3) = P(Y=0) + P(Y=1) + \cdots + P(Y=3)\). Applying the probability mass function for a Poisson distribution with \(\lambda = 5\), we find that
\[\begin{align*} P(Y \le 3) &= P(Y=0) + P(Y=1) + P(Y=2) + P(Y=3) \\ &= \frac{e^{-5}5^0}{0!} + \frac{e^{-5}5^1}{1!} + \frac{e^{-5}5^2}{2!} + \frac{e^{-5}5^3}{3!}\\ &= 0.27. \end{align*}\]
We can verify through R:
## [1] 0.265Therefore, there is a 27% chance of 3 or fewer tickets being issued within one month.
3.4 Continuous Random Variables
A continuous random variable can take on an uncountably infinite number of values. With continuous random variables, we define probabilities using probability density functions (pdfs). Probabilities are calculated by computing the area under the density curve over the interval of interest. So, given a pdf, \(f(y)\), we can compute
\[\begin{align*} P(a \le Y \le b) = \int_a^b f(y)dy. \end{align*}\] This hints at a few properties of continuous random variables:
- \(\int_{-\infty}^{\infty} f(y)dy = 1\).
- For any value \(y\), \(P(Y = y) = \int_y^y f(y)dy = 0\).
- Because of the above property, \(P(y < Y) = P(y \le Y)\). We will typically use the first notation rather than the second, but both are equally valid.
3.4.1 Exponential Random Variable
Suppose we have a Poisson process with rate \(\lambda\), and we wish to model the wait time \(Y\) until the first event. We could model \(Y\) using an exponential distribution, where
\[\begin{equation} f(y) = \lambda e^{-\lambda y} \quad \textrm{for} \quad y > 0, \tag{3.8} \end{equation}\] where \(\operatorname{E}(Y) = 1/\lambda\) and \(\operatorname{SD}(Y) = 1/\lambda\). Figure 3.6 displays three exponential distributions with different \(\lambda\) values. As \(\lambda\) increases, \(\operatorname{E}(Y)\) tends towards 0, and distributions “die off” quicker.
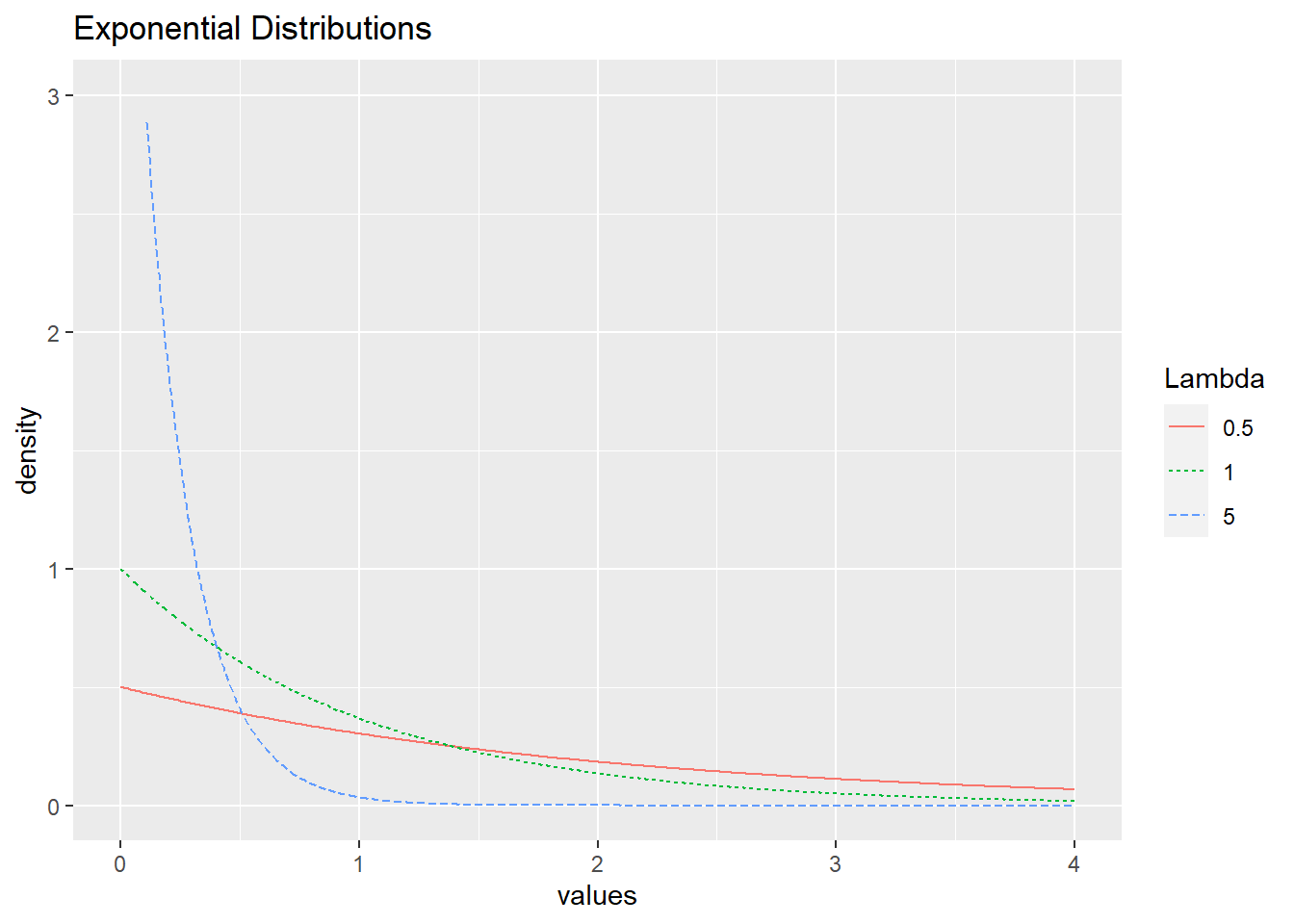
Figure 3.6: Exponential distributions with \(\lambda = 0.5, 1,\) and \(5\).
If we wish to use R, pexp(y, lambda) outputs the probability \(P(Y < y)\) given \(\lambda\).
Example 7: Refer to Example 6. What is the probability that 10 days or fewer elapse between two tickets being issued?
We know the town’s police issue 5 tickets per month. For simplicity’s sake, assume each month has 30 days. Then, the town issues \(\frac{1}{6}\) tickets per day. That is \(\lambda = \frac{1}{6}\), and the average wait time between tickets is \(\frac{1}{1/6} = 6\) days. Therefore,
\[\begin{align*} P(Y < 10) = \int_{0}^{10} \textstyle \frac16 e^{-\frac16y} dy = 0.81. \end{align*}\]
We can also use R:
## [1] 0.8111Hence, there is a 81% chance of waiting fewer than 10 days between tickets.
3.4.2 Gamma Random Variable
Once again consider a Poisson process. When discussing exponential random variables, we modeled the wait time before one event occurred. If \(Y\) represents the wait time before \(r\) events occur in a Poisson process with rate \(\lambda\), \(Y\) follows a gamma distribution where
\[\begin{equation} f(y) = \frac{\lambda^r}{\Gamma(r)} y^{r-1} e^{-\lambda y}\quad \textrm{for} \quad y >0. \tag{3.9} \end{equation}\]
If \(Y \sim \textrm{Gamma}(r, \lambda)\) then \(\operatorname{E}(Y) = r/\lambda\) and \(\operatorname{SD}(Y) = \sqrt{r/\lambda^2}\). A few gamma distributions are displayed in Figure 3.7. Observe that means increase as \(r\) increases, but decrease as \(\lambda\) increases.
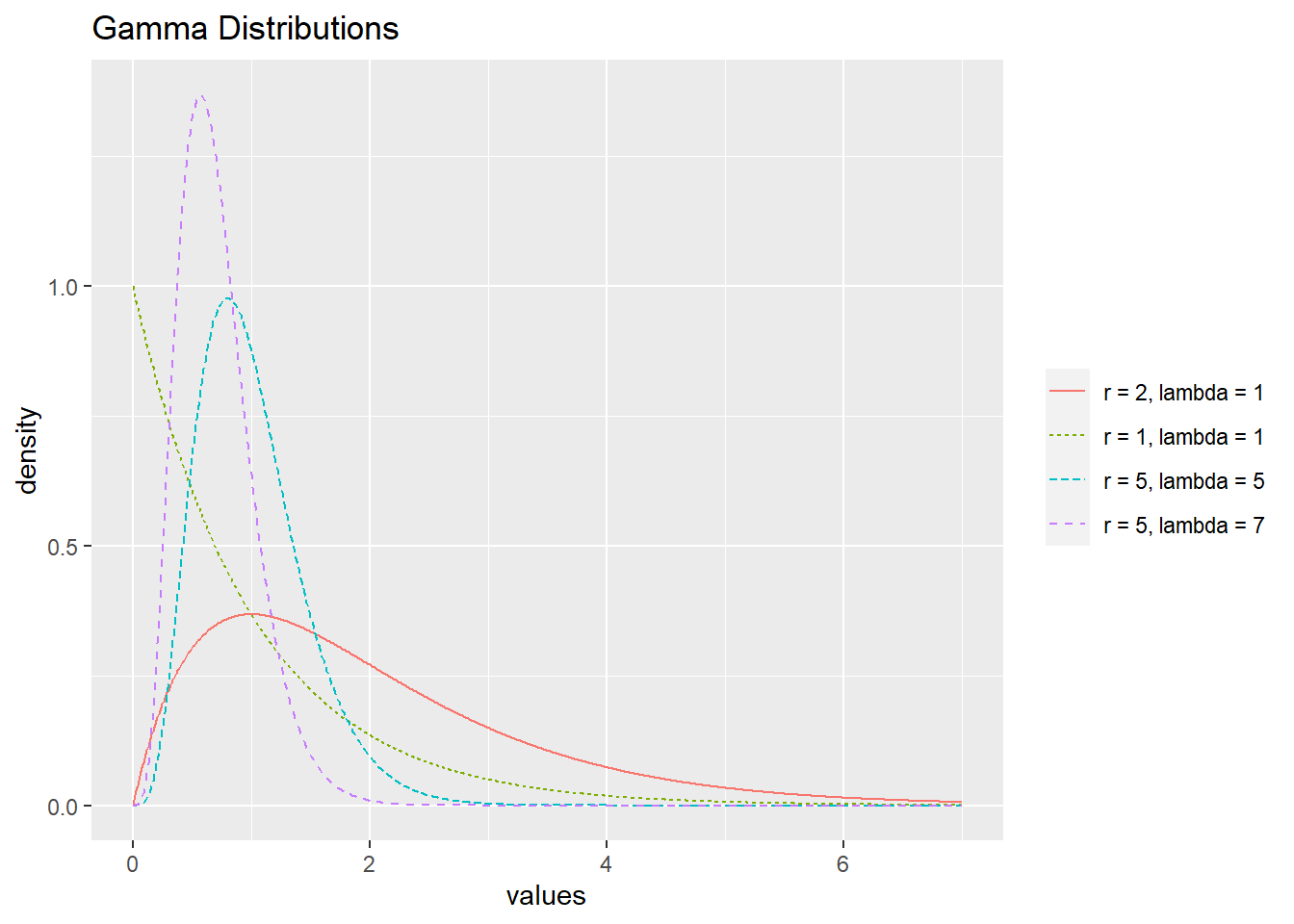
Figure 3.7: Gamma distributions with different values of \(r\) and \(\lambda\).
Note that if we let \(r = 1\), we have the following pdf,
\[\begin{align*} f(y) &= \frac{\lambda}{\Gamma(1)} y^{1-1} e^{-\lambda y} \\ &= \lambda e^{-\lambda y} \quad \textrm{for} \quad y > 0, \end{align*}\] an exponential distribution. Just as how the geometric distribution was a special case of the negative binomial, exponential distributions are in fact a special case of gamma distributions!
Just like negative binomial, the pdf of a gamma distribution is defined for all real, non-negative \(r\).
In R, pgamma(y, r, lambda) outputs the probability \(P(Y < y)\) given \(r\) and \(\lambda\).
Example 8: Two friends are out fishing. On average they catch two fish per hour, and their goal is to catch 5 fish. What is the probability that they take less than 3 hours to reach their goal?
Using a gamma random variable, we set \(r = 5\) and \(\lambda = 2\). So,
\[\begin{align*} P(Y < 3) = \int_0^3 \frac{2^4}{\Gamma(5)} y^{4} e^{-2y}dy = 0.715. \end{align*}\]
Using R:
## [1] 0.7149There is a 71.5% chance of catching 5 fish within the first 3 hours.
3.4.3 Normal (Gaussian) Random Variable
You have already at least informally seen normal random variables when evaluating LLSR assumptions. To recall, we required responses to be normally distributed at each level of \(X\). Like any continuous random variable, normal (also called Gaussian) random variables have their own pdf, dependent on \(\mu\), the population mean of the variable of interest, and \(\sigma\), the population standard deviation. We find that
\[\begin{equation} f(y) = \frac{e^{-(y-\mu)^2/ (2 \sigma^2)}}{\sqrt{2\pi\sigma^2}} \quad \textrm{for} \quad -\infty < y < \infty. \tag{3.10} \end{equation}\]
As the parameter names suggest, \(\operatorname{E}(Y) = \mu\) and \(\operatorname{SD}(Y) = \sigma\). Often, normal distributions are referred to as \(\textrm{N}(\mu, \sigma)\), implying a normal distribution with mean \(\mu\) and standard deviation \(\sigma\). The distribution \(\textrm{N}(0,1)\) is often referred to as the standard normal distribution. A few normal distributions are displayed in Figure 3.8.
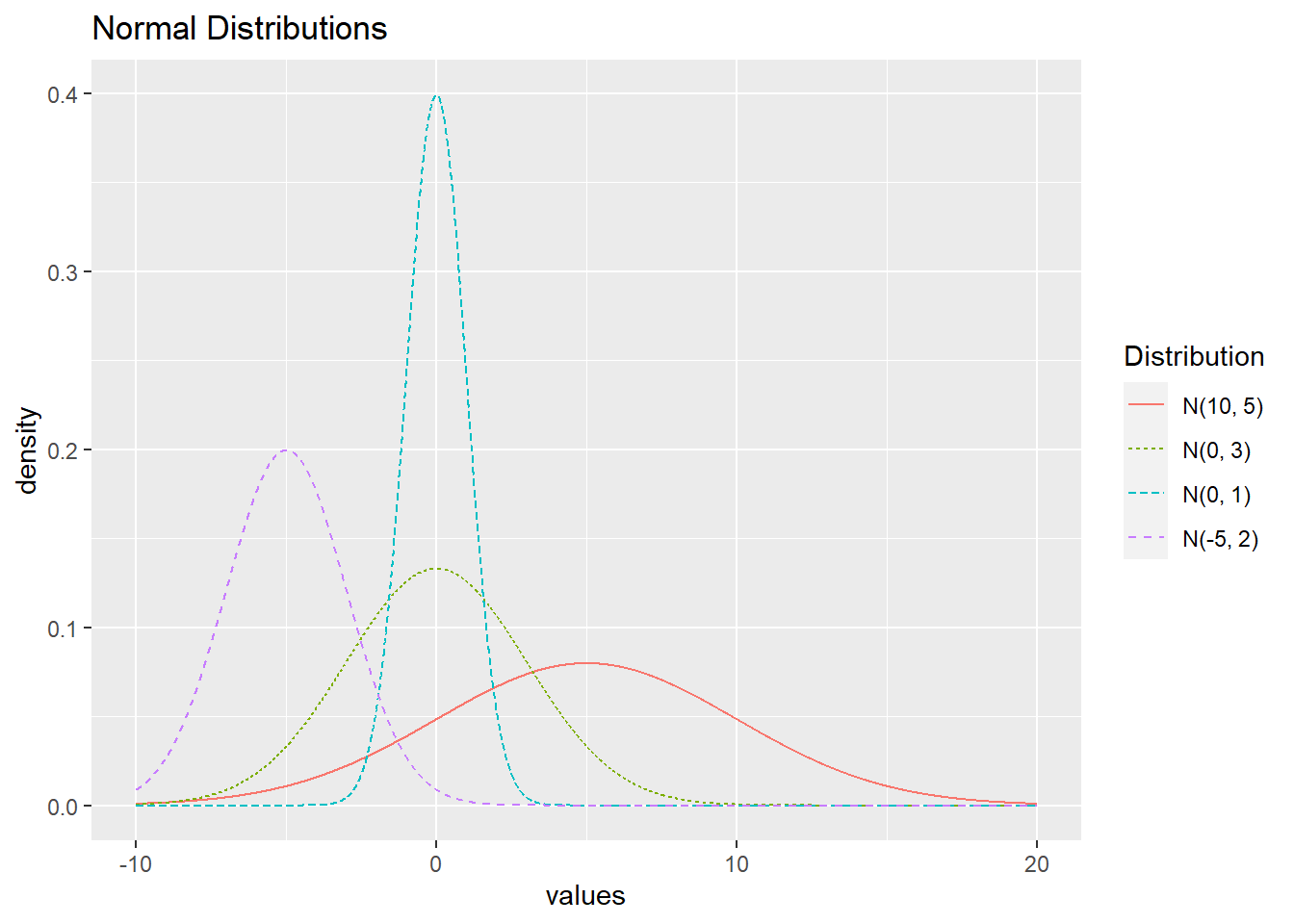
Figure 3.8: Normal distributions with different values of \(\mu\) and \(\sigma\).
In R, pnorm(y, mean, sd) outputs the probability \(P(Y < y)\) given a mean and standard deviation.
Example 9: The weight of a box of Fruity Tootie cereal is approximately normally distributed with an average weight of 15 ounces and a standard deviation of 0.5 ounces. What is the probability that the weight of a randomly selected box is more than 15.5 ounces?
Using a normal distribution,
\[\begin{align*} P(Y > 15.5) = \int_{15.5}^{\infty} \frac{e^{-(y-15)^2/ (2\cdot 0.5^2)}}{\sqrt{2\pi\cdot 0.5^2}}dy = 0.159 \end{align*}\]
We can use R as well:
## [1] 0.1587There is a 16% chance of a randomly selected box weighing more than 15.5 ounces.
3.4.4 Beta Random Variable
So far, all of our continuous variables have had no upper bound. If we want to limit our possible values to a smaller interval, we may turn to a beta random variable. In fact, we often use beta random variables to model distributions of probabilities—bounded below by 0 and above by 1. The pdf is parameterized by two values, \(\alpha\) and \(\beta\) (\(\alpha, \beta > 0\)). We can describe a beta random variable by the following pdf:
\[\begin{equation} f(y) = \frac{\Gamma(\alpha + \beta)}{\Gamma(\alpha)\Gamma(\beta)} y^{\alpha-1} (1-y)^{\beta-1} \quad \textrm{for} \quad 0 < y < 1. \tag{3.11} \end{equation}\]
If \(Y \sim \textrm{Beta}(\alpha, \beta)\), then \(\operatorname{E}(Y) = \alpha/(\alpha + \beta)\) and \(\operatorname{SD}(Y) = \displaystyle \sqrt{\frac{\alpha \beta}{(\alpha + \beta)^2 (\alpha+\beta+1)}}\). Figure 3.9 displays several beta distributions. Note that when \(\alpha = \beta\), distributions are symmetric. The distribution is left-skewed when \(\alpha > \beta\) and right-skewed when \(\beta > \alpha\).
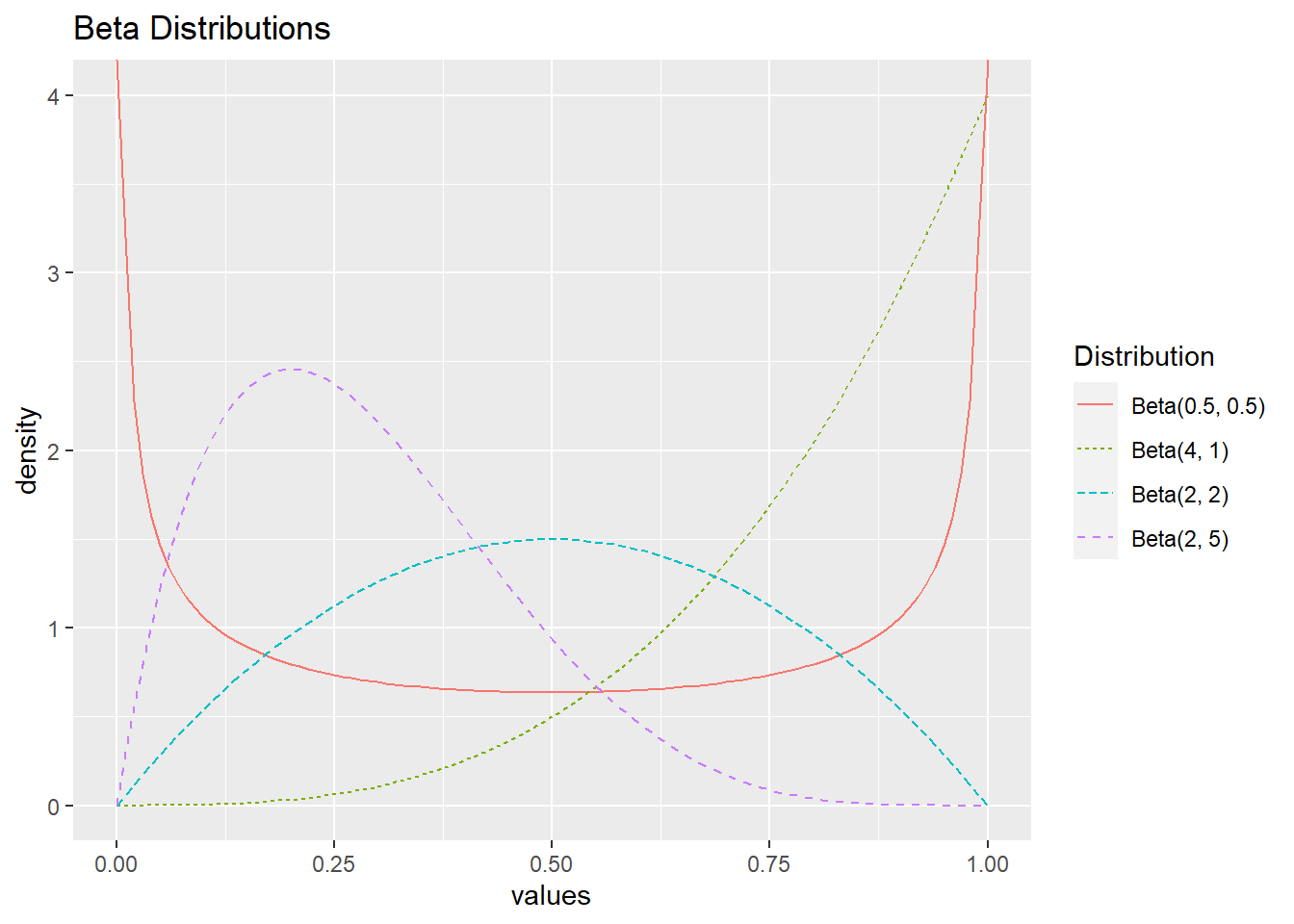
Figure 3.9: Beta distributions with different values of \(\alpha\) and \(\beta\).
If \(\alpha = \beta = 1\), then
\[\begin{align*} f(y) &= \frac{\Gamma(1)}{\Gamma(1)\Gamma(1)}y^0(1-y)^0 \\ &= 1 \quad \textrm{for} \quad 0 < y < 1. \end{align*}\] This distribution is referred to as a uniform distribution.
In R, pbeta(y, alpha, beta) yields \(P(Y < y)\) assuming \(Y \sim \textrm{Beta}(\alpha, \beta)\).
Example 10: A private college in the Midwest models the probabilities of prospective students accepting an admission decision through a beta distribution with \(\alpha = \frac{4}{3}\) and \(\beta = 2\). What is the probability that a randomly selected student has probability of accepting greater than 80%?
Letting \(Y \sim \textrm{Beta}(4/3,2)\), we can calculate
\[\begin{align*} P(Y > 0.8) = \int_{0.8}^1 \frac{\Gamma(4/3 + 2)}{\Gamma(4/3)\Gamma(2)} y^{4/3-1} (1-y)^{2-1}dy = 0.06. \end{align*}\]
Alternatively, in R:
## [1] 0.0593Hence, there is a 6% chance that a randomly selected student has a probability of accepting an admission decision above 80%.
3.5 Distributions Used in Testing
We have spent most of this chapter discussing probability distributions that may come in handy when modeling. The following distributions, while rarely used in modeling, prove useful in hypothesis testing as certain commonly used test statistics follow these distributions.
3.5.1 \(\chi^2\) Distribution
You have probably already encountered \(\chi^2\) tests before. For example, \(\chi^2\) tests are used with two-way contingency tables to investigate the association between row and column variables. \(\chi^2\) tests are also used in goodness-of-fit testing such as comparing counts expected according to Mendelian ratios to observed data. In those situations, \(\chi^2\) tests compare observed counts to what would be expected under the null hypotheses and reject the null when these observed discrepancies are too large.
In this course, we encounter \(\chi^2\) distributions in several testing situations. In Section 2.6.5 we performed likelihood ratio tests (LRTs) to compare nested models. When a larger model provides no significant improvement over a reduced model, the LRT statistic (which is twice the difference in the log-likelihoods) follows a \(\chi^2\) distribution with the degrees of freedom equal to the difference in the number of parameters.
In general, \(\chi^2\) distributions with \(k\) degrees of freedom are right skewed with a mean \(k\) and standard deviation \(\sqrt{2k}\). Figure 3.10 displays chi-square distributions with different values of \(k\).
The \(\chi^2\) distribution is a special case of a gamma distribution. Specifically, a \(\chi^2\) distribution with \(k\) degrees of freedom can be expressed as a gamma distribution with \(\lambda = 1/2\) and \(r = k/2\).
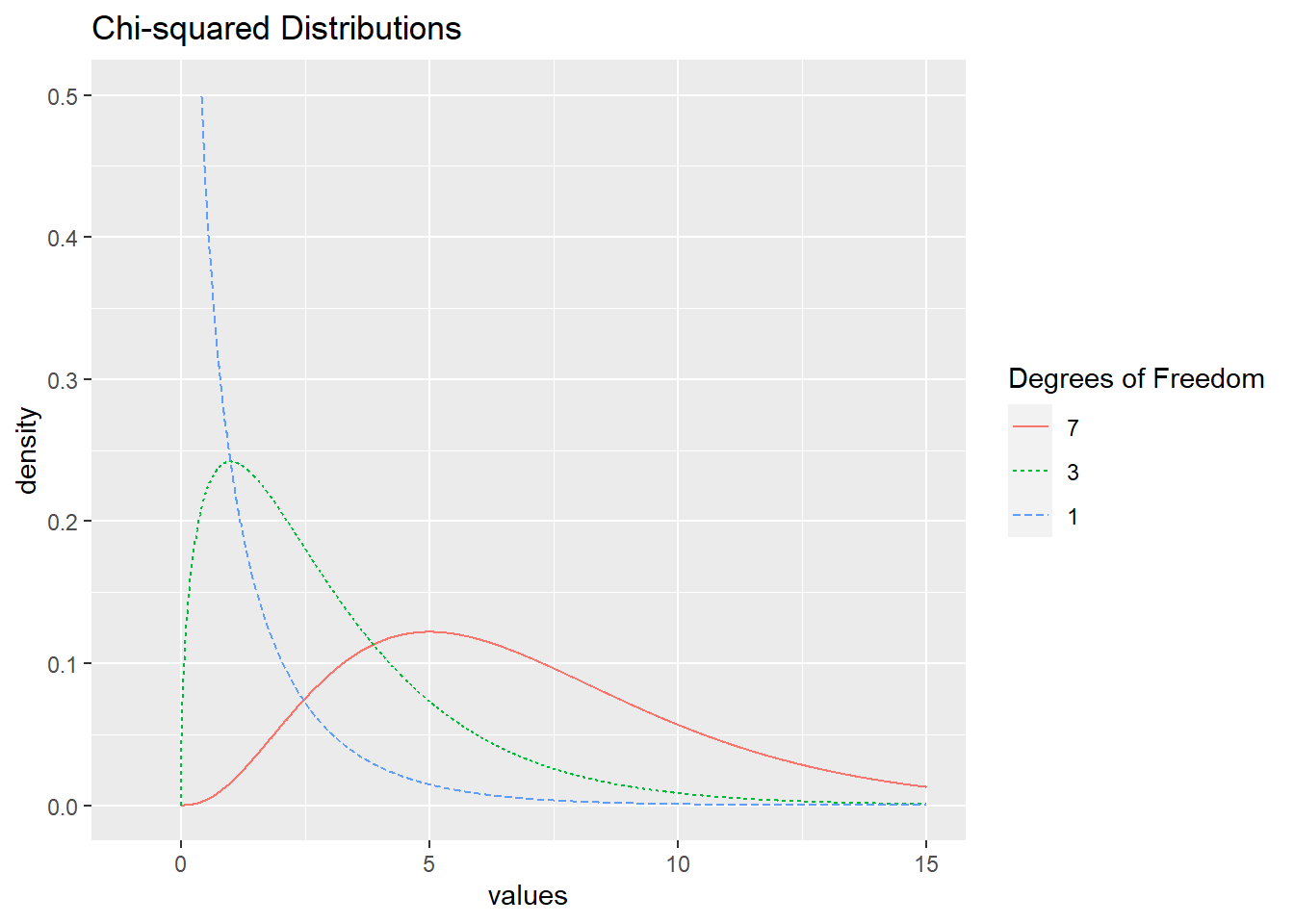
Figure 3.10: \(\chi^2\) distributions with 1, 3, and 7 degrees of freedom..
In R, pchisq(y, df) outputs \(P(Y < y)\) given \(k\) degrees of freedom.
3.5.2 Student’s \(t\)-Distribution
You likely have seen Student’s \(t\)-distribution (developed by William Sealy Gosset under the penname Student) in a previous statistics course. You may have used it when drawing inferences about the means of normally distributed populations with unknown population standard deviations. \(t\)-distributions are parameterized by their degrees of freedom, \(k\).
A \(t\)-distribution with \(k\) degrees of freedom has mean \(0\) and standard deviation \(k/(k-2)\) (standard deviation is only defined for \(k > 2\)). As \(k \rightarrow \infty\) the \(t\)-distribution approaches the standard normal distribution.
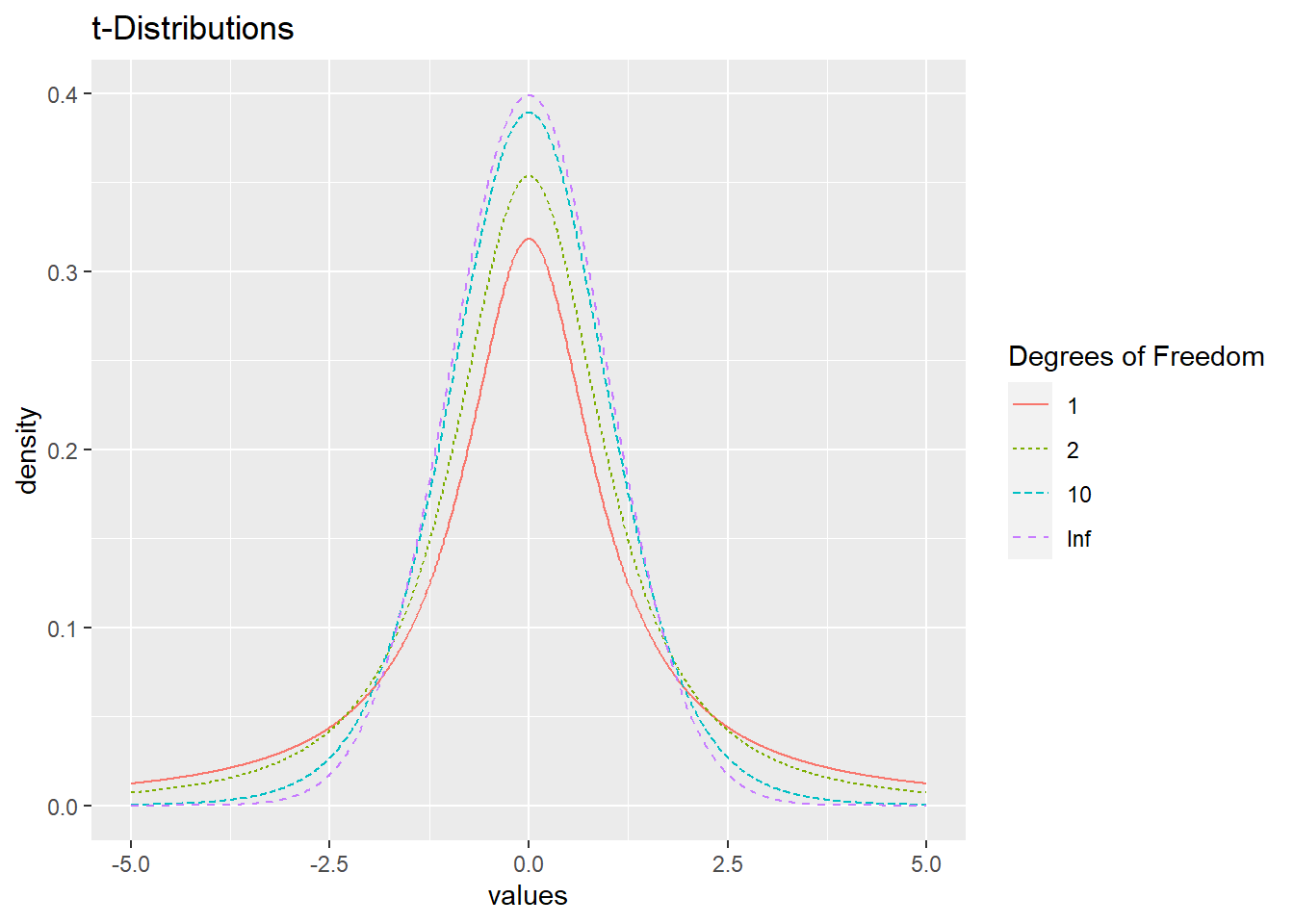
Figure 3.11: \(t\)-distributions with 1, 2, 10, and Infinite degrees of freedom.
Figure 3.11 displays some \(t\)-distributions, where a \(t\)-distribution with infinite degrees of freedom is equivalent to a standard normal distribution (with mean 0 and standard deviation 1). In R, pt(y, df) outputs \(P(Y < y)\) given \(k\) degrees of freedom.
3.5.3 \(F\)-Distribution
\(F\)-distributions are also used when performing statistical tests. Like the \(\chi^2\) distribution, the values from an \(F\)-distribution are non-negative and the distribution is right skewed; in fact, an \(F\)-distribution can be derived as the ratio of two \(\chi^2\) random variables. R.A. Fisher (for whom the test is named) devised this test statistic to compare two different estimates of the same variance parameter, and it has a prominent role in Analysis of Variance (ANOVA). Model comparisons are often based on the comparison of variance estimates, e.g., the extra sums-of-squares \(F\) test. \(F\)-distributions are indexed by two degrees-of-freedom values, one for the numerator (\(k_1\)) and one for the denominator (\(k_2\)). The expected value for an \(F\)-distribution with \(k_1, k_2\) degrees of freedom under the null hypothesis is \(\frac{k_2}{k_2 - 2}\), which approaches \(1\) as \(k_2 \rightarrow \infty\). The standard deviation decreases as \(k_1\) increases for fixed \(k_2\), as seen in Figure 3.12, which illustrates several F-distributions.
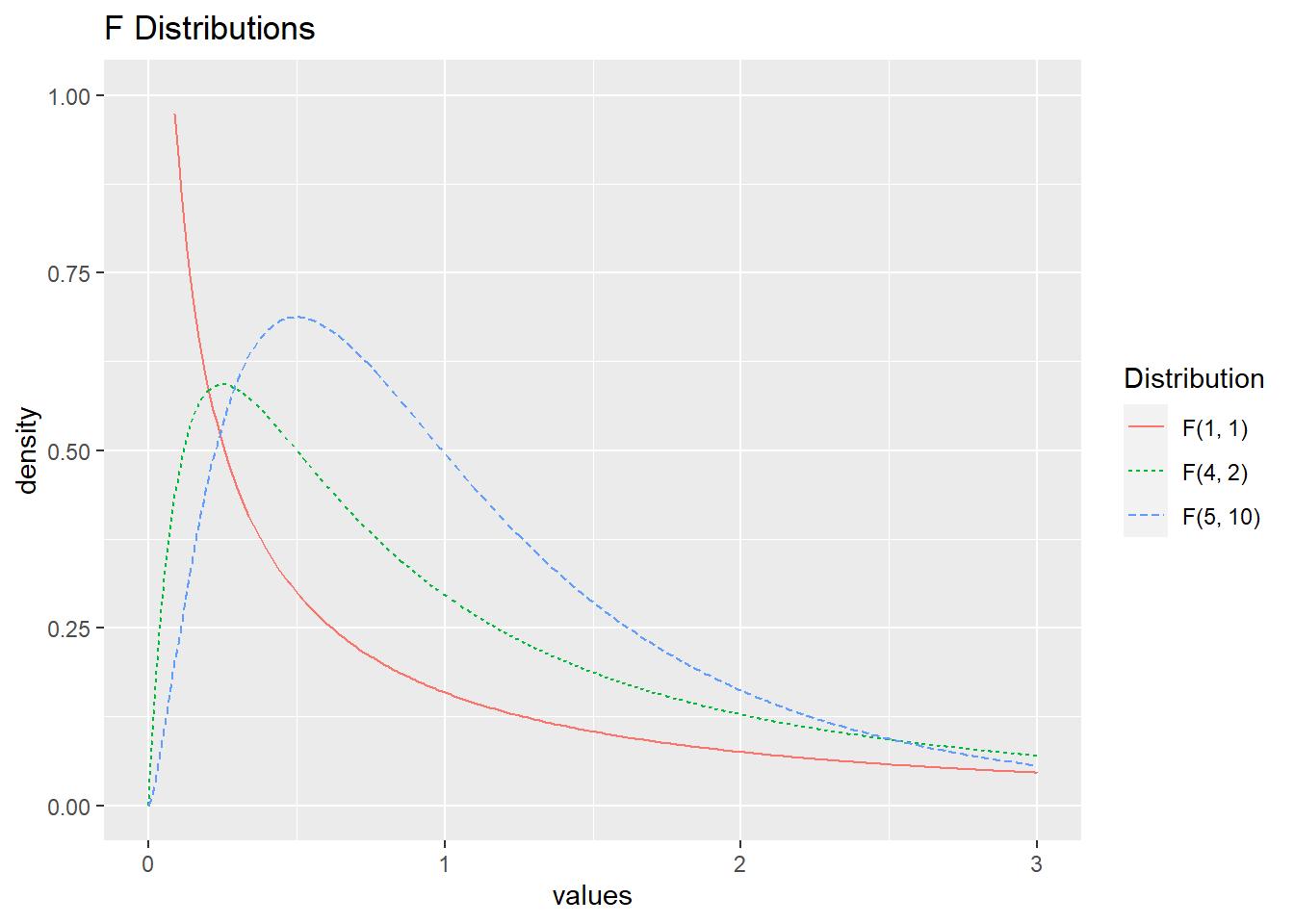
Figure 3.12: \(F\)-distributions with different degrees of freedom.
3.6 Additional Resources
Table 3.1 briefly details most of the random variables discussed in this chapter.
| Distribution Name | pmf / pdf | Parameters | Possible Y Values | Description |
|---|---|---|---|---|
| Binomial | \({n \choose y} p^y (1-p)^{n-y}\) | \(p,\ n\) | \(0, 1, \ldots , n\) | Number of successes after \(n\) trials |
| Geometric | \((1-p)^yp\) | \(p\) | \(0, 1, \ldots, \infty\) | Number of failures until the first success |
| Negative Binomial | \({y + r - 1\choose r-1} (1-p)^{y}(p)^r\) | \(p,\ r\) | \(0, 1, \ldots, \infty\) | Number of failures before \(r\) successes |
| Hypergeometric | \({m \choose y}{N-m \choose n-y}\big/{N \choose n}\) | \(n,\ m,\ N\) | \(0, 1, \ldots , \min(m,n)\) | Number of successes after \(n\) trials without replacement |
| Poisson | \({e^{-\lambda}\lambda^y}\big/{y!}\) | \(\lambda\) | \(0, 1, \ldots, \infty\) | Number of events in a fixed interval |
| Exponential | \(\lambda e^{-\lambda y}\) | \(\lambda\) | \((0, \infty)\) | Wait time for one event in a Poisson process |
| Gamma | \(\displaystyle\frac{\lambda^r}{\Gamma(r)} y^{r-1} e^{-\lambda y}\) | \(\lambda, \ r\) | \((0, \infty)\) | Wait time for \(r\) events in a Poisson process |
| Normal | \(\displaystyle\frac{e^{-(y-\mu)^2/ (2 \sigma^2)}}{\sqrt{2\pi\sigma^2}}\) | \(\mu,\ \sigma\) | \((-\infty,\ \infty)\) | Used to model many naturally occurring phenomena |
| Beta | \(\frac{\Gamma(\alpha + \beta)}{\Gamma(\alpha)\Gamma(\beta)} y^{\alpha-1} (1-y)^{\beta-1}\) | \(\alpha,\ \beta\) | \((0,\ 1)\) | Useful for modeling probabilities |
3.7 Exercises
3.7.1 Conceptual Exercises
At what value of \(p\) is the standard deviation of a binary random variable smallest? When is standard deviation largest?
How are hypergeometric and binomial random variables different? How are they similar?
How are exponential and Poisson random variables related?
How are geometric and exponential random variables similar? How are they different?
A university’s college of sciences is electing a new board of 5 members. There are 35 applicants, 10 of which come from the math department. What distribution could be helpful to model the probability of electing \(X\) board members from the math department?
Chapter 1 asked you to consider a scenario where “The Minnesota Pollution Control Agency is interested in using traffic volume data to generate predictions of particulate distributions as measured in counts per cubic feet.” What distribution might be useful to model this count per cubic foot? Why?
Chapter 1 also asked you to consider a scenario where “Researchers are attempting to see if socioeconomic status and parental stability are predictive of low birthweight. They classify a low birthweight as below 2500 g, hence our response is binary: 1 for low birthweight, and 0 when the birthweight is not low.” What distribution might be useful to model if a newborn has low birthweight?
Chapter 1 also asked you to consider a scenario where “Researchers are interested in how elephant age affects mating patterns among males. In particular, do older elephants have greater mating success, and is there an optimal age for mating among males? Data collected includes, for each elephant, age and number of matings in a given year.” Which distribution would be useful to model the number of matings in a given year for these elephants? Why?
Describe a scenario which could be modeled using a gamma distribution.
3.7.2 Guided Exercises
Beta-binomial distribution. We can generate more distributions by mixing two random variables. Beta-binomial random variables are binomial random variables with fixed \(n\) whose parameter \(p\) follows a beta distribution with fixed parameters \(\alpha, \beta\). In more detail, we would first draw \(p_1\) from our beta distribution, and then generate our first observation \(y_1\), a random number of successes from a binomial (\(n, p_1\)) distribution. Then, we would generate a new \(p_2\) from our beta distribution, and use a binomial distribution with parameters \(n, p_2\) to generate our second observation \(y_2\). We would continue this process until desired.
Note that all of the observations \(y_i\) will be integer values from \(0, 1, \ldots, n\). With this in mind, use
rbinom()to simulate 1,000 observations from a plain old vanilla binomial random variable with \(n=10\) and \(p=0.8\). Plot a histogram of these binomial observations. Then, do the following to generate a beta-binomial distribution:- Draw \(p_i\) from the beta distribution with \(\alpha=4\) and \(\beta=1\).
- Generate an observation \(y_i\) from a binomial distribution with \(n=10\) and \(p = p_i\).
- Repeat (a) and (b) 1,000 times (\(i=1,\ldots,1000\)).
- Plot a histogram of these beta-binomial observations.
Compare the histograms of the “plain old” binomial and beta-binomial distributions. How do their shapes, standard deviations, means, possible values, etc. compare?
Gamma-Poisson mixture I. Use the R function
rpois()to generate 10,000 \(x_i\) from a plain old vanilla Poisson random variable, \(X \sim \textrm{Poisson}(\lambda=1.5)\). Plot a histogram of this distribution and note its mean and standard deviation. Next, let \(Y \sim \textrm{Gamma}(r = 3, \lambda = 2)\) and usergamma()to generate 10,000 random \(y_i\) from this distribution. Now, consider 10,000 different Poisson distributions where \(\lambda_i = y_i\). Randomly generate one \(z_i\) from each Poisson distribution. Plot a histogram of these \(z_i\) and compare it to your original histogram of \(X\) (where \(X \sim \textrm{Poisson}(1.5)\)). How do the means and standard deviations compare?Gamma-Poisson mixture II. A negative binomial distribution can actually be expressed as a gamma-Poisson mixture. In the previous problem’s gamma-Poisson mixture \(Z \sim \textrm{Poisson}(\lambda)\) where \(\lambda \sim \textrm{Gamma}(r = 3, \lambda' = 2)\). Find the parameters of a negative binomial distribution \(X \sim \textrm{Negative Binomial}(r, p)\) such that \(X\) is equivalent to \(Z\). As a hint, the means of both distributions must be the same, so \(r(1-p)/p = 3/2\). Show through histograms and summary statistics that your negative binomial distribution is equivalent to your gamma-Poisson mixture from Problem 2. Argue that if you want a NB(\(r\), \(p\)) random variable, you can instead sample from a Poisson distribution, where the \(\lambda\) values are themselves sampled from a gamma distribution with parameters \(r\) and \(\lambda' = \frac{p}{1-p}\).
Mixture of two normal distributions Sometimes, a value may be best modeled by a mixture of two normal distributions. We would have 5 parameters in this case— \(\mu_1, \sigma_1, \mu_2, \sigma_2, \alpha\), where \(0 < \alpha < 1\) is a mixing parameter determining the probability that an observation comes from the first distribution. We would then have \(f(y) = \alpha\ f_1(y) + (1-\alpha)\ f_2(y)\) (where \(f_i(y)\) is the pdf of the normal distribution with \(\mu_i, \sigma_i\)). One phenomenon which could be modeled this way would be the waiting times between eruptions of Old Faithful geyser in Yellowstone National Park. The data can be accessed in R through
faithful, and a histogram of wait times can be found in Figure 3.13. The MLEs of our 5 parameters would be the combination of values that produces the maximum probability of our observed data. We will try to approximate MLEs by hand. Find a combination of \(\mu_1, \sigma_1, \mu_2, \sigma_2, \alpha\) for this distribution such that the logged likelihood is above -1050. (The commanddnorm(x, mean, sd), which outputs \(f(y)\) assuming \(Y \sim \textrm{N}(\mu, \sigma)\), will be helpful in calculating likelihoods.)
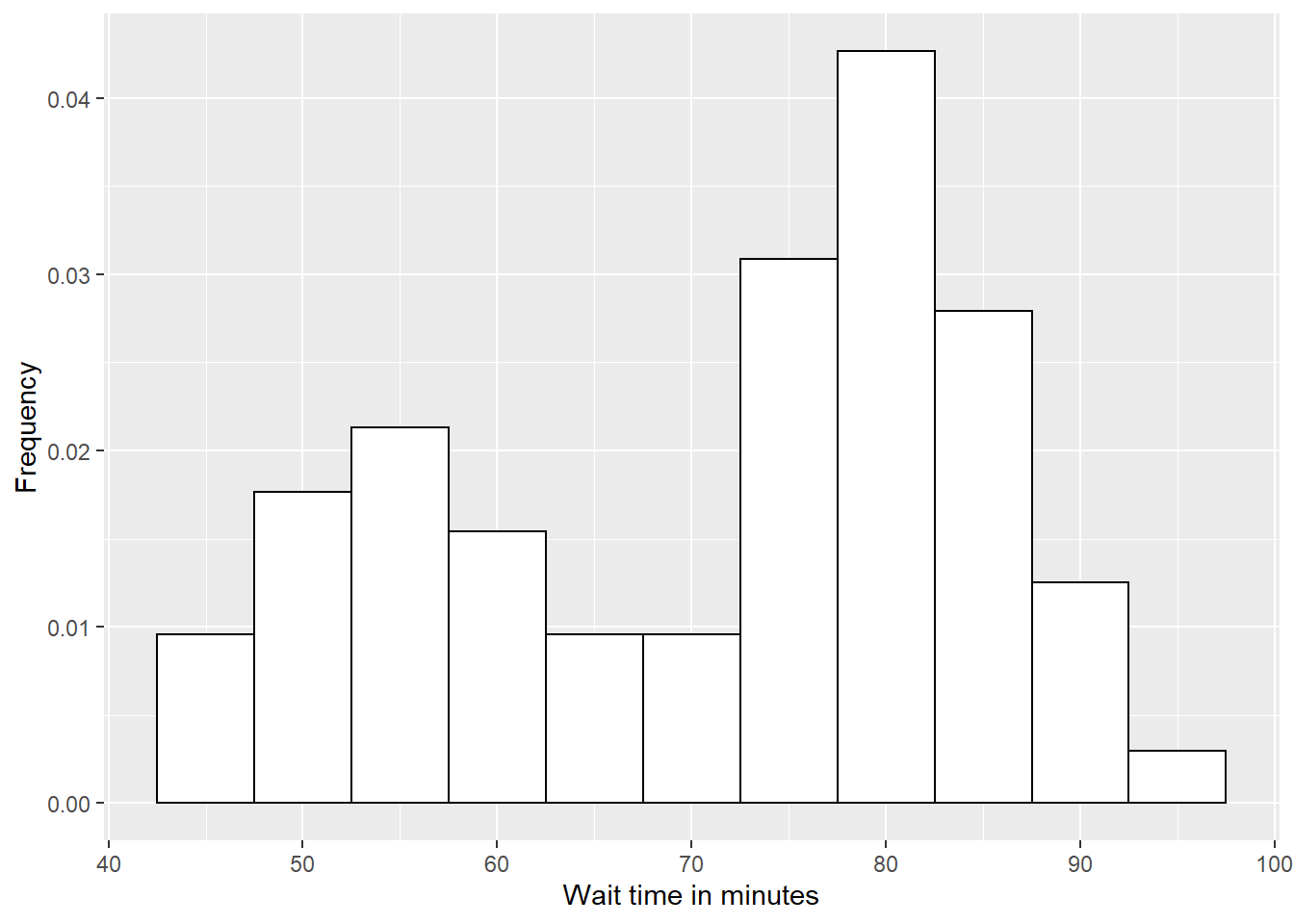
Figure 3.13: Waiting time between eruptions of Old Faithful.