1 数据概况
1.1 数据预处理
Amos无法对原始数据进行管理,一般情况下需要先用数据管理软件进行预处理。例如stata、spss和R语言。
这里我们先用stata挑选出了感兴趣的观测变量,并使用最简单的缺失值处理方法:删除所有作为缺失值的观测样本。
# 注:以下为stata的代码格式,不可在R中使用!
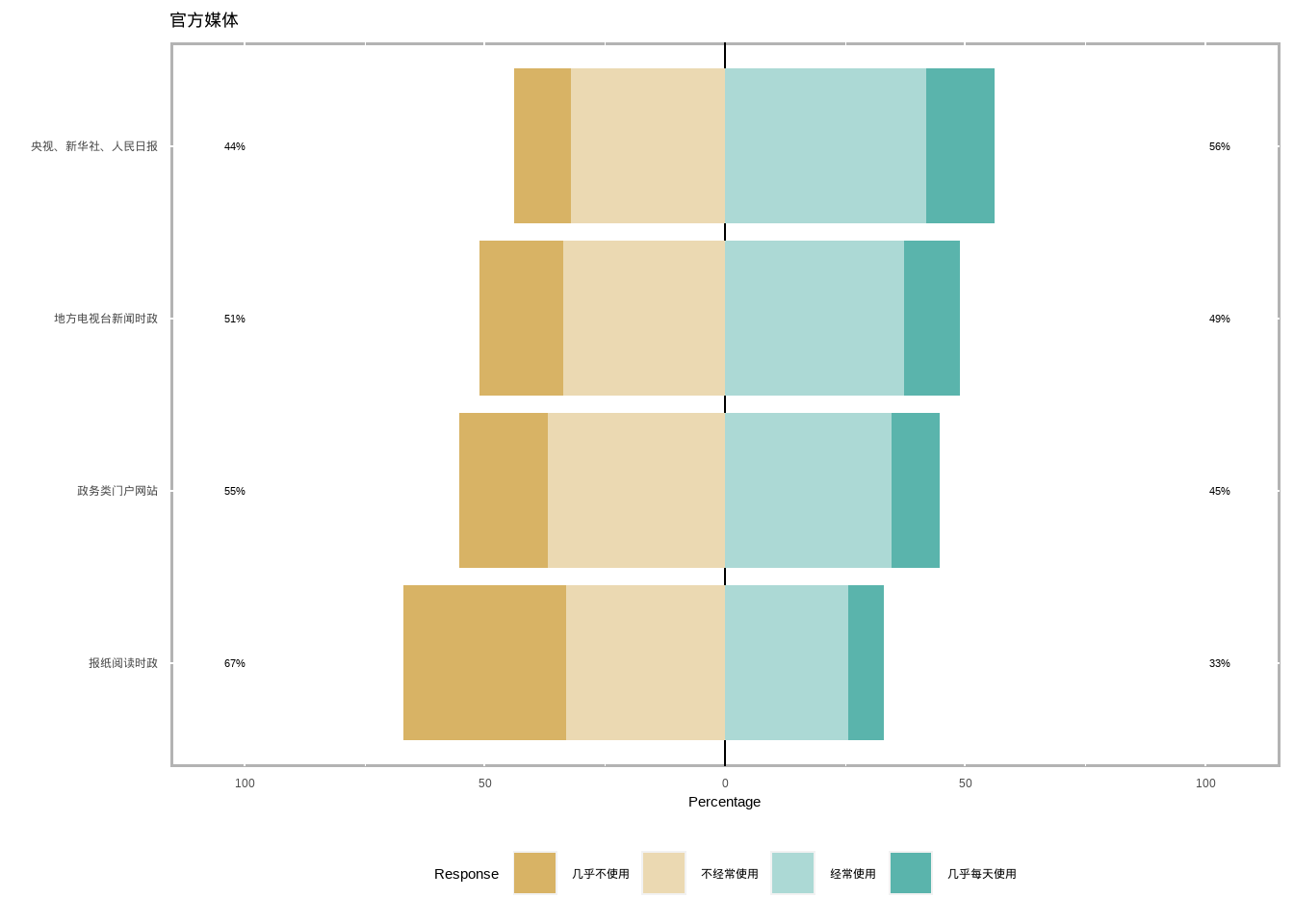
# keep Q15_R13 Q15_R14 Q15_R16 Q15_R22 ///官方媒体
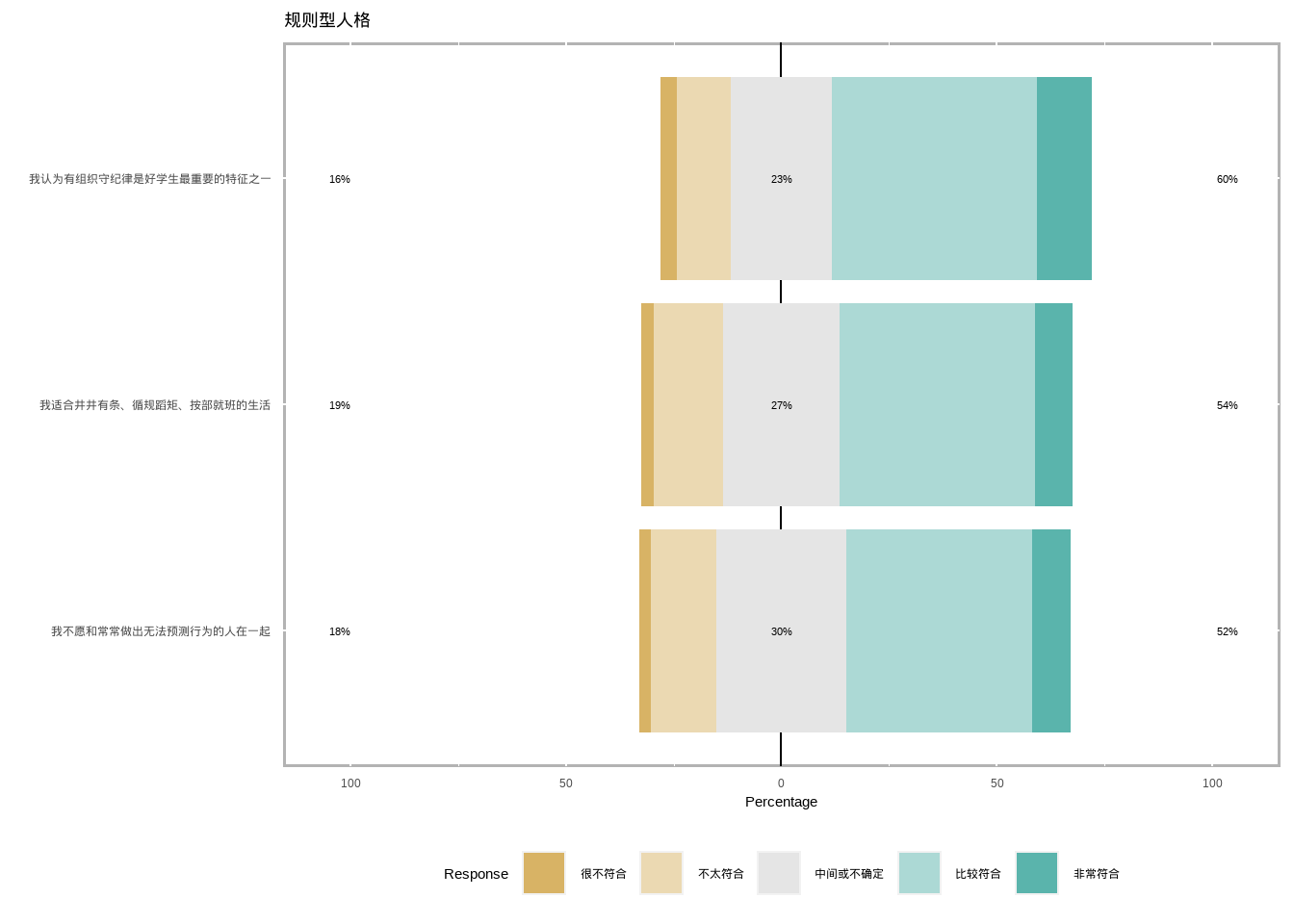
# Q20_R9 Q20_R10 Q20_R11 ///规则型人格
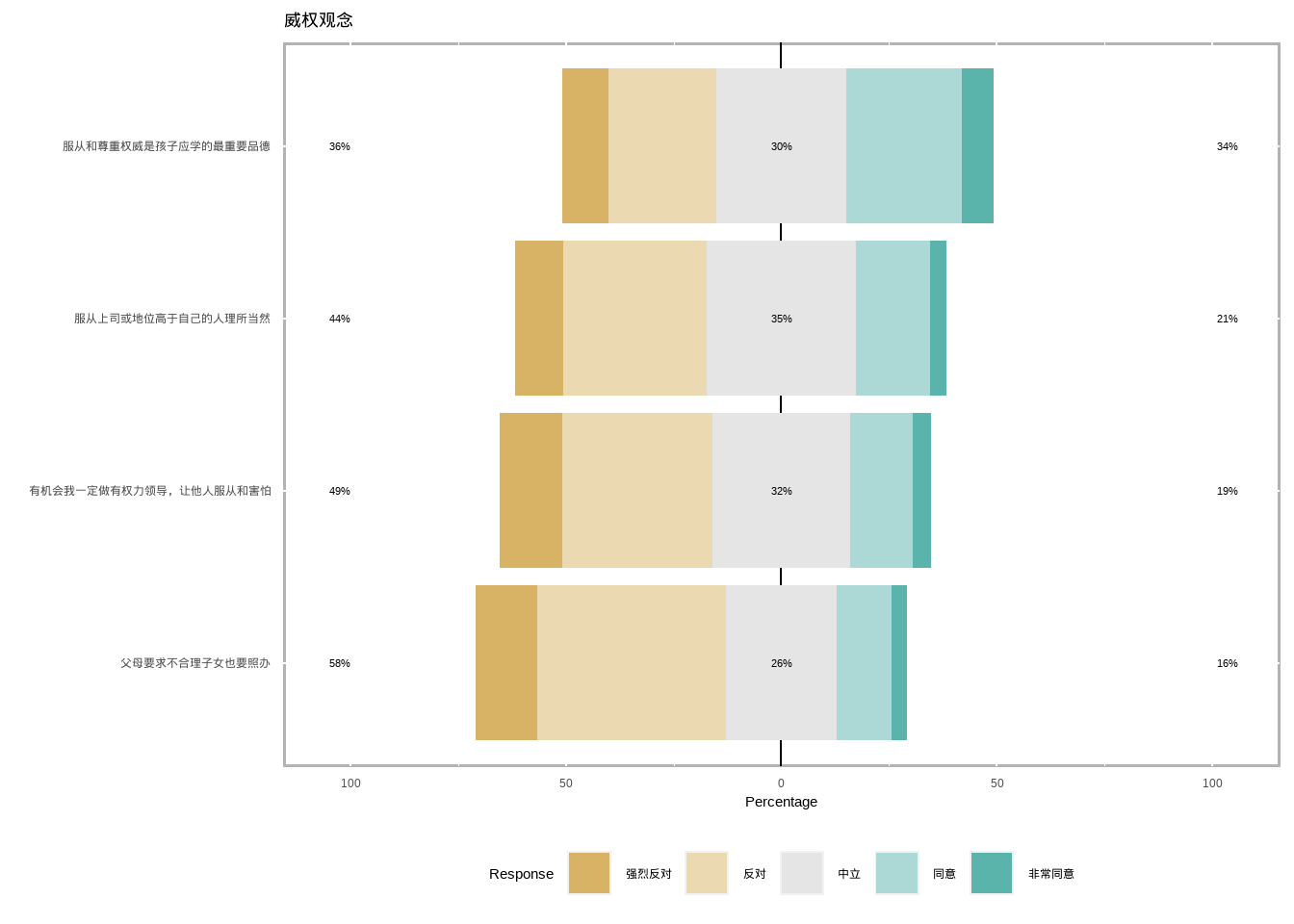
# Q23_R13 Q23_R14 Q23_R15 Q24_R15 ///威权观念
# Q24_R4 Q24_R5 Q24_R6 Q24_R7
# save //需要保存后才能统一删除行缺失值
# dropmiss, obs any //删除挑选变量中所有的缺失值
# count //查看剩下多少样本量原始数据的样本量一共为2379,进行特定变量的筛选并统一删除缺失值后,还剩下2149,数据缺失率为9.67%。
以下R的代码是将外部图片插入到Rmd文件中,picture是在大项目中的存放图形的子文件夹,按这样的格式插入即可。
knitr::include_graphics("picture/variable.png")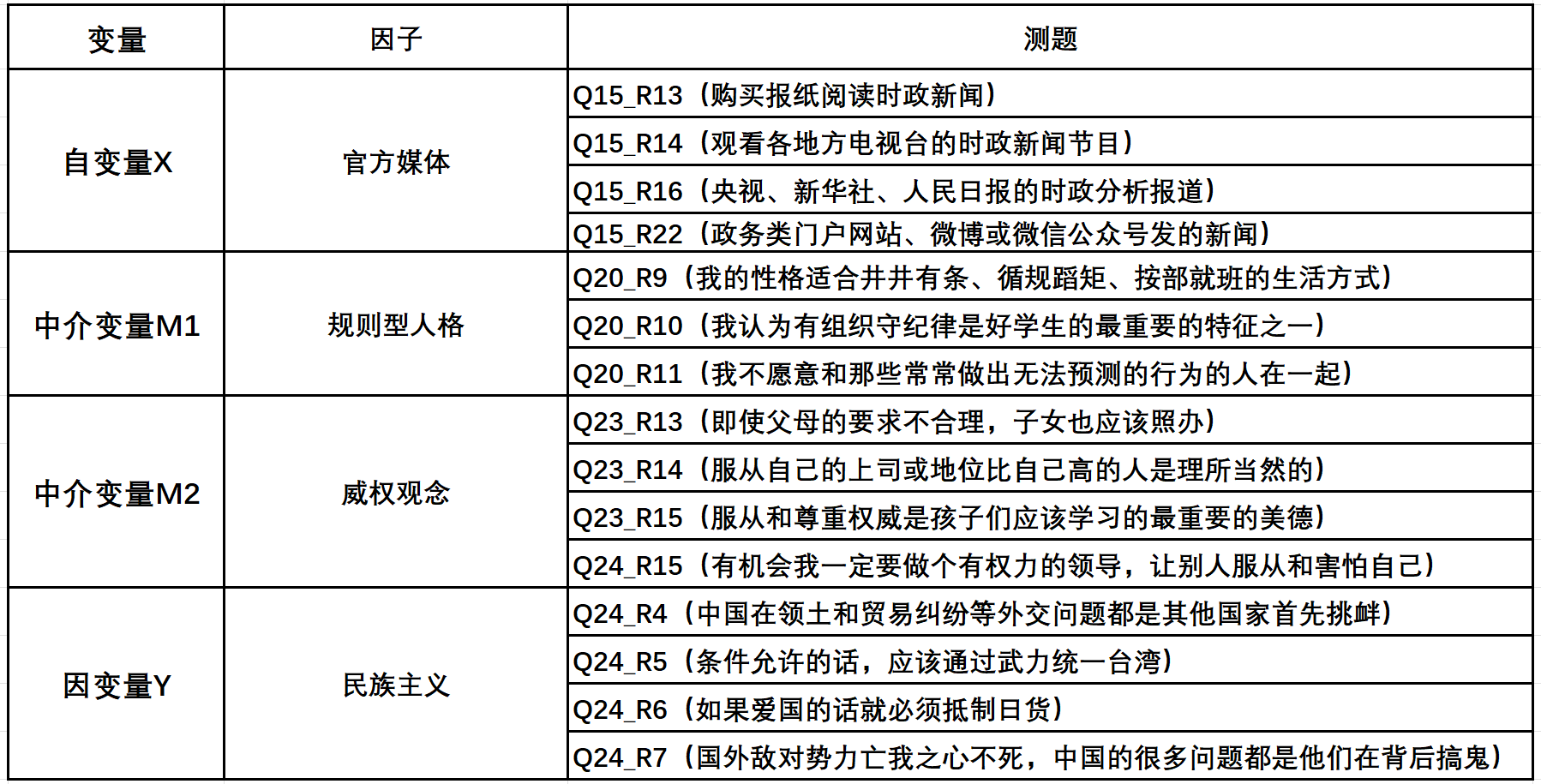
图1.1: variable consequence
以上为各测题及以它们为基础构建的因子。由于结构方程模型进行的是验证性因子分析,故已预设我们选取了需要的因子及其测题。
一般而言是通过以下两种方式:
- 使用SPSS进行探索性因子分析
- 具有强力的理论支撑
为方便数据展示,现在导入R语言中查看数据情况。我们直接以stata的格式导入。
library(haven)
netizen <- read_stata("eman.dta")数据的诊断
##
## Attaching package: 'dlookr'## The following object is masked from 'package:base':
##
## transform## ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.1.1 ✔ readr 2.1.4
## ✔ forcats 1.0.0 ✔ stringr 1.5.0
## ✔ ggplot2 3.4.2 ✔ tibble 3.2.1
## ✔ lubridate 1.9.2 ✔ tidyr 1.3.0
## ✔ purrr 1.0.1
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ tidyr::extract() masks dlookr::extract()
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors