Chapter 4 Machine Learning Model Classes

Training a machine learning model using the caret package is deceptively simple. We just use the train function, specify our outcome variable and data set, and specify the model we would like to apply via the argument method.
However, there are over 200 available models in the caret package from which to choose13, and users can also specify their own models. Each model will have a different composition and different requirements, which we refer to as tuning parameters.
We can group different machine learning models into classes, and in this section we will provide a brief overview of some of the most popular classes of machine learning models, that will be suitable for supervised learning, following Thulin (2021).
The main classes of machine learning models are:
- Decision Trees
- Model Trees
- Random Forests
- Boosted Trees
- Linear Discriminant Analysis
- Support Vector Machines
- Nearest Neighbour Classifiers
We won’t go into all the mathematics behind these models. Rather, in the labs we will focus on the R code required to apply them to our data.
4.0.1 Tree Models
Tree models encompass several classes of machine learning model.
The simplest type of tree model is a decision tree model. The easiest way to describe a decision tree model is probably to show one - take a look at the result below, which uses our filtered penguin data:
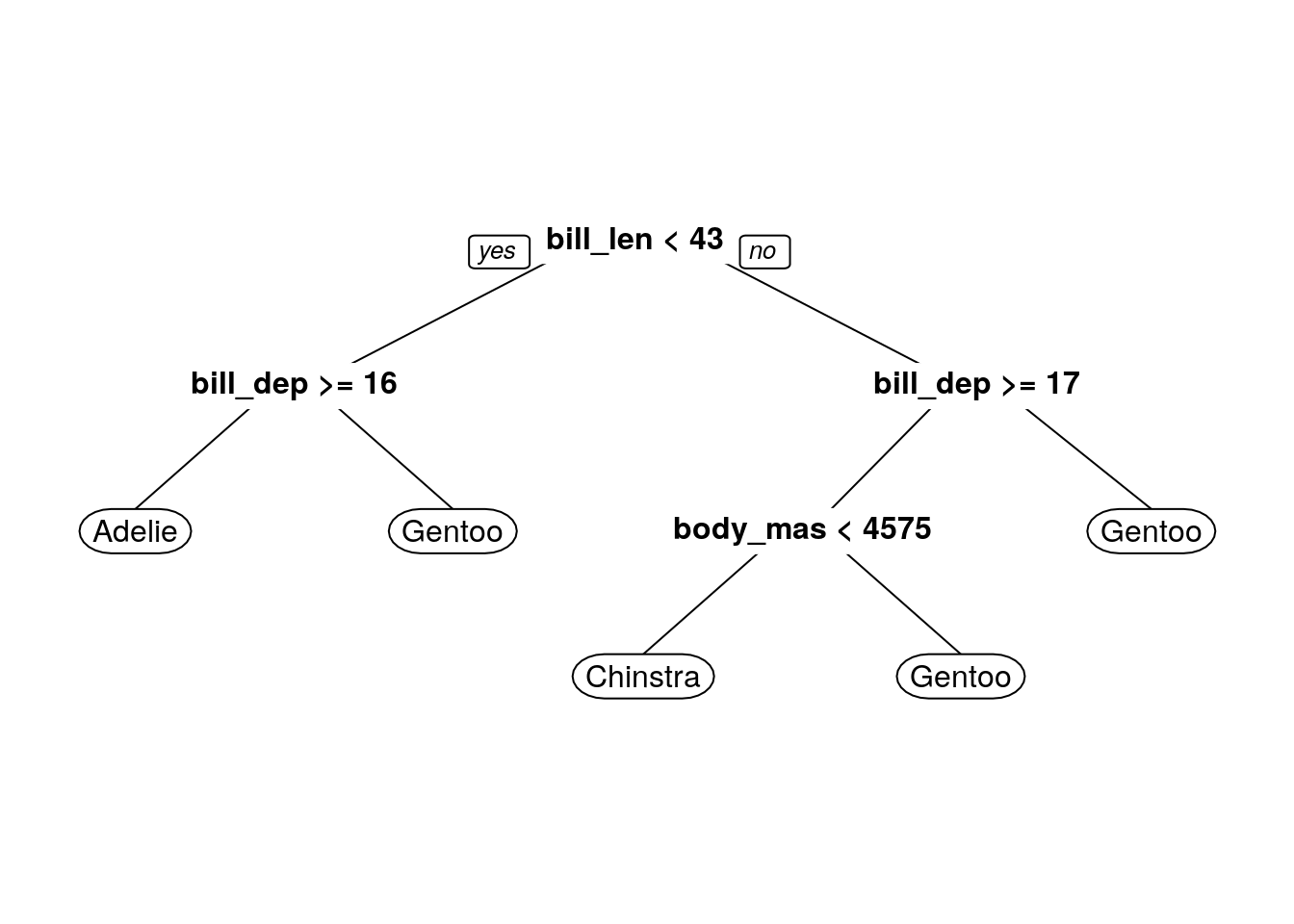
By starting at the top of the graph (the root), we can make decisions by following the branches until we arrive at a leaf node - i.e. Adelie, Chinstrap or Gentoo. The path from the root to the leaf represents the classification rules used in the model.
A model tree is like a decision tree, except that the regression model fitting process is more sophisticated.
Rather than using a single tree, we can use an ensemble method and combine multiple predictive models14. Random Forests and Boosted Trees are examples of ensemble tree models.
Random forest models combine multiple decision trees to achieve better results than any single decision tree considered could offer. Boosted tree models combine multiple decision trees, like random forest models, but use new trees to ‘boost’ (i.e. help) poorly performing trees.
4.0.2 Linear Models
A linear discriminant analysis (LDA) model is a type of linear model that uses Bayes’ theorem to classify new observations based on characteristics of the outcome variable classes.
4.0.3 Non-linear Models
A support vector machine (SVM) is a type of non-linear model that operates similarly to LDA models, with a focus on clearly separating outcome variable classes.
Nearest Neighbour Classifiers are another class of non-linear models, that assess distances between observations, grouping nearby observations together - a bit like k-means clustering.
4.1 Example - Gradient Boosting Machine model
To conclude this section, let’s go through an example application of the train function, using our filtered penguin data.
A gradient boosting machine is a type of boosted tree machine learning model.
To use this model, we specify method = gbm in the caret train function (you will need the gbm R package installed if you would like to replicate this - it may have been installed as part of the caret package installation).
Let’s take a look at this process now:
library(gbm)
set.seed(1650)
gbm_fit <- train(species ~ ., data = ml_penguin_train,
method = "gbm",
verbose = FALSE)
gbm_fit## Stochastic Gradient Boosting
##
## 268 samples
## 5 predictor
## 3 classes: 'Adelie', 'Chinstrap', 'Gentoo'
##
## No pre-processing
## Resampling: Bootstrapped (25 reps)
## Summary of sample sizes: 268, 268, 268, 268, 268, 268, ...
## Resampling results across tuning parameters:
##
## interaction.depth n.trees Accuracy Kappa
## 1 50 0.9744014 0.9597142
## 1 100 0.9764335 0.9629586
## 1 150 0.9756984 0.9619450
## 2 50 0.9758126 0.9620003
## 2 100 0.9755111 0.9614753
## 2 150 0.9747583 0.9602375
## 3 50 0.9781188 0.9656771
## 3 100 0.9778702 0.9651857
## 3 150 0.9741996 0.9592696
##
## Tuning parameter 'shrinkage' was held constant at a value of 0.1
##
## Tuning parameter 'n.minobsinnode' was held constant at a value of 10
## Accuracy was used to select the optimal model using the largest value.
## The final values used for the model were n.trees = 50, interaction.depth =
## 3, shrinkage = 0.1 and n.minobsinnode = 10.Here we can see that the method has been carried out using different combinations of tuning parameters - which here include the number of training iterations to conduct (trees), the complexity of the trees (interaction.depth), and the adaptability or learning rate of the algorithm (shrinkage).
We are primarily interested in the Accuracy column in the output - this tells us the predictive accuracy of the model (based on the training data).
We can see that for 50 iterations, and an iteration complexity of 3, the gradient boosting machine achieves an accuracy of 97.81% using the training data.
We can use the plot function to visualise the results of this training process:
plot(gbm_fit)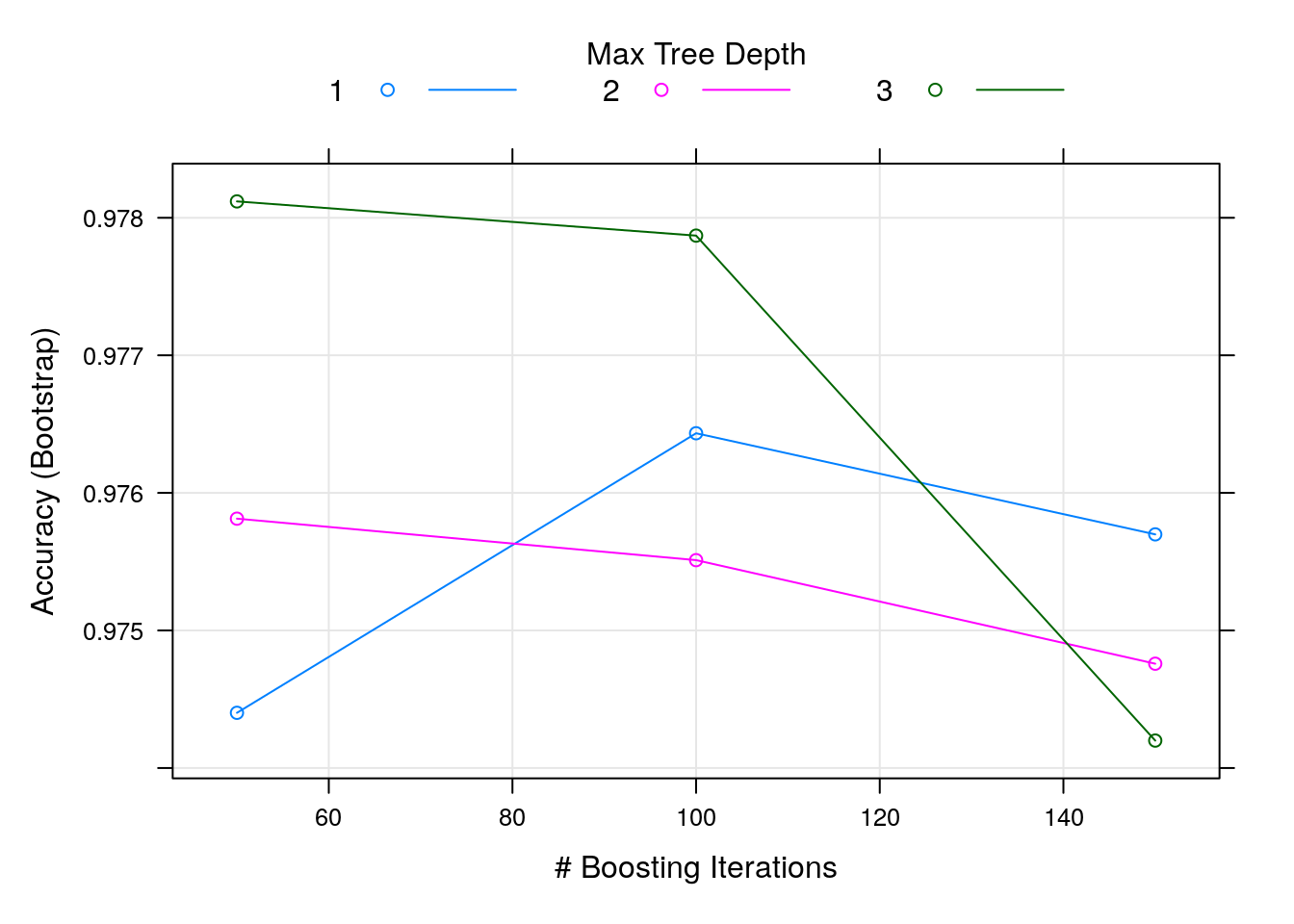
To use the top model to predict the species of penguin in our validation data, we can use the predict function used earlier (by default, the best performing model will be called from the gbm_fit object here):
ml_predictions <- predict(gbm_fit, newdata = ml_penguin_validate)
head(ml_predictions)## [1] Adelie Adelie Adelie Adelie Adelie Chinstrap
## Levels: Adelie Chinstrap GentooNote that if you would like to see the probability associated with each result, you can include the argument type = "prob" within the predict function.
To compare these predictions with the actual species of penguin, we can use the following code - note that if the predicted and actual species match, we obtain a TRUE result, which counts as a 1, so that the output here denotes the number of correct predictions:
sum(ml_predictions == ml_penguin_validate$species)## [1] 63This is an excellent result, considering that our validation data consists of observations for 65 penguins.
We could extend this modelling process by tuning the parameters, but our results here are perfectly sufficient, and further work is beyond the scope of this subject.