Chapter 2 Des données, méthodes et outils pour une thèse ouverte
[à écrire]
Parler du fait qu’on a fait l’ensemble du travail en utilisant des logiciels libres et gratuits : Ubuntu, R, QGIS, OTB, Grass, Qfield, geopackage, etc. Dire qu’on a scripté toutes les analyses et qu’on les a exposées (transparence, reproductibilité, ouverture à la critique). Dire qu’on a fait des codes génériques et que cela a servi à d’autres: post doc de Denis, post doc de Christophe Dire qu’on a décrit les données, les codes Bien expliquer la différence entre logiciel libre, propriétaire, code source ouvert, etc; En annexe, mettre un tableau qui donne tous les outils/librairies utilisés et leur place dans la gestion des données (ie collecte terrain, analyse, stockage, etc)
<– Avec l’intérêt grandissant de la communauté scientifique pour la gestion des données, de nombreux outils informatiques facilitant cette dernière ont émergé ou pris de l’ampleur. Pour une grande majorité, il s’agit d’outils libres et éventuellement à code source ouvert, qui permettent de fluidifier la gestion des données à toutes les étapes : –> - en amont du projet : - au niveau du recueil :
2.1 La théorie : pourquoi une “thèse ouverte”, et comment ?
2.1.1 Quelques mots sur la science ouverte
[à écrire]
2.1.2 Les données
[à écrire]
2.1.2.1 De l’intérêt de gérer rigoureusement les données
Un nombre important de jeux de données a été généré dans le cadre du projet REACT. Pour REACT comme pour de nombreux autres projets, les données sont très souvent la base des travaux de recherche et valorisation du travail. Aujourd’hui, avec des projets générant des données toujours plus nombreuses, variées, volumineuses, et avec le mouvement croissant vers la science ouverte, elle revêt une importance particulière. Par ailleurs, dans un futur proche et avec des initiatives telles le Plan national pour la science ouverte, la garantie de la bonne gestion et valorisation des données brutes sera un élément indispensable à l’obtention de financements pour de tels projets de recherche. Au delà des obligations réglementaires, on peut citer les éléments suivants parmi les arguments en faveur d’une gestion appropriée et rigoureuse des données :
- Un gain de temps significatif lors de l’analyse des données par les membres du projet, en particulier lors d’analyses qui utilisent de nombreuses données, en équilibrant les temps dédiés à la préparation / mise en forme des données et à la modélisation statistique.
- Une décription exhaustive de chaque jeu de données. Les métadonnées donnent un cadre pour renseigner de nombreuses informations relatives au jeu de données : titre, description, personnes impliquées dans la production, couvertures spatiale et temporelle, signification des colonnes, droits associés au jeux de données, etc.
- Un point d’entrée unique vers les données et partagé par tous les membres du projet. On observe régulièrement, dans les projets qui englobent de nombreux acteurs, que chacun possède “sa” version d’un jeu de données. Une gestion appropriée des données permet de centraliser les données, en ayant ainsi la certitude que chacun utilise les mêmes versions des données, et que tous puissent profiter des traitements et “améliorations” effectuées par l’un des membres.
- La valorisation des jeux de données comme produit scientifique à part entière. Ainsi, un jeu de données peut faire l’objet par exemple d’un data paper, forme d’article scientifique qui décrit exhaustivement un jeu de données qui pourra alors être réutilisé par la communauté scientifique et cité dans une bibliographie.
- La reconnaissance du travail que tout-un-chacun a fourni dans la production des données. Un jeu de données bien décrit permet de citer toutes les personnes qui ont participé à sa production : bailleur de fonds, technicien de terrain et/ou de laboratoire, gestionnaire de données, etc. De la même manière, il est possible d’encadrer la réutilisation des données, via l’attribution de droits d’accès/utilisation des données par des parties tierces.
- La possibilité d’ouvrir efficacement les données, afin que d’autres se les approprient et amenènent leurs propres idées, questionnements ou points de vue sur leurs thématiques d’intérêt, et ainsi faire grandir la science.
Qu’entend-on par “gestion appropriée et rigoureuse” des données ? Globalement, il s’agit de toutes les méthodes de gestion qui permettent d’amener les données à un niveau FAIR (acronyme pour Findable, Accessible, Interoperable, Reusable). Selon Wikipedia, la notion de FAIR data recouvre les manières de construire, stocker, présenter ou publier des données de manière à permettre que la donnée soit « Facile à trouver, Accessible, Interopérable et Réutilisable ». Dans la section suivante, nous proposons quelques pistes pour gérer les données dans le cadre de projets de recherche du type REACT.
2.1.2.2 Quelques pistes pour gérer efficacement les données
Il est donc important de réfléchir à la chaîne d’aquisition et de valorisation des données dès la phase de définition du projet, en se posant des questions sur la collecte, la documentation, les aspects éthiques et juridiques, le stockage et la sauvegarde, le partage et l’ouverture des données. Les réponses à ces questions sont idéalement formalisées dans un Plan de gestion des données. Des outils, tels DMP OPIDOR, proposent un cadre pour mettre en place un plan de gestion de données dans le montage d’un projet de recherche.
Ces données ont été collectées tout au long des trois années de la phase de terrain du projet, par de nombreuses personnes et selon divers protocoles
En amont du projet : la réflexion sur la chaîne d’aquisition des données et les rôles
[à écrire]
Pendant le projet : la centralisation et la description des données
[à écrire]
Note : les bases de données relationnelles
Dans la section suivante, nous présentons l’intérêt d’utiliser une base de données relationnelle pour stocker les données d’un tel travail.
Lorsque de nombreux jeux de données sont utilisés, et à fortiori quand ils présentent un aspect relationnel - c’est-à-dire que certains jeux de données sont liés entre eux, les réunir au sein d’une base de données relationnelle plutôt que les conserver dans des dossiers “classiques” d’un ordinateur présente plusieurs avantages, parmi lesquels :
- Offre d’un “support” (point d’entrée) unique pour l’ensemble des jeux de données.
- Vérification des contraintes de relations entre les jeux de données via le modèle relationnel de la base de données implémenté au prélabable. Par exemple, si l’on décide dans le modèle relationnel de la base de données qu’un ménage (défini par un lot d’attribut stockés dans une table, une ligne par ménage) doit nécéssairement dépendre d’un village (défini lui aussi par son lot d’attributs dans une table dédiée), la base de données n’acceptera un nouveau ménage (i.e. une nouvelle entrée dans la table ménage) que si le village associé existe bien dans la table village. Dans le cas contraire, la base rejettera l’entrée en nous avertissant que la contrainte est violée. Ces contraintes permettent d’identifier automatiquement et de corriger nombre d’erreurs dans les jeux de données.
- Capacité à utiliser le Standard Query Language (SQL) pour requêter la base de données. Le SQL est un puissant langage de requêtes de bases de données relationnelles. Certaines fonctions sont particulièrement efficaces sur des jeux de données volumineux.
- Capacité, pour certains systèmes de gestion de bases de données (SGBD), à gérer les données spatialisées (vectorielles et/ou rasterisées), avec de nombreux bénéfices associés, parmi lesquels :
- analyses spatiales via des fonctions SQL dédiées ;
- facilité d’utilisation de la base de données avec des logiciels de SIG (QGIS, ArcGIS, etc.) et d’analyses de données spatialisées (R, Python, etc.) ;
- compatibilité avec les géoservices (par exemple, ceux définis par l’Open Geospatial Consortium) qui permettent de rendre les données FAIR.
La nature des données du projet REACT justifie pleinement l’utilisation d’une base de données relationnelle : nombreux jeux de données, spatialisés pour beaucoup, liés entre eux (i.e. “imbriqués” les uns dans les autres, par exemple les individus recensés habitent dans des ménages qui eux mêmes se situent dans des villages, ces trois niveaux étant décrits respectivement dans des tables).
Lorsque l’on décide d’utiliser une base de données relationnelle pour stocker les données, la question du système de gestion de bases de données (SGBD) à utiliser se pose. Une base de données relationnelle est implémentée dans un système de gestion de bases de données relationnelles (SGBDR). Un SGBDR peut être vu comme un “logiciel” qui permet d’executer un langage normalisé de manipulation des bases de données (le plus connu est le SQL) : créer les tables de la base, les contraintes relationnelles entre les tables, manipuler les tables (les remplir, mettre à jour, supprimer, etc.), requêter les tables, etc. Il existe de nombreux systèmes de gestion de bases de données relationnelles. Ils diffèrent, entre autre, par leur type de license (propriétaire ou libre), leur coût, leur capacité à stocker et requêter des volumes importants de données, leur capacité à gérer les données spatialisées.
Nous avons décidé d’utiliser le SGBD GeoPackage (GPKG) pour stocker les données de nos travaux (et du projet REACT par extension). Geopackage est un SGBD relativement récent (créé en 2014), ouvert, non-propriétaire, embarqué (c’est à dire qu’il se matérialise par un fichier stocké dans l’ordinateur et portable - au contraire d’un sytème client-serveur) et spatialisé. Il peut être vu comme un “container” de données qui gère à la fois les données vecteur, raster et non spatialisées. Très concrêtement, il se matérialise par un fichier (extension *.gpkg), que l’on stocke dans un dossier de son ordinateur ou appareil mobile et que l’on peut s’échanger au même titre que tout fichier informatique. Le format GeoPackage est défini sur la base de standards de données (OGC ou autres), ainsi, bien que récent, de nombreux logiciels historiques permettent de l’ouvrir et de manipuler les données qui y sont contenues. Notons que le logiciel de SIG Quantum GIS en a fait son format par défaut à partir de la version 3, contre précédemment le format propriétaire d’ESRI, format de données phare des SIG : le Shapefile.
Après le projet : l’archivage et l’ouverture des données
[à écrire]
-> embargo -> anonymisation
2.1.3 Les analyses
2.1.3.1 De l’intérêt de gérer rigoureusement les analyses
Avec les données, les codes (ou scripts) constituent l’autre matière première de ce travail - et en général de tout travail d’analyse de données. Les scripts sont des algorithmes de manipulation et analyse de données traduits dans un langage de programmation.
[à écrire]
2.1.3.2 Quelques pistes pour gérer efficacement les codes d’analyses des données
[à écrire] discuter package, github, markdown, bookdown
2.1.4 Les publications
2.1.4.1 De l’intérêt d’ouvrir les publications
[à écrire]
2.1.4.2 Quelques pistes pour publier “ouvert”
[à écrire]
2.1.5 Quelques outils pour la science ouverte
[à écrire] [ici parler des outils qui permettent de gérer efficacement les données et les codes. Faire un tableau]
2.2 La pratique : gestion des données et des codes dans le projet REACT et dans la thèse
2.2.1 La base de données du projet REACT
Pour l’ensemble des raisons précédemment mentionnées, nous avons décidé de stocker et de décrire les données du projet REACT, ainsi que l’ensemble des données générées dans le cadre de nos travaux de thèse, au sein d’une unique base de données relationnelle. La section suivante décrit les données présentes dans la base de données. La dernière section montre comment explorer la base de données avec différents logiciels.
2.2.1.1 Les données disponibles dans la base de données
Le tableau suivant présente les jeux de données utilisés dans nos travaux et disponibles dans la base de données. Le tableau est lui-même issu de la base de données (table metadata_tables).
Le nom des tables dans la base est indiqué dans le tableau par la colonne identifier. Pour faciliter la lecture, seules quelques colonnes de la table metadata_tables ont été intégrées ci-dessous. La table metadata_tables stockée dans la base de données contient de nombreuses colonnes additionnelles, donnant des informations utiles à la compréhensions et réutilisation des donneés, telles qu’une description exhaustive des jeux de données, les personnes ayant contribué à leur production, etc.
2.2.1.2 Accéder à la base de données et la manipuler
La base de données est disponible en téléchargement à l’adresse suivante : [lien final restant à définir] . Le fichier zippé disponible au téléchargement contient la base de données (fichier react.gpkg) et un projet QGIS (react.qgs) associé.
Comme indiqué dans la section précédente, le format GeoPackage est défini sur la base de standards de données (princiapelement OGC) gérés nativement par de nombreux logiciels. Ainsi, il existe de nombreux moyens d’explorer et manipuler les données présentes dans la base. Dans cette section, nous détaillons succintement comment ouvrir et explorer la base de données avec trois logiciels gratuits et multi-plateformes : DB Browser for SQLite, Quantum GIS et R.
Avec DB Browser for SQLite
DB Browser for SQLite (DB4S) est un logiciel léger qui permet de manipuler les bases de données SQLite, SGBD sur lequel s’appuie le format GeoPackage. Le logiciel est téléchargeable à l’adresse suivante : https://sqlitebrowser.org/dl/. Pour ouvrir la base de données dans DB4S, il s’agit simplement de double-cliquer sur le fichier react.gpkg contenant la base de données (à priori, l’ordinateur reconnaît DB4S comme logiciel par défaut pour ouvrir les fichiers au format *.gpkg). La figure suivante présente la base de données ouverte sous DB4S.
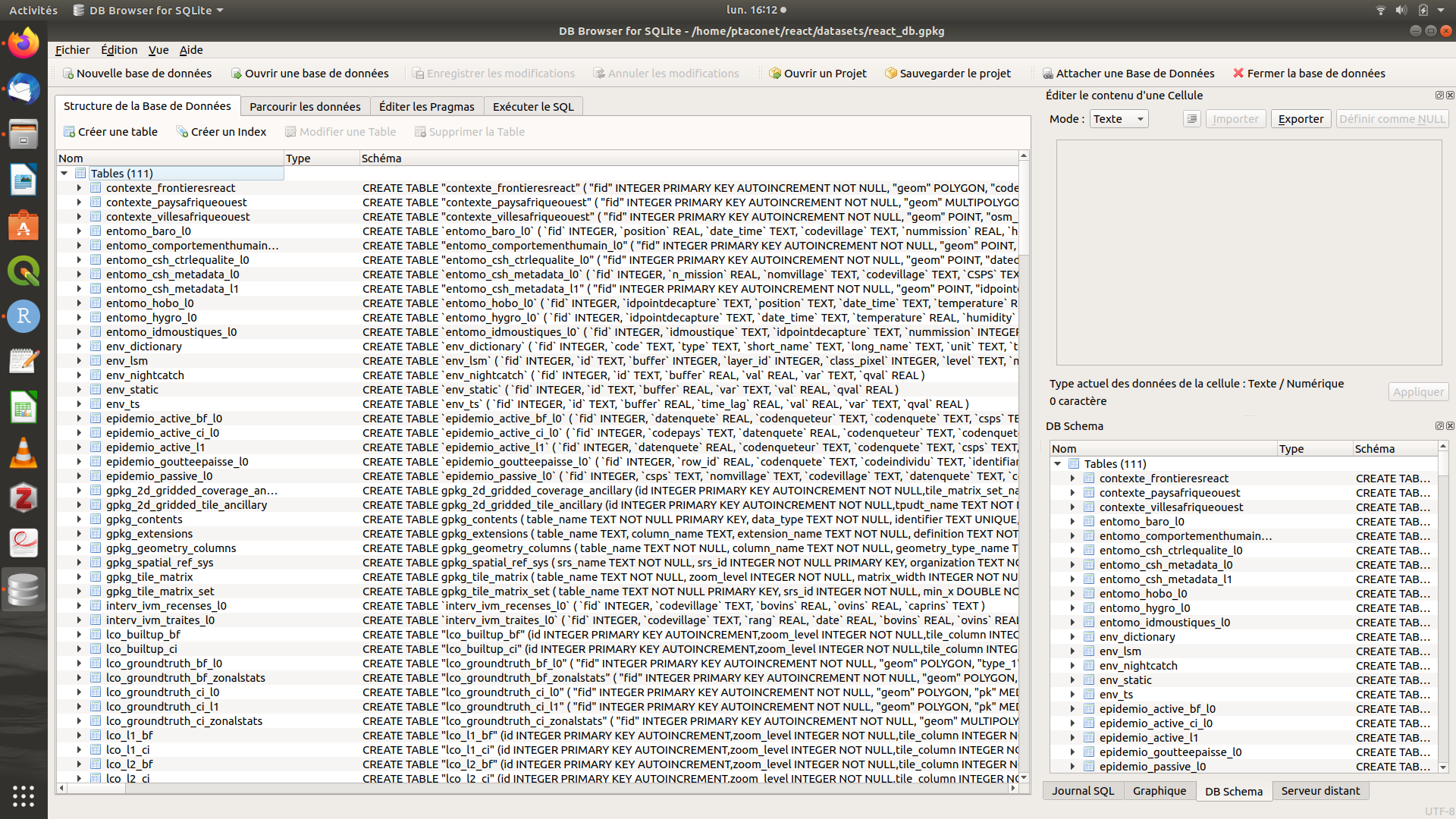
Figure 2.1: Capture d’écran de DB4S - onglet principal
Pour l’utilisateur de la base de données, l’onglet principal est Parcourir les données : à travers cet onglet, l’utilisateur se voit proposer les tables présentes dans la base dans une liste déroulante. Il s’agit simplement de séléctionner la table d’intérêt pour qu’elle apparaisse. NB : toutes les tables préfixées par gpkg_, rtree_ et sqlite_ ne sont pas des données du projet REACT. Ce sont des tables automatiquement générées par le SGBD et nécéssaires pour le bon fonctionnement de la base de données. Il s’agit donc - sans les modifier - de les ignorer.
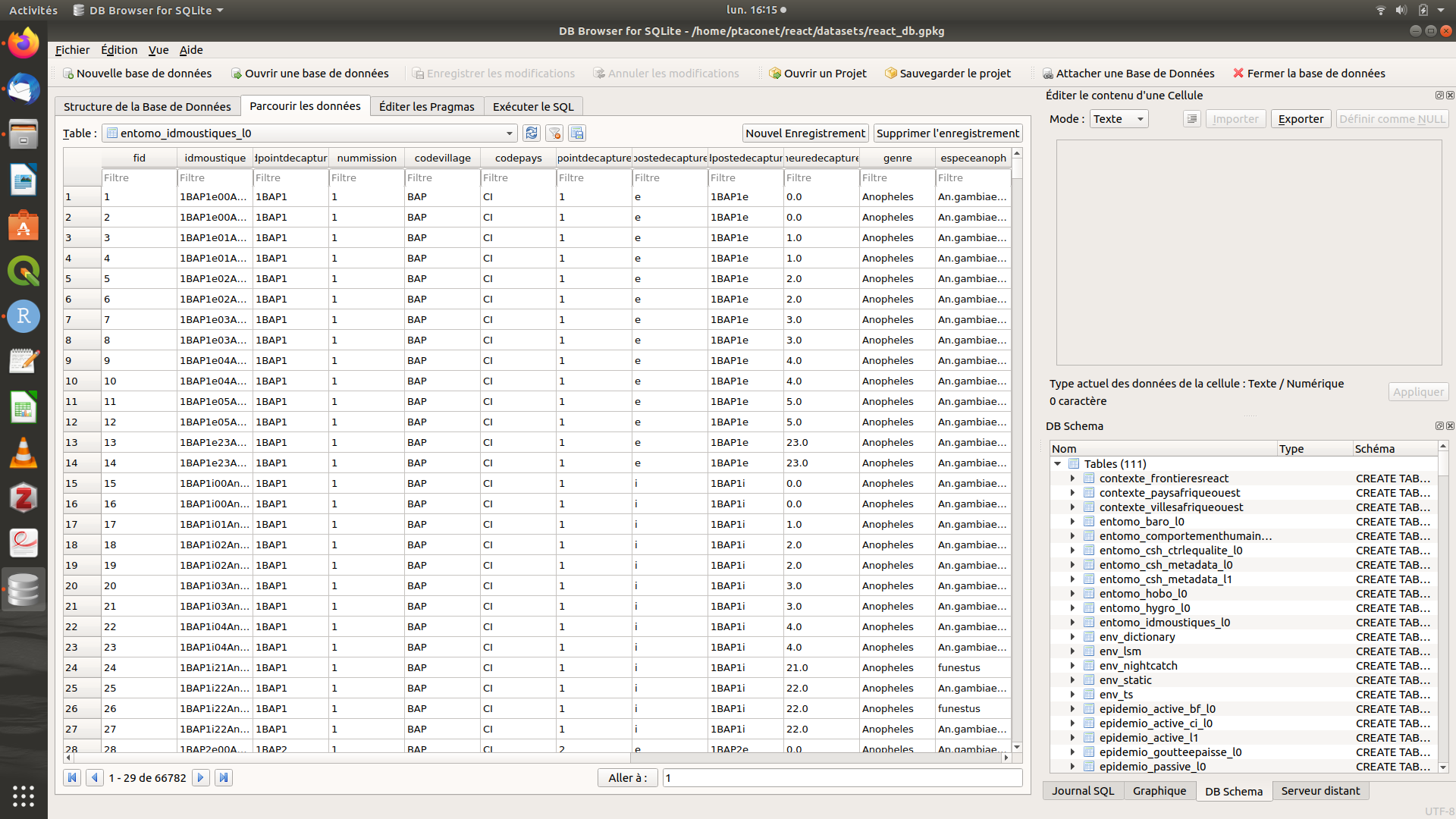
Figure 2.2: Capture d’écran de DB4S - onglet ‘Parcourir les données’
Avec Quantum GIS
Quantum GIS (QGIS) est un logiciel désormais bien connu de SIG. Il permet de lire nombre de formats de données géospatiales, dont le GPKG, qui par ailleurs est le format par défaut du logiciel depuis sa version 3. QGIS est téléchargeable à l’adresse suivante : https://www.qgis.org/fr/site/forusers/download.html. Pour ouvrir la base de données, aller dans l’explorateur (Couche > Gestionnaire des sources de données > Explorateur) puis identifier le lien vers la base de données sous l’option GeoPackage. L’ensemble des données de la base (vecteur, raster et non-spatiales) est alors listé. Double-cliquer sur la table d’intérêt pour l’ouvrir et la visualiser.
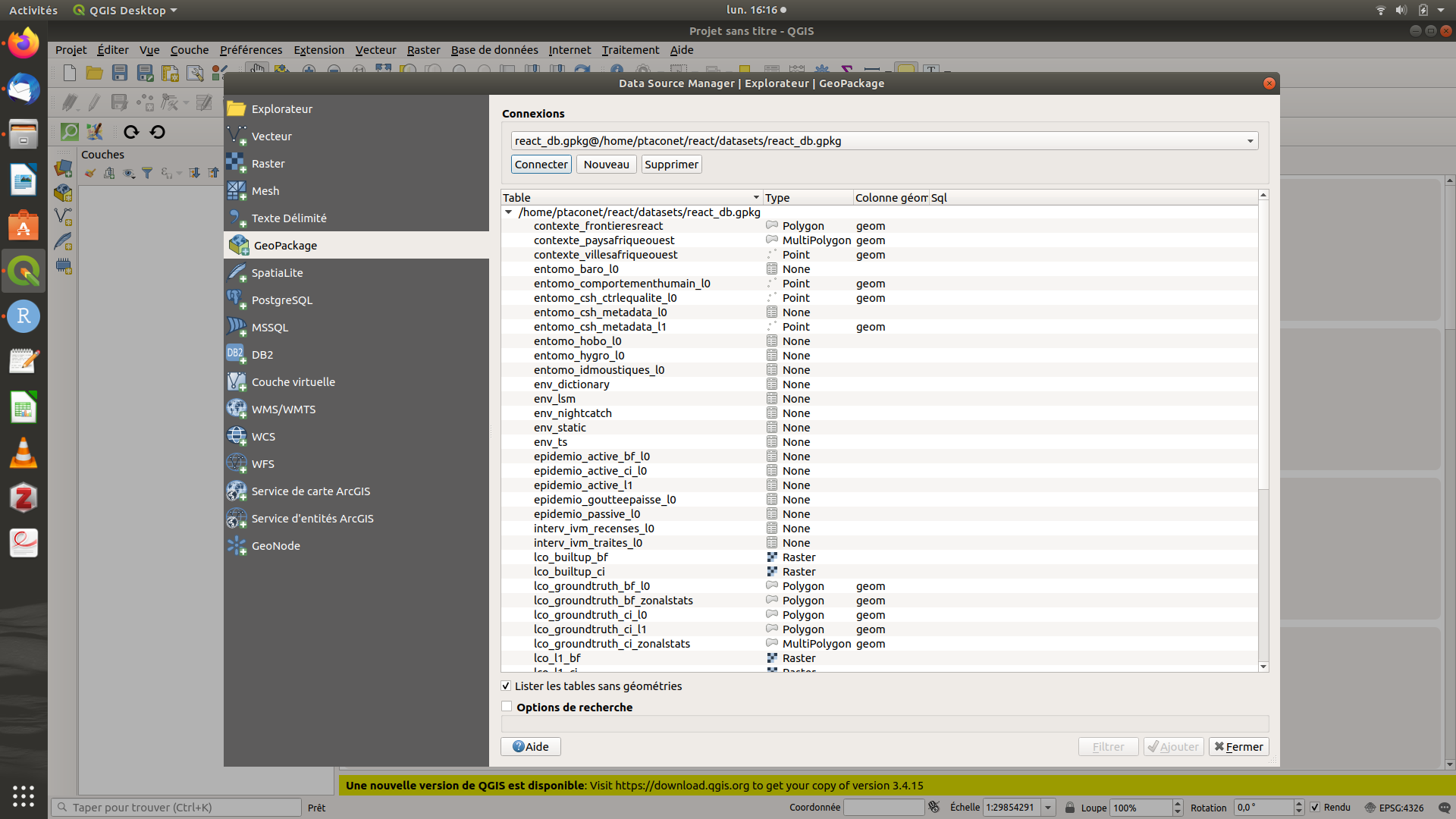
Figure 2.3: Capture d’écran de QGIS - explorateur de données
Nous avons par ailleurs préparé un projet QGIS qui permet d’explorer une partie des tables de la base. Le projet QGIS est téléchargeable au même lien que la base de données (il est disponible dans le fichier zippé). Pour l’ouvrir, il faut placer le projet (fichier react.qgs) et la base de données (fichier react_db.gpkg) dans le même dossier sur l’ordinateur, puis ouvrir le projet en double-cliquant dessus.
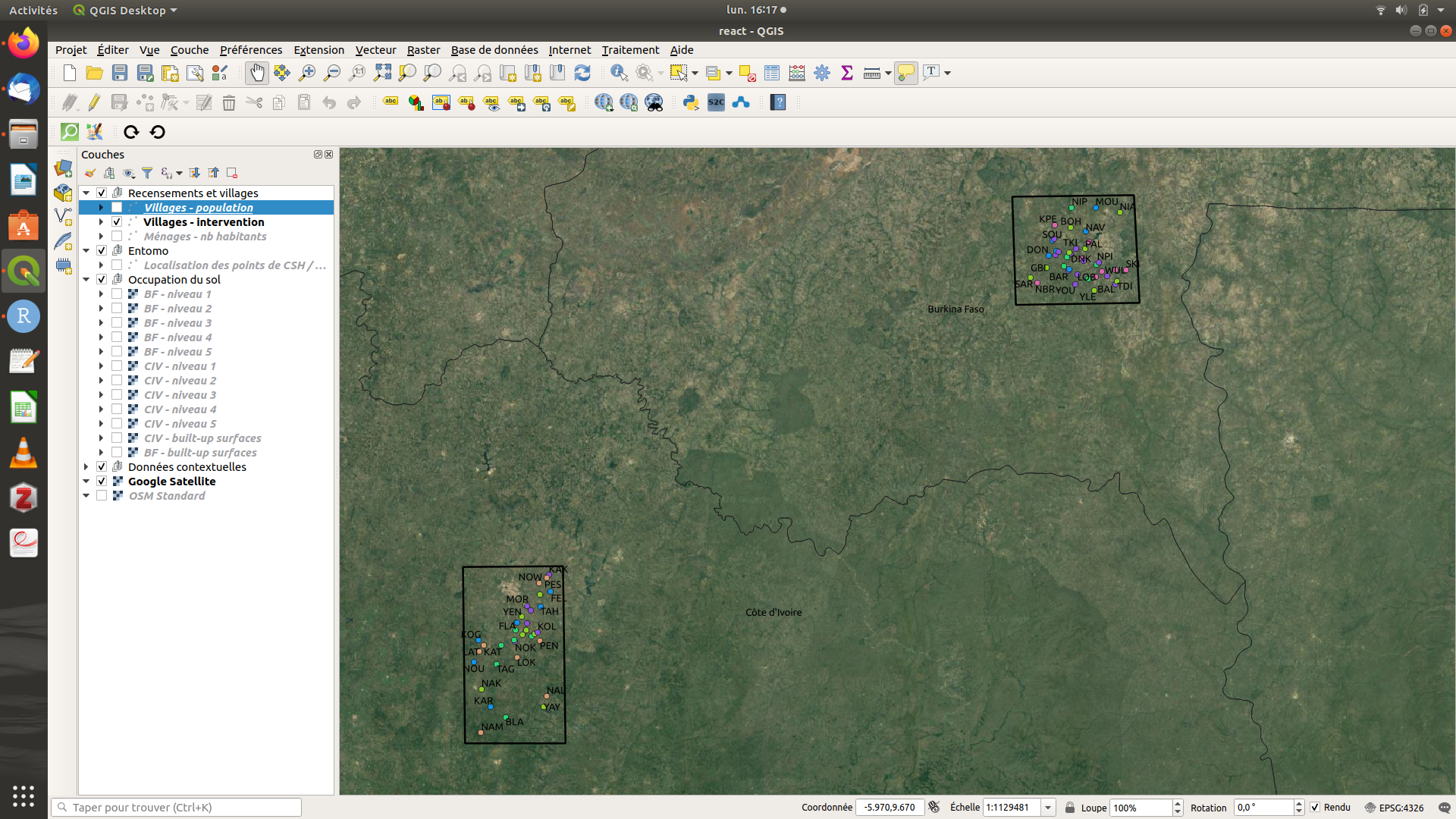
Figure 2.4: Capture d’écran du projet QGIS react.qgs
Une version en ligne du projet QGIS (contenant uniquement les données publiques du projet) est accessible sur le serveur QGIS Cloud à l’adresse suivante : https://qgiscloud.com/ptaconet/react_4cloud/.
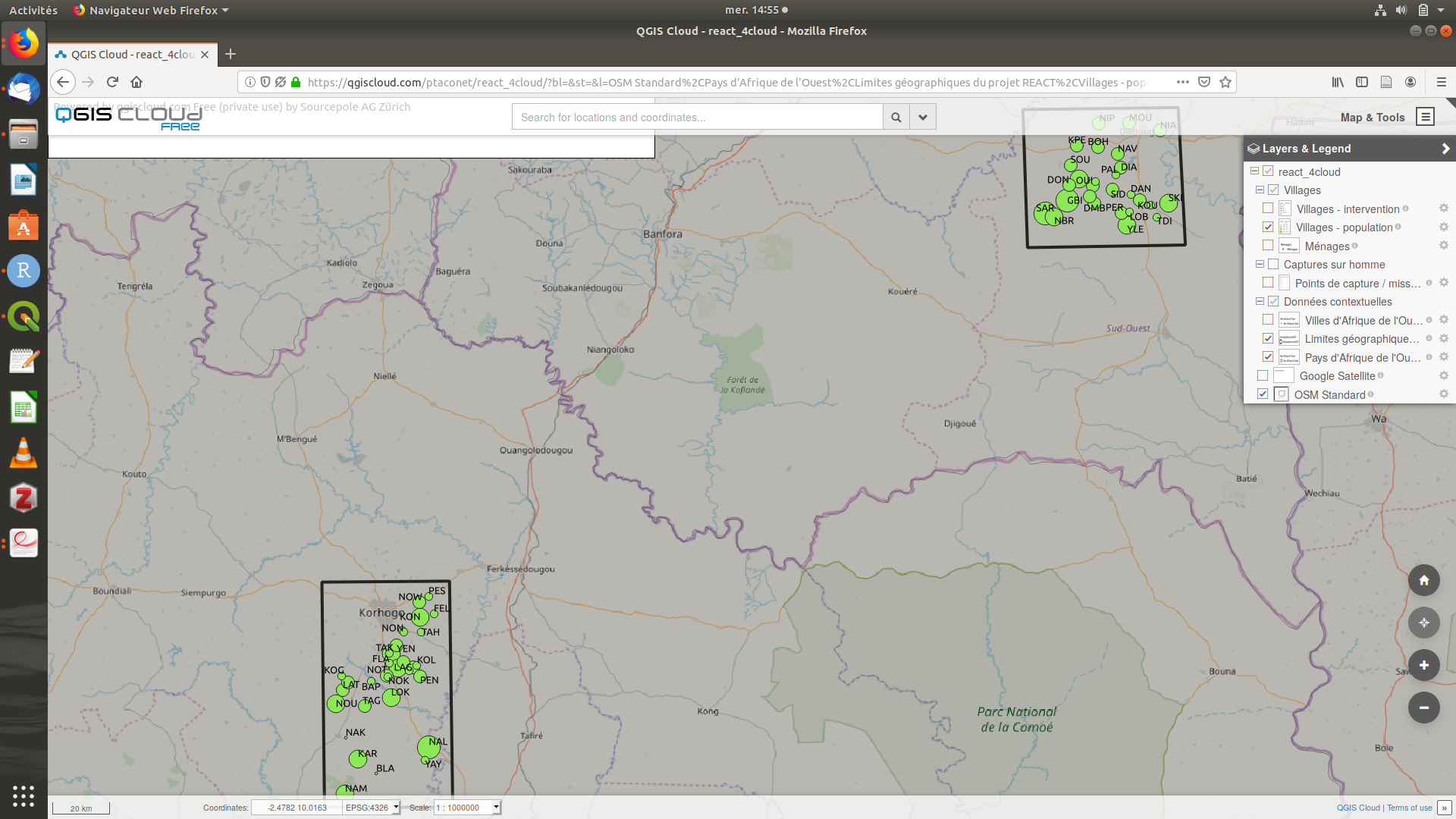
Figure 2.5: Capture d’écran du projet QGIS Cloud react.qgs
Avec R / RStudio
R est un langage de programmation ouvert pour le traitement de données et l’analyse statistique. C’est le langage de programmation que nous avons utilisé pour réaliser l’ensemble des analyses de ce travail de thèse. RStudio est un environnement de développement (autrement dit un logiciel qui facilite la programmation) pour R. R est téléchargeable à l’adresse suivante : https://cran.r-project.org/ et RStudio à l’adresse suivante : https://rstudio.com/.
Figure 2.6: Capture d’écran de RStudio
Le code suivant propose deux options pour ouvrir et explorer la base de données, avec les packages RSQLite ou sf :
# Lien en local vers la base de données (fichier react_db.gpkg)
path_to_db <- "/home/ptaconet/react/datasets/react_db.gpkg" # lien local vers la base de données (fichier au format *.gpkg)
#### Option 1 : avec le package RSQLite
library(RSQLite)
con <- dbConnect(RSQLite::SQLite(),path_to_db)
# Pour lister toutes les tables de la base :
(RSQLite::dbListTables(con))
# Ouvrir la table "recensement_village_l1" de la base de données en tant que data.frame
tab<-RSQLite::dbReadTable(con,"recensement_villages_l1")
head(tab)
#### Option 2 : avec le package sf
library(sf)
tab<-sf::st_read(path_to_db,"recensement_villages_l1") # L'avantage par rapport à RSQLite est que sf détecte l'aspect spatial des données (si présent) et l'ouvre dans R en tant qu'objet de classe sf (simple feature)
head(tab)