Chapter 1 Considérations Théoriques
Vous trouverez dans les sections suivantes, quelques points qui me semblent essentiels d’éclaircir quand on souhaite réaliser les analyses en modèles linéaires mixtes.
Tout d’abord, nous aborderons certains termes fréquemment rencontrés dans ce type d’analyse et leur donnerons une définition simple.
Ensuite, nous exposerons quelques avantages et inconvénients des modèles linéaires mixtes, notamment par rapport aux ANOVA qui constituent également des modèles linéaires mais non mixtes (i.e. ils ne peuvent tenir compte de facteurs fixes et aléatoires en même temps).
Nous insisterons un peu plus sur l’intérêt de modéliser les variables aléatoires et notamment la plus simple et couramment modélisée : le facteur sujet.
Puis nous parlerons rapidement des conditions d’application de ces tests mais aussi des conditions d’application que nous ne sommes pas tenus de respecter.
Enfin, nous présenterons une typologie des différents MLM et une conception plus hiérarchique de ces modèles. Cette dernière partie préparera les exercices pratiques, dans la mesure où on ne peut faire de MLM que si nous avons une bonne représentation de notre design expérimental.
1.1 Terminologie
Les modèles linéaires mixtes (MLM ; ou encore modèles multi-niveaux) sont des modèles statistiques qui permettent de tenir compte d’effets d’intérêts (effets fixes) et d’effets aléatoires propres à l’échantillon (effets aléatoires) dans la prédiction de la variable dépendante.
L’adjectif linéaire fait référence à la combinaison linéaire des différents facteurs :
\[Y = βX + uZ + ε\]
Où Y est le comportement ou résultat à prédire, de nature continue. X est un facteur fixe, Z un facteur aléatoire et ε le résidu.
β est l’équivalent du coefficient de régression dans les régressions linéaires et correspond aux effets fixes dans les modèles linéaires mixtes.
u correspond à l’effet aléatoire.
Leur caractère mixte fait référence au fait qu’ils sont en mesure de modéliser à la fois des effets fixes et des effets aléatoires.
X peut également faire référence à des covariables. Cette dénomination est mathématiquement similaire à “facteurs fixes”, puisqu’il n’y a aucune différence ni dans sa notation mathématique, ni dans son implémentation dans les logiciels. Toutefois, en psychologie, une covariable est souvent considérée comme une variable ayant un effet sur le comportement (Y) mais qui n’est pas toujours une variable expérimentale. Nous y ferons référence en ce sens lorsque ce sera nécessaire.
1.1.1 Les effets
1.1.1.1 Les effets fixes
Les effets fixes sont associés à des variables (i.e. facteurs fixes) qui peuvent être continues (e.g. : âge, poids) ou catégorielles (e.g. genre, niveau socio-culturel).
Ils sont l’équivalent des coefficients de régression des modèles de régression linéaire et constituent bien souvent les variables d’intérêt pour lesquelles nous cherchons à estimer les paramètres (e.g. β) et sur lesquelles nous posons nos hypothèses. Autrement dit, ils décrivent la relation entre les prédicteurs (X) et le comportement (Y).
Dans un MLM, tous les niveaux de tous les facteurs fixes peuvent (et doivent) être représentés. C’est à partir de ces niveaux que les contrastes d’intérêts sont réalisés.
1.1.1.2 Les effets aléatoires
Notre échantillon d’observations utilisé pour notre étude comporte souvent des paramètres dont nous connaissons la valeur et qui est propre à cet échantillon et non à la population à laquelle nous voulons généraliser les résultats (e.g. le facteur sujet ou la classe à laquelle appartiennent des enfants). Ce sont donc des paramètres sur lesquels nous ne posons pas d’hypothèse. Ces paramètres relèvent de facteurs et d’effets aléatoires.
Les effets aléatoires peuvent agir sur deux paramètres de la prédiction du comportement par les effets fixes : une déviation de l’intercept ou une déviation de la pente.
1.1.1.3 Exemple
Imaginons que nous réalisions une étude chez des enfants sur l’effet de la menace du stéréotype. Dans notre étude, nous présentons un exercice de mathématiques qui est présenté comme soit distinguant les garçons et les filles (condition d’effet de menace du stéréotype), soit comme ne montrant aucune différence entre les garçons et les filles (condition contrôle). Il s’agit de notre première VI (ou facteur expérimental). Notre seconde VI est le genre : nous nous attendons à ce que les filles soient soumises à l’effet de la menace du stéréotype, contrairement aux garçons. Une analyse classique en ANOVA prendrait uniquement ces deux facteurs. Dans un modèle linéaire mixte, ces variables constitueraient des variables fixes pour lesquels nous aimerions tester les effets fixes et généraliser à la population dont est extraite l’échantillon.
Toutefois, imaginons que les enfants soient issus de différentes classes au sein d’une école. Le fait qu’ils appartiennent à différentes classes peut avoir son importance : il y a peut-être un ratio garçons/filles différent en fonction des classes ou en moyenne, certaines classes ont de meilleurs résultats en mathématiques que d’autres. Cette information peut certes avoir son importance, mais elle appartient à l’échantillon et non à la population dont est extrait l’échantillon et ne constitue pas une variable dont nous aimerions tester expérimentalement l’effet. Ce type de variable serait intégrée en tant que variable aléatoire dans un MLM. Plus simplement encore, certaines filles pourraient ne pas être soumises à l’effet de menace du stéréotype ou en tout cas, pas très fortement. Prendre en compte cette variabilité individuelle est aussi possible en tant que variable aléatoire.
Notez qu’un facteur aléatoire peut l’être pour une étude mais pas une autre. Par exemple, le fait que des enfants appartiennent à une classe en particulier peut ne pas faire partie des hypothèses que nous testons et donc, faire partie des variables aléatoires. Par contre, si nous voulons tester l’effet de l’appartenance à une classe (effet d’une pédagogie ou d’un enseignant), cette variable peut devenir une variable fixe.
1.1.2 Résumé
| Caractéristiques | Facteurs fixes | Facteurs aléatoires |
|---|---|---|
| Nature | Continue ou catérgorielle | Catégorielle |
| Intérêt expérimental | Oui | Non (mais cela peut changer en fonction de l’étude & des hypothèses |
| Question posée | Les effets des différents traitements | La variabilité entre les niveaux |
| Représentation de tous les niveaux possibles | Oui (propre à l’étude) | Non (l’échantillon est extrait d’une population) |
| Effets fixes | Effets aléatoires | |
| Paramètre | À estimer | Connu |
| Intérêt dans le modèle | Caractériser la relation comportement/prédicteur | Caractériser les déviations aléatoires propres aux observations |
| Niveau de représentation | Population | Échantillon |
1.1.3 Conclusion
Alors que les effets fixes représentent des tendances moyennes, les effets aléatoires représentent les déviations de ces tendances en fonction de facteurs catégoriels.
L’un des avantages de cette modélisation est de résoudre le problème de non-indépendance des données. En effet et contrairement aux régressions multiples, l’intercept et la pente de la droite de régression sont adaptés aux valeurs des facteurs aléatoires (e.g. adaptées aux participants et/ou aux items). Ceci peut par exemple permettre de prendre en compte le fait qu’un individu réponde particulièrement rapidement ou qu’un item produise très fréquemment des mauvaises réponses (modulation de l’intercept). Dans la même veine, il est ainsi possible de rendre compte qu’un participant peut subir plus fortement l’effet d’une condition expérimentale qu’un autre (modulation de la pente).
À noter que ces déviations d’intercept et de pente sont supposées suivre une distribution normale.
1.2 Avantages et inconvénients des modèles linéaires mixtes
1.2.1 L’indépendance des observations
En psychologie, il est fréquent de prendre plusieurs mesures chez un même sujet. C’est notoirement le cas dans les modèles à mesures répétées où le sujet sera confronté à différentes modalités d’un même facteur (e.g. il verra des visages neutres et exprimant une émotion dans une tâche de présentation de visages) ou les modèles d’analyse longitudinale où des sujets sont suivis sur une longue période de temps.
Toutefois, l’indépendance des observations est un prérequis pour la majeure partie des tests statistiques utilisés en psychologie. Par exemple, les analyses de régression produisent les paramètres d’une droite de régression commune à toute les observations, négligeant que certaines d’entres elles pourraient être corrélées. Cette non prise en compte de la corrélation entre des observations diminue la puissance du test à représenter la réalité.
Les MLM se dispensent de l’indépendance des observations. Mieux encore, ils permettent de modéliser la corrélation entre les observations. C’est un peu ce qui se passe lorsque nous intégrons les sujets en tant que variable aléatoire dans le modèle : nous considérons que les données du sujet 1 sont plus ressemblantes entre elles que les données des sujets 1 et 2 confondues (voir la section Modéliser les facteurs aléatoires).
1.2.2 Comparaison avec les ANOVA
Robustes, résistants à certaines violations des conditions d’applications, flexibles et faciles à interprétés, les ANOVA sont peut-être les tests statistiques les plus utilisés pour tester l’effet d’un facteur expérimental.
Pourtant, ces tests restent limités par certains aspects et notamment par leur incapacité à prendre en compte des variations entre les observations ou encore la corrélation entre les observations.
Il y a tout un tas de conditions d’application dont nous tenons rarement compte lorsque nous réalisons une ANOVA. Parfois par ignorance, par négligence ou tout simplement parce que nous avons l’habitude de travailler avec des échantillons qui respectent ces conditions. Mais listons tout de même quelques conditions que les MLM n’ont pas besoin de respecter, contrairement à d’autres tests dont les ANOVA.
- Les variances peuvent être hétérogènes
- Les résidus peuvent ne pas être totalement indépendants (cf l’indépendance des observations)
- La sphéricité de la matrice de covariance (égalité des variances des différences entre toutes les conditions) n’est pas nécessaire
- Le design peut ne pas être équilibré
- Le design peut être complexe dans l’emboîtement et le croisement des facteurs
Ci-dessous un tableau présentant d’autres atouts des modèles linéaires mixtes comparés aux analyses de variance.
| ANOVA | MLM |
|---|---|
| Modélisent la variabilité sujet et item séparément (i.e. deux modèles différents) | Peuvent modéliser la variabilité sujet et item en un seul modèle |
| Dans un modèle à mesures répétées, les données manquantes invalident les données de l’observation : les données d’un participants sont considérées comme appartenant à la même observation | Les données manquantes n’invalident pas l’observation : chaque donnée est considérée individuellement |
| Les VI sont catégorielles | Les VI peuvent être continues ou catégorielles |
| Informent sur la significativité d’un effet mais pas sa magnitude ou sa direction | Informent sur la significativité, la magnitude et la direction d’un effet |
| Supportent difficilement les designs déséquilibrés | Supportent facilement les designs déséquilibrés |
| Nécessité de variances homogènes | Les variances peuvent être hétérogènes |
| Indépendances des résidus | Les résidus peuvent ne pas être indépendants |
| Sphéricité de la matrice de covariance | Sphéricité de la matrice de covariance non nécessaire |
1.2.3 Inconvénients des MLM
- Très flexible, ils nécessitent une véritable réflexion quant au modèle à stipuler
- Nécessite parfois plus de données que ce que nous avons, d’autant plus lorsque le modèle est complexe
1.2.3.1 Une bonne représentation du design
Avec le développement des logiciels, il est devenu incroyablement facile de réaliser une ANOVA, à tel point que les enseignements en statistiques se consacrent moins à la nature des calculs sous-jacents qu’au développement des compétences de sélection du modèle de l’ANOVA (e.g. mesures répétées, indépendantes ou mixtes) et du test des conditions d’application.
Le développement de cette compétence peut d’ailleurs grandement aider l’appropriation des MLM dans la mesure où le chercheur doit avoir une idée extrêmement précise de la nature de son design, notamment des variables qui peuvent être intégrées en tant que facteurs fixes ou aléatoires.
Cette difficulté est plus liée à la grande flexibilité des MLM qu’à l’interface du logiciel utilisé : les erreurs de construction du modèle sont tout autant possibles avec SPSS qu’avec R. Puisqu’ils sont flexibles, ils nécessitent une véritable réflexion de la part du chercheur.
Est-ce que ce facteur est un facteur fixe ou aléatoire ? Est-ce que je peux intégrer ce facteur en tant que variable aléatoire ? Est-ce qu’il faut que je modélise les facteurs fixes et l’ensemble des interactions possibles ? Est-ce que ces deux facteurs sont croisés ou emboîtés ? Est-ce que j’ai assez de données pour que le modèle soit tenable ?
C’est souvent avec ce genre de questions que nous nous rendons compte que notre design expérimental est bien plus complexe que ce que nous pensions et qu’il aurait peut-être fallu y réfléchir à deux fois avant de lancer l’étude…
1.2.3.2 Plusieurs possibilités
Le corolaire de cette flexibilité est qu’il y a souvent plusieurs solutions pour un même design. J’ai cru remarquer que ceci tenait souvent à deux critères :
- Le ratio données/complexité du modèle. Plus un modèle est complexe, plus il faudra de données pour qu’il soit tenable.
- La justification de l’inclusion ou non des variables. Il y a deux stratégies pour établir son modèle :
- Faire le modèle le plus proche de la réalité possible (qu’on pourrait nommer modèle exhaustif), au risque de ne pas avoir assez de données pour le faire tenir.
- Faire le modèle qui explique le plus simplement possible les données (qu’on pourrait nommer modèle parcimonieux), au risque de négliger des variables explicatives.
- Faire le modèle le plus proche de la réalité possible (qu’on pourrait nommer modèle exhaustif), au risque de ne pas avoir assez de données pour le faire tenir.
Mais il est relativement rare de parvenir à un modèle unique en une seule fois. Bien souvent, nous nous retrouvons à réduire un modèle exhaustif en supprimant des variables peu explicatives ou à agrémenter un modèle parcimonieux en intégrant des variables à fort potentiel explicatif. La première approche est une approche top-down, la seconde est plutôt step-up.
1.3 Modéliser les facteurs aléatoires
1.3.1 Un exemple
Pour illustrer la pertinence de modéliser les effets aléatoires, nous reprendrons l’exemple de Brown (2021) sur la modélisation de l’effet aléatoire sujet (assez systématiquement inclus dans les MLM).
Dans l’exemple fictif de Brown (2021), 4 participants devaient traiter des items qui variaient selon le degré de difficulté (sur des paramètres simples, tels que leur fréquence d’usage). L’hypothèse est que plus les mots sont difficiles, plus les temps de réaction sont élevés. Bien que cette hypothèse soit raisonnablement généralisable, il est tout à fait possible que 1) des sujets aient tendance à répondre plus ou moins rapidement que d’autres et 2) que des sujets soient plus ou moins soumis à cet effet de difficulté que d’autres.
Modéliser les effets aléatoires va permettre de tenir compte de ces cas de figure et même mieux : cela va permettre de généraliser à d’autres valeurs des facteurs aléatoires, non représentées dans les données (ce que ne permet pas l’ANOVA).
1.3.1.1 Cas N°1 : Un modèle des plus simples
Dans un modèle de régression simple, seuls les effets fixes sont modélisés. In fine, le modèle propose une droite de régression qui permet de prédire le temps de réaction en fonction de la difficulté de l’item pour tous les sujets.
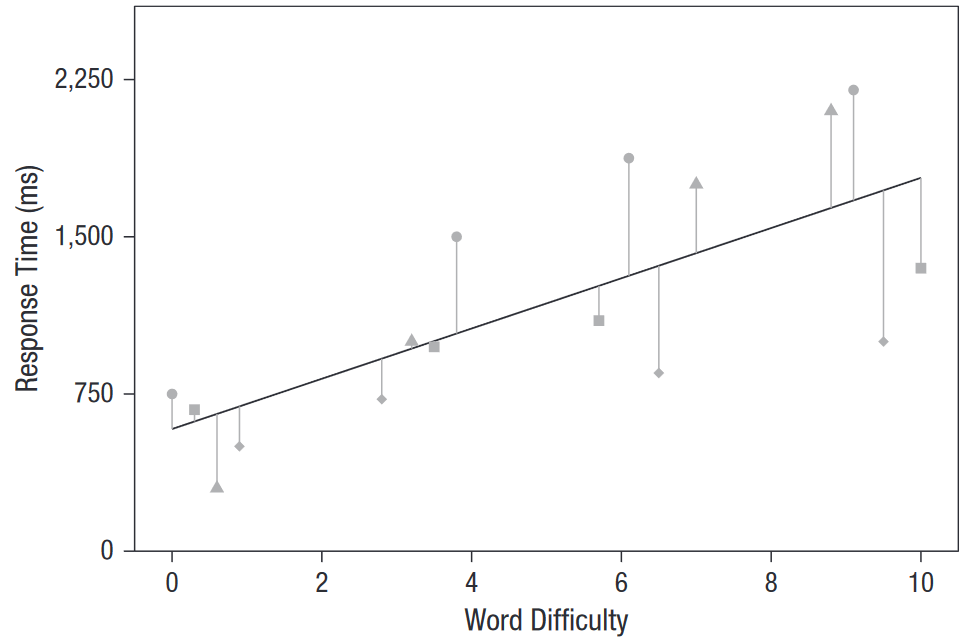
Figure 1.1: Cas N°1 - modélisation des effets fixes uniquement
Nous constatons ici qu’effectivement, plus un item est difficile, plus le temps de réaction est grand. Le modèle a construit une droite de régression qui s’applique à tous les sujets (les icônes sont informatives pour nous, le modèle n’en tient pas compte). Notons que l’erreur résiduelle est relativement élevée (précisément : 410ms), le modèle pourrait expliquer un peu mieux les données.
1.3.1.2 Cas N°2 : Effet aléatoire - l’intercept
Imaginons que nous souhaitions prendre en compte que certains sujets ont tendance à répondre plus rapidement que d’autres. Autrement dit, prendre en compte la variabilité inter-sujet de performance générale. C’est ce qui est représenté dans la figure ci-dessous.
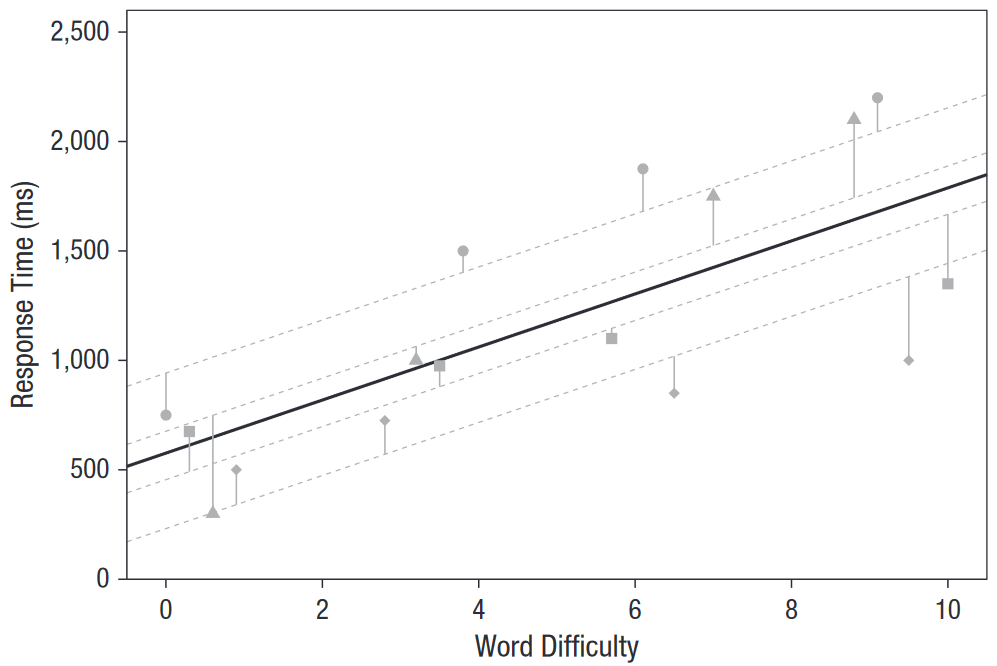
Figure 1.2: Cas N°2 - modélisation de l'effet aléatoire - intercept
Nous constatons ici que bien que l’effet de la difficulté du mot sur le temps de réaction soit identique pour tous les sujets (i.e. les pentes sont identiques) et que l’effet moyen de la difficulté du mot (facteur fixe) soit représenté en courbe pleine, chaque sujet dispose de sa propre courbe de régression. Le modèle prédit bien mieux les réponses de chaque participant et présente une erreur résiduelle moindre par rapport au modèle précédent (ici, 275ms).
1.3.1.3 Cas N°3 : Effet aléatoire - l’intercept & la pente
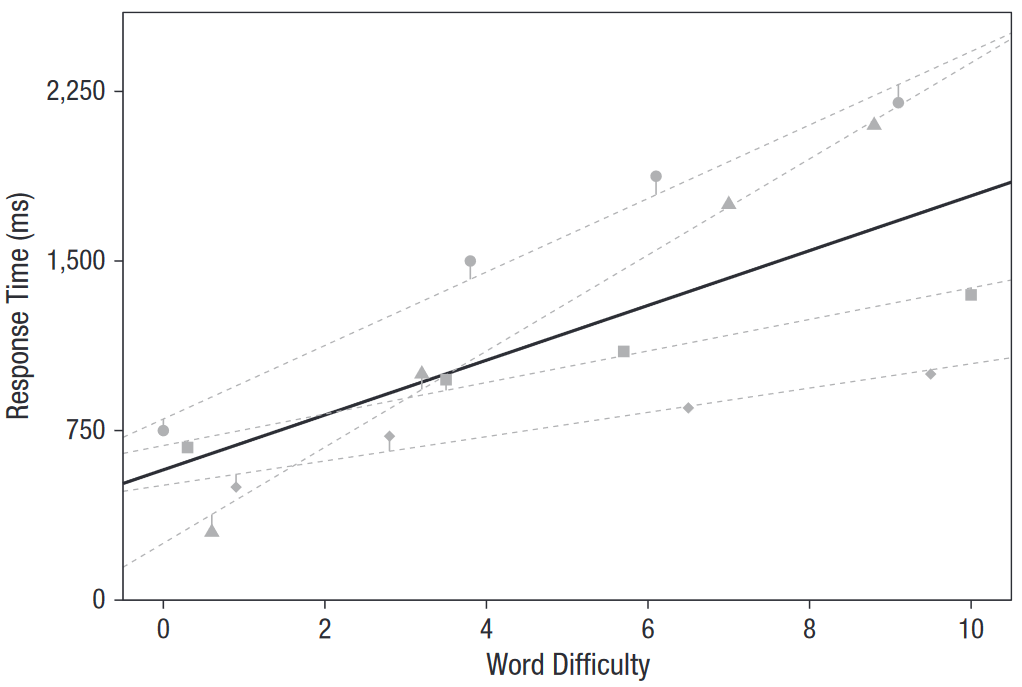
Figure 1.3: Cas N°3 - modélisation de l'effet aléatoire - intercept & pente
Ici, non seulement la droite de régression varie pour chaque sujet en fonction de sa tendance générale à répondre plus ou moins rapidement (i.e. l’intercept) mais aussi en fonction de l’intensité de l’effet du facteur fixe (i.e. difficulté du mot) sur le comportement (ici, le temps de réaction). L’effet de difficulté du mot sur le temps de réaction reste toujours valable mais varie en fonction des sujets. De plus, le modèle produit ici une erreur résiduelle moindre que les deux premiers modèles (75ms).
Notez que le même raisonnement peut s’appliquer aux items utilisés pour l’étude. Depuis les premières études comportementales et l’utilisation des ANOVA en psycholinguistique, il est courant de produire des ANOVA sur les sujets et les items. Pourquoi cela ? Rappelez-vous que l’un des intérêts des tests statistiques est de généraliser à l’ensemble de la population dont est extrait l’échantillon. Imaginez que vous ayez construit un ensemble d’énoncés ironiques auxquels vous confrontez les sujets. Si vous réalisez une ANOVA sur les sujets (notée F1), vous pourrez généraliser les résultats à l’ensemble de la population. Mais rien ne vous dit que les résultats sont applicables à l’ensemble des énoncés ironiques. Pour cela, vous devrez réaliser une ANOVA sur les items (notée F2). L’avantage des MLM par rapport aux ANOVA est de pouvoir, en un seul modèle, généraliser à la population des individus et des items.
N’oublions pas que les effets aléatoires sont nécessairement catégoriels. Si la mesure de votre facteur ne l’est pas, alors le facteur sera entré en tant que facteur fixe.
1.3.2 Puis-je tout modéliser ?
Il y a une règle d’or à respecter lorsque nous voulons modéliser les effets aléatoires : ils doivent être de nature intra. Reprenons l’exemple de Brown développé ci-dessus et attardons-nous sur le lien qu’entretien le facteur difficulté avec le facteur sujet et le facteur item.
1.3.2.1 Avec le facteur sujet
Chaque sujet (chaque modalité du facteur sujet) est confronté à toutes les modalités du facteur difficulté. De fait, le facteur difficulté est, par rapport au facteur sujet, un facteur intra. La modélisation de la variation de son effet chez les sujets a du sens.
1.3.2.2 Avec le facteur item
Chaque item (chaque modalité du facteur item) n’appartient qu’à une modalité du facteur : ici, un mot ne peut pas être à la fois facile et difficile, ils ont été sélectionnés et classés par rapport à cette propriété. De fait, le facteur difficulté est, par rapport au facteur item, un facteur inter. La variation de son effet chez les items n’a pas de sens.
1.3.2.3 D’autres exemples
Pour vous donner une idée un peu plus représentative de ce que peuvent être des facteurs aléatoires, nous pouvons prendre un exemple courant dans les tutoriels sur les MLM : celui de l’étude chez des enfants.
Imaginons une étude portant sur l’effet de la menace du stéréotype chez des enfants de CE1 de différentes écoles. Nous faisons passer un test de mathématique qui est présenté soit comme mettant en évidence une différence entre les garçons et les filles, en faveur des premiers (condition de menace du stéréotype), soit comme ne montrant aucune différence entre les garçons et les filles (condition neutre). Nous aurions donc au moins deux effets fixes : le sexe et la condition de menace.
Mais comme tout expérimentateur le verra et d’autant plus celles et ceux qui travaillent avec ce type de population, d’autres facteurs peuvent avoir un effet sur la réussite à cet exercice. D’emblée, nous pensons au fait que les élèves appartiennent à des écoles différentes. Mais au sein des écoles, les élèves peuvent aussi appartenir à des classes différentes.
Nous pourrions inclure les écoles et les classes en tant que facteurs fixes mais cela impliquerait que 1) nous pensons que ce sont des facteurs d’intérêt théorique et 2) nous aimerions généraliser nos résultats aux modalités de ces facteurs.
Nous voilà donc avec des facteurs qui peuvent avoir un effet mais pas d’intérêt théorique, qui sont imbriqués et qui rendent le design bancal. Les ANOVA (bien que résistantes) ne sont pas très douées pour prendre en compte ce type de facteurs. Les MLM le font très bien en les considérant comme des facteurs aléatoires. Nous pourrons ainsi prendre en compte que ces facteurs existent, qu’ils induisent une variation dans les données, qu’ils sont imbriqués, rendent le design non équilibré et en plus, nous pourrons dire que nous généralisons les données au-delà de la présence des valeurs observées pour ces facteurs.
1.3.2.4 Considérations supplémentaires
Nous aurons compris que la nature de notre design impliquera un ensemble de contraintes sur la constitution de notre modèle. C’est ce que j’appelle des contraintes pratiques : en pratique, nous ne pouvons pas modéliser de facteur aléatoire continu ni inter-sujet ou inter-item.
D’autres contraintes pratiques émergeront et seront liées à la quantité de données que nous avons pour tester notre modèle.
Enfin, des contraintes théoriques viendront également s’appliquer à votre modèle. Certaines sont évidentes et sont liées aux facteurs fixes (ceux dont vous voulez tester l’effet). D’autres sont plus subtiles et impliquent des covariables, qu’elles soient inhérentes aux sujets ou aux items. D’autres sont plus contestables et viennent des reviewers (un reviewer avait exiger l’inclusion en facteur fixe, d’un facteur que considérais comme aléatoire et qui de plus, n’avait aucun effet significatif en tant que facteur fixe).
À toutes ces contraintes, vous pouvez apporter une réponse qui dépendra de votre approche top-down (du modèle exhaustif au modèle parcimonieux) ou step-up (du modèle parcimonieux au modèle exhaustif), du test d’hypothèse (le facteur participe-t-il significativement au modèle ?) ou théorique (même si le facteur ne joue pas significativement sur le modèle, son implication théorique mérite-t-elle son inclusion ?).
Résumé: Inclure des facteurs fixes ou aléatoires nécessite une véritable démarche intellectuelle. Pour les facteurs fixes, nous nous demanderons si un facteur ou une interaction fait partie d’un plan d’hypothèses. Pour les facteurs aléatoires, nous nous demanderons s’il y a des raisons de supposer que l’intercept et/ou la pente d’un effet peuvent varier en fonction d’un facteur catégoriel ou de non-intérêt théorique.
1.4 Conditions d’application des modèles linéaires mixtes
1.4.1 La nature de la variable dépendante
La variable dépendante doit nécessairement être de nature continue. Si vous voulez étudier l’effet de la concrétude de mots (facteur fixe) sur leur temps de traitement (VD continue), les MLM peuvent tout à fait s’appliquer.
Si par contre, vous voulez étudier l’effet du genre (facteur fixe) sur le nombre de chutes (VD discrète) chez la personne âgée, les MLM risquent de ne pas être tout à fait adaptés (bien qu’en réalité, ils peuvent relativement bien s’accommoder de ce genre de déviation).
Ultimement, si vous voulez étudier l’effet d’un Master de psychologie (facteur fixe) sur la nature du contrat de travail des étudiants (VD catégorielle), alors les MLM vont vous maudire sur 10 générations.
Pour les VD de nature discrète ou catégorielle, vous devrez passer par des modèles linéaires mixtes généralisés - qui dépassent le cadre de ce document.
1.4.2 La nature des variables aléatoires
Les variables aléatoires doivent être de nature catégorielles. Pourquoi ? Principalement parce que nous considérons que les valeurs de ces variables pour notre échantillon ne sont qu’une partie de ce qui est observable et qu’elles sont propres à chaque observation et chaque échantillon.
Dit autrement, les variables aléatoires nous permettent de dire que “dans le cas où j’ai telle valeur de ma variable aléatoire, l’effet de mon prédicteur sur ma variable dépendante est caractérisé par tel intercept et telle pente”. Ce ne sera pas le cas pour une autre valeur de la même variable aléatoire (voir l’exemple de la section Modéliser les facteurs aléatoires).
À partir du moment où nous parlons de “cas” pour une variable, il est plus intuitif de considérer qu’il s’agit d’une variable catégorielle.
Petite information supplémentaire : il est couramment admis qu’une variable aléatoire doit présenter minimum 6 modalités.
1.4.3 La nature des variables fixes
Les MLM sont moins exigeants concernant les variables fixes que les variable aléatoires.
Les variables fixes peuvent être continues (e.g. âge, poids, QI), catégorielles (e.g. genre, émotion représentée) ou de toute autre nature.
Ce sont sur ces variables que vous testerez vos hypothèses. Dans un premier temps, vous voudrez tester l’effet d’une variable fixe sur la prédiction de la variable dépendante. Par exemple, vous avez manipulé l’expression émotionnelle de visages et recueilli le temps de réponse des sujets. Vous voudrez donc dans un premier temps, savoir si votre variable “expression émotionnelle” à trois modalités (neutre, joie, colère) a un effet sur le temps de réaction.
Dans un second temps, vous voudrez savoir dans quelle mesure chacune des modalités de la variable manipulée participe à la prédiction de la variable dépendante. Par exemple, vous serez intéressés par l’effet de l’expression de la joie par rapport à la colère. Et pour cela, vous devrez comparer les différentes modalités par des contrastes.
1.4.4 La normalité
La normalité dans les MLM concerne principalement deux aspects : les résidus et les variables aléatoires. Mais tout comme les ANOVA, les MLM peuvent supporter une légère violation de ces conditions d’application.
1.4.5 Les non conditions d’application
Histoire de bien insister sur les avantages des MLM, notamment par rapport aux ANOVA, voici une liste non exhaustive des conditions d’application que les MLM ne sont pas obligés de respecter :
- L’homogénéité des variances
- L’indépendance des résidus
- La sphéricité de la matrice de covariances (dans le cas de mesures répétées)
- L’équilibre du design
- La nature complètement emboîtée ou complètement croisée
- L’absence de données manquante pour un sujet
##Typologie et modélisations
Il me semble que l’un des plus grands freins à l’utilisation des MLM est leur apparente difficulté à construire le modèle le plus fidèle. À mon avis, c’est aussi le point fort des MLM : là où les ANOVA sont plus rigides et nous invitent à nous poser plus simplement la question de la nature indépendante ou répétée des mesures et des groupes, les MLM nous poussent à aller plus loin en ayant une bonne représentation de notre design expérimental, des variables (fixes ou aléatoires) qui sont importantes et de leurs interactions (emboîtées, croisées partiellement ou totalement).
Rien que la modélisation des variables aléatoires (inexistantes dans les ANOVA) nécessite une gymnastique intellectuelle différente.
Et c’est souvent à cause de ce changement d’habitude (de paradigme, diront certains) que les chercheurs ne vont pas plus loin dans les MLM. Quand bien même je vous aurais convaincu de l’intérêt de modéliser les variables aléatoires, est-ce que je pourrais vous convaincre de vous poser la question de l’emboîtement de vos variables ? Du croisement partiel de celles-ci ? Pas sûr…
Pour briser l’apparente difficulté de la modélisation des MLM, je vais vous présenter les principaux types de MLM et essaierai de faire le parallèle avec les ANOVA, que vous connaissez probablement mieux. Vous verrez également que ce sera l’occasion de considérer les MLM comme des modèles statistiques multiniveaux.
Pourquoi différentes manières de conceptualiser les MLM ? Pour deux raisons : -Si nous sommes familiers avec les ANOVA, il est plus facile de penser les MLM comme nous pensons les ANOVA, en ajoutant simplement les variables aléatoires. -Les ANOVA représentent des modèles relativement simples. Sur des modèles complexes, la comparaison entre les MLM et les ANOVA trouve ses limites. -Certains logiciels opérationnalisent les MLM selon une logique “ANOVA” avec des facteurs emboîtés ou croisés alors que d’autres opérationnalisent les MLM comme des modèles hiérarchiques avec des niveaux d’analyses différents.
1.4.6 Une première manière de voir les choses
Je trouve cette première manière de voir les différents MLM assez proche de celle dont nous considérons les ANOVA. C’est souvent la plus simple lorsque nous commençons à manipuler les MLM mais pas toujours la plus pertinente pour représenter les modèles les plus complexes.
Ici, nous verrons trois types de modèles : les modèles de groupes (en clusters), les modèles à mesures répétées et les modèles longitudinaux.
Le français est une langue assez mal adaptée à l’expression scientifique. En tout cas, mon français. Dans les cases de ce type, vous trouverez les termes anglophones les plus courants.
1.4.6.1 Les modèles en clusters
Le regroupement
Dans ce type de modèle, la VD est recueillie une seule fois par sujet et les sujets sont regroupés (ou emboîtés) dans des groupes. Ces groupes peuvent être d’intérêt (facteur fixe) ou non (facteur aléatoire).
Exemple : Nous avons lancé une étude portant sur la perception de l’agréabilité d’un enseignant en fonction du genre des étudiants. Les valeurs de jugement ont été recueillies une fois par étudiant mais on aimerait tenir compte du fait que les étudiants appartiennent à différents groupes TD. Schématiquement, nous aurions ceci :

Figure 1.4: Représentation schématique d'un modèle en cluster simple
Il apparaît évident que les sujets peuvent être d’un groupe TD ou d’un autre mais pas des deux (bien que les étudiants aient tendance à repousser les limites du système), c’est un modèle à regroupements.
- Les modèles sont clustered data
- Les sujets sont grouped into ou nested dans des clusters
La notion de niveaux
Ici, les étudiants appartiennent à des groupes TD différents d’une même université. Nous appelons ce type de modèles, des modèles linéaires mixtes à deux niveaux :
- Le premier niveau est celui des étudiants : il constitue le niveau d’analyse (niveau auquel correspondent les observations).
- Le second niveau est celui des groupes TD : c’est un niveau dans lequel s’emboîte le premier niveau, celui des étudiants.

Figure 1.5: Représentation schématique d'un modèle en cluster simple
Imaginons maintenant que nous étendons notre groupe de sujets aux étudiants d’une autre université dans laquelle intervient le même enseignant. Notre modèle pourrait ressembler à ceci :

Figure 1.6: Représentation schématique d'un modèle en cluster à 3 niveaux
- Le premier niveau est celui des étudiants : il constitue le niveau d’analyse (niveau auquel correspondent les observations).
- Le second niveau est celui des groupes TD : c’est un niveau dans lequel s’emboîte le premier niveau, celui des étudiants.
- Le troisième niveau est celui de l’université : c’est un niveau dans lequel s’emboîte le second niveau, celui des groupes TD.
Et voilà, vous venez de comprendre pourquoi les modèles linéaires mixtes sont parfois appelés modèles multi-niveaux !
1.4.6.2 Les modèles à mesures répétées
Dans ce type de modèle, des mesures de la VD sont prises plusieurs fois chez un même sujet (ou même niveau d’analyse) au travers de différents niveaux d’une variable.
Exemple : Reprenons l’étude précédente de jugement de l’agréabilité de l’enseignant par les étudiants. Cette fois-ci nous nous intéressons à l’effet de l’enseignement dispensé par l’enseignant : des cours de statistiques vs des cours de psychopathologie. Notre modèle pourrait ressembler à ceci :
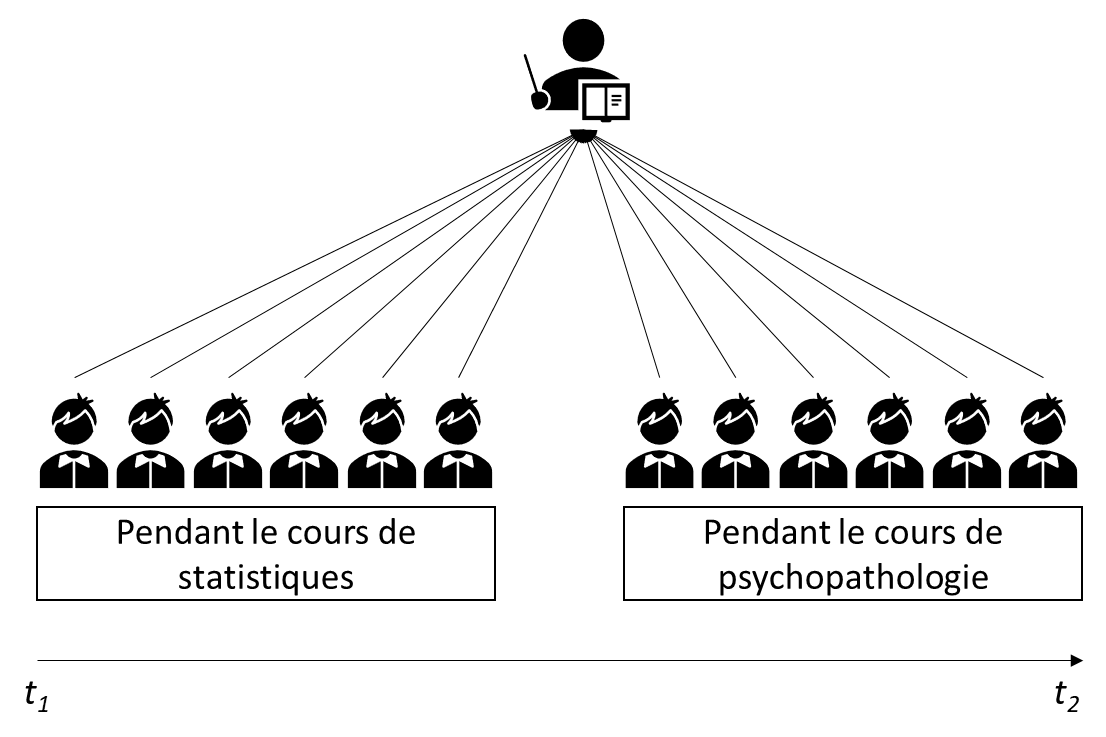
Figure 1.7: Représentation schématique d'un modèle simple à mesures répétées
Ici, chaque étudiant suit les deux cours. Autrement dit, chaque unité d’analyse est confrontée à toutes les modalités de la variable fixe : nous répétons la mesure de la VD à tous les niveaux de la VI.
1.4.6.3 Les modèles longitudinaux
Conceptuellement, la différence entre les modèles longitudinaux et les modèles à mesures répétées est le facteur temps. Certains considèrent donc les modèles longitudinaux comme des cas particuliers de modèles à mesures répétées pour lesquels le temps représente une durée assez longue et constitue une variable d’intérêt.
Il est vrai que dans les deux cas, l’accent est mis sur le fait que ces modèles sont capables de prendre en compte la corrélation entre les données répétées. Toutefois, il y a certains cas où il vaut mieux distinguer les deux modèles, que ce soit pour des aspects théoriques et de méthodologie ou plus techniques comme lorsqu’il s’agit de mettre en évidence une évolution différente de la VD au cours du temps en fonction des sujets via l’analyse d’une courbe de croissance.
On parle alors de growth curve models
1.4.6.4 Les modèles longitudinaux emboîtés
La réalité est complexe et puisqu’en psychologie nous nous intéressons à la réalité, nos modèles expérimentaux sont souvent complexes. Les modèles longitudinaux emboîtés sont des modèles pour lesquels les sujets sont regroupés dans des groupes et les valeurs de la VD sont recueillies plusieurs fois pour un même sujet.
Exemple : Nous reprenons notre étude sur le jugement de l’agréabilité de l’enseignant par les étudiants en fonction de l’enseignement (tous les étudiants suivent les deux enseignements) et nous prenons en considération le fait que les étudiants appartiennent à différents groupes TD.
De fait, les étudiants évaluent deux fois l’enseignant (mesure répétée) mais les étudiants appartiennent à des groupes TD différents (facteur de groupe).
1.4.7 Une seconde manière de voir les choses
Nous avons commencé à évoquer cette seconde manière de conceptualiser un modèle linéaire mixte en évoquant les différents niveaux : celui du sujet (niveau d’analyse), celui de la classe (niveau d’emboîtement des sujets) et celui de l’université (niveau d’emboîtement de la classe).
C’est ce qui permet de penser les MLM comme des modèles multi-niveaux ou encore des modèles hiérarchiques.
Dans une conception hiérarchique des MLM, nous pouvons distinguer le niveau 1 des autres niveaux :
- Le Niveau 1 est le niveau d’analyse des données. C’est le plus détaillé et certains le considèrent comme le niveau le plus bas. Concrètement dans votre jeu de données, c’est la ligne qui traduit l’observation. C’est sur ce niveau qu’est mesurée la VD.
- Dans un modèle en cluster, il s’agit du sujet.
- Dans un modèle en mesures répétées (ou longitudinal), il s’agit des mesures recueillies.
- Le Niveau 2 est le niveau hiérarchique supra-ordonné au niveau 1 dans le jeu de données.
- Dans un modèles en cluster, il s’agit du groupe auquel appartient le sujet.
- Dans un modèle en mesures répétées (ou longitudinal), il s’agit du sujet qui regroupe plusieurs mesures.
- Le Niveau 3 est le niveau hiérarchique supra-ordonné au niveau 2 dans le jeu de données.
- Dans un modèles en cluster, il s’agit d’un groupe incluant différents sous-groupes définis dans le niveau 2.
- Dans un modèle en mesures répétées (ou longitudinal), il s’agit des groupes auxquels appartiennent les sujets.
Tableau d’exemples
| Niveaux | Modèle en cluster | Modèle en mesures répétées |
|---|---|---|
| Niveau 1 | Les étudiants | Les 2 (temps de) mesures d’agréabilité |
| Niveau 2 | Le groupe TD | Les étudiants (qui ont chacun produit 2 mesures d’agréabilité) |
| Niveau 3 | L’université | Le groupe TD |
1.4.8 Une notion importante : facteurs croisés ou emboîtés ?
Une dernière difficulté dans la modélisation des MLM et qui deviendra plus concrète lorsqu’il s’agira d’écrire les modèles dans le logiciel, est la notion de croisement ou emboîtement des facteurs. Nous l’avons déjà évoqué dans Une première manière de voir les choses mais il y a quelques subtilités à garder en mémoire :
- Le croisement ou l’emboîtement des facteurs peut concerner les facteurs fixes tout comme les facteurs aléatoires.
- Des facteurs sont dits emboîtés lorsque le niveau de l’un ne peut être observé que dans un niveau de l’autre.
- Des facteurs sont dits croisés lorsque le niveau de l’un peut être observé au travers plusieurs niveaux de l’autre.
1.4.8.1 Exemples
Facteurs emboîtés
Prenons notre exemple de jugement de l’agréabilité de l’enseignant par les étudiants de 2 groupes TD.
Figure 1.8: Représentation schématique d'un modèle en cluster simple
Ici, les étudiants constituent le niveau d’analyse (Niveau 1) et chaque étudiant représente un niveau du facteur SUJET.
Ils appartiennent à des groupes TD différents (Niveau 2), facteur GROUPE TD à 2 modalités : Groupe TD1 et Groupe TD2.
Étant donné que chaque étudiant ne peut appartenir qu’à un seul groupe TD, chacune des modalités du facteur SUJET n’apparaît que dans une modalité du facteur GROUPE TD.
Les facteurs SUJET et GROUPE TD sont donc emboîtés.
Facteurs croisés
Figure 1.9: Représentation schématique d'un modèle simple à mesures répétées
Ici, les mesures d’agréabilité représentent le niveau d’analyse (Niveau 1).
Il y a deux mesures par étudiant, qui représentent un cluster de mesures, facteur SUJET (Niveau 2), chaque étudiant représentant un niveau de ce facteur.
Chacun de ces étudiants a produit un jugement pendant un cours de statistiques et un cours de psychopathologie, facteur ENSEIGNEMENT (Niveau 3) à deux niveaux (statistiques ; psychopathologie).
Étant donné que tous les étudiants ont participé aux deux cours, autrement dit que tous les niveaux du facteur SUJET sont observés dans tous les niveaux du facteur ENSEIGNEMENT, les facteurs SUJET et ENSEIGNEMENT sont croisés.