Chapter 2 Modelling multiple water publics
2.1 Synopsis
Following media reports about chronic river pollution, water is moving up the environmental policy agenda in the UK. Social studies of environmental governance suggest that the public policy process should invite the articulation of multiple environmental knowledges rather than exclusively relying on professional expertise (Latour, 2004; Whatmore, 2009). Less agreement exists about how such articulation should be organised in practice. Social media analysis can be a means of discovering the different ways in which diverse social actors form publics which articulate specific knowledge claims about environmental matters such as water (Marres, 2015). Such analysis has the potential to complement formal stakeholder consultations with organised interested groups and engagement efforts addressed at a general public.
In this exploratory project, we use topic modelling of a corpus of 97,000 mined posts from the micro-blogging platform Twitter in order to identify how water matters to a sample of UK-based users of the platform. We find that distinct modes of articulating concern with the issue of water obtained among our sample of platform users. Moreover, some issues articulations are shared across segments of our sample in discernible patterns. In a dialogue with literatures on technoscientific issues and environmental publics, we consider segmenting two distinct water publics based on the way in which their modes of engagement with the water environment register as joint but antagonistic implications in the water issue.
2.2 Sample
The current body of social media analysis literature suggests using hashtags indicating interest in a shared topic in order to create data sets affording the study of issue publics (Marres, 2015). However, the authors are not aware of any hashtag that would indicate shared and enduring interest in water in the UK apart from ephemeral hashtags promoting specific events of limited interest such as local awareness days (e.g. #LondonWaterWeek). Moreover the ontological multiplicity of issues and their attendant publics complicates the methodological convention to take shared hashtags as a proxy for interest in an issue.
As a result we constructed a sample of 173 accounts of Twitter users selected on the basis of ethnographic domain knowledge acquired by one of the authors during fieldwork prior to this study. Two years of participant observation in UK water management informed the initial categorisation of water management actors into 6 distinct categories: Activist (n=18), including campaign groups as well as individual activists; Charities (n=57), including organisations such as Rivers Trusts with a primarily charitable purpose; Government (n=22) including the Environment Agency and its regional branches as well as local authorities and the water sector regulator; Industry (n=35) including water companies in England as well as sector consultancies; Journalist (n=12) including media organisations and individuals reporting on the water sector; and Partnerships (n=29) including catchment partnerships in England. These categories are consistent with the literature on multi-level water governance (Weale et al., 2002). We will revisit this initial categorisation in the discussion section.
2.3 Methodology
To ground this research in empirical methods, a Latent Dirichlet Allocation (LDA) model was applied to our dataset of tweets. The LDA model is an unsupervised machine learning algorithm that belongs to the wider artificial intelligence and topic modelling tool box. Since its application to machine learning in 2003, the LDA model has been applied to a range of natural language processing studies (Kresetel et al 2009, Henderson and Eliassi-Rad 2009 and Tirunillai and Tellis 2014 ). LDA is a tri-level hierarchical Bayesian model and functions by clustering sets of observations into unobserved groups to illustrate similarities within the data.
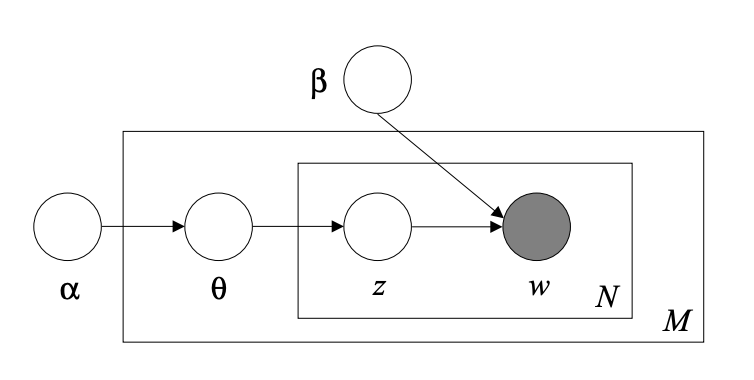
Graphical representation of the LDA model (Blei et al 2003 p997)
The outer rectangle represents the documents and the inner rectangle represents the repetition of topics and words in the document.
- \(\ M\) denotes the number of documents.
- \(\ N\)is the number of words in a given document.
- \(\alpha\) is the parameter of the Dirichlet prior on the per-document topic distributions.
- \(\beta\) is the parameter of the Dirichlet prior on the per-topic word distribution.
- \(\theta_{i}\) is the topic distribution for document i.
- \(\varphi_{k}\) is the word distribution for topic k.
- \(Z_{ij}\) is the word distribution for topic k.
- \(W_{ij}\) is the specific word.
In our case, the LDA model considers each tweet as a separate document with each word in the document considered as part of one or more topics. As a generative statistical model, LDA provides a probability of each word belonging to a certain topic (Blei et al 2003). To run a LDA model a predefined number of topics must be defined. Setting the number of topics too small will result in a generalisation; while setting the number of topics too large will make it difficult to clearly segregate topics. This study’s approach to tackling the dichotomy of balancing granularity versus generalization was to run three models where the number of topics varied between two, five and ten.
The following R libraries were used throughout this methodology.
library(readr) #Read Csv files
library(dplyr) #Sort and clean data
library(SnowballC) #Stem words
library(tm) #Clean text
library(stringr) #Clean text
library(qdapRegex) #Clean text
library(wordcloud) #Create wordclouds
library(purrr) #Functional programming tools
library(ggplot2) #Plot graphs
library(topicmodels) #Conduct topic analysis
library(knitr)Tweets were mined using the rtweet package. This package directly interacts with the twitter API in order to fetch data based on a set of queries. In our case, we used the get_timelines function to scrape up to 5000 tweets from our sample. A full dataset from our mine can be found here.
Our mined data was cleaned using the tm and qdapRegex packages. In order to provide a meaningful corpus, we removed links, punctuation, numbers, stop words and an array of words we deemed unfit for analysis. In the example below, we show how our data was cleaned for our sample of activist tweets.
activistTweets <- read_csv("merged_activist_tweets.csv")
#Subset data to only include screen name and text
activistTweets <- subset(activistTweets,
select = c("screen_name", "text"))
#clean text
act_tweets <- iconv(activistTweets$text, to = "ASCII", sub = " ") # Convert to basic ASCII text to avoid silly characters
act_tweets <- gsub("(RT|via)((?:\\b\\W*@\\w+)+)", "", act_tweets) # Remove the "RT" (retweet) and usernames
act_tweets = gsub("http.+ |http.+$", " ", act_tweets) # Remove html links
act_tweets = gsub("http[[:alnum:]]*", "", act_tweets) # Remove html links
act_tweets = gsub("[[:punct:]]", " ", act_tweets) # Remove punctuation
act_tweets = gsub("[ |\t]{2,}", " ", act_tweets) # Remove tabs
act_tweets = gsub("^ ", "", act_tweets) # Leading blanks
act_tweets = gsub(" $", "", act_tweets) # Lagging blanks
act_tweets = gsub(" +", " ", act_tweets) # General spaces
act_tweets = gsub("amp", " ", act_tweets) # remove amp
act_tweets = gsub("can", " ", act_tweets) # remove can
act_tweets = gsub("will", " ", act_tweets) # remove will
act_tweets = gsub("like", " ", act_tweets) # remove like
act_tweets = gsub("got", " ", act_tweets) # remove got
act_tweets = gsub("way", " ", act_tweets) # remove way
act_tweets = gsub("one", " ", act_tweets) # remove one
act_tweets = tolower(act_tweets)
act_tweets = unique(act_tweets)
#Transform tweets into vector corpus
act_tweetsCorpus <- Corpus(VectorSource(act_tweets))
#More data cleaning
act_tweetsCorpus <- tm_map(act_tweetsCorpus, removeWords, stopwords("english"))
act_tweetsCorpus <- tm_map(act_tweetsCorpus, removeNumbers)
act_tweetsCorpus <- tm_map(act_tweetsCorpus, stemDocument)Once we had tidy data, we were able to begin the topic modeling. As a primlinary step we converted our corpus into a document term matrix and found the frequency of words. Following this we created three topic model algorithms which used a Gibbs sampling method. Gibbs sampling is an algorithm for successively sampling conditional distributions of variables, whose distribution over states converges to the true distribution in the long run ( Griffiths 2009 ) In the example below, we show how our topic models were produced for our sample of activist tweets.
#Convert corpus into document term matrix
act_dtm <- DocumentTermMatrix(act_tweetsCorpus)
#Find frequency of words
doc.length = apply(act_dtm, 1, sum)
act_dtm = act_dtm[doc.length > 0,]
freq = colSums(as.matrix(act_dtm))
length(freq)
ord = order(freq, decreasing = TRUE)
freq[head(ord, n = 20)]
#LDA model with 5 topics selected
lda_5 = LDA(act_dtm, k = 5, method = 'Gibbs',
control = list(nstart = 5, seed = list(1505,99,36,56,88), best = TRUE,
thin = 500, burnin = 4000, iter = 2000))
#LDA model with 2 topics selected
lda_2 = LDA(act_dtm, k = 2, method = 'Gibbs',
control = list(nstart = 5, seed = list(1505,99,36,56,88), best = TRUE,
thin = 500, burnin = 4000, iter = 2000))
#LDA model with 10 topics selected
lda_10 = LDA(act_dtm, k = 10, method = 'Gibbs',
control = list(nstart = 5, seed = list(1505,99,36,56,88), best = TRUE,
thin = 500, burnin = 4000, iter = 2000))
#Top 10 terms or words under each topic
top10terms_5 = as.matrix(terms(lda_5,10))
top10terms_2 = as.matrix(terms(lda_2,10))
top10terms_10 = as.matrix(terms(lda_10,10))
topicprob_5 = as.matrix(lda_5@gamma)
topicprob_2 = as.matrix(lda_2@gamma)
topicprob_10 = as.matrix(lda_10@gamma)2.4 Results
Whereas the results of an initial word frequency analysis for each category largely confirmed prior expectations, topic modelling turned up results worthy of further investigation. We discuss results in turn.
2.4.1 Frequency analysis
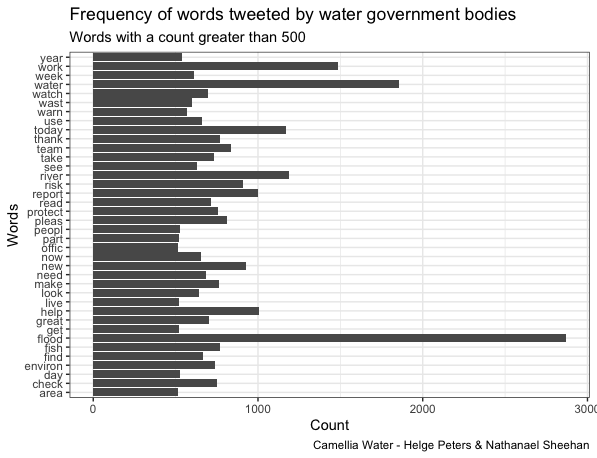
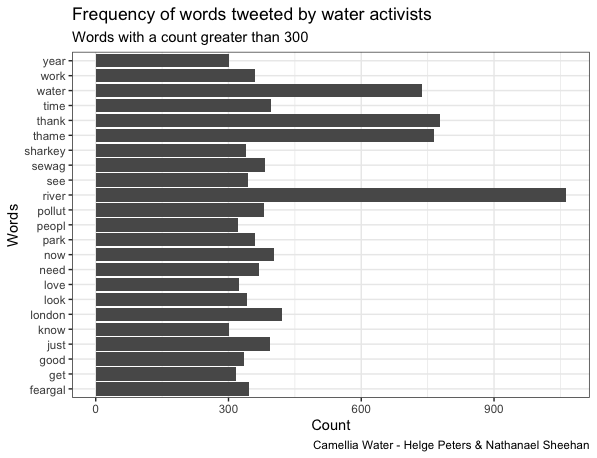
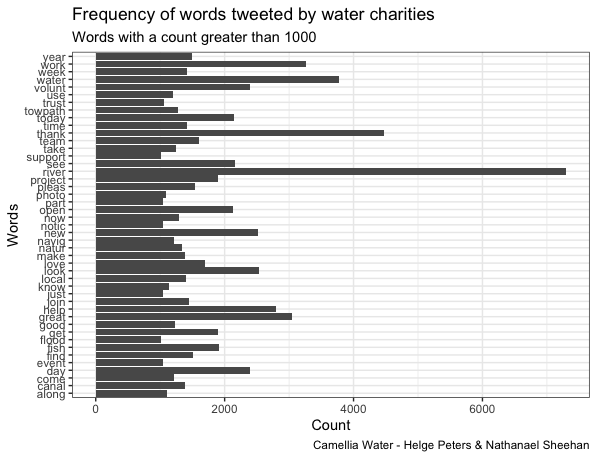
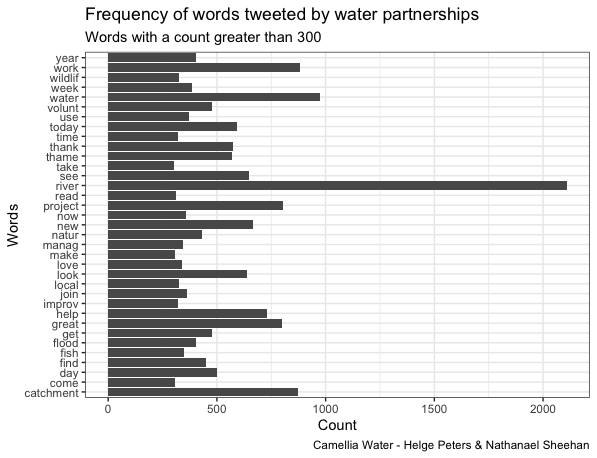
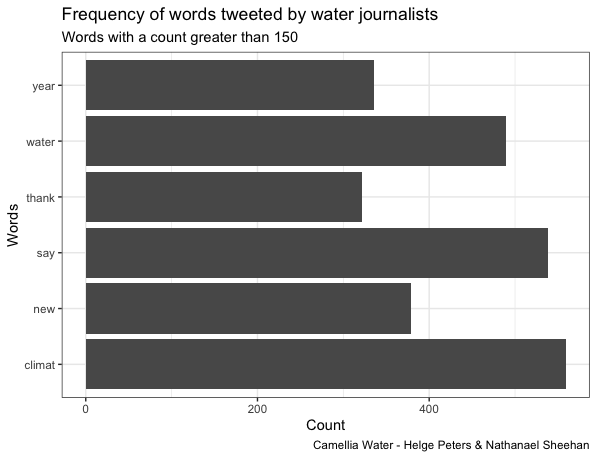
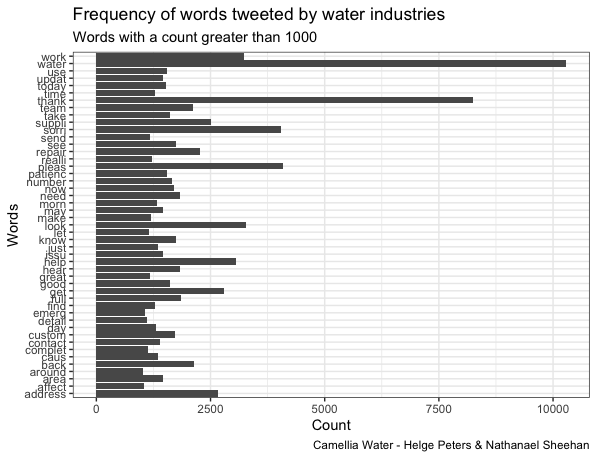
Tweets in the Activist category most frequently contained the terms “river, thank, Thames, water”, confirming our fieldwork-based assumption of rivers as primary matters of concern to activists and likely reflecting the London-centric over-representation of Twitter accounts in this category in the overall sample. Charities most frequently mentioned the terms “river, thank, water, work, volunteer”, confirming a focus on rivers that was to be expected from a sample largely composed of Rivers and Canal Trusts as well as reflecting their outreach efforts including hands-on volunteering opportunities. In contrast, tweets in the category Government most frequently contained the terms “flood, water, work, river, today”, likely reflecting the Environment Agency’s priority on flood risk management. Tweets within the Industry category most frequently contained the terms “water, thank, please, sorry, look”, which implies the use of social media by water companies for customer engagement and service notifications. A comparatively small sample of tweets within the category Journalist suggests a common ranking of issue prominence in environmental reporting by mentioning the term “climate” more frequently than “water”. Finally, tweets in the category Partnerships most frequently mentioned the terms “river, water, work, catchment, project”, indicating a focus on applied catchment management of the accounts contained in this category.
2.4.2 Topic modelling
Topic modelling generated ten, five and two topics of tweets within each of the six categories consisting of a set of ten words for each topic. We labelled topics based on our interpretation of the likely semantic relation between terms in the set and then selected six topics from across categories for manual verification: a) plastic, b) pollution, c) place, d) biophilia, e) water use, and f) water sector. Word sets for these topics are shown in table 2.1. Below we summarise the semantic content of the six manually verified topics.
- plastic: plastic pollution, microplastics, plastic rubbish, litter picks and clean-up efforts along blue-green spaces, and the reduction of plastics consumption
- pollution: rubbish, human waste and its impact on water quality and wildlife, especially sewage pollution and fishlife
- place: water bodies and water-related landscape elements, typically discussing their condition, improvement projects as well as forms of use including use conflicts
- biophilia: encounters with nonhuman nature within river ecosystems that are described with strongly emotive language as pleasant and beautiful, often related to outdoor activities such as walking or kayaking along a river, at particular times of day such as mornings, frequently accompanied by photographs.
- water use: reduction of water consumption, behaviour change and domestic appliance upgrades for saving water, to a lesser extent over-abstraction and leakage.
- water sector: corporate communications about developments within the water industry as well as its relationship with regulators and stakeholders, public criticism of political economy of the water sector and its environmental outcomes.
| plastic | pollution | place | biophilia | water.use | water.sector |
|---|---|---|---|---|---|
| plastic | sewage | river | look | home | sector |
| ocean | sewer | park | beautiful | use | future |
| pollution | pollution | brook | amazing | water | innovation |
| thames | overflow | bridge | walk | know | management |
| help | quality | valley | love | help | industry |
| clean | fish | canal | day | tap | ofwat |
| dump | towpath | photo | pipe | market | |
| industry | lock | along | run | business | |
| company | navigation | morning | safe | company |
In a further step we compared the occurrence of topics across actor categories. The majority of topics identified by the LDA model were specific to one actor category. Each of the topics manually verified and listed above occurred in at least two categories. Topic occurrence across more than one actor category suggests the formation of a public based on shared modes of engaging with the issue of water (Eden, 2017). We summarise topic occurrence across categories in table 2.2. For instance, the topic pollution was likely to occur in tweets of the categories Activist and Partnerships but not in any of the others. In contrast, plastics was a shared topic of Activists and Charities, the latter sharing a concern with water use with Industry and Government (but not with Activists). The topics biophilia and place both occurred across the categories Activist, Charity and Partnerships, suggesting a link between interest in specific places and their modalities of use with appreciative accounts of encounters with nonhuman life. Finally, the topic water sector was shared between Industry, Government and Journalist categories but not any of the others.
| X | Activist | Charity | Partnership | Industry | Government | Journalist |
|---|---|---|---|---|---|---|
| plastic | x | x | ||||
| pollution | x | x | ||||
| place | x | x | x | |||
| biophilia | x | x | x | |||
| water use | x | x | x | |||
| water sector | x | x | x |
2.5 Discussion
Whereas the results of word frequency analysis largely confirm prior assumptions about the way in which actors within a category would communicate on Twitter, topic modelling generated interesting results that invite further investigation. For the most part the topics modelled by LDA were consistent with ethnographic and qualitative evidence about the enactment of inland water as an issue in the UK. However, notably absent were topics such as the state of chalk streams, agricultural impacts, ‘wild’ swimming, drought, or the cost of water, which occasionally attract public attention in the UK. The absence of salient and broadly shared topics such as pollution and plastic in the category Journalist warrants further investigation as well. Possible reasons include bias introduced by small sample size (n=12) and the relative novelty of inland water quality as an object of public concern and media reporting. Another possible explanation is the relative prevalence of reporting on other environmental issues over inland water in such a way that the algorithm would not detect a distinct topic. Talk about the water sector deploying a distinctly managerial, and at times promotional, language had been identified exclusively from accounts of industry, government and the media. The absence of this topic from any of the other categories leads us to hypothesise the formation of an epistemic community (Haas, 2008) of private and public sector water professionals, who succeed at attracting media attention to their specific problematisations of the commercial and regulatory aspects of water in the UK. However, this hypothesis would need to be further investigated with social network and NLP analysis, possibly complemented with qualitative interviews. The results above also lead us to question the relative success of actors in shaping media reporting of inland water in the UK, which would form an interesting object of further study.
Further patterns in the distribution of topics across categories are suggestive of the formation of publics with divergent stakes in and concerns with water. Tweets targeting individuals for behaviour change related to water consumption were shared across industry, public bodies and charities, but less so by activists and catchment partnerships. The latter were more likely to address institutional responsibility over individual consumptive behaviour change as evidenced by their campaigning on sewage and plastic pollution. In light of prior ethnographic evidence about the unmet expectations which London residents maintain about inland water quality as a responsibility of local authorities and statutory bodies, this finding invites further investigation into causes and perceptions of environmental improvement under-delivery. The data we mined evidenced the interpellation of an environmental subjectivity as a citizen-consumer on the part of public, private and third sector organisations as well as behaviour change campaigns targeting individual water use in domestic space at the expense of concerns with public space and collective responses. Thus, the data suggest the potential contribution of computational methods to the study of environmentality (Luke, 2011).
A specifically salient pattern is the co-occurence of the topics “biophilia” and “place”, partly also of both of these topics with “pollution” and “plastic”, across the categories Activist, Charity and Partnership. Apart from indicating coalition building between actors from these categories this pattern also invites theorising a substantive link: as noted in the results section the co-occurence of the topics biophilia and place suggests a substantive, perhaps even causal, connection between interest in specific places and their modalities of use with appreciative accounts of encounters with nonhuman life (cf. Barua, 2017). This finding corroborates prior findings based on small-n qualitative evidence suggesting that wildlife appreciation, frequently informed by a deontological ethics of responsibility towards nonhuman nature, motivates place-based environmental stewardship action towards the London water environment.
As catchment partnerships are often hosted by charities and invite the participation of concerned citizens, the data suggest that the place-based appreciation of water bodies and attendant concerns with pollution are successfully introduced to the agenda of these participatory governance arrangements. However, the data also suggest that the uptake of such concerns in catchment partnerships does not necessarily translate into policy priorities addressed by social media communications issuing from government and industry.
Finally, the data suggest the intriguing possibility of segmenting digital water publics in a dialogue with cognate work on environmental publics in human geography and science and technology studies. For instance, Eden (2017) suggests pluralising the notion of the public by classifying environmental publics along their shared modes of engagement with the natural environment. Moreover, Marres (2015) summarises a body of social media analysis of technoscientific and environmental controversies which attempts to avoid ontological assumptions as to the relationship between actors, their societal domains and position on a contested issue. Instead, such research inductively traces a socio-material network by following the practical and discursive enactment of an issue.
With the aid of LDA algorithm we have modelled topics occurring across actor categories, which we may interpret as indicating shared modes of engagement with the natural environment. Based on the patterning of these modes of engagement, we infer a binary segmentation of two water publics: on the one hand, a place-based public which emphasises the practical encounter with the water environment and demonstrates concern with sewage and plastic pollution. On the other, a professional public characterised by water professionals who emphasise the commercial aspects of the water sector and are concerned with service delivery and management innovation. These two publics enact the water issue differently: as an issue of collective responsibility for environmental quality and as an issue of managing an incentive structure for individual consumption choices, respectively. However, further research is needed to ground this segmentation in evidence about the joint and antagonistic implication (Marres, 2017) of actors in the water issue.
Such further research could make use of close readings of social media texts such as tweets and replies in order to ground our computationally inferred categorisation of water publics, which is by necessity etic, in the emic understandings of the water issue brought forth by Twitter users themselves. The following interaction serves to illustrate the potential of such a subsequent step of interpretive analysis. On 8 December 2020, the Twitter account of the Environmental Audit Committee (EAC) of the UK House of Commons announced an inquiry into water quality and invited the submission of evidence (Figure 2). The text of the tweet stated in full:

Tweet from the Environmental Audit Committee
Within one day this tweet collected 65 replies (including quote tweets). Of these replies, 21 took issue with the emphasis which the second question put on consumer behaviour as a cause of water pollution, suggesting instead that the responsibility for water pollution and its rectification rests with various private and public sector institutions such as water companies, agricultural business, and regulatory and planning bodies. The first question about indicators provided a further, less prominent, point of contention, with some commentators calling for more diligent enforcement of existing targets rather than developing a new management system for inland water quality. A significant portion of replies taking issue with either question in the original tweet were written by Twitter users who identified themselves as environmental activists or charity workers on their user profile. The way in which the discourse occasioned by this single EAC tweet relates the societal domain of discourse participants (as campaigners or public sector professionals) to their enactment of the water issue (as currently under-delivered institutional responsibility or a matter of management system innovation and consumer choice, respectively) maps closely onto the occurrence of topics across actor categories which we previously modelled based on a 97,000 tweet data set. However a portion of replies to the tweet were written in a sarcastic or elliptic style, which requires contextualised reading to be meaningfully parsed and thus commonly confounds computational methods. This example serves to illustrate how grounding model-inferred etic claims in a close reading of social media conversations informed by rich contextual understanding can increase confidence in the robustness of findings.