![]()
Códigos Auditoría CCU
2021-12-01
1. Modelo Cervezas
# Cargar librerías de trabajo en R
library(readxl)
library(scales)
library(ggplot2)
library(ggpubr)
library(forecast)
library(dplyr)
library(car)
library(ggcorrplot)
library(FitAR)Importar los datos, dependiendo la ubicación que se encuentren en el directorio
ruta = "/Users/mivicuna/Desktop/Proyecto CCU/Información CCU/Cervezas 26-08-2021 V5/DataFrameCervezasInterna.xlsx"
datoscer = read_excel(ruta,col_types = c("date", "numeric","numeric",
"numeric", "numeric", "numeric", "numeric"))1.1 Análisis Descriptivo
1.1.1 Venta Volumen de Cervezas
A continuación se grafica la variable objetivo de venta volumen de cerveza desde Enero 2014 a Agosto 2021.
plot1.1 = ggplot(datoscer,aes(x = PERIODO, y = CERVEZAS)) +
geom_point(colour = "skyblue4", alpha = 0.7) +
geom_line(colour = "skyblue4", alpha = 0.7) +
labs(title = "Volumen Industria Cerveza",
x = "Fecha",
y = "Volumen en millones") +
theme_bw() +
scale_y_continuous(labels = label_number(suffix = "M", scale = 1e-6)) El histograma de la venta volumen de cervezas está dado por
plot1.2 = ggplot(data = datoscer, aes(x = CERVEZAS)) +
geom_histogram(alpha = 0.7, color="black", fill =
"slategray4") +
labs(title = "Histograma del Volumen Industria
Cerveza",
x = "Volumen Industria Cerveza",
y = "Frecuencia") +
scale_x_continuous(labels = label_number(suffix = "M", scale = 1e-6)) +
theme_bw()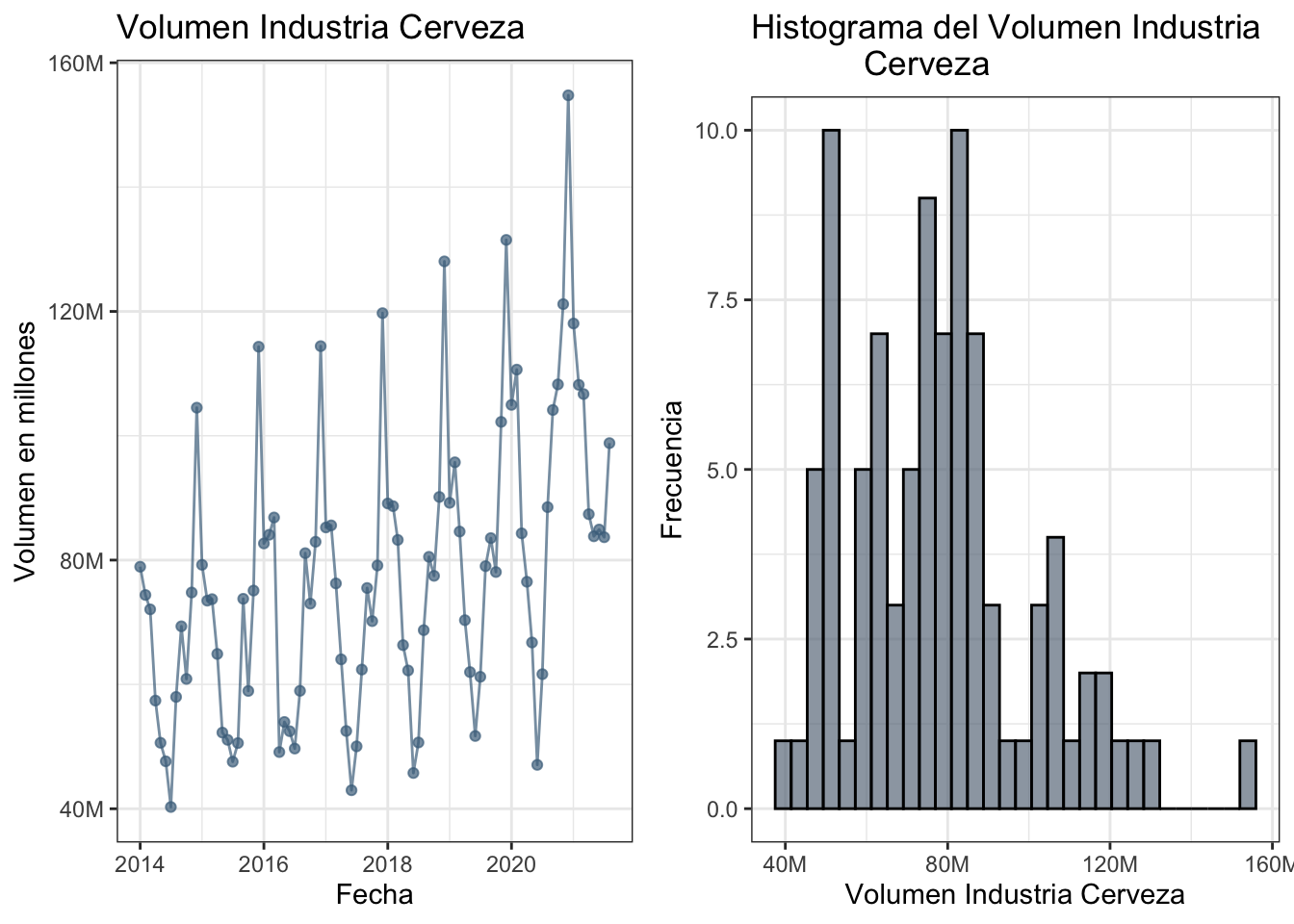
Las medidas descriptivas de la venta volumen de cervezas se calculan mediante
1.1.2 Variables Independientes
Los gráficos de tendencia para cada una de las dimesiones predictoras del modelo
#====== Desempleo ======#
plot2.1 = ggplot(datoscer,aes(x = PERIODO)) +
geom_point(aes(y = DESEMPLEO), alpha = 0.7, colour = "skyblue4") +
geom_line(aes(y = DESEMPLEO), alpha = 0.7, colour = "skyblue4") +
labs(title = "Tasa de Desempleo \n INE",
x = "Fecha", y = "Valor Tasa") +
theme_bw()
#====== Precio Cervezas ======#
plot2.2 = ggplot(datoscer,aes(x = PERIODO)) +
geom_point(aes(y = PCERVEZAS_T), alpha = 0.7, colour = "skyblue4") +
geom_line(aes(y = PCERVEZAS_T), alpha = 0.7, colour = "skyblue4") +
labs(title = "Precio Industria \n Cerveza",
x = "Fecha", y = "Precio") +
theme_bw()
#====== Temperatura Máxima ======#
plot2.3 = ggplot(datoscer,aes(x = PERIODO)) +
geom_point(aes(y = TEMP_MAX), alpha = 0.7, colour = "skyblue4") +
geom_line(aes(y = TEMP_MAX), alpha = 0.7, colour = "skyblue4") +
labs(title = "Temperatura Máxima \n Promedio",
x = "Fecha",y = "Temperatura") +
theme_bw()
#====== Índice de Movilidad ======#
plot2.4 = ggplot(datoscer,aes(x = PERIODO)) +
geom_point(aes(y = MOVILIDAD), alpha = 0.7, colour = "skyblue4") +
geom_line(aes(y = MOVILIDAD), alpha = 0.7, colour = "skyblue4") +
labs(title = "Índice de Movibilidad",
x = "Fecha",
y = "Valor del índice") +
theme_bw()
#====== Retiros ======#
plot2.5 = ggplot(datoscer,aes(x = PERIODO)) +
geom_point(aes(y = RETIROS), alpha = 0.7, colour = "skyblue4") +
geom_line(aes(y = RETIROS), alpha = 0.7, colour = "skyblue4") +
labs(title = "Variable Retiros \n AFP",
x = "Fecha",
y = "Valor del índice") +
theme_bw()
ggarrange(plot2.1,plot2.2,plot2.3,plot2.4,plot2.5,ncol=3,nrow=2)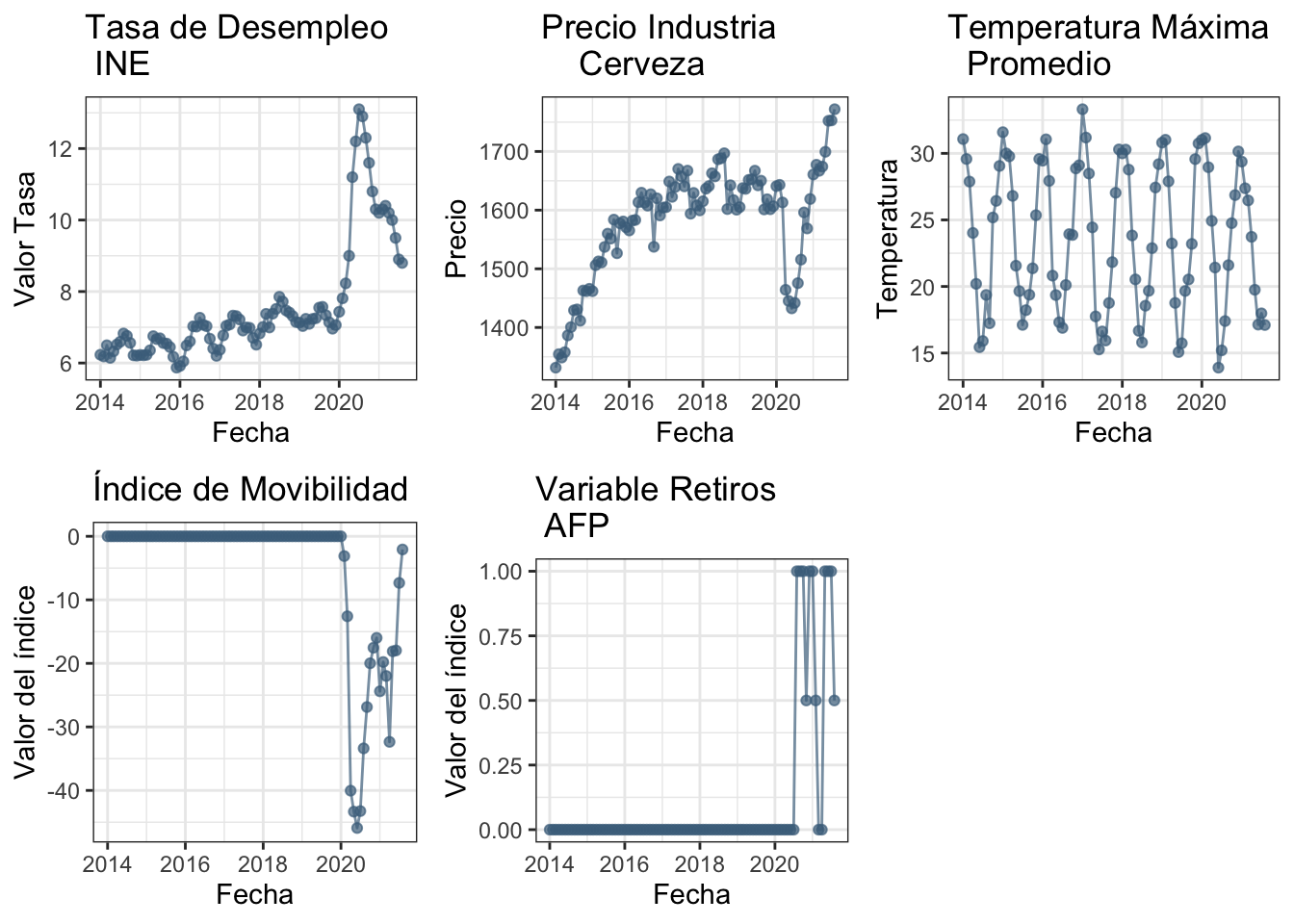
Los histogramas de distribuciones de cada dimensión predictiva
#====== Desempleo ======#
plot3.1 = ggplot(data = datoscer, aes(x = DESEMPLEO)) +
geom_histogram(alpha = 0.7, color="black", fill = "slategray4") +
labs(title = "Histograma de la tasa \n de desempleo",
x = "Tasa desempleo", y = "Frecuencia") +
theme_bw()
#====== Precio Cervezas ======#
plot3.2 = ggplot(data = datoscer, aes(x = PCERVEZAS_T)) +
geom_histogram(alpha = 0.7, color="black", fill = "slategray4") +
labs(title = "Histograma de precio \n industria cerveza",
x = "Precio Cerveza", y = "Frecuencia") +
theme_bw()
#====== Temperatura Máxima ======#
plot3.3 = ggplot(data = datoscer, aes(x = TEMP_MAX)) +
geom_histogram(alpha = 0.7, color="black", fill = "slategray4") +
labs(title = "Histograma de la \n temperatura máxima",
x = "Temperatura máxima", y = "Frecuencia") +
theme_bw()
#====== Índice de Movilidad ======#
plot3.4 = ggplot(data = datoscer, aes(x = MOVILIDAD)) +
geom_histogram(alpha = 0.7, color="black", fill = "slategray4") +
labs(title = "Histograma de índice \n de movilidad ",
x = "índice movilidad",y = "Frecuencia") +
theme_bw()
#====== Retiros ======#
plot3.5 = ggplot(data = datoscer, aes(x = RETIROS)) +
geom_histogram(alpha = 0.7, color="black", fill = "slategray4") +
labs(title = "Histograma de retiros \n AFP",
x = "Retiros AFP", y = "Frecuencia") +
theme_bw()
ggarrange(plot3.1,plot3.2,plot3.3,plot3.4,plot3.5,ncol=3,nrow=2)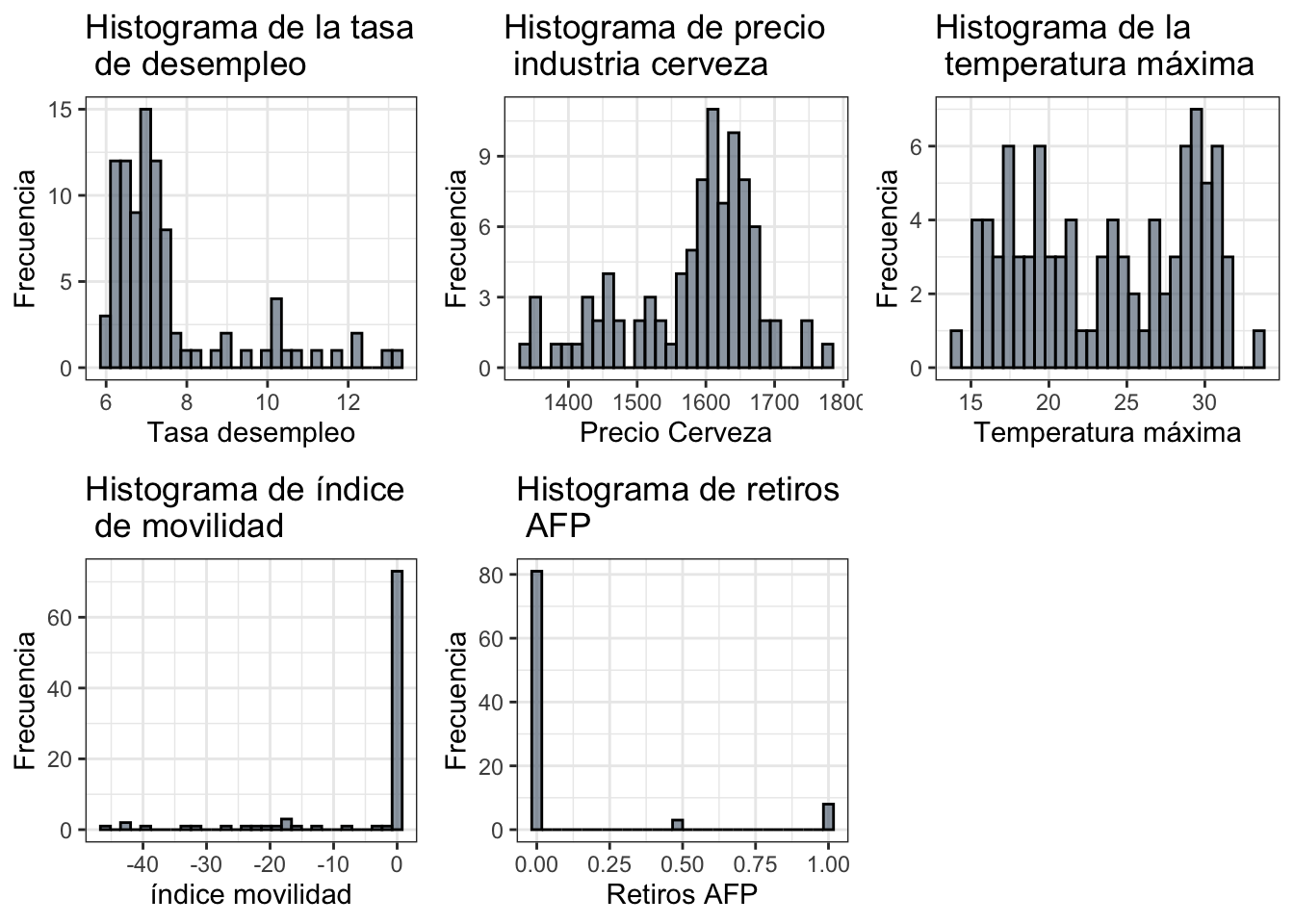
1.2 Análisis Bivariado
A continuación los gráficos de dispersión de la variable objetivo con las dimensiones independientes
subset2.1 <- select(datoscer,-c(PERIODO,CERVEZAS))
Cervezas <- datoscer$CERVEZAS
myplots <- list()
for(i in 1:ncol(subset2.1)){
col <- names(subset2.1)[i]
aux <- bind_cols(Cervezas = Cervezas,select(datoscer,col))
ggp <- ggplot(aux, aes_string(x = col , y = "Cervezas")) +
geom_point(color = "slategray4",alpha=0.7) +
geom_smooth(method = "lm",col="red") +
labs(y = "Volumen Industria Cerveza") +
scale_y_continuous(labels = label_number(suffix = " M", scale = 1e-6))
theme_bw()
myplots[[i]] <- ggp
rm(ggp,aux,col)
}plot3.3 <- ggarrange(myplots[[1]],myplots[[2]],myplots[[3]],
myplots[[4]],myplots[[5]],
nrow = 2, ncol = 3, common.legend = TRUE)
annotate_figure(plot3.3,top = text_grob("Gráficos de dispersión las variables independientes"))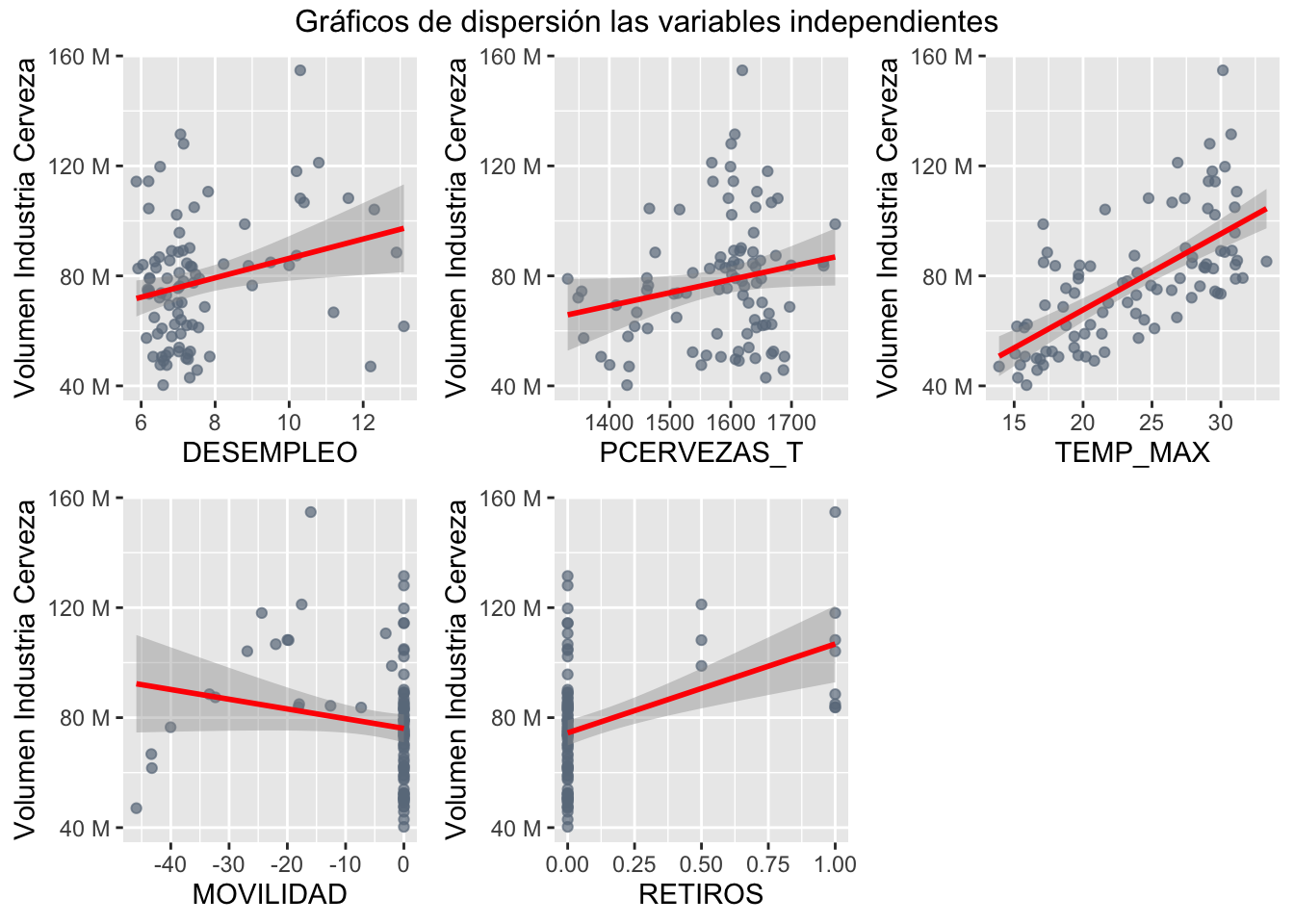
Cálculo de correlaciones de la variable objetivo con las dimensiones utilizadas
tibble(Variable = row.names(cor(subset2.1, Cervezas)),
Correlacion = as.numeric(cor(subset2.1, Cervezas))) %>%
arrange(desc(abs(Correlacion)))## # A tibble: 5 x 2
## Variable Correlacion
## <chr> <dbl>
## 1 TEMP_MAX 0.666
## 2 RETIROS 0.416
## 3 DESEMPLEO 0.258
## 4 PCERVEZAS_T 0.201
## 5 MOVILIDAD -0.175Ajuste del Modelo CCU
Cervezas = ts(datoscer$CERVEZAS, frequency=12, start=c(2014,1))
TYPCYD = ts(as.matrix(select(datoscer,-c(PERIODO,CERVEZAS))), frequency=12,
start=c(2014,1))
## Modelo Ajustado con la función auto.arima()
arimaCervezas = auto.arima(Cervezas, xreg=TYPCYD)Se ajusta el modelo obtenido con la función auto.arima( ) utilizando la función Arima( ) del paquete forecast de R,
## Ajustar el modelo obtenido con autoarima con la función Arima
model_auto_arima_cerv = Arima(Cervezas,order = c(3, 0, 0),
seasonal = list(order = c(0, 1, 1),
period = 12),include.drift =TRUE,xreg = TYPCYD )Se evalúa la significancia de los parámetros realizando test \(H_0:\beta_i = 0\) v/s \(H_1: \beta_i \neq 0\) para \(i=1,2,3,4,5\)
1.3 Análisis Multivariado
A continuación los gráficos de heatmap de correlaciones de a pares de las dimensiones independientes
variables = colnames(subset2.1[,1:5])
corr_variables = matrix(round(cor(subset2.1[,1:5]),3),nrow=5,ncol=5, dimnames = list(variables,variables))
ggcorrplot(corr_variables, hc.order = TRUE, outline.col = "black", lab = TRUE, ) +
theme(axis.text.x = element_text(size = 8),
axis.text.y = element_text(size = 8)) 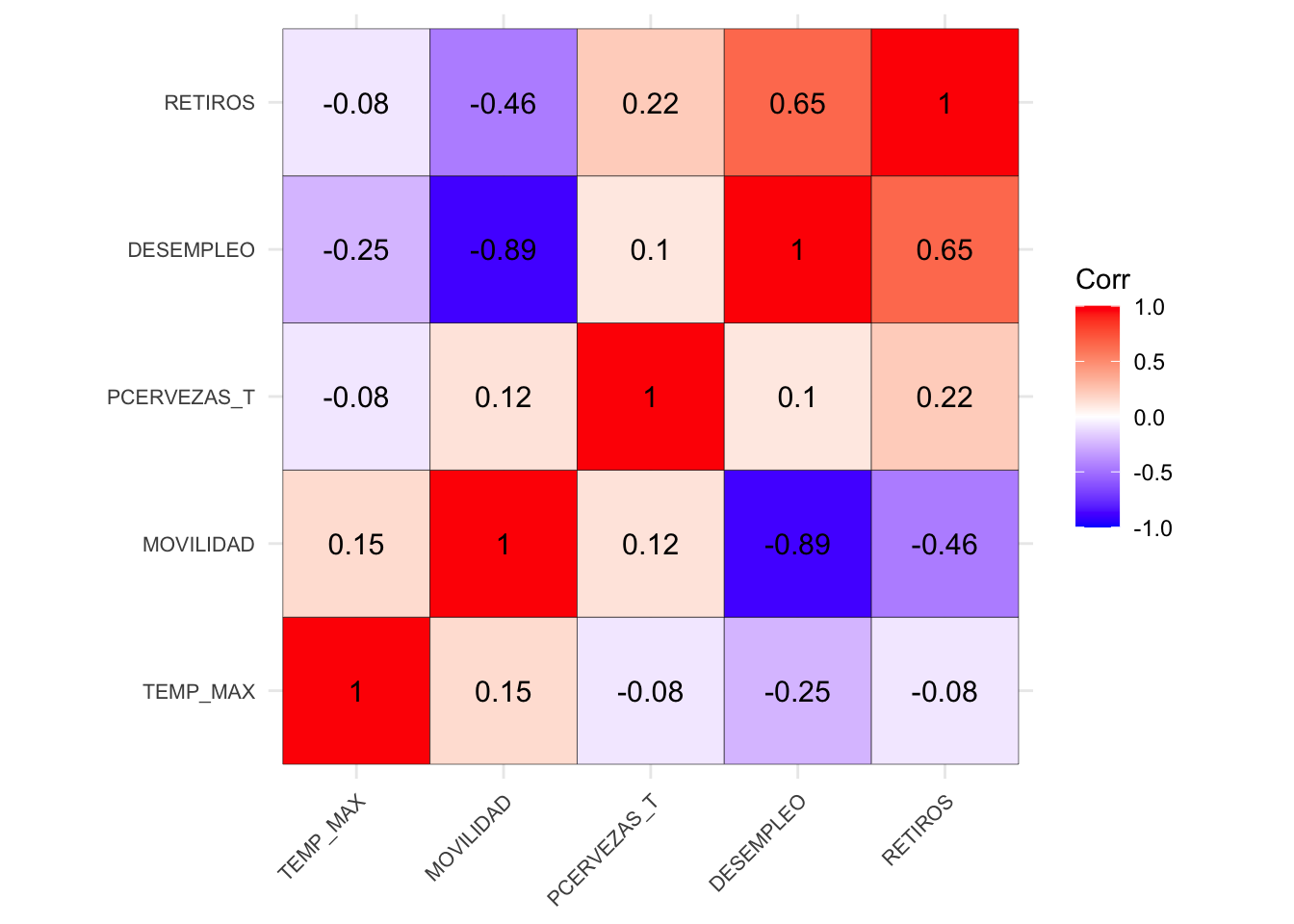
1.4 Verificación de los supuestos
1.4.1 Normalidad
datoscer$Residuos <- residuals(model_auto_arima_cerv)
# Residuos Estandarizados
datoscer$Residuos_z = (datoscer$Residuos - mean(datoscer$Residuos))/sd(datoscer$Residuos)
# ===== QQ-plot =====#
plot4.3 <- ggplot(datoscer, aes(sample = Residuos_z)) +
stat_qq() +
geom_abline(slope=1) +
labs(title = "Normal Q-Q Plot",
x = "Theoretical Quantiles",
y = "Sample Quantiles") +
theme_bw()
x = seq(min(seq(min(datoscer$Residuos_z),max(datoscer$Residuos_z),len=1000)),
max(datoscer$Residuos_z),len=1000)
gg = dnorm(x,0,1)
datosplot <- data.frame(x = x, y = gg)
plot4.4 <- ggplot(data = datoscer, aes(x = Residuos_z)) +
geom_histogram(aes(y=..density..),alpha = 0.5,
color="black", fill = "gray50") +
geom_point(data=datosplot, aes(x=x,y=y),
color="skyblue4") +
labs(title = "Distribución Normal",
x = "Residuos") +
theme_bw()
ggarrange(plot4.3,plot4.4,ncol=2)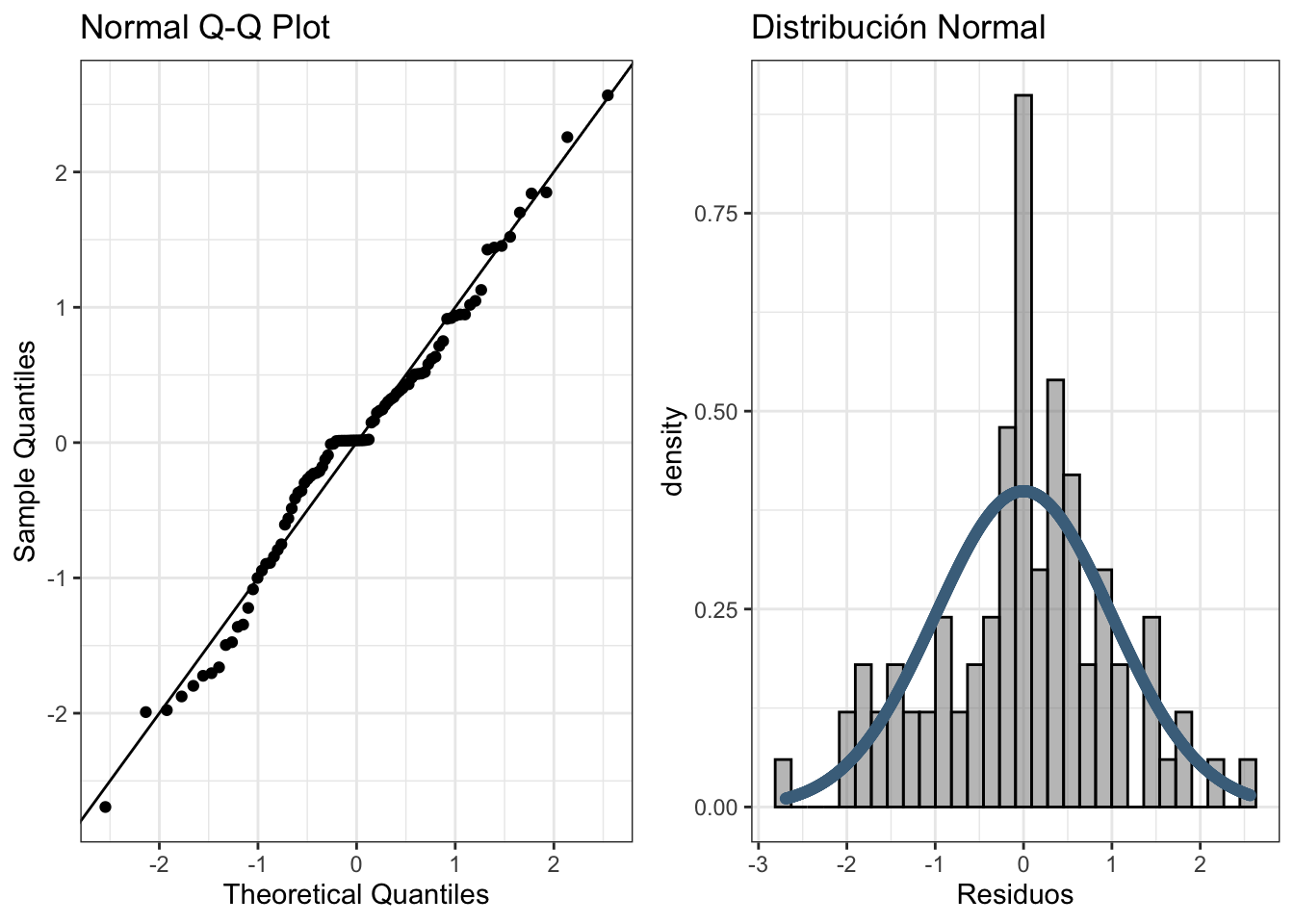
1.4.2 Independencia
plot1 = ggAcf(datoscer$Residuos,lag=30) +
labs(title = "ACF Residuos Modelo Cervezas") +
ylim(-0.3,0.3) +
theme_bw()
plot1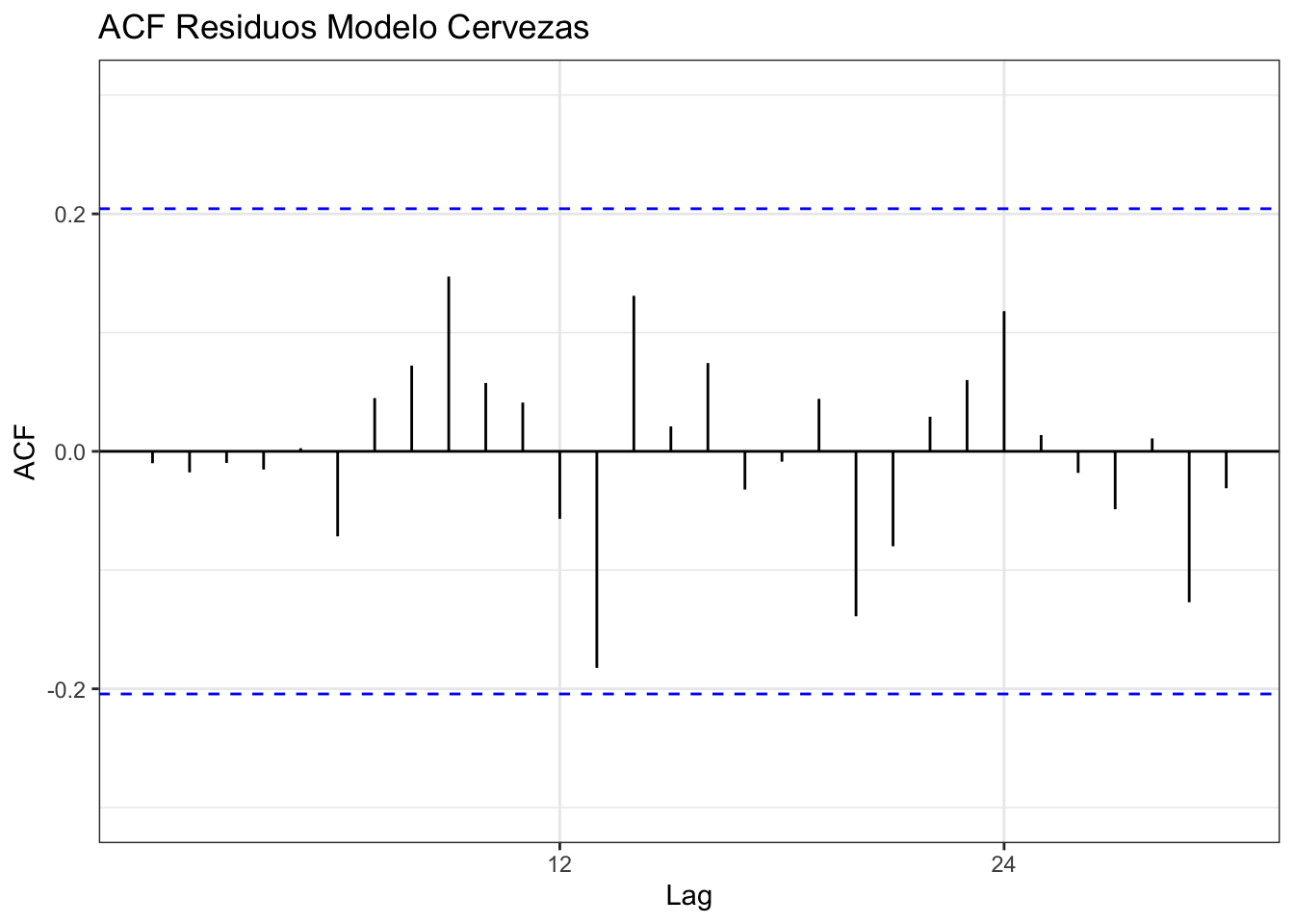
El test de Ljung-Box para testear simúltaneamente que sean incorrelacionados los errores para varios lag de tiempo
Est = c()
valorp = c()
for( i in 1:12){
Test = Box.test(datoscer$Residuos, lag = i, type = "Ljung-Box")
Est[i] = Test$statistic
valorp[i] = Test$p.value
}
tibble(Lag = seq(1,12),Estadistico = Est, valor_p = valorp)## # A tibble: 12 x 3
## Lag Estadistico valor_p
## <int> <dbl> <dbl>
## 1 1 0.00951 0.922
## 2 2 0.0397 0.980
## 3 3 0.0490 0.997
## 4 4 0.0721 0.999
## 5 5 0.0728 1.00
## 6 6 0.588 0.997
## 7 7 0.793 0.998
## 8 8 1.33 0.995
## 9 9 3.59 0.936
## 10 10 3.94 0.950
## 11 11 4.12 0.966
## 12 12 4.47 0.973Gráfico de los valores-p del test Ljung-Box
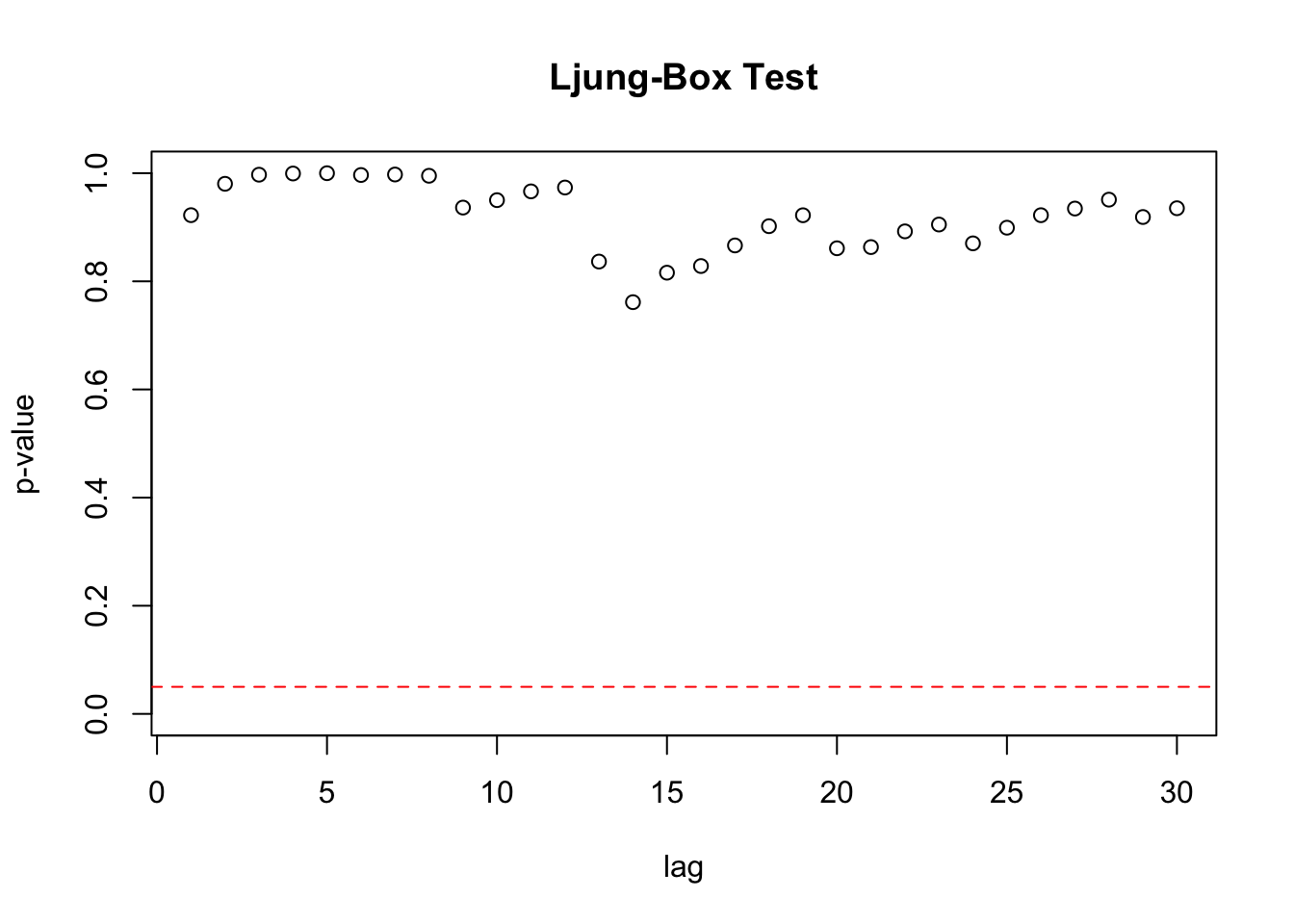
1.4.3 No colinealidad
Regresion_Model_Cer <- lm(CERVEZAS ~ -1 + DESEMPLEO + PCERVEZAS_T +TEMP_MAX + MOVILIDAD +RETIROS,data=datoscer )tibble(Variable = names(vif(Regresion_Model_Cer)), VIF = round(vif(Regresion_Model_Cer),3))%>%as.data.frame()## Variable VIF
## 1 DESEMPLEO 193.789
## 2 PCERVEZAS_T 189.882
## 3 TEMP_MAX 18.857
## 4 MOVILIDAD 8.578
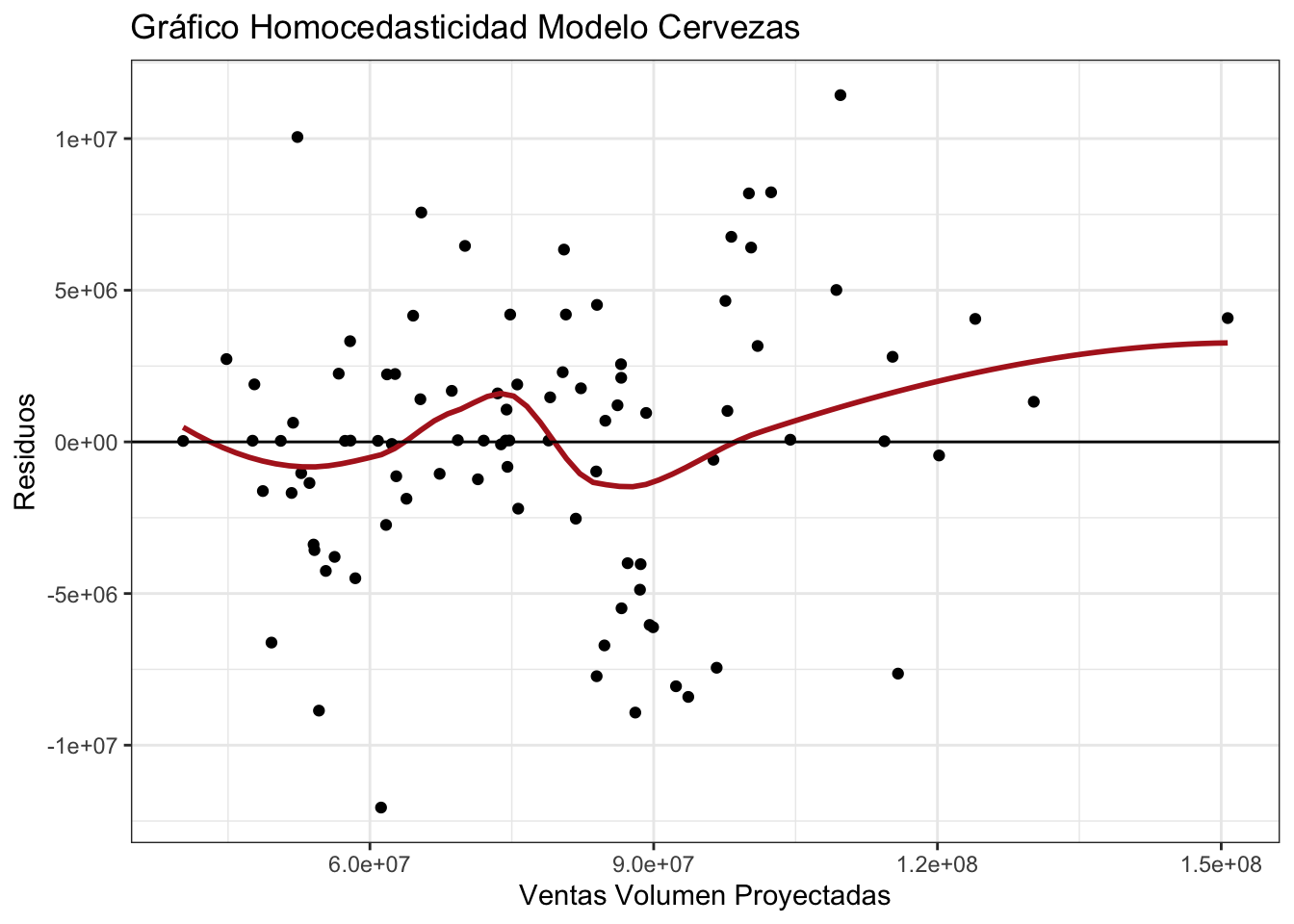
## 5 RETIROS 1.8931.4.4 Homocedasticidad
plot1 = ggplot(data = subset2.1, aes(model_auto_arima_cerv$fitted,model_auto_arima_cerv$residuals)) +
geom_point() +
geom_smooth(color = "firebrick", se = FALSE) +
geom_hline(yintercept = 0) +
labs( title = "Gráfico Homocedasticidad Modelo Cervezas ",
y = "Residuos",
x = "Ventas Volumen Proyectadas") +
theme_bw()
plot1