Chapter 3 Data Vizualization
In this chapter I will cover how to visualize data using ggplot2, a package included in the tidyverse. ggplot2 provides a few distinct advantages. It is integrated into the tidyverse, allowing it to interact with data frames (tibbles) in meaningful ways to produce better looking and more customizable graphs using less code. It also uses a layered format, allowing multiple visualizations of the same type to be combined and allowing for easy modification of different aspects of visualization. This will be discussed in greater detail in Section 4.1: The Grammar of Graphics.
For work in this chapter we will be using a couple different packages. As always, we will use the tidyverse, which contains ggplot2, the focus of this chapter.5859 Additionally we will use nycflights13, a package that provides sample data to work with as we learn the tools available through ggplot2.60
nycflights13 contains a variety of data sets pertaining to flights departing New York City in 2013.61 The code chunk below shows the three most prominent ones.
## # A tibble: 336,776 × 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 1 1 517 515 2 830 819
## 2 2013 1 1 533 529 4 850 830
## 3 2013 1 1 542 540 2 923 850
## 4 2013 1 1 544 545 -1 1004 1022
## 5 2013 1 1 554 600 -6 812 837
## 6 2013 1 1 554 558 -4 740 728
## 7 2013 1 1 555 600 -5 913 854
## 8 2013 1 1 557 600 -3 709 723
## 9 2013 1 1 557 600 -3 838 846
## 10 2013 1 1 558 600 -2 753 745
## # ℹ 336,766 more rows
## # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
## # tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
## # hour <dbl>, minute <dbl>, time_hour <dttm>## # A tibble: 26,115 × 15
## origin year month day hour temp dewp humid wind_dir wind_speed
## <chr> <int> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 EWR 2013 1 1 1 39.0 26.1 59.4 270 10.4
## 2 EWR 2013 1 1 2 39.0 27.0 61.6 250 8.06
## 3 EWR 2013 1 1 3 39.0 28.0 64.4 240 11.5
## 4 EWR 2013 1 1 4 39.9 28.0 62.2 250 12.7
## 5 EWR 2013 1 1 5 39.0 28.0 64.4 260 12.7
## 6 EWR 2013 1 1 6 37.9 28.0 67.2 240 11.5
## 7 EWR 2013 1 1 7 39.0 28.0 64.4 240 15.0
## 8 EWR 2013 1 1 8 39.9 28.0 62.2 250 10.4
## 9 EWR 2013 1 1 9 39.9 28.0 62.2 260 15.0
## 10 EWR 2013 1 1 10 41 28.0 59.6 260 13.8
## # ℹ 26,105 more rows
## # ℹ 5 more variables: wind_gust <dbl>, precip <dbl>, pressure <dbl>,
## # visib <dbl>, time_hour <dttm>## # A tibble: 3,322 × 9
## tailnum year type manufacturer model engines seats speed engine
## <chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
## 1 N10156 2004 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
## 2 N102UW 1998 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
## 3 N103US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
## 4 N104UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
## 5 N10575 2002 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
## 6 N105UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
## 7 N107US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
## 8 N108UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
## 9 N109UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
## 10 N110UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
## # ℹ 3,312 more rowsggplot2 includes sample data sets provided within the package as well. These data sets are displayed in the code chunk below.
## # A tibble: 53,940 × 10
## carat cut color clarity depth table price x y z
## <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
## 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
## 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
## 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
## 4 0.29 Premium I VS2 62.4 58 334 4.2 4.23 2.63
## 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
## 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
## 7 0.24 Very Good I VVS1 62.3 57 336 3.95 3.98 2.47
## 8 0.26 Very Good H SI1 61.9 55 337 4.07 4.11 2.53
## 9 0.22 Fair E VS2 65.1 61 337 3.87 3.78 2.49
## 10 0.23 Very Good H VS1 59.4 61 338 4 4.05 2.39
## # ℹ 53,930 more rows## # A tibble: 234 × 11
## manufacturer model displ year cyl trans drv cty hwy fl class
## <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
## 1 audi a4 1.8 1999 4 auto… f 18 29 p comp…
## 2 audi a4 1.8 1999 4 manu… f 21 29 p comp…
## 3 audi a4 2 2008 4 manu… f 20 31 p comp…
## 4 audi a4 2 2008 4 auto… f 21 30 p comp…
## 5 audi a4 2.8 1999 6 auto… f 16 26 p comp…
## 6 audi a4 2.8 1999 6 manu… f 18 26 p comp…
## 7 audi a4 3.1 2008 6 auto… f 18 27 p comp…
## 8 audi a4 quattro 1.8 1999 4 manu… 4 18 26 p comp…
## 9 audi a4 quattro 1.8 1999 4 auto… 4 16 25 p comp…
## 10 audi a4 quattro 2 2008 4 manu… 4 20 28 p comp…
## # ℹ 224 more rows## # A tibble: 574 × 6
## date pce pop psavert uempmed unemploy
## <date> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1967-07-01 507. 198712 12.6 4.5 2944
## 2 1967-08-01 510. 198911 12.6 4.7 2945
## 3 1967-09-01 516. 199113 11.9 4.6 2958
## 4 1967-10-01 512. 199311 12.9 4.9 3143
## 5 1967-11-01 517. 199498 12.8 4.7 3066
## 6 1967-12-01 525. 199657 11.8 4.8 3018
## 7 1968-01-01 531. 199808 11.7 5.1 2878
## 8 1968-02-01 534. 199920 12.3 4.5 3001
## 9 1968-03-01 544. 200056 11.7 4.1 2877
## 10 1968-04-01 544 200208 12.3 4.6 2709
## # ℹ 564 more rowsThis chapter is meant to serve as a guide on how to produce effective graphics using tidy data. Throughout the chapter, I will link more comprehensive resources that go into further depth about the grammar of graphics and the intricacies of ggplot2. This chapter provides an outline of the steps required to produce visualizations, as well as a cursory introduction to the foundational theory of effective graphics.
3.1 The Grammar of Graphics
ggplot2 uses the theoretical framework called the grammar of graphics as the basis for its organization. There are three essential components to a graphic:62
data: the clean data containing the variable(s) of interestgeom: the type of geometric object in the plot- e.g. line, point, bar, box
aes: aesthetic attributes of the geometric object- e.g. x/y variables, color, shape, size
- can be mapped (coordinated) to variables
For our first plot, we will plot the displ and hwy variables from the mpg data set. The code chunk below demonstrates the most basic syntax for producing a graphic using ggplot.63
(example1 <- ggplot(data = mpg, aes(x = displ, y = hwy)) + # data =, x =, and y = are not required
geom_point())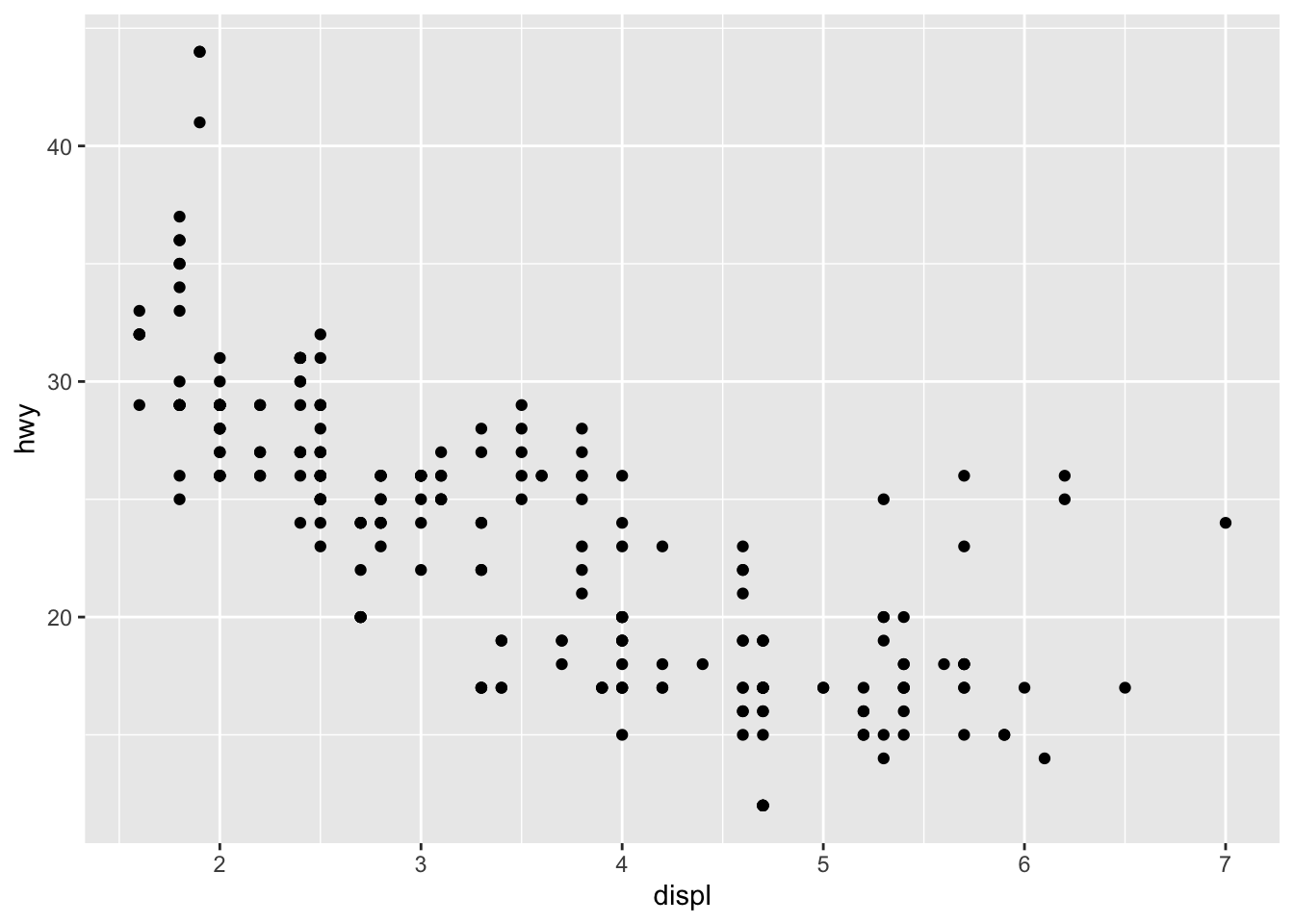
In this plot, displ refers to engine displacement (in liters) and hwy refers to highway miles per gallon. It is always crucial to know what each variable you are working with refers to. If you are unsure, check the code book for your data set. For the data sets we are working with in this chapter, their code books can be found in their documentation. This link provides the code book for mpg. In terms of the grammar discussed above, the data is mpg, the geom is a scatter plot (designated by adding the + geom_point()), and the aes refers to the variables assigned to each axis within aes() in the first line. I saved this plot as example1 and put parentheses around the whole statement so it would print.
Below, I break example1 into its different components. In the first line, the data = parameter tells ggplot2 the relevant data frame. The x and y parameters within aes() tell ggplot which variables are assigned to each axis. This covers the most basic components of each visualization, taking care of the data and aes features of the visualization. There is no geom in the example below, so only a blank graph with assigned axes is outputted.
![]()
After establishing the basic grid where the data will be visualized, the next step is to add geoms. Our first example graph used the geom geom_point() to create a scatter plot. One of the most powerful features of ggplot2 is its ability to layer multiple geoms over the same visualization. Only certain geoms are able to be layered together. The code chunk below demonstrates how to use multiple geoms. Each one can be added using the following code template: + geom_function(). Different types of geoms will be covered in detail later in Section 4.4: Geoms.
ggplot(data = mpg, aes(x = displ, y = hwy)) +
geom_point() +
geom_smooth() # the geom_smooth function adds a line of best fit with a confidence interval## `geom_smooth()` using method = 'loess' and formula = 'y ~ x'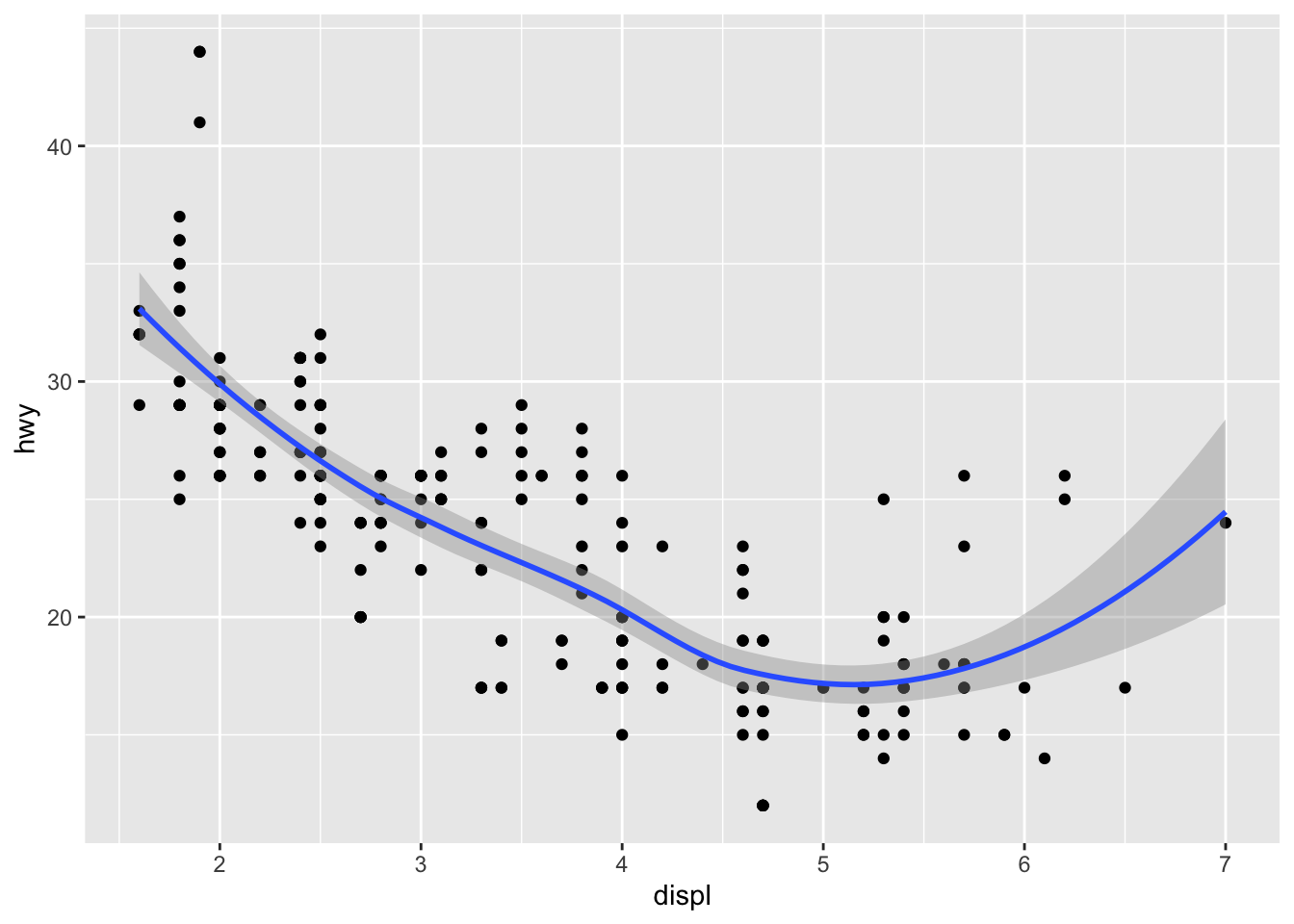
If you would like to vary the parameters in ggplot() between geoms, specify them differently within each geom function instead of within ggplot(). It is important to note that everything written within ggplot() applies to all geoms. The code chunk below demonstrates how to layer two geoms using different variables. To differentiate between the two different variables, you must assign each one a different color. To assign an attribute that is not mapped to an aesthetic (within aes()) place it after aes() as demonstrated below. The two different variables on the same axis (the y-axis in this example) must share a unit for this to make sense (both cty and hwy are in miles per gallon).
ggplot(data = mpg) +
geom_point(aes(x = displ, y = hwy), color = "black") +
geom_point(aes(x = displ, y = cty), color = "red")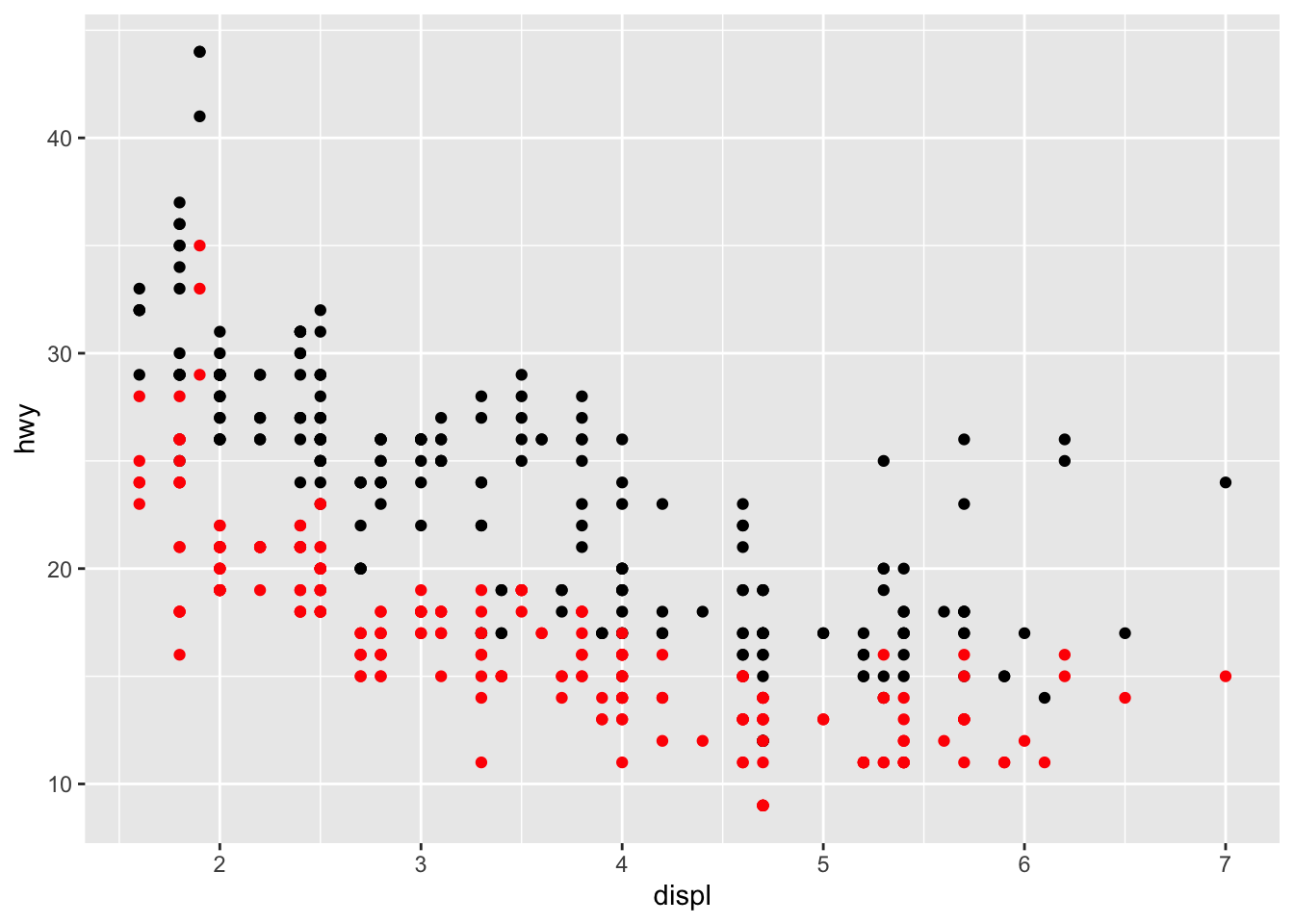
The issue with the plot above is that it does not automatically generate a legend. While this demonstrates how geoms can be layered, there is a better way to make this graph covered in Section 4.2.1: Color.
3.2 Aesthetics
The most basic aesthetic attributes included in just about every type of plot are the assignment of the axes. Some types of plots (e.g histogram) only require the x-axis. Other types of aesthetic attributes can be used to differentiate between observations based on categorical or numeric variables.
The first important differentiation about aesthetics, alluded to earlier, is the difference between putting something within aes() and putting something behind it. When an attribute is within aes(), the computer assumes that you are referring to a variable within the data. When an attribute is after the aesthetics (e.g.aes(), color = "blue"), then it applies the aesthetic change to the whole geom without mapping it to a variable. The difference is demonstrated in the code chunk below using the example1 scatter plot and in the examples dealing with different types of aesthetics.
# when color is within aes(), the computer thinks "red" is a categorical variable and incorrectly makes a legend
ggplot(data = mpg) +
geom_point(aes(x = displ, y = hwy, color = "red"))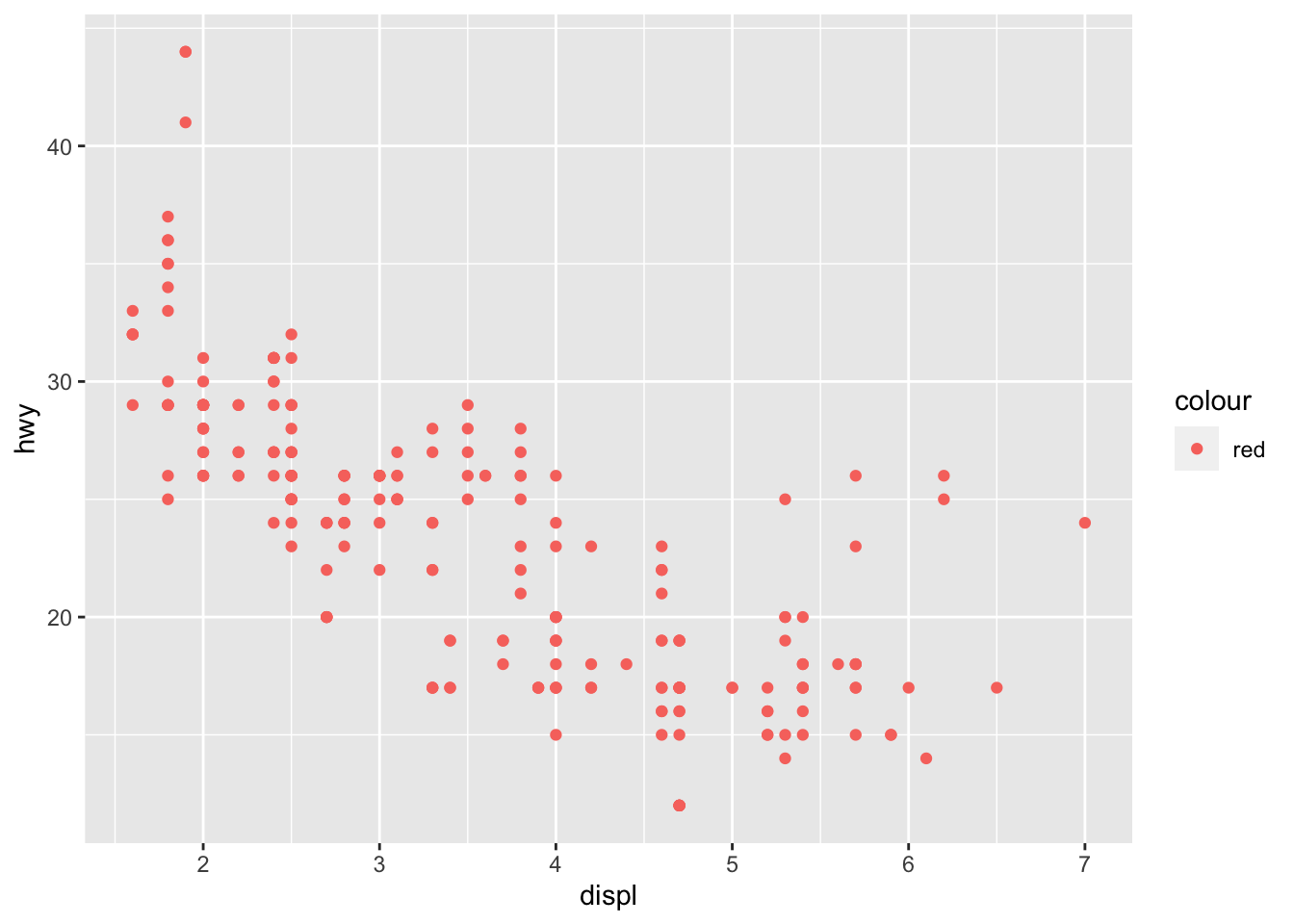
# when the color is after aes(), all points are colored red
ggplot(data = mpg) +
geom_point(aes(x = displ, y = hwy), color = "red")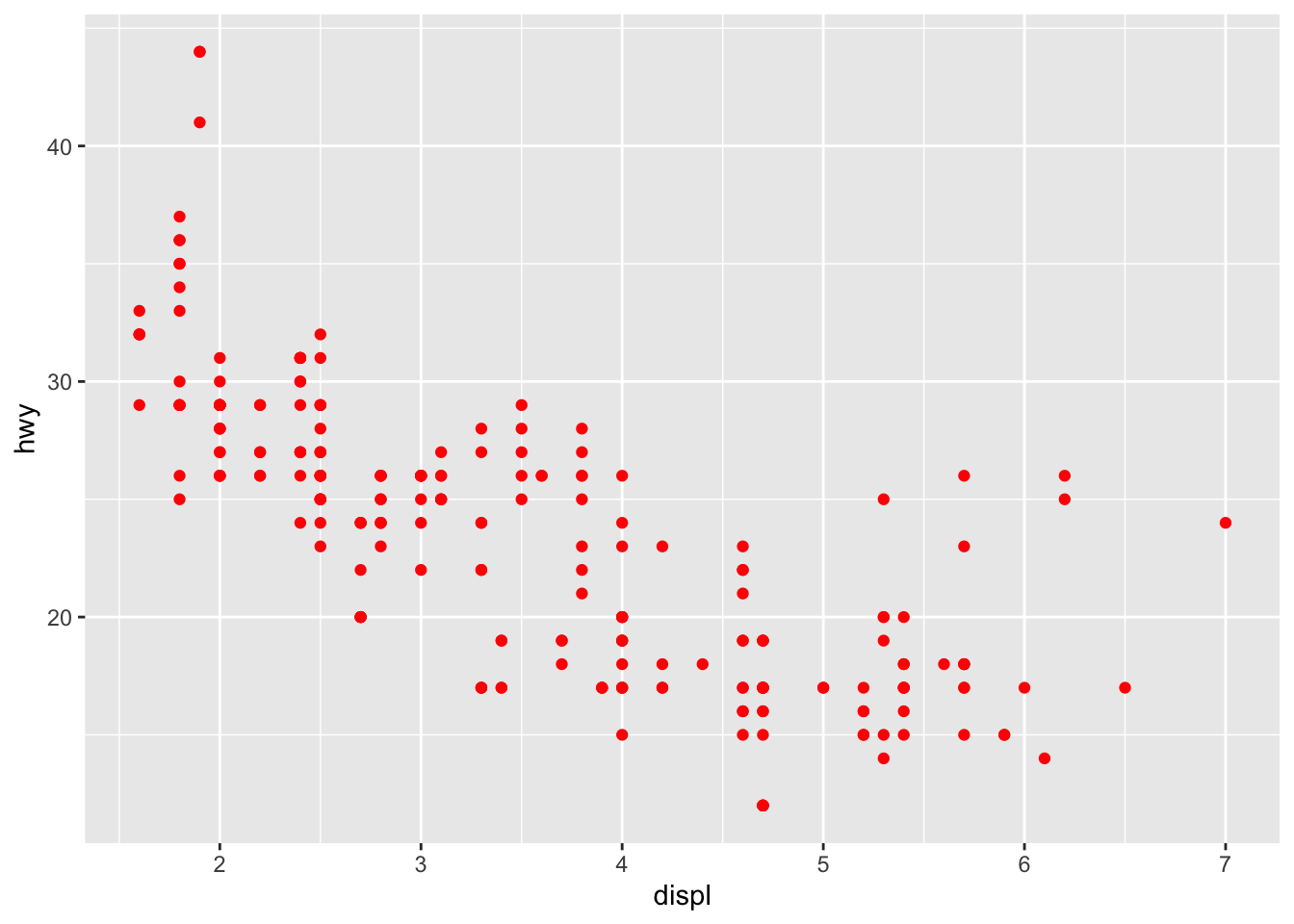
The important point here is that everything within aes() corresponds to a variable, when everything afterwards modifies an attribute of the visualization in a fixed manner.
This section will cover the basic attributes of a scatter plot, through a variety of examples using the data sets mentioned at the beginning of the chapter. Each of these attributes has different visual aspects that make them better or worse for categorical or continuous variables. Replicating and modifying these examples is the best way to practice getting comfortable making visualizations. All examples in this section will modify the example1 plot, which uses the mpg data set.
3.2.1 Color
Color is a powerful attribute that lends itself well to both categorical variables and continuous ones. When used outside of aesthetic mapping purposes, it can be used to create graphics that are more visually appealing. When trying to communicate information through color, make sure that the uninformed reader is able to easily differentiate between categories or read the scale if the variable is continuous. Experimentation using different attributes to represent a variable is how to find the clearest way to communicate meaning through aesthetics.
In the plot below, color is used to differentiates between different classes of car, a categorical variable. Importantly, each class of car is identifiable through the legend.
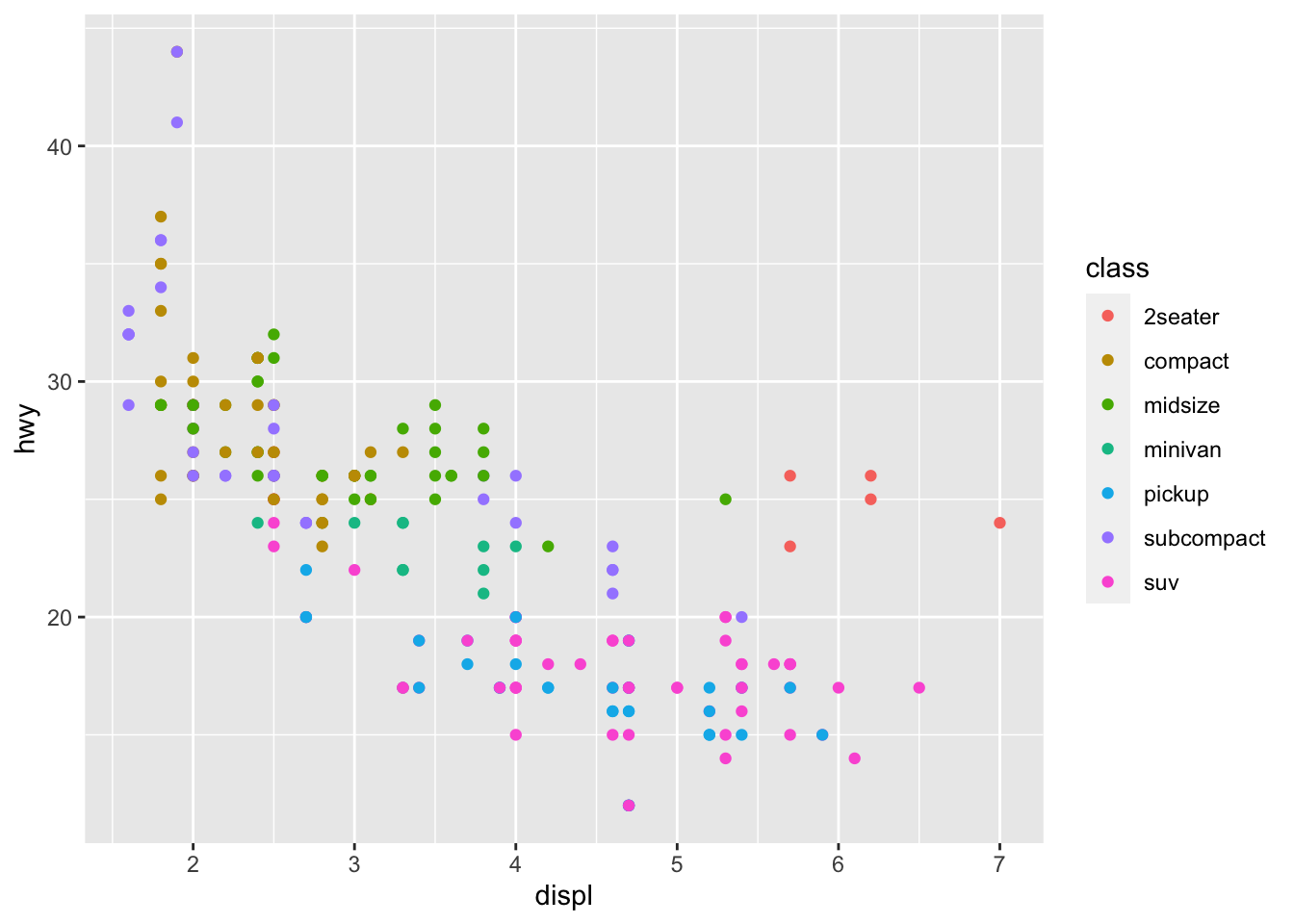
The next example uses scaled color to represent the continuous variable cty, referring to the city miles per gallon. Often, when there are many points in a scatter plot or a wide range of values represented by color, the visualization can become unclear to the observer. Each visualization is unique and must be individually assessed in this respect.
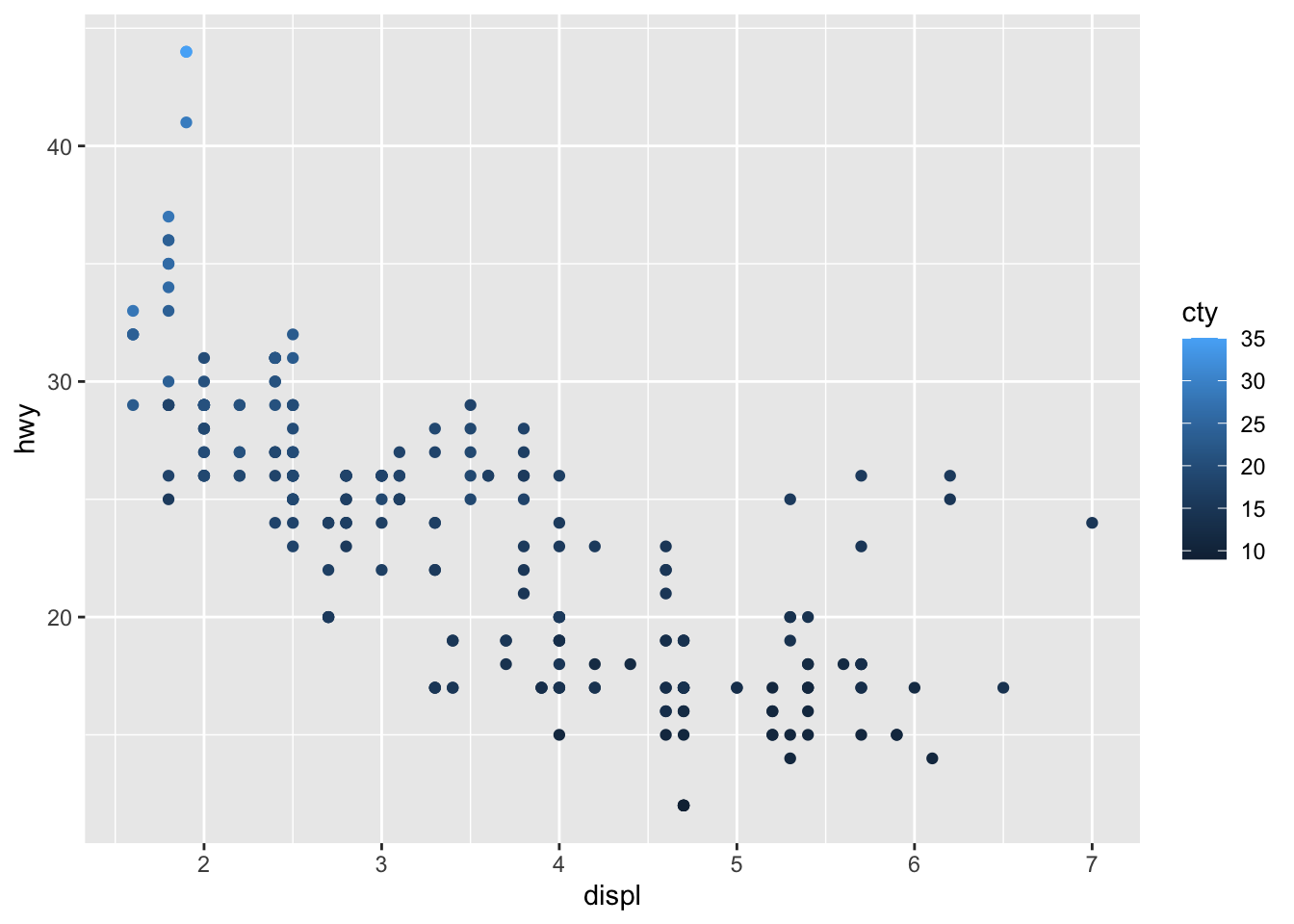
Using the color aesthetic addresses the problem of layering geoms to manually set different colors above. Unfortunately, the mpg data set does not come in a format where this can be done without wrangling the data. The code chunk below demonstrates how to modify the data using pivot_longer(), creating a single mpg variable where a new categorical variable designates if the mpg variable refers to highway or city. That new cateogrical variable is then mapped to color.
mpg |>
pivot_longer(c(hwy, cty), names_to = "mpg_type", values_to = "mpg") |>
ggplot(aes(x=displ, y=mpg, color=mpg_type)) +
geom_point()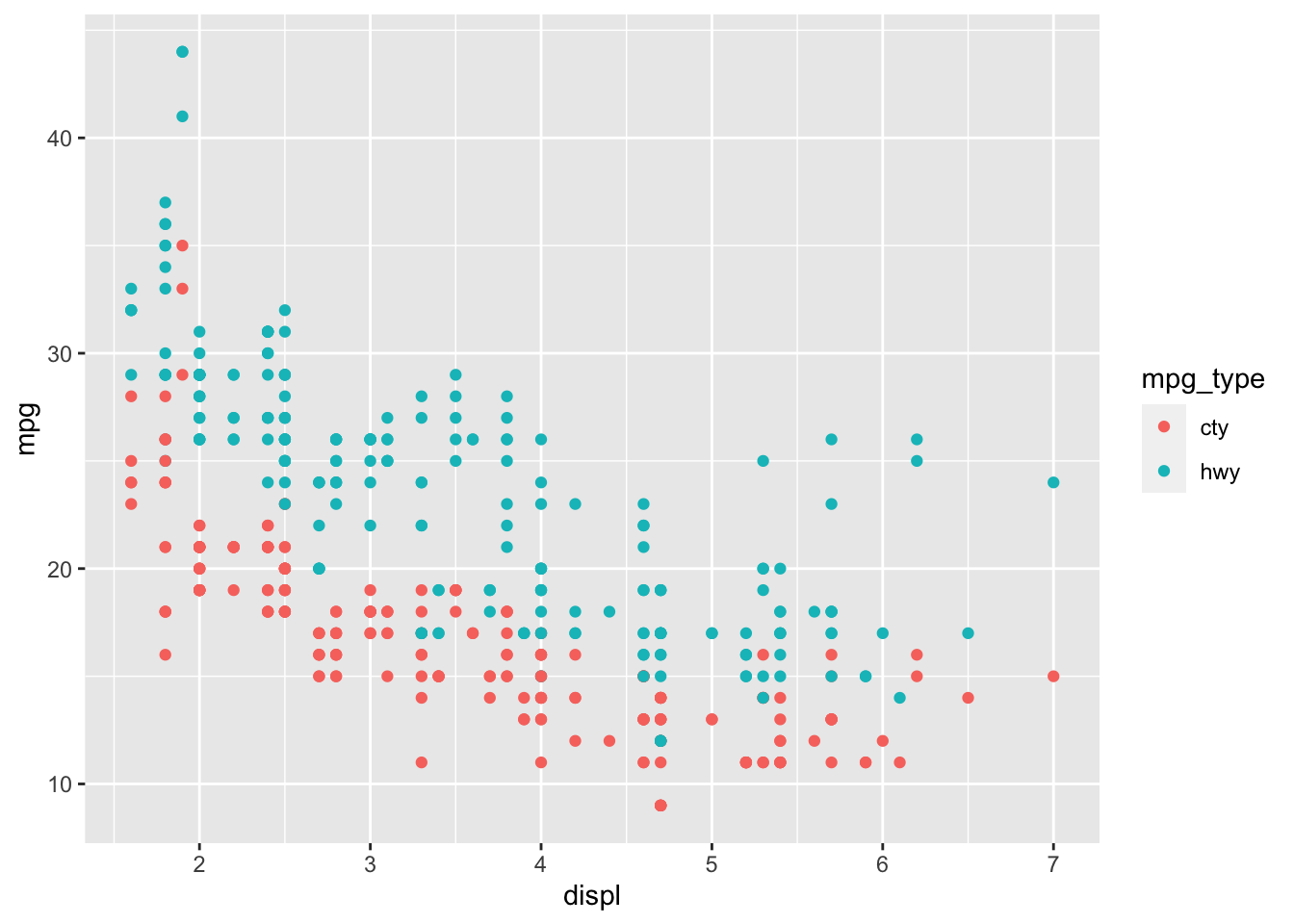
3.2.2 Shape
Shape is only used to represent categorical variables. It can be used to represent a continuous variable, but only if that variable is simplified into a categorical variable that designates a level or range for the continuous variable (e.g. low, medium, high).
The code chunk below shows an example of mapping shape to the drive train variable (drv) and changing the shape for look without mapping to a variable.
# mapping shape to the class variable
ggplot(data = mpg) +
geom_point(aes(x = displ, y = hwy, shape = drv))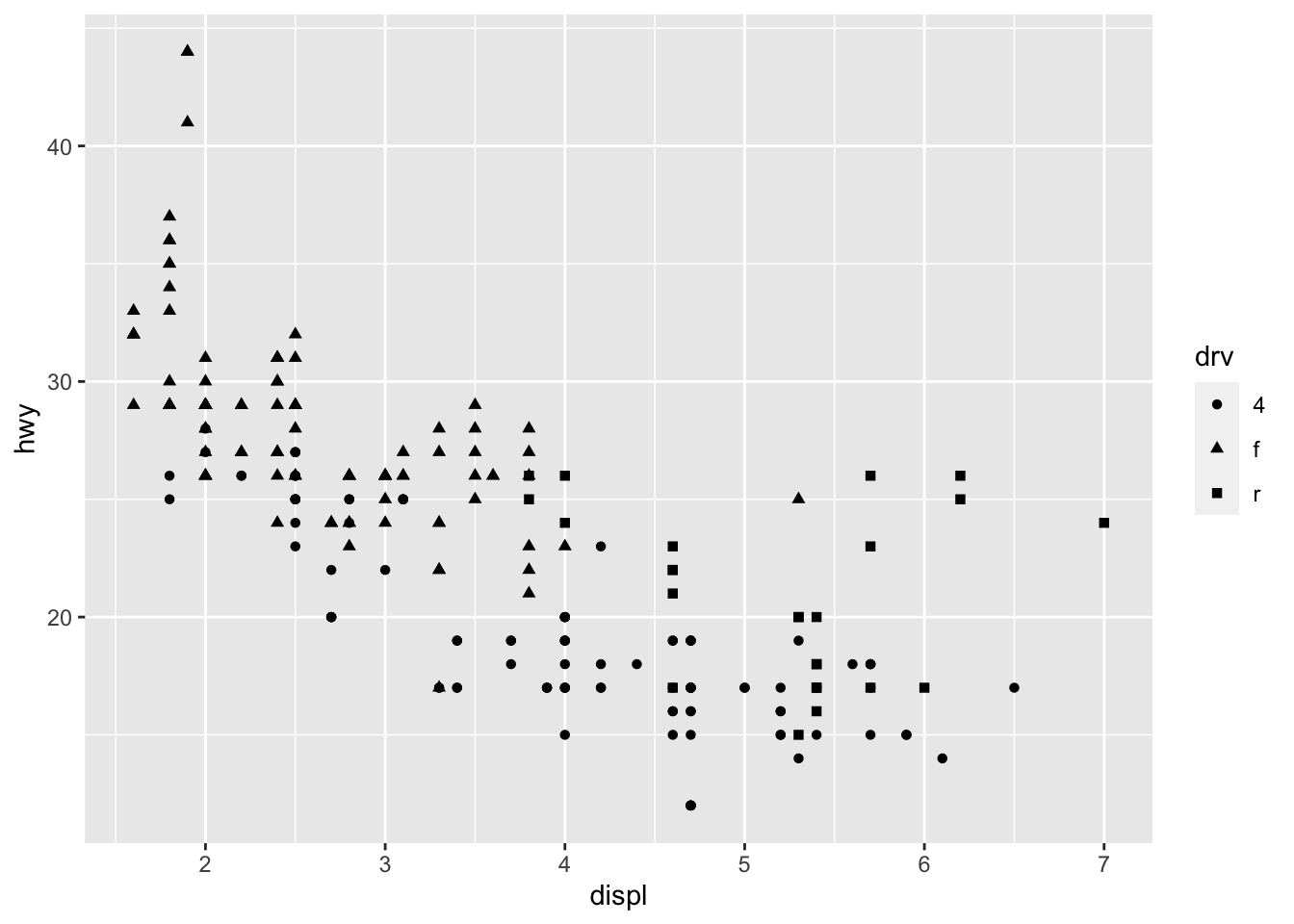
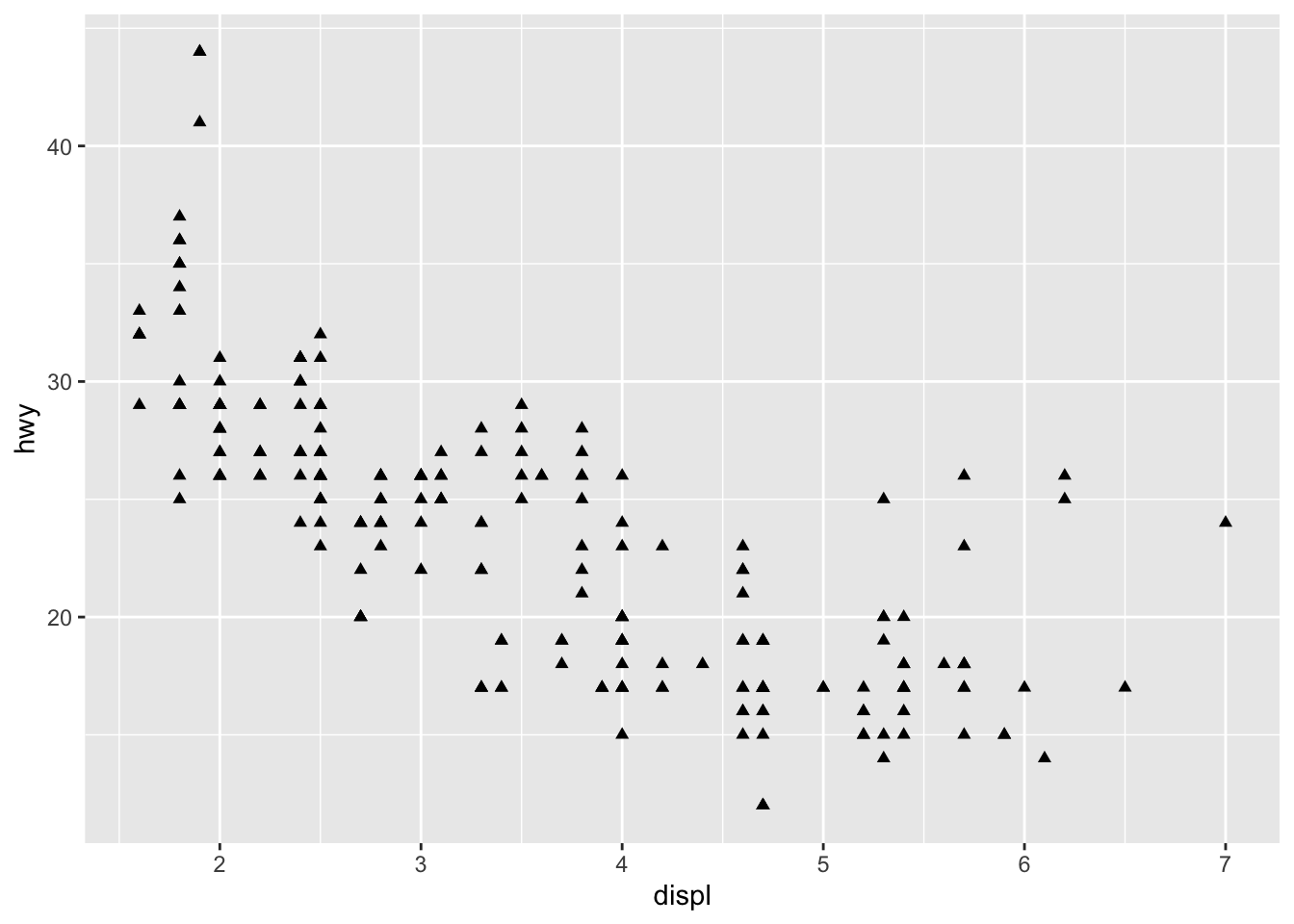
For information of which shape corresponds to which number, when not using mapping, look at the aesthetics mapping section of R for Data Science.64
3.2.3 Size
Size can be used to designate categorical variables, but often it can be hard to differentiate between levels and it makes the graph less legible. I would recommend only using size with a continuous variable, as it lends itself well to meaningful visual comparisons on a continuous scale. The example below maps size to the city miles per gallon variable (cty) from mpg.
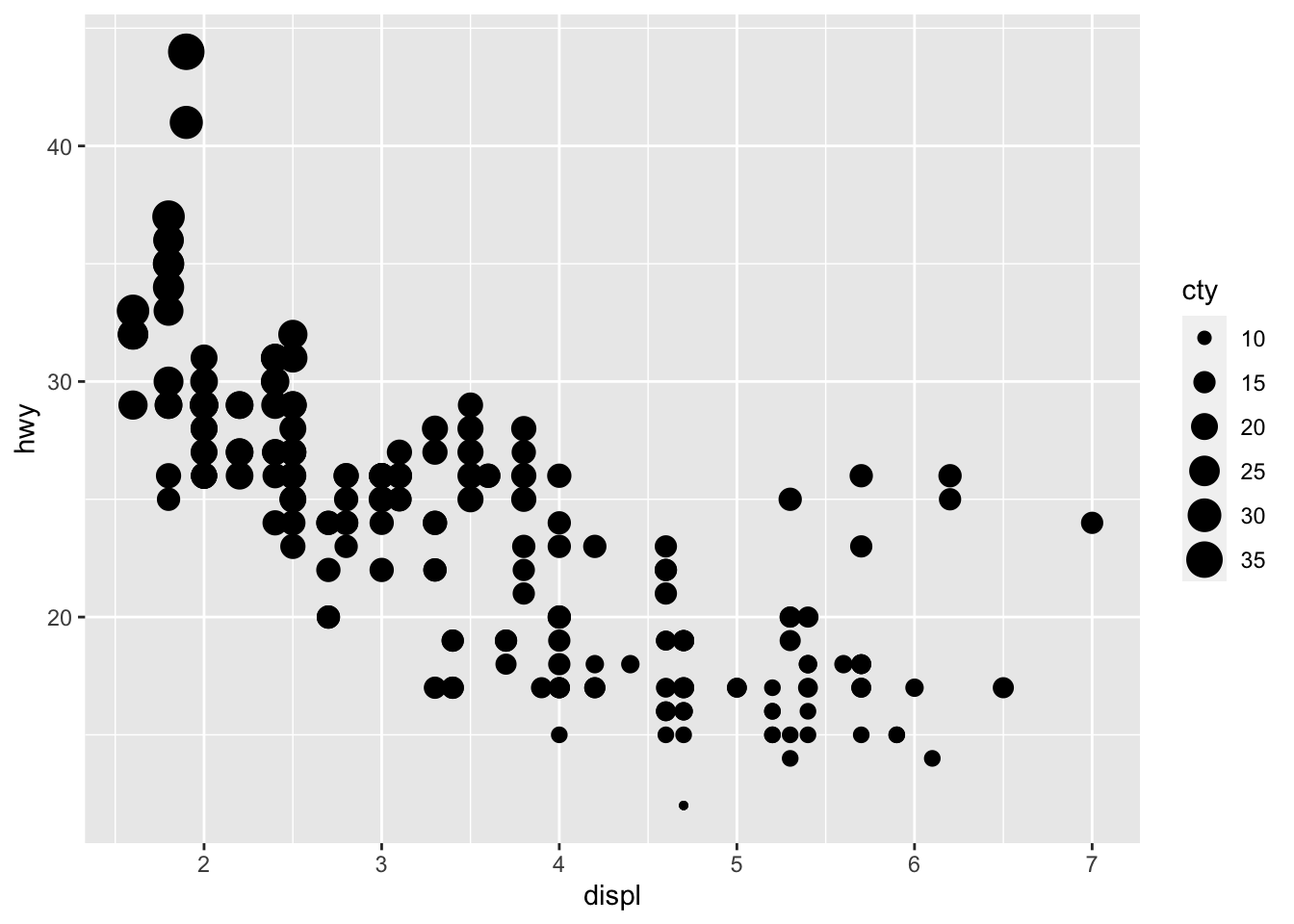
As demonstrated above using color, the size parameter can also be used outside of aes() to uniformly change all points. Often, when a graph is hard to read, reducing the size of points can make it more legible. This can be observed in the faceting example below.
3.2.4 Shading
Shading can be changed through the alpha = parameter. The first example below reproduces a plot using the same variables as the size example, except cty is mapped to alpha instead of size. The second examples uses the same variables as the first example from the color section, except it maps class to alpha instead of color.
# using alpha to map a continuous variable
ggplot(data = mpg) +
geom_point(aes(x = displ, y = hwy, alpha = cty))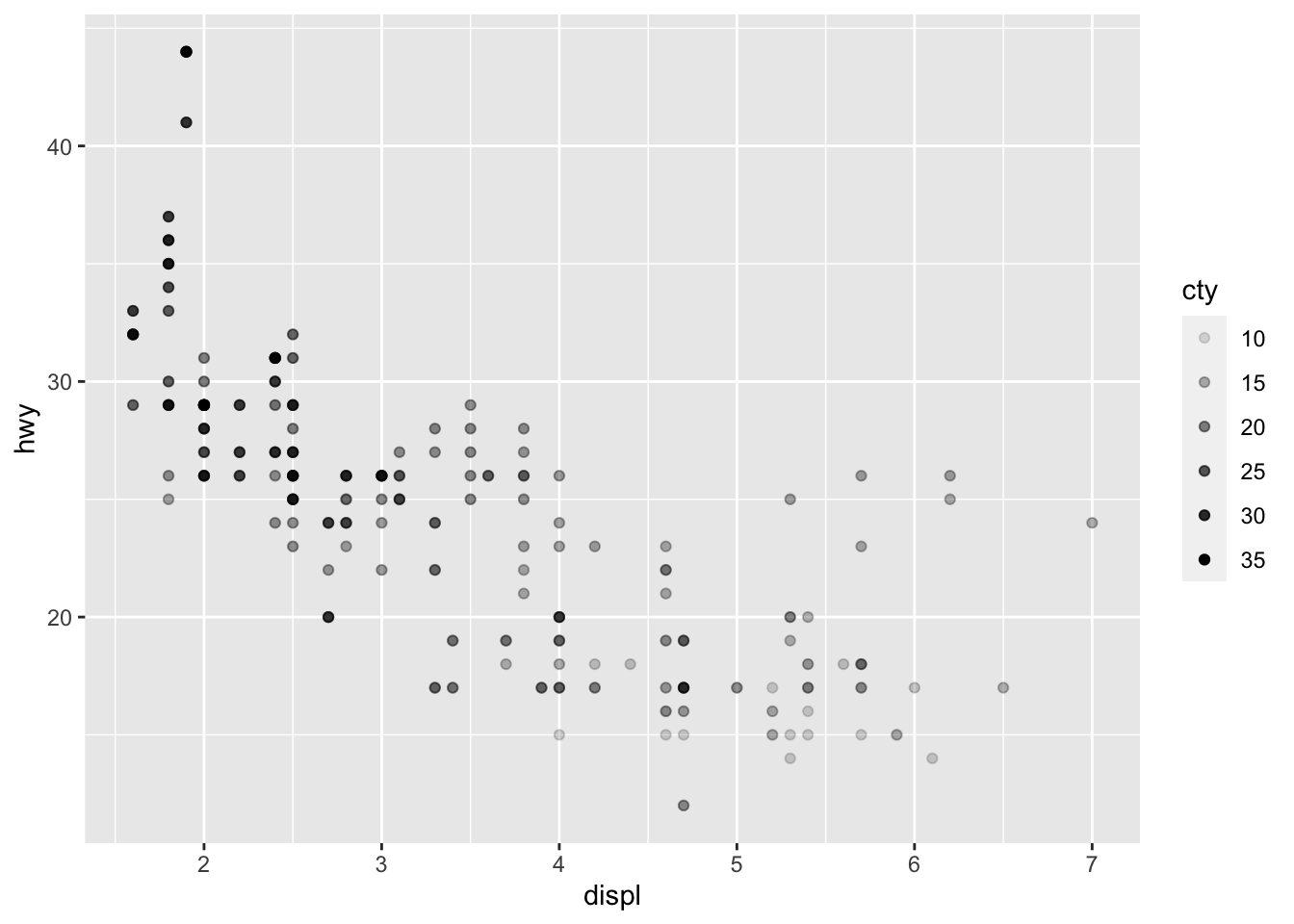
# using alpha to map a categorical variable
ggplot(data = mpg) +
geom_point(aes(x = displ, y = hwy, alpha = class))## Warning: Using alpha for a discrete variable is not advised.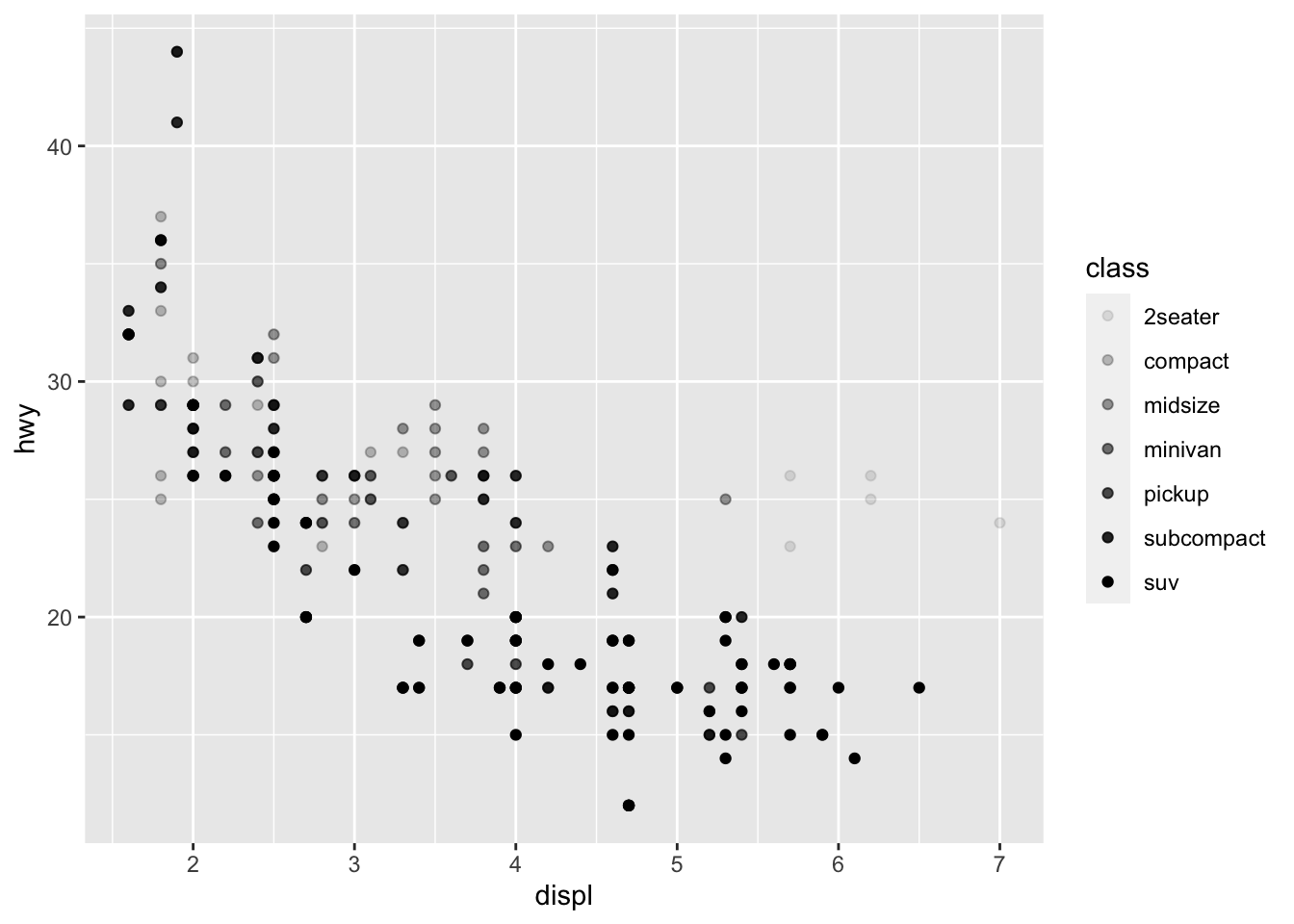
While shading can be mapped to a categorical variable, it is not recommended as it is better suited for continuous distinctions.
3.3 Faceting
Faceting tells the computer to create separate graphs around a categorical variable using the specified geoms. This cannot be used with continuous variables. Faceting can be a powerful tool for observing differences between observations belonging to different categories and for creating effective time series graphs (covered in Section 4.7: Plotting Time Series). There are two function used to create facets: facet_wrap() and facet_grid(). facet_wrap() is used for faceting by a single variable, while facet_grid() is used to facet using two variables.
ggplot(data = mpg) +
geom_point(aes(x = displ, y = hwy)) +
facet_wrap(~ class) # '~ variable' is crucial to the syntax of faceting 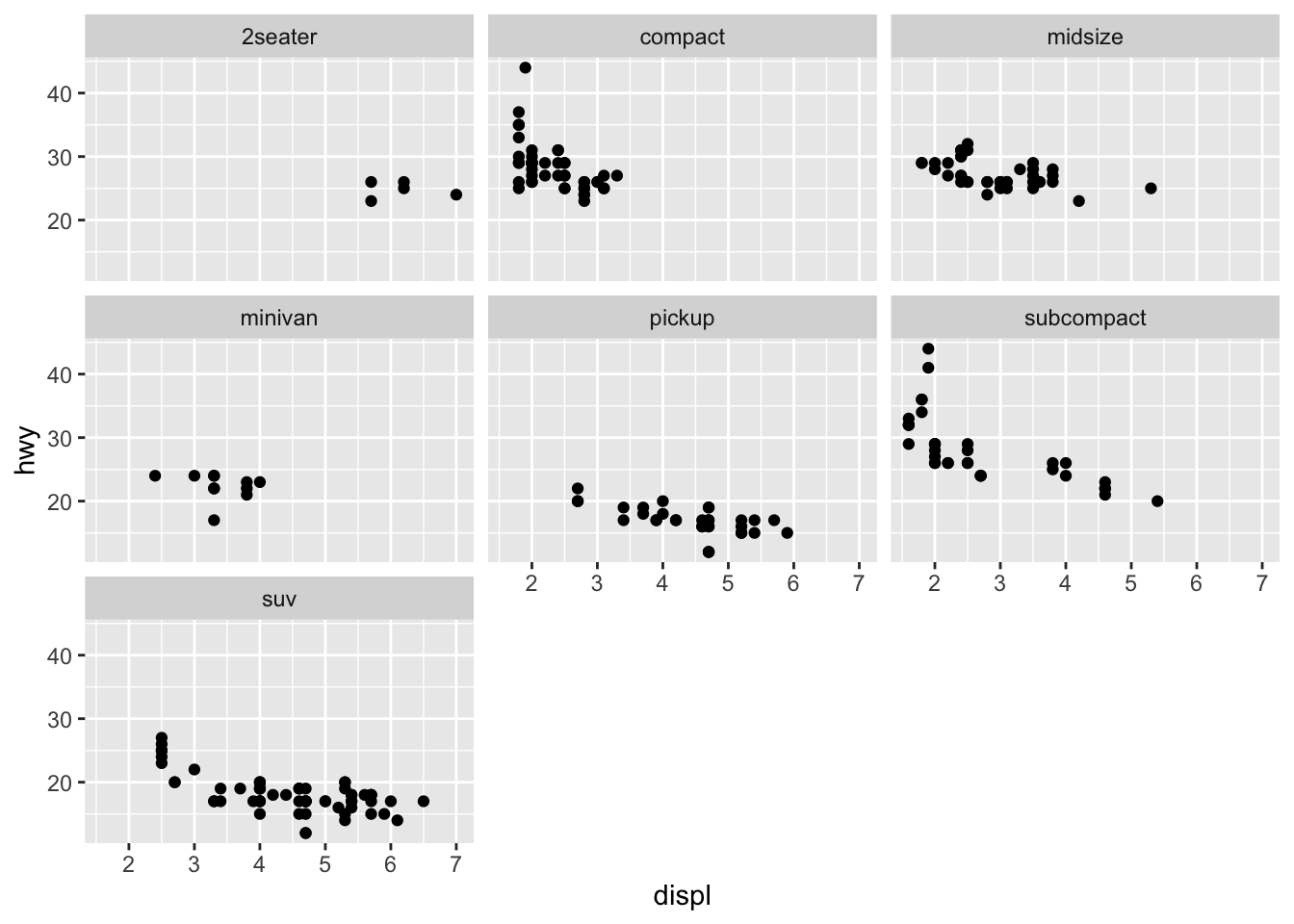
ggplot(data = mpg) +
geom_point(aes(x = displ, y = hwy), size = 0.5) + # size is changed for legibility
facet_grid(drv ~ class) # in this case '~' separates the two variables you want to facet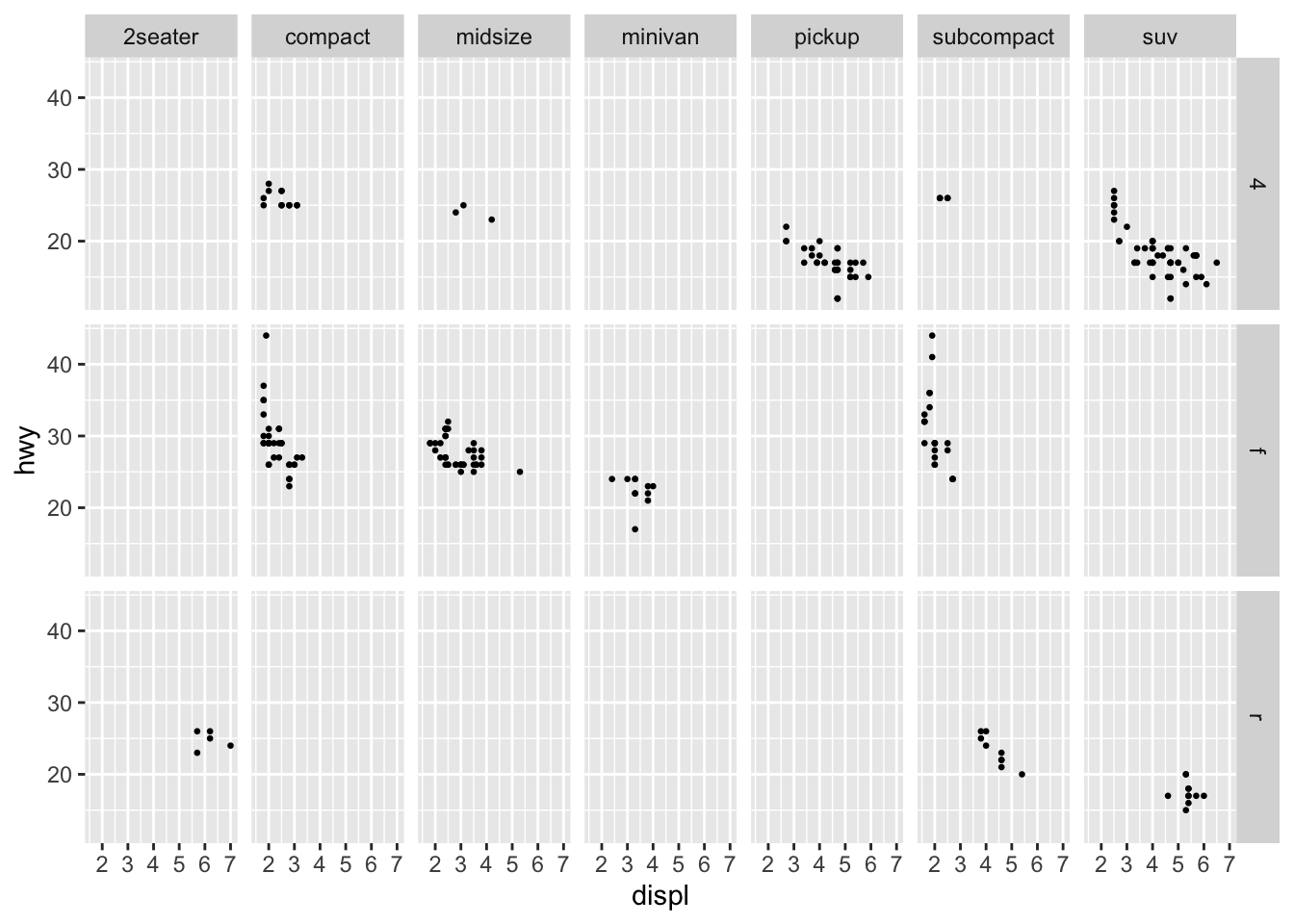
This feature of ggplot2 is very powerful as it allows a clear comparison of hwy and displ between different classes of cars. Trends within and between categories are able to be observed much more easily. This can be combined with other aesthetics to create visualizations that provide a great deal of information. Be cautious that you are not including too much information in one visualization. Sometimes it is best to produce individual facets manually for more in-depth analysis.
3.4 Geoms: Types of Plots
This section will cover different types of geoms and how to use them in ggplot2. First, I will go over the five named graphs covered in Statistical Inference in Data Science: A Modern Dive into R and the Tidyverse: scatter plots, line graphs, histograms, box plots, and bar charts.65 Within each of these sections I will cover more unorthodox approaches to producing similar types of graphics. Many of these geoms can be combined to provide more information in each visualization as well. Each of these graphics has data which they are useful for; the best way to determine which one is best for your data is experimentation.
3.4.1 Scatter Plots
So far we have extensively covered scatter plots in the earlier examples. To create a scatter plot, we use the geom_point() function demonstrated in examples above. Scatter plots are useful for visualizing the relationship between two continuous variables. They can be used for categorical variables as well, but convey much less information. For the examples in this section, I use the carat and price variables from the diamonds data set.
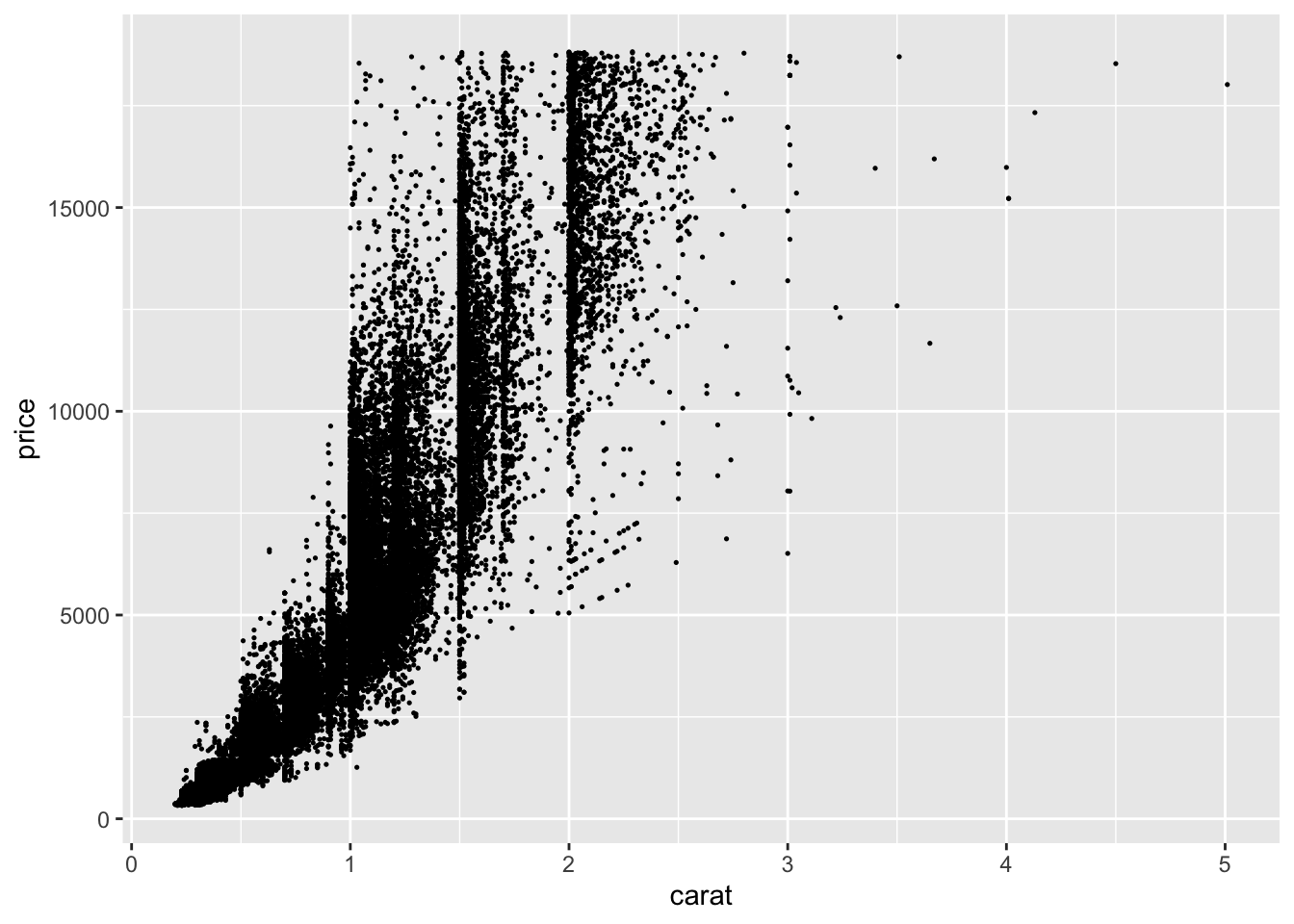
I choose this example because it is a classic example of over-plotting.66 This means that there are too many points close together. In the plot above, this is so extreme there appear to be large black masses in much of the graph. I adjusted the size to try and mitigate this, but it only provided a slight improvement.
One possible solutions is to use the alpha = parameter to adjust the transparency of the points. This is demonstrated in the code chunk below. This helps slightly but there is still a large amount of congestion.
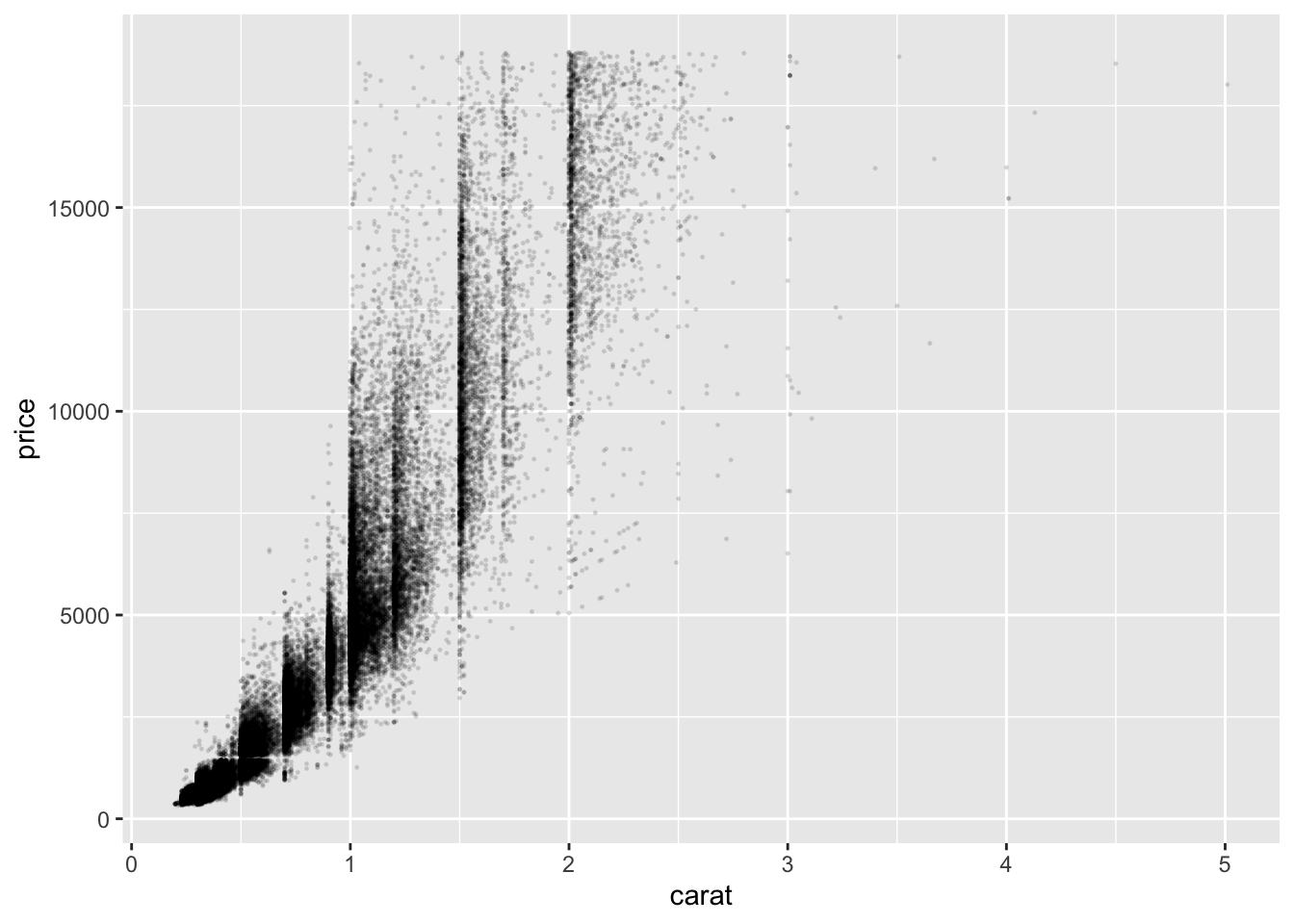
The other method for mitigating the overlap of our data points is to jitter them. This means that each point is slightly randomly moved. This should be done with caution. While it does not modify the data itself, randomly jittering the points can produce a misleading visualization. This can be done through using geom_jitter() instead of geom_point().67 To specify how much jitter to add, you can use the width = and height = arguments.68 I do not recommend using this; it is never a light decision to modify data. If you do, make sure you note that they are jittered in the visualization.
An alternative way to deal with over-plotting is to use an alternative geom that visualizes the density through color. These geoms, geom_bin2d() and geom_hex() mitigate the overlap of points through binning the observations. The code chunk below demonstrates how to use these two examples using the carat and price variables in the previous examples.69
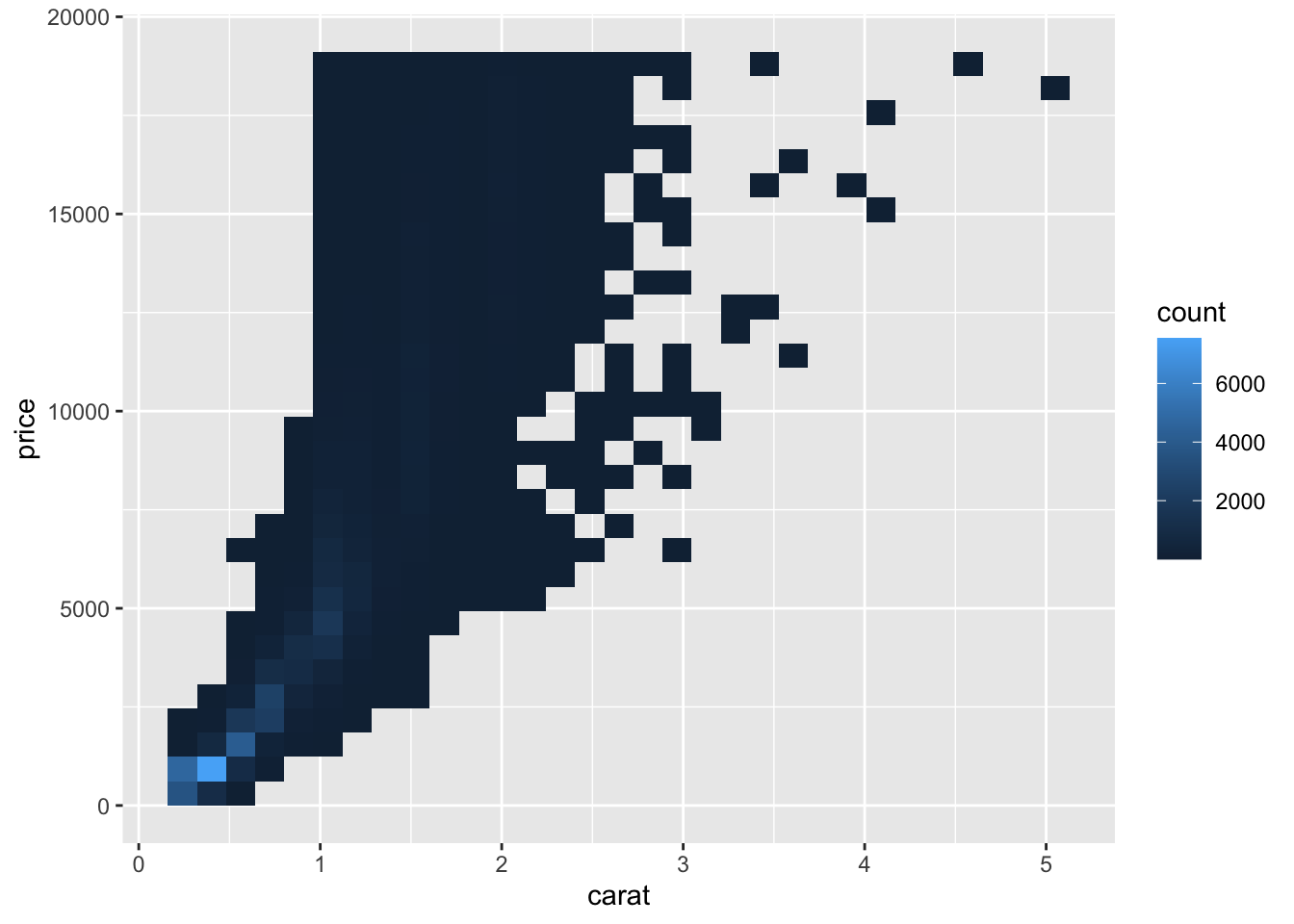
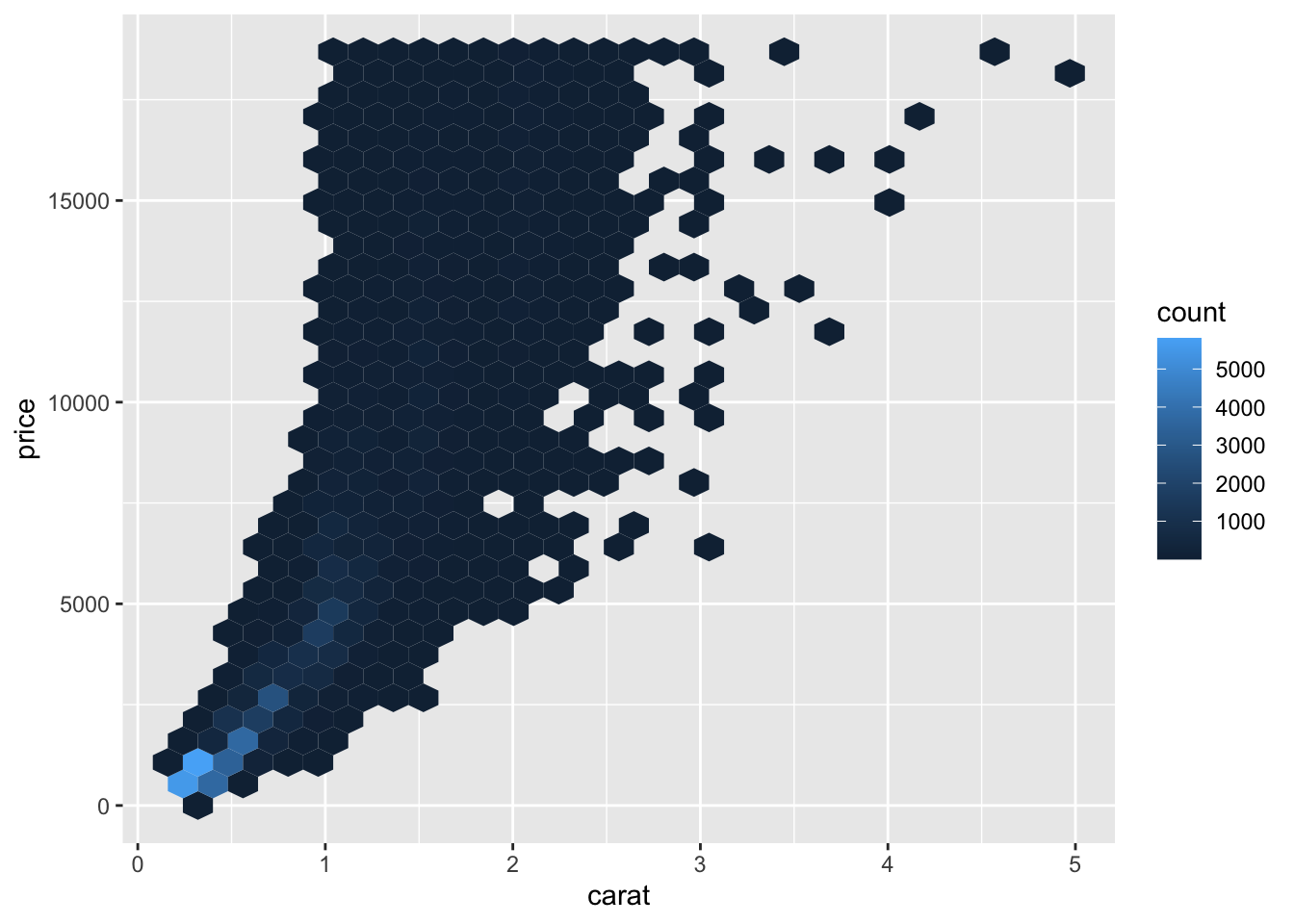
3.4.2 Line Graphs
When producing a visualization, the variable on the x-axis is usually called the explanatory variable and the variable on the y-axis is usually called the dependent variable. Line graphs inherently imply that the points are sequential because they are connected visually. Therefore, line graphs are usually used when the explanatory variable (x-axis) is some unit of time.
To create a line graph, instead of geom_point() use geom_line(). In the example below, I use the time_hour and temp variables in the weather data frame from nycflights13. To restrict the number of observations, I only use the weather from January 2013.
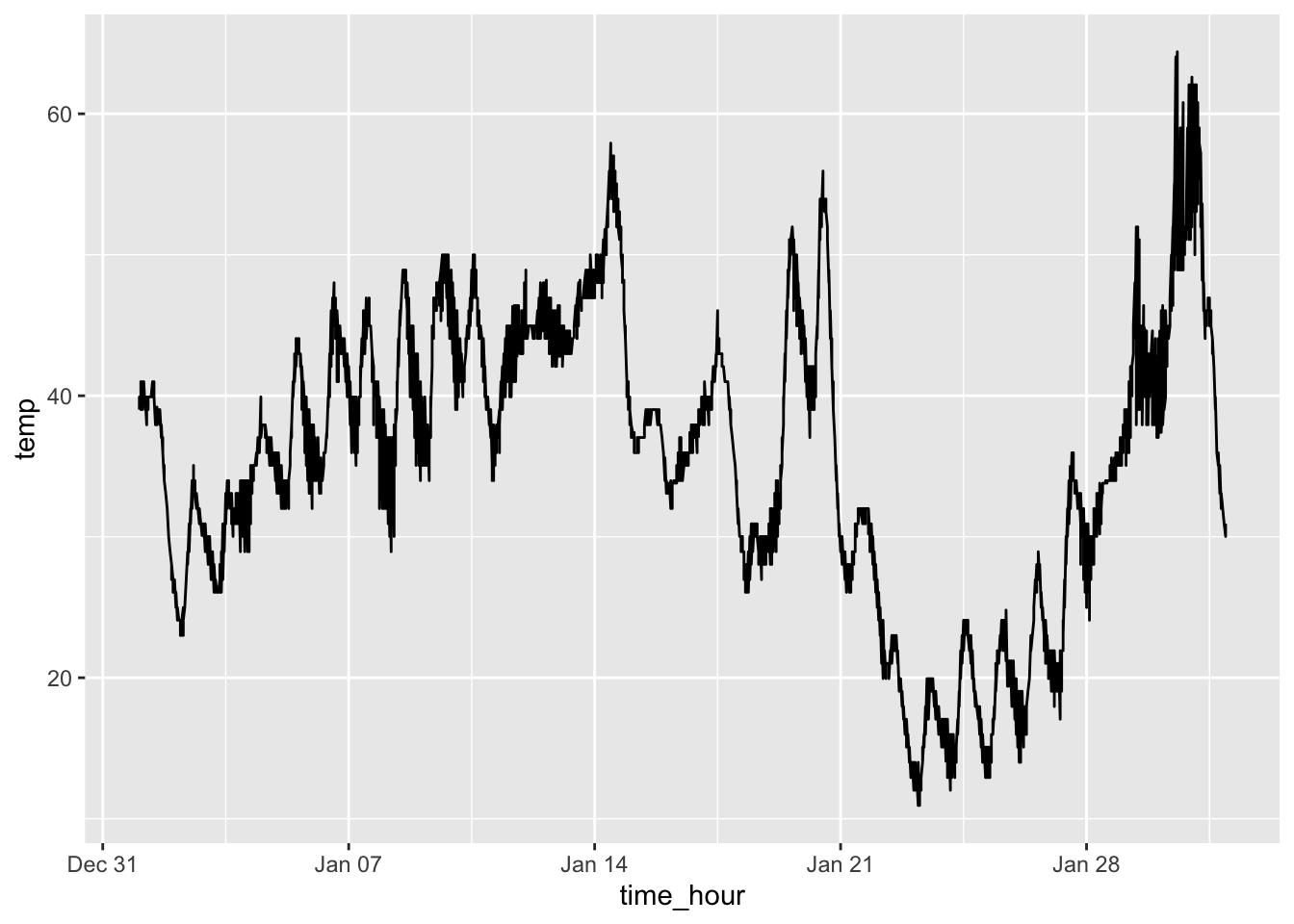
This produces a line graph that appears to have too many observations for the scale of the x-axis (by day). There are a few ways to mitigate this. You could only use the temperature from a certain time each day. This reduces the number of observations included in the graph making it much more legible. Another possible solutions would be to calculate an average for each day and use that instead. Both solutions are demonstrated in the code chunk below. The graph of the average temperatures produces a much better looking graph. This is where the data wrangling skills from the previous chapter really come in handy.
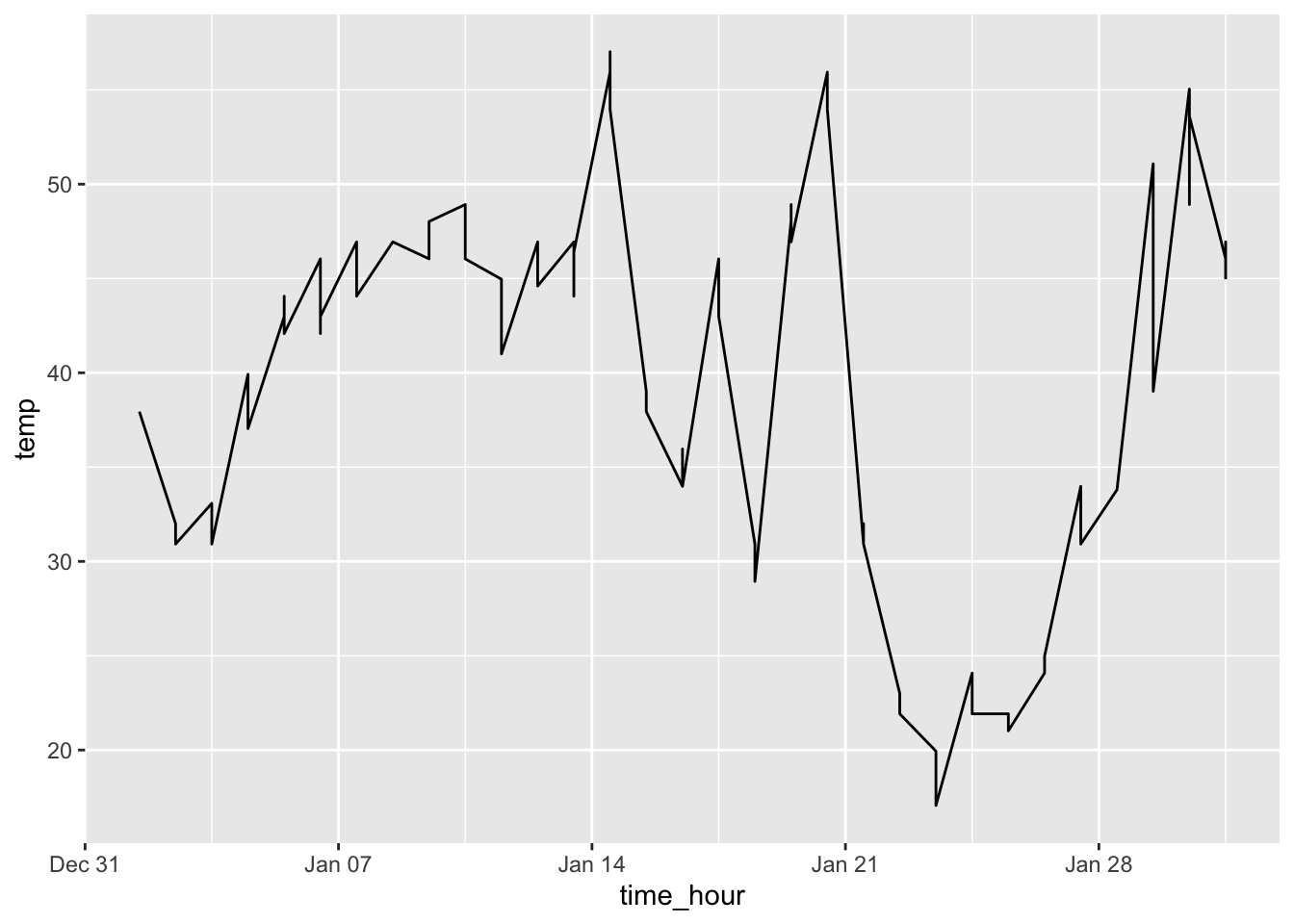
weather |>
filter(month == 1) |>
group_by(day) |>
summarize(avg_temp = mean(temp)) |> # need to rename mean temp to a proper name for coding
ggplot(aes(x = day, y = avg_temp)) +
geom_line()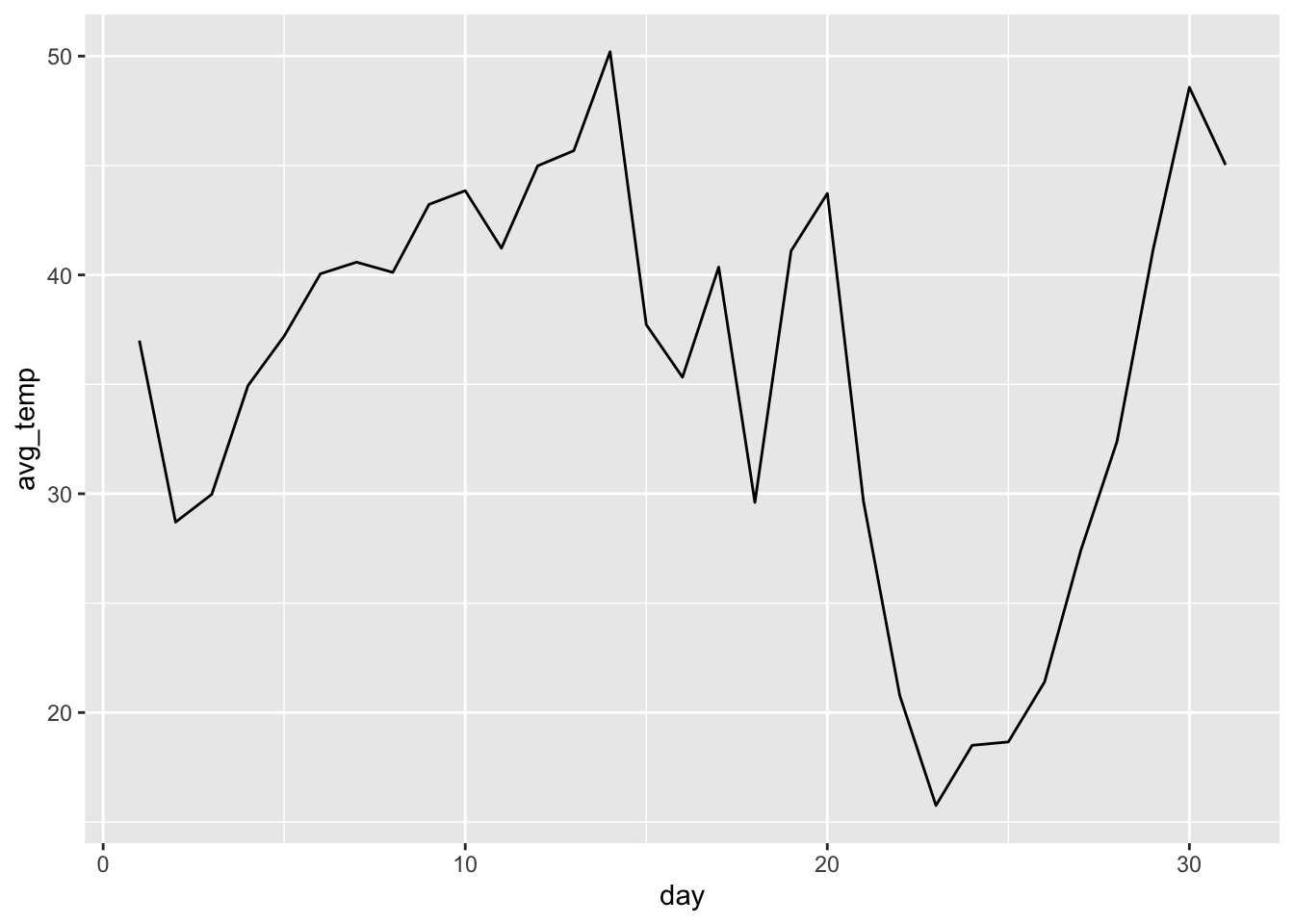
3.4.3 Histograms and Frequency Polygons
A histogram is useful for visualizing the distribution of a variable. In a histogram, only the x-axis is assigned a variable. That variable is sectioned into bins. This means that all the observations are broken up into a number of groups, specified through the parameter bins =. When bins = is not specified, ggplot2 defaults to 30 bins. The more bins you use, the greater the level of detail in the histogram. The other way to set bins is to use the binwidth = argument. This specifies the range of each bin and makes the appropriate number of bins based on the specified size.
In a histogram, the y-axis is usually the count of the observations that fit into each bin. The other option for the y-axis is the density of observations in each bin. This is a number between 0 and 1 that shows the percentage of observations within each bin. In the code chunk below, I use the price variable from the diamonds data set to demonstrate the geom_histogram() function. The first example shows a histogram using the default count stat with 100 bins. The second example shows a histogram using density instead of count and a bin width of 100. The geom_density() function, in the second example, adds the red line indicating the continuous density in addition to the bars.
# histogram using the default count stat and bins = argument
diamonds |>
ggplot(aes(x = price)) +
geom_histogram(bins = 100)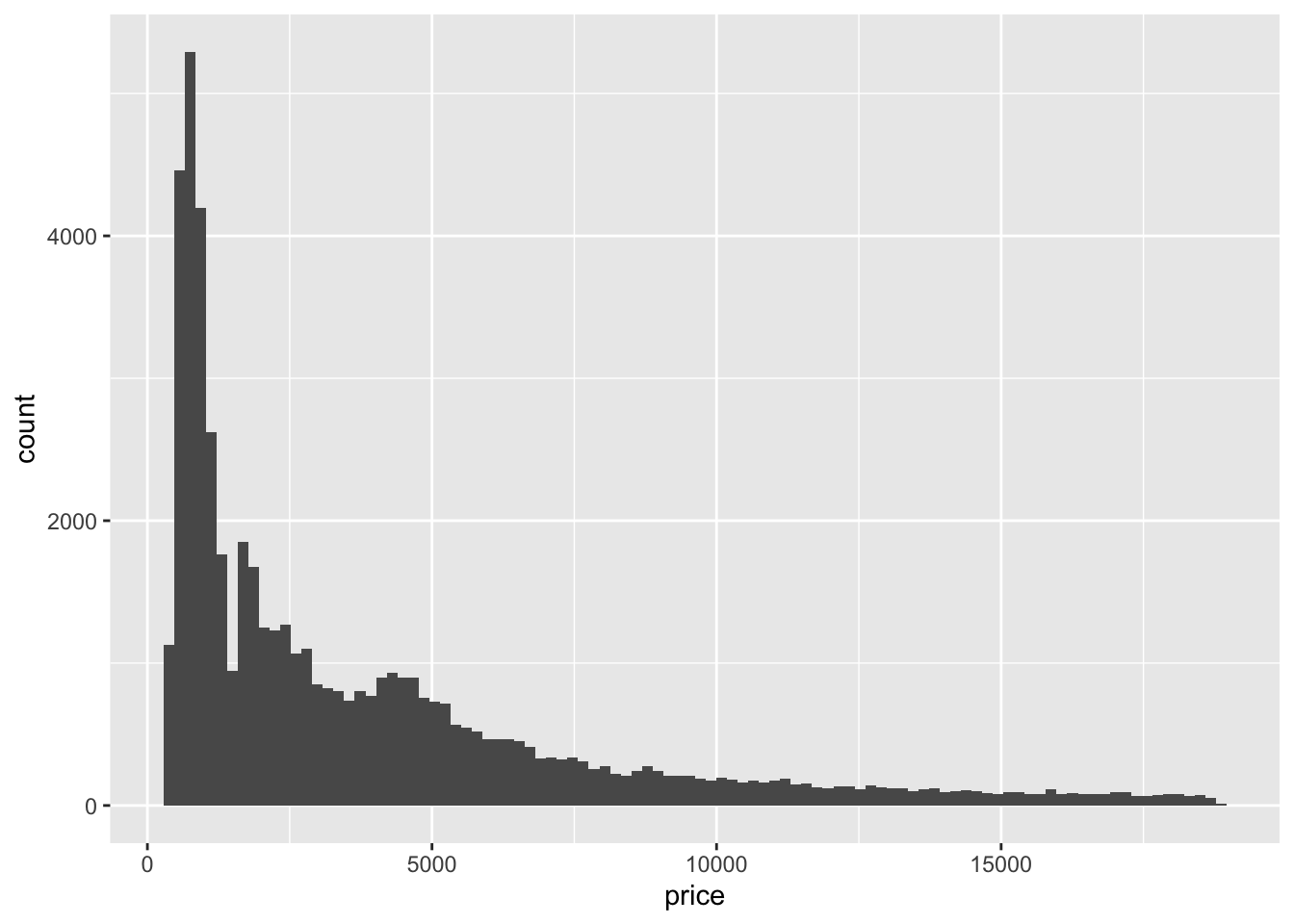
# histogram using density instead of count and the bidwidth = argument
diamonds |>
ggplot(aes(x = price, y = after_stat(density))) +
geom_histogram(binwidth = 100) +
geom_density(color = "red") # adds the red line indicating the density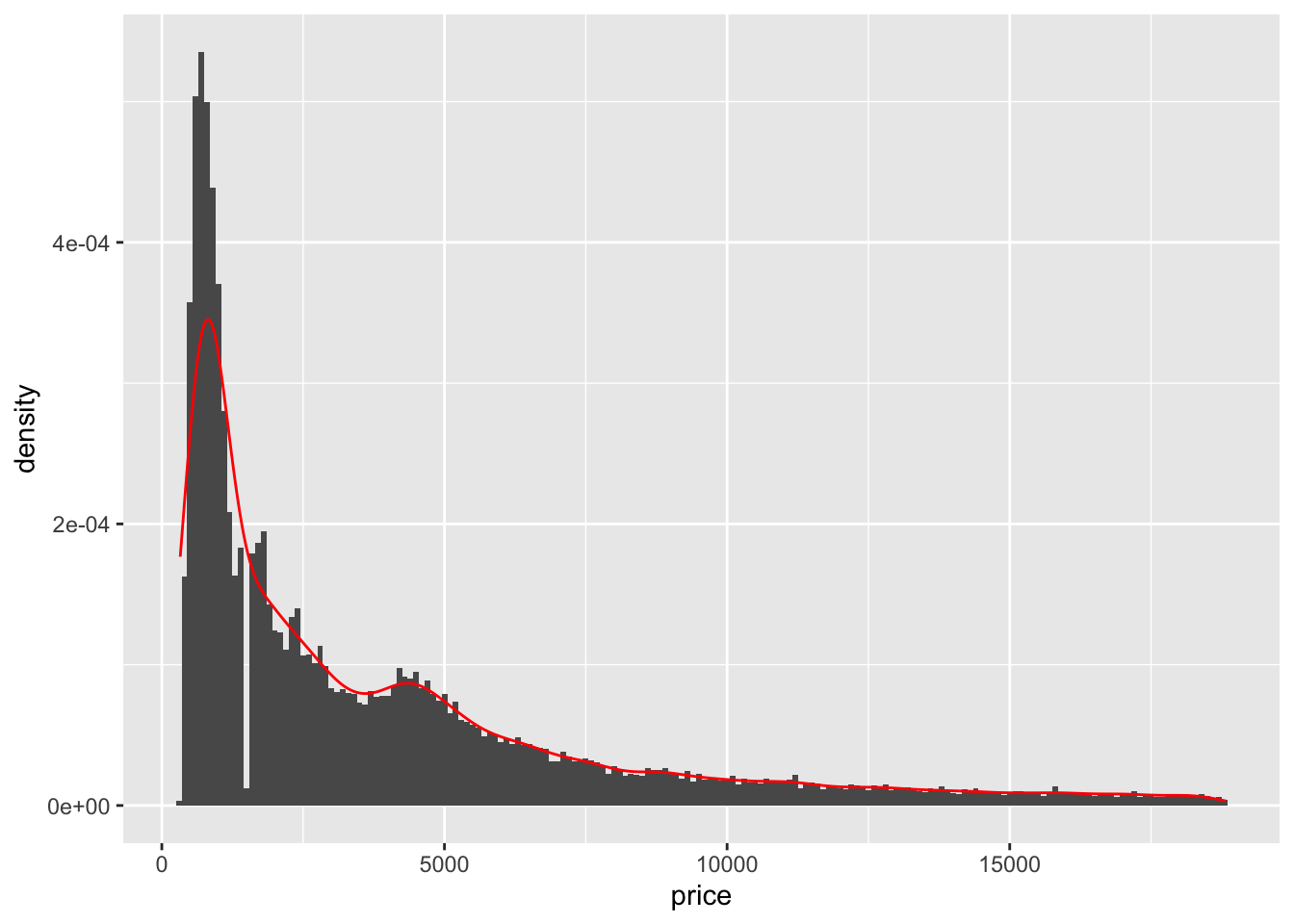
Frequency polygons are another useful way to show the distribution of a single variable. To create a frequency polygon in ggplot2, use the geom_freqpoly() function. When trying to observe the difference in the distribution of a variable between categories, frequency polygons offer a much better direct visual comparison. In the code chunk below, I demonstrate how to make a simple frequency polygon using the same variable as above and then use the cut variable to demonstrate how to use it to compare distributions between categories.70
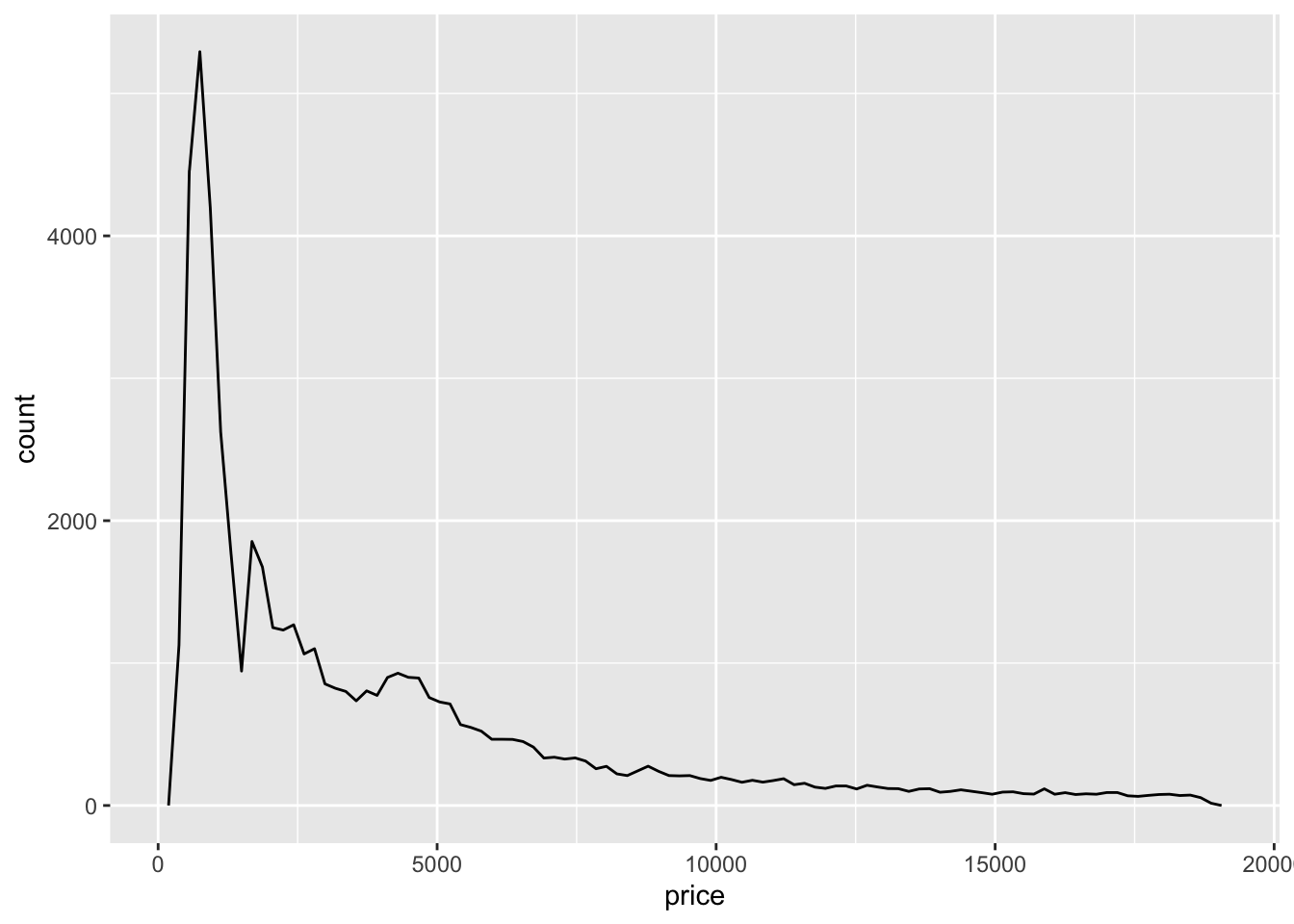
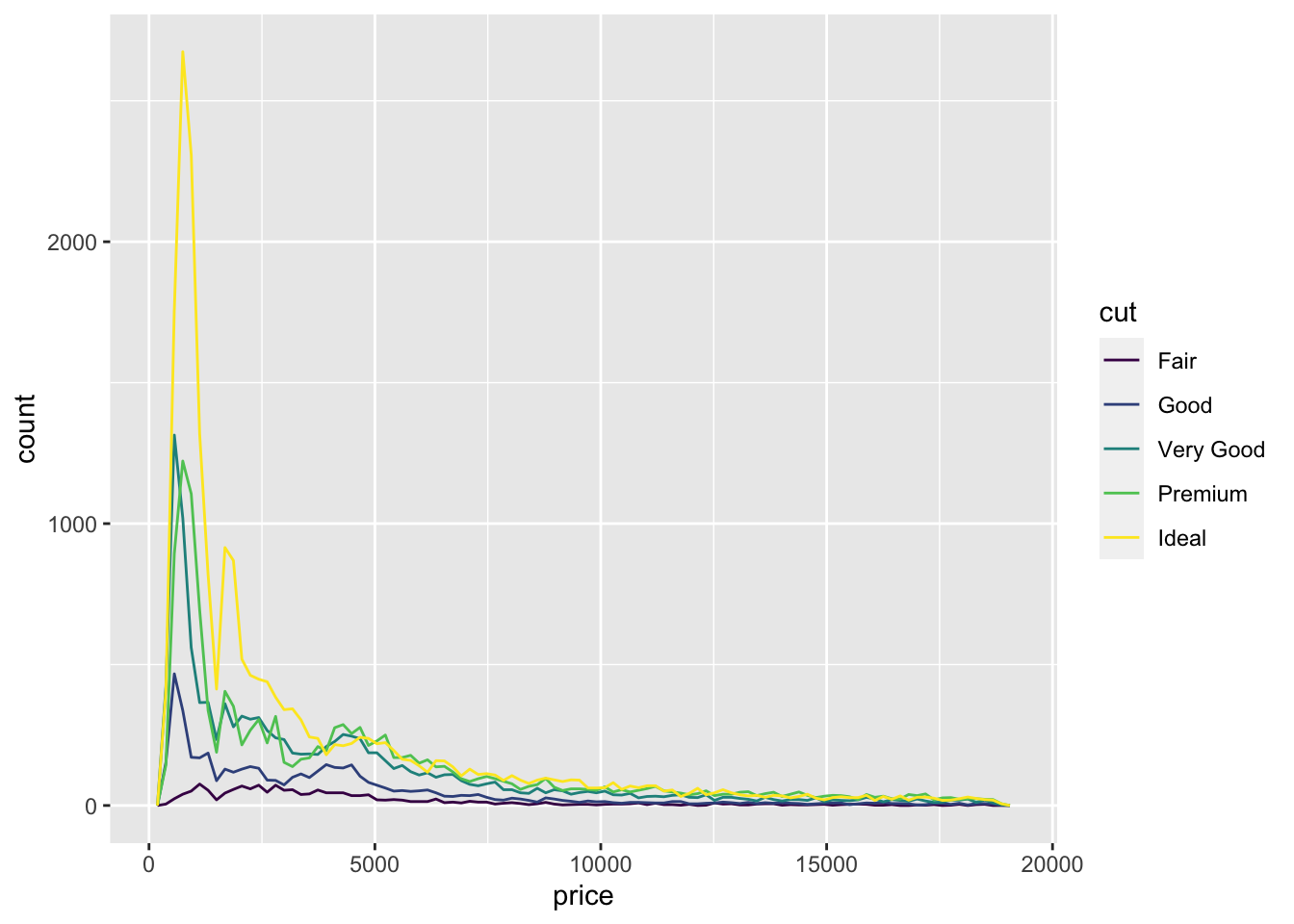
3.4.4 Box Plots
Box plots are another type of visualization that lends itself well to analyzing the distribution of observations across different categories. They are very useful for large data sets because each box plot looks the same regardless of the number of observations plotted. This feature is because box plots are all based off the five number summary: minimum, first quartile (25th percentile), median, third quartile (75th percentile), and maximum.72 To create a box plot, we use the geom_boxplot() function and usually two different variables, one continuous and one categorical. Typically, the continuous variable is mapped to the y-axis and the categorical one is mapped to the x-axis, though this can be reversed. The code chunk below demonstrates the syntax for making a box plot using the same variables as the histogram examples.
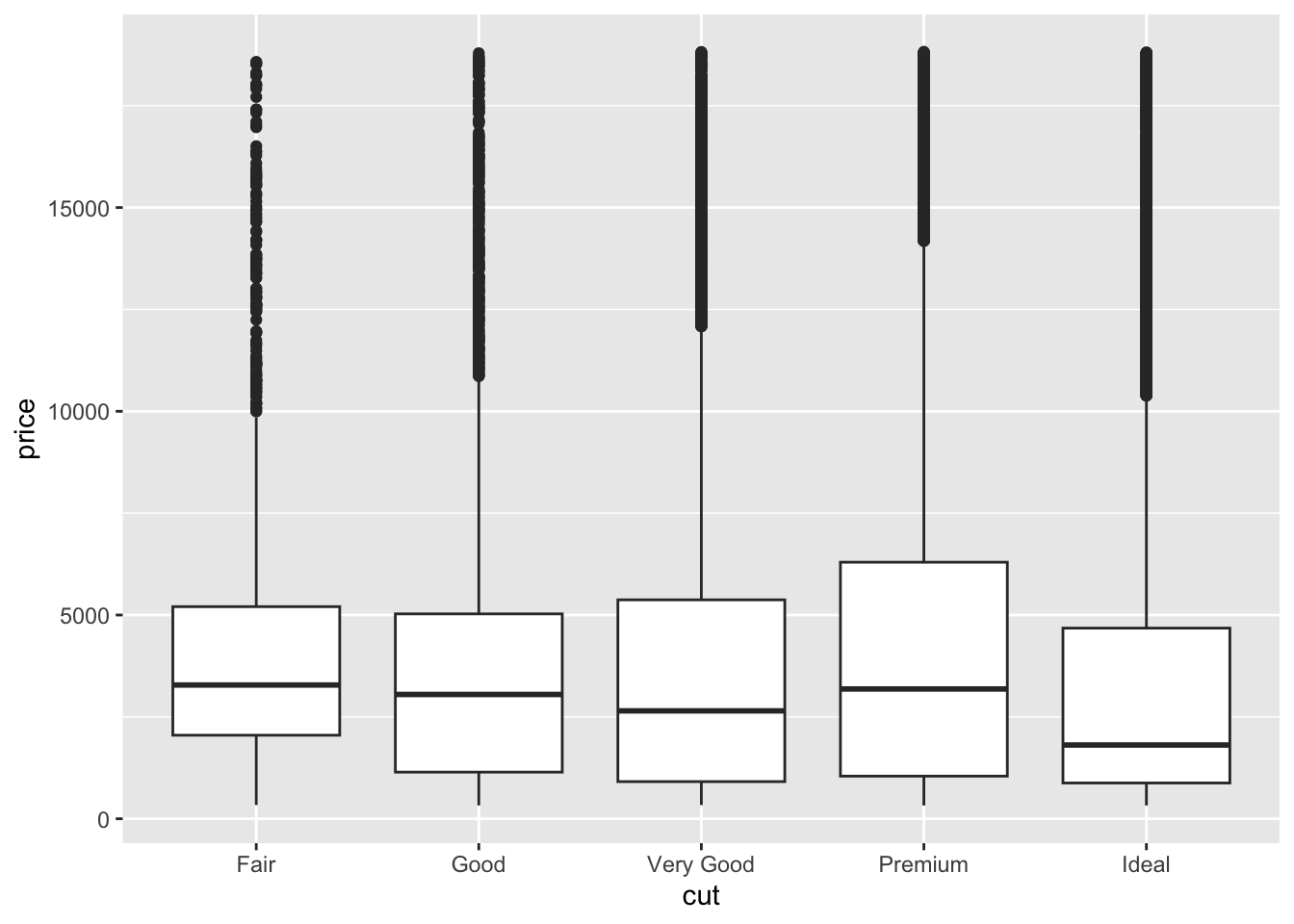
While the uniform look of box plots regardless of the number of observations can be an advantage, some analysis may require a visualization that is more sensitive to the intricacies of the distribution. geom_violin() is a similar type of visualization that sacrifices the identification of outliers for a focus on where the observations fall. The code chunk below demonstrates geom_violin() using the same variables as the example above.
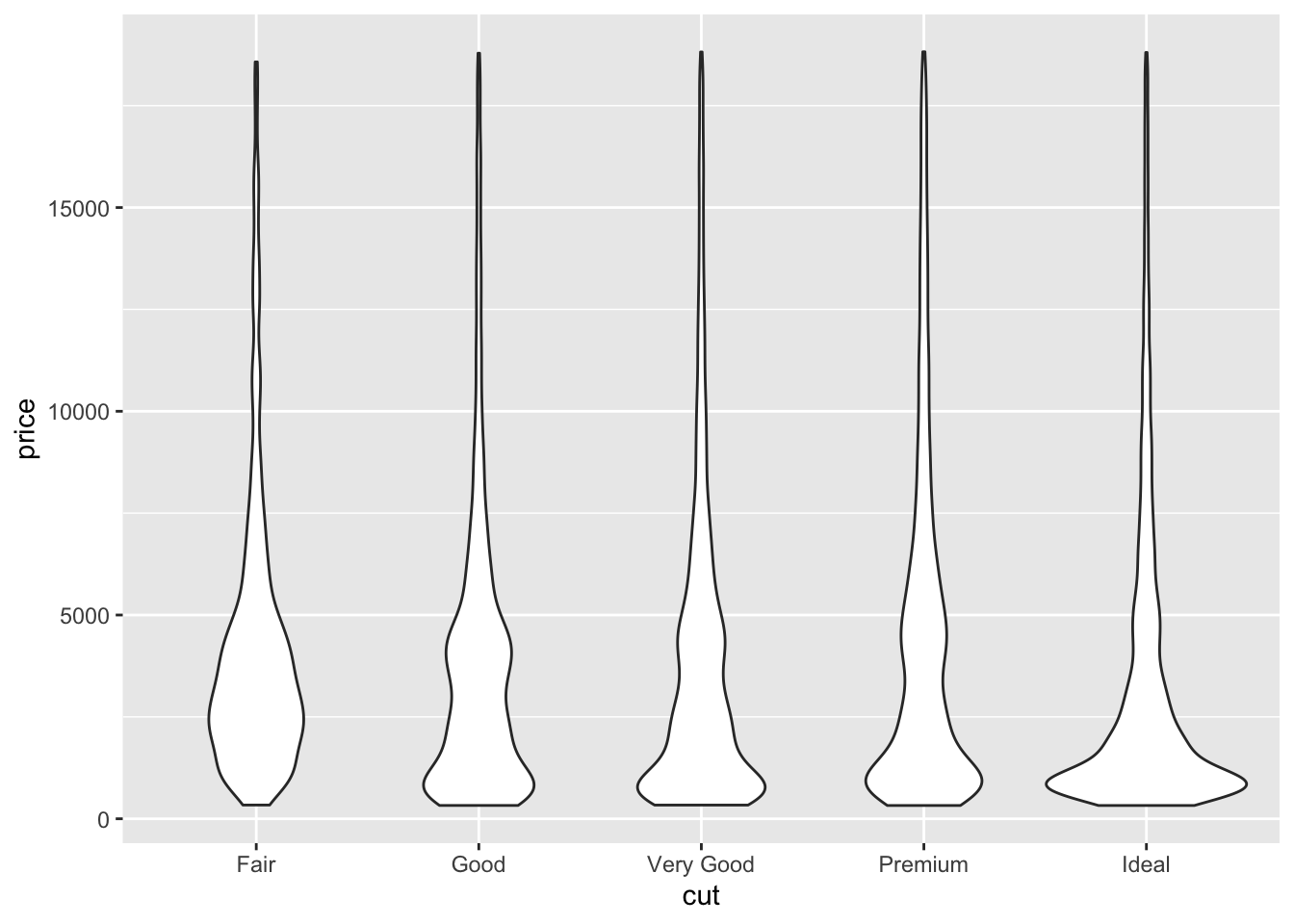
3.4.5 Bar Charts
Bar charts are most useful for visualizing the distribution of a categorical variable.73 In ggplot2, the function for creating bar charts is geom_bar(). Notably, this function summarizes the data, automatically counting the number of observations in each category. If the data is summarized using the skills learned in Chapter 2, you should use the geom_col() function and specify both a x = and y = parameter. The code chunk below demonstrates both how to use the geom_bar() function, and how to generate the correct summary table and then use the geom_col() function. Both methods produce the same output and use the cut variable from the diamonds data set.
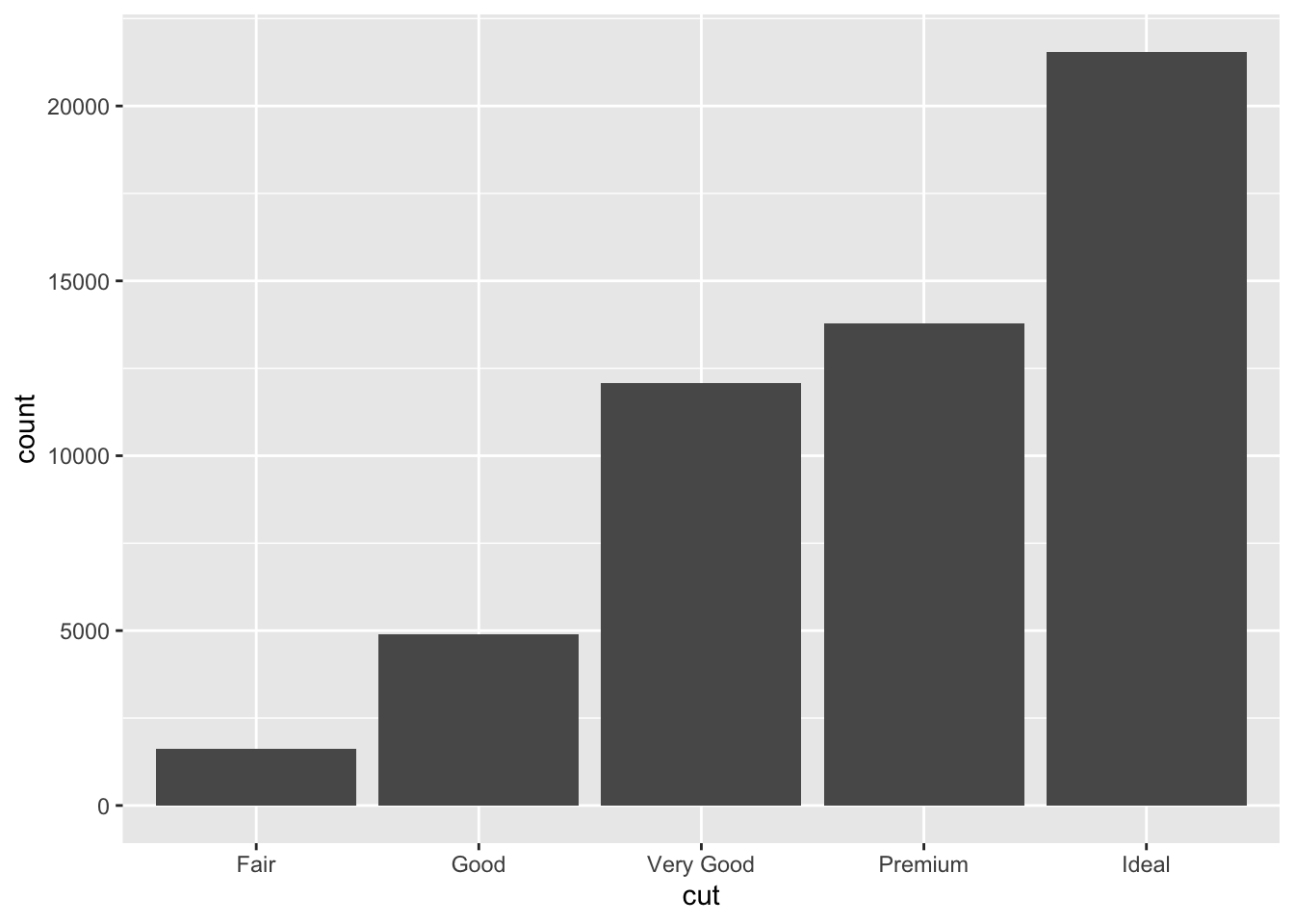
diamonds |>
group_by(cut) |>
summarize(count = n()) |> # run this code without the plotting to see the summary table
ggplot(aes(x = cut, y = count)) +
geom_col()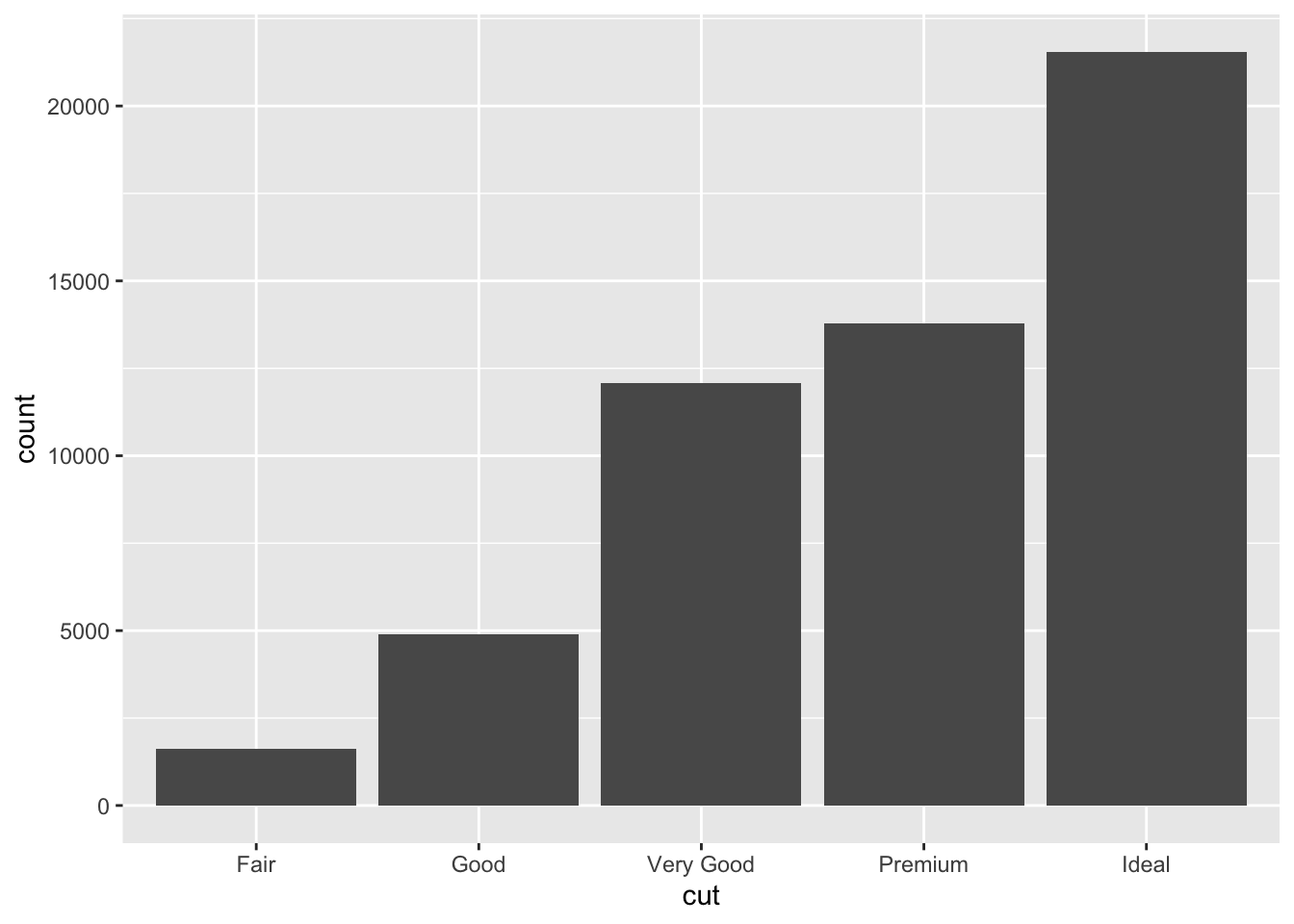
The aesthetics of bar charts are also very useful for analyzing the relationship between two categorical variables.74 In the code chunk below, I generate the same graph using geom_bar() and map the color = and fill = aesthetics to the color variable in the diamonds data set. This allows for visual comparison of the number of observations that have a certain color between the different categories of cuts.
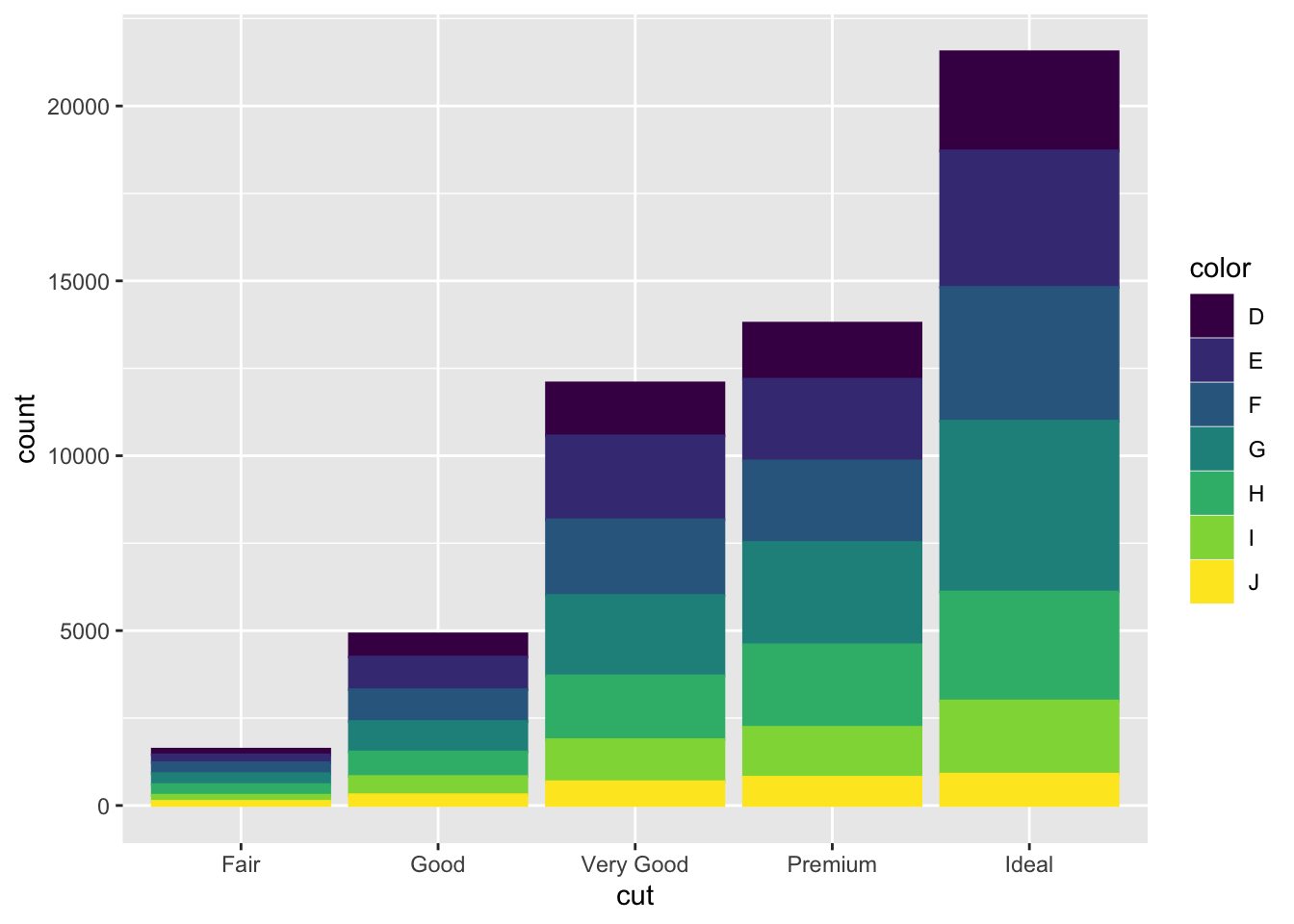
Bar charts have an argument called position = that allows you to change the layout of how each bar is arranged in the context of mapping another variable to color. The default position argument, shown in the previous example, is position = "stack". This means the different categories of color are stacked on top of each other. When position = stack, it can be hard to visually compare the number of observations of the color categories between cut categories. The first example below, using position = "fill", standardizes the size of each bar, allowing for direct comparison between categories. The second example, using position = "dodge", unstacks the bars so the exact level of each colored bar can be directly compared.
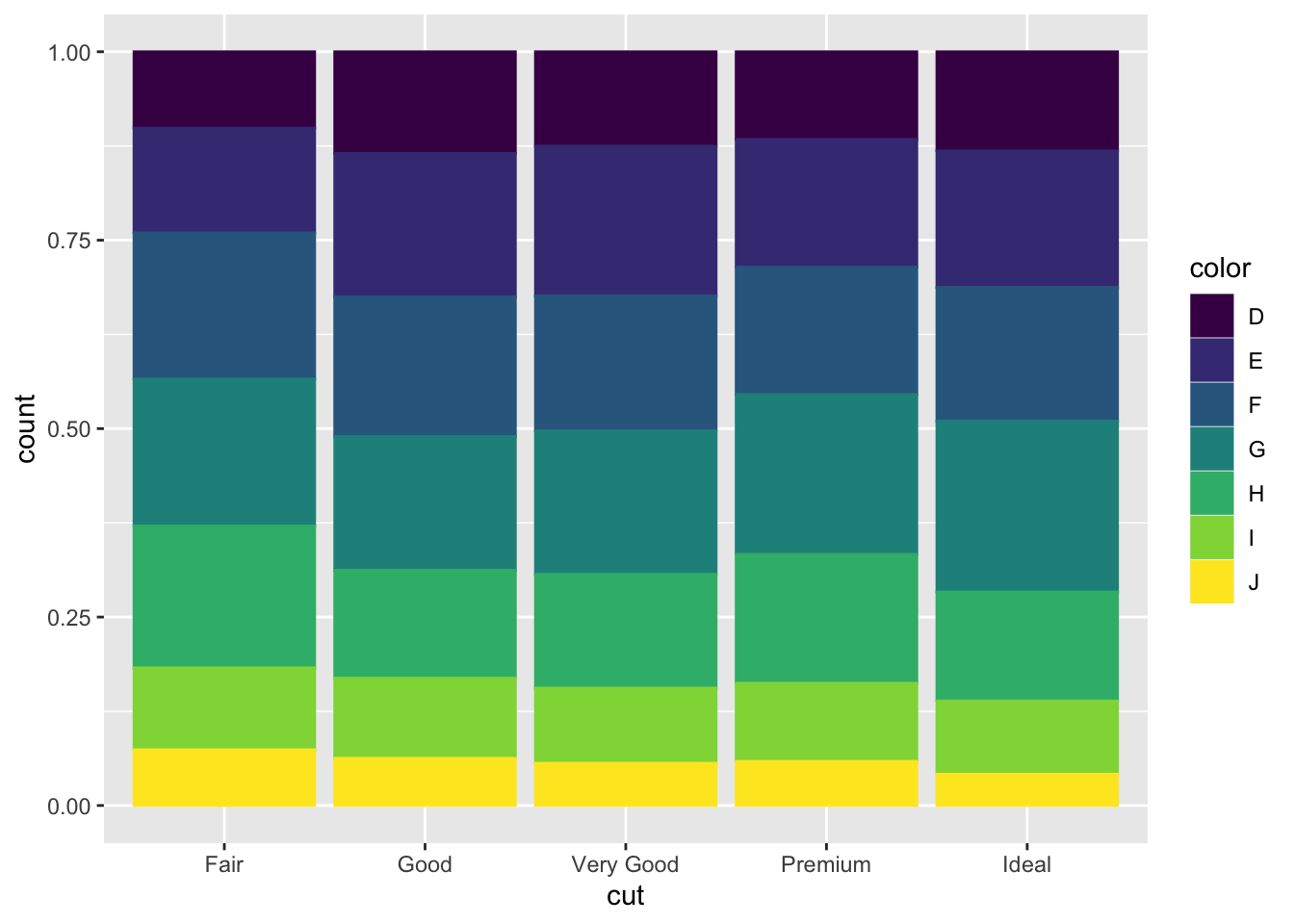
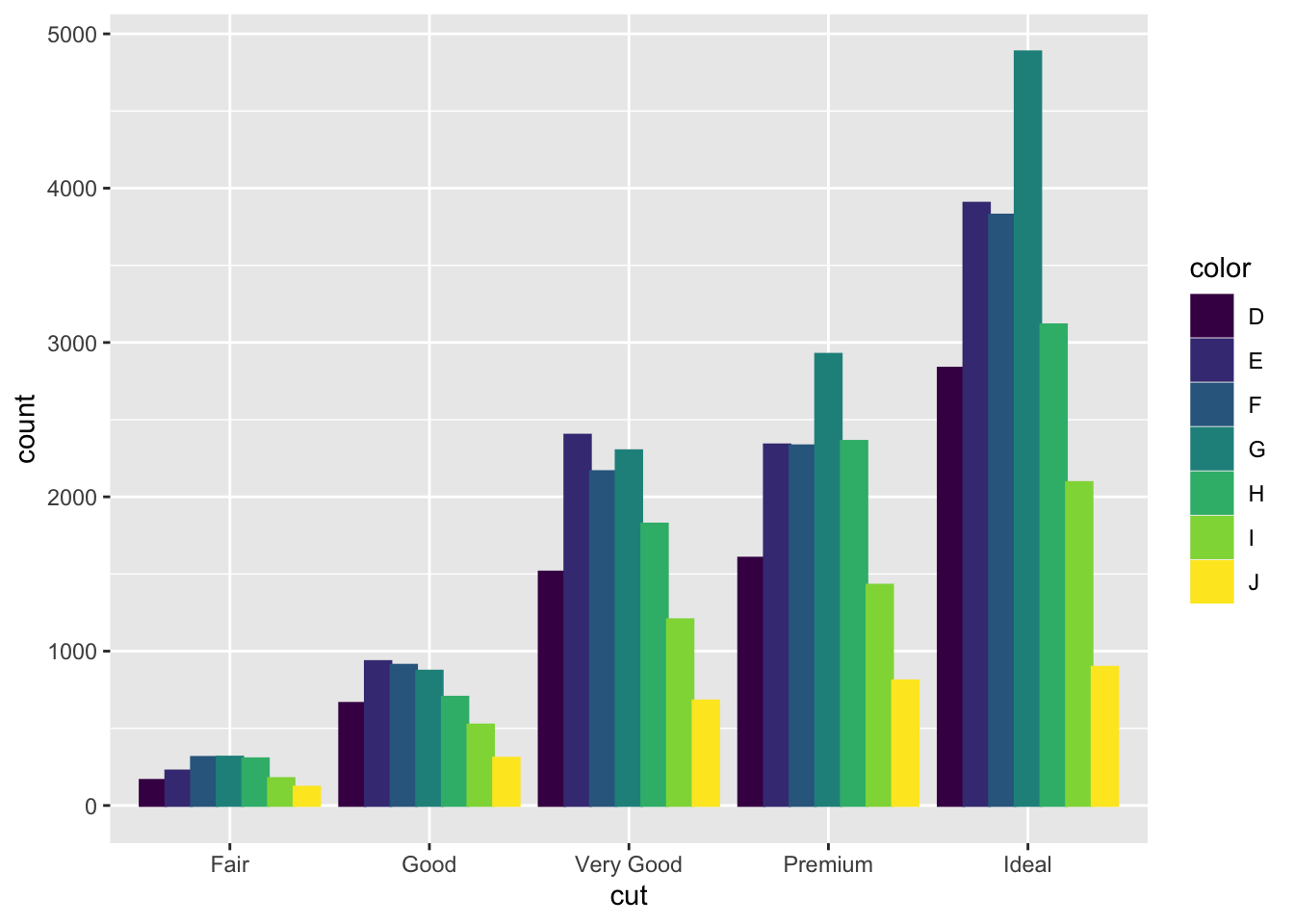
3.4.6 Additional Geom Layers
For reference below I have included images of the ggplot2 cheat sheet. This reference includes almost any possible geom you could want to use in creating a visualization. This resource is available online here.

One important note is to avoid pie charts! Research has shown that they often lead to misinterpretations of data.75 Visually it is very hard to compare one piece of the pie to another due to the arrangement. Often, bar charts are a much better tool for these types of visualizations.
3.5 Modifying Data and Axes
As discussed above, over-plotting is a common issue that can make well though-out graphs illegible. Faceting is one solution, but can lead to the individual facet graphs being to small to be of much use. In this section I will discuss other possible solutions to common over-plotting issues.
3.5.1 Filtering
This may seem a little obvious, but a common and useful solution is to simply plot less data through filtering. Filtering data is covered in this section. In the Line Graphs section example, I use filtering to select only flights in January 2013. Piping is an important tool with these types of problems. Piping allows you to take a data frame, pipe it through any modifiers to wrangle it into the desired form, and then pipe the result straight into ggplot(). This removes the intermediary step of saving a modified version of your data before you create a new graph. If you are using the modified data multiple times, it is worth it to save it so you do not have to repeat code. An important part of data science is having a focused question. While looking at a very large data set in a meaningful way can be very important, when working with large data always ask yourself if you need all the data you have to answer your question.
3.5.2 xlim() and ylim()
Another way to limit the scope of a visualization is to modify the axes. This can be useful when talking about a specific feature of the data and can also be done through filtering.
For this example, I will use data from nycflights13. The code chunk below demonstrates the process of combining the seats variable from the planes data frame with the flights data frame. Refer to the chapter 2 for more information on the specifics of this.
(flight_size <- flights |> # notice I selected the key (tailnum) and desired var (seats) from planes to join
left_join(planes |> select(tailnum, seats), by = "tailnum")) |> # this prevents unwanted data in the new data frame
select(month, day, distance, dep_delay, seats) # select only variable I will use in visualization## # A tibble: 336,776 × 5
## month day distance dep_delay seats
## <int> <int> <dbl> <dbl> <int>
## 1 1 1 1400 2 149
## 2 1 1 1416 4 149
## 3 1 1 1089 2 178
## 4 1 1 1576 -1 200
## 5 1 1 762 -6 178
## 6 1 1 719 -4 191
## 7 1 1 1065 -5 200
## 8 1 1 229 -3 55
## 9 1 1 944 -3 200
## 10 1 1 733 -2 NA
## # ℹ 336,766 more rowsAfter combining the data frame, I created below a scatter plot of the departure delay (dep_delay) and flight distance (distance) of all the planes that left NYC in January of 2013. In this scatter plot, I mapped the size aesthetic to the number of seats on the plane. The most obvious issue with this visualization is over-plotting. All of the points are clustered in the bottom left corner of the graph and leave a massive sections of blank space.
(axes_example <- flight_size |>
filter(month == 1 & day == 1) |>
ggplot(aes(x = distance, y = dep_delay, size = seats)) +
geom_point())## Warning: Removed 148 rows containing missing values (`geom_point()`).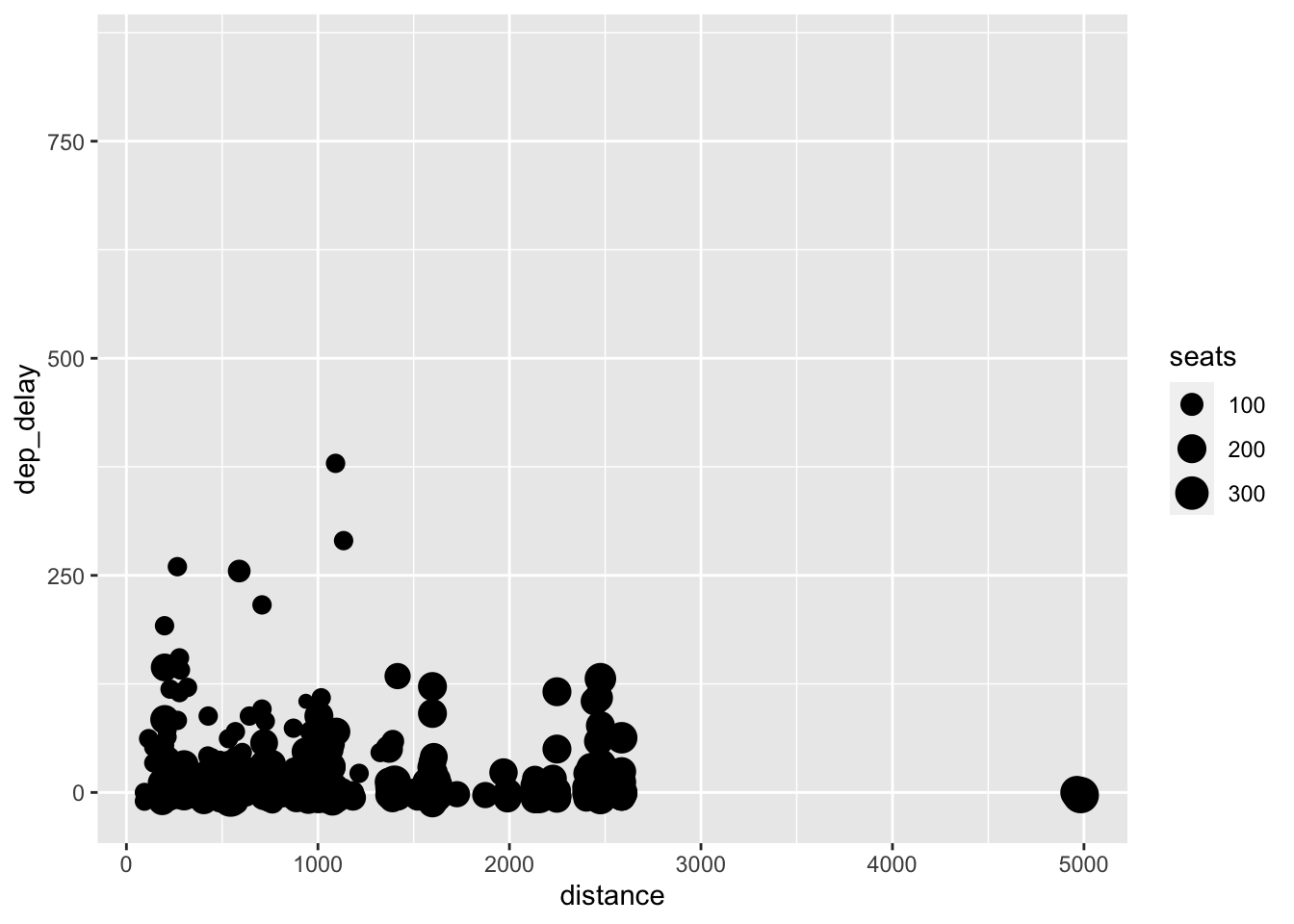
To mitigate this issue, I first modify the y-axis. I use the ylim(min, max) function for this. There does not appear to be any flights where dep_delay is greater than 400, so I limit the y axis from 0 to 400. The scale of the x-axis still appears to be causing over-plotting issues.
## Warning: Removed 488 rows containing missing values (`geom_point()`).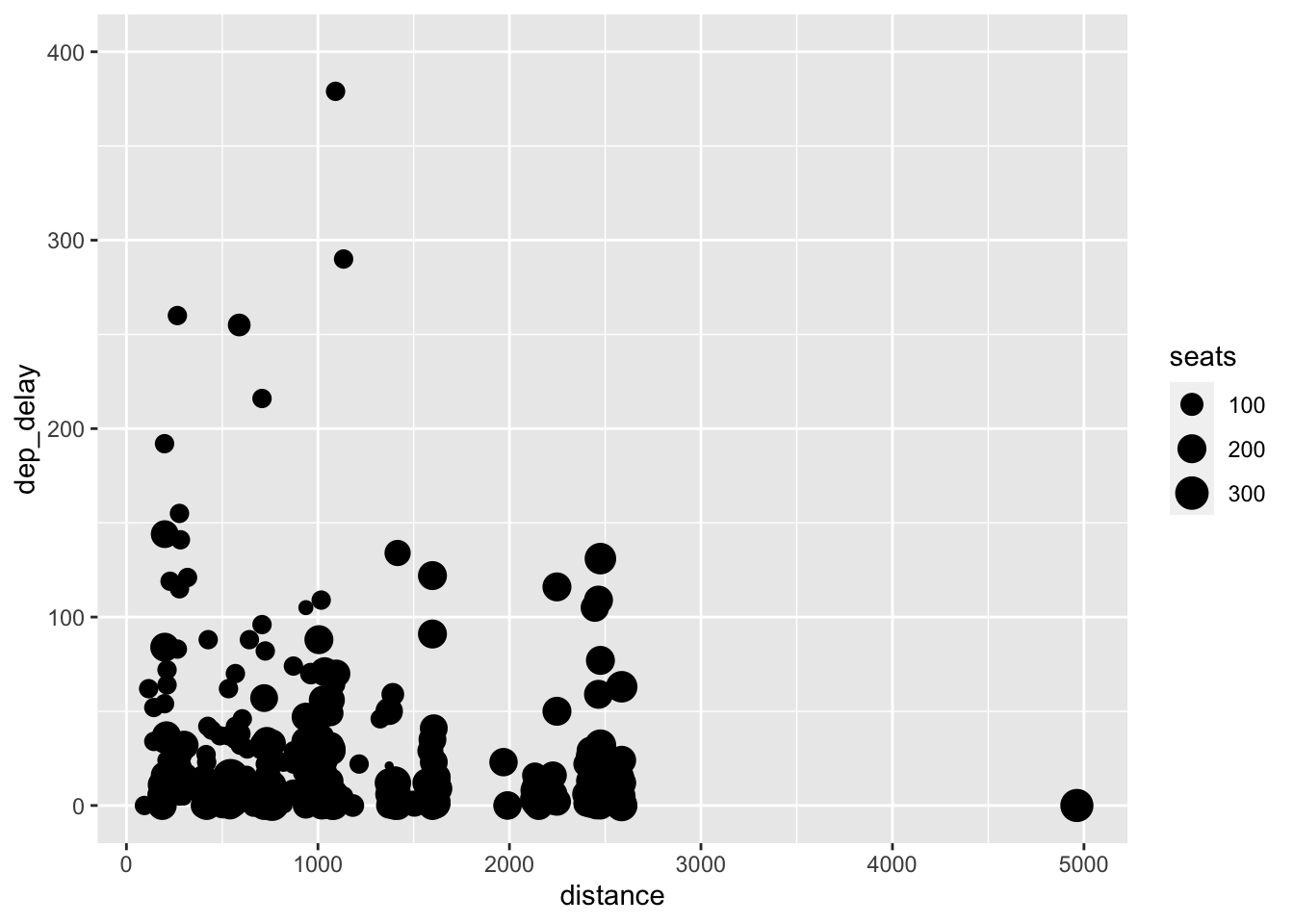
To limit the x-axis, I use the xlim(min, max) function. I choose to limit the x-axis to 3000, excluding one observation with a distance of 5000. The exclusion of data must always be noted, otherwise your visualization is misleading. In this case, it is such an extreme outlier and is only one observation so it has little effect on the visualization and is worth the added clarity.
## Warning: Removed 489 rows containing missing values (`geom_point()`).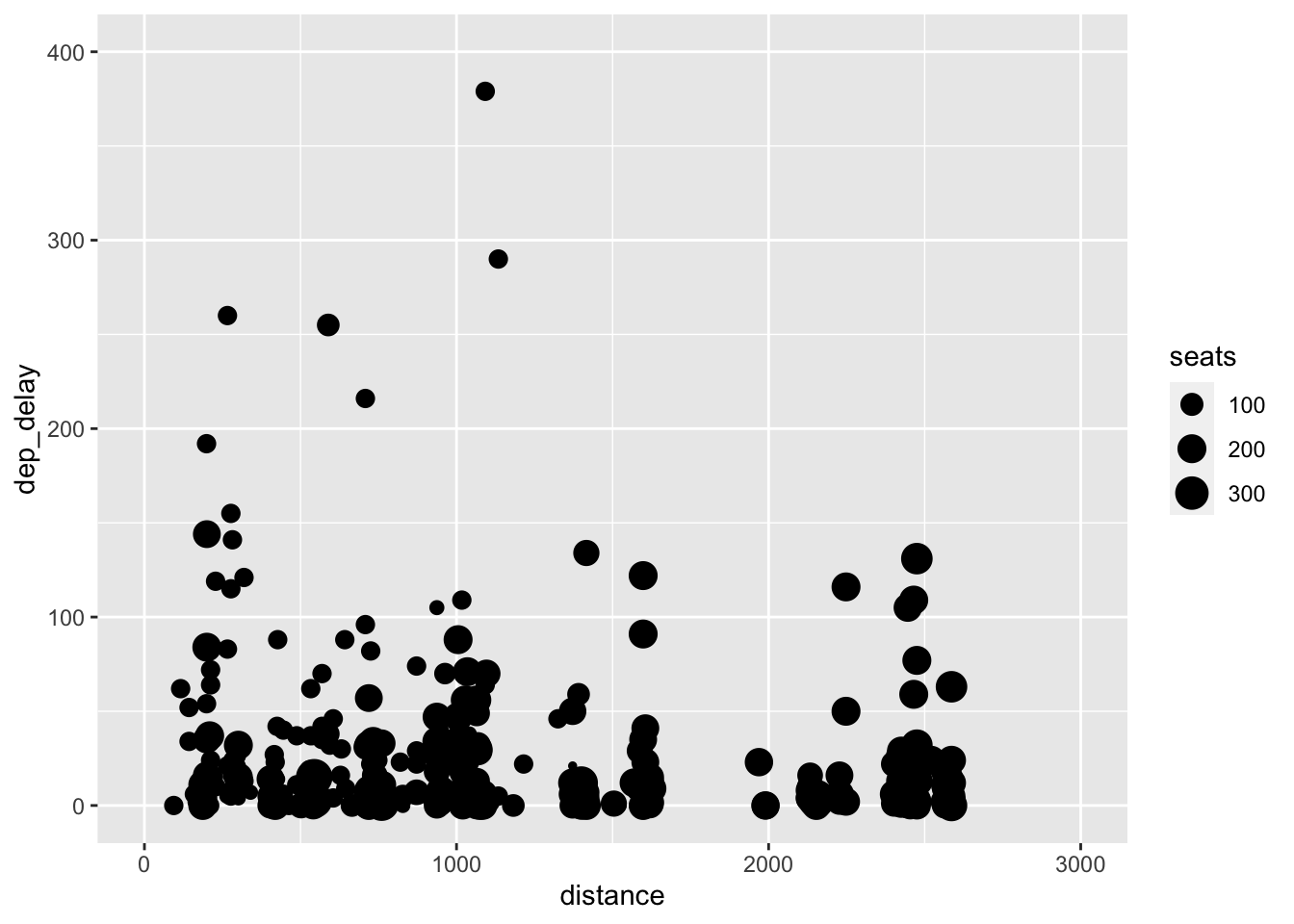
This graph still suffers from a lack of clarity due to over-plotting but serves as a good example of how to experiment to find the best way to visualize data, while introducing these important functions.
3.6 Titles
One of the wonderful features of ggplot2 is that it allows for complete customization of the titles. The variable names displayed on axes, while clear and concise for coding purposes, often do not provide enough information for academic work. It is important that axes titles are clear to the uninformed reader. Always provide units for axes titles and specify the time frame of your data in the header if applicable. Ideally you indicate the source on the graph as well. The titles are added through + labs(). This is demonstrated in the code chunk below. Look up the labs() function documentation for further options.
example1 + labs(title = "Scatter Plot of Highway Miles Per Gallon and Engine Size", subtitle = "source: ggplot2", x = "Engine Displacement (Liters)", y = "Highway Miles Per Gallon")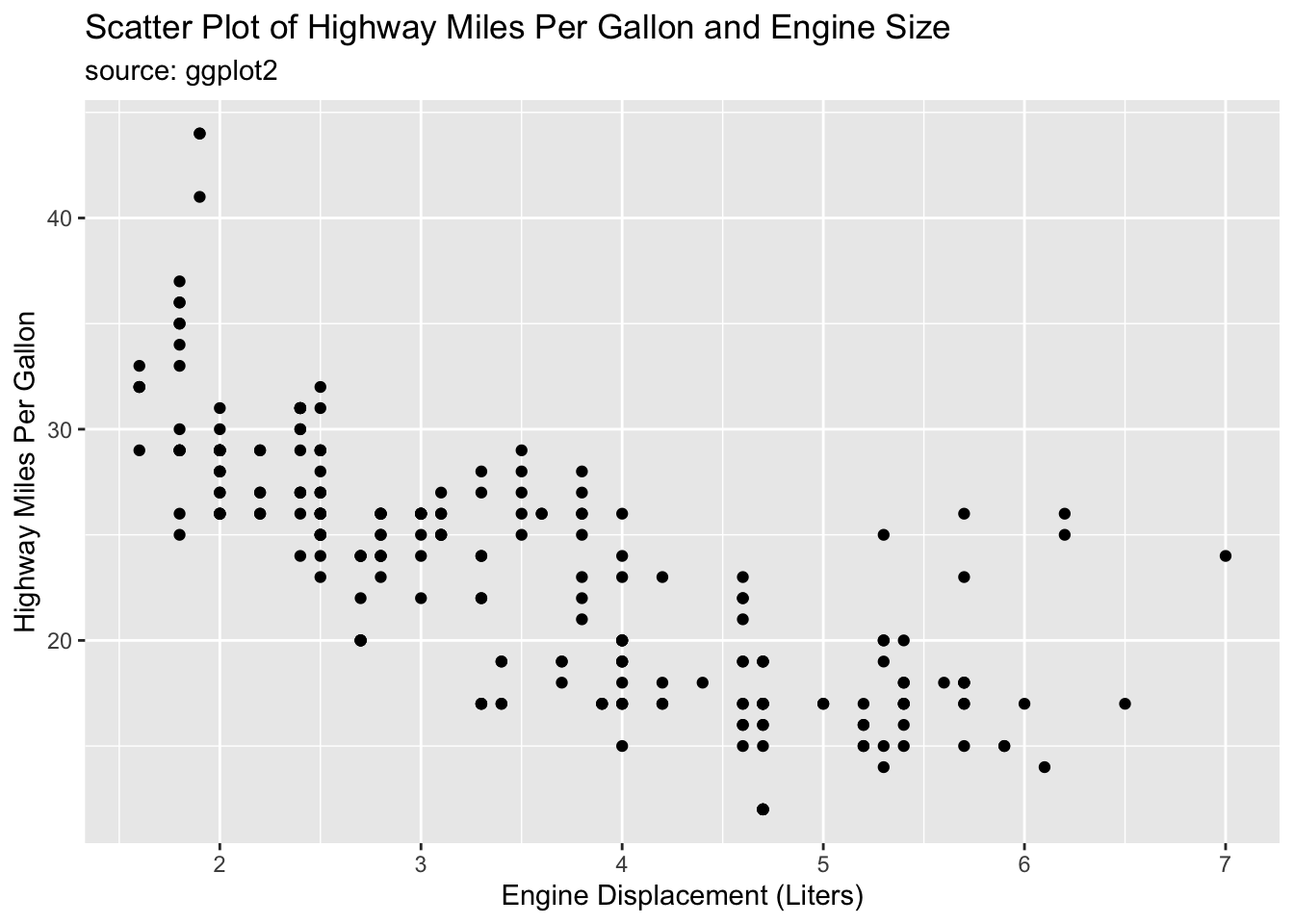
This example also demonstrates how to modify visualizations after they are saved within R. In this example, I call example1 above and use + labs() to modify titles.
3.7 Plotting Time Series
This section covers the unique difficulties of properly plotting time series data. Time series data is any data that has a sequence through time. For this section we will use the economics data set included with ggplot2. This data set is presented in the code chunk below. When dealing with time series data the first important feature of the data set to identify is the time interval between observations. In our example, observations are taken on a monthly basis. The second important feature of a time series to identify is the span of the data in question. These data span from January of 1967 to April of 2015.
## # A tibble: 574 × 6
## date pce pop psavert uempmed unemploy
## <date> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1967-07-01 507. 198712 12.6 4.5 2944
## 2 1967-08-01 510. 198911 12.6 4.7 2945
## 3 1967-09-01 516. 199113 11.9 4.6 2958
## 4 1967-10-01 512. 199311 12.9 4.9 3143
## 5 1967-11-01 517. 199498 12.8 4.7 3066
## 6 1967-12-01 525. 199657 11.8 4.8 3018
## 7 1968-01-01 531. 199808 11.7 5.1 2878
## 8 1968-02-01 534. 199920 12.3 4.5 3001
## 9 1968-03-01 544. 200056 11.7 4.1 2877
## 10 1968-04-01 544 200208 12.3 4.6 2709
## # ℹ 564 more rowsIt is crucially important that the variable indicating time is stored in a date object. Looking at the data frame above you can see that the date variable has the type <date>. This ensures that ggplot2 correctly recognizes that each value stands for a point in time and treats them properly. It also allows you to reference different components of the date_time object using function available through the lubridate package (included in the tidyverse).
In the code chunk below I plot the median duration of unemployment in weeks (uempmed) over time (date). When plotting time series, I prefer to use geom_line(), to visually show the connected nature of the points, with geom_point() to indicate where each individual observation falls.
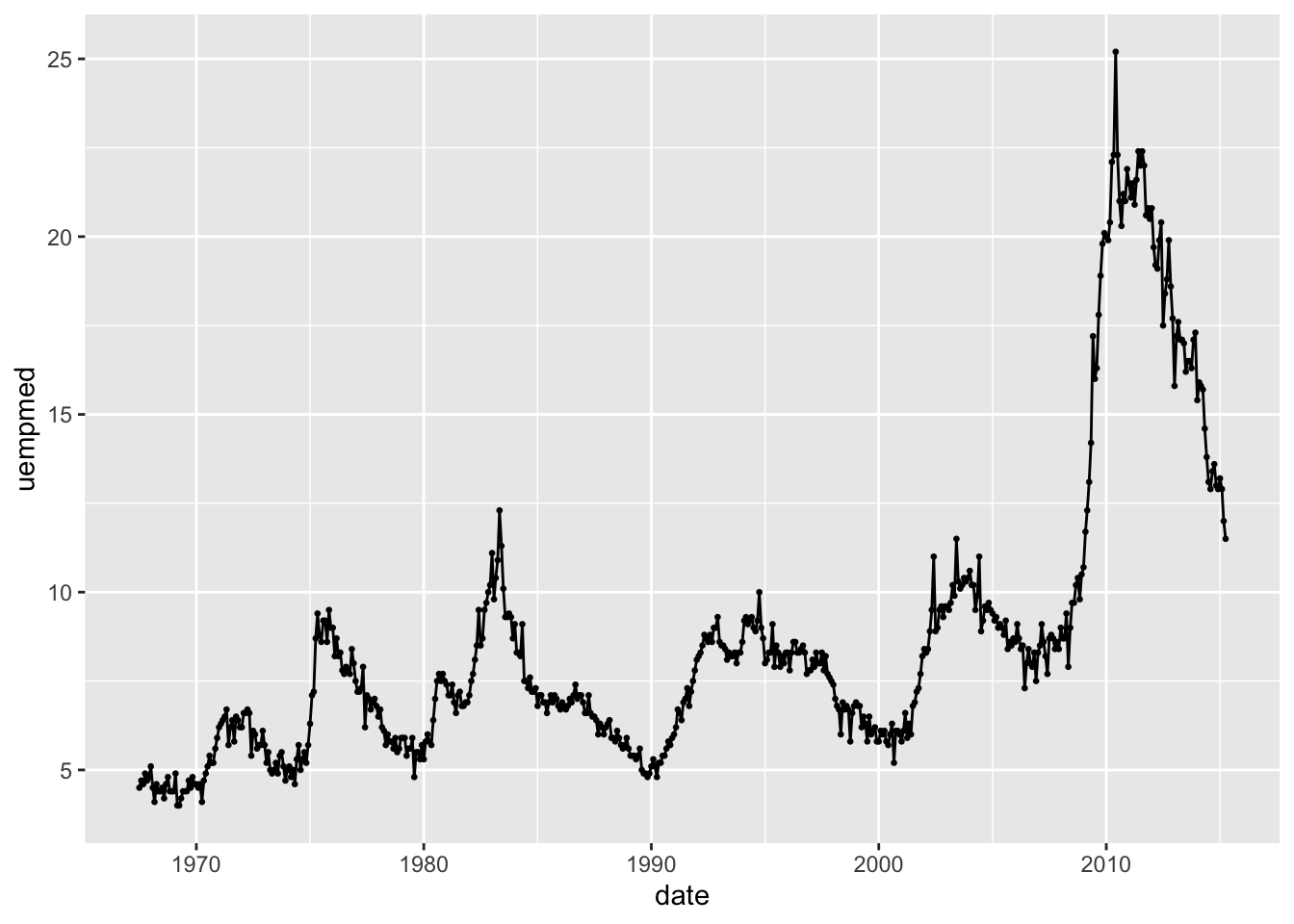
The span of this data set causes the observations to be slightly too closely clustered together. In the code chunk below, I restricted the observations to be from 1980 to 1989 to demonstrate the effectiveness of this method on a smaller time frame. Notice how I used the year() function on the date object, allowing me to filter by year.
economics |>
filter(year(date) < 1990 & year(date) >= 1980) |>
ggplot(aes(x = date, y = uempmed)) +
geom_point(size = 0.5) +
geom_line()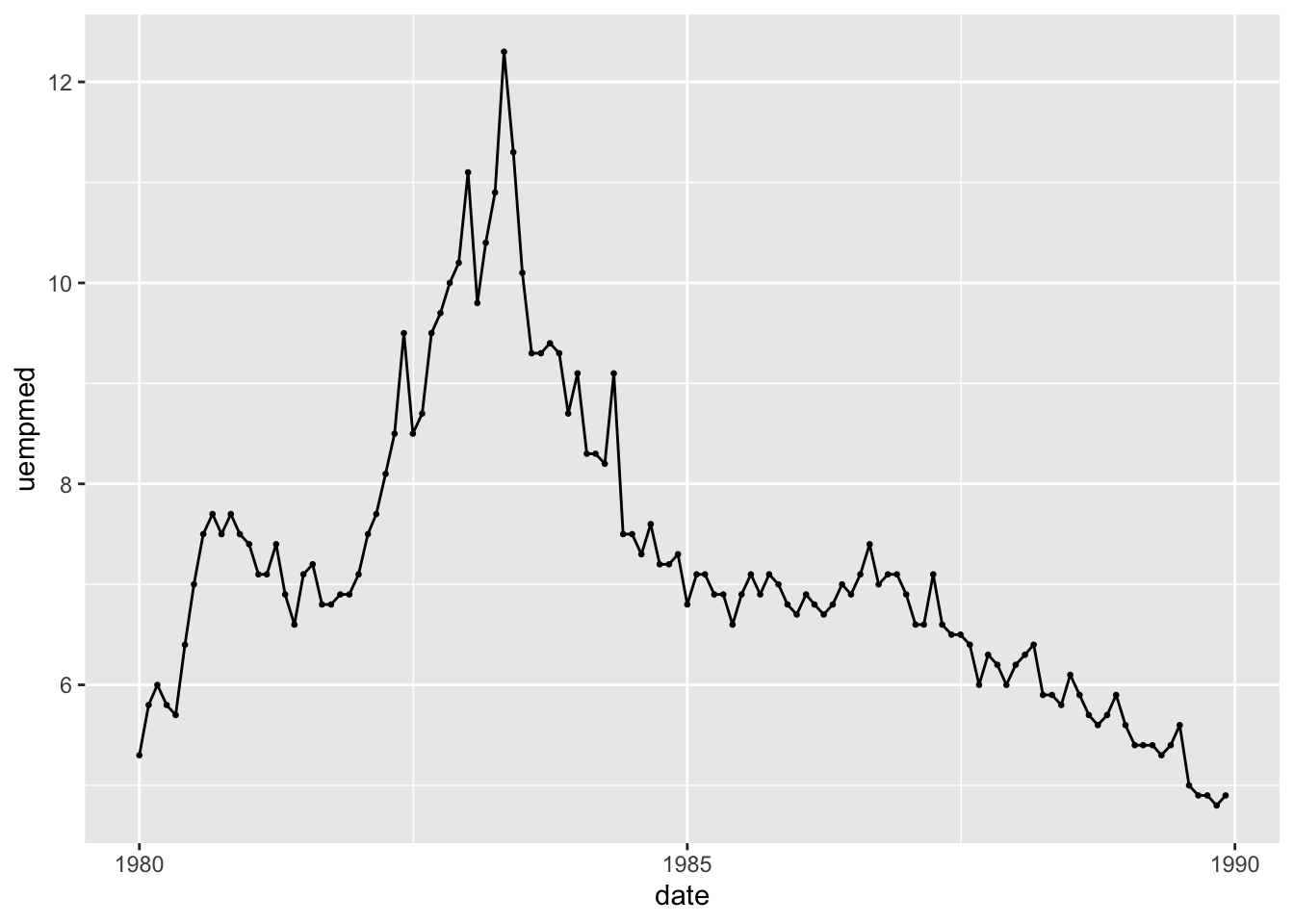
Returning to the original example in this section, faceting is the best method to use to improve the clarity of the plot of the complete time series without restricting the observations plotted. This also allows the trend within each year to be easily visually compared as each year has its own plot.
economics |>
ggplot(aes(x = month(date), y = uempmed)) +
geom_point(size = 0.5) +
geom_line() +
facet_wrap(~year(date))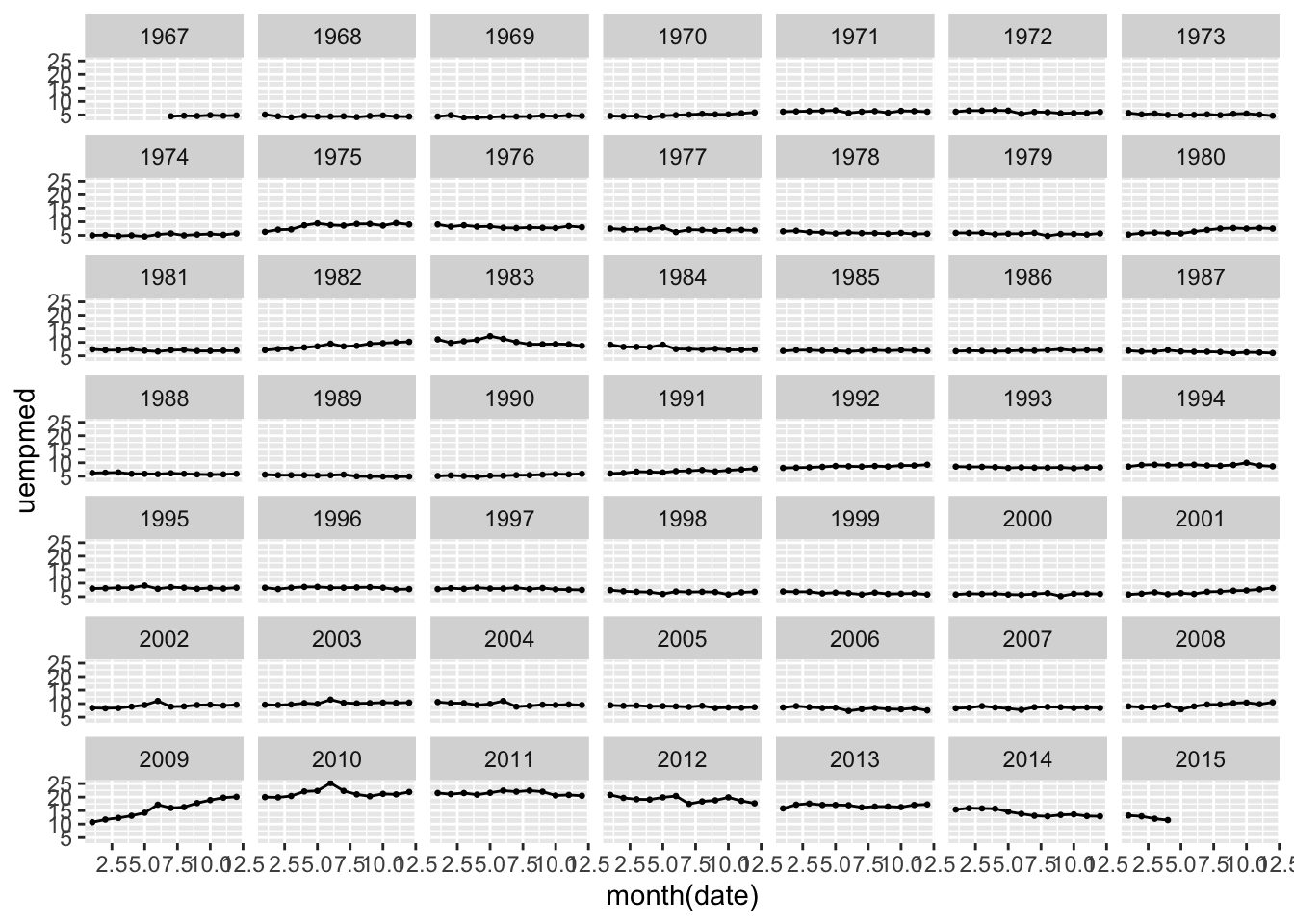
3.8 Saving and Showing Graphics
For display, visualizations should be saved in the format of a .png. This format allows them to be easily references in a separate document if desired. To save a visualization, you should use the ggsave("filename", plot = ) function. In the code chunk below, I save the first plot I made in this chapter by referencing its name in the plot = parameter. Crucially, the filename = parameter must have quotation marks around it and end with the proper file type. If the plot = parameter is not specified, then the function will automatically save the last plot you made.
## Saving 7 x 5 in imageggsave() can be used to save other file formats as well. Refer to the ggsave() documentation for more information and working examples.
3.9 Conclusion
After reading this section, you should have a functional understanding of the grammar of graphics, the syntax of ggplot2, and how to make informative and functional data visualizations for basic statistics. Throughout this chapter, I combined resources from a variety of free, online resources. These resources go into greater detail on the technical side of these topics, and provide more working examples. The purpose of this chapter is to quickly give a foundation in the basics of these topics. If something does not make sense, or your you would like to know more do not hesitate to refer to these resources (available in references).