Chapter 4 Levels of reproducible analysis
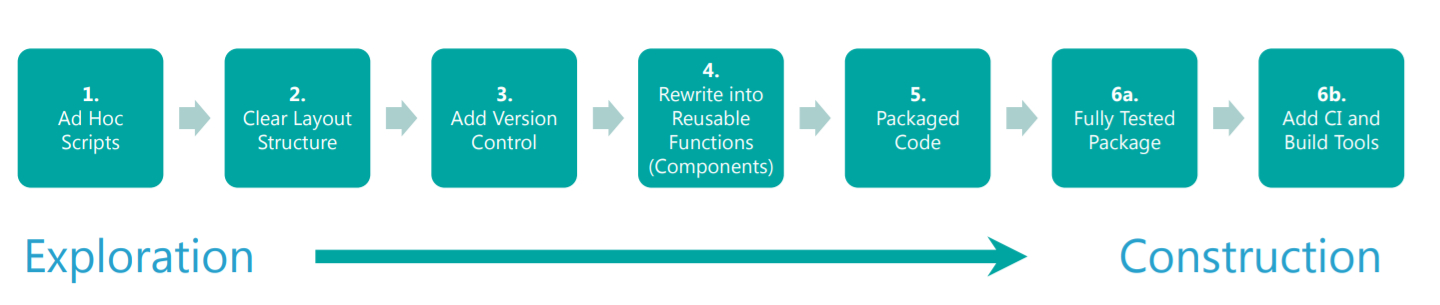
Building a reproducible analytical pipeline (which we will shorten to RAP) can be viewed as a layered process. This section of the guidance will go through many of the steps. You might start off with a basic coding project and add additional levels of enhancement to the project as you go. This layered approach gives a framework for progressing through the different levels of sophistication that are possible - and deciding whether it is appropriate to make the project more elaborate.
How far you get will depend on the skill level in your team, the infrastructure available in your department and pragmatic choices about whether the final stages are proportionate to assure fitness for use. For smaller pieces of work, the most sophisticated levels might be too time consuming to put in place, with minimal benefit. However for regular work that you are going to repeat, the more levels you can build in, the more assurance you will have that your code is doing what you expect it to do and that your outputs are as you intended. Deciding how far to go should be pragmatic and proportionate. Think about the minimal level that you need to achieve before your code is put into production.
Many projects consists of one or more ad hoc scripts to do a number of steps such as data validation or producing tables. This is level one of the RAP process.
The second step is to organize your code into a clear structure. The layout will depend on the project and the tools, but in general this involves separating the code into sections that do particular tasks such as modifying the data or running validation checks. This is an opportunity to start applying coding standards if you are not following them, and that will make the process easier to follow.
The next step is to add version control. Version control software such as git and cloud-based code repositories such as GitHub or Gitlab, allow changes to the code to be made collaboratively and recorded. In addition, changes can be rolled back to a previous state. This provides reassurance in that any change can be reversed allowing new methods or approaches to be tried without fear that this will break the current process. This automatically builds documentation into the production process and creates a record of what has been done and why which can be audited in future. This is covered in depth in chapter 5 on GIT.
Another step is to re write the code into reusable functions. Functions are organised, reusable pieces of code that perform a specific task. Functions help to keep code clean and allow code re-usability. They can be given useful and informative names and stored separately, making workflows clean and easy to follow. Using functions helps to eliminate mistakes when copying and pasting. More importantly, their use means that when you need to add new functionality you only need to change a single function and those changes will cascade to wherever the function is called.
One of the difficulties that can arise in more manual methods of production is that there are many files separated out over different locations, all relating to different but interdependent stages of the process. Often, the process itself requires the use of several tools, such as Excel, SAS and Microsoft Word. Each part of the process needs to be documented and kept up to date, and, in the worst cases, they are only connected through manual intervention. A third step in the process ofo building a reproducible pipeline is to package your code. Packaging brings together all of the scripts that run the pipeline, together with documentation, tests and dummy data that can be used to verify that everything is working. Packaging can gives the project a defined structure. Because the documentation is part of the package and closely intertwined with the code which aids in institutional knowledge transfer.
In R, the fundamental unit of shareable code is the package. A package bundles together code, data, documentation, and tests, and is easy to share with others. - Hadley Wickham
We recommend that testing should be implemented as part of the process of building an analytical pipeline, when this is pragmatic and proportionate. Chapter 4, Testing, covers this in more detail.
The final stages of the RAP process, levels six and seven, are about ensuring that the package is fully tested, that tests are integrated into the version control system and building in functionality to ensure that all tests are run automatically. This improves resilience. Tests are run automatically, and failures are notified automatically on the version control site. Code coverage statistics let users know what percentage of the code (and data) in the package is covered by tests.
Public Health & Intelligence Reproducible Analytical Pipelines