Chapter 2 MRP with Noncensus Variables
When our sample population is different than our target population, MRP can only adjust for the predictors included in the model. As these are restricted by the variables in the poststratification table, which in turn are limited by the questions asked in the census, the characteristics that we can use for poststratification are quite reduced. This is the reason researchers tend to use simple demographic and geographic variables, which unfortunately do not provide much help if the bias in the survey originates from non-response in voters of a certain party, for instance. As a potential solution, Kastellec et al. (2015) propose extending the postratification table using a survey that contains one or multiple non-census variables that could help adjusting for the differences between the sample and the target population. For instance, if our survey asked for partisanship, we could use the CCES to extend the poststratification table such as that it also contains this variable. The extension is done in two steps. First, we fit a multilevel model in which we try to predict partisanship in the CCES based on the variables available in the census. Second, we use this model to predict, for each cell in the original poststratification table, what proportion of subjects are Democrats, Republicans, or Independents. This extended poststratification table that contains partisanship will allow us to (a) generate MRP estimates that adjust for differential party nonresponse in the original survey; and/or (b) obtain estimates outcome of interest by party.
For this case study we will continue using the previous example of studying support for the right of employers to exclude abortion coverage.
# Read CCES data with the same outcome variable and predictors, but also including
# party. This is done by the clean_cces2 function (not shown, see Github code)
cces_all_df <- read_csv("data_public/chapter1/data/cces18_common_vv.csv.gz")
cces_all_df <- clean_cces2(cces_all_df, remove_nas = TRUE)
# Read poststratification table
poststrat_df <- read_csv("data_public/chapter1/data/poststrat_df.csv")
# Read state-level predictors and add them to the CCES and poststratification table
statelevel_predictors_df <- read_csv('data_public/chapter1/data/statelevel_predictors.csv')
cces_all_df <- left_join(cces_all_df, statelevel_predictors_df,
by = "state", keep = FALSE)
poststrat_df <- left_join(poststrat_df, statelevel_predictors_df,
by = "state", keep = FALSE)2.1 Model-based Extension of the Poststratification Table
As we have described, we start fitting a multilevel model to predict partisanship as a function of the same demographic and geographic variables used in the standard MRP model, which will allow us to predict the proportion of Republicans, Democrats, and Independents in each row of the poststratification table. As there are three levels for partisanship, we use a Bayesian multinomial (i.e. unordered) logistic regression which can be fitted in brms (currently, rstanarm does not support multinomial logistic regression).
For this extension step we should use a survey that we think is to some degree representative with respect to the variable that we are trying to include in the poststratification table. In our example, if we extended our census-based poststratification table using a highly non-representative survey with respect to party, we would indeed generated a biased poststratification table and ultimately obtain compromised MRP estimates. In other words, this is our opportunity to bring outside information in order to generate a richer poststratification table that can adjust for potential biases in the main survey, so we need to make sure that the survey we use to extend the poststratification table is trustworthy with respect to the non-census variable.
In this example, we will use a 5,000-person sample of the CCES to extend the poststratification table to include partisanship, which is addressed in the CCES:
Generally speaking, do you think of yourself as a …? (Democrat, Republican, Independent, Other, Not Sure)
For simplicity, we included the few respondents that indicated “Other” or “Not Sure” as Independents.
# Setting seed to arbitrary number for reproducibility
set.seed(1010)
# Taking random sample from the CCES survey
cces_unbiased_df <- cces_all_df %>% sample_n(5000)
fit_party <- brm(party ~ (1 | state) + (1 | eth) + (1 | age) + (1 | educ) + male +
(1 | male:eth) + (1 | educ:age) + (1 | educ:eth) +
repvote + factor(region),
family = "categorical",
data = cces_unbiased_df,
prior = c(prior(normal(0, 5), class = Intercept),
prior(normal(0, 1), class = b),
prior(exponential(0.5), class = sd, dpar = muIndependent),
prior(exponential(0.5), class = sd, dpar = muRepublican)),
control = list(adapt_delta = 0.9, max_treedepth = 10),
seed = 1010)This model gives us, for each poststratification cell \(j\), an estimate for the proportion of Democrats (\(\hat{\theta}_{{\rm Democrat}, j}\)), Republicans (\(\hat{\theta}_{{\rm Republican}, j}\)), and Independents (\(\hat{\theta}_{{\rm Independent}, j}\)). We can multiply these quantities by the number of people in cell \(j\) to estimate the number of Democrats (\(N_j \: \hat{\theta}_{{\rm Democrat}, j}\)), Republicans (\(N_j \: \hat{\theta}_{{\rm Republican}, j}\)), and Independents (\(N_j \: \hat{\theta}_{{\rm Independent}, j}\)), obtaining an extended poststratification table in which each cell has been expanded into three. That is, if the original poststratification table had \(J\) rows (e.g. 12,000 in our case), the new one will have \(3 J\) (e.g. 36,000). There is, however, a certain complication that must be taken into account. The model-based estimates for the proportion of Democrats, Republicans, and Independents are not single numbers, but several draws from the posterior distribution that capture the uncertainty about these estimates. For instance, if we have 500 draws for \(\hat{\theta}_{{\rm Democrat}, j}\), \(\hat{\theta}_{{\rm Republican}, j}\), and \(\hat{\theta}_{{\rm Independent}, j}\), we can imagine 500 poststratification tables with different numbers for each cell.
# Use posterior_epred to predict partisanship for original poststratification table
pred_mat <- brms::posterior_epred(fit_party, newdata = poststrat_df, ndraws = 500, transform = TRUE)
# Extend poststratification table
poststrat_df_threefold <- poststrat_df[rep(seq_len(nrow(poststrat_df)), each = 3), ]
poststrat_df_threefold$party <- rep(c("Democrat", "Republican", "Independent"), nrow(poststrat_df))
# Calculate new numbers for the cells of the new poststratification table. K
# is a matrix containing 36000 rows (one for each cell of the poststratification table)
# and 500 columns (corresponding to the 500 draws).
K_theta <- apply(pred_mat, 1, function(x){as.vector(t(x))})
K <- K_theta * rep(poststrat_df$n, each = 3)In sum, we started with a poststratification table with 12,000 rows. Here we can see the first three rows:
| state | eth | male | age | educ | n |
|---|---|---|---|---|---|
| AL | White | -0.5 | 18-29 | No HS | 23948 |
| AL | White | -0.5 | 18-29 | HS | 59378 |
| AL | White | -0.5 | 18-29 | Some college | 104855 |
We have used a model-based approach to include partisanship in this poststratification table, that now has 36,000 rows (again, each row in the original table has been split into three). However, in order to consider the uncertainty in these model-based estimates we have actually built 500 different poststratification tables. Here we show the first 9 rows of one of these 500 poststratification tables:
| state | eth | male | age | educ | party | n |
|---|---|---|---|---|---|---|
| AL | White | -0.5 | 18-29 | No HS | Democrat | 7139.0 |
| AL | White | -0.5 | 18-29 | No HS | Republican | 8433.4 |
| AL | White | -0.5 | 18-29 | No HS | Independent | 8375.6 |
| AL | White | -0.5 | 18-29 | HS | Democrat | 16589.1 |
| AL | White | -0.5 | 18-29 | HS | Republican | 21971.6 |
| AL | White | -0.5 | 18-29 | HS | Independent | 20817.3 |
| AL | White | -0.5 | 18-29 | Some college | Democrat | 32922.8 |
| AL | White | -0.5 | 18-29 | Some college | Republican | 33892.6 |
| AL | White | -0.5 | 18-29 | Some college | Independent | 38039.6 |
2.2 Adjusting for Nonresponse Bias
We have described how to extend the poststratification table by including partisanship. Now, we will use this poststratification table to adjust for differential party nonresponse.
2.2.1 Setting up example with an artificially nonrepresentative sample
To demostraty how non-census MRP can adjust for party, we will use a survey that is biased with respect to party. As we are already familiar with the CCES dataset, what we are going to do is to take a different sample of 5,000 respondents that simulates a high nonresponse rate among Republicans and, to a lesser degree, Independents.
# Random sample of 5,000 that weights by party
cces_biased_df <- cces_all_df %>% sample_n(5000, weight = I((cces_all_df$party=="Democrat")*1 +
(cces_all_df$party=="Independent")*0.75 +
(cces_all_df$party=="Republican")*0.5))Previously, we saw that the national average support for requiring companies to cover abortion in their insurance plans was around 43.4% according to the CCES. Comparatively, this biased sample of the CCES gives an estimate of 38.9%. This is not surprising, as missing Republicans and Independents in the survey should reduce support for the employers’ right to decline abortion coverage.
2.2.2 Standard MRP
We fit a standard MRP (i.e. without including party) on the nonrepresentative sample, using the same model as in the MRP introduction and the non-extended poststratification table.
fit_abortion_standard <- stan_glmer(abortion ~ (1 | state) + (1 | eth) + (1 | age) + (1 | educ) + male +
(1 | male:eth) + (1 | educ:age) + (1 | educ:eth) +
repvote + factor(region),
family = binomial(link = "logit"),
data = cces_biased_df,
prior = normal(0, 1, autoscale = TRUE),
prior_covariance = decov(scale = 0.50),
adapt_delta = 0.99,
seed = 1010)standard_epred_mat <- rstanarm::posterior_epred(fit_abortion_standard, newdata = poststrat_df, draws = 500)
standard_mrp_estimates_vector <- (standard_epred_mat %*% poststrat_df$n)/sum(poststrat_df$n)## Standard MRP estimate mean, sd: 0.379 0.008The standard MRP with the nonrepresentative sample gives a national-level estimate of 37.9% (\(\pm\) 0.8%). As this estimate does not consider partisanship, standard MRP is not being able to adjust for the smaller statement support that results from oversampling Democrats.
2.2.3 Non-census MRP with partisanship as a predictor
In the first section we have created a poststratification table that contains partisanship. After doing this, the next step of the non-census MRP approach is to fit the same model as we did in the standard MRP, but also including party as a predictor:
\[ Pr(y_i = 1) = logit^{-1}( \alpha_{\rm s[i]}^{\rm state} + \alpha_{\rm a[i]}^{\rm age} + \alpha_{\rm r[i]}^{\rm eth} + \alpha_{\rm e[i]}^{\rm educ} + \beta^{\rm male} \cdot {\rm Male}_{\rm i} + \alpha_{\rm g[i], r[i]}^{\rm male.eth} + \alpha_{\rm e[i], a[i]}^{\rm educ.age} + \alpha_{\rm e[i], r[i]}^{\rm educ.eth} + \alpha_{\rm p[i]}^{\rm party} ) \]
\[ \begin{align*} \alpha_{\rm s}^{\rm state} &\sim {\rm Normal}(\gamma^0 + \gamma^{\rm south} \cdot {\rm South}_{\rm s} + \gamma^{\rm midwest} \cdot {\rm Midwest}_{\rm s} + \gamma^{\rm west} \cdot {\rm West}_{\rm s} + \gamma^{\rm repvote} \cdot {\rm RepVote}_{\rm s}, \sigma_{\rm state}) \textrm{ for s = 1,...,50}\\ \alpha_{\rm a}^{\rm age} & \sim {\rm Normal}(0,\sigma_{\rm age}) \textrm{ for a = 1,...,6}\\ \alpha_{\rm r}^{\rm eth} & \sim {\rm Normal}(0,\sigma_{\rm eth}) \textrm{ for r = 1,...,4}\\ \alpha_{\rm e}^{\rm educ} & \sim {\rm Normal}(0,\sigma_{\rm educ}) \textrm{ for e = 1,...,5}\\ \alpha_{\rm g,r}^{\rm male.eth} & \sim {\rm Normal}(0,\sigma_{\rm male.eth}) \textrm{ for g = 1,2 and r = 1,...,4}\\ \alpha_{\rm e,a}^{\rm educ.age} & \sim {\rm Normal}(0,\sigma_{\rm educ.age}) \textrm{ for e = 1,...,5 and a = 1,...,6}\\ \alpha_{\rm e,r}^{\rm educ.eth} & \sim {\rm Normal}(0,\sigma_{\rm educ.eth}) \textrm{ for e = 1,...,5 and r = 1,...,4}\\ \alpha_{\rm p}^{\rm party} & \sim {\rm Normal}(0,\sigma_{\rm party}) \textrm{ for p = 1,2,3}\\ \end{align*} \]
fit_abortion_noncensus <- stan_glmer(abortion ~ (1 | state) + (1 | eth) + (1 | age) + (1 | educ) + male +
(1 | male:eth) + (1 | educ:age) + (1 | educ:eth) +
repvote + factor(region) + (1 | party),
family = binomial(link = "logit"),
data = cces_biased_df,
prior = normal(0, 1, autoscale = TRUE),
prior_covariance = decov(scale = 0.50),
adapt_delta = 0.99,
seed = 1010)Using posterior_epred allows us to estimate abortion coverage support for each of the cells in the extended poststratification table. As we set draws = 500, we obtain 500 estimates for each cell. In standard MRP, we will weight each the statement support estimates for each poststratification cell by the number of people in that cell according to the model-based estimates obtained in the previous section. However, as in this case the number of people in each cell was estimated with uncertainty, we need to propagate the uncertainty in the first (party prediction) model to the final MRP estimates. Essentially, what we can do is randomly pick one of the 500 statement support estimates for each poststratification cell (i.e. a 36,000 vector) we have just obtained and weight it by one of the 500 poststratification tables that resulted from the first model. Repeating the process for the remaining draws gives us a distribution of 500 MRP estimates for national support that correctly captures the uncertainty in the two models.
# Use posterior_epred to predict stance on abortion insurance coverage for extended poststratification table
noncensus_epred_mat <- rstanarm::posterior_epred(fit_abortion_noncensus, newdata = poststrat_df_threefold, draws = 500)
# Calculate national MRP estimates propagating uncertainty from the two models
noncensus_mrp_estimates_vector <- colSums(t(noncensus_epred_mat)*K) / sum(K[,1])## Noncensus MRP estimate mean, sd: 0.417 0.008Our national-level estimate for the right to exclude abortion coverage from employer-sponsored insurance resulting from this non-census variable MRP is 41.7% (0.8%). Unsurprisingly, this is much closer to the full (unbiased) 60,000 participant survey (43.4 \(\pm\) 0.2%) than the standard MRP estimate seen above (37.9 \(\pm\) 0.8%). Using an extended poststratification table that contained partisanship allowed us to adjust for differential partisan nonresponse.
Of course, we can also obtain state-level estimates and compare standard MRP with non-census MRP.
# Create empty dataframe
state_estimates_df <- data.frame(
state = state_abb,
standard_mrp_state_estimate = NA,
standard_mrp_state_estimate_se = NA,
noncensus_mrp_state_estimate = NA,
noncensus_mrp_state_estimate_se = NA,
full_cces_state_estimate = NA,
full_cces_state_estimate_se = NA,
n_full = NA
)
# Loop to populate the dataframe
for(i in 1:nrow(state_estimates_df)) {
# Filtering condition for standard_epred_mat (12,000 rows)
filtering_condition <- which(poststrat_df$state == state_estimates_df$state[i])
# Filtering condition for noncensus_epred_mat (36,000 rows)
filtering_condition_threefold <- which(poststrat_df_threefold$state == state_estimates_df$state[i])
# Standard MRP estimate
state_standard_epred_mat <- standard_epred_mat[ ,filtering_condition]
k_filtered <- poststrat_df[filtering_condition, ]$n
standard_mrp_state_estimates_vector <- state_standard_epred_mat %*% k_filtered / sum(k_filtered)
state_estimates_df$standard_mrp_state_estimate[i] <- mean(standard_mrp_state_estimates_vector)
state_estimates_df$standard_mrp_state_estimate_se[i] <- sd(standard_mrp_state_estimates_vector)
# Noncensus MRP estimate
state_noncensus_epred_mat <- noncensus_epred_mat[ ,filtering_condition_threefold]
K_filtered <- K[filtering_condition_threefold, ]
noncensus_mrp_state_estimates_vector <- colSums(t(state_noncensus_epred_mat)*K_filtered) / colSums(K_filtered)
state_estimates_df$noncensus_mrp_state_estimate[i] <- mean(noncensus_mrp_state_estimates_vector)
state_estimates_df$noncensus_mrp_state_estimate_se[i] <- sd(noncensus_mrp_state_estimates_vector)
# Full survey estimate
state_estimates_df$full_cces_state_estimate[i] <- mean(filter(cces_all_df, state==state_estimates_df$state[i])$abortion)
state_estimates_df$n_full[i] <- nrow(filter(cces_all_df, state==state_estimates_df$state[i]))
state_estimates_df$full_cces_state_estimate_se[i] <- get_se_bernoulli(state_estimates_df$full_cces_state_estimate[i], state_estimates_df$n_full[i])
}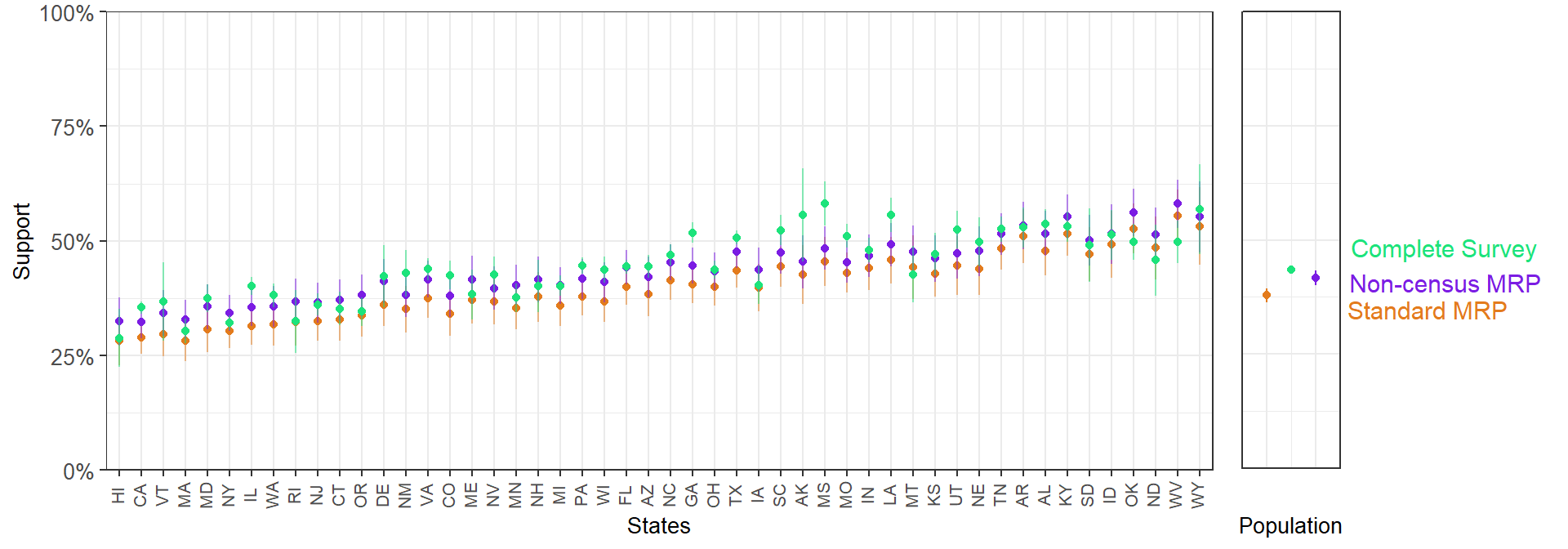
In general, we see that the estimates from the standard MRP are upwardly biased with respect to the 60,000 survey estimates. Conversely, the MRP with non-census variables is able to adjust for the differential partisan nonresponse.
2.3 Obtaining Estimates for Non-census Variable Subgroups
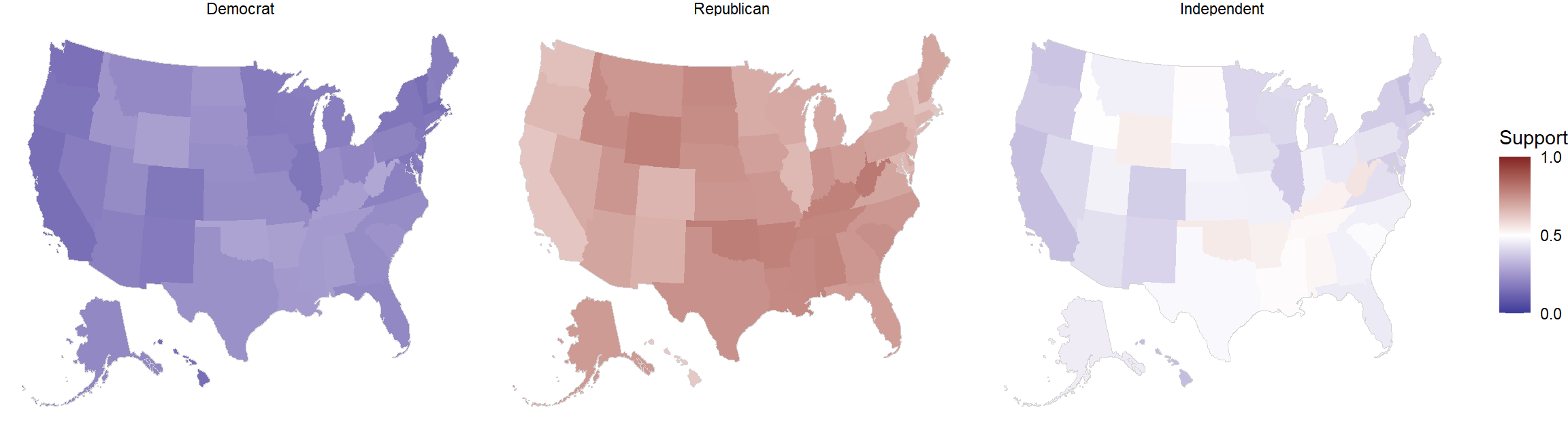
Even if we do not suspect that our survey population is different from our target population with respect to a non-census variable, using non-census MRP can allow us to obtain different estimates for the levels of the non-census variable. Here, we obtain and plot support for declining coverage of abortions by state and party within state.
subgroup_estimates_df <- cces_biased_df %>% expand(state, party) %>%
mutate(noncensus_mrp_subgroup_estimate = NA,
noncensus_mrp_subgroup_estimate_se = NA)
for(i in 1:nrow(subgroup_estimates_df)) {
filtering_condition_threefold <- which(poststrat_df_threefold$state == subgroup_estimates_df$state[i] &
poststrat_df_threefold$party == subgroup_estimates_df$party[i])
subgroup_noncensus_epred_mat <- noncensus_epred_mat[ ,filtering_condition_threefold]
K_filtered <- K[filtering_condition_threefold, ]
noncensus_mrp_subgroup_estimates_vector <- colSums(t(subgroup_noncensus_epred_mat)*K_filtered) / colSums(K_filtered)
subgroup_estimates_df$noncensus_mrp_subgroup_estimate[i] <- mean(noncensus_mrp_subgroup_estimates_vector)
subgroup_estimates_df$noncensus_mrp_subgroup_estimate_se[i] <- sd(noncensus_mrp_subgroup_estimates_vector)
}