Capítulo 5 Hora de começar um código
Começar um código não precisa ter nenhuma mágica. Você precisa apenas presumir que outra pessoa vai abrir seu código, mesmo que isso nunca aconteça.
5.1 Deixe seu quintal apresentável
Um quintal limpo e apresentável é como um bom convite de boas-vindas para uma casa. Ele melhora toda a aparência dela, mesmo que a casa esteja suja por dentro.
O início de um código é o seu quintal. Use ele para apresentar bem o seu código e quais são os seus objetivos. Aqui está uma boa apresentação:
# Nome do codigo: Faturamento.R
# Autor: Isaac Neves Geraldo
# Data de criacao: 2023-12-12
# Data de ultima modificacao: 2023-12-13
# Objetivos:
# - Fazer batimentos com tabelas de clientes;
# - Calcular o faturamento da empresa com base nos pagamentos dos clientes
# Palavras-chave: faturamento, pagamentos, clientes, batimento
# 01. Preparacoes ---------------------------------------------------------
# Pacotes utilizados:
# - dplyr (manipulacao de dados)
# - tidyr (arrumacao de dados)
# - data.table (ler e salvar arquivos com mais rapidez)
# - stringr (tratar e trabalhar com textos)
# Para instalar os pacotes acima, descomente e rode a linha abaixo:
#install.packages(c("dplyr", "tidyr", "data.table", "stringr"))Copie e cole este modelo no início do seus códigos:
# Nome do codigo:
# Autor:
# Data de criacao:
# Data de ultima modificacao:
# Objetivos:
# Palavras-chave:
# 01. Preparacoes ---------------------------------------------------------
# Pacotes utilizados:
# Para instalar os pacotes acima, descomente e rode a linha abaixo:
#install.packages(c("nome_do_pacote_1", "nome_do_pacote_2"))5.2 Seções de código são como gaveteiros
Da mesma forma que usamos um gaveteiro para separar nossas roupas por tipo (íntimas, meias, camisetas, calças etc.), podemos utilizar seções de códigos para separar o nosso código por utilidade.
Uma seção de código é, por padrão, desta forma:
# Nome da sessao ----------------------------------------------------------
print("Olá, estou dentro de uma seção!")Mas você pode utilizar seções de outras formas, como:
#### Secao 1 ####
# Secao 2 ----
# Secao 3 #####Recomendo que utilize a seção padrão, do primeiro exemplo. Ela pode ser facilmente inserida utilizando o atalho CTRL + SHIFT + R:
Desta forma, conseguimos adicionar diversas seções, separando nosso código por funcionalidades, utilidades ou classes:
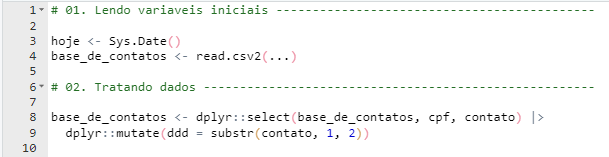
Você pode ocultar um bloco de código com a setinha para baixo, auxiliando a melhor visualização dos blocos restantes:
 (Note a numeração das linhas)
(Note a numeração das linhas)
Utilizar seções é uma ótima forma de trabalhar com códigos grandes, que possuem diversas funcionalidades. Não tenha medo de inserir seções no seu código, elas promovem mais organização e facilidade na visualização dele. Uma boa dica é numerar suas seções (01., 02., 03., …), deixa o código mais limpo e ordenado.
5.3 Comentários e mais comentários
Escreva comentários. Não preciso dizer mais nada, apenas comente tudo, ou quase tudo. Escreva o máximo possível, explique até coisas que são banais, porque nunca se sabe quem vai precisar mexer naquele código algum dia.
Mas o que são comentários? Simples, são trechos do código que não são executados porque não possuem valores semânticos. Para comentar em SQL, usamos -- antes do comentário. No R, utilizamos o #:
# Este é um comentário
print("Este é um comando que será executado normalmente")
# print("Este é um comando que NÃO será executado")Você também pode utilizar o atalho CTRL + SHIFT + C para comentar uma ou mais linhas.
Não deixe seu código sem comentários. Seja extremamente comunicativo e explicativo, mesmo que seja redundante. Não tenha medo de exagerar nos comentários, explique como se você fosse enviar aquele código para uma criança de 6 anos (que entende um pouco de dados). Exemplo:
# Nome do codigo: TRATAMENTO_BASE_CONTATOS.R
# Autor: Isaac Neves Geraldo
# Data de criacao: 2023-12-19
# Data de ultima modificacao: 2023-12-19
# Objetivos:
# - Ler e transformar arquivo de base de contatos
# Palavras-chave: tratamento, base, contatos
# 01. Preparacoes ---------------------------------------------------------
# Pacotes utilizados:
# Para instalar os pacotes acima, descomente e rode a linha abaixo:
#install.packages(c("dplyr"))
# 01. Lendo variaveis iniciais --------------------------------------------
# Declarando variavel de dia atual
hoje <- Sys.Date()
# Lendo base de contatos
base_de_contatos <- read.csv2(...)
# 02. Tratando dados ------------------------------------------------------
# Selecionando colunas cpf e contato
base_de_contatos <- dplyr::select(base_de_contatos, cpf, contato) |>
# Criando coluna de DDD extraindo os 2 primeiros digitos dos dados na coluna de contato
dplyr::mutate(ddd = substr(contato, 1, 2))Lembre-se de que um código bem estruturado é a chave para o sucesso!
5.4 Komonos
Komono, em japonês, significa “pequenos objetos”. A escritora e consultora Marie Kondo usa o termo para se referir a itens diversos, sem muitas classificações, como utensílios de cozinha, ferramentas, cabos, eletrônicos etc.
Usarei este termo, então, para me referir a pequenos detalhes no código que são gerais, i.e., não entram nas demais classificações.
5.4.1 Variáveis
Declarar variáveis em diversas linguagens de programação costuma seguir a mesma sintaxe. Por exemplo, se quero declarar uma variável x, que recebe o valor 10, faço:
x = 10
Mas no R, a coisa funciona diferente. Você não deve usar o operador = para atribuições, e sim o operador <-, chamado pelo comando ALT + -. Desta forma:
x <- 10
Nunca utilize variáveis com letras maiúsculas, espaços ou caracteres especiais. Por exemplo, se quero declarar uma variável de base de telefones:
# Bom:
base_telefones <- read.csv2(...)
# Ruim:
BASE_TELEFONES <- read.csv2(...)
basetelefones <- read.csv2(...)
base telefones <- read.csv2(...) # esse nem vai funcionar
`base telefones` <- read.csv2(...)
Base_telefones <- read.csv2(...)
BaseTelefones <- read.csv2(...)
báse_telefônes <-read.csv2(...)É importante manter um padrão e limpeza visual até mesmo nos nomes das suas variáveis. Deixe o maiúsculo para nomes de colunas (e olhe lá). Evite também usar nomenclaturas já existentes, nomes comuns, nomes de funções ou o mesmo nome para variáveis diferentes. Isso vai apenas causar confusão.
5.4.2 Se você não fizer certo, então vai dar errado
Condicionais são formas de se dizer ao seu programa que um trecho de código só vai ser executado caso determinada condição é obedecida. As principais condicionais do R são if, else if e else. Também temos a função ifelse(), que trarei em outro momento do livro.
O if é a estrutura condicional mais simples em R. Ela avalia uma condição e executa um bloco de código se a condição for verdadeira:
# Declarando variavel de idade
idade <- 18
# Se idade for maior ou igual a 18, então exibe mensagem "Você é maior de idade."
if (idade >= 18) {
print("Você é maior de idade.")
}O bloco else é executado se a condição no if for falsa.
# Declarando variavel de idade
idade <- 16
# Se idade for maior ou igual a 18, então exibe mensagem "Você é maior de idade."
if (idade >= 18) {
print("Você é maior de idade.")
# Senão, exibe mensagem "Você é menor de idade."
} else {
print("Você é menor de idade.")
}Se você tiver mais de duas condições, você pode usar else if.
# Declarando variavel de nota
nota <- 75
# Se nota for maior ou igual a 90, então exibe mensagem "Aprovado com distinção."
if (nota >= 90) {
print("Aprovado com distinção.")
# Se nota for maior ou igual a 70, então exibe mensagem "Aprovado."
} else if (nota >= 70) {
print("Aprovado.")
# Senão, então exibe mensagem "Reprovado."
} else {
print("Reprovado.")
}Você pode combinar múltiplas condições usando operadores lógicos como && (E) e || (OU).
# Declarando variavel de idade
idade <- 25
# Declarando variavel de validacao (se o usuario possui cartao)
tem_cartao <- TRUE
# Se idade for maior ou igual a 18 E usuario possui cartao (tem cartao == TRUE), então exibe mensagem "Você pode fazer compras."
if (idade >= 18 && tem_cartao) {
print("Você pode fazer compras.")
# Senão, então exibe mensagem "Reprovado."
} else {
print("Você não pode fazer compras.")
}Além das básicas, também possuímos as condicionais mais voltadas para dados e manipulação, como o case_when(), do pacote dplyr, o próprio ifelse() e até o swith().
5.4.3 Loops!
Um loop é basicamente uma repetição de um bloco de código. No mundo da programação, os principais são o for (), o while () e o do {...} while (). Aprenda a utilizá-los no seu dia a dia e descubra um mundo totalmente novo!
Por exemplo: digamos que eu preciso ler vários arquivos de uma pasta até eu encontrar o arquivo que eu preciso, e parar por aí. Todos estes arquivos possuem a mesma estrutura (colunas), porém com dados diferentes. Neles há uma coluna codigo, que possui o código de cada cliente entrante na base total. Digamos que eu queira trazer as informações de um cliente cujo código é igual a 092318, mas não sei em que base ele se encontra, então vou precisar caçar de base em base para encontrar este cara.
Posso usar um while, por exemplo:
# Declarando variavel de lista de arquivos
lista_arquivos <- list.files(
path = "C:/users/usuario/CAMINHO/ARQUIVOS/",
full.names = TRUE
)
# Declarando variavel de codigo do cliente
codigo_cliente <- "092318"
# Declarando variavel que ira validar se o cliente esta presente no dataframe
possui_cliente <- FALSE
# Declarando variavel de iteracao
i <- 1
# Enquanto possui_cliente for igual a FALSE, o bloco de código será repetido
while (possui_cliente == FALSE) {
# Lendo arquivo i da pasta
arquivo <- read.csv2(file = lista_arquivos[i], ...)
# Se codigo_cliente (092318) se encontra na coluna "codigo", entao possui_cliente = TRUE
if (codigo_cliente %in% arquivo$codigo) {
# Se esta condicao for verdadeira, o loop para por aqui
possui_cliente <- TRUE
# Exibindo nome do arquivo em que se encontra o cliente procurado
print(paste0("O cliente ", codigo_cliente, " se encontra no arquivo ", lista_arquivos[i]))
# Trazendo as informcoes apenas do cliente procurado
arquivo <- dplyr::filter(arquivo, codigo == codigo_cliente)
}
}Ou até mesmo um for:
# Declarando variavel de lista de arquivos
lista_arquivos <- list.files(
path = "C:/users/usuario/CAMINHO/ARQUIVOS/",
full.names = TRUE
)
# Declarando variavel de codigo do cliente
codigo_cliente <- "092318"
# Declarando variavel que ira validar se o cliente esta presente no dataframe
possui_cliente <- FALSE
# Para i entre 1 e o tamanho da lista de arquivo (qtde. de arquivos na pasta), repetir bloco de texto
for (i in 1:length(lista_arquivo)) {
# Lendo arquivo i da pasta
arquivo <- read.csv2(file = lista_arquivos[i], ...)
# Se codigo_cliente (092318) se encontra na coluna "codigo", entao possui_cliente = TRUE
if (codigo_cliente %in% arquivo$codigo) {
# Se esta condicao for verdadeira, o loop para por aqui
possui_cliente <- TRUE
# Exibindo nome do arquivo em que se encontra o cliente procurado
print(paste0("O cliente ", codigo_cliente, " se encontra no arquivo ", lista_arquivos[i]))
# Trazendo as informcoes apenas do cliente procurado
arquivo <- dplyr::filter(arquivo, codigo == codigo_cliente)
# "Quebra" loop, ou seja, o loop para por aqui, no momento em que o cliente é encontrado
break
}
}Loops são feitos para você não repetir o mesmo código mais de uma vez. A regra é clara: se você for repetir o mesmo trecho no código mais de duas vezes, está errado. Considere utilizar um loop nestes casos.
5.4.4 Funções
Assim como os loops, elas servem para que você reduza o seu código para que um trecho seja executado mais de uma vez. Uma função é, como o próprio nome diz, um bloco de código que possui alguma funcionalidade executável. Uma função, na maioria dos casos, pode conter parâmetros de entrada e receber argumentos para sua execução.
Por que utilizar funções? As funções personalizadas permitem que você agrupe um conjunto de instruções em um bloco coeso e reutilizável de código. Isso oferece várias vantagens, como:
Reutilização de código: Ao encapsular um conjunto de instruções em uma função, você pode reutilizá-la em diferentes partes do seu código, economizando tempo e evitando repetições desnecessárias.
Organização do código: Funções bem nomeadas ajudam a tornar seu código mais legível e organizado, facilitando a manutenção e colaboração com outros programadores.
Abstração: Ao criar funções personalizadas, você pode abstrair a complexidade do código subjacente, fornecendo uma interface simples para os usuários. Isso torna o código mais intuitivo e facilita o uso por outras pessoas.
A sintaxe de uma função é a seguinte:
nome_da_funcao <- function(argumentos_da_funcao) {
# Código (tudo o que sua função fará)
return(retorno_da_funcao)
}Um exemplo: preciso consolidar vários arquivos .csv dentro de uma pasta. Porém, suponhamos que eu precise fazer isso em outras três pastas também, sendo, ao total, quatro pastas: PASTA1, PASTA2, PASTA3, PASTA4.
Desta forma, posso escrever uma função consolidarCSV():
# Declarando a funcao consolidarCSV, que recebe o argumento "caminho"
# Por padrao, o argumento "caminho" recebe "~", que é a pasta padrão setada no R
consolidarCSV <- function(caminho = "~") {
# Criando dataframe vazio
consolidado <- data.frame()
# Para i entre 1 e a quantidade de arquivos de padrao .csv dentro do caminho, executar bloco de código
for (i in 1:length(list.files(pattern = "csv"))) {
# Lendo arquivo i do caminho
base <- read.csv2(
file = paste0(caminho,"/", list.files(pattern = "csv")[i]),
sep = ";",
header = TRUE,
colClasses = "character"
)
# Unindo consolidado com o arquivo recem lido
consolidado <- dplyr::bind_rows(consolidado, base)
}
# Retornando o consolidado para a variavel que chama a função
return(consolidado)
}
# Chamando a função:
consolidado_pasta_1 <- consolidarCSV(caminho = ".../PASTA1")
consolidado_pasta_2 <- consolidarCSV(caminho = ".../PASTA2")
consolidado_pasta_3 <- consolidarCSV(caminho = ".../PASTA3")
consolidado_pasta_4 <- consolidarCSV(caminho = ".../PASTA4")As funções personalizadas são uma ferramenta poderosa para tornar seu código mais organizado, reutilizável e fácil de entender. Experimente criar suas próprias funções e descubra como elas podem otimizar suas tarefas e simplificar a análise de dados.
5.4.5 Snippets
Se você já se pegou repetindo trechos de código constantemente ou se deseja agilizar o desenvolvimento de projetos, os snippets são uma ferramenta indispensável para você. Nesta seção, iremos explorar o que são snippets, como criá-los e como utilizá-los eficientemente.
5.4.5.1 Que são snippets?
Snippets são pequenos blocos de código pré-definidos que podem ser inseridos rapidamente em um editor de código. Eles são como atalhos que poupam tempo e esforço, permitindo que você insira trechos de código comuns ou complexos com apenas alguns caracteres ou teclas de atalho. Esses trechos podem conter variáveis, placeholders ou até mesmo interações com o usuário.
5.4.5.2 Criando um snippet
Criar seus próprios snippets no R é simples e altamente personalizável. A maneira mais comum de fazer isso é usar o editor de snippets dentro do próprio RStudio.
Vá em Tools > Global Options… > Code
Na seção Snippets, marque a caixinha
Enable code snippets, como na imagem abaixo:
Clique em
Edit snippets...
Agora você poderá criar ou modificar os snippets presentes. Para uma demonstração, vá até a última linha e cole o seguinte comando:
snippet lerCSV
${1:data_frame} <- read.csv(
file = paste0("C:/users/",Sys.info()["user"],"/Desktop/${2:nome_arquivo}.csv"),
sep = ";",
header = TRUE,
colClasses = "character"
)
snippet salvarCSV
write.csv2(
${1:data_frame},
file = paste0("C:/users/",Sys.info()["user"],"/Desktop/${2:nome_arquivo}.csv"),
row.names = FALSE,
na = "",
quote = FALSE
)Clique em Save e Apply. Pronto! Agora você tem dois novos snippets úteis. Uma vez que você tenha seus snippets criados, a utilização deles é bastante simples. Ao digitar o prefixo do snippet e pressionar a tecla de ativação (geralmente “Tab” ou “Enter”), o snippet será inserido no código, permitindo que você o personalize de acordo com suas necessidades. Você pode navegar entre os campos editáveis (os que estão dentro do $(n:variável)), como variáveis ou placeholders, usando a tecla de tabulação.
Os snippets são uma ferramenta poderosa para aumentar sua produtividade ao trabalhar com R. Ao criar e utilizar snippets personalizados, você pode agilizar o processo de desenvolvimento, economizando tempo e esforço. Aproveite essa técnica para automatizar tarefas repetitivas e criar blocos de código complexos.
5.4.6 Pacotes úteis
Existem muitos pacotes úteis em R para uma variedade de propósitos. Aqui estão alguns dos melhores pacotes em diferentes categorias:
Manipulação de dados:
dplyr: Excelente para manipulação de dados, oferecendo funções intuitivas para filtrar, selecionar, ordenar e agregar dados.
tidyr: Ótimo para organizar e transformar dados, especialmente útil para lidar com dados desarrumados (messy data) e para criar tabelas organizadas.
Visualização de dados:
ggplot2: Uma das ferramentas mais poderosas para criação de gráficos em R, permitindo a construção de visualizações complexas e personalizadas de forma relativamente simples.
plotly: Oferece uma maneira interativa de criar gráficos, permitindo a criação de visualizações dinâmicas e responsivas.
Análise de texto:
tm: Ótimo para análise de texto, oferecendo funções para pré-processamento de texto, criação de corpora e análise de texto.
tidytext: Integrado com a filosofia tidyverse, facilita a análise de texto usando os princípios de tidy data.
Relatórios dinâmicos:
rmarkdown: Permite a criação de relatórios dinâmicos que combinam código R, texto e visualizações em uma variedade de formatos, incluindo HTML, PDF e Word.
knitr: Usado em conjunto com rmarkdown, fornece funcionalidades para incorporar código R em documentos, facilitando a criação de relatórios reproduzíveis.
Esses são apenas alguns exemplos dos muitos pacotes disponíveis em R, e a escolha dos melhores pacotes depende do contexto específico da análise de dados e das tarefas a serem realizadas.
Particularmente, os pacotes que eu mais utilizo no meu dia a dia são: dplyr, tidyr, stringr, alguns para conexões em bancos de dados, como o DBI, RPostgreSQL e RODBC, e o data.tables, que oferece opções rápidas de leitura e escrita de arquivos.
5.4.7 Identação
A identação, ou seja, o recuo consistente das linhas de código, é um aspecto crucial da escrita de código em R. Enquanto não afeta diretamente o funcionamento do programa, a identação desempenha um papel essencial na legibilidade e manutenção do código. Aqui estão algumas razões pelas quais a identação é tão importante:
1. Clareza e legibilidade: A identação torna o código mais claro e fácil de ler, especialmente quando se trabalha com blocos de código aninhados, como loops e condicionais. Um código bem identado facilita para você e outros programadores entenderem a estrutura e a lógica do programa.
2. Facilita a depuração: Quando ocorrem erros no código, uma identação consistente pode ajudar a identificar rapidamente onde está o problema. Com uma identação adequada, é mais fácil seguir o fluxo de execução do programa e identificar possíveis fontes de erros.
3. Boas práticas de programação: A identação é uma das boas práticas de programação amplamente adotadas pela comunidade de desenvolvedores. Seguir essas práticas não apenas torna o código mais legível, mas também ajuda a manter um padrão de qualidade e consistência em todo o código.
Para aplicar a identação de forma eficaz em R, você pode aproveitar os atalhos de teclado disponíveis em ambientes de desenvolvimento integrados (IDEs) como RStudio:
1. Recuo de blocos de código: Use a combinação de teclas Ctrl + I para aplicar identação ao bloco de código selecionado. Isso é útil para recuar ou desrecuar blocos de código, como funções, loops e condicionais.
2. Formatação automática: IDEs como o RStudio oferecem a opção de formatação automática do código, incluindo a aplicação de identação consistente. Isso pode ser feito usando o atalho Ctrl + Shift + A para formatar todo o script de uma vez. Basta selecionar todo o código ou algum trecho e utilizar a tecla de atalho.
Ao adotar esses atalhos de teclado e boas práticas de identação, você torna seu código mais fácil de entender, depurar e manter, promovendo assim uma melhor colaboração e eficiência no desenvolvimento de software em R.