Chapitre 2 Analyse en Composantes Principales
2.1 Objectifs
L’objectif de ce TP est de réaliser une analyse en composante principale sur base de données électorales.
2.2 Données
- données des élections présidentielles 2022 par communes : pres2022comm.csv (https://unehistoireduconflitpolitique.fr/telecharger.html)
Ce fichier contient les résultats des élections présidentielles de 2022 en format csv. Ces fichiers ont été générés à partir des résultats électoraux disponibles sur le site du Ministère de l’Intérieur et sur data.gouv.fr. J. Cagé et T. Piketty (2023) : Une histoire du conflit politique. Élections et inégalités sociales en France, 1789-2022. Le Seuil.
communes: communes-20220101.shp (1)
arrondissement municipaux: arrondissements_municipaux-20180711.shp (2)
table commune - région : commune2021.csv (3)
revenus par commune : FILO2021_DEC_COM.xlsx (4)
population par commune: population_insee_2021.xlsx (5)
- INSEE: https://www.data.gouv.fr/fr/datasets/decoupage-administratif-communal-francais-issu-d-openstreetmap/
- INSEE: https://www.data.gouv.fr/fr/datasets/decoupage-administratif-communal-francais-issu-d-openstreetmap/
- INSEE: https://www.insee.fr/fr/information/2560452
- INSEE: https://www.insee.fr/fr/statistiques/7756855?sommaire=7756859
- INSEE : https://www.insee.fr/fr/statistiques/7739582?sommaire=7728826
Pour ce TP nous utiliserons les packages suivants:
De façon maintenant habituelle:
Et deux packages développés pour réaliser des ACP et visualiser les résultats:
#install_version("estimability", "1.4.1")
#install.packages("FactoMineR")
#install.packages("factoextra")
library(FactoMineR)
library(factoextra)Les objectifs pour réaliser une ACP sont généralement :
Débroussailler un large set de données avec plein de variables
Réaliser un indicateur synthétique
Préparer à une classification
Dans le cas ici, on va plutôt réaliser une ACP suivant le premier objectif sur les votes exprimés aux élections en Île de France aux élections présidentielles de 2022. L’objectif sera de voir on retrouve des structures dans la géographie de cette élection.
2.2.1 Importation des données
2.2.1.1 Élections 2022
Importation des données:
data<-read_delim("data/France/pres2022comm.csv", delim=",") %>%
select(1:19) %>%
filter(codecommune!="75056") # %>% # On enlève la communes de Paris## Rows: 34867 Columns: 97
## ── Column specification ─────────────────────────────────────
## Delimiter: ","
## chr (4): dep, nomdep, codecommune, nomcommune
## dbl (93): inscrits, votants, exprimes, voixARTHAUD, voixP...
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.On prend une table pour ne sélectionner que l’Île de France:
## Rows: 37742 Columns: 12
## ── Column specification ─────────────────────────────────────
## Delimiter: ","
## chr (11): TYPECOM, COM, REG, DEP, CTCD, ARR, NCC, NCCENR,...
## dbl (1): TNCC
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.2.2.1.2 Communes
## Reading layer `communes_arrond_ile_de_france' from data source `C:\Users\hugop\Nextcloud\git\manuel_geo_quanti\data\France\communes_arrond_ile_de_france.gpkg'
## using driver `GPKG'
## Simple feature collection with 1287 features and 4 fields
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: 1.446244 ymin: 48.12015 xmax: 3.559221 ymax: 49.24143
## Geodetic CRS: WGS 84# On importe les arrondissements de Paris, Lyon et Marseille
arrond_lyon_mars_paris<- st_read("data/France/arrondissements_municipaux-20180711-shp/arrondissements_municipaux-20180711.shp")%>%
select(-surf_km2) %>%
rename(geom=geometry)## Reading layer `arrondissements_municipaux-20180711' from data source `C:\Users\hugop\Nextcloud\git\manuel_geo_quanti\data\France\arrondissements_municipaux-20180711-shp\arrondissements_municipaux-20180711.shp'
## using driver `ESRI Shapefile'
## Simple feature collection with 45 features and 4 fields
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: 2.224122 ymin: 43.19714 xmax: 5.532476 ymax: 48.90216
## Geodetic CRS: WGS 84communes<-bind_rows(communes,arrond_lyon_mars_paris) # On joint communes et arrondissements
rm(arrond_lyon_mars_paris)On ne garde que les communes de l’Ile de France:
communes<-communes %>%
left_join(communes_table, by=c("insee"="COM"))%>%
filter(REG==11) %>%
select(-c(5:15))## Warning in sf_column %in% names(g): Detected an unexpected many-to-many relationship between `x`
## and `y`.
## ℹ Row 17 of `x` matches multiple rows in `y`.
## ℹ Row 31675 of `y` matches multiple rows in `x`.
## ℹ If a many-to-many relationship is expected, set
## `relationship = "many-to-many"` to silence this warning.On calcul la densité par communes:
communes<-communes %>%
mutate(surface=as.numeric(st_area(geom))/10000) # On calcul le superficie de chaque communesOn créé un objet département pour la cartographie:
departements_Paris<-communes %>%
left_join(communes_table, by=c("insee"="COM")) %>%
filter(REG==11) %>%
group_by(DEP,REG) %>%
summarise(geom=st_union(geom))## Warning in sf_column %in% names(g): Detected an unexpected many-to-many relationship between `x`
## and `y`.
## ℹ Row 17 of `x` matches multiple rows in `y`.
## ℹ Row 31675 of `y` matches multiple rows in `x`.
## ℹ If a many-to-many relationship is expected, set
## `relationship = "many-to-many"` to silence this warning.## `summarise()` has grouped output by 'DEP'. You can override
## using the `.groups` argument.2.2.2 Recodage
Pour réaliser l’ACP il faut d’abord recoder les variables. On utilise généralement des variables en proportion:
data<-data %>%
mutate(ARTHAUD=voixARTHAUD/exprimes,
POUTOU=voixPOUTOU/exprimes,
ROUSSEL=voixROUSSEL/exprimes,
MELENCHON=voixMELENCHON/exprimes,
JADOT=voixJADOT/exprimes,
HIDALGO=voixHIDALGO/exprimes,
LASSALLE=voixLASSALLE/exprimes,
MACRON=voixMACRON/exprimes,
PECRESSE=voixPECRESSE/exprimes,
ZEMMOUR=voixZEMMOUR/exprimes,
DUPONTAIGNAN=voixDUPONTAIGNAN/exprimes,
MLEPEN=voixMLEPEN/exprimes)
# De façon raccourcie, il est possible de réaliser de la façon suivante:
# - en utilisant des pivot (tidyr) et un group by
# data<-data %>%
# pivot_longer(cols= 8:19,names_to ="candidat", values_to = "voix" ) %>%
# mutate(voix=voix/exprimes) %>%
# pivot_wider(values_from = "voix", names_from = "candidat")
# - de façon encore plus synthétique, en utilisant un across:
# data<-data %>%
# mutate(across(8:19, ~ . /exprimes))2.3 Première visualisation des données
2.3.1 Une carte par variable
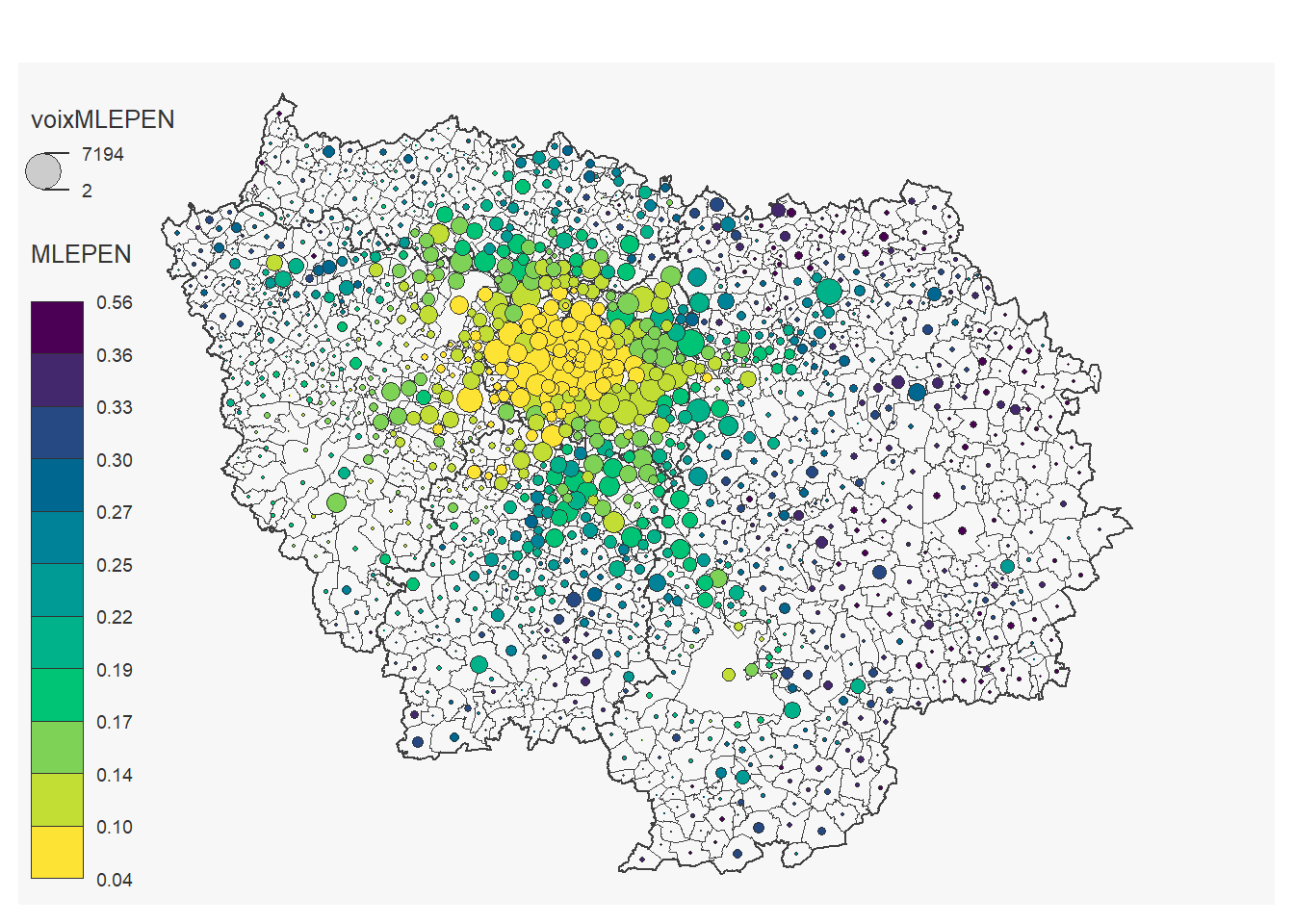
On peut réaliser une carte pour chaque candidat:
for (i in 12:23) {
# mf_export(x = communes_voix ,
# filename =paste0("TP09/cartes_candidats/carte_",names(communes_voix)[i],".png" ),
# width = 900)
mf_map(x = communes_voix, col = NA, border = "gray25", lwd = 0.1)
mf_map(x = departements_Paris, col = NA, border = "gray25", lwd = 1, add=T)
mf_map(communes_voix ,
var= c(names(communes_voix)[i], names(communes_voix)[i+12]),
#val_max=max(unlist(communes_voix[,11:22])),
type="prop_choro",
pal="Viridis",
inches=0.1,
add=T)
#dev.off()
}## 184 '0' values are not plotted on the map.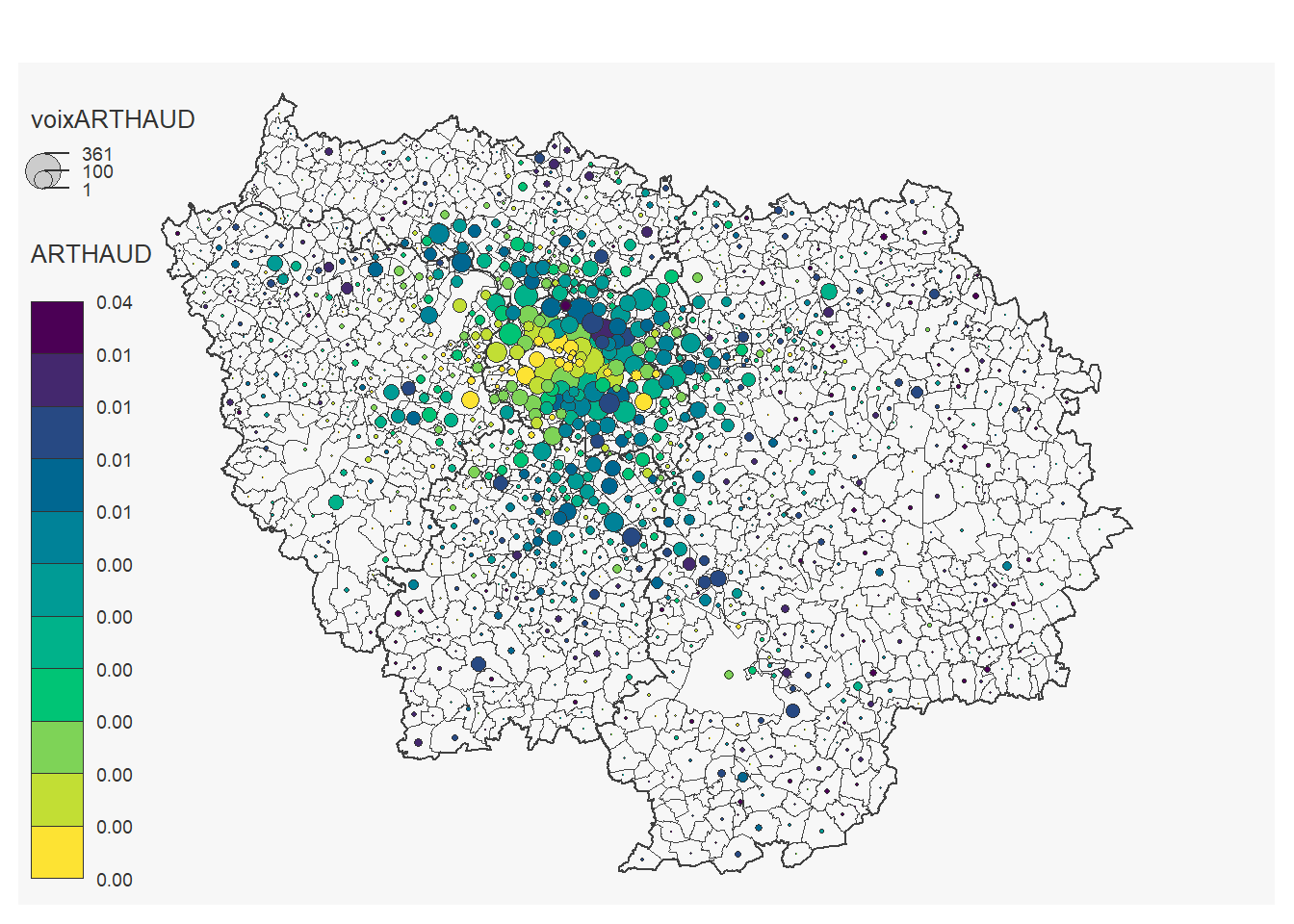
## 101 '0' values are not plotted on the map.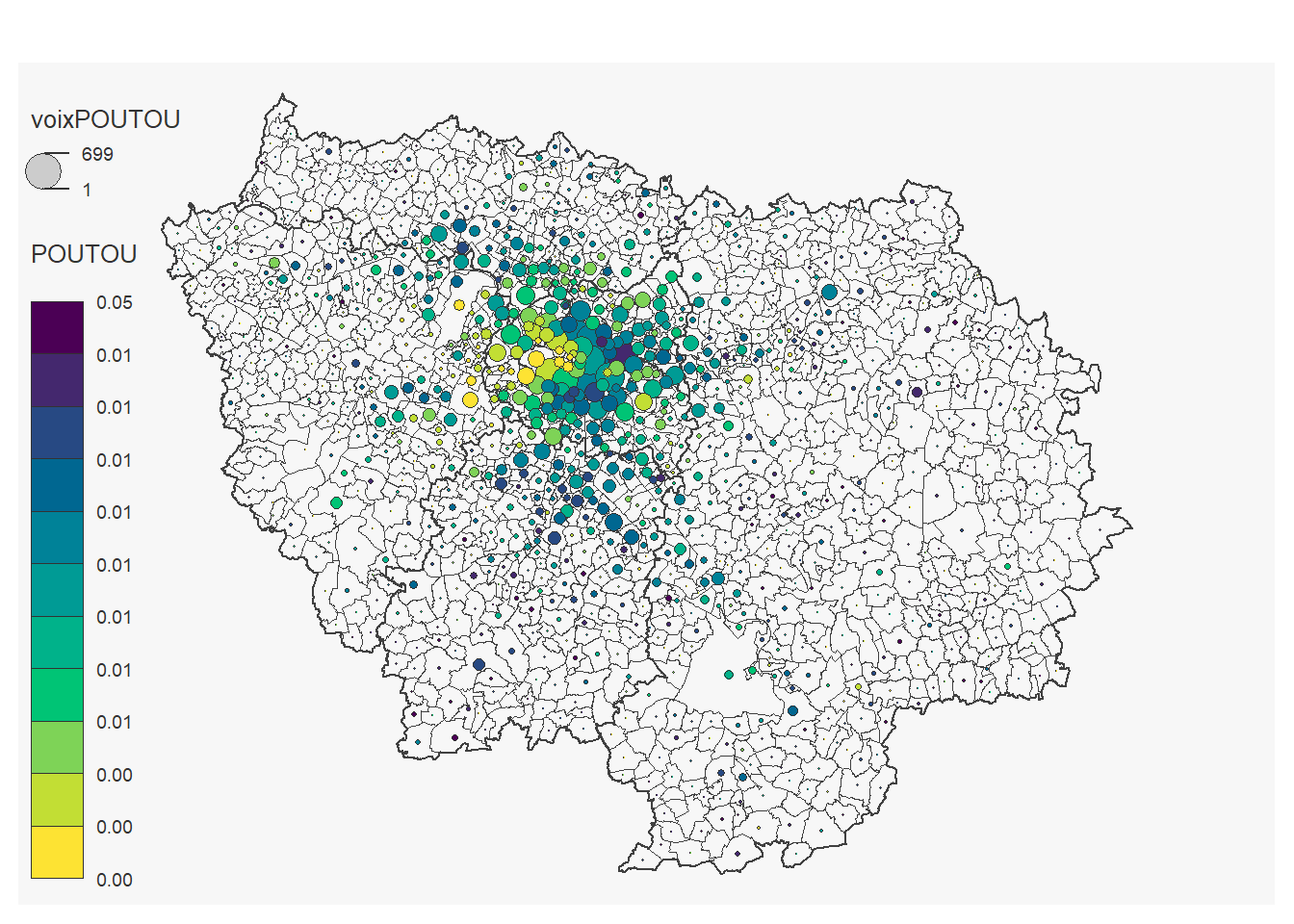
## 42 '0' values are not plotted on the map.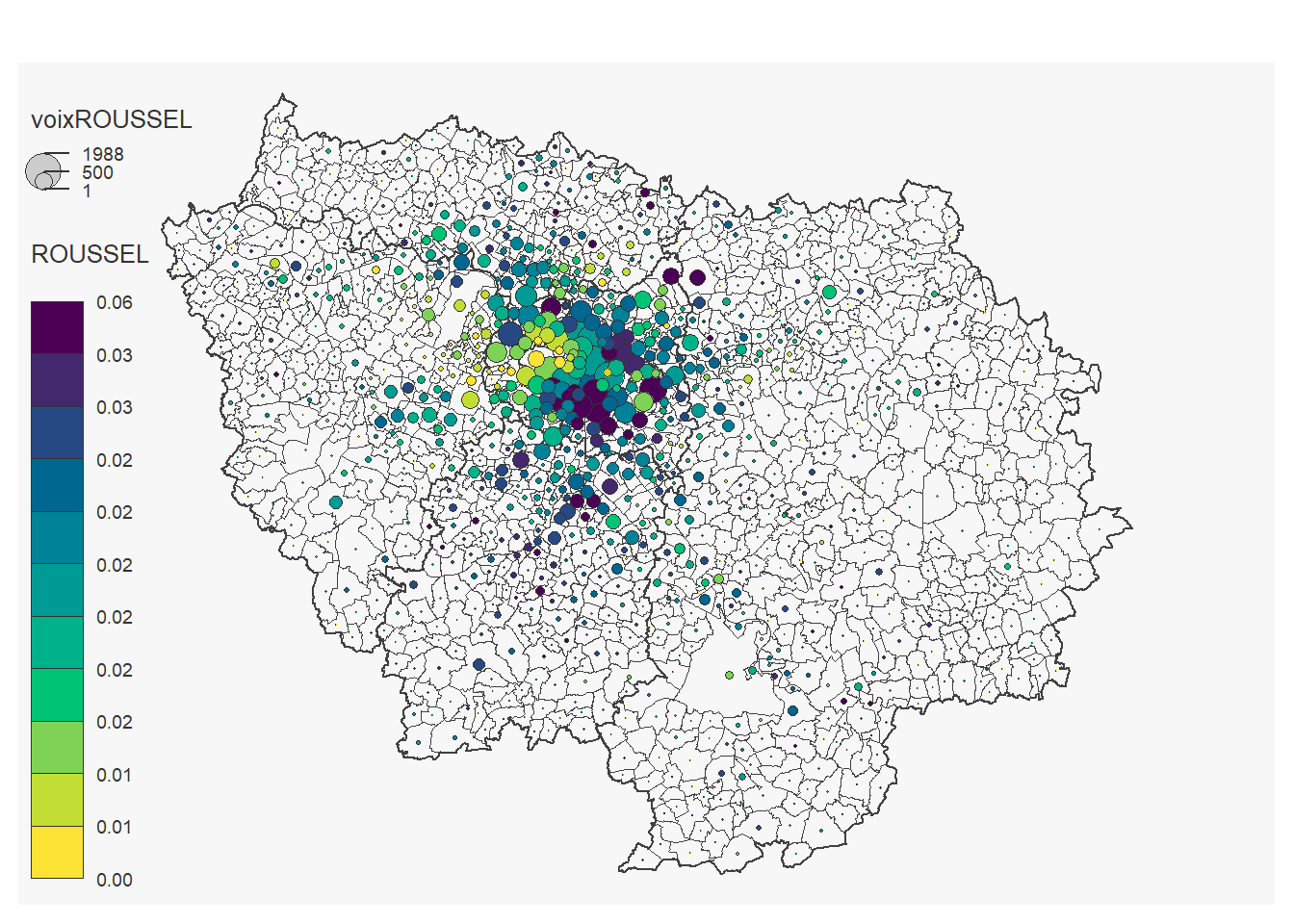
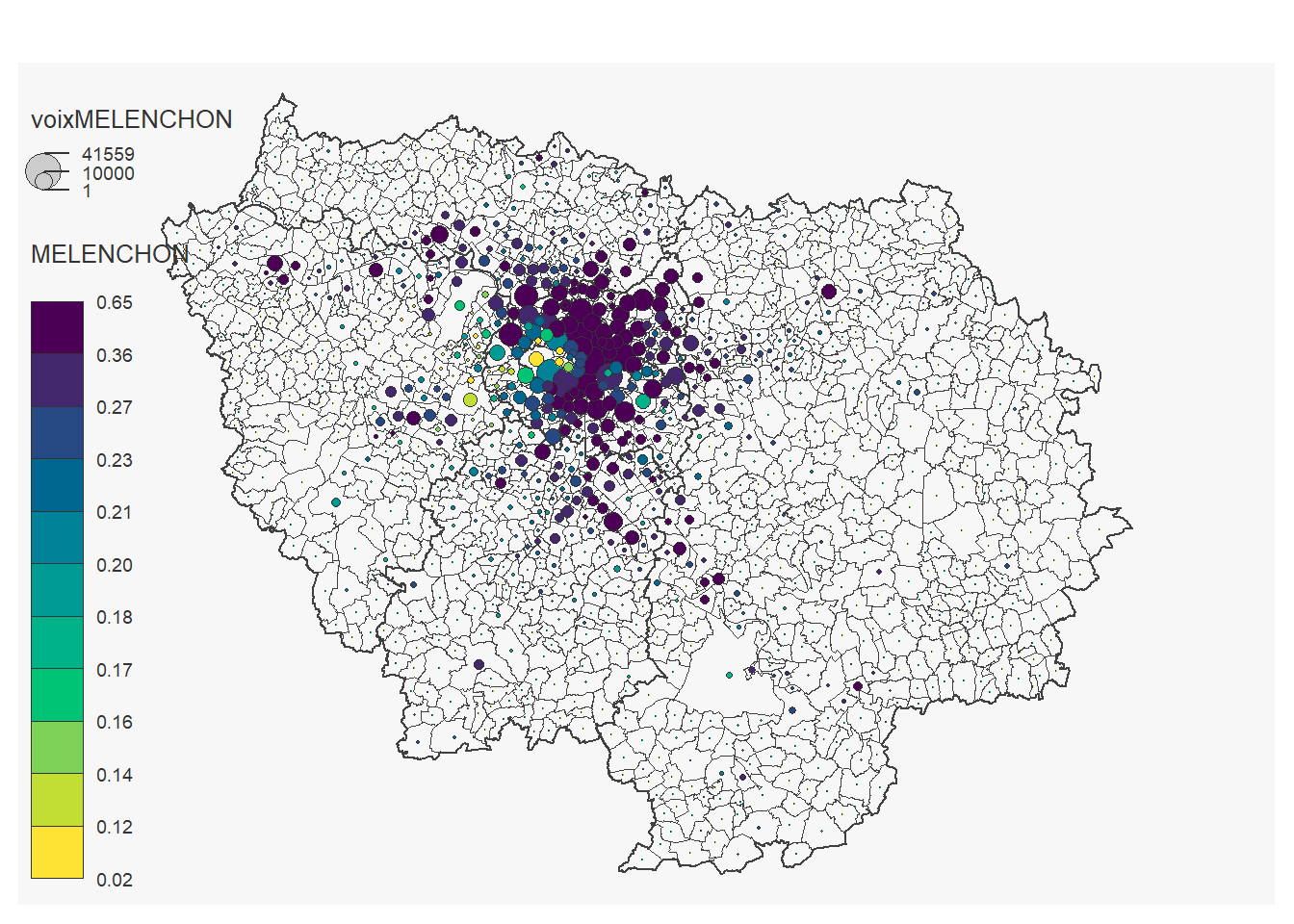
## 8 '0' values are not plotted on the map.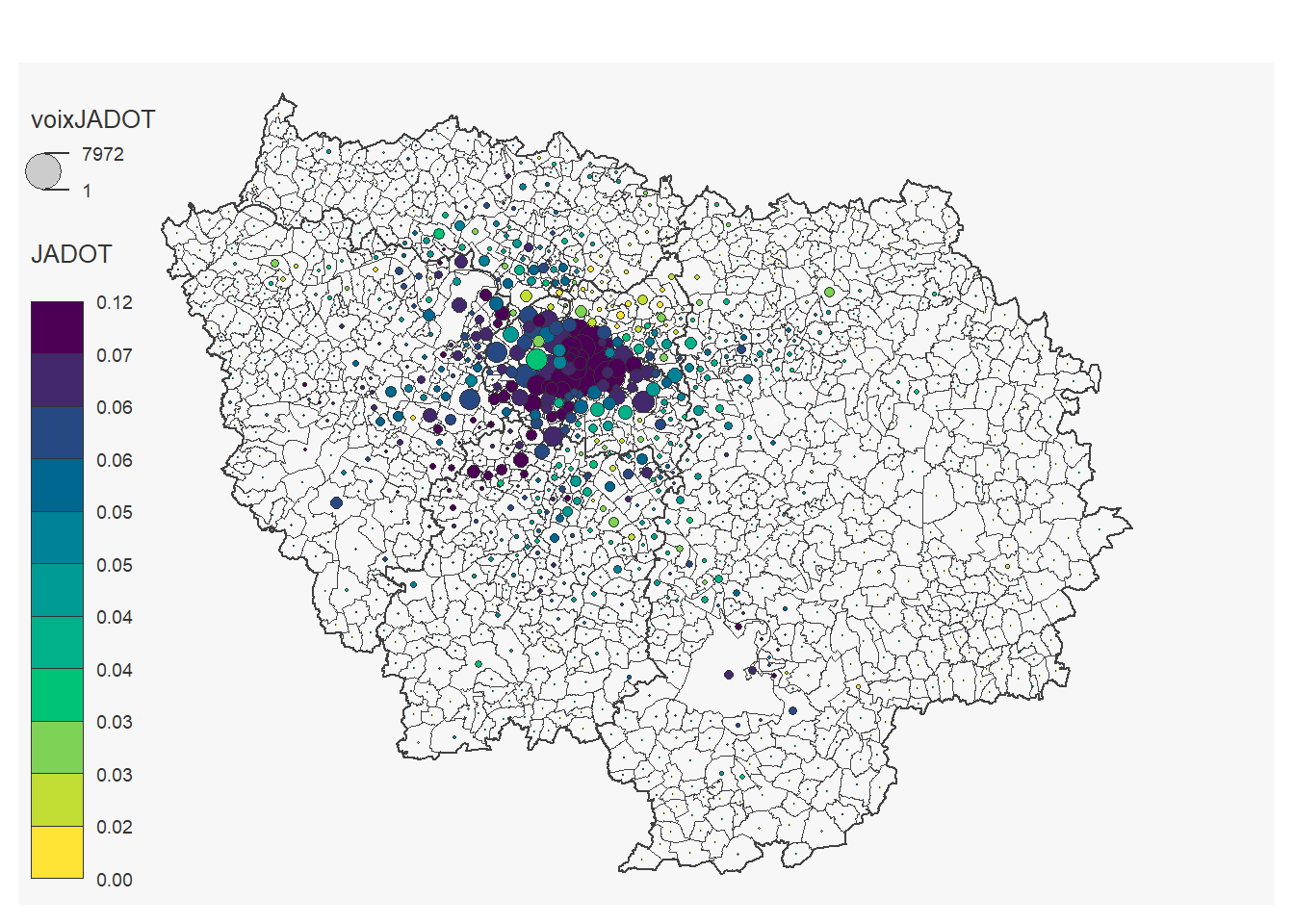
## 97 '0' values are not plotted on the map.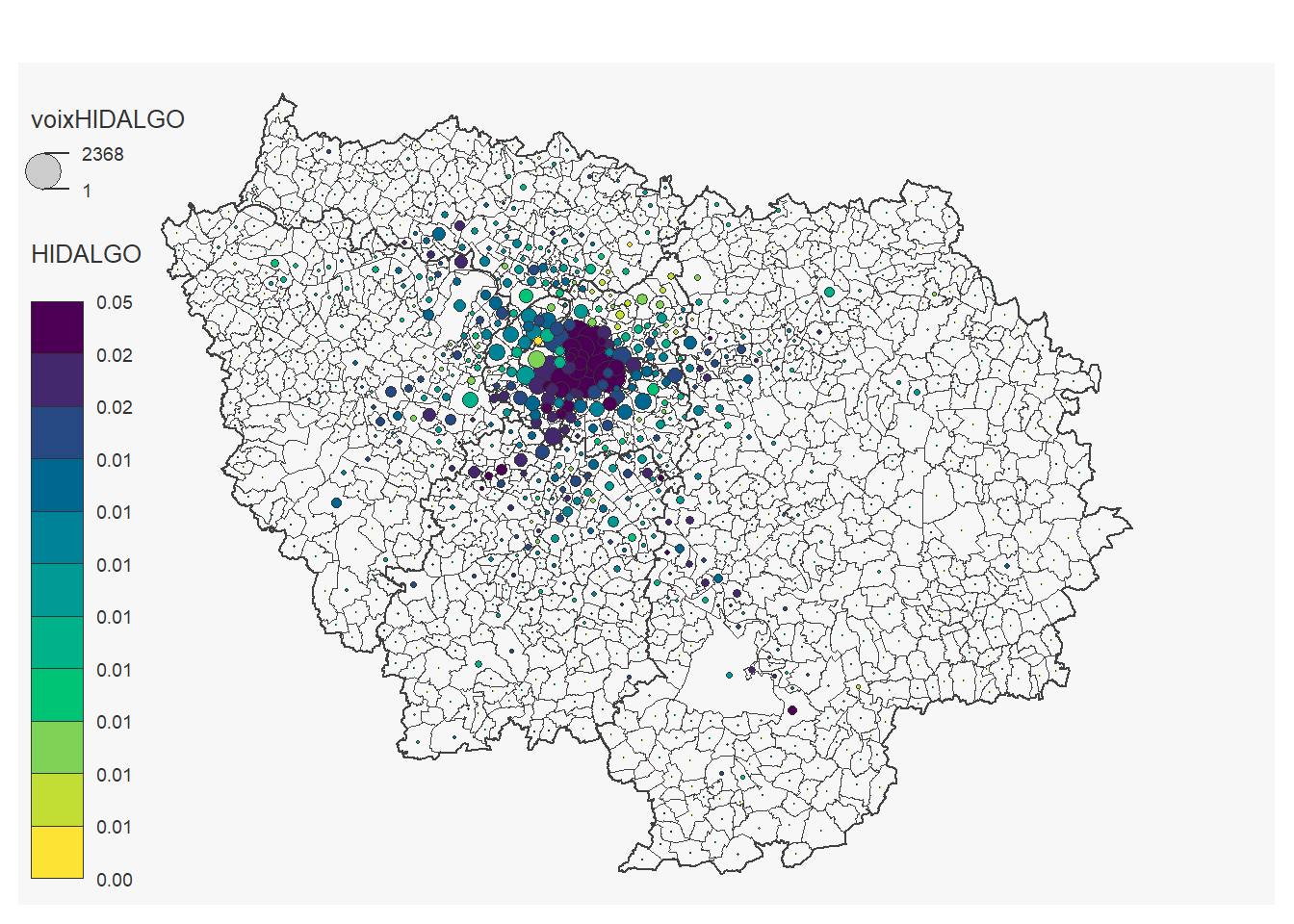
## 18 '0' values are not plotted on the map.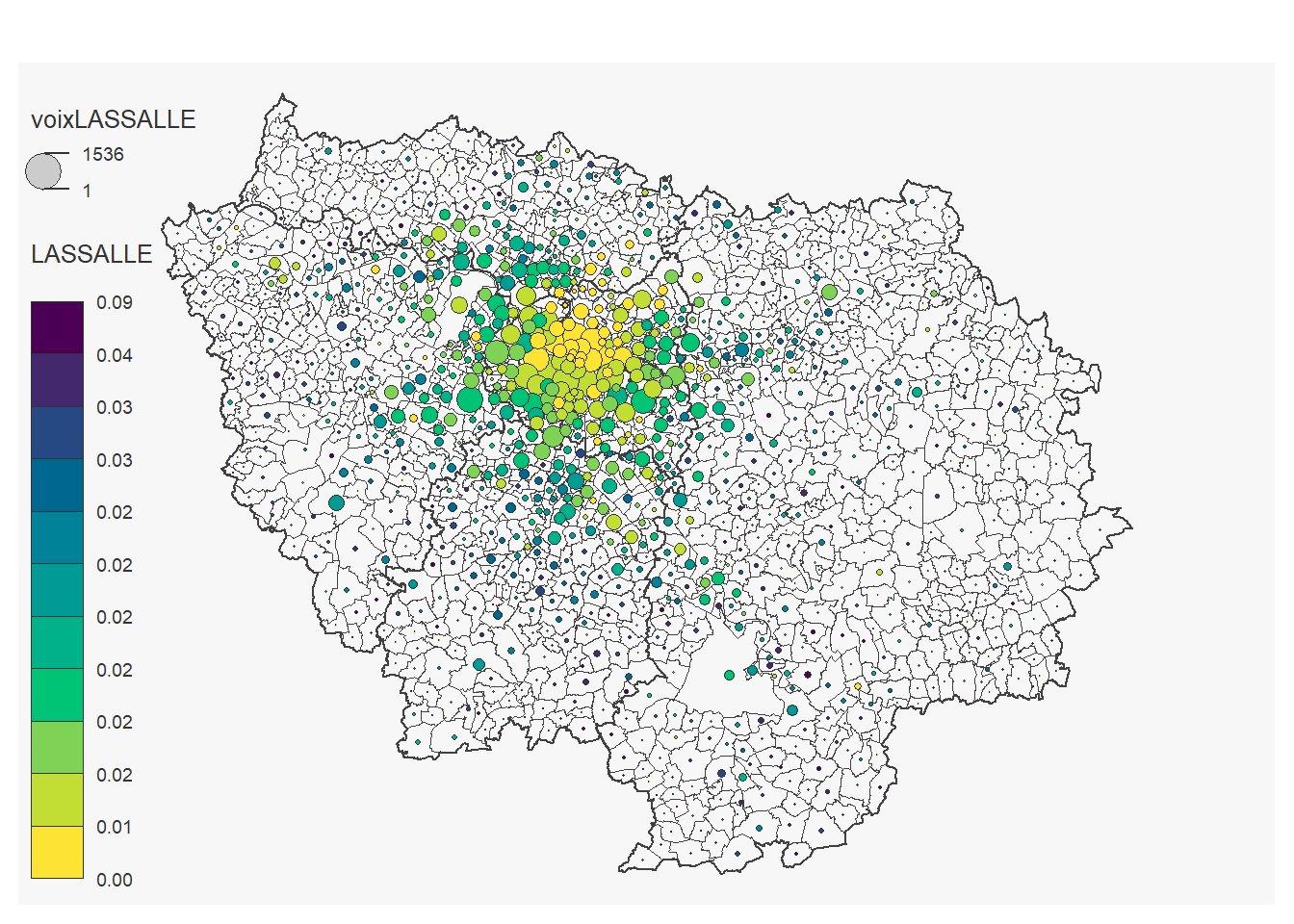
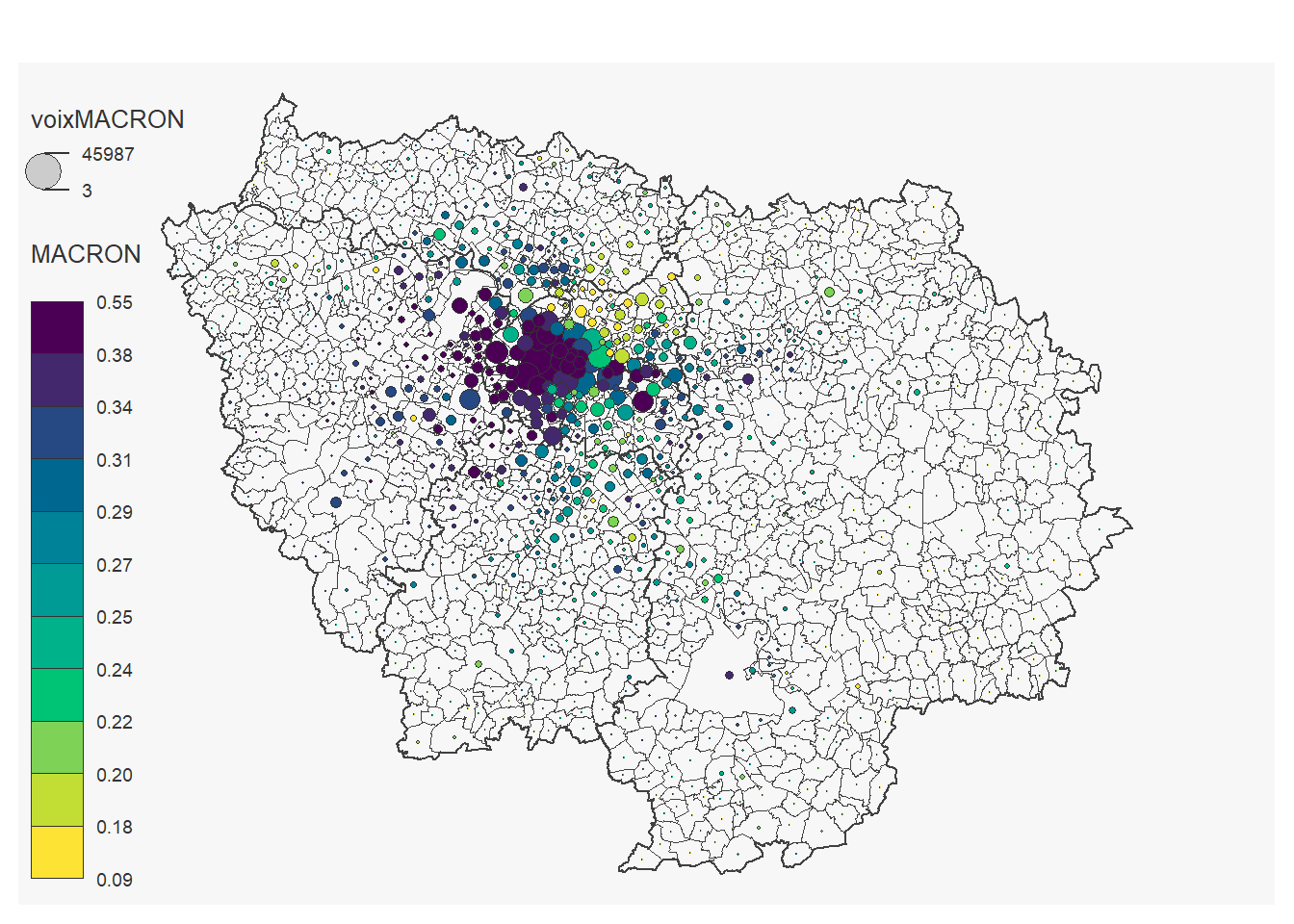
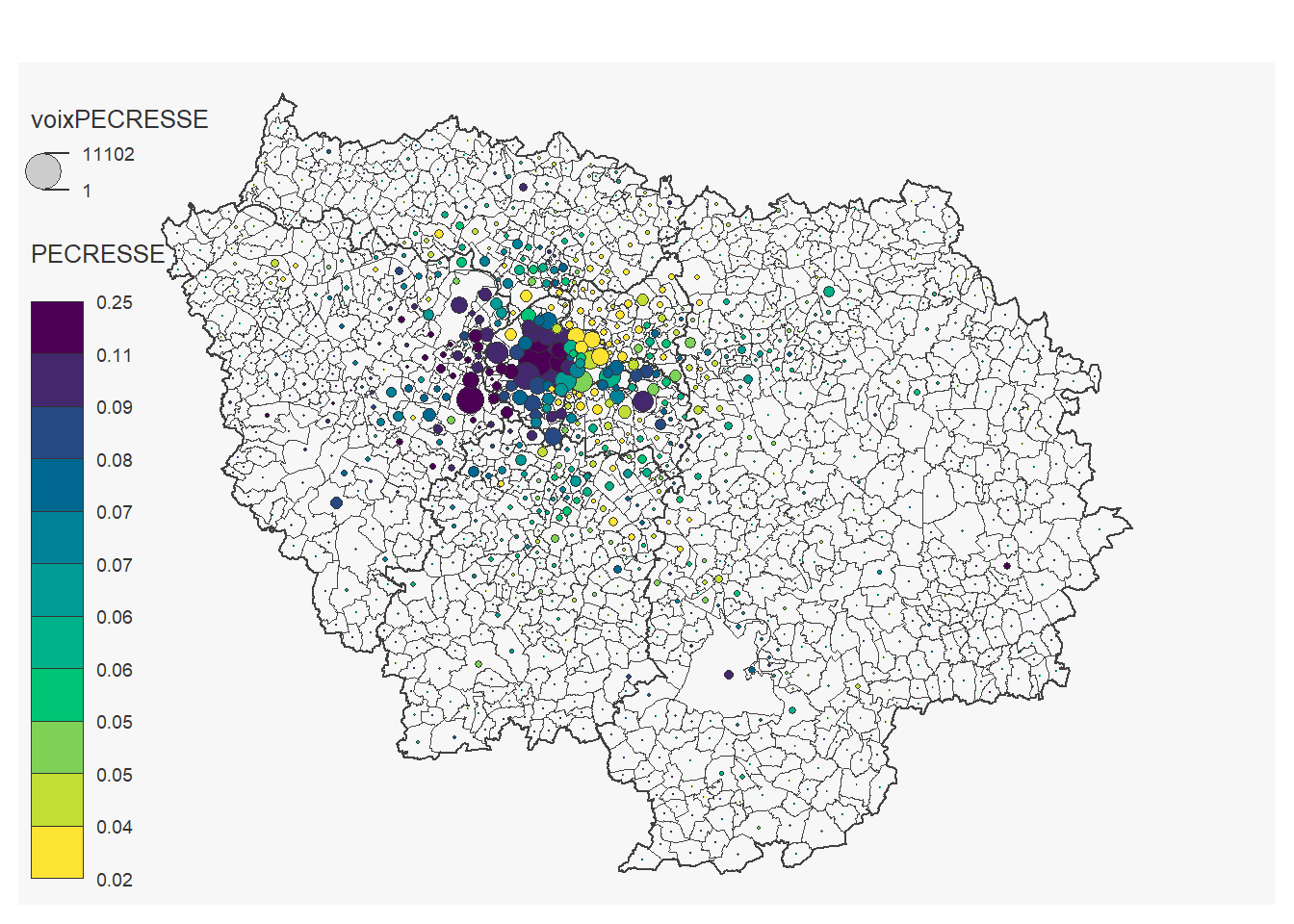
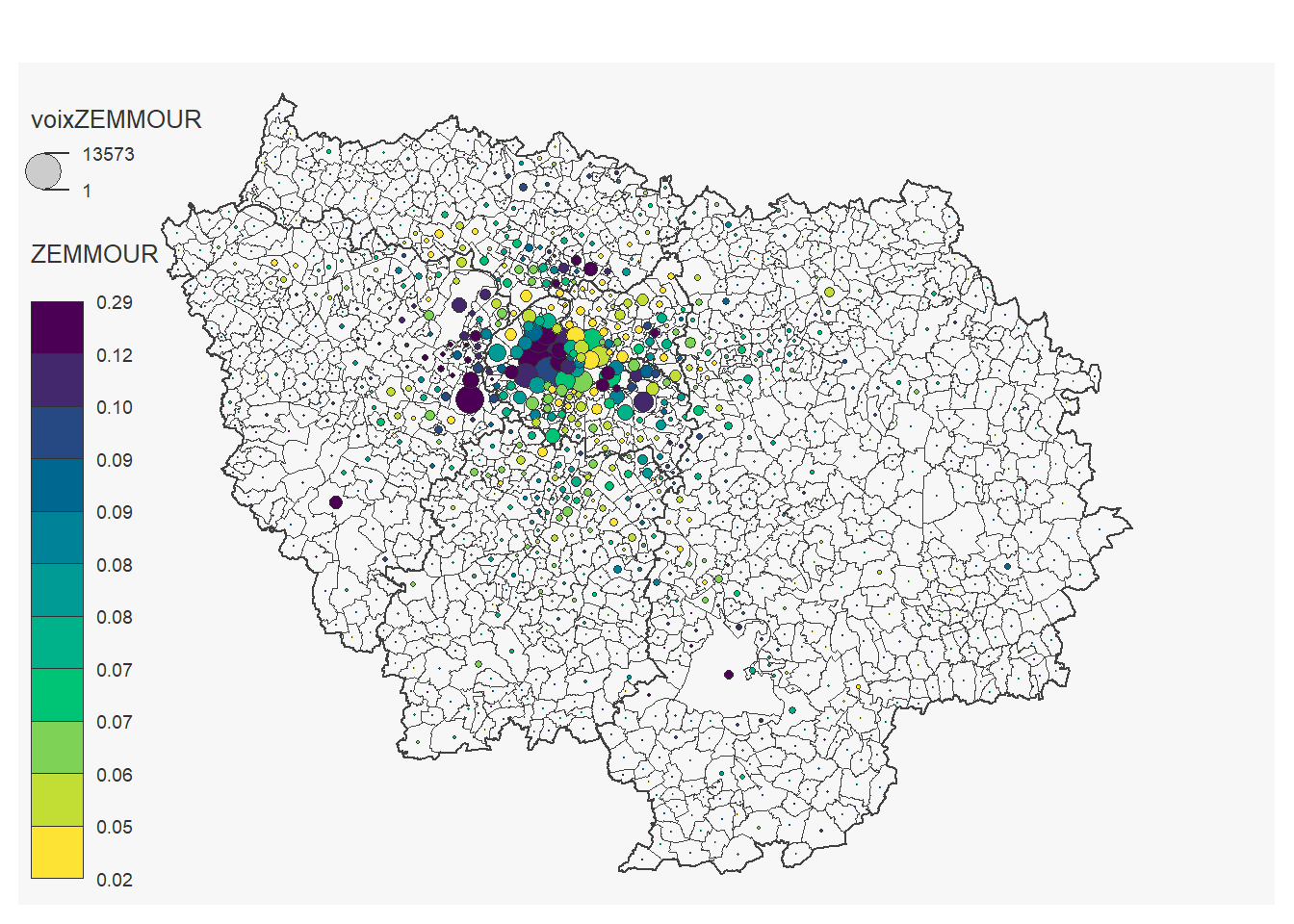
## 19 '0' values are not plotted on the map.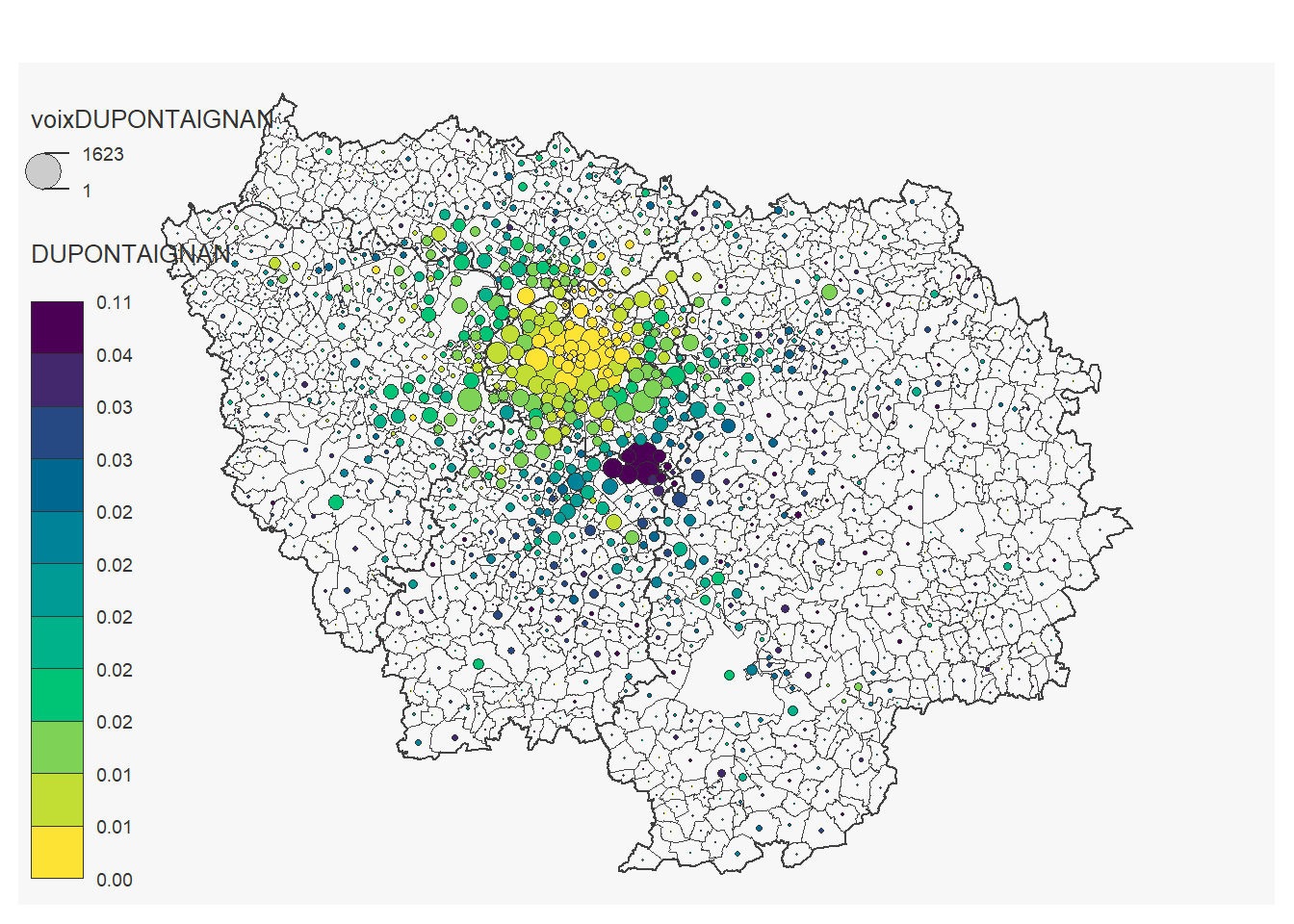
2.3.2 Matrice de corrélation
On peut réaliser une matrice de corrélation:
cor.mat <- round(cor(data[,20:31], use="complete.obs"),2) # round(,2) permet d'arrondir à deux décimale et use="complete.obs" permet d'exclure les NA
cor.mat## ARTHAUD POUTOU ROUSSEL MELENCHON JADOT HIDALGO
## ARTHAUD 1.00 0.09 0.05 0.05 -0.16 -0.04
## POUTOU 0.09 1.00 0.14 0.00 -0.06 -0.03
## ROUSSEL 0.05 0.14 1.00 0.17 -0.01 0.12
## MELENCHON 0.05 0.00 0.17 1.00 -0.15 0.11
## JADOT -0.16 -0.06 -0.01 -0.15 1.00 0.33
## HIDALGO -0.04 -0.03 0.12 0.11 0.33 1.00
## LASSALLE 0.08 0.10 0.01 -0.35 -0.06 -0.07
## MACRON -0.29 -0.24 -0.22 -0.29 0.58 0.20
## PECRESSE -0.13 -0.07 -0.26 -0.54 0.06 -0.11
## ZEMMOUR -0.07 -0.13 -0.27 -0.53 0.10 -0.14
## DUPONTAIGNAN 0.05 0.06 0.09 -0.29 -0.07 -0.11
## MLEPEN 0.20 0.17 0.03 -0.40 -0.54 -0.31
## LASSALLE MACRON PECRESSE ZEMMOUR DUPONTAIGNAN
## ARTHAUD 0.08 -0.29 -0.13 -0.07 0.05
## POUTOU 0.10 -0.24 -0.07 -0.13 0.06
## ROUSSEL 0.01 -0.22 -0.26 -0.27 0.09
## MELENCHON -0.35 -0.29 -0.54 -0.53 -0.29
## JADOT -0.06 0.58 0.06 0.10 -0.07
## HIDALGO -0.07 0.20 -0.11 -0.14 -0.11
## LASSALLE 1.00 -0.17 0.08 0.14 0.16
## MACRON -0.17 1.00 0.25 0.25 -0.16
## PECRESSE 0.08 0.25 1.00 0.32 -0.02
## ZEMMOUR 0.14 0.25 0.32 1.00 -0.01
## DUPONTAIGNAN 0.16 -0.16 -0.02 -0.01 1.00
## MLEPEN 0.31 -0.68 -0.03 -0.03 0.29
## MLEPEN
## ARTHAUD 0.20
## POUTOU 0.17
## ROUSSEL 0.03
## MELENCHON -0.40
## JADOT -0.54
## HIDALGO -0.31
## LASSALLE 0.31
## MACRON -0.68
## PECRESSE -0.03
## ZEMMOUR -0.03
## DUPONTAIGNAN 0.29
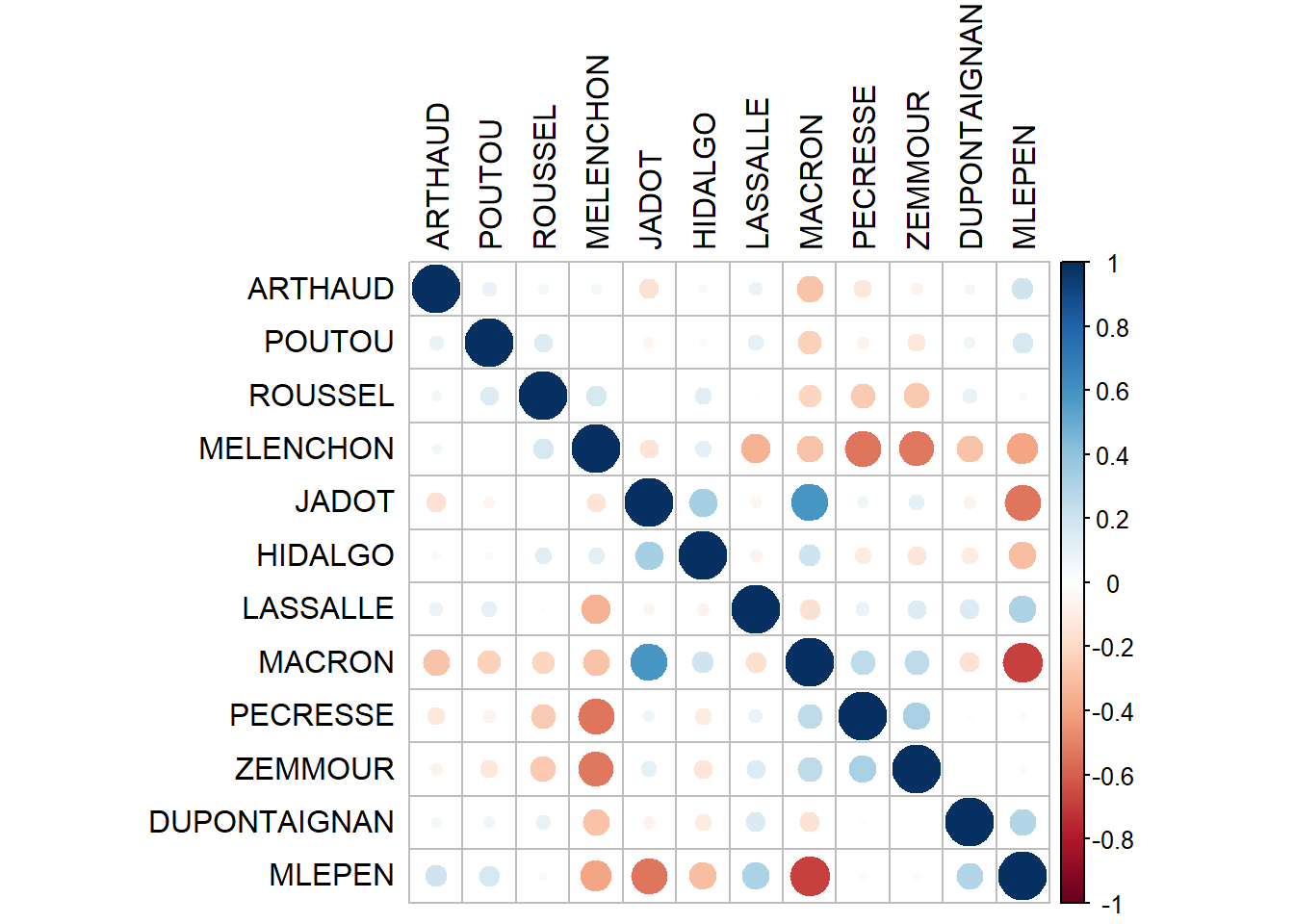
## MLEPEN 1.00Le package corrplot permet de visualiser cette matrice de corrélation de façon plus intuitive:
On peut exporter le résultat avec la fonction png de la façon suivante:
#png(file="TP09/matrice_correlation.png", width = 1000, height = 1000)
corrplot(cor.mat, tl.col="black")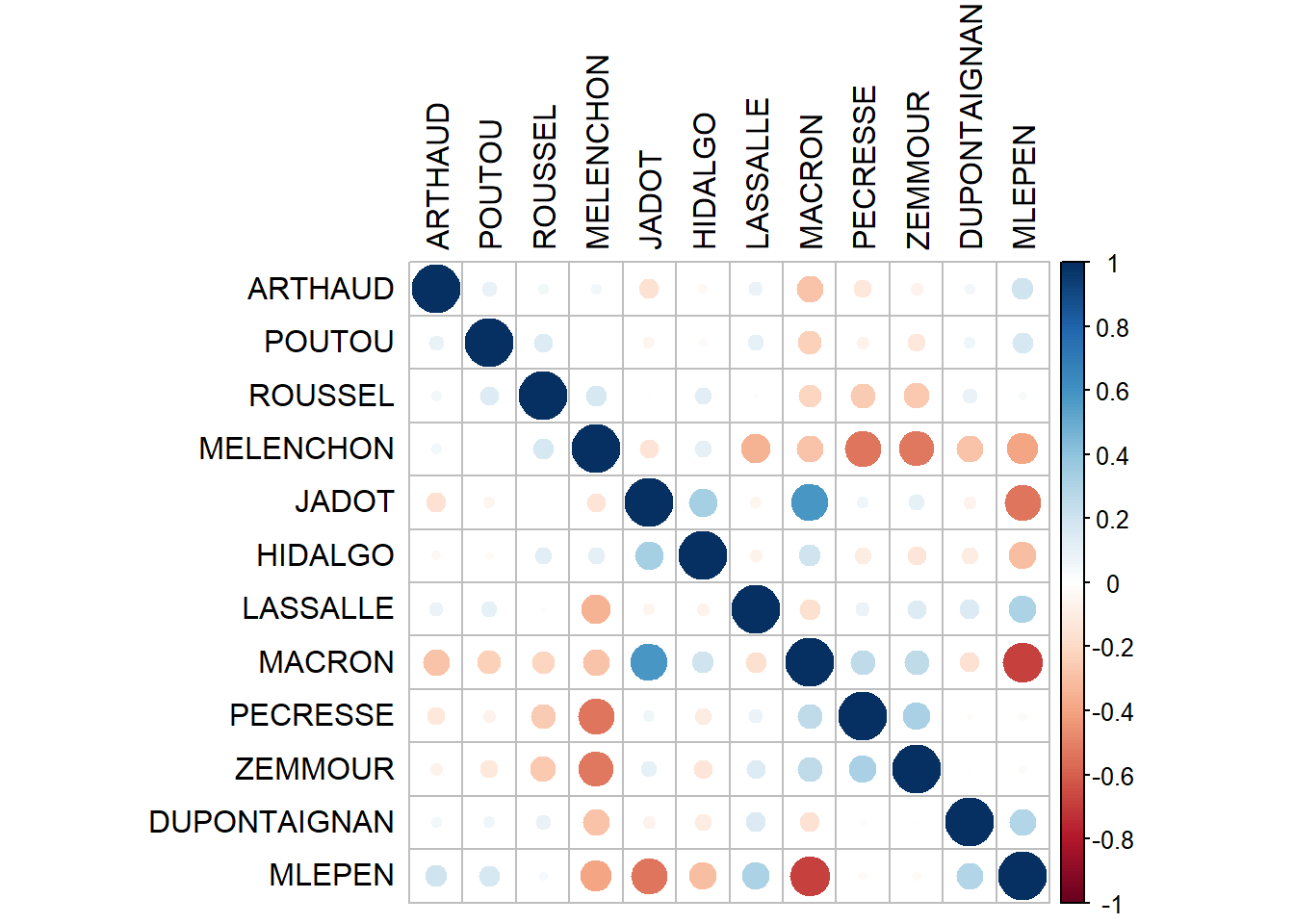
On voit entre autres des corrélations :
positives entre :
le vote pour Hidalgo, Jadot et Macron,
le vote Pécresse, Zemmour et Macron
négative entre:
le vote Marine Le Pen et le vote Jadot-Macron
le vote Mélanchon et le vote Pecresse-Zemmour
Très peu de corrélation entre les vote Zemmour et Marine Lepene.
2.4 Réaliser l’ACP
2.4.1 Une ACP non pondérée
L’objet pca est une liste dans lequel se trouve tous les résultats de l’ACP. On peut y accéder directement ou utiliser des fonctions préfaites pour visualiser les résultats:
# name description
# 1 "$eig" "eigenvalues"
# 2 "$var" "results for the variables"
# 3 "$var$coord" "coord. for the variables"
# 4 "$var$cor" "correlations variables - dimensions"
# 5 "$var$cos2" "cos2 for the variables"
# 6 "$var$contrib" "contributions of the variables"
# 7 "$ind" "results for the individuals"
# 8 "$ind$coord" "coord. for the individuals"
# 9 "$ind$cos2" "cos2 for the individuals"
# 10 "$ind$contrib" "contributions of the individuals"
# 11 "$call" "summary statistics"
# 12 "$call$centre" "mean of the variables"
# 13 "$call$ecart.type" "standard error of the variables"
# 14 "$call$row.w" "weights for the individuals"
# 15 "$call$col.w" "weights for the variables"2.4.2 Pondérer le calcul de l’ACP
Dans le cas précédent chacuns des individus à le même poid et chaque variable également. On peut décider de modifier les poids.
Pourtant, il existe de grandes différences entre communes:
# mf_export(x = communes_voix ,
# filename =paste0("TP09/cartes_votes_exprimes.png" ),
# width = 900)
mf_map(x = communes_voix, col = NA, border = "gray25", lwd = 0.1)
mf_map(x = departements_Paris, col = NA, border = "gray25", lwd = 1, add=T)
mf_map(communes_voix ,
var= "exprimes",
type="prop",
inches=0.1,
add=T)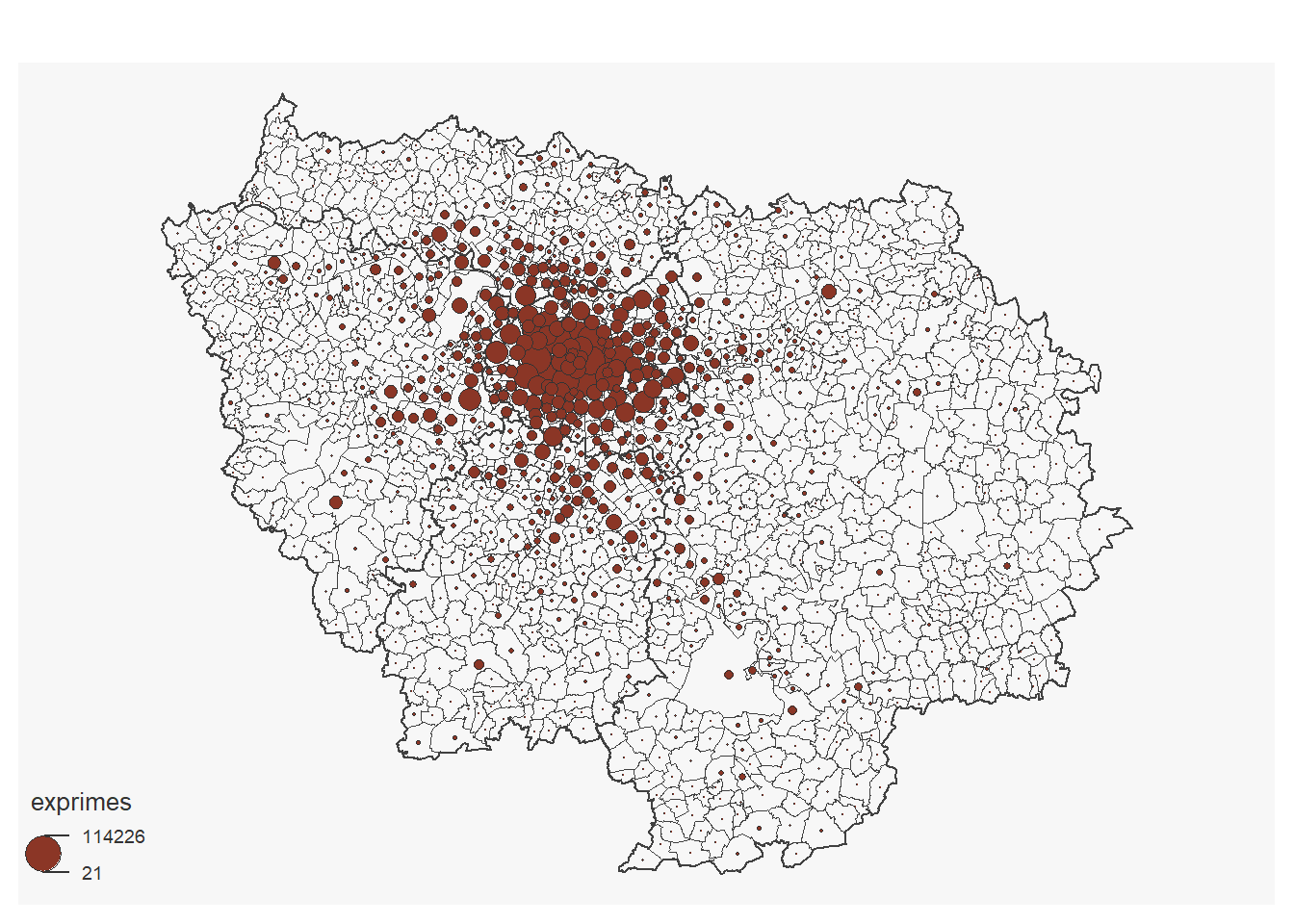
Si on souhaite pondérer les entités on peut utiliser “row.w =”:
Pour pondérer les variables on peut utiliser col.w Attention: pour pondérer, il faut que tous les poids soient >0. Dans le cas présent ça ne pose pas de problème.
2.5 Visualiser les résultats
2.5.1 Cercles de corrélation
Ce résultat sont stocker dans l’objet pca:
## Dim.1 Dim.2 Dim.3
## ARTHAUD 0.75783970 0.193700662 0.053886556
## POUTOU 0.70415312 0.004765184 0.418058777
## ROUSSEL 0.66687033 -0.124984377 0.299327347
## MELENCHON 0.74370403 -0.538863968 -0.340415783
## JADOT -0.45229731 -0.533488252 0.663311687
## HIDALGO -0.10246245 -0.687312206 0.620349032
## LASSALLE 0.07686699 0.764044366 0.449976355
## MACRON -0.94011924 -0.048504652 0.166318959
## PECRESSE -0.88585300 0.321419606 -0.009943942
## ZEMMOUR -0.79129943 0.372205374 -0.100007056
## DUPONTAIGNAN 0.19419953 0.681063286 0.357058840
## MLEPEN 0.45088539 0.809295495 0.102917819
## Dim.4 Dim.5 Dim.6
## ARTHAUD -0.33202051 0.22476966 -0.270976655
## POUTOU -0.07460159 0.23692366 0.499863557
## ROUSSEL 0.62640195 0.14923271 -0.131302409
## MELENCHON -0.02007377 -0.09595007 0.007735581
## JADOT -0.03924331 -0.01890221 -0.069747306
## HIDALGO -0.17878940 -0.04634065 -0.040984394
## LASSALLE -0.03134172 0.14026444 -0.191952534
## MACRON 0.02380460 0.02352660 -0.043682377
## PECRESSE 0.04293183 0.14109764 0.017812438
## ZEMMOUR 0.06375980 0.19413646 0.158100636
## DUPONTAIGNAN 0.04326915 -0.55375208 0.082126654
## MLEPEN -0.06620236 0.04182531 -0.004296971
## Dim.7 Dim.8 Dim.9
## ARTHAUD 0.38461093 -0.05343325 -0.0045179775
## POUTOU 0.02458871 -0.12931404 -0.0007009491
## ROUSSEL 0.12543543 0.02976306 -0.0269964797
## MELENCHON -0.03917968 -0.02553644 0.1644913917
## JADOT 0.01101491 -0.04680005 -0.0019169799
## HIDALGO -0.01196939 0.24982650 0.0054539159
## LASSALLE -0.29553028 -0.08181916 0.2339225539
## MACRON 0.04938810 -0.18414230 -0.1216818436
## PECRESSE 0.11278338 -0.11425240 -0.0094676328
## ZEMMOUR 0.20993077 0.27169444 0.1793777244
## DUPONTAIGNAN 0.22599626 -0.03151295 0.0577028315
## MLEPEN -0.15138365 0.19561196 -0.2456237780
## Dim.10 Dim.11 Dim.12
## ARTHAUD -0.008370156 -0.0140271624 3.282270e-10
## POUTOU 0.015475982 -0.0156209607 3.891439e-10
## ROUSSEL 0.028203308 -0.0056358853 1.336890e-09
## MELENCHON 0.010914950 0.0401760796 2.360485e-08
## JADOT -0.225853682 0.1036719950 3.831603e-09
## HIDALGO 0.183340122 -0.0166654983 1.030643e-09
## LASSALLE 0.025984130 -0.0303200827 9.593980e-10
## MACRON 0.031798367 -0.1759761971 1.521580e-08
## PECRESSE 0.152069481 0.2019841257 5.393004e-09
## ZEMMOUR -0.079291052 -0.0469535055 5.553946e-09
## DUPONTAIGNAN 0.017115750 0.0000869299 1.563518e-09
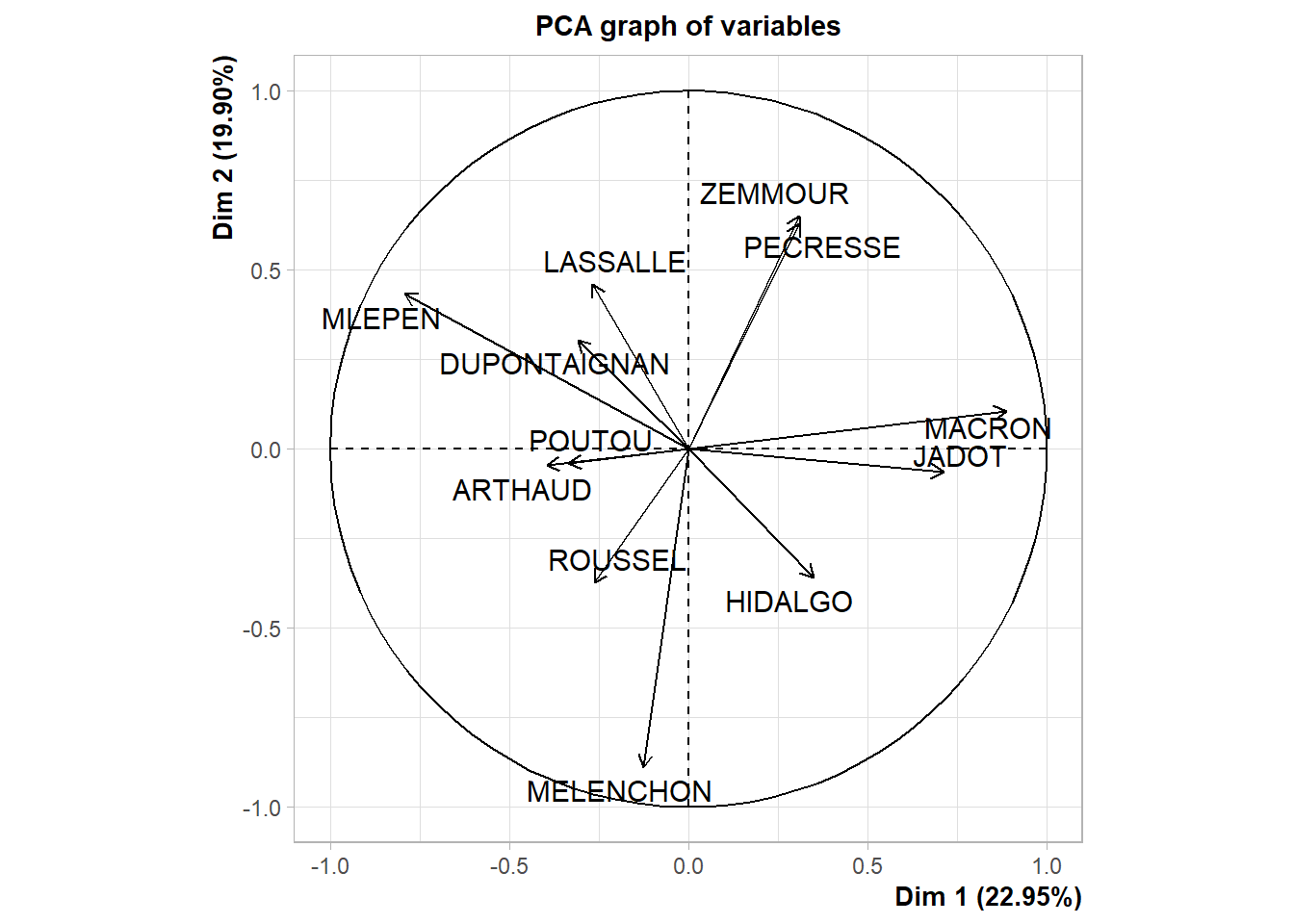
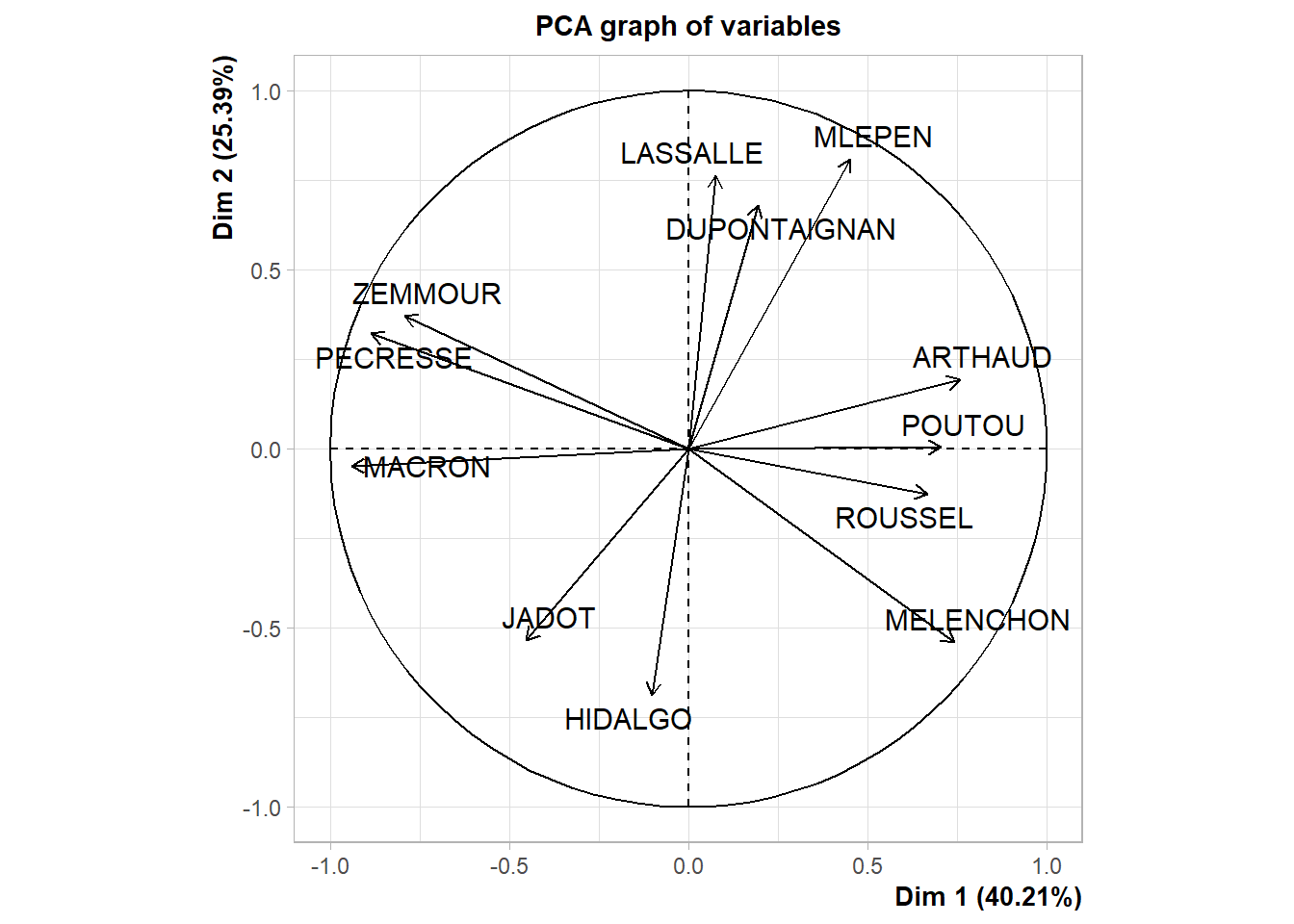
## MLEPEN -0.040599884 0.0428961375 1.323804e-08Les cercle de corrélation permettent de visualiser entre les variables et les dimensions produites par l’ACP.
#ggsave(cercle_1_2,filename="TP09/cercle_correlation_1_2.png", width=7, height=7, bg="white")
#rm(cercle_1_2)On peut décider de visualiser d’autres axes en modifiant le paramètre axes:
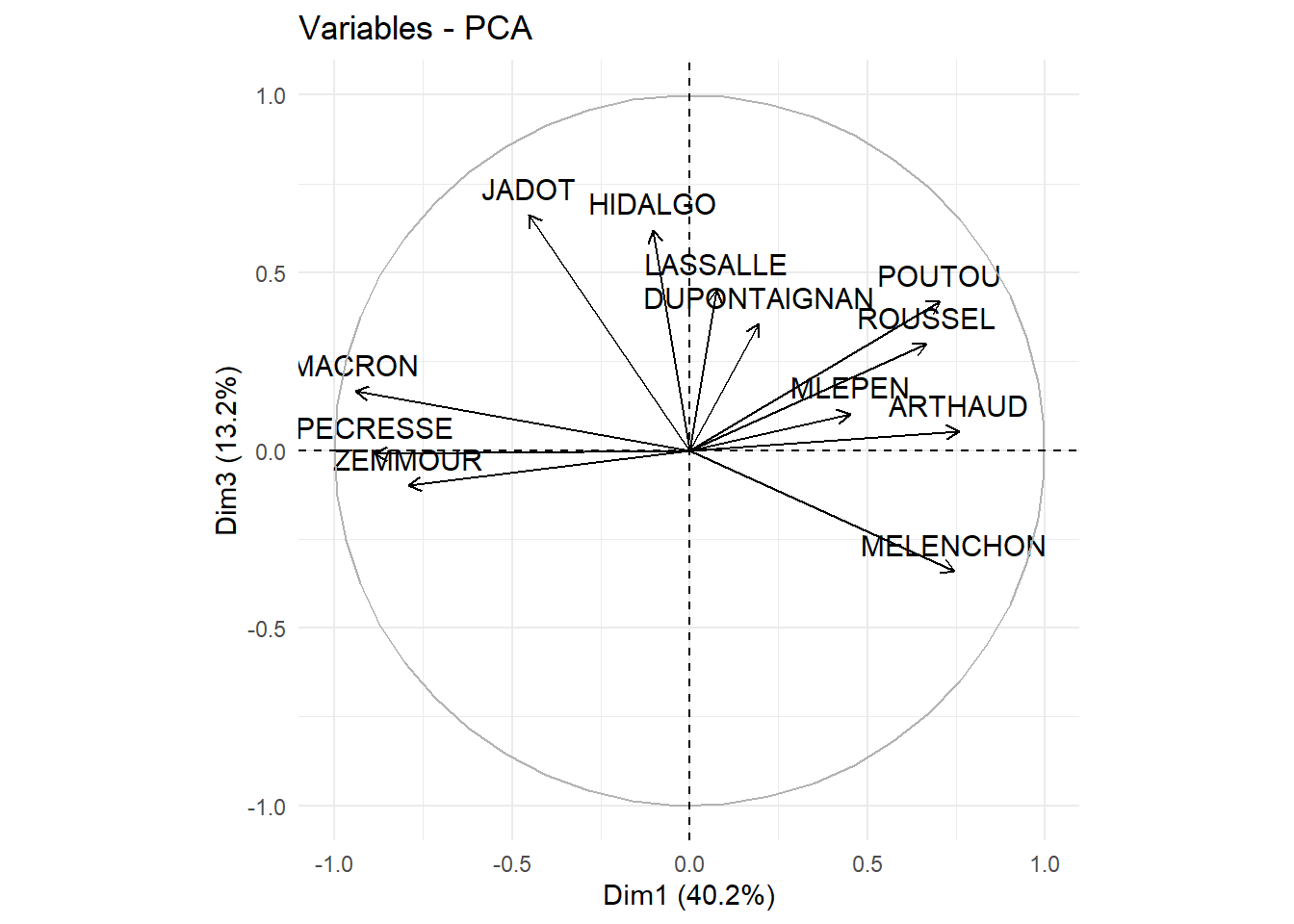
#ggsave(cercle_1_3,filename="TP09/cercle_correlation_1_3.png", width=7, height=7, bg="white")
#rm(cercle_1_3)Pour faciliter la lecture, on peut inverser un axe en multipliant par -1 (dans notre cas, il est plus intuitif d’avoir la gauche politique à gauche et la droite à droite):
pca$var$coord[,1]<- -1*pca$var$coord[,1]
cercle_1_2<-fviz_pca_var(pca, axes = c(1, 2) )+
theme_minimal()
cercle_1_2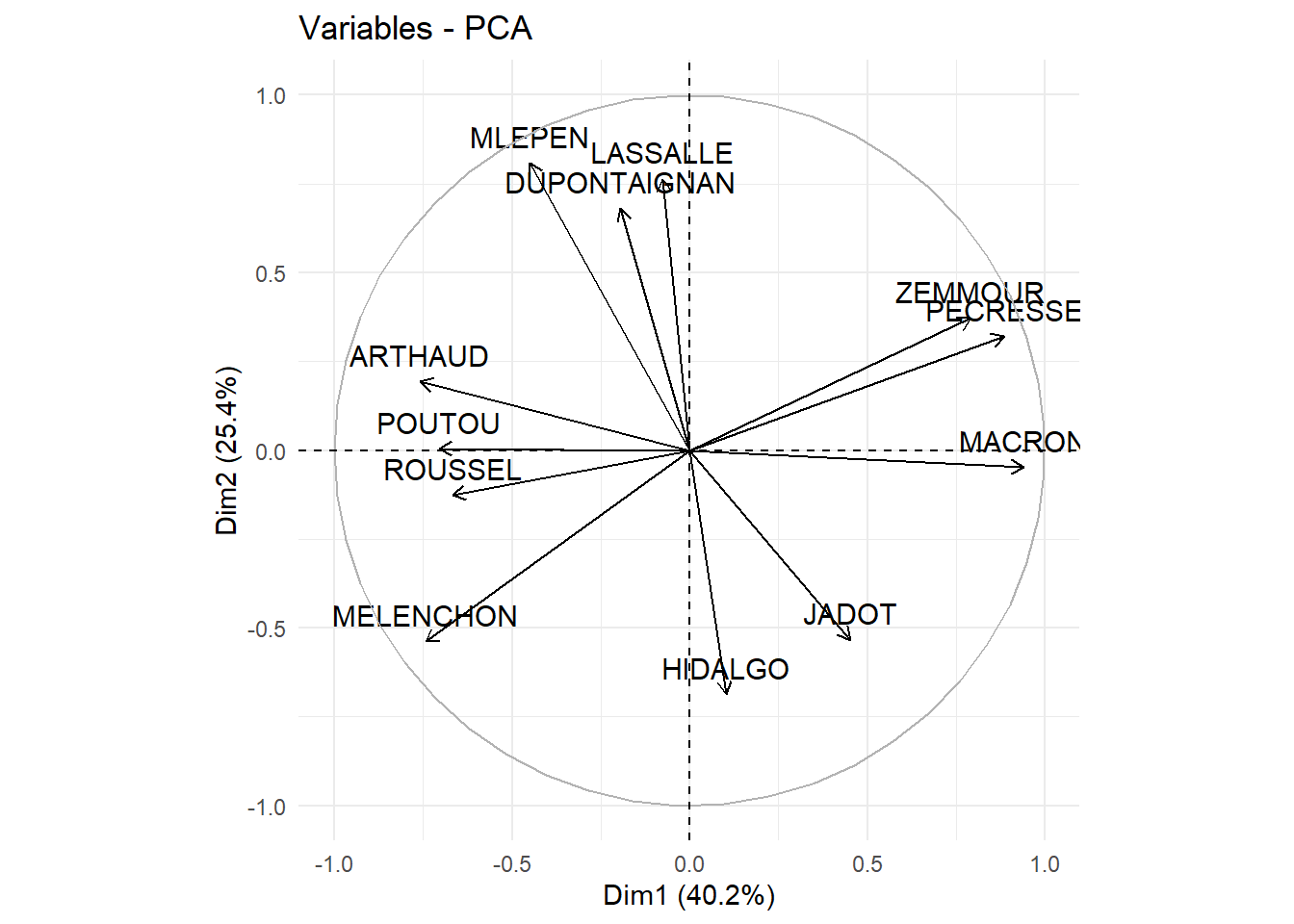
Il faut alors aussi le faire sur les coordonnées des individus:
On peut décider de ne pas afficher toutes les variables (si il y en a trop ça devient illisible). Ici, on décide d’afficher surtout (en modifiant la tranparance) celles qui ont le plus contribué à la construction de les deux axes (alpha.var=“contrib”) ou celle qui sont le plus prise en compte par les deux axes (alpha.var=“cos2”), soit encore de sélectionner celles qui ont un cos2 supérieur à un seuil (select.var = list(cos2 = 0.75) ) ou les 3 qui contribuent le plus (select.var = list(contrib = 3))):
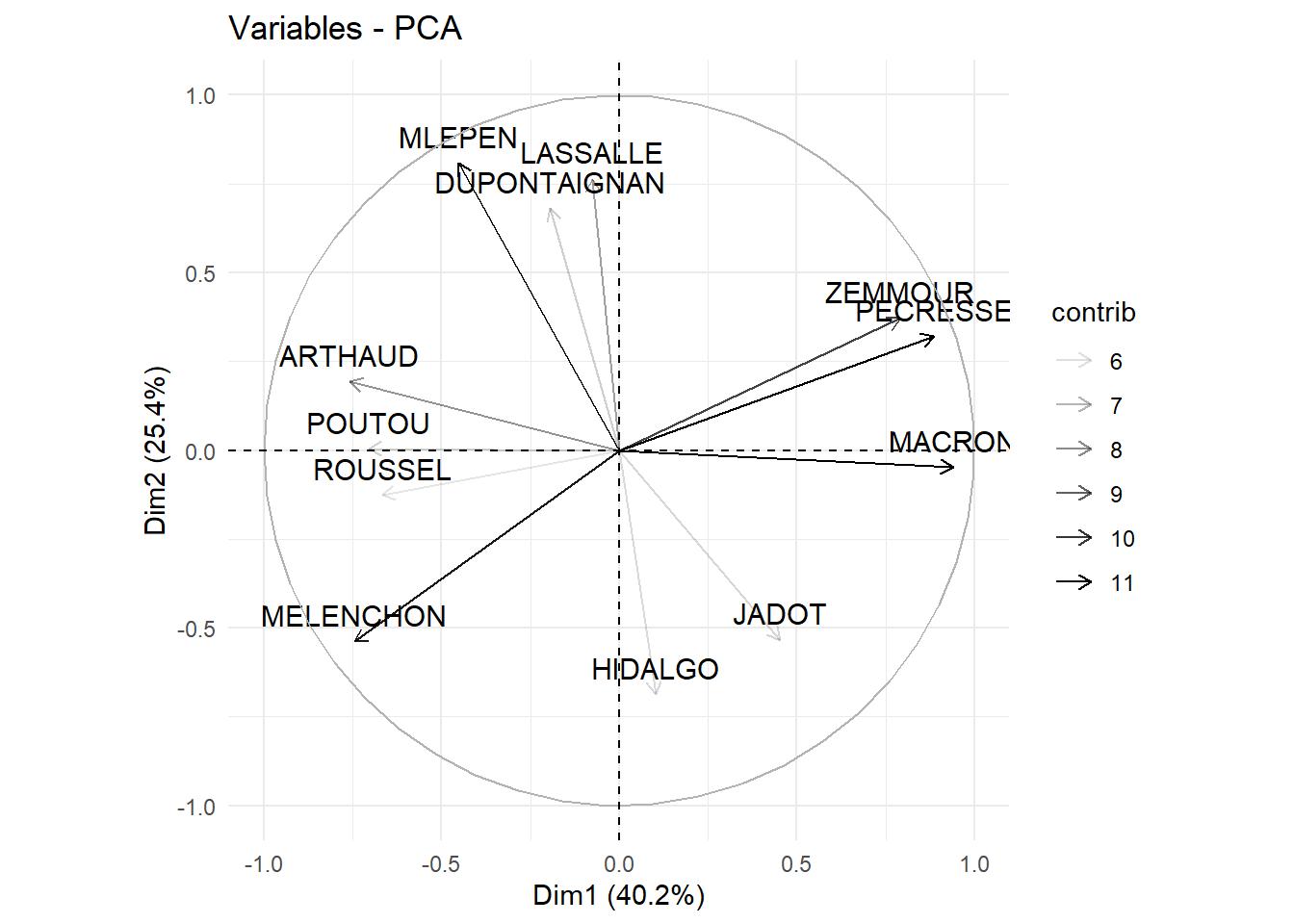
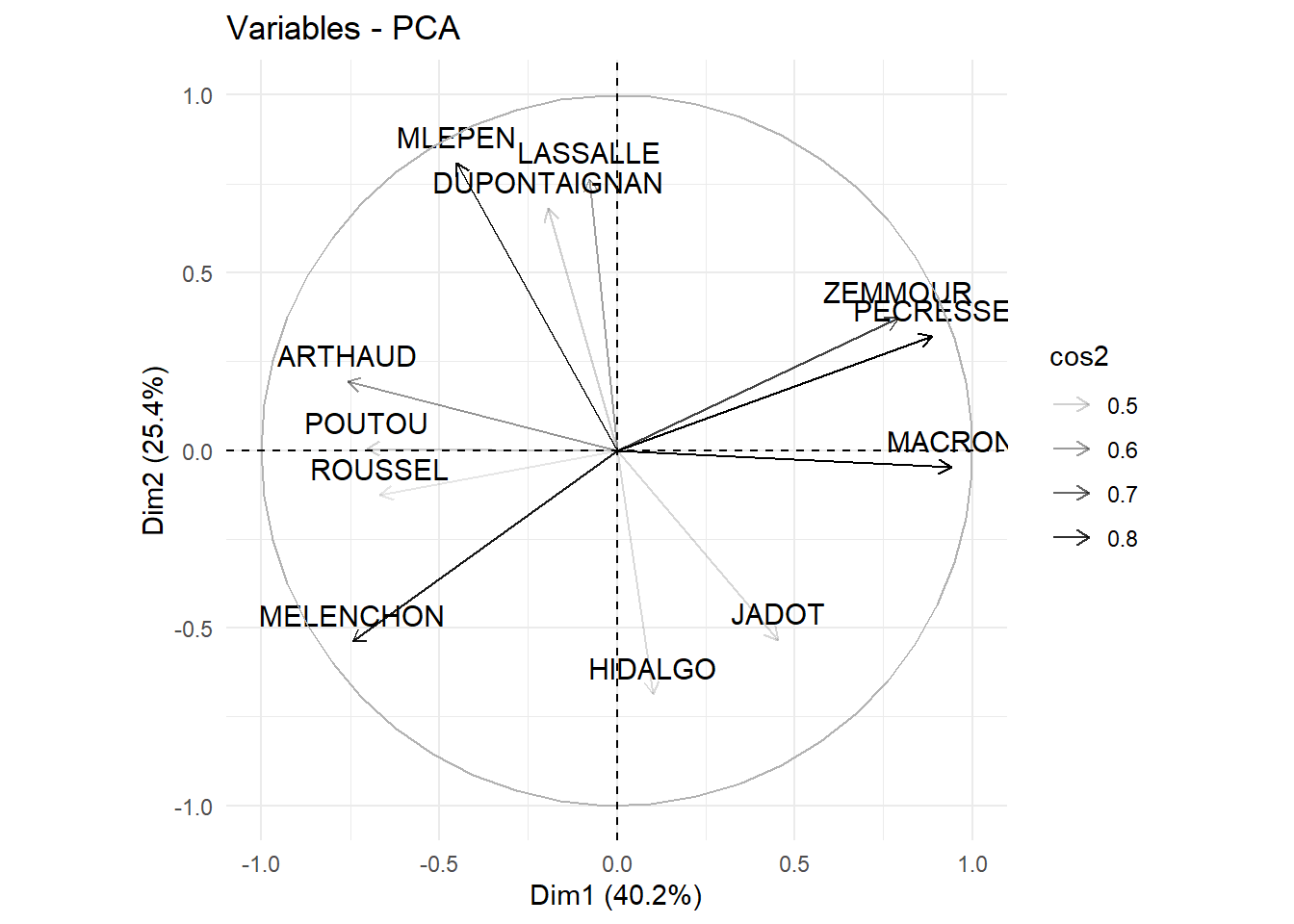
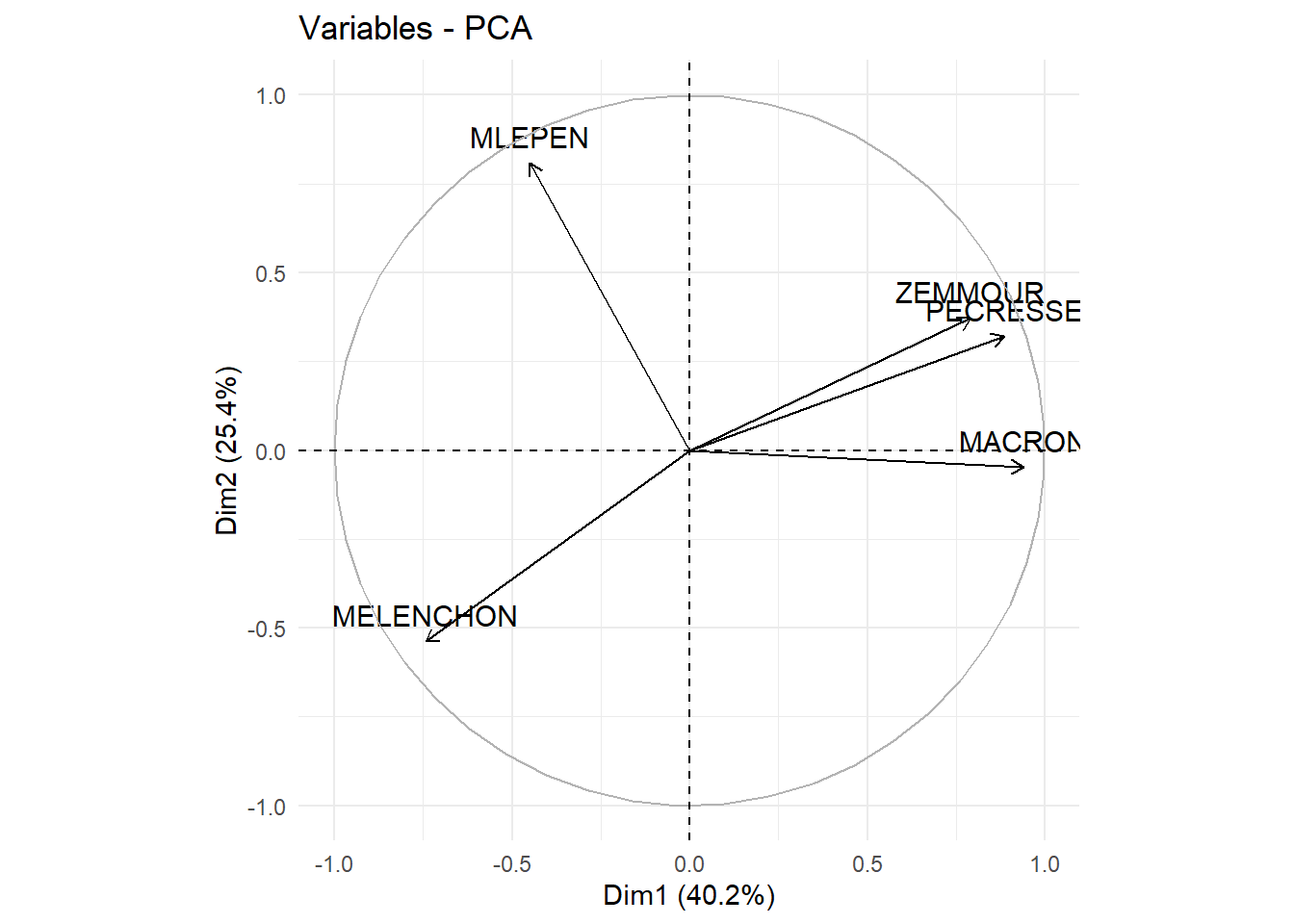
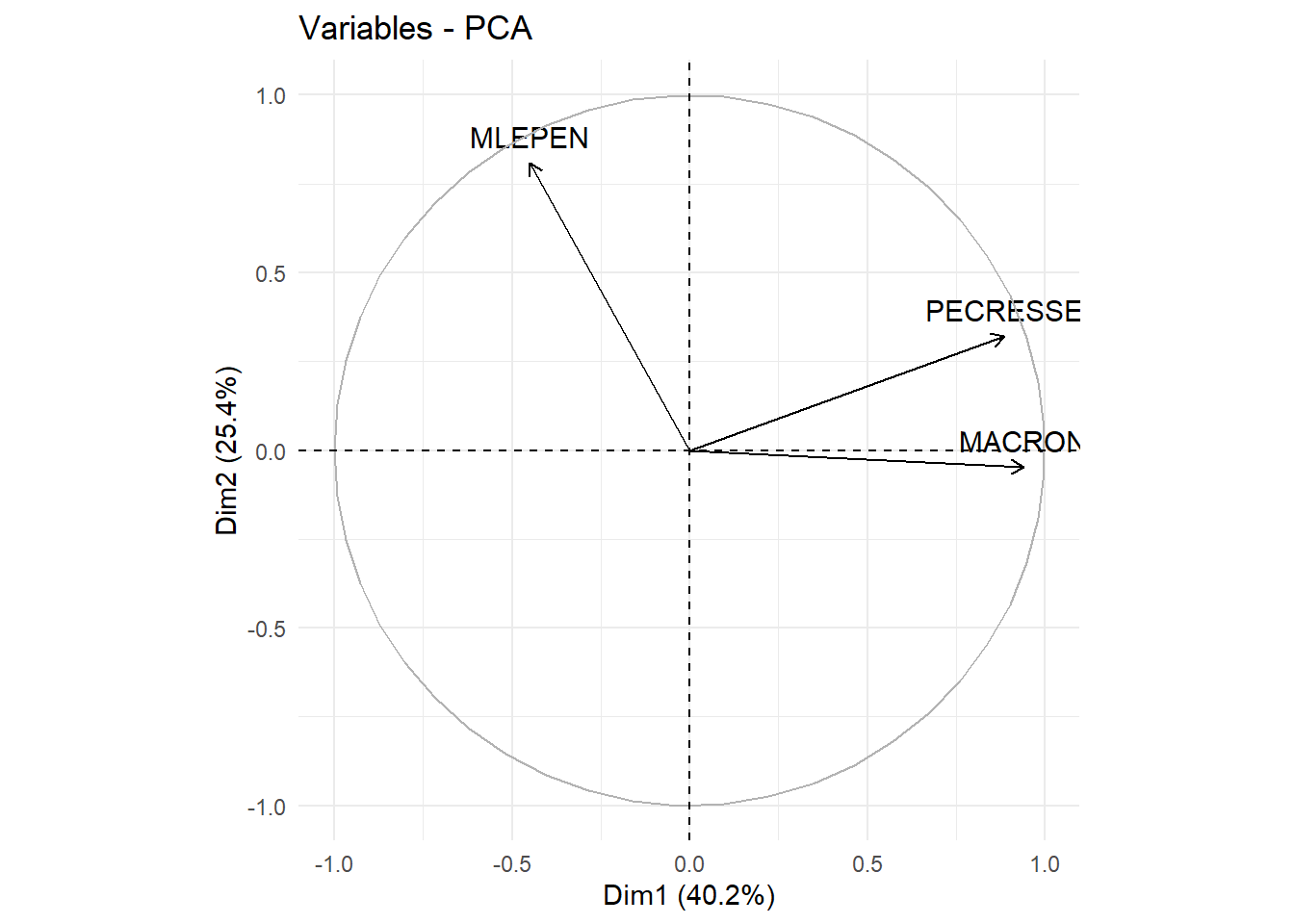
Il est peut aussi être pertinent d’utiliser l’argument repel=T pour utiliser le package repel pour les étiquettes et éviter qu’elle ne se chevauches:
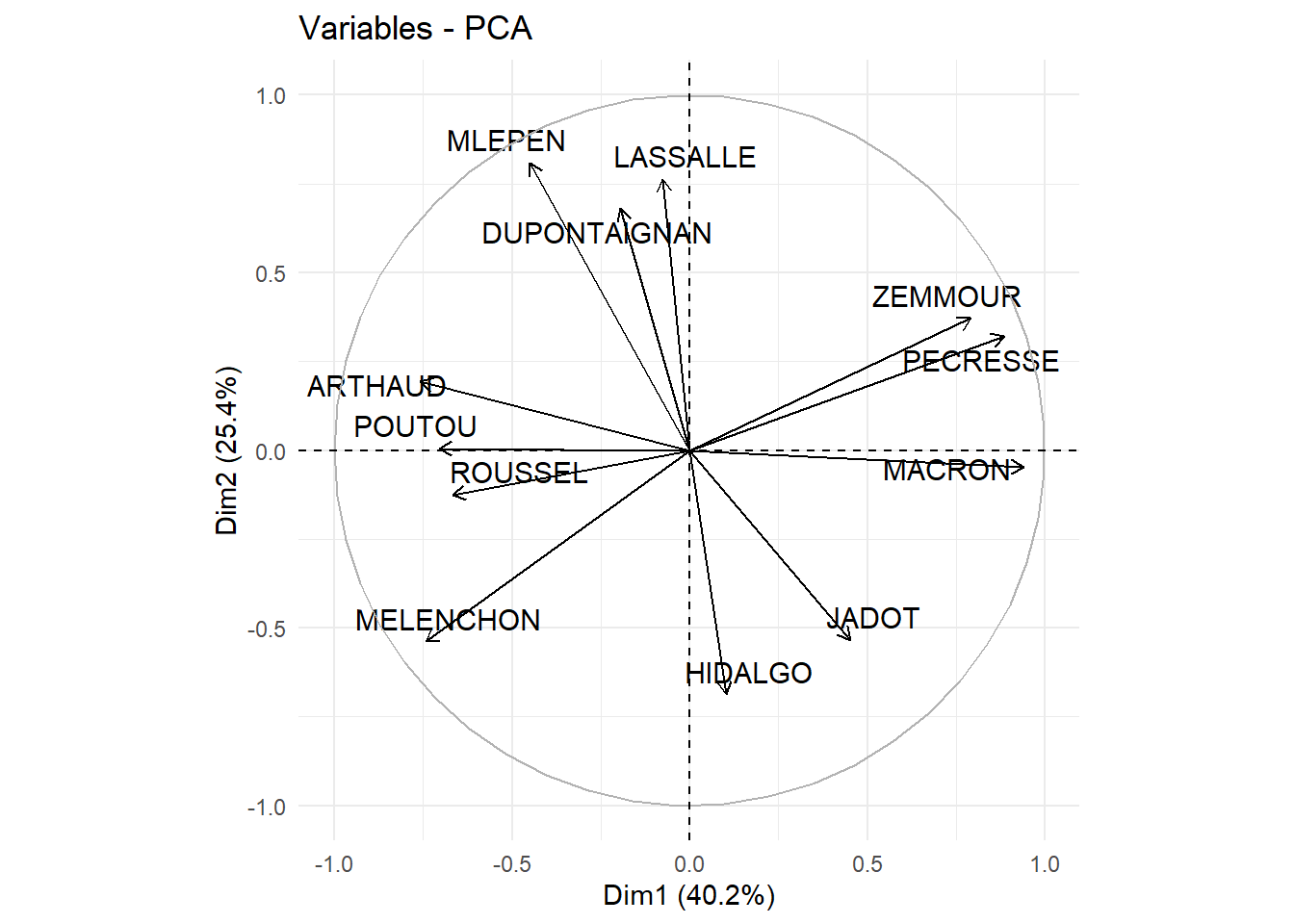
2.5.2 Contributions de chaque variables
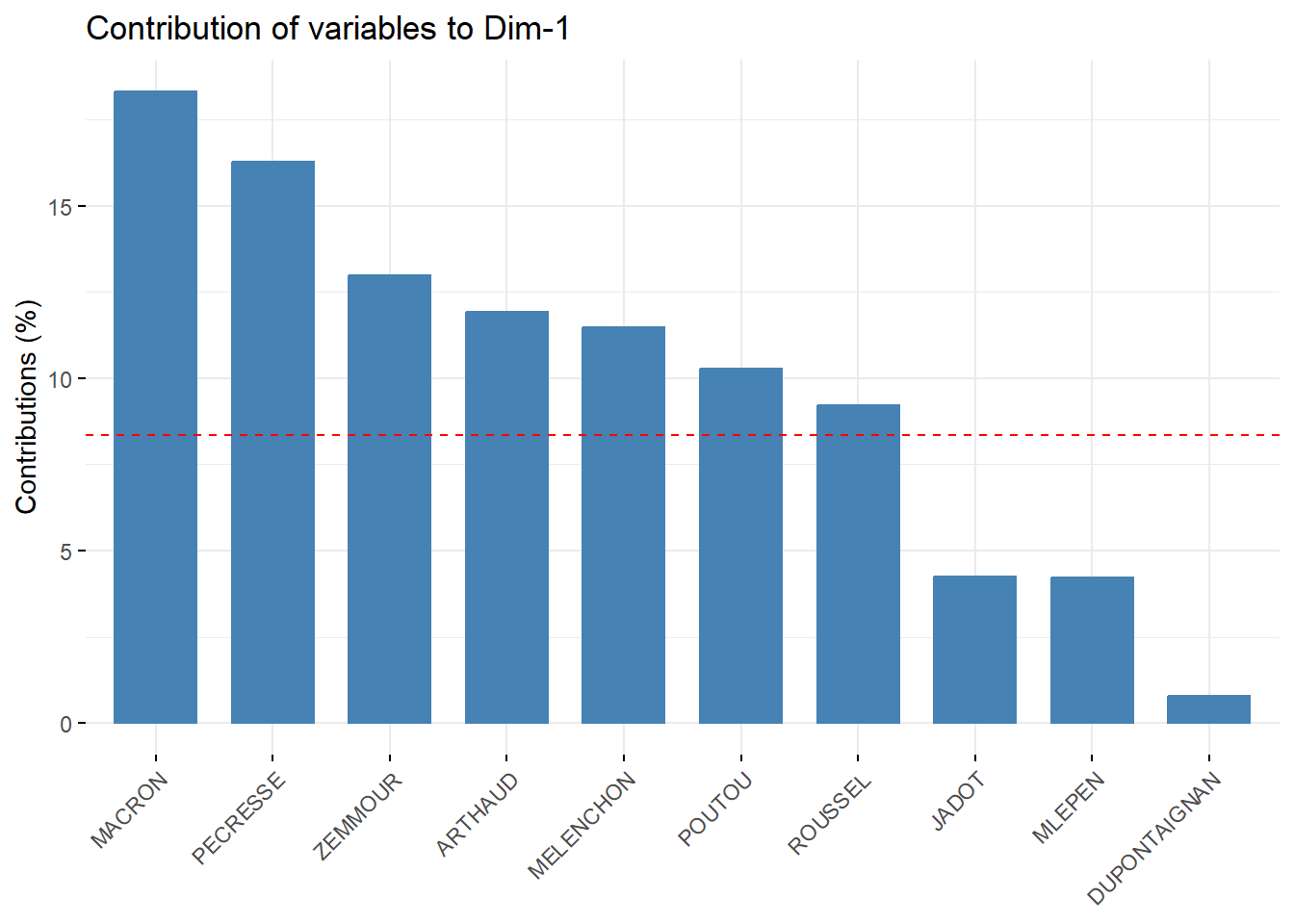
La contribution de chaque variable à la construction de chacune de dimension:
## Dim.1 Dim.2 Dim.3
## ARTHAUD 11.9038406 1.231246e+00 0.183052896
## POUTOU 10.2770061 7.451467e-04 11.017687192
## ROUSSEL 9.2175433 5.126181e-01 5.648180142
## MELENCHON 11.4639072 9.528856e+00 7.305250657
## JADOT 4.2401420 9.339684e+00 27.736460944
## HIDALGO 0.2176015 1.550210e+01 24.259841866
## LASSALLE 0.1224650 1.915665e+01 12.764245064
## MACRON 18.3188531 7.720568e-02 1.743810408
## PECRESSE 16.2650617 3.390215e+00 0.006233513
## ZEMMOUR 12.9781893 4.546192e+00 0.630488306
## DUPONTAIGNAN 0.7816796 1.522150e+01 8.037025154
## MLEPEN 4.2137107 2.149298e+01 0.667723858
## Dim.4 Dim.5 Dim.6
## ARTHAUD 19.83392132 9.58930308 17.567987257
## POUTOU 1.00132471 10.65438844 59.780728472
## ROUSSEL 70.59679126 4.22707266 4.124807104
## MELENCHON 0.07249975 1.74743980 0.014316739
## JADOT 0.27708309 0.06781672 1.163893177
## HIDALGO 5.75125091 0.40760167 0.401878970
## LASSALLE 0.17673574 3.73427942 8.815479728
## MACRON 0.10195308 0.10505823 0.456531526
## PECRESSE 0.33161753 3.77877609 0.075911050
## ZEMMOUR 0.73142974 7.15362007 5.980334606
## DUPONTAIGNAN 0.33684917 58.20260409 1.613713804
## MLEPEN 0.78854370 0.33203971 0.004417566
## Dim.7 Dim.8 Dim.9 Dim.10
## ARTHAUD 38.26088046 1.1309610 1.056017e-02 0.05892929
## POUTOU 0.15638066 6.6239329 2.541885e-04 0.20145614
## ROUSSEL 4.06960429 0.3508970 3.770484e-01 0.66905864
## MELENCHON 0.39703930 0.2583124 1.399810e+01 0.10020919
## JADOT 0.03138149 0.8675954 1.901157e-03 42.90604037
## HIDALGO 0.03705574 24.7230208 1.538862e-02 28.27347030
## LASSALLE 22.58997116 2.6517620 2.830917e+01 0.56791122
## MACRON 0.63089386 13.4317208 7.660100e+00 0.85049882
## PECRESSE 3.29004564 5.1707694 4.637305e-02 19.45128139
## ZEMMOUR 11.39892589 29.2405834 1.664638e+01 5.28825575
## DUPONTAIGNAN 13.21034744 0.3933712 1.722571e+00 0.24640866
## MLEPEN 5.92747407 15.1570737 3.121215e+01 1.38648022
## Dim.11 Dim.12
## ARTHAUD 2.190093e-01 0.01030897
## POUTOU 2.716054e-01 0.01449063
## ROUSSEL 3.535471e-02 0.17102445
## MELENCHON 1.796628e+00 53.31743705
## JADOT 1.196316e+01 1.40484268
## HIDALGO 3.091431e-01 0.10164445
## LASSALLE 1.023255e+00 0.08807739
## MACRON 3.446917e+01 22.15420622
## PECRESSE 4.541062e+01 2.78309654
## ZEMMOUR 2.453912e+00 2.95168558
## DUPONTAIGNAN 8.411265e-06 0.23392274
## MLEPEN 2.048139e+00 16.76926331On peut également afficher de façon graphique avec fviz_contrib:
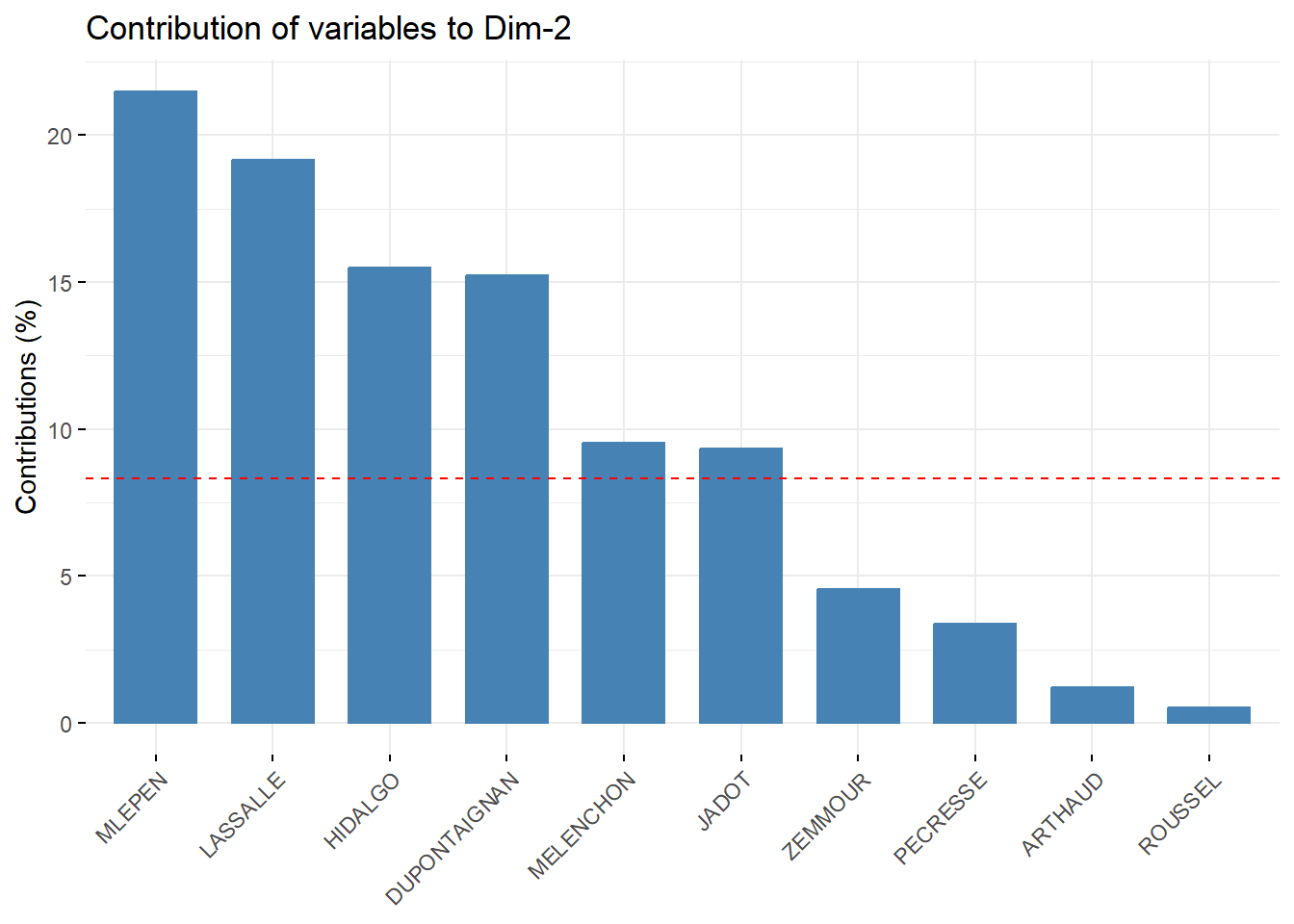
2.5.3 Valeurs propres et % de la variance expliquée
Pour afficher les valeurs propres (eigen value) et le pourcentage de variance expliquée, on peut simplement afficher le tableau compris dans l’objet pca
## eigenvalue percentage of variance
## comp 1 4.824670e+00 4.020558e+01
## comp 2 3.047316e+00 2.539430e+01
## comp 3 1.586296e+00 1.321913e+01
## comp 4 5.558034e-01 4.631695e+00
## comp 5 5.268516e-01 4.390430e+00
## comp 6 4.179668e-01 3.483056e+00
## comp 7 3.866235e-01 3.221863e+00
## comp 8 2.524500e-01 2.103750e+00
## comp 9 1.932934e-01 1.610779e+00
## comp 10 1.188874e-01 9.907285e-01
## comp 11 8.984151e-02 7.486793e-01
## comp 12 1.045041e-15 8.708673e-15
## cumulative percentage of variance
## comp 1 40.20558
## comp 2 65.59988
## comp 3 78.81902
## comp 4 83.45071
## comp 5 87.84114
## comp 6 91.32420
## comp 7 94.54606
## comp 8 96.64981
## comp 9 98.26059
## comp 10 99.25132
## comp 11 100.00000
## comp 12 100.00000On peut faire un graphique de la variance expliquées:
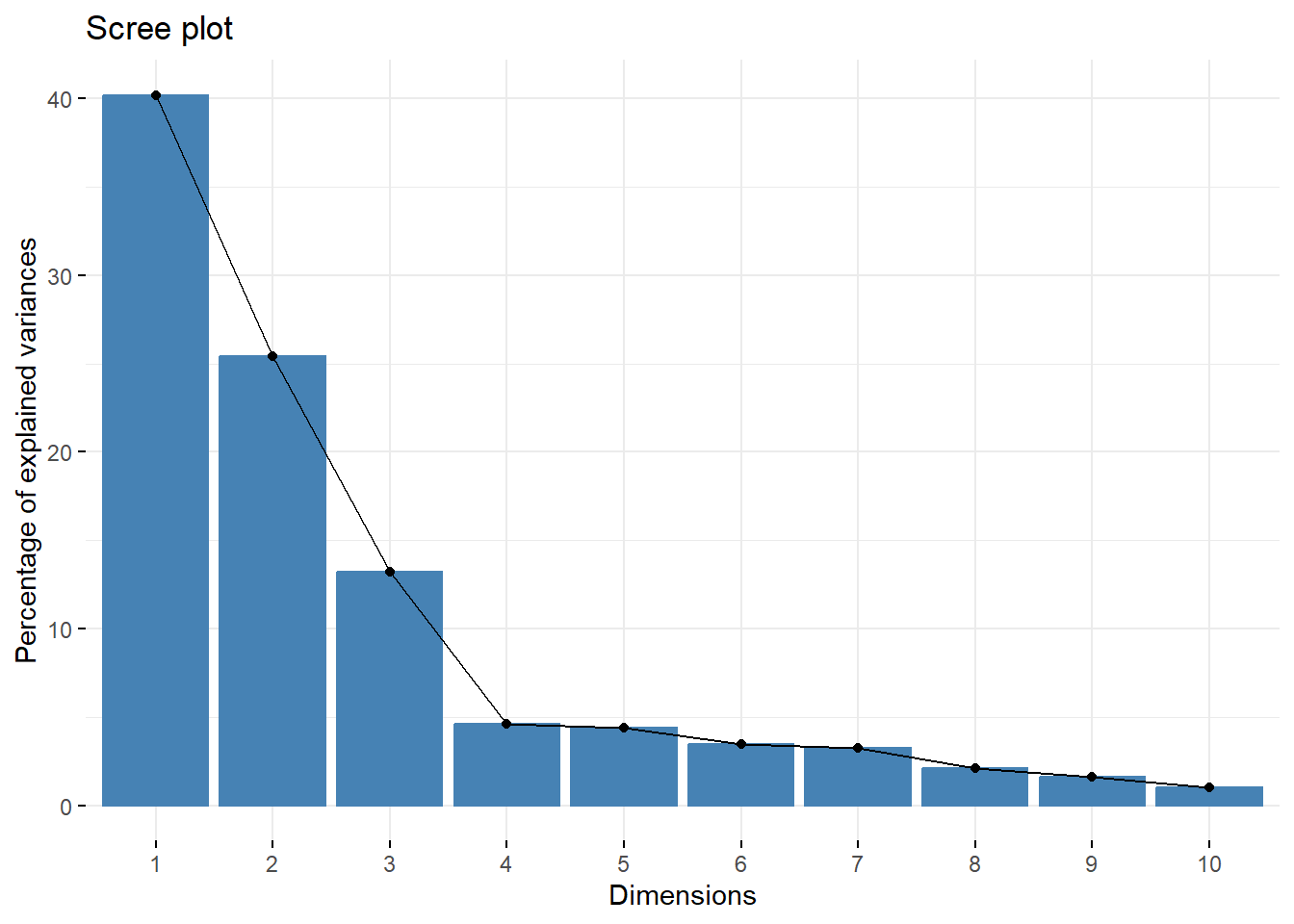
Ces informations sont utiles pour nous aider à décider combien de composante retenir. Généralement, on s’arrange avec ces règles non-strictes: - eigenvalue > 1 - variance cumulée > 70% - gain faible d’une composante supplémentaire (ajouter une dimension supplémentaire ne permet pas de gagner beaucoup en variance expliquée)
2.5.4 Carte de scores
Chaque individus est reprojeter sur les nouvelles dimensions. Leurs scores sont stocké dans l’objet pca:
## Dim.1 Dim.2 Dim.3 Dim.4 Dim.5
## 1 3.067555 -1.7114152 0.08150264 -0.185735850 -0.41247012
## 2 2.511828 -2.7064534 0.70245008 -0.193923389 -0.70891924
## 3 2.031107 -3.0966114 1.07311078 -0.404287195 -0.18691460
## 4 2.201343 -2.4124210 1.18680228 -0.001301227 -0.20907736
## 5 1.991101 -2.2577563 1.02941720 -0.014047196 -0.02204558
## 6 3.955340 -0.8826657 -0.20675170 0.106337247 0.01854102
## Dim.6 Dim.7 Dim.8 Dim.9 Dim.10
## 1 -0.1498315 -0.31386218 0.51897558 -0.4392267 0.16799431
## 2 -0.4567220 -0.53505432 0.36256495 -0.6205415 -0.13143940
## 3 -0.5270521 -0.32566793 0.04083631 -0.7457277 -0.17322620
## 4 0.2881203 -0.18494092 0.55795434 -0.3835738 0.18158093
## 5 -0.1995434 -0.07027549 0.24404548 -0.1594431 0.07828135
## 6 -0.1812643 0.07415939 -0.23014907 -0.3167121 0.16569411
## Dim.11 Dim.12
## 1 -0.45550607 -2.122990e-09
## 2 -0.64944655 -2.768542e-09
## 3 -0.51307636 -6.765777e-09
## 4 -0.51829968 -1.631543e-09
## 5 -0.03678451 -1.845831e-09
## 6 -0.35174294 -2.268829e-09On peut souhaiter les visualiser dans un graphique à deux dimensions:
Forcément cela à du sens que si on a peu d’individus. Si les individus sont des entités géographiques, on peut souhaiter en faire des cartes.
On peut récupérer les score de chaque individus en collant avec bind_rows les coordonnées avec le set de données initiale. On doit utiliser ici bind_rows plutôt qu’une jointure (left_join, right_join) parce que l’agorythme de FactoMineR ne conserve pas d’ID lors de la réalisation de l’ACP mais il conserve bien l’ordre des lignes mise en entrée:
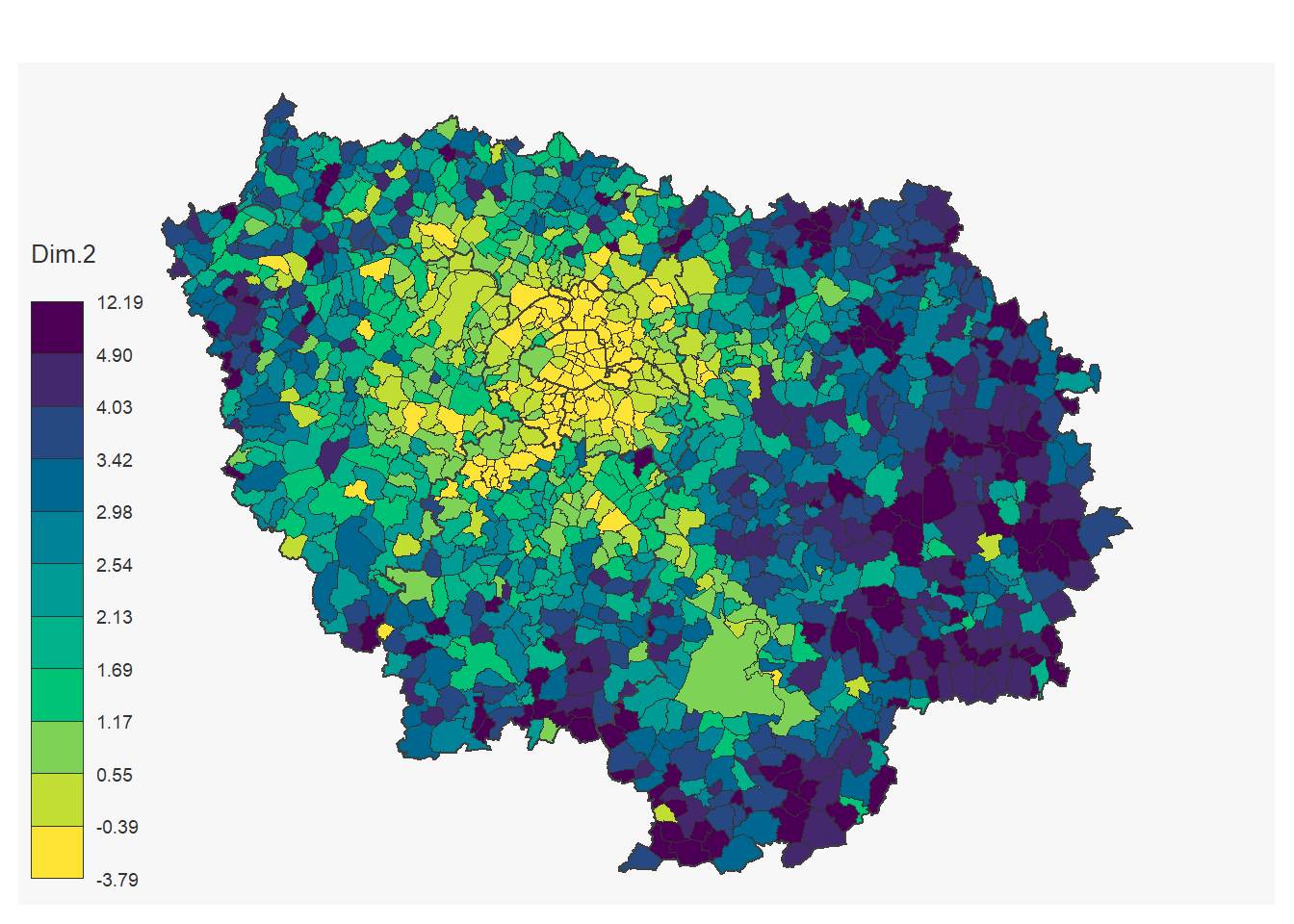
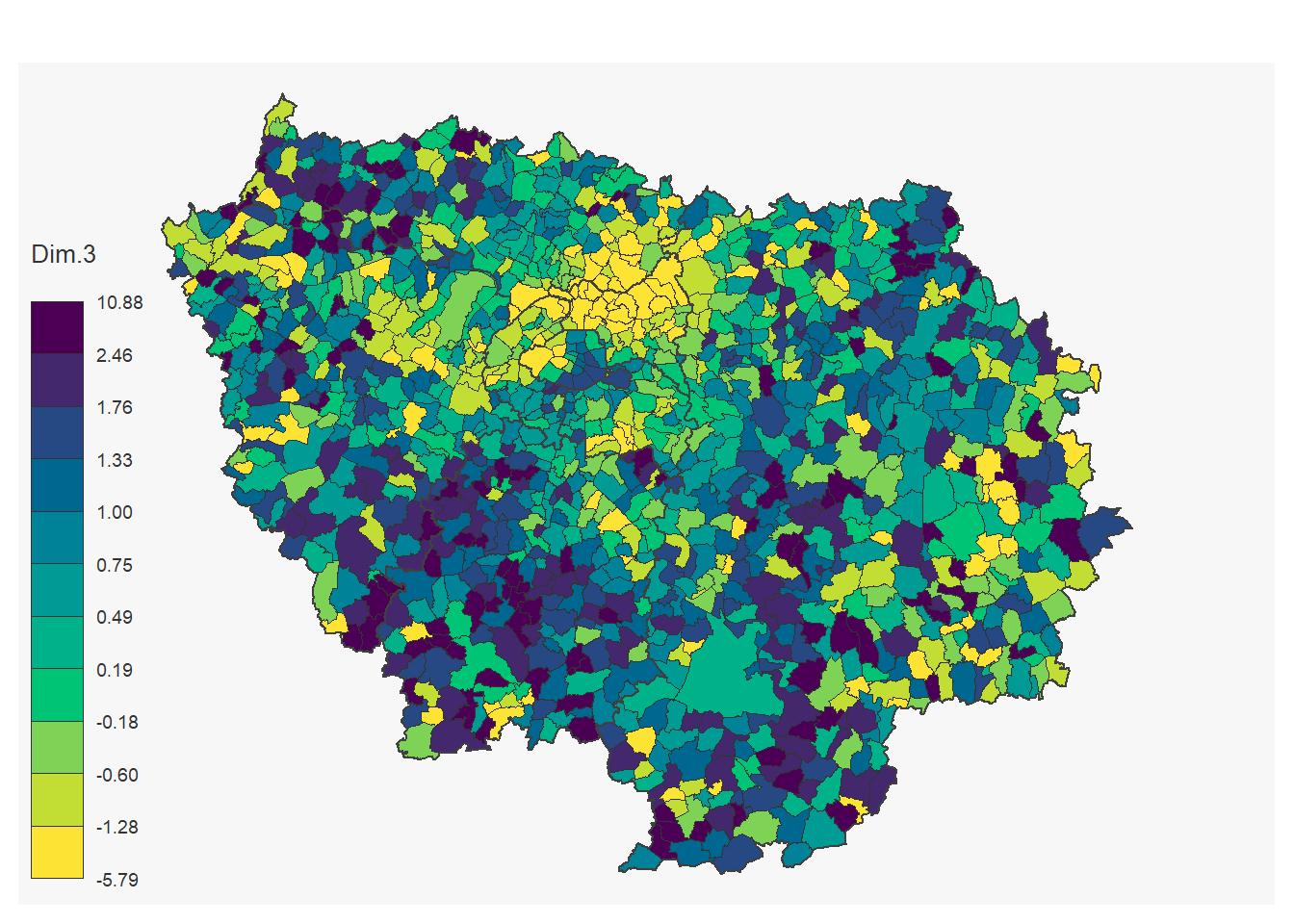
On réalise une boucle pour visualiser les 3 premières dimensions en faisant d’abord la jointure entre nos résultats et l’objet commune:
communes_pca<-communes %>%
inner_join(data_pca, by=c("insee"="codecommune"))
for (i in 1:3){
# mf_export(x = communes_pca ,
# filename =paste0("TP09/carte_acp_dim",i,".png" ),
# width = 900)
mf_map(communes_pca ,
var= paste0("Dim.",i),
type="choro",
pal= "Viridis",
lwd=0.001)
mf_map(x = departements_Paris, col = NA, border = "gray25", lwd = 1, add=T)
# dev.off()
}
2.6 Ajouter des variables supplémentaires
Pour aider à l’interprétation des axes, il peut être utile d’importer des nouvelles variables qui ne seront pas utilisées dans l’ACP mais qu’on pourra néanmoins utiliser comme repère.
2.6.1 Importation des données
2.6.1.1 Population
On importe les données de population:
pop<-read_excel("data/France/population_insee_2021.xlsx", sheet="Communes") %>%
mutate(codecommune=paste0(`Code département`, `Code commune`)) %>%
filter(`Code région`=="11") # on garde que la France métropolitaineOn joint avec le fichier spatial des communes et calcul la densité de population
communes_pop<- communes %>%
left_join(pop, by=c("insee"="codecommune")) %>%
mutate(densite_ha=`Population totale`/surface) %>%
select(insee, densite_ha)On peut réaliser une carte de la densité de population
# mf_export(x = communes_pop ,
# filename =paste0("TP09/carte_densite.png" ),
# width = 900)
mf_map(communes_pop ,
var= "densite_ha",
type="choro",
pal= "Viridis",
lwd=0.001)
mf_map(x = departements_Paris, col = NA, border = "red", lwd = 1, add=T)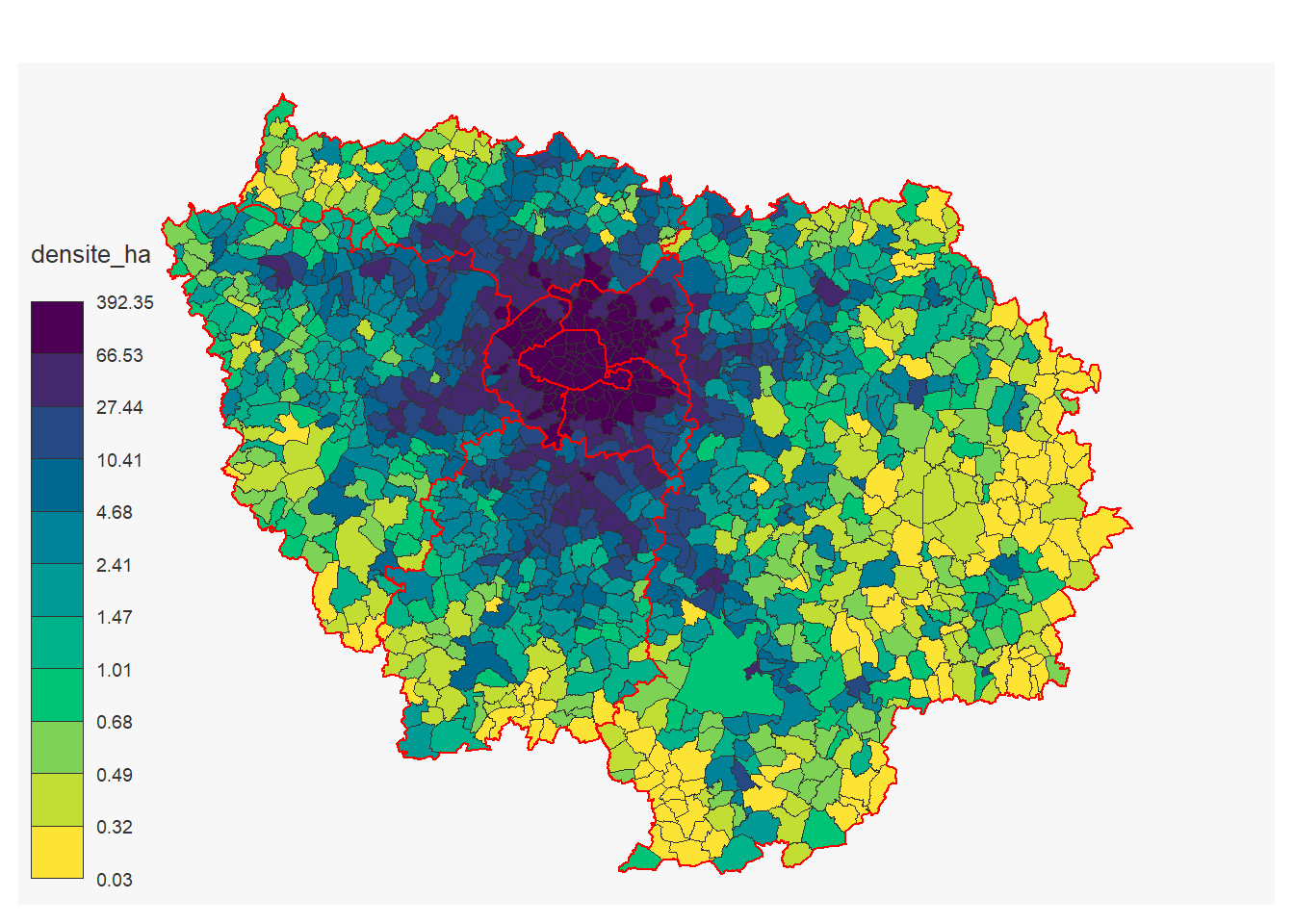
On enlève transforme l’objet en dataframe et on enlève la colonne geom:
On réalise la jointure avec les données de base:
2.6.1.2 Revenus
On importe les données de revenus, on conserve les champ qui nous intéresse et on transforme le champ revenu médian en “numeric”:
revenus<-read_excel("data/France/FILO2021_DEC_COM.xlsx", sheet=2) %>%
mutate(revenus=as.numeric(revenu_median)) %>%
select(CODGEO, revenus)On joint avec le fichier spatial des communes et les revenus:
On peut réaliser une carte de revenu:
# mf_export(x = communes_revenus ,
# filename =paste0("TP09/carte_revenus.png" ),
# width = 900)
mf_map(communes_revenus ,
var= "revenus",
type="choro",
pal= "Viridis",
lwd=0.001)
mf_map(x = departements_Paris, col = NA, border = "red", lwd = 1, add=T)
On réalise la jointure avec les données de base:
2.6.2 ACP avec les variables supplémentaires
## Warning in PCA(data[, 20:33], quanti.sup = 13:14, row.w =
## data$exprimes, : Missing values are imputed by the mean of
## the variable: you should use the imputePCA function of the
## missMDA package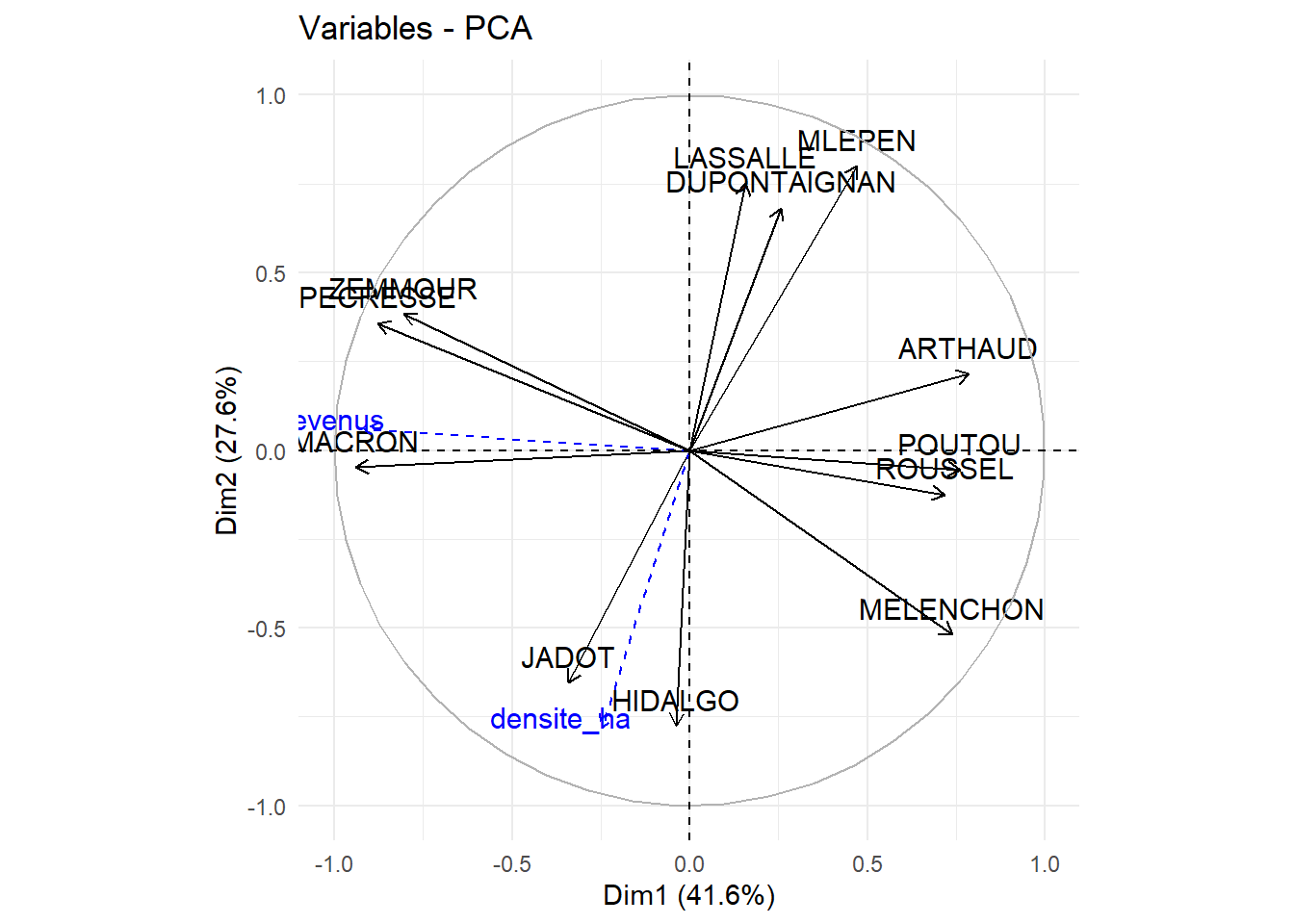
#ggsave(cercle_1_2,filename="TP09/cercle_correlation_1_2_revenu_pop.png", width=7, height=7, bg="white")
rm(cercle_1_2)
cercle_1_3<-fviz_pca_var(pca, axes = c(1, 3))+
theme_minimal()
cercle_1_3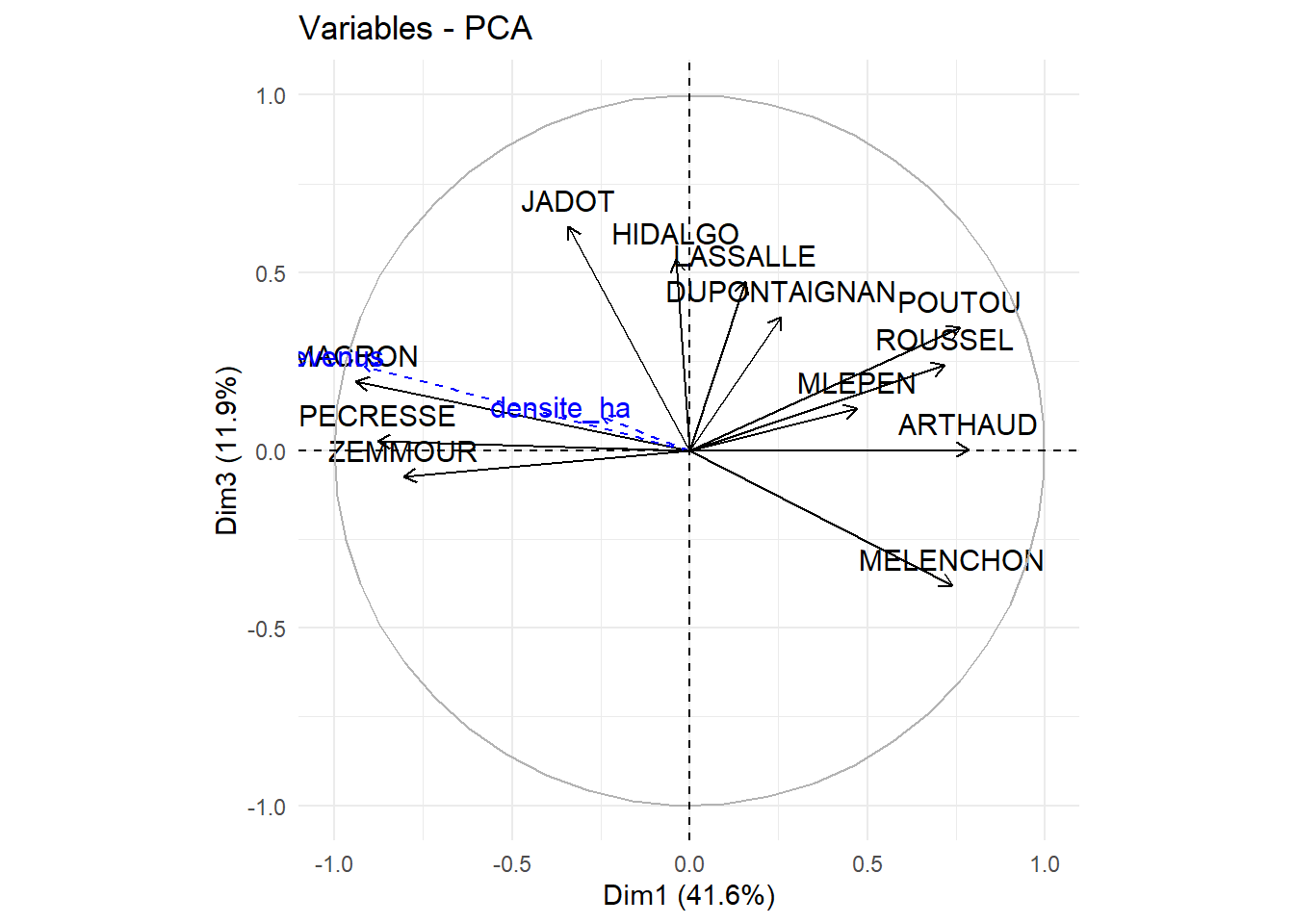
#ggsave(cercle_1_3,filename="TP09/cercle_correlation_1_3_revenu_pop.png", width=7, height=7, bg="white")
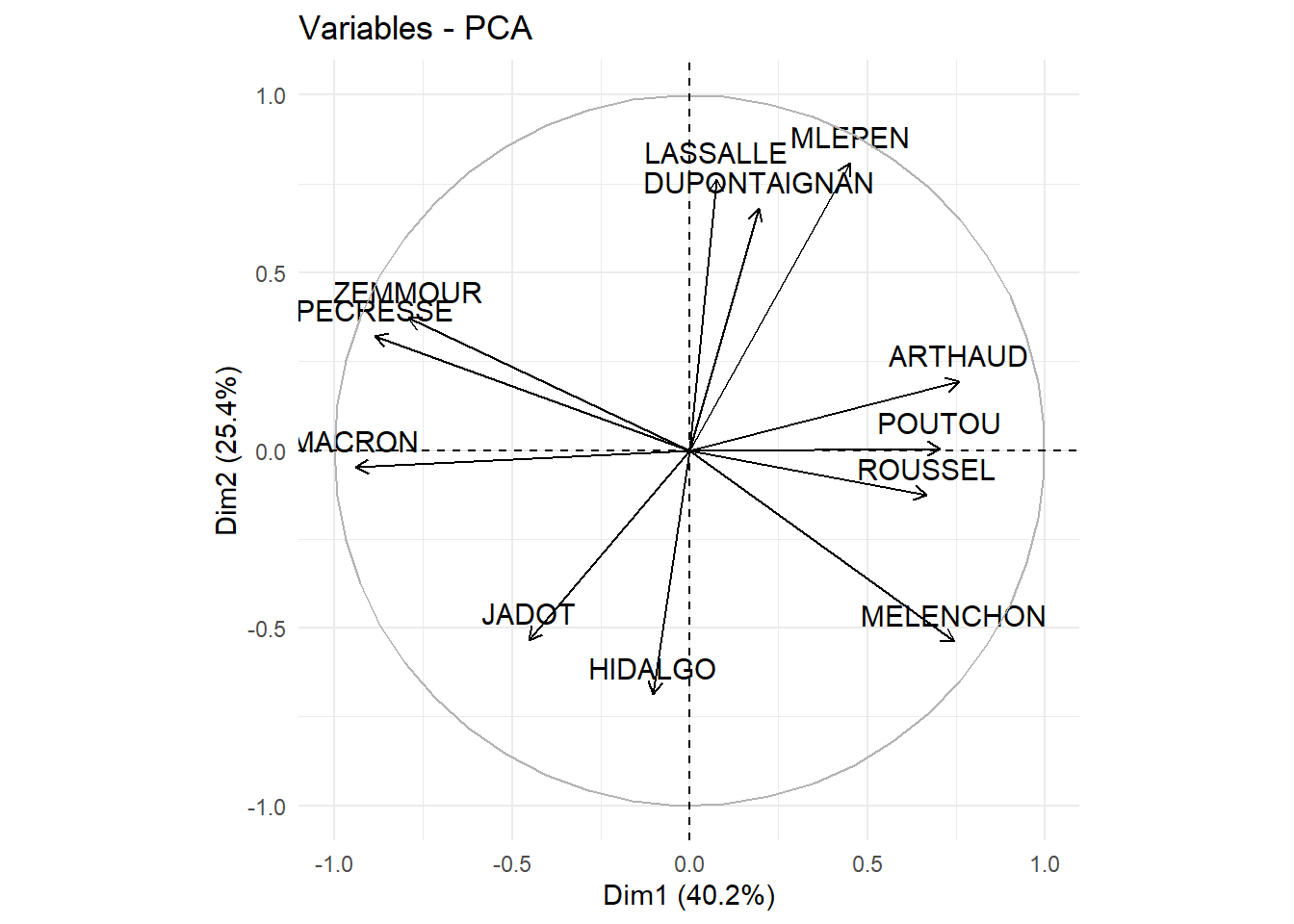
rm(cercle_1_3)On observe des fortes corrélations entre la première dimension qui dépeind une opposition gauche-droite et la variable de revenus, les revenus élevés étant associés aux communes où le vote de droite est important. La seconde dimension est quant à elle fortement corrélée à la densité de population et permet d’interprétée cette dernière comme l’opposition centre urbain-périphérie
2.7 Aller plus loin
Il est possible de faire des ACP sur des données d’enquêtes soit en utilisant les poids comme présenté précédement soit grâce au package :svyprcomp (https://r-survey.r-forge.r-project.org/survey/html/svyprcomp.html)
On peut vouloir réaliser des légères rotations des axes pour améliorer la lecture des axes: https://stats.stackexchange.com/questions/59213/how-to-compute-varimax-rotated-principal-components-in-r https://dimension.usherbrooke.ca/pages/87