Data Science avec R
2019-03-05
Chapitre 1 Introduction
1.1 Un autre livre sur la data science! Vraiment?
En décidant d’écrire un livre sur la data science, j’ai longuement débattu dans ma propre tête, je me suis posé plusieurs questions dont une qui revenait constamment: “a-t-on vraiment besoin d’un autre livre sur la data science?” “N’en-t-on pas assez?” Avec le succès dont jouit la discipline, ce n’est certainement pas les ressources qui manquent, aussi bien en ligne que dans les librairies. Et surtout, je me demandais bien “qu’avais-je à dire qui n’avait pas été dit”? Et pourtant, quelques raisons m’ont poussé à reconsidérer ma position.
La première est assez égoïte. On n’apprend jamais aussi bien qu’en enseignant. Pour m’assurer que j’avais bien assimilé les connaissances que j’avais acquises dans ce domaine, il n’y avait rien de mieux que de me livrer à un exercice de pédagogue. Expliquer à d’autres ce que j’avais appris. N’est-ce pas là que réside l’ultime test pour un apprenant! C’est partant de cette idée que je me suis mis à faire des diapositives dans le cadre des mes enseignements. Très tôt, j’ai réalisé que les diapositives ne sauraient jouer leur rôle, qui est d’offrir un aperçu synthétique d’une idée développée par un narrateur, et satifaire l’apprenant qui souhaiterai obtenir des explications détaillées. Ce travail revient au narrateur, à défaut de qui l’on se tourne vers un manuel. Donc, il me fallait bien accompagner les diapositives d’un support plus détaillé pour mieux outiller mes étudiants.
La seconde raison est le contexte. Malgré l’abondance et la qualité des ressources disponibles sur la data science et malgré l’accès de plus en plus facile - coût faible et gratuité pour beaucoup -, il demeure que l’étudiant africain peut souvent se sentir éloigné du contexte à travers lequel la data science est présentée. Or, cell-ci est avant tout une discipline de contexte. Bien que mélangeant informatique, mathématiques, statistiques…et bien d’autres expertises, elle est avant tout un outil, mobilisée pour répondre à des questions. Et ces questions sont très contextuelles. Il ne fait aucun doute que le disponibilité et l’accéssibilité des données sur le monde industrialisé rend leur utilisation commode pour introduire la data science à un jeune africain est très commode. Mais la distance entre le contexte présenté et celui qui est vécu par le bénéficiaire pose un problème. Elle empêche l’appropriation de la discipline. De ce fait, je me suis trouvé dans ce constat une raison de m’engager dans ce projet et surtout de me forcer à utiliser des données sur le contexte local. Après tout, l’être humain n’est-il pas plus enclin à vous prêter attention quand vous lui parlez de lui-même?
1.2 La data science
Comme toute discipline qui connaît une expansion rapide, il est difficile de définir la data science. Elle est vaste et riche, tant de par les disciplines dont elle emprunte des morceaux pour se contituer en entité que de par les branches qu’elle pousse avec sa propre croissance.
Commençons par quelques exemples
Fait de la data science:
- l’économiste qui examine le niveau du PIB sur 30 ans et cherche à dégager des scénarii pour des futures évolutions;
le sociologue qui s’appuie le taux de natalité et le taux de participation des femmes au marché du travail pour comprendre l’évolution de la place de la femme dans la société;
le météorologue qui cherche à prédire la pluviométrie de la semaine à venir en modélisant les données historiques;
l’épidémiologue qui cartographie le taux de prévalence du paludisme pour appuyer un programme stratégique;
etc.
Le caractère transversale de la data science apparait ici quand on sait que ces individus sont de disciplines différentes et poursuivent des questions tout aussi distantes les unes des autres. Et pourtant, les données les réunissent tous. Ils ont chacun besoin de trouver dans celles-ci un appui pour améliorer leur propre compréhension du phénomène étudié, tester leurs hypothèses, fonder leurs recommandations ou même…reconforter leurs propres idées ou mieux s’armer pour rejetter celles de leurs adversaires (les données ne sont aussi neutres que celui qui les manipule!)
Selon , la data science est un champ interdisciplinaire qui utilise les méthode, processus, algorithmes et systèmes scientifiques pour extraire des données - tant structurées que non structurées - des informations utiles à la compréhension et à la prise de décision. De ce fait, elle s’appuie sur diverses méthodes (mathématiques, statistiques, informatiques, etc.) pour tirer des données une compréhension meilleure de phénomènes d’intérêt.
1.3 Le data scientist
Et le data scientist dans tout ça? Il est apparait désormais comme la perle rare. Un individu capable de parler aux hommes, aux machines et aux données. Aux:
hommes, il pose les questions auxquelles il a la charge d’offrir des réponses.
machines, il parle à travers des langages spécifiques (R, Python, Julia,…), des langages qui ressemblent à bien d’égards à ceux avec lesquels il s’entretient avec les humains car ils sont basés sur des règles précises et sont vivants et évolutifs;
données, il applique des méthodes d’investigation où l’expérience, l’intuition, le sens artistique interviennent tout autant que la connaissance du domaine d’intervention. Dans les données disponibles, il cherche à séparer les bonnes des mauvaises, les utiles des nuisibles. A celles qu’il sélectionne, il cherche le bon format, la bonne structure. Sur celles qu’il retient, il teste des modèles, sans oublier la place importante de la visualisation à tous les niveaux. Bref, un vrai détective!
Face à la génération massive des données, le besoin de data scientist se fait pressant partout. De ce fait l’engouement ne manque pas pour les jeunes désireux de se lancer. Mais le portrait de super-homme généralement fait du data scientist (ne cherchez pas plus loin que les lignes d’en dessus!), l’on peut croire qu’il faut être spécial pour embrasser la profession. Du tout! Celà dit, certaines compétences sont utiles.
Alors, qu’est-ce qu’il faut pour être data scientist?
pas nécéssairement un diplôme avancé en mathématiques ou en statistiques…quoiqu’il est utile de maîtriser des concepts de bases (les concepts algébriques comme le vecteur, la matrice,… et les notions statistiques comme la moyenne, l’écart-type, etc.);
pas forcément un diplôme en informatique ou en programmation…quoiqu’il est utile de connaître les notions de bases (qu’est-ce qu’un objet, un environnement? quels types d’objets peut-on manipuler dans un environnement donnée…?);
une connaissance avérée dans un domaine spécifique dans lequel l’on peut soulever des questions, mobiliser des outils théoriques auxquels on confronte les résultats de l’analyse conduite sur les données;
un esprit curieux, quelle que soit l’avenue que l’on emprunte.
Vous pourrez avoir une meilleure idée en surfant sur le net (Google est votre ami!)
1.4 R
1.4.1 Qu’est-ce que c’est que R?
Voici basiquement ce que Wikipédia dit. est un langage de programmation et un logiciel gratuit et libre. Il est surtout utilisé pour le développement de programmes statistiques et des analyses de données. Il gagne en popularité depuis quelques années avec l’émergence de la data science et du fait qu’il est gratuit et ouvert (open-source). R est née d’un projet de recherche mené par deux chercheurs, Ross Ihaka et Robert Gentleman à l’université d’Auckland (Nouvelle-Zélande) en 1993. En 1997 est mis en place le Comprehension R Archive Network (CRAN) qui centralise les contributions au projet
Depuis le projet connaît une croissance soutenue, grâce à des contributions de la part de milliers de personnes à travers le monde.
1.4.2 Pourquoi R?
Pour un apprenti data scientist, le choix du langage et/ou du programme est une décision critique. Considérant le temps qu’il investira en apprentissage et le retour qu’il espéra à travers l’utilisation de ses nouvelles connaissances dans sa profession, il est utile de considerer divers critères dont:
l’accessibilité de l’outil en termes de coûts: tous les langages de programmation ne sont pas gratuits comme R! Certains coûtent…chers mêmes ;
l’accessibilité du langage en termes de syntaxe: R est très compréhensible (surtout pour quelqu’un qui se retrouve un peu avec la langue anglaise);
la popularité du langage parmi les paires: tout le monde s’est mis à l’anglais, même dans les pays où ce n’est pas la langue dominante. N’est-ce pas? De la même façon, il est important pour le data scientist d’embrasser un langage qui est aussi utilisé par ceux avec lesquels il sera amené à collaborer. A ce niveau, R est très populaire.
la dynamique de développement du langage: le langage étant un investissement en soit, il est important de miser sur ceux qui présentent un avenir. Et ceux-ci sont ceux qui mutent avec la technologie et les besoins des utilisateurs. A ce niveau encore, R présente des arguments. Il dispose du réseau CRAN alimenté par des milliers de contributeurs, divers aussi bien de par leur position dans le monde que de par leur discipline.
1.4.3 R dans l’écosystème des langages
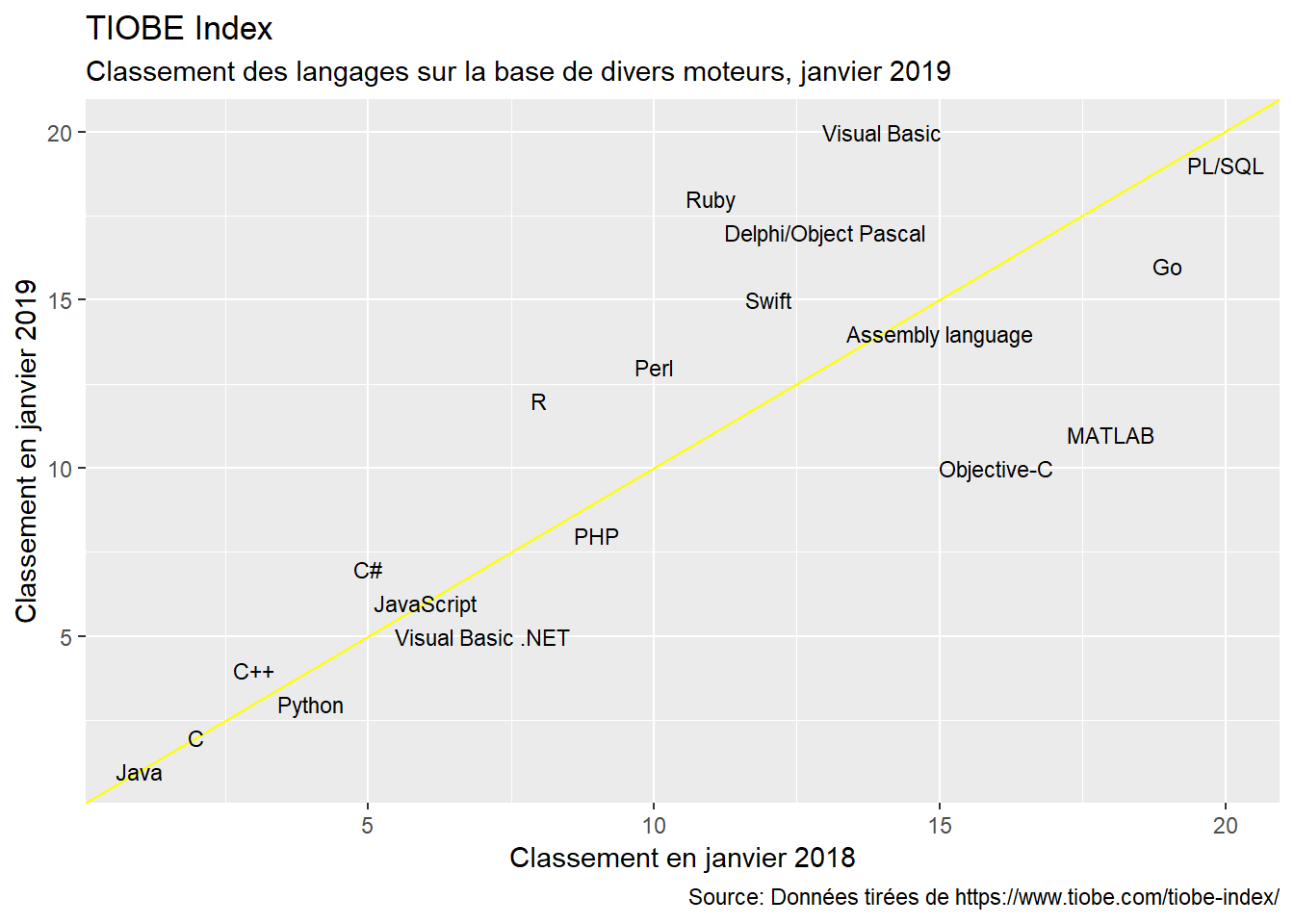
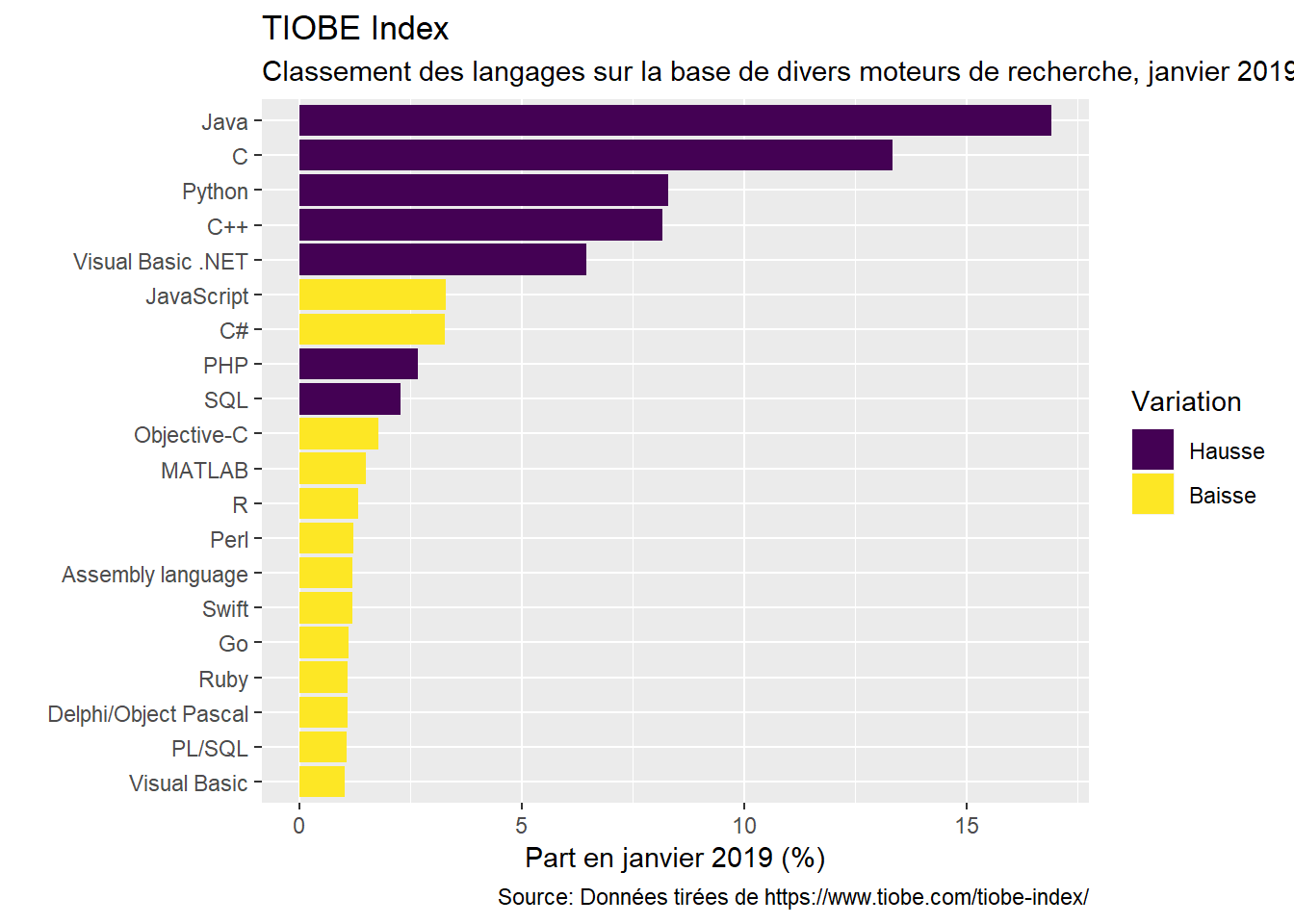
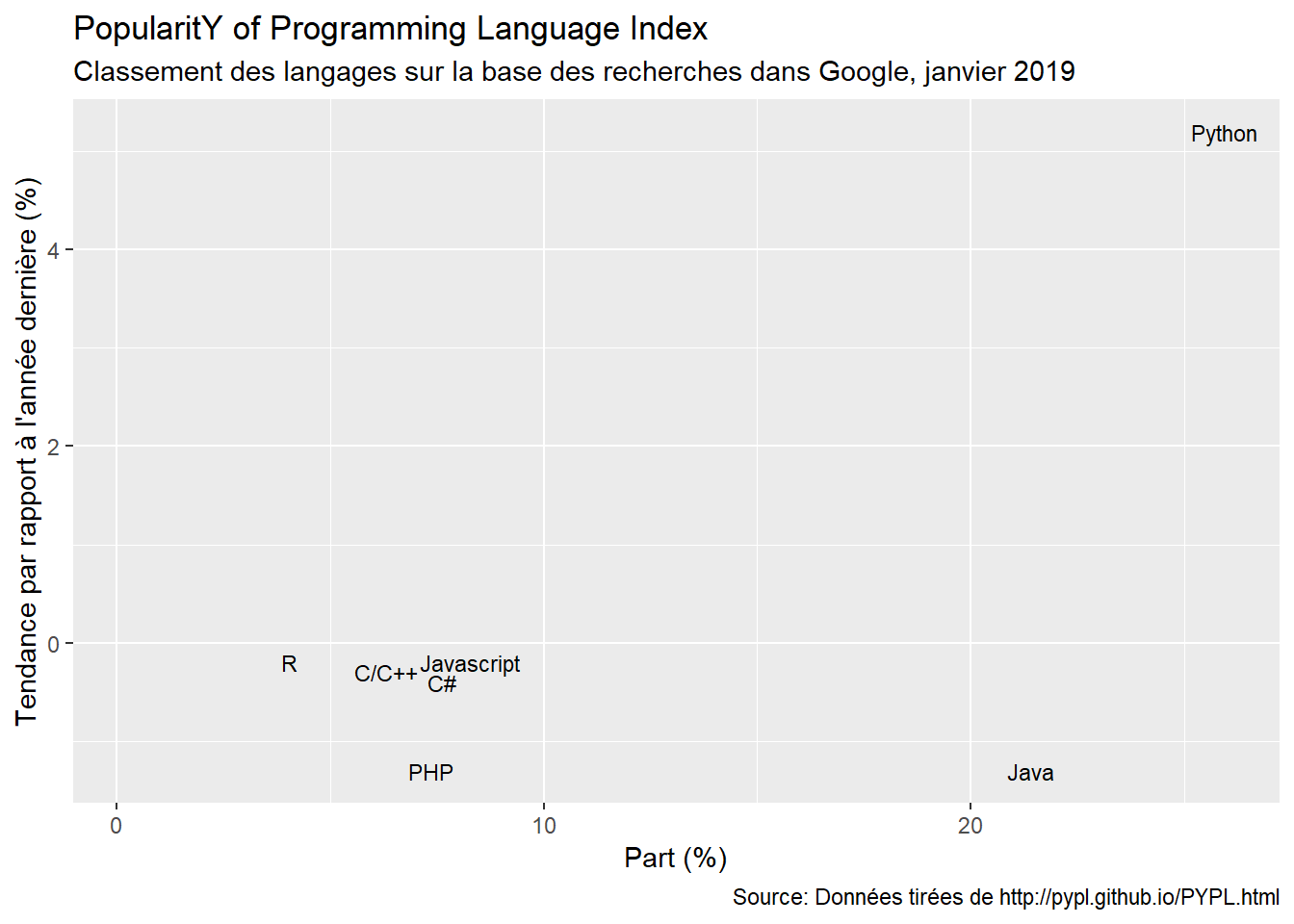
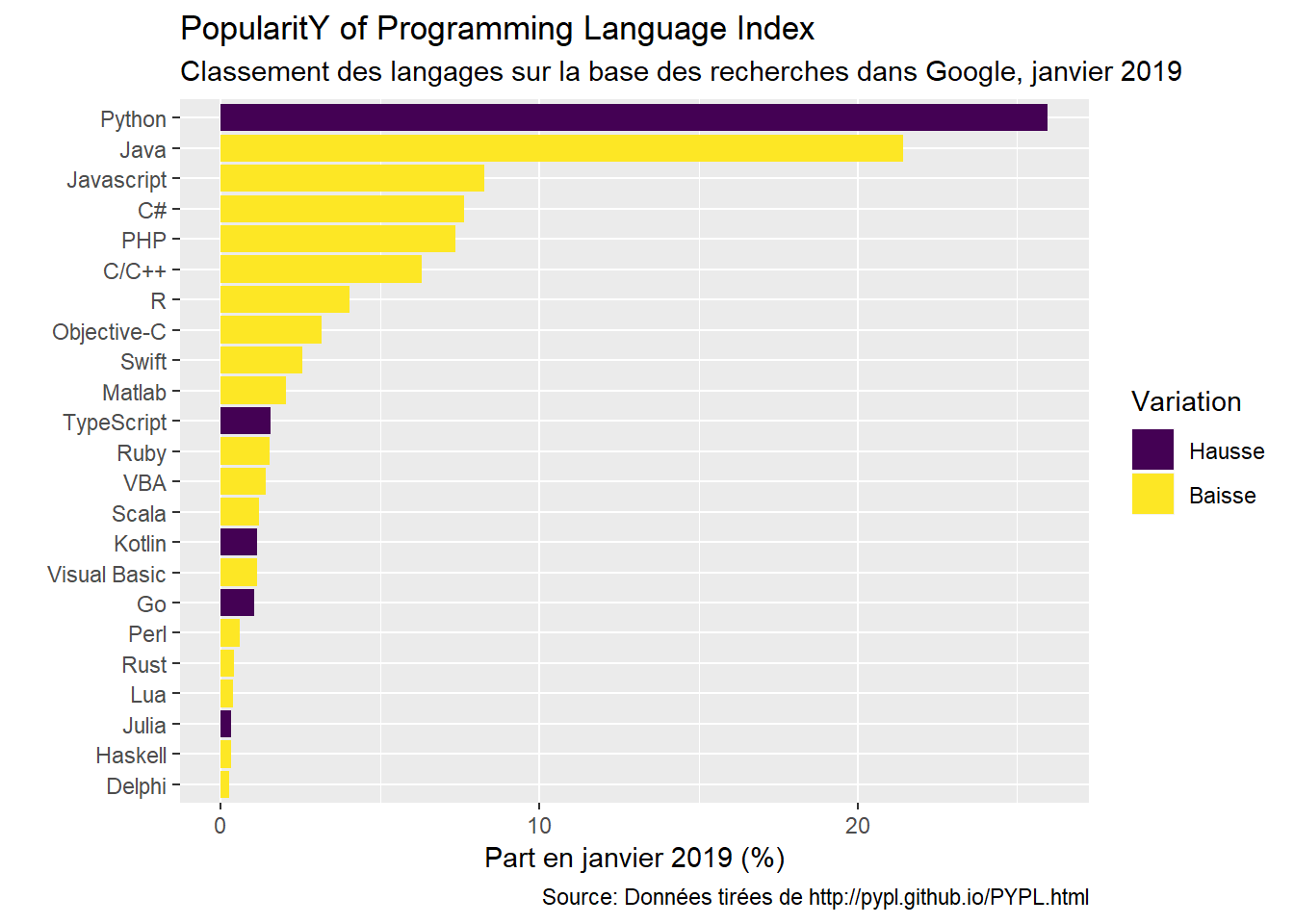
Ce qui apparait des différentes figures, c’est que R parvient à se tailler une place parmi les langages les plus populaires au monde. Et celà, malgré le fait que c’est une langage spécialisée. Si sur les dix dernières années, le langage s’est enrichi avec la diversification de ses contributeurs, il reste à la base un langage élaboré par des statisticiens pour des statisticiens. De ce fait, il est excéllent pour l’analyse de données, mais fort peu utile pour certaines tâches…comme le développement d’un site web.
1.5 RStudio
1.5.1 Qu’est-ce que c’est que RStudio
C’est une IDE (Integrated Development Environment) ou Environnement Intégré de Développement
Il sert d’interface entre R et l’utilisateur, offre à celui diverses commodités d’utilisation
Maintenant, vous avez les outils nécéssaires pour commencer la formidable aventuRe!