Chapter 2 Introduction to how the Web is Written and rvest
Before we start to extract data from the web, we will briefly touch upon how the web is written. This is since we will harness this structure to extract content in an automated manner. Basic commands will be shown thereafter.
Please make sure to run the following chunk. If you have not installed needs yet, please do so by uncommenting the first line. needs will then load or, if necessary, install the packages that are required for today’s tutorial.
2.1 HTML 101
Web content is usually written in HTML (Hyper Text Markup Language). An HTML document is comprised of elements that are letting its content appear in a certain way.
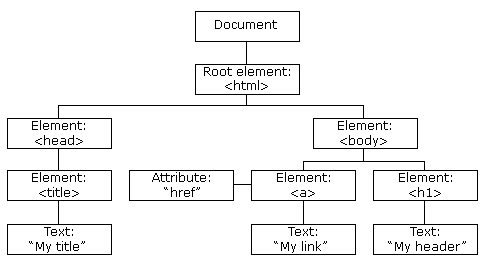
The way these elements look is defined by so-called tags.

The opening tag is the name of the element (p in this case) in angle brackets, and the closing tag is the same with a forward slash before the name. p stands for a paragraph element and would look like this (since RMarkdown can handle HTML tags, the second line will showcase how it would appear on a web page:
<p> My cat is very grumpy. <p/>
My cat is very grumpy.
The <p> tag makes sure that the text is standing by itself and that a line break is included thereafter:
<p>My cat is very grumpy</p>. And so is my dog. would look like this:
My cat is very grumpy
. And so is my dog.
There do exist many types of tags indicating different kinds of elements (about 100). Every page must be in an <html> element with two children <head> and <body>. The former contains the page title and some metadata, the latter the contents you are seeing in your browser. So-called block tags, e.g., <h1> (heading 1), <p> (paragraph), or <ol> (ordered list), structure the page. Inline tags (<b> – bold, <a> – link) format text inside block tags.
You can nest elements, e.g., if you want to make certain things bold, you can wrap text in <b>:
My cat is very grumpy
Then, the <b> element is considered the child of the <p> element.
Elements can also bear attributes:

Those attributes will not appear in the actual content. Moreover, they are super-handy for us as scrapers. Here, class is the attribute name and "editor-note" the value. Another important attribute is id. Combined with CSS, they control the appearance of the element on the actual page. A class can be used by multiple HTML elements whereas an id is unique.
2.2 Extracting content in rvest
To scrape the web, the first step is to simply read in the web page. rvest then stores it in the XML format – just another format to store information. For this, we use rvest’s read_html() function.
To demonstrate the usage of CSS selectors, I create my own, basic web page using the rvest function minimal_html():
basic_html <- minimal_html('
<html>
<head>
<title>Page title</title>
</head>
<body>
<h1 id="first">A heading</h1>
<p class="paragraph">Some text & <b>some bold text.</b></p>
<a> Some more <i> italicized text which is not in a paragraph. </i> </a>
<a class="paragraph">even more text & <i>some italicized text.</i></p>
<a id="link" href="www.nyt.com"> The New York Times </a>
</body>
')
basic_html## {html_document}
## <html>
## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
## [2] <body>\n <h1 id="first">A heading</h1>\n <p class="paragraph">Some ...CSS is the abbreviation for cascading style sheets and is used to define the visual styling of HTML documents. CSS selectors map elements in the HTML code to the relevant styles in the CSS. Hence, they define patterns that allow us to easily select certain elements on the page. CSS selectors can be used in conjunction with the rvest function html_elements() which takes as arguments the read-in page and a CSS selector. Alternatively, you can also provide an XPath which is usually a bit more complicated and will not be covered in this tutorial.
pselects all<p>elements.
## {xml_nodeset (1)}
## [1] <h1 id="first">A heading</h1>.titleselects all elements that are ofclass“title”
## {xml_nodeset (0)}There are no elements of class “title”. But some of class “paragraph”.
## {xml_nodeset (2)}
## [1] <p class="paragraph">Some text & <b>some bold text.</b></p>
## [2] <a class="paragraph">even more text & <i>some italicized text.</i>\n ...p.paragraphanalogously takes every<p>element which is ofclass“paragraph”.
## {xml_nodeset (1)}
## [1] <p class="paragraph">Some text & <b>some bold text.</b></p>#linkscrapes elements that are ofid“link”
## {xml_nodeset (1)}
## [1] <a id="link" href="www.nyt.com"> The New York Times </a>You can also connect children with their parents by using the combinator. For instance, to extract the italicized text from “a.paragraph,” I can do “a.paragraph i”.
## {xml_nodeset (1)}
## [1] <i>some italicized text.</i>You can also look at the children by using html_children():
## {xml_nodeset (1)}
## [1] <i>some italicized text.</i>## {xml_nodeset (8)}
## [1] <p>rvest helps you scrape (or harvest) data from web pages. It is designe ...
## [2] <p>If you’re scraping multiple pages, I highly recommend using rvest in c ...
## [3] <h2 id="installation">Installation<a class="anchor" aria-label="anchor" h ...
## [4] <p>If the page contains tabular data you can convert it directly to a dat ...
## [5] <p></p>
## [6] <p>Developed by <a href="http://hadley.nz" class="external-link">Hadley W ...
## [7] <p></p>
## [8] <p>Site built with <a href="https://pkgdown.r-lib.org/" class="external-l ...Unfortunately, web pages in the wild are usually not as easily readable as the small example one I came up with. Hence, I would recommend you to use the SelectorGadget – just drag it into your bookmarks list.
Its usage could hardly be simpler:
- Activate it – i.e., click on the bookmark.
- Click on the content you want to scrape – the things the CSS selector selects will appear green.
- Click on the green things that you don’t want – they will turn red; click on what’s not green yet but what you want – it will turn green.
- copy the CSS selector the gadget provides you with and paste it into the
html_elements()function.
2.3 Recap: Scraping HTML pages with rvest
So far, I have shown you how HTML is written and how to select elements. However, what we want to achieve is extracting the data the elements contained in a proper format and storing it in some sort of tibble. Therefore, we need functions that allow us to grab the data.
The following overview taken from the web scraping cheatsheet shows you the basic “flow” of scraping web pages plus the corresponding functions. In this tutorial, I will limit myself to rvest functions. Those are of course perfectly compatible with things, for instance, RSelenium, as long as you feed the content in XML format (i.e., by using read_html()).
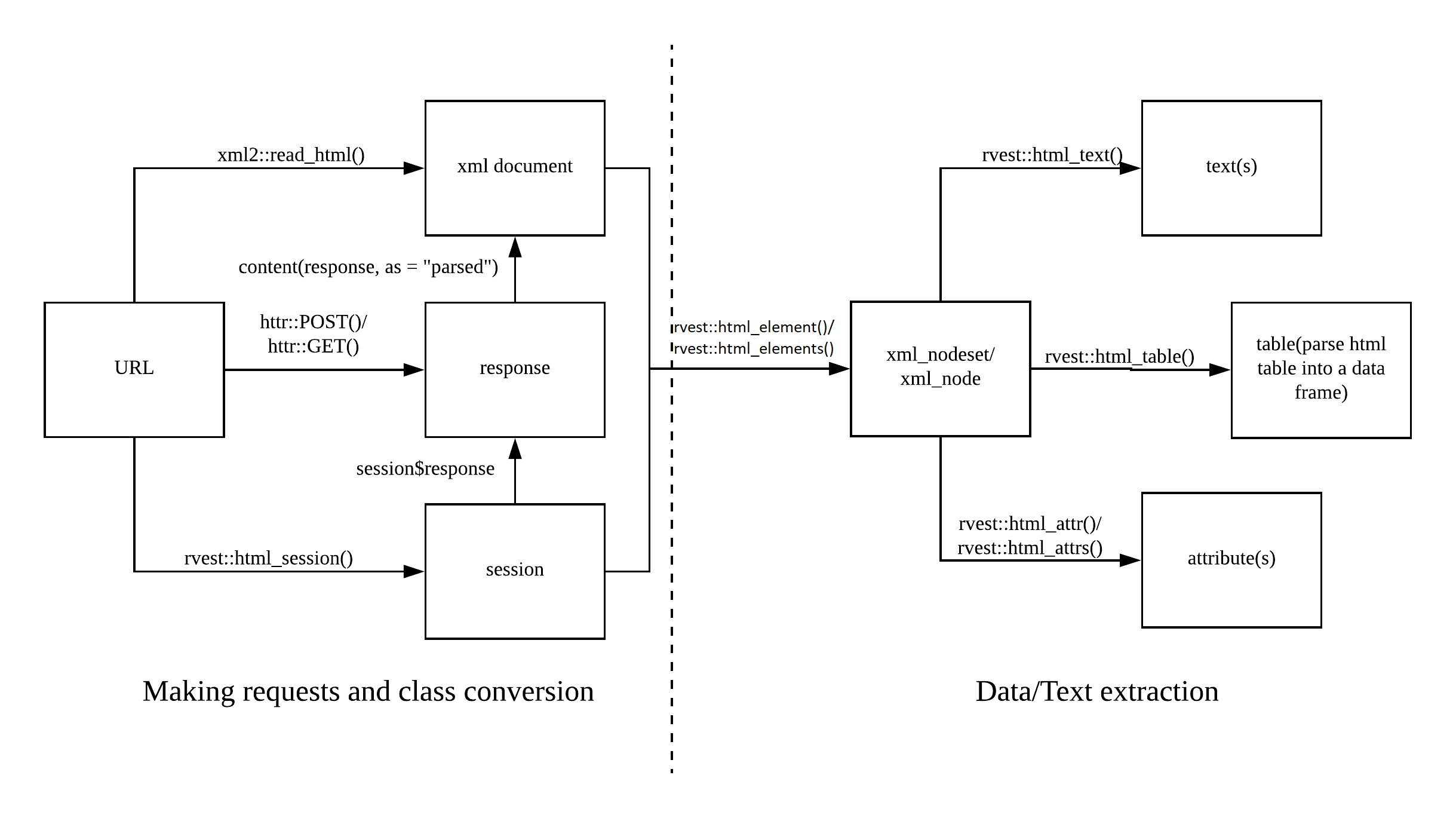
In the first part, I will introduce you to scraping singular pages and extracting their contents. rvest also allows for proper sessions where you navigate on the web pages and fill out forms. This is to be introduced in the second part.
2.3.1 html_text() and html_text2()
Extracting text from HTML is easy. You use html_text() or html_text2(). The former is faster but will give you not-so-nice results. The latter will give you the text like it would be returned in a web browser.
The following example is taken from the documentation
# To understand the difference between html_text() and html_text2()
# take the following html:
html <- minimal_html(
"<p>This is a paragraph.
This is another sentence.<br>This should start on a new line"
)# html_text() returns the raw underlying text, which includes white space
# that would be ignored by a browser, and ignores the <br>
html |> html_element("p") |> html_text() |> writeLines()## This is a paragraph.
## This is another sentence.This should start on a new line# html_text2() simulates what a browser would display. Non-significant
# white space is collapsed, and <br> is turned into a line break
html |> html_element("p") |> html_text2() |> writeLines()## This is a paragraph. This is another sentence.
## This should start on a new lineA “real example” would then look like this:
2.3.2 Extracting tables
The general output format we strive for is a tibble. Oftentimes, data is already stored online in a table format, basically ready for us to analyze them. In the next example, I want to get a table from the Wikipedia page that contains the senators of different States in the United States I have used before. For this first, basic example, I do not use selectors for extracting the right table. You can use rvest::html_table(). It will give you a list containing all tables on this particular page. We can inspect it using str() which returns an overview of the list and the tibbles it contains.
Here, the table I want is the sixth one. We can grab it by either using double square brackets – [[6]] – or purrr’s pluck(6).
## Rows: 100
## Columns: 12
## $ State <chr> "Alabama", "Alabama", "Alaska", "Alaska",…
## $ Portrait <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ Senator <chr> "Tommy Tuberville", "Katie Britt", "Lisa …
## $ Party <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ Party <chr> "Republican", "Republican", "Republican",…
## $ Born <chr> "(1954-09-18) September 18, 1954 (age 68)…
## $ `Occupation(s)` <chr> "College football coachInvestment managem…
## $ `Previous electiveoffice(s)` <chr> "None", "None", "Alaska House of Represen…
## $ Education <chr> "Southern Arkansas University (BS)", "Uni…
## $ `Assumed office` <chr> "January 3, 2021", "January 3, 2023", "De…
## $ Class <chr> "2026Class 2", "2028Class 3", "2028Class …
## $ `Residence[1]` <chr> "Auburn[2]", "Montgomery", "Girdwood", "A…## alternative approach using css
senators <- us_senators |>
html_elements(css = "#senators") |>
html_table() |>
pluck(1) |>
clean_names()You can see that the tibble contains “dirty” names and that the party column appears twice – which will make it impossible to work with the tibble later on. Hence, I use clean_names() from the janitor package to fix that.
2.3.3 Extracting attributes
You can also extract attributes such as links using html_attrs(). An example would be to extract the headlines and their corresponding links from r-bloggers.com.
A quick check with the SelectorGadget told me that the element I am looking for is of class “.loop-title” and the child of it is “a”, standing for normal text. With html_attrs() I can extract the attributes. This gives me a list of named vectors containing the name of the attribute and the value:
Links are stored as attribute “href” – hyperlink reference. html_attr() allows me to extract the attribute’s value. Hence, building a tibble with the article’s title and its corresponding hyperlink is straight-forward now:
tibble(
title = r_blogger_postings |> html_text2(),
link = r_blogger_postings |> html_attr(name = "href")
)## # A tibble: 20 × 2
## title link
## <chr> <chr>
## 1 Introduction to Linear Regression in R: Analyzing the mtcars Dataset w… http…
## 2 Bayesian structural equation model tutorial http…
## 3 Learnings and Reflection from Case Studies: What is Next for the R Val… http…
## 4 Use of R for Meta-Research in Zürich http…
## 5 Introduction to Supervised Text Classification in R workshop http…
## 6 Pulling a formula from a recipe object http…
## 7 rOpenSci’s Communication Channels for Safe and Friendly Exchange http…
## 8 Simplifying Model Formulas with the R Function ‘reformulate()’ http…
## 9 R Consortium Funding for R User Groups! Highlighting R-Ladies São Paulo http…
## 10 Automating End-to-End Cypress Tests in Rhino: A Guide to Seamless UI T… http…
## 11 World Cup – World Soccer Analytics http…
## 12 Football – World Soccer Analytics http…
## 13 Olympics – World Soccer Analytics http…
## 14 Comments on: How does an FA Cup Trophy Impact League Position? http…
## 15 How does an FA Cup Trophy Impact League Position? – World Soccer Analy… http…
## 16 The Growth of Soccer (1872 – Present) – World Soccer Analytics http…
## 17 Comments on: The Growth of Soccer (1872 – Present) http…
## 18 Winners at the World Cup – World Soccer Analytics http…
## 19 Comments on: Winners at the World Cup http…
## 20 Comments on: A Change in Age at the Olympics http…