11 Correlation
Correlation is the simplest measure of association between two continuous variables. There are a number of different types of correlation measures that will explore in this chapter. All of these measures attempt to define how changess in one variable are associated with changes in another variable.
11.1 Pearson Correlation
Pearson’s correlation is measured by \(r\) and ranges between -1 and +1. +1 indicates that the variables X and Y are maximally positively correlated, such that as values of X increase so do values of Y. -1 indicates a compleltely negative correlation such that as values of X increase, values of Y decrease. A value of 0 indicates that there is no overall relationship.
The below image shows a positive correlation of \(r=0.6\), a zero correlation of \(r=0\) and a negative correlation of \(r=-0.6\) for 20 datapoints in each scatterplot.
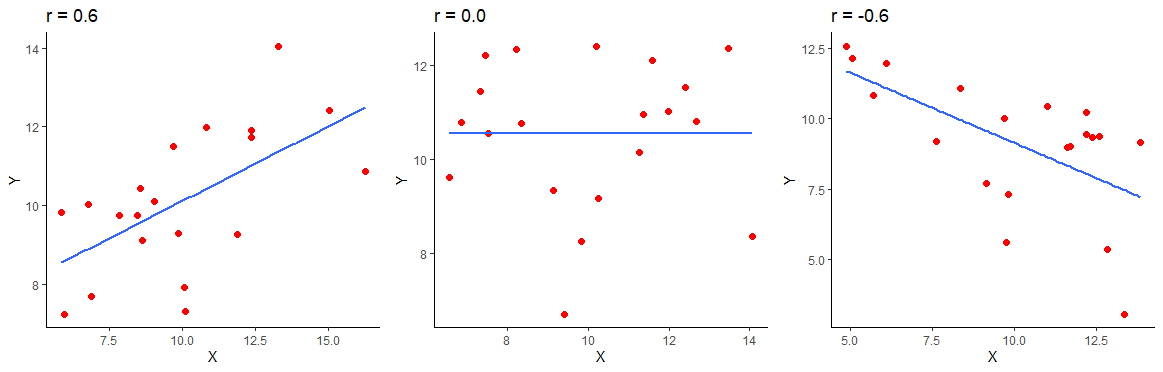
The below image shows scatterplots, each with a sample size of 30. The trendline is to help demonstrate how correlations of different magnitudes look in terms of their association.
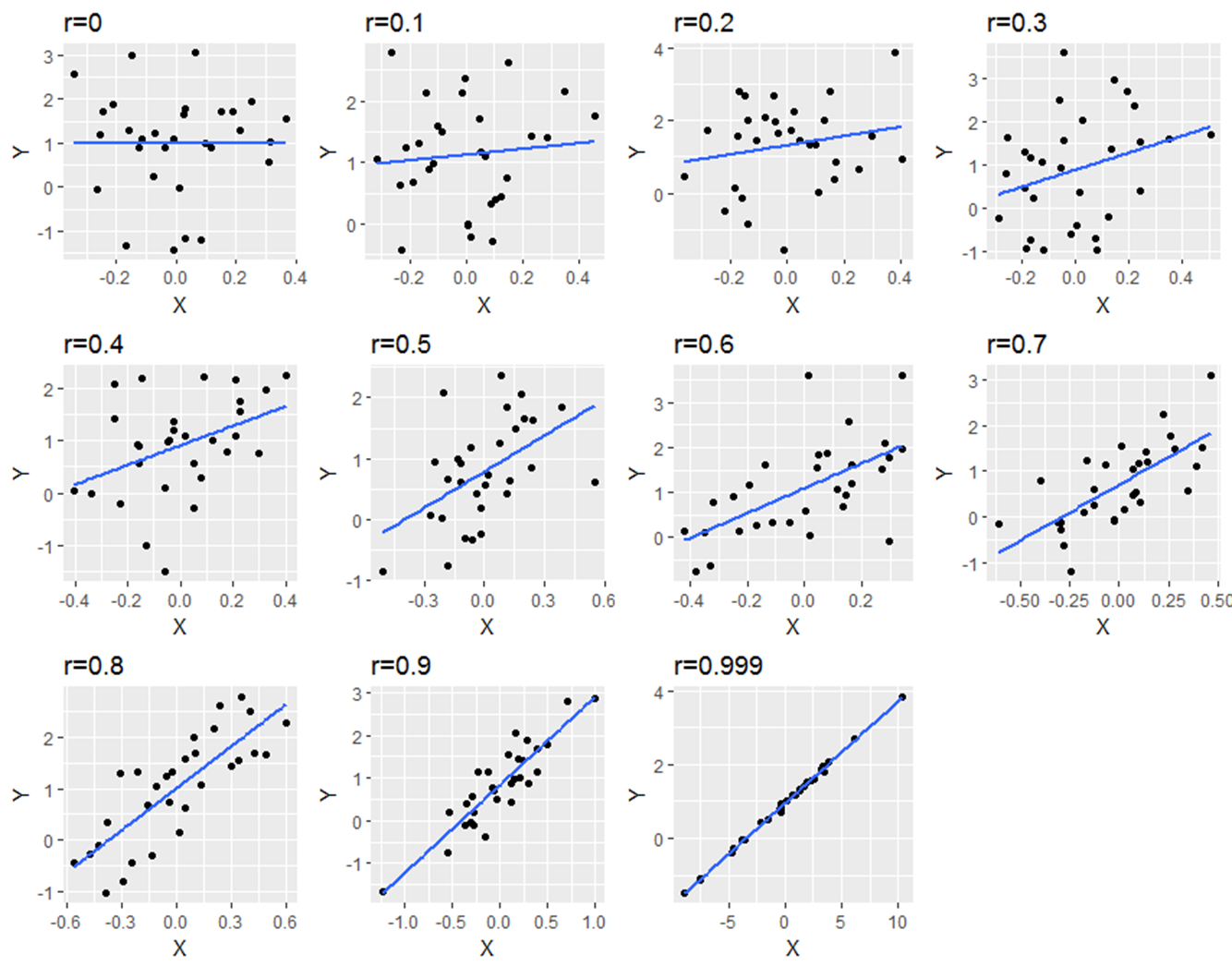
Correlations
11.2 Cross-products
The formula for calculating the Pearson’s correlation coefficient for a sample is:
\(\Large r = \frac{\sum_{}^{} z_{x}z_{y}}{n - 1}\)
When we have a population, we can use the formula:
\(\Large \rho = \frac{\sum_{}^{} z_{x}z_{y}}{N}\)
Notice that for a population we use a different notation for the Pearson’s correlation coefficient.
Essentially, the steps are to convert all the X and Y scores into their respective z-scores. Then you multiply these two values together to get the cross-product. After summing up all the cross-products for each data point, we divide this number by n-1 if we’re dealing with a sample (we usually are), or N if we’re dealing with a population.
The sum of the cross-products will therefore be largely positive if positive z-scores are multiple together or if negative z-scores are multiplied together. The sum of the cross-products will be largely negative if negative z-scores are multipled with positive z-scores.
The following example should help make this clearer. Look at the following data, its scatterplot and the correlation coefficient. They show that we have a positive correlation of r=0.84. Let’s break it down how we got that value.
library(tidyverse)
x <- c(1.1, 1.5, 2.1, 3.5, 3.6, 3.5, 2.6, 5.6, 4.4, 3.9)
y <- c(2.8, 2.9, 1.6, 5.5, 4.7, 8.1, 3.3, 7.7, 7.1, 5.8)
df <- data.frame(x, y)
df## x y
## 1 1.1 2.8
## 2 1.5 2.9
## 3 2.1 1.6
## 4 3.5 5.5
## 5 3.6 4.7
## 6 3.5 8.1
## 7 2.6 3.3
## 8 5.6 7.7
## 9 4.4 7.1
## 10 3.9 5.8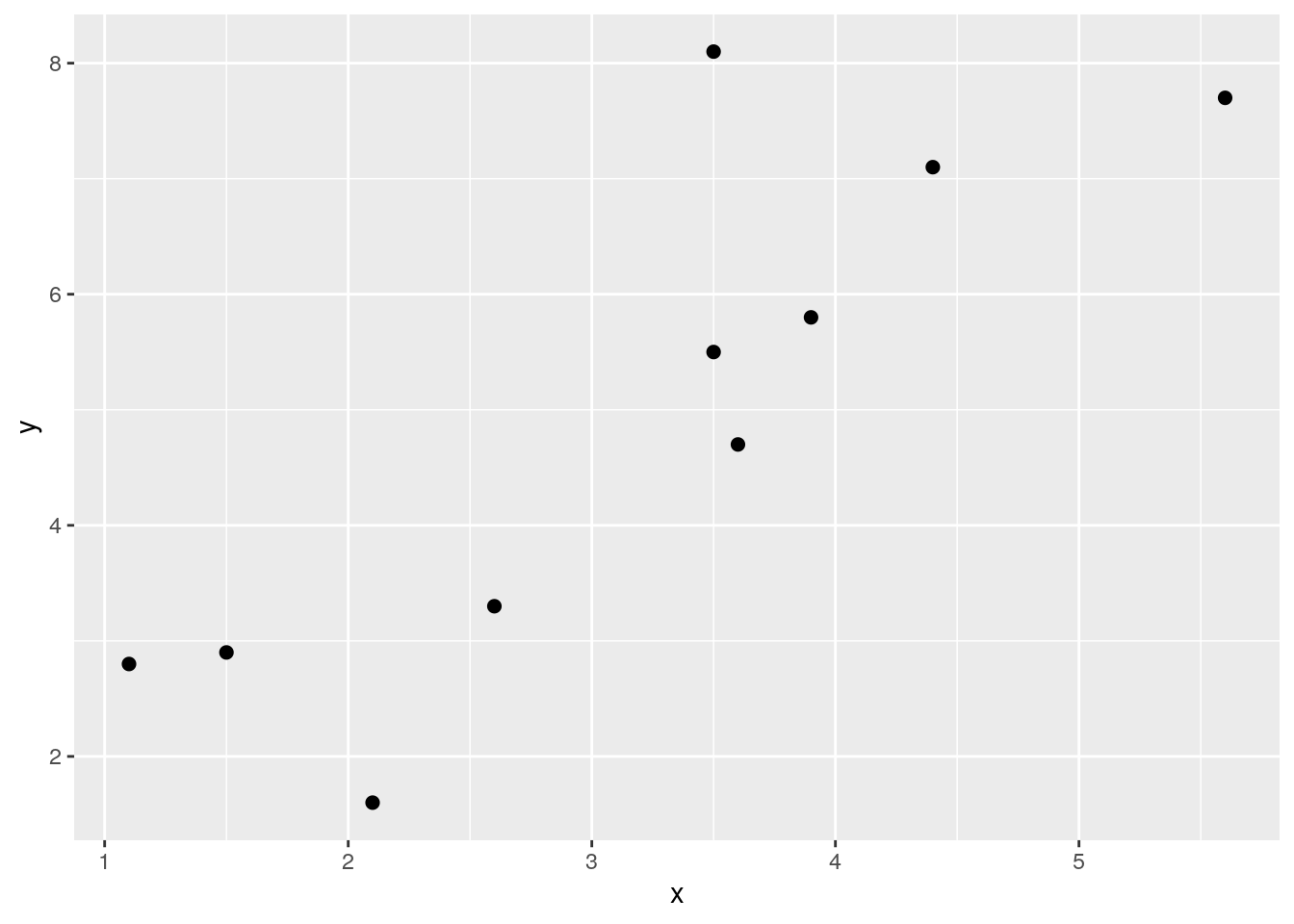
## [1] 0.8418262First, let’s calculate the means and standard deviation (using sd so a sample standard deviation) of x and y. We need to get these values so we can calculate the z-scores of each.
## [1] 3.18## [1] 1.370158## [1] 4.95## [1] 2.259916Now, we can calculate the z-scores, remembering that the formula for that is:
\(\Large z = \frac{x - \overline{x}}{s_{x}}\)
# step 2. Calculate z-scores of x, and z-scores of y.
df$zx <- (x - mean(x)) / sd(x) # z scores of x
df$zy <- (y - mean(y)) / sd(y) # z scores of y
df## x y zx zy
## 1 1.1 2.8 -1.5180729 -0.9513626
## 2 1.5 2.9 -1.2261358 -0.9071132
## 3 2.1 1.6 -0.7882302 -1.4823557
## 4 3.5 5.5 0.2335497 0.2433718
## 5 3.6 4.7 0.3065340 -0.1106236
## 6 3.5 8.1 0.2335497 1.3938569
## 7 2.6 3.3 -0.4233088 -0.7301155
## 8 5.6 7.7 1.7662195 1.2168592
## 9 4.4 7.1 0.8904082 0.9513626
## 10 3.9 5.8 0.5254868 0.3761201Following this, we simply multiple the z-scores of x and y against each other for every data point:
## x y zx zy zxzy
## 1 1.1 2.8 -1.5180729 -0.9513626 1.44423785
## 2 1.5 2.9 -1.2261358 -0.9071132 1.11224399
## 3 2.1 1.6 -0.7882302 -1.4823557 1.16843751
## 4 3.5 5.5 0.2335497 0.2433718 0.05683941
## 5 3.6 4.7 0.3065340 -0.1106236 -0.03390988
## 6 3.5 8.1 0.2335497 1.3938569 0.32553483
## 7 2.6 3.3 -0.4233088 -0.7301155 0.30906432
## 8 5.6 7.7 1.7662195 1.2168592 2.14924036
## 9 4.4 7.1 0.8904082 0.9513626 0.84710104
## 10 3.9 5.8 0.5254868 0.3761201 0.19764615We now have all of our cross-products. Notice why the majority are positive. This is because we have multiplied positive \(z_{x}\) with positive \(z_{y}\) or we multiplied negative \(z_{x}\) with negative \(z_{y}\). This happens because datapoints that tend to be above the mean for x are also above the mean for y, and points that are below the mean of x are also below the mean of y.
We can add this up to get the sum of the cross-products. That is the \(\sum_{}^{} z_{x}z_{y}\) in the formula.
## [1] 7.576436We now divide that by n-1 as we have a sample, to get the correlation coefficient r. That gives us an estimation of the average cross-product.
# step 5- calculate 'r' by dividing by n-1. (for a sample)
sum(df$zxzy) / 9 # our n was 10, so n-1 = 9## [1] 0.8418262## [1] 0.8418262Just as a quick second example, here is a work through calculating a negative correlation. Notice the \(z_{x}\) and \(z_{y}\) scores that are multiplied together. They are largely opposite in terms of signs. This is what leads to a negative sum of cross-products and the negative correlation. Why? Because data points that are above the mean for x are generally below the mean in terms of y and visa-versa.
### Example 2. Negative Correlation.
x <- c(1.1, 1.5, 2.1, 3.5, 3.6, 3.5, 2.6, 5.6, 4.4, 3.9)
y <- c(10.4, 10.0, 8.4, 8.5, 8.4, 6.3, 7.1, 6.2, 8.1, 10.0)
df <- data.frame(x, y)
ggplot(df, aes(x = x, y = y)) + geom_point(size=2)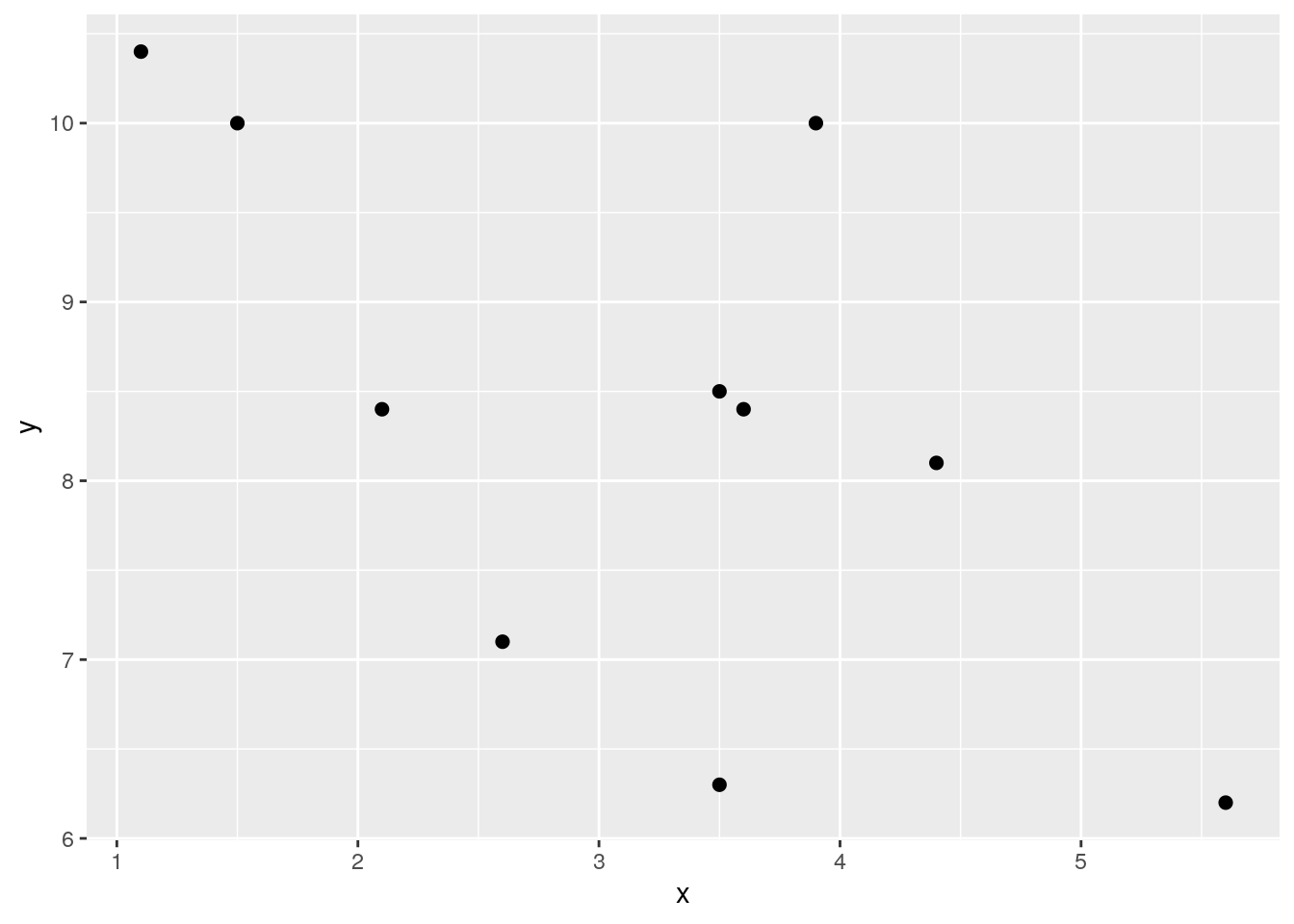
## [1] -0.6112965Here is the code, truncated for space:
# Calculate z-scores for each x and each y
df$zx <- (x - mean(x)) / sd(x)
df$zy <- (y - mean(y)) / sd(y)
# Calculate the cross-product: zx * zy
df$zxzy <- df$zx * df$zy
# let's look at the dataframe
# notice the cross products:
df## x y zx zy zxzy
## 1 1.1 10.4 -1.5180729 1.37762597 -2.09133671
## 2 1.5 10.0 -1.2261358 1.11012578 -1.36116500
## 3 2.1 8.4 -0.7882302 0.04012503 -0.03162776
## 4 3.5 8.5 0.2335497 0.10700008 0.02498983
## 5 3.6 8.4 0.3065340 0.04012503 0.01229968
## 6 3.5 6.3 0.2335497 -1.36425096 -0.31862038
## 7 2.6 7.1 -0.4233088 -0.82925058 0.35102907
## 8 5.6 6.2 1.7662195 -1.43112601 -2.52768263
## 9 4.4 8.1 0.8904082 -0.16050011 -0.14291061
## 10 3.9 10.0 0.5254868 1.11012578 0.58335643## [1] -0.6112965## [1] -0.611296511.3 Conducting a Pearson Correlation Test
Although cor() gives you the correlation between two continuous variables, to actually run a significance test, you need to use cor.test().
Let’s use some BlueJay data to do this. We’ll just use data on male birds.
library(tidyverse)
jays <- read_csv("data/BlueJays.csv")
jayM <- jays %>% filter(KnownSex == "M") # we'll just look at Males
nrow(jayM) # 63 observations## [1] 63## # A tibble: 6 x 9
## BirdID KnownSex BillDepth BillWidth BillLength Head Mass Skull Sex
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 0000-00000 M 8.26 9.21 25.9 56.6 73.3 30.7 1
## 2 1142-05901 M 8.54 8.76 25.0 56.4 75.1 31.4 1
## 3 1142-05905 M 8.39 8.78 26.1 57.3 70.2 31.2 1
## 4 1142-05909 M 8.71 9.84 25.5 57.3 74.9 31.8 1
## 5 1142-05912 M 8.74 9.28 25.4 57.1 75.1 31.8 1
## 6 1142-05914 M 8.72 9.94 30 60.7 78.1 30.7 1Let’s say you’re interested in examining whether there is an association between Body Mass and Head Size. First we’ll make a scatterplot between the Mass and Head columns. We’ll also investigate the correlation using cor().
ggplot(jayM, aes(x=Mass, y=Head)) +
geom_point(shape = 21, colour = "navy", fill = "dodgerblue") +
stat_smooth(method="lm", se=F)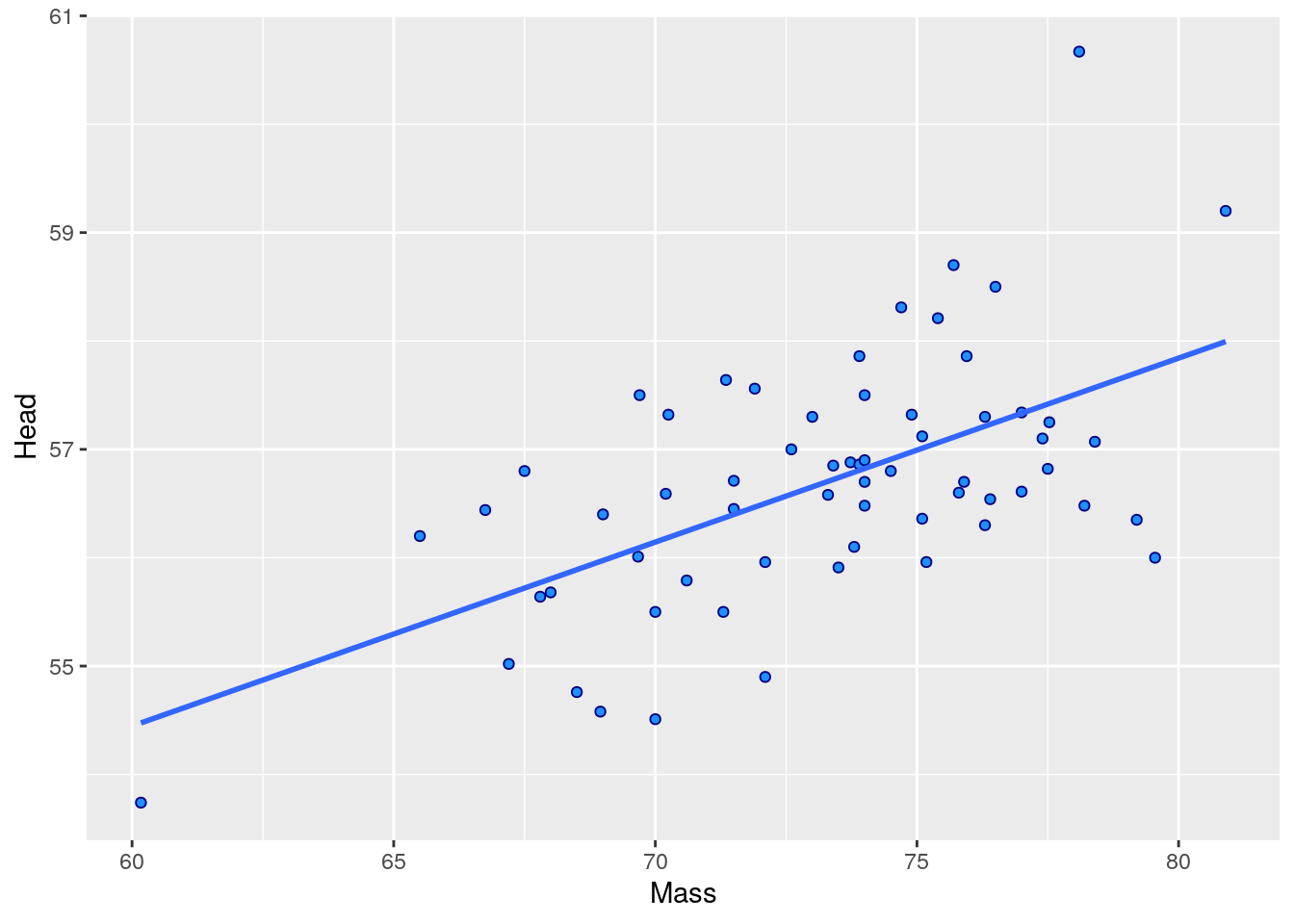
## [1] 0.5773562To run the significance test, we do the following:
##
## Pearson's product-moment correlation
##
## data: jayM$Head and jayM$Mass
## t = 5.5228, df = 61, p-value = 7.282e-07
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.3846090 0.7218601
## sample estimates:
## cor
## 0.5773562This gives us a lot of information. Firstly, at the bottom it repeats the correlation coefficient cor. At the top, it gives us the value of t which is essentially how surprising it is for us to get the correlation we did assuming we were drawing our sample from a population where there is no correlation. Associated with this t value is the degrees of freedom which is equal to n-2, so in this case that is 63-2 = 61. The p-value is also given. If we are using alpha=0.05 as our significance level, then we can reject the hypothesis that there is no overall correlation in the population between Body Mass and Head size if p<0.05.
The default for cor.test() is to do a two-tailed test. This is testing whether your observed correlation r is different from r=0 in either the positive or negative direction. This default version also gives us the confidence interval for the correlation coefficient. Essentially, this gives us the interval in which we have a 95% confidence that the true population r lies (remember we just have data from one sample that theoretically comes from a population).
It’s also possible however that you had an a priori prediction about the direction of the effect. For instance, you may have predicted that Body Mass would be positively correlated with Head Size. In this case, you could do a one-tailed correlation test, where your alternative hypothesis is that there is a positive correlation and the null is that the correlation coefficient is equal to 0 or less than 0.
To do one-tailed tests you need to add the alternative argument.
# testing if there is a positive correlation
cor.test(jayM$Head, jayM$Mass, alternative = "greater") ##
## Pearson's product-moment correlation
##
## data: jayM$Head and jayM$Mass
## t = 5.5228, df = 61, p-value = 3.641e-07
## alternative hypothesis: true correlation is greater than 0
## 95 percent confidence interval:
## 0.4187194 1.0000000
## sample estimates:
## cor
## 0.5773562##
## Pearson's product-moment correlation
##
## data: jayM$Head and jayM$Mass
## t = 5.5228, df = 61, p-value = 1
## alternative hypothesis: true correlation is less than 0
## 95 percent confidence interval:
## -1.0000000 0.7017994
## sample estimates:
## cor
## 0.577356211.3.1 Significance Testing a Pearson Correlation
In the above section we demonstrated how to do a one-tailed and two-tailed significance test in R. Let’s discuss a little more the output that is produced from cor.test() and what its relevance is.
Most importantly, we need to discuss the observed \(t\) statistic and the degrees of freedom. As already described above, the degrees of freedom are equal to \(n-2\). The \(t\) value represents how likely it was to get the sample correlation that we got in our sample if the true population correlation was actually \(\rho=0\).
There are several ways to calculate \(t\), but here is a nice shortcut formula:
\(\Large t = r\sqrt{\frac{n-2}{1-r^2}}\)
You’ll also see this same formula written like this:
\(\Large t = \frac{r}{\sqrt{\frac{1-r^2}{n-2}}}\)
So, as an example, if we calculated a correlation coefficient of \(r=0.42\) from a sample size of 19, then we could calculate our observed \(t\) value as follows:
## [1] 1.908163We calculate the observed \(t\) value to be \(t = 1.91\). We can visualize our sampling distribution of possible correlations as a \(t\)-distribution with degrees of freedom equal to 17 (19-2).
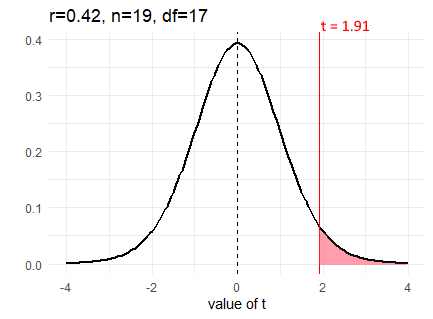
Like with other t-distributions, we can calculate how likely we were to get our observed value of \(t\) by calculating the area under the curve in the tails. For a positive \(t\)-value we want to know the area under the curve for values greater than our \(t\)-value. That would tell us how likely we were to get that value. We do this in the same way as with t-tests, using pt(). We put in our \(t\)-value, and our degrees of freedom. Because pt() returns the area under the curve to the left of our \(t\)-value, we need to do 1 - pt() to get the area to the right:
## [1] 0.03670244Therefore, our p-value here is \(p=0.04\). But, be careful. This is only the p-value for a one-tailed test. If we are conducting a two-tailed significance test, then we need to account for samples that are as extremely negative as well as extremely positive as our observed value. We must double the p-value to account for the area under both tails.
## [1] 0.07340487Our p-value is \(p=0.073\) for a two-tailed test.
Below is a sample of data that actually has a correlation of \(r=0.42\) and a sample size of 19.
x <- c(-0.73, 0.89, 1.36, -1.30, 1.07, 0.76, -1.32, -1.31, 0.46, 2.09, 0.36, -0.70, -1.34, -1.99, -0.39, -0.51, -0.92, 1.37, 2.31)
y <-c(0.69, 0.29, -0.52, -0.05, -1.08, 0.37, -0.31, -0.33, 0.76, 1.37, 0.91, 0.19, 0.10, -2.00, -1.72, 0.53, -0.52, -0.20, 0.63)
dfxy <- data.frame(x=x, y=y)
ggplot(dfxy, aes(x=x, y=y)) +
geom_point(size=2, color = "#123abc", alpha=.7)+
stat_smooth(method="lm", se=F) +
theme_classic()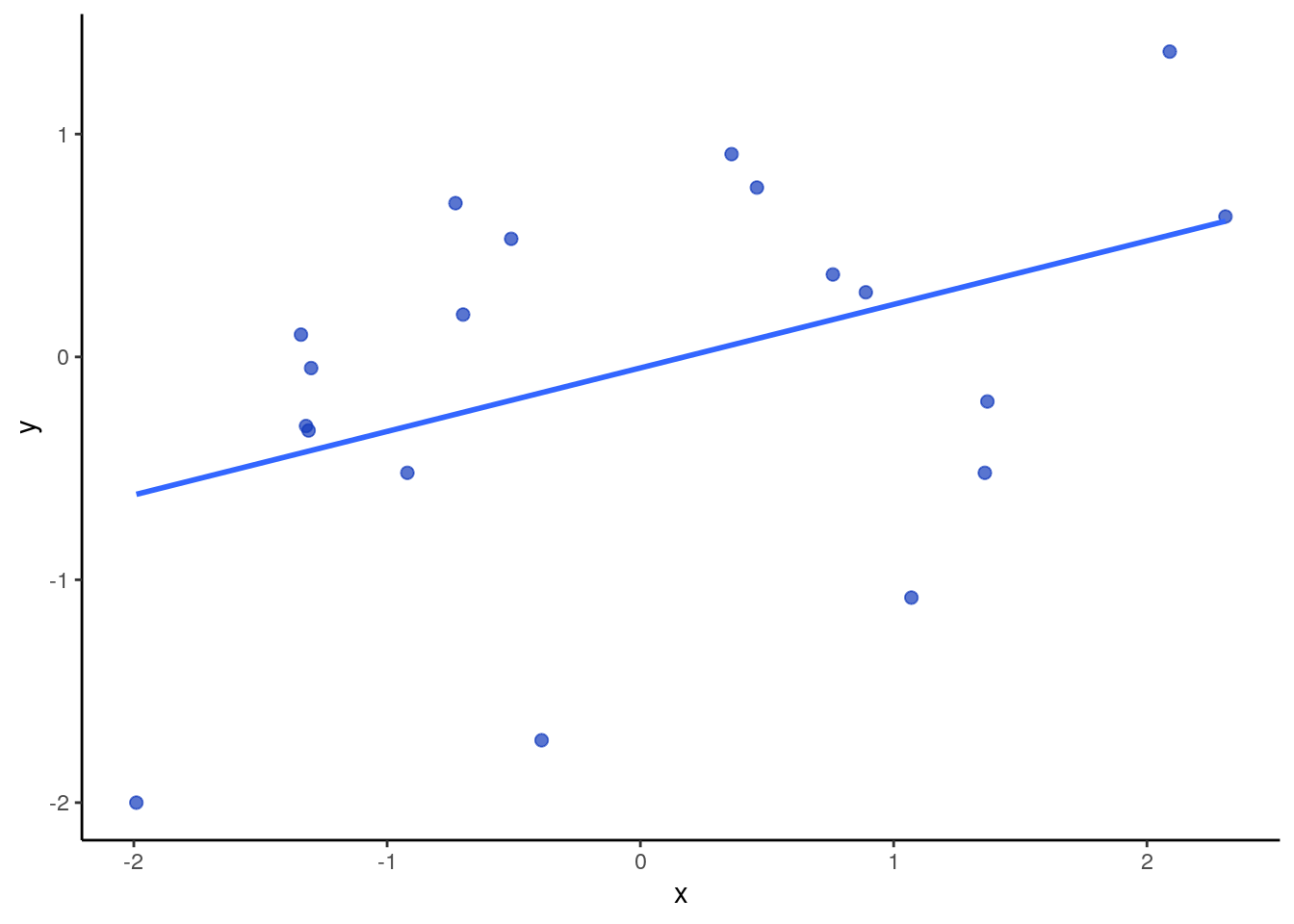
Let’s look at the output if we conduct a two-tailed significance test on our sample \(r\):
##
## Pearson's product-moment correlation
##
## data: x and y
## t = 1.9081, df = 17, p-value = 0.07341
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## -0.0422865 0.7341500
## sample estimates:
## cor
## 0.4199895We get our correlation of \(r=0.42\), degrees of freedom = 17, and observed \(t\)-value of \(t=1.91\). We also see the p-value of \(p=0.07\).
If we were to do a one-tailed test (assuming we had an a priori prediction as to the direction of the correlation):
##
## Pearson's product-moment correlation
##
## data: x and y
## t = 1.9081, df = 17, p-value = 0.03671
## alternative hypothesis: true correlation is greater than 0
## 95 percent confidence interval:
## 0.03644971 1.00000000
## sample estimates:
## cor
## 0.4199895
Now we see that we get the same \(t\)- and p-values, but the probability is half as with the two-tailed test.
Additionally the R output of cor.test() gives us a 95% confidence interval around our sample Pearson correlation r. Remember, r is just an estimate of the true population correlation coefficient \(\rho\). Therefore, this 95% confidence interval represents a measure of how certain we are in this estimate. We should use the 95% confidence interval that is outputted when we do a two-tail test. We discuss this in more detail below.
11.4 Assumptions of Pearson’s Correlation
The Pearson Correlation Coefficient requires your data to be approximately normally distributed. To do this we have various options how to test for normality.
Firstly, we could do a Shapiro-Wilk test, which formally determines whether our data are normal. This is done using shapiro.test(), where we assume our data are from a normal population if the resulting p-value is above 0.05. If the p-value is below 0.05 then we have evidence to reject that our data come from a normal population.
With our data above, this would look like this when running the test on each variable:
##
## Shapiro-Wilk normality test
##
## data: jayM$Mass
## W = 0.97222, p-value = 0.1647##
## Shapiro-Wilk normality test
##
## data: jayM$Head
## W = 0.96521, p-value = 0.07189We can also make a QQ-plot for each variable. Essentially what we require from this plot is for the majority of our data to fall on the straight line - especially the datapoints in the middle. Some deviation at the tails is ok. This plot orders our data and plots the observed data against values on the x-axis that we would expect to get if our data was truly from a normal population.
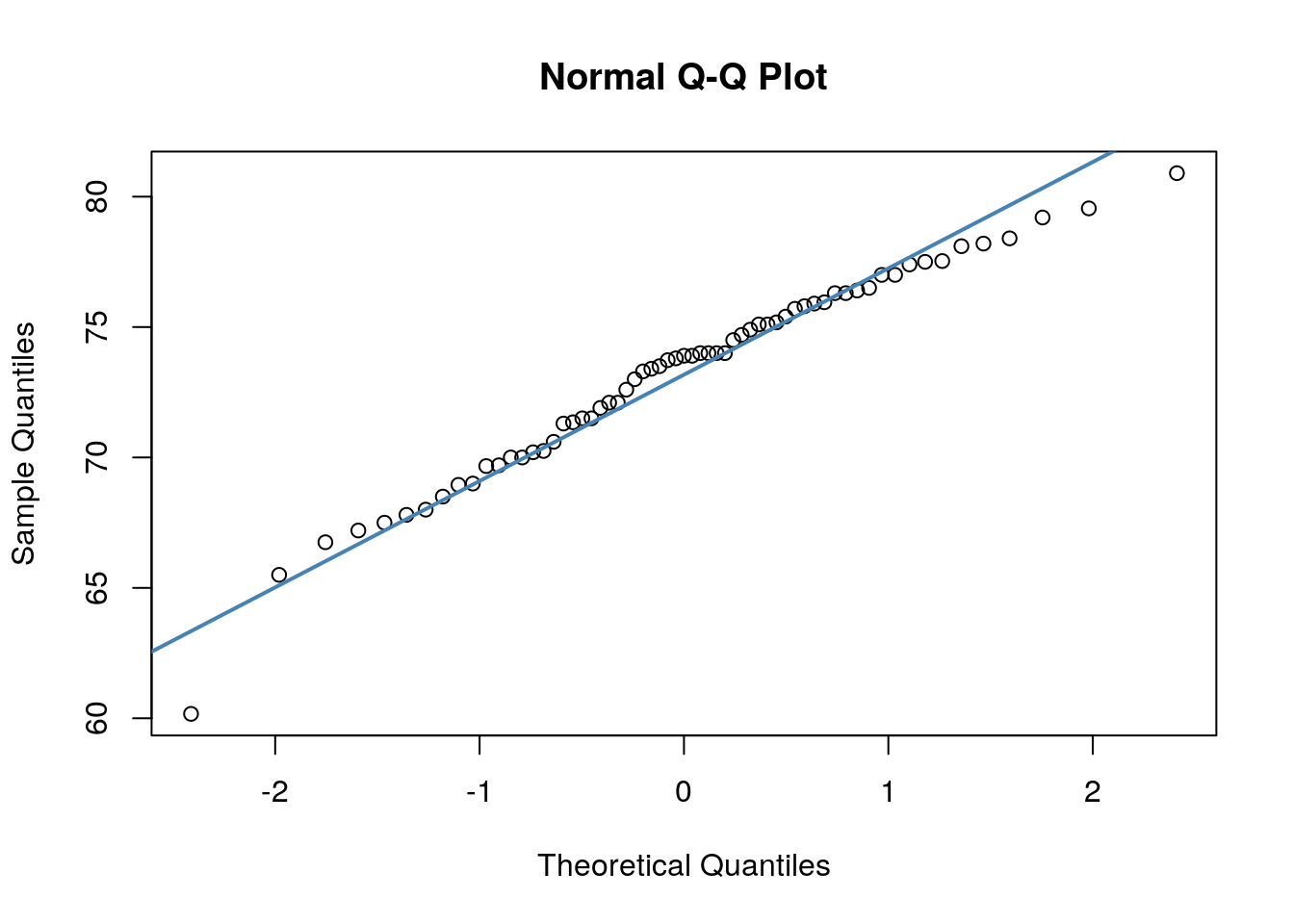
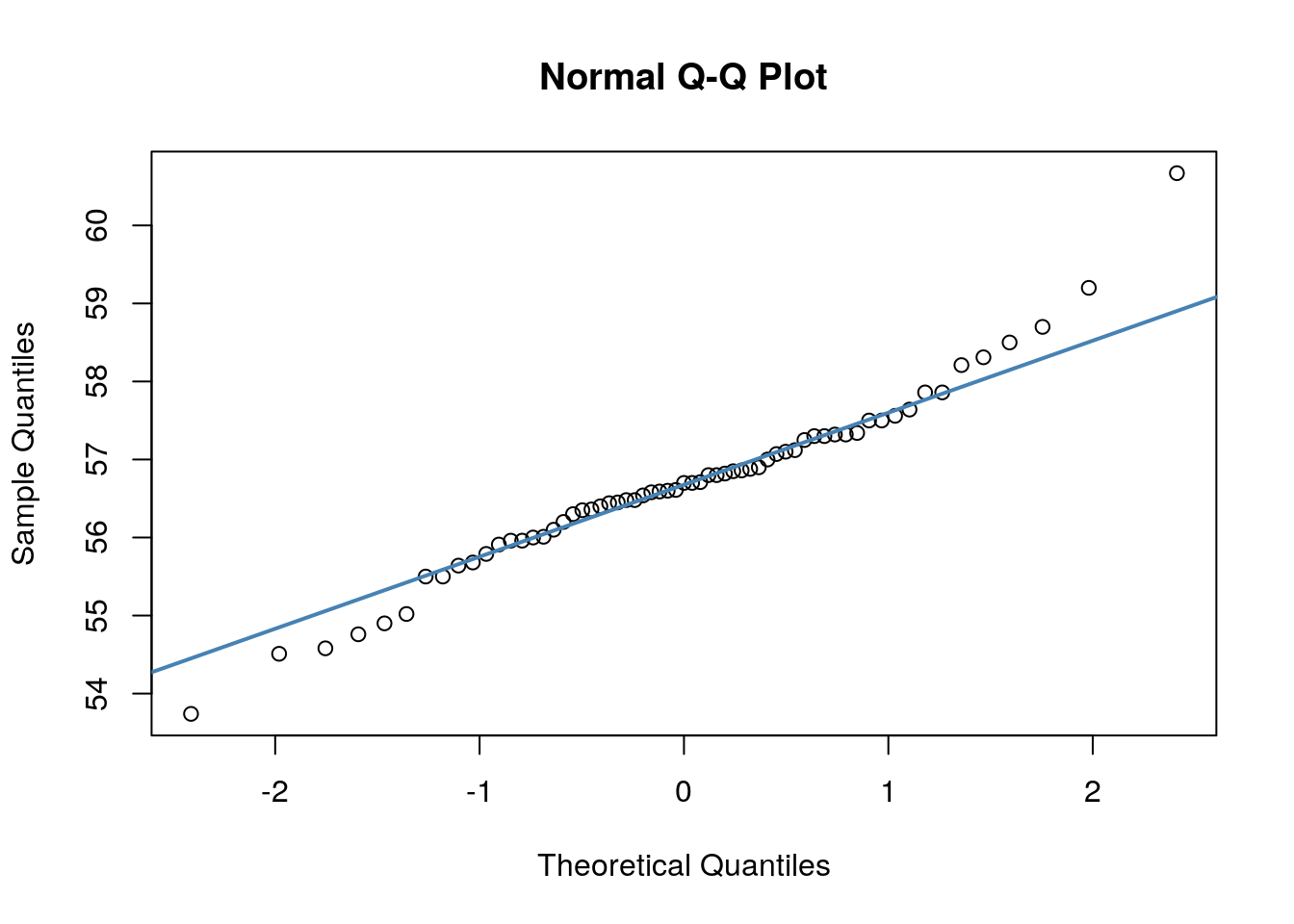
Both of these QQ plots are ok, and indicate normality, as does our Shapiro-Wilk tests. Therefore we would be ok to use a Pearson Correlation test with these data.
What should you do though if either of your continuous variables are not approximately normally distributed? In that case, there are other correlation coefficients and associated significance tests that you could run instead. We describe these in more detail in Section 11.7.
11.5 Confidence Intervals for r
When we run a correlation on our data we get one correlation coefficient \(r\) from our sample. Ideally we would be able to give a confidence interval around this correlation coefficient to describe how certain or uncertain we are in the correlation coefficient. This is possible to do, but it’s a bit long-winded. Let’s look at how it is done.
The main thing to realize is that our sample of data that we calculate our observed correlation coefficient from is technically just one sample that we could have got from a population. We could have picked a slightly different sample, and got a slightly different correlation. Let’s work through this using an example.
Say we have a population of 25,000 subjects (datapoints) and the true population correlation coefficient is \(\rho=0.75\) (When we’re dealing with a population we use \(\rho\) for the Pearson’s correlation coefficient rather than \(r\).).
This is our population. We have 25,000 rows of x and y data:
## # A tibble: 6 x 2
## x y
## <dbl> <dbl>
## 1 6.45 4.89
## 2 5.31 3.86
## 3 4.68 6.31
## 4 7.29 6.30
## 5 5.70 4.58
## 6 6.72 5.52## # A tibble: 6 x 2
## x y
## <dbl> <dbl>
## 1 5.88 4.26
## 2 4.01 3.17
## 3 5.06 5.47
## 4 7.00 6.27
## 5 8.60 8.18
## 6 3.84 4.12## [1] 25000We could plot this to examine the population data:
ggplot(dfr, aes(x=x,y=y))+
geom_point(alpha=.05) +
theme_classic() +
stat_smooth(method='lm',se=F) +
ggtitle("Population of 25,000 r=0.75")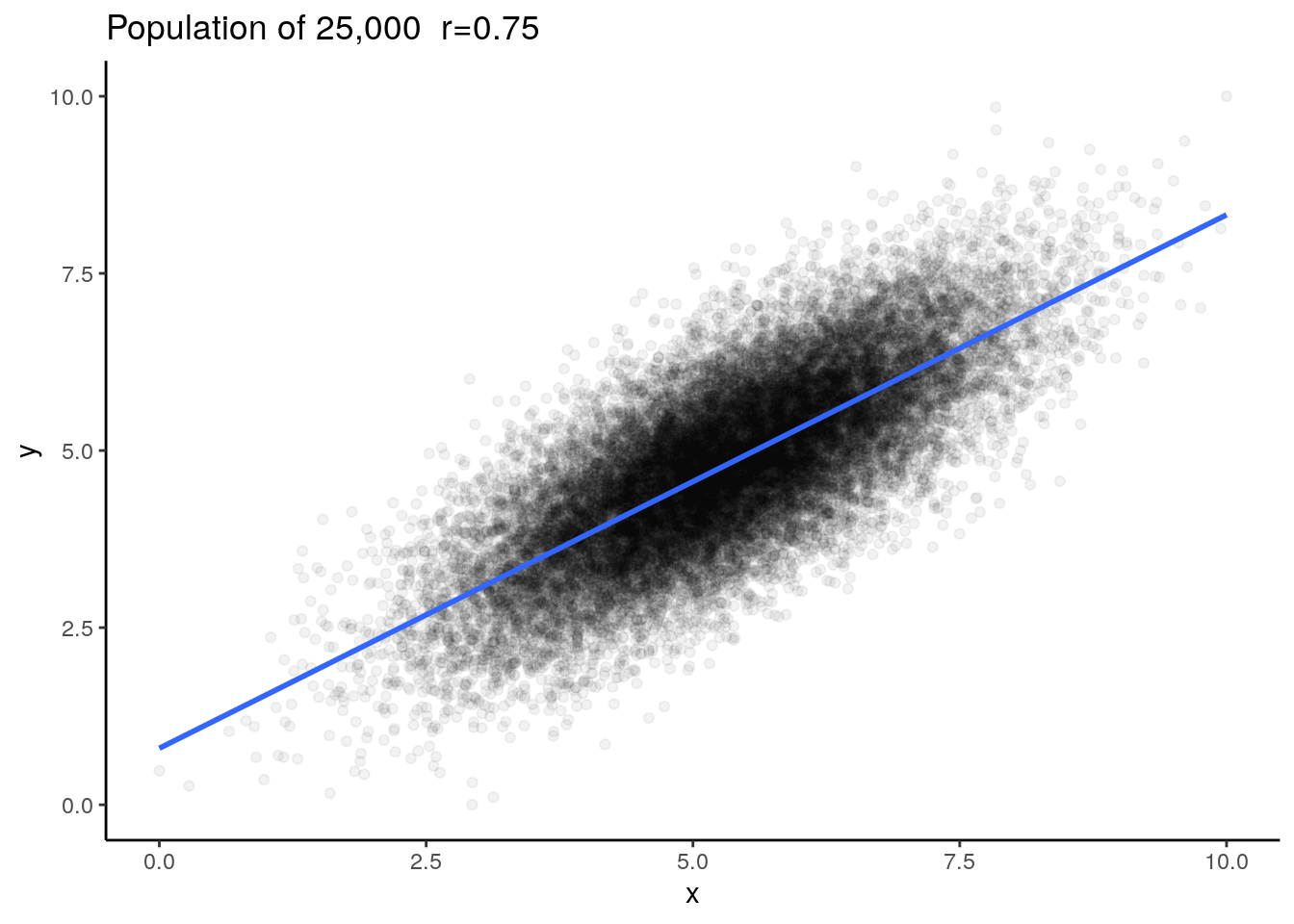
We can check the correlation for the population and we find that \(\rho=0.75\).
## [1] 0.75If we were interested in trying to find the correlation between x and y but were unable to measure all 25,000 individuals in the population, we might pick one sample to test. Imagine we pick a sample size of \(n=15\). Let’s pick 15 datapoints at random from our population and find out the correlation coefficient \(r\) of this sample:
set.seed(1) # so we get the same results
# this code selects 15 rows at random
samp1 <- dfr[sample(1:nrow(dfr),15, T),]
samp1## # A tibble: 15 x 2
## x y
## <dbl> <dbl>
## 1 5.21 3.52
## 2 4.99 4.30
## 3 6.26 5.37
## 4 7.58 6.31
## 5 5.88 4.89
## 6 3.63 4.40
## 7 3.89 3.62
## 8 8.61 8.02
## 9 6.53 7.78
## 10 5.18 5.53
## 11 6.70 4.69
## 12 3.63 3.87
## 13 4.28 3.63
## 14 5.51 5.52
## 15 5.58 5.45We can make a quick plot of our sample of 15, and calculate the sample correlation:
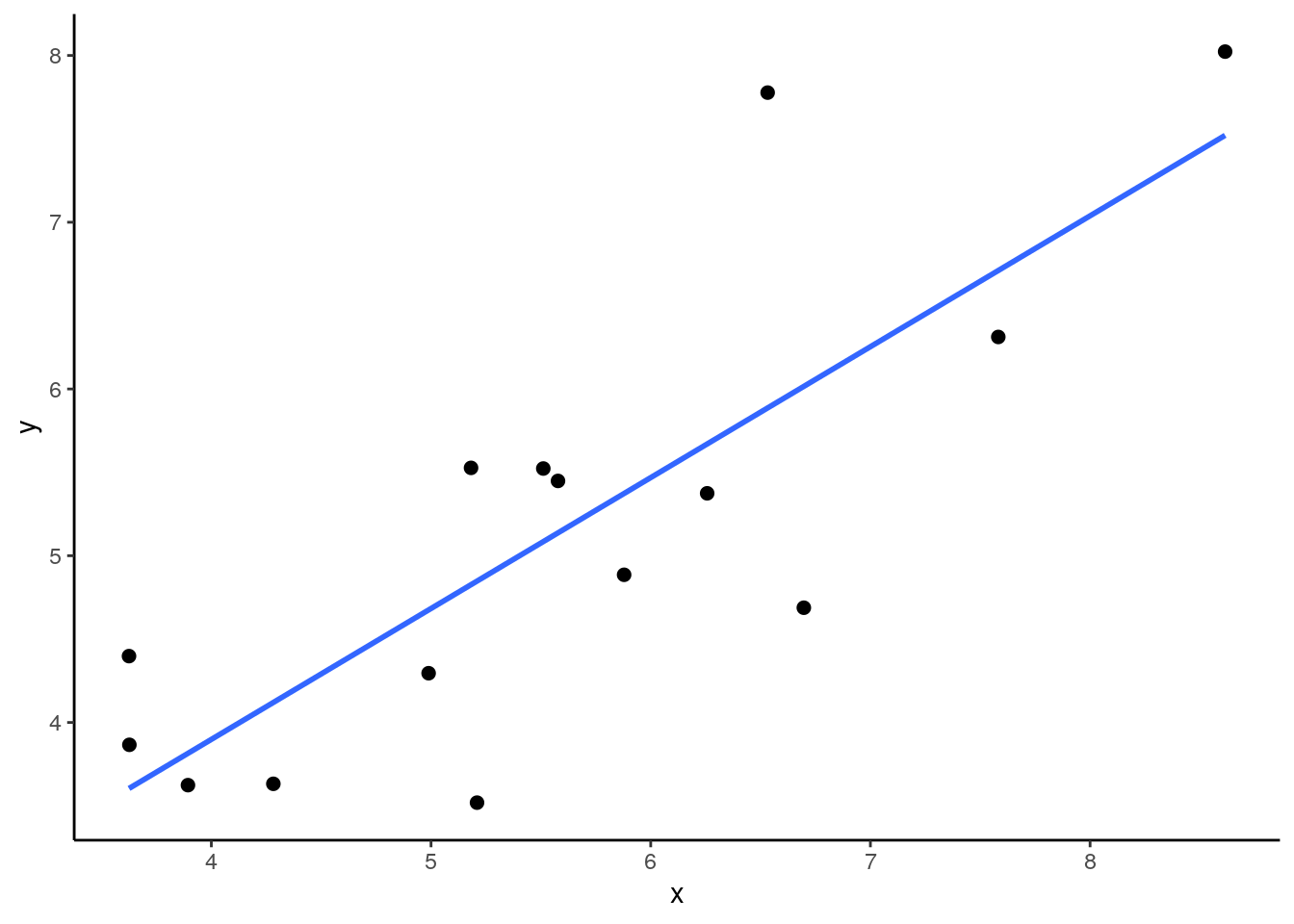
## [1] 0.8032389In our sample we get \(r=0.80\) which is a little bit higher than our population correlation. What if we take a few more samples of size 15? What would we get for those sample correlations? Let’s do it:
## [1] 0.8596689## [1] 0.7906216## [1] 0.7779393## [1] 0.5526942The next three samples have correlations that are also higher than the population correlation. The fifth sample we collected is much lower with the sample correlation being \(r=0.55\). As you might have worked out by now, if we keep doing this over and over again (thousands of times) we would end up with a sampling distribution of correlation coefficients. Let’s do that:
#this code is to get 50,000 correlation coefficients from samples of n=15
results <- vector('list',50000)
for(i in 1:50000){
samp <- dfr[sample(1:nrow(dfr),15, T),]
results[[i]] <- cor(samp$x, samp$y)
}
dfr.results <- data.frame(r = unlist(results))
head(dfr.results)## r
## 1 0.7510068
## 2 0.7967477
## 3 0.8542031
## 4 0.7193954
## 5 0.7892438
## 6 0.8128191Because we now have a sampling distribution of correlation coefficients, we can plot this in a histogram.
ggplot(dfr.results, aes(x=r)) +
geom_histogram(aes(y = ..density..), color = "black", fill = "purple", alpha=.4, binwidth = .01) +
geom_density(alpha = 0.7, fill = "mistyrose") +
theme_classic() +
xlab("Sample correlation r") +
ggtitle("Sampling Distribution of Correlation Coefficients")+
geom_vline(xintercept=0.75, lty=1, lwd=1, color="red")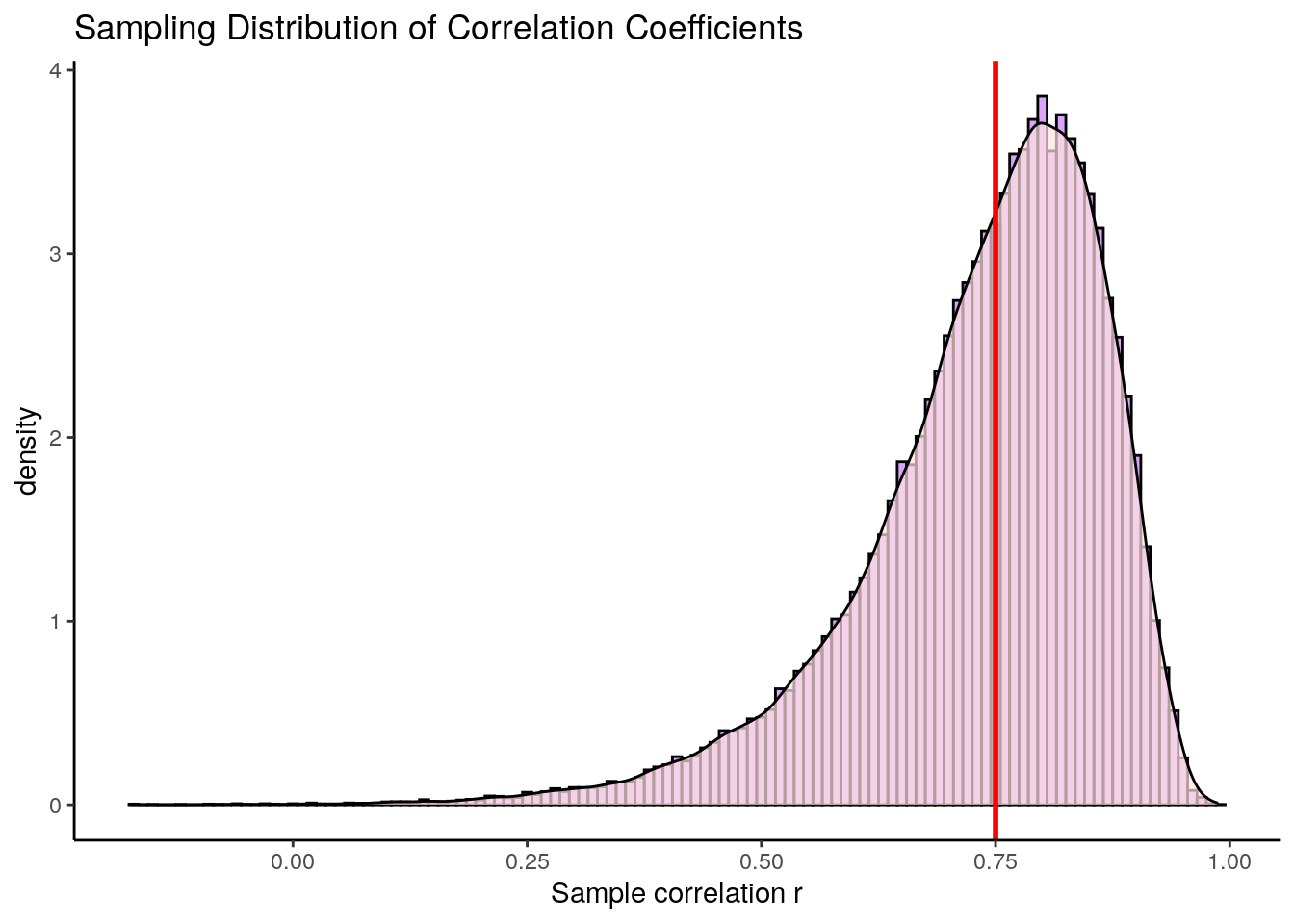
What is the first thing that you notice about this sampling distribution? Hopefully it is that it is not symmetrical. It is highly skewed. This is because correlation coefficients are bounded between -1 and +1. We do not get an approximately normally distributed sampling distribution (with the one exception being when the population correlation \(\rho=0\). The red line represents our original population coefficient of \(\rho=0.75\).
There is however a trick that we can employ to make this sampling distribution approximately normal. We can do something called Fisher Transform our sample correlations in the sampling distribution. So for every value of \(r\) in our sampling distribution, we can apply the following formula:
\(\Large z' = 0.5 \times \log(\frac{1 + r}{1 - r})\)
\(z'\) is referred to as the Fisher Transformed \(r\) value. So, if we had a sample correlation of \(r=0.56\), that would equate to a \(z'\) value of \(z'=0.63\):
## [1] 0.6328332Alternatively, a correlation of \(r=0.75\) would have a Fisher transformed score of \(z'=0.97\):
## [1] 0.9729551Notably, a correlation of \(r=0.0\) has a Fisher transformed score of \(z'=0.00\):
## [1] 0If we apply this formula to all the \(r\) values in our sampling distribution and replot the distribution, it now looks like this:
#put Fisher transformed scores into a column called 'zt'
dfr.results$zt <- 0.5 * log( (1+dfr.results$r) / (1-dfr.results$r) )
head(dfr.results)## r zt
## 1 0.7510068 0.9752603
## 2 0.7967477 1.0896426
## 3 0.8542031 1.2714979
## 4 0.7193954 0.9063907
## 5 0.7892438 1.0694231
## 6 0.8128191 1.1352814ggplot(dfr.results, aes(x=zt)) +
geom_histogram(aes(y = ..density..), color = "black", fill = "purple", alpha=.4, binwidth = .05) +
geom_density(alpha = 0.7, fill = "mistyrose") +
theme_classic() +
xlab("Fisher Transformed z'") +
ggtitle("Sampling Distribution of Correlation Coefficients")+
geom_vline(xintercept=0.97, lty=1, lwd=1, color="red")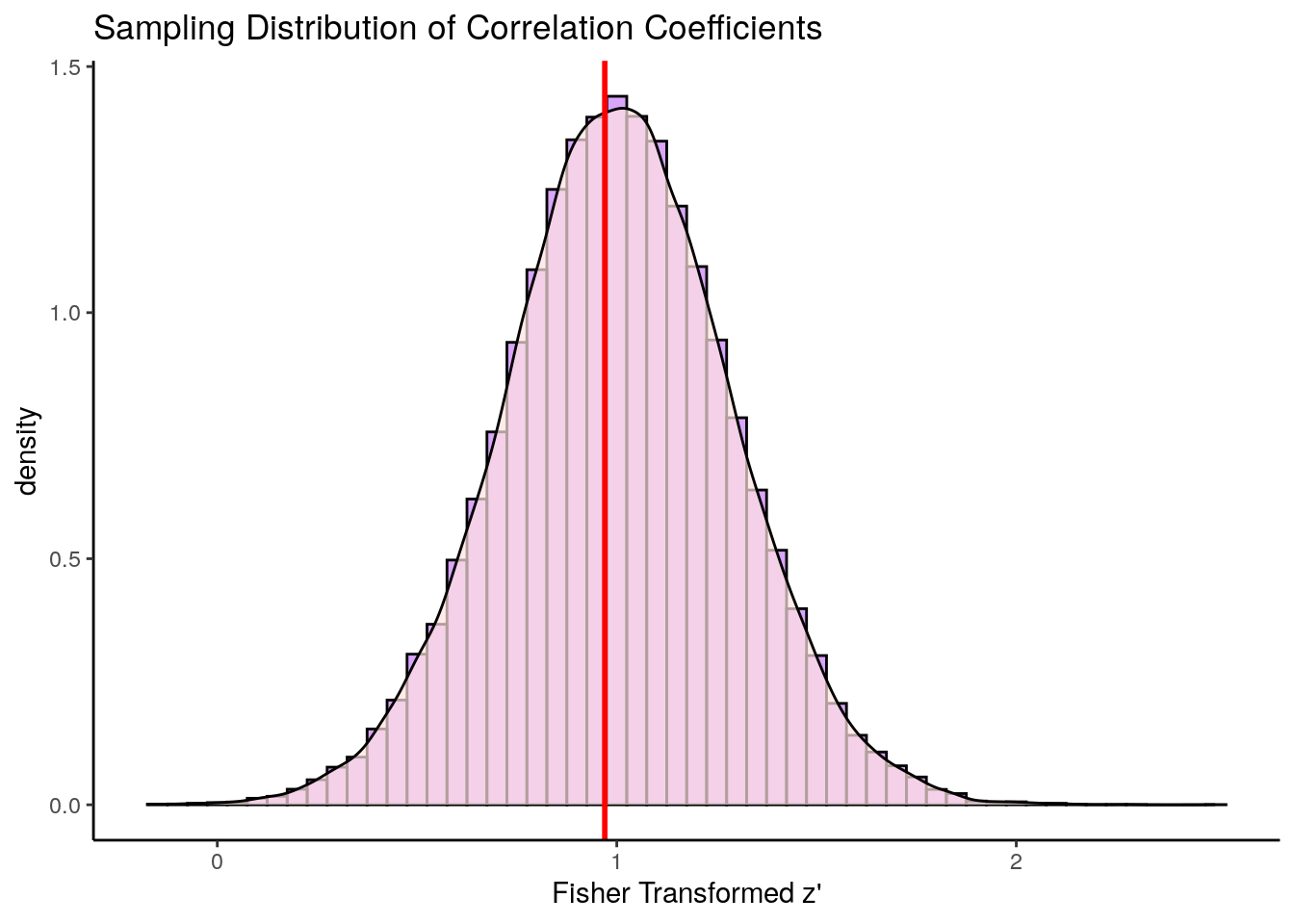
This distribution is approximately symmetrical. The red line here represents the population correlation coefficient of \(r=0.75\) which is \(z'=0.97\). This is the approximate mean of the distribution.
The standard deviation of this transformed sampling distribution can be calculated by this formula:
\(\Large se = \sqrt{\frac{1}{n-3}}\)
So, because we have a sample size of \(n=15\) the standard deviation of this sampling distribution is \(se = 0.289\):
## [1] 0.2886751Now we have an approximately normal sampling distribution with a standard deviation, we can start to do similar things to what we did with other sampling distributions such as calculate confidence intervals.
Let’s calculate a confidence interval around a sample of \(r=0.56\). What we assume is that the Fisher transformed score of \(r=0.56\) is the mean of the sampling distribution. Therefore we assume that \(z' = 0.63\) is the mean of the sampling distribution. Because we want to have 95% of the distribution inside the confidence interval, then we want to know which values are 1.96 standard deviations away from the mean. This is because we’re assuming the transformed sampling distribution to be approximately normal, and in a standard normal curve 95% of the data is \(\pm 1.96\) standard deviations of the mean (see section 10.2.
The formula is:
\(CI_{95\%} = z' + (1.96 \times se)\)
In our example, 1.96 standard deviations away from the mean is:
## [1] 1.19644## [1] 0.06356We can visualize this as follows:
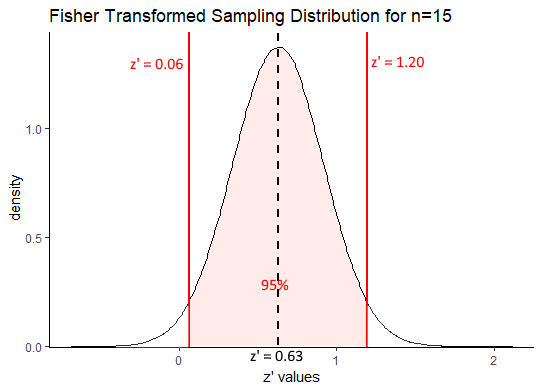
Our confidence interval in terms of Fisher Transformed z’ values is \(z' = 0.63[0.06, 1.20]\). One thing we can immediately draw from that is that a correlation of \(r=0\) is unlikely to be the true population correlation. This is because when \(r=0\), the transformed value is also equal to 0 and \(z'=0\) is not within the 95% confidence interval. Also, it is notable that our true population correlation coefficient of $ rho=0.75$ which equates to \(z'=0.97\) is included within the correlation coefficient.
As with other 95% confidence interval measures, what this really means is that in 95% of our samples we will capture the true population correlation coefficient when we create confidence intervals around our sample correlation coefficient.
Although we can directly determine if a population correlation of \(\rho=0\) is within our confidence interval or not, leaving the confidence interval in Fisher transformed \(z'\) values isn’t that interpretable. Thefore, you can tansform \(z'\) values back to \(r\) values using the following formula:
\(\Large r = \frac{\exp(2z')-1}{1 + \exp(2z')}\)
So for each bit of our confidence interval, transforming the \(z'\) values back to \(r\) values we get the following:
## [1] 0.5580522## [1] 0.0599281## [1] 0.8336546Our 95% confidence interval in terms of \(r\) is therfore \(r = 0.56[0.06, 0.83]\) which is very wide! but doesn’t include \(r=0\). If we were to increase our sample size then our confidence intervals would get tighter - and our individual estimate of the correlation coefficient would get close to the true population correlation coefficient \(\rho\).
Correlation Confidence Interval Example
Because the above is a little bit tricky, let’s look at a second example. In a study, researchers found a correlation of \(r= -0.654\) based on 34 observations. What is the 95% confidence interval of this correlation ?
First, convert the \(r\) value to a Fisher Transformed \(z'\) value and assume that is the mean of the symmetrical sampling distribution, and we get \(z' = -0.78\):
## [1] -0.7822566Second, we know the standard deviation of this symmetrical sampling distribution is equal to \(se = \sqrt{\frac{1}{n-3}}\), so it’s equal to 0.1796:
## [1] 0.1796053Third, we want to know the values of \(z'\) that are 1.96 times the sampling distribution standard deviation from the mean, to get the lower and upper bounds of our confidence intervals:
## [1] -0.4302302## [1] -1.134283In terms of Fisher transformed values, our 95% confidence interval is therefore \(z' = -0.78[-1.13, -0.43]\). Notice that 0 is not inside the confidence interval, suggesting that the population correlation coefficient is not equal to 0.
We can also convert all of these back to \(r\) values:
## [1] -0.6527067## [1] -0.8110193## [1] -0.4053213So our 95% Confidence interval is \(r = -0.65[-0.41, -0.81]\). Notice with the larger sample size, we get a much tighter confidence interval.
11.6 Partial Correlations
An important consideration when running a correlation is the third variable problem. In brief, this is when we have the situation that a purported association between X and Y is actually being driven by both of their association with a third variable Z. It is important to consider that a correlation may only exist because both variables are correlated with something else. Alternatively, we may wish to get an “adjusted” correlation between X and Y based on their relationship with Z. This is essentially the theory behing partial correlations.
If we have measured the correlation between X and Y (which we’ll call \(r_{xy}\)) as well as each of their correlations with Z (which we’ll call \(r_{xz}\) and \(r_{yz}\) respectively) then we can calculate this adjusted partial correlation between X and Y which we’ll call \(r_{xy.z}\). To do this, we use this horrible looking formula:
\(\Large r_{xy.z} = \frac{r_{xy} - (r_{xz}\times r_{yz}) } {\sqrt{1-r_{xz}^2} \times \sqrt{1-r_{yz}^2}}\)
In reality though, it’s pretty easy to plug the correct values for \(r\) or \(r^2\) into this formula and get the result required.
Let’s use an example. In these data we have 50 participants who logged the number of hours that they engaged in a task. We also have a column that shows their score in that task, and a column that records how tired they were. Higher tiredness scores means that they were more tired. (We’ve changed this from the column name in the original video to make it clear!)
gs <- read_csv("data/gamescore.csv")
colnames(gs)[4]<-"tiredness" # change this column name to make it more clear
nrow(gs)## [1] 50## # A tibble: 6 x 4
## name hours score tiredness
## <chr> <dbl> <dbl> <dbl>
## 1 Ebert, Julia 11.6 95.2 4.5
## 2 Vasquez, Horacio 8.5 109. 6.1
## 3 Yoakum, Anthony 8 110. 6.6
## 4 Kroha, Abagail 10.7 95.4 7.3
## 5 Baray Perez, Daysi 3 81.2 7.7
## 6 Mcalister, Katherine 8.5 124. 7.2Say we predicted that the more hours played would lead to a higher score in the task. We might make our scatterplot and then run a one-tailed Pearson’s correlation significance test:
# scatterplot
ggplot(gs, aes(x=hours, y=score)) +
geom_point(color="navy") +
stat_smooth(method="lm",se=F) +
theme_classic()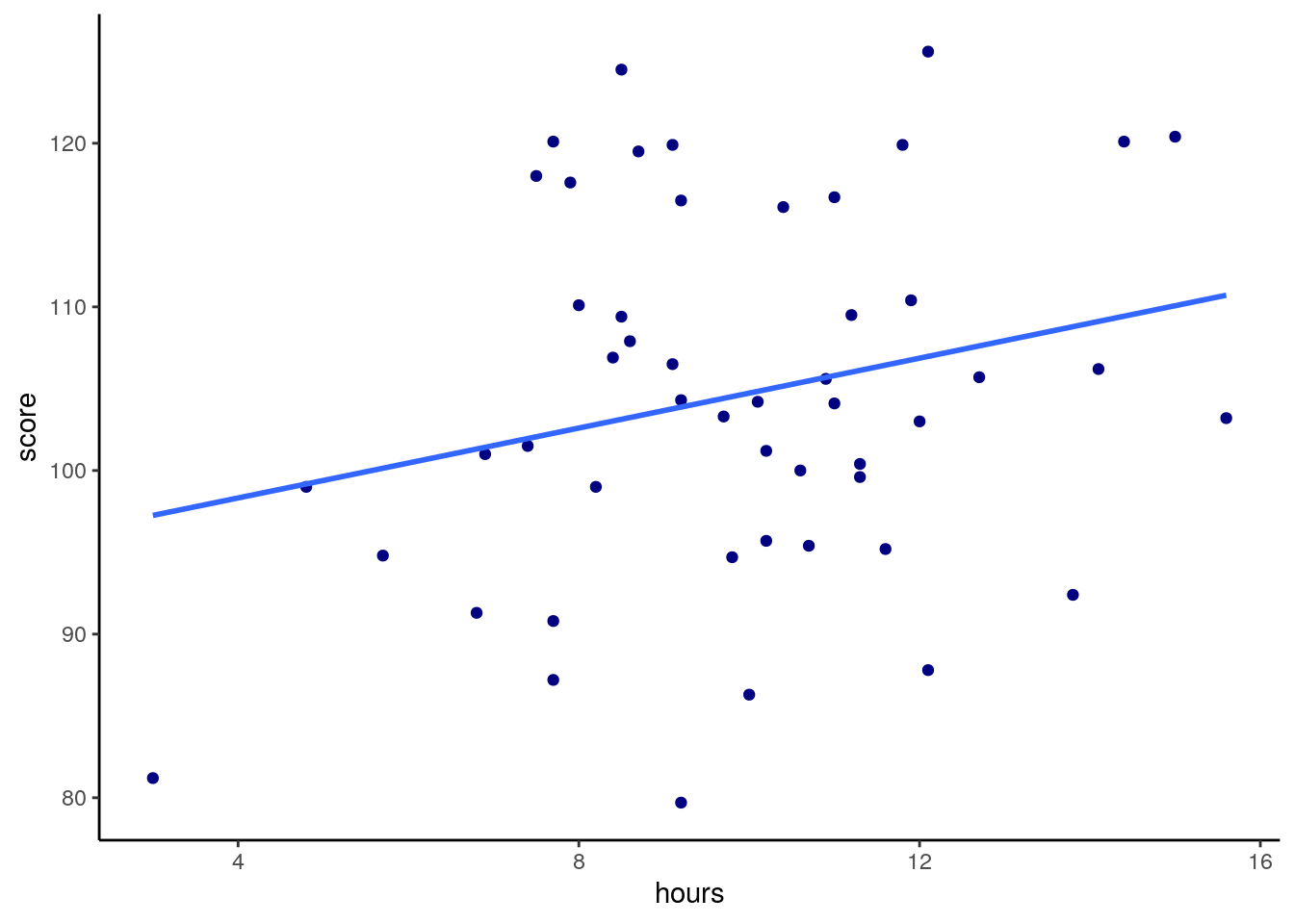
##
## Pearson's product-moment correlation
##
## data: gs$hours and gs$score
## t = 1.6887, df = 48, p-value = 0.04888
## alternative hypothesis: true correlation is greater than 0
## 95 percent confidence interval:
## 0.001470868 1.000000000
## sample estimates:
## cor
## 0.2368152We can see from this plot that we have a correlation of r=0.24 between hours and score, which is a low to moderate correlation. Our one-tailed significance test also tells us that we have a significant difference of p=0.049 that this is a significantly positive correlation, although the effect is smallish.
What if we considered each of these variables’ relationship with tiredness ?
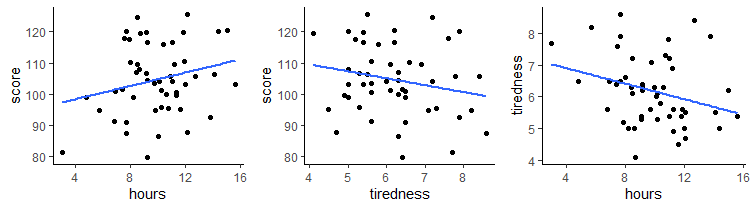
We can calculate the Pearson correlation for tiredness against score and for hours against tiredness, in addition to our original correlation of hours against score.
## [1] 0.2368152## [1] -0.2099467## [1] -0.2867374As you can see, tiredness is negatively correlated with score, meaning individuals who reporte themselves as more tired scored lower in the task. Hours was also negatively correlated with tiredness, meaning individuals who were more tired spent fewer hours on the task.
It’s therefore possible that an individual’s tiredness could affect both the number of hours that an individual engages in the task, as well as their overall performance. These relationships may affect the overall obseved relationship between hours and score.
If we were to do this in R, we’d use the pcor.test() function from the ppcor package. We just need to tell it what our original X and Y are as well as our third variable Z.
## estimate p.value statistic n gp Method
## 1 0.1885594 0.1944534 1.316311 50 1 pearsonThis output tells us that the adjust correlation, i.e. the partial correlation for \(r_{xy}\) is 0.19. There is a p-value associated with that correlation of p=0.194 which indicates that the correlation is no longer significant. This means that the relationship between test score and hours is no longer signficant after you take into account that they are both related to tiredness.
We can also look at this ‘by hand’ using the formula above:
r.xy <- cor(gs$hours, gs$score) # r = 0.24
r.xz <- cor(gs$tiredness, gs$score) # r = -0.21
r.yz <- cor(gs$hours, gs$tiredness) # r = -0.29numerator <- r.xy - (r.xz * r.yz)
denominator <- (sqrt(1 - r.xz^2) * (sqrt(1 - r.yz^2)) )
numerator/denominator## [1] 0.1885594We get the same result!
11.7 Non-parametric Correlations
When at least on of our variables are not normal, then we need to consider alternative approaches to the Pearson correlation for assessing correlations.
Let’s take this example, where we are interested in seeing if there’s an association between saturated fat and cholesterol levels across a bunch of different cheeses:
## # A tibble: 6 x 9
## type sat_fat polysat_fat monosat_fat protein carb chol fiber kcal
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 blue 18.7 0.8 7.78 21.4 2.34 75 0 353
## 2 brick 18.8 0.784 8.60 23.2 2.79 94 0 371
## 3 brie 17.4 0.826 8.01 20.8 0.45 100 0 334
## 4 camembert 15.3 0.724 7.02 19.8 0.46 72 0 300
## 5 caraway 18.6 0.83 8.28 25.2 3.06 93 0 376
## 6 cheddar 21.1 0.942 9.39 24.9 1.28 105 0 403# let's make a scatterplot of saturated fat against cholesterol
ggplot(cheese, aes(x = sat_fat, y = chol)) + geom_point() +
stat_smooth(method="lm",se=F)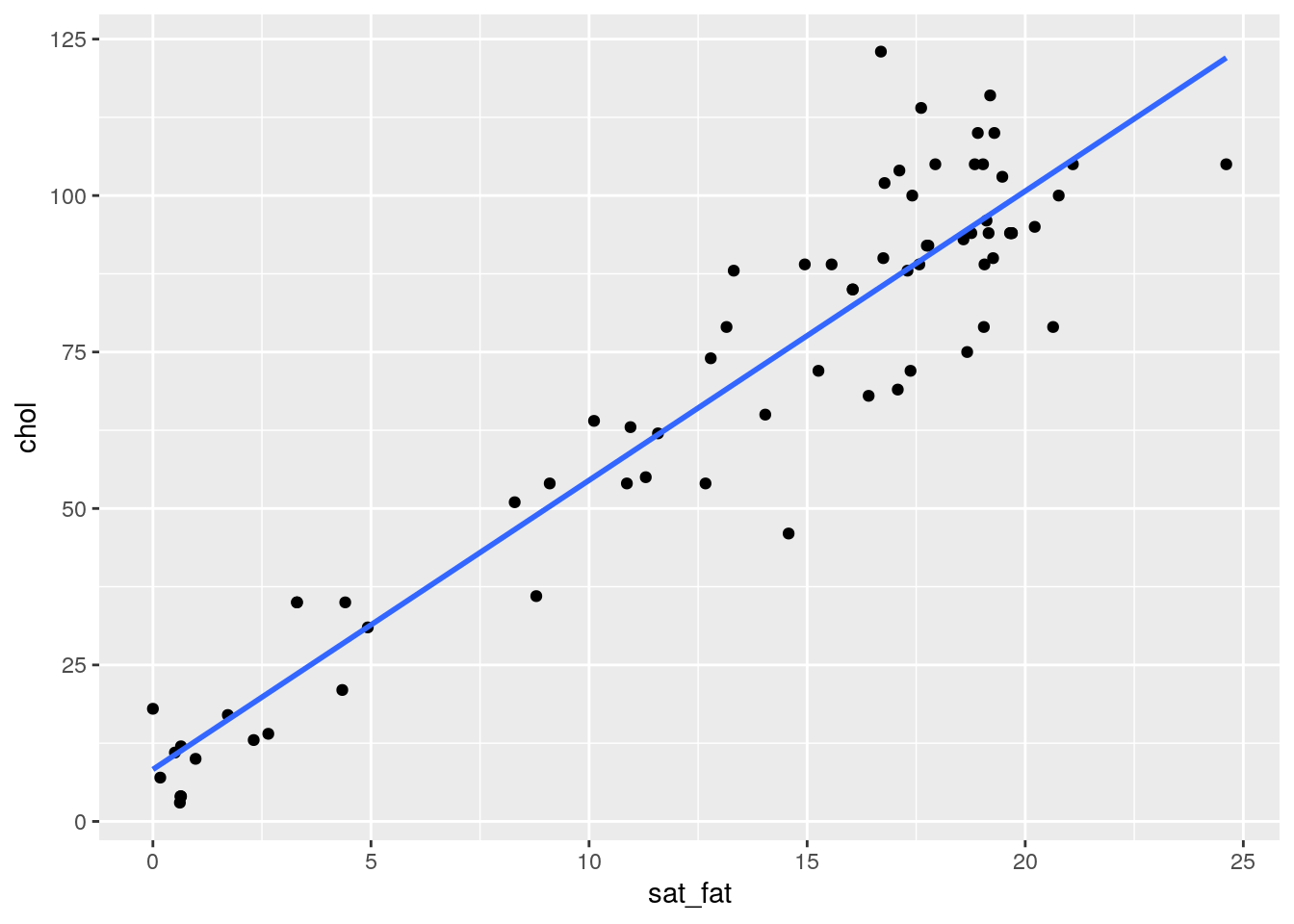
It looks like there is a pretty obvious relationship, but let’s check the normality of each variable before progressing. Firstly the Shapiro-Wilk tests suggest that our data do not come from a normal distribution:
##
## Shapiro-Wilk normality test
##
## data: cheese$sat_fat
## W = 0.85494, p-value = 6.28e-07##
## Shapiro-Wilk normality test
##
## data: cheese$chol
## W = 0.90099, p-value = 2.985e-05Secondly, we have quite dramatic deviation from the straight line of our datapoints in our QQ plots. This indicates that our dat are likley skewed.
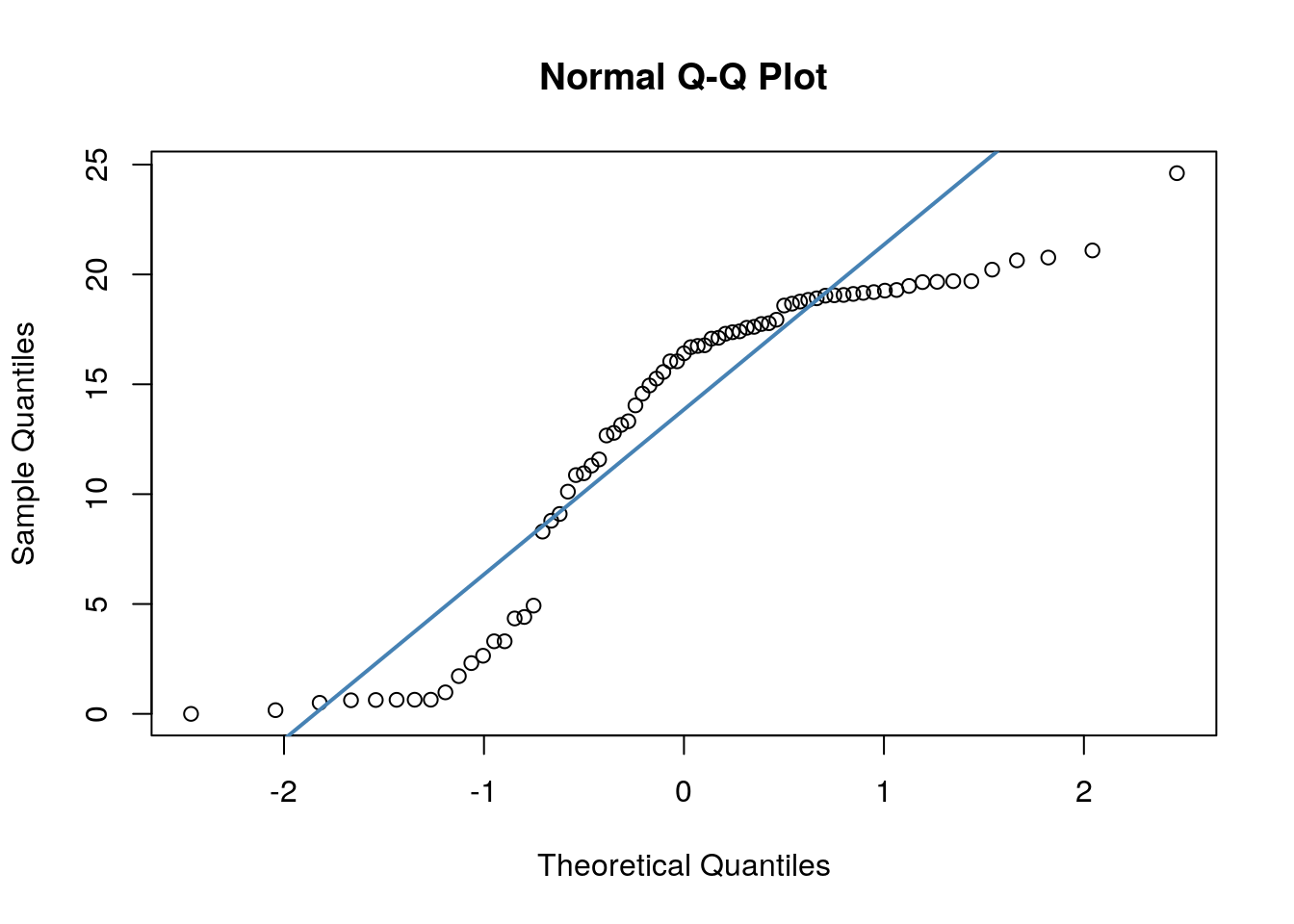
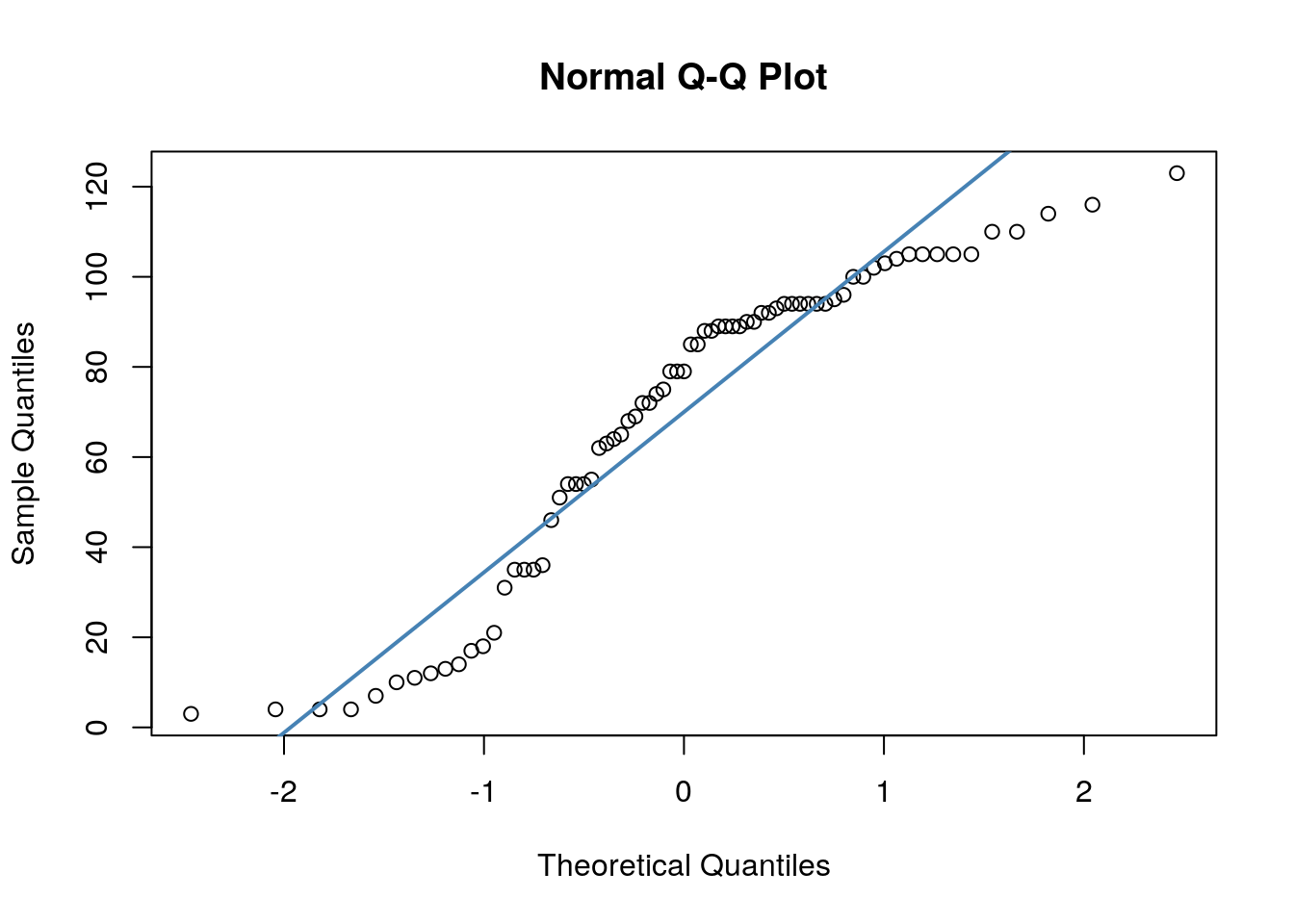
We could be thorough and check this by plotting histograms of our data:
library(gridExtra)
p1 <- ggplot(cheese, aes(x=sat_fat)) + geom_histogram(color="black", fill="lightseagreen")
p2 <- ggplot(cheese, aes(x=chol)) + geom_histogram(color="black", fill="lightseagreen")
grid.arrange(p1,p2,nrow=1)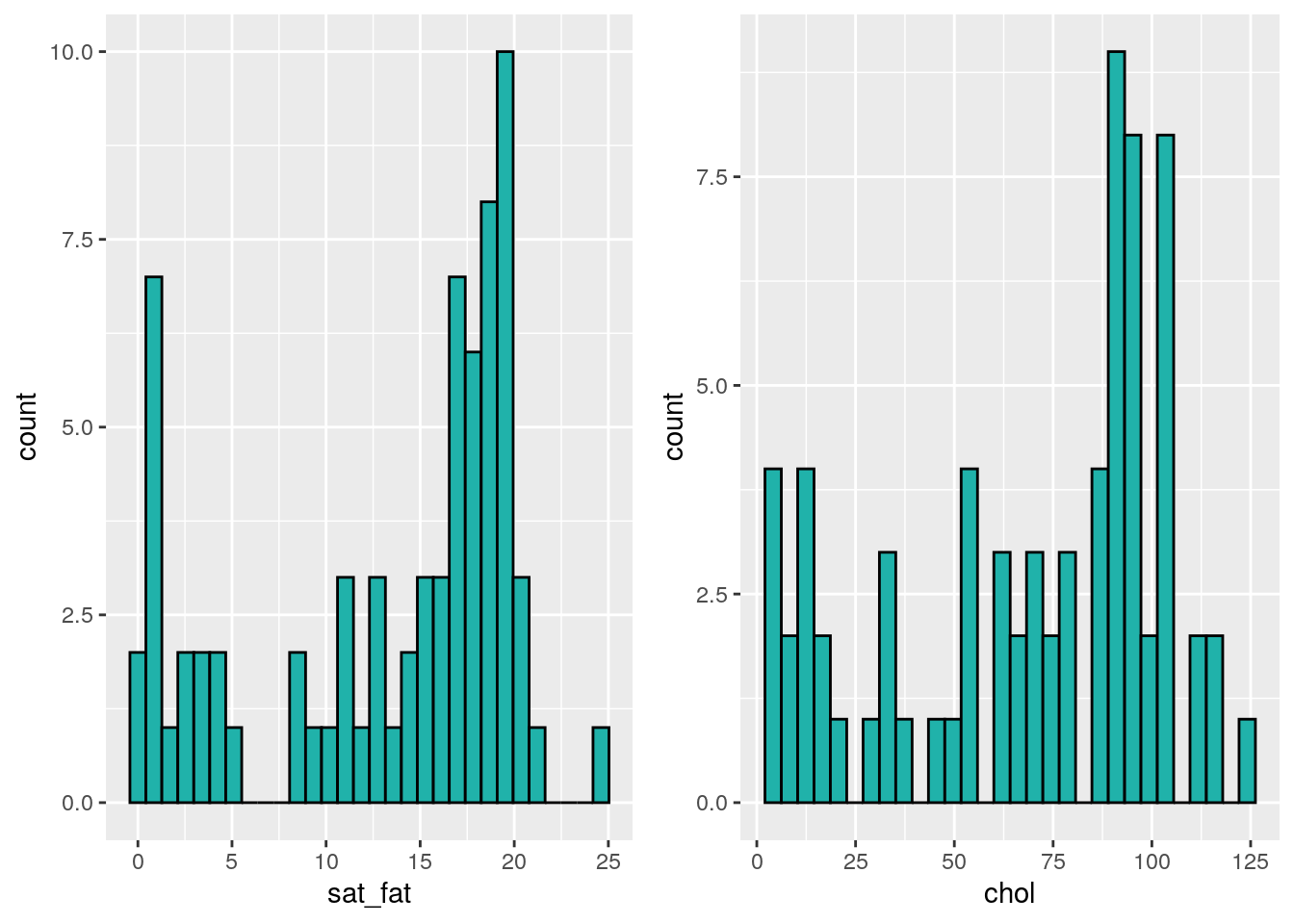
Because our data do not appear to be normal, we cannot do a Pearson correlation coefficient. We should instead use a non-parametric correlation method. There are several of these to choose from. We don’t plan to go into the details here of how these methods determine their correlation coefficients or conduct significance test. In brief, these methods generally rank order the datapoints along the x and y axes and then determine how ordered these ranks are with respect to each other.
Probably the most commonly used non-parametric correlation test is called the Spearman Rank Correlation test.
To run this, we can use cor() to get the correlation or cor.test() to run the signficance test in the same way we did the Pearson test. However, the difference here is that we specify method="spearman" at the end.
## [1] 0.8677042##
## Spearman's rank correlation rho
##
## data: cheese$sat_fat and cheese$chol
## S = 8575.9, p-value < 2.2e-16
## alternative hypothesis: true rho is not equal to 0
## sample estimates:
## rho
## 0.8677042The correlation coefficient here is 0.87 and is termed rho instead of r. With the significance test, you get a test-statistic S which relates to how well ordered the ranked data are. Also provided is a p-value. As with the Pearson, the default is a 2-tailed test, testing whether the obsvered correlation could have come from a population with a correlation of 0. If the p-value is below 0.05 (using alpha = 0.05 as our criterion), then that is reasonable evidence that there is a significant correlation.
You may also notice with Spearman Rank correlations that you are forever getting warnings about computing p-values with ties. Don’t worry at all about this - although this is an issue with the test and how it calculates the p-value, it isn’t of any real practical concern.
If you were interested in conducting a one-tailed correlation test, you could do that in the same way as you did for the Pearson. For instance, if you predicted that cholesterol and saturated fat would have a positive correlation, you could do the following to do a one-tailed test:
##
## Spearman's rank correlation rho
##
## data: cheese$sat_fat and cheese$chol
## S = 8575.9, p-value < 2.2e-16
## alternative hypothesis: true rho is greater than 0
## sample estimates:
## rho
## 0.8677042You may also notice that the output of the Spearman Rank test does not give confidence intervals for the value of rho. This is unfortunate and is one of the drawbacks of doing a non-parametric correlation.
Finally, there are several other types of non-parametric correlations you could choose from if you didn’t want to do a Spearman Rank correlation. We personally recommend using a method called Kendalls Tau B correlation, which can be done like this:
##
## Kendall's rank correlation tau
##
## data: cheese$sat_fat and cheese$chol
## z = 8.8085, p-value < 2.2e-16
## alternative hypothesis: true tau is not equal to 0
## sample estimates:
## tau
## 0.7102531This output gives you a tau value which is the correlation coefficient, and a p-value which you can interpret in the same way as the other tests.
Ranked Data
If at least one of your variables of your data are rank (ordinal) data, then you should use non-parametric correlations.
In the following example, the data show the dominance rank, age, body size and testosterone levels for a group of 18 animals. Lower numbers of the ranks, indicate a higher ranking animal. An animal with rank 1 means that it is the most dominant individual.
Perhaps with such data you may be interested in seeing if there was an association between dominance rank and testosterone levels. Because your dominance rank measure is ordinal (a rank), then you should pick a non-parametric correlation.
## # A tibble: 6 x 4
## drank age size testosterone
## <dbl> <dbl> <dbl> <dbl>
## 1 3 13 183 4.8
## 2 7 9 155 3.9
## 3 7 5.5 144 3.8
## 4 1 11.5 201 6.4
## 5 12 3.5 125 1.8
## 6 4 10 166 4.3ggplot(test, aes(x = drank, y = testosterone)) +
geom_point() +
stat_smooth(method = "lm", se=F) +
xlab("Dominance Rank") +
ylab("Testosterone Level") 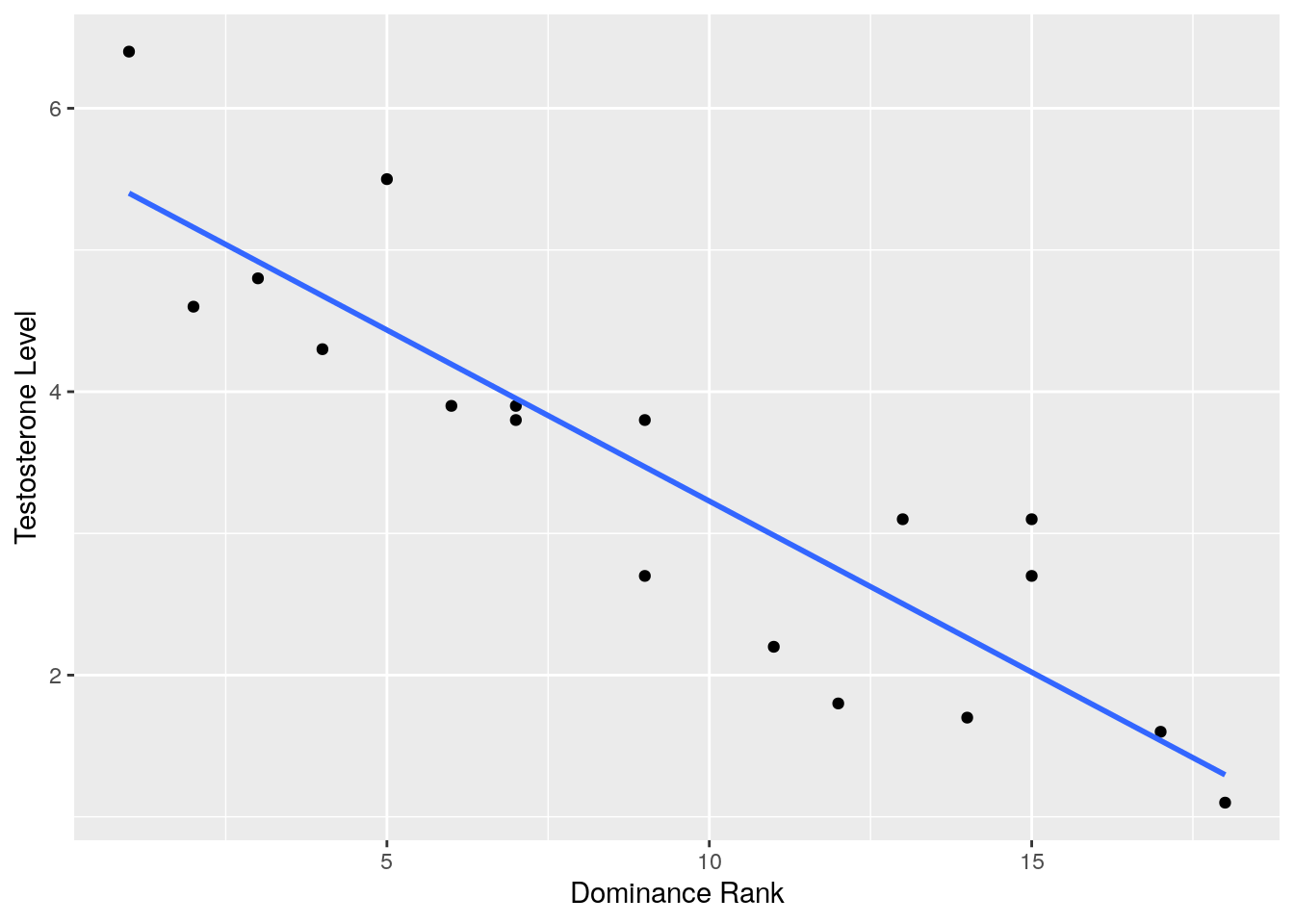
## [1] -0.9083378If you had the a priori prediction, that more dominant animals would have higher testosterone, then you could do a one-tailed test. This would mean that you expect there to be a negative correlation - as the rank number gets higher, the levels of testosterone would fall. In this case, you’d use alternative = "less".
##
## Spearman's rank correlation rho
##
## data: test$drank and test$testosterone
## S = 1849.2, p-value = 9.367e-08
## alternative hypothesis: true rho is less than 0
## sample estimates:
## rho
## -0.9083378Non-parametric Partial Correlation
If you look back to section 11.6 calculate the partial correlation for a Pearson correlation. We also used the funtion pcor.test() from the ppcor package to do this for us. We can actually use the same formula or function to do partial correlations for non-parametric correlations.
For example, let’s examine the Spearman correlations between anxiety, exam score and revision.
These are the data:
## [1] 102## # A tibble: 6 x 5
## code revise exam anxiety gender
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 1 4 40 86.3 Male
## 2 2 11 65 88.7 Female
## 3 3 27 80 70.2 Male
## 4 4 53 80 61.3 Male
## 5 5 4 40 89.5 Male
## 6 6 22 70 60.5 FemaleUsing the Shapiro-Wilk test we note that our data are not approximately normal:
# note these data are not approximately normal:
# all p<0.05, therefore reject null that they are approximately normal
shapiro.test(exams$revise)##
## Shapiro-Wilk normality test
##
## data: exams$revise
## W = 0.81608, p-value = 6.088e-10##
## Shapiro-Wilk normality test
##
## data: exams$exam
## W = 0.95595, p-value = 0.001841##
## Shapiro-Wilk normality test
##
## data: exams$anxiety
## W = 0.85646, p-value = 1.624e-08We can investigate the individual correlations by plotting the scatterplots and calculating the Spearman correlations:
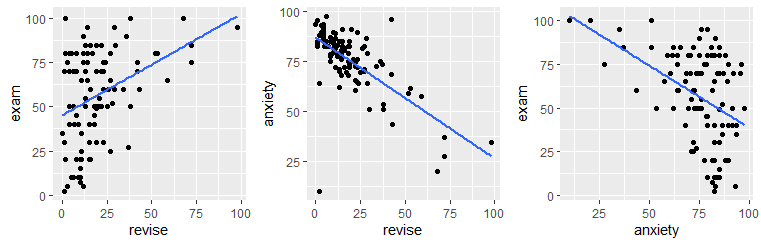
## [1] 0.3330192## [1] -0.6107712## [1] -0.3887703If we were interested in the correlation between revision time and exam performance controlling for anxiety, we would need to do a partial correlation. We can just use the ppcor.test() function:
## estimate p.value statistic n gp Method
## 1 0.1310034 0.1916154 1.314798 102 1 spearmanAgain, we see that the relationship between these two variables is reduced considerably to \(\rho=0.13\) when we controll for each of their relationships with anxiety.
11.8 Point-Biserial Correlation
Throughout the entirety of this chapter we’ve been discussing various correlation measures between two continuous variables. This little subsection is here just to point out that you can in fact also measure the correlation between a categorical variable and a continuous variable.
In the following dataset, we have data on the number of hours that various cats spend away from their house over a one week period. They are tracked via cool GPS collars, and these data make pretty pictures of how far they traveled from their homes.

## [1] 60## # A tibble: 6 x 3
## time sex sex1
## <dbl> <chr> <dbl>
## 1 41 male 1
## 2 40 female 0
## 3 40 male 1
## 4 38 male 1
## 5 34 male 1
## 6 46 female 0The data have a time column that is the number of hours away from home. A sex column which is the sex of the cat, and a sex1 column which is the sex of the cat coded as a number. This final column exists to help us make the dotplot below and to help run a correlation:
# dot plot
ggplot(cats, aes(sex1,time)) +
geom_jitter(width = .05) +
scale_x_continuous(breaks=c(0,1), labels=c("female", "male"))+
stat_smooth(method='lm',se=F) +
theme_classic()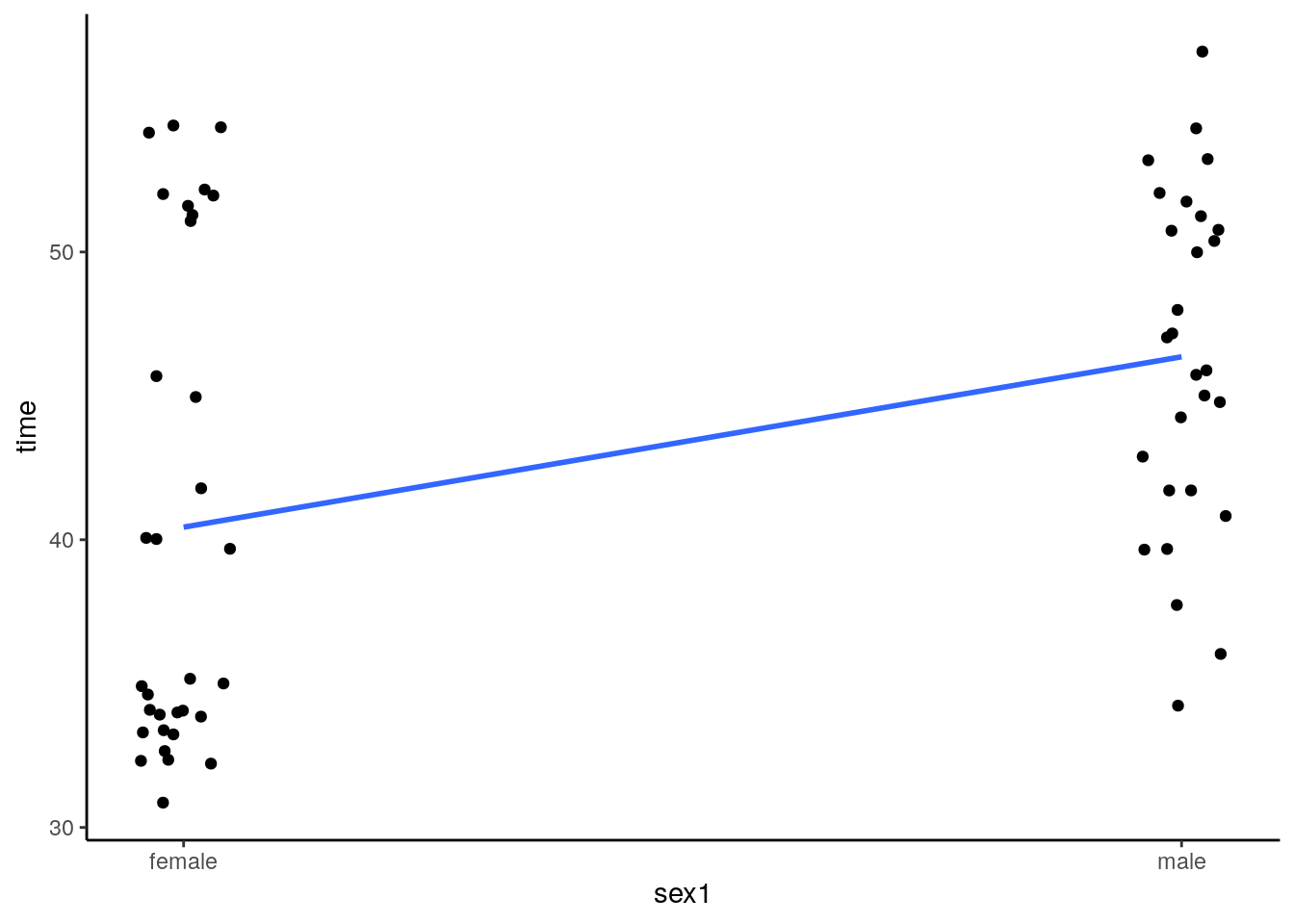
What we have in this plot are individual points representing each cat. The points are jittered to make overlapping datapoints more readable. We have also put a trendline through the data. How was this achieved? Essentially, all the females are given the value 0, and all the males are given the value 1. We then run a Pearson’s correlation using the X values to be 0 or 1, and the Y values to be the time measurement.
Doing this, we can simply run a Pearson’s correlation test using cor.test():
##
## Pearson's product-moment correlation
##
## data: cats$sex1 and cats$time
## t = 3.1138, df = 58, p-value = 0.002868
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.137769 0.576936
## sample estimates:
## cor
## 0.3784542These results suggests that there is a positive relationship between cat sex and time spent away from home, with male cats spending more time away than female cats.
Looking at the dotplot again, it looks like the female data are possibly bimodal. As the data are in long format, we can filter out the male and female data:
catsF_time <- cats %>% filter(sex=="female") %>% .$time
catsM_time <- cats %>% filter(sex=="male") %>% .$time
shapiro.test(catsF_time)##
## Shapiro-Wilk normality test
##
## data: catsF_time
## W = 0.81663, p-value = 8.505e-05##
## Shapiro-Wilk normality test
##
## data: catsM_time
## W = 0.97521, p-value = 0.7246Clearly our suspicions about the female data are true, they do not appear to come from an approximately normal distribution. In that case, we could run a point-biserial Spearman correlation. This is just the same procedure, but instead we apply the Spearman test:
##
## Spearman's rank correlation rho
##
## data: cats$time and cats$sex1
## S = 23048, p-value = 0.004774
## alternative hypothesis: true rho is not equal to 0
## sample estimates:
## rho
## 0.3596003Just as a note - there are probably ‘better’ ways of running such a point-biserial correlation than using cor.test(), but what we’ve shown here is probably sufficient to get the idea across that you can convert two groups to 0’s and 1’s and then run a correlation to test for group differences.