Chapter 4 Functions
I can not over emphasize the importance of functions. As a data scientist most of the time you will be writing functions. Only in couple of cases where you have to write complicated classes there too methods are nothing more than functions. Having solid grasp of best practices in functions is a must for everybody working in any language what-so-ever. Hopefully this chapter will help you in best coding practices for functions.
4.1 Metadata or Information header
As I mentioned in the previous chapter it is a good practice to create sections for everything you do in R. functions are no exception to the rule. But along with that there are a couple of information you should write along with the function.
I worked in a few MNC where we had to write metadata of every function before writing it down. It makes it easier for code-reviewer to understand you code and for the entire team to collaborate in the project. It’s good for personal projects too… Let me give you an example of what I mean by this.
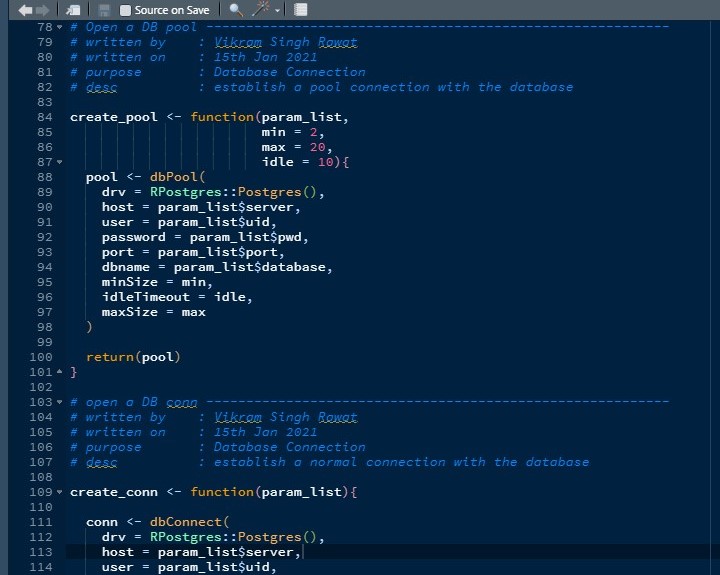
functions metadata
You can see that if you are working on large teams or may be in big corporate settings where anybody can be reassigned to a different project. This data helps by identifying who wrote what and why.
Examples of some important tags can be :
- written by
- written on
- parameters
- modified by
- modified on
- purpose
- descriptions
You can create your own tags based on usecases and information needed for further scenarios. You can also use roxygen tags for these.
4.2 Pass everything through parameters
I have seen people writing functions with calling things from global environments. Take a look at the code below.
foo <- function(x){
return( x + y)
}
y <- 10
foo(5)## [1] 15Here the value of foo is based on y which is not a part of the function instead it’s in global environment and function always have to search global environment for the object. consider these scenarios:
bar <- function(x, y){
y <- y
return(
foo(x)
)
}
bar(5, 20)## [1] 15you would assume that the answer is 25 but it’s 15 because foo was created in the global environment and it will always look up value in global environment before anything else. This is called Lexical Scoping it’s okay if you don’t know it. It is very confusing and could mess up your code at any point in time. I am an experienced R programmer I too have trouble getting my head around it.
We can avoid all these situations by following the best coding practices that have been used in software industries for years. Function should be a self contained code which shouldn’t be impacted by the outer world. Only is certain scenarios you allow to deviate from these rules but it’s a good coding practice none the less. now in the above example instead of relying on the global variable if I just had created a parameter for Y, my code would be simpler to write and easier to understand and I would not have to think about lexical scoping on every step.
foo <- function( x, y ){
return( x + y )
}
bar <- function( x, y ){
return(
foo( x, y )
)
}
bar(5, 20)## [1] 25Now this code returns 25 as we all expected and trust me the Y is still available in global environment but that doesn’t impact the foo or bar at all. Now you can nest this function under multiple other functions and it will behave exactly like it should.
There is a golden rule you should take away from this section. Avoid Global Variables at all costs. As much as possible pass everything through the parameters. That what they are for right !!!
4.3 Use Return Statement
It is a very simple thing yet most of the R users never worry about it because R takes care of finer details for you. But return statements actually make your code easier to read.
Suppose you have to review code return statement makes it easier to glance at the code and understand what is it doing. Almost all the programming languages are habitual with it. There are no good advantage I can tell you for a return statement other than readability. But just by following these practices R community as a whole could get more respect in programming community. So please use Return statements wherever possible. In Big MNC your code will never pass reviewer unless it has return statements.
It also is good for functions that don’t return anything you can just return true or false depending on the fact that the function ran without producing any error. Functions where you modify a data.table or where you change something in the database etc… It’s a standard practice in old programming languages like C++ and it’s a good practice indeed. We as a community should embrace these practices which will help us down the road.
4.4 Keep a consistency in Return Type
Return type of a function should be consistent regardless of what happens in a code. You may assume this is so simple that it goes without saying who would in their sane mind return character vector instead of a numerical one and you would be right. But Things get complicated when people start to work in composite data types like Lists and Dataframes.
Working with lists people get confused and forget this basic principle. I have seen function returning list of 2 elements on some conditions and 3 on other and 4 on some more. It makes it harder for users to work on those return values.
Don’t even get me started on dataframes. People write functions that do some magic stuff on dataframes and it sometimes return a dataframe of 10 columns, sometime 11 and sometime 8. It’s such a common mistake to make. I understand if you are fetching a table from database and returning that same table via functions but during manipulations you must add empty columns or delete existing ones to make it consistent for the end user regardless of the conditions you have in the functions.
4.5 Use Sensible Names for parameters too…
Yet another simple thing but because most of us including me come from non computer science background we have a tendency to use names like x, y, z, beta, theta, gamma, string etc… in our function parameters. I too am guilty of doing it in above code for foo and bar functions and in general. Many good and well established libraries in R are guilty of this sin too… But in long run these words don’t make much sense. It’s hard to maintain that code and it’s hard for user as well. Let’s take an example :
join <- function(x, y) x + y
join(x = 12, y = 12)## [1] 24do you see that as a user who hasn’t written or even looked at the code it’s already hard for him to understand what does x and y stands for. Only to get an error like this.
join(x = "mtcars", y = "iris")## Error in x + y: non-numeric argument to binary operatorI know it is a stupid example but I see it every time in real code. When you only need numeric values why not include that information in the parameter name. something like:
join <- function(num_x, num_y) num_x + num_yIt may not seem like much but this small change makes the life of the user so much better where he doesn’t need to consult the documentation again and again. Their are other ways you can come up with sensible names in your code just to avoid this issue. It’s a standard practice during code review to check the names and these names are never allowed in production environment. We will discuss more about names in another chapter but for now understand that parameter names are just as important as the name of the function and it should be meaningful and easier to understand. There should be some information buried in the name.
4.6 use tryCatch
During deployment we would not like the shiny app or rest api or the chron job to fail. It’s not a good experience to have for either the developer or the client. Best way to avoid it is wrap every function in a tryCatch block and log the errors. This way if you app has some bugs ( which every app does ). It will not crash and not destroy the experience of all the other people using it.
Let’s bring back the foo function :
foo <- function( x, y ){
tryCatch(
expr = {
return( x + y )
},
error = function(e){
print(
sprintf("An error occurred in foo at %s : %s",
Sys.time(),
e)
)
})
}
foo("mtcars", "iris")## [1] "An error occurred in foo at 2022-04-04 21:52:03 : Error in x + y: non-numeric argument to binary operator\n"Now imagine this line to be printed in a json file or inserted in a database with time stamp and other information instead of crashing the entire code only a particular functionality will not run which is huge. This is the difference between staying late on Saturday night to fix a bug vs telling them that I will fix it on Monday. To me that is big enough.
4.7 Write simple and unique functions
Task of one function should be to do one thing and one thing only. There are numerous times when people assume they have written excellent code because everything is in a function.
Purpose of a function is to reduce one unique task in a single line. If your function does multiple things then it’s a good Idea to Break your function into multiple one and then create a function which uses all of them.
average_func <- function( mult_params ){
tryCatch(
expr = {
###
# code to do stuff 1
###
###
# code to do stuff 2
###
},
error = function(e){
###
# code to log errors
###
})
}Now imagine if today you are logging on a json file and tomorrow client wants to log it into a database. Changing it on every function is not only time consuming but dangerous in terms that now you can break the code.
Now compare that to this code.
stuff_1 <- function(params_1){
###
# code to do stuff 1
###
}
stuff_2 <- function(params_2){
###
# code to do stuff 1
###
}
log_func <- function( log_params){
###
# code to log errors
###
}
best_func <- function( mult_params ){
tryCatch(
expr = {
stuff_1()
stuff_2()
},
error = function(e){
log_func()
})
}Here in this code every function has a clear responsibility and the main function is just a composite of multiple unique functions and it will be very easy to debug this code or change the functionality entirely. This idea is called function composition. Which actually means you can always create a bigger and better function by combining multiple smaller ones. This is a neat trick in functional programming and R is no exception.
4.8 Don’t load libraries or source code inside a function
You may assume nobody does it. But I have seen people doing it times and times again.
foo <- function( x ){
library(data.table)
setDT(x)
}
bar <- function( x ){
source(file = "")
}In functional programming terminology these functions are called impure functions . Function which change the global environment or some persistent changes are called impure functions. They require very delicate handling of the entire project. If I don’t know how many packages and what version of them am I dependent on or what files have I loaded in my environment it makes debugging the code a lot more harder.
By following this style of code you are making the debugging harder for your project. In fact I would argue that you should remove all the external dependencies from a function. Take this code for example.
foo <- function(x){
exl <- readxl::read_excel(path = "increased/external/dependency")
##
### do some data operation in the function
##
return(exl)
}
bar <- function(
x,
filepath = "increased/external/dependency"){
exl <- readxl::read_excel(path = filepath)
##
### do some data operation in the function
##
return(exl)
}Foo and bar are both doing the same thing and both are relying on an external path for code to work. But because bar is clearly stating the filepath as an argument it is easier to change and adapt to new needs.
If you still need to rely on a package call it from the main script not from a function. And if you absolutely need some functions of a package inside a particular function then use qualified imports and don’t load the entire package.
4.9 Use Package::Function() approach
R classes work differently than the traditional oops we all are aware of. Instead of object_of_class.Method syntax like other programmings have, we in R use method( object_of_class ) syntax. Where just by changing name collision is a pretty common thing.
It’s a pretty common thing in R that 2 packages use same function name for different operations. So It’s always better to use qualified imports fancy name for mentioning which package does the function comes from.
4.9.1 You should load libraries in the order of their usage
# library("not_used_much")
# library("least_used")
# library("fairly_used")
# library("most_used")
# library("cant_do_without_it")R uses the loading sequence to identify which function to give preference. It’s usually to the last package loaded. It’s called masking and it’s not a reliable technique but it’s better to arrange your code in that order for sake of simplicity.
and Yes do not forget to mention the package name clearly. like prefer writing this always:
# dplyr::filter()
# stats::filter()
#
# ## instead of
#
# filter()For your small project this might not be a big deal but when multiple people are working on a code everybody might not be familiar with the packages you are using and they might not know that there is a naming collision between 2 functions. It’s a best practice to explicitly tell R that this function comes from this package. It saves a lot of your time and for the person who is going to maintain your code too… And it makes your debug experience a little better.
4.10 Conclusion
In this chapter we discussed the best practices for writing functions in R. Here are the key takeaways from the chapter.
- write information about the function at top of it.
- avoid global variable and pass everything through parameters
- use return statement to end your function
- keep consistency in return types of a function
- use logical names for parameter
- use tryCatch in every function
- functions are supposed to do one thing and one thing only
- create bigger function through function composition only not through huge scripts.
- don’t try to change global environment without letting the user know
- Use qualified imports with syntax package::functions every time possible