Kapitola 5 Vizualizácia pomocou ggplot2
R-ko má niekoľko systémov na vizualizáciu údajov. Ten základný bol predstavený v kapitolách Úvod do R a Prieskumná analýza údajov. Okrem toho sa zvykli používať grafické nástroje balíka lattice. Jedným z najelegantnejších a v súčasnosti najpopulárnejším je grafický systém balíku ggplot2. Implementuje tzv. grafickú gramatiku (angl. grammar of graphics), čo je premyslený systém popisu a výstavby grafov. Predtým, ako si ukážeme konkrétne príklady grafov podobne ako pri prieskumnej analýze údajov, je vhodné najskôr pochopiť filozofiu gramatiky grafov.
Kapitola vznikla na podklade kníh (Wickham a Grolemund 2016, kap. 3; Ismay a Kim 2019, kap. 2; R. Peng 2016, kap. 15 a 16; Wickham 2016).
5.1 Filozofia
V skratke nám gramatika hovorí:
A statistical graphic is a mapping of data variables to aesthetic attributes of geometric objects.
(Grafika používaná v štatistike je zobrazenie premenných do estetických atribútov geometrických objektov.)
Grafiku teda môžeme rozložiť na tri základné časti:
- data – súbor dát obsahujúci požadované premenné,
- geom – príslušný geometrický objekt, napr. bod (point), línie (line), stĺpec (bar), text, mnohouholník (polygon),
- aes - estetické atribúty geometrického objektu – napr. x/y poloha, farba (color), tvar (shape), veľkosť (size), priehľadnosť (alpha), výplň (fill), typ čiary (linetype), príslušnosť ku skupine (group) – na ktoré sú „namapované” (čiže zobrazené) premenné z datasetu.
5.1.1 Od klasiky ku ggplot
Princíp gramatiky grafiky je do určitej miery prítomný aj v štandardných nástrojoch systému R, balík ggplot2 však ide značne ďalej (technicky i esteticky), je teda užitočné začrtnúť premostenie oboch grafických systémov.
Teória sa najlepšie pochopí na príklade. Vezmime si dátový rámec mpg z balíku ggplot2, ktorý obsahuje údaje o hospodárnosti využitia paliva vybraných modelov automobilov z rokov 1999 – 2008. Medzi 11 premennými sa nachádza zdvihový objem displ a spotreba paliva v meste cty (obe v litroch), počet valcov (cyl) a typ náhonu drv (predný f, zadný r, na všetky 4).
data(mpg, package = "ggplot2")
head(mpg)
## manufacturer model displ year cyl trans drv cty hwy fl class
## 1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compact
## 2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compact
## 3 audi a4 2.0 2008 4 manual(m6) f 20 31 p compact
## 4 audi a4 2.0 2008 4 auto(av) f 21 30 p compact
## 5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compact
## 6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compactJednoduchý graf závislosti medzi zdvihovým objemom a spotrebou paliva dostaneme funkciou plot, kde každá premenná je priradená zodpovedajúcej (horizontálnej a vertikálnej) polohe bodu. Práve body ako geometrické objekty sú prednastavenou reprezentáciou, ktorú môžme zmeniť argumentom type. Pridanie ďalšej premennej do grafu závislosti je možné cez estetické atribúty ako farba (col), či veľkosť bodu (size), hodnoty premenných však musia zodpovedať očakávaným hodnotám atribútov (napr. prirodzené čísla pre farbu). To je dosť nepohodlné obmedzenie.
plot(x = mpg$displ, y = mpg$cty)
plot(x = mpg$displ, y = mpg$cty, col = mpg$cyl, type ="p")
Nepohodlné je aj neustále uvádzanie pôvodu premennej (t.j. príslušnosť ku dátovému rámcu mpg). To sa dá našťastie pomerne ľahko vyriešiť použitím prostredia with alebo metódy plot.formula, v ktorej je vzťah premenných zapísaný formou „závislá ~ nezávislá”.
with(mpg, plot(x = displ, y = cty, col = cyl) )
plot(cty ~ displ, data = mpg, col = cyl)Zmena geometrie však nemusí byť bezproblémová, napr. type = "l" by nezachoval farbu líniových segmentov spájajúcich body.
Tu balík ggplot2 prichádza na pomoc s funkciou qplot (quickplot), v ktorej napr. typu geometrického objektu type zodpovedá argument geom a atribútu col argument color. Keďže premenná cyl je numerická, funkcia by ju automaticky zobrazila na spojitú farebnú paletu. Ak to nechceme, konverzia na faktor je nutná:
ggplot2::qplot(x = displ, y = cty, color = as.factor(cyl), data = mpg)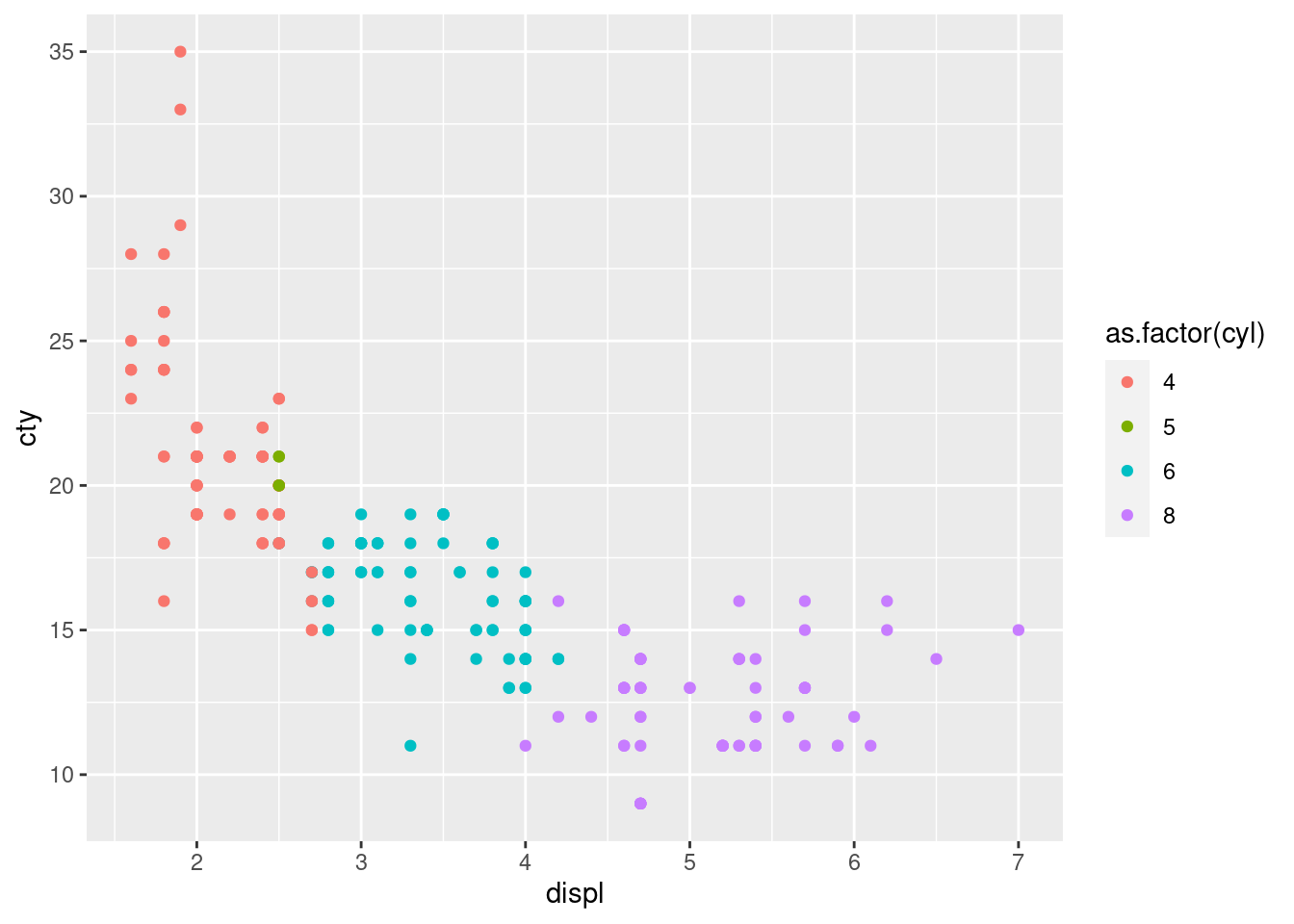
To žiaľ zanechá nepekný odkaz v legende. Riešenie tohto kozmetického problému spočíva v predspracovaní dát, ale keďže argument data (z dôvodu zachovania podobnosti s funkciou plot) nie je prvý v poradí, umiestnenie do potrubia príkazov je komplikovanejší:
mpg %>%
dplyr::mutate(cyl = as.factor(cyl)) %>%
{ ggplot2::qplot(x = displ, y = cty, color = cyl, data = ., geom = "point") }Obmedzení funkcie qplot je však viac. Pre využitie plného potenciálu balíku ggplot2 sa preto oplatí prejsť na všeobecnejší zápis ggplot(dáta, zobrazenie) + geometrické + vrstvy.
library(ggplot2)
head(mpg)
## # A tibble: 6 × 11
## manufacturer model displ year cyl trans drv cty hwy fl class
## <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
## 1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa…
## 2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa…
## 3 audi a4 2 2008 4 manual(m6) f 20 31 p compa…
## 4 audi a4 2 2008 4 auto(av) f 21 30 p compa…
## 5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa…
## 6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa…
ggplot(data = mpg, mapping = aes(x = displ, y = cty, size = cyl, color = drv)) +
geom_point()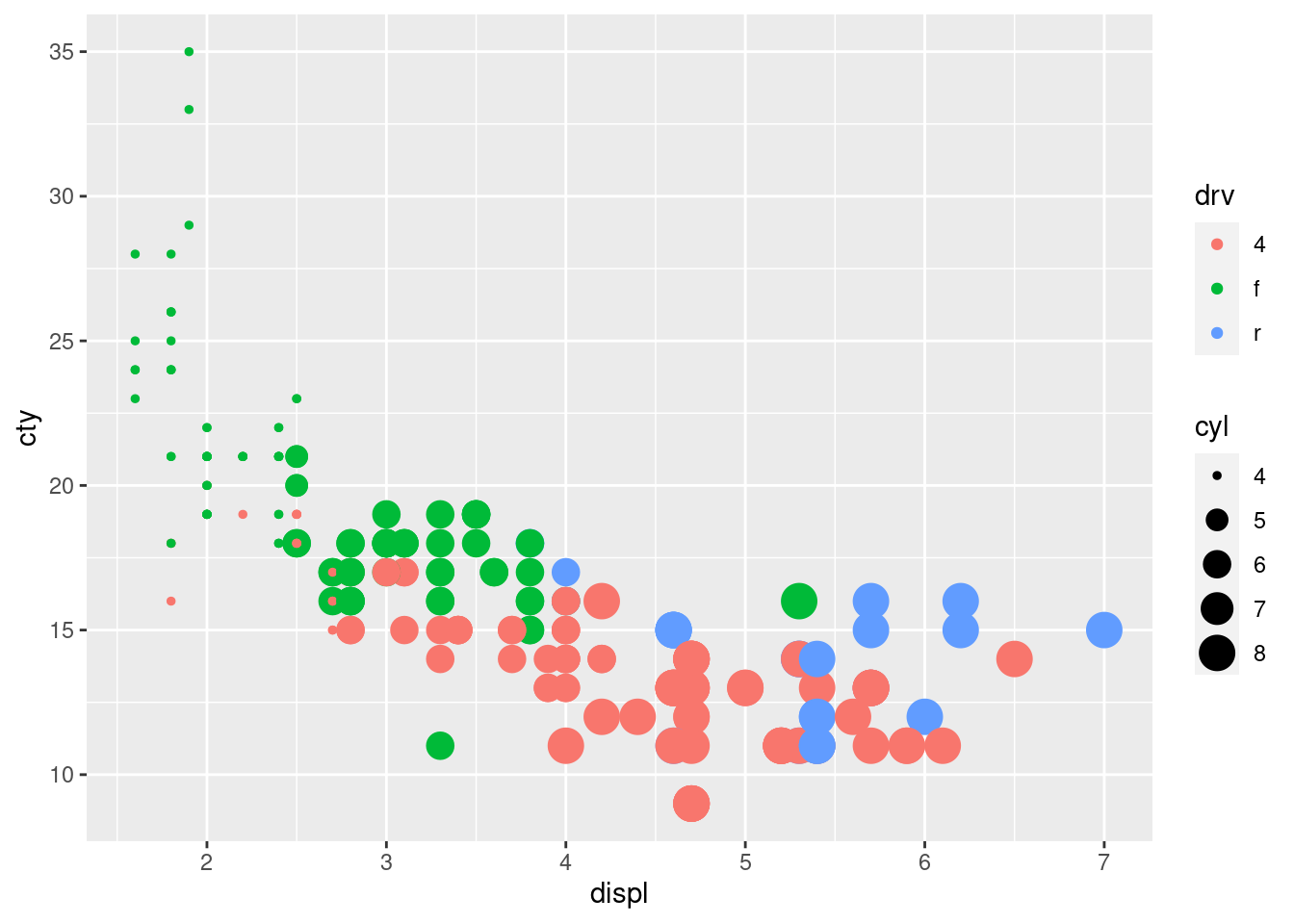
Z pohľadu gramatiky bola v tomto príklade:
- premenná displ zo súboru data zobrazená (namapovaná) na x-ovú súradnicu bodov points,
- premenná cty zo súboru data zobrazená na y-ovú súradnicu bodov points,
- premenná drv zo súboru data zobrazená na veľkosť size bodov points,
- premenná cyl zo súboru data zobrazená na farbu color bodov points.
Vidíme, že komponent data zodpovedá konkrétnemu dátovému rámcu mpg, kde premenné štandardne zodpovedajú stĺpcom, ďalej že typ geometrických objektov sú body, ktoré sú zobrazené vo svojej vrstve. (Skúste spustiť iba prvú časť príkazu, tú pred spojkou +. Čo sa stalo?)
5.1.2 Ďalšie zložky
Okrem spomínaných troch zložiek grafickej gramatiky sú k dispozícii aj ďalšie:
- facet – rozdelenie jediného grafu do tabuľky viacerých grafov podľa hodnôt určitej premennej,
- position – úprava polohy, napr. stĺpcov v stĺpcovom grafe (dodge, stack, fill) alebo rozochvenie bodov (jitter) v bodovom grafe,
- scale – stupnica, ktorú estetické mapovanie používa, napr. muž = modrá, žena = červená,
- coord – súradnicový systém pre geometrické objekty,
- stat – štatistická transformácia ako napr. triedenie (binning), kvantily, vyhladzovanie a pod.
Systematicky sa zložkám venujú publikácie spomenuté v úvode kapitoly. Expresný tutoriál vizualizácie pomocou ggplot2 – od statických grafov až po animácie – možno nájsť napr. na stránke http://satrdayjoburg.djnavarro.net/slides.
Prehľadne sú možnosti a voľby subsystému ggplot2 zosumarizované v ťaháku dostupnom aj z ponuky Help > Cheatsheets prostredia RStudio.
V ďalšej podkapitole si prejdeme tie najbežnejšie grafy, akými sú bodové, líniové, krabicové a stĺpcové grafy vrátane histogramu.
5.2 Príklady najčastejších grafov
Niektoré grafy sú vhodné pre spojité, numerické náhodné premenné, iné pre diskrétne, kvalitatívne premenné. Každý typ grafu si ilustrujeme na zaujímavom datasete a ukážeme aj jeho rôzne variácie. Začneme tými, ktoré zobrazujú vzájomný vzťah medzi numerickými premennými – bodové a líniové grafy.
5.2.1 Bodový graf
Bodový graf je najjednoduchší graf pre vyjadrenie vzťahu dvoch kvantitatívnych náhodných premenných. Z datasetu flights (balík nycflights13, info o 336 776 odletoch z New Yorku v roku 2013) použijeme premenné dep_delay (meškanie odletov, v minútach) a arr_delay (meškanie príletov) všetkých letov spoločnosti Alaska Airlines (spolu 714 letov)
alaska_flights <- nycflights13::flights %>%
dplyr::filter(carrier == "AS")a zobrazíme ich na x-ovú a y-ovú polohu (súradnicu). Nakoniec pridáme vrstvu s bodmi. Pre ušetrenie opätovného písania si základ grafu pred pridaním geometrickej vrstvy uložíme.
g <- ggplot(data = alaska_flights, mapping = aes(x = dep_delay, y = arr_delay))
g + geom_point()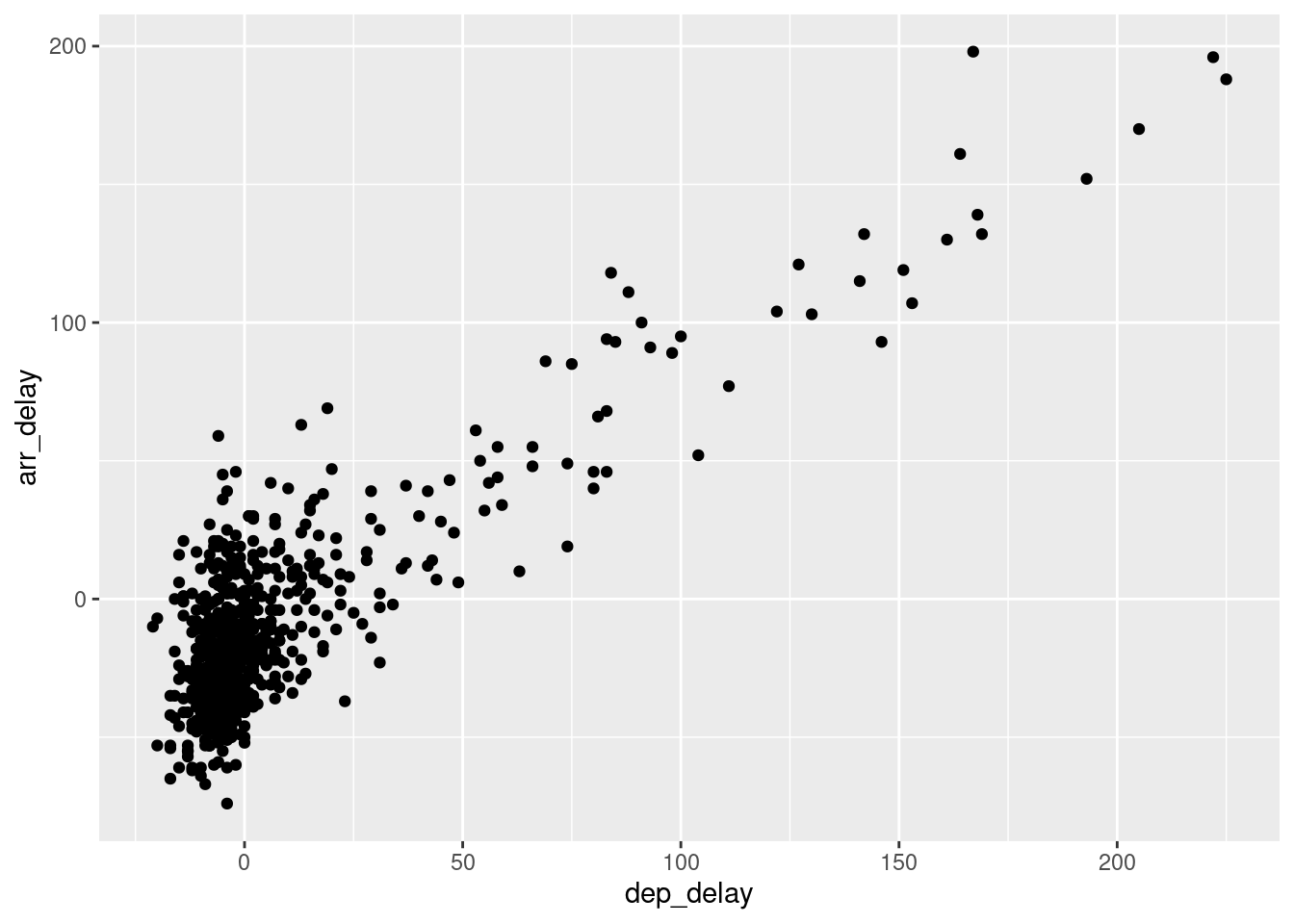
Väčšina bodov je sústredná okolo počiatku (0,0), teda bodu indikujúceho nemeškanie. Záporné hodnoty reprezentujú predčasné odlety/prílety. Varovné hlásenie vypísané v konzole upozorňuje na odstránenie 5 riadkov s aspoň jednou chýbajúcou hodnotou. Znak + sa kvôli prehľadnosti odporúča vždy umiesntiť na koniec riadku.
Body v mraku blízko počiatku (0,0) sa zjavne prekrývajú (overplotting) a tak je ťažké určiť ich počet. Riešením problému s prekrývaním je zvyčajne nastaviť priehľadnosť, alebo body jemne rozochvieť. To prvé docielime nastavením koeficientu nepriehľadnosti alpha, ktorý nadobúda hodnoty od 0 po 1 (prednastavená hodnota):
g + geom_point(alpha = 0.2)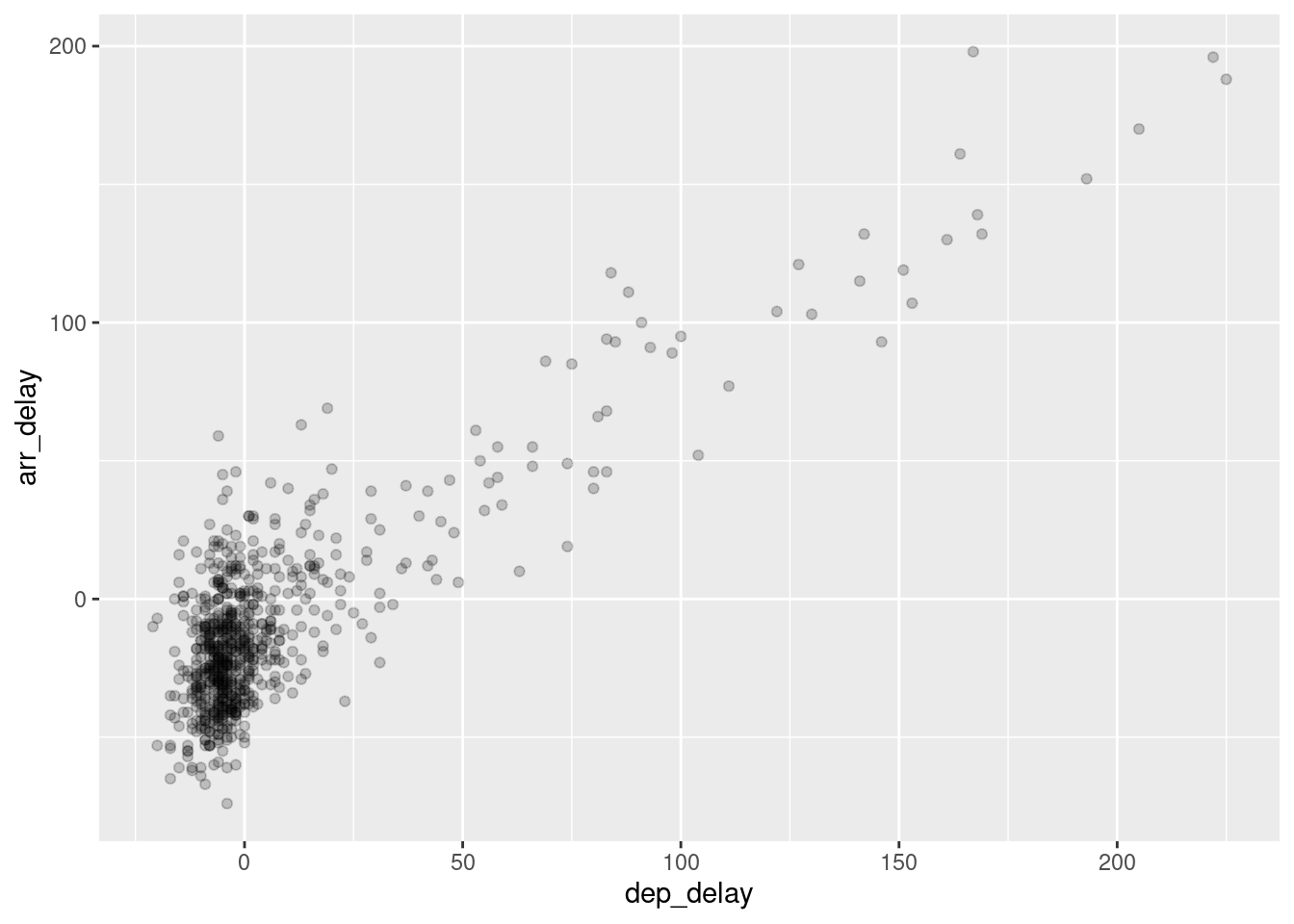
Všimnime si, že nie je obalený funkciou aes. To preto, lebo úroveň priehľadnosti sa tu nemení so žiadnou premennou, iba sme zmenili prednastavenú hodnotu. Druhá metóda – teda použitie komponentu position na rozochvenie bodov (angl. jitter) – v tomto prípade nie je veľmi užitočná, a to ani zvýšením rozsahu (obrázok vpravo):
g + geom_point(position="jitter") # alebo g + geom_jitter()
g + geom_jitter(width = 30, height=30)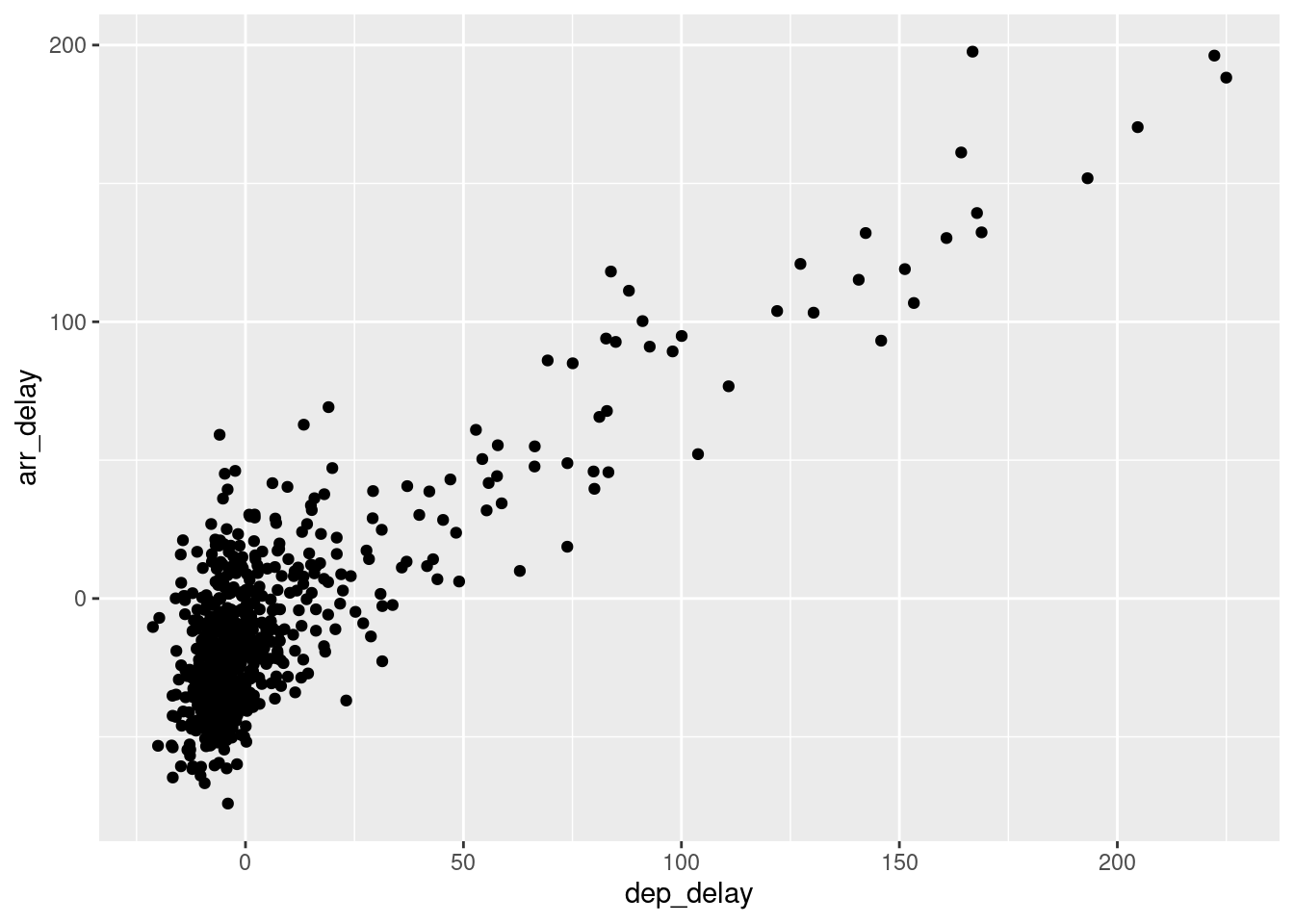
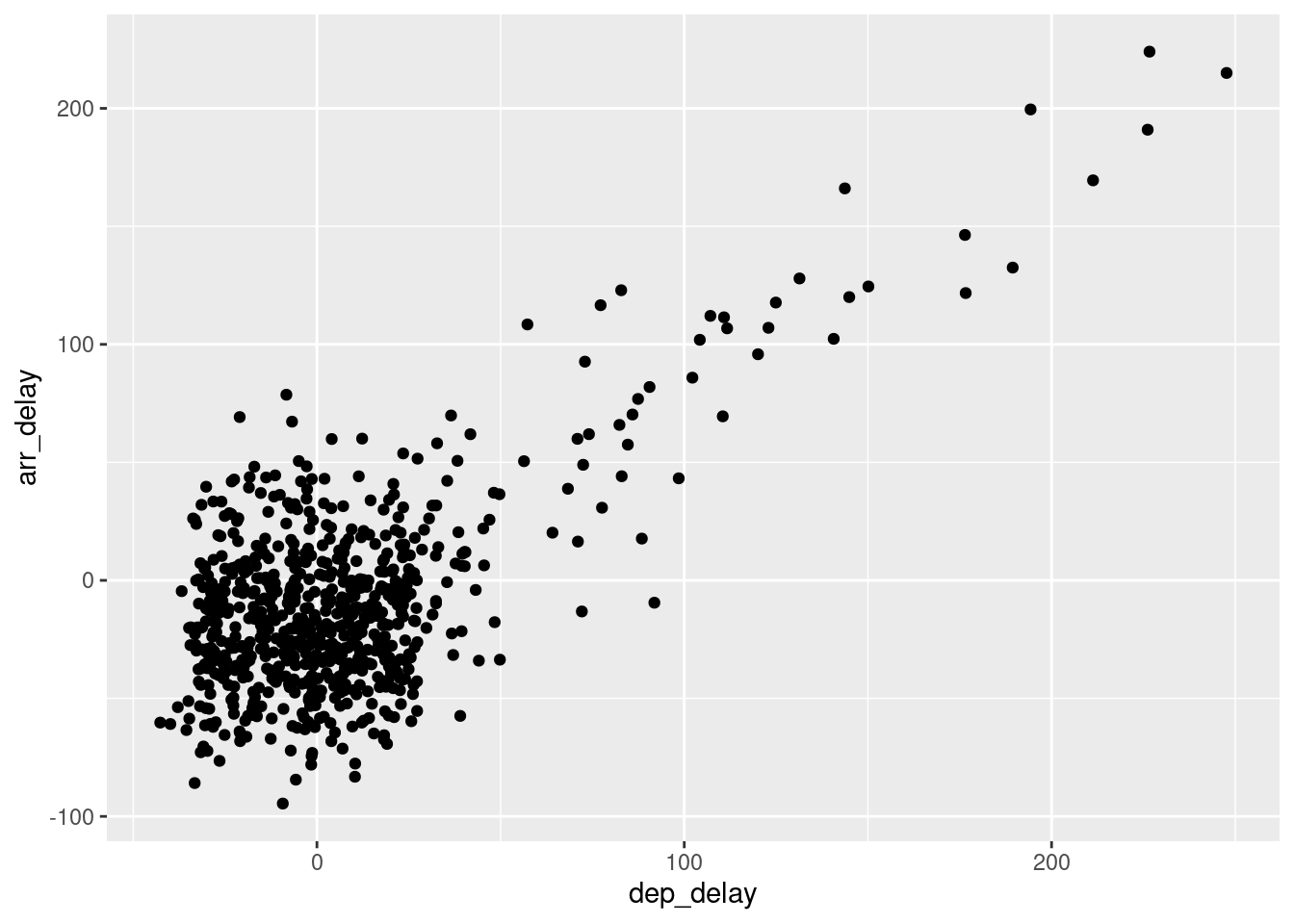
Takýto rozsah šumu zjavne zhoršil informačnú kvalitu údajov.
Ak je údajov príliš veľa, rozumnou alternatívou je diskretizácia spojitej premennej a zobrazenie hustoty pomocou štvorčekov (geom_bin2d) alebo šesťuholníkov (geom_hex, je však nutné nainštalovať balík hexbin).
5.2.2 Líniový graf
Keď má vysvetľujúca (angl. explanatory) premenná na osi x sekvenčný charakter (najčastejšie čas), na vyjadrenie jej vzťahu s premennou na osi y sa využíva líniový graf. Ilustrujeme ho na datasete weather, v ktorom premenná temp predstavuje hodinový záznam teploty (vo Fahrenheitoch) na meteostaniciach na troch hlavných letiskách New Yorku v roku 2013. Nás bude konkrétne zaujímať iba letisko Newark (premenná origin, hodnota EWR) prvých 15 januárových dní.
data(weather, package = "nycflights13")
weather %>%
dplyr::filter(origin == "EWR" & month == 1 & day <= 15) %>%
ggplot(mapping = aes(x = time_hour, y = temp)) +
geom_line()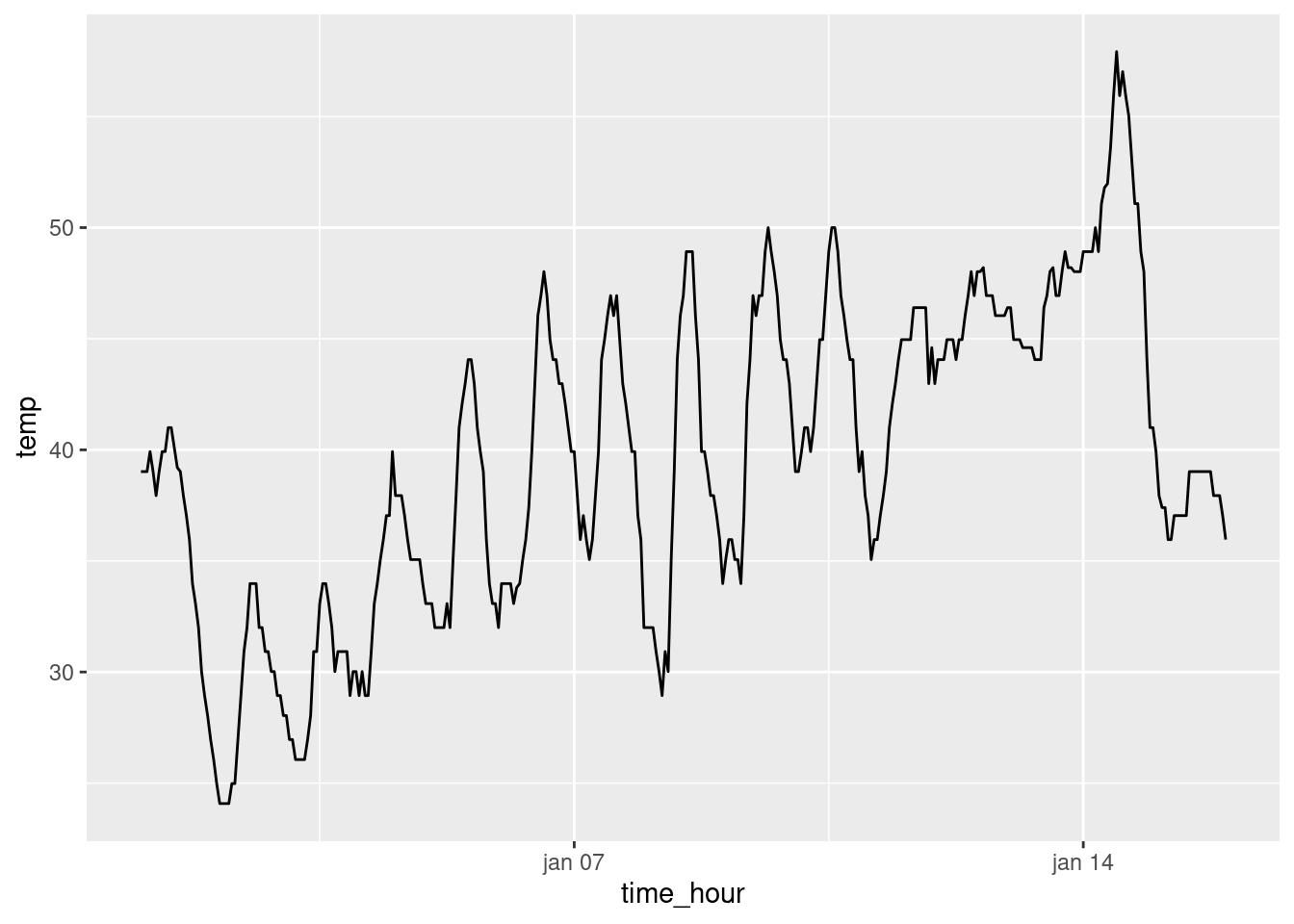
Vďaka pipe operátoru je súslednosť príkazov prehľadná. Najskôr dátový rámec weather z balíka nycflights13 je vo funkcii filter zbavený všetkých riadkov okrem tých, ktoré spĺňajú zadanú podmienku. Takýto modifikovaný dátový rámec je následne zdrojom údajov pre funkciu ggplot, aby mohla zobraziť časovú premennú na os x a teplotu na os y. Pridaním geometrickej vrstvy geom_line sa zobrazí graf časového radu.
5.2.3 Histogram
Ako bolo spomenuté v kapitole o prieskumnej analýze, jediná spojitá premenná sa často zobrazuje prostredníctvom tabuľky početnosti jej hodnôt v jednotlivých intervaloch (bins). Grafická reprezentácia sa nazýva histogram. Takýto geometrický objekt vyžaduje údaje transformované štatistickou metódou (komponent stat), konkrétne zatriedením hodnôt do intervalov. Metóda stat = "bin" je pre geom_histogram prednastavená, tak ako je napr. stat = "identity" prednastavená pre geom_point či geom_line.
g <- ggplot(data = weather, mapping = aes(x = temp))
g + geom_histogram()
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.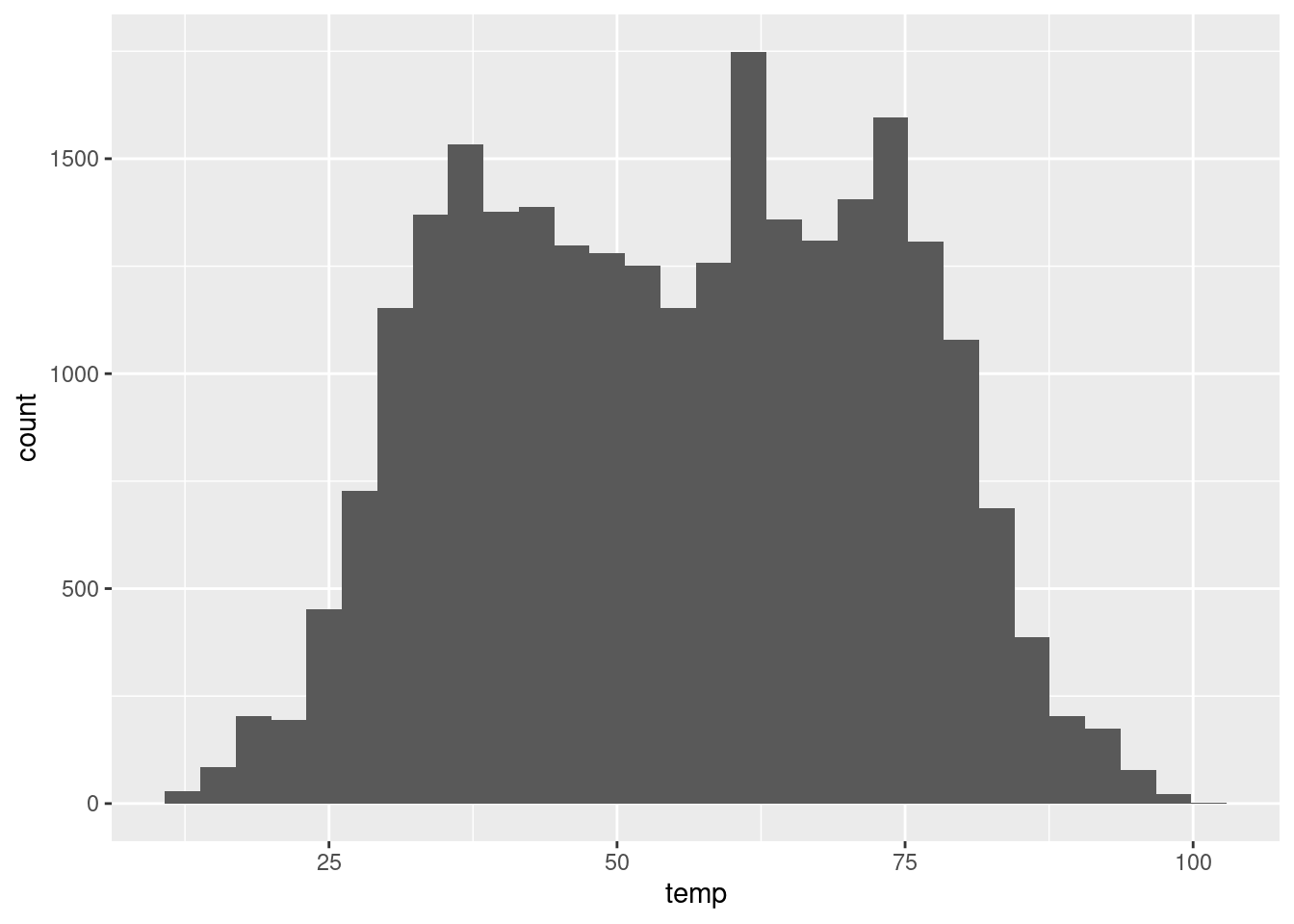
Špecifikovať sa dá napr. počet intervalov alebo ich šírka, a farba lemu či výplne stĺpcov, pridať môžeme aj vrstvu s kobercový grafom (rug). Zároveň si všimnime rozdiel medzi atribútom color a fill:
g + geom_histogram(bins = 40, color = "white")
g + geom_histogram(binwidth = 10, color = "white", fill = "steelblue") +
geom_rug()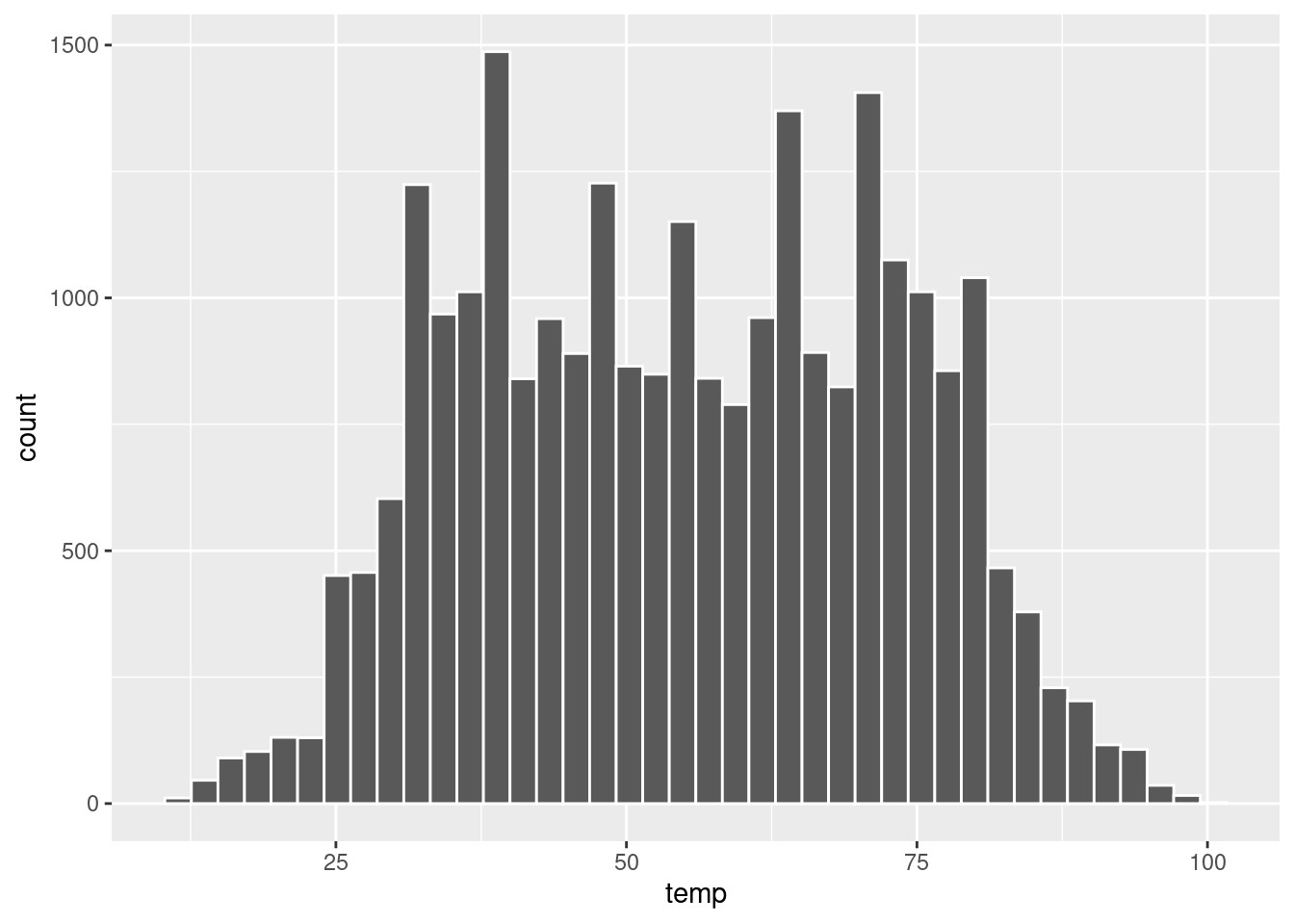
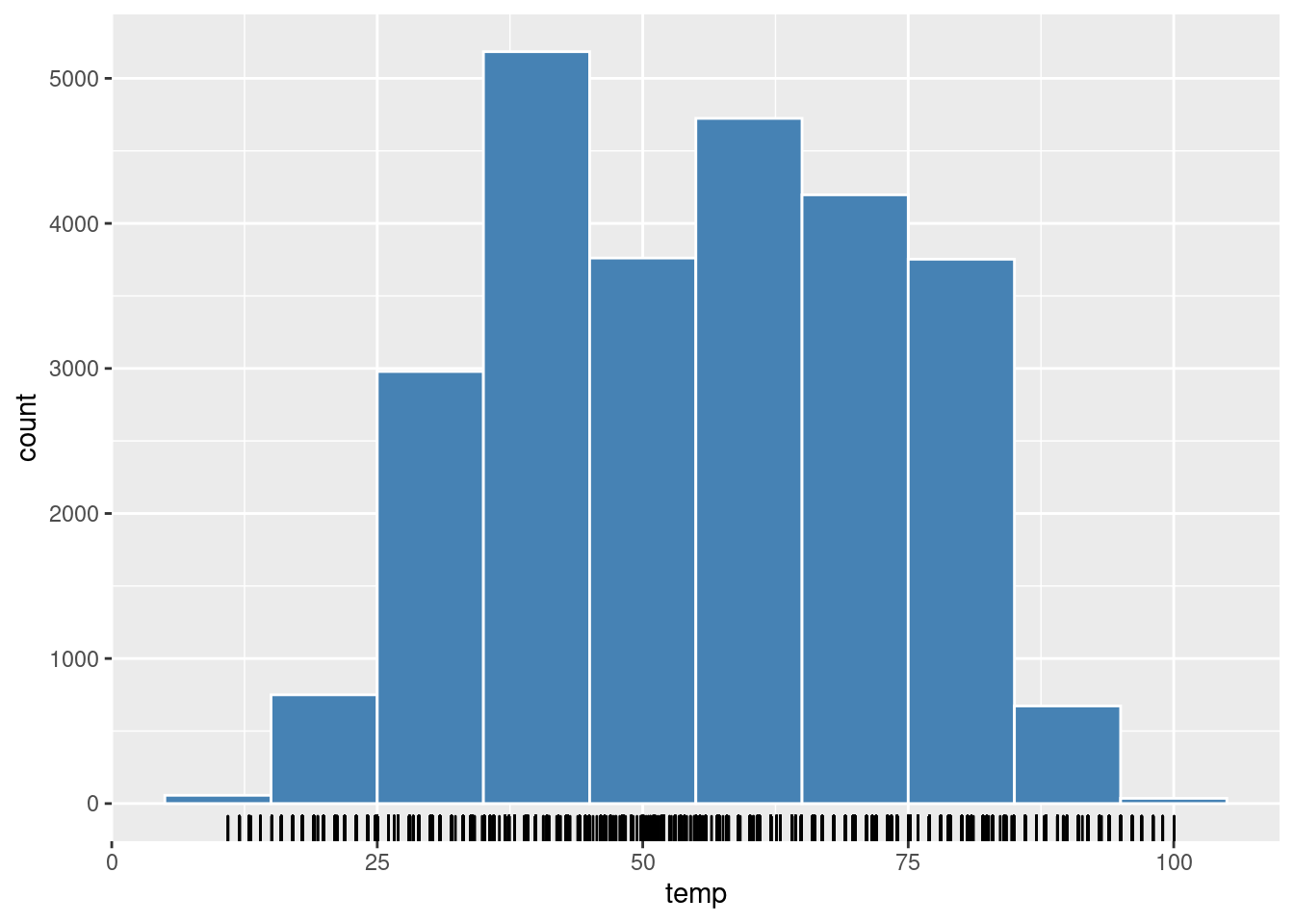
Užitočným konceptom je fazetovanie (angl. faceting) – čiže rozdelenie grafu jedného celku na grafy jeho častí – pomocou komponentu facet. Ten nám umožní napr. rozdeliť histogram teploty podľa mesiacov (povedzme do 4 riadkov) a tak vidieť jej sezónny charakter.
g + geom_histogram(binwidth = 5, color = "white") +
facet_wrap(vars(month), nrow = 4)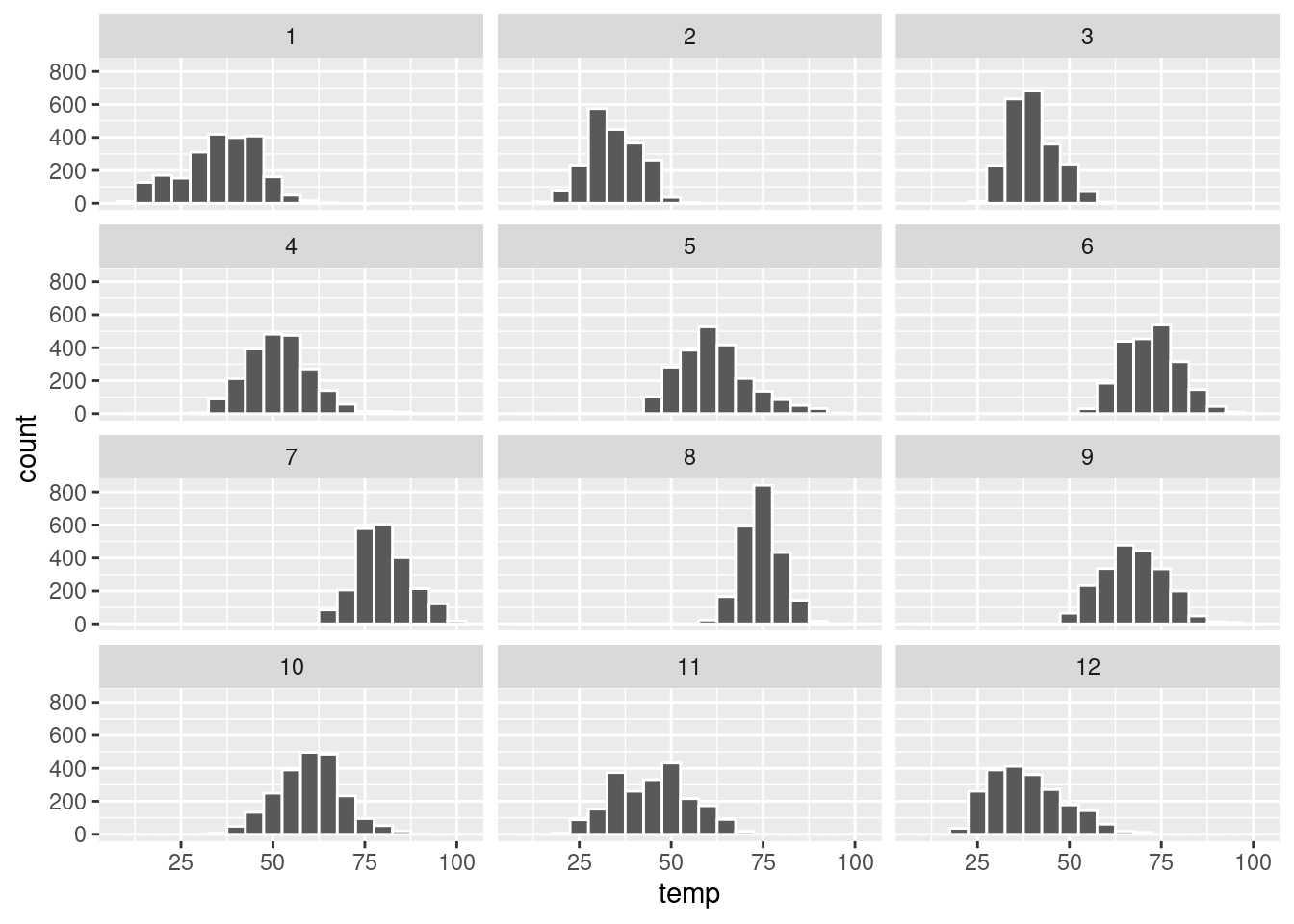
Do fazetovania sa dajú zapojiť aj dve premenné, vtedy im treba priradiť polohu pomocou facet_grid, napr. nasledujúci príkaz zobrazí vzťah objemu a spotreby pomocou mriežky \(3 \times 4 = 12\) grafov, ktorej riadky zodpovedajú úrovniam typu náhonu drv a stĺpce úrovniam premennej cyl.
ggplot(data = mpg) +
aes(x = displ, y = cty) +
geom_point() +
facet_grid(drv ~ cyl)Samozrejme faceting sa dá skombinovať s akýmkoľvek druhom grafu.
5.2.4 Krabicový a husľový graf
Na to, aby sme videli sezónnosť rozdelenia teploty, rozdelili sme histogram do 12 okienok. To nemusí byť vždy najprehľadnejší spôsob podania informácie. Krabicovým grafom sa to dá povedať zrozumiteľnejšie, prípadne aj so zobrazením vrstvy diskrétnych bodov pozorovaní (s rozochvenou polohou), treba len zabezpečiť, aby premenná month bola (pochopená ako) kategoriálna, preto je v druhom z nasledujúcich príkladov použitá aj funkcia factor.
ggplot(data = weather, aes(x = month, y = temp, group = month)) + geom_boxplot()
g <- ggplot(data = weather, mapping = aes(x = factor(month), y = temp))
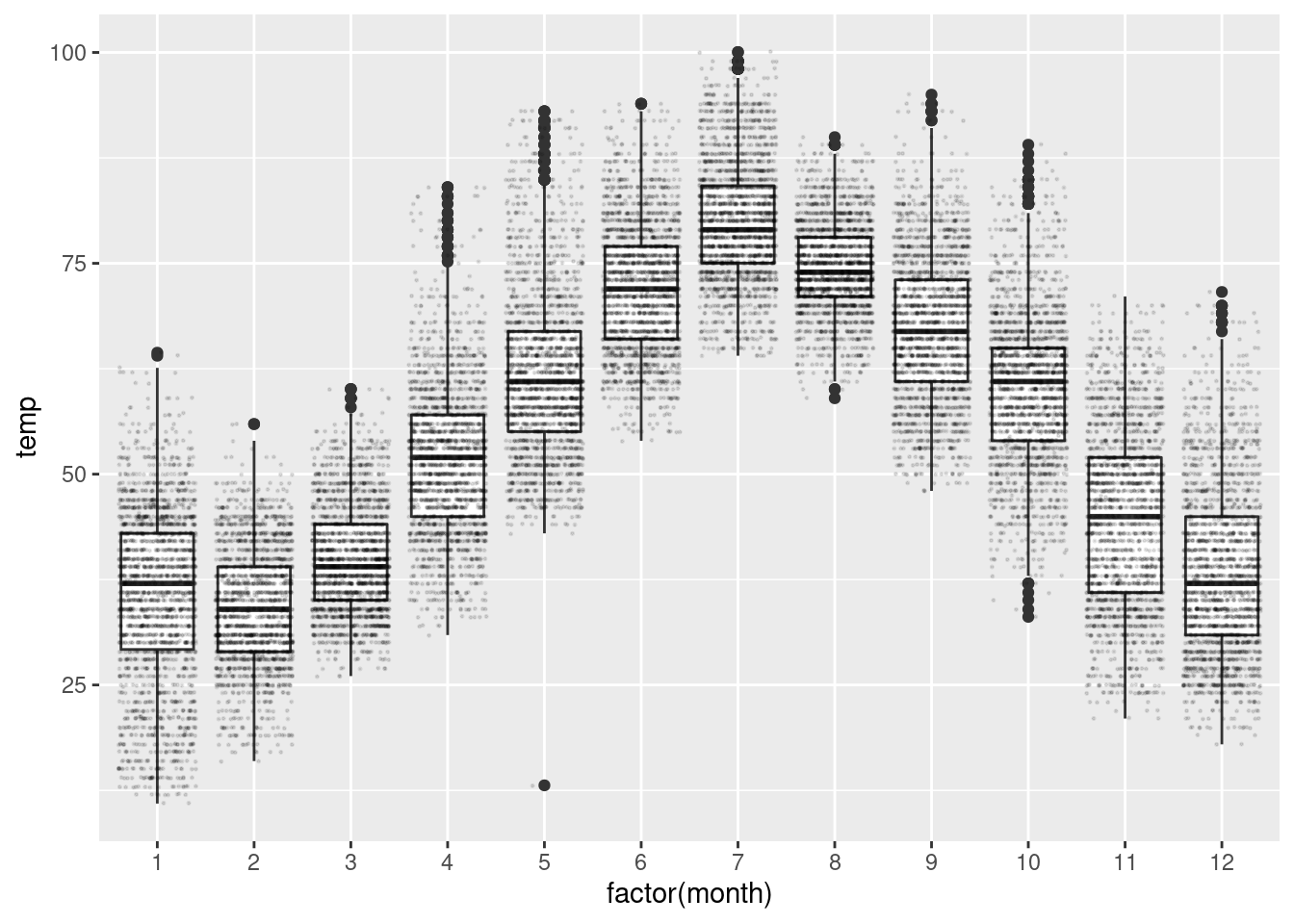
g + geom_boxplot() + geom_jitter(alpha = 0.1, size = 0.2)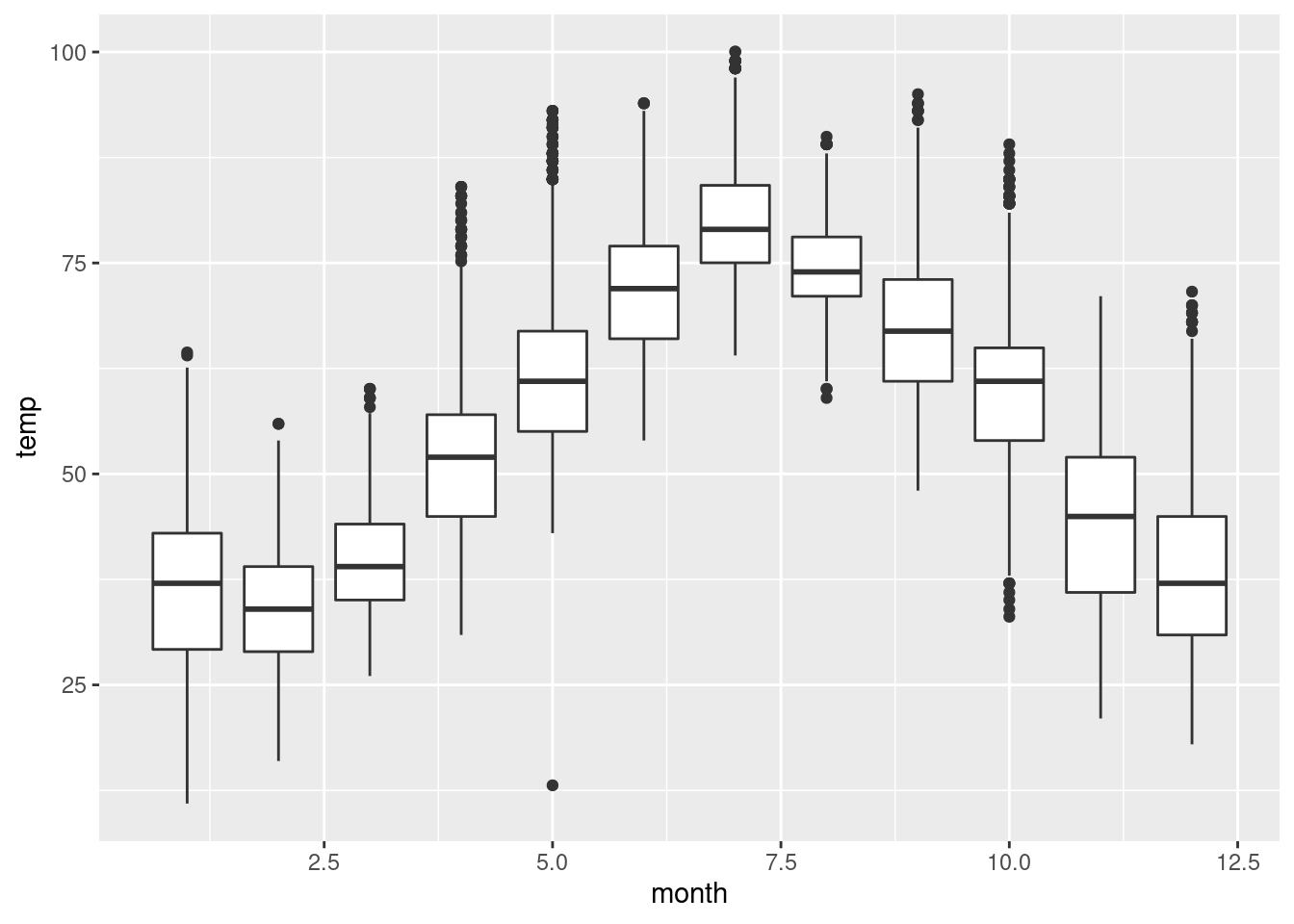
Podobne sa vytvorí vrstva s husľovým grafom doplnený o hlavné kvartily.
g + geom_violin(draw_quantiles = c(0.25,0.5,0.75)) 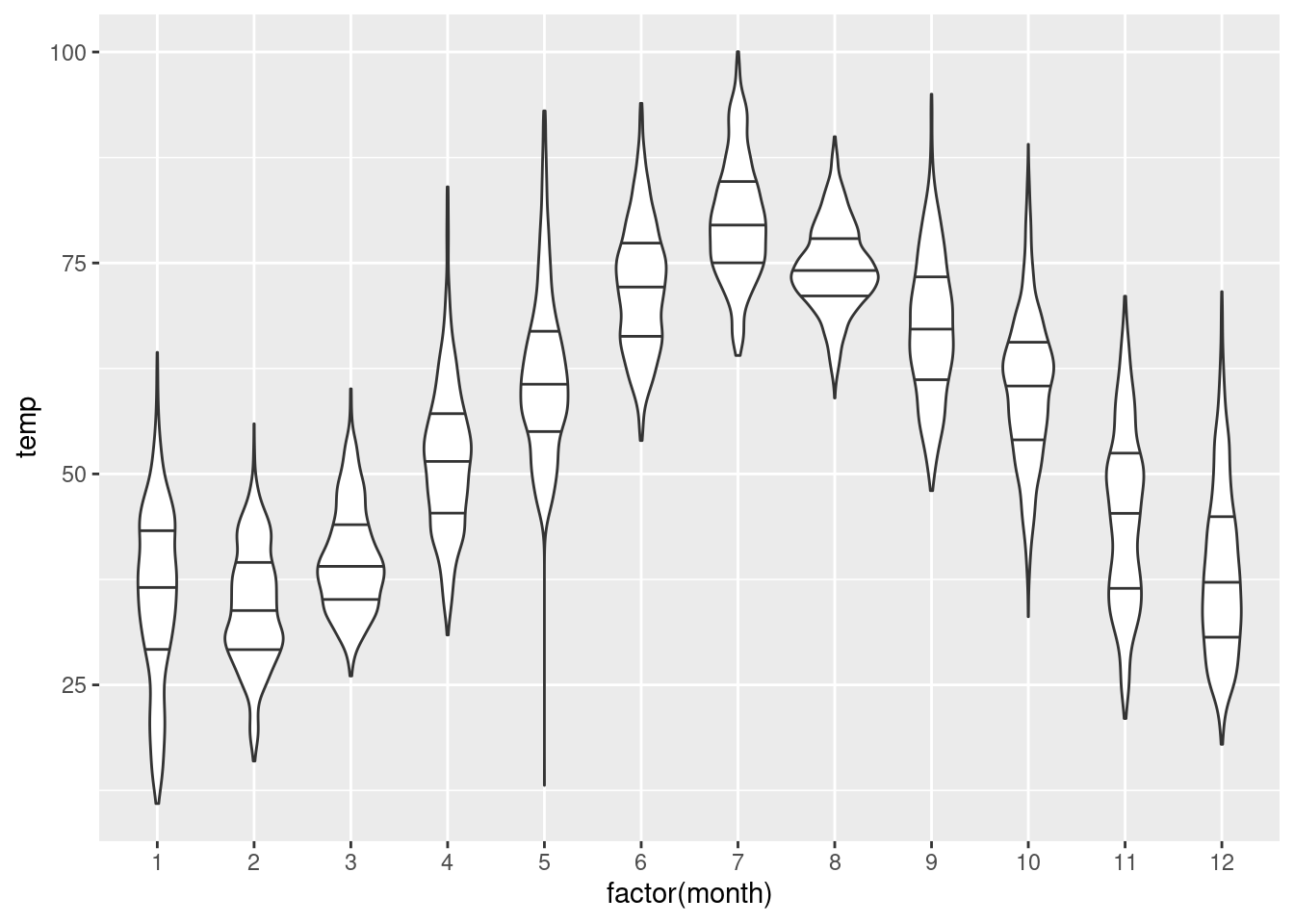
5.2.5 Stĺpcový graf
To, čo sa klasickým spôsobom dalo zobraziť pomocou dvojstupňového príkazu data %>% table() %>% barplot(), ggplot zabezpečí pomocou geom_bar(stat = "count"):
data(flights, package = "nycflights13")
ggplot(data = flights, mapping = aes(x = carrier)) +
geom_bar(fill = "steelblue")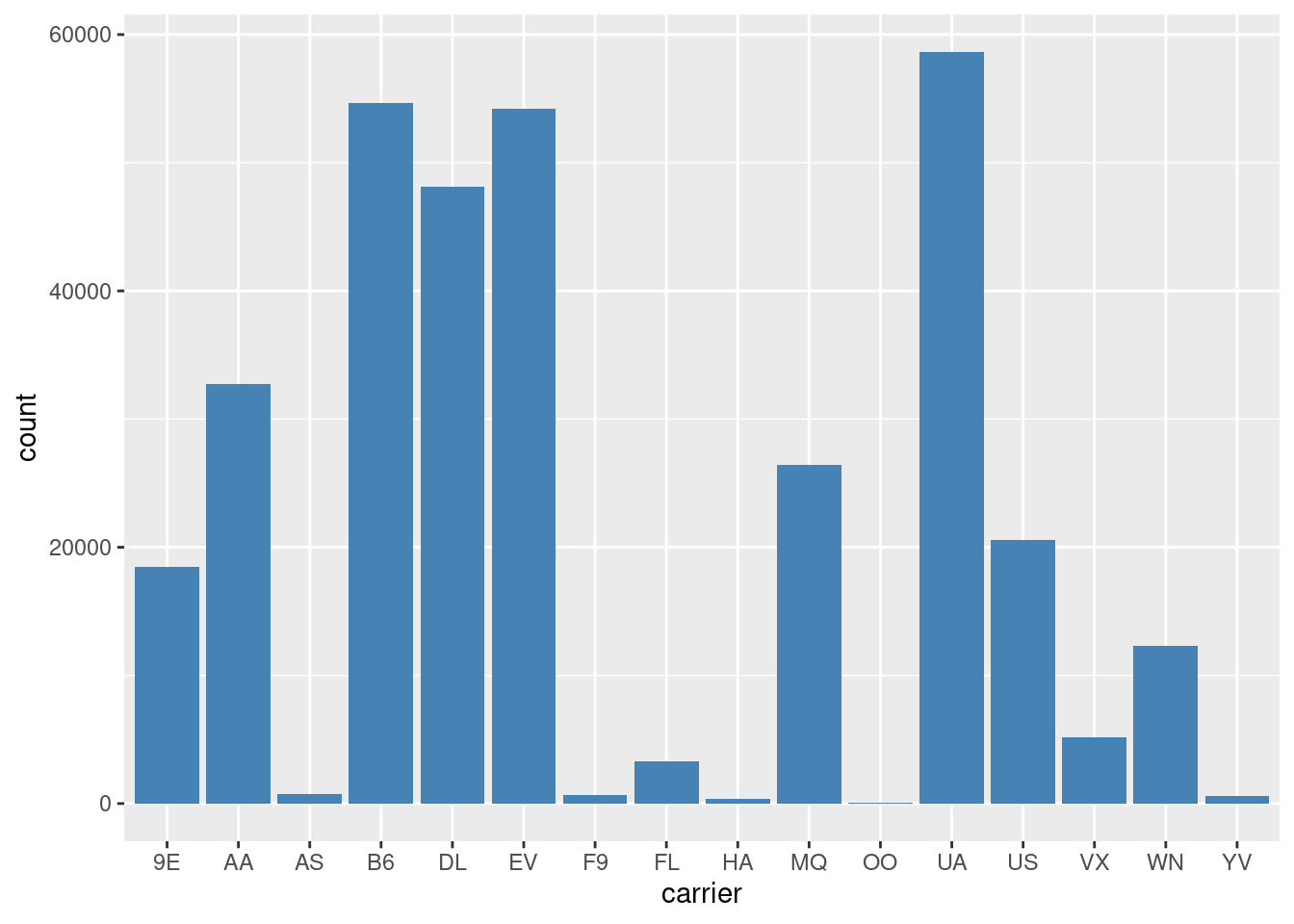
Okrem vizualizácie tabuľky početnosti jednej kategoriálnej premennej sa stĺpcové grafy používajú aj na vyjadrenie združeného rozdelenia dvoch kategoriálnych premenných. V nasledujúcom príklade sú početnosti odletov jednotlivých dopravcov (carrier) odlíšené podľa letiska (origin) farebnou výplňou (fill) stĺpcov. Všimnime si rozdielny kontext, v ktorom vystupuje parameter fill oproti predošlému grafu.
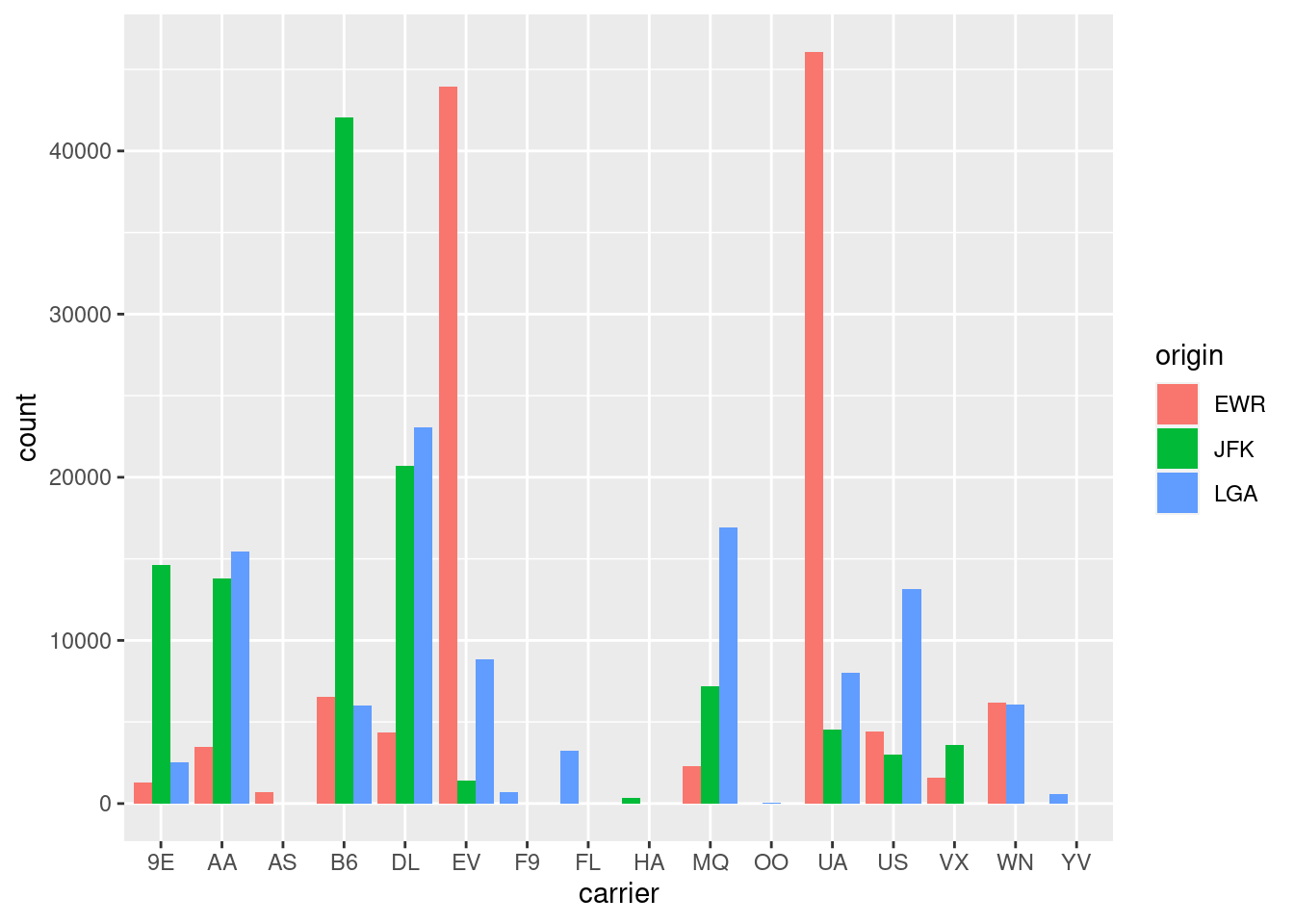
g <- ggplot(data = flights, mapping = aes(x = carrier, fill = origin))
g + geom_bar()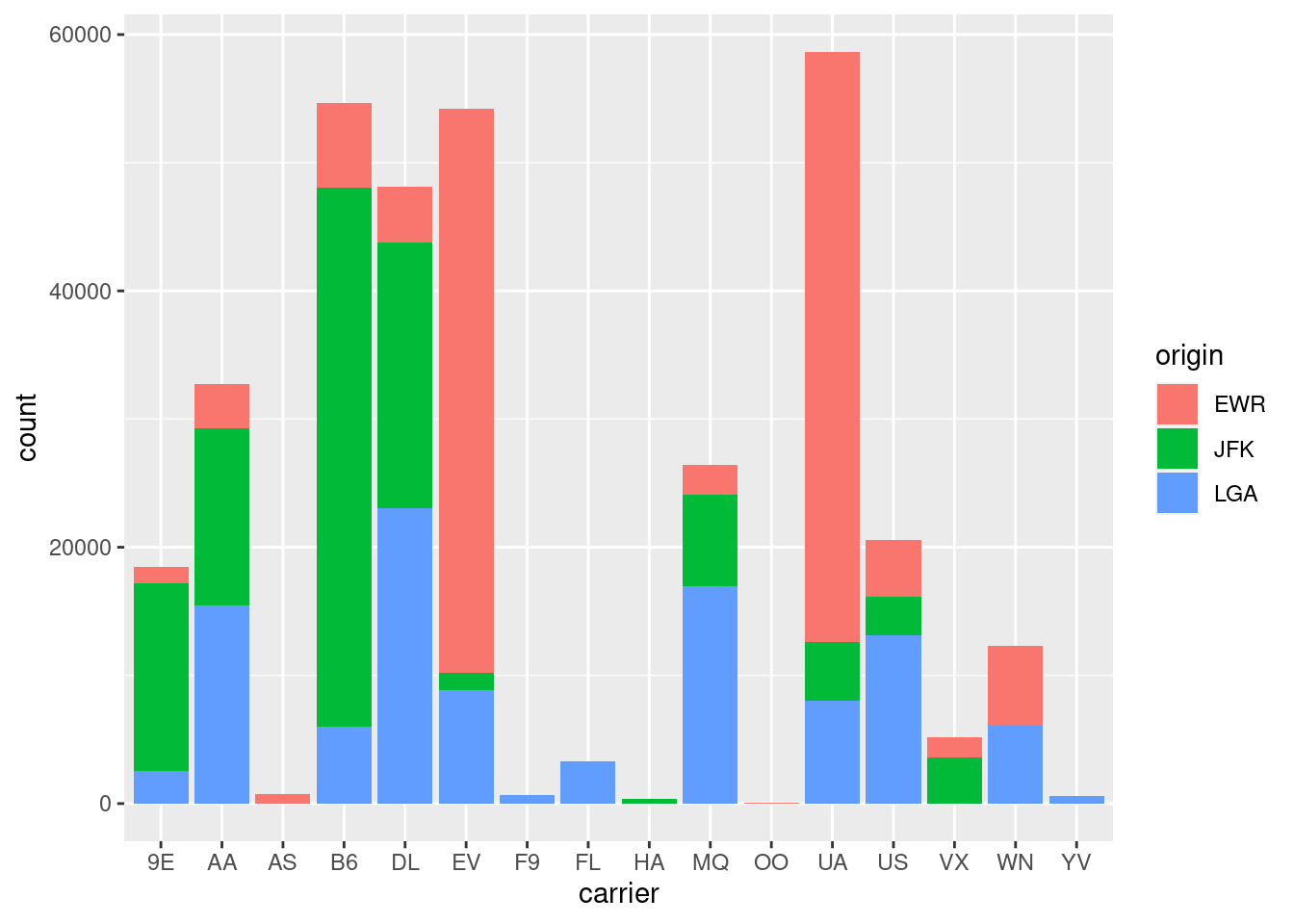
Pomer (proportion) odletov medzi letiskami sa ľahšie identifikuje z relatívnych početností:
g + geom_bar(position = "fill")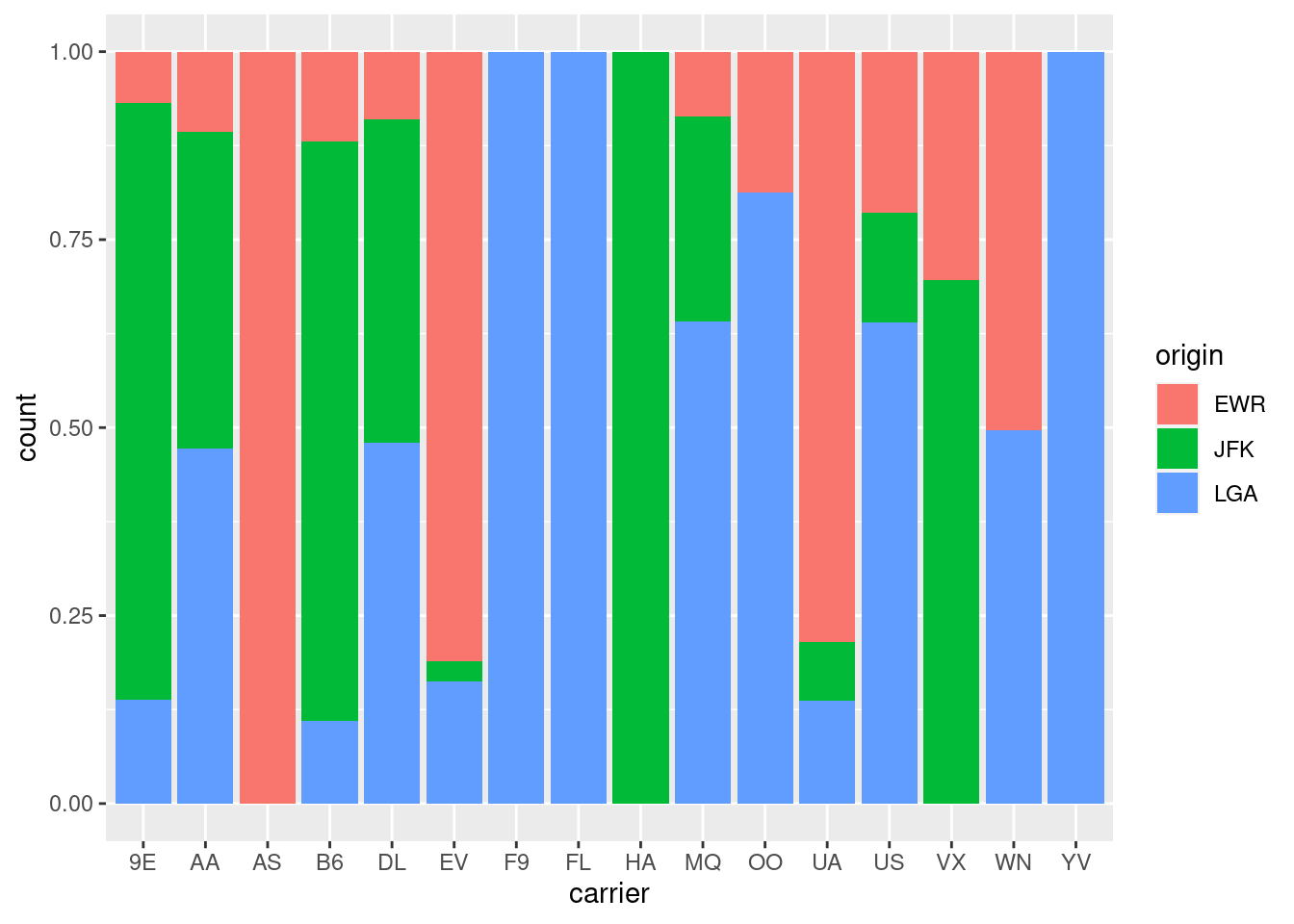
Alternatívnou hodnotou komponentu position ku predvolenému, vertikálnemu naskladaniu stĺpcov (stack) je umiestniť stĺpce vedľa seba (dodge). Možnosti ggplot však týmto ani zďaleka nekončia, grafy sa dajú rôznym spôsobom dolaďovať, napr. ak nám nevyhovuje vyplnenie prázdneho miesta (pri nulovej početnosti) ostatnými stĺpcami v prvom grafe (nad dopravcami AS, F9…), použijeme vylepšenie (preserve):
g + geom_bar(position = "dodge")
g + geom_bar(position = position_dodge(preserve = "single"))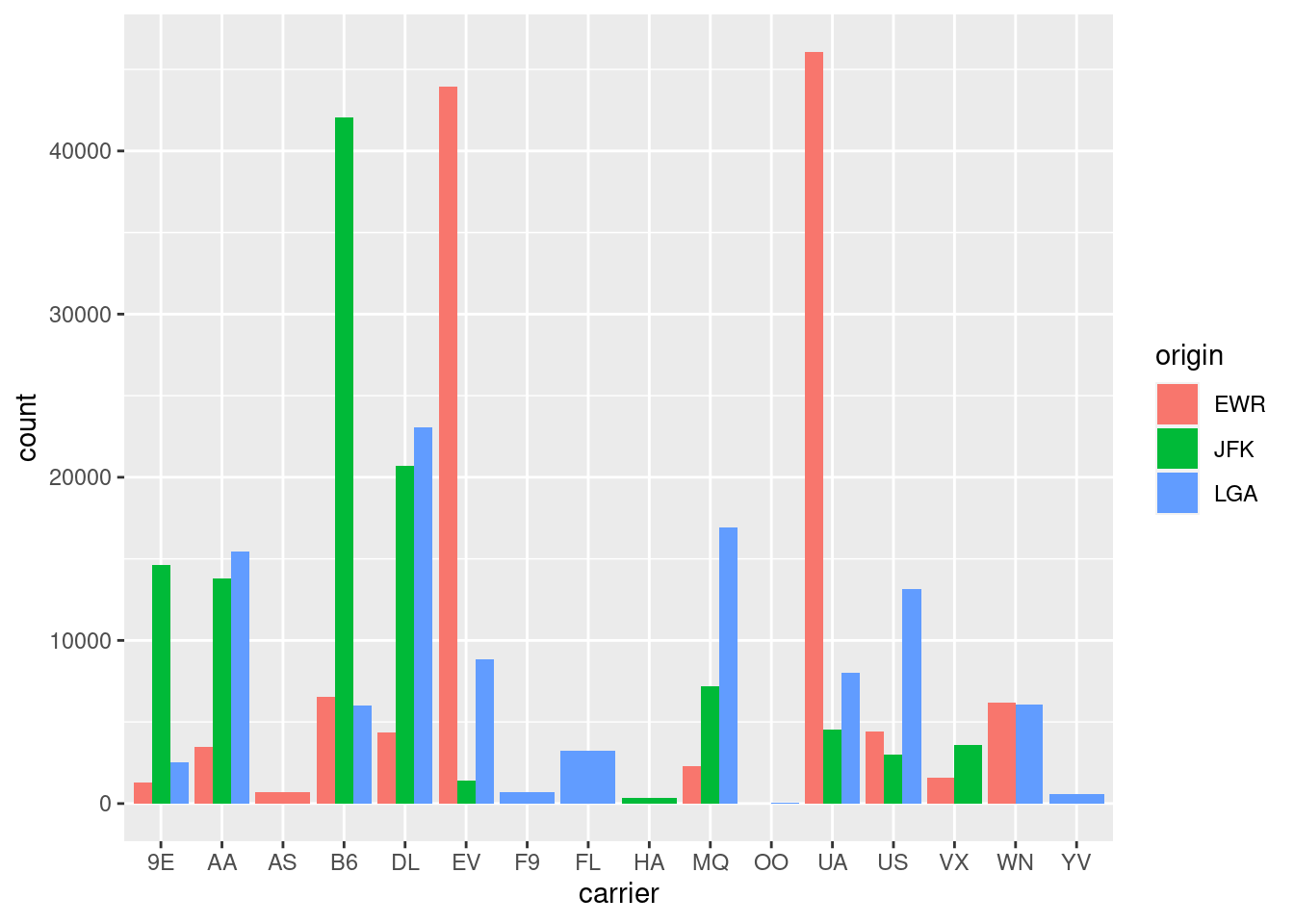
Jednoduchou (na uskutočnenie) no výraznou modifikáciou (vo výsledku) je napr. zmena súradnicového systému – výmenou osí (coord_flip), pridanie nadpisu grafu a popisu osí (labs),
g + geom_bar() + coord_flip() +
labs(x = "prepravca", y = "počet", title = "Odlety z New Yorku")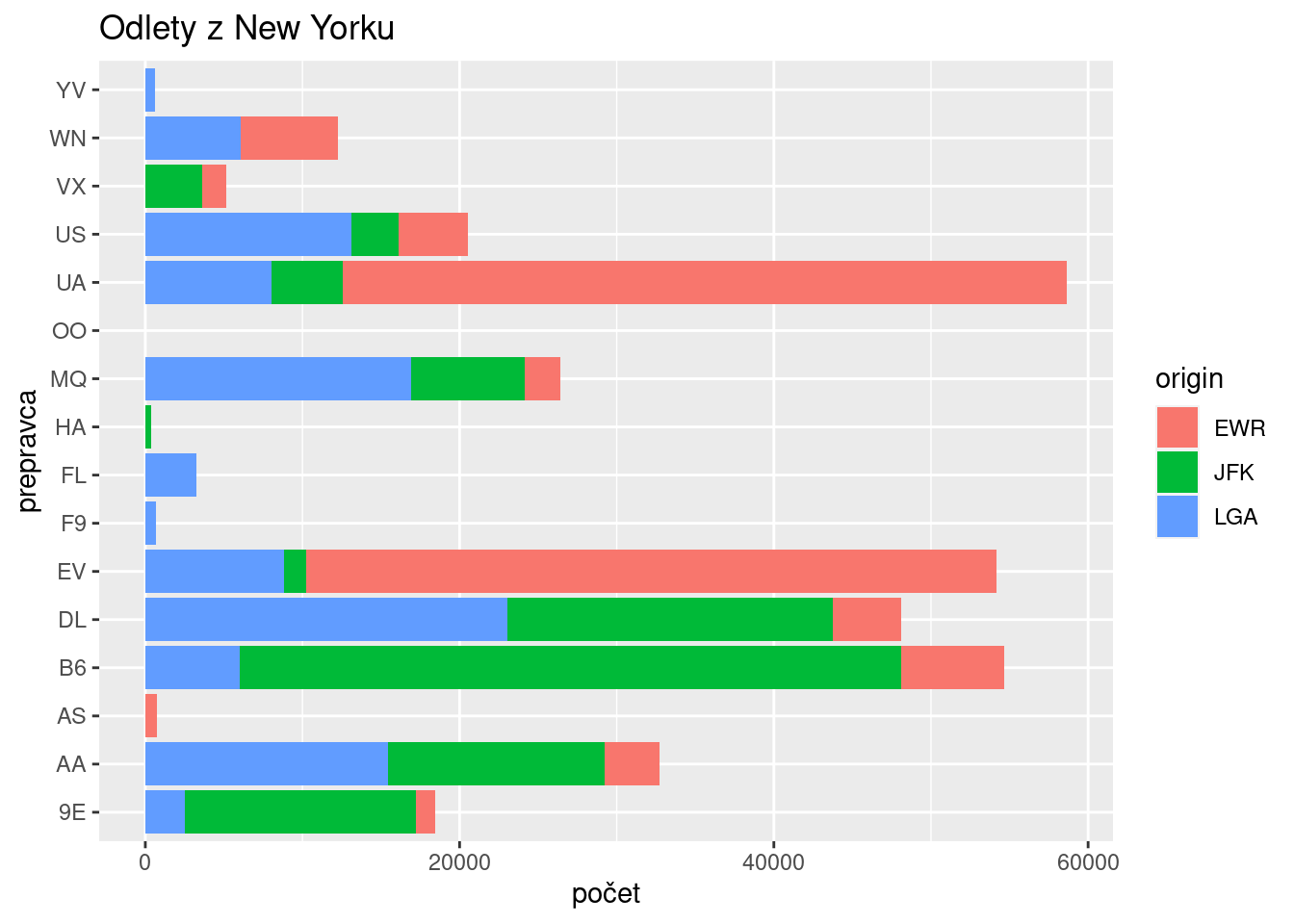
alebo použitie namiesto karteziánskeho – polárny súradnicový systém (coord_polar) a zmena celkovej témy (theme_…):
g + geom_bar() + coord_polar() + theme_minimal()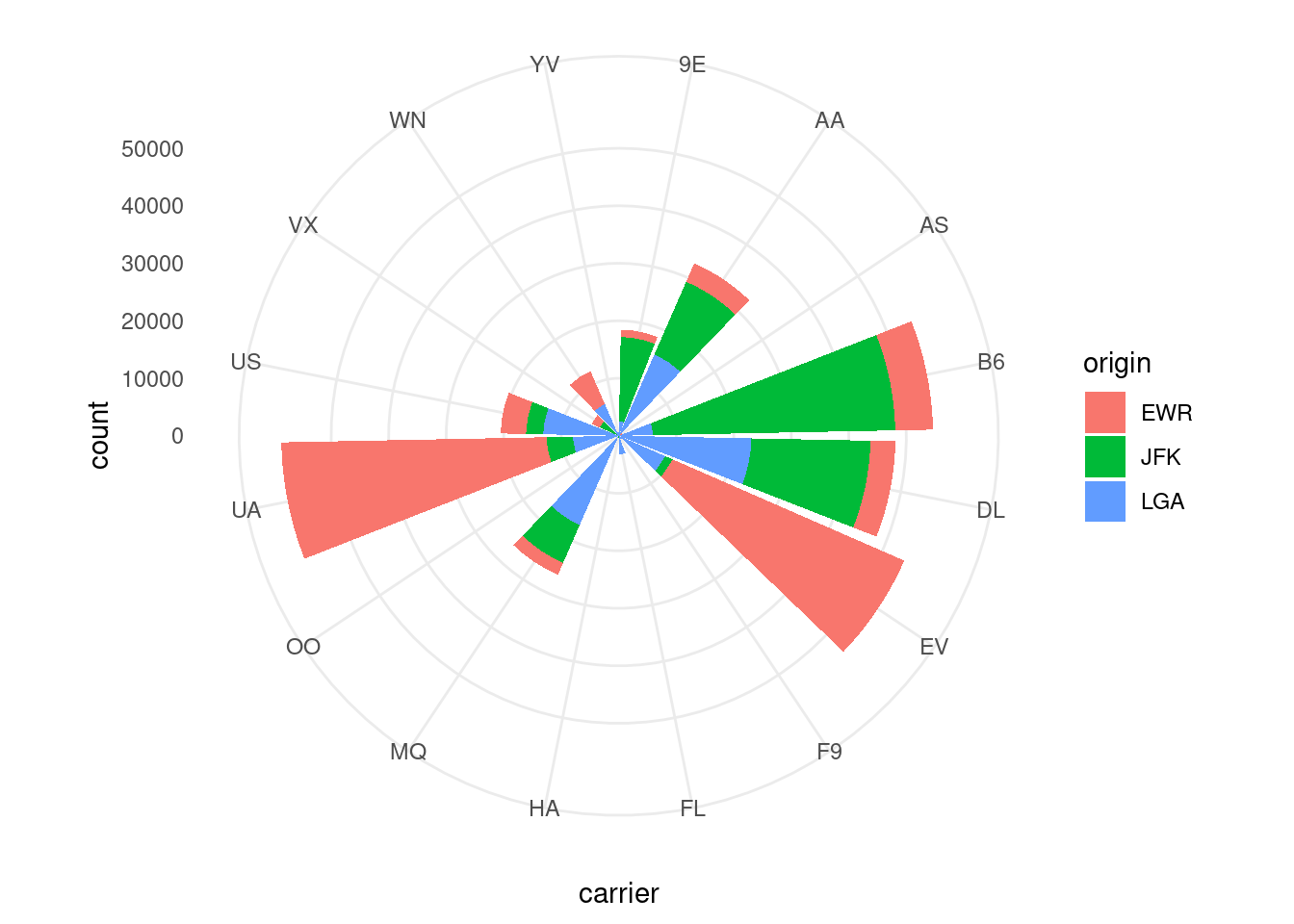
Ďalšie detaily o voľbe a nastaveniach komponentov ggplot sa dajú rýchlo nájsť v nápovede, na referenčnej stránke, v ťaháku, alebo v spomínanej literatúre.
5.3 Špeciálne grafy
Grafy v predošlej časti patria medzi tie najbežnejšie. V nasledujúcom si ukážeme niekoľko špecifických aplikácií knižnice ggplot2.
5.3.1 Mapa
Z ďalších objektov geometrickej zložky sa s výhodou dá použiť geom_polygon pre zobrazenie geo-priestorovej informácie. Napr. vykreslenie mapy s popisom zaberie zopár riadkov kódu. Najprv potrebujeme polohové údaje o hraniciach z balíku maps (stačí ho iba nainštalovať) a následne každú skupinu (angl. group) vrcholov vykresliť ako mnohouholník (polygón):
dat_world_map <- map_data("world")
dat_world_map[9:13,] # pohľad na údaje
## long lat group order region subregion
## 9 -69.91181 12.48047 1 9 Aruba <NA>
## 10 -69.89912 12.45200 1 10 Aruba <NA>
## 12 74.89131 37.23164 2 12 Afghanistan <NA>
## 13 74.84023 37.22505 2 13 Afghanistan <NA>
## 14 74.76738 37.24917 2 14 Afghanistan <NA>
ggplot(dat_world_map, aes(x = long, y = lat, group = group)) +
geom_polygon(fill="lightgray", colour = "white") +
coord_fixed(ratio = 1.3) # optimálny pomer osí pre mapy malej mierky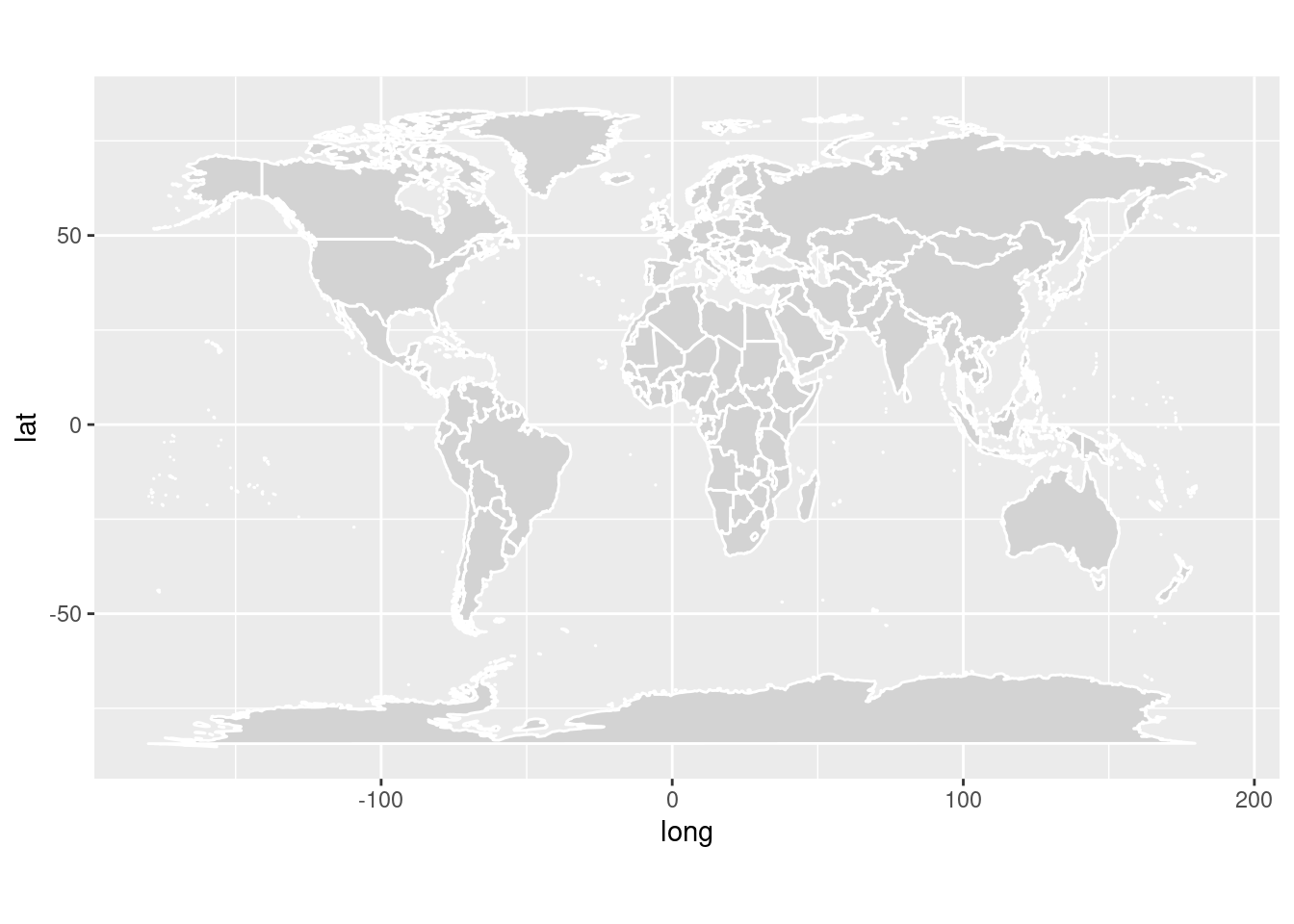
Jednotlivé štáty môžeme vyfarbiť rôznou farbou. Keďže obyčajné mapping = aes(fill=region) by zvolilo nevhodnú paletu farieb, radšej použijeme tú z balíka viridis (opäť si ju ggplot2 importuje sám). Zameriame sa na Európu, vyberieme zopár krajín EU a namiesto legendy zobrazíme textové popisky regiónov priamo do stredu polygónov:
someEU_countries <- c(
"Portugal", "Spain", "France", "Switzerland", "Germany",
"Austria", "Belgium", "UK", "Netherlands",
"Denmark", "Poland", "Italy",
"Croatia", "Slovenia", "Hungary", "Slovakia",
"Czech republic"
)
dat_someEU_map <- map_data("world", region = someEU_countries)
dat_someEU_labels <- dat_someEU_map %>%
dplyr::group_by(region) %>%
dplyr::summarise(long = mean(long), lat = mean(lat))
head(dat_someEU_labels, 3)
## # A tibble: 3 × 3
## region long lat
## <chr> <dbl> <dbl>
## 1 Austria 13.5 47.6
## 2 Belgium 4.73 50.6
## 3 Croatia 16.3 44.6
ggplot(dat_someEU_map, aes(x = long, y = lat)) +
geom_polygon(aes( group = group, fill = region)) +
geom_text(aes(label = region), data = dat_someEU_labels, size = 3, hjust = 0.5) +
scale_fill_viridis_d(alpha=0.5) + # priehladnosť zjemní farby
coord_fixed(ratio = 1.3) + # aby tvary krajín nepôsobili deformovane
theme_void() +
theme(legend.position = "none") # odstráni legendu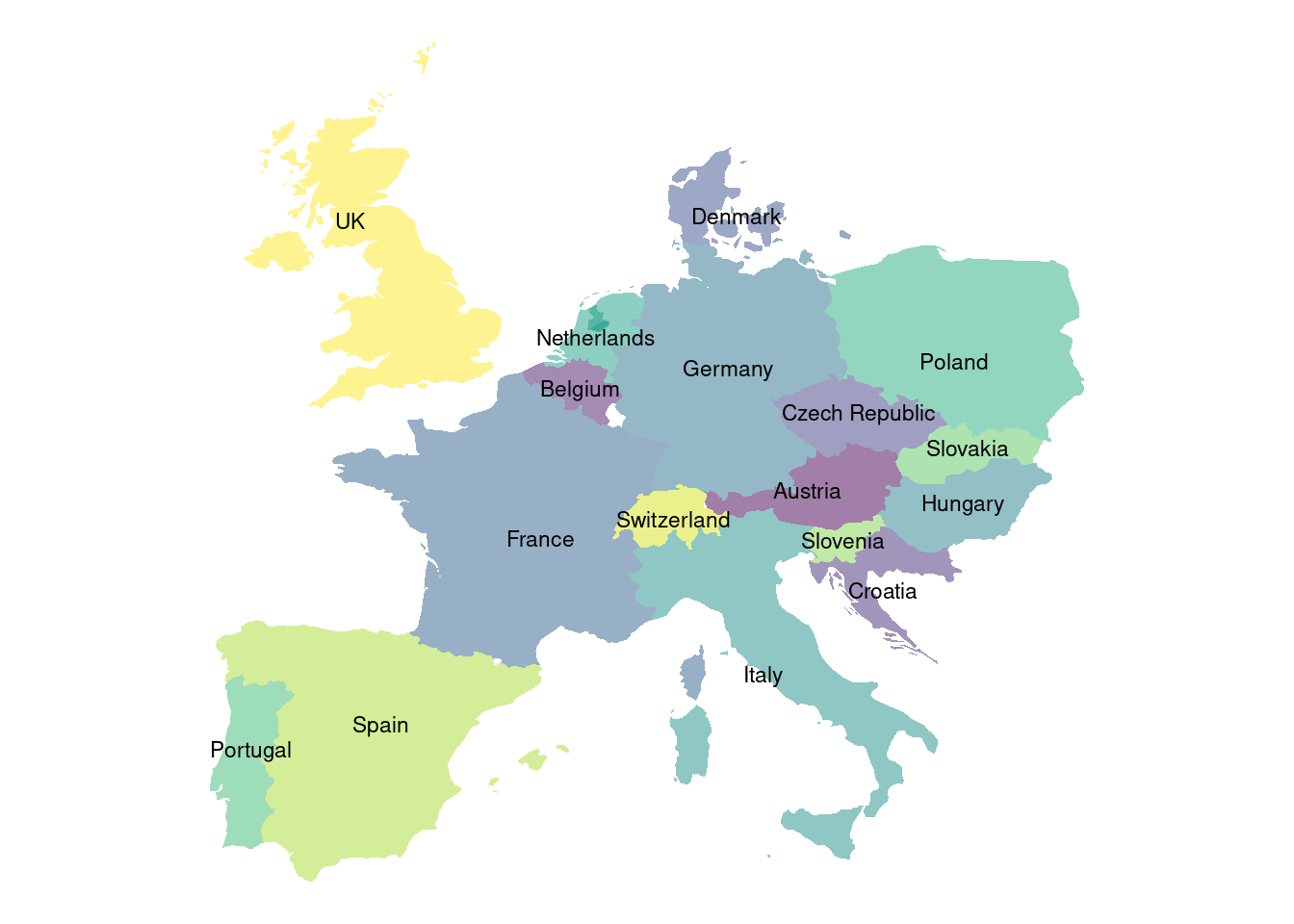
Farby však môžu vyjadrovať aj dôležitú informáciu, v nasledujúcom príklade je to rozšírenie koronavírusu v jednotlivých krajinách sveta ku dňu 2.2.2022:
# načítať súbor priamo
url_corona <- "https://datahub.io/core/covid-19/r/countries-aggregated.csv"
# alebo "https://raw.githubusercontent.com/datasets/covid-19/main/data/countries-aggregated.csv"
dat_corona <- read.csv(file = url(url_corona)) |>
dplyr::filter(Date <= "2022-02-02")
# alebo najprv stiahnuť a potom načítať lokálne
# download.file(url = url_corona, destfile = "data/countries-aggregated.csv")
# dat_corona <- read.csv(file = "data/countries-aggregated.csv")Prehliadneme štruktúru a skontrolujeme aktuálnosť súboru pomocou posledných záznamov:
dat_corona %>% tail(3)
## # A tibble: 3 × 5
## Date Country Confirmed Recovered Deaths
## <date> <chr> <dbl> <dbl> <dbl>
## 1 2022-01-31 Zimbabwe 229666 0 5338
## 2 2022-02-01 Zimbabwe 229851 0 5350
## 3 2022-02-02 Zimbabwe 230012 0 5352V súbore údajov dat_world_map sú teda uložené geolokačné údaje a v dat_corona sú údaje o počte potvrdených prípadov nákazy (Confirmed), počte vyliečených (Recovered) a počte obetí (Deaths) každý deň od 22.1.2020. Keďže nás zaujíma aktuálna situácia, zvolíme konkrétny deň. Pred zobrazením údajov v jednom grafe je potrebné oba súbory zlúčiť (dplyr::full_join) do jedného dátového rámca, a to podľa spoločného znaku: tu je to podľa krajiny. Prekážkou je, že názvy niektorých krajín sa medzi súbormi líšia, napr. „US” a „USA” (ostatné zistíte napr. príkazom setdiff(unique(dat_world_map$region), dat_corona$Country)) a v mape by sa prejavila ako prázdne miesta. Táto nekonzistentnosť v dátových podkladoch sa dá vyriešiť štandardizáciou názvov, napr. pomocou balíku countrycode, ktorý viac-menej automaticky rozpozná názov krajiny a vráti všeobecne platný názov, napr. ‘United States’. Krajiny, ktoré sa mu nepodarí rozpoznať, vypíše vo varovnom hlásení, v našom prípade ide o pomerne exotické a rozlohou zanedbateľné krajiny.
dat_corona <- dat_corona %>%
dplyr::filter(Date == "2022-02-02") %>%
dplyr::mutate(Country = countrycode::countrycode(
sourcevar = Country, origin = 'country.name', destination = 'country.name')
)
## Warning in countrycode_convert(sourcevar = sourcevar, origin = origin, destination = dest, : Some values were not matched unambiguously: Diamond Princess, Micronesia, MS Zaandam, Summer Olympics 2020, Winter Olympics 2022
dat_world_map <- dat_world_map %>%
dplyr::mutate(region = countrycode::countrycode(
sourcevar = region, origin = 'country.name', destination = 'country.name')
)
## Warning in countrycode_convert(sourcevar = sourcevar, origin = origin, destination = dest, : Some values were not matched unambiguously: Ascension Island, Azores, Barbuda, Bonaire, Canary Islands, Grenadines, Heard Island, Chagos Archipelago, Madeira Islands, Micronesia, Saba, Saint Martin, Siachen Glacier, Sint Eustatius, Virgin IslandsPo zlúčení, pri ktorom ako identifikátor vystupuje názov krajiny, sa počet nakazených ľudí (Confirmed) zobrazí na farbu výplne (fill) mnohouholníkov na stupnici (gradient) v logaritmickej mierke (aby sa dali rozoznať rozdiely v krajinách s nízkou početnosťou nakazených):
p <- dplyr::full_join(x = dat_corona, y = dat_world_map,
by = c("Country" = "region")) %>%
ggplot(mapping = aes(x = long, y = lat, group = group)) +
geom_polygon(mapping = aes(fill = Confirmed)) +
scale_fill_gradient(trans = "log10", low = "white", high = "red") +
coord_fixed(ratio = 1.3)
p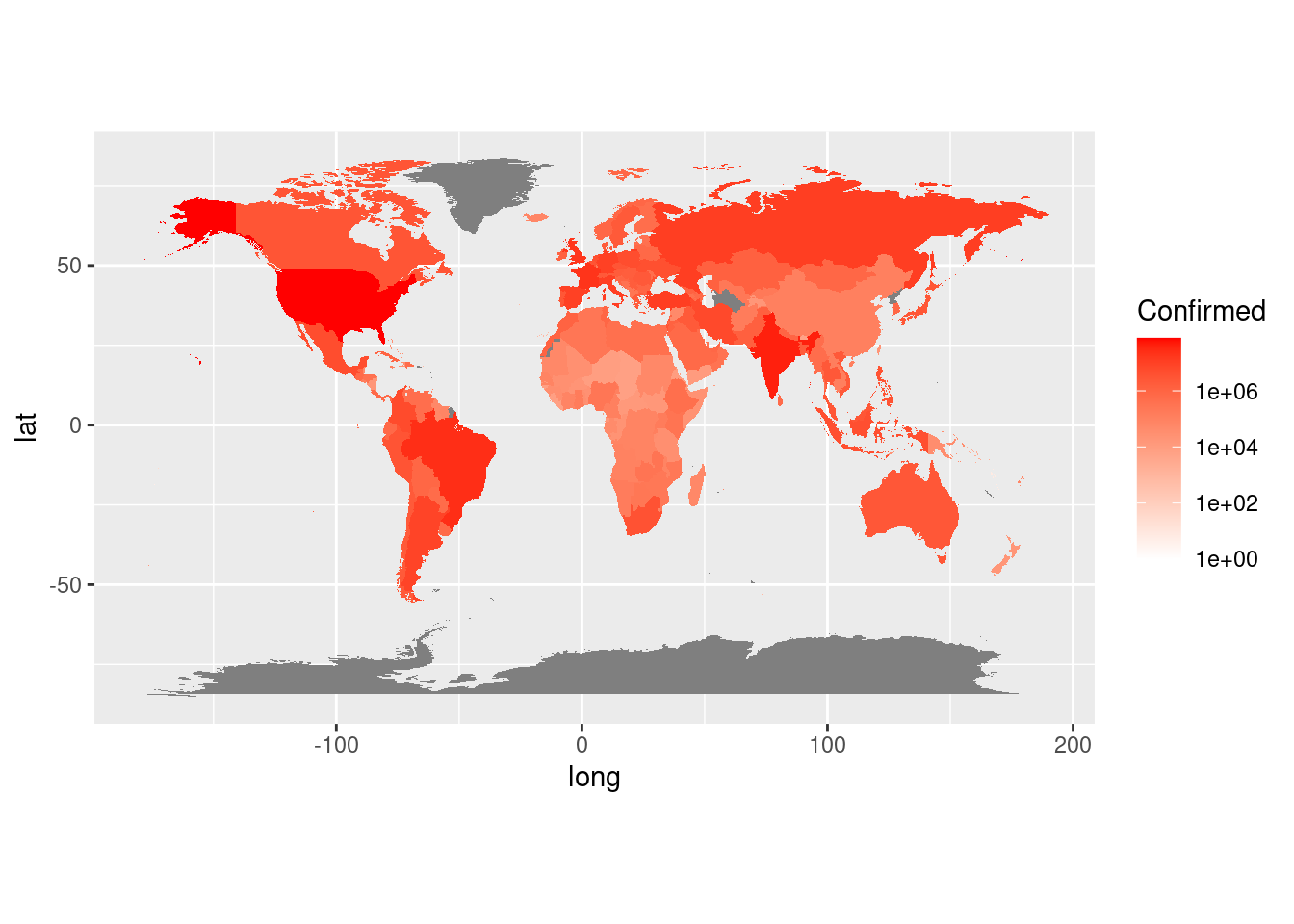
Takýto graf sa nazýva choropleth chart. Šedé zóny predstavujú regióny, pre ktoré nie sú dostupné informácie o šírení choroby COVID-19. Ideálne by bolo zobraziť hustotu nákazy (podiel prípadov nákazy na celú populáciu), prípadne rozdeliť väčšie krajiny na subregióny, no to si vyžaduje import ďalších údajov, čo už presahuje náš záber.
Priblíženie (zoom) oblasti, ktorá nás zaujíma, je s ggplot jednoduché, a to dvoma spôsobmi:
p + coord_fixed(xlim = c(-10,40), ylim = c(30,70), ratio=1.3)
## Coordinate system already present. Adding new coordinate system, which will replace the existing one.
p + xlim(-10,40) + ylim(30,70)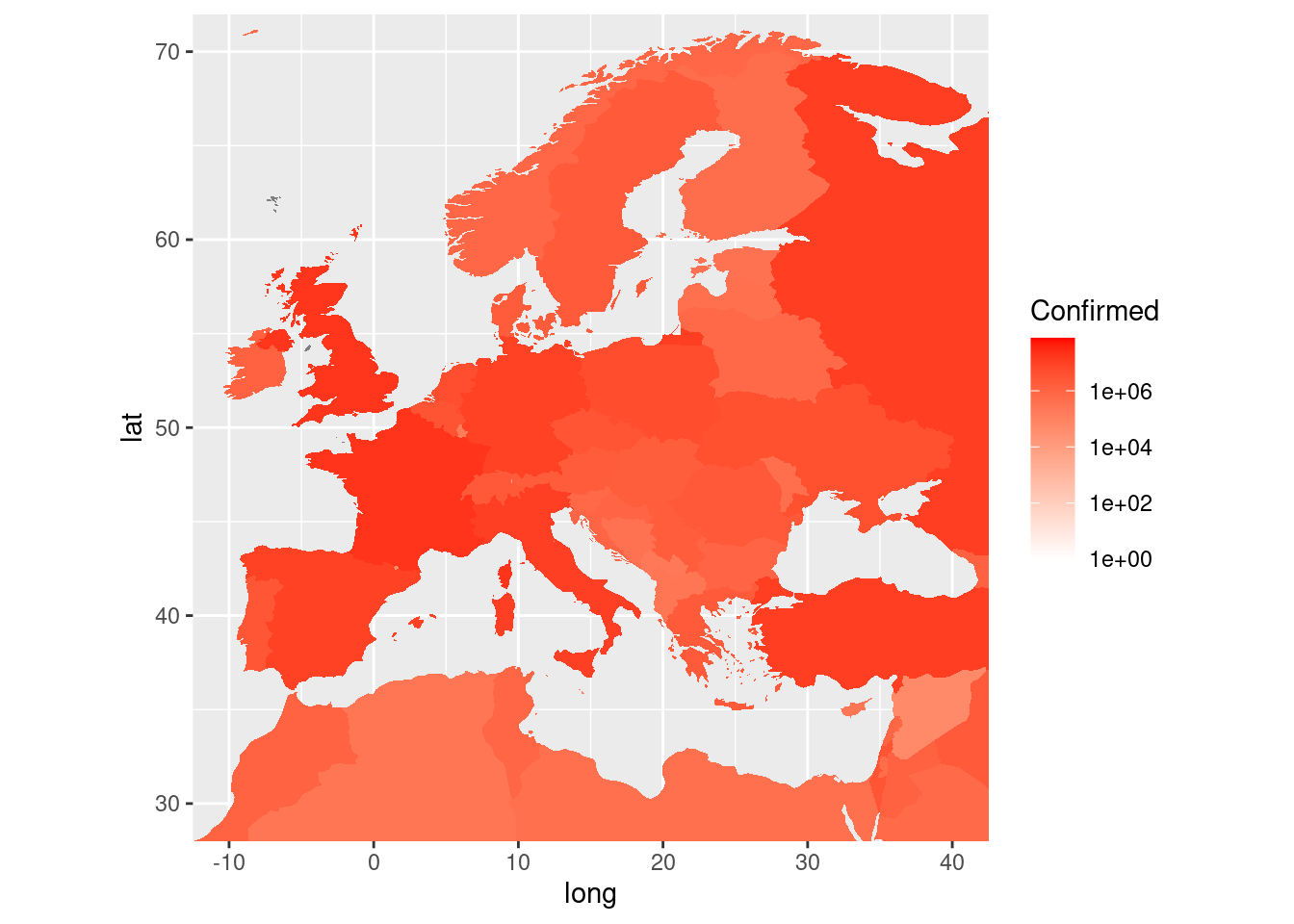
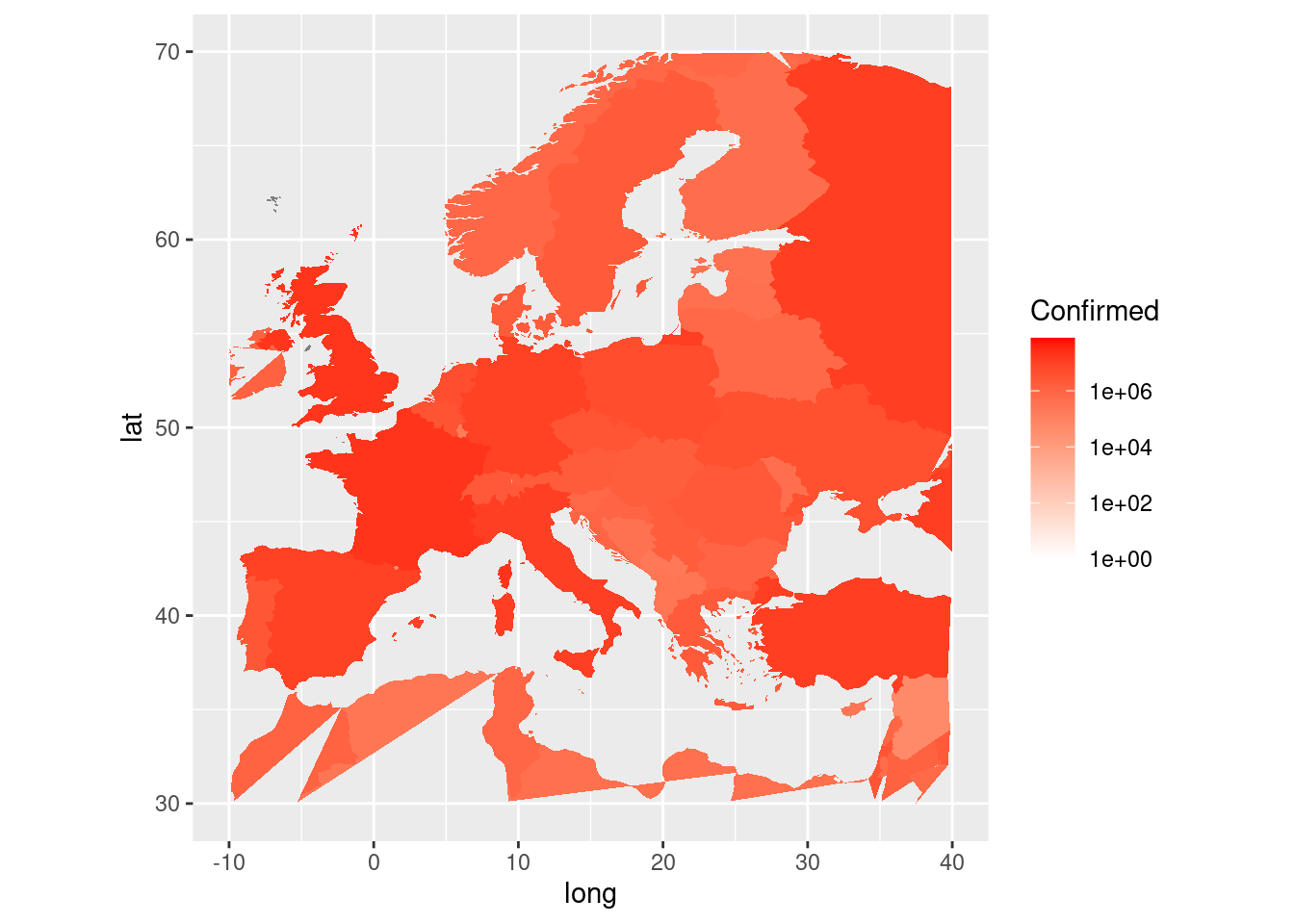
Viete vysvetliť rozdiel? Ako by ste zvýraznili hranice štátov?
Ďalšiu inšpiráciu na tvorbu mapových grafov možno nájsť napr. na stránkach
- https://eriqande.github.io/rep-res-web/lectures/making-maps-with-R.html
- https://www.earthdatascience.org/courses/earth-analytics/spatial-data-r/make-maps-with-ggplot-in-R/
5.3.2 Rozšírenia
Už samotný balík ggplot2 ponúka veľa rôznych druhov grafov, no vďaka svojmu frameworku umožnil ďalším balíkom pomerne jednoducho priniesť do „ekosystému” ešte väčšie množstvo špecializovaných grafov, stačí si pozrieť ukážky na stránke https://www.r-graph-gallery.com.
Napríklad hustotu spojitej premennej podmienenú inou premennou je možné zobraziť buď klasicky, prekrytím líniových a plošných prvkov (plocha znázorňuje pravdepodobnosť) pomocou geom_density, alebo efektnejšie, pomocou balíku ggridges posunutím do vlastnej úrovne, takže vytvoria zdanie tretieho rozmeru.
ggplot(iris) + aes(x = Sepal.Length, fill = Species) +
geom_density(alpha = 0.7)
ggplot(iris) + aes(x = Sepal.Length, y = Species, fill = Species) +
ggridges::geom_density_ridges(alpha = 0.7)
## Picking joint bandwidth of 0.181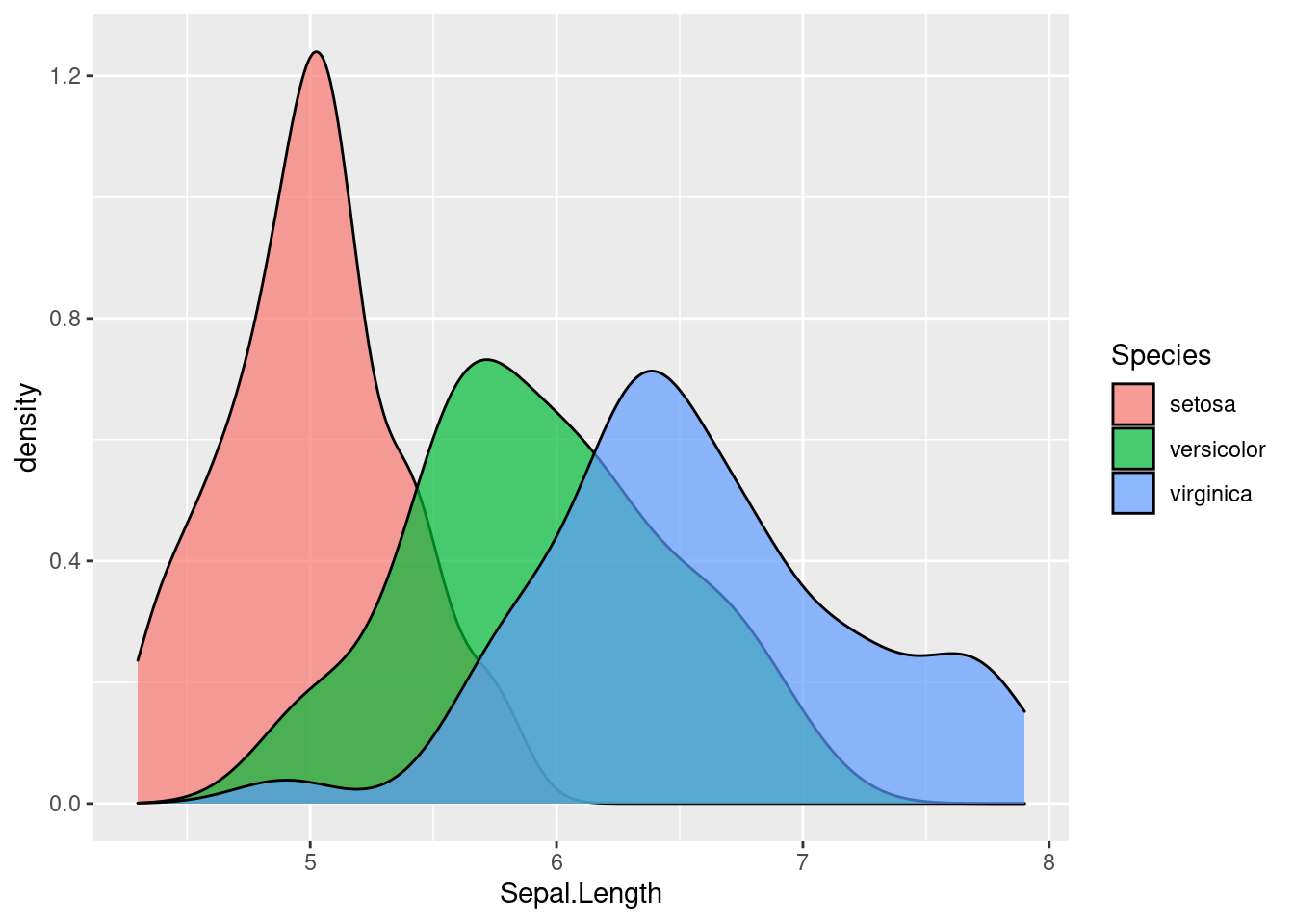
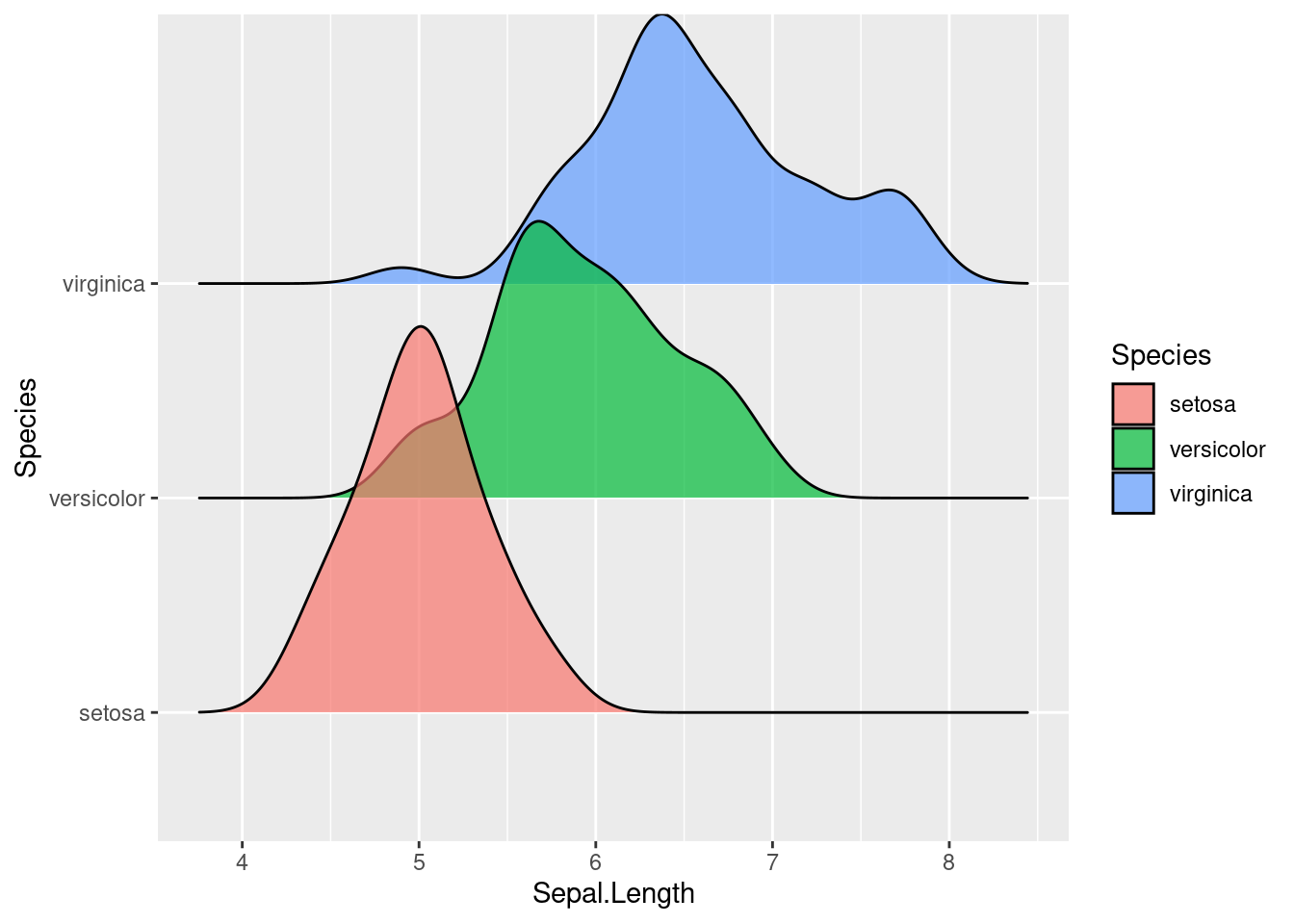 Tieto hrebeňové grafy sa dajú samozrejme dopĺňať rôznymi prvkami, napr. bodmi v ploche pod hustotou, značkami kvantilov, kobercovým grafom a podobne, rovnako hustota môže byť nahradená stĺpcovým grafom alebo polygónom, a nakoniec ani nemusí ísť o hustotu, dá sa zobraziť ľubovolná, vlastná funkcia.
Tieto hrebeňové grafy sa dajú samozrejme dopĺňať rôznymi prvkami, napr. bodmi v ploche pod hustotou, značkami kvantilov, kobercovým grafom a podobne, rovnako hustota môže byť nahradená stĺpcovým grafom alebo polygónom, a nakoniec ani nemusí ísť o hustotu, dá sa zobraziť ľubovolná, vlastná funkcia.
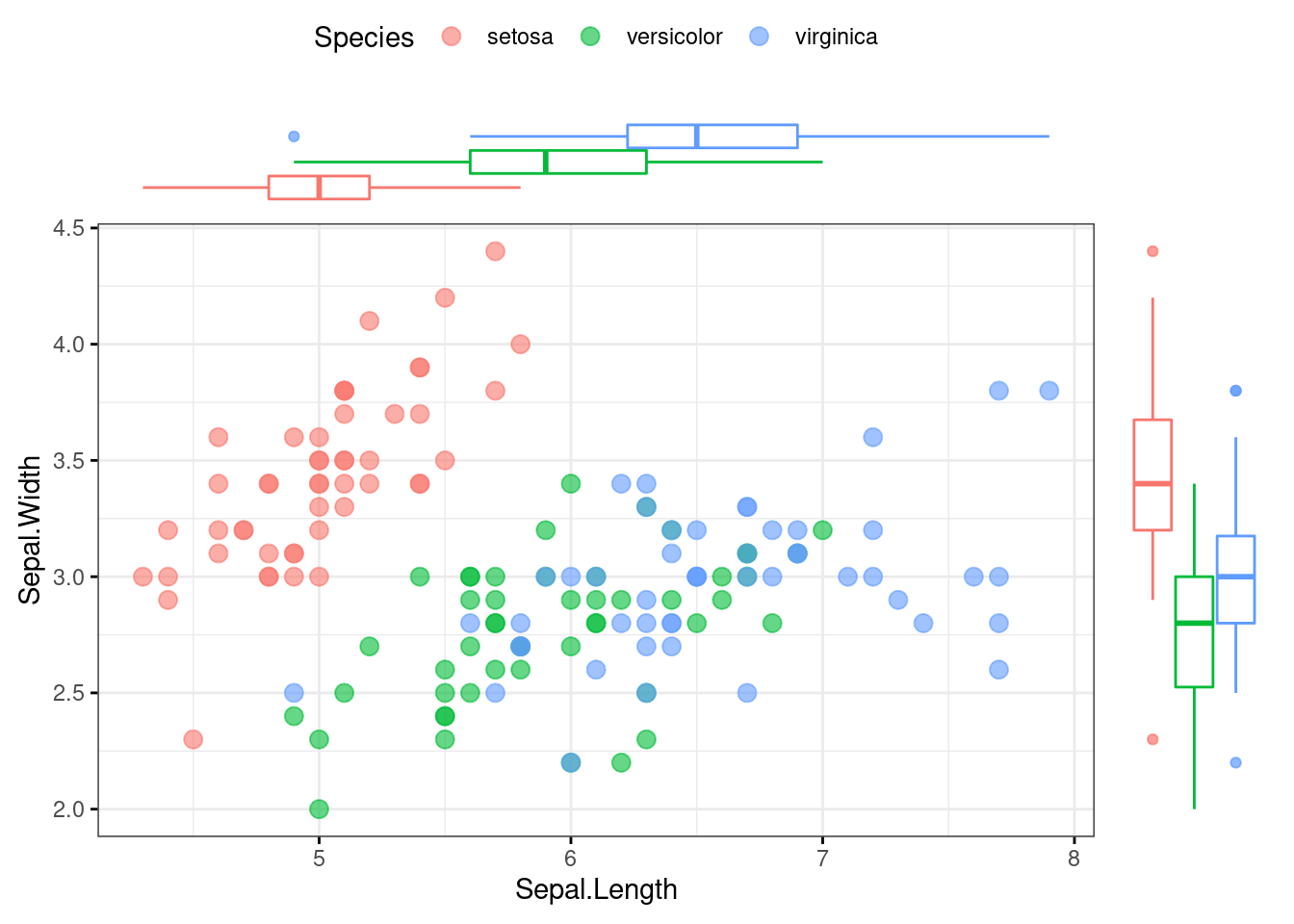
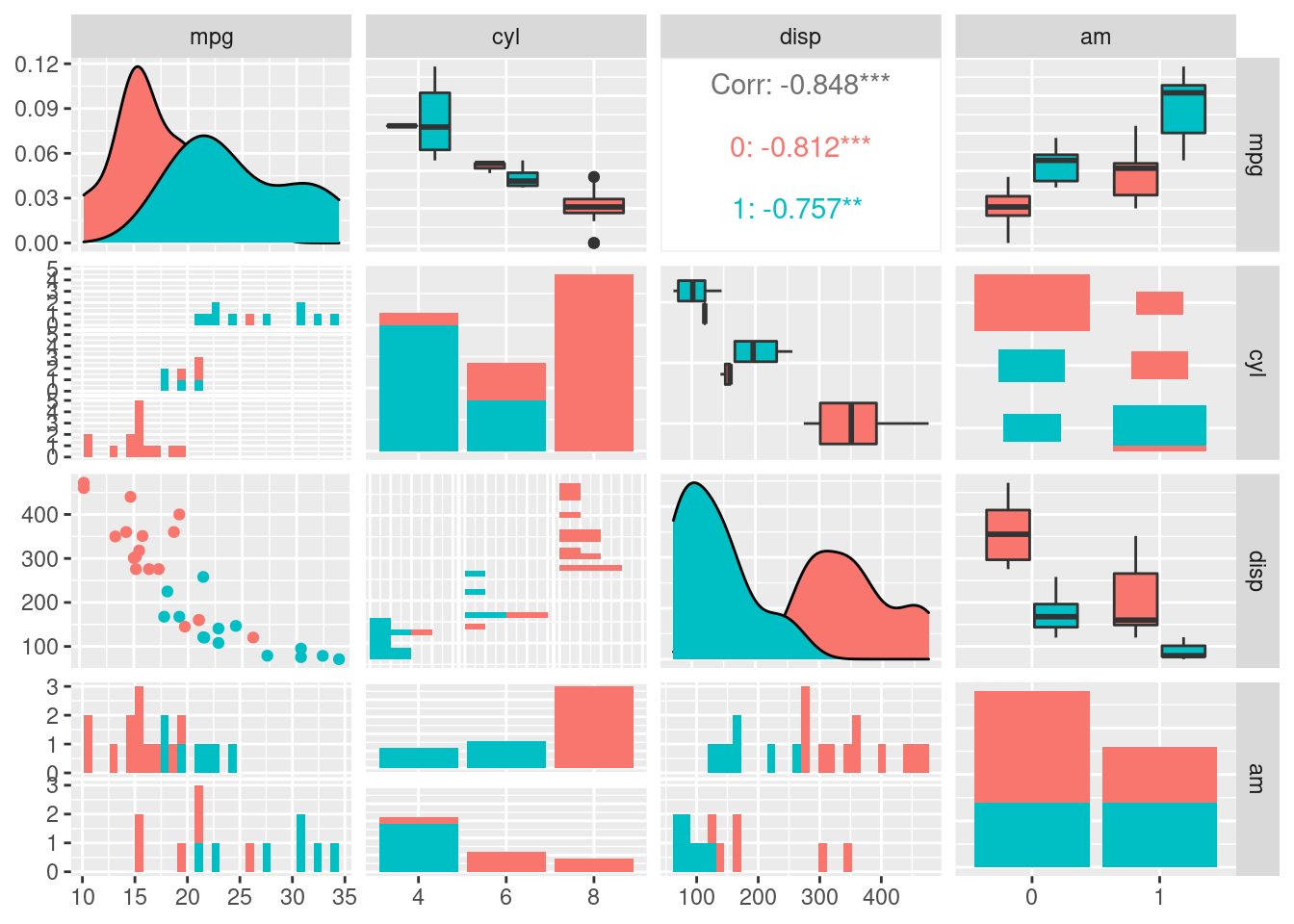
Veľké množstvo špecficky zameraných a nielen v prieskumnej analýze užitočných funkcií poskytujú balíky ggpubr a ggally. Ich aplikácia nesleduje rovnakú syntax (spájania vrstiev) ako predošlé ukážky, naopak, všetky nastavenia sa dejú na úrovni argumentov špecializovaných funkcií. V nasledujúcich príkladoch najskôr zobrazíme bodový graf lemovaný krabicovými grafmi, znázorňujúci tak individuálne vlastnosti – marginálne rozdelenie – premenných (dĺžku a šírku kališného lístku kosatcov) spolu s ich vzťahom. Ďalším je mozajka párových grafov viacerých premenných a rôzneho typu, kde marginálne rozdelenia figurujú na diagonále a vzťah medzi premennými je popísaný mimo-diagonálnymi grafmi.
iris %>%
ggpubr::ggscatterhist(
x = "Sepal.Length", y = "Sepal.Width", color = "Species",
size = 3, alpha = 0.6, margin.plot = "boxplot", ggtheme = theme_bw()
)
mtcars %>%
dplyr::mutate(across(c(cyl, am, vs), as.factor)) %>%
GGally::ggpairs(
columns = c("mpg", "cyl", "disp", "am"),
mapping = ggplot2::aes(color = vs)
)
Často by sme chceli do jedného grafu umiestniť také množstvo informácií, že nám nestačia estetické atribúty a grafu hrozí neprehľadnosť. Ako ďalší rozmer sa vďaka balíku gganimate ponúka čas. V nasledujúcom príklade sa pomocou animácie zobrazuje vývoj vzťahu medzi výkonnosťou ekonomiky a priemerným vekom dožitia v krajinách na rôznych svetadieloch:
ggplot(gapminder::gapminder) +
aes(x = gdpPercap, y = lifeExp, size = pop, color = continent,
frame = year) + # premenná year sa zobrazí na časovú os
geom_point() +
scale_x_log10() +
labs(x = "HDP na hlavu", y = "priemerný vek dožitia",
title = "Rok: {frame_time}") + # umiestnenie roku v nadpise
gganimate::transition_time(year) + # rozpohybovanie
gganimate::shadow_wake(wake_length = 0.1) # tieňové stopy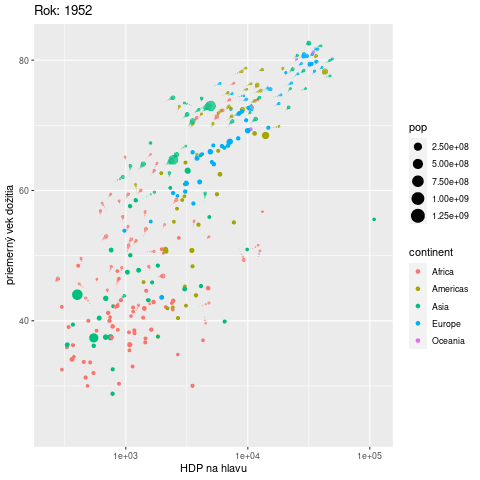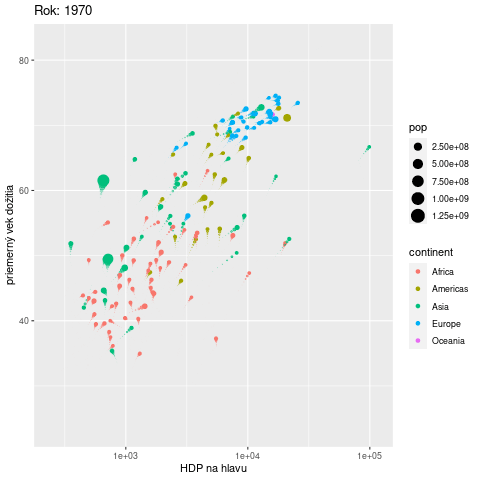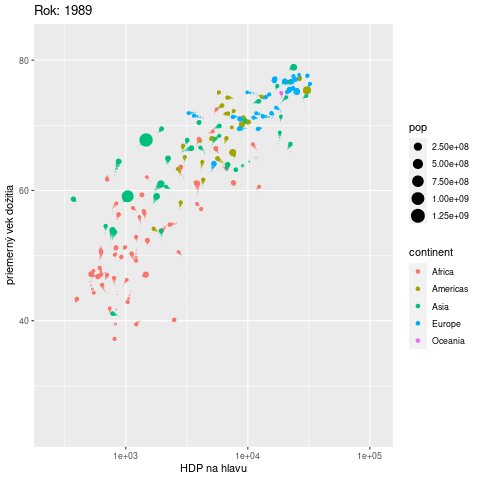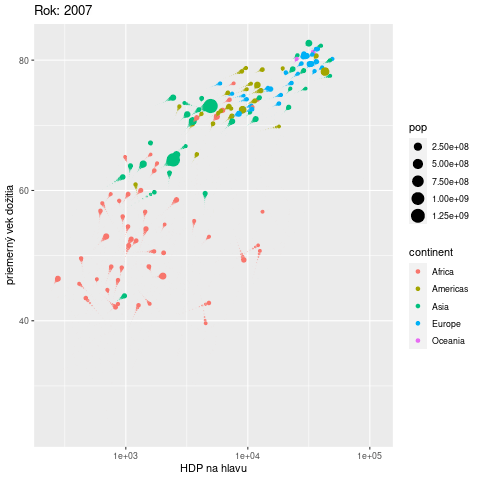
Nie vždy sa dá (alebo je rozumné) komunikovať všetky informácie v jedinom grafe, a ani pomocou faziet (faceting). I napriek tomu však môže byť grafická informácia podaná v kompaktnej forme – a to uložením viacerých, aj odlišných grafov vedľa seba. V systéme R je veľa spôsobov, ako to dosiahnuť. V kontexte ggplot spomenieme ten najpopulárnejší: pomocou balíku patchwork. V nasledujúcom príklade sa najprv vytvoria jednotlivé grafy, uložia sa ako GG objekty, a nakoniec iba jednoduchými operátormi zošijú dokopy ako záplaty (angl. patch):
library(patchwork)
p1 <- ggplot(mtcars) +
geom_point(aes(disp, mpg)) +
ggtitle('Graf 1')
p2 <- ggplot(mtcars) +
geom_boxplot(aes(gear, disp, group = gear)) +
ggtitle('Graf 2')
p3 <- ggplot(mtcars) +
geom_bar(aes(gear)) +
facet_wrap(~cyl) +
ggtitle('Graf 3')
( p1 | (p2 / p3) ) + plot_annotation(title = "Mozaika grafov")
5.4 Cvičenie
- Načítajte data frame Cars93 z balíka MASS.
- Odfiltrujte všetkých neamerických výrobcov a zobrazte histogram pre cenu automobilu s rozdelením do približne 5 kategórií.
- Zobrazte závislosť dojazdu v meste od zdvihového objemu s veľkosťou bodov podľa hmotnosti, tvarom bodov podľa typu vozidla a farbou podľa počtu valcov, pričom grafická informácia bude rozdelená do troch grafov pod sebou podľa typu náhonu (DriveTrain).
- Zobrazte časový rad vývoja počtu potvrdených prípadov choroby COVID-19 v krajinách V4 odlíšených farebne. Postup príkazov (tip v zátvorke):
- načítať dáta zo súboru https://raw.githubusercontent.com/datasets/covid-19/main/data/countries-aggregated.csv (alebo iného dostupného datasetu obsahujúceho stĺpce Date, Country, Confirmed),
- zmeniť premennú Date z typu factor/character na typ date, (as.Date)
- filtrom prepustiť len 4 krajiny a obmedziť začiatok časového radu na 1.9.2020, (filter,
%in%) - zobraziť premennú Date na os x, Confirmed na os y, Country na group a color a pridať líniový komponent.
- Experimentálne zobrazte iný typ grafu, než aké boli prebraté, či už s jednou, dvoma alebo troma premennými a vysvetlite, čím je zaujímavý.