Chapter 4 Stats used in eeb II

There is much counting in ecology & evolutionary biology (eeb) (Zuur et al. 2009). We count individuals, species, populations, interactions, and then map out diversity and distributions to infer process. Many disciplines use similar logic in the structure of their evidence and experimental design with statistics.
Learning outcomes
- Practice your critical workflow for data and statistics that is replicable and literate.
- Appreciate the value of generalized statistical models that connect to one another conceptually.
- Do a GLM.
Critical thinking
Exploratory data analyses is everything we have done. This is a primary approach to better understanding your evidence without introducing bias. Transparency is key.
Workflow we have developed but that you nuance based on your cognitive and critical thinking style and strengths.
- Tidy data.
- Inspect data structure.
- Data viz.
- Basic exploratory data analyses.
However, now that we are ready to apply models, we add in one more tiny step. Continue to visualize the data to better understand its typology and underlying distribution. Then, you are ready to fit your models. Exploratory data analyses is an intermediate step to this end. EDA includes testing assumptions in the data, fitting basic models that ignore covariates, fitting relevant and logical models to explore the data, training your data, and exploring sensitivity (Ellison 2001). This process builds a viable path for further inquiry, and it is a model builder that is predicated upon critital thinking to ensure you inference (deduction, induction) is aligned with your evidence (Yu 1994).
A statistical model is an elegant, representative simplification of the patterns you have identified through data viz and EDA (Mengersen et al. 2013). It is a formal mathematical relationship between factors of interest. It should capture data/experimental structure including the key variables, appropriate levels, and relevant covariation or contexts that mediate outcomes. It should support the data viz. It should provide an estimate of the statistical likelihood or probability of differences. Ideally, the underlying coefficients should also be mined to convey an estimate of effect sizes. A t.test, chi.square test, regression/linear model, general linear model, or generalized linear mixed model are all examples of models that describe and summarize patterns and each have associated assumptions about the data they embody. Hence, the final step pre-model fit, is explore distributions.
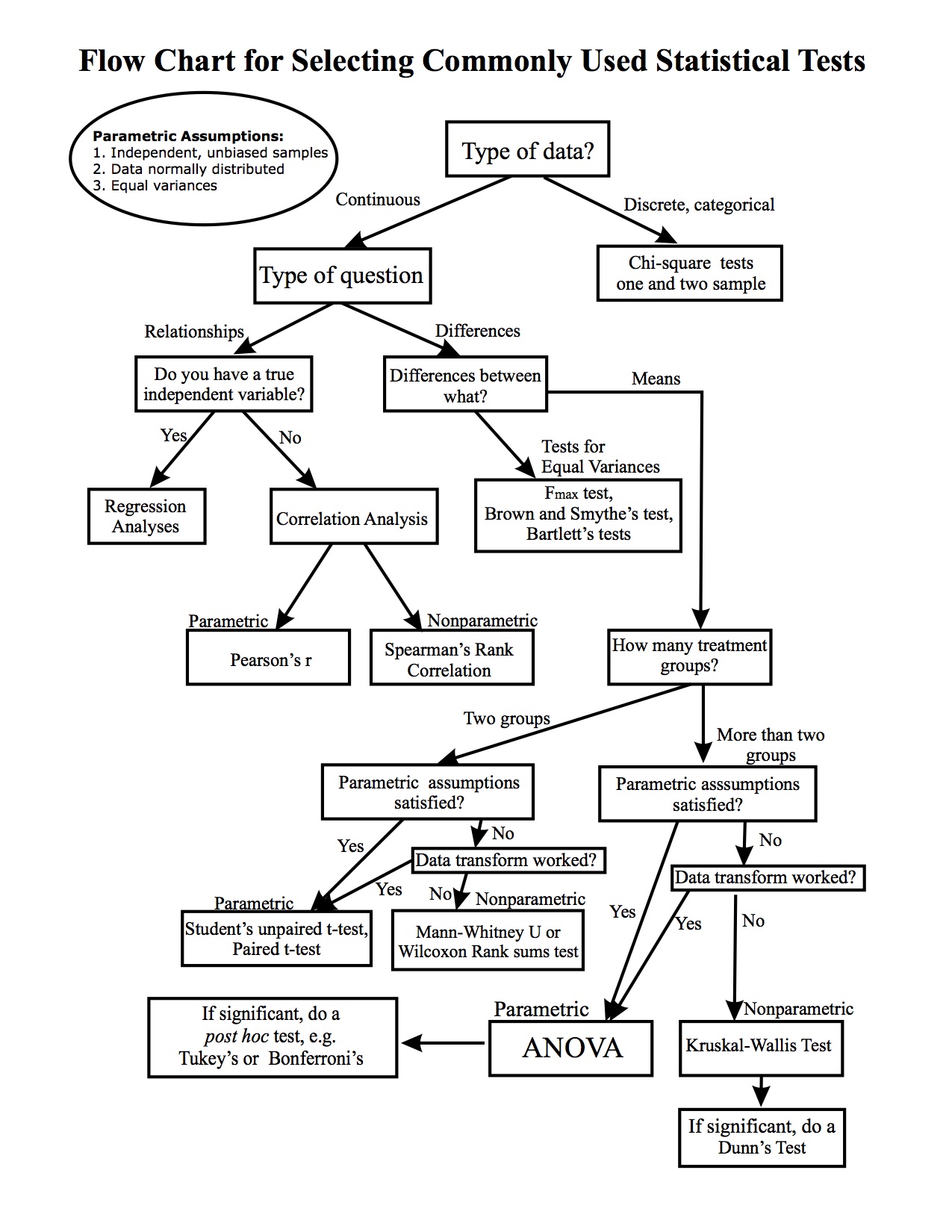
Conceptually, there are two kind of models. Those that look back and those that look forward. Think tardis or time machine. A model is always a snapshot using your time machine. It can be a grab of what happened or a future snap of what you predict. In R, there is simple code to time travel in either direction. Actually, there is no time - Arrow of time - only an observer potential perception of it. Statistical models are our observers here. These observers use ‘probability distributions’ as we described in the first week sensu statistical thinking to calibrate what the think critically when observed or will observe given the evidence at hand. Here are two super resources to further support this in a proximate sense that align with critical thinking. Choosing the correct statistical test made easy (Gunawardana 2004), and a flowchart for selecting commonly used statistics developed by Bates College.
{kind=link}
Adventure time
Here is an impressive dataset describing bird counts in Toronto. These data were collected by York University undergraduates in an experimental design course. Explore whether there is a bias in detection by behaviour and identify the most common species by location in Toronto - at least as estimated using these data. For your curiosity, here are data collected in another larger citizen science endeavour - The Christmas Bird Count for Southern Ontario region centered around the Greater Toronto Area.
Deeper dive: If you wish to adventure further afield, contrast the two datasets. Explore fitting a different family to the data or explore offset argument versus covariates.
library(tidyverse)
birds <- read_csv(url("https://knb.ecoinformatics.org/knb/d1/mn/v2/object/urn%3Auuid%3Aa84a9673-878a-4c43-ba08-570b2d38bdc9"))
birds## # A tibble: 826 × 11
## year experiment source rep date locat…¹ species frequ…² behav…³ initi…⁴
## <dbl> <chr> <chr> <dbl> <chr> <chr> <chr> <dbl> <chr> <chr>
## 1 2020 balcony bir… full 1 10/1… Holdit… Agelai… 3 flying RD
## 2 2020 balcony bir… full 1 10/1… Holdit… Agelai… 4 flying RD
## 3 2020 balcony bir… full 1 10/1… Holdit… Agelai… 1 perchi… RD
## 4 2020 balcony bir… full 1 10/1… High P… Aix sp… 4 swimmi… AB
## 5 2020 balcony bir… full 1 10/9… Vaughan Anas p… 4 flying TA
## 6 2020 balcony bir… full 1 10/9… Vaughan Anas p… 6 flying TA
## 7 2020 balcony bir… full 1 10/9… Vaughan Anas p… 9 flying TA
## 8 2020 balcony bir… full 1 10/9… Vaughan Anas p… 10 flying TA
## 9 2020 balcony bir… full 1 10/9… Vaughan Anas p… 2 inacti… TA
## 10 2020 balcony bir… full 1 10/9… Vaughan Anas p… 2 inacti… TA
## # … with 816 more rows, 1 more variable: citation_DOI <chr>, and abbreviated
## # variable names ¹location, ²frequency, ³behaviour, ⁴inititalsReflection questions
- When do you move from EDA to model fitting?
- Are there ways to mitigate bias and p-hacking through formal workflows?
- Did building a model such as GLM align with critical thinking and intuition, i.e from critical thinking was it accurate and fair? Did the EDA-to-model process legitimately represent the patterns in the observations recorded.