Chapter 4 실전 설문조사 데이터 전처리
이번 장에서는 JCI 인증에 대한 임상간호사의 인식과 태도, 직무스트레스라는 연구에 사용된 테이터를 가지고 전처리 연습을 해본다. 사용할 데이터(JCI인증.xlsx) 및 논문(JCI인증.hwp)은 다음 주소에서 다운로드 받을 수 있다(http://web-r.org/book/14125). 자료를 다운받지 않아도 웹R의 무료서버에 접속하여 내장된 데이터를 이용할 수 있다.
4.1 데이터 불러오기
웹R에 접속한 후 무료서버접속 페이지를 통해 무료서버에 접속한다. 먼저 언어를 한국어로 선택한다. 서버에 내장되어 있는 데이터를 불러오기 위해 Data files in Sever 버튼을 누른다(2).
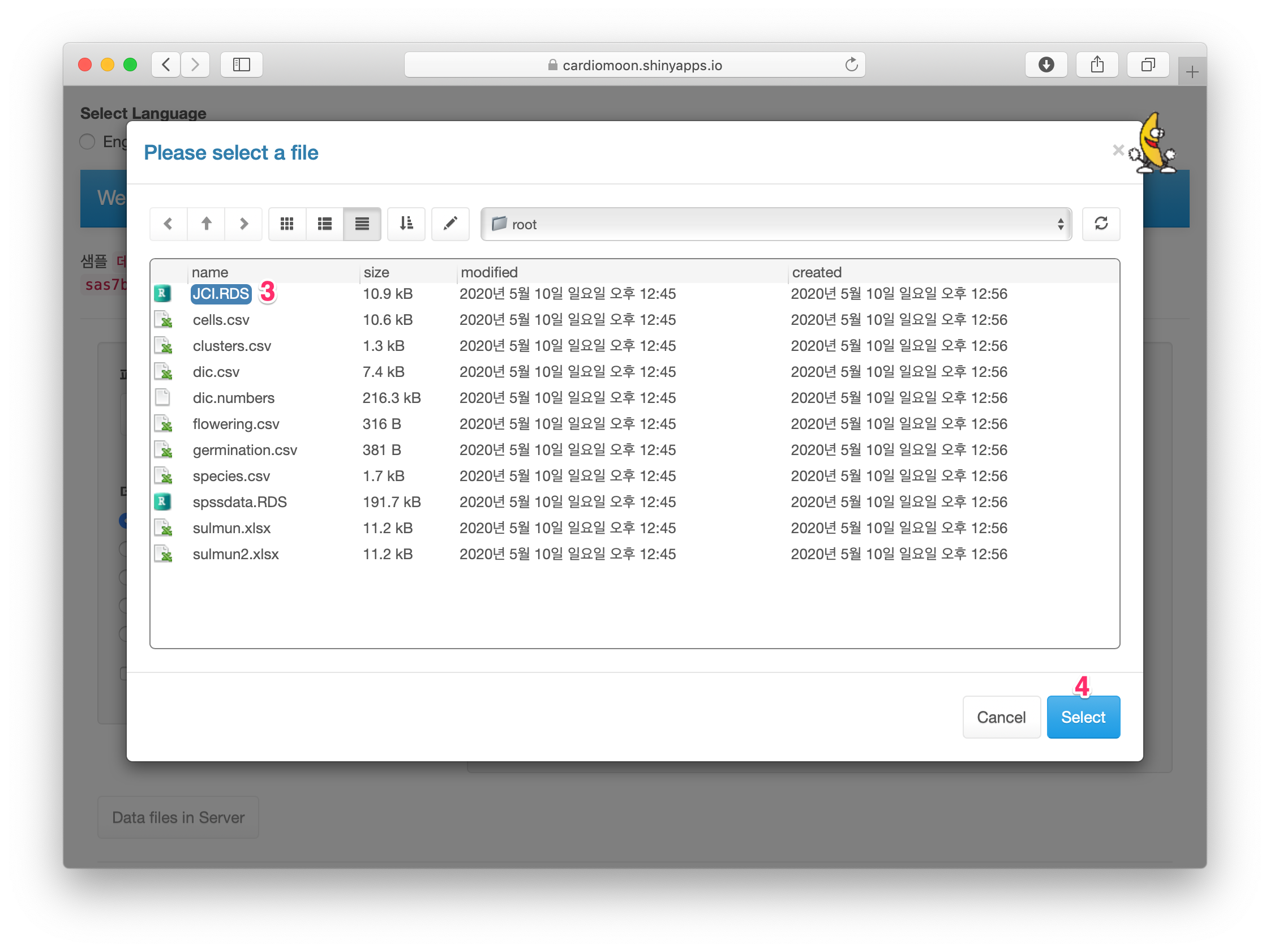
내장되어 있는 데이터 중 JCI.RDS 파일을 선택하고(3) Select 버튼을 누른다(4).
4.2 일치도(Cronbach의 alpha)
이 데이타는 JCI 인증에 대한 임상간호사의 인식과 태도, 직무스트레스에 관한 연구로 직무스트레스에 관한 설문은 모두 13개로 다음과 같다.
- JCI 인증을 준비하면서 추가업무가 많아 항상 시간에 쫓기며 일했다.
- JCI 인증을 준비하면서 나는 직무로 인해 잠을 깊이 자지 못하고 자주 깼다.
- JCI 인증을 준비하면서 평가업무가 힘들어 이직을 고려해 본적이 있다.
- JCI 인증을 준비하면서 행정적 업무로 인해 연장근무를 하였다.
- JCI 인증을 준비하면서 직접적인 현장활동 업무강화로 연장근무를 하였다.
- JCI 인증을 준비하면서 나의 심적 스트레스가 증가하였다.
- 우리병원은 평가 업무 분장시 부서간 마찰로 업무협조가 잘 이루어지지 않았다.
- JCI 인증을 준비하면서 내부구성원의 불만이 증가 하였다.
- JCI 인증을 준비하면서 부가적 업무준비로 고객접점 관리가 소홀하였다.
- JCI 인증 준비로 인한 업무표준화로 고객접점 관리에 효과적으로 대응을 할 수 있었다.
- 나의 능력을 개발하고 발휘할 수 있는 기회가 주어진다.
- 나의 업무수행 과정에서 나는 결정할 권한이 주어지며 영향력을 행사 할 수 있다.
- 일에 대한 나의 업적을 고려할 때 나는 직장에서 제대로 존중과 신임을 받고 있다.
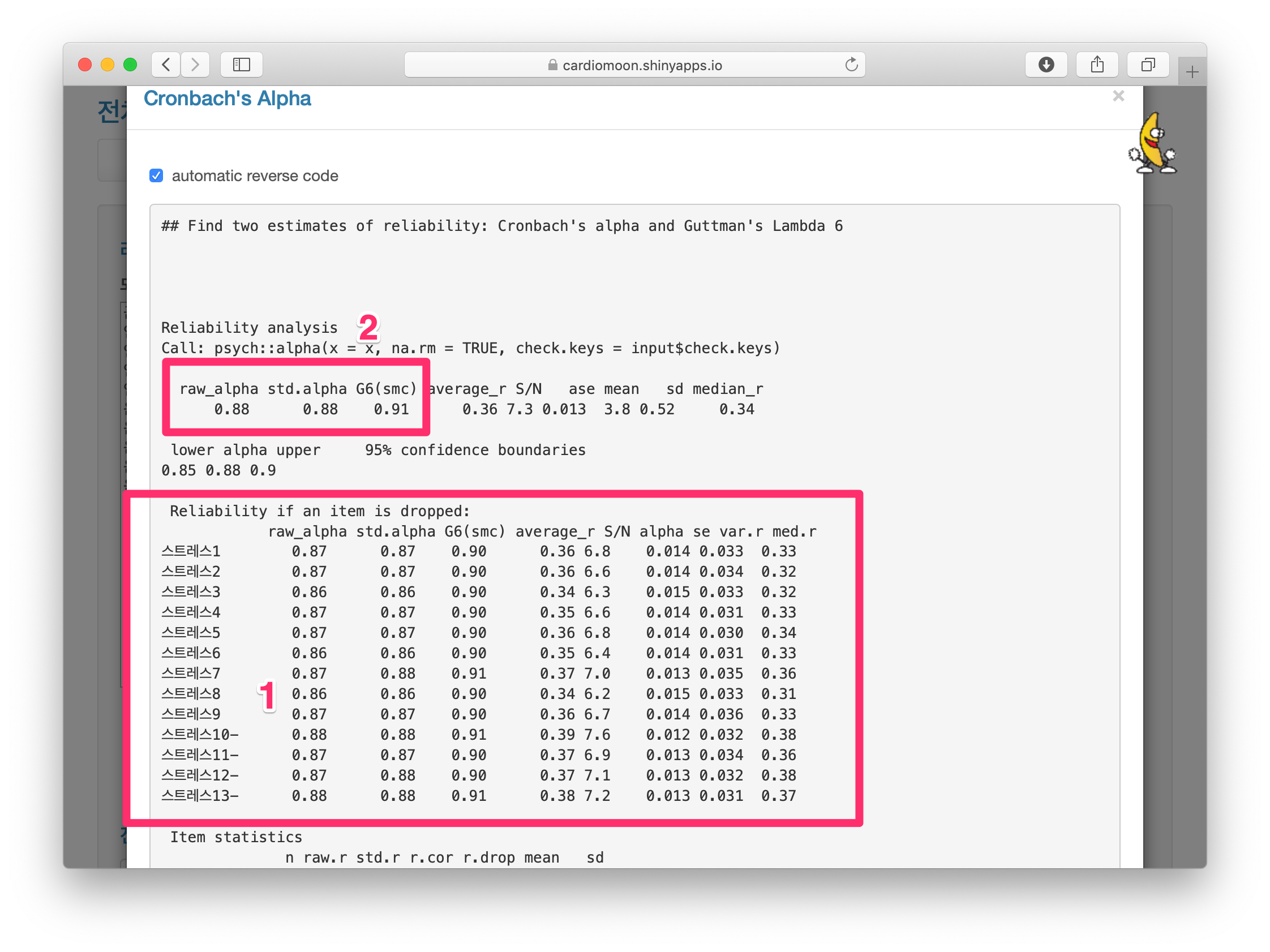
이들 설문을 자세히 보면 1-9까지는 설문의 내용이 JCI인증에 대한 부정적인 평가를 묻는 질문으로 되어 있고 10-13까지는 설문의 내용이 JCI인증에 대한 긍정적인 평가를 묻는 질문으로 되어 있다. 이들 설문에 대한 일치도를 계산하려면 다음과 같이 한다. 먼저 메인 메뉴의 dataWranging을 선택한 후 스트레스1-스트레스13까지의 13개의 열을 선택하고(1) Cronbach’s alpha 버튼을 누른다(2).
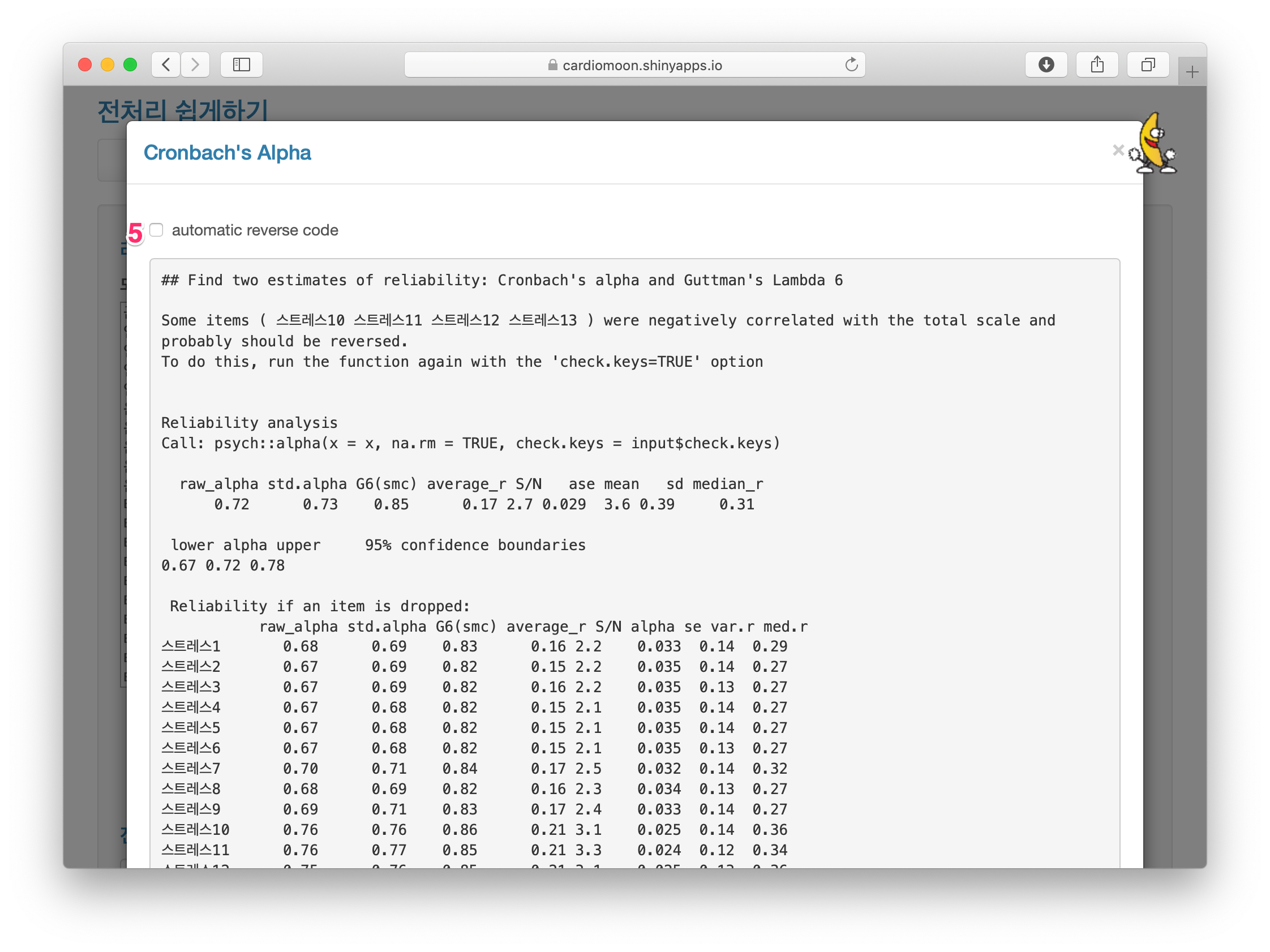
다음 화면이 나타난다. 화면의 글을 읽어보면 일부의 항목(스트레스 10-13)이 전체 값과 음의 상관관계를 보이므로 코딩을 뒤집어 할 것을 권유하고 있다. 현 상태의 Cronbach의 alpha값은 0.73으로 나타난다. 프로그램에서 권하는 대로 automatic reverse code를 선택하면(5) 화면이 바뀐다.
4.3 자동으로 코드 역순으로
automatic reverse code를 선택하면 일부항목에서 스트레스10부터 스트레스13까지 스트레스10- 과 같이 항목에 -가 표시된다(1). 이 항목들은 자동으로 코드를 역순으로 취한 후 Cronbach의 alpha값을 계산한 것으로 이 때 alpha값은 0.73에서 0.88로 증가되는 것을 알 수 있다.
4.4 합계구하기(1)
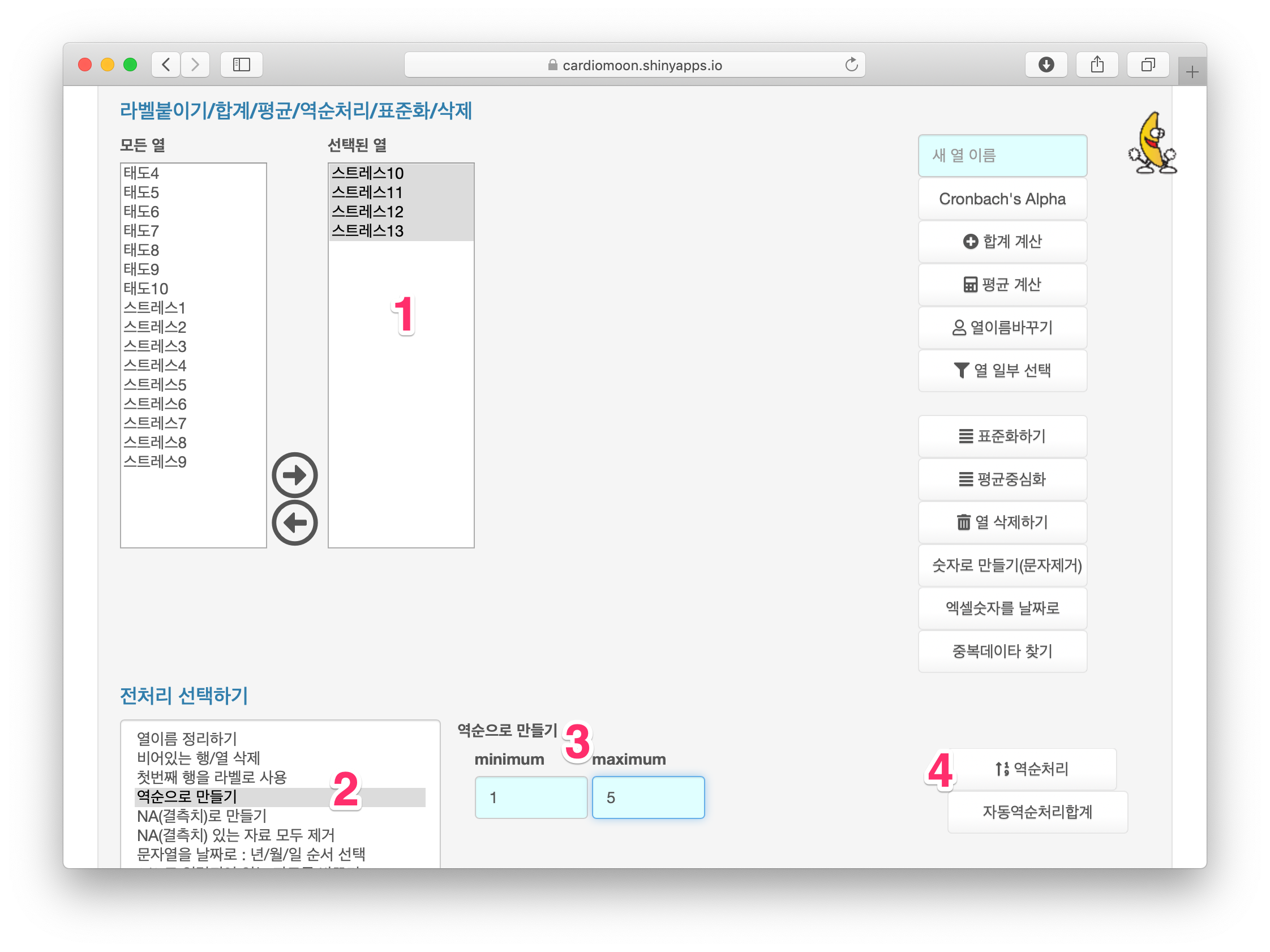
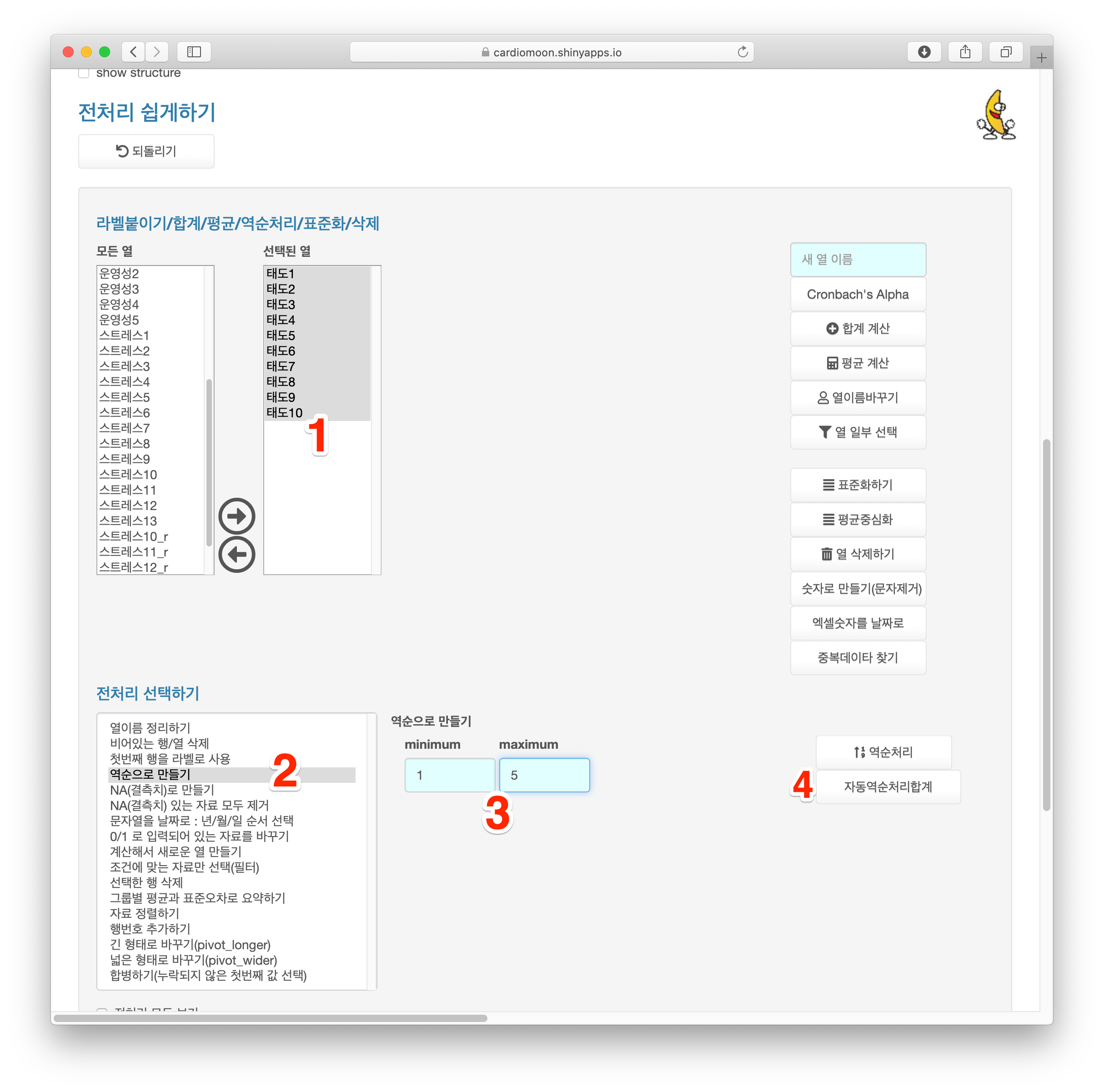
간호사의 직무 스트레스의 합계와 평균을 구하려면 먼저 스트레스10부터 스트레스13까지의 항목을 역순으로 만든다. 먼저 스트레스10 - 스트레스13 항목을 선택한 후(1) 전처리 중 역순으로 만들기를 선택하고(2) 최소값에 1, 최대값에 5를 입력한 후(3) 역순처리 버튼을 누른다(4).
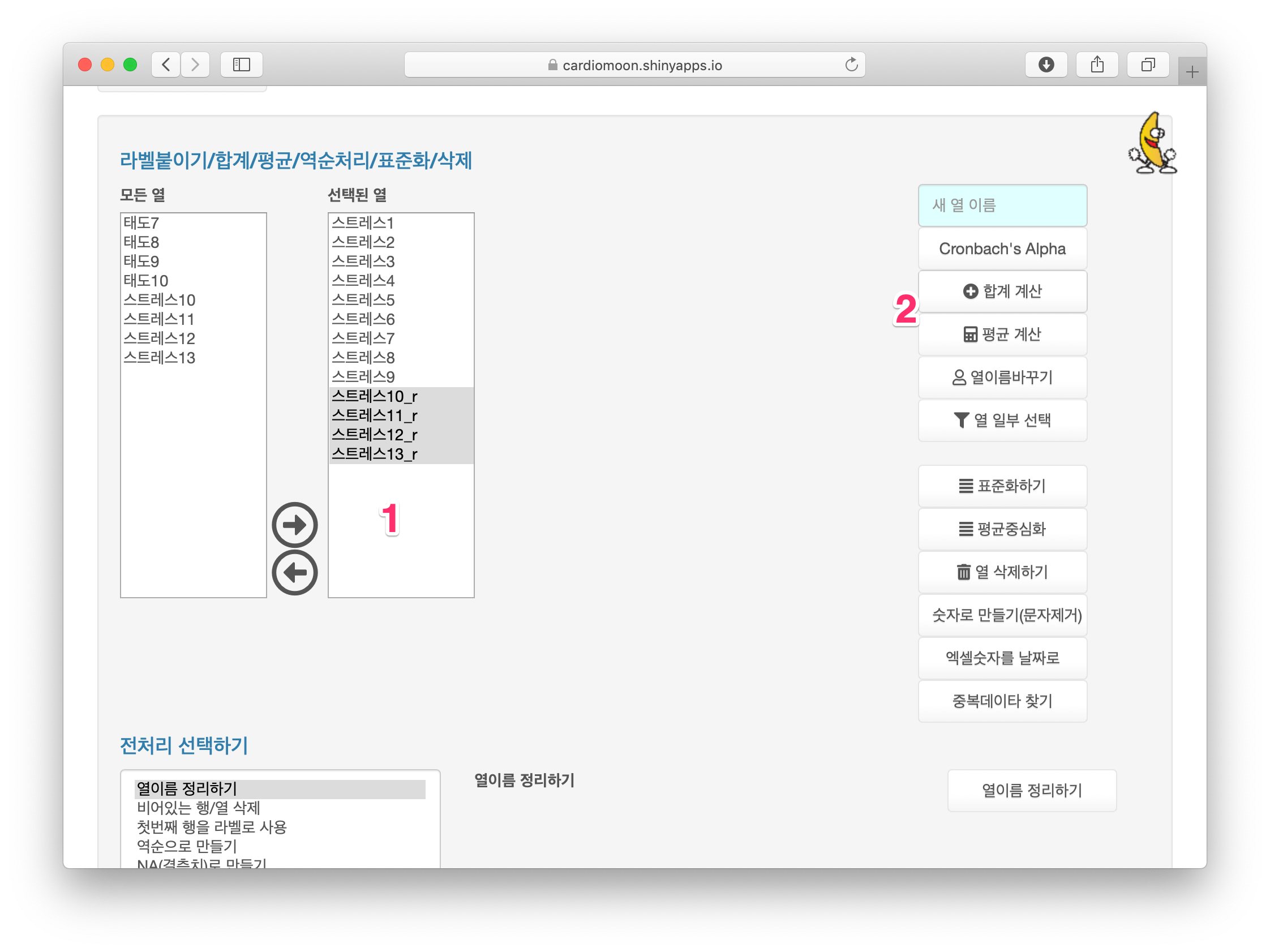
계속해서 스트레스1 - 스트레스9와 스트레스10_r부터 스트레스 13_r을 선택한 후(1) 합계 계산 또는 평균 계산 버튼을 눌러 계산한다.
4.5 자동역순처리합계
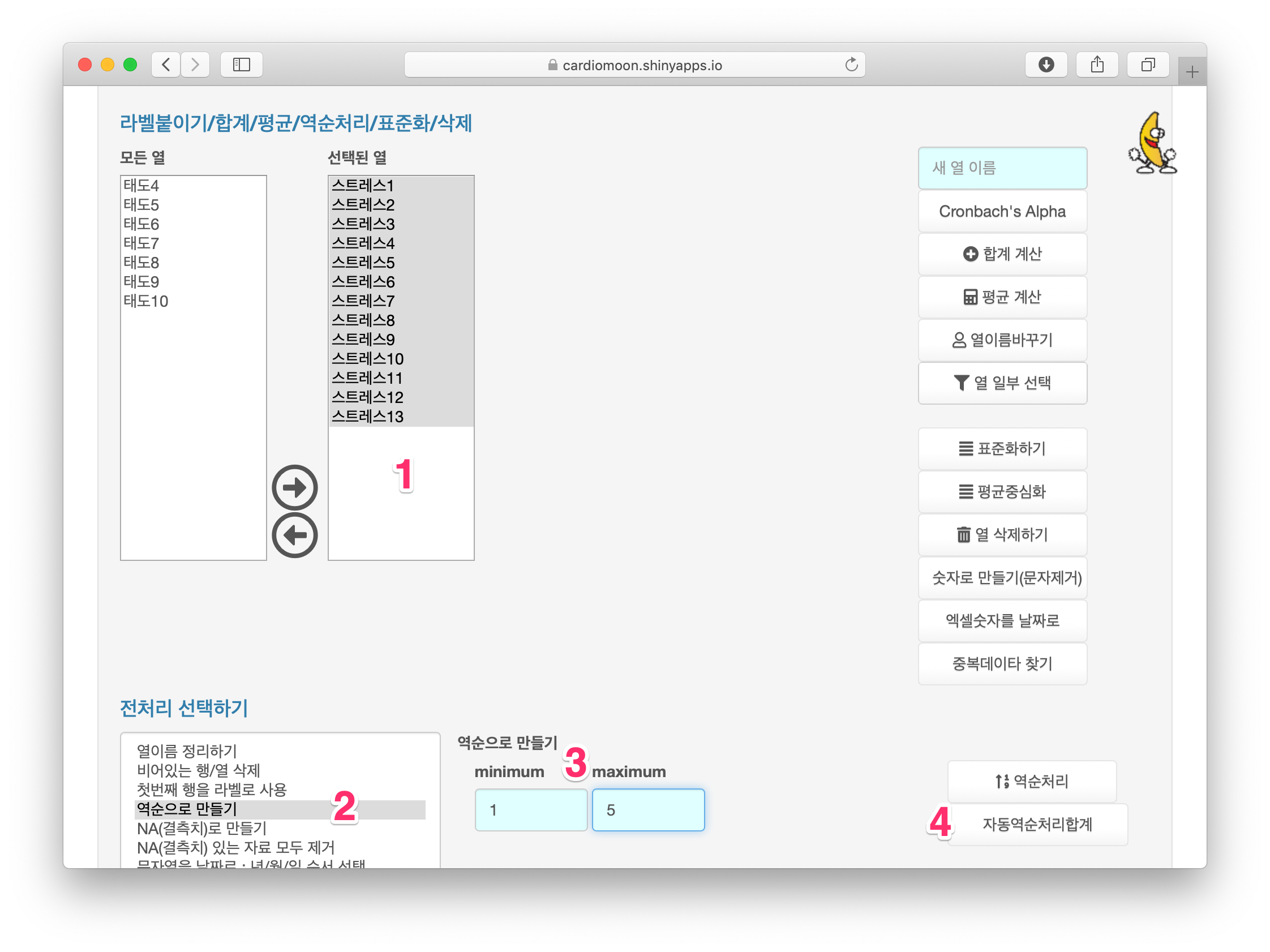
매번 위와 같이 Cronbach의 alpha값을 구하고 역순처리할 항목을 알아낸 후 역순처리하고 합계 및 평군을 계산하려면 무척 번거로울 뿐만 아니라 실수의 여지도 있다. 웹R에서는 이 과정을 자동으로 처리해준다. 먼저 스트레스1-13까지 항목을 선택한 후 전처리 중 역순으로 만들기를 선택하고(2) 최소값에 1, 최대값에 5를 입력한 후(3) 자동역순처리합계 버튼을 누른다(4). 웹R에서는 자동으로 역순처리할 항목들을 역순처리한 후 합계와 평균을 계산해준다. 즉 스트레스10_r 부터 스트레스13_r 과 스트레스합계, 스트레스평균이 계산된다.
4.6 일치도 구하기 : 간호사의 태도
JCI 인증에 대한 간호사의 태도는 태도1 - 태도10에 정리되어 있다. 이 문항들을 살펴보면 다음과 같다. 1. 평가기준에 따른 적정한 시설, 장비, 인력 등을 확보할 수 있는 근거가 되었다. 2. 현재 갖추어진 지침에 따라 체계적으로 정착화 될 때까지 JCI인증을 받아야 한다. 3. 평가수검 우수 결과 도출로 대외적인 인지도 상승효과를 가져왔다. 4. 지속적인 평가 수검으로 우리병원 규모에 맞는 질적 경쟁력을 확보한다. 5. 현재 논의되고 있듯이 평가수검 병원에 대한 상대적인 보상체계가 주어졌다. 6. 공공병원 현실에 맞지 않는 평가기준이 많아 별도 평가기준으로 받아야한다. 7. 평가시 임시적인 대응이 많아 근본적인 질향상 효과가 없다. 8. 얻어지는 결과에 비해 투입될 비용 부담이 크다. 9. 평가로 인한 부가적인 업무로 직접적인 고객응대에 더 소홀하게 된다. 10. 현재 병원의 평가시스템 미비로 평가대비 구조적 문제가 많다.
이들 문항들을 자세히 보면 1-5까지는 설문의 내용이 JCI인증에 대한 긍정적인 평가를 묻는 질문으로 되어 있고 6-10까지는 부정적인 평가를 묻는 질문으로 되어 있다. 이들 문항에 대한 일치도를 구하려면 태도1 - 태도10 을 선택한 후(1) Cronbach’s Alpha 버튼을 누른다(2).
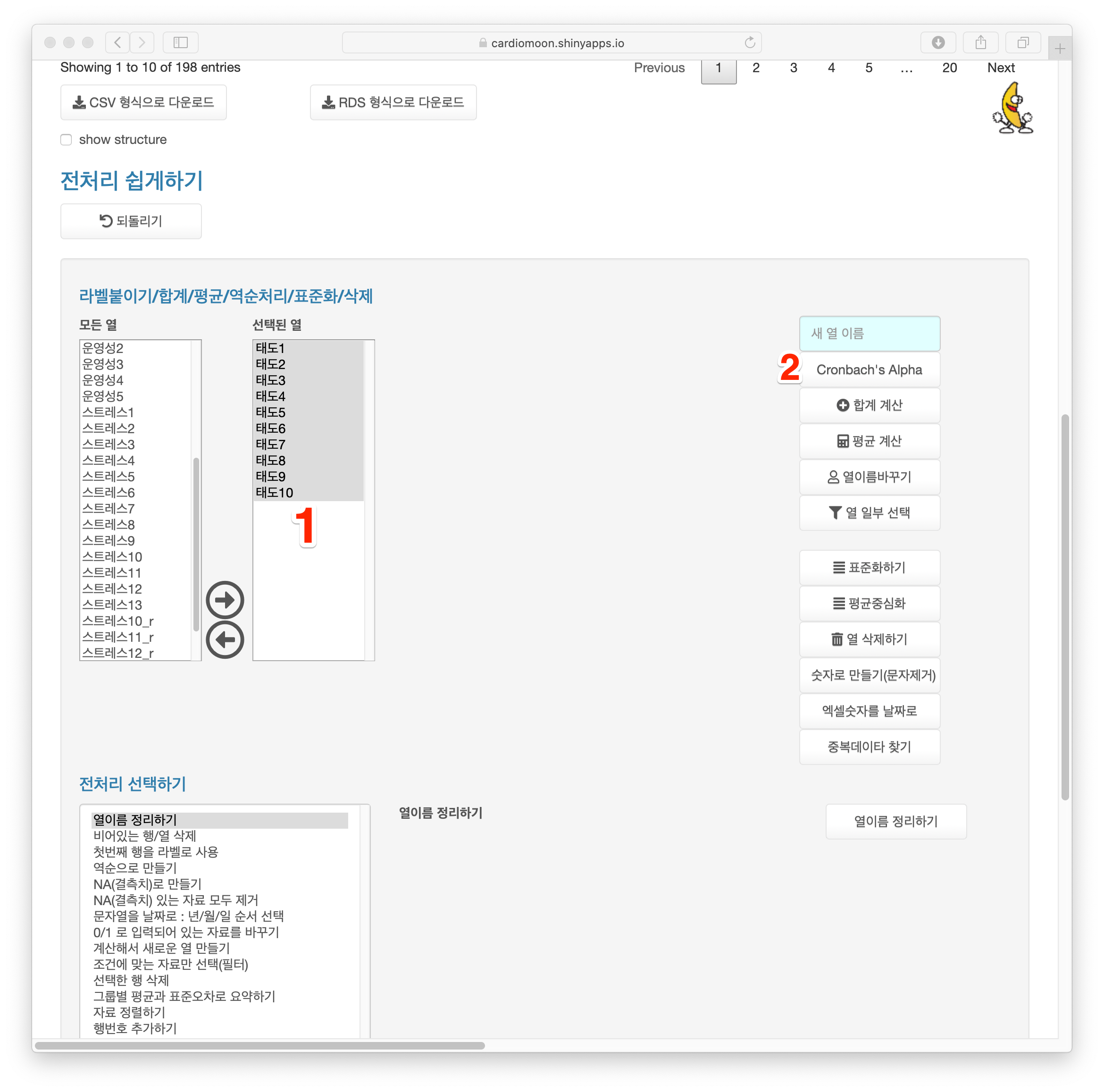
automatic reverse code 를 선택하지 않았을 때(1) 일치도(std.alpha) 는 0.6이며 태도6부터 태도10까지는 전체 값과 비교할 때 음의 상관관계가 있으므로 코드를 역순처리할 것을 권하고 있다.
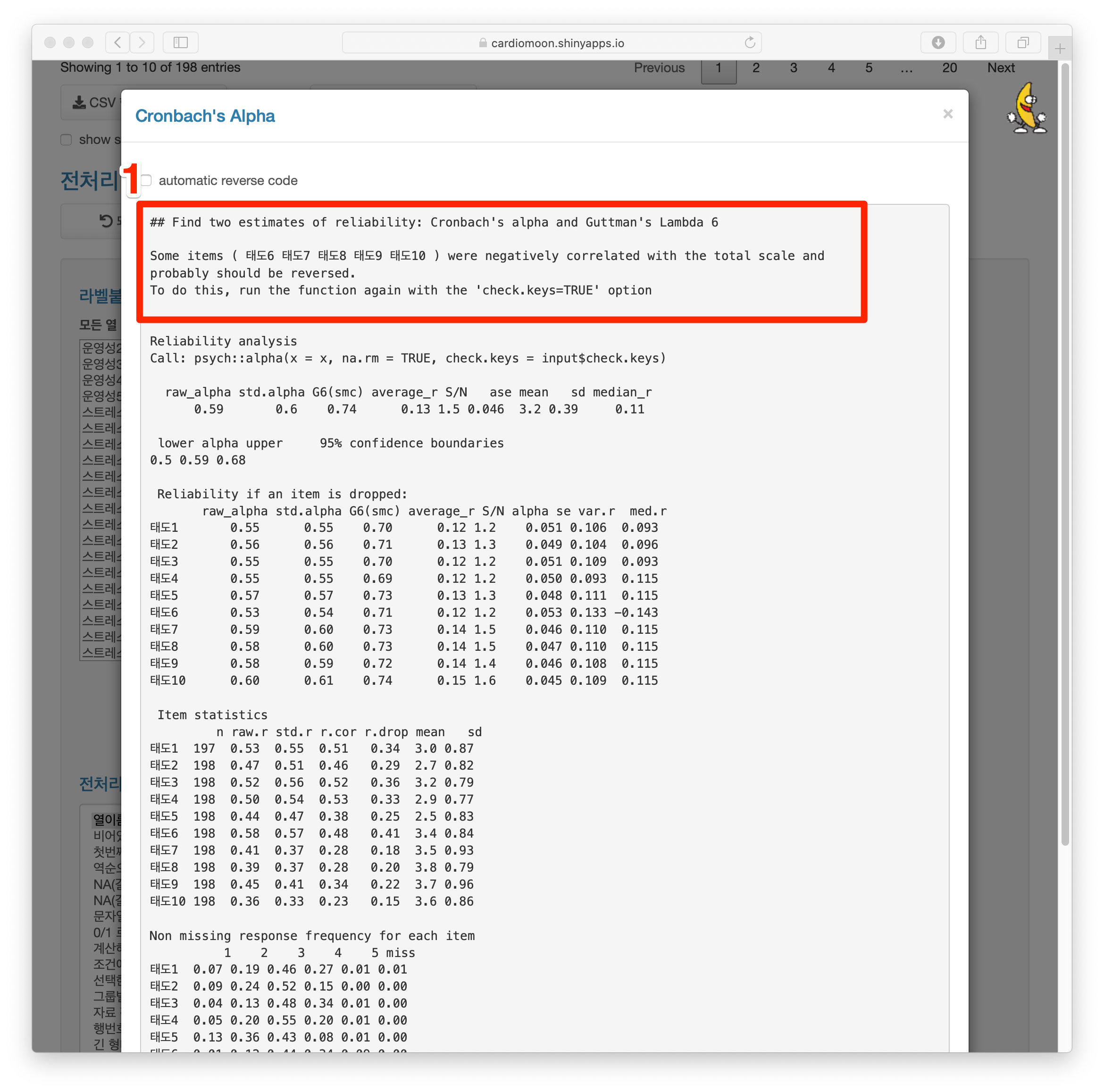
automatic reverse code 를 선택하면(1) 일치도(std.alpha) 가 0.8로 증가된다. 이떄 태도6 부터 태도10까지는 태도6-과 같이 항목에 -가 표시된다.
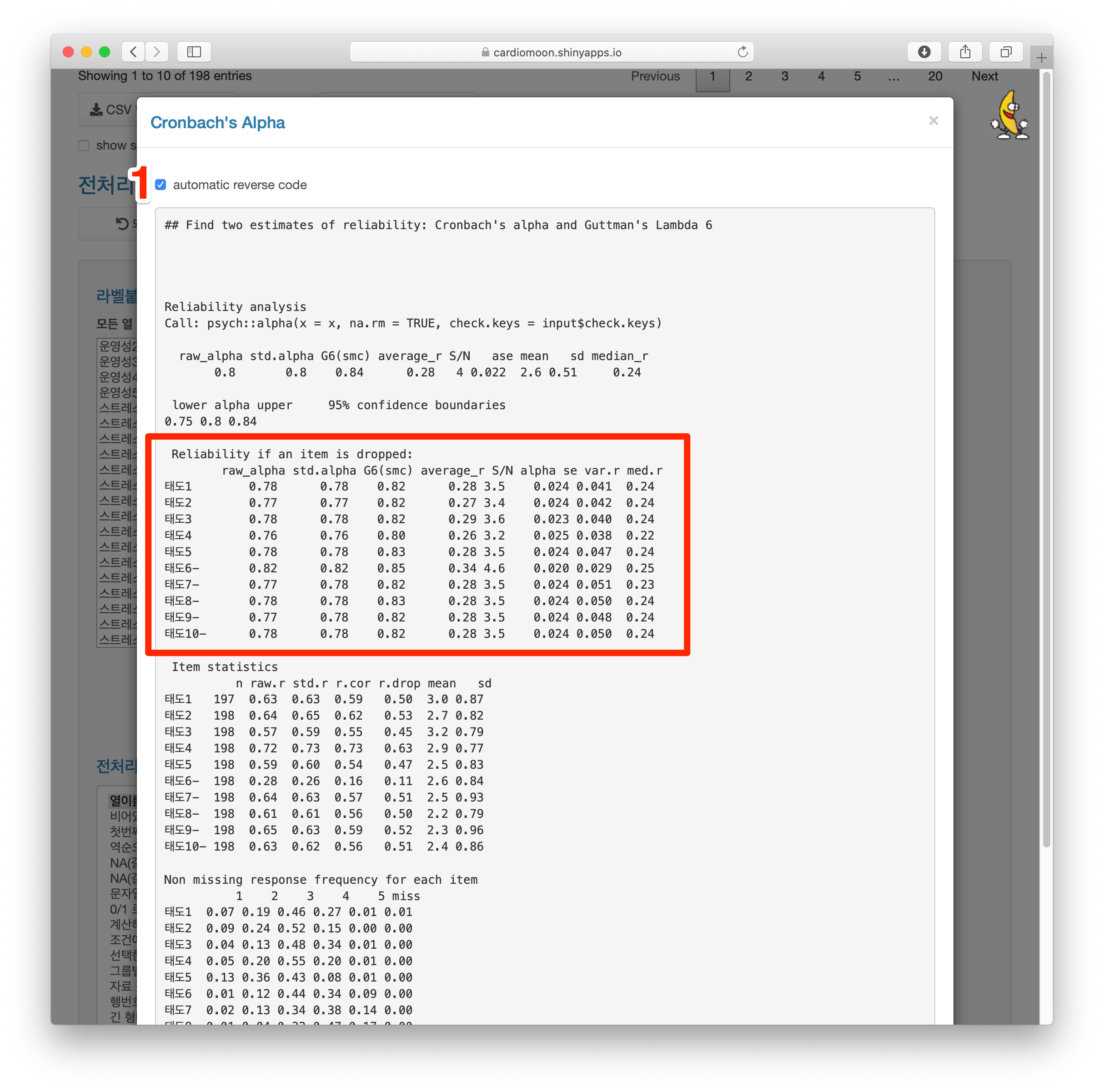
계속해서 태도1 부터 태도10까지의 열이 선택되어 있는 상태(1)에서 전처리 중 역순으로 만들기(2)를 선택한 후 최소값에 1, 최대값에 5를 입력하고(3) 자동역순처리합계 버튼을 누른다(4).
태도6_r 부터 태도10_r 까지가 계산되어 있고 태도합계, 태도평균도 계산되어 있는 것을 알 수 있다.
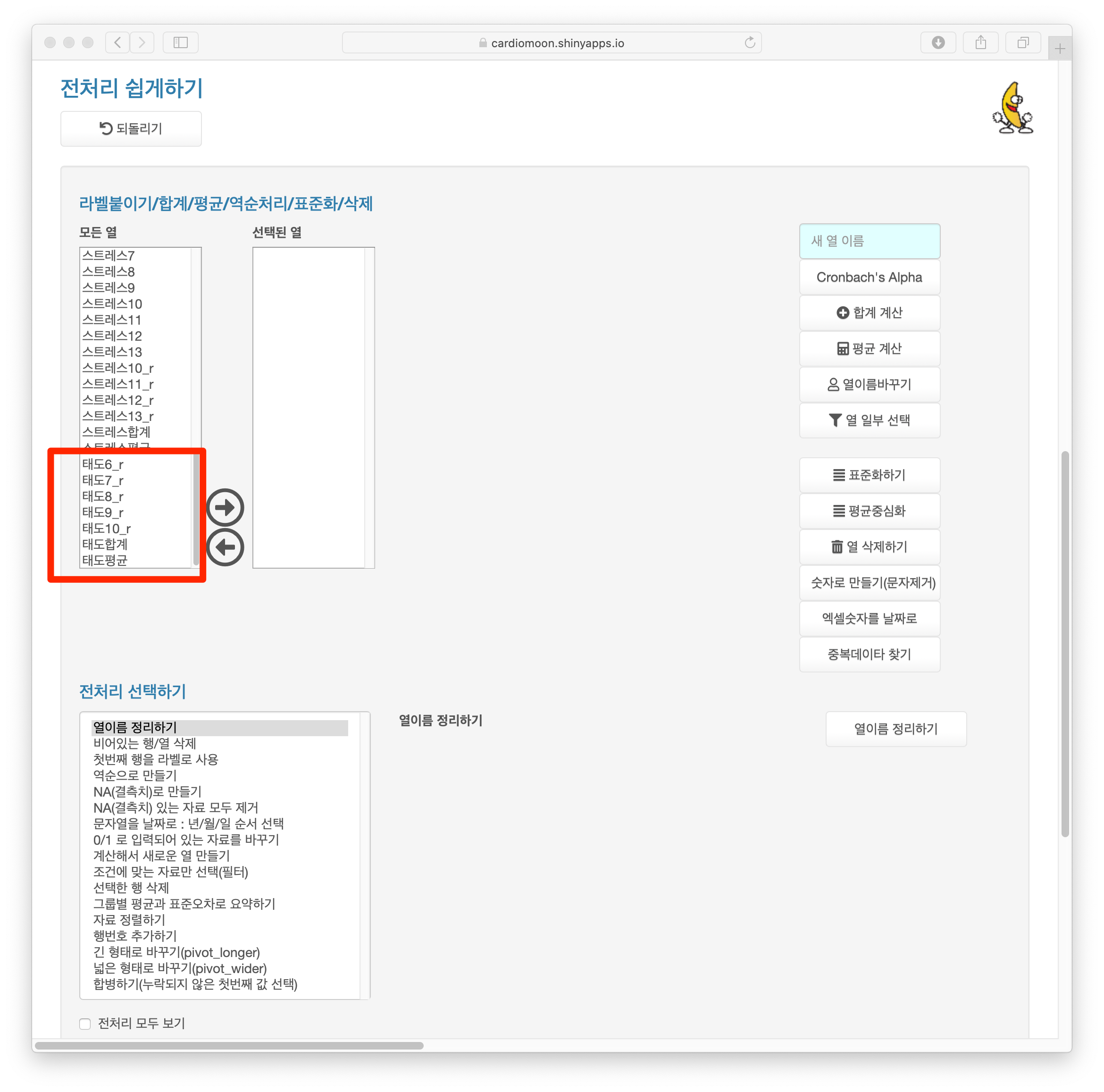
4.7 평균중심화와 표준화하기
연속형변수인 경우 평균중심화 또는 표준화를 시행할 경우가 있다. 평균중심화는 개별변수의 값에서 그 변수의 평균값을 뺀 것을 말한다. 또한 표준화는 개별변수의 값에서 그 변수의 평균값을 뺀 후 그 변수의 표준편차로 나눈 것을 말한다.
\[\begin{equation} mean\;centering : x_i - \bar{x} \\ standardize : \frac{x_i - \bar{x} }{sd(x)} \end{equation}\]
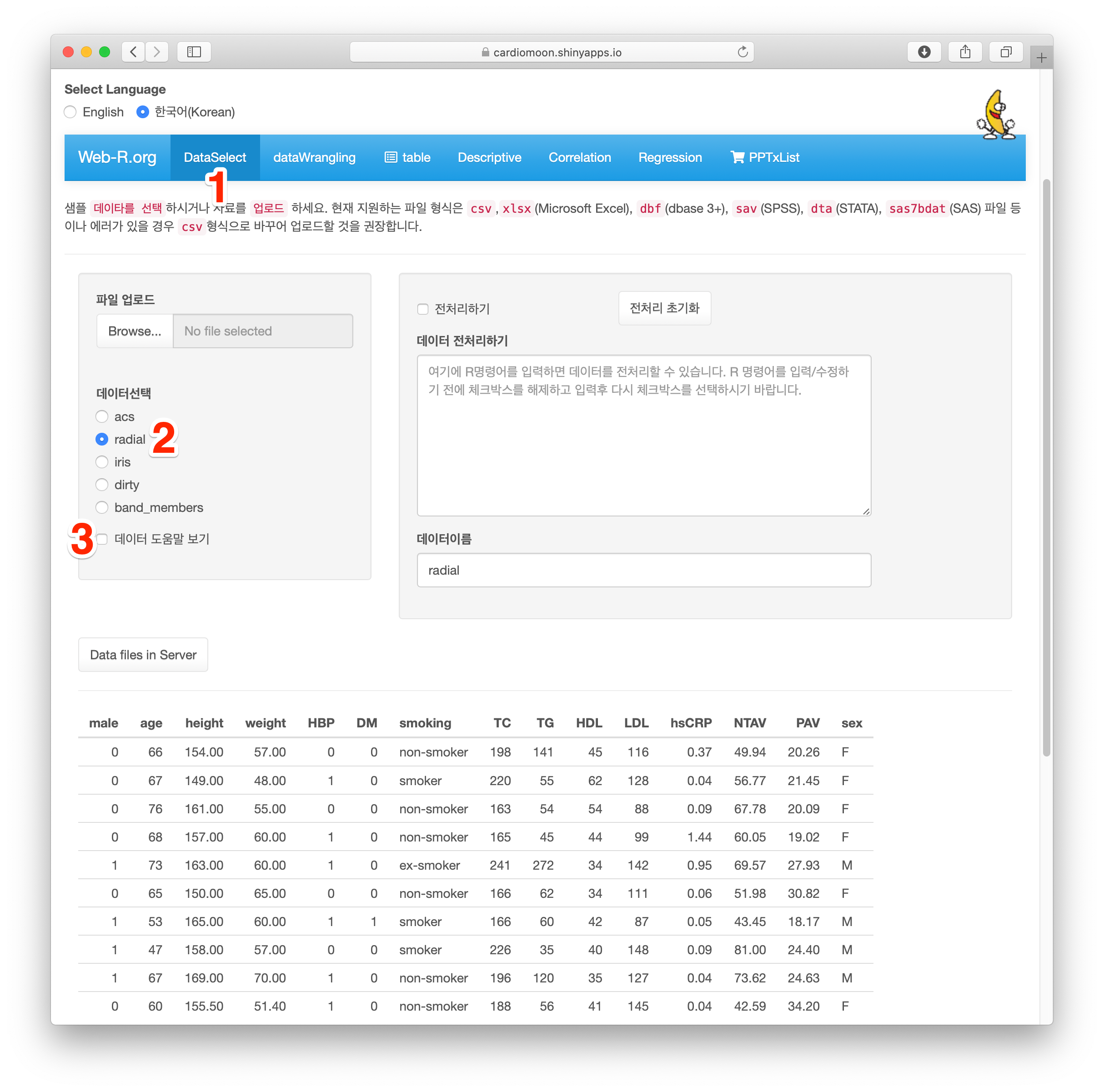
먼저 메인 메뉴의 DataSelect(1)에서 두번째 예제인 radial(2)을 선택해 본다. 이 데이터에 대한 도움말을 보고 싶을 때에는 데이터 도움말 보기를 선택하면 된다(3).
이 데이터 중 환자의 나이와 키, 몸무게를 표준화해보자. 메인메뉴의 dataWrangling을 선택하고(1) age, height, weight의 세개의 열을 선택한 후(2) 표준화하기 버튼을 누른다(3).
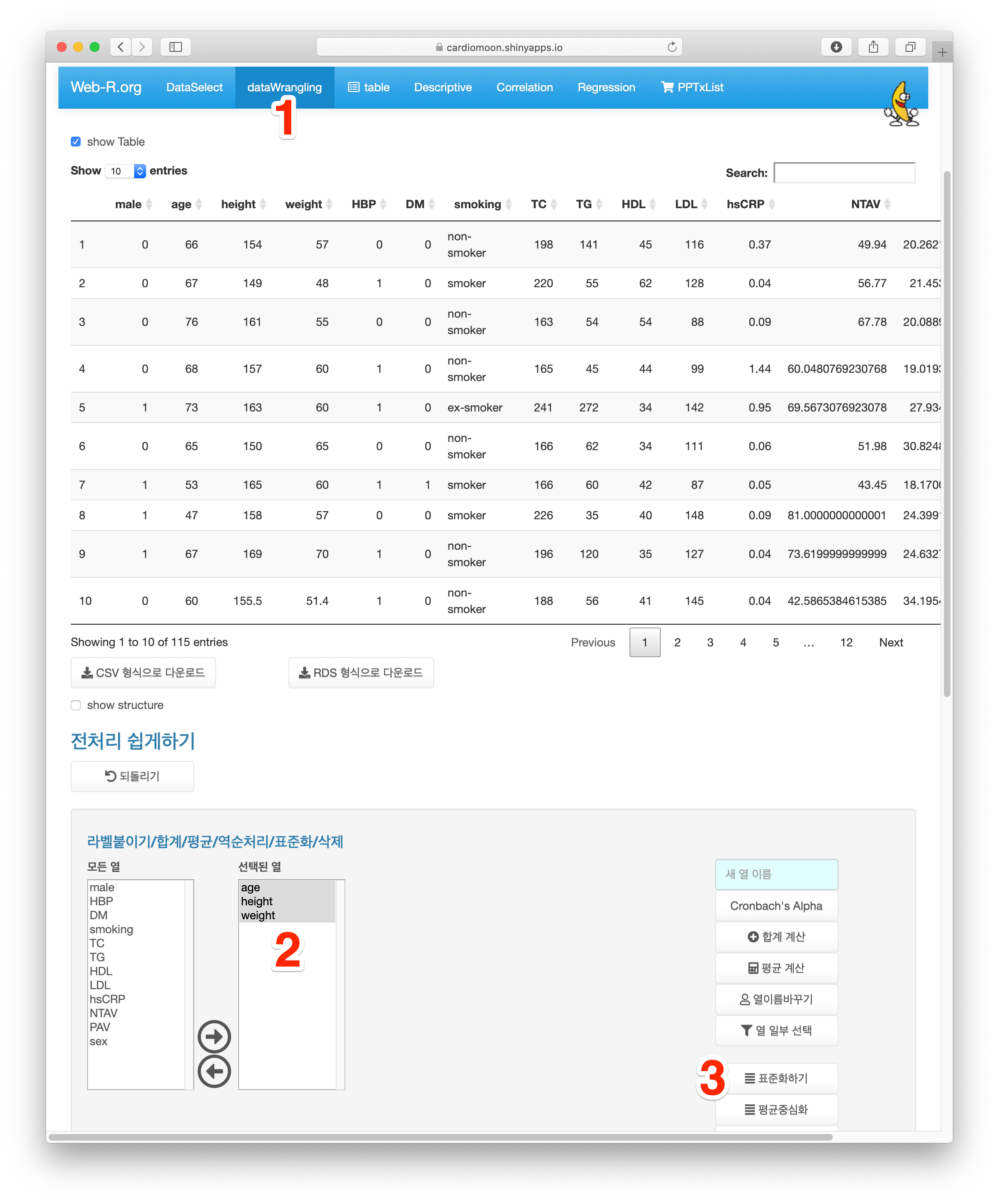
표준화를 한 경우 열이름에 _std가 붙는다. 이 경우 표준화한 age_std, height_std 및 weight_std 열이 새로 생긴다. 평균중심화한 경우 _mc가 붙는다.
4.8 0/1로 입력되어 있는 자료를 바꾸기
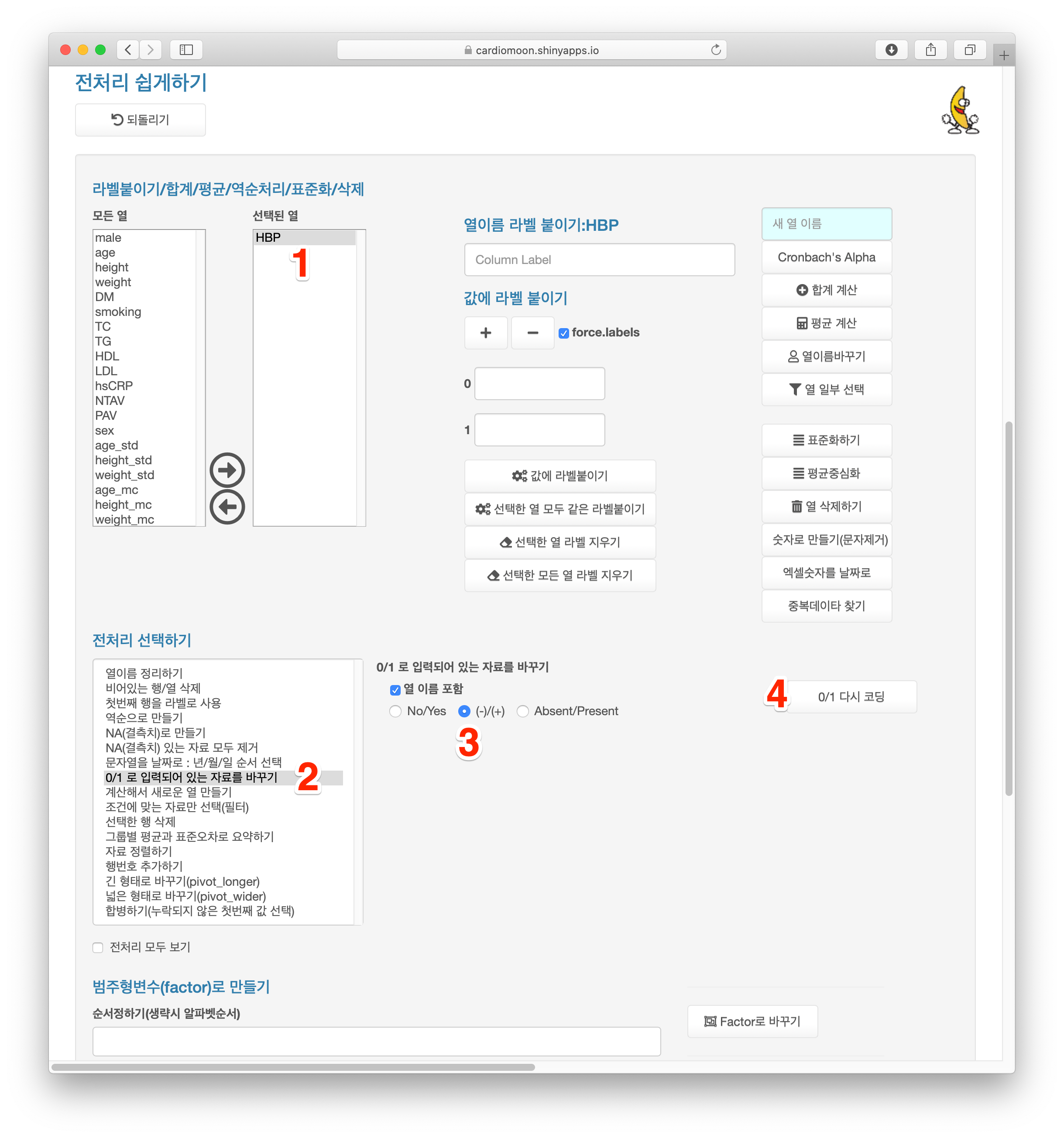
radial 데이터에는 고혈압(HBP), 당뇨(DM) 등의 병력이 없는 경우는 0, 있는 경우는 1로 입력되어 있다. 이 경우 라벨붙이기를 통해 0, 1 값을 고혈압유무로 라벨을 붙일 수 도 있고 아예 0/1의 값을 HBP(-)/HBP(+) 와 같이 바꿀 수도 있다. HBP를선택한 후(1) 전처리 중 0/1로 입력되어 있는 자료를 바꾸기(2)를 선택하고 열이름포함 및 (-)/(+)를 선택한 후(3) 0/1 다시코딩 버튼(4)을 누르면 HBP 열의 0과 1이 각각 HBP(-), HBP(+) 로 바뀌는 것을 알 수 있다.
4.9 범주형 변수의 순서 정하기
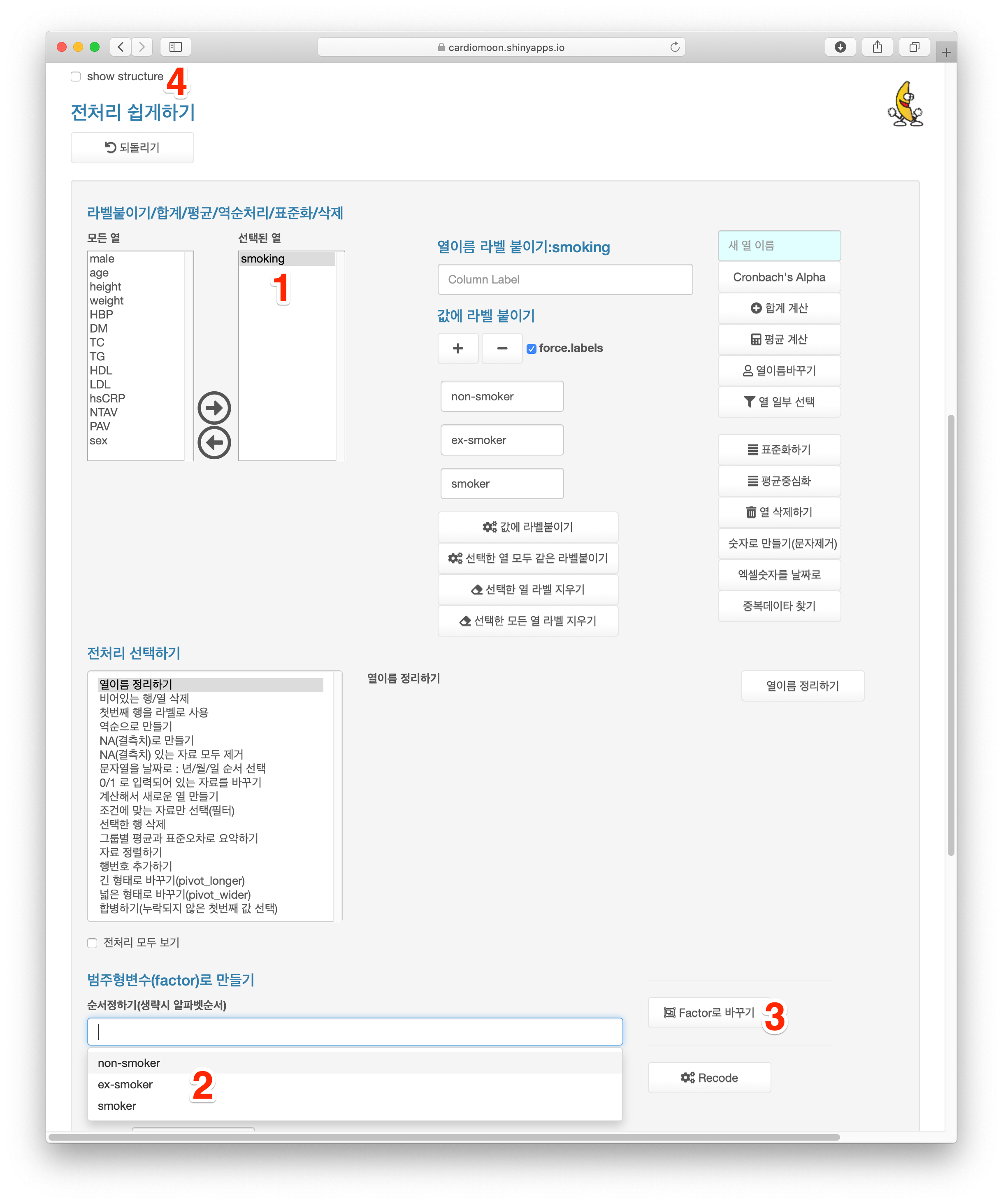
radial 데이터의 smoking은 흡연여부가 기록되어 있는데 ex-smoker, non-smoker, smoker의 세 개의 값으로 되어 있다. 이 경우 따로 순서를 정하지 않는 경우 알파벳 순서에 의해 ex-smoker, non-smoker, 순으로 통계처리가 되지만 연구자에 따라 이 세 개의 값 중 비흡연(non-smoking), 담배를 끊은 사람(ex-smoker), 현재 흡연하는 사람(smoker)의 순서로 처리되는 것을 원할 수 있다. 이 경우 범주형변수의 순서를 정해주어야 하는데 먼저 smoking을 선택한 후(1) 범주형변수의 순서정하기에서 non-smoker, ex-smoker, smoker 순으로 클릭한 후(2) Factor로 바꾸기 버튼(3)을 누르면 순서가 바뀐다. 이 순서는 show structure(4) 를 선택해 데이터의 구조를 보면 확인할 수 있다.
4.10 계산해서 새로운 열 만들기
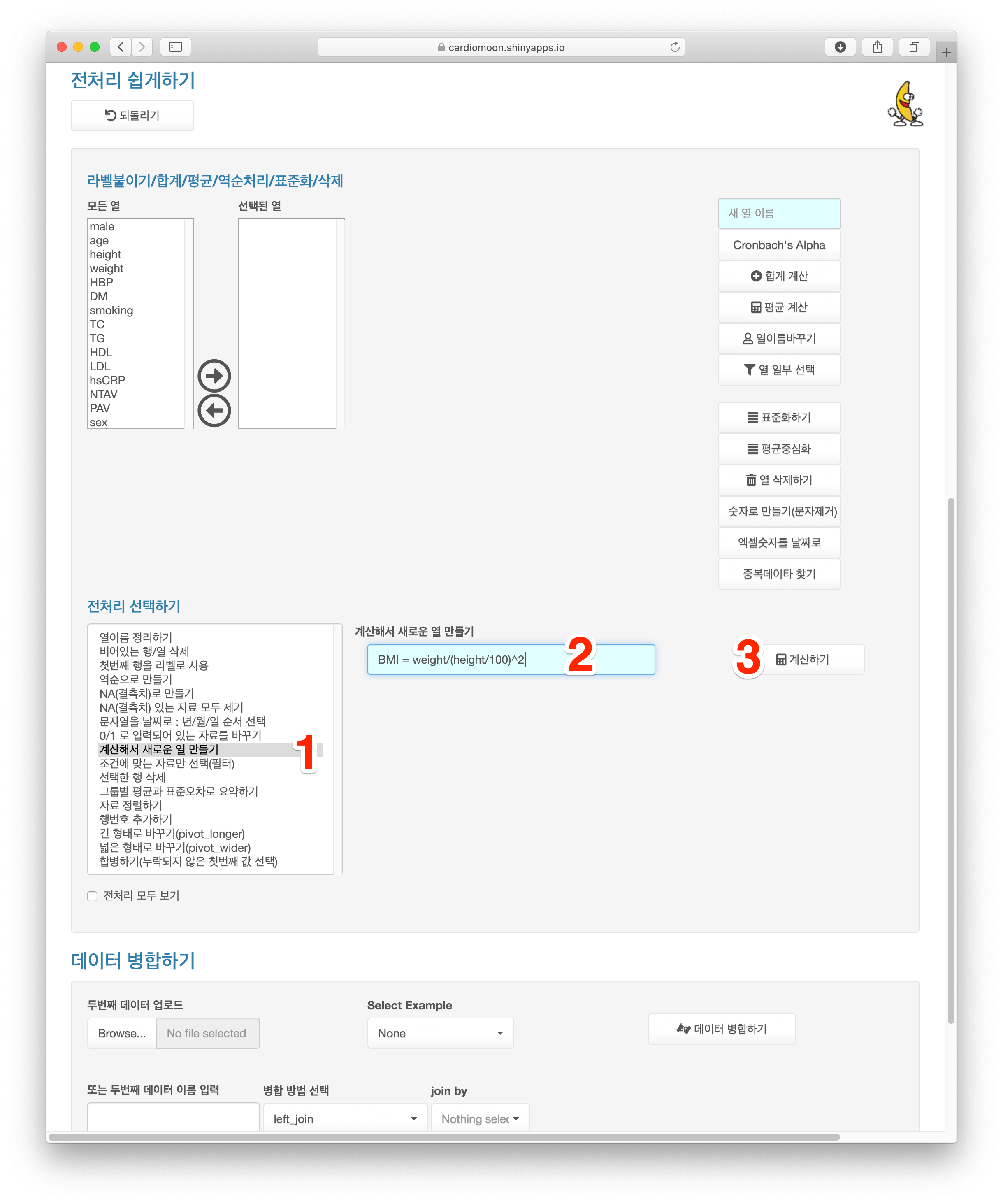
경우에 따라 데이터에 있는 열을 이용하여 새로운 열을 만드는 경우가 있다. 예를 들어 radial 데이터에서 키와 몸무게를 이용하여 체질량지수(Body Mass Index, BMI)를 계산하려면 전처리 선택하기에서 계산해서 새로운 열 만들기 를 선택한 후 계산식에 BMI=weight/(height/100)^2 를 입력하고 계산하기 버튼을 누르면 된다.
4.11 서브그룹 만들기1
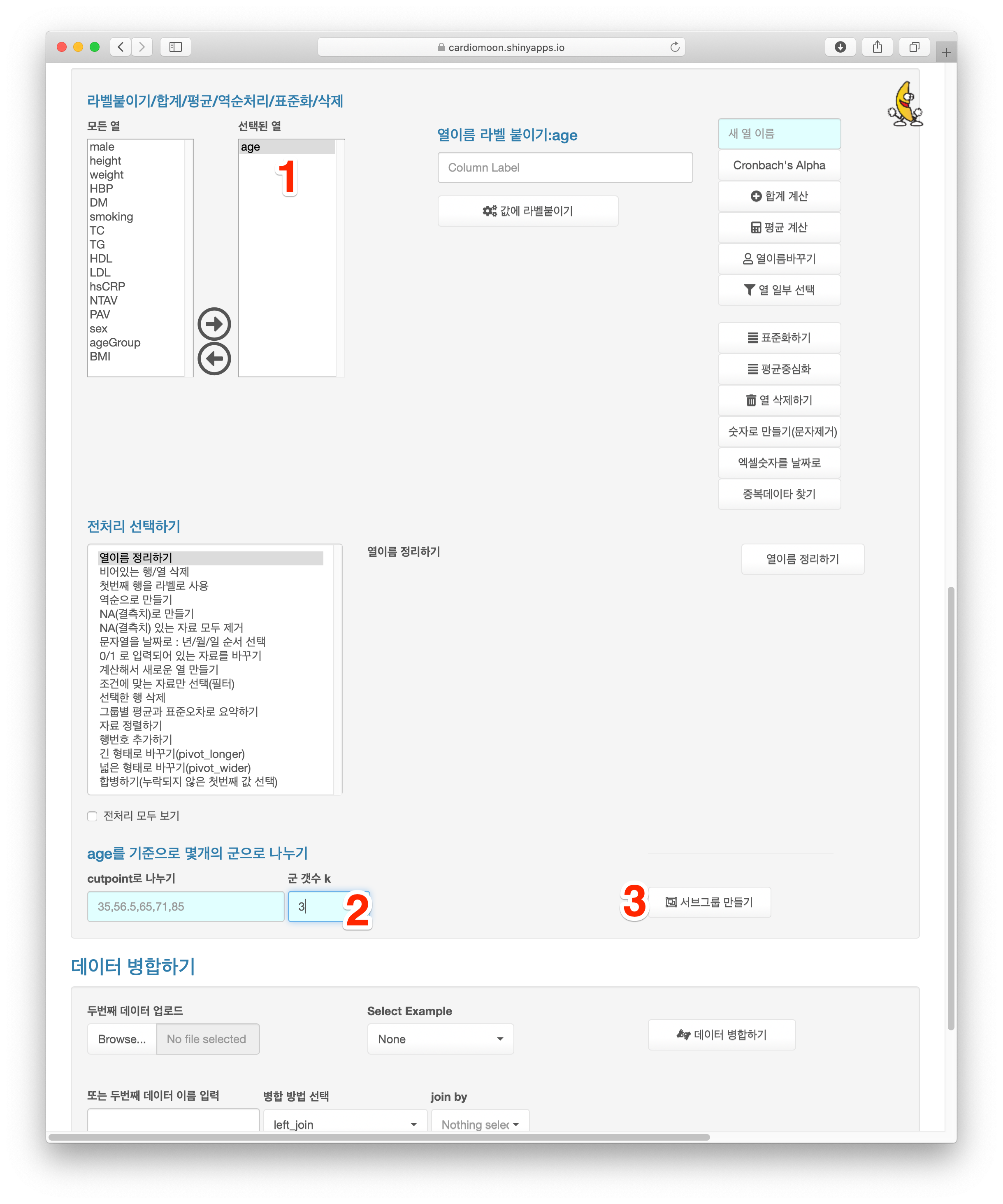
경우에 따라 연속형 변수를 기준으로 몇 개의 군으로 나누어 통계처리를 할 때가 있다. 예를 들어 radial 데이터에서 나이를 기준으로 세 개의 군으로 나누고자 하면 먼저 age를 선택하고 군갯수k에 3을 입력 후 서브그룹 만들기 버튼을 누르면 된다. 이 때에는 세 개의 군의 갯수가 최대한 비슷하도록 ageGroup이라는 변수에 1, 2, 3으로 입력된다.
4.12 서브그룹 만들기2
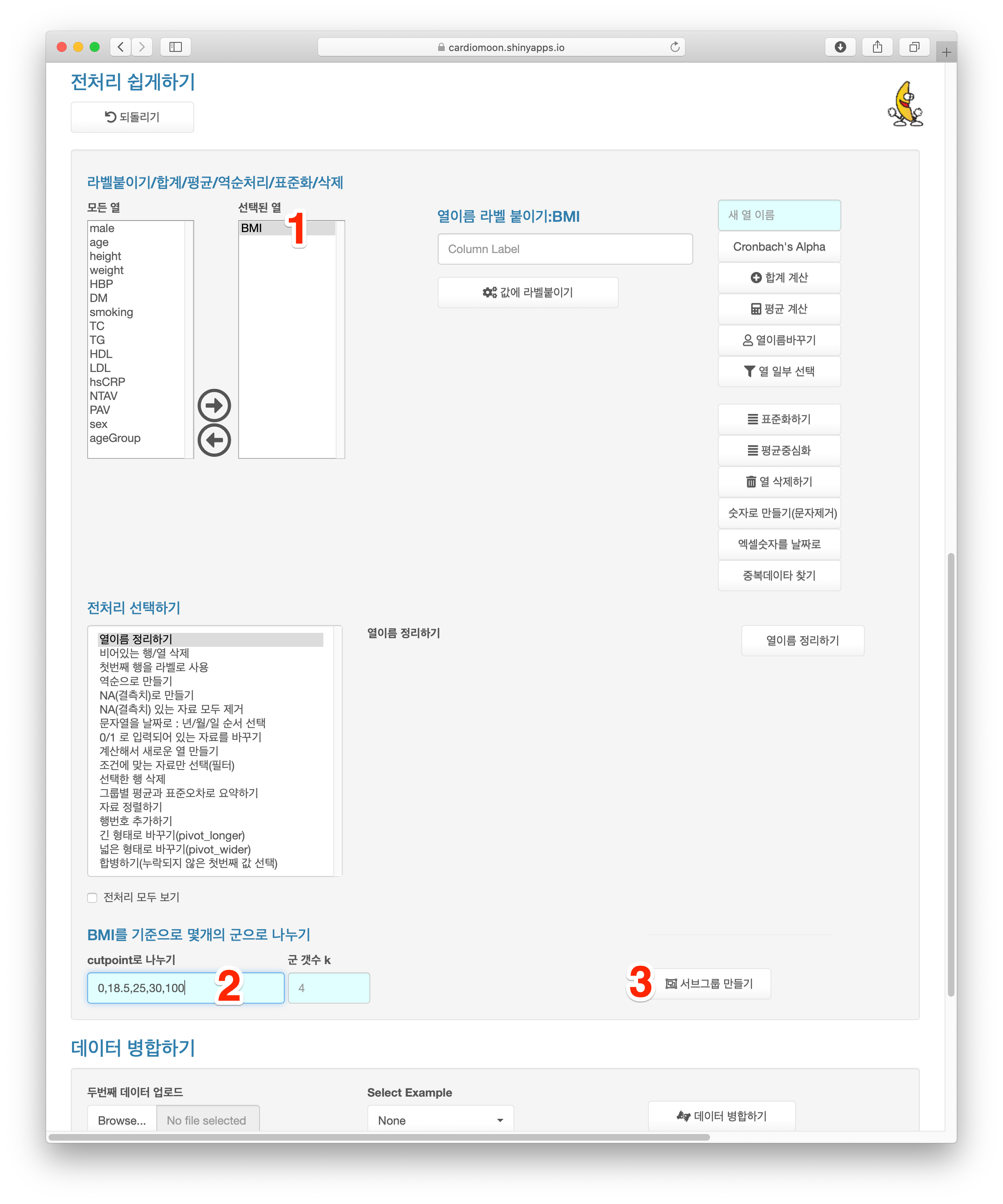
위의 방법은 우리가 정해준 군들의 갯수가 최대한 비슷하도록 기준을 임의로 정해 나누어주는 방법이다. 하지만 경우에 따라 기준이 정해져 있는 경우도 있다. 위에서 계산한 체질량지수(BMI)의 경우 저체중은 18.5 미만, 정상은 18.5-24.9, 과체중은 25-29.9, 비만은 30이상으로 그 기준이 정해져 있다. 이런 경우 cutpoint를 지정해 서브그룹을 나눌수 있는데 먼저 BMI를 선택하고(1) cutpoint에 0,18.5,25,30,100을 입력한 후(2) 서브그룹 만들기 버튼을 누르면 네 개의 군으로 나누어진다. 이떄 주의할 점은 cutpoint는 18.5,25,30의 세 개이지만 최소값, 최대값으로 대충의 값인 0과 100을 앞뒤로 넣어주어야 한다.
4.13 긴 형태로 바꾸기(pivot_longer)
통계처리나 그래프를 그리기 위해 데이터의 형태를 긴 형태(long form)로 바꾸어야 할 때가 있다. 먼저 dataSelect 메뉴에서 iris 데이터를 선택한다. 아래의 테이블에서 보이는 형태가 전형적인 넓은 형태(wide form)의 데이터로 이 중 Sepal.Length, Sepal.Width, Petal.Length 및 Petal.Width를 long from으로 바꾸어 본다.
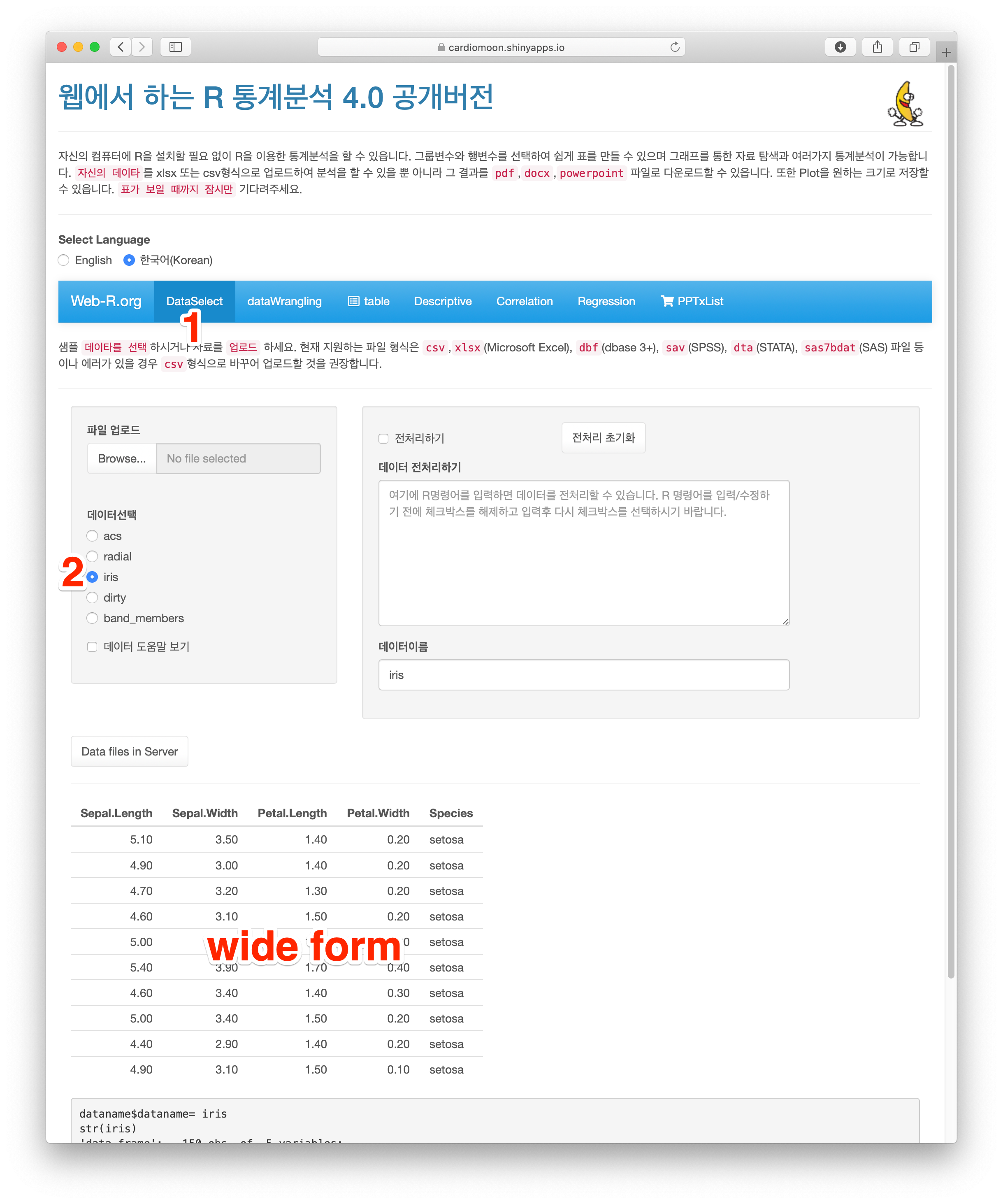
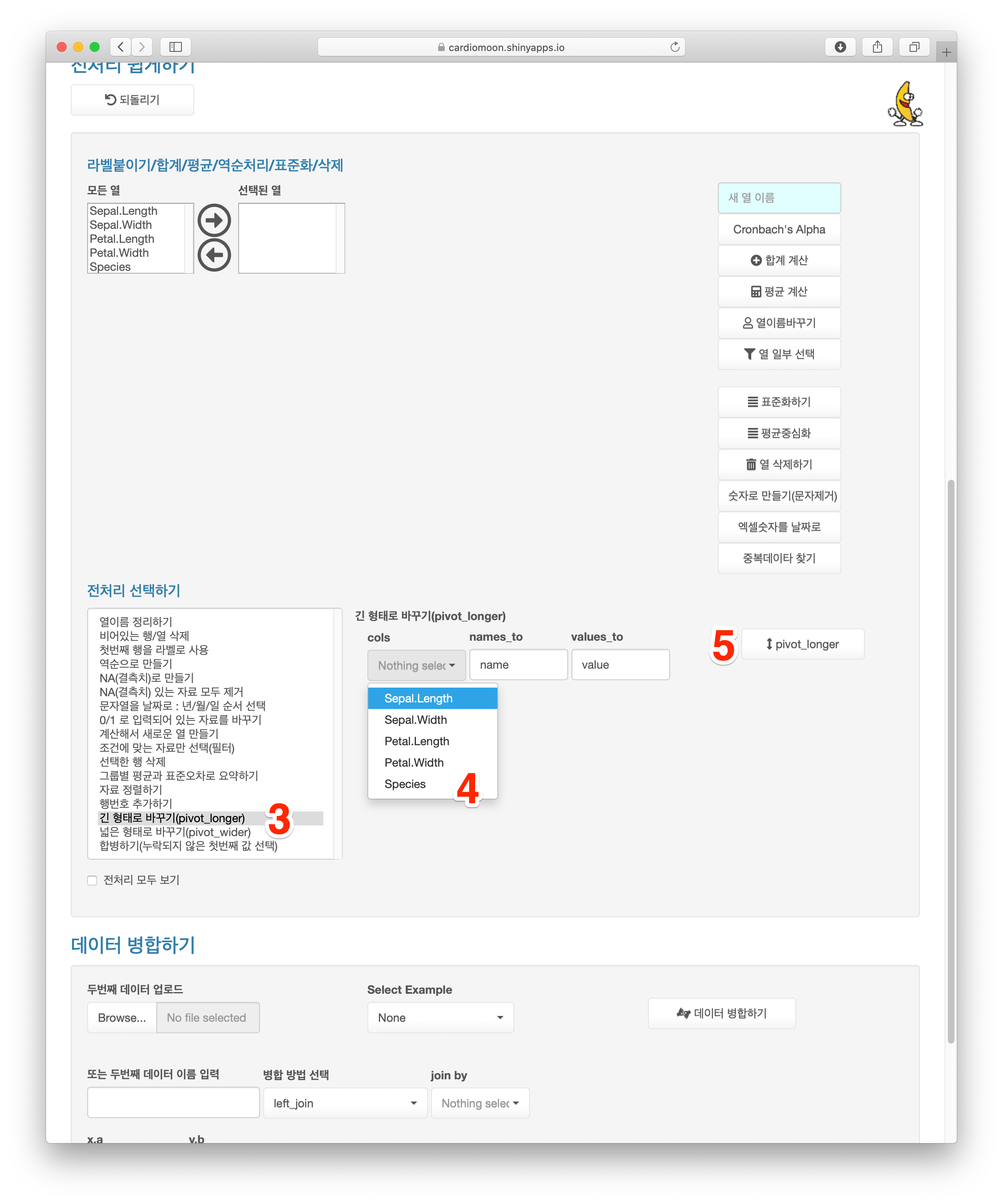
dataWranging 메뉴에서 전처리 선택하기 중 긴 형태로 바꾸기를 선택하고(3) cols에 Sepal.Length, Sepal.Width, Petal.Length, Petal.Width를 선택하고(4) pivot_longer 버튼을 누른다(5).
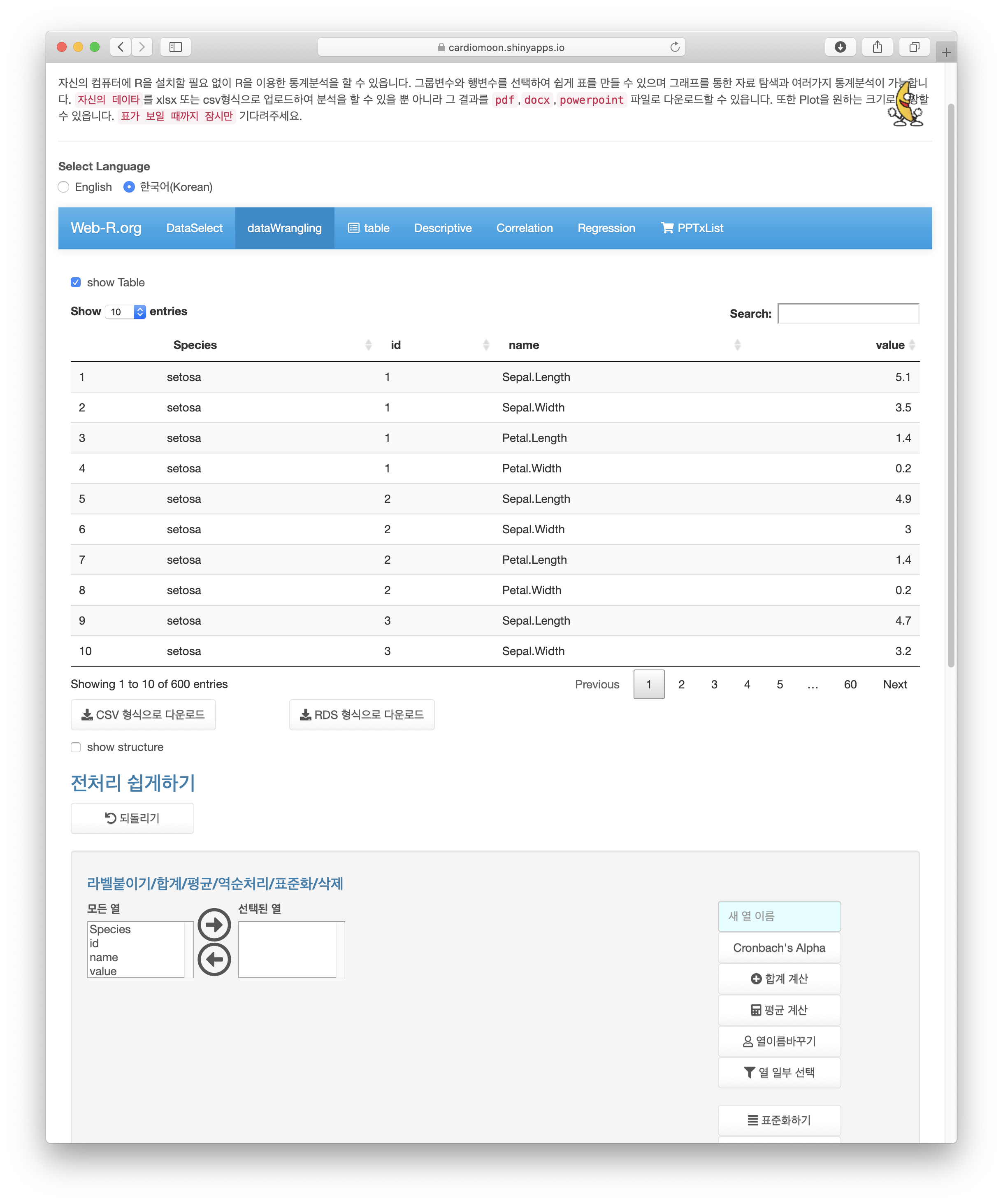
화면을 위로 올려 확인해보면 긴 형태(long form)의 데이터로 바뀐 것을 알 수 있다. 이를 다시 wide form 으로 바꾸려면 데이터의 id가 필요한데 웹R에서는 데이터의 id가 없는 경우 id를 추가해준다.
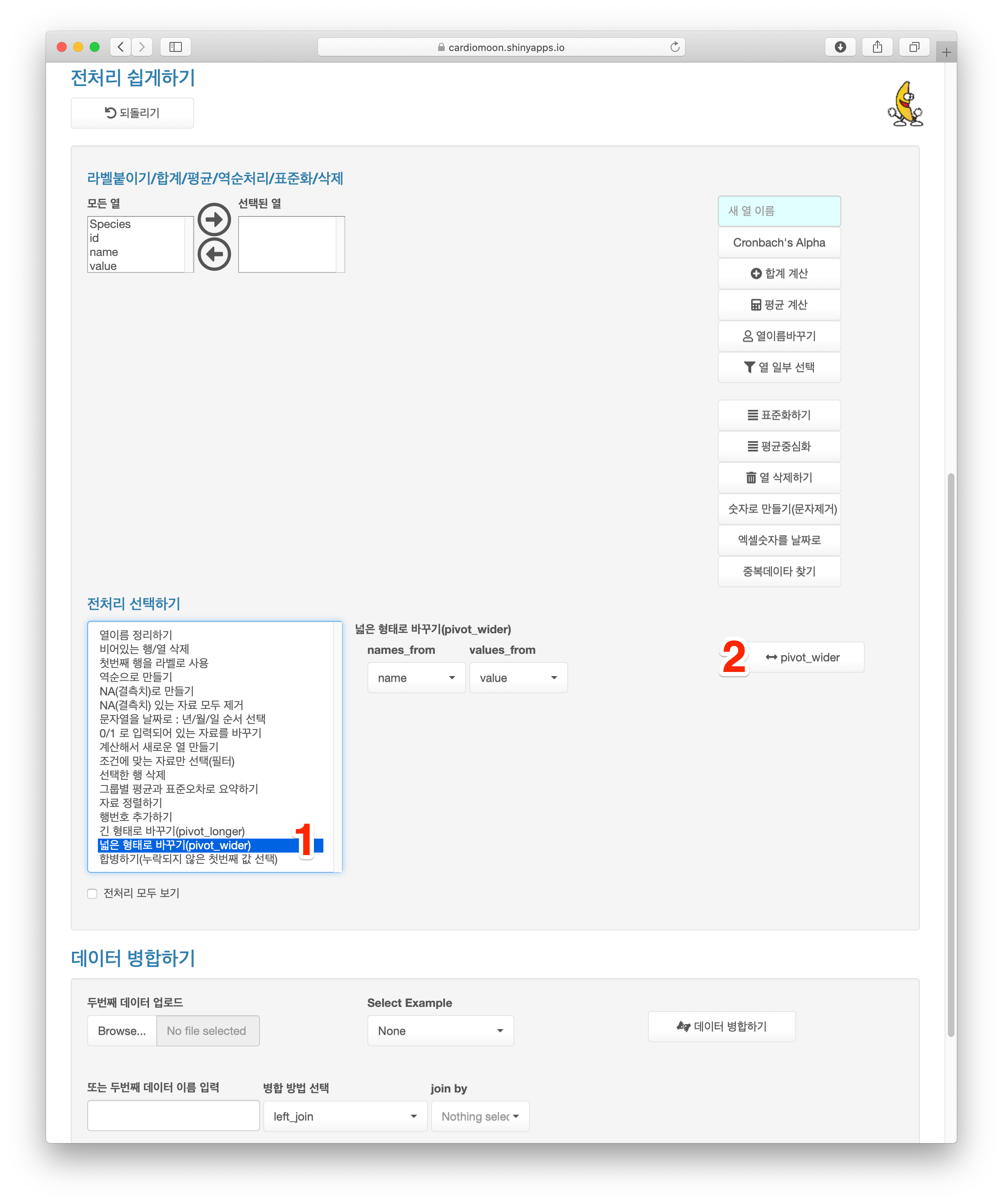
4.14 넓은 형태로 바꾸기(pivot_wider)
위 데이터를 다시 넓은 형태로 바꾸어 보자. 전처리 중 넓은 형태로 바꾸기를 선택하고(1) pivot_wider 버튼을 누른다(2).
데이터의 형태가 다시 넓은 형태로 바뀌었다.
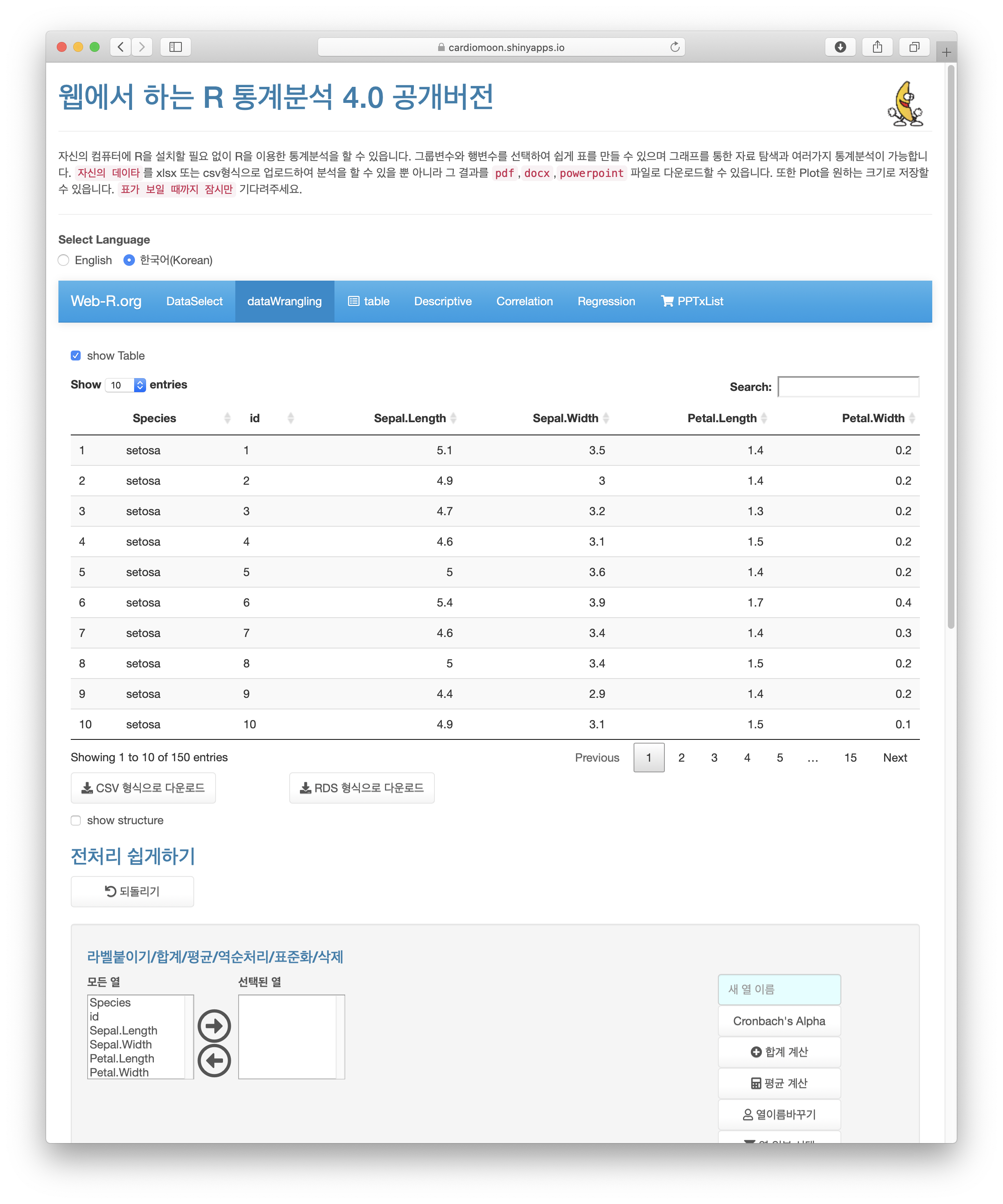
4.15 두 개의 데이터 병합하기
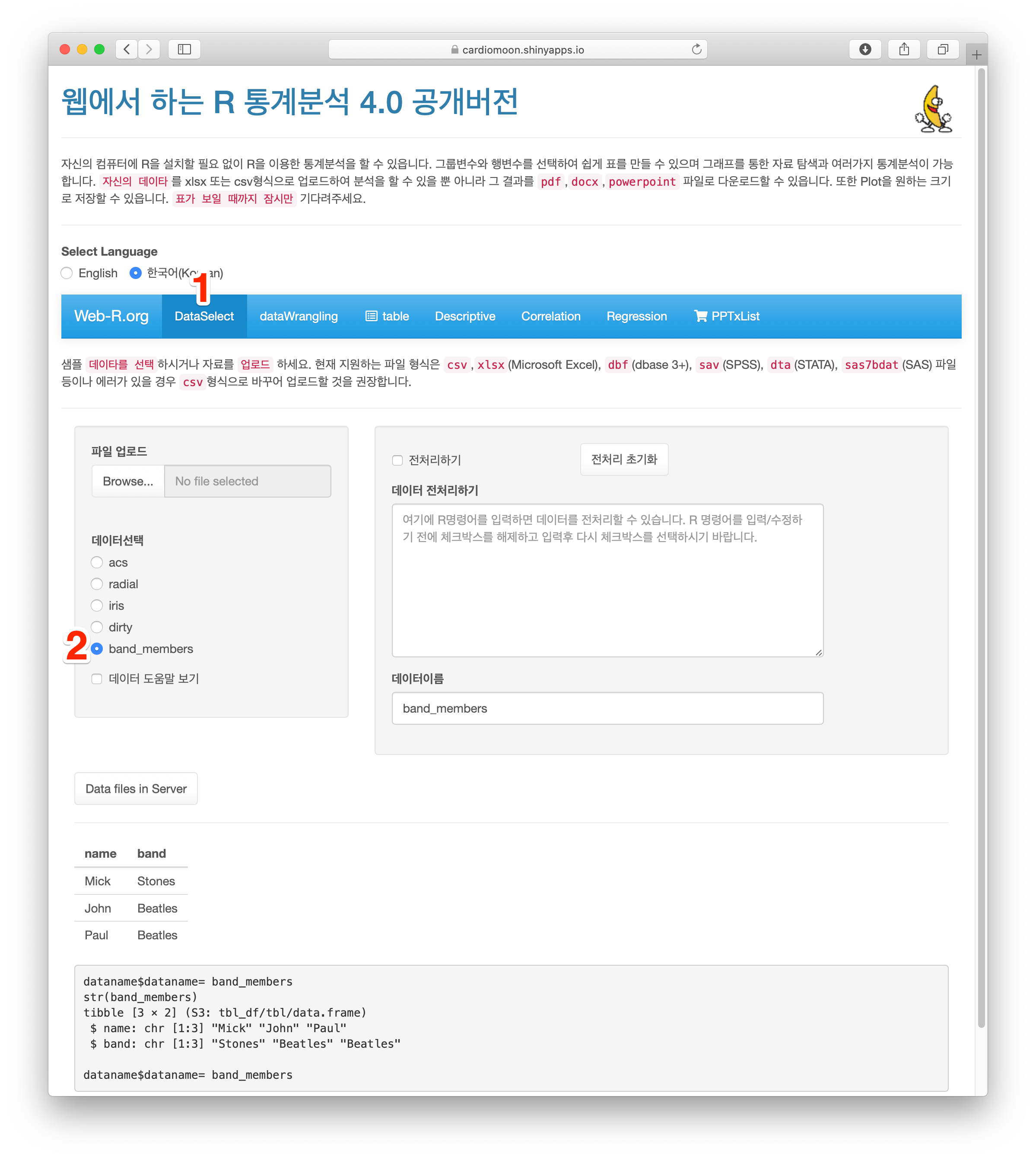
전처리에서 두 개의 데이터를 병합할 수 있다. 먼저 dataSelect 메뉴(1)에서 예제 데이터로 band_members를 선택한다(2).
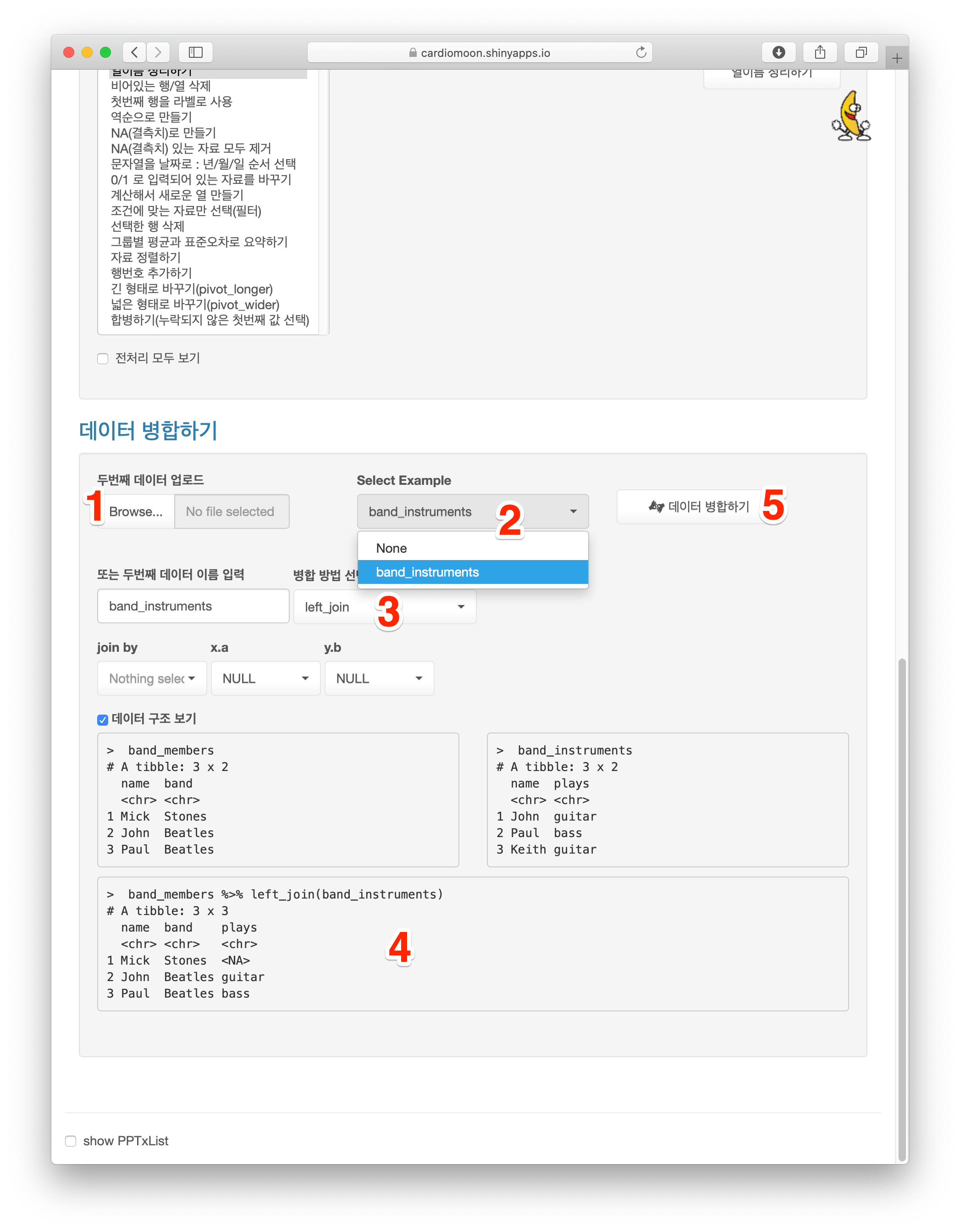
dataWrangling 메뉴에서 화면을 아래쪽으로 이동한다. 두번째 데이터를 업로드하려면 Browse… 버튼을 이용하면 된다. 여기서는 Select Example 중 band_instruments(2) 를 선택한다. 데이터의 병합 방법은 left_join, right_join, inner_join, full_join, semi_join, anti_join, nest_join, bind_rows, bind_cols 등이 있는데 병합방법 선택(3)에서 선택할 수 있고 두 데이터의 구조 및 선택한 방법에 의한 병합의 결과를 미리 볼 수 있다(4). 미리 본 병합의 결과대로 병합을 하려면 데이터 병합하기 버튼을 누른다(5).
4.16 전처리가 끝난 데이터 다운로드
전처리가 끝나면 전처리가 끝난 데이터를 반드시 RDS형식으로 다운로드 받은 후 다시 업로드하여 통계분석을 진행하여야 한다. 그 이유는 전처리 하기 전의 데이터 이름과 전처리한 이후의 데이터 이름이 같기 때문에 이후 데이터 처리 과정에서 혼란이 빚어지기 때문이다.