Bab 6 Eksplorasi dan Visualisasi
//TODO: Membahas cara eksplorasi data secara numerik maupun visual menggunakan grafik dasar R dan package {ggplot2}.
Seperti yang sudah disinggung di awal bahwa R adalah sebuah bahasa pemrograman yang penggunaan utamanya untuk kebutuhan pengolahan data dan analisis statistik. Saat ini lebih terkenal dengan istilah analisis data dan data science. Kegiatan analisis data ini tentunya tidak akan terlepas dari eksplorasi data. Terutama ketika baru pertama kali mendapatkan data tersebut. Kegiatan eksplorasi ini bertujuan untuk mengenal lebih dalam data yang kita gunakan. Metode yang umumnya digunakan ketika melakukan eksplorasi data adalah secara numerik/tabulasi atau secara visual dengan memanfaatkan grafik. Kegiatan eksplorasi dan menyiapkan data untuk kebutuhan analisis data umumnya memerlukan waktu 60%-80% dari seluruh waktu yang dibutuhkan untuk analisis data.
Kita akan bekerja dari sebuah dataframe karena umumnya kegiatan analisis data bersumber dari data yang berbentuk tabular (baris sebagai observasi dan kolom sebagai variabel). Data iris sudah tersedia di R, namun kita akan mulai dari import data karena hampir semua data akan diimport terlebih dahulu, baik itu dari file data atau database. Data iris mempunyai dua tipe data, yaitu numeric dan character.
6.1 Eksplorasi Tabulasi
Kita import terlebih dahulu data yang akan digunakan dari file iris.csv di dalam folder data. Kita gunakan fungsi read_csv() dari package {readr} sebagai latihan menggunakan package.
## Rows: 150 Columns: 5
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (1): Species
## dbl (4): Sepal.Length, Sepal.Width, Petal.Length, Petal.Width
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Untuk mengetahui banyaknya baris data pada iris_csv kita dapat gunakan fungsi nrow(), sedangkan untuk mengetahui banyaknya kolom kita gunakan fungsi ncol().
nrow(iris_csv)## [1] 150ncol(iris_csv)## [1] 5Jadi ada 150 observasi (baris) dan 5 variabel (kolom) dari data yang sudah diimport. Hal ini perlu kita sesuaikan dengan banyaknya baris dan kolom dari data asli yang ada di file data tersebut. Jika sudah sama maka kita dapat lanjut ke tahapan lain. Jika masih ada yang tidak sesuai maka perlu diketahui dahulu letak kesalahannya dan perbaiki sehingga semuanya sudah sesuai. Setelah itu kita dapat mengetahui nama-nama variabel yang ada pada dataframe tersebut dengan menggunakan fungsi colnames() atau names().
colnames(iris_csv)## [1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"names(iris_csv)## [1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"Pada kasus ini kedua fungsi tersebut menghasilkan output yang sama, yaitu nama kolom dari dataframe. Atau kita juga dapat menggunakan fungsi str() untuk melihat informasi itu semua ditambah dengan preview beberapa baris pertama dataframe tersebut.
str(iris_csv)## spc_tbl_ [150 × 5] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ Sepal.Length: num [1:150] 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
## $ Sepal.Width : num [1:150] 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
## $ Petal.Length: num [1:150] 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
## $ Petal.Width : num [1:150] 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
## $ Species : chr [1:150] "setosa" "setosa" "setosa" "setosa" ...
## - attr(*, "spec")=
## .. cols(
## .. Sepal.Length = col_double(),
## .. Sepal.Width = col_double(),
## .. Petal.Length = col_double(),
## .. Petal.Width = col_double(),
## .. Species = col_character()
## .. )
## - attr(*, "problems")=<externalptr>Sekarang mari kita eksplorasi masing-masing variabel.
Kita mulai dengan variabel pertama, yaitu Sepal.Length. Seperti yang sudah dibahas pada bagian 2.9 bahwa ada beberapa cara agar kita dapat mengakses nilai dari suatu variabel di dataframe. Salah satunya adalah dengan menggunakan tanda dollar $. Jika Anda menggunakan RStudio versi terbaru, Anda dapat mengetik iris_csv kemudian diikuti tanda $ maka akan muncul nama-nama variabel dari dataframe tersebut.
iris_csv$Sepal.Length## [1] 5.1 4.9 4.7 4.6 5.0 5.4 4.6 5.0 4.4 4.9 5.4 4.8 4.8 4.3 5.8 5.7 5.4 5.1
## [19] 5.7 5.1 5.4 5.1 4.6 5.1 4.8 5.0 5.0 5.2 5.2 4.7 4.8 5.4 5.2 5.5 4.9 5.0
## [37] 5.5 4.9 4.4 5.1 5.0 4.5 4.4 5.0 5.1 4.8 5.1 4.6 5.3 5.0 7.0 6.4 6.9 5.5
## [55] 6.5 5.7 6.3 4.9 6.6 5.2 5.0 5.9 6.0 6.1 5.6 6.7 5.6 5.8 6.2 5.6 5.9 6.1
## [73] 6.3 6.1 6.4 6.6 6.8 6.7 6.0 5.7 5.5 5.5 5.8 6.0 5.4 6.0 6.7 6.3 5.6 5.5
## [91] 5.5 6.1 5.8 5.0 5.6 5.7 5.7 6.2 5.1 5.7 6.3 5.8 7.1 6.3 6.5 7.6 4.9 7.3
## [109] 6.7 7.2 6.5 6.4 6.8 5.7 5.8 6.4 6.5 7.7 7.7 6.0 6.9 5.6 7.7 6.3 6.7 7.2
## [127] 6.2 6.1 6.4 7.2 7.4 7.9 6.4 6.3 6.1 7.7 6.3 6.4 6.0 6.9 6.7 6.9 5.8 6.8
## [145] 6.7 6.7 6.3 6.5 6.2 5.9typeof(iris_csv$Sepal.Length)## [1] "double"Seperti yang kita lihat, variabel Sepal.Length bertipe numeric atau double. Pertama, kita akan lakukan eksplorasi untuk mengetahui nilai rata-rata dari variabel ini. Kita dapat gunakan fungsi mean() seperti berikut.
mean(iris_csv$Sepal.Length)## [1] 5.843333Kita dapatkan nilai rata-rata dari variabel Sepal.Length adalah sekitar 5.843333. Kenapa “sekitar”? Karena mungkin saja nilai yang ditampilkan hanyalah pembulatan dengan 6 (enam) digit setelah tanda desimal. Selanjutnya kita masukkan nilai-nilai dari variabel Sepal.Length ke dalam object bernama sepal_length yang berupa vector.
sepal_length <- iris_csv$Sepal.LengthKita juga dapat menghitung nilai tengah atau median (Q2) dengan fungsi median(). Untuk mendapatkan nilai ragam (variance) dan simpangan baku (standard deviation)? Kita gunakan fungsi var() dan sd().
median(sepal_length)## [1] 5.8var(sepal_length)## [1] 0.6856935sd(sepal_length)## [1] 0.8280661Untuk mendapatkan nilai minimum dan maksimum kita gunakan fungsi min() dan max(). Untuk mendapatkan keduanya sekaligus kita gunakan fungsi range().
min(sepal_length)## [1] 4.3max(sepal_length)## [1] 7.9range(sepal_length)## [1] 4.3 7.9Kita juga dapat gunakan fungsi quantile() untuk mendapatkan nilai statistik Q1 (data pada urutan ke 25%) dan Q3 (data pada urutan ke 75%).
## 25% 75%
## 5.1 6.4Untuk menampilkan statistik lima serangkai (Min, Q1, Q2, Q3, dan max) bersamaan kita dapat gunakan fungsi summary().
summary(sepal_length)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 4.300 5.100 5.800 5.843 6.400 7.900Selain dapat digunakan untuk sebuah vector numeric, fungsi summary() juga dapat kita gunakan untuk beberapa variabel numeric sekaligus pada sebuah dataframe.
summary(iris_csv)## Sepal.Length Sepal.Width Petal.Length Petal.Width
## Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
## 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
## Median :5.800 Median :3.000 Median :4.350 Median :1.300
## Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
## 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
## Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
## Species
## Length:150
## Class :character
## Mode :character
##
##
## Seperti kita lihat, nilai yang dihasilkan oleh fungsi summary() untuk variabel Species sangat berbeda dibandingkan variabel yang lain. Hal ini karena Species adalah variabel character, sehingga fungsi summary() hanya menampilkan banyaknya observasi (Length), Class dan Mode.
typeof(iris_csv$Species)## [1] "character"Untuk variabel tipe character umumnya eksplorasi yang dilakukan adalah dengan membuat tabulasi atau tabel frekuensi. kita dapat gunakan fungsi table() untuk menghitung banyaknya observasi masing-masing kategori pada variable tersebut.
table(iris_csv$Species)##
## setosa versicolor virginica
## 50 50 50Kita bisa lihat bahwa masing-masing kategori pada variabel Species mempunyai jumlah yang sama. Tentu saja ketika kita menghitung proporsi atau persentase jumlah masing-masing kategori terhadap banyaknya observasi seluruh data (baris) maka nilainya akan sama untuk semua kategori. Untuk menghitung nilai proporsi kita gunakan fungsi prop.table() dengan inputnya adalah tabulasi hasil dari function table().
frekuensi <- table(iris_csv$Species)
prop.table(frekuensi)##
## setosa versicolor virginica
## 0.3333333 0.3333333 0.3333333Selanjutnya kita juga dapat menghitung nilai statistik dari suatu variabel numerik berdasarkan kategori suatu variabel bertipe character. Misalnya kita hitung nilai rata-rata dari variabel Sepal.Length berdasarkan kategori dari Species. Kita gunakan fungsi aggregate()
aggregate(Sepal.Length ~ Species, data = iris_csv, FUN = mean)## Species Sepal.Length
## 1 setosa 5.006
## 2 versicolor 5.936
## 3 virginica 6.588Selanjutnya Anda dapat mencoba eksplorasi seperti di atas dengan menggunakan variabel lain.
6.2 Grafik Dasar di R
6.2.1 Barplot
Barplot atau diagram batang adalah salah satu jenis visualisasi yang digunakan untuk menampilkan informasi berupa frekuensi, persentase atau nilai statistik lain dari beberapa nilai kategorik dalam suatu variabel. Bentuk dari barplot sendiri berupa batang untuk masing-masing kategori dengan ketinggian berdasarkan nilai yang ingin ditampilkan. Barplot sangat cocok digunakan ketika ingin membandingkan nilai masing-masing kategori.
Contoh berikut ini adalah tampilan barplot untuk membandingkan banyaknya amatan untuk masing-masing kategori pada variabel Species di data iris_csv. Untuk mendapatkan frekuensi dari variabel ini kita gunakan fungsi table() dengan input berupa vector kategorik, yaitu variabel Species.

rataan <- aggregate(Sepal.Length ~ Species, data = iris_csv, FUN = mean)
barplot(Sepal.Length ~ Species, data = rataan)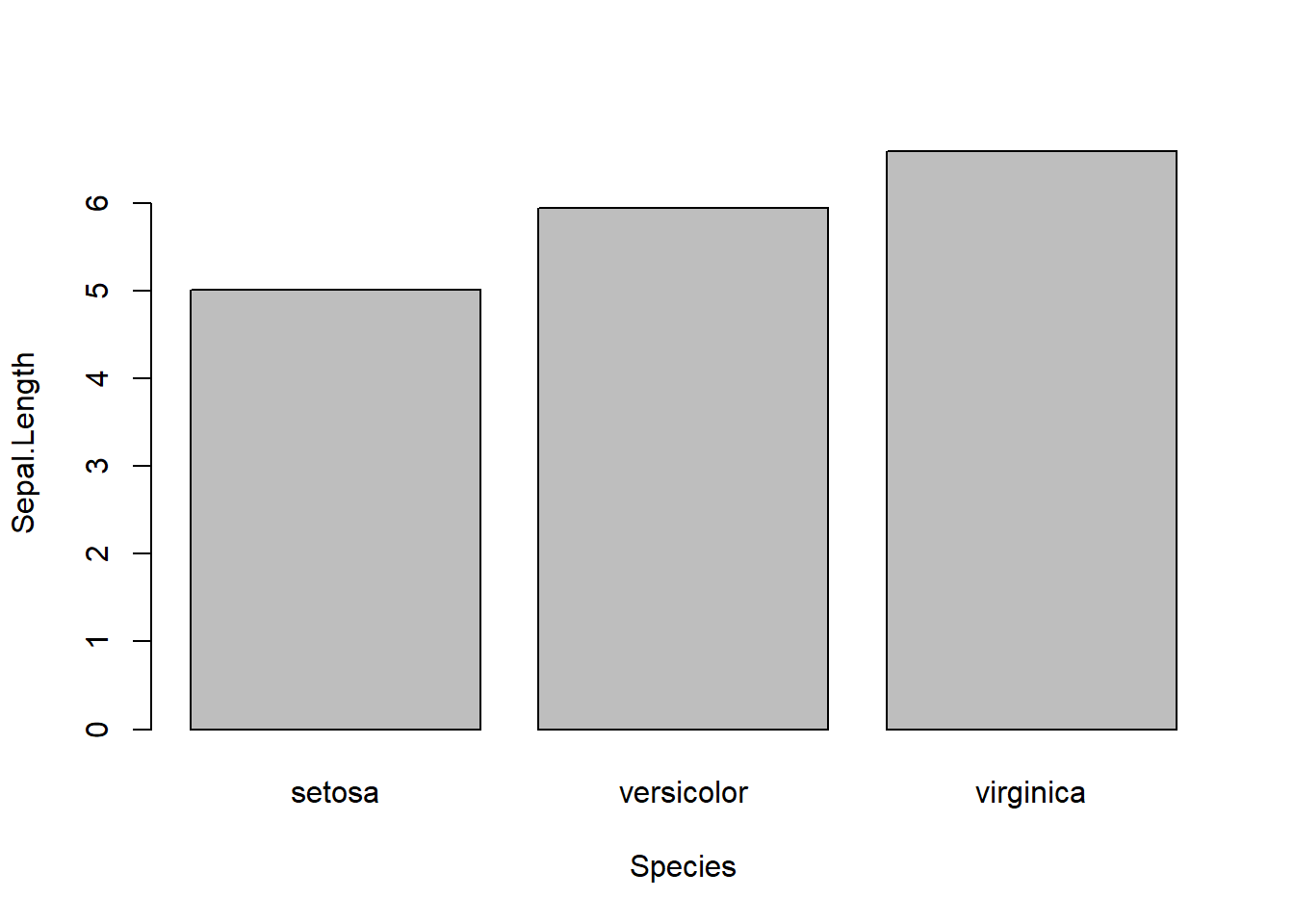
barplot(Sepal.Length ~ Species, data = rataan, col = "skyblue")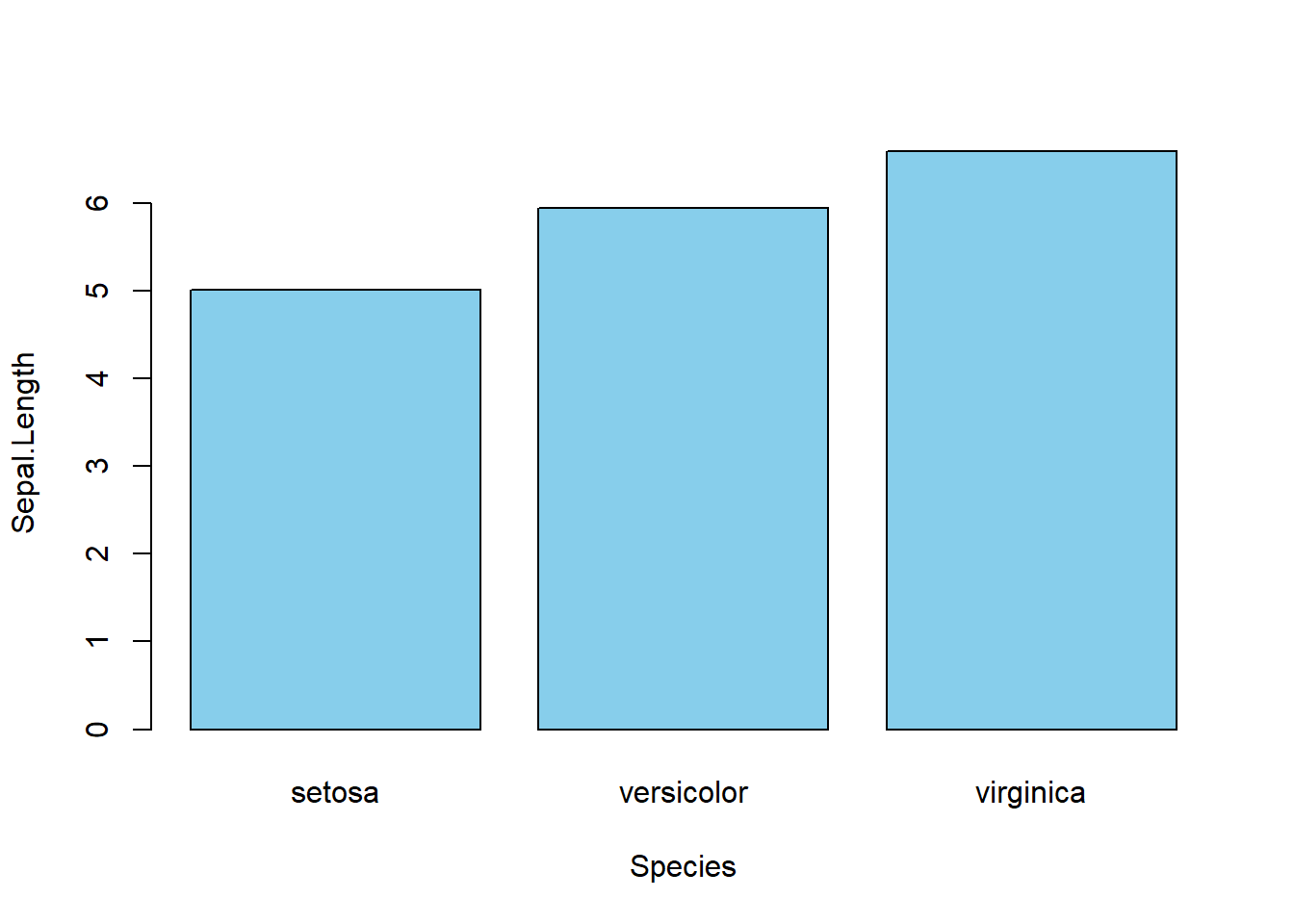
6.2.2 Histogram & Fungsi Kepekatan
Histogram adalah sebuah visualisasi terkait sebaran data numerik. Histogram juga dapat digunakan untuk melihat pola kisaran nilai yang banyak muncul dari data numerik tersebut. Untuk membuat histogram menggunakan grafik dasar di R kita dapat gunakan fungsi hist() dengan argument datanya berupa vector numeric.
hist(sepal_length) Kita dapat tentukan banyaknya batang pada histogram dengan menambahkan nilai pada argument
Kita dapat tentukan banyaknya batang pada histogram dengan menambahkan nilai pada argument breaks. Untuk membuat tampilan lebih menarik dan informasi yang ingin disampaikan lebih mudah diterima kita dapat menambahkan keterangan pada histogram judul (main), judul axis (xlab dan ylab). Untuk menambahkan warna pada batang histogram, kita dapat tambahkan pada argument col. Perhatikan contoh berikut ini.
hist(sepal_length, breaks = 15,
main = "Distribution of Sepal Length",
xlab = "Sepal Length", col = "skyblue") Selanjutnya, untuk dapat menghasilkan dugaan peluang kepekatan (density) suatu data numeric kita dapat gunakan fungsi
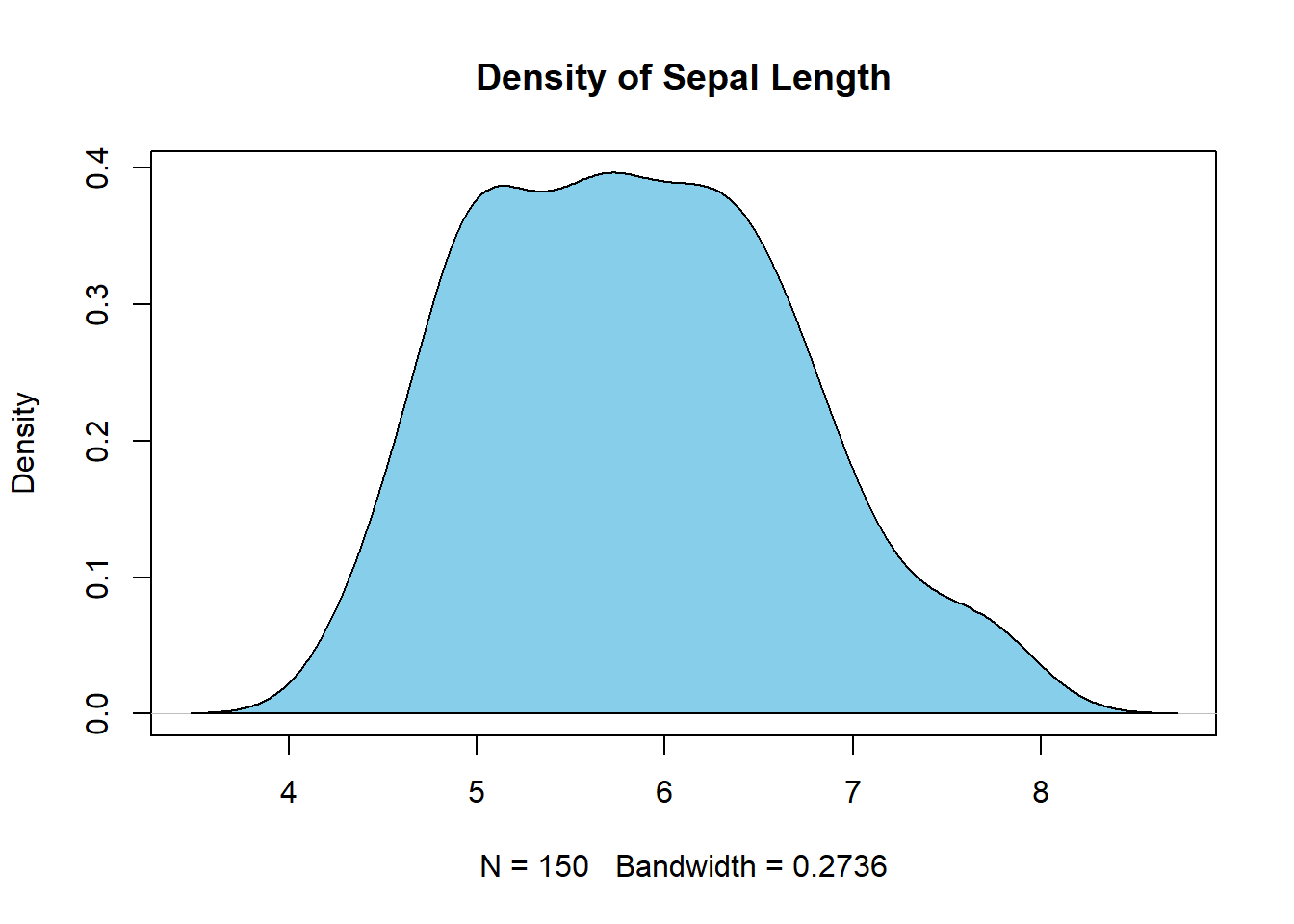
Selanjutnya, untuk dapat menghasilkan dugaan peluang kepekatan (density) suatu data numeric kita dapat gunakan fungsi density(). Argument pertama dari fungsi ini adalah sebuah vector numeric. Keluaran (output) dari fungsi tersebut adalah sebuah object list yang terdiri dari nilai x, y, bw, n, call, data.name, has.na dan atribut class. Nilai x adalah titik data numeric yang digunakan untuk pendugaan kepekatan. Nilai y adalah nilai dugaan kepekatan (density), sedangkan bw adalah nilai bandwidth yang digunakan. Umumnya nilai dugaan kepekatan ini disajikan dalam bentuk visual grafik berupa kurva kepekatan peluang (density curve).
dens <- density(sepal_length)
dens##
## Call:
## density.default(x = sepal_length)
##
## Data: sepal_length (150 obs.); Bandwidth 'bw' = 0.2736
##
## x y
## Min. :3.479 Min. :0.000148
## 1st Qu.:4.790 1st Qu.:0.034088
## Median :6.100 Median :0.153218
## Mean :6.100 Mean :0.190407
## 3rd Qu.:7.410 3rd Qu.:0.378921
## Max. :8.721 Max. :0.396476plot(dens)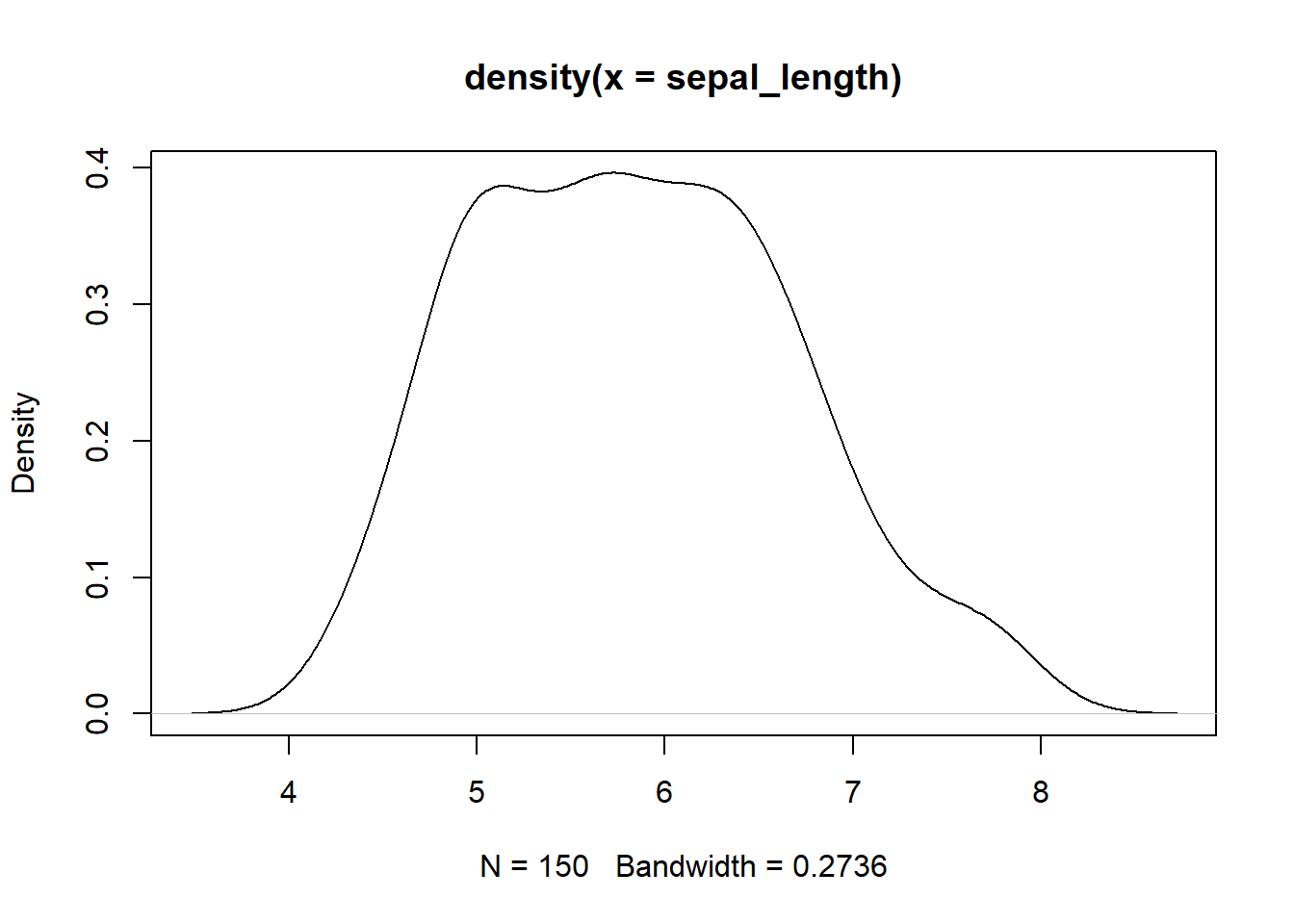
Kita dapat mengatur warna yang ingin kita gunakan agar tampilan kurvanya lebih menarik dengan menggunakan fungsi polygon() setelah membuat kurva kepekatan. Perhatikan contoh dibawah ini.
6.2.3 Boxplot
Jenis visualisasi berikutnya untuk data numeric adalah diagram kotak-garis atau biasa disebut dengan boxplot. Visualisasi ini dapat memberikan kepada Anda bentuk sebaran dengan nilai minimum, Q1 (data ke-25% setelah diurutkan dari besar ke kecil), Q2 (data ke-50% atau median), Q3 (data ke-75%) dan nilai maksimum serta pencilan (outlier) jika ada. Data yang digunakan untuk membuat boxplot adalah data numerik.
boxplot(sepal_length) 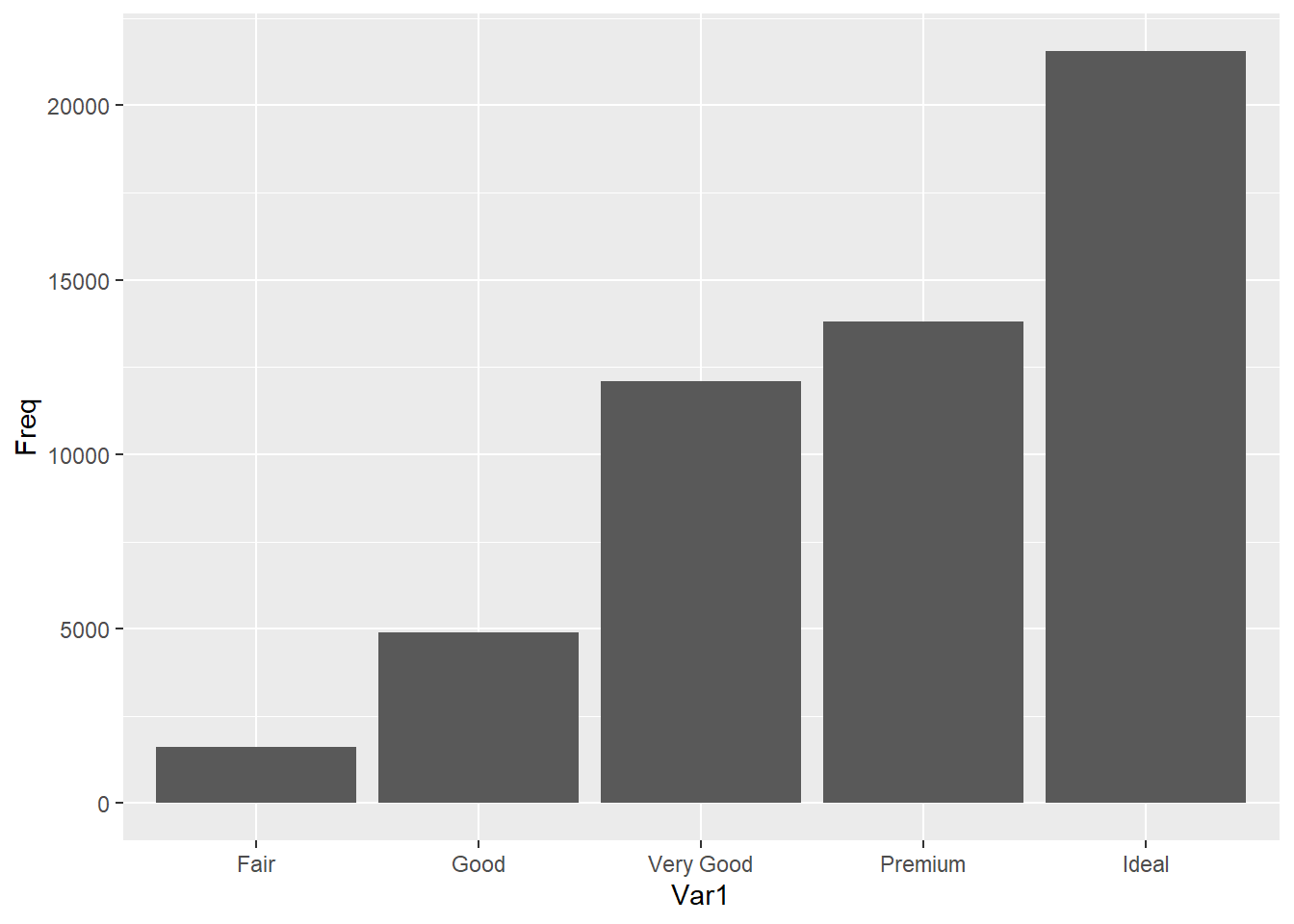 Anda juga dapat membagi data berdasarkan peubah kategorik. Contoh di bawah ini menunjukkan penggunaan dan hasil dari visualisasi sebaran peubah
Anda juga dapat membagi data berdasarkan peubah kategorik. Contoh di bawah ini menunjukkan penggunaan dan hasil dari visualisasi sebaran peubah Sepal.Length berdasarkan peubah Species pada data iris_csv.
boxplot(Sepal.Length ~ Species, data = iris_csv) Jika Anda ingin mengubah tampilan boxplot yang tadinya tegak lurus menjadi mendatar, Anda cukup menambahkan argumen
Jika Anda ingin mengubah tampilan boxplot yang tadinya tegak lurus menjadi mendatar, Anda cukup menambahkan argumen horizontal = TRUE.
boxplot(Sepal.Length ~ Species, data = iris_csv, horizontal = TRUE)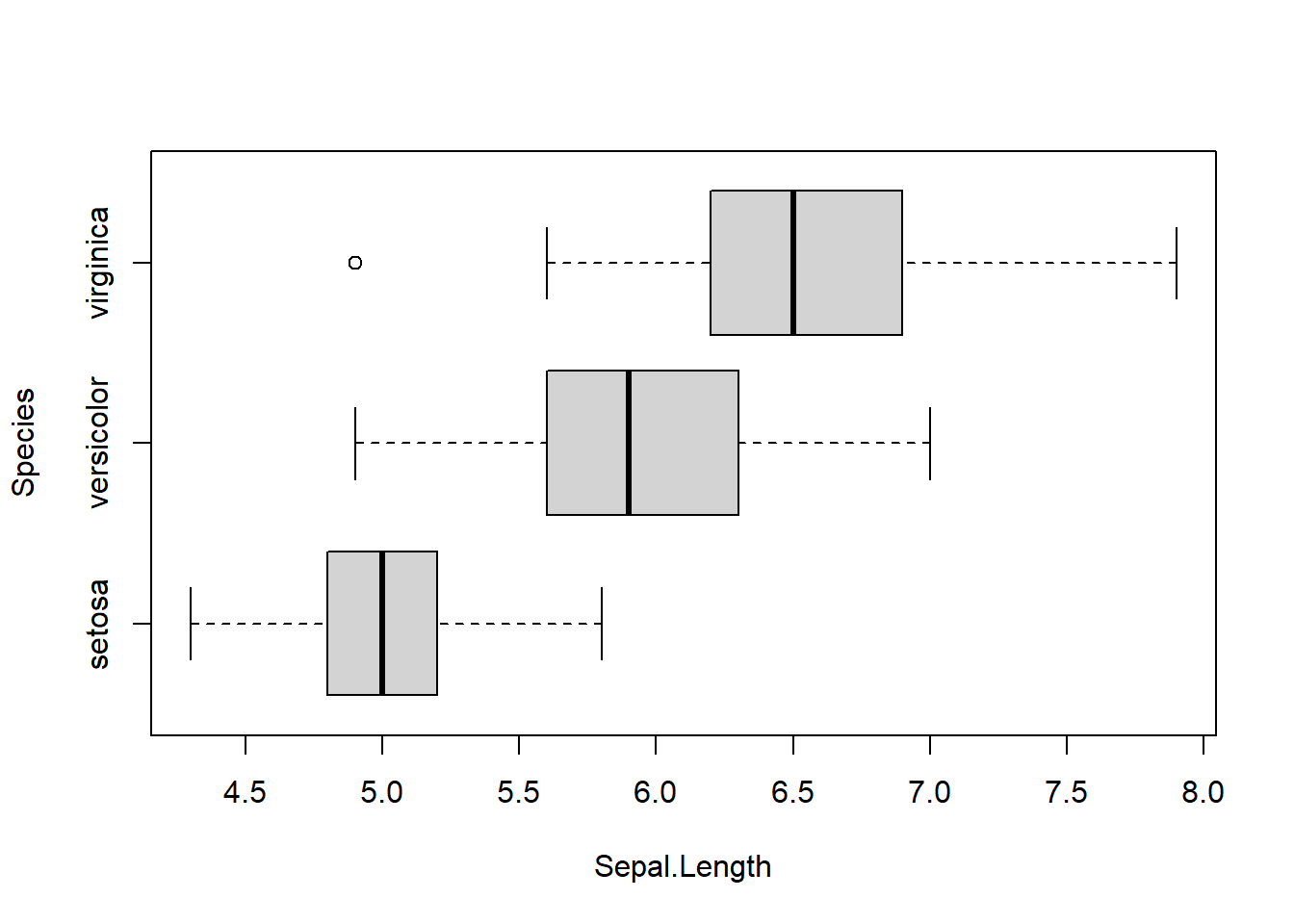
6.2.4 Scatter plot
Scatter plot atau plot tebaran atau diagram pencar, merupakan jenis visualisasi untuk dua buah variable numerik yang ditampilkan berupa titik atau simbol lainnya. Untuk membuat scatter plot Anda dapat gunakan fungsi plot() dengan argumen x dan y berupa vector numerik yang mempunyai panjang yang sama.
x <- iris_csv$Sepal.Length
y <- iris_csv$Sepal.Width
plot(x, y)
Anda dapat mengganti jenis titik dengan menggunakan argumen pch dengan nilai antara 0 dan 25. Misalnya pada contoh di bawah ini menggunakan pch = 19 untuk titiknya berwarna hitam penuh.
plot(x, y, pch = 19)
Jika Anda ingin memberi warna untuk titik-titik tersebut, Anda dapat gunakan argumen col. Untuk nilai dari argumen ini Anda dapat tuliskan langsung nama warnanya dalam bahasa Inggris seperti red, blue, skyblue, dan seterusnya. Atau Anda juga dapat gunakan kode HEX.
plot(x, y, pch = 19, col = "skyblue")
6.2.5 Line chart
Line chart atau diagram garis umumnya digunakan untuk melihat trend yang terjadi pada suatu data. Variable yang ditempatkan pada sumbu-x (horizontal) biasanya adalah data waktu atau tanggal. Untuk membuat line chart menggunakan base R Anda juga dapat gunakan fungsi plot() dengan tambahan argumen type = "l". Artinya tipe plot yang akan dibuat adalah (l)ine atau garis.
6.3 Visualisasi {ggplot2}
Jika Anda belum pernah install package {ggplot2} maka Anda perlu install terlebih dahulu package tersebut dengan perintah berikut ini. Pastikan R yang Anda gunakan dapat mengakses internet.
install.packages("ggplot2")Untuk mengaktifkan package {ggplot2} Anda perlu jalankan perintah berikut ini.
6.3.1 Dasar-dasar {ggplot2}
Package {ggplot2} adalah salah satu package yang sangat terkenal dan sering digunakan oleh pengguna R saat ini. Package ini menghasilkan visualisasi berupa grafik yang sangat bagus dengan cara yang cukup mudah. Dasar dari {ggplot2} adalah grammar of graphics yang juga menjadi singkatan untuk dua huruf g di nama package ini. Sumber bacaan utama dari bagian ini adalah https://ggplot2-book.org/index.html. Anda dapat mempelajari lebih detail tentang Grammar of Graphics di buku tersebut dan referensi yang digunakan.
Pembuatan grafik menggunakan {ggplot2} terdiri dari beberapa bagian. Pada dasarnya, ggplot2 bekerja dengan tiga komponen utama: data, aesthetic mapping, dan geometric objects. Data adalah informasi yang ingin divisualisasikan, aesthetic mapping menentukan bagaimana variabel dalam data dipetakan ke elemen visual seperti sumbu x, sumbu y, warna, atau ukuran, sedangkan geometric objects (geom) adalah bentuk visual yang digunakan untuk merepresentasikan data, seperti titik, garis, atau batang.
Bagian pertama selalu diawali dengan fungsi ggplot(). Fungsi ini akan menyiapkan layer dasar untuk grafik yang akan dibuat. Ketika Anda ketik ggplot() dan jalankan di console, maka di bagian tab Plots di RStudio akan muncul kanvas berwarna abu-abu. Pada fungsi ini Anda dapat menggunakan data yang Anda miliki dengan menyebutkannya pada argumen data =. Data yang digunakan umumnya berupa dataframe atau yang semacamnya (tibble, data.table, dst). Argumen mapping = aes()untuk memberitahukan kepada ggplot2 variabel apa saja yang akan menjadi aesthetic dengan menyebutkan masing-masing dalam fungsi aes() tersebut.
Setelah fungsi ggplot() pasti akan diikuti oleh tanda + sebagai tanda untuk menambahkan layer berikutnya dan minimal satu geometrik atau geom. Misalnya geom_point() untuk membuat scatterplot, geom_histogram() untuk membuat histogram, geom_density() untuk membuat plot kepekatan peluang, geom_bar() atau geom_col() untuk membuat barchart, dan lain-lain. Jika Anda menggunakan RStudio, Anda dapat ketik geom_ kemudian akan muncul pilihan geometrik-geometrik yang sudah disiapkan oleh {ggplot2}. Jika tidak muncul pilihannya, Anda dapat tekan tombol Tab di keyboard Anda.
Bentuk minimal untuk membuat grafik menggunakan {ggplot2} adalah sebagai berikut.
Ada beberapa cara yang umum digunakan ketika menggunakan {ggplot2}. Data yang digunakan hanya satu dan semua variabel yang dibutuhkan untuk aesthetic pada bagian geom sama.
Package {ggplot2} juga menyediakan beberapa dataframe yang dapat digunakan untuk latihan ataupun kebutuhan mengajarkan {ggplot2}. Tentu saja Anda juga dapat menggunakan dataframe Anda sendiri jika diinginkan. Salah satu dataframe yang disediakan adalah diamonds, yaitu data tentang harga dan karakter dari 53.940 berlian. Anda dapat membaca keterangan tentang data ini lebih lanjut dengan mengetik ?diamonds dan akan muncul halaman help dari data tersebut.
diamonds## # A tibble: 53,940 × 10
## carat cut color clarity depth table price x y z
## <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
## 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
## 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
## 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
## 4 0.29 Premium I VS2 62.4 58 334 4.2 4.23 2.63
## 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
## 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
## 7 0.24 Very Good I VVS1 62.3 57 336 3.95 3.98 2.47
## 8 0.26 Very Good H SI1 61.9 55 337 4.07 4.11 2.53
## 9 0.22 Fair E VS2 65.1 61 337 3.87 3.78 2.49
## 10 0.23 Very Good H VS1 59.4 61 338 4 4.05 2.39
## # ℹ 53,930 more rows6.3.2 Barplot
Untuk membuat bar plot/bar chart/diagram batang menggunakan ggplot2 Anda dapat gunakan geom_bar(). Misalnya kita ingin melihat sebaran dari data kategorik ordinal kualitas potongan berlian (cut).
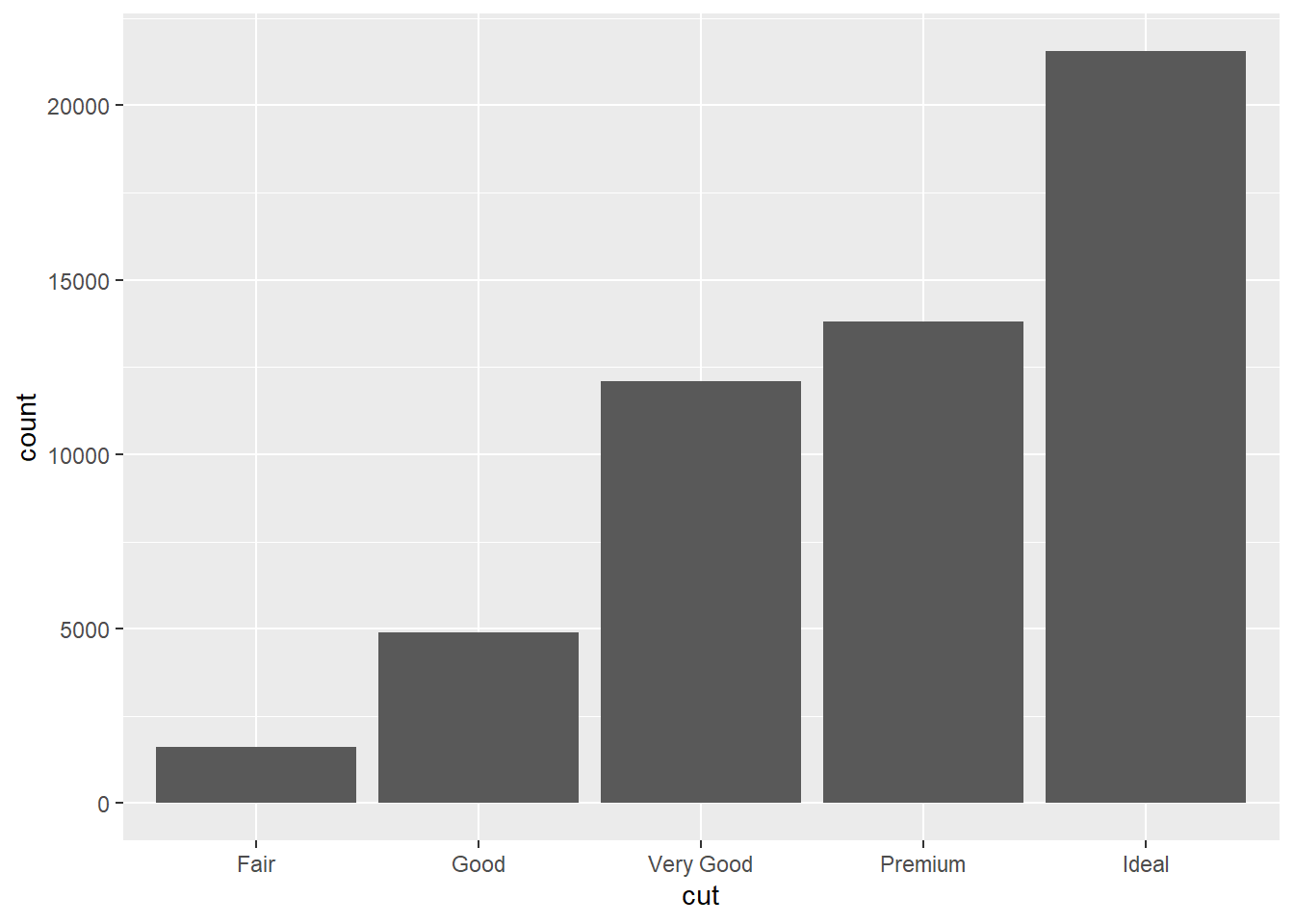
Jika data yang kita miliki sudah dalam bentuk ringkasan, misalnya sebuah tabel frekuensi, maka kita dapat buat barplot menggunakan tambahan argumen pada geom_bar() seperti berikut ini. Pertama kita buat dulu contoh data berupa tabel frekuensi dari variabel cut pada dataframe diamonds. Kita simpan hasilnya sebagai dataframe freqtab.
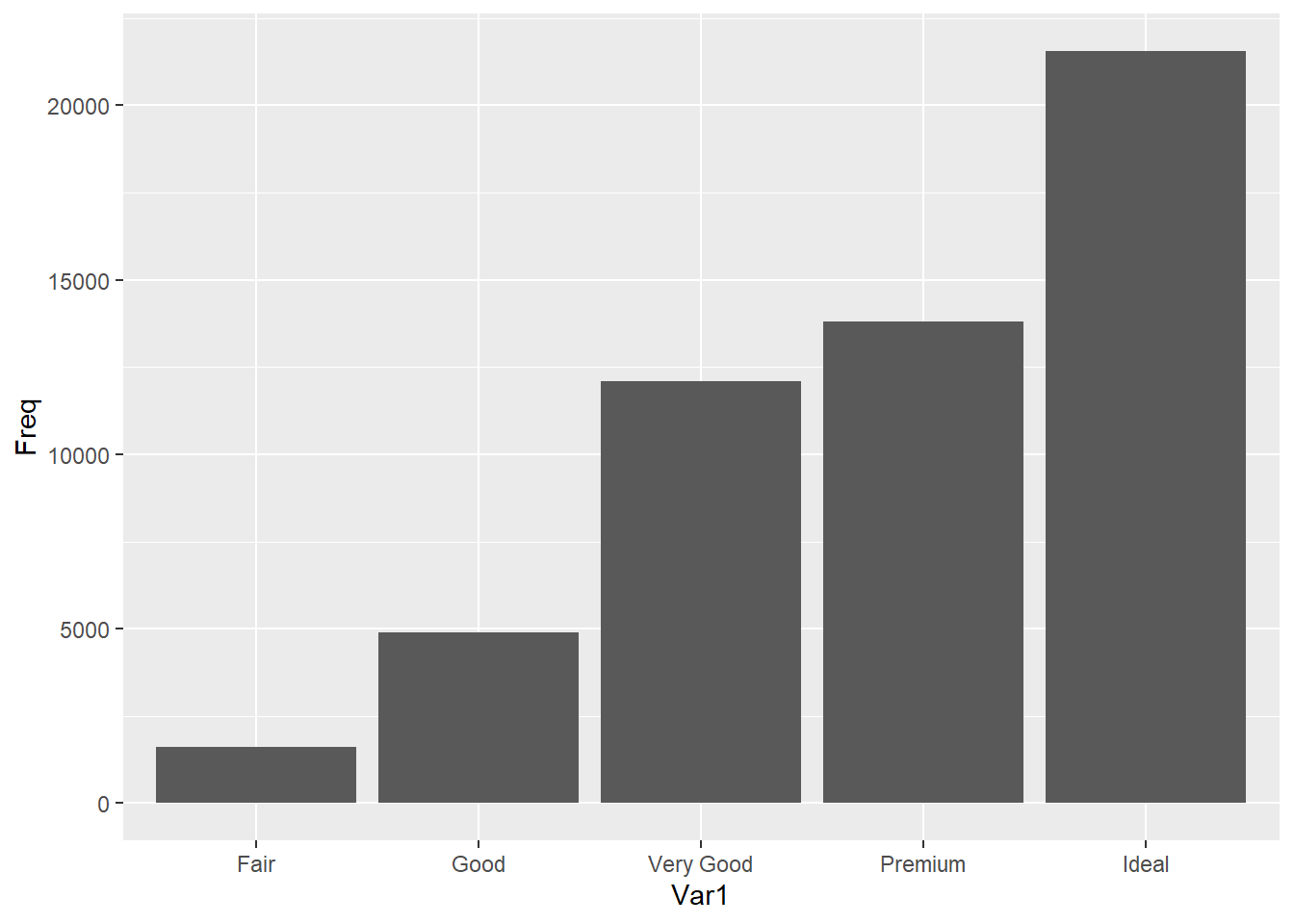
freqtab <- as.data.frame(table(diamonds$cut))
freqtab## Var1 Freq
## 1 Fair 1610
## 2 Good 4906
## 3 Very Good 12082
## 4 Premium 13791
## 5 Ideal 21551Argumen data pada ggplot() merujuk pada tabel frekuensi yang sudah kita buat sebelumnya. Karena ada dua informasi yang kita butuhkan, yaitu kategori dan frekuensinya, maka kita pasangkan kategori yaitu Var1 sebagai argumen x dan variabel nilai frekuensinya yaitu Freq sebagai argumen y. Secara default, geom_bar() menggunakan stat = "count", yang berarti ia akan menghitung jumlah observasi (frekuensi) untuk setiap kategori dari variabel yang disebutkan pada sumbu x dan menampilkannya sebagai tinggi batang. Namun, ketika Anda menggunakan stat = "identity", Anda memberitahu ggplot2 untuk menggunakan nilai yang sudah ada di data sebagai tinggi batang, bukan menghitung frekuensi.
 Cara lain yang dapat digunakan untuk membuat diagram batang ketika data yang kita miliki sudah dalam bentuk tabel frekuensi adalah dengan
Cara lain yang dapat digunakan untuk membuat diagram batang ketika data yang kita miliki sudah dalam bentuk tabel frekuensi adalah dengan geom_col().
Perbedaan antara geom_bar() dan geom_col():
geom_bar():
- Secara default menggunakan
stat = "count", yang menghitung frekuensi observasi untuk setiap kategori pada sumbux.
- Cocok digunakan ketika Anda hanya memiliki variabel kategorikal dan ingin melihat distribusi frekuensinya.
- Jika ingin menggunakan nilai numerik sebagai tinggi batang, Anda harus menambahkan
stat = "identity".
geom_col():
- Secara default menggunakan
stat = "identity", yang berarti Anda harus menyediakan variabel kategori pada sumbuxdan nilai numerik untuk sumbuysebagai tinggi batang.
- Cocok digunakan ketika Anda sudah memiliki nilai numerik yang ingin ditampilkan sebagai tinggi batang.
- Lebih ringkas dan langsung daripada
geom_bar(stat = "identity").
Kita juga dapat mengubah warna dari batang dengan menambahkan argumen fill. Hal ini dapat dilakukan pada geom_bar() atau geom_col(). Kita dapat menggunakan beberapa cara untuk memberi warna pada ggplot.
- Menggunakan nama kode warna seperti
"red","white","black","firebrick","skyblue","green", dan sebagainya untuk warna statis.
- Menggunakan kode warna seperti kode HEX,
"#ffffff"untuk warna putih,"#000000"untuk warna hitam,"#0000fa"untuk warna biru, dan sebagainya.
- Menggunakan nilai dari variabel dengan cara menuliskan argumen
filldi dalamaes()dan nilainya adalah nama variabel.
 Kita dapat mengontrol tingkat transparansi (opacity) dari elemen visual seperti titik, garis, batang, atau area. Untuk mengatur tingkat transparansi ini kita dapat menggunakan argumen
Kita dapat mengontrol tingkat transparansi (opacity) dari elemen visual seperti titik, garis, batang, atau area. Untuk mengatur tingkat transparansi ini kita dapat menggunakan argumen alpha. Nilai alpha berkisar antara 0 (sepenuhnya transparan/tidak terlihat) hingga 1 (sepenuhnya padat/tidak transparan). Dengan mengatur alpha, kita dapat membuat visualisasi yang lebih estetik atau informatif, terutama ketika ada tumpang tindih (overlap) antara elemen-elemen plot.
 Dalam ggplot2, kita dapat menambahkan judul plot, label sumbu x, dan label sumbu y menggunakan fungsi
Dalam ggplot2, kita dapat menambahkan judul plot, label sumbu x, dan label sumbu y menggunakan fungsi labs() atau ggtitle(), xlab(), dan ylab(). Fungsi-fungsi ini memungkinkan kita untuk memberikan konteks dan informasi tambahan pada visualisasi, sehingga plot menjadi lebih mudah dipahami. Fungsi labs() adalah cara yang paling fleksibel dan umum digunakan untuk menambahkan judul plot, label sumbu x, dan label sumbu y. Anda juga dapat menambahkan subtitle, caption, dan label untuk legend menggunakan fungsi ini.
ggplot(data = freqtab, mapping = aes(x = Var1, y = Freq)) +
geom_col() +
labs(title = "Frekuensi berdasarkan 'cut'",
x = "Cut Level",
y = "Frekuensi")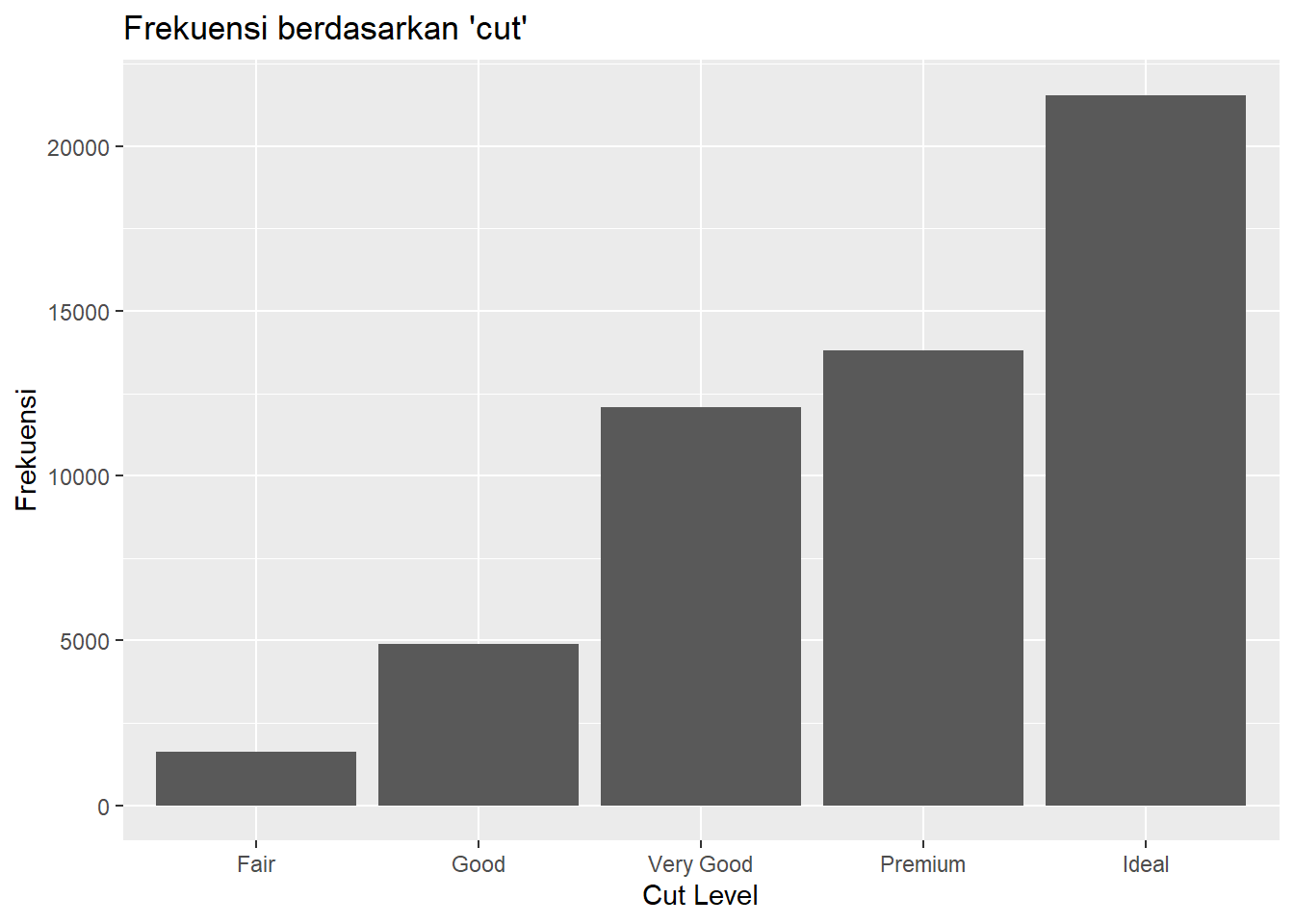
Menambahkan teks sebagai label data pada bar plot adalah cara yang efektif untuk menampilkan nilai numerik secara langsung di atas atau di dalam batang. Cara ini dapat membantu pembaca memahami data dengan lebih cepat tanpa harus merujuk ke sumbu y. Di ggplot2, Anda dapat menggunakan fungsi geom_text() atau geom_label() untuk menambahkan teks sebagai label data.
ggplot(data = freqtab, mapping = aes(x = Var1, y = Freq)) +
geom_col() +
labs(title = "Frekuensi berdasarkan 'cut'",
x = "Cut Level",
y = "Frekuensi") +
geom_text(aes(label = Freq), vjust = -0.25)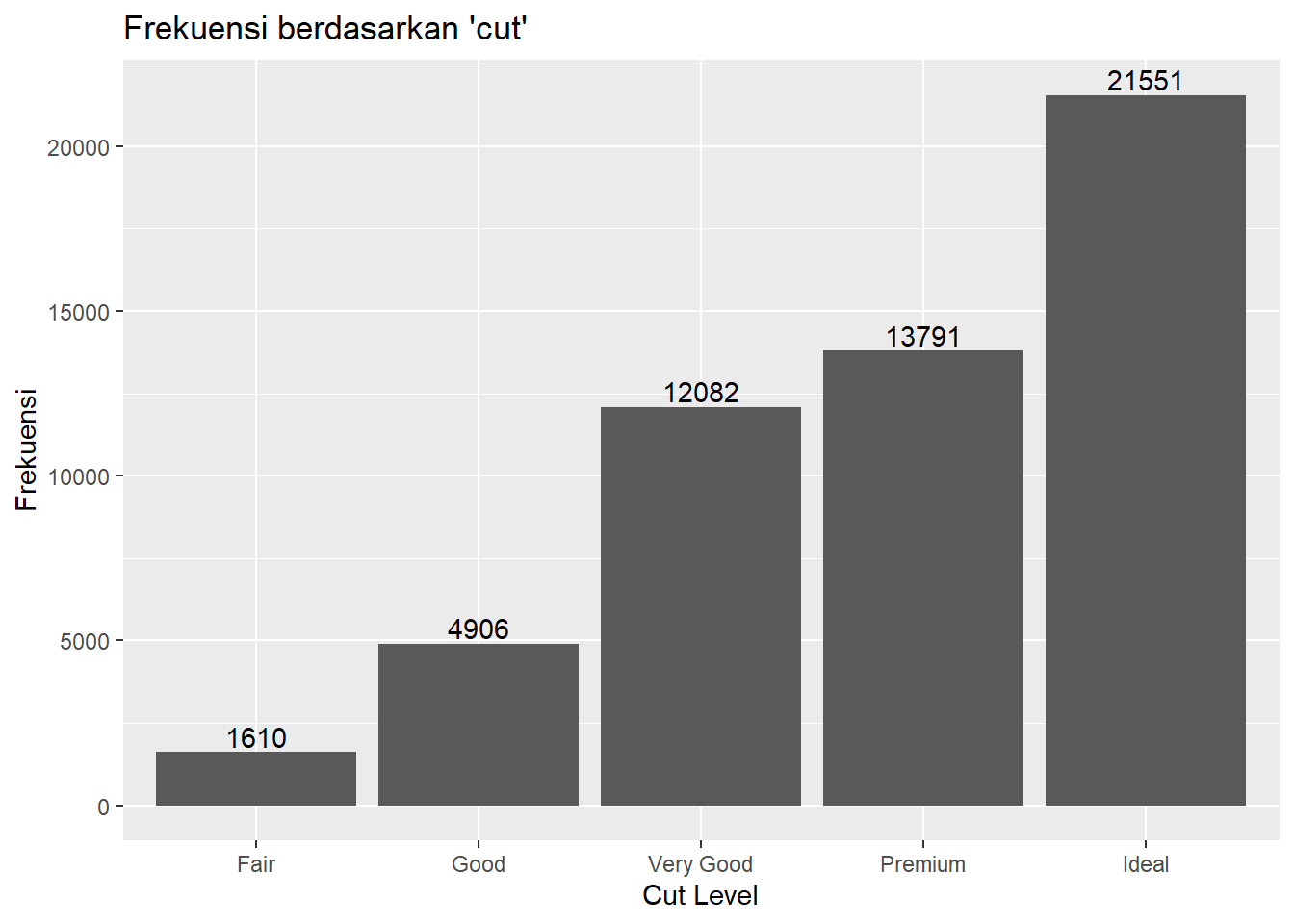
Argumen vjust = -0.25 digunakan untuk mengatur posisi teks sedikit di atas batang (vjust negatif untuk posisi di atas, positif untuk di bawah). Untuk mengatur ukuran teks dapat menggunakan size. Perbedaan geom_label() dan geom_text() adalah menambahkan latar belakang (background) di belakang teks, sehingga teks lebih mudah dibaca.
ggplot(data = freqtab, mapping = aes(x = Var1, y = Freq)) +
geom_col() +
labs(title = "Frekuensi berdasarkan 'cut'",
x = "Cut Level",
y = "Frekuensi") +
geom_label(aes(label = Freq), vjust = -0.25, size = 4)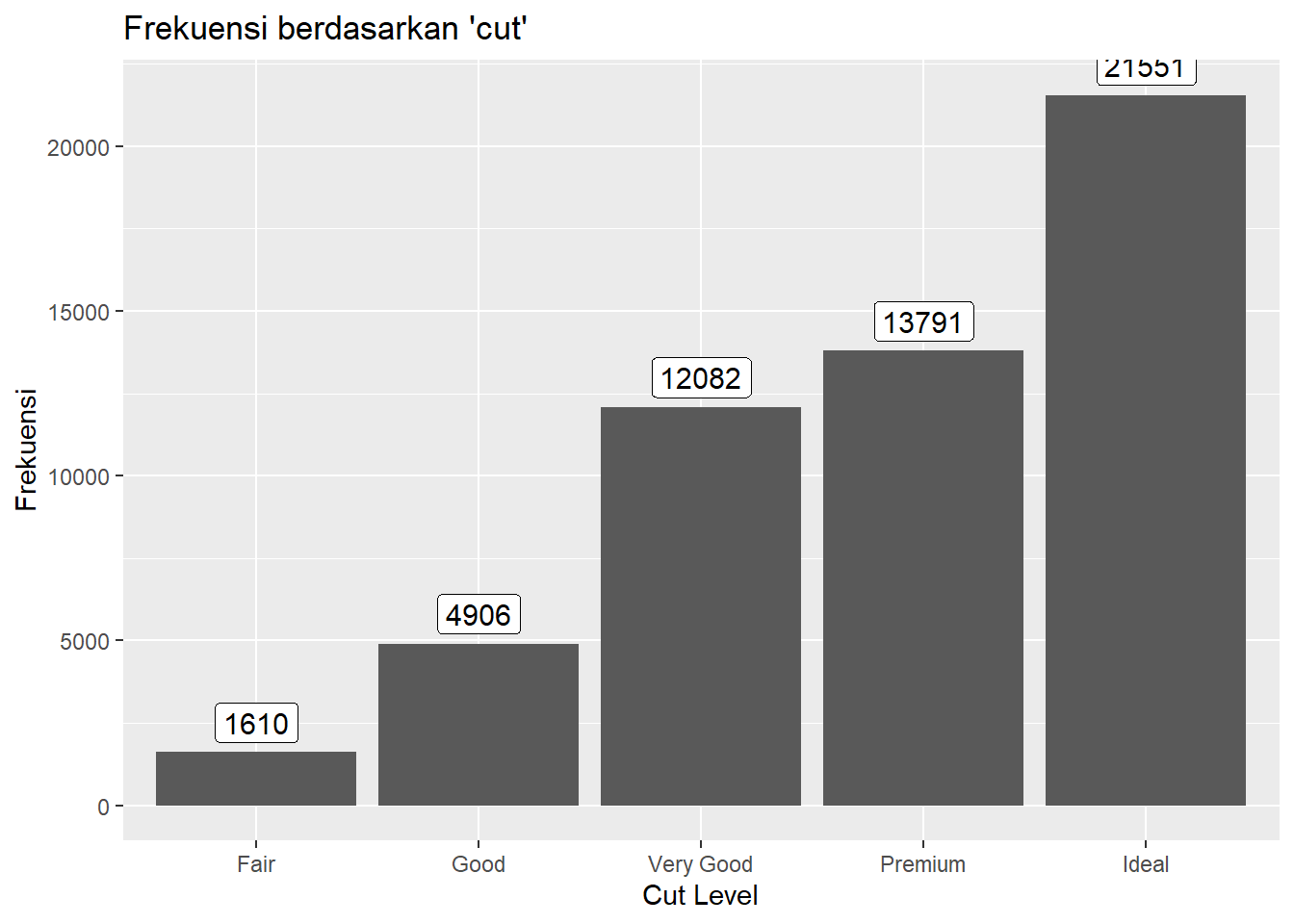
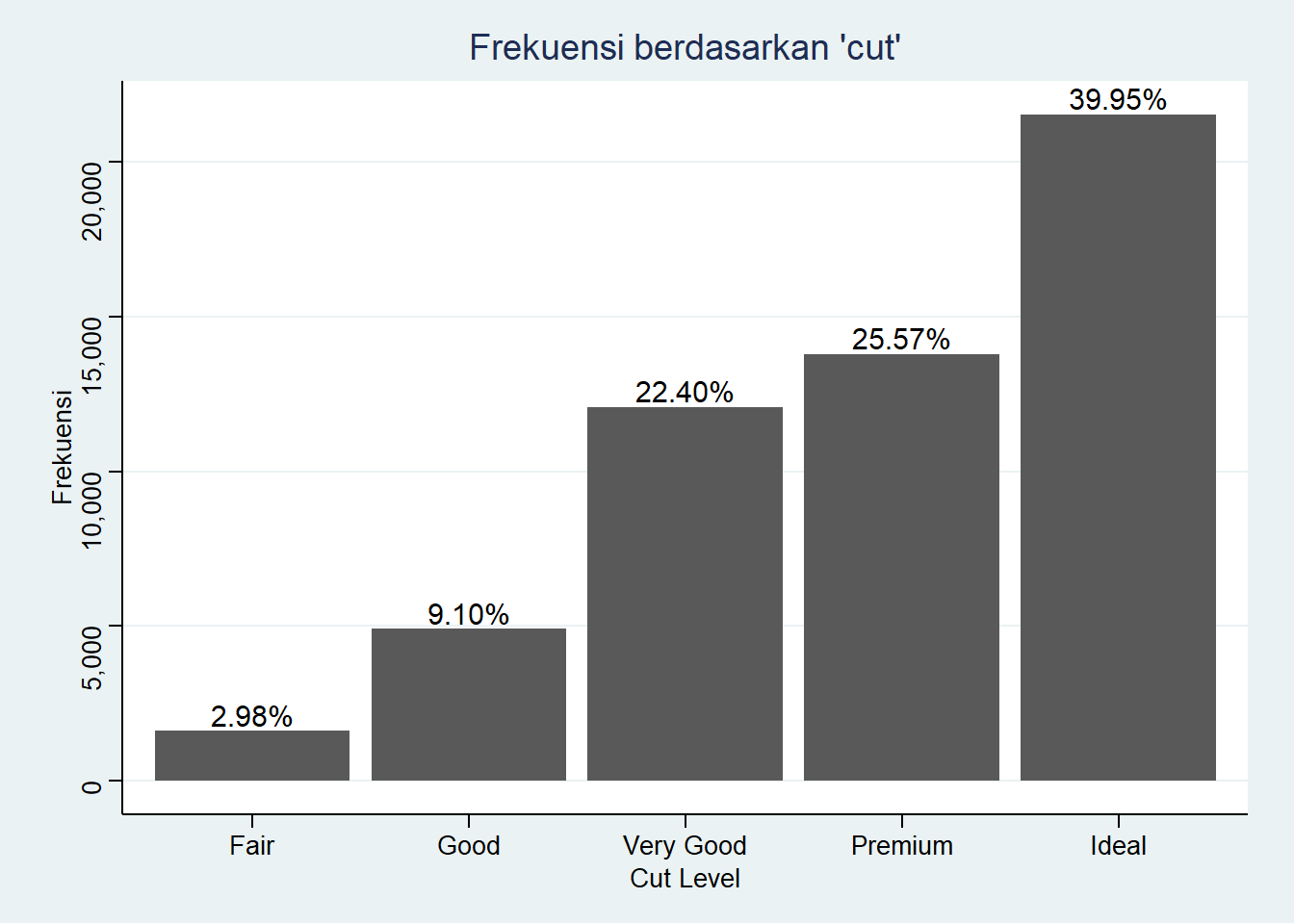
Terkadang nilai yang ingin ditampilan di atas batang adalah persentase masing-masing kategori terhadap seluruh data yang ada. Pertama, kita perlu menghitung persentase per kategori. Kita dapat melakukannya dengan membuat variabel baru hasil dari variabel Freq yang sudah ada sebelumnya dibagi dengan jumlah variabel Freq. Misalnya kita buat variabel baru tersebut dengan nama persen. Untuk memudahkan tampilan nilai persentase di atas batang, kita gunakan function percent() dari package scales dengan accuracy = 0.01 artinya tampilkan hingga dua angka di belakang tanda desimal.
##
## Attaching package: 'scales'## The following object is masked from 'package:readr':
##
## col_factorfreqtab$persen <- freqtab$Freq/sum(freqtab$Freq)
ggplot(data = freqtab, mapping = aes(x = Var1, y = Freq)) +
geom_col() +
labs(title = "Frekuensi berdasarkan 'cut'",
x = "Cut Level",
y = "Frekuensi") +
geom_text(
aes(label = percent(persen, accuracy = 0.01)),
vjust = -0.25, size = 4)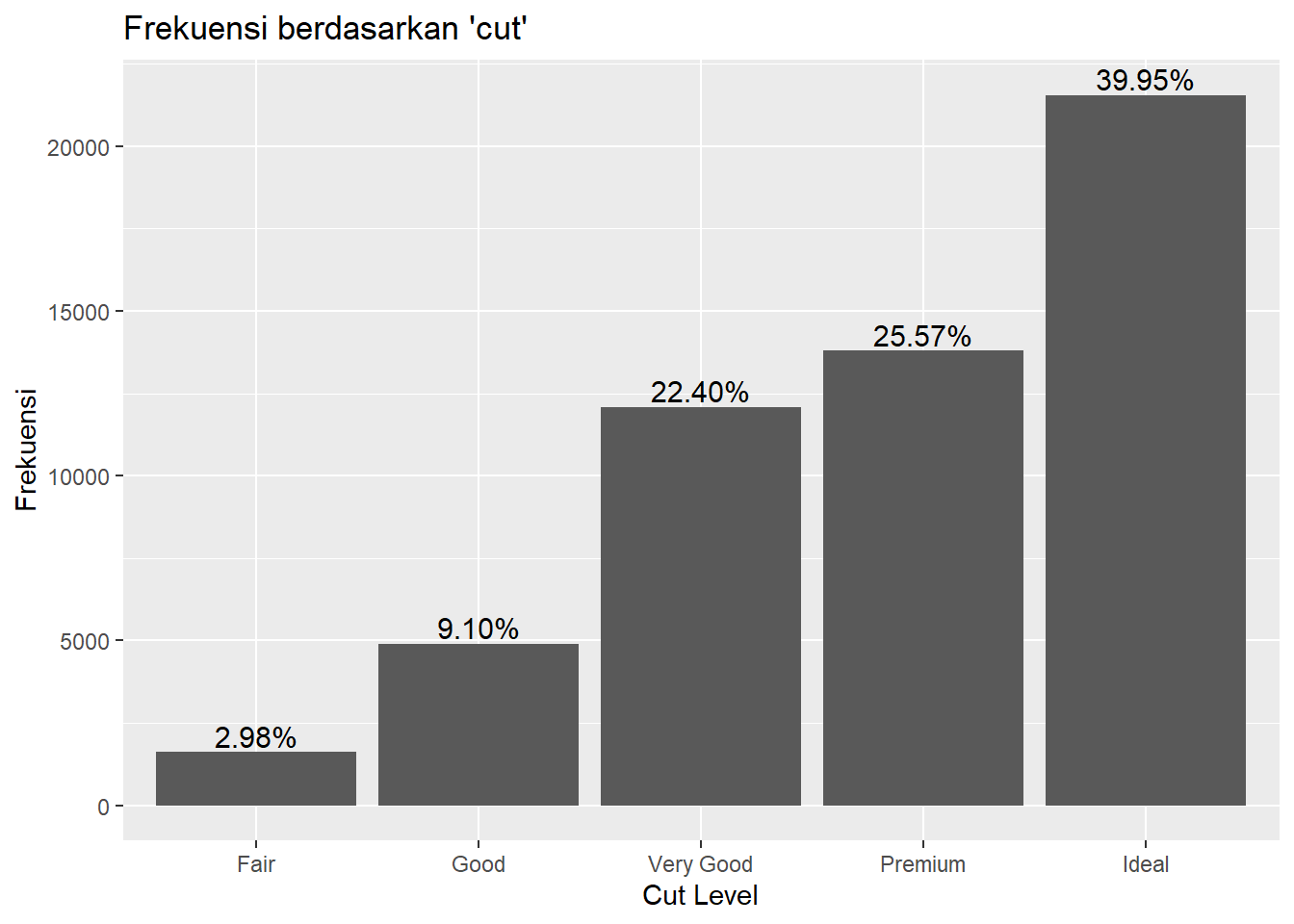
Kita dapat mengatur urutan dari geom, scale, labs, themes, dan lainnya agar lebih rapi. Kita bisa gunakan argumen labels pada scale_*_continuous() untuk meberikan format pada nilai sumbu yang kita pilih, dan kita gunakan function comma untuk format pemisah ribuan menggunakan tanda koma.
ggplot(data = freqtab, mapping = aes(x = Var1, y = Freq)) +
geom_col() +
geom_text(
aes(label = percent(persen, accuracy = 0.01)),
vjust = -0.25, size = 4) +
scale_y_continuous(labels = comma) +
labs(title = "Frekuensi berdasarkan 'cut'",
x = "Cut Level",
y = "Frekuensi") +
theme(legend.position = "none")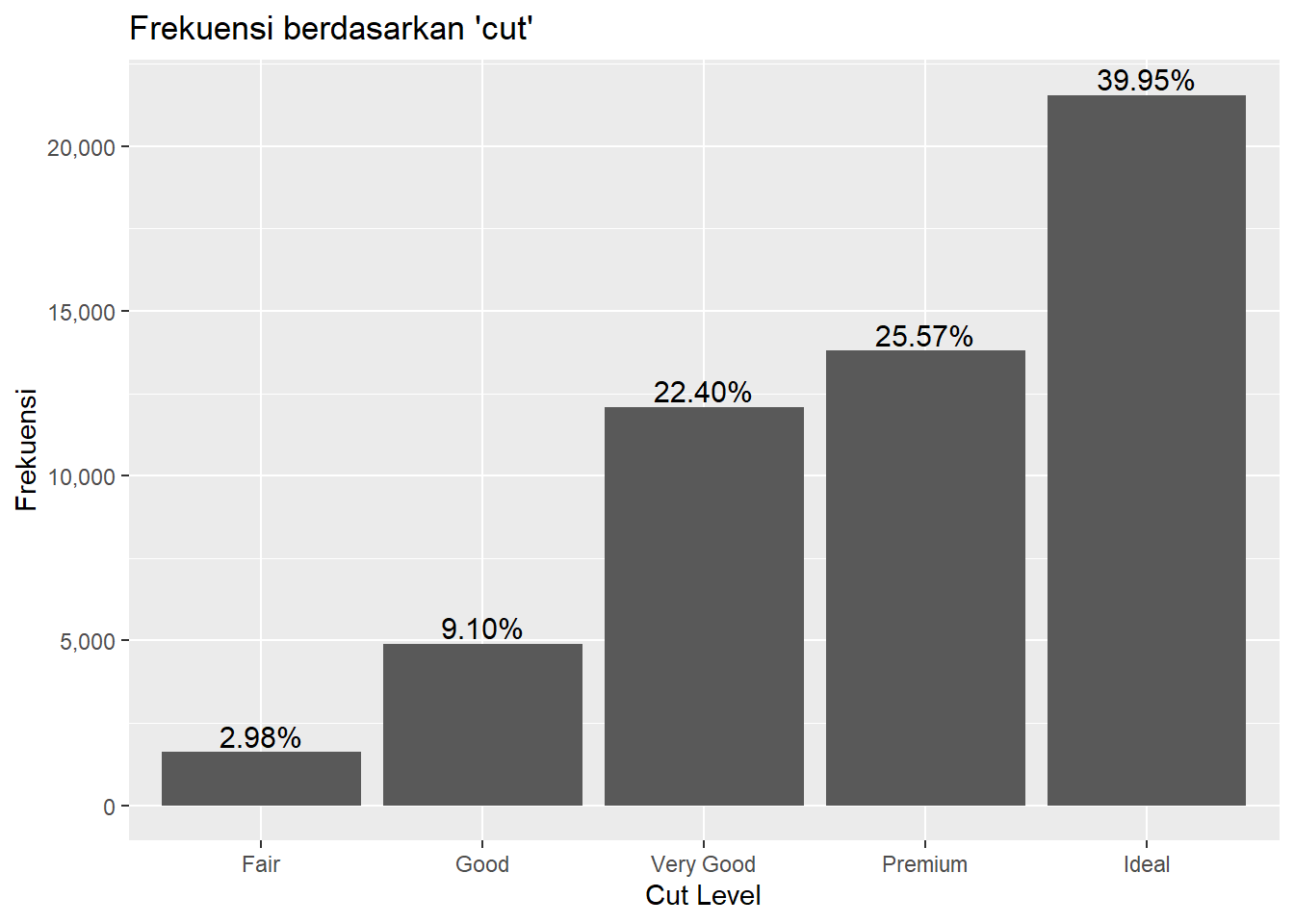
6.3.3 Histogram & Density
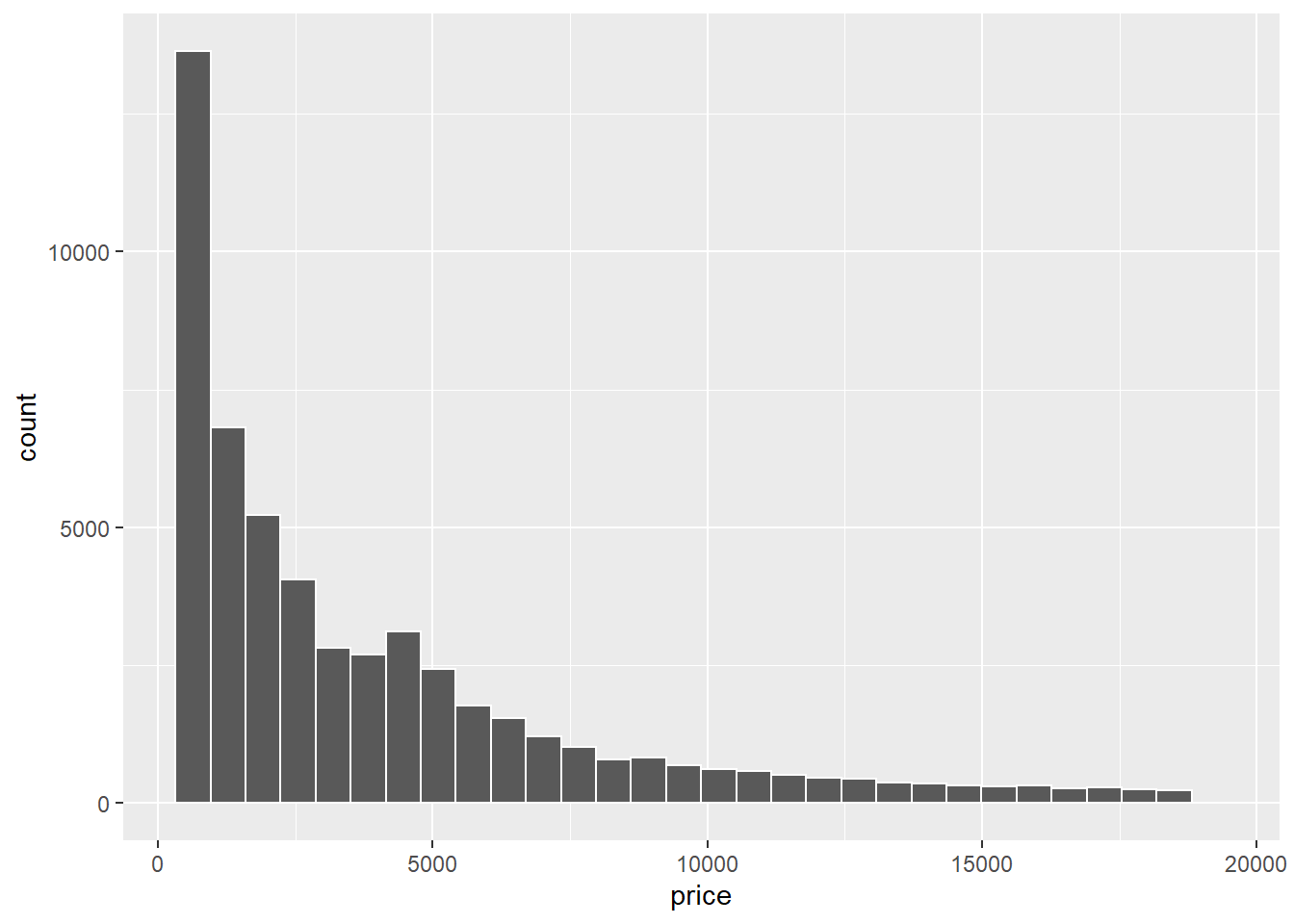
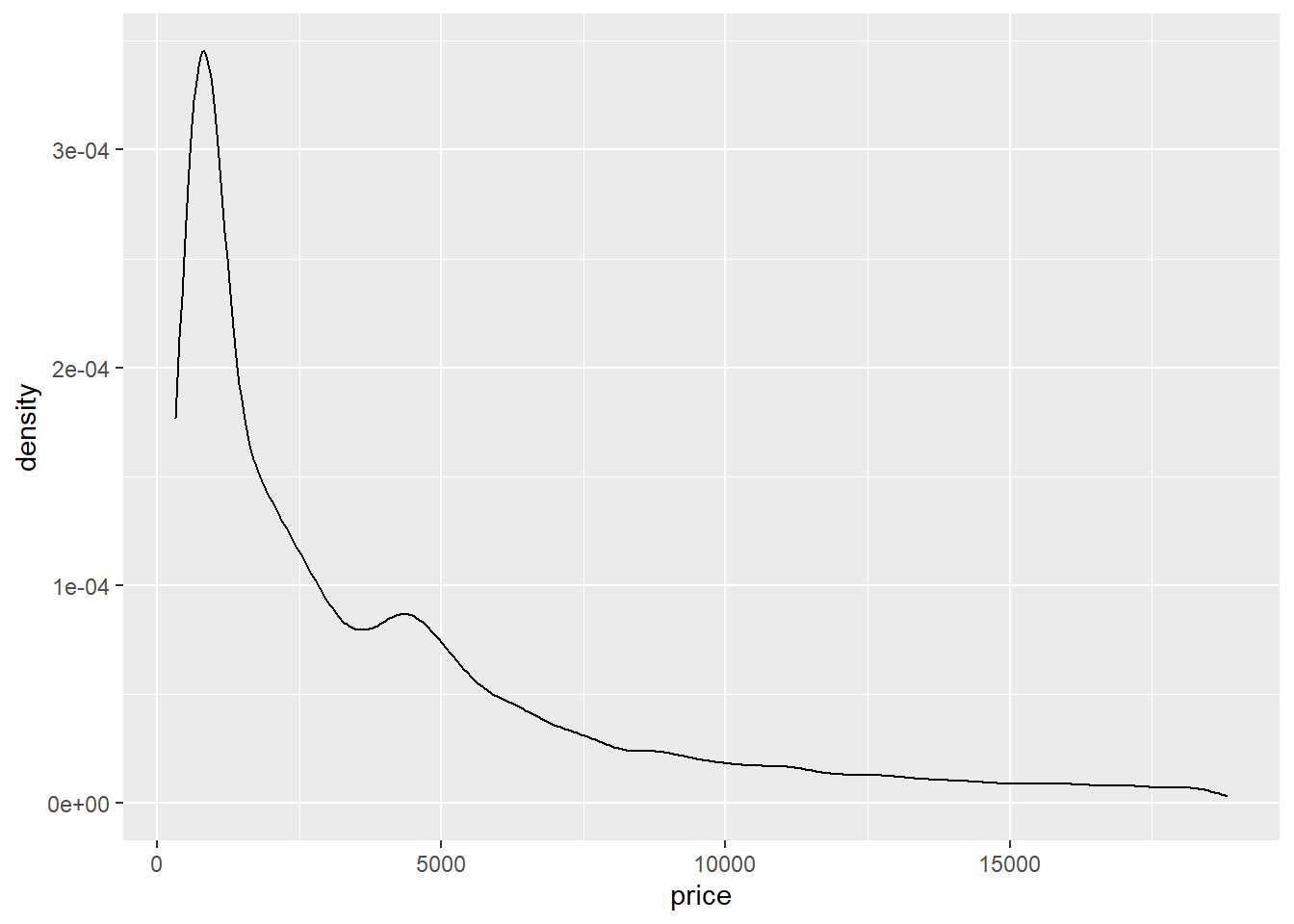
Untuk membuat histogram menggunakan package {ggplot2} Anda dapat gunakan geom_histogram(). Variable yang digunakan adalah sebuah variable numerik. Misalnya kita gunakan variable price pada data diamonds.
ggplot(data = diamonds, mapping = aes(x = price)) +
geom_histogram()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.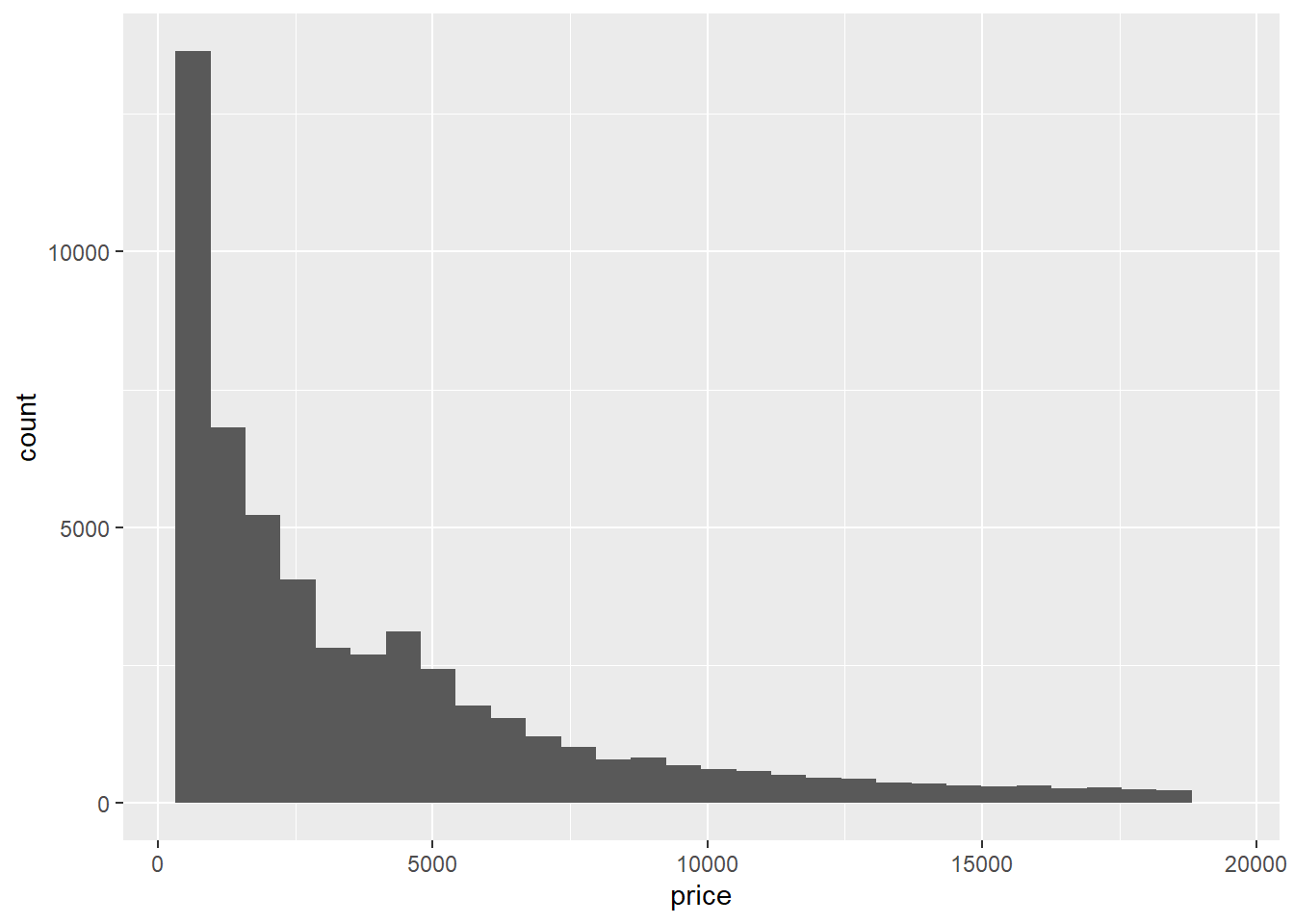
Secara defaut, geom_histogram() menggunakan 30 bins (batang). Oleh karena itu geom_histogram() akan memberikan message (bukan warning atau error) yang memberitahukan bahwa nilai bins yang digunakan adalah 30. Anda dapat mengganti nilai bins tersebut dengan menambahkan argumen bins = 50 jika Anda ingin histogram yang dibuat mempunyai 50 bin.
ggplot(data = diamonds, mapping = aes(x = price)) +
geom_histogram(bins = 50)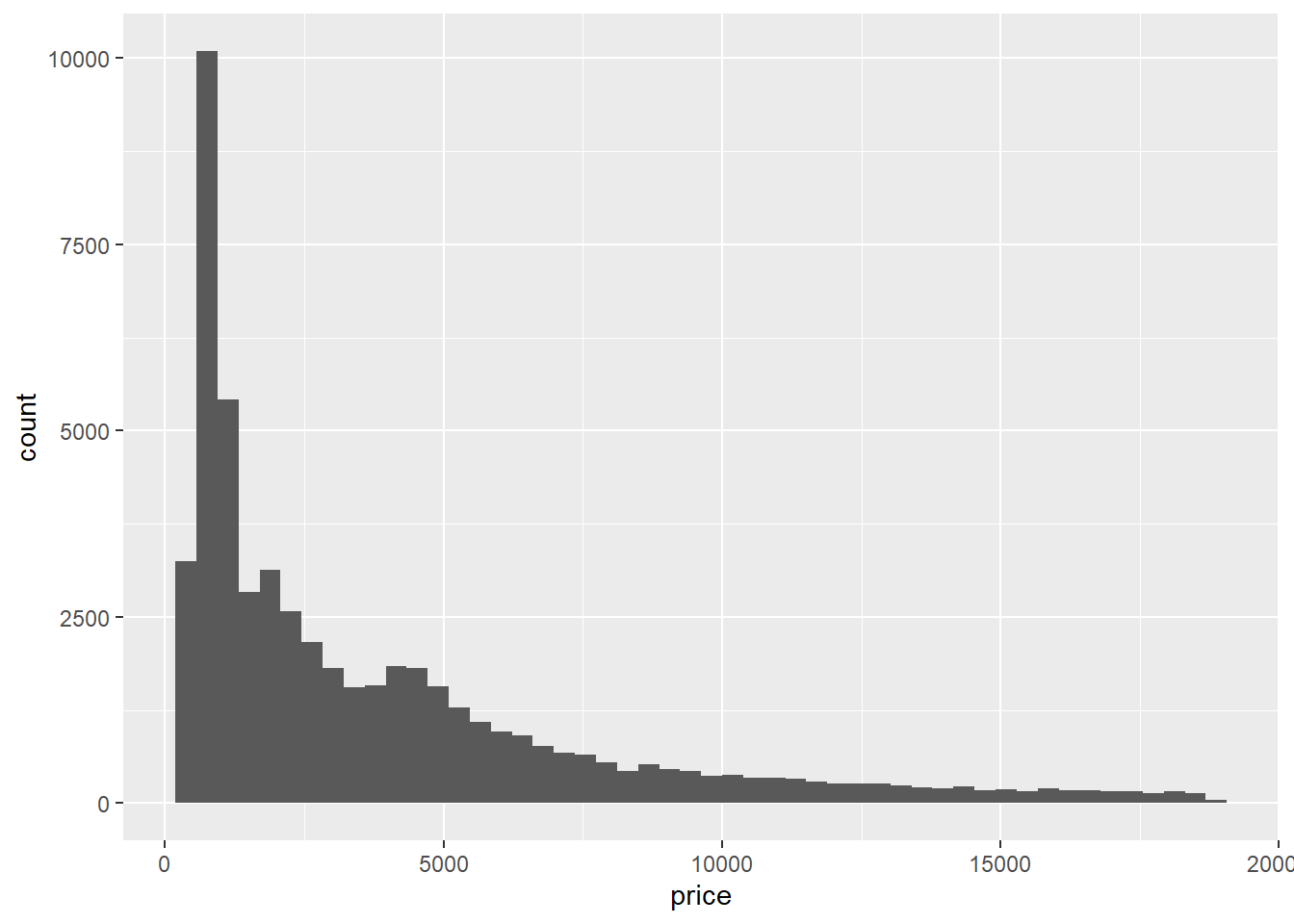
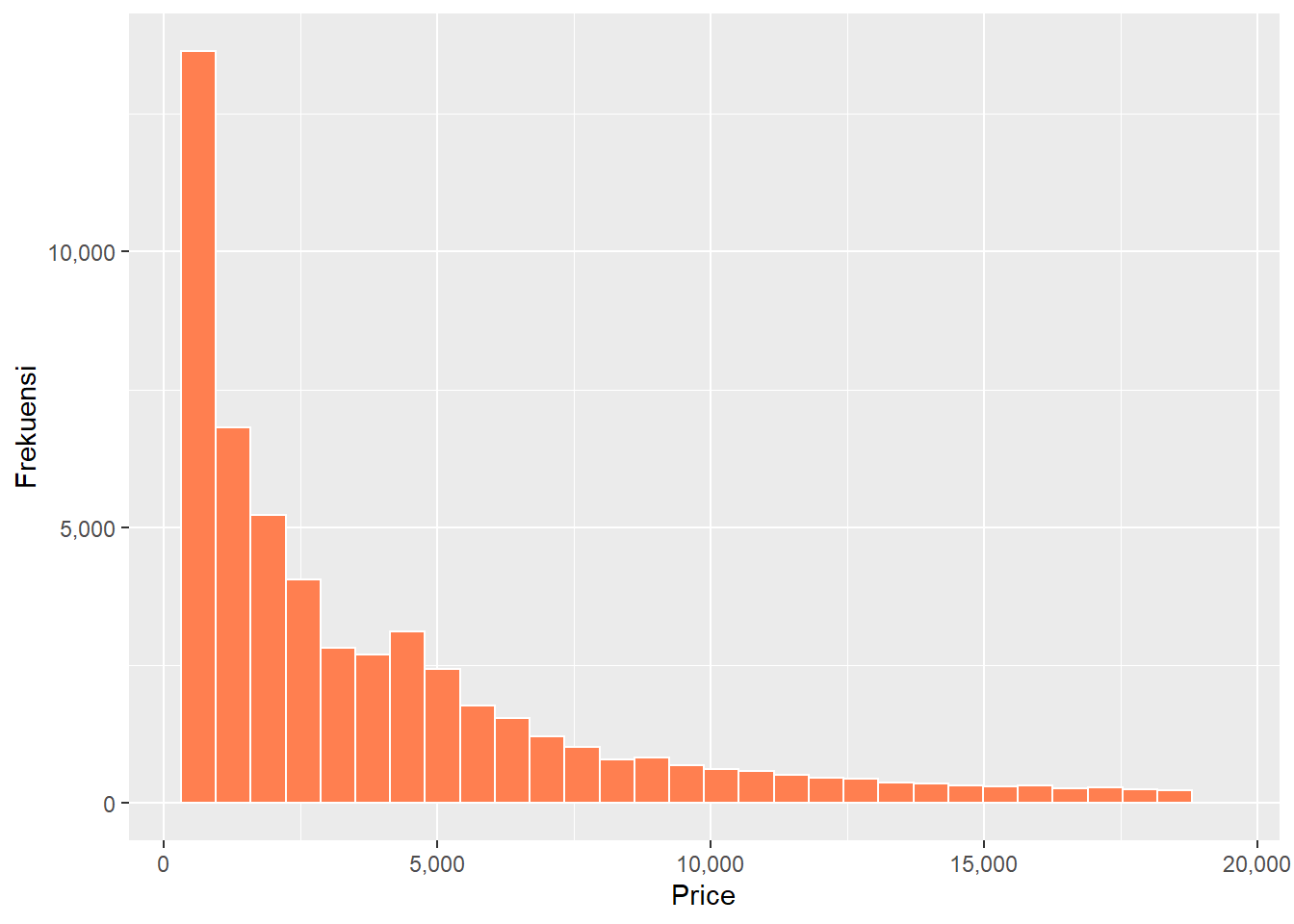
Berikutnya Anda dapat memberikan warna pemisah antar batang. Misalnya untuk memberikan pemisah dengan warna putih Anda dapat tambahkan argumen color = "white".
ggplot(data = diamonds, mapping = aes(x = price)) +
geom_histogram(bins = 30, color = "white") Argumen
Argumen color digunakan untuk warna garis pemisah, sedangkan untuk mengubah warna batang Anda dapat gunakan argumen fill.
ggplot(data = diamonds, mapping = aes(x = price)) +
geom_histogram(bins = 30, color = "white", fill = "coral")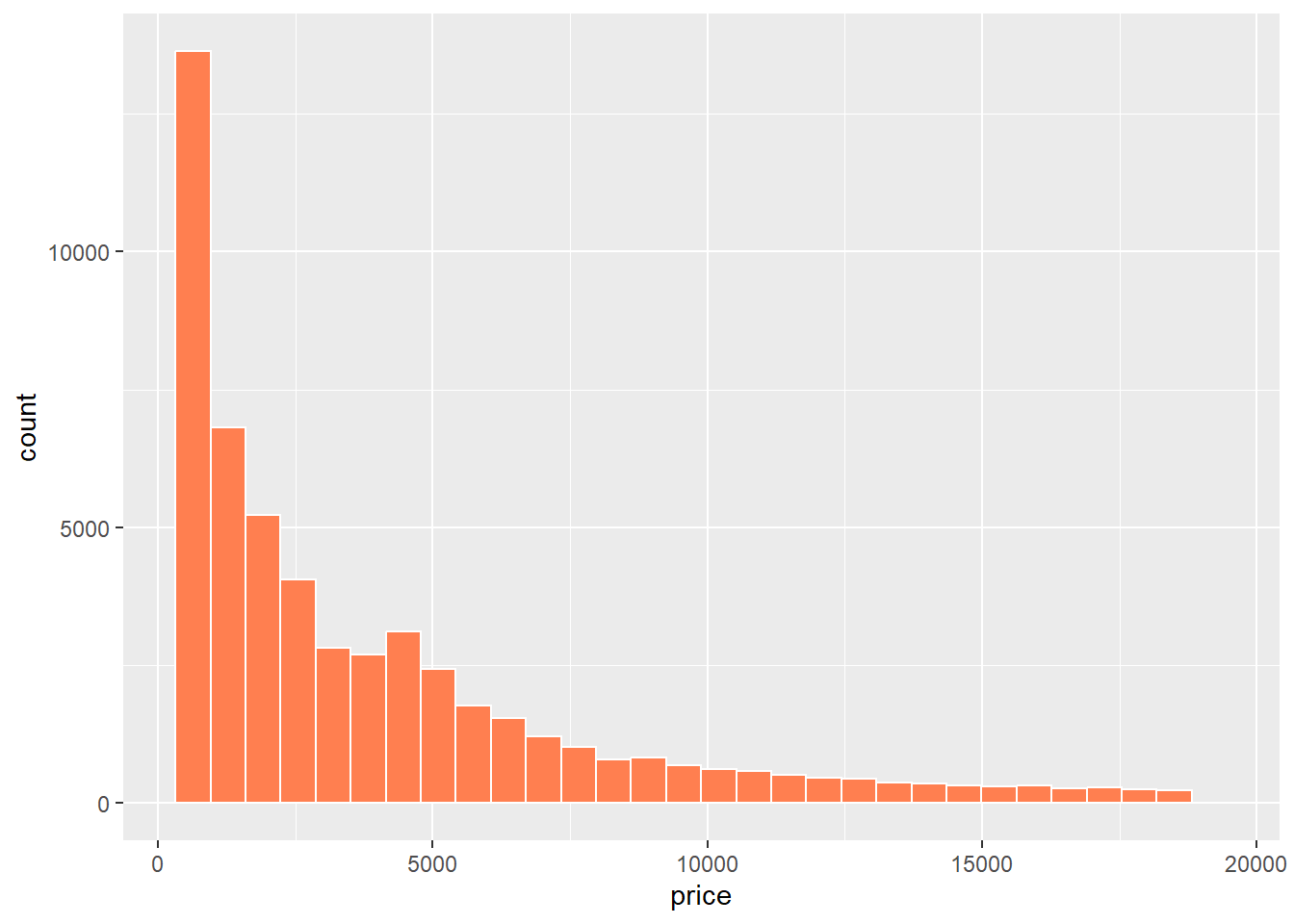
Kita juga dapat mengubah format penulisan nilai pada sumbu x dan y. Karena keduanya merupakan nilai numerik, kita dapat gunakan function scale_x_continuous() untuk sumbu x dan scale_y_continuous() untuk sumbu y. Misalnya kita ingin membuat format penulisan nilai di kedua sumbu tersebut sebagai numerik yang dipisahkan dengan tanda koma (,) sebagai pemisah ribuan. Setelah itu kita tambahkan judul untuk masing-masing sumbu menggunakan function labs().
ggplot(data = diamonds, mapping = aes(x = price)) +
geom_histogram(bins = 30, color = "white", fill = "coral") +
scale_x_continuous(labels = comma) +
scale_y_continuous(labels = comma) +
labs(x = "Price",
y = "Frekuensi")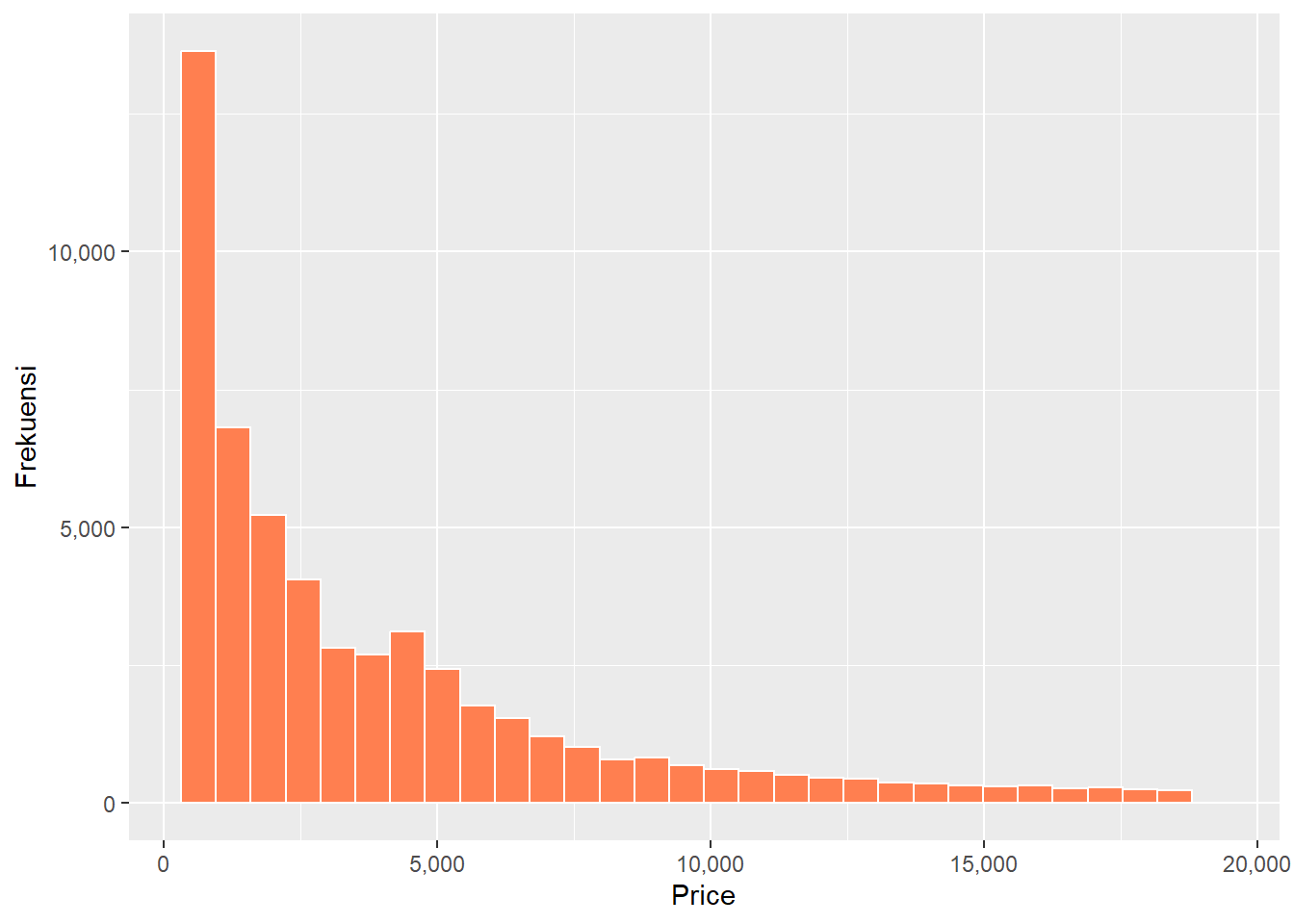
Untuk membuat density plot menggunakan ggplot2 kita cukup menggunakan function geom_density(). Sama halnya dengan geom_histogram(), setelah menuliskan data yang akan digunakan untuk analisis pembuatan density plot dan menuliskan variabel yang akan digunakan di bagian mapping aesthetic, kita dapat menambahan kan geom_density() setelah tanda +.
ggplot(data = diamonds, mapping = aes(x = price)) +
geom_density()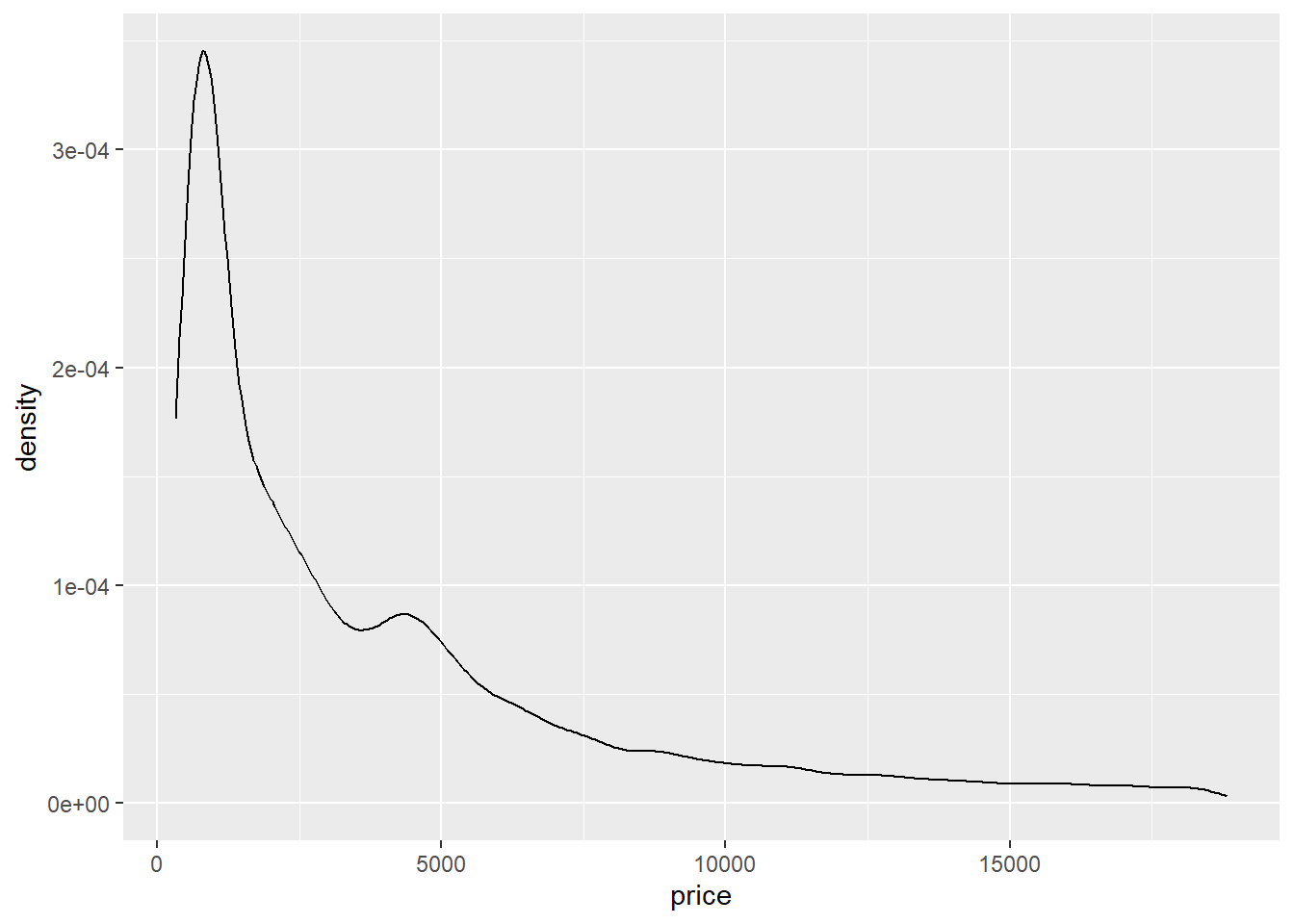
Untuk mengatur warna, transaparansi, dan properti lainnya dari geom_density() dapat dilakukan seperti pada geom_histogram(). Perbedaan antara geom_density() dan geom_histogram() adalah kita tidak menggunakan argumen bins atau binwidth di geom_density() .
ggplot(data = diamonds, mapping = aes(x = price)) +
geom_density(fill = "coral", alpha = 0.7) +
scale_x_continuous(labels = comma) +
scale_y_continuous(labels = comma) +
labs(x = "Price")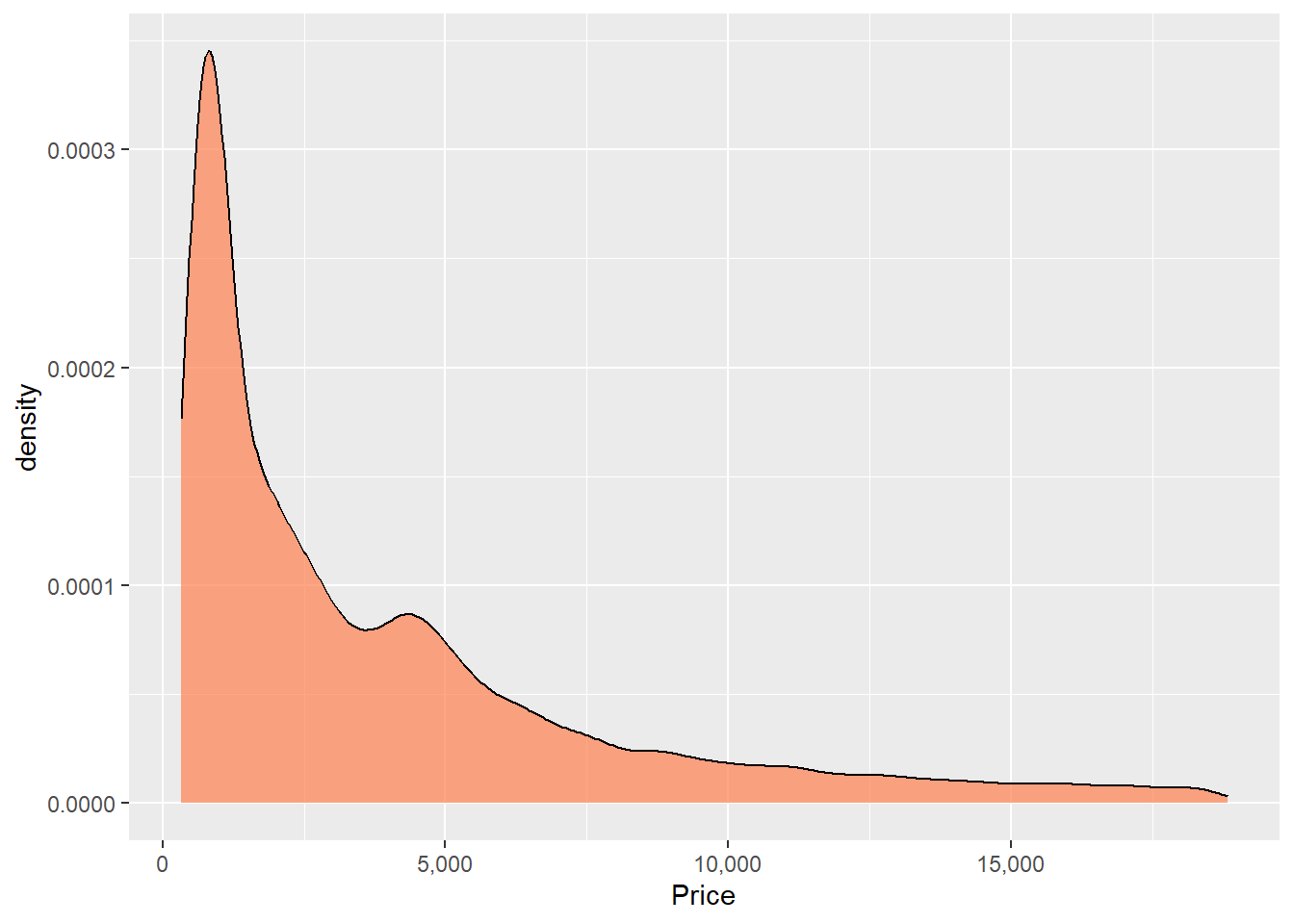
Kita juga dapat membandingkan sebaran menggunakan density plot berdasarkan kategori.
ggplot(data = diamonds, mapping = aes(x = price, fill = cut, color = cut)) +
geom_density(alpha = 0.7) +
scale_x_continuous(labels = comma) +
scale_y_continuous(labels = comma) +
labs(x = "Price")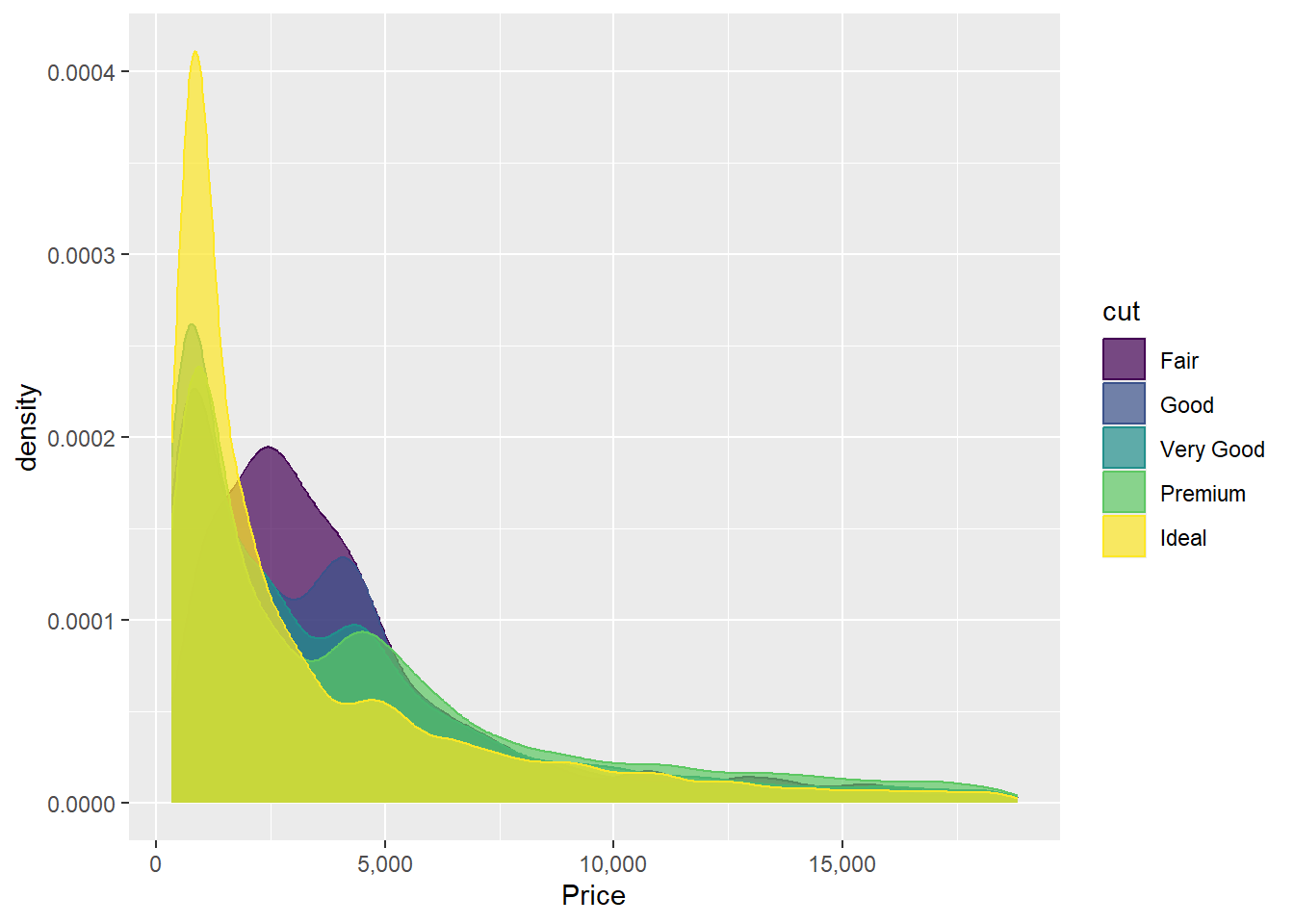
6.3.4 Boxplot
Sekarang mari kita buat boxplot untuk melihat bentuk sebaran data numerik berdasarkan nilai kuartilnya. Untuk membuat boxplot di ggplot2 kita dapat gunakan function geom_boxplot().
ggplot(data = diamonds, mapping = aes(x = price)) +
geom_boxplot()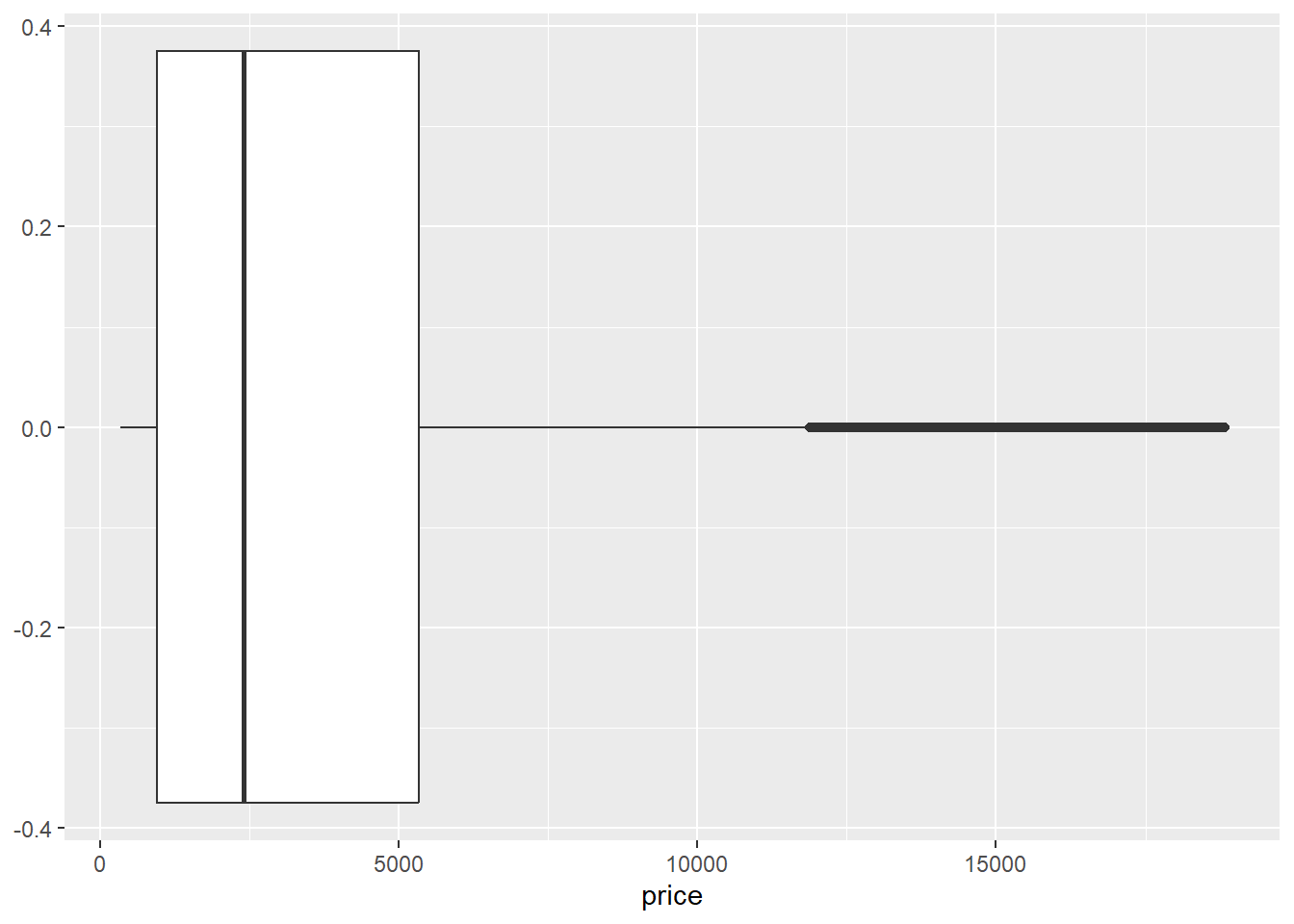
Berikutnya kita dapat membuat boxplot dari data numerik dan membandingkan sebarannya berdasarkan kategori dari sebuah variabel kategorik. Misalnya kita ingin membandingkan sebaran harga berlian (price) berdasarkan tingkat warna (color).
ggplot(data = diamonds, mapping = aes(x = price, y = color)) +
geom_boxplot()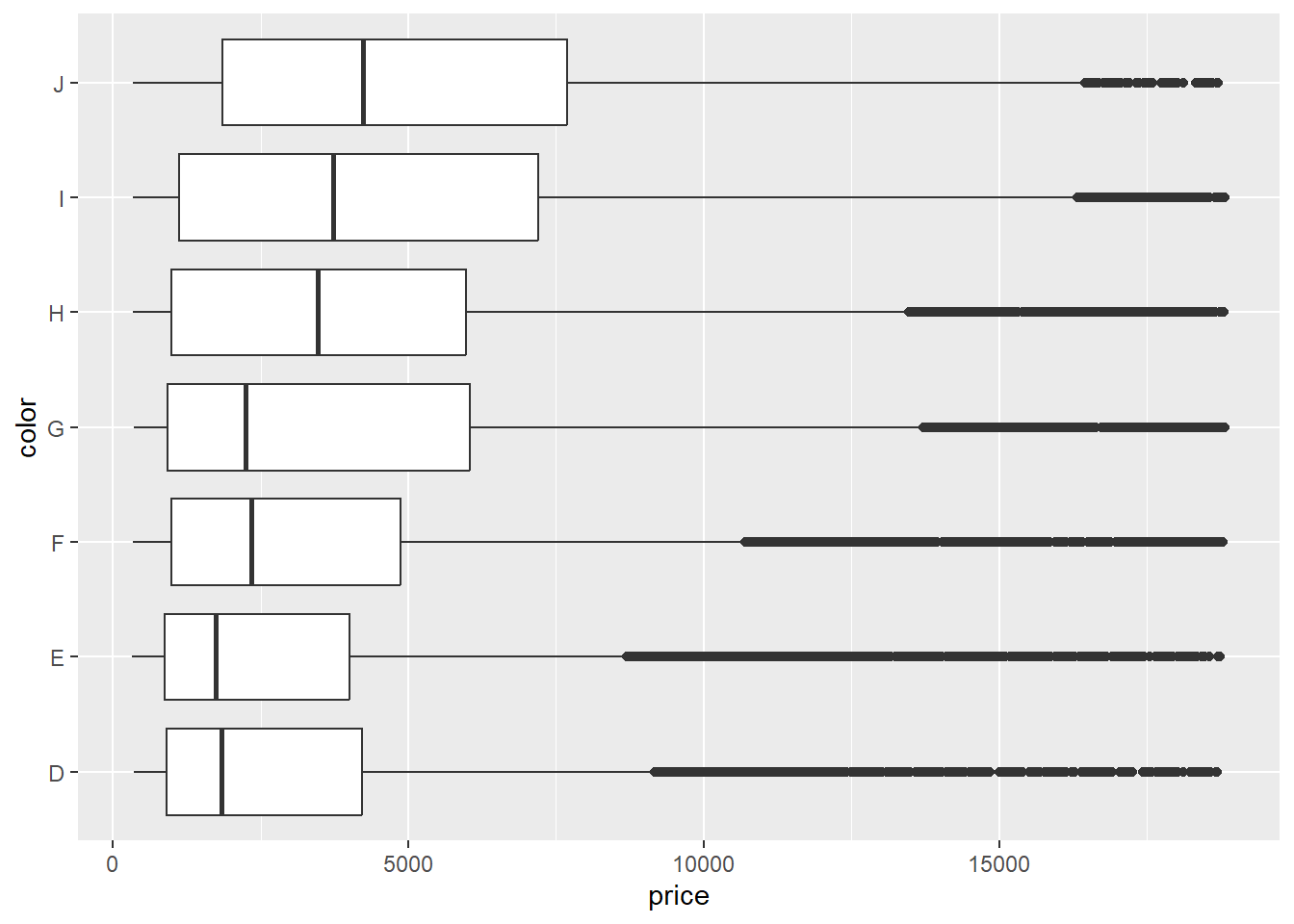
Jika ingin memberi warna berbeda untuk setiap kotak berdasarkan kategorinya kita dapat menambahkan argumen fill dengan nilai berupa nama variabel dari kategori yang ingin kita gunkan untuk perbandingan boxplot. Misalnya kita ingin membandingkan sebaran dari variabel harga berlian (price) berdasarkan warnanya (color) menggunakan boxplot dan menyesuaikan warnanya berdasarkan kategori dari color. Untuk menghilangkan legend dari color kita dapat tambahkan theme(legend.position = "none").
ggplot(data = diamonds, mapping = aes(x = carat, y = color, fill = color)) +
geom_boxplot() +
theme(legend.position = "none")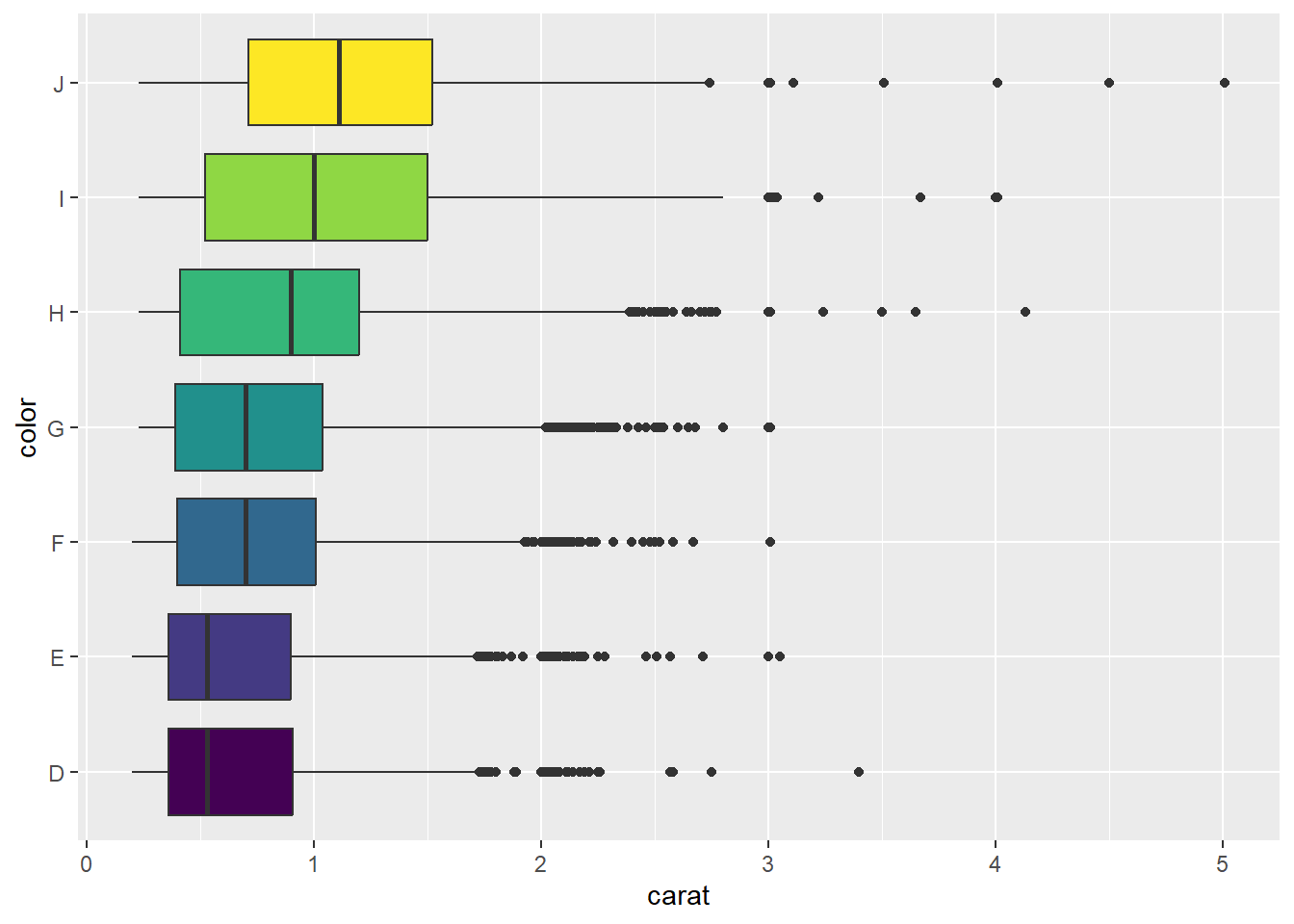
6.3.5 Scatter plot
Untuk membuat scatter plot menggunakan ggplot2 kita dapat menggunakan geom_point(). Variabel yang digunakan pada bagian aes() adalah dua buah variabel numerik untuk x dan y. Misalnya kita ingin melihat pola tebaran antara carat dan price.
ggplot(data = diamonds, mapping = aes(x = carat, y = price)) +
geom_point()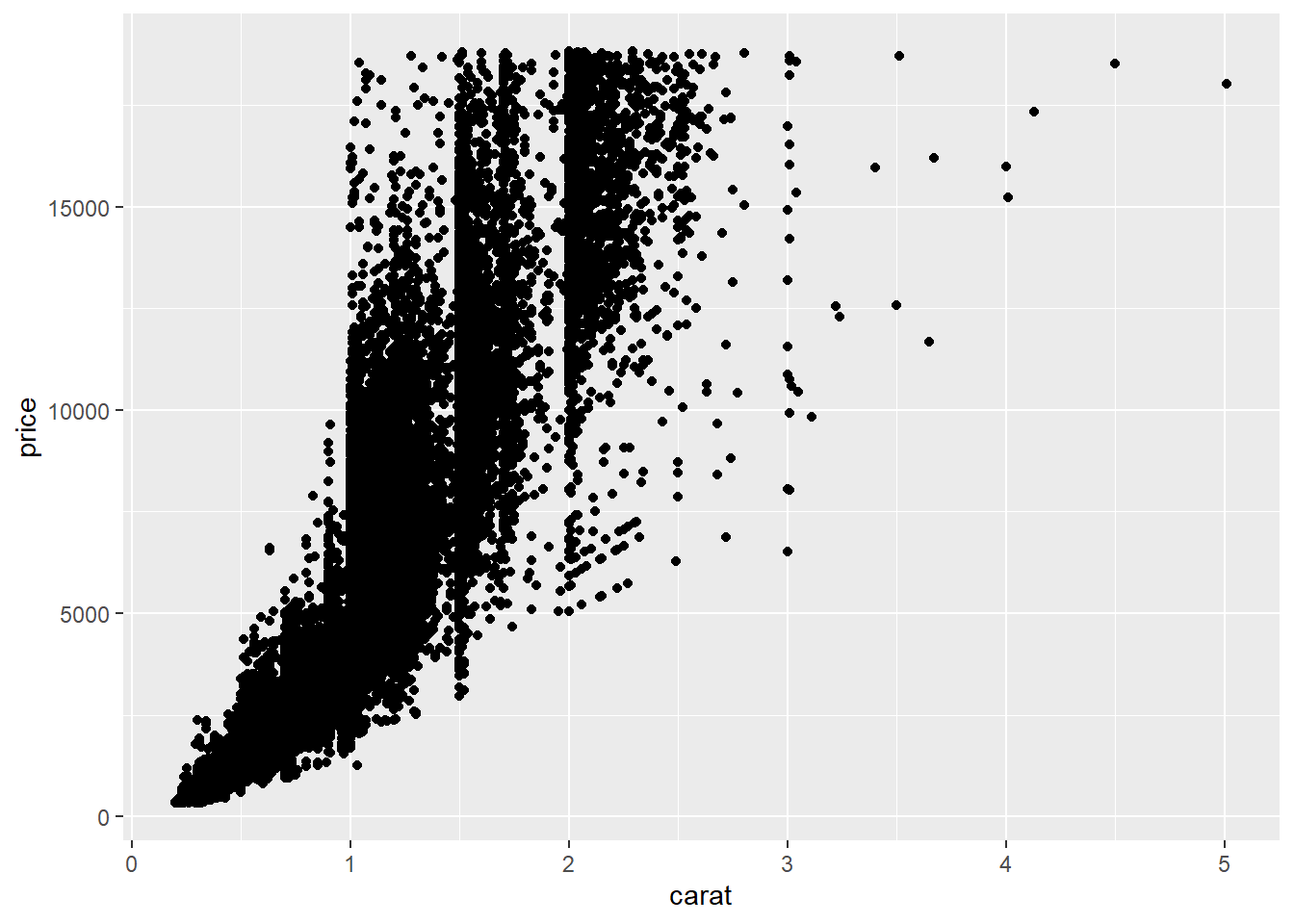
Kita juga dapat memberikan warna untuk setiap titik. Misalnya warna masing-masing titik menyesuaikan dengan kategori pada bvariabel cut.
ggplot(data = diamonds, mapping = aes(x = carat, y = price, color = cut)) +
geom_point()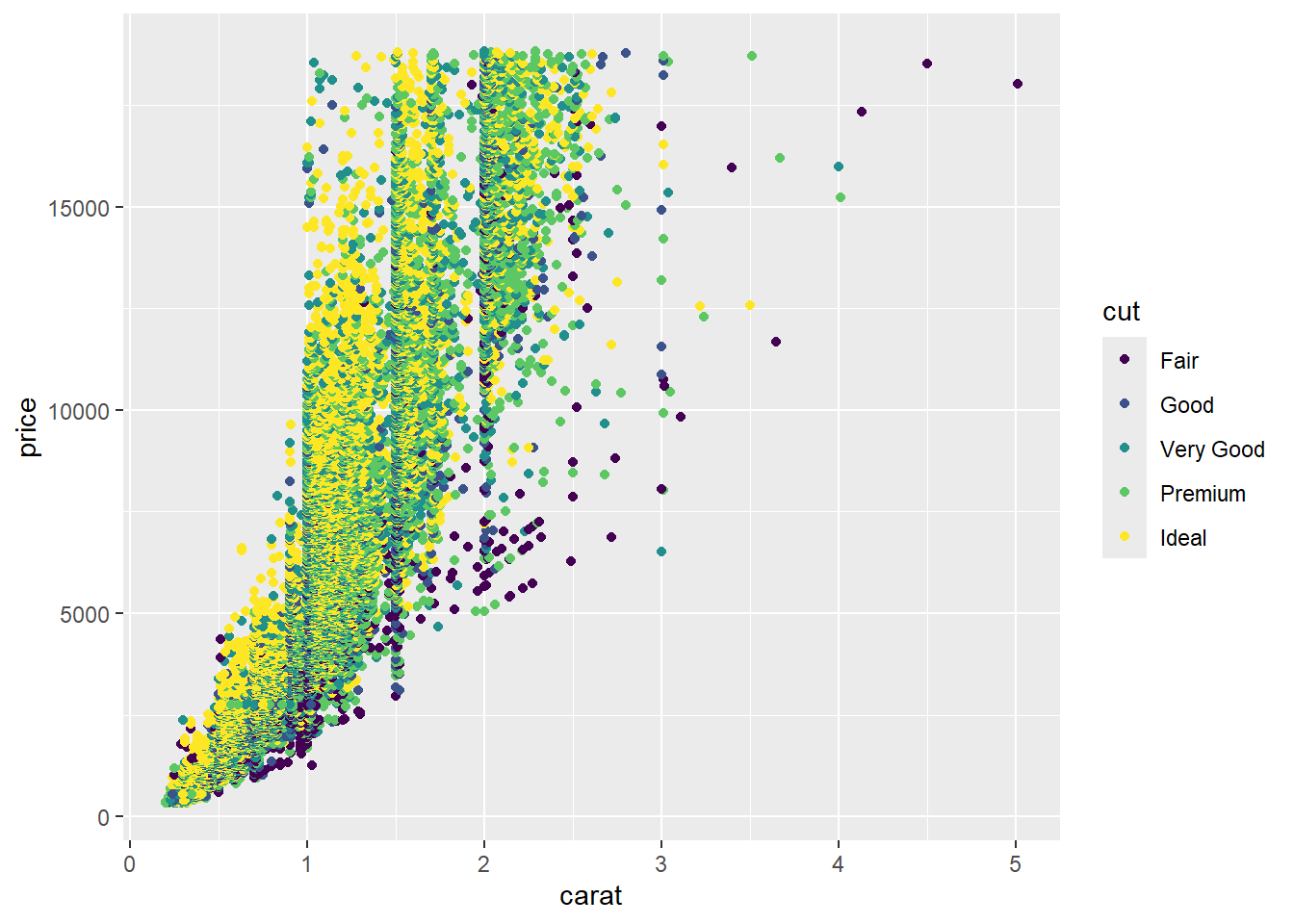
6.3.6 Line chart
Pada bagian pertama, kita membuat line chart menggunakan dataset linedata yang terdiri dari 100 observasi. Kita perlu membuat data ini terlebih dahulu karena data diamonds tidak memiliki variabel yang dapat digunakan sebagai indeks pada line chart. Variabel x mewakili indeks dari 1 hingga 100, sedangkan variabel y dihasilkan secara acak dengan distribusi normal yang memiliki mean 100 dan standar deviasi 12. Variabel y yang nantinya ditempatkan di sumbu y.
set.seed(1001)
linedata <- data.frame(x = 1:100,
y = rnorm(100, mean = 100, 12))
head(linedata)## x y
## 1 1 126.26378
## 2 2 97.86943
## 3 3 97.77670
## 4 4 69.92157
## 5 5 93.31226
## 6 6 98.27729Grafik pertama menampilkan garis yang menghubungkan titik-titik data dengan geom_line(), sementara grafik kedua menambahkan garis smoothing (geom_smooth()) untuk melihat tren atau pola umum dari data. Garis smoothing ini membantu mengidentifikasi apakah ada kecenderungan tertentu dalam data, seperti peningkatan atau penurunan seiring waktu.
ggplot(data = linedata, mapping = aes(x = x, y = y)) +
geom_line() +
geom_smooth()## `geom_smooth()` using method = 'loess' and formula = 'y ~ x'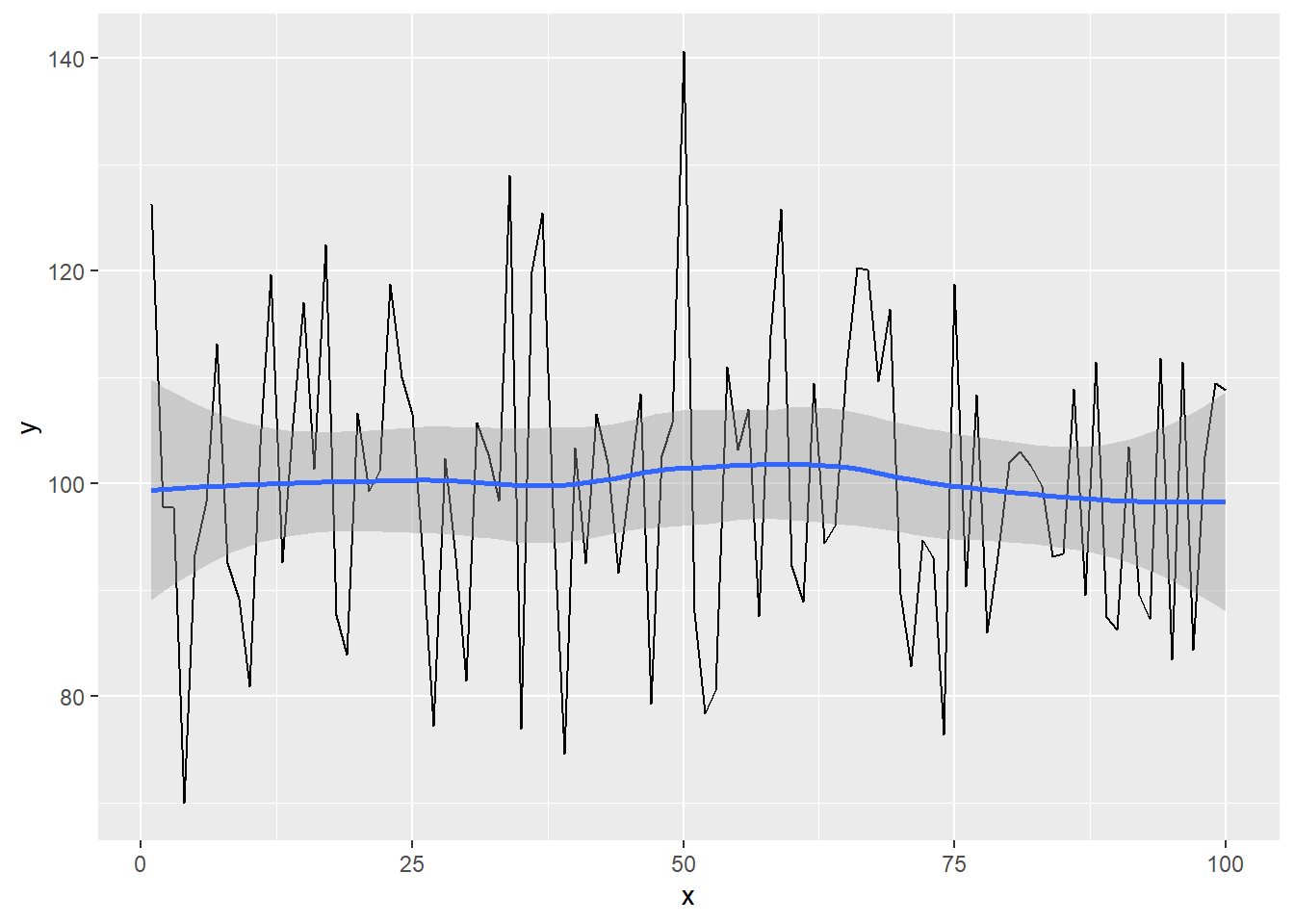
6.3.7 Faceting
Selanjutnya, kita menggunakan dataset diamonds untuk membuat visualisasi dengan teknik faceting. Faceting memungkinkan kita membagi data menjadi beberapa subplot berdasarkan kategori tertentu. Pada contoh pertama, kita membuat bar chart yang menunjukkan sebaran clarity (tingkat kejernihan berlian) untuk setiap kategori cut (potongan berlian). Ini membantu membandingkan distribusi kejernihan berlian di antara berbagai jenis potongan.
ggplot(diamonds, aes(x = clarity)) +
geom_bar() +
facet_wrap(~cut)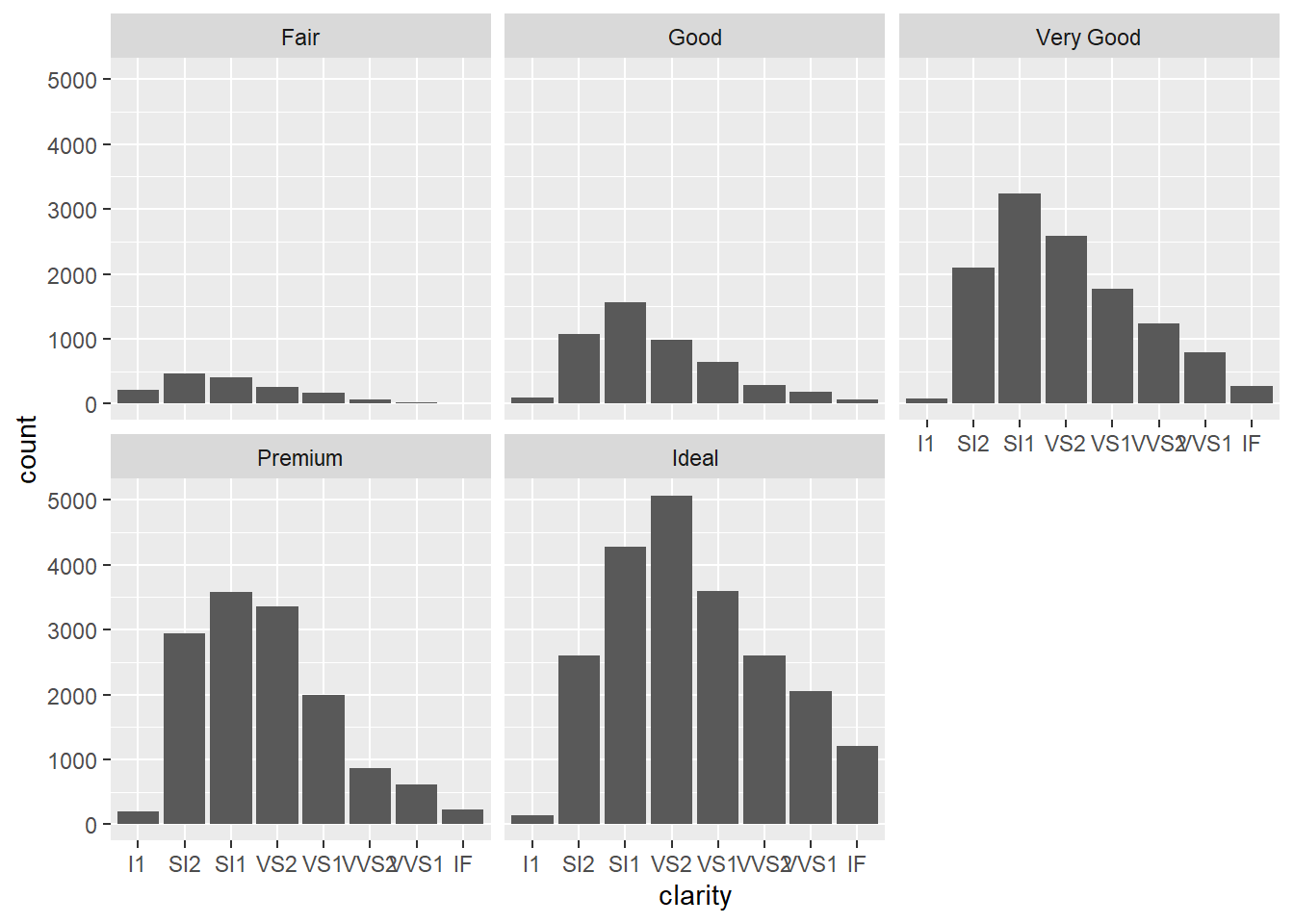
Pada contoh kedua, kita membuat histogram untuk variabel price (harga) yang juga difacet berdasarkan cut. Hal ini memungkinkan kita melihat sebaran harga berlian untuk setiap kategori potongan.
ggplot(diamonds, aes(x = price)) +
geom_histogram() +
facet_wrap(~cut)## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.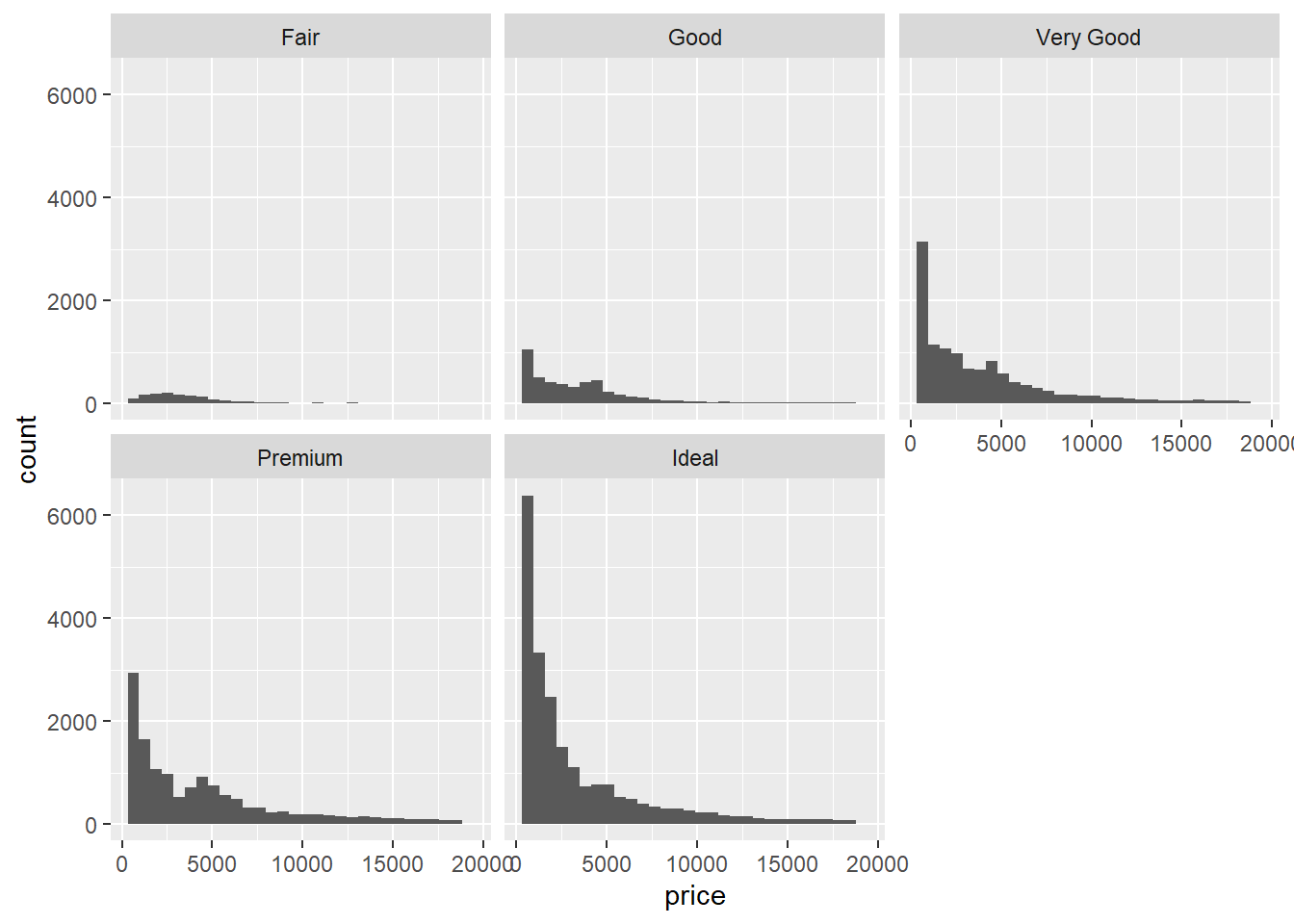
Selanjutnya, kita membuat scatter plot yang menunjukkan hubungan antara carat (berat berlian) dan price (harga), dengan warna titik yang berbeda berdasarkan cut. Faceting digunakan untuk memisahkan scatter plot ini berdasarkan kategori cut, sehingga kita dapat melihat pola hubungan antara berat dan harga untuk setiap jenis potongan.
ggplot(data = diamonds, mapping = aes(x = carat, y = price, color = cut)) +
geom_point() +
facet_wrap(~cut) +
theme(legend.position = "none")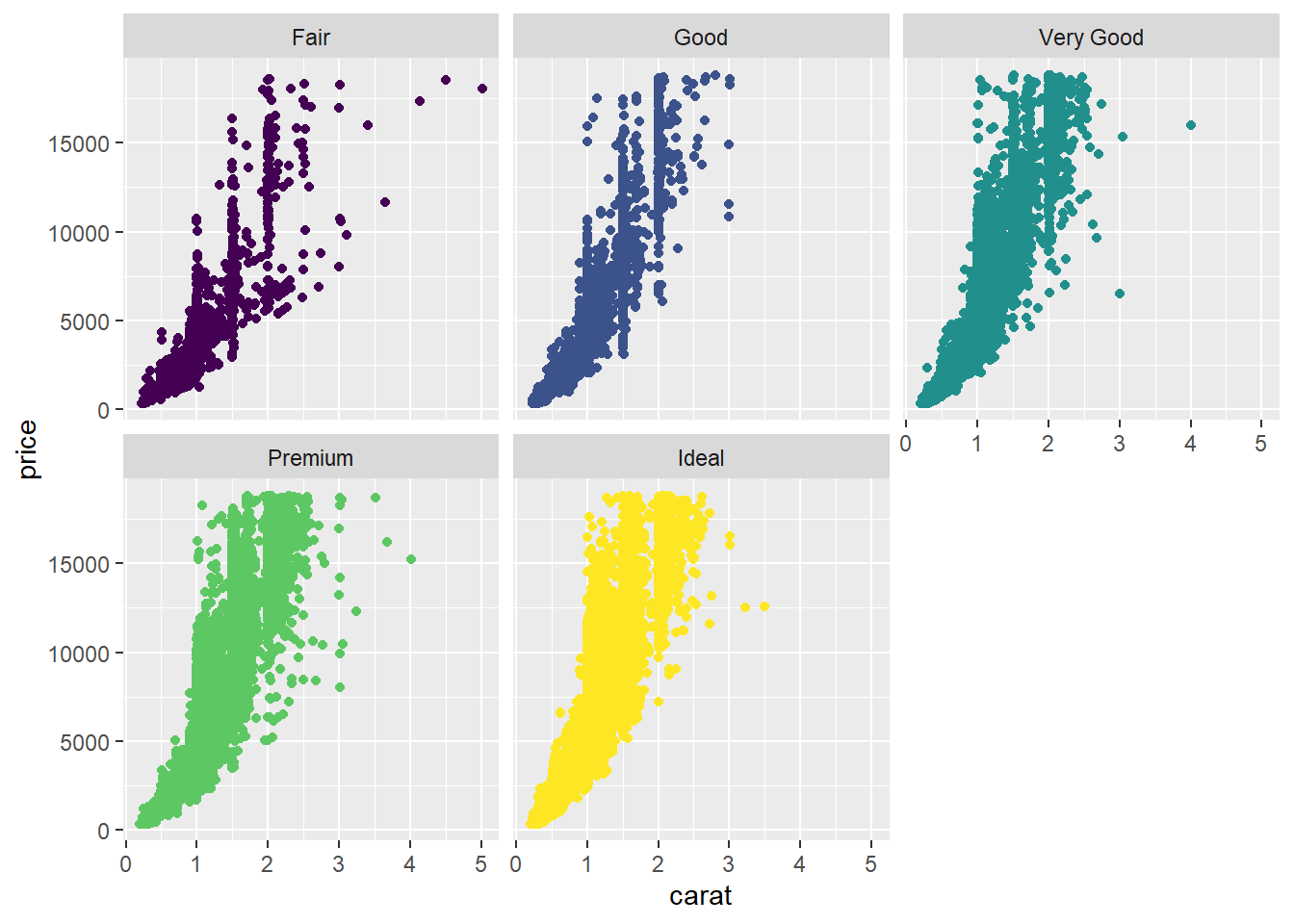
6.3.8 Annotation dan Theme
Pada bagian terakhir ini, kita fokus pada annotation dan theme untuk meningkatkan tampilan visualisasi. Kita akan membuat bar chart yang menampilkan frekuensi dari setiap level cut pada dataframe diamonds. Grafik yang kita buat ini dilengkapi dengan teks yang menunjukkan persentase frekuensi di atas setiap bar dengan geom_text(), sehingga informasi menjadi lebih jelas. Selain itu, kita mencoba berbagai tema seperti theme_grey(), theme_classic(), theme_dark(), theme_minimal(), dan theme_stata() dari package ggthemes. Setiap tema memberikan tampilan yang berbeda, mulai dari yang sederhana hingga yang lebih modern, sehingga kita dapat memilih tema yang paling sesuai dengan kebutuhan visualisasi. Penghapusan legenda dengan theme(legend.position = "none") juga dilakukan untuk menyederhanakan tampilan grafik.
library(ggplot2)
library(scales)
ggplot(data = freqtab, mapping = aes(x = Var1, y = Freq)) +
geom_col() +
geom_text(
aes(label = percent(persen, accuracy = 0.01)),
vjust = -0.25, size = 4) +
scale_y_continuous(labels = comma) +
labs(title = "Frekuensi berdasarkan 'cut'",
x = "Cut Level",
y = "Frekuensi") +
theme_grey() 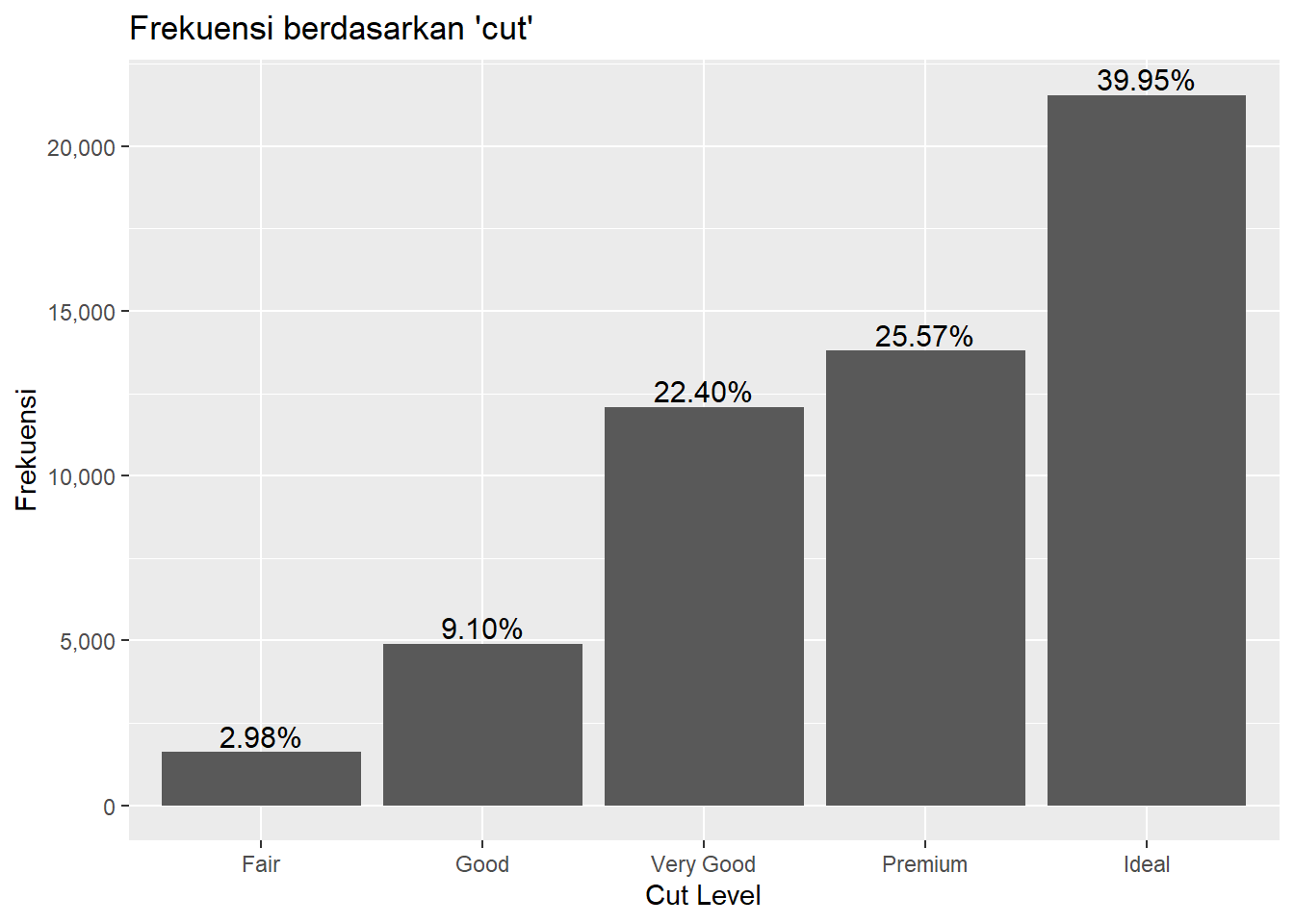
ggplot(data = freqtab, mapping = aes(x = Var1, y = Freq)) +
geom_col() +
geom_text(
aes(label = percent(persen, accuracy = 0.01)),
vjust = -0.25, size = 4) +
scale_y_continuous(labels = comma) +
labs(title = "Frekuensi berdasarkan 'cut'",
x = "Cut Level",
y = "Frekuensi") +
theme_classic() 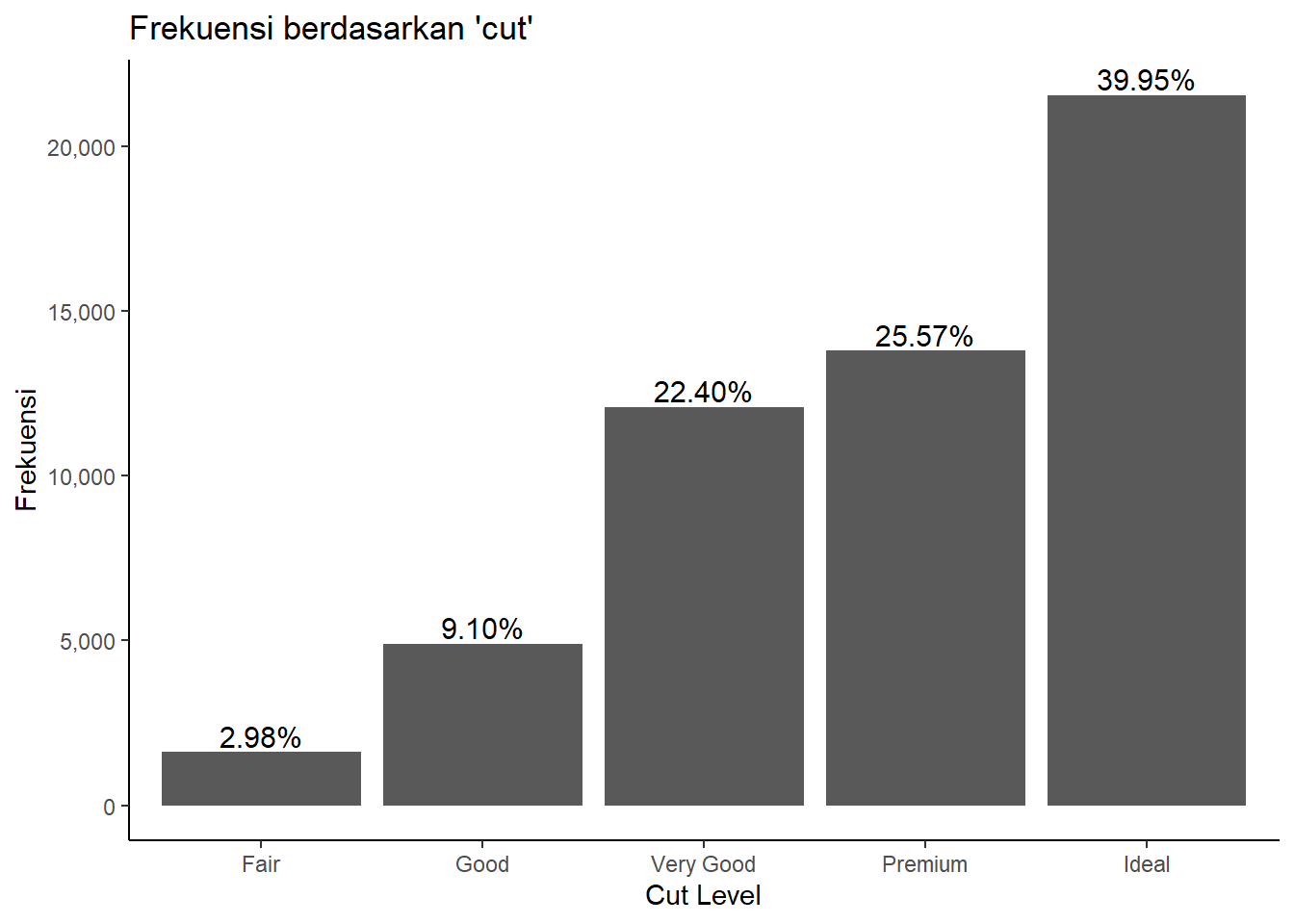
ggplot(data = freqtab, mapping = aes(x = Var1, y = Freq)) +
geom_col() +
geom_text(
aes(label = percent(persen, accuracy = 0.01)),
vjust = -0.25, size = 4) +
scale_y_continuous(labels = comma) +
labs(title = "Frekuensi berdasarkan 'cut'",
x = "Cut Level",
y = "Frekuensi") +
theme_dark() 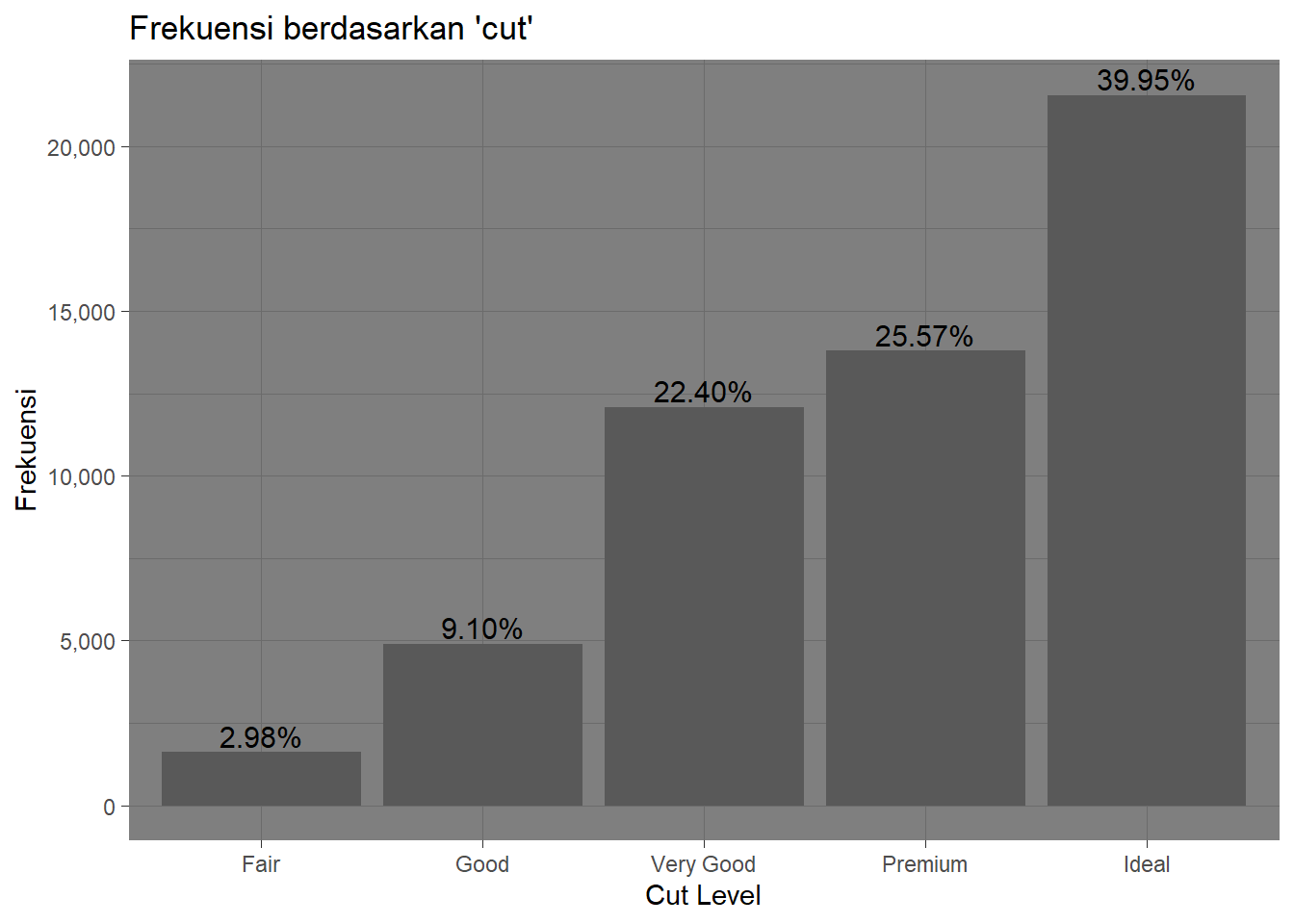
ggplot(data = freqtab, mapping = aes(x = Var1, y = Freq)) +
geom_col() +
geom_text(
aes(label = percent(persen, accuracy = 0.01)),
vjust = -0.25, size = 4) +
scale_y_continuous(labels = comma) +
labs(title = "Frekuensi berdasarkan 'cut'",
x = "Cut Level",
y = "Frekuensi") +
theme_minimal() 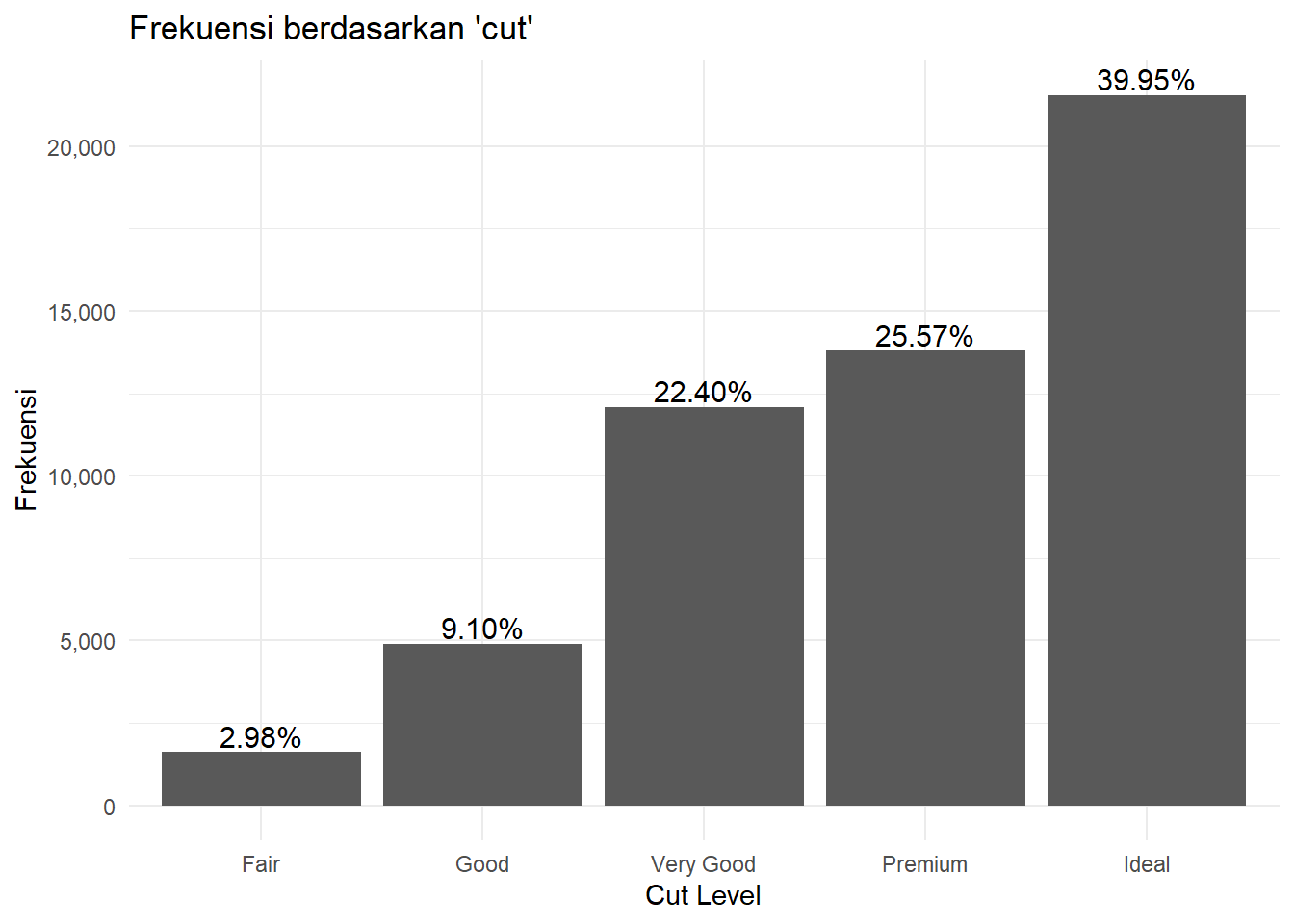
Berikut ini ketika kita menggunakan package {ggthemes}.
library(ggthemes)
ggplot(data = freqtab, mapping = aes(x = Var1, y = Freq)) +
geom_col() +
geom_text(
aes(label = percent(persen, accuracy = 0.01)),
vjust = -0.25, size = 4) +
scale_y_continuous(labels = comma) +
labs(title = "Frekuensi berdasarkan 'cut'",
x = "Cut Level",
y = "Frekuensi") +
ggthemes::theme_stata()