4 When \(\boldsymbol{\beta}\)s vary among groups: multilevel linear model
Multilevel linear model is also known as random coefficients model (RCM), linear mixed model (LMM), and hierarchical linear model (HLM).
4.1 Multilevel data and heterogeneity (non-dependence)
Following are two real data examples.
- Repeated measure design.
The sleepstudy data set in the lme4 packages, containing the average reaction time per day (in milliseconds) for 18 subjects in a sleep deprivation study over 10 days (day 0-day 9):
Overall, the average reaction time increase in days. However, we observe great heterogeneity. If we fitted multiple linear regression to the data of each individual, the resulting regression lines vary markedly in that different subject has different intercepts and slopes. More specifically, we observe wider variation in slopes than in intercepts.
- Hierarchical design: nested in cluster.
Data are from Barcikowski (1981), High School & Beyond Survey, a data set from a nationally representative sample of U.S. public and Catholic high schools. 7185 students nested within 160 schools.
- DV: mathach, math achievement,
- IV:
- ses, social economic status,
- sector, public school vs Catholic school.
- ID, school.
It is clearly shown that different schools have different slopes and intercepts, implying school-level heterogeneity that is completely masked by multiple linear regression.
Heterogeneity sometimes refers to non-dependence. For example, students in the same school share similar environment (same math textbook, same math teacher, same study body, etc.), thus students tend to have math achievement similar to their peers from the same school than those from other school. Put another way, data are independent within school but not independent across school.
So why not fitting multiple linear regression to each group? If so, we wind up with smaller sample size and consequently lower statistical power for each regression models. Multilevel linear model uses all \(n\) observations and takes heterogeneity into account by modeling regression coefficients (intercept and slopes) as random variables. Not surprisingly, multilevel linear model enjoys better model fit due to incorporating underlying heterogeneity of data.
4.2 The basic multilevel linear model
- Random intercept and random slopes
\[\begin{align*}
\text{Level 1: }y_{ij} &= \beta_{0j}+\beta_{1j}x_{1ij}+\cdots+\beta_{pj}x_{pij}+\epsilon_{ij} \\
\text{Level 2: }\beta_{0j} &= \gamma_{00}+u_{0j} \\
\text{Level 2: }\beta_{1j} &= \gamma_{10}+u_{1j} \\
&\cdots\\
\text{Level 2: }\beta_{pj} &= \gamma_{p0}+u_{pj} \\
\text{Mixed: }y_{ij} &= \blue\gamma_{00}+(\gamma_{10}x_{1ij}+\cdots+\gamma_{p0}x_{pij})+\\
&\quad \enspace \red(u_{1j}x_{1ij}+\cdots+u_{pj}x_{pij})+u_{0j}+\epsilon_{ij},
\end{align*}\] where \(\blue\text{blue}\) terms are fixed effects, \(\red\text{red}\) terms are random effects, \(j=1,\cdots,m\) represents grouping variable (i.e., subject in sleepstudy data, and sector in Barcikowsk’s data), \(i=1,\cdots,n_j\) represents observation (i.e., subject) within \(j\)th group, total sample size \(n=n_1+\cdots+n_m\), \(x_1\), \(\cdots\), \(x_p\) are \(p\) independent variables, \(y\) is dependent variable, \(\epsilon_{ij}\sim iid N(0,\sigma^2_{\epsilon})\), \[\begin{align*}
\begin{pmatrix}
u_{0j}\\
u_{1j}\\
\vdots\\
u_{pj}
\end{pmatrix}\sim MVN(\bs{0},\bSigma_{\bs{u}}),\bSigma_{\bs{u}}=\begin{bmatrix}
\sigma^2_{u_{0j}} & & & \\
\sigma_{u_{1j},u_{0j}} & \sigma^2_{u_{1j}} & & \\
\vdots & \vdots & \ddots & \\
\sigma_{u_{pj},u_{0j}} & \sigma_{u_{pj},u_{1j}} & \cdots & \sigma^2_{u_{pj}}
\end{bmatrix}.
\end{align*}\] In this model,
- Random intercept only
\[\begin{align*} \text{Level 1: }y_{ij} &= \beta_{0j}+\beta_1x_{1ij}+\cdots+\beta_px_{pij}+\epsilon_{ij} \\ \text{Level 2: }\beta_{0j} &= \gamma_{00}+u_{0j} \\ \text{Mixed: }y_{ij} &= \blue\gamma_{00}+\beta_1x_{1ij}+\cdots+\beta_px_{pij}+\red u_{0j}+\epsilon_{ij}, \end{align*}\] where \(u_{0j}\sim N(0, \sigma^2_{u_{0j}})\).
- Random slopes only
\[\begin{align*} \text{Level 1: }y_{ij} &= \beta_0+\beta_{1j}x_{1ij}+\cdots+\beta_{pj}x_{pij}+\epsilon_{ij} \\ \text{Level 2: }\beta_{1j} &= \gamma_{10}+u_{1j} \\ &\cdots\\ \text{Level 2: }\beta_{pj} &= \gamma_{p0}+u_{pj} \\ \text{Mixed: }y_{ij} &= \blue\beta_0+(\gamma_{10}x_{1ij}+\cdots+\gamma_{p0}x_{pij})+\red(u_{1j}x_{1ij}+\cdots+u_{pj}x_{pij})+\epsilon_{ij}, \end{align*}\] where \[\begin{align*} \begin{pmatrix} u_{1j}\\ \vdots\\ u_{pj} \end{pmatrix}\sim MVN(\bs{0},\bSigma_{\bs{u}}),\bSigma_{\bs{u}}=\begin{bmatrix} \sigma^2_{u_{1j}} & & \\ \vdots & \ddots & \\ \sigma_{u_{pj},u_{1j}} & \cdots & \sigma^2_{u_{pj}} \end{bmatrix}. \end{align*}\]
Suppose we only have 1 \(x\) and 1 \(y\):
- Random intercept and random slope
\[\begin{align*} \text{Level 1: }y_{ij} &= \beta_{0j}+\beta_{1j}x_{ij}+\epsilon_{ij} \\ \text{Level 2: }\beta_{0j} &= \gamma_{00}+u_{0j} \\ \text{Level 2: }\beta_{1j} &= \gamma_{10}+u_{1j} \\ \text{Mixed: }y_{ij} &= \blue\gamma_{00}+\gamma_{10}x_{ij}+\red u_{1j}x_{ij}+u_{0j}+\epsilon_{ij}, \end{align*}\] where \[\begin{align*} \begin{pmatrix} u_{0j}\\ u_{1j} \end{pmatrix}\sim\begin{bmatrix} \sigma^2_{u_{0j}} & \\ \sigma_{u_{1j},u_{0j}} & \sigma^2_{u_{1j}} \end{bmatrix}. \end{align*}\]
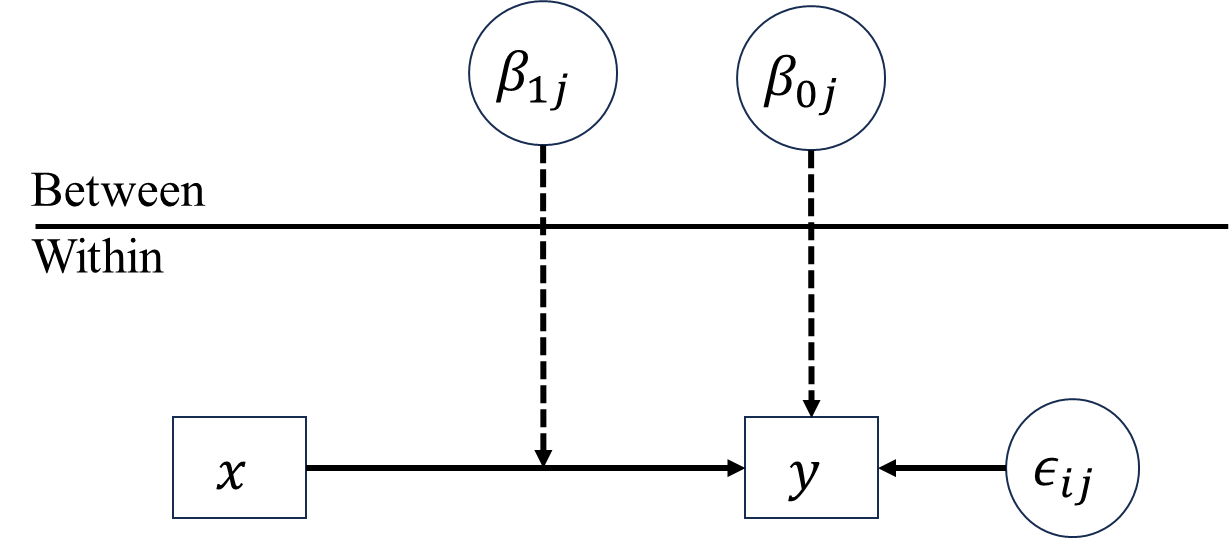
- Random intercept only
\[\begin{align*} \text{Level 1: }y_{ij} &= \beta_{0j}+\beta_1x_{ij}+\epsilon_{ij} \\ \text{Level 2: }\beta_{0j} &= \gamma_{00}+u_{0j} \\ \text{Mixed: }y_{ij} &= \blue\gamma_{00}+\beta_1x_{ij}+\red u_{0j}+\epsilon_{ij}, \end{align*}\] where \(u_{0j}\sim N(0,\sigma^2_{u_{0j}})\).
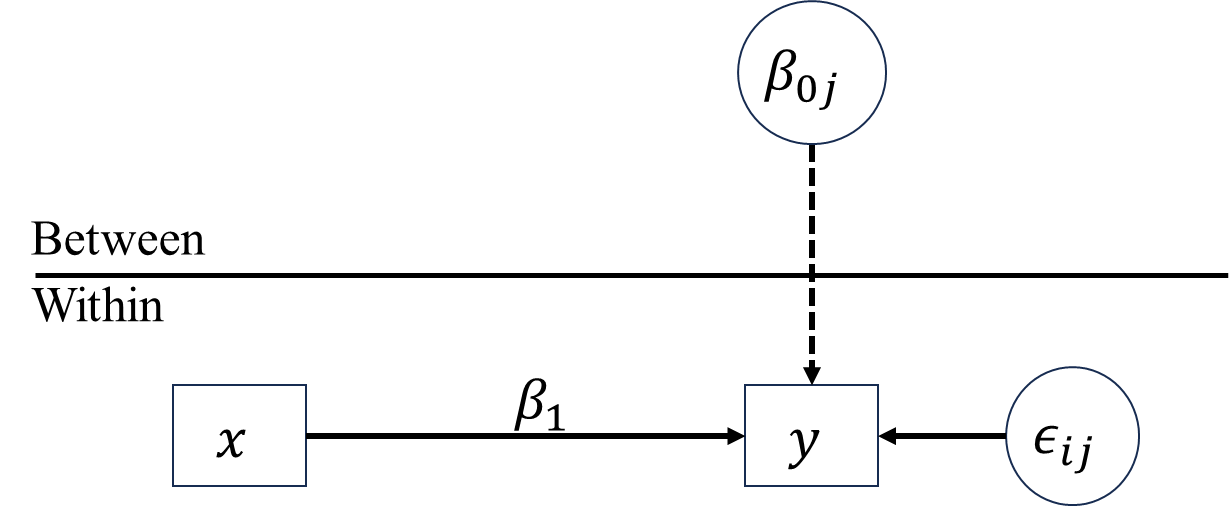
- Random slope only
\[\begin{align*} \text{Level 1: }y_{ij} &= \beta_0+\beta_{1j}x_{ij}+\epsilon_{ij} \\ \text{Level 2: }\beta_{1j} &= \gamma_{10}+u_{1j} \\ \text{Mixed: }y_{ij} &= \blue\beta_0+\gamma_{10}x_{ij}+\red u_{1j}x_{ij}+\epsilon_{ij}, \end{align*}\] where \(u_{1j}\sim N(0,\sigma^2_{u_{1j}})\).

4.3 Syntax style
- Mplus: multilevel model
- lme4: linear mixed model
4.4 Variance decomposition and intra-class correlation (ICC)
4.4.1 Variance decomposition
- Random intercept and random slopes
\[\begin{align*} \text{Mixed: }y_{ij} &= \blue\gamma_{00}+(\gamma_{10}x_{1ij}+\cdots+\gamma_{p0}x_{pij})+\\ &\quad \enspace \red(u_{1j}x_{1ij}+\cdots+u_{pj}x_{pij})+u_{0j}+\epsilon_{ij}\\ \Var(y_{ij})&=\Var(u_{1j}x_{1ij}+\cdots+u_{pj}x_{pij}+u_{0j}+\epsilon_{ij})\\ &=\green x_{1ij}^2\sigma^2_{u_{1j}}+\cdots+x_{pij}^2\sigma^2_{u_{pj}}+\sigma^2_{u_{0j}}+\\ &\quad \enspace \green 2\sum_{k'=k+1}^{p}\sum_{k=1}^{p-1}x_{kij}x_{k'ij}\sigma_{u_{kj},u_{k'j}}+2\sum_{k}^{p}x_{kij}\sigma_{u_{kj},u_{0j}}+\\ &\quad \enspace \grey\sigma^2_{\epsilon_{ij}}\\ &=\green\sigma^2_{B}+\grey\sigma^2_{W}. \end{align*}\] where \(\sigma^2_B\) is the between-group variance and \(\sigma^2_W\) is the within-group variance, since \(e_{ij}\) is random error, it is assumed to be independent to all other random terms, therefore, \(\sigma_{u_{0j},e_{ij}}=\sigma_{u_{kj},e_{ij}}=0\).
- Random intercept only
\[\begin{align*} \text{Mixed: }y_{ij} &= \blue\gamma_{00}+\beta_1x_{1ij}+\cdots+\beta_px_{pij}+\red u_{0j}+\epsilon_{ij}\\ \Var(y_{ij})&=\Var(u_{0j}+\epsilon_{ij})\\ &=\green \sigma^2_{u_{0j}}+\grey\sigma^2_{\epsilon_{ij}}. \end{align*}\]
- Random slopes only
\[\begin{align*} \text{Mixed: }y_{ij} &= \blue\beta_0+(\gamma_{10}x_{1ij}+\cdots+\gamma_{p0}x_{pij})+\red(u_{1j}x_{1ij}+\cdots+u_{pj}x_{pij})+\epsilon_{ij}\\ \Var(y_{ij})&=\Var(u_{1j}x_{1ij}+\cdots+u_{pj}x_{pij}+\epsilon_{ij})\\ &=\green x_{1ij}^2\sigma^2_{u_{1j}}+\cdots+x_{pij}^2\sigma^2_{u_{pj}}+\green 2\sum_{k'=k+1}^{p}\sum_{k=1}^{p-1}x_{kij}x_{k'ij}\sigma_{u_{kj},u_{k'j}}+\grey\sigma^2_{\epsilon_{ij}}. \end{align*}\] Suppose we only have 1 \(x\) and 1 \(y\):
- Random intercept and random slope
\[\begin{align*} \text{Mixed: }y_{ij} &= \blue\gamma_{00}+\gamma_{10}x_{ij}+\red u_{1j}x_{ij}+u_{0j}+\epsilon_{ij}\\ \Var(y_{ij})&=\Var(u_{1j}x_{ij}+u_{0j}+\epsilon_{ij})\\ &=\green x_{ij}^2\sigma^2_{u_{1j}}+\sigma^2_{u_{0j}}+2x_{ij}\sigma_{u_{1j},u_{0j}}+\grey\sigma^2_{\epsilon_{ij}}.\\ \end{align*}\]
- Random intercept only
\[\begin{align*} \text{Mixed: }y_{ij} &= \blue\gamma_{00}+\beta_1x_{ij}+\red u_{0j}+\epsilon_{ij}\\ \Var(y_{ij})&=\Var(u_{0j}+\epsilon_{ij})\\ &=\green \sigma^2_{u_{0j}}+\grey\sigma^2_{\epsilon_{ij}}.\\ \end{align*}\]
- Random random slope only
\[\begin{align*} \text{Mixed: }y_{ij} &= \beta_{0}+\gamma_{10}x_{ij}+\red u_{1j}x_{ij}+\epsilon_{ij}\\ \Var(y_{ij})&=\Var(u_{1j}x_{ij}+\epsilon_{ij})\\ &=\green x_{ij}^2\sigma^2_{u_{1j}}+\grey\sigma^2_{\epsilon_{ij}}.\\ \end{align*}\]
4.4.2 Intra-class correlation (ICC)
An convenient summary of the “importance” of grouping variables is the proportion of the total variance accounted for, denoted as variance partition coefficient (VPC) \[\begin{align*}
VPC&=\frac{\sigma^2_B}{\sigma^2_B+\sigma^2_W}.
\end{align*}\] For multilevel linear model with random slopes, VPC becomes a function of \(x\)s. For example, by fitting a multilevel model with both random intercept and slope to the sleepstudy data while fixing the corvariance between the error term , we have \[\begin{align*}
\text{Level 1: }Reaction_{ij}&=\beta_{0j}+\beta_{1j}Days_{ij}+\epsilon_{ij}\\
\text{Level 2: }\beta_{0j}&=\gamma_{00}+u_{0j}\\
\text{Level 2: }\beta_{1j}&=\gamma_{10}+u_{1j},\\
\end{align*}\] \(\sigma_{u_{0j},u_{1j}}=0\). Base on the estimated parameters, we can draw the following scatter plot,
#> Linear mixed model fit by REML. t-tests use Satterthwaite's method [
#> lmerModLmerTest]
#> Formula: Reaction ~ Days + (Days || Subject)
#> Data: sleepstudy
#>
#> REML criterion at convergence: 1743.7
#>
#> Scaled residuals:
#> Min 1Q Median 3Q Max
#> -3.9626 -0.4625 0.0204 0.4653 5.1860
#>
#> Random effects:
#> Groups Name Variance Std.Dev.
#> Subject (Intercept) 627.57 25.051
#> Subject.1 Days 35.86 5.988
#> Residual 653.58 25.565
#> Number of obs: 180, groups: Subject, 18
#>
#> Fixed effects:
#> Estimate Std. Error df t value Pr(>|t|)
#> (Intercept) 251.405 6.885 18.156 36.513 < 2e-16 ***
#> Days 10.467 1.560 18.156 6.712 2.59e-06 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Correlation of Fixed Effects:
#> (Intr)
#> Days -0.184#> Groups Name Std.Dev.
#> Subject (Intercept) 25.0513
#> Subject.1 Days 5.9882
#> Residual 25.5653Intra-class correlation (ICC) is defined as \[\begin{align*} ICC&=\frac{\sigma^2_{u_{0j}}}{\sigma^2_{u_{0j}}+\sigma^2_{W}}. \end{align*}\] For a random intercept only model, ICC = VPC, otherwise ICC is a biased estimator of VPC, thus the common practice is reporting variance components.
Based on ICC we can calculate the reliability of \(j\)th group (Heck & Thomas, 2020, equation 3.5) \[\begin{align*} \lambda_j&=\frac{\sigma^2_{u_{0j}}}{\sigma^2_{u_{0j}}+\sigma^2_W/n_j}. \end{align*}\]
Reference:
4.5 Effects decomposition and centering
4.5.1 Within effect, between effect, contextual effect
Within effect describes the relationship between within-level background variables and within-level outcome variable. For example, how does student’s ses impact their math achievement within a given school?
Contextual effect describes the impact of the context on the relationship between between-level background variable (i.e. group mean ses) and within-level outcome variable (i.e. math achievement). In the Barcikowski’s data example, contextual effect explores whether two students from different schools with the same level of average ses have different levels of math achievement. Another classic example of contextual effect is the Big Fish-Little Pond effect (Marsh & Parker, 1984). This effect describes the situation in which high achieving students in a school that is low achieving on average, will feel better about their abilities than high achieving students in a school with higher average achievement.
| Y | X | Group | Within effect | Contextual effect |
|---|---|---|---|---|
| Health | Vaccination (1 or 0) | Community | Positive: Within a specific community, getting vaccination decreases individual’s risk of contracting a disease | Positive: Community with higher vaccination rate (average vaccination) decreases its dweller’s risk of contracting a disease |
| Profits | Overfishing | Lake | Positive: Within a specific lake, if a professional fisherman exceeded his fishing quota, his profits will increase because of larger catch | Negative: Lake with higer level of overfishing (average overfishing), the profits of all fishmen will decrease because of smaller catches |
| Competitive advantage | Innovativeness | Industry | Positive: Within a industry, if a firm was innovative, it can develop valuable capabilities that lead to competitive advantage | Negative: Industry with higher level of innovativeness (average innovativeness) have more innovations, but innovativeness is less likely to lead to competitive advantage |
| Performance | Gender (1 or 0) | Team | Zero: Within a specific team, one’s gender has no effect one’s performance | Inverted U-shapde: Team with half mean and half women (medium level of average gender) works best |
Between effect = within effect + contextual effect. Between effect describes the relationship between the group-level average background variables and the group-level average outcome variable. For example, how does a school’s average ses affect the average math achievement of the students in this school?
Multiple linear regression mixes the above effects together. In multilevel linear model, we can extract the three effects and further explain our findings. However, the way how these three effects are decomposed in a multilevel liear model is influenced by whether and how do we center our data.
4.5.2 Centering or not? that is the question.
4.5.2.1 Raw data
Let’s use Barcikowsk’s data as an example. With a multilevel linear model with both random slope and random intercept, fix the covariance between random intercept and random slope at 0, we have \[\begin{align*} \text{Level 1: }mathach_{ij} &= \beta_{0j}+\beta_{1j}ses_{ij}+\epsilon_{ij} \\ \text{Level 2: }\beta_{0j} &= \gamma_{00}+u_{0j} \\ \text{Level 2: }\beta_{1j} &= \gamma_{10}+u_{1j} \\ \text{Mixed: }mathach_{ij} &= \blue\gamma_{00}+\gamma_{10}ses_{ij}+\red u_{1j}ses_{ij}+u_{0j}+\epsilon_{ij}, \end{align*}\]
#> Linear mixed model fit by REML. t-tests use Satterthwaite's method [
#> lmerModLmerTest]
#> Formula: mathach ~ ses + (ses || ID)
#> Data: Barcikowsk
#>
#> REML criterion at convergence: 46640.7
#>
#> Scaled residuals:
#> Min 1Q Median 3Q Max
#> -3.12410 -0.73160 0.02253 0.75467 2.93201
#>
#> Random effects:
#> Groups Name Variance Std.Dev.
#> ID (Intercept) 4.853 2.2029
#> ID.1 ses 0.424 0.6511
#> Residual 36.822 6.0681
#> Number of obs: 7185, groups: ID, 160
#>
#> Fixed effects:
#> Estimate Std. Error df t value Pr(>|t|)
#> (Intercept) 12.6527 0.1903 146.2881 66.50 <2e-16 ***
#> ses 2.3955 0.1184 158.8487 20.23 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Correlation of Fixed Effects:
#> (Intr)
#> ses 0.000In Barcikowsk’s data, \(\hat{\gamma_{10}}\) is 2.3955, meaning that student’s \(mathach\) increase 2.3955 with 1-unit increase in \(ses\). However, this effect of \(ses\) on \(mathach\) is actually a confounded version of the within- and between- effects. We shall leave the explanation to the end of Section 4.5.2.
To properly decompose them, we need to use \(meanses_j\) as a between level predictor, \[\begin{align*} \text{Level 1: }mathach_{ij} &= \beta_{0j}+\beta_{1j}ses_{ij}+\epsilon_{ij} \\ \text{Level 2: }\beta_{0j} &= \gamma_{00}+b_{01}meanses_j+u_{0j} \\ \text{Level 2: }\beta_{1j} &= \gamma_{10}+u_{1j} \\ \text{Mixed: }mathach_{ij} &= \blue\gamma_{00}+\gamma_{10}ses_{ij}+b_{01}meanses_j+\\ &\quad \enspace \red u_{1j}ses_{ij}+u_{0j}+\epsilon_{ij}. \end{align*}\]
#> Linear mixed model fit by REML. t-tests use Satterthwaite's method [
#> lmerModLmerTest]
#> Formula: mathach ~ ses + mean_group_ses + (ses || ID)
#> Data: Barcikowsk
#>
#> REML criterion at convergence: 46562.4
#>
#> Scaled residuals:
#> Min 1Q Median 3Q Max
#> -3.15390 -0.72254 0.01774 0.75562 2.95378
#>
#> Random effects:
#> Groups Name Variance Std.Dev.
#> ID (Intercept) 2.7129 1.6471
#> ID.1 ses 0.4835 0.6953
#> Residual 36.7793 6.0646
#> Number of obs: 7185, groups: ID, 160
#>
#> Fixed effects:
#> Estimate Std. Error df t value Pr(>|t|)
#> (Intercept) 12.6759 0.1510 153.1039 83.926 <2e-16 ***
#> ses 2.1923 0.1227 182.5178 17.867 <2e-16 ***
#> mean_group_ses 3.7762 0.3839 182.9834 9.836 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Correlation of Fixed Effects:
#> (Intr) ses
#> ses -0.003
#> mean_grp_ss 0.007 -0.258- \(\hat{\gamma_{00}}=12.6759\) is the predicted student’s \(mathach\) when \(ses=0\) and \(meanses=0\), however, it makes no sense for \(ses\) and \(meanses\) to be equal to 0, thus the intepretation of \(\hat{\gamma_{00}}\) is lacking of practical meaning, for which centering can be a helping hand,
- \(\gamma_{10}\) is clearly the within effect. \(\hat{\gamma_{10}}=2.1923\), meaning that student’s predicted \(mathach\) increase 2.1923 with 1-unit increase in \(ses\) controlling \(meanses\), that is, if two students from the same school, \(meanses\) remained constant, the difference of their predicted \(mathach\) only depend on their \(ses\)s.
- \(b_{01}\) represents the contextual effect. \(\hat{b_{01}}=3.7762\), meaning that student’s predicted \(mathach\) increase 3.7762 with 1-unit increase in school’s \(meanses\) controlling \(ses\), that is, if two student having identical \(ses\)s, the difference of their predicted \(mathach\) only depend on the \(meanses\) of their school, thus \(b_{01}\) represent the contextual effect.
- between effect = 2.1923 + 3.7762 = 5.9685.
4.5.2.2 Centering in multiple linear regression
Centering change the scale of independent variable and facilitate the interpretation of intercept.
Note
Note that we only center background variables and leave the dependent variables in their orginal scale.
For example, suppose we fit a simple linear regression, with raw data we have \[\begin{align*} y_i=\beta_0+\beta_1x_i+\epsilon_i, \end{align*}\] of which the intercept is interpretated as the prediction of \(y\) when \(x=0\). After centering \(x\) we have \[\begin{align*} y_i&=\beta_0+\beta_1(x_i-\bar{x})+\epsilon_i\\ y_i&=\beta_0+\beta_1(xc_i)+\epsilon_i,\\ \end{align*}\] of which the intercept is interpretated as the prediction of \(y\) when \(xc_i=0\), i.e. \(x_i=\bar{x}\).
In multilevel linear model, there are basically two types of centering strategies for the within level background variables, grand-mean centering (GMC) and group-mean centering, aka cluster-mean centering (CMC). CMC is used throughout this chapter to avoid identical initials.
4.5.2.3 Grand-mean centering (GMC)
Let’s fit a multilevel linear model with both random slope and random intercept to Barcikowsk’s data, and fix the covariance between random intercept and random slope at 0. \(ses\) now is grand-mean centered. \[\begin{align*} \text{Level 1: }mathach_{ij} &= \beta_{0j}+\beta_{1j}sesGMC_{ij}+\epsilon_{ij} \\ \text{Level 2: }\beta_{0j} &= \gamma_{00}+u_{0j} \\ \text{Level 2: }\beta_{1j} &= \gamma_{10}+u_{1j} \\ \text{Mixed: }y_{ij} &= \blue\gamma_{00}+\gamma_{10}sesGMC_{ij}+\red u_{1j}sesGMC_{ij}+u_{0j}+\epsilon_{ij},\\ \end{align*}\] \(\gamma_{00}\) represents the predicted \(mathach\) when \(ses\) equal to the grand mean, \(\gamma_{10}\) represents the change in \(mathach\) given 1-unit change in \(sesGMC\).
#> Linear mixed model fit by REML. t-tests use Satterthwaite's method [
#> lmerModLmerTest]
#> Formula: mathach ~ I(ses - mean_grand_ses) + (ses || ID)
#> Data: Barcikowsk
#>
#> REML criterion at convergence: 46640.7
#>
#> Scaled residuals:
#> Min 1Q Median 3Q Max
#> -3.12410 -0.73160 0.02253 0.75467 2.93201
#>
#> Random effects:
#> Groups Name Variance Std.Dev.
#> ID (Intercept) 4.853 2.2029
#> ID.1 ses 0.424 0.6511
#> Residual 36.822 6.0681
#> Number of obs: 7185, groups: ID, 160
#>
#> Fixed effects:
#> Estimate Std. Error df t value Pr(>|t|)
#> (Intercept) 12.6531 0.1903 146.2881 66.50 <2e-16 ***
#> I(ses - mean_grand_ses) 2.3955 0.1184 158.8487 20.23 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Correlation of Fixed Effects:
#> (Intr)
#> I(-mn_grn_) 0.000Similarly, without \(meanses\) in the between level, we are unable to decompose within- and between- effect.
Note
Note that, it is usually recommended to grand-mean center the group mean variable before adding it to between level for better interpretation.
\[\begin{align*} \text{Level 1: }mathach_{ij} &= \beta_{0j}+\beta_{1j}sesGMC_{ij}+\epsilon_{ij} \\ \text{Level 2: }\beta_{0j} &= \gamma_{00}+b_{01}meanses_j+u_{0j} \\ \text{Level 2: }\beta_{1j} &= \gamma_{10}+u_{1j} \\ \text{Mixed: }y_{ij} &= \blue\gamma_{00}+\gamma_{10}sesGMC_{ij}+b_{01}meansesGMC_j+\\ &\quad \enspace \red u_{1j}sesGMC_{ij}+u_{0j}+\epsilon_{ij}. \end{align*}\]
#> Linear mixed model fit by REML. t-tests use Satterthwaite's method [
#> lmerModLmerTest]
#> Formula: mathach ~ I(ses - mean_grand_ses) + mean_group_ses_cen + (ses ||
#> ID)
#> Data: Barcikowsk
#>
#> REML criterion at convergence: 46562.4
#>
#> Scaled residuals:
#> Min 1Q Median 3Q Max
#> -3.15390 -0.72254 0.01774 0.75562 2.95378
#>
#> Random effects:
#> Groups Name Variance Std.Dev.
#> ID (Intercept) 2.7129 1.6471
#> ID.1 ses 0.4835 0.6953
#> Residual 36.7793 6.0646
#> Number of obs: 7185, groups: ID, 160
#>
#> Fixed effects:
#> Estimate Std. Error df t value Pr(>|t|)
#> (Intercept) 12.6767 0.1510 153.1025 83.931 <2e-16 ***
#> I(ses - mean_grand_ses) 2.1923 0.1227 182.5178 17.867 <2e-16 ***
#> mean_group_ses_cen 3.7762 0.3839 182.9834 9.836 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Correlation of Fixed Effects:
#> (Intr) I(-m__
#> I(-mn_grn_) -0.003
#> mn_grp_ss_c 0.007 -0.258- \(\hat{\gamma_{00}}=12.6767\) is the prediction of \(mathach\) when \(sesGMC=0\) (\(ses_{ij}\) is equal to the grand mean) and \(meansesGMC=0\) (\(meanses\) is equal to the average \(meanses\) of all schools),
- Within effect: \(\hat{\gamma_{10}}=2.1923\), meaning that student’s predicted \(mathach\) increase 2.1923 with 1-unit increase in \(sesGMC\) controlling \(meansesGMC\), that is, if two students from the same school, \(meansesGMC\) remained constant, the difference of their predicted \(mathach\) only depend on their \(sesGMC\)s.
- Contextual effect: \(\hat{b_{01}}=3.7762\), meaning that student’s predicted \(mathach\) increase 3.7762 with 1-unit increase in school’s \(meansesGMC\) controlling \(sesGMC\), that is, if two student having identical \(sesGMC\)s, the difference of their predicted \(mathach\) only depend on the \(meansesGMC\) of their school, thus \(b_{01}\) represent the contextual effect.
- Between effect = 2.1923 + 3.7762 = 5.9685.
4.5.2.4 Cluster-mean centering (CMC)
Centering \(ses\) with cluster-mean we have \[\begin{align*} \text{Level 1: }mathach_{ij} &= \beta_{0j}+\beta_{1j}sesCMC_{ij}+\epsilon_{ij} \\ \text{Level 2: }\beta_{0j} &= \gamma_{00}+u_{0j} \\ \text{Level 2: }\beta_{1j} &= \gamma_{10}+u_{1j} \\ \text{Mixed: }y_{ij} &= \blue\gamma_{00}+\gamma_{10}sesCMC_{ij}+\red u_{1j}sesCMC_{ij}+u_{0j}+\epsilon_{ij},\\ \end{align*}\]
#> Linear mixed model fit by REML. t-tests use Satterthwaite's method [
#> lmerModLmerTest]
#> Formula: mathach ~ I(ses - mean_group_ses) + (ses || ID)
#> Data: Barcikowsk
#>
#> REML criterion at convergence: 46718.2
#>
#> Scaled residuals:
#> Min 1Q Median 3Q Max
#> -3.09777 -0.73211 0.01331 0.75450 2.92142
#>
#> Random effects:
#> Groups Name Variance Std.Dev.
#> ID (Intercept) 8.7395 2.9563
#> ID.1 ses 0.5101 0.7142
#> Residual 36.7703 6.0638
#> Number of obs: 7185, groups: ID, 160
#>
#> Fixed effects:
#> Estimate Std. Error df t value Pr(>|t|)
#> (Intercept) 12.6320 0.2461 153.8997 51.32 <2e-16 ***
#> I(ses - mean_group_ses) 2.1417 0.1233 162.9470 17.37 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Correlation of Fixed Effects:
#> (Intr)
#> I(-mn_grp_) -0.002- Within effect: \(\hat{\gamma_{10}}=2.1417\), meaning that with everything else hold at constant, student’s \(mathach\) increase 2.1417 with 1-unit increase in \(sesCMC\), this is constant across different schools.
Note
Noted that with cluster-mean centering, \(\gamma_{10}\) is not a confounded version of the within- and between- effects anymore, instead it is an unambiguous estimate of within effect. Again, we shall leave the explanation to the end of Section 4.5.2.
Add group mean (grand-mean centered) as a between-level predictor we have \[\begin{align*} \text{Level 1: }mathach_{ij} &= \beta_{0j}+\beta_{1j}sesCMC_{ij}+\epsilon_{ij} \\ \text{Level 2: }\beta_{0j} &= \gamma_{00}+b_{01}meansesGMC_j+u_{0j} \\ \text{Level 2: }\beta_{1j} &= \gamma_{10}+u_{1j} \\ \text{Mixed: }y_{ij} &= \blue\gamma_{00}+\gamma_{10}sesCMC_{ij}+b_{01}meansesGMC_j+\\ &\quad \enspace \red u_{1j}sesCMC_{ij}+u_{0j}+\epsilon_{ij}. \end{align*}\]
#> Linear mixed model fit by REML. t-tests use Satterthwaite's method [
#> lmerModLmerTest]
#> Formula: mathach ~ I(ses - mean_group_ses) + mean_group_ses_cen + (ses ||
#> ID)
#> Data: Barcikowsk
#>
#> REML criterion at convergence: 46562.4
#>
#> Scaled residuals:
#> Min 1Q Median 3Q Max
#> -3.15390 -0.72254 0.01774 0.75562 2.95378
#>
#> Random effects:
#> Groups Name Variance Std.Dev.
#> ID (Intercept) 2.7129 1.6471
#> ID.1 ses 0.4835 0.6953
#> Residual 36.7793 6.0646
#> Number of obs: 7185, groups: ID, 160
#>
#> Fixed effects:
#> Estimate Std. Error df t value Pr(>|t|)
#> (Intercept) 12.6767 0.1510 153.1025 83.93 <2e-16 ***
#> I(ses - mean_group_ses) 2.1923 0.1227 182.5178 17.87 <2e-16 ***
#> mean_group_ses_cen 5.9685 0.3717 156.1926 16.06 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Correlation of Fixed Effects:
#> (Intr) I(-m__
#> I(-mn_grp_) -0.003
#> mn_grp_ss_c 0.006 0.064- \(\hat{\gamma_{00}}=12.6767\) is the prediction of \(mathach_{ij}\) when \(sesCMC_{ij}=0\) (\(ses_{ij}\) is equal to the average \(ses\) of \(j\)th school) and \(meansesGMC_j=0\) (\(meanses_j\) is equal to the average \(meanses\) of all school),
- Within effect: \(\hat{\gamma_{10}}=2.1923\), meaning that with everything else hold at constant, student’s \(mathach\) increase 2.1923 with 1-unit increase in \(sesCMC\), which is the effect of \(ses\) on \(mathach\) on individual level.
- Between effect: \(\hat{b_{01}}=5.9685\) now becomes the between effect. It describes how \(meanses\) impacts \(mathach\) controlling \(sesCMC\), that is, if two student’s from two schools having identical \(sesCMC\)s, the difference of their predicted \(mathach\)s lies in the \(meanses\) of their schools. But why is \(b_{01}\) the between effect rather than the contextual effect?
- Contextual effect: Because the identical \(sesCMC\)s of these two students only impliy that they have the same position with regard to ses within school (e.g., \(sesCMC = 1\) means their \(ses\)s are all 1 sd above the \(meanses\)s of their schools), but their school can have different \(meanses\)s. Therefore identical \(sesCMC\)s mask the abosolute difference between school \(meanses\)s, i.e. the contextual effect. But no worry, the contextual effect is captured by \(b_{01}\) already, \[\begin{align*} \text{Mixed: }y_{ij} &= \blue\gamma_{00}+\gamma_{10}sesCMC_{ij}+b_{01}meansesGMC_j+\\ &\quad \enspace \red u_{1j}sesCMC_{ij}+u_{0j}+\epsilon_{ij}\\ &=\blue\gamma_{00}+\gamma_{10}sesCMC_{ij}+(b_{01}-\gamma_{10}+\gamma_{10})meansesGMC_j+\\ &\quad \enspace \red u_{1j}sesCMC_{ij}+u_{0j}+\epsilon_{ij}\\ &=\blue\gamma_{00}+\gamma_{10}(sesCMC_{ij}+meansesGMC_j)+(b_{01}-\gamma_{10})meansesGMC_j+\\ &\quad \enspace \red u_{1j}sesCMC_{ij}+u_{0j}+\epsilon_{ij}\\ &=\blue\gamma_{00}+\gamma_{10}sesGMC_{ij}+(b_{01}-\gamma_{10})meansesGMC_j+\\ &\quad \enspace \red u_{1j}sesCMC_{ij}+u_{0j}+\epsilon_{ij}, \end{align*}\] thus in this exmple, contextual effect is 5.9685 - 2.1923 = 3.7762.
Note
If you added the group means as a between level predictor, then you will obtain exactly the same within-group effect estimate (and p-value) for your within level predictor regardless of which method of centering you use.
Now let’s explain the two puzzles:
- Why is \(\gamma_{01}\) a smashed version of within- and between- effect when fitting multilevel linear model to raw data without group mean in between level?
Because \[\begin{align*} ses_{ij}&=(ses_{ij} - meanses_j)+meanses_j\\ &=sesCMC_{ij}+meanses_j, \end{align*}\] thus the multilevel linear model with random intercept and random slope can be rewrriten as \[\begin{align*} \text{Mixed: }mathach_{ij} &= \blue\gamma_{00}+\gamma_{10}ses_{ij}+\red u_{1j}ses_{ij}+u_{0j}+\epsilon_{ij}\\ \text{Mixed: }mathach_{ij} &= \blue\gamma_{00}+\gamma_{10}sesCMC_{ij}+\gamma_{10}meanses_j+\red u_{1j}ses_{ij}+u_{0j}+\epsilon_{ij}, \end{align*}\] it is easy to see that \(\gamma_{10}\) represents both within effect and between effect.
- Why is \(\gamma_{01}\) an unambiguous estimate of within effect with or without group mean in between level?
Because \[\begin{align*} sesCMC_{ij}&=(ses_{ij} - meanses_j)\\ \text{Mixed: }mathach_{ij} &= \blue\gamma_{00}+\gamma_{10}sesCMC_{ij}+\red u_{1j}sesCMC_{ij}+u_{0j}+\epsilon_{ij}\\ \text{Mixed: }mathach_{ij} &= \blue\gamma_{00}+\gamma_{10}ses_{ij}-\gamma_{10}meanses_j+\red u_{1j}sesCMC_{ij}+u_{0j}+\epsilon_{ij}, \end{align*}\]
4.5.3 Summary
| Within level predictor | Group mean as between level predictor | \(\gamma_{10}\) | \(b_{01}\) |
|---|---|---|---|
| raw | no | Confound within- and between- effect | NA |
| GMC | no | Confound within- and between- effect | NA |
| CMC | no | Within effect | NA |
| raw | yes | Within effect | Contextual effect |
| GMC | yes | Within effect | Contextual effect |
| CMC | yes | Within effect | Between effect |
- If raw data can equal to 0, no need for centering;
- In a two level model, if group mean variable contained considerable amount of heterogeneity, it should be a between-level predictor.
Reference:
- My advisor told me I should group-mean center my predictors in my multilevel model because it might “make my effects significant” but this doesn’t seem right to me. What exactly is involved in centering predictors within the multilevel model?
- Chapter 8 Centering Options and Interpretations
https://www.bristol.ac.uk/cmm/learning/support/datasets/