Chapter 1 Generalised linear models for count data: Poisson regression
1.1 Poisson regression
Count data are inherently discrete, and often when using linear models, we see non-normal distributions of residuals. In Chapter ?? we discussed a data set on the scores that a group of students got for an assignment. There were four criteria, and the score consisted of the number of criteria that were met for each student’s assignment. The scores were predicted by the performance on previous exams (a standardised measure). Figure ?? showed that after an ordinary linear model analysis, the residuals did not look normal at all.
Table 1.1 shows part of the data that were analysed. The dependent variable was score. Similar to logistic regression, perhaps we can find a distribution other than the normal distribution that is more suitable for this kind of dependent variable. For dichotomous data (1/0) we found the Bernoulli distribution very useful. For count data like this variable score, the traditional distribution is the Poisson distribution.
| ID | score | previous |
|---|---|---|
| 1 | 0 | 0.41 |
| 2 | 2 | -0.47 |
| 3 | 4 | 0.07 |
| 4 | 0 | -0.50 |
| 5 | 2 | -0.83 |
| 6 | 3 | 0.17 |
The normal distribution has two parameters, the mean and the variance. The Bernoulli distribution has only one parameter (the probability), and the Poisson distribution has also only one parameter, \(\lambda\) (Greek letter ‘lambda’). \(\lambda\) is a parameter that indicates tendency. Figure 1.1 shows a Poisson distribution with a tendency of 4.
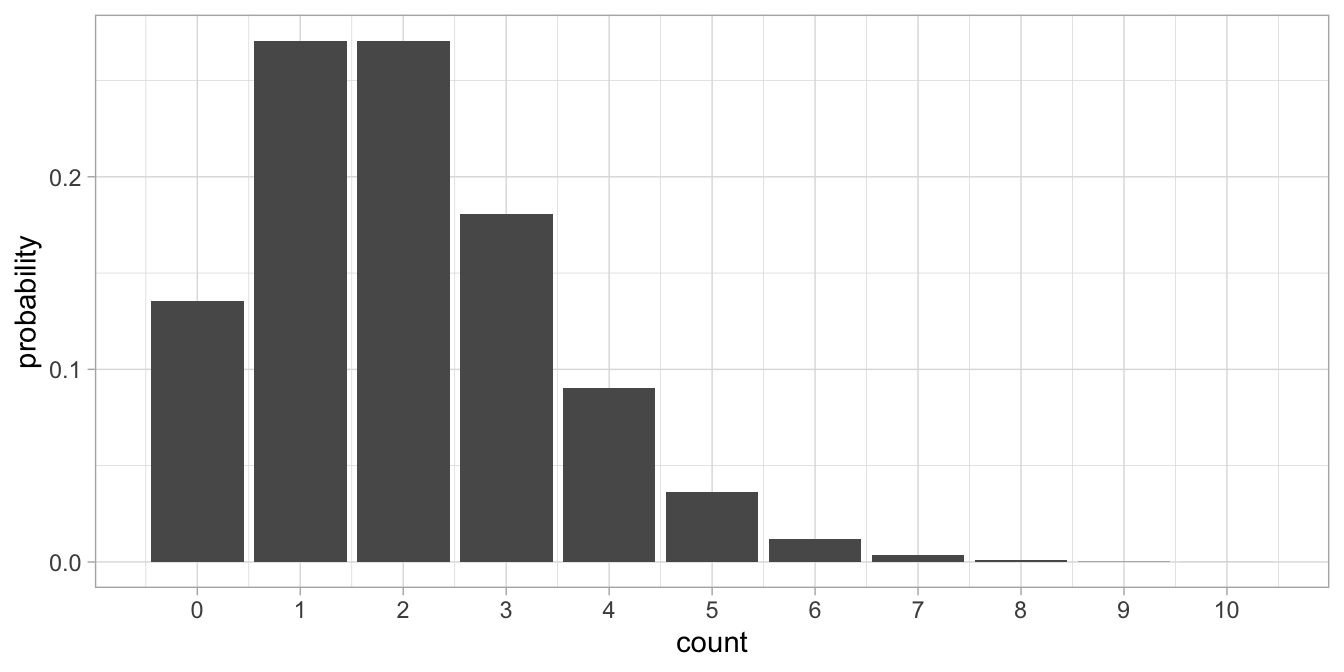
Figure 1.1: The Poisson probability distribution with lambda = 4.
What we see is that the values tend to cluster around the lambda parameter value of 4 (therefore we call it a tendency parameter). We see only discrete values, and no values below 0. We see a few values higher than 10. If we take the mean of the distribution, we will find a value of 4. If we would compute the variance of the distribution we would also find 4. In general, if we have a Poisson distribution with a tendency parameter \(\lambda\), we know from theory that both the mean and the variance will be equal to \(\lambda\).
A Poisson model could be suitable for our data: a linear equation could predict the parameter \(\lambda\) and then the actual data show a Poisson distribution.
\[\begin{aligned} \lambda &= b_0 + b_1 X \\ Y &\sim Poisson(\lambda)\end{aligned}\]
However, because of the additivity assumption, the equation \(b_0 + b_1 X\) can lead to negative values. A negative value for \(\lambda\) is not logical, because we then have a tendency to observe data like -2 and -4 in our data, which is contrary to having count data, which consists of non-negative integers. A Poisson distribution always shows integers of at least 0, so one way or another we have to make sure that we always have a \(\lambda\) of at least 0.
Remember that we saw the reverse problem with logistic regression: there we wanted to have negative values for our dependent variable logodds ratio, so therefore we used the logarithm. Here we want to always have positive values for our dependent variable, so we can use the inverse of the logarithm function: the exponential. Then we have the following model:
\[\begin{aligned} \lambda &= \textrm{exp}(b_0 + b_1 X)= e^{b_0+b_1X} \\ Y &\sim Poisson(\lambda)\end{aligned}\]
This is a generalised linear model, now with a Poisson distribution and an exponential link function. The exponential function makes any value positive, for instance \(\textrm{exp}(0)=1\) and \(\textrm{exp}(-10)=0.00005\).
Let’s analyse the assignment data with this generalised linear model. Our dependent variable is the number of criteria met for the assignment (a number between 0 and 4), and the independent variable is previous, which is a standardised mean of a number of previous exams grades. That means that a student with previous = 0 , that student had a mean grade for previous exams equal to the mean grade for all students. We expect that a high mean grade on previous exams is associated with a higher score on the present assignment. When we run the analysis, the result is as follows:
\[\begin{aligned} \lambda &= \textrm{exp}(0.158 -0.055 \times \texttt{previous}) \\ \texttt{score} &\sim Poisson(\lambda)\end{aligned}\]
What does it mean? Well, similar to logistic regression, we can understand such equations by making some predictions for interesting values of the independent variable. For instance, a value of 0 for previous means an average grade on previous exams that is equal to the mean of all students. So if we choose previous = 0, then we have the prediction for an average student. If we fill in that value, we get the equation \(\lambda=\textrm{exp}(0.158 -0.055 \times 0)= \textrm{exp} (0.158)= 1.17\). Thus, for an average student, we expect to see a score of around 1.17.
Another interesting value of previous might be -2. That represents a student with generally very low grades. Because the average grades were standardised, only about 2.5% of the students has a lower average grade than -2. If we fill in that value, we get: \(\lambda=\textrm{exp}(0.158 -0.055 \times -2)= 1.31\). Thus, for a low performing student, we expect to see a score of around 1.31.
The last value of previous for which we calculate \(\lambda\) is +2, representing a high-performing student. We then get \(\lambda=\textrm{exp}(0.158 -0.055 \times 2)= 1.05\). Thus, for a high performing student, we expect to see a score of around 1.31.
If we look at the pattern in these expected scores, we see that the students with relatively lower grades on previous exams tend to have somewhat higher scores for the assignment. That is what we find in this data set. In the next section we will see how to perform the analysis in R, and how to check whether there is also a relationship in the population of students.
1.2 Poisson regression in R
Poisson regression is a form of a generalised linear model analysis, similar to logistic regression. However, instead of using a Bernoulli distribution we use a Poisson distribution. For a numeric predictor like the variable previous, the syntax is as follows.
## # A tibble: 2 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 0.158 0.0925 1.71 0.0881
## 2 previous -0.0549 0.0899 -0.610 0.542## 2.5 % 97.5 %
## (Intercept) -0.02919483 0.3335813
## previous -0.23069637 0.1215225We see the same values for the intercept and the effect of previous as in the previous section. We now also see 95% confidence intervals for these parameter values. For both, the value 0 is included in the confidence intervals, therefore we know that we cannot reject the null-hypothesis that these values are 0 in the population of students. This is also reflected by the test statistics, which are \(z\)-statistics, similar to logistic regression. Remember that the \(z\)-statistic is computed by \(b/SE\). For large enough samples, the \(z\)-statistic follows a standard normal distribution. From that distribution we know that a value of -0.610 is not significant at the 5% level. It has an associated \(p\)-value of 0.542.
We can write:
"Scores for the assignment (1-4) for 100 students were analysed using a generalised linear model with a Poisson distribution (Poisson regression), with independent variable previous. The scores were not predicted by the average score of previous assignments, \(b = -0.055, z = -0.610, p = .542\). Therefore we found no evidence of a relationship between the average of previous assignments and the score on the present assignment in the population of students."
1.3 Association between two categorical variables
Poisson models are used when you count things, and when you are interested in how two or more variables are associated. Let’s go back to Chapter ??. There we discussed the situation where we have two categorical variables, and you want to see how they co-vary. We made a crosstable that showed the counts of each combination of the levels of the categorical variables.
Imagine we do a study into the gender balance in companies. In one particularly large, imaginary company, there are about 100,000 employees. For a random sample of 1000 employees, we know their gender (female or male), and we know whether they have a position in senior management or not (leadership: yes or no). It turns out that there are 22 female senior managers, and only 8 male senior managers. If we would randomly pick a senior manager from this sample, they would more likely be a woman than a man, right? Can we therefore conclude that there is a positive gender bias, in that senior managers in this company are more often female? Think about it carefully, before you read on.
The problem is, you should first know how many men and how many women there are in the first place. Are there relatively many female leaders, given the gender distribution in this company? In Table 1.2 you find the crosstable of the data. From this table we see that there are 800 women in the sample and 200 men.
| gender | no | yes | Total |
|---|---|---|---|
| female | 778 | 22 | 800 |
| male | 192 | 8 | 200 |
| Total | 970 | 30 | 1000 |
Thus, we see see more female leaders than male leaders, but we also see many more women than men working there in the first place.
It is clear that the data in the table are count data. They can therefore be analysed using Poisson regression. Later in this chapter we will see how we can do that. But first we have to realise that the counts are a bit different than the counts we observed in the assignment example where we counted the number of criteria that were met for each student’s assignment. The dependent variable there was a count variable, but it also had a clear meaning: the count reflected the quality of a student’s work.
In the example here, we simply count the number of employees in a data set that fit a set of criteria (i.e. being a woman and being a senior manager). Technically, both variables are count variables, but conceptually they might feel different for you.
Therefore, before we dive deeper into Poisson models, we will look at a very traditional way of analysing count data in crosstables: computing the Pearson chi-square statistic.
1.4 Cross-tabulation and the Pearson chi-square statistic
Table 1.2 shows that there were 800 women and 200 men in the data set, and of these there were in total 30 employees in senior management. Now if 30 people out of 1000 are in senior management, it means that a proportion of \(\frac{30}{1000}= 0.03\) are in senior management. You might argue that there is only a gender balance if that same proportion is observed in both men and women.
Let’s look at the proportion of women in senior management. We observe 22 female leaders out of a total of 800 women. That’s equal to a proportion of \(\frac{22}{800} = 0.0275\). That is quite close but not equal to 0.03.
Now let’s look at the men. We observe 8 male leaders out of a total of 200 men. That’s equal to a proportion of \(\frac{8}{200} = 0.04\). That is quite close but not equal to 0.03.
Relatively speaking, therefore, there are more men in a senior management role (4%) than there are women in a senior management role (2.75%). Overall there are more women leaders in this data set, but taking into account the gender ratio, there are relatively fewer women than men in the leadership.
Now the question remains whether this difference in leadership across gender is real. These data come from only one particular month, from only 1000 employees instead of all 100,000. Every month new people get hired, get fired, or simply leave. With a huge turn-over, the numbers change all the time. The question is whether we can generalise from these data to the whole company: is there a general gender bias in this company, or are the results we look at due to the random sampling?
The Pearson chi-square test is based on comparing that what you expect given a hypothesis, with what you actually observed. Suppose our hypothesis is that there is a perfect gender balance: the proportion of leaders among the women is equal to the proportion of leaders among the men.
Before we continue, we assume that the total numbers of both genders and the leadership positions are reflective of the actual situation. We therefore assume the proportion of women is 0.8 and the proportion of men is 0.2. We also assume the proportion of senior managers is 3% and the proportion of other employees is 97%.
Assuming gender balance, we expect that a proportion of 0.03 of the women are in a leadership position, and we also expect a proportion of 0.03 of the men are in a leadership position. Given there are 800 women in the data set, under the gender balance assumption we expect \(0.03\times 800 = 24\) women with a leadership role. Given there are 200 men, under the gender balance assumption we expect \(0.03 \times 100 = 6\) men with a leadership role.
Now that we have the number of people that we expect based on gender balance, we can compare them with the actual observed numbers. Let’s calculate the deviations of what we observed from what we expect.
We observed 22 women in a leadership position, where we expected 24, so that is a deviation of \(22-24=-2\) (observed minus expected).
We observed 8 men in the leadership, where we expected 6, which results in a deviation of \(8-6=+2\) (observed minus expected).
We also have the observed counts of the employees not in the leadership. Also for them we can calculate expected numbers based on gender balance. A proportion of .97 are not in the leadership. We therefore expect \(0.97 \times 800= 776\) women. We observed 778, so then we have a deviation of \(778-776 = +2\).
For the men we expect \(0.97\times 200 = 194\) to be without a leadership role, which results in a deviation of \(192 - 194 = -2\).
If we would add these deviations up, we should be able to say something about how much the observed numbers deviate from the expected numbers. However, if we do that, we get a total of 0, since half of the deviations are positive and half of them are negative. In order to avoid that and get something that is very large when the deviations are very different from 0, we could instead take the squares of these differences and then add them up (the idea is similar to that of computing the variance as an indicator of how much values deviate from each other). Another reason for taking the squares is that the sign of the deviation doesn’t really matter; it is only the distance from 0 that is relevant.
If we take the deviations, square them, and add them up, we get:
\[(-2)^2 + 2^2 + 2^2 + (-2)^2 = 16\] However, we should not forget that a deviation of 2 is only a relatively small deviation when the expected number is large, like 776. Observing 778 instead of the expected 776 is not such a big deal: it’s only a 0.26% increase. In contrast, if you expect only 6 people and suddenly you observe 8 people, that is relatively speaking a large difference (a 33% increase). We should therefore off-set the observed deviations from what we expected. We then get:
\[\frac{(-2)^2}{24} + \frac{2^2}{6} + \frac{2^2}{776} + \frac{(-2)^2}{194} = 0.86\]
What we actually did here was computing a test statistic that helps us to decide whether we have evidence in this data set that speaks against gender balance. It is called the Pearson chi-square statistic and it indicates to what extent the proportions observed in one categorical variable (say leadership membership vs non-membership) are different for the different categories of another categorical variable (say males and females). We observed different leadership proportions for males and females and this test statistic helps us decide if the proportions were also significantly different.
In formula form, the Pearson chi-square statistic looks like this:
\[X^2 = \sum_i \frac{(O_i-E_i)^2}{E_i}\]
For every cell \(i\) in the crosstable, here 4 cells, we compute the difference between the observed count (O) and expected count (E). We square these difference first, then divide them by the expected count, and the resulting numbers we add up (summation). As we saw, we ended up with \(X^2 = 0.86\).
If the null-hypothesis is true, the sampling distribution of \(X^2\) is a chi-square distribution. The shape of this distribution depends on the degrees of freedom, similar to the \(t\)-distribution. The degrees of freedom for Pearson’s chi-square are determined by the number of categories for variable 1, \(K_1\), and the number of categories for variable 2, \(K_2\): \(\textrm{df} = (K_1 - 1)(K_2 - 1)\). Thus, with a \(2 \times 2\) crosstable there is only one degree of freedom: \((2-1)\times(2-1)= 1\).
The chi-square distribution with one degree of freedom is plotted in Figure 1.2.
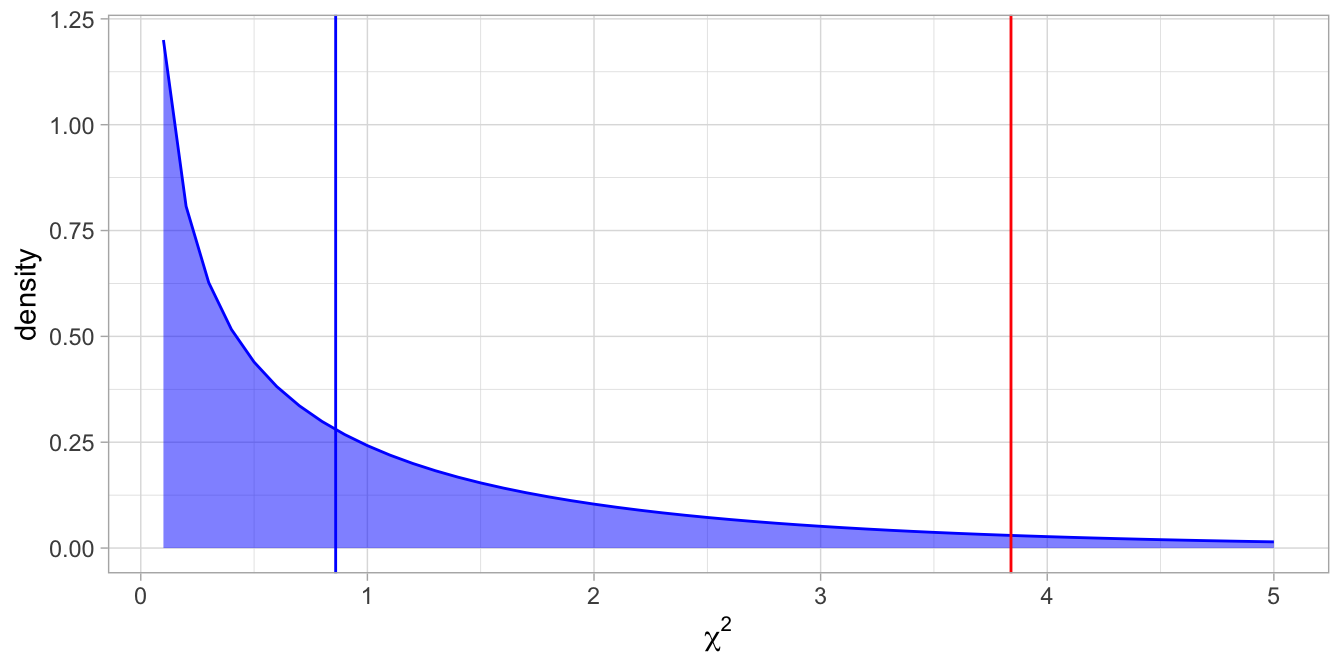
Figure 1.2: The chi-square distribution with one degree of freedom. Under the null-hypothesis we observe values larger than 3.84 only 5% of the time, indicated by the red line. The blue line represents the value based on the data.
The observed value of the test statistic is 0.86 and plotted in blue. The critical value for the null-hypothesis to be rejected at an alpha of 5% is 3.84 and depicted in red. The null-hypothesis can clearly not be rejected. There is no evidence that there is any gender imbalance in this large company of 100,000 employees.
1.5 Pearson chi-square in R
The Pearson chi-square test is based on data from a crosstable. The data that you have are most often not in such a format, so you have to create that table first.
Suppose you have the dataframe with the 1000 employees. We have the variable ID of the employee, a variable for the gender, and a variable for whether they are in senior management.
The top 3 rows of the data might look like this:
## # A tibble: 3 × 3
## ID gender leader
## <int> <chr> <chr>
## 1 1 male no
## 2 2 male no
## 3 3 male noAs we saw in Chapter ??, we can create a table with the tabyl() function from the janitor package.
## gender no yes
## female 778 22
## male 192 8Next we plug the crosstable into the function chisq.test().
##
## Pearson's Chi-squared test with Yates' continuity correction
##
## data: companytable
## X-squared = 0.48325, df = 1, p-value = 0.487Two things strike us: the value for the X-squared is not equal to the 0.86 that we computed by hand. But we also see that R used Yates’ continuity correction. This continuity correction is important if some of your expected cell counts are rather low. Here we saw that we expected only 6 men in senior management.
If we don’t let R apply this continuity correction, we obtain our manually computed statistic of 0.86:
##
## Pearson's Chi-squared test
##
## data: companytable
## X-squared = 0.85911, df = 1, p-value = 0.354Generally you should use the corrected version. We then report:
"Using data on 1000 employees the observed proportion of women in a leadership role was 0.0275. The observed proportion of men in a leadership role was 0.04. A Pearson chi-square test with continuity correction showed that this difference was not significant, X2(1) = 0.48, p = 0.487. The null-hypothesis that the proportions are equal in the population could not be rejected."
1.6 Analysing crosstables with Poisson regression in R
If we want to analyse the same data with a Poisson regression, we need to create a dataframe with a count variable. We start from the original dataframe companydata and count the number of men and women with and without a senior management role.
## # A tibble: 3 × 3
## ID gender leader
## <int> <chr> <chr>
## 1 1 male no
## 2 2 male no
## 3 3 male no## # A tibble: 4 × 3
## # Groups: gender [2]
## gender leader count
## <chr> <chr> <int>
## 1 female no 778
## 2 female yes 22
## 3 male no 192
## 4 male yes 8We now have a dataframe with the count data in long format, exactly what we need for the Poisson linear model. We take the count variable as dependent variable, and let gender and leader be the predictors:
##
## Call: glm(formula = count ~ gender + leader, family = poisson, data = .)
##
## Coefficients:
## (Intercept) gendermale leaderyes
## 6.654 -1.386 -3.476
##
## Degrees of Freedom: 3 Total (i.e. Null); 1 Residual
## Null Deviance: 1503
## Residual Deviance: 0.8003 AIC: 31.27In the output we see that the effect of being male is negative, saying that there are fewer men than women in the data. The leadership effect is also negative: there are fewer people in a leadership role than people not in that role.
We can look at what the model predicts regarding the counts:
## # A tibble: 4 × 4
## # Groups: gender [2]
## gender leader count pred
## <chr> <chr> <int> <dbl>
## 1 female no 778 776.
## 2 female yes 22 24.0
## 3 male no 192 194.
## 4 male yes 8 6You see that the model makes the same predictions as under the assumption that there is a gender balance. The deviations in the observed compared to the predicted (expected) are 2 again, similar as we saw when computing the chi-square test. We want to know however, whether the ratio of leaders is the same in males and females: in other words whether the effect of leadership on counts is different for men and women. We therefore check if there is a significant gender by leader interaction effect.
model2 <- companycounts %>%
glm(count ~ gender + leader + gender:leader, family = poisson, data = .)
model2 %>% tidy()## # A tibble: 4 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 6.66 0.0359 186. 0
## 2 gendermale -1.40 0.0806 -17.4 1.55e-67
## 3 leaderyes -3.57 0.216 -16.5 4.12e-61
## 4 gendermale:leaderyes 0.388 0.421 0.921 3.57e- 1We see a positive interaction effect: the specific combination of being a male and a leader, has an extra positive effect of 0.388 on the counts in the data. The effect is however not significant, since the \(p\)-value is .357.
We see that the \(p\)-value is very similar to the \(p\)-value for the uncorrected Pearson chi-square test (.354) and different from the corrected one (.487). Every \(p\)-value with these kinds of analyses is only an approximation. The \(p\)-values are dissimilar here because the expected number of males in a senior management role is pretty low. For data sets with higher counts, the differences between the methods will disappear. Generally, the Pearson chi-square with continuity correction gives you best results for relatively low expected counts (counts of 5 or less).
If you would like to report the results form this Poisson analysis instead of a Pearson chi-square test, you could write:
"Using data on 1000 employees the observed proportion of women in a leadership role was 0.0275. The observed proportion of men in a leadership role was 0.04. A Poisson regression with number of employees as the dependent variables and main effects of gender, leadership and their interaction showed a non-signficant interaction effect, B = 0.388, SE = 0.421, z = 0.92, p = .357. The null-hypothesis that the proportions are equal in the population could not be rejected."
If the data set is large enough and the numbers are not too close to 0, the same conclusions will be drawn, whether from a \(z\)-statistic for an interaction effect in a Poisson regression model, or from a cross-tabulation and computing a Pearson chi-square. The advantage of the Poisson regression approach is that you can do much more with them, for instance more than two predictors, and including also numeric variables as predictors. In the Poisson regression, you also make it more explicit that when computing the \(z\)-statistic, you take into account the main effects of the variables (the row and column totals). You do that also for the Pearson chi-square, but it is less obvious: we did that by first calculating the proportion of males and females and then calculating the overall proportion of senior management roles, before calculating the expected numbers. The next section shows that you can more easily answer advanced research questions with Poisson regression than with Pearson’s chi-squares and crosstables.
1.7 Going beyond 2 by 2 crosstables (advanced)
If your categorical variables have more than 2 categories you can still do a Pearson chi-square test. You only run into trouble when you have more than two categorical variables, and you want to study the relationship between them. Let’s turn to an example with three categorical variables. Suppose in the employee data, we have data on gender, leadership role, and also whether people work either at the head office in central London, or whether they work at one of the dozens of distribution centres across the world. Do we see a different gender bias in the head office compared to the distribution centres?
Let’s have a look at the data again. Now we make separate tables, one for the head office and one for the distribution centres, see Figure 1.3.

Figure 1.3: The crosstables of gender and leadership, separately for the distribution centres (left table) and the head office (right table).
Remember that in the complete data set, we observed 4% of leadership in the men and 2.75% in the women. Now let’s look only at the data from the distribution centres. Out of 707 women, 1 of them is in senior management, leading to a proportion of 0.001. Out of 145 men, 4 of them are a senior manager, leading to a proportion of 0.028. Thus, at the distribution centres there seems to be a gender bias in that men tend to be more often in senior management positions than women, taking into account overall differences in gender representation. Contrast this with the situation at the head office in London. There, 21 out of 93 women are in senior management, a proportion of 0.23. For the men, 4 out of 55 are in senior management, a proportion of 0.07. Thus, at the head office, senior management positions are relatively speaking more prevalent among the women than the men. The opposite of what we observed in the distribution centres.
The next question is then, can we generalise this conclusion to the population of the entire company? For that we can do a Poisson analysis. First we prepare the data in such a way that for every combination of gender, leadership and location, we get a count. We do that in the following way.
## # A tibble: 3 × 4
## ID gender leader location
## <int> <chr> <chr> <chr>
## 1 182 female yes distribution
## 2 197 female yes headoffice
## 3 231 female yes headofficecompanycounts <- companydata_location %>%
group_by(gender, leader, location) %>%
summarise(count = n()) %>%
arrange(location)
companycounts## # A tibble: 8 × 4
## # Groups: gender, leader [4]
## gender leader location count
## <chr> <chr> <chr> <int>
## 1 female no distribution 706
## 2 female yes distribution 1
## 3 male no distribution 141
## 4 male yes distribution 4
## 5 female no headoffice 72
## 6 female yes headoffice 21
## 7 male no headoffice 51
## 8 male yes headoffice 4Next, we apply a Poisson regression model. We predict the counts by taking the gender totals, the leader totals and the location totals.
##
## Call: glm(formula = count ~ gender + leader + location, family = poisson,
## data = .)
##
## Coefficients:
## (Intercept) gendermale leaderyes locationheadoffice
## 6.494 -1.386 -3.476 -1.750
##
## Degrees of Freedom: 7 Total (i.e. Null); 4 Residual
## Null Deviance: 2168
## Residual Deviance: 117.9 AIC: 166.4Generally, there are fewer males, fewer leaders, and fewer people in the head office compared to the other categories. In the previous analysis we saw that a gender bias in leadership was modelled using an interaction effect. Now that we have data on location, there could also be a gender bias in location (relatively more women in the head office), or a location bias in leadership (relatively more leaders in the head office). We can therefore add these two-way interaction effects. But most importantly, we want to know whether the gender bias in management (the interaction between gender and leadership) is moderated by location. This we can test by a adding a three-way interaction effect: gender by leader by location. Putting it all together we get the following R code:
companycounts %>%
glm(count ~ gender + leader + location +
gender:leader + gender:location + leader:location +
gender:leader:location, family = poisson, data = .)The exact same model can be achieved with less typing, by using the *:
## # A tibble: 8 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 6.56 0.0376 174. 0
## 2 gendermale -1.61 0.0922 -17.5 2.73e-68
## 3 leaderyes -6.56 1.00 -6.56 5.56e-11
## 4 locationheadoffice -2.28 0.124 -18.5 4.90e-76
## 5 gendermale:leaderyes 3.00 1.12 2.67 7.55e- 3
## 6 gendermale:locationheadoffice 1.27 0.205 6.18 6.53e-10
## 7 leaderyes:locationheadoffice 5.33 1.03 5.17 2.37e- 7
## 8 gendermale:leaderyes:locationheadoffice -4.31 1.26 -3.42 6.29e- 4The only parameter relevant for our research question is the last one concerning the gender by leader by location interaction effect. Its value -4.31 is negative, indicating that the particular combination of being male, being a leader and working at the head office leads to a relatively lower count. There is thus a gender by location bias in leadership, in that the males are relatively more present in leadership positions at the distribution centres than at the head office. The effect is significant, so we can conclude that the gender bias shows a different patter at the head office than at the distribution centres.
We report:
"Using data on 1000 employees the observed proportion of women in a leadership role was 0.0275. The observed proportion of men in a leadership role was 0.04. Taking into account differences across location we saw that women at distribution centres were relatively less often in senior management position than men (0.1% vs. 2.8%). At the head office, women were relatively more often in a senior management position than men (23% vs. 7%). A Poisson regression with number of employees as the dependent variables and main effects of gender, leadership, location and all their two-way and three-way interaction effects showed a significant three-way interaction effect, B = -4.31, SE = 1.26, z = -3.42, p < .001. The null-hypothesis that the gender bias is equal in the two types of locations of the company can be rejected."
1.8 Take-away points
A Poisson regression model is a form of a generalised linear model.
Poisson regression is appropriate in situations where the dependent variable is a count variable (\(0, 1, 2, 3, \dots\)).
Whereas the normal distribution has two parameters (mean \(\mu\) and variance \(\sigma^2\)), the Poisson distribution has only one parameter: \(\lambda\).
A Poisson distribution with parameter \(\lambda\) has mean equal to \(\lambda\) and variance equal to \(\lambda\).
\(\lambda\) can take any real value between 0 and \(\infty\).
Poisson models can be used to analyse crosstable data. This can also be done using Pearson’s chi-square, but Poisson models allow you to easily go beyond two categorical variables, and include numerical predictors.