
| \(\text{Unit i} \quad\) | \(Name \quad\) | \(X1_{i}^{Age} \quad\) | \(X2_{i}^{Educ.} \quad\) | \(D_{i}^{Unempl.} \quad\) | \(Y_{i}^{Lifesat.} \quad\) |
|---|---|---|---|---|---|
| 1 | Sofia | 29 | 1 | 1 | 3 |
| 2 | Sara | 30 | 2 | 1 | 2 |
| 3 | José | 28 | 0 | 0 | 5 |
| 4 | Yiwei | 27 | 2 | 1 | ? |
| 5 | Julia | 25 | 0 | 0 | 6 |
| 6 | Hans | 23 | 0 | 1 | ? |
| .. | .. | .. | .. | .. | .. |
| 1000 | Hugo | 23 | 1 | 0 | 8 |
Seminar:
Digitalisierung, Künstliche Intelligenz und Demokratie
Updated: Jul 18, 2024
2 Digitalisierung & Big Data & KI & Demokratie
- Terminfindung: https://forms.gle/vgLK7m6F7c2ASBfL7

Global Information Storage Capacity

Source: https://en.wikipedia.org/wiki/Big_data
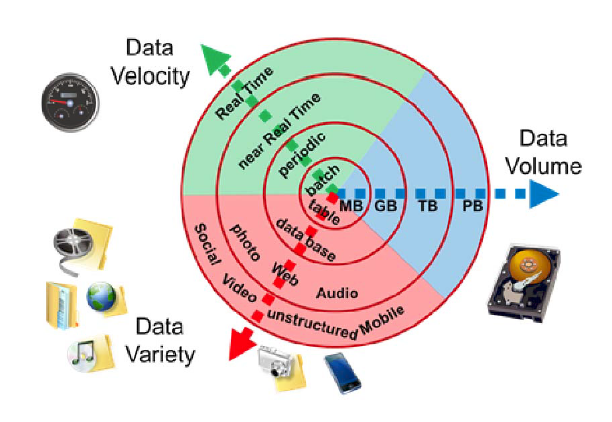
Platform usage (1): Social Media Adoption
- Q: Why is it hard to estimate social media platform users?
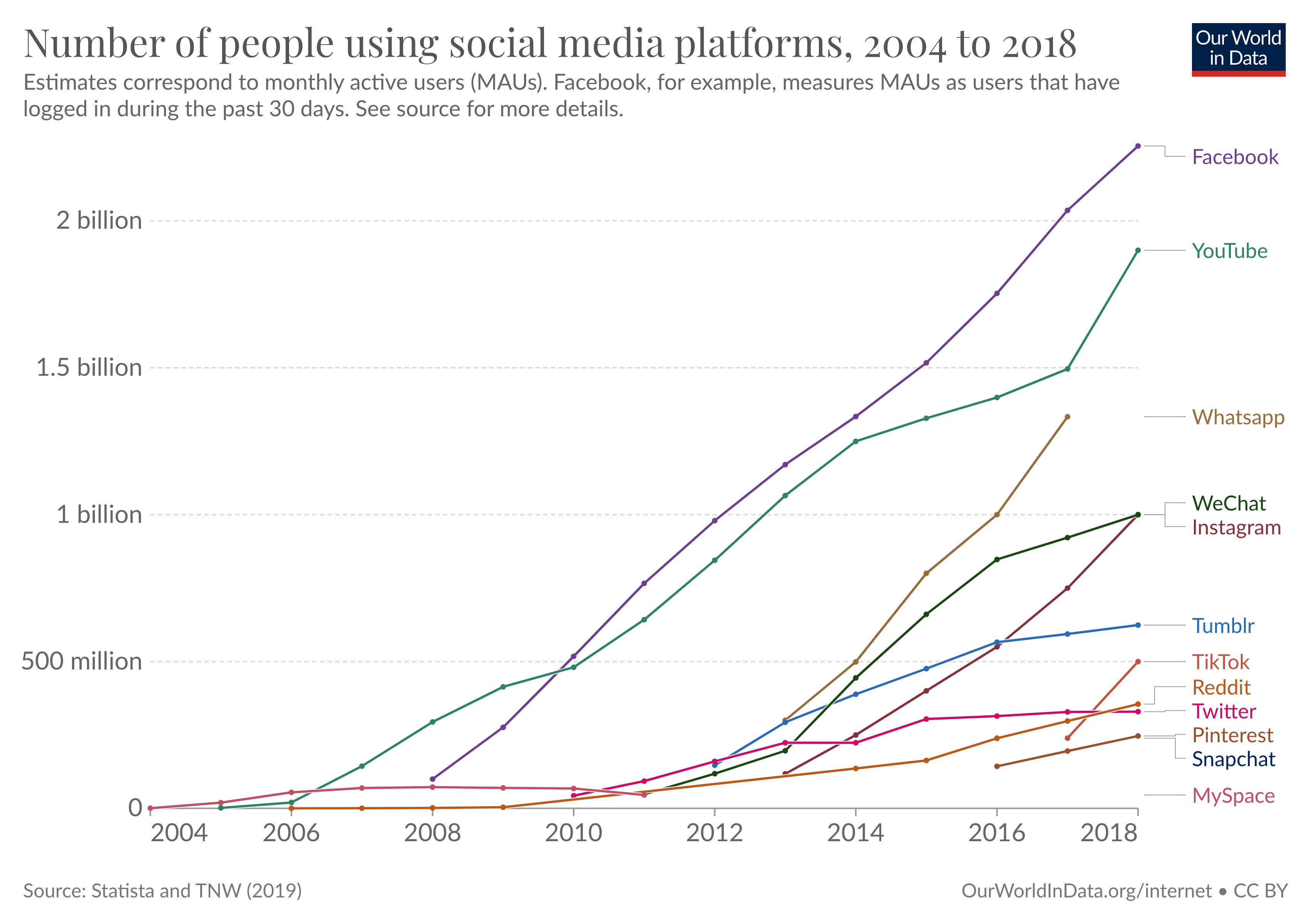
Platform usage (2): Social Media Adoption (Barchart)
- Q: Anything surprising for you in this graph?
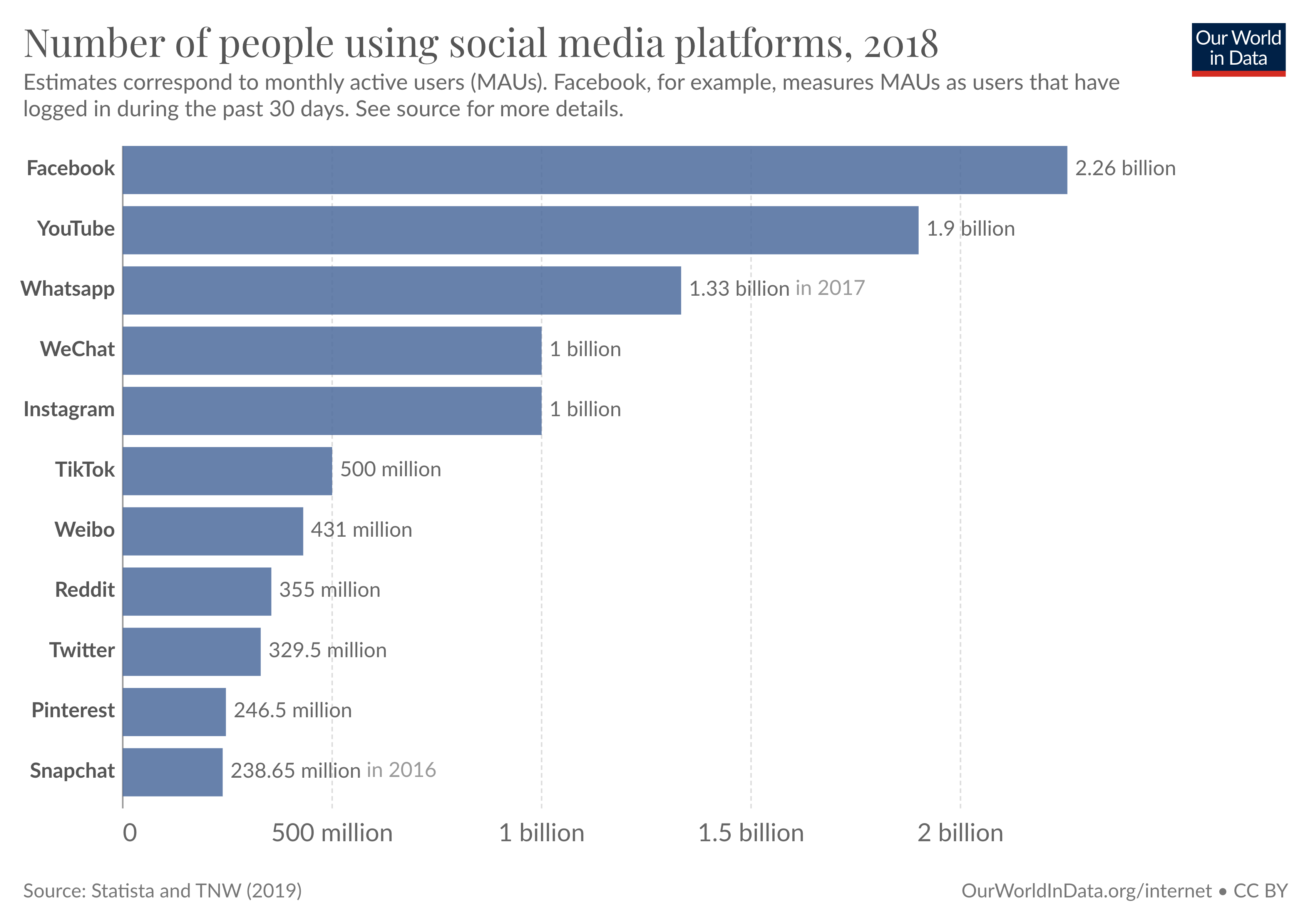
Platform usage (3): Social Media Adoption (Barchart)
Insights
- Platforms may come and go… (e.g., Myspace, Vine)
- Platform companies (e.g., Google, Facebook, etc.) invest in AI
- Usage depends very much on age/cohort!
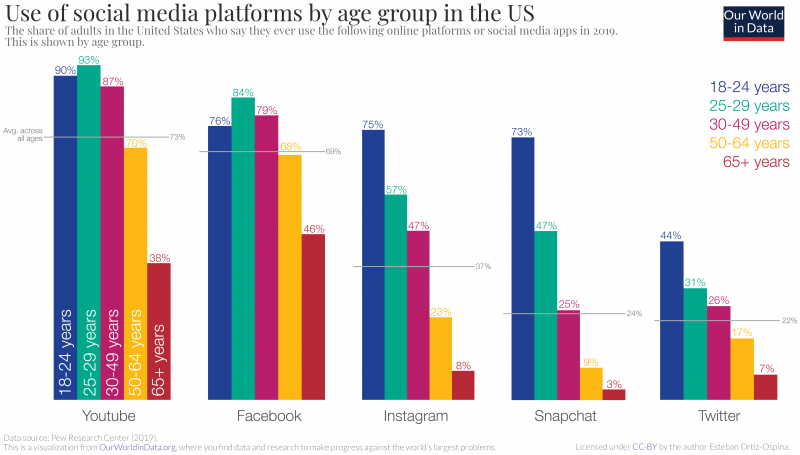
- See, e.g., Our world in data, Statista for more statistics
Big data & new data (2)
- Bad graph but highlights the idea!
![Source: https://en.wikipedia.org/wiki/Big_data]()
Big data & new data (3) (Entwisle and Elias 2013)

Big data & new data (4)

Exercise: What data can reveal about you…
- Look at the picture below (Bern!). What does it show? What can we learn/measure with such data?
Insights
- Geo-locations + time stamps of individuals among most powerful data
- Data may have non-obvious use cases (Mayer-Schönberger and Cukier 2012, 82, 86) (e.g. traffic prediction)
- Inventors/data collectors themselves might not foresee the positive or negative potential of their data
- Visualization strongly affects what you see (with/without lines)
- Indirect data & identification
- Database better memory than myself!
Normative vs. empirische analytische Fragen (1)
- Welches ist die normative, welches die empirisch-analytische Forschungsfrage?

Analytische Blickwinkel auf Fake News
- Was für Forschungsfragen könnten man stellen? (https://app.diagrams.net/)
Insights
- Akteursfokus: Wer sendet/liest Falschinformationen?
- Inhaltsfokus: Welche Falschinformationen breiten sich aus?
- Netzwerkfokus: Wie (schnell) breitet sich die Falschinformation im Netzwerk aus? Wer sind zentrale Akt
- Plattformfokus: Auf welchen Plattformen breitet sich die Falschinformation aus?
- Kombination aus unterschiedlichen Foki usw.

10 Blockchain & DLT
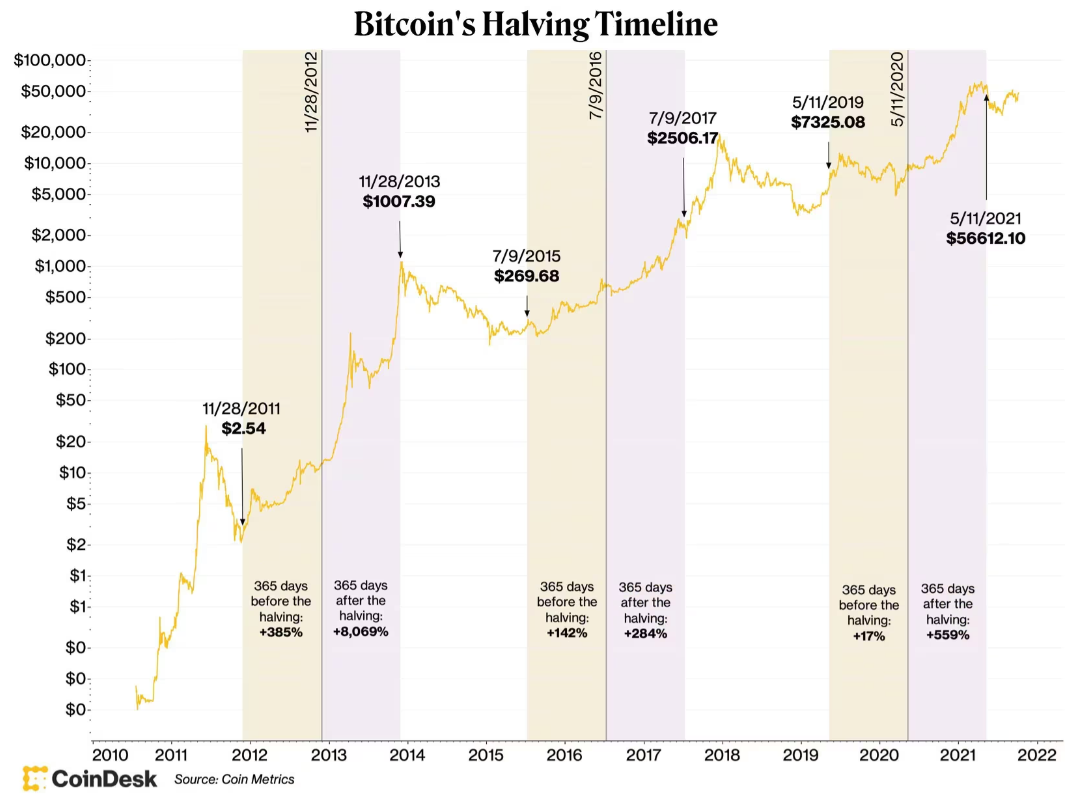
- Source: Coindesk
Was ist Blockchain?
- Digitaler Ledger/Digital Ledger (glorified excel sheet): Ein digitales Notizbuch , in dem Transaktionen aufgezeichnet werden
- Blöcke/Blocks: Transaktionen werden in digitalen Containern, den sogenannten Blöcken, gespeichert
- Kette/Chain: Jeder Block ist mit dem vorherigen verbunden, wodurch eine Kette entsteht
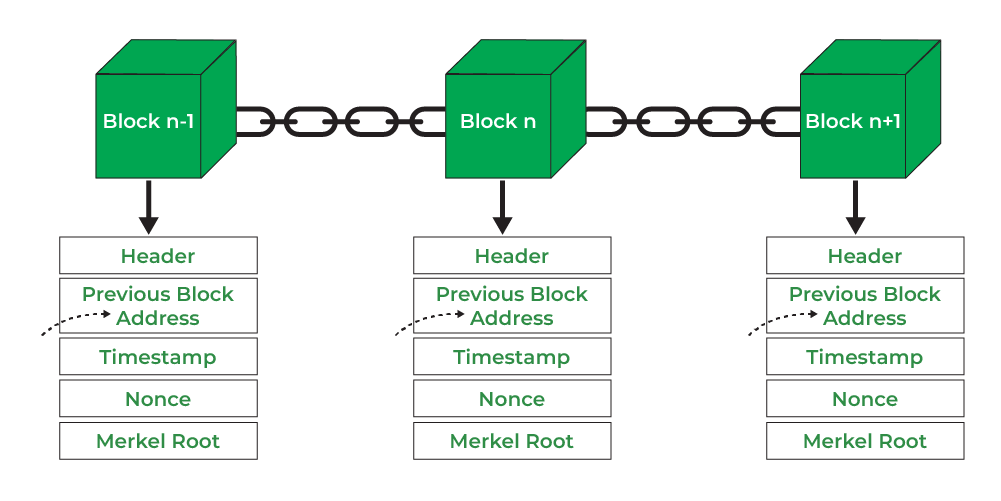
- Dezentralisiert/Decentralized: Daten sind auf viele Computer (Knoten) weltweit verteilt
- Sicher/Secure: Es ist schwierig, Informationen zu ändern, ohne die gesamte Kette zu beeinflussen
- Transparent/Transparent: Transaktionen sind für jeden im Netzwerk sichtbar
Footnotes
“We estimated the world’s technological capacity to store, communicate, and compute information, tracking 60 analog and digital technologies during the period from 1986 to 2007. In 2007, humankind was able to store 2.9 × 1020 optimally compressed bytes, communicate almost 2 × 1021 bytes, and carry out 6.4 × 1018 instructions per second on general-purpose computers. General-purpose computing capacity grew at an annual rate of 58%. The world’s capacity for bidirectional telecommunication grew at 28% per year, closely followed by the increase in globally stored information (23%). Humankind’s capacity for unidirectional information diffusion through broadcasting channels has experienced comparatively modest annual growth (6%). Telecommunication has been dominated by digital technologies since 1990 (99.9% in digital format in 2007), and the majority of our technological memory has been in digital format since the early 2000s (94% digital in 2007).”
Rather than programmers crafting data-processing rules by hand, could a computer automatically learn these rules by looking at data?
Neben Zusammenfassungen im Text bitte tabellarische Übersicht.
Neben Zusammenfassungen im Text bitte tabellarische Übersicht.