Chapter 16 Internet Archive API
You will need to install the following packages for this chapter (run the code):
# install.packages('pacman')
library(pacman)
p_load('httr', 'jsonlite', 'tibble',
'archiveRetriever')16.1 Provided services/data
- What data/service is provided by the API?
The Internet Archive API (Internet Archive 2016) and the archiveRetriever (Gavras and Isermann 2022) give access to mementos stored in the Internet Archive. The Internet Archive is a non-profit organisation which builds and provides a digital library of Internet sites and other digitally stored artefacts such as books, audio recordings, videos, images and software programs. Today, the library stores about 588 billion web pages and covers a time span of over 25 years (Internet Archive 2022). The Internet Archive API offers options to search and query the Internet Archive and to retrieve information on whether a certain Url is archived and currently available in the Internet Archive. Additionally, the API allows users to retrieve the Urls and the specific time stamps of the mementos available, and gives options to limit the time frame of any search and the type of resource searched for. The R-package archiveRetriever offers easy access to the base functions of the Internet Archive API. Additionally, the archiveRetriever is designed to help with web scraping information from the Internet Archive. Besides offering access to the availability and Urls of Internet Archive mementos, the archiveRetriever allows to retrieve the Urls of the mementos of any sub pages that may be linked to in the original memento. Further, the archiveRetriever offers a function to easily scrape information from these mementos.
16.2 Prerequesites
- What are the prerequisites to access the API (authentication)?
The API is free and accessible without any authentification via HTTP Urls, httr and the archiveRetriever.
16.3 Simple API call
- What does a simple API call look like?
The API provides searches and options that can be accessed via HTTP Urls. These Urls take the pattern:
http://web.archive.org/cdx/search/cdx?parameters/
As parameters, the API takes the obligatory input url. Further, you can refine your search by setting a timeframe for your search with the parameters from and to, and specify the match type of the Url with matchType as being exact, prefix, host, or domain to indicate whether you are looking for results matching the exact Url, results with the given Url as prefix, all matching results from the host archive.org, or all matching results from the host archive.org including all sub hosts *.archive.org (Internet Archive 2016).
Further, you can collapse search results by any of the other parameters with collapse. To collapse results by day you could for example use the option collapse=timestamp:8 to collapse by time unit indicated by the 8th character of the time stamp (time stamps are stored in the format yyyymmddhhmmss).
A complete API call can then look like the example below:
The output of the API is a json-file containing information on mementos stored in the Internet Archive. Most importantly, the json-file returns the timestamp and the original Url of the memento. This information can then be used to generate memento Urls.
A detailed description of the different functions of the API can be found on github (Internet Archive 2016).
16.4 API access
- How can we access the API from R (httr + other packages)?
Instead of typing the API request into our browser, we can use the httr package’s GET() function to access the API from R.
# Load required packages
library(httr)
library(jsonlite)
library(tibble)
# API call
res <- GET("http://web.archive.org/cdx/search/cdx?", query = list(
url = "nytimes.com",
matchType = "url",
from = "20191201",
to = "20191202",
collapse = "timestamp:8",
output = "json"
))
# Translate json output to tibble
result <- httr::content(res, type = "text")
result <- fromJSON(result)
result <- as_tibble(result)
names(result) <- result[1,]
result <- result[-1,]
result## # A tibble: 2 x 7
## urlkey timestamp original mimetype statuscode digest length
## <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 com,nytimes)/ 20191201001433 https://www.nytimes.com/ text/html 200 OOQU3TP4EY6UOYZXEEQHBLFGTF2YN23Y 97721
## 2 com,nytimes)/ 20191202000444 https://www.nytimes.com/ text/html 200 HGU4C322VIJHO4KAZGWME7AD6FSEA5SV 122943This output can also be used to generate the Urls of the stored mementos.
# Generate vector of memento Urls
urls <- paste0("https://web.archive.org/web/", result$timestamp, "/", result$original)
urls## [1] "https://web.archive.org/web/20191201001433/https://www.nytimes.com/" "https://web.archive.org/web/20191202000444/https://www.nytimes.com/"Using the archiveRetriever
Alternatively, we can use the archiveRetriever to access selected functions of the Internet Archive API. The archiveRetriever offers four different functions, archive_overview(), retrieve_urls(), retrieve_links(), and scrape_urls(). While archive_overview() and retrieve_urls() work as a wrapper for the Internet Archive API, retrieve_links() and scrape_urls() go beyond the functionality of the API and simplify larger data collections and web scraping from the Internet Archive.
archive_overview() queries the Internet Archive API to get an overview over the dates for which mementos of a specific Url are stored in the Internet Archive. The function outputs a nicely formatted calendar to graphically display the Url’s availability in the Internet Archive.
library(archiveRetriever)
archive_overview("nytimes.com", startDate = "20051101", endDate = "20051130")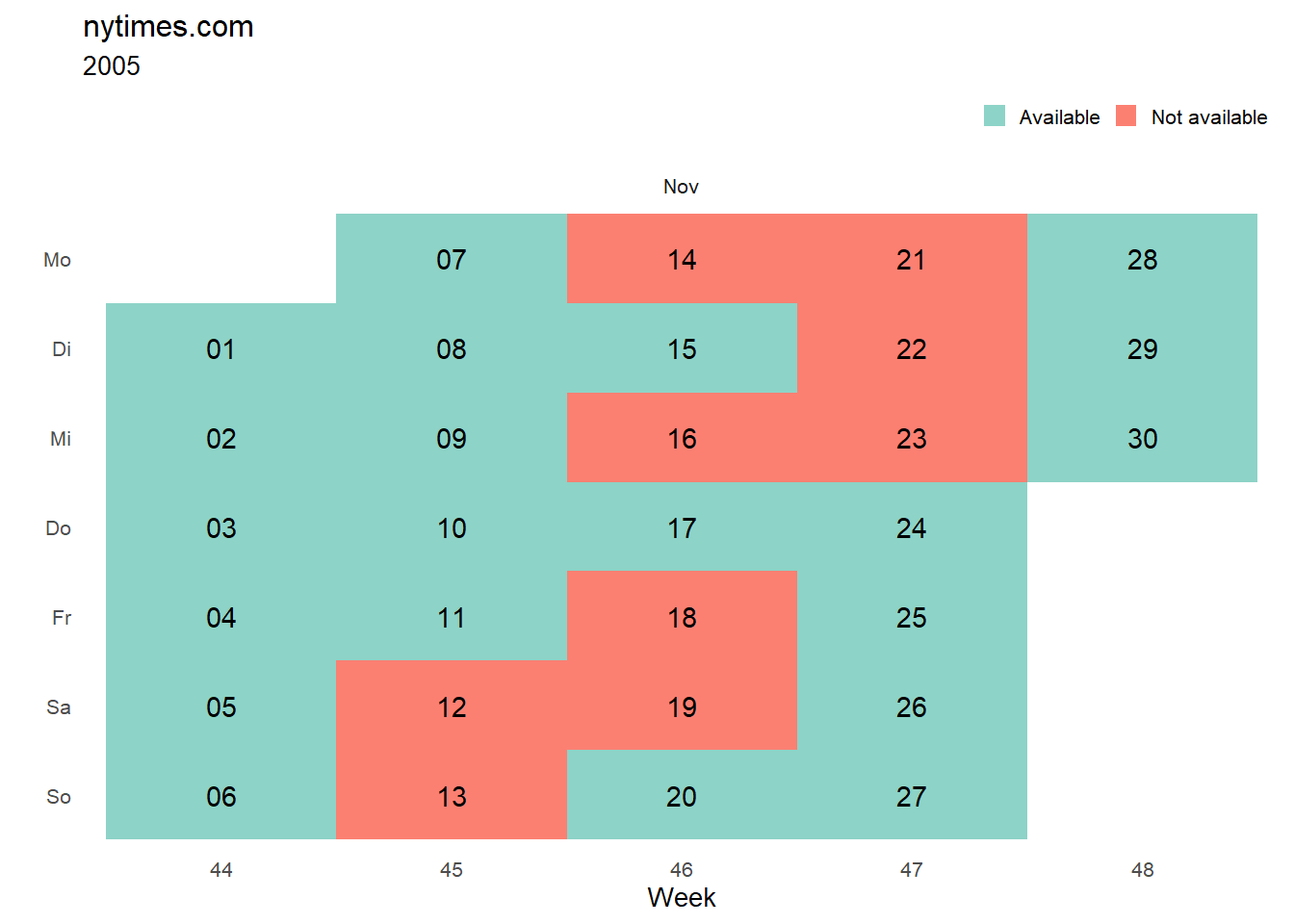
retrieve_urls() offers direct access to the memento Urls of any Url stored in the Internet Archive. The function takes the base Url and the time frame as inputs and returns a vector of memento Urls. For convenience, retrieve_urls() automatically collapses mementos by day. However, this can be deactivated with the option collapseDate = FALSE.
urls <- retrieve_urls(homepage = "nytimes.com", startDate = "20191201", endDate = "20191202", collapseDate = FALSE)
head(urls)## [1] "http://web.archive.org/web/20191201001433/https://www.nytimes.com/" "http://web.archive.org/web/20191201003228/http://nytimes.com/" "http://web.archive.org/web/20191201003239/https://www.nytimes.com/" "http://web.archive.org/web/20191201010836/https://www.nytimes.com/"
## [5] "http://web.archive.org/web/20191201011129/http://www.nytimes.com/" "http://web.archive.org/web/20191201011131/https://www.nytimes.com/"Oftentimes researchers and practitioners do not know the specific Urls they are interested in, but want to retrieve information from all or some subpages of a base Url, e.g. when scraping news content from online newspapers. For this purpose, the archiveRetriever offers the function retrieve_links(). retrieve_links() takes any number of memento Urls (obtained via retrieve_urls()) as input and returns a data.frame listing all links of mementos referenced to in the original memento. This enables users e.g. to obtain all mementos of newspaper articles from the New York Times linked to on the memento of the homepage of the newspaper.
links <- retrieve_links("http://web.archive.org/web/20191201001433/https://www.nytimes.com/")
head(links)## # A tibble: 6 x 2
## baseUrl links
## <chr> <chr>
## 1 http://web.archive.org/web/20191201001433/https://www.nytimes.com/ http://web.archive.org/web/20191201001433/https://www.nytimes.com/
## 2 http://web.archive.org/web/20191201001433/https://www.nytimes.com/ http://web.archive.org/web/20191201001433/https://www.nytimes.com/
## 3 http://web.archive.org/web/20191201001433/https://www.nytimes.com/ http://web.archive.org/web/20191201001433/https://www.nytimes.com/es/
## 4 http://web.archive.org/web/20191201001433/https://www.nytimes.com/ http://web.archive.org/web/20191201001433/https://cn.nytimes.com/
## 5 http://web.archive.org/web/20191201001433/https://www.nytimes.com/ http://web.archive.org/web/20191201001433/https://myaccount.nytimes.com/auth/login?response_type=cookie&client_id=vi
## 6 http://web.archive.org/web/20191201001433/https://www.nytimes.com/ http://web.archive.org/web/20191201001433/https://myaccount.nytimes.com/auth/login?response_type=cookie&client_id=viFinally, memento Urls and their time stamps are seldom the information of interest for anyone using the Internet Archive. Therefore, the archiveRetriever offers the function scrape_urls() to easily scrape any content from Internet Archive mementos obtained by the previous functions. The function takes a memento of the Internet Archive and a named vector of XPaths (or CSS) as obligatory inputs and results in a tibble with the content scraped using the XPath/CSS selectors.
nytimes_article <- scrape_urls(Urls = "http://web.archive.org/web/20201001004918/https://www.nytimes.com/2020/09/30/opinion/biden-trump-2020-debate.html",
Paths = c(title = "//h1[@itemprop='headline']",
author = "//span[@itemprop='name']",
date = "//time//text()",
article = "//section[@itemprop='articleBody']//p"))
nytimes_article## # A tibble: 1 x 5
## Urls title author date article
## <chr> <chr> <chr> <chr> <chr>
## 1 http://web.archive.org/web/20201001004918/https://www.nytimes.com/2020/09/30/opinion/biden-trump-2020-debate.html After That Fiasco, Biden Should Refuse to Debate Trump Again Frank Bruni Sept. 30, 2020 "I wasn’t in the crowd of people who believed Joe Biden shouldn’t deign to debate President Tru~scrape_urls() comes with many options that facilitate the scraping of large amounts of Internet Archive mementos and make the scraping more flexible. A detailed description of the different functions of the archiveRetriever including scrape_urls() can be found on github and in the package documentation.
16.5 Social science examples
The Internet Archive is still a rarely used source for social sciences. While there are some works focused directly on the Internet Archive and its contents (e.g. Milligan, Ruest, and Lin 2016; Littman et al. 2018; Hale, Blank, and Alexander 2017), or the development of the internet itself (e.g. Hale et al. 2014; Brügger, Laursen, and Nielsen 2017), research using he Internet Archive as data source for questions unrelated to the Internet or the Internet Archive itself are scarce. A notable exception is Gavras (2022), who uses the Internet Archive to access newspaper articles from a total of 86 online newspapers in 29 countries across Europe to research European media discourse.