Información general
Estadística descriptiva
Como primera instancia, se comienza a generar un análisis de estadísticas generales para poder conocer un poco mejor la información que se tiene. En el siguiente cuadro podemos observar la media, mediana, varianza y cuantiles:
A partir de ello podemos comenzar a tener una idea de la información que tenemos para trabajar. Lo primero que se puede notar es el hecho de que los datos sobre cantidades de empresas son bastante homogéneos, pero no es el caso con los datos de las características del mercado, ya que estos pueden alcanzar máximos muy dispares entre Property A y Property B, por ejemplo. Por otra parte, encontramos que existen múltiples outliers (datos atípicos) en la información, los cuales podemos eliminarlos de manera sencilla, sin embargo, en este caso se busca al mejor contendiente para expandir operaciones por parte de la empresa, por lo que vamos a requerir principalmente esos datos atípicos (los más altos) para poder descubrir potenciales ganadores.
Normalización de los datos
Para poder pasar los datos a una misma escala, se realizaran diferentes transformaciones a la información. Primero, para las características de mercado vamos a dividir los valores entre su valor máximo y luego dividirlas entre 3, esto para poder sacar para cada caso un ranking que vaya del 0 al 0.3 como máximo, siendo este último valor el más óptimo para cada caso. Después de lo anterior se van a sumar los 3 valores para así obtener un ranking que vaya del 0 al 0.99 (considerando que este último podría ser periódico), siendo el 0.99 el más óptimo para este caso. La fórmula en cuestión para el cálculo sería la siguiente:
Ranking=Pαmax(Pα)3+Pβmax(Pβ)3+Pcmax(Pc)3
Ahora, para el caso de la cantidad de empresas que se tienen en el mercado, aquí la información es mucho más homogenea, pero para poder compararla con el otro valor calculado se requiere transformarla a una escala que vaya de 0 a 1, por lo que simplemente se van a sumar la cantidad total de empresas que existen en una zona determinada y después se van a dividir los valores entre el máximo observado, de la siguiente manera:
Ranking empresas=Iα+Iβ+Icmax(Iα+Iβ+Ic)
Finalmente, dividimos ambos rankings entre 2 para poder obtener una escala que vaya de 0 a 0.99, por lo que el cálculo final es el siguiente:
Calificación=Ranking empresas2+Ranking2
A continuación se mostrará una tabla con los resultados obtenidos:
Analizando la información
Gráficamente podemos observar las calificaciones finales de la siguiente manera:
Por lo que rápidamente podríamos concluir que la ciudad de New York sería el candidato perfecto, sin embargo, esto no necesariamente es así. Si agrupamos las calificaciones por estado y obtenemos la media, podemos observar lo siguiente:
Podemos notar que todo el estado de New York se va hasta la quinta posición en el ranking, lo que implica que solo una de sus ciudades (New York) tiene una buena calificación, pero el resto de ellas aún se encuentra muy lejos de crecer industrialmente. Esto se puede corroborar al analizar la información en un mapa interactivo, tal que:
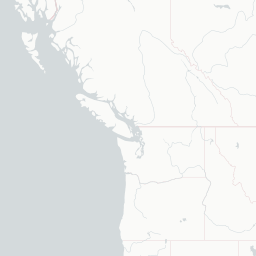
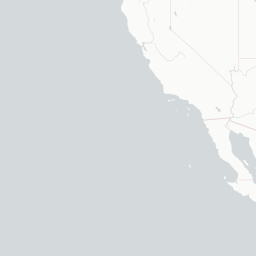

Lo que podemos observar principalmente es el hecho de que, la mayoría de las empresas tienden a agruparse hacía la parte noroeste del país, por lo que ese también será un factor a considerar.
Correlación entre las variables
En este caso, al tratar de descartar una variable por su correlación con las demás, se observó que todas presentaban un comportamiento relativamnte similar, con una relación positiva entre ellas, además de que la correlación en todos los casos se mantenía entre 60%-80%. Esto se puede ver de manera interactiva en la app realizada para visualizar los datos.
Otras consideraciones económicas
El veredicto final no solo depende de la información proporcionada, ya que hay que considerar algo muy importante: Los costos de transporte. La ciudad con una mayor calificación (New York) no tiene a su alrededor demasiadas empresas, en el resto de las ciudades, además de que sus características de mercado son bastante pobres, lo que implica que la empresa podría sutuarse en un estado que, al no tener el resto de las zonas/ciudades industrializadas puede aumentar los costos de transporte, tanto de insumos como de productos vendidos a otras compañias por la propia empresa, lo que puede volver ineficiente en el mediano plazo la colocación de la empresa en este lugar. En este punto, valdría la pena generar un problema de maximización lineal para, considerando los costos de transporte y calificación promedio por estado, ver realmente cuál es la ciudad más óptima para la colocación de la empresa.
Posibles ganadores
Si bien no está claro cuál caso es el más óptimo, debido a que no se ha podido calcular la cuestión de costos, considerando la información anterior se puede decir que a nivel ciudad, la más óptima es la ciudad de New York, mientras que a nivel estado se podría considerar a GA (Georgía) como el estado más equilibrado en cuanto a industrialización y el que podría tener un mayor margen de reducción de costos.
Referencias bibliográficas
[1] Wooldridge, J. M. (2010). Econometric analysis of cross section and panel data. MIT press.
[2] Anselin, L. (2001). Spatial econometrics. A companion to theoretical econometrics, 310330.Chicago
[3] LeSage, J. (2015). Spatial econometrics. In Handbook of research methods and applications in economic geography. Edward Elgar Publishing.
[4] Crickard III, P. (2014). Leaflet. js essentials. Packt Publishing Ltd.
[5] Edler, D., & Vetter, M. (2019). The simplicity of modern audiovisual web cartography: An example with the open-source javascript library leaflet. js. KN-Journal of Cartography and Geographic Information, 69(1), 51-62.
[6] Li, D., Mei, H., Shen, Y., Su, S., Zhang, W., Wang, J., … & Chen, W. (2018). ECharts: a declarative framework for rapid construction of web-based visualization. Visual Informatics, 2(2), 136-146.
[7] Maronna, R. A., Martin, R. D., Yohai, V. J., & Salibián-Barrera, M. (2019). Robust statistics: theory and methods (with R). John Wiley & Sons.
[8] Potter, G., Wong, J., Alcaraz, I., & Chi, P. (2016). Web application teaching tools for statistics using R and shiny. Technology Innovations in Statistics Education, 9(1).