| ID1 | Dolor1 | ID2 | Dolor2 | ID3 | Dolor3 |
|---|---|---|---|---|---|
| 1 | moderado | 16 | leve | 31 | ninguno |
| 2 | ninguno | 17 | leve | 32 | moderado |
| 3 | leve | 18 | moderado | 33 | ninguno |
| 4 | ninguno | 19 | ninguno | 34 | ninguno |
| 5 | severo | 20 | ninguno | 35 | leve |
| 6 | ninguno | 21 | leve | 36 | ninguno |
Estadística descriptiva para variables cualitativas
Bioestadística básica/Posgrados CUCS
Pérez-Guerrero Edsaúl Emilio
Instituto de Investigación en Ciencias Biomédicas
2024-09-01
Contenido
- Introducción
- Tablas de frecuencias
- La función
table() - Gráficos de barras
- Gráficos de sectores
- Gráficos de mosaicos
- La función
cut()
Etapas del análisis estadístico
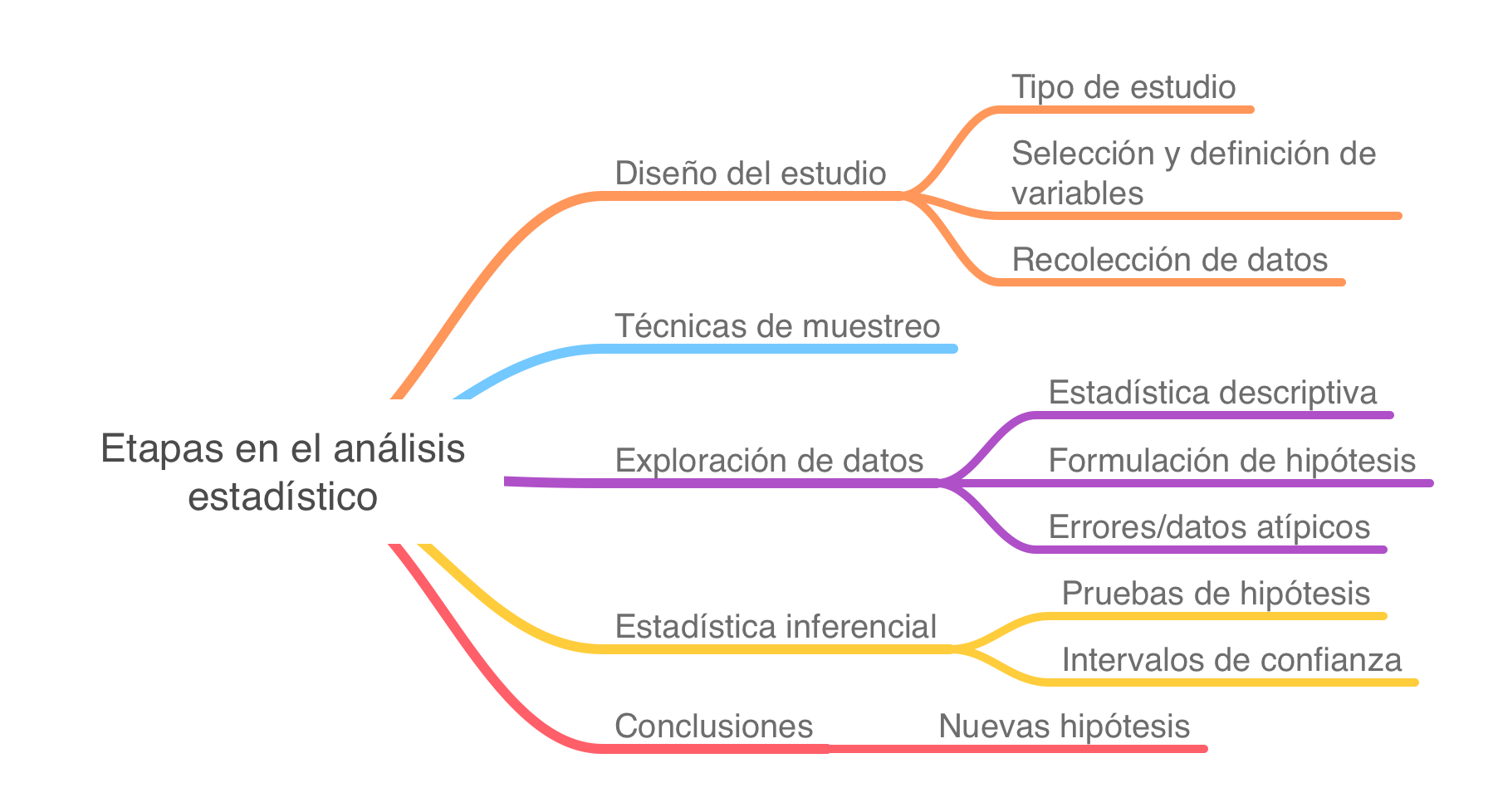
Etapas en el análisis estadístico
¿Cómo podemos resumir y presentar variable cualitativa?
Estdística descriptiva para varibles cualitativas
Estdística descriptiva para varibles cualitativas
Estdística descriptiva para varibles cualitativas
Estdística descriptiva para varibles cualitativas
- La estadística descriptiva tiene por misión resumir la información que proporciona un conjunto de datos y de las variables
- Consiste en presentar y resumir los datos, para ello, empleamos tablas, estimación de estadísticos y gráficos.
Estdística descriptiva para varibles cualitativas
- Conteos, frecuencias
- Tablas de frecuencias
- Gráficas
- Barras
- Sectores
- Mosaicos
- Otros
- Gráficas
Datos sobre el dolor de un grupo de pacientes
Datos sobre el dolor de un grupo de pacientes resumidos
| Categoría del dolor | Frecuencia | Frecuencia relativa | Frecuencia acumulada | Frecuencia relativa acumulada |
|---|---|---|---|---|
| Severo | 4 | 0.70 | 60 | 1.00 |
| Moderado | 8 | 0.13 | 56 | 0.93 |
| Leve | 17 | 0.28 | 48 | 0.80 |
| Ninguno | 31 | 0.52 | 31 | 0.52 |
Medidas de resúmen para variable cualitativas
Existen algunas medidas que podemos utilizar para presentar más ampliamente nuestros datos:
Frecuencia
Frecuencia relativa (proporción)
Frecuencia acumulada
Frecuencia relativa
Frecuencia absoluta
La frecuencia absoluta (fa): es el número de veces que se ha observado dicha modalidad
Son los conteos que podemos hacer a las categorías de las variable cualitativas
\[\sum{fa=n}\]
Frecuencia relativa (proporciones)
La frecuencia relativa (fr): Es la frecuencia absoluta dividida entre el número de casos.
Se puede expresar como proporción o como porcentaje
\[\sum{fr=\frac{fa}{n}}\]
Frecuencia acumulada
La frecuencia acumulada es el resultado que se obtiene de la suma sucesiva de las frecuencias absolutas o relativas, cuando se realiza de menor a mayor según sus valores
Los datos se pueden ir sumando en orden ascendente o descendente
El criterio para el orden dependende de muchos factores
Ejemplo 1
En un servicio de Traumatología, con objeto de realizar una correcta planificación, interesa conocer la localización de la patología principal de los pacientes atendidos en urgencia, para lo cual se estudia una muestra de 186 elegida entre los pacientes atendidos durante los últimos 6 meses. La variable de interés es la zona afectada. Es una variable cualitativa dividida en 5 modalidades: rodilla, cadera, tobillo, cráneo y otras
Ejemplo 1
Al final del estudio se obtuvo que en los 6 meses se atendieron 30 problemas relacionados con rodilla, 28 con cadera, 41 con tobillo, 34 cráneo y 53 otras.
- Obtenga la frecuencia absoluta, frecuencia relativa, % y frecuencia acumulada
03:00
Ejemplo 1
| Zona afectada | fa | fr | fr como porcentaje | Frecuencia acumulada |
|---|---|---|---|---|
| Rodilla | 30 | -- | -- | -- |
| Cadera | 28 | -- | -- | -- |
| Tobillo | 41 | -- | -- | -- |
| Cráneo | 34 | -- | -- | -- |
| Otras | 53 | -- | -- | -- |
| Total | 186 | -- | -- | -- |
Ejemplo 1
| Zona | fa | fr(n) | fr(%) | fa_acum |
|---|---|---|---|---|
| Rodilla | 30 | 0.161 | 16.1 | 30 |
| Cadera | 28 | 0.151 | 15.1 | 58 |
| Tobillo | 41 | 0.220 | 22.0 | 99 |
| Cráneo | 34 | 0.183 | 18.3 | 133 |
| Otras | 53 | 0.285 | 28.5 | 196 |
| Total | 186 | 1.000 | 100.0 | -- |
¿Cómo obtener una tabla de frecuencias con R?
table()permite conocer las frecuencias de un objeto, incluso si los tipos de datos no son caulitativos.prop.tablepermite obtener las proporciones de un objeto. Es necesario que el objeto sea un tablaaddmarginspermite obtener las frecuencias acumuladas de un determinado objeto.Es necesario que el objeto sea una matriz.cumsum()realiza la suma acumulativa de las frecuencias de un objeto.
Ejemplo 2
Partiremos de un objeto llamado grados
Obenter frecuencias
Obenter proporciones
Obtener porcentajes
Obtener frecuencias acumuladas
Tablas como objetos
Obenter frecuencias
Obenter proporciones
Obtener porcentajes
Obtener frecuencias acumuladas
Tabla con todos los datos
Copie el código
data_freq <-
data.frame(
Nombres= names(x), # Obtener los nombres
Freq =as.numeric(x), # necesario convertir a numérico para la suma
Freq_Rela = as.numeric(prop.table(x)), # Frecuencia relativa
Freq_Acum = as.numeric(cumsum(x)), # Frecuencia acumulada
Freq_Rela_Acum = as.numeric (cumsum(prop.table(x))))
print(data_freq) # Imprimir la tabla de frecuencias Tabla con todos los datos
Nombres Freq Freq_Rela Freq_Acum Freq_Rela_Acum
1 A 268 0.268 268 0.268
2 B 252 0.252 520 0.520
3 C 233 0.233 753 0.753
4 D 247 0.247 1000 1.000Reto 1
Utilizando la base de datos Base Descripitivos.rds realice una tabla de frecuencia para la variable Ocupación
07:00
Reto 1. Solución
Freq Freq_Rela Freq_Acum Freq_Rela_Acum Nombre
1 50 0.1501502 50 0.1501502 Licenciatura
2 62 0.1861862 112 0.3363363 Posgrado
3 52 0.1561562 164 0.4924925 Preparatoria
4 45 0.1351351 209 0.6276276 Primaria completa
5 63 0.1891892 272 0.8168168 Primaria incompleta
6 61 0.1831832 333 1.0000000 SecundariaTablas de frecuencias utilizando otras librerías
Janitor
df$Escolaridad n percent valid_percent
Licenciatura 50 0.14285714 0.1501502
Posgrado 62 0.17714286 0.1861862
Preparatoria 52 0.14857143 0.1561562
Primaria completa 45 0.12857143 0.1351351
Primaria incompleta 63 0.18000000 0.1891892
Secundaria 61 0.17428571 0.1831832
<NA> 17 0.04857143 NAquestionr
n % val% %cum val%cum
Licenciatura 50 14.3 15.0 14.3 15.0
Posgrado 62 17.7 18.6 32.0 33.6
Preparatoria 52 14.9 15.6 46.9 49.2
Primaria completa 45 12.9 13.5 59.7 62.8
Primaria incompleta 63 18.0 18.9 77.7 81.7
Secundaria 61 17.4 18.3 95.1 100.0
NA 17 4.9 NA 100.0 NA
Total 350 100.0 100.0 100.0 100.0questionr
n % val% %cum val%cum
Primaria incompleta 63 18.0 18.9 18.0 18.9
Posgrado 62 17.7 18.6 35.7 37.5
Secundaria 61 17.4 18.3 53.1 55.9
Preparatoria 52 14.9 15.6 68.0 71.5
Licenciatura 50 14.3 15.0 82.3 86.5
Primaria completa 45 12.9 13.5 95.1 100.0
NA 17 4.9 NA 100.0 NA
Total 350 100.0 100.0 100.0 100.0Agrupación de datos
Agrupación de datos
| Intervalo | Frecuencia | Frecuencia relativa | fa | fr |
|---|---|---|---|---|
| 142-149 | 2 | 0.014 | 144 | 1.000 |
| 134-141 | 40 | 0.278 | 142 | 0.986 |
| 126-133 | 36 | 0.250 | 102 | 0.708 |
| 118-125 | 21 | 0.146 | 66 | 0.458 |
| 110-117 | 18 | 0.125 | 45 | 0.313 |
| 10-109 | 8 | 0.056 | 27 | 0.188 |
| 94-101 | 14 | 0.097 | 19 | 0.132 |
| 86-93 | 5 | 0.035 | 5 | 0.035 |
Agrupación de datos
- Los datos de variables cuantititivas pueden presentarse en forma tabular mediante un arreglo ordenad, donde los valores se agrupan en intervalos de clase.
- No deben traslaparse
- Consecutivos
Agrupación de datos
- Definir el número de intervalo de clase (aprox. 5-15). Puede utilizar la siguiente formula:
\[k=1+3.322*log(n)\]
Agrupación de datos
- Definir la amplitud de cada intervalo (prueba y error). Por ejemplo la edad en niños menores de 1o años se puede agrupar en menores a 1 años, 1 a 4 y 5 a 10.
- Ordenar datos
- Contar número de observaciones que incluye el intervalo de clase.
La función cut()
En ocasiones, es de nuestro interés fracciones o segmentar una variable de cuantitativa para poder obtener categorías de la misma
La función cut()
x: vector numérico
breaks: puntos de corte, debe ser mayor a 2
labels: etiquetas de cada categoría
right: indica hacía donde debe cerrarse el intervalo ]. El valor predeterminado es el izquierdo ( ], es decir no incluirá el número del lado izquierdo pero si el del lado derecho.
La función cut()
La función cut(). Ejemplo
Utilizando el objeto edad realice cortes de manera que pueda identificar cuantos pacientes tienen una edad menor o igual a 10, de 11 a 30 años incluyendo el 30 y el resto de los pacientes. No cambie las etiquetas de los niveles. Nombre este nuevo objeto como edad1, pida los conteos de los niveles utilizando la función table, realice una gráfica de barras con esta nueva variable
La función cut(). Ejemplo
La función cut(). Ejemplo
Podemos comprobar exactamente cuantos datos son iguales a 30
La función cut(). Ejemplo
¿Qué sucede si cambiamos el argumentoro right=F
La función cut(). Ejemplo
¿Qué sucede si cambiamos el argumentoro right=F?¿Qué cambió?
edad2
[0,10) [10,30) [30,Inf)
197 410 193 La función cut(). Ejemplo
Cambie las etiquetas de los niveles edad1 y edad2 por: “Grupo edad 1”, “Grupo de edad 2”, “Grupo de edad 3”. Para ello utilice el argumento labels
Realice un tabla de conteos
07:00
La función cut(). Ejemplo
La función cut(). Ejemplo
Gráficos
Gráficos utilizados para estidística descriptiva de variables cualitativas
Gráficas - Barras. Función barplot - Sectores. Función pie - Mosaicos. Función mosaicplot - Gráficos de donas. Tidyverse (ggplot2) Se verá en próximas clases - Circle Packing. (ggplot2) Se verá en próximas clases
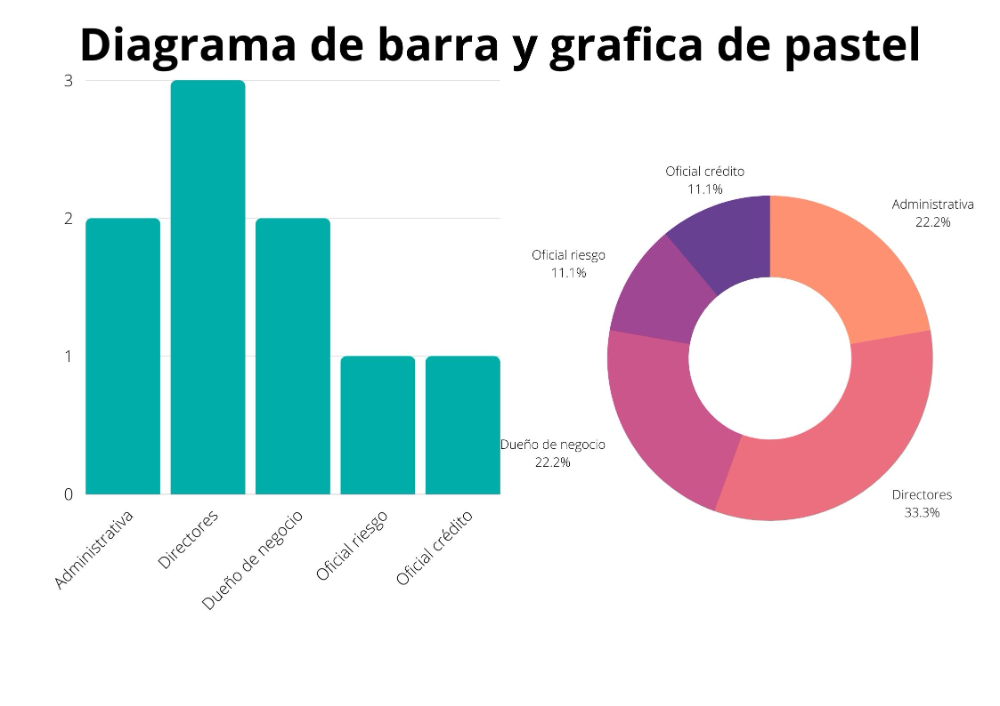
Gráficos de barras
Un gráfico de barras es una herramienta útil para representar la frecuencia o proporción de diferentes categorías de una variable cualitativa.
Por ejemplo se utiliza si tenemos datos como el tipo de enfermedad, la clasificación de severidad de una enfermedad, el grupo sanguíneo de pacientes, etc.
Gráficos de barras
En R utilizamos la función barplot que se alimenta de tablas
Vamos a generar algunos datos
Gráficos de barras
Vamos a crear nuestro primer gráfico de barras
Gráficos de barras

Gráficos de barras
Podemos mejorar nuestro gráfico
Gráficos de barras

Colores R

Colores R

Reto 2
Genere un gráfico de barras utilizando el objeto grados y cambie los colores para cada una de las barras. Además el eje de las y deberá estar en porcentaje
05:00
Reto 2
Reto 2

Gráficos de sectores
El gráfico de sectores, también conocido como gráfico circular o gráfico de pastel, es una representación visual utilizada para mostrar la proporción o distribución de diferentes categorías dentro de un conjunto de datos.
Cada categoría se representa como un sector circular en el gráfico, y el tamaño de cada sector es proporcional a la frecuencia o proporción de esa categoría en relación con el total
Grñaficos de sectores
Este tipo de gráfico es útil para visualizar la composición relativa de una variable cualitativa en un conjunto de datos
\[Tamaño \ sector= \frac{f}{n} \times 360\]
Gráfico de sectores
Gráfico de sectores

Reto 3
Genere un gráfico de sectores para el objeto Grados, cambie el título y los colores
05:00
Reto 3
Reto 3

Gráfico de mosaicos
- El gráfico de mosaico, también conocido como gráfico de mosaico o gráfico de barras apiladas, es una representación visual utilizada para mostrar la relación entre dos variables categóricas.
- Cada rectángulo en el gráfico representa una combinación única de categorías dond el tamaño es relativo a las frecuencias
Gráfico de mosaico
set.seed(123) # Para reproducibilidad
# Crear un conjunto de datos de ejemplo
tratamiento <- sample(c("A", "B", "C"), 100, replace = TRUE)
resultado <- sample(c("Éxito", "Fracaso"), 100, replace = TRUE)
# Combina los datos en un data frame
datos <- data.frame(tratamiento, resultado)
# Visualiza los primeros datos
head(datos) tratamiento resultado
1 C Éxito
2 C Fracaso
3 C Fracaso
4 B Éxito
5 C Éxito
6 B ÉxitoGráfico de mosasico

La función rprop
La función rprop de la librería questionr permite obtener tablas de contingencia o cruzadas con porcentajes
ggplot2
ggplot2es una librería de visualización de datos enRque implementa la gramática de gráficos, una forma de describir y construir gráficos de manera más intuitiva y flexible que las funciones base deR.
Mismas gráficas con ggplot2
copien el siguiente código:
# Crear el dataframe con variables cualitativas
datos_salud <- data.frame(
Sexo = factor(c("Masculino", "Femenino", "Femenino", "Masculino", "Femenino",
"Masculino", "Masculino", "Masculino", "Femenino", "Masculino")),
Fumador = factor(c("Sí", "No", "Sí", "No", "Sí",
"Sí", "No", "No", "Sí", "No")),
Diagnóstico = factor(c("Diabetes", "Hipertensión", "Cáncer", "Hipertensión", "Diabetes",
"Cáncer", "Diabetes", "Hipertensión", "Cáncer", "Hipertensión")),
Tratamiento = factor(c("Medicamento A", "Medicamento B", "Quimioterapia", "Medicamento B", "Insulina",
"Quimioterapia", "Insulina", "Medicamento B", "Quimioterapia", "Medicamento B"))
)Gráficos de barras en ggplot2
Entendiendo a ggplot2
Gráficos de barras en ggplot2
Entendiendo a ggplot2
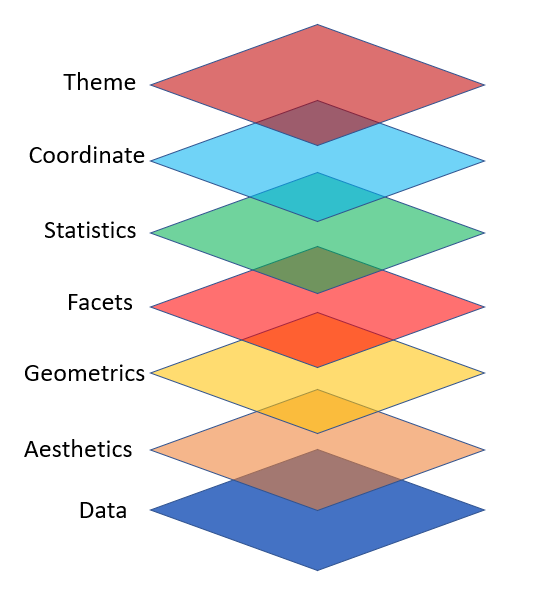
Capas en ggplot2
Gráficos de barras en ggplot2
Gráficos de barras en ggplot2
Gráficos de barras en ggplot2
Gráficos de barras en ggplot2
Gráficos de barras en ggplot2
Gráficos de barras en ggplot2
Gráficos de barras en ggplot2
Gráficos de barras en ggplot2

Reto 4
Cree gráficos de barras para las variables Fumador, Diagnóstico y Tratamiento utilizando ggplot2
07:00
![]()
Bioestadística básica/Posgrados CUCS