11.9 Pruebas no paramétricas comparación de variables cuantitativas 2
Bioestadística/Universidad de Guadalajara
1 Introducción
Cuando se quiere comparar una variables de tipo cuantititivo u ordinal entre dos o entre más de dos grupos pero esta no presenta una distribución normal no se puede emplear la prueba t-student o las prueba de ANOVA de una vía. Ya que estas pruebas no son libres de parámetros y requieren que se cumplan algunos supuestos (por ejemplo de la normalidad). Por lo tanto, al no poder emplear estas pruebas, debe de recurrirse a ciertas alternativas no-paramétricas (libres de parámetros).
Las pruebas a saber son:
- Prueba U-Mann-Whitney. Prueba que compara la suma de rangos de variables en dos grupos independientes. Es el equivalente no paremétrico de la prueba t-student para muestra independientes.
- Prueba Prueba de los rangos de wilcoxon. Prueba que compara la suma de rangos de dos variables medidas en dos grupos dependientes. Es el equivalente no paremétrico de la prueba t-student para muestras pareadas
- Prueba de Kruskkal-Wallis. Prueba que compara la suma de rangos en más de dos grupos independientes. Es el equivalente no paremétrico de la prueba del ANOVA de una vía.
Se describen a continuación cada una de estás pruebas. En cada sub-tema, primero se describe el fundamento de la prueba, seguido de la forma de realizarlo manualmente y finalmente como se puede utilizar R para poder realizarlo.
2 Prueba U-Mann-Whitney
La prueba U de Mann-Whitney es una prueba estadística que se utiliza para determinar si Una variables de tipo cuantativo u ordinal es diferente entre dos grupos independientes. Es el equivalente a la prueba t-student para muestras independientes.
En la prueba U de Mann-Whitney la variable a comparar debe ser por lo menos de tipo ordinal. Además los grupos deberán ser independientes (no relacionados entre sí) y se deben de tener una muestra suficiente (más de 5 valores en cada grupo, aunque también depende de qué tan grande sea la diferencia entre los grupos).
La prueba U de Mann-Whitney es una prueba basada en rangos que compara los valores de dos grupos. Un resultado significativo sugiere que los valores para los dos grupos son diferentes. La prueba de Mann-Whitney no aborda hipótesis sobre las medianas de los grupos. En cambio, la prueba aborda si es probable que una observación en un grupo sea mayor que una observación en el otro.
Aunque es un prueba de paramétros, necesita el cumplimiento de los siguientes supuestos:
- las muestras son aleatorias e independientes y
- la escala de medición es ordinal o cuantitativa
- la forma de los datos debe ser similar entre los grupos
- se deben de tener datos suficientes.
Puede encontrar mayor información referene a esta prueba en:
http://www.statstutor.ac.uk/resources/uploaded/mannwhitney.pdf
https://www.tqmp.org/RegularArticles/vol04-1/p013/p013.pdf
https://www.medigraphic.com/pdfs/imss/im-2013/im134k.pdf
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7643794/
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6377068/
https://www.statstest.com/mann-whitney-u-test/#What_is_a_Mann-Whitney_U_Test
https://data.library.virginia.edu/the-wilcoxon-rank-sum-test/
2.1 Pasos para reliazar la prueba de U-Mann_Whitney
La siguiente explicación sobre como realizar la prueba de U-Mann-Whitney fue tomada del libro Bioestadística de los autores Celis y Labrada.
Debemos de partir de una muestra aleatoria, por lo tanto el primer paso es obtener esta muestra.
Posteriormente, debemos de identificar si las muestras tienen un número igual de elementos, ya que en el caso de ser diferentes debemos de identificarlas. Si las muestras son diferentes, se identifica a la muestra más pequeña con la letra \(X\) y a la otra con la letra \(Y\). Si ambas tienen el mismo tamaño, no tiene importancia qué letra les corresponde, solemente debemos de indentificar un grupo 1 y un grupo 2.
Se designan las observaciones de la muestra de tamaño \(n_1\) obtenida de la población \(X\) con \(x1 , x2 , . . ., xi , . . ., xn\) y las observaciones de la muestra de tamaño \(n_2\) obtenida de la población \(Y\) con \(y1 , y2 , . . ., yi , . . ., yn\). Es decir debemos de indentificar los componentes de cada una de las muestras.
Sin perder de vista al grupo al que pertenecen (X o Y), las dos muestras se combinan y se ordenan de menor a mayor. Posteriormente, se le asigna la posición 1 a la observación con el valor más pequeño y la posición \(n_1 + n_2\) es decir, la más alta, a la observación con el valor más grande. Estos valores de la posición de cada uno de los datos nos servirán para estimar los rangos.
Cuando hay dos o más observaciones con el mismo valor, o empatadas (en términos de rangos), se les asigna la media de las posiciones que ocuparían si no hubiera empates. La selección sobre cual dato va antes o después no importa para esots fines. Por ejemplo, si dos observaciones tienen el valor 10 y les corresponden las posiciones 4 y 5, a las dos se les asigna la posición 4.5. Los mismos valores siempre corresponden al mismo rango
El siguiente paso es estimar, tomando como base los rangos, al estadístico de prueba. Existen dos estadísticos de prueba, una propuesto por Wilxcoson (estadístico U) y otro propuesto por Mann y Whitney (estadístico T).
El estadístico T, es el más fácil de calcular y corresponde a la suma de los rangos (obtenidos de las posiciones) asignados a la muestra más pequeña, \(n_1\) , o de cualquiera de las dos si tienen el mismo tamaño.
El estadístico U se estima con la siguient formula
\[U=n_1n_2+0.5n_1(n_1+1)-T\]
Se prefiere el estadístico T para muestras grandes
- Rechazar o no \(H_0\) depende de la magnitud de T (o de U) y del nivel de significancia (\(\alpha\)).
Cuando las muestras son grandes, de 10 o más elementos en cada grupo, el estadístico T tiene una distribución aproximadamente normal con media se puede calcular el estadístico de prueba z mediante:
\[z=\frac{T-u_t}{\sigma_T}\]
La idea en la que se fundamenta este test es la siguiente: si las dos muestras comparadas proceden de la misma población, al juntar todas las observaciones y ordenarlas de menor a mayor, cabría esperar que las observaciones de una y otra muestra estuviesen intercaladas aleatoriamente. Por lo contrario, si una de las muestras pertenece a una población con valores mayores o menores que la otra población, al ordenar las observaciones, estas tenderán a agruparse de modo que las de una muestra queden por encima de las de la otra
2.1.1 Un ejemplo del cáculo manual para U-Mann-Whitney
Un investigador desea conocer si las horas de sueño son distintas en dos grupos en grupo de pacientes tratados con benzodicepinas. El grupo 1 corresponde a pacientes medicados con clonazepam y el grupo 2 a pacientes con lorazepam. La tabla 1 muestra las horas de sueño de estos pacientes.
| clonzepam | lorazepam |
|---|---|
| 10 | 13 |
| 6 | 17 |
| 8 | 14 |
| 10 | 12 |
| 12 | 10 |
| 13 | 9 |
| 11 | 15 |
| 9 | 16 |
| 5 | 11 |
| 11 | 8 |
| 9 | 7 |
Solución
La solución de este tipo de ejercicios se facilita si construimos una tabla como la que sigue y se va adecuando conforme avanzamos en los cálculos
| Valor de la variable (H de sueño) | Posición | Rango | Grupo al que pertenece | ||
|---|---|---|---|---|---|
| - | |||||
| - | |||||
| - | |||||
| - | |||||
| - | |||||
| - | |||||
| - | |||||
| - | |||||
| - | |||||
| - | |||||
| - | |||||
| - | |||||
| - | |||||
| - | |||||
| - | |||||
| - |
- Crear objetos
clonazepam <- c(10,6,8,10,12,13,11,9,5,11,9)
lorazepam <- c(13, 17,14,12,10,9,15,16,11,8,7)- Formular hipótesis
- \(H_O\) Rangos de lorazepam = a clonzepam
- \(H_A\) Los rangos de los grupos son distintas Otra opción sería:
- \(H_O\) Las horas de sueño son iguales en los pacientes con lorazepam y clonazepam
- \(H_A\) Las horas de sueño son distintas en los pacientes con lorazepam y clonazepamson
Tome en en cuenta que la opción mas correcta sería hablar de sumas de rangos y no de medias.
- Ordenar las muestras sin que se pierda su identidad, para ello cree un df llamado datos que contie una variable con los nombres de los tratamientos y otas variable con las horas de sueño
Horas <- c(clonazepam, lorazepam)
Tratamientos <- rep(x=c("clonazepam", "lorazepam"),
each=11)
datos <- data.frame(Horas, Tratamientos)| Horas | Tratamientos |
|---|---|
| 10 | clonazepam |
| 6 | clonazepam |
| 8 | clonazepam |
| 10 | clonazepam |
| 12 | clonazepam |
| 13 | clonazepam |
| 11 | clonazepam |
| 9 | clonazepam |
| 5 | clonazepam |
| 11 | clonazepam |
| 9 | clonazepam |
| 13 | lorazepam |
| 17 | lorazepam |
| 14 | lorazepam |
| 12 | lorazepam |
| 10 | lorazepam |
| 9 | lorazepam |
| 15 | lorazepam |
| 16 | lorazepam |
| 11 | lorazepam |
| 8 | lorazepam |
| 7 | lorazepam |
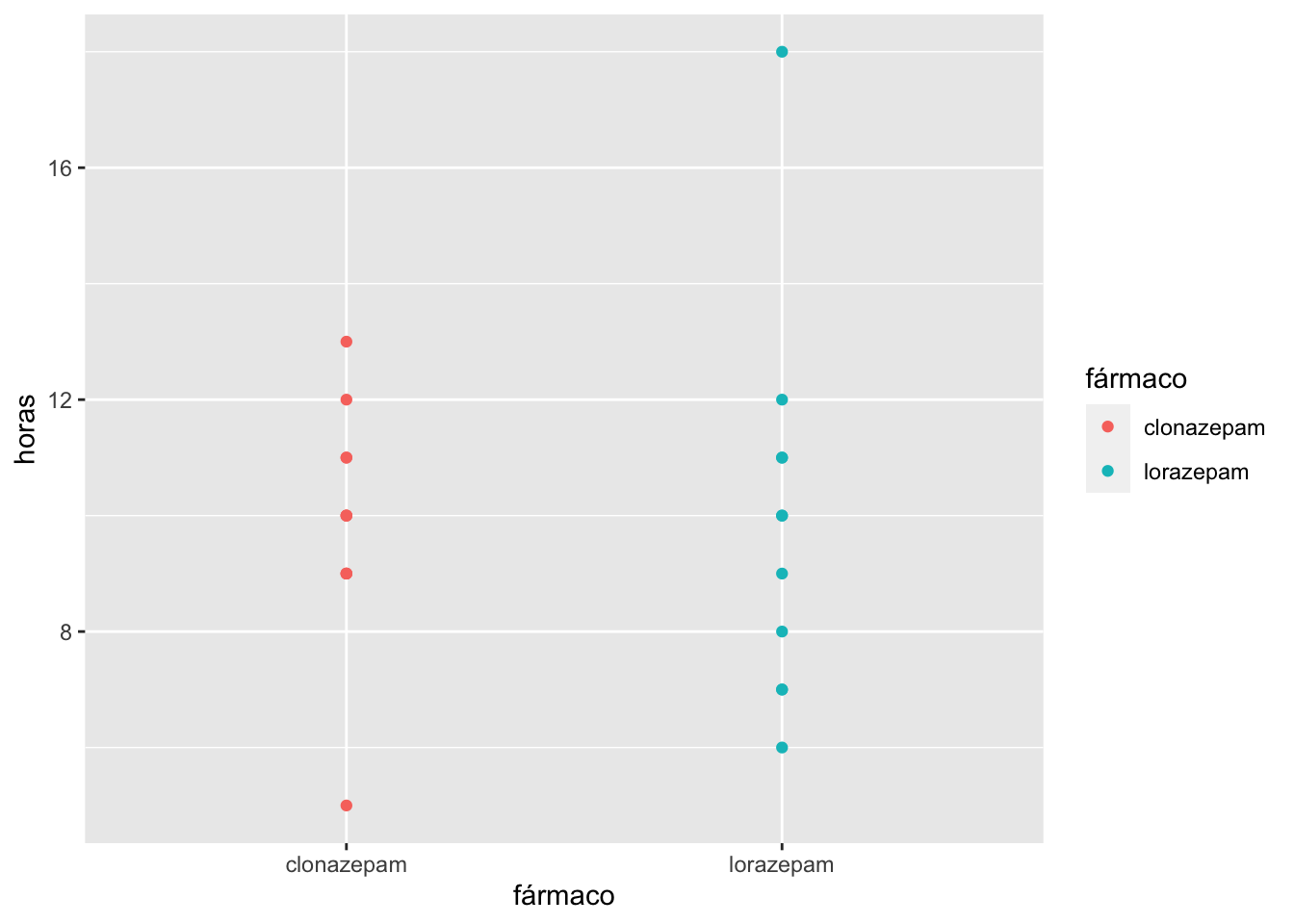
Si hacemos una visualización de los datos veremos lo siguiente:
Para ordenar los datos podemos usar la función order según lo escrito en el siguien código, si es más fácil, simplemente corte y pegue
print(datos[order(datos$Horas, decreasing = TRUE), ] )| Horas | Tratamientos | |
|---|---|---|
| 13 | 17 | lorazepam |
| 19 | 16 | lorazepam |
| 18 | 15 | lorazepam |
| 14 | 14 | lorazepam |
| 6 | 13 | clonazepam |
| 12 | 13 | lorazepam |
| 5 | 12 | clonazepam |
| 15 | 12 | lorazepam |
| 7 | 11 | clonazepam |
| 10 | 11 | clonazepam |
| 20 | 11 | lorazepam |
| 1 | 10 | clonazepam |
| 4 | 10 | clonazepam |
| 16 | 10 | lorazepam |
| 8 | 9 | clonazepam |
| 11 | 9 | clonazepam |
| 17 | 9 | lorazepam |
| 3 | 8 | clonazepam |
| 21 | 8 | lorazepam |
| 22 | 7 | lorazepam |
| 2 | 6 | clonazepam |
| 9 | 5 | clonazepam |
- Ya que los datos se encuentran ordenados deberán de asignarles una posición y un rango. La posición se refiere al orden en el que encuentran los datos ordenados y el rango es muy similar a la posición pero en el caso de valores de horas de sueño iguales deberá estimarse un promedio. La siguiente tabla muestra todos los datos correctos.
| Horas de sueño | Posición | Rango | Grupo |
|---|---|---|---|
| 5 | 1 | 1 | clonazepan |
| 6 | 2 | 2 | clonazepan |
| 7 | 3 | 3 | lorazepam |
| 8 | 4 | 4.5 | clonazepan |
| 8 | 5 | 4.5 | lorazepam |
| 9 | 6 | 7 | clonazepan |
| 9 | 7 | 7 | clonazepan |
| 9 | 8 | 7 | lorazepam |
| 10 | 9 | 10 | clonazepan |
| 10 | 10 | 10 | clonazepan |
| 10 | 11 | 10 | lorazepam |
| 11 | 12 | 13 | clonazepan |
| 11 | 13 | 13 | clonazepan |
| 11 | 14 | 13 | lorazepam |
| 12 | 15 | 15.5 | clonazepan |
| 12 | 16 | 15.5 | lorazepam |
| 13 | 17 | 17.5 | clonazepan |
| 13 | 18 | 17.5 | lorazepam |
| 14 | 18 | 19 | lorazepam |
| 15 | 19 | 20 | lorazepam |
| 16 | 20 | 21 | lorazepam |
| 17 | 21 | 22 | lorazepam |
- Estimar el valor de T. Este valor corresponde a la suma de los rangos que corresponden a la muestra más pequeña. Si las muestras tienen la misma cantidad de datos se elige cualquiera. Para este ejemplo voy a elegir lorazepam.
Tlorazepam <- 3+4.5+7+10+13+15.5+17.5+19+20+21+22
Tlorazepam[1] 152.5Empleamos la siguiente formula:
\[U=n_1n_2+0.5n_1(n_1+1)-T\]
y sustituimos
\[U=11*11+0.5*11(12)-152.5\]
U1 <- 11*11+0.5*11*12-152.5
U1[1] 34.5- Comparar el valor obtenido con los valore de tablas. El valor que obtenemos deberá ser menor que el valor de las tablas para ser significativo.
https://www.real-statistics.com/statistics-tables/mann-whitney-table/
En R lo podemos determinar utilizando el comando pwilcox
pwilcox(q=34.5, m=11, n=11)*2[1] 0.08794611El valor de p puede no coincidir con el obtenido en la prueba pero es parecido ya que hay varias formas de determinarlo
2.2 Como realizarlo en R
Las prueba de U-Mann-Whitney fue desarrollada en dos versiones independientes que conducen a la misma conclusión: la de Mann y Whitney, y la Wilcoxon. Por ello se conoce como prueba de Mann-Whitney-Wilcoxon. Este antecedente es la razón por la que en R se utiliza la función wilcox.test que contiene los siguientes argumentos:
- x
- numeric vector of data values. Non-finite (e.g., infinite or missing) values will be omitted.
- y
- an optional numeric vector of data values: as with x non-finite values will be omitted.
- alternative
- a character string specifying the alternative hypothesis, must be one of “two.sided” (default), “greater” or “less”. You can specify just the initial letter.
- mu
- a number specifying an optional parameter used to form the null hypothesis. See ‘Details’.
- paired
- a logical indicating whether you want a paired test.
- exact
- a logical indicating whether an exact p-value should be computed.
- correct
- a logical indicating whether to apply continuity correction in the normal approximation for the p-value.
- conf.int
- a logical indicating whether a confidence interval should be computed.
- conf.level
- confidence level of the interval.
- tol.root
- (when conf.int is true:) a positive numeric tolerance, used in uniroot(*, tol=tol.root) calls.
- digits.rank
- a number; if finite, rank(signif(r, digits.rank)) will be used to compute ranks for the test statistic instead of (the default) rank(r).
- formula
- a formula of the form lhs ~ rhs where lhs is a numeric variable giving the data values and rhs either 1 for a one-sample or paired test or a factor with two levels giving the corresponding groups. If lhs is of class “Pair” and rhs is 1, a paired test is done
Utilizando los objetos creados anteriormente el código quedaría:
wilcox.test(clonazepam, lorazepam, paired = F)# Es necesario especificar que los datos no son pareados Warning in wilcox.test.default(clonazepam, lorazepam, paired = F): cannot
compute exact p-value with ties
Wilcoxon rank sum test with continuity correction
data: clonazepam and lorazepam
W = 34.5, p-value = 0.09265
alternative hypothesis: true location shift is not equal to 0En el ejemplo anterior se utilizó la coma para indicar las comparaciones, dado que estamos trabajando con dos objetos diferentes.
Finalmente podremos comprobar las diferencias visualmente realizando un boxplot.
boxplot(lorazepam, clonazepam, main="Comparación de las horas de sueño entre dos benzodiacepinas")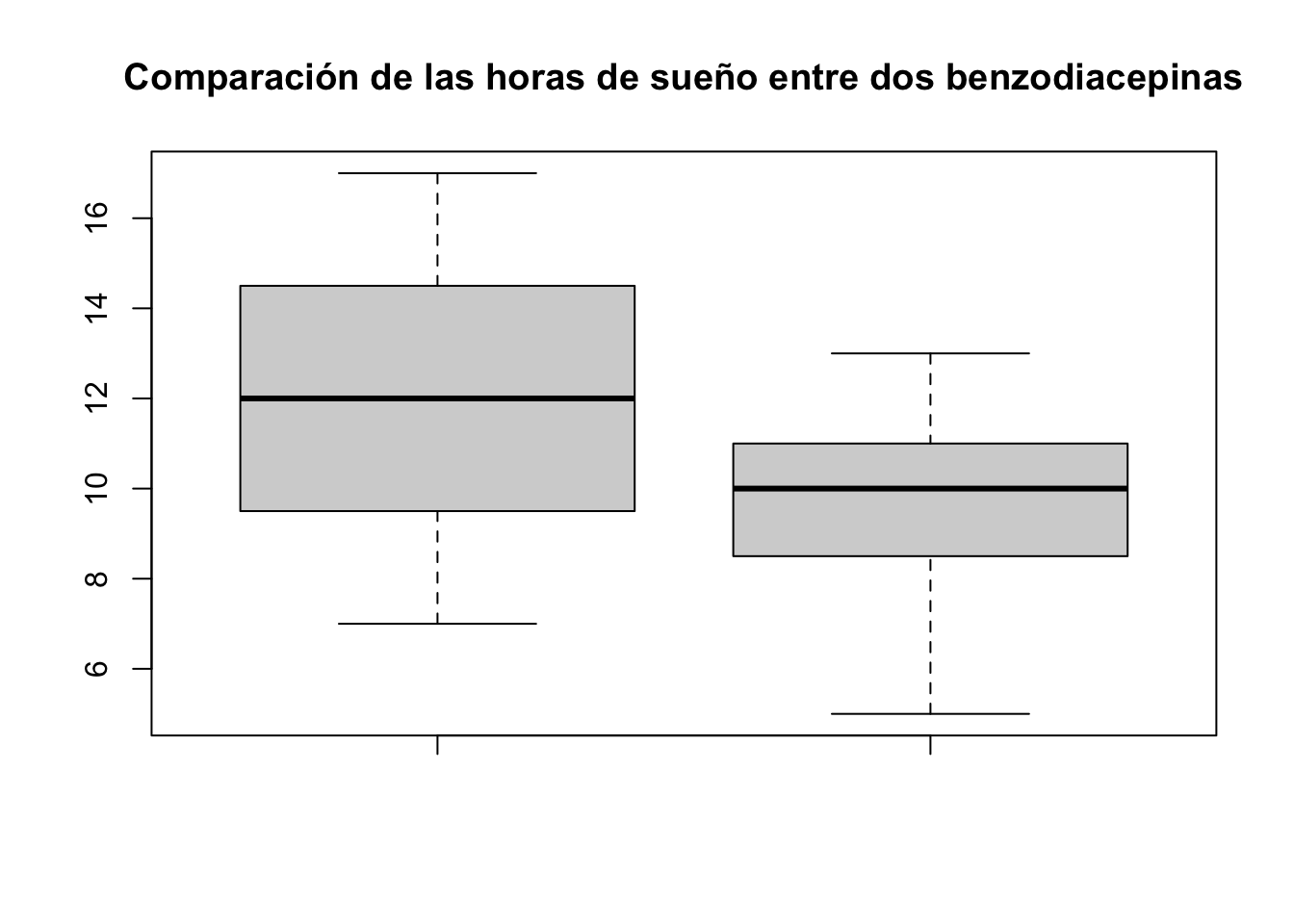
Aunque un gráfico más completo sería:
#Cargar librerías
library(ggplot2)
library(ggstatsplot)You can cite this package as:
Patil, I. (2021). Visualizations with statistical details: The 'ggstatsplot' approach.
Journal of Open Source Software, 6(61), 3167, doi:10.21105/joss.03167library(gapminder)# Crear grafica, con el df datos creado anteriormente
ggbetweenstats(
data = datos, #Objeto con la base de datos
x = Tratamientos, # Nombre de la variable de agrupación
y = Horas, # Nombre de las variable numerica
title = "Comparación de las horas de sueño", # titulo
type = "np") # Prueba no paramétrica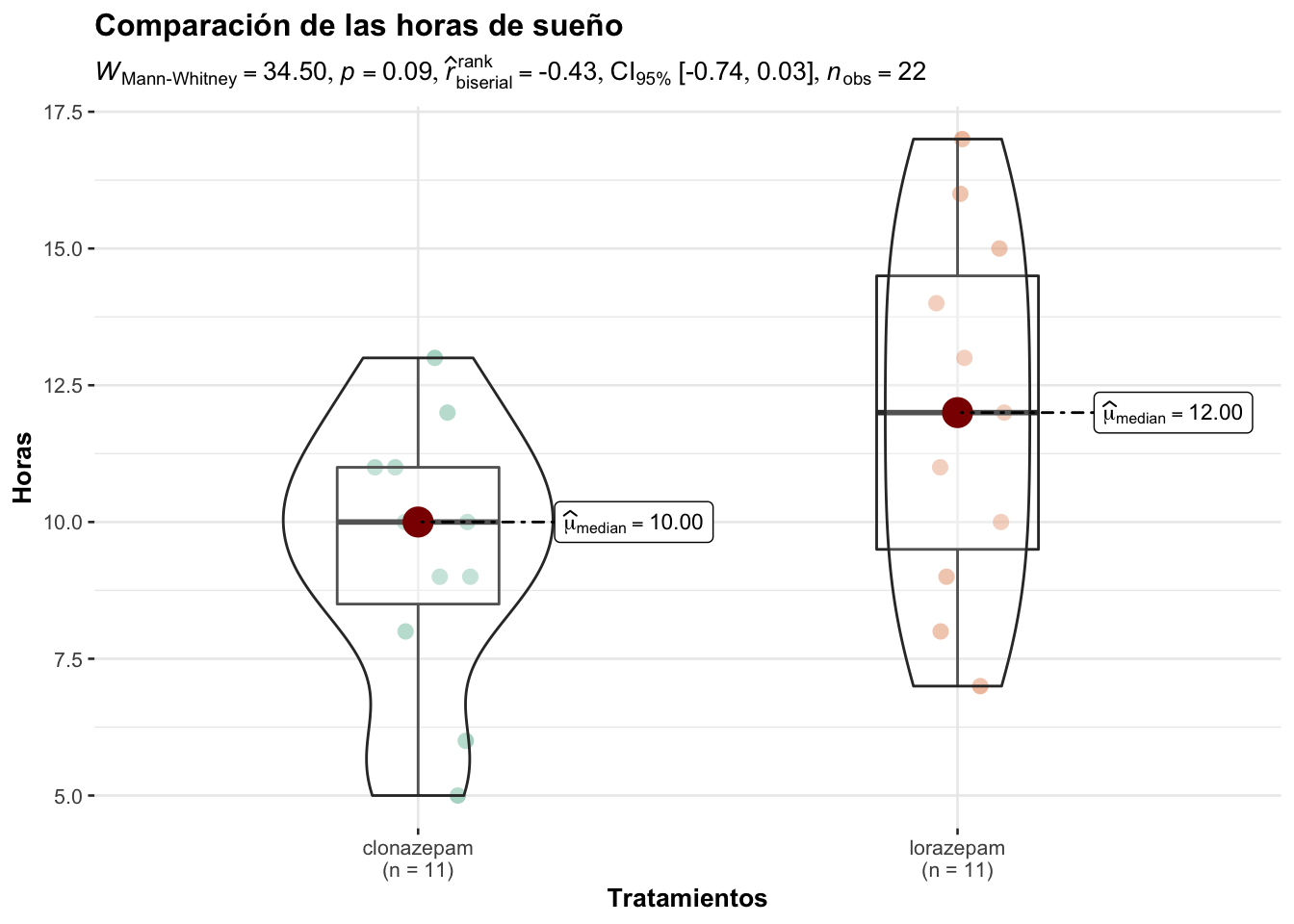
Podemos pedir los intervalos de confianza para la diferencia de las medianas.
wilcox.test(clonazepam,lorazepam, paired=F, alternative="two.sided", conf.int=T)Warning in wilcox.test.default(clonazepam, lorazepam, paired = F, alternative =
"two.sided", : cannot compute exact p-value with tiesWarning in wilcox.test.default(clonazepam, lorazepam, paired = F, alternative =
"two.sided", : cannot compute exact confidence intervals with ties
Wilcoxon rank sum test with continuity correction
data: clonazepam and lorazepam
W = 34.5, p-value = 0.09265
alternative hypothesis: true location shift is not equal to 0
95 percent confidence interval:
-5.000018e+00 4.461794e-05
sample estimates:
difference in location
-2.999923 Para la estimación de los intervalos de confianza R utiliza el estimador de Hodges-Lehmann que a su vez hace una estimación de las diferencias de la mediana por pares.
2.3 Ejercicios prueba U-Mann-Whitney en R
Utilizando la base de datos SLE-DataSet2 resuelva los siguientes ejercicios. Resuelvalo utilizando en R. En R ingrese los datos en la función de wilx.test los datos como formula por ejemplo: wilcox.test(variable cuantitativa~variable de agrupación, paired=F, conf.int=T). Realice una gráfica utilizando la función ggbetweenstats
- ¿La edad es igual entre los pacientes y los controles? asuma que los datos no siguen una distribución normal.
- Realice un boxplot que muestre la comparación de la edad. Cambie el título de su gráfica.
- ¿Las concentraciones de Leptina (leptin) son iguales entre los controles y los pacientes con Lupus. Realice un boxplot
- ¿Las concentraciones de adiponectina (Adiponectin) son iguales entre los controles y los pacientes con Lupus?. Realice un boxplot
- ¿El peso (Weight) es igual entre los controles y los pacientes con Lupus?. Realice un boxplot
- ¿La estatura (Height) es igual entre los controles y los pacientes con Lupus?. Repita los pasos del 3 al 6
- Con las preguntas anteriores y realizando estadística descriptiva (medianas y rangos) llene la siguiente tabla
| Variable | Groups | Median | Min-Max | p-value | Conclusion |
|---|---|---|---|---|---|
| Age | SLE | – | – | – | – |
| Controls | – | – | |||
| Leptin | SLE | – | – | – | – |
| Controls | – | – | |||
| Adiponectin | SLE | – | – | – | – |
| Controls | – | – | |||
| Weight | SLE | – | – | – | – |
| Controls | – | – | |||
| Height | SLE | – | – | – | – |
| Controls | – | – |
2.3.1 ¿Cómo obtener resultados de estadísticos separados por alguna variable de agrupación?
La familia de funciones apply son un grupo de funciones que permiten asignar una función a vectores y data frame completos. También estás funciones nos permiten obtener estadísticos como la media o mediana separadas por una variable de agrupación. Para obtener los estadísticos de la tabala anterior utilizaremos la función tapply.
La función tapply requiere de un argumento X (variable de prueba), INDEX (variable de agrupación) y FUN (función que queremos aplicar). Una vez exportada la base datos de la mediana, valor mínimo y máximo para edad serían:
tapply(X=Age, INDEX=Groups_SLEvsCL, FUN=median)## Para la medianaControl Gruop SLE patients
44 43 tapply(X=Age, INDEX=Groups_SLEvsCL, FUN=min)## Para el valor mínimoControl Gruop SLE patients
22 22 tapply(Age, Groups_SLEvsCL, max)## Para el valor maximoControl Gruop SLE patients
75 73 Aunque también la podríamos hacer utilizando la función Summarize de la librería FSA.
# Si requiere instalar
install.packages("FSA")FSA::Summarize(SLE_dataset2$Age~SLE_dataset2$Groups_SLEvsCL) SLE_dataset2$Groups_SLEvsCL n mean sd min Q1 median Q3 max
1 Control Gruop 83 44.44578 10.01615 22 39.0 44 50.0 75
2 SLE patients 103 42.59223 11.26546 22 34.5 43 50.5 73Los mismos resultados los podemos obtener con el siguiente código:
FSA::Summarize(Age~Groups_SLEvsCL, data=SLE_dataset2) Groups_SLEvsCL n mean sd min Q1 median Q3 max
1 Control Gruop 83 44.44578 10.01615 22 39.0 44 50.0 75
2 SLE patients 103 42.59223 11.26546 22 34.5 43 50.5 733 Prueba de los rangos de wilcoxon
La prueba de Wilcoxon para rangos con signo de pares comparados es alternativa a la prueba de los signos, con la ventaja de que reconoce la magnitud de las diferencias observadas en cada par muestreado. Es el equivalente no paramétrico de la prueba t-student para muestras pareadas.
Para realizar esta prueba se deben de cumplir con los siguientes supuestos:
Cada par de sujetos muestreados es aleatorio.
Las observaciones proceden de una población con distribución simétrica.
La variable de interés es cuantitativa u ordinal.
Los pasos para su realización se enumeran a continuación:
Se calcula la diferencia para cada par. Los pares con diferencia igual a 0 se eliminan, y el tamaño de la muestra se reduce.
Sin tener en cuenta el signo de la diferencia, los pares se ordenan de menor a mayor considerando la magnitud absoluta. Al par con la menor diferencia se le asigna la primera posición, al de mayor diferencia se le asigna la última.
Siempre que existan dos o más observaciones con la misma diferencia, o empatadas, se les asigna la media de las posiciones que ocuparían si no hubiera empates. Por ejemplo, si dos observaciones tienen el valor 5 y les corresponden las posiciones 7 y 8, a las dos se les asigna la posición 7.5.
Calcular \(T=\) Suma de posiciones de diferencias positivos o negativos
La decisión estadística de rechazar o no la hipótesis nula depende de la magnitud de T y del nivel de significancia (\(\alpha\))
Cuando la muestra (o las n diferencias) es mayor de 25 o más elementos, el estadístico T tiene una distribución aproximadamente normal con media
\[z=\frac{T-\mu_R}{\sigma_R}\]
La descripción de estos paso fue tomada del libro Bioestadística de los autores Celis y Labrada.
3.1 Ejemplo prueba de rangos de wilcoxon.
Unos investigadores desean conocer si el tratamiento experimental influye en el peso de dos grupos de ratones. La siguiente tabla muestra los pesos de los ratones antes y después del tratamiento experimental
| peso antes | peso después |
|---|---|
| 90 | 80 |
| 95 | 89 |
| 80 | 72 |
| 79 | 84 |
| 89 | 94 |
| 95 | 80 |
| 99 | 89 |
| 84 | 72 |
| 78 | 84 |
| 69 | 64 |
| 74 | 80 |
| 95 | 89 |
| 99 | 72 |
| 84 | 84 |
| 78 | 94 |
| 69 | 84 |
| 74 | 94 |
Los pasos para resolver manualmente este ejemplo son:
- Calcular la diferencia entre cada par eliminando los 0.
| peso antes | peso después | diferencias |
|---|---|---|
| 90 | 80 | 10 |
| 95 | 89 | 6 |
| 80 | 72 | 8 |
| 79 | 84 | -5 |
| 89 | 94 | -5 |
| 95 | 80 | 15 |
| 99 | 89 | 10 |
| 84 | 72 | 12 |
| 78 | 84 | -6 |
| 69 | 64 | 5 |
| 74 | 80 | -6 |
| 95 | 89 | 6 |
| 99 | 72 | 27 |
| 84 | 84 | 0 |
| 78 | 94 | -16 |
| 69 | 84 | -15 |
| 74 | 94 | -20 |
- Estimar el valor absoluto para cada diferencia
| peso antes | peso después | diferencias | diferencias valor absoluto |
|---|---|---|---|
| 90 | 80 | 10 | 10 |
| 95 | 89 | 6 | 6 |
| 80 | 72 | 8 | 8 |
| 79 | 84 | -5 | 5 |
| 89 | 94 | -5 | 5 |
| 95 | 80 | 15 | 15 |
| 99 | 89 | 10 | 10 |
| 84 | 72 | 12 | 12 |
| 78 | 84 | -6 | 6 |
| 69 | 64 | 5 | 5 |
| 74 | 80 | -6 | 6 |
| 95 | 89 | 6 | 6 |
| 99 | 72 | 27 | 27 |
| 84 | 84 | 0 | 0 |
| 78 | 94 | -16 | 16 |
| 69 | 84 | -15 | 15 |
| 74 | 94 | -20 | 20 |
- Sin tener en cuenta el signo de la diferencia, los pares se ordenan de menor a mayor considerando la magnitud absoluta. Al par con la menor diferencia se le asigna la primera posición, al de mayor diferencia se le asigna la última.
| peso antes | peso después | diferencias | diferencias valor absoluto | Rango |
|---|---|---|---|---|
| 84 | 84 | 0 | 0 | |
| 79 | 84 | -5 | 5 | 1 |
| 89 | 94 | -5 | 5 | 2 |
| 69 | 64 | 5 | 5 | 3 |
| 95 | 89 | 6 | 6 | 4 |
| 78 | 84 | -6 | 6 | 5 |
| 74 | 80 | -6 | 6 | 6 |
| 95 | 89 | 6 | 6 | 7 |
| 80 | 72 | 8 | 8 | 8 |
| 90 | 80 | 10 | 10 | 9 |
| 99 | 89 | 10 | 10 | 10 |
| 84 | 72 | 12 | 12 | 11 |
| 95 | 80 | 15 | 15 | 12 |
| 69 | 84 | -15 | 15 | 13 |
| 78 | 94 | -16 | 16 | 14 |
| 74 | 94 | -20 | 20 | 15 |
| 99 | 72 | 27 | 27 | 16 |
a las variables con el mismo valor, se estima el promedio
| peso antes | peso después | diferencias | diferencias valor absoluto | Rango | Rango |
|---|---|---|---|---|---|
| 84 | 84 | 0 | 0 | ||
| 79 | 84 | -5 | 5 | 1 | 2 |
| 89 | 94 | -5 | 5 | 2 | 2 |
| 69 | 64 | 5 | 5 | 3 | 2 |
| 95 | 89 | 6 | 6 | 4 | 5.5 |
| 78 | 84 | -6 | 6 | 5 | 5.5 |
| 74 | 80 | -6 | 6 | 6 | 5.5 |
| 95 | 89 | 6 | 6 | 7 | 5.5 |
| 80 | 72 | 8 | 8 | 8 | 8 |
| 90 | 80 | 10 | 10 | 9 | 9.5 |
| 99 | 89 | 10 | 10 | 10 | 9.5 |
| 84 | 72 | 12 | 12 | 11 | 11 |
| 95 | 80 | 15 | 15 | 12 | 12.5 |
| 69 | 84 | -15 | 15 | 13 | 12.5 |
| 78 | 94 | -16 | 16 | 14 | 14 |
| 74 | 94 | -20 | 20 | 15 | 15 |
| 99 | 72 | 27 | 27 | 16 | 16 |
- Se suman los valores de los rangos para las diferencias positivas y para las diferencias negativas
Tpositivo <- 2+7+5.5+8+9.5+9.5+11+12.5+16
Tnegativo <- 15+14+12.5+5.5+5.5+2+2- Valor de T para valores positivos: 81
- Valor de T para valores negativos: 56.5
- Se compara el valor de más grande con el valor de tablas y se obtiene el valor de p
3.2 ¿Cómo hacerlo en R?
- Se crean dos objetos, uno para peso antes y otro para peso después
Peso_Antes <- c(74, 78, 69, 78, 74, 79, 89, 84, 69, 95, 95, 80, 90, 99,84,95, 99)
Peso_Despues <- c(94, 94, 84, 84, 80, 84, 94, 84, 64, 89, 89, 72, 80, 89, 72, 80, 72)- Se utiliza la función
wilcox.testcon el argumentopaired=T
wilcox.test(Peso_Antes, Peso_Despues, paired = T, conf.int = T)Warning in wilcox.test.default(Peso_Antes, Peso_Despues, paired = T, conf.int =
T): cannot compute exact p-value with tiesWarning in wilcox.test.default(Peso_Antes, Peso_Despues, paired = T, conf.int =
T): cannot compute exact confidence interval with tiesWarning in wilcox.test.default(Peso_Antes, Peso_Despues, paired = T, conf.int =
T): cannot compute exact p-value with zeroesWarning in wilcox.test.default(Peso_Antes, Peso_Despues, paired = T, conf.int =
T): cannot compute exact confidence interval with zeroes
Wilcoxon signed rank test with continuity correction
data: Peso_Antes and Peso_Despues
V = 79.5, p-value = 0.5685
alternative hypothesis: true location shift is not equal to 0
95 percent confidence interval:
-5.499992 9.000023
sample estimates:
(pseudo)median
1.849605 - Hacer un boxplot para visualizar sus resultados
boxplot(Peso_Despues, Peso_Antes, main="Comparación de los peso antes y después del tratamiento")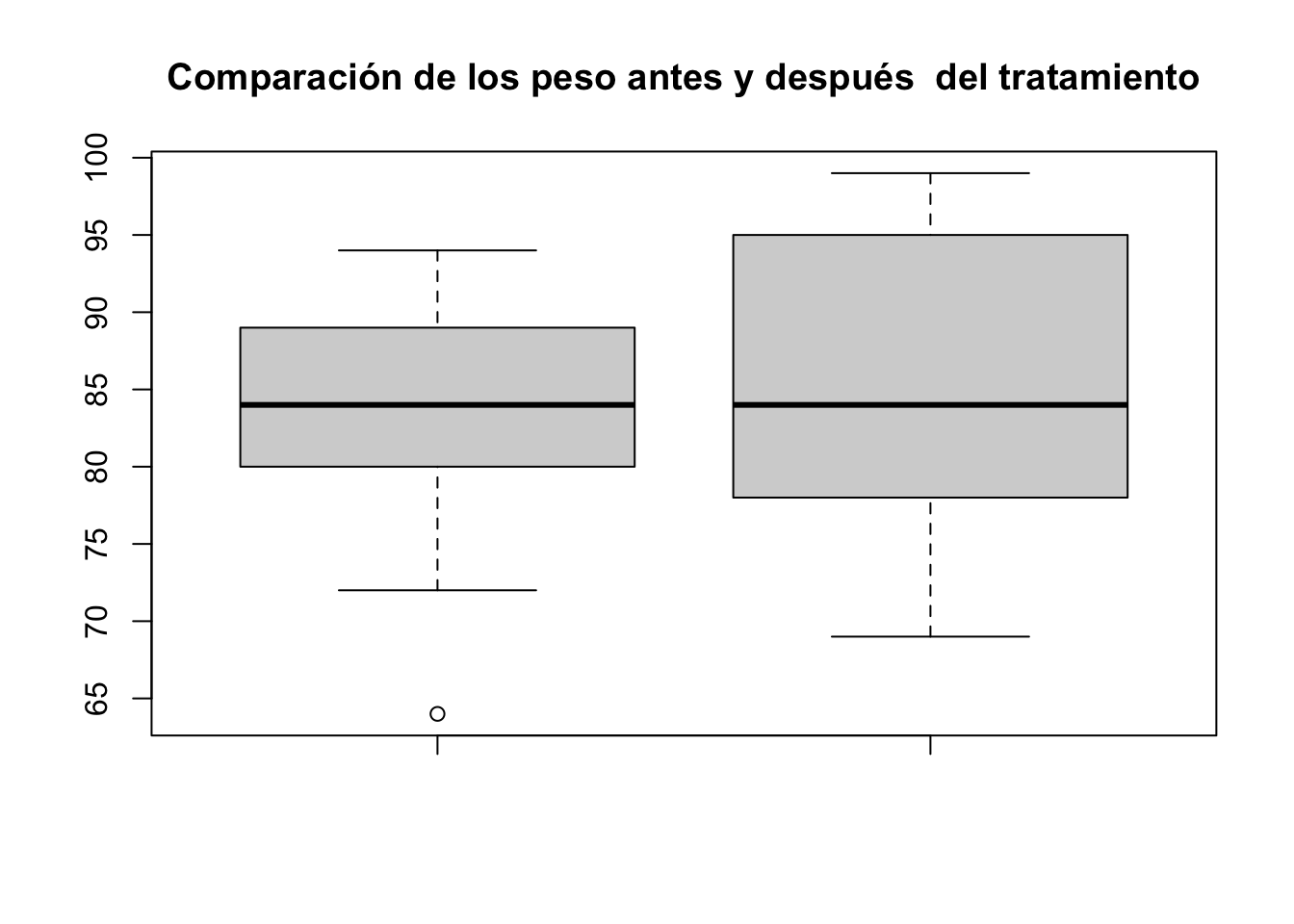
- Gráfico con más información
# Crear df para organizar los datos
Pesos <- c(Peso_Antes, Peso_Despues)
Tiempo <- rep(x=c("Antes", "Despues"), each=17)
df <- data.frame(Pesos, Tiempo)ggstatsplot::ggwithinstats(
data=df,
x=Tiempo,
y=Pesos,
type="np"
)Registered S3 methods overwritten by 'car':
method from
hist.boot FSA
confint.boot FSA 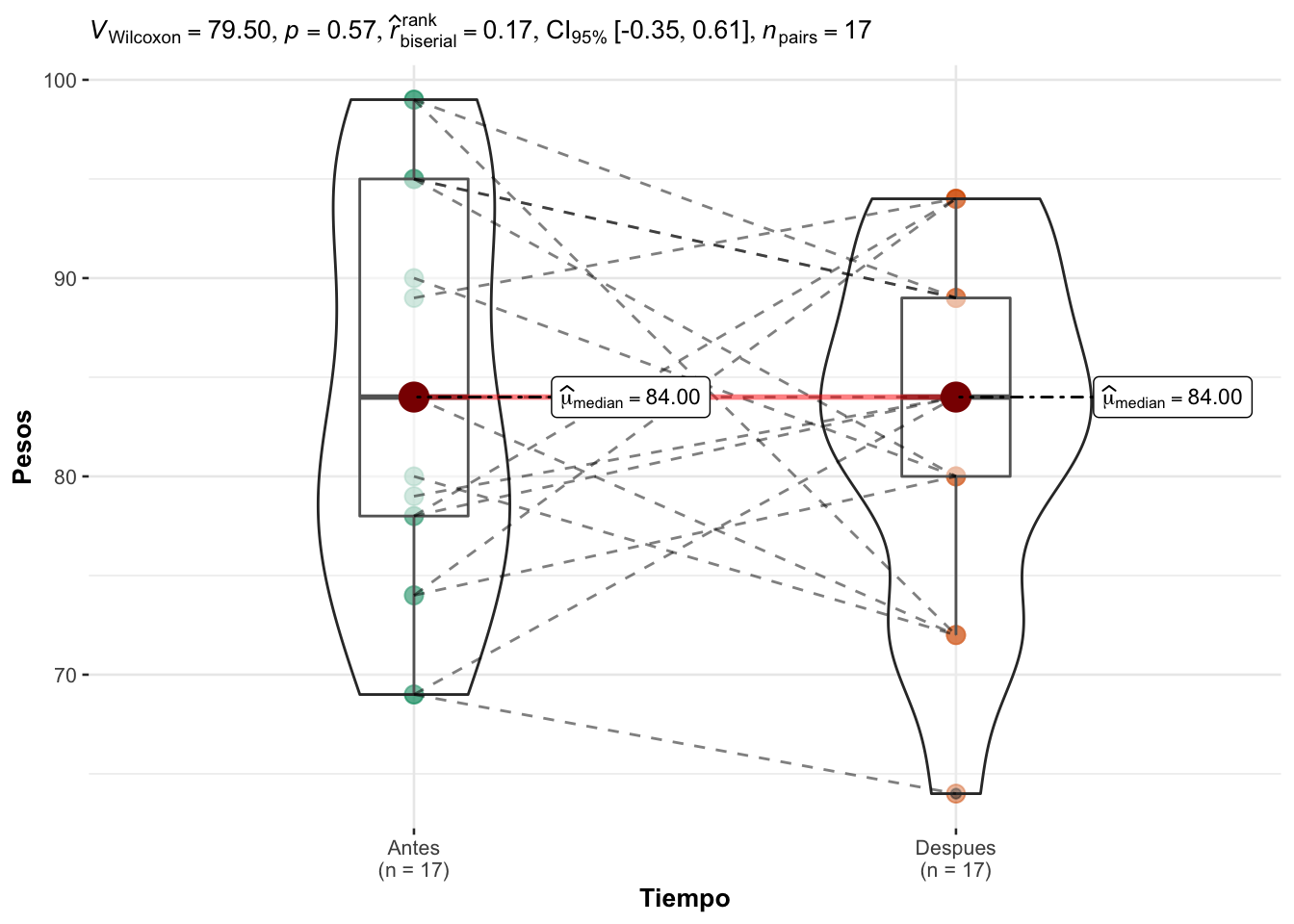
3.3 Ejercicios para Rangos de Wilcoxon
Utilizando la base de datos SLE_DataSet2 conteste las siguientes preguntas. Asuma que los datos no se distribuyen normalmente y cree gráficos utilizando la función ggwithinstats.
- En lo pacientes con Lupus se presentaron cambios en las concentraciones de Leptina a los 6 meses y los 12 meses con respecto a la basal. Utilice la variable Leptin, Leptin6M y Leptin12M.
- En lo pacientes con Lupus se presentaron cambios en las concentraciones de Adiponectina a los 6 meses y los 12 meses con respecto a la basal. Utilice la variable Adiponectin, Adiponectin6M y Adiponectin12M.
4 Prueba de Kruskal-Wallis
Cuando se desea comparar una variable cuantitiva u ordinal en tres o más grupos y esta variable no se comporta de forma normal o la muestra es muy pequeño se utiliza la prueba de Kruskal-Wallis. Esta prueba es el equivalente no paramétrico del ANOVA de una vía.
Los supuestos de esta prueba son:
Cada una de las muestras ha sido tomada al azar de su población.
Hay independencia entre las observaciones dentro de cada muestra, así como entre las muestras.
Los datos representan medidas por lo menos en una escala ordinal.
Los pasos para para verificar la hipótesis nula de que las medianas poblacionales son iguales utilizando la prueba de Kruskall-Wallis son:
Se toma una muestra aleatoria independiente de cada población.
Los datos se acomodan en una tabla r × c, en el que las columnas representan los grupos muestreados.
Para obtener un valor del estadístico de prueba, hay que empezar asignando el orden de la posición a las observaciones de las muestras combinadas, n 1 + n 2 + … + n k = N. Se otorga la posición 1 a la más pequeña de las observaciones N, la posición 2 a la siguiente más pequeña y así sucesivamente hasta la posición N que se da a la más grande. A las observaciones empatadas se les asigna la media de las posiciones que ocuparían si no hubiera igualdades.
Como estadístico de prueba, KW se calcula mediante una de las dos fórmulas siguientes. Cuando no hay empate en el orden de las observaciones, se utiliza:
\[KW=\Bigg[\frac{12}{N(N+1)}\sum^k_{j=1}n_j\bar{R}^2_j\Bigg]-3(N+1)\]
en la que \(k\) representa el número de muestras o grupos, \(n_j\) es el tamaño de la muestra en la muestra o grupo j-ésimo, \(N\) es el total de elementos en las muestras y \(\bar{R}^2_j\) es el promedio de las posiciones en la muestra o grupo j-ésimo.
En caso de observaciones empatadas, la fórmula es:
\[KW=\frac{\Bigg[\frac{12}{N(N+1)}\sum^k_{j=1}n_j\bar{R}^2_j\Bigg]-3(N+1)}{1- \Bigg[\sum^g_{j=1}(t^3_i-t_i)\Bigg] \Bigg/(N^3-N)}\]
En ésta, g es el número de agrupaciones empatadas en la misma posición y t i es el número de observaciones empatadas en la misma posición
- La decisión de rechazar o no \(H_0\) en el nivel de significación a depende de la magnitud de KW. Cuando el número de muestras o grupos es igual a tres y el tamaño de cada muestra es menor de seis, se consulta el valor de tablas, en el cual se encontrarán los valores críticos de esta prueba. Para buscarlos, se localizan los tamaños de muestra correspondientes para cada una de las muestras (se designa como \(n_1\) la más grande, \(n_2\) la intermedia y \(n_3\) la más pequeña) y luego se revisan las columnas de valores críticos para cada nivel de significancia hasta que se encuentre que el valor de KW calculado es igual que el mayor al tabulado en la celda correspondiente a los tamaños de las muestras y al nivel de significancia. Cuando el número de muestras o grupos es mayor de tres, o los tamaños de muestra son superiores a cinco, el valor de KW sigue la distribución \(\chi^2\) con \(k - 1\) \(gl\).
4.1 Ejemplo de la prueba de Kruskall-Wallis de forma manual
Se parte de los siguientes datos donde se muestran las edades de tres grupos de pacientes.
| Grupo A | Grupo B | Grupo C |
|---|---|---|
| 23 | 45 | 18 |
| 41 | 55 | 30 |
| 54 | 60 | 34 |
| 66 | 70 | 40 |
| 78 | 72 | 44 |
Se desea conocer si las edades son distintas entres los tres grupos
- Ordenar todos los datos sin importar el grupo al que pertenecen
| 18 | Grupo C |
|---|---|
| 23 | Grupo A |
| 30 | Grupo C |
| 34 | Grupo C |
| 40 | Grupo C |
| 41 | Grupo A |
| 44 | Grupo C |
| 45 | Grupo B |
| 54 | Grupo A |
| 55 | Grupo B |
| 60 | Grupo B |
| 66 | Grupo A |
| 70 | Grupo B |
| 72 | Grupo B |
| 78 | Grupo A |
- Se le asigna un rango a cada uno de los datos
| Valor | Rango | Grupo |
|---|---|---|
| 18 | 1 | Grupo C |
| 23 | 2 | Grupo A |
| 30 | 3 | Grupo C |
| 34 | 4 | Grupo C |
| 40 | 5 | Grupo C |
| 41 | 6 | Grupo A |
| 44 | 7 | Grupo C |
| 45 | 8 | Grupo B |
| 54 | 9 | Grupo A |
| 55 | 10 | Grupo B |
| 60 | 11 | Grupo B |
| 66 | 12 | Grupo A |
| 70 | 13 | Grupo B |
| 72 | 14 | Grupo B |
| 78 | 15 | Grupo A |
- Se suman los rangos de cada grupo
- Para el Grupo A: 2+6+9+12+15=44
- Para el Grupo B: 8+10+11+13+14=56
- Para el Grupo C: 1+2+4+5+7=20
- De acuerdo o no la presencia de empates se utilizan las siguientes formulas para calcular el estadístico de prueba
- Cuando no hay empate en el orden de las observaciones, se utiliza:
\[KW=\Bigg[\frac{12}{N(N+1)}\sum^k_{j=1}n_j\bar{R}^2_j\Bigg]-3(N+1)\]
en la que \(k\) representa el número de muestras o grupos, \(n_j\) es el tamaño de la muestra en la muestra o grupo j-ésimo, \(N\) es el total de elementos en las muestras y \(\bar{R}^2_j\) es el promedio de las posiciones en la muestra o grupo j-ésimo.
- En caso de observaciones empatadas, la fórmula es:
\[KW=\frac{\Bigg[\frac{12}{N(N+1)}\sum^k_{j=1}n_j\bar{R}^2_j\Bigg]-3(N+1)}{1- \Bigg[\sum^g_{j=1}(t^3_i-t_i)\Bigg] \Bigg/(N^3-N)}\]
En ésta, g es el número de agrupaciones empatadas en la misma posición y t i es el número de observaciones empatadas en la misma posición
##¿Cómo hacerlo en R?
En Rse utiliza la función kruskal.test. La función tiene los siguientes argumentos:
- x
- a numeric vector of data values, or a list of numeric data vectors. Non-numeric elements of a list will be coerced, with a warning.
- g
- a vector or factor object giving the group for the corresponding elements of x. Ignored with a warning if x is a list.
- formula
- a formula of the form response ~ group where response gives the data values and group a vector or factor of the corresponding groups.
- data
- an optional matrix or data frame (or similar: see model.frame) containing the variables in the formula formula. By default the variables are taken from environment(formula).
- subset
- an optional vector specifying a subset of observations to be used.
- na.action
- a function which indicates what should happen when the data contain NAs. Defaults to getOption(“na.action”)
4.1.1 Ejemplo utilizando R
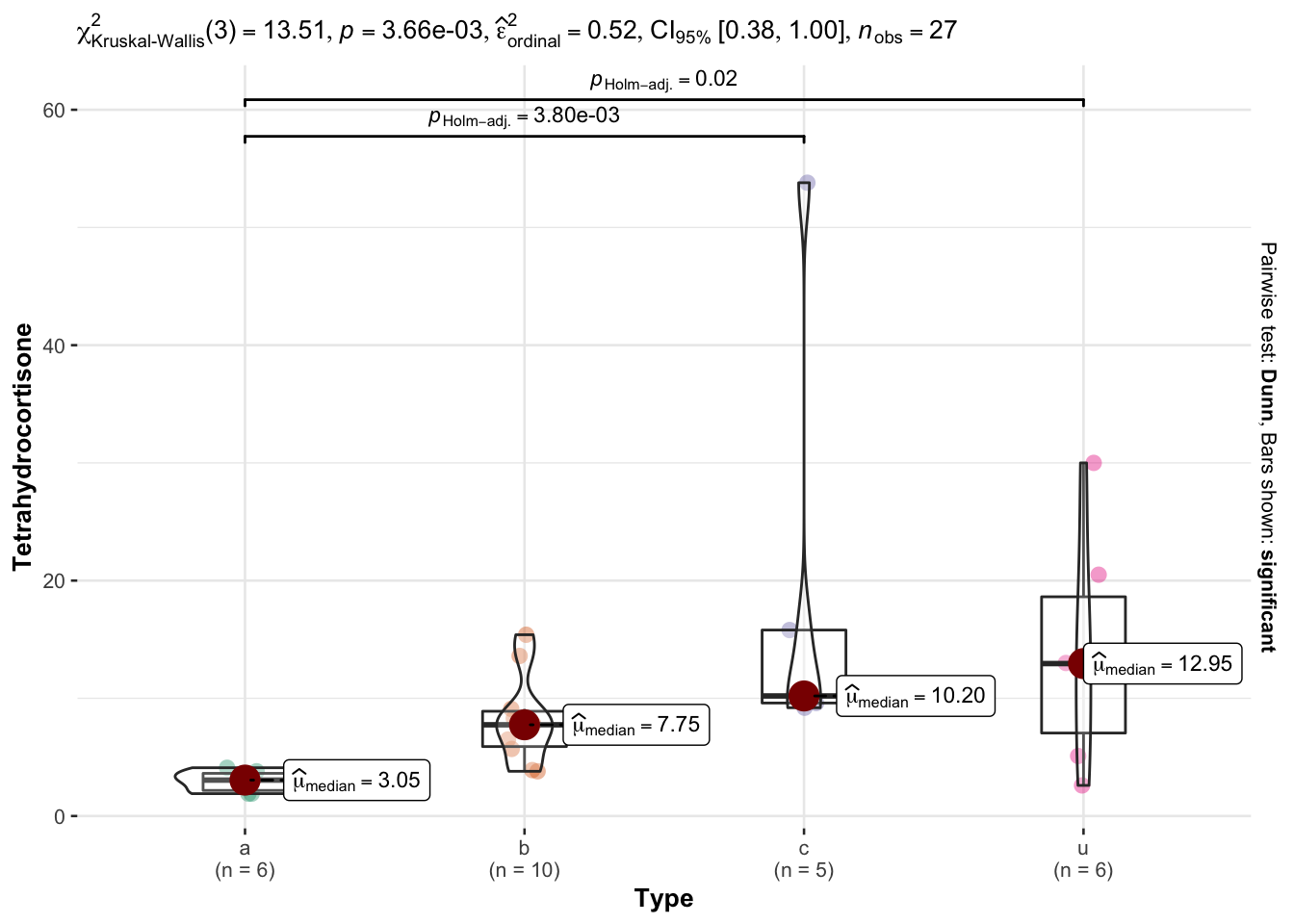
¿Los niveles de Tetrahydrocortisone son iguales entre los distintos tipos de Cushing?
Para realizar este ejemplo cargue la base de datos “Cushings” que se encuentra en el paquete “MASS”. Si es necesario instale utilizando el comando: `library(“MASS”)``
library(MASS)# Para cargar la librería
Attaching package: 'MASS'The following object is masked from 'package:dplyr':
selectdata(Cushings)# Para cargar la base de datos
head(Cushings)#ver los primeros seis datos Tetrahydrocortisone Pregnanetriol Type
a1 3.1 11.70 a
a2 3.0 1.30 a
a3 1.9 0.10 a
a4 3.8 0.04 a
a5 4.1 1.10 a
a6 1.9 0.40 aattach(Cushings)# adjuntar base de datos
names(Cushings)# para conocer como se llaman las variables[1] "Tetrahydrocortisone" "Pregnanetriol" "Type" Siempre es importante realizar gráficas para ver la distribución, valores atípicos, y tendencia de los datos.
boxplot(Tetrahydrocortisone~Type, main="Niveles de Tetrahydrocortisone en los pacientes con Cushing")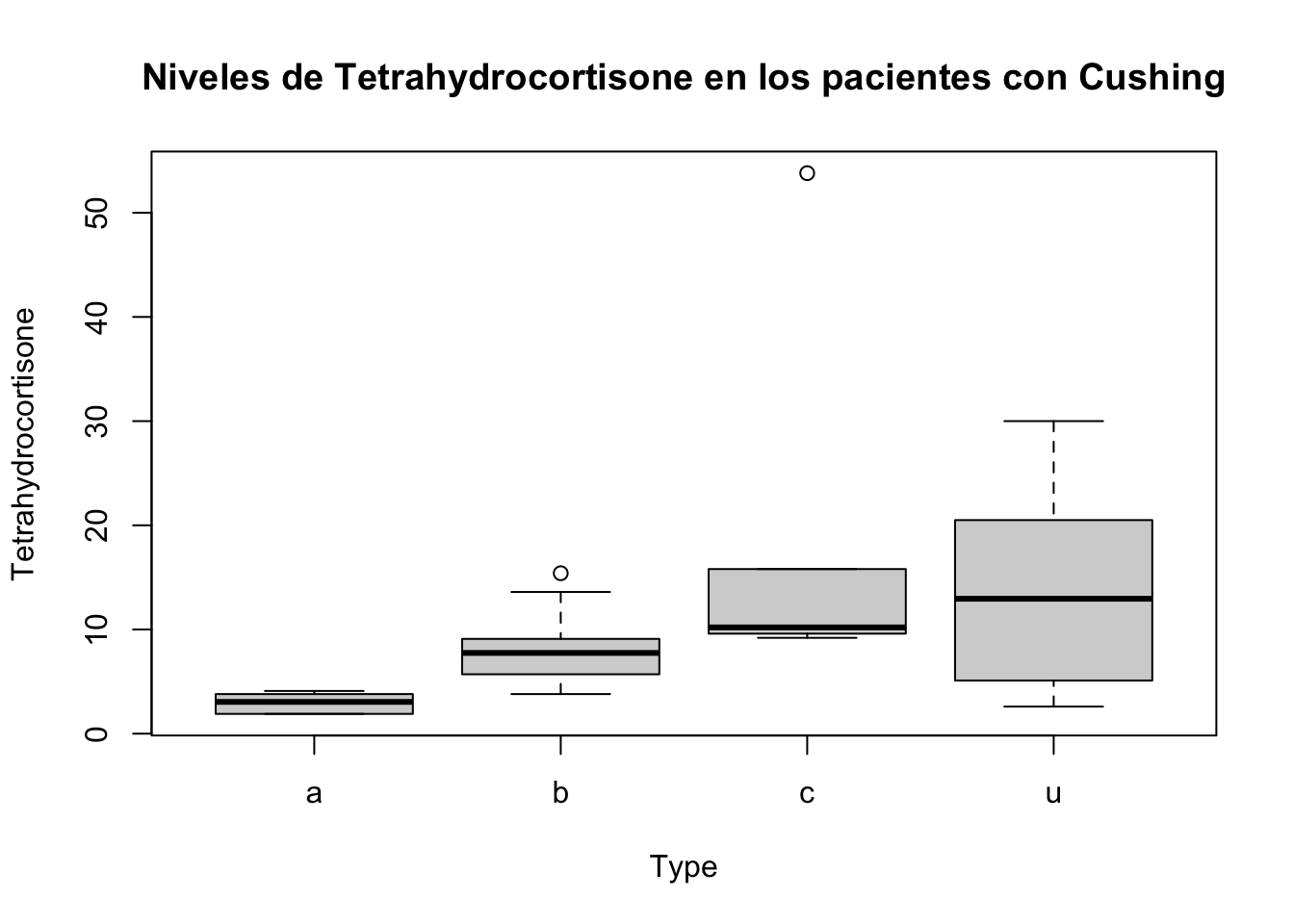
Ahora usamos la función kruskal.test. Esta función requiere del uso de formula para su realización, es decir los datos deben de ser cargados en la función de la forma Variable de interes~Variable de agrupación
kruskal.test(Tetrahydrocortisone~Type)
Kruskal-Wallis rank sum test
data: Tetrahydrocortisone by Type
Kruskal-Wallis chi-squared = 13.509, df = 3, p-value = 0.003655Un gráfico más informativo sería
ggstatsplot::ggbetweenstats(
data = Cushings,
x=Type,
y=Tetrahydrocortisone,
type="np"
)
4.1.2 Ejercicios de practica en para kruskall-wallis R
- ¿Los niveles de Pregnanetriol son iguales entre los tipos de Cushing?
- Usando la librería MASS llame a la base de datos “genotype”. Esta base de datos contiende los resultados de una investigación realizad por Bailey y cols. en 1953 en la que investigaron la herencia del y su asociación con el crecimiento de varios grupo de ratas. En este estudio, las camadas de ratas se separaron de sus madres naturales, y fueron criadas por madres adoptivas. Las madres y las camadas pueden tener cuatro genotipos diferentes: A, B, I y J. Supongamos que queremos investigar si el aumento de peso (Wt) de la camada (en gramos) a los 28 días está relacionado con el genotipo de la madre adoptiva Madre (A, B, I y J). Utilice la prueba de Kruskall-Wallis.
- Resuelva los ejercicios utilizando
R - La edad es distinta en los pacientes con Lupus con actividad renal, los pacientes con lupus sin actividad renal y los controles. Asume estadística no paramétrica
- Las concentraciones de Adiponectina son distintas en los pacientes con Lupus con actividad renal, los pacientes con lupus sin actividad renal y los controles. Asume estadística no paramétrica
- Las concentraciones de leptina son distintas en los pacientes con Lupus con actividad renal, los pacientes con lupus sin actividad renal y los controles. Asume estadística no paramétrica
- Usando la librería MASS llame a la base de datos “genotype”. Esta base de datos contiende los resultados de una investigación realizad por Bailey y cols. en 1953 en la que investigaron la herencia del y su asociación con el crecimiento de varios grupo de ratas. En este estudio, las camadas de ratas se separaron de sus madres naturales, y fueron criadas por madres adoptivas. Las madres y las camadas pueden tener cuatro genotipos diferentes: A, B, I y J. Supongamos que queremos investigar si el aumento de peso (Wt) de la camada (en gramos) a los 28 días está relacionado con el genotipo de la madre adoptiva Madre (A, B, I y J). Utilice la prueba de Kruskall-Wallis.
- Entregue un reporte de Markdown con todos sus ejercicios