11.8 Pruebas de hipótesis para la comparación de variables cuantitativas en dos grupos con distrubución normal
Bioestadística
CUCS/UDG
Introducción
Cuando es de nuestro interés comparar una variables cuantitativa entre dos grupos, podemos emplear la prueba Z o la prueba t student. La elección de una prueba u otra dependerá del conocimiento que tengamos de la varianza poblacional. Si conocemos la varianza poblacional se emplea Z, si por el contrario, no conocemos esta varianza la prueba que debemos utilizar es la prueba t student.
Prueba t de student
La prueba t student para muestras independientes se utiliza para la comparación de medias de grupos independientes. En general las hipótesis que se pueden plantear son:
| Tipo de hipótesis | |||
|---|---|---|---|
| 1 | Bilateral | ||
| 2 | Unilateral | ||
| 3 | Unilateral |
A su vez, la selección de la prueba t-student adecuada se basará en la homogeneidad de la varianzas. Es decir, si las varianzas de los dos grupo a comparar son iguales deberá de elegir la prueba de t-student para varianzas homogeneas. En el caso de que las varianzas no sean iguales (homogenas) deberá plantear una prueba t-student para varianzas distintas.
Prueba t de student R
En R podemos utilizar la función t.test() que posee los siguientes argumentos:
X: un vector numérico (no vacío) de valores de datos.
y: un vector numérico opcional (no vacío) de valores de datos.
alternative: una cadena de caracteres que especifica el tipo de hipótesis. Las opciones a saber son: “two.sided” (default) para una hipótesis bilateral, “greater” cuando se quiere probar si la media 1 es mayor que la media 2 o “less” (lo contrario a greater). Puede especificar solo la letra inicial.
paired: una indicación lógica si desea una prueba t pareada.
var.equal: una variable lógica que indica si se deben tratar las dos varianzas como si fueran iguales. Si es VERDADERO, la varianza agrupada se usa para estimar la varianza; de lo contrario, se usa la aproximación de Welch (o Satterthwaite) a los grados de libertad.
conf.level: nivel de confianza del intervalo.
formula: se utiliza para introducir los datos a manera de formula.
data: Argumento que se utilza para identificar el data frame del que provienen los datos. Si se usó la función
attach()o el simbolo de$no es necesario utilizar este argumento.
En R la función t.test se puede utilizar de dos formas de hacerlo:
- Utilizando “x” y “y”: t.test(x=objeto1, y=objeto2). Requiere de dos objetos con los datos numéricos
- Utilizando la formula: t.test(Variable de prueba~Variable agrupación) Requiere de un objeto con la variable numérica y de un objeto que permita identificar los grupos
Vamos a resolver un ejercicio.
Ejercicio de practica para la prueba t con objetos separados
Un estudio de los investigadores Eidelman et al.tiene como objetivo examinar las características de destrucción pulmonar en personas que fuman cigarros antes de desarrollar un marcado enfisema pulmonar. Se practicaron mediciones de tres indices de destrucción pulmonar en los pulmones de personas longevas que no fumaban y en personas con tabaquismo que murieron repentinamente fuera del hospital por causas no respiratorias. Una calificación alta indica un mayor daño pulmonar. Los datos fueron guardados en dos objetos para uno de los índices de destrucción pulmonar de una muestra de 9 personas que no fuman y 16 fumadores. Se pretende saber si es posible concluir, con base en los datos, que las personas que sí fuman, en general, tienen los pulmones mas dañados que las personas no fumadoras, como lo indican las mediciones. No se conocen las variancias poblacionales, pero se supone que son iguales. Utilice un nivel de confianza del 98%.
Para la resolución de este ejercicio vamos a crear dos objetos, uno para la calificación de los fumadores y otro para la calificación de los no fumadores:
Calif_No_Fumadores<-c(18.1,6.0,10.8,11.0,7.7,17.9,8.5,13.0,18.9)
Calif_Fumadores<- c(16.6,13.9,11.3,26.5, 17.4, 15.3, 15.8, 12.3,
18.6, 12.0, 24.1, 16.5, 21.8, 16.3, 23.4,
18.8)Lo primero es graficar, podemos hacerlo mediante un boxplot. Más adelante utilizaremos la función plotmeans()
boxplot(Calif_Fumadores, Calif_No_Fumadores, ylab="Calificaciones",
main="Calificación de daño pulmonar", col=c("cadetblue", "cadetblue2"),
names = c("Fumadores", "No fumadores"), frame = FALSE) 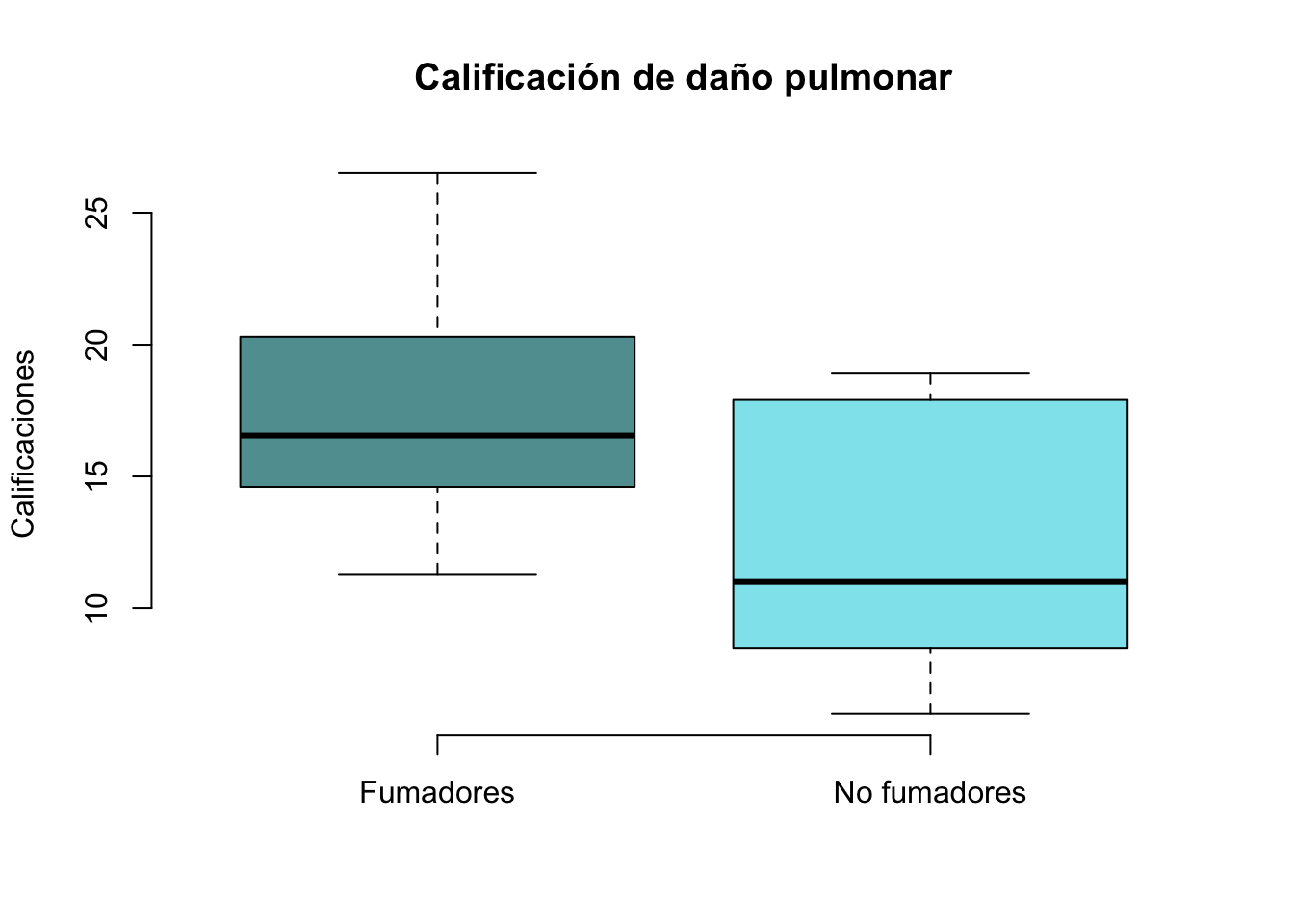
La gráfica anterior parece indicar que la calificación en el grupo de fumadores es mayor que en el grupo de los no fumadores. Vamos a comprobarlo mediante la prueba t de student. Se selecciona la prueba para viarnazas iguales (el problema lo indica)
t.test(Calif_Fumadores, Calif_No_Fumadores, alternative = "greater",
conf.level = 0.98, var.equal = T)
Two Sample t-test
data: Calif_Fumadores and Calif_No_Fumadores
t = 2.658, df = 23, p-value = 0.007027
alternative hypothesis: true difference in means is greater than 0
98 percent confidence interval:
0.9237087 Inf
sample estimates:
mean of x mean of y
17.53750 12.43333 Utilizamos el argumento alternative="greater" ya que nos interesa probar que la calificación de los fumadores es mayor que los no fumadores (la media del grupo es mayor que la media del grupo 2). Además, utilizamos un nivel de confianza del 98%. De momento asumimos que ambos grupos tienen varianzas iguales.
Supongamos ahora que es nuestro interés conocer que simplemente si las medias son diferentes y cambiamos el argumento alternative="two.sided".
t.test(Calif_Fumadores, Calif_No_Fumadores, alternative = "two.sided",
conf.level = 0.98, var.equal = T)
Two Sample t-test
data: Calif_Fumadores and Calif_No_Fumadores
t = 2.658, df = 23, p-value = 0.01405
alternative hypothesis: true difference in means is not equal to 0
98 percent confidence interval:
0.3036205 9.9047128
sample estimates:
mean of x mean of y
17.53750 12.43333 Aunque podrías omitir el argumento alternative="two.sided" ya que por se encuentra predefinido. El siguiente código dará el mismo resultado:
t.test(Calif_Fumadores, Calif_No_Fumadores,
conf.level = 0.98, var.equal = T)
Two Sample t-test
data: Calif_Fumadores and Calif_No_Fumadores
t = 2.658, df = 23, p-value = 0.01405
alternative hypothesis: true difference in means is not equal to 0
98 percent confidence interval:
0.3036205 9.9047128
sample estimates:
mean of x mean of y
17.53750 12.43333 Otra opción para utilizar la función t.test() es mediante el uso de formula. Para ello, vamos a importar la base de datos Calif_Fum utilizando el menú de RStudio. Asegúrese de que su objeto con la base de datos fue nombrado como Calif_Fum.
Ahora ya podemos utilizar la función t.test() como formula:
t.test(Calif_Fum$Calificacion~Calif_Fum$Grupo, conf.level = 0.98, var.equal = T)
Two Sample t-test
data: Calif_Fum$Calificacion by Calif_Fum$Grupo
t = 2.658, df = 23, p-value = 0.01405
alternative hypothesis: true difference in means between group Fumadores and group No Fumadores is not equal to 0
98 percent confidence interval:
0.3036205 9.9047128
sample estimates:
mean in group Fumadores mean in group No Fumadores
17.53750 12.43333 También ahora ya podemos hacer un gráficos de medias
library(gplots)
Attaching package: 'gplots'The following object is masked from 'package:stats':
lowessplotmeans(Calif_Fum$Calificacion~Calif_Fum$Grupo)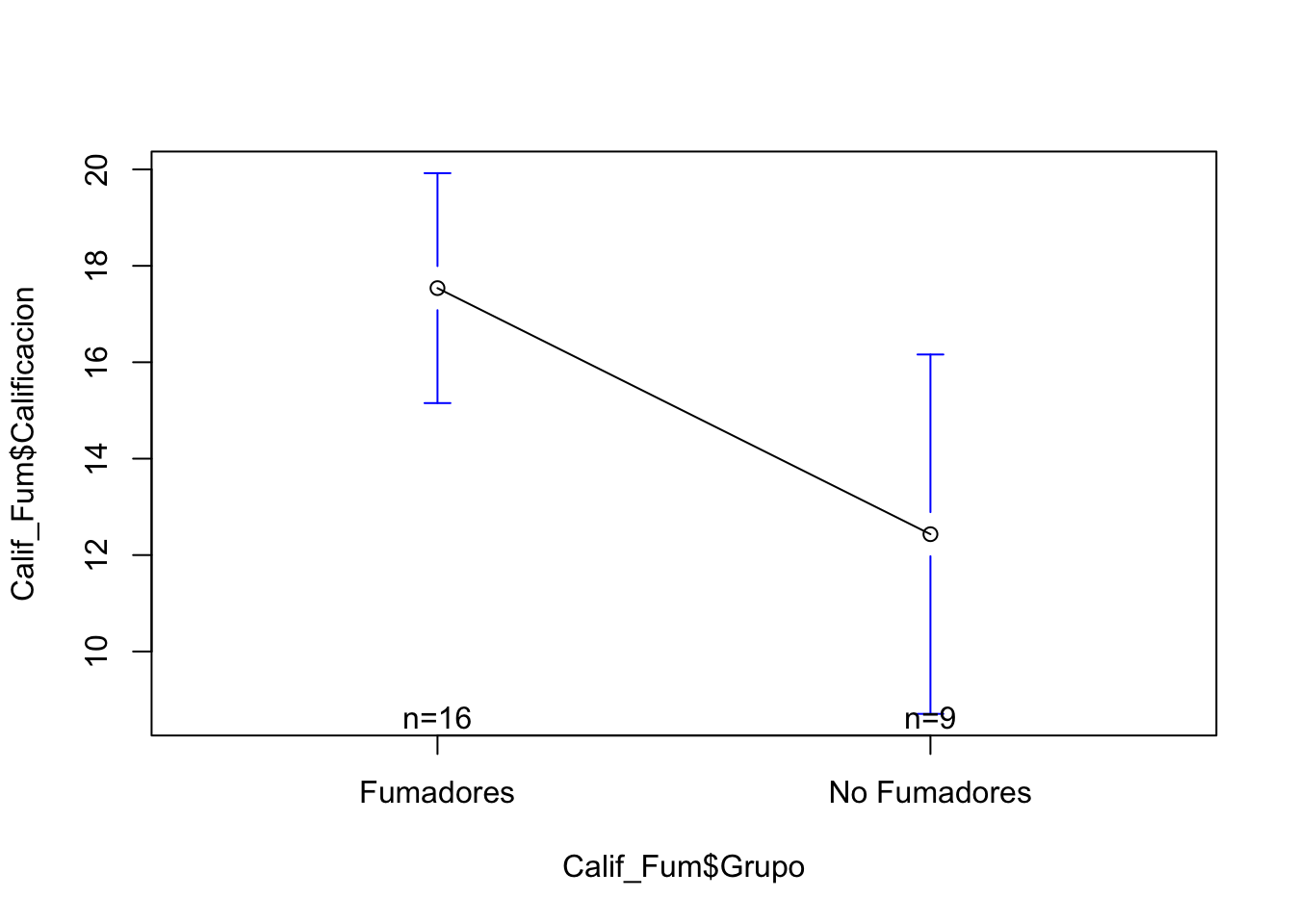
Test de welch
En estadística, la prueba t de Welch, o prueba t de varianzas desiguales, es una prueba de ubicación de dos muestras que se utiliza para probar la hipótesis de que dos poblaciones tienen medias iguales. Lleva el nombre de su creador, Bernard Lewis Welch, y es una adaptación de la prueba t de Student, y es más confiable cuando las dos muestras tienen varianzas desiguales y/o tamaños de muestra desiguales.
Para evaluar la igualdad de varianzas existen varias opciones, sin embargo, en este curso utilizaremos el test de barttlet mediante la función bartlett.test(). Utilizamos la base Calif_Fum.
bartlett.test(Calif_Fum$Calificacion~Calif_Fum$Grupo)
Bartlett test of homogeneity of variances
data: Calif_Fum$Calificacion by Calif_Fum$Grupo
Bartlett's K-squared = 0.065041, df = 1, p-value = 0.7987Note como es necesario introducir los datos como formula. La prueba nos dice que las varianzas son iguales entre los grupos.
A pesar del resultado, asumamos que las varianzas no son iguales para ejemplificar como realizar el test de welch cambiando el argumento var.equal = F
t.test(Calif_Fum$Calificacion~Calif_Fum$Grupo, conf.level = 0.98, var.equal = F)
Welch Two Sample t-test
data: Calif_Fum$Calificacion by Calif_Fum$Grupo
t = 2.5964, df = 15.593, p-value = 0.01978
alternative hypothesis: true difference in means between group Fumadores and group No Fumadores is not equal to 0
98 percent confidence interval:
0.01088222 10.19745111
sample estimates:
mean in group Fumadores mean in group No Fumadores
17.53750 12.43333 En R podemos crear gráficas que sean mas ilustrativas, para ello, vamos instalar las librearías ggstatsplot, ggplot2 y gapminder.
install.packages("ggplot2")
install.packages("ggstatsplot")
install.packages("gapminder")Una vez instalados, llamamos a las librerías
library(ggplot2)
library(ggstatsplot)
library(gapminder)ggbetweenstats(
data = Calif_Fum, #Objeto con la base de datos
x = Grupo, # Nombre de la variable de agrupación
y = Calificacion, # Nombre de las variable numerica
title = "Comparación de la calificación en fumadores vs no fumadores ", # titulo
type = "parametric") # Prueba paramétrica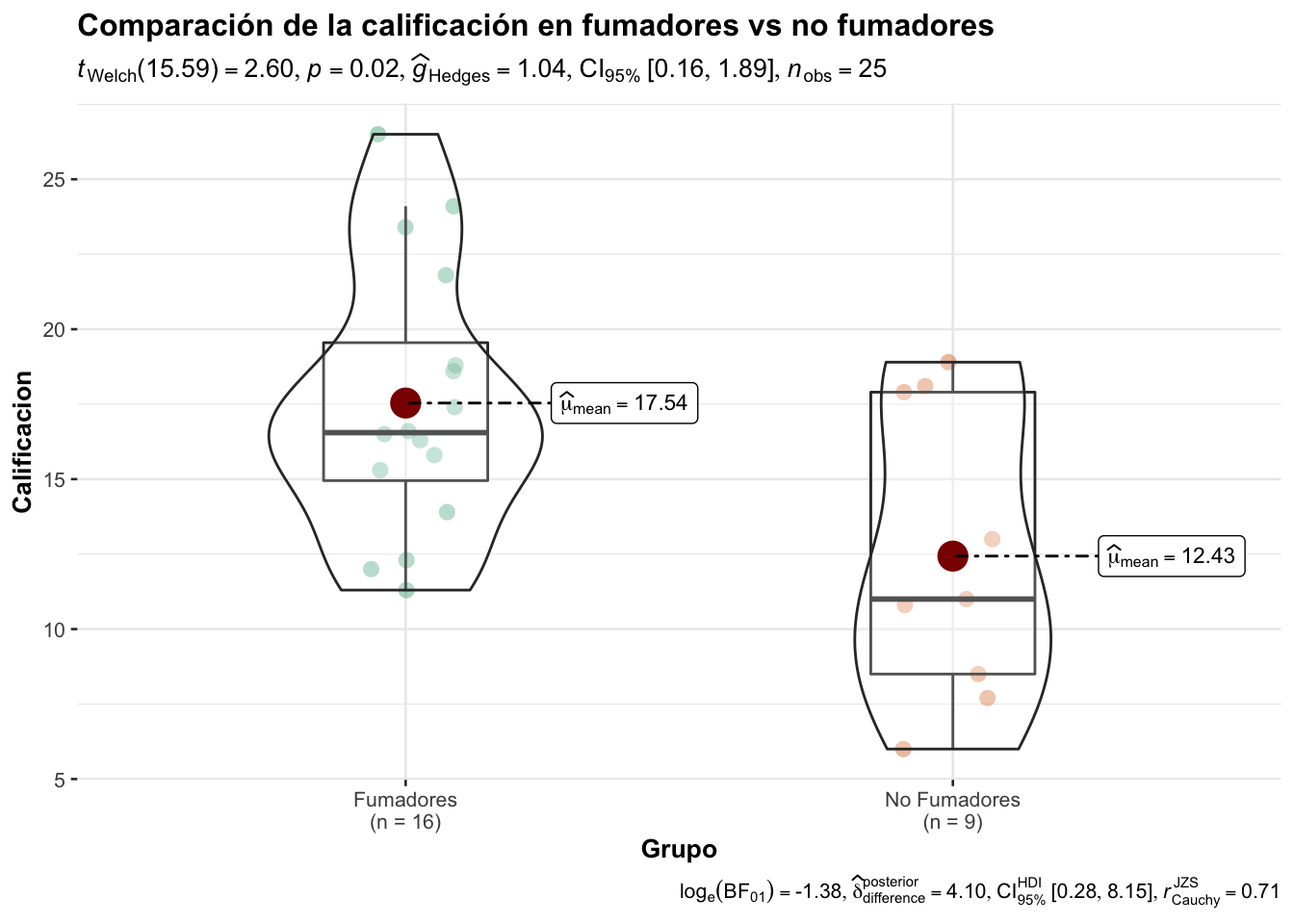
El tamaño del efecto: se define como el grado de generalidad que posee esa superioridad de A sobre B en la población de la que se obtuvo la muestra estudiada.
Puede encontrar más información sobre la gráfica anterior en: https://indrajeetpatil.github.io/ggstatsplot/
Ejercicios para la prueba t de student para muestras independientes clase:
- Utilizando la base de datos “Pima.tr” describa si hay diferencias en los niveles de glucosa, la presión arterial, en sikin, índice de masa corporal, en ped y edad entre las mujeres con diabetes y las mujeres sin diabetes. Para este problema utilice únicamente la función
t.testdeRno realice la prueba de hipótesis por pasos. Para cada una de las variables entregue los siguiente:
- Realice un boxplot para cada variable agrupadando entre las mujeres con diabetes y sin diabetes
- Una gráfica utilizando la función
ggbetweenstats - Resultado de la prueba
- Conclusión
- Utilizando la base de datos “Pima.tr” describa si hay diferencias en los niveles de glucosa, la presión arterial entre las mujeres con más de 40 años y las que mujeres con 40 años o menos.
Prueba t para variables dependientes
Un método que se utiliza con frecuencia para averiguar la eficacia de un tratamiento o procedimiento experimental es aquel que hace uso de observaciones relacionadas que resultan de muestras no independientes.
- Mediciones a través del tiempo
- Dos mediciones en el mismo sujeto
- Diseño cruzados
En estos casos la prueba de hipótesis más adecuada es la prueba t de student para muestras pareadas. Dado que se trabaja con la diferencia de las medias, no es necesario realizar prueba de homogeneidad de varainzas. !Es la misma muestra!
Vamos a resolver un ejemplo
Ejercicio práctico para la prueba t student para muestras pareadas
Nancy Stearns Burgess condujo un estudio para determinar la perdida de peso, la composición corporal, la distribución de grasa corporal y la tasa metabólica en reposo en individuos obesos antes y después de 12 semanas de tratamiento con dieta muy baja en calorías (DMBC), y comparar la hidrodensitometría con el análisis de impedancia bioeléctrica. Los 17 individuos (nueve mujeres y ocho hombres) que participaron en el estudio eran pacientes externos de un programa de tratamiento con base hospitalaria para la obesidad. Los pesos de las mujeres antes y después del tratamiento de 12 semanas de DMBC se muestran en dos objetos. Se pretende saber si estos datos ofrecen suficiente evidencia que permita concluir que el tratamiento es eficaz para reducir el peso en mujeres obesas.
Se crean dos objetos para ello:
antes<-c(117.3, 111.4,98.6,104.3,105.4,100.4, 81.7,89.5,78.2)
despues<-c(83.3,85.9,75.8,82.9,82.3,77.7,62.7,69.0,63.9)
# Crear un df para poder utilizar la función como fórmula
Medicion <- rep(x=c("antes", "despues"), each=9, times=1)
Peso <- c(antes, despues)
df <- data.frame(Medicion,Peso)Tratamos de probar si:
- Lo que se busca es saber si existe la suficiente evidencia para concluir que el programa de dietas es eficaz.
- Si es posible rechazar la hipótesis nula que indica que el cambio en la media de la población
Podemos graficar, el siguiente código tiene objetivo mostrar todos los argumenots de la función boxplot, ustede puede copiar y pegar o hacer un gráfico más sencillo:
boxplot(antes, despues, # Datos
horizontal = FALSE, # Horizontal or vertical plot
lwd = 2, # Lines width
col = c("#76EEC6", "#FFE4C4"), # Color
xlab = "Grupos", # X-axis label
ylab = "Peso", # Y-axis label
main = "Comparación del peso antes y después de la intervención", # Title
border = "black", # Boxplot border color
outpch = 25, # Outliers symbol
outbg = "green", # Outliers color
whiskcol = "blue", # Whisker color
whisklty = 2, # Whisker line type
names=c("Peso antes", "Peso despues"), #Nombres de los grupos
lty = 1) # Line type (box and median)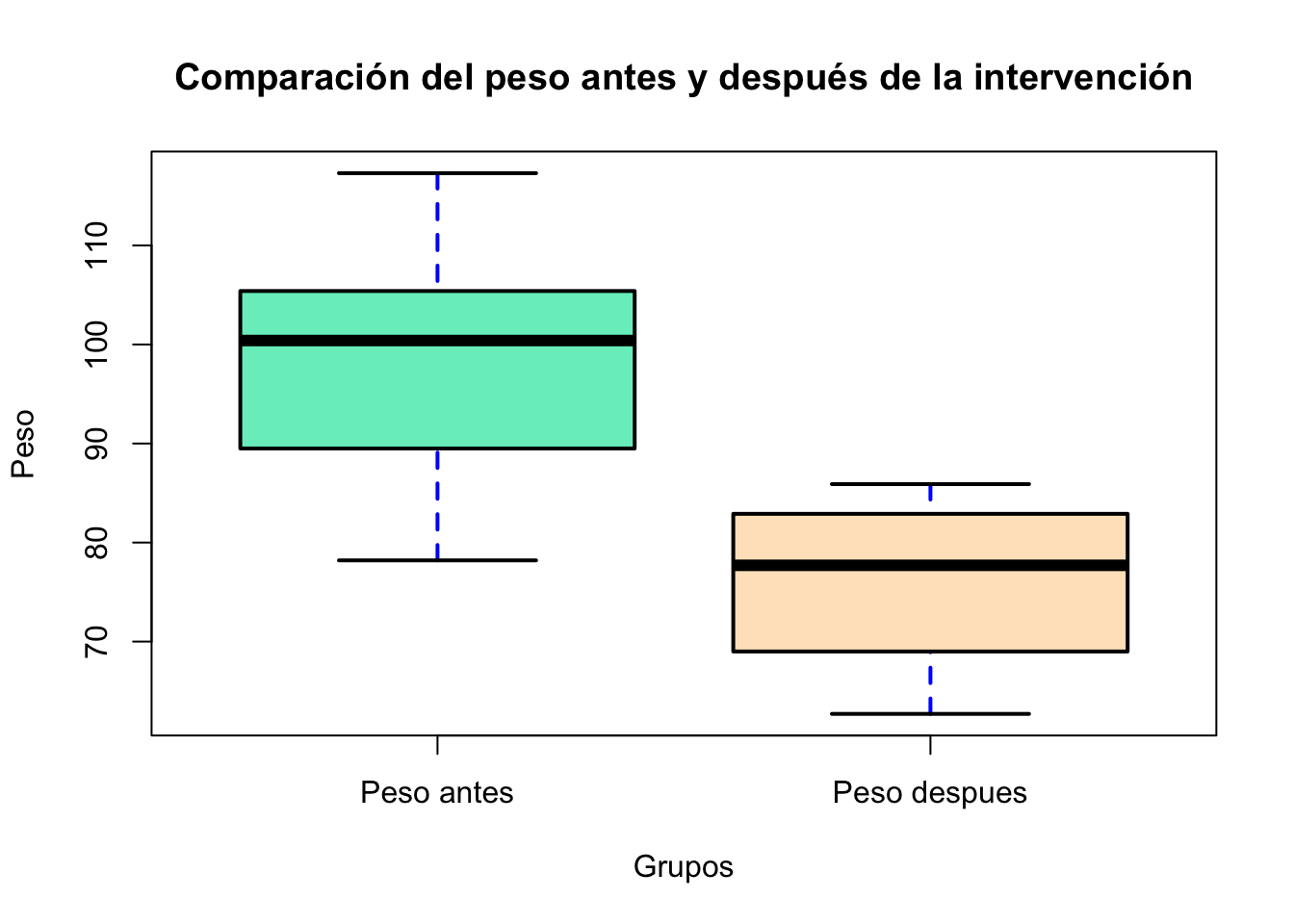
Con la función ggwithinstast de la libraría ggstastplot podemos tener una gráfica más informativa
ggwithinstats(
data = df,
x = Medicion,
y = Peso,
title = "Comparación del peso antes y después"
)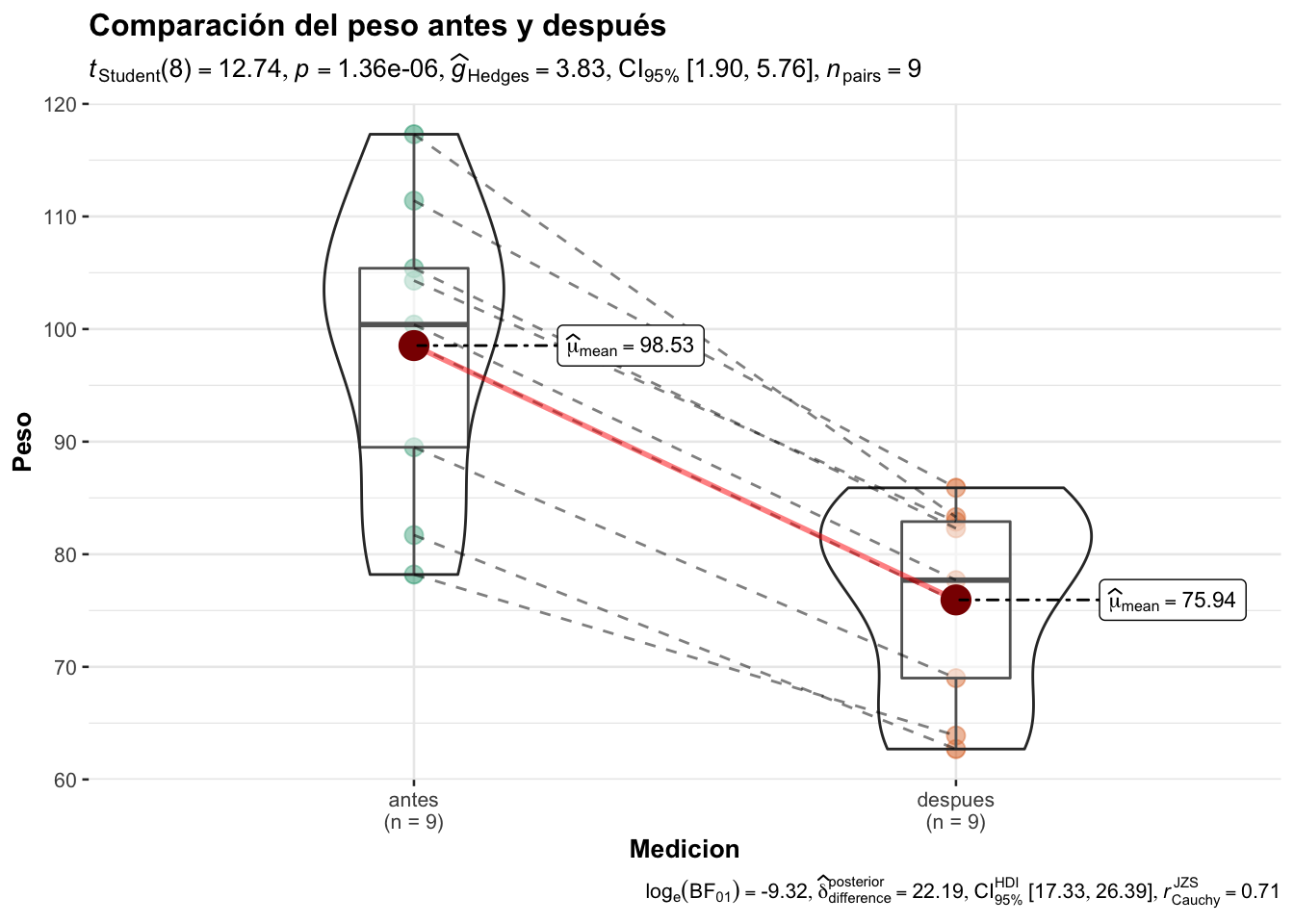
Para realizar la prueba t, puede emplear el siguiente código:
t.test(x=antes, y=despues, alternative = "greater",
paired = T, var.equal = T)
Paired t-test
data: antes and despues
t = 12.74, df = 8, p-value = 6.787e-07
alternative hypothesis: true mean difference is greater than 0
95 percent confidence interval:
19.29166 Inf
sample estimates:
mean difference
22.58889 Si utilizamos la función t.test mediante formula el código sería el siguiente:
t.test(df$Peso~df$Medicion, paired = T)Note como es necesario que las variables sean ingresadas desde un data frame
En el caso que nuestra hipótesis sea a dos colas:
t.test(x=antes, y=despues, alternative = "two.sided",
paired=T, var.equal = T)
Paired t-test
data: antes and despues
t = 12.74, df = 8, p-value = 1.357e-06
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
18.50003 26.67775
sample estimates:
mean difference
22.58889 Note que el único argumento que se debe de cambiar para indicarle a R que la muestra es pareada es: paired=T
Ejercicios clase prueba t de student pareada
La “Base_Prueba_t_pareada” es una base de datos que contiene la mediciones de adipocinas en pacientes con insuficiencia hepática. Contiene mediciones de estas adipocinas séricas a distintos tiempos: Basales, 3 meses, 6 y 12 meses
¿Existe evidencia para demostrar que los pacientes con insuficiencia hepática presentaron algún cambio entre las mediciones basales de leptina (Leptin) y las mediciones de leptina a los 6 meses (Leptin6M)?
¿Existe evidencia para demostrar que los pacientes con insuficiencia hepática presentaron algún cambio entre las mediciones basales de leptina (Leptin) y las mediciones de leptina a los 12 meses (Leptin12M)?
Ejercicios tarea
Resuelva cada uno de los siguientes ejercicios. La resolución debe de incluir cuando menos:
- Gráficas
- Selección de prueba t
- Prueba t
- Conclusión
Problema 1.
Frigerio et al. midieron la energía consumida en 32 mujeres de Gambia. Dieciséis de los individuos estudiados eran mujeres en periodo de lactancia (L) y el resto eran mujeres no embarazadas que no estaban en etapa de lactancia (NENL). Se reportaron los siguientes datos:
Para el grupo de mujeres en periodo de lactancia:
5289, 6209, 6054, 6665, 6343, 7699, 5678, 6954, 6916, 4770, 5979, 6305, 6502, 6113, 6347, 5657
Para el grupo de mujeres que no estaban en etapa de lactancia
9920, 8581, 9305, 10765, 8079, 9046, 7134, 8736, 10230, 7121, 8665, 5167, 8527, 7791, 8782, 6883
¿Proveen estos datos suficiente evidencia que permita concluir que las poblaciones muestreadas difieren respecto a la media de consumo de energía? Utilice
Ejercicio adaptado de BIOESTADÍSTICA, 4A ED Daniel , Wayne W.
Qué pueden concluir los investigadores?. Utilice t.test
Ejercicio adaptado de BIOESTADÍSTICA, 4A ED Daniel , Wayne W.
Problema 2.
¿La privación sensorial tiene algún efecto sobre la frecuencia de las ondas alfa de las personas? Se divide aleatoriamente en dos grupos a veinte voluntarios. Los individuos en el grupo A se sometieron a un periodo de privación sensorial durante 10 días, mientras que los individuos del grupo B sirvieron como grupo de control. Al terminar el periodo experimental, se midió la frecuencia de las ondas alfa a partir de los electroencefalogramas de estas personas. Los resultados son los siguientes:
| Grupo | Ondas_alfa |
|---|---|
| GrupoA | 10.2 |
| GrupoA | 9.5 |
| GrupoA | 10.1 |
| GrupoA | 10 |
| GrupoA | 9.8 |
| GrupoA | 10.9 |
| GrupoA | 11.4 |
| GrupoA | 10.8 |
| GrupoA | 9.7 |
| GrupoA | 10.4 |
| GrupoB | 11 |
| GrupoB | 11.2 |
| GrupoB | 10.1 |
| GrupoB | 11.4 |
| GrupoB | 11.7 |
| GrupoB | 11.2 |
| GrupoB | 10.8 |
| GrupoB | 11.6 |
| GrupoB | 10.9 |
| GrupoB | 10.9 |
Utilice
Problema 3.
Utilizando la base de datos “Pima.tr” describa si hay diferencias en los niveles de glucosa, la presión arterial, en sikin, índice de masa corporal, en ped y edad entre las mujeres al menos 3 embarazos y aquellas mujeres con menos de 3 embarazos. Utilice la variable npreg para identificar el número de embarazos.
Problema 4.
Utilizando la base de datos “Pima.tr” describa si hay diferencias en los niveles de glucosa, la presión arterial entre las mujeres con un índice de masa corporal de 27.6 o más y aquella mujeres con un índice de masa corporal menor a 27.6.
Problema 5
Utilice la baes de datos “Base_Prueba_t_pareadaLos” para resolver este ejercicio.
Los investigadores asignaron una intervención para reducir las concentraciones de adiponectina en los pacientes con insuficiencia hepática, para ello realizaron mediciones basales de esta adipocina (Adiponectin) y mediciones a los 6 meses (Adiponectin6M) y a los 12 meses (Adiponectin12M). ¿Pueden concluir los investigadores que se presentó una disminución de las concentraciones séricas de adiponectina?
Ejercicio 4
Utilice la baes de datos “Base_Prueba_t_pareadaLos” para resolver este ejercicio.
Los investigadores a cargo del estudio realizaron la medición de un biomarcador que se asocia a una enfermedad más grave en los pacientes con insuficiencia hepática, se ha validado que a mayores concentraciones de este biomarcador se presenta una enfermedad más grave. ¿Existe evidencia para demostrar que los pacientes empeoraron a los 6 meses y a los 12 meses con respecto a la medición basal?. La variable “Biomarcador” tiene las mediciones basales del biomarcador de interés. Mientras que variables “Biomarcador6M” y “Biomarcador12M” las mediciones a los 6 y 12 meses