7 Agrupación de la información
7.1 Introducción: Medidas de distancia/proximidad
Tanto las técnicas de reducción de dimensiones como las de agrupamiento, están basadas en determinar la semejanza (proximidad, similaridad) o disparidad (distancia, disimilaridad) existente; entre las variables las primeras, entre los individuos/variables las segundas.
Lo primero a decidir será, pues, si optamos por centrar el análisis en medir disparidad o semejanza, lo cual dependerá en buena parte de los objetivos planteados en la investigación.
Otra cuestión a considerar a la hora de optar por una medida u otra es la escala de medida de la/s variable/s considerada/s (escala de intervalo, datos binarios, frecuencias).
Cuando se trabaja con \(p>2\) variables, la distancia euclídea (la medida de distancia más utilizada en escala de intervalo) presenta un inconveniente, que considera las p variables estocásticamente independientes. Este inconveniente puede resolverse introduciendo la distancia de Mahalanobis, la cual tiene en cuenta las correlaciones entre !as variables, y por tanto la redundancia existente entre las mismas. En análisis discriminante, donde se trabaja con g poblaciones con distribuciones \(N_p(\mu_i,\Sigma)\), la regla de la máxima verosirnilitud para asignar a un sujeto a la población j correspondiente (j = 1,…, g), es equivalente a efectuar la asignación a la población más cercana considerando como medida la distancia de Mahalanobis, es decir, se elige la población cuya distancia sea mínima.
Se llaman de distancia o de disimilaridad porque cuanto mayor es el valor de la medida, mayor será la diferencia entre los individuos.Los distintos tipos que existen dependen de la escala en la que éstas estén formuladas. Cuando la variable está medida en una escala de intervalo las distancias más empleadas son las siguientes:
Distancia euclídea
Es la raíz cuadrada de la suma de las diferencias al cuadrado entre los dos elementos en la variable o variables consideradas.
\[EUCLID(X,Y) = \sqrt {\sum(X_i-Y_i)^2}\]
Distancia euclídea al cuadrado
\[SEUCLID(X,Y) = \sum{(X_i-Y_i)^2}\]
Distancia métrica de Chebychev
Es la distancia máxima en valores absolutos entre los valores de los elementos.
\[CHEBYCHEV(X,Y) = Max_i {|X_i-Y_i|}\]
Distancia de Manhattan o Bloque
La suma de las diferencias absolutas entre los valores de los elementos.
\[BLOCK(X,Y) = \sum {|X_i-Y_i|}\]
Distancia de Minkowski
La raíz p-ésima de la suma de las diferencias absolutas elevada a la potencia p-ésima entre los valores de los elementos.
\[MINKOWSKI(X,Y) = \sqrt[p]{\sum {|X_i-Y_i|^p}}\]
7.2 Análisis de componentes principales
El Análisis de Componentes Principales (ACP) es una técnica estadística de síntesis de la información, o reducción de la dimensión (número de variables).
Dadas \(n\) observaciones de \(p\) variables, se buscan \(m<p\) variables que sean combinaciones lineales de las \(p\) originales y que estén incorreladas, recogiendo la mayor parte de la información o variabilidad de los datos. Hay que tener presente que, si las variables originales están incorreladas de partida, entonces no tiene sentido realizar un análisis de componentes principales.
Se considera una serie de variables \((x_1,x_2,...x_p)\) sobre un grupo de objetos o individuos y se trata de calcular, a partir de ellas, un nuevo conjunto de variables \((y_1,y_2,...y_p)\), incorreladas entre sí, cuyas varianzas vayan decreciendo progresivamente. Cada \(y_j\) (donde \(j=1,...,p\)) es una combinación lineal de las \(x_1,x_2,...x_p\) originales, es decir:
\[y_j=a_{j1}x_1+a_{j2}x_2+...+a_{jP}x_p=a'_jx\]
donde \(a'_j=(a_{j1},a_{j2},...,a_{jP})\) y
\[x= \begin{bmatrix} x_{1}\\ x_{2}\\ \vdots\\ x_{p} \end{bmatrix}\]
El objeto del análisis es maximizar la varianza del componente obtenido, pero manteniendo la ortogonalidad de la transformación, esto es:
\[a'_ja_j=\sum_{k=1}^p a_{kj}^2=1\]
La varianza del primer componente, por tanto, será:
\[Var(y_1)=Var(a'_1 x)=a'_1\sigma a_1\]
El problema consiste en maximizar la función \(a'_1\sigma a_1\) donde \(\sigma\) es la matriz de covarianzas de las \(p\) variables, sujeta a la restricción \(a'_1a_1=1\). Para resolver dicho problema, se Utilizan los multiplicadores de Lagrange, siendo por tanto la función objetivo:
\[L(a_1)=a'_1\sigma a_1-\lambda (a'_1a_1-1)\]
A continuación, se busca el maximo derivando según la incognita \(a_1\):
\[\frac{\partial L(a_1)}{\partial a_1}=0 \longrightarrow (\sigma - \lambda I)a_1=0\]
La solución del sistema de ecuaciones requiere que el determinante \(\mid \sigma - \lambda I \mid\) sea no nulo, de manera que \(\lambda\) es un autovalor de \(\sigma\), que al ser definida positiva, tendrá \(p\) autovalores distintos.
Entonces, para maximizar la varianza de \(y_1\) se tiene que tomar el mayor autovalor, \(\lambda_1\) y el correspondiente autovector será \(a_1\).
Dado que \(\sigma a_1=\lambda a_1\), si multiplicamos a ambos lados por \(a'_1\):
\[a'_1 \sigma a_1 = \lambda a'_1a_1 = \lambda\] Es decir, \(\lambda\) será igual a la varianza de \(y_1\)
El segundo componente principal, \(y_2=a'_2x\) ha de estar incorrelacionado con \(y_1\), es decir:
\[cov(y_1,y_2)=cov(a'_1x,a'_2x)=a'_1 \sigma a_2=0\]
Para maximizar la \(Var(y_2)=a'_2\sigma a_2\) se imponen ahora dos restricciones:
\[a'_2a_2=1 \\ a'_2a_1=0\]
El objetivo que se plantea es maximizazr la suma de las varianzas de \(y_1=a'_1 x\) y \(y_2=a'_2 x\), donde \(a_1\) y \(a_2\) son los vectores que definen el plano. La función objetivo será por tanto:
\[L(a_1, a_2) = a'_1\sigma a_1 + a'_2\sigma a_2-\lambda_1 (a'_1a_1-1) - \lambda_2 (a'_2a_2-1)\] Derivando respecto a las incógnitas, \(a_1\) y \(a_2\), e igualando a cero:
\[\frac{\partial L(a_1, a_2)}{\partial a_1}=0 \longrightarrow (\sigma - \lambda_1 I)a_1=0\\\frac{\partial L(a_1, a_2)}{\partial a_2}=0 \longrightarrow (\sigma - \lambda_2 I)a_2=0 \] que indica que \(a_1\) y \(a_2\) deben ser vectores propios de \(\sigma\).
Es claro que \(\lambda_1\) y \(\lambda_2\) deben ser los dos autovalores mayores de la matriz \(\sigma\) y \(a_1\) y \(a_2\) sus correspondientes autovectores. Observemos que la covarianza entre \(y_1\) y \(y_2\), dada por \(a'_1 \sigma a_2\) es cero, ya que \(a'_1 a_2 = 0\), y las variables \(y_1\) y \(y_2\) estarán incorreladas.
Puede demostrarse análogamente que el espacio de dimensión \(m\) que mejor representa a los puntos viene definido por los vectores propios asociados a los \(m\) mayores valores propios de \(\sigma\). Estas direcciones se denominan direcciones principales de los datos y a las nuevas variables por ellas definidas componentes principales.
Entonces todos los \(p\) componentes de \(y\) se pueden expresar como el producto de una matriz formada por los autovectores de \(\sigma\), multiplicada por el vector \(x\) que contiene las variables originales:
\[y=Ax\]
donde \(A= \begin{bmatrix} a'_{1}\\ a'_{2}\\ \vdots \\ a'_{p} \end{bmatrix}\) y la \(Var(y_j)=\lambda_j\), y la \(Cov(y_j,y_s)=0\).
Calcular los componentes principales equivale, por tanto, a aplicar una transformación ortogonal A a las variables \(x\) (ejes originales) para obtener unas nuevas variables \(y\) incorreladas entre sí. Esta operación puede interpretarse como elegir unos nuevos ejes coordenados, que coincidan con los “ejes naturales” de los datos.
Si sumamos todos los autovalores,tendremos entonces la varianza total de los componentes, que por las propiedades del operador traza, acaba siendo igual que la varianza de las variables originales, es decir:
\[\sum_{j=1}^p Var(y_j)= \sum_{j=1}^p (\lambda_j)=\sum_{j=1}^p Var(x_j)\]
El porcentaje de varianza total que recoge cada componente principal, \(\frac {\lambda_j} {\sum_{j=1}^p (\lambda_j)}\) es el critierio utilizado para reducir las \(p\) variables de nuestro conjunto de datos, por \(m\) combinaciones lineales de dichas variables.
El ACP se emplea sobre todo en análisis exploratorio de datos (Analisis factorial) y para construir modelos predictivos cuando las variables explicativas tienen problemas de colinealidad.
El ACP comporta el cálculo de la descomposición en autovalores de la matriz de covarianza. Normalmente, las variables originales se tipifican primero, lo cual implica el trabajar con la matriz de correlación, y dado que \(Var(x_j)=1\ \forall j\):
\[\sum_{j=1}^p Var(y_j)= \sum_{j=1}^p (\lambda_j)=\sum_{j=1}^p Var(x_j)=p\]
Las covarianzas entre cada componente principal y las variables \(x\) vienen dadas por el producto de las coordenadas del vector propio que define el componente por su valor propio:
\[Cov(y_i,x)=Cov(a'_ix,x_1,...,x_p)=a'_i\lambda_i=(a_{i1}\lambda_i, a_{i2}\lambda_i,..,a_{ip}\lambda_i)\] y, por tanto, las correlaciones:
\[Corr(y_i,x_j)=\frac {Cov(y_i,x_j)}{\sqrt {Var(y_i)Var(x_j)}}=a_{ij}\sqrt \frac {\lambda_i}{Var(x_j)}\] o, en términos matriciales:
\[Corr(y,x) = \Lambda^{1/2} AD\] donde \(\Lambda^{1/2}\) es la matriz diagonal con términos \(\sqrt \lambda_i\) y \(D\) es también diagonal, registrando las inversas de las desviaciones típicas de cada variable.
Las m componentes principales (m < p) proporcionan la predicción lineal óptima con m variables del conjunto de variables \(x\).
Si estandarizamos los componentes principales, dividiendo cada uno por su desviación típica, se obtiene la estandarización multivariante de los datos originales. Si trabajamos con las variables originales tipificadas, entonces \(Corr(y_i,x_j)=a_{ij}\).
Por tanto, la transformación mediante componentes principales conduce a variables incorreladas, pero con distinta varianza. Puede interpretarse como rotar los ejes de la elipse que definen los puntos para que coincidan con sus ejes naturales. La estandarización multivariante produce variables incorreladas con varianza unidad, lo que supone buscar los ejes naturales y luego estandarizarlos. En consecuencia, si estandarizamos los componentes se obtienen las variables estandarizadas de forma multivariante.
Cuando las escalas de medida de las variables son muy distintas, la maximización de las funciones objetivo dependerá decisivamente de estas escalas de medida y las variables con valores más grandes tendrán más peso en el análisis. Si queremos evitar este problema, conviene estandarizar las variables antes de calcular los componentes, de manera que las magnitudes de los valores numéricos de las variables \(x\) sean similares. Por otra parte, si las variabilidades de las \(x\) son muy distintas, las variables con mayor varianza van a influir más en la determinación de la primera componente, siendo éste otro problema que evita la estandarización.
Por tanto, cuando las variables \(x\) originales están en distintas unidades conviene aplicar el análisis de la matriz de correlaciones o análisis normado. Cuando las variables tienen las mismas unidades, ambas alternativas son posibles. Si las diferencias entre las varianzas de las variables son informativas y queremos tenerlas en cuenta en el análisis, no debemos estandarizar las variables: por ejemplo, supongamos que teenemos dos índices con la misma base pero uno fluctúa mucho y el otro es casi constante. Este hecho es informativo, y para tenerlo en cuenta no se deben estandarizar las variables, de manera que el índice de mayor variabilidad tenga más peso. Por el contrario, si las diferencias de variabilidad no son relevantes se eliminan con el análisis normado. En caso de duda, conviene realizar ambos análisis, y seleccionar aquél que conduzca a conclusiones más informativas.
El análisis de componentes principales (PCA) puede realizarse con una función de la librería básica de «R»: prcomp o princomp.
Para nuestro ejemplo, partimos del dataframe USArrests que contiene información sobre el número de arrestos por cada 100.000 residentes, por asalto, asesinato y violación en cada uno de los 50 estados de los Estados Unidos en 1973. También se da el porcentaje de la población que vive en áreas urbanas. Las variables, en concreto, serían:
Murder. Arrestos por asesinato (por 100.000 hab.)
Assault. Arrestos por asalto (por 100.000 hab.)
UrbanPop. Porcentaje de población urbana
Rape. Arrestos por violación (por 100.000 hab.)
El análisis realizado sería el siguiente:
require(graphics)
str(USArrests)## 'data.frame': 50 obs. of 4 variables:
## $ Murder : num 13.2 10 8.1 8.8 9 7.9 3.3 5.9 15.4 17.4 ...
## $ Assault : int 236 263 294 190 276 204 110 238 335 211 ...
## $ UrbanPop: int 58 48 80 50 91 78 77 72 80 60 ...
## $ Rape : num 21.2 44.5 31 19.5 40.6 38.7 11.1 15.8 31.9 25.8 ...# scale = TRUE para análisis normado
prcomp(USArrests, scale = TRUE)## Standard deviations (1, .., p=4):
## [1] 1.5748782744 0.9948694148 0.5971291155 0.4164493820
##
## Rotation (n x k) = (4 x 4):
## PC1 PC2 PC3 PC4
## Murder -0.5358994749 0.4181808654 -0.3412327280 0.6492278043
## Assault -0.5831836349 0.1879856042 -0.2681484278 -0.7434074799
## UrbanPop -0.2781908746 -0.8728061931 -0.3780157931 0.1338777308
## Rape -0.5434320914 -0.1673186354 0.8177779076 0.0890243227# Sin porcentaje de población urbana. La fórmula se establece sin variable dependiente
prcomp(~ Murder + Assault + Rape, data = USArrests, scale = TRUE)## Standard deviations (1, .., p=3):
## [1] 1.5357669768 0.6767948935 0.4282154425
##
## Rotation (n x k) = (3 x 3):
## PC1 PC2 PC3
## Murder -0.5826005597 0.5339532186 -0.6127565162
## Assault -0.6079818196 0.2140235835 0.7645600125
## Rape -0.5393836250 -0.8179779129 -0.1999435899plot(prcomp(USArrests, scale = TRUE))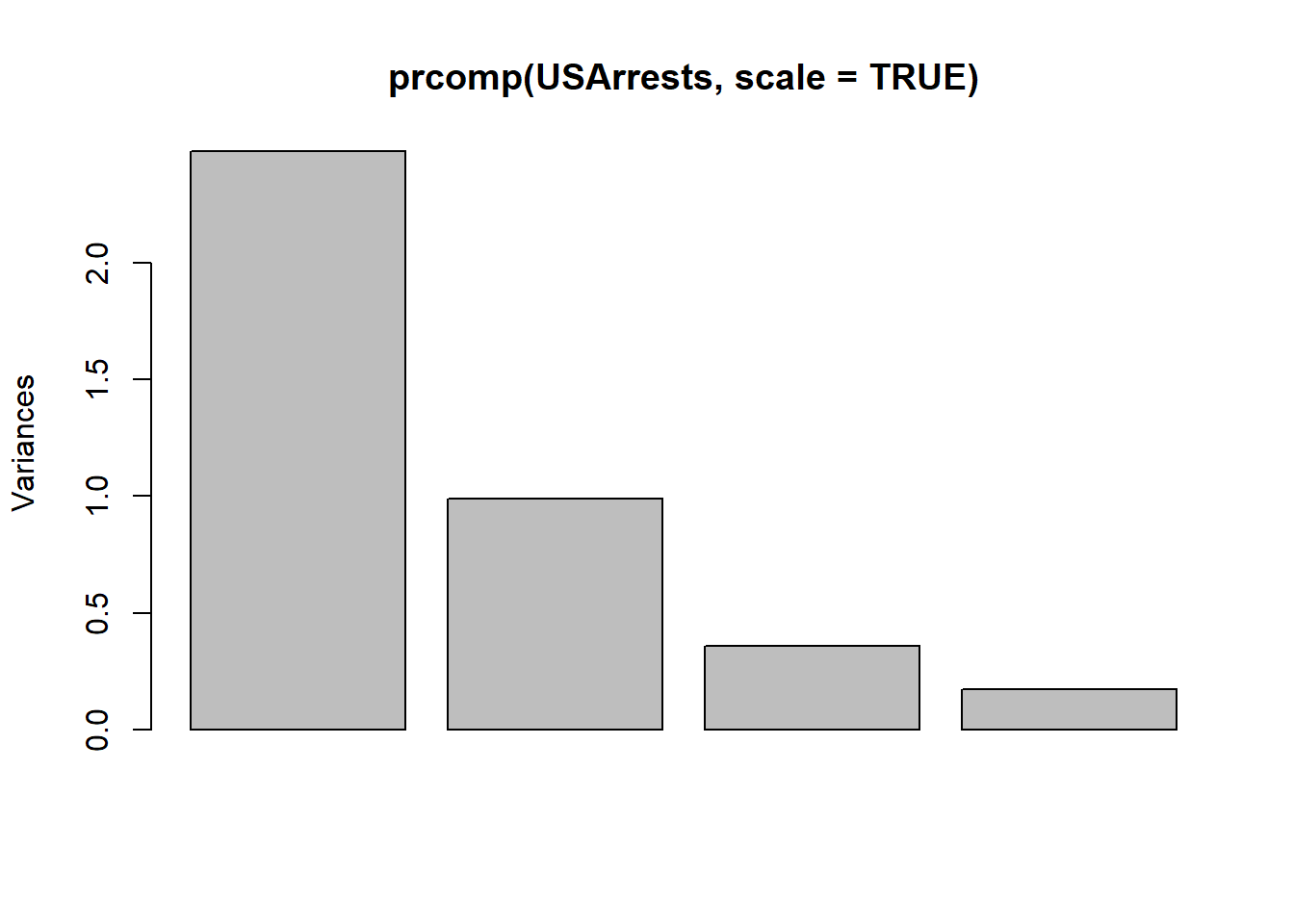
summary(prcomp(USArrests, scale = TRUE))## Importance of components:
## PC1 PC2 PC3 PC4
## Standard deviation 1.574878 0.9948694 0.5971291 0.4164494
## Proportion of Variance 0.620060 0.2474400 0.0891400 0.0433600
## Cumulative Proportion 0.620060 0.8675000 0.9566400 1.0000000biplot(prcomp(USArrests, scale = TRUE))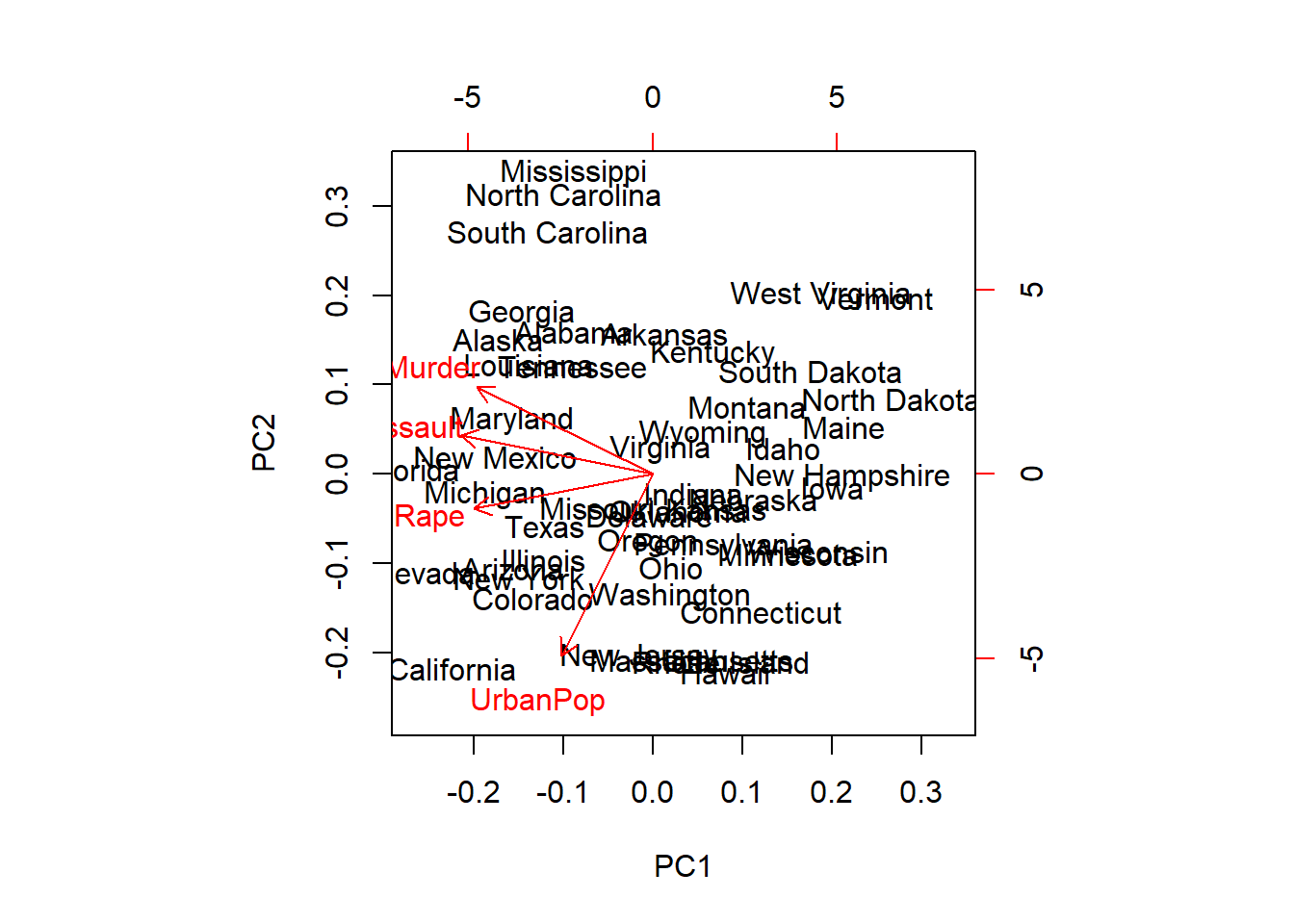
Si no tipificamos las variables, la variable con mayor varianza (arrestos por asalto) será la que recoja la primera componente, acumulando el mayor peso en el análisis, frente a los arrestos por asesinato.
prcomp(USArrests)## Standard deviations (1, .., p=4):
## [1] 83.732400246 14.212401849 6.489426073 2.482790000
##
## Rotation (n x k) = (4 x 4):
## PC1 PC2 PC3 PC4
## Murder 0.04170432063 -0.04482165627 0.07989065942 -0.99492173125
## Assault 0.99522128143 -0.05876002786 -0.06756973508 0.03893829764
## UrbanPop 0.04633574612 0.97685747991 -0.20054628735 -0.05816914306
## Rape 0.07515550059 0.20071806645 0.97408059218 0.07232501964# scale = FALSE es el valor por defecto
plot(prcomp(USArrests))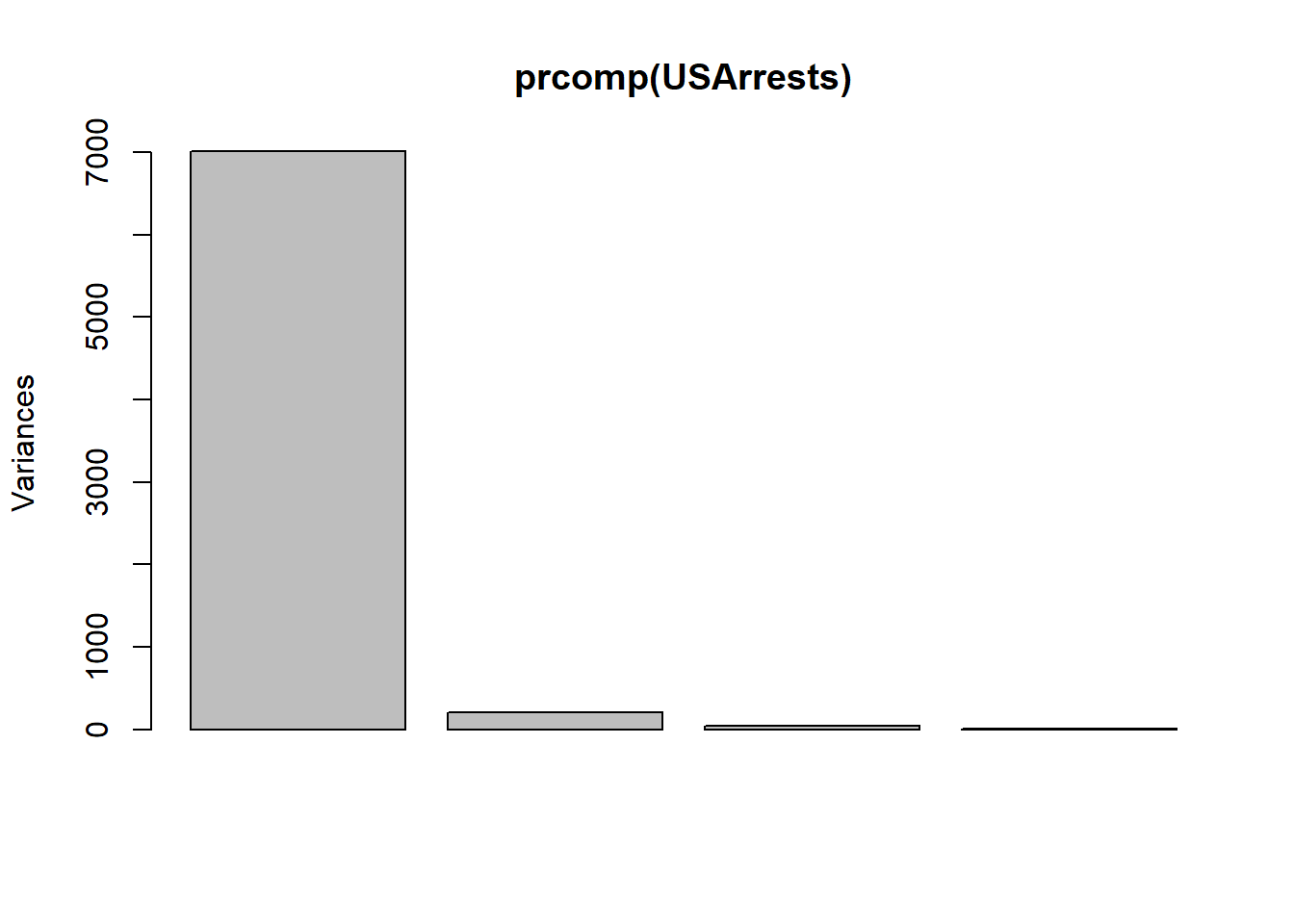
summary(prcomp(USArrests))## Importance of components:
## PC1 PC2 PC3 PC4
## Standard deviation 83.73240 14.21240 6.489426 2.48279
## Proportion of Variance 0.96553 0.02782 0.005800 0.00085
## Cumulative Proportion 0.96553 0.99335 0.999150 1.00000biplot(prcomp(USArrests))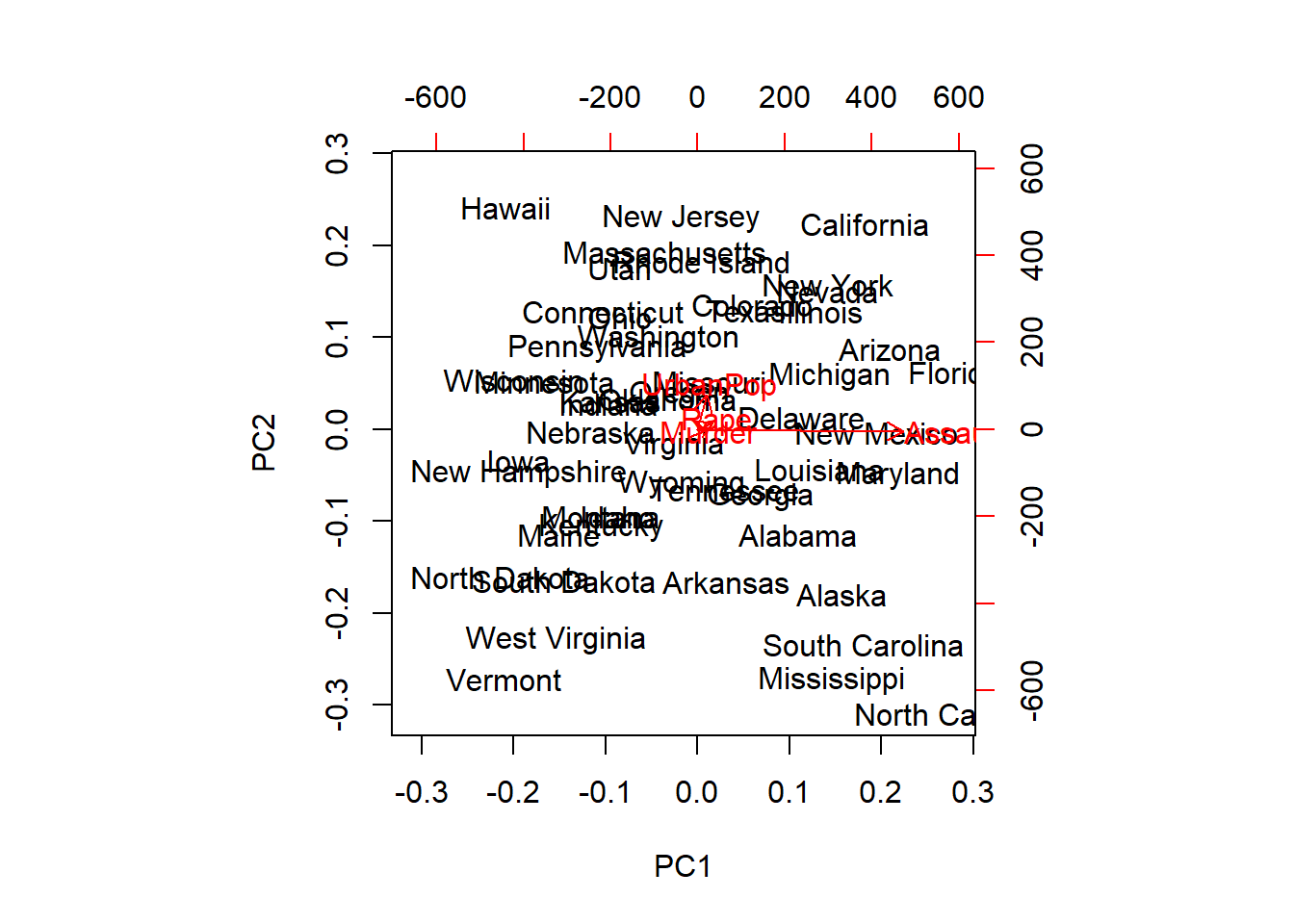
7.3 Análisis factorial
El análisis factorial exploratorio, se utiliza para tratar de descubrir la estructura interna de un número relativamente grande de variables. La hipótesis a priori del investigador es que pueden existir una serie de factores asociados a grupos de variables. Las cargas de los distintos factores se utilizan para intuir la relación de éstos con las distintas variables. Es el tipo de análisis factorial más común.
El análisis factorial confirmatorio, AFC, trata de determinar si el número de factores obtenidos y sus cargas se corresponden con los que cabría esperar a la luz de una teoría previa acerca de los datos. La hipótesis a priori es que existen unos determinados factores preestablecidos y que cada uno de ellos está asociado con un determinado subconjunto de las variables. El análisis factorial confirmatorio entonces arroja un nivel de confianza para poder aceptar o rechazar dicha hipótesis.
El análisis de componentes principales es el método apropiado de extracción de factores, cuando el interés primordial se centra en la predicción o el número mínimo de factores necesarios para justificar la porción máxima de varianza representada en la serie de variables original, y cuando el conocimiento previo sugiere que la varianza específica y de error representan una porción relativamente pequeña de la varianza total.
Por el contrario, cuando se pretende identificar las dimensiones latentes o las construcciones representadas en las variables originales y se tiene poco conocimiento de la varianza específica y el error, lo más apropiado es utilizar el método factorial común, si bien las complicaciones del análisis factorial común han contribuido al análisis generalizado de la técnica de componentes principales.
Para interpretar bien los factores se utiliza una rotación de ejes, ya que las soluciones factoriales no rotadas extraen factores según su orden de importancia. El primer factor tiende a ser un factor general por el que casi toda variable se ve afectada significativamente, dando cuenta del mayor porcentaje de varianza. Los métodos de rotación ortogonales mas utilizados son VARIMAX, QUARTIMAX y EQUIMAX.
En la practica no se utiliza un criterio único de los factores a extraer, si bien se utiliza como primera aproximación el gráfico de autovalor para el criterio de contraste de caida. Despues de interpretar los factores extraidos hay que valorar su carácter práctico.
7.3.1 Planteamiento
Consideramos las variables observadas \(X_1, X_2, X_3, ...X_p\) como variables tipificadas (con media cero y varianza unidad) y vamos a formalizar la relación entre las variables definiendo el siguiente modelo factorial:
\[X_1 =l_{11}F_1 + l_{12}F_2 +...+ l_{1K}F_K + u_1 \\ X_2=l_{21}F_1+l_{22}F_2+...+l_{2K}F_K + u_2 \\ … \\ X_P=l_{P1}F_1+l_{P2}F_2+ ...+l_{PK}F_K + u_p\]
En este modelo \(F_1, F_2,..., F_k\) son los factores comunes, \(u_1, u_2,..., u_p\) son los factores únicos o unicidades y \(l_{ij}\) es el peso del factor j en la variable i, denominado también carga factorial o saturación de una variable en un factor. Según la formulación del modelo, cada una de las p variables observables es una combinación lineal de k factores comunes a todas las variables (\(k<p\)) y de un factor único para cada variable. Así, todas las variables originales están influenciadas por todos los factores comunes, mientras que para cada variable existe un único factor que es específico para esa variable. Tanto los factores comunes como los específicos son variables no observables. De forma matricial el modelo queda:
\[X=LF+U\] donde \(X\) es la matriz formada por las variables originales, \(L\) es la matriz de cargas factoriales, \(F\) es la matriz formada por los factores comunes y \(U\) es la matriz formada por los factores únicos o específicos.
7.3.2 Hipótesis en el modelo factorial
Para poder aplicar la teoría de la inferencia estadística en el modelo factorial es necesario formular hipótesis sobre los factores comunes y sobre los específicos. Estas hipótesis son:
\(E(F) = 0\). la esperanza del vector de factores communes es cero.
\(Cov(F) = I\). La matriz de covarianzas de los factores communes es la matriz identidad.
\(E(U)=0\). La esperanza del vector de factores únicos se supone que es el vector cero.
\(Cov(U)= \Psi = diag(\psi_1,…,\psi_p)\). Las varianzas de los factores únicos pueden ser distintas y dichos factores están incorrelacionados entre si.
\(Cov(F, U)= 0\). La matriz de covarianzas entre los factores communes y los factores únicos es la matriz cero.
7.3.3 Comunalidad y especificidad (unicidad)
Dado que la variable \(X_j\) está tipificada (media cero y varianza unidad), se puede descomponer su variabilidad como:
\[Var(X_j) = 1 = (l_{j1}^2 + \cdots + l_{jk}^2) + \psi_j^2 = h_j^2 + \psi_j^2\]
Donde \(h_j^2\) es la parte de varianza de la variable \(X_j\) debida a los factores comunes, y se denomina comunalidad. Por otro lado, \(\psi_j^2\) es la parte de la varianza de la variable \(X_j\) debida a los factores únicos o específicos y se denomina especificidad o unicidad.
7.3.4 Diseño del análisis
Los pasos a seguir son los siguientes:
Selección de variables: Seleccionamos variables métricas. En caso contrario, necesitamos realizar una transformación de no métricas a métricas.
Tamaño muestral: La muestra no debe ser inferior a 50 observaciones. Lo aconsejable es que sea >= 100. Como regla general, deben tenerse por lo menos cinco veces más observaciones que variables, tomando como ratio óptimo un ratio de diez a uno.
Cálculo de la matriz de correlaciones. El primer paso del análisis es el cálculo de la matriz de correlaciones de todas las variables que entran en el análisis. Una vez que se dispone de esta matriz concierne examinarla para comprobar si sus características son adecuadas para realizar un Análisis Factorial. Uno de los requisitos que deben cumplirse para que el Análisis Factorial tenga sentido es que las variables estén altamente correlacionadas. Pueden utilizarse diferentes métodos para comprobar el grado de asociación entre las variables:
El determinante de la matriz de correlaciones: un determinante muy bajo indicará altas correlaciones entre las variables, pero no debe ser cero (matriz no singular), pues esto indicaría que algunas de las variables son linealmente dependientes y no se podrían realizar ciertos cálculos necesarios en el Análisis Factorial).
Test de Esfericidad de Bartlett: Comprueba que la matriz de correlaciones se ajuste a la matriz identidad, es decir ausencia de correlación significativa entre las variables. Esto significa que la nube de puntos se ajustará a una esfera perfecta, expresando así la hipótesis nula por: \[H_0: R=I \Rightarrow H_0:|R|=1\] es decir, que el determinante de la matriz de correlaciones es igual a 1. Bartlett introdujo un estadístico para este contraste basado en la matriz de correlacion \(R\), que bajo la hipótesis nula \(H_0\) tiene una distribución chi-cuadrado con \(p(p-1)/2\) grados de libertad. La expresión del estadístico es la siguiente: \[\chi^2 = -[n - 1- \frac {2p+5} {6}] \ \ ln|R|\] cuando p > 0,05, es decir que no tenemos evidencias para rechazar la hipótesis nula, significa que las variables no están correlacionadas y por tanto no tiene mucho sentido llevar a cabo un Análisis Factorial. Este contraste es útil cuando el tamaño muestral es pequeño.
Indice KMO de Kaiser-Meyer-Olkin. En un modelo con varias variables, el coeficiente de correlación parcial mide la correlación existente entre ellas una vez se han descontado los efectos lineales del resto de variables. En el modelo factorial, se pueden considerar tanto los efectos de las otras variables como los correspondientes a los factores comunes. Por lo tanto, el coeficiente de correlación parial entre dos variables sería equivalente al coeficiente de correlación parcial entre los factores únicos de esas dos variables. Pero de acuerdo con el modelo factorial los coeficientes de correlación teóricos calculados entre cada par de factores únicos son nulos por hipótesis, y como los coeficientes de correlación parcial constituyen una aproximación a dichos coeficientes teóricos, deben estar próximos a cero. El índicde KMO de adecuación global del modelo está basado en los coeficientes de correlación observados en cada par de variables y en sus coeficientes de correlación parcial de la siguiente forma: \[KMO = \frac {\sum_j \sum_{h \ne j} r_{jh}^2} {\sum_j \sum_{h \ne j} r_{jh}^2 + \sum_j \sum_{h \ne j} a_{jh}^2}\] donde \(r_{jh}^2\) representa al coeficiente de correlación simple al cuadrado y \(a_{jh}^2\) al coeficiente de correlación parcial al cuadrado. En el caso de que exista adecuación de los datos a un modelo de Análisis Factorial, el valor de los coeficientes de correlación parcial será pequeño y por tanto el valor de KMO será próximo a la unidad. Por tanto, valores bajos del indice KMO desaconsejan la utilización del Análisis Factorial. Como baremo para interpretar el índice KMO podría tomarse según Kaiser:
| Criterio | Valoración | |------------------|--------------| | 1 >= KMO >= 0.9 | muy bueno | |0.9 >= KMO >= 0.8 | meritorio | | 0.8 >= KMO >= 0.7| mediano | |0.7 >= KMO >= 0.6 | mediocre | |0.6 >= KMO > 0.5 | bajo | | KMO <= 0.5 | inaceptable | | | |Correlación Anti-imagen. El negativo del coeficiente de correlación parcial. Deberá haber pocos coeficientes altos para que sea razonable aplicar el Análisis Factorial.
Medida de Adecuación de la Muestra (MSA, mesure of sampling adequacy). Equivalente a KMO, pero evaluando cada variable \(X_1,...,X_p\). Por tanto: \[MSA_j = \frac {\sum_{h \ne j} r_{jh}^2} {\sum_{h \ne j} r_{jh}^2 + \sum_{h \ne j} a_{jh}^2}\]
Coeficiente de Correlación Múltiple. Deberá ser alto. Esta técnica, por defecto, toma los valores de la correlación múltiple al cuadrado como los valores iniciales de comunalidad.
7.3.5 Extracción de los factores
Existen diversos procedimientos de extracción de los factores. Veamos algunos de ellos:
- Componentes principales. Como hemos visto, se forman combinaciones lineales independientes de las variables observadas. La primera componente tiene la varianza máxima. Las componentes sucesivas explican progresivamente proporciones menores de la varianza y no están correlacionadas las unas con las otras. Por tanto, se trata de considerar como factores los k primeros componentes principales. El análisis de componentes principales se utiliza para obtener la solución factorial inicial. Puede utilizarse cuando una matriz de correlaciones es singular.
Siguiendo el apartado anterior:
\[y=Ax \Rightarrow A'y=x\]
El modelo factorial quedaría definido como:
\[L = A_{(k)}'= \begin{bmatrix} a_{1}, a_{2},..., a_{k} \end{bmatrix}\ \ \ \ \ F = y_{(k)}= \begin{bmatrix} y_{1}\\ y_{2}\\ \vdots \\ y_{k} \end{bmatrix} \ \ \ \ \ U = X - LF\]
Mínimos cuadrados no ponderados. Los factores se obtienen minimizando la suma de los cuadrados de las diferencias entre las matrices de correlaciones observada y reproducida, ignorando las diagonales.
Mínimos cuadrados generalizados. Se minimiza la suma de los cuadrados de las diferencias entre las matrices de correlación observada y reproducida. Las correlaciones se ponderan por el inverso de su unicidad, de manera que las variables que tengan un valor alto de unicidad reciban un peso menor que aquéllas que tengan un valor bajo de unicidad.
Método de máxima verosimilitud. Proporciona las estimaciones de los parámetros que con mayor probabilidad han producido la matriz de correlaciones observada, bajo el supuesto de que la muestra procede de una distribución normal multivariada. Las correlaciones se ponderan por el inverso de la unicidad de las variables, y se emplea un algoritmo iterativo.
Factor o Eje principal. Parte de la matriz de correlaciones original con los cuadrados de los coeficientes de correlación múltiple insertados en la diagonal principal como estimaciones iniciales de las comunalidades. Las saturaciones factoriales resultantes se utilizan para estimar de nuevo las comunalidades y reemplazan a las estimaciones previas en la diagonal de la matriz. Las iteraciones continúan hasta que el cambio en las comunalidades, de una iteración a la siguiente, satisfaga el criterio de convergencia para la extracción.
Análisis Alfa. Considera a las variables incluidas en el análisis como una muestra del universo de las variables posibles. Este método maximiza el Alfa de Cronbach para los factores.
Análisis Imagen. Fue desarrollado por Guttman y está basado en la teoría de las imágenes. La parte común de una variable, llamada la imagen parcial, se define como su regresión lineal sobre las restantes variables, en lugar de ser una función de los factores hipotéticos.
Sin entrar en demasiados detalles, el primero es adecuado cuando se trata de resumir la mayor parte posible de la información inicial (varianza) en el menor número de factores posibles que, por otra parte, es la utilización más frecuente del Análisis Factorial. El método de ejes principales es más adecuado cuando se trata de identificar factores o dimensiones que reflejen lo que las variables comparten en común. Dado que, básicamente, todos los métodos ofrecen resultados muy similares, se suele utilizar siempre el primero de ellos.
7.3.6 La matriz factorial o de componentes
A partir de una matriz de correlaciones, el Análisis Factorial extrae otra matriz que reproduce la primera de forma más sencilla. Esta nueva matriz se denomina matriz factorial y adopta la siguiente forma:
| 1 | 2 | |
|---|---|---|
| 1 | \(p_{11}\) | \(p_{21}\) |
| 2 | \(p_{12}\) | \(p_{22}\) |
| 3 | \(p_{13}\) | \(p_{23}\) |
| 4 | \(p_{14}\) | \(p_{24}\) |
| 5 | \(p_{15}\) | \(p_{25}\) |
| 6 | \(p_{16}\) | \(p_{26}\) |
Cada columna es un factor y hay tantas filas como variables originales. Los elementos \(p_{ij}\) pueden interpretarse como índices de correlación entre el factor i y la variable j, aunque estrictamente sólo son correlaciones cuando los factores no están correlacionados entre sí, es decir, son ortogonales. Estos coeficientes reciben el nombre de pesos, cargas, ponderaciones o saturaciones factoriales. Los pesos factoriales indican el peso de cada variable en cada factor. Lo ideal es que cada variable cargue alto en un factor y bajo en los demás. Cada variable se podría escribir en función de los factores de la siguiente forma:
\[V_1 =p_{11}F_1 + p_{21}F_2 \\ V_2 =p_{12}F_1 + p_{22}F_2 \\ … \\ V_6 =p_{16}F_1 + p_{26}F_2\]
La suma de los cuadrados de los pesos por filas indican la cantidad total de varianza de cada variable que explica el conjunto de factores considerados, es decir, las comunalidades.
7.3.7 Autovalores o valores propios
El cuadrado de una carga factorial indica la proporción de la varianza explicada por un factor en una variable particular.
La suma de los cuadrados de los pesos de cualquier columna de la matriz factorial es lo que denominamos autovalores e indican la cantidad total de varianza que explica ese factor para las variables consideradas como grupo.
Las cargas factoriales pueden tener como valor máximo 1, por tanto, el valor máximo que puede alcanzar el valor propio es igual al número de variables.
Si dividimos el valor propio entre el número de variables, nos indica la proporción (tanto por ciento si multiplicamos por 100) de la varianza de las variables que explica el factor.
7.3.8 Número de factores a conservar
La matriz factorial puede presentar un número de factores superior al necesario para explicar la estructura de los datos originales. Generalmente hay un conjunto reducido de factores, los primeros, que son los que explican la mayor parte de la variabilidad total. Los otros factores suelen contribuir relativamente poco.
Uno de los problemas que se plantean, por tanto, consiste en determinar el número de factores que debemos conservar, de manera que se cumpla el principio de parsimonia. No debe olvidarse que el número de factores es una variable relacionada directamente con la pérdida de información e inversamente con la interpretabilidad de los resultados. Los procedimientos más habituales son los siguientes:
Criterio de los autovalores. Sólamente aquellos factores que tengan un autovalor superior a la unidad se retendrán para el análisis. La lógica de este criterio es que un factor, para ser útil, debe servir para explicar la varianza de, al menos, una variable. Este criterio es adecuado cuando el número de variables está entre 20 y 50. Cuando es inferior a 20, hay una tendencia a que este procedimiento extraiga pocos factores y demasiados si hay más de 50 variables. Este criterio también se llama “Criterio de la varianza media”. Se eligen aquellas componentes (factores) cuyo autovalor sea mayor que la varianza media medida como: ∑(autovalores)/ p, donde p es el número de variables. Cuando trabajamos con la matriz de correlaciones (R) o datos estandarizados, la varianza media es igual a uno ya que ∑(autovalores)/p = p/p=1. Hay que tener en cuenta que este criterio es solo aplicable cuando trabajamos con la matriz de correlaciones.
Criterio de porcentaje de varianza explicada. El fin de este criterio es asegurar la significatividad de los resultados del análisis factorial. Aunque no se ha establecido unos niveles objetivos, se considera que en las ciencias naturales hay que extraer factores hasta que se explique por lo menos el 95% de la varianza, mientras que en las ciencias sociales el 60% (incluso menos), es un nivel considerado como razonable.
Criterio del gráfico de sedimientación o del contraste de caída. El gráfico de sedimientación se obtiene al representar en ordenadas las raíces características y en abcisas el número de factores. Uniendo todos los puntos se obtiene una figura que, en general, se parece al perfil de una montaña con una pendiente fuerte hasta llegar a la base, formada por una meseta con una ligera inclinación. De acuerdo con el criterio gráfico, se retienen todos aquellos factores previos a la zona de sedimentación.

- Criterio a priori. Ya se sabe de antemano cuántos factores hay que extraer sobre la base de un estudio previo.
Por último, los factores pueden ser calculados en base a la matriz de covarianzas o de correlaciones. Se considera más adecuado, en general, el criterio de la matriz de correlaciones, puesto que de esta manera el análisis no estará influenciado por las unidades de medida.
7.3.9 Rotación de los factores
La matriz factorial indica, como sabemos, la relación entre los factores y las variables. Sin embargo, a partir de la matriz factorial muchas veces resulta difícil la interpretación de los factores. Es frecuente que varias variables presenten coeficientes factoriales elevados en más de un factor, cuando lo que interesa es que la mayor parte de su variabilidad quede explicada por un solo factor.
Esto lleva al desarrollo del principio de estructura simple, según el cual las variables han de saturar básicamente en un factor, es decir, que sus coeficientes factoriales han de ser elevados en un solo factor y bajos en el resto. Este principio es exigido en la mayoría de los análisis e incluye los siguientes supuestos:
Cada factor o componente ha de tener unos pocos coeficientes factoriales elevados y el resto próximos a cero.
Cada variable original ha de presentar un coeficiente factorial elevado en un solo factor (saturar solo a un factor).
Los factores o componentes no han de tener la misma distribución. Deben mostrar unos modelos diferentes de coeficientes factoriales elevados y bajos.
Si buscamos simplificar la estructura factorial tenemos que proceder a la rotación. La rotación consiste en girar los ejes factoriales para que éstos se aproximen a las variables originales. La finalidad es facilitar la interpretación de la matriz factorial, forzando a las variables a definirse más en una dimensión latente, con preferencia a otras. De esta forma se obtiene una mayor diferenciación entre los factores que logran un perfil más definido.
Tras la rotación el número de factores se mantiene al igual que el porcentaje de varianza total explicada por el modelo original y la comunalidad de las variables. Lo que varía es la composición de los factores al cambiar los coeficientes factoriales de cada variable en cada factor. Esto también altera la proporción de variabilidad explicada por cada factor. En la rotación se redistribuye la varianza entre todos los factores.
Existen diferentes procedimientos de rotación que se pueden englobar en dos grandes grupos:
Rotación ortogonal. Parte del supuesto de incorrelación de las dimensiones latentes. Todo factor o componente es independiente de los demás por lo que los ejes factoriales forman entre sí un ángulo de 90º. Dentro de este tipo de rotaciones destacan se encuentran:
Varimax: Es el más empleado y el que se aplica por defecto en la mayoría de los paquetes estadísticos. Fue propuesto por Kaiser y su finalidad es simplificar la estructura factorial maximizando la varianza de los coeficientes factoriales al cuadrado para cada factor. En la aplicación de la rotación varimax pueden emplearse coeficientes factoriales brutos o normalizados. Lo habitual es utilizar normalizados (o estandarizados) para equilibrar la influencia de variables con distintas comunalidades en la solución factorial. La aplicación de los coeficientes normalizados proporciona a cada variable original igual peso en la rotación. De esta forma se evita que variables con comunalidades más elevadas influyan más en la solución factorial. Esta rotación es muy adecuada cuando las variables presentan comunalidades altas en unas variables y bajas en otras.
Quartimax: Este procedimiento también busca la maximización de la varianza, pero en este caso la de los coeficientes factoriales al cuadrado para cada variable. De esta manera cada variable deberá tener una correlaión elevada en unos pocos factores y baja en otros. Analíticamente quartimax es más sencillo que varimax, pero este último ofrece una separación más clara de los factores.
Equamax: Este procedimiento se presenta como una síntesis de los dos anteriores. Busca tanto la simplificación de variables como de factores. Es el menos utilizado.
Rotación oblicua. Muestra mayor adecuación a situaciones habituales de interrelación entre dimensiones latentes. Al permitirse la correlación, los ejes factoriales no son perpendiculares entre sí. La consideración de dimensiones interrelacionadas comporta mayor complejidad en la interpretación de la solución factorial, aunque ésta es teórica y empíricamente más realista. Dentro de este tipo de rotaciones destacan:
Oblimin. Es uno de los procedimientos de rotación oblicua más utilizado. Suele aplicarse con coeficientes factoriales normalizados, obtenidos de la división del coeficiente factorial al cuadrado por la raíz cuadrada de la comunalidad de la variable respectiva. Este procedimiento de rotación resulta de la combinación de dos criterios:
Quartimin. Se asemeja al quartimax en la rotación ortogonal. Minimiza la suma de los productos de los coeficientes factoriales y produce factores de mayor oblicuidad.
Biquartimin o covarimin. Minimiza la covarianza de los coeficientes factoriales cuadrados. Tiende a generar factores menos oblicuos y, también suele utilzar coeficientes factoriales normalizados.
Oblimax. Criterio alternativo al quartimin. Persigue la simplificación de la estructura factorial aumentando el número de coeficientes factoriales elevados y bajos. Disminuye los de rango medio.
Promax. Es uno de los procedimientos más novedosos. Se caracteriza por conseguir la solución oblicua aplicando algunas funciones de la solución ortogonal, como la matriz “target”: aquella que el investigador tiene en mente o cree que existe. Este criterio se utiliza cuando se quiere comprobar la congruencia de una estructura factorial con otra que se conoce.
7.3.10 Puntuaciones factoriales
En ocasiones el análisis factorial es un paso previo a otros análisis. Por eso, una vez que se tienen los factores puede interesar conocer que puntuación obtendrían los sujetos en estos factores. Para contestar a esto hay que calcular lo que se conoce como puntuaciones factoriales de cada individuo. Estos coeficientes de puntuaciones factoriales se extraen de la matriz de coeficientes de puntuaciones factoriales.
Sin embargo, salvo que se haya aplicado el análisis en componentes principales para la extracción de los factores, no se obtienen unas puntuaciones exactas para los factores. En su lugar, es preciso realizar estimaciones para obtenerlas. Algunos métodos para realizar estas estimaciones son los de mínimos cuadrados, regresión, Anderson-Rubin y Bartlett.
7.3.10.1 Interpretación de los factores
En la fase de interpretación juega un papel preponderante la teoría y el conocimiento sustantivo. A efectos prácticos se sugieren dos pasos en el proceso de interpretación:
- Estudiar la composición de las saturaciones factoriales significativas de cada factor.
- Intentar dar nombre a los factores. Nombre que se debe dar de acuerdo con la estructura de sus saturaciones, es decir, conociendo su contenido.
Dos cuestiones que pueden ayudar a la interpretación son:
Ordenar la matriz rotada de forma que las variables con saturaciones altas en un factor aparezcan juntas.
La eliminación de las cargas factoriales bajas (generalmente aquellas que van por debajo de 0,25).
Llamaremos variable compleja a aquella que satura altamente en más de un factor y que no debe ser utilizada para dar nombre a los factores.
Factores bipolares, son aquellos factores en los que unas variables cargan positivamente y otras tienen carga negativa.
7.3.11 Casos de Heywood y otras anomalías sobre estimaciones de comunalidad
Como las comunalidades son correlaciones al cuadrado, es de esperar que siempre estén entre 0 y 1. Sin embargo, una peculiaridad matemática del modelo de factor común es que las estimaciones finales de comunalidad podrían exceder 1.
Si una comunalidad es igual a 1, estamos ante un caso Heywood, y si excede de 1, ante un caso ultra-Heywood. Un caso ultra-Heywood implica que algún factor único tiene varianza negativa, una clara evidencia de que algo está mal. Las causas posibles, incluyen las siguientes:
- Malas estimaciones de comunalidad previa.
- Demasiados factores comunes.
- Muy pocos factores comunes.
- No hay suficientes datos para proporcionar estimaciones estables.
- El modelo de factor común no es un modelo apropiado para los datos.
Un caso ultra-Heywood hace que una solución factorial sea inválida. Los analistas no están de acuerdo sobre si una solución factorial con un caso Heywood puede considerarse legítima o no.
Teóricamente, la comunalidad de una variable no debe exceder su confiabilidad. La violación de esta condición se conoce como un caso cuasi-Heywood y debe considerarse con la misma sospecha que un caso ultra-Heywood.
Los elementos de la estructura factorial y las matrices de estructura de referencia pueden exceder 1 solo en presencia de un caso ultra-Heywood. Por otro lado, un elemento del patrón factorial podría superar 1 en una rotación oblicua.
El método de Máxima Verosimilitud es especialmente susceptible a casos cuasi- o ultra-Heywood. Durante el proceso de iteración, una variable con alta comunalidad recibe un alto peso; esto tiende a aumentar su comunalidad, lo que aumenta su peso, y así sucesivamente.
A menudo se afirma que la correlación múltiple al cuadrado de una variable con las otras variables es un límite inferior a su comunalidad. Esto es cierto si el modelo de factores comunes se ajusta perfectamente a los datos, pero generalmente no es el caso con datos reales. Una estimación de comunalidad final que es menor que la correlación múltiple al cuadrado puede, por lo tanto, indicar ajuste pobre, posiblemente debido a factores no suficientes. De ninguna manera es un problema tan serio como un caso ultra-Heywood.
Los métodos de factor que usan el método de Newton-Raphson en realidad pueden producir comunalidades menores que 0, un resultado aún más desastroso que un caso ultra-Heywood.
La correlación múltiple al cuadrado de un factor con las variables puede superar 1, incluso en ausencia de casos ultra-Heywood. Esta situación también es motivo de alarma. El Análisis Alfa parece ser especialmente propenso a este problema, pero no ocurre con la Máxima Verosimilitud. Si una correlación múltiple al cuadrado es negativa, hay demasiados factores retenidos.
Con datos que no se ajustan perfectamente al modelo de factores comunes, puede esperarse que algunos de los valores propios sean negativos. Si un método de factor iterativo converge adecuadamente, la suma de los valores propios correspondientes a los factores rechazados debe ser 0; por lo tanto, algunos valores propios son positivos y algunos negativos. Si un Análisis de Factor o Eje Principal no produce ningún valor propio negativo, las estimaciones de comunalidad previa son probablemente demasiado grandes. Los autovalores negativos causan que la proporción acumulada de varianza explicada exceda de 1 para un número suficientemente grande de factores. La proporción acumulada de varianza explicada por los factores retenidos debe ser de aproximadamente 1 para el Análisis de Ejes Principales y debe converger a 1 para los métodos iterativos. Ocasionalmente, un solo factor puede explicar más del 100 por ciento de la varianza común en un Análisis de Ejes Principales, lo que indica que las estimaciones de comunalidad previa son demasiado bajas.
El Análisis de Componentes Principales, a diferencia del análisis de factor común, no presenta ninguno de estos problemas si la matriz de covarianza o correlación se calcula correctamente a partir de un conjunto de datos sin valores faltantes. Varios métodos de valores perdidos para la correlación o el redondeo severo de las correlaciones pueden producir valores propios negativos en los Componentes Principales.
7.3.12 Ejemplo con R
A continuación se va a realizar un análisis factorial con R en donde se parte de la base de datos Seatbelts, que contiene datos mensuales de conductores de Gran Bretaña, muertos o heridos entre Enero de 1969 y Diciembre de 1983. Utilizamos la libreria “Rela”.
library(rela)
Belts <- Seatbelts[,1:7]
summary(Belts)## DriversKilled drivers front
## Min. : 60.0000 Min. :1057.000 Min. : 426.0000
## 1st Qu.:104.7500 1st Qu.:1461.750 1st Qu.: 715.5000
## Median :118.5000 Median :1631.000 Median : 828.5000
## Mean :122.8021 Mean :1670.307 Mean : 837.2188
## 3rd Qu.:138.0000 3rd Qu.:1850.750 3rd Qu.: 950.7500
## Max. :198.0000 Max. :2654.000 Max. :1299.0000
## rear kms PetrolPrice
## Min. :224.0000 Min. : 7685.0 Min. :0.08117889
## 1st Qu.:344.7500 1st Qu.:12685.0 1st Qu.:0.09257748
## Median :401.5000 Median :14987.0 Median :0.10447669
## Mean :401.2083 Mean :14993.6 Mean :0.10362400
## 3rd Qu.:456.2500 3rd Qu.:17202.5 3rd Qu.:0.11405551
## Max. :646.0000 Max. :21626.0 Max. :0.13302742
## VanKilled
## Min. : 2.000000
## 1st Qu.: 6.000000
## Median : 8.000000
## Mean : 9.057292
## 3rd Qu.:12.000000
## Max. :17.000000Cálculo de la matriz de correlaciones:
correl=cor(Belts,use="pairwise.complete.obs")
correl## DriversKilled drivers front rear
## DriversKilled 1.0000000000 0.8888263684 0.7067596370 0.3533510185
## drivers 0.8888263684 1.0000000000 0.8084114058 0.3436684967
## front 0.7067596370 0.8084114058 1.0000000000 0.6202247611
## rear 0.3533510185 0.3436684967 0.6202247611 1.0000000000
## kms -0.3211015934 -0.4447631444 -0.3573823377 0.3330068886
## PetrolPrice -0.3866060898 -0.4576675397 -0.5392393740 -0.1326272138
## VanKilled 0.4070411620 0.4853994918 0.4724207231 0.1217580839
## kms PetrolPrice VanKilled
## DriversKilled -0.3211015934 -0.3866060898 0.4070411620
## drivers -0.4447631444 -0.4576675397 0.4853994918
## front -0.3573823377 -0.5392393740 0.4724207231
## rear 0.3330068886 -0.1326272138 0.1217580839
## kms 1.0000000000 0.3839003754 -0.4980355895
## PetrolPrice 0.3839003754 1.0000000000 -0.2885584074
## VanKilled -0.4980355895 -0.2885584074 1.0000000000La prueba de esfericidad de Bartlett, como vimos, contrasta la hipótesis nula de que la matriz de correlaciones es una matriz identidad, en cuyo caso no existirían correlaciones significativas entre las variables y el modelo factorial no sería pertinente.
library(psych)##
## Attaching package: 'psych'## The following object is masked from 'package:car':
##
## logit## The following objects are masked from 'package:ggplot2':
##
## %+%, alphacortest.bartlett(Belts)## R was not square, finding R from data## $chisq
## [1] 968.7578864
##
## $p.value
## [1] 1.260100725e-191
##
## $df
## [1] 21Para calcular los componentes principales basados en la matriz de correlaciones:
Belts.pc<-princomp(Belts, cor=TRUE)
summary(Belts.pc,loadings=TRUE)## Importance of components:
## Comp.1 Comp.2 Comp.3 Comp.4
## Standard deviation 1.920351456 1.2141728520 0.8489512909 0.78140438282
## Proportion of Variance 0.526821388 0.2106022449 0.1029597563 0.08722754421
## Cumulative Proportion 0.526821388 0.7374236329 0.8403833893 0.92761093348
## Comp.5 Comp.6 Comp.7
## Standard deviation 0.57544454265 0.32988394429 0.258386584886
## Proportion of Variance 0.04730520309 0.01554620239 0.009537661036
## Cumulative Proportion 0.97491613658 0.99046233896 1.000000000000
##
## Loadings:
## Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 Comp.6 Comp.7
## DriversKilled 0.444 0.136 0.521 0.360 0.519 0.323
## drivers 0.480 0.100 0.377 -0.505 -0.596
## front 0.475 0.198 -0.103 -0.417 -0.414 0.612
## rear 0.226 0.686 -0.322 -0.277 0.406 -0.361
## kms -0.276 0.627 0.606 -0.365 0.168
## PetrolPrice -0.327 0.141 0.829 0.277 -0.311
## VanKilled 0.334 -0.259 0.526 -0.627 0.387A continuación se realiza un Analisis factorial con la libreria psych, Para especificar el método de extracción de los factores se dispone del parámetro “fm”, el cuál puede tomar los siguientes valores:
“minres” o “uls”. Solución de Mínimos Cuadrados no ponderados.
“ols”. Difiere muy levemente de “minres” en que minimiza toda la matriz residual usando un procedimiento de MCO pero usa la primera derivada empírica. Esto será más lento.
“wls”. Solución de Mínimos Cuadrados Ponderados, MCP (WLS en inglés).
“gls”. Solución de Mínimos Cuadrados Generalizados ponderados, MCG (GLS en inglés).
“pa”. Solución de Factor o Eje Principal.
“ml”. Solución de Máxima Verosimilitud.
“minchi”. Se minimiza el chi-cuadrado ponderado por el tamaño de la muestra, al tratar correlaciones por pares con diferente número de sujetos por par.
“minrank”. Solución de Rango Mínimo (método en prueba).
“old.min”. Solución de Mínimos Cuadrados no ponderados de la forma en que se hizo antes de abril de 2017.
Como método de extracción utilizamos los Mínimos Cuadrados Generalizados (fm = “gls”).
Representando el gráfico de autovalor para el criterio de contraste de caida, decidimos extrar 3 factores. Como vemos a continuación, se ha detectado un caso ultra-Heywwod.
library(psych)
fa.parallel(correl, n.obs = length(Belts), fm = "gls")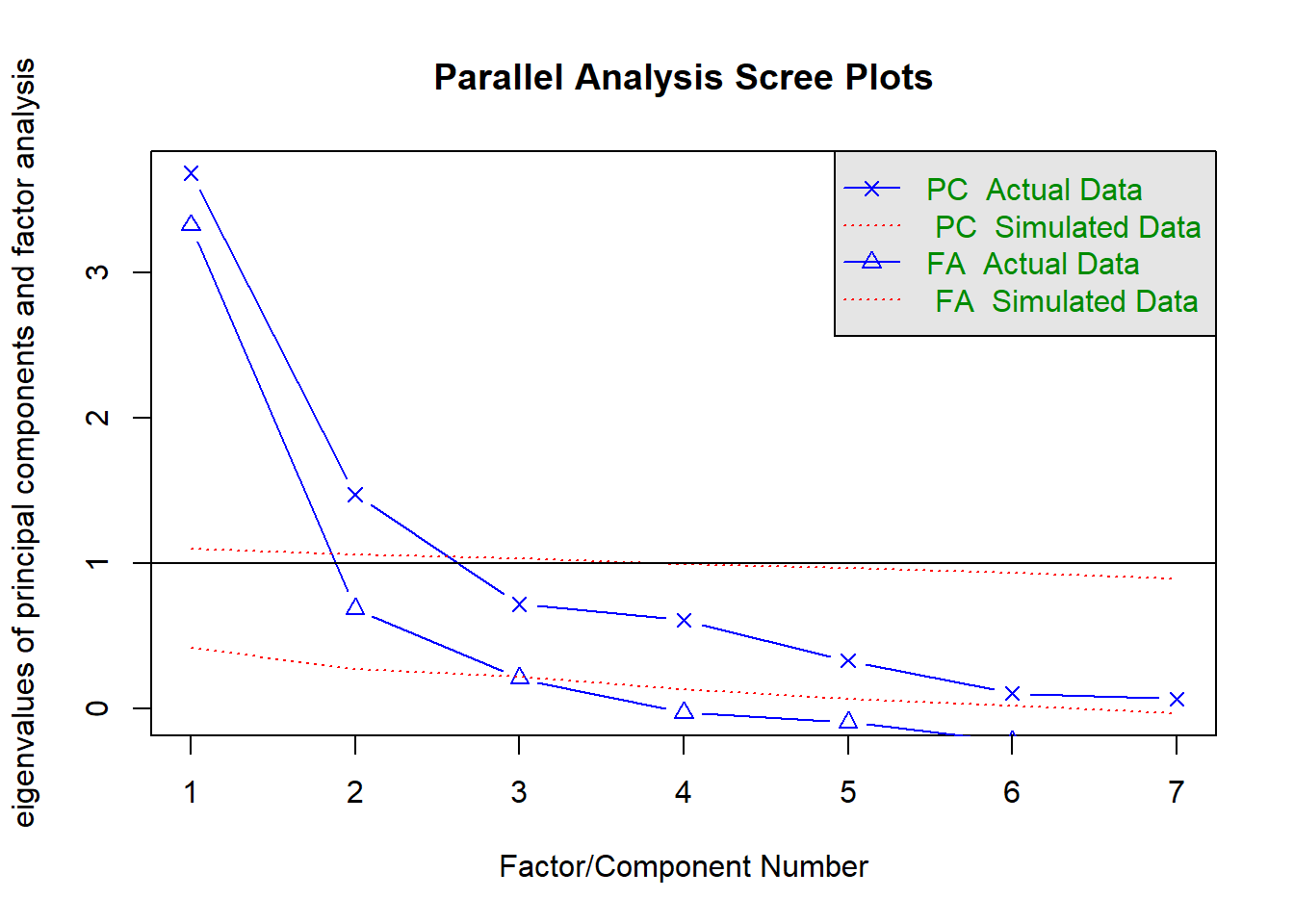
## Parallel analysis suggests that the number of factors = 2 and the number of components = 2Belts.ps <- fa(correl, n.obs = length(Belts), fm = "gls", nfactors = 3, rotate ="varimax")
print(Belts.ps) # Factor loadings as $loadings## Factor Analysis using method = gls
## Call: fa(r = correl, nfactors = 3, n.obs = length(Belts), rotate = "varimax",
## fm = "gls")
## Standardized loadings (pattern matrix) based upon correlation matrix
## GLS3 GLS1 GLS2 h2 u2 com
## DriversKilled 0.28 0.84 0.22 0.84 0.158 1.4
## drivers 0.43 0.85 0.23 0.96 0.043 1.7
## front 0.59 0.47 0.64 0.99 0.012 2.8
## rear -0.07 0.21 0.88 0.82 0.182 1.1
## kms -0.83 -0.20 0.37 0.87 0.129 1.5
## PetrolPrice -0.52 -0.22 -0.18 0.36 0.642 1.6
## VanKilled 0.53 0.29 0.07 0.37 0.627 1.6
##
## GLS3 GLS1 GLS2
## SS loadings 1.88 1.87 1.46
## Proportion Var 0.27 0.27 0.21
## Cumulative Var 0.27 0.54 0.74
## Proportion Explained 0.36 0.36 0.28
## Cumulative Proportion 0.36 0.72 1.00
##
## Mean item complexity = 1.7
## Test of the hypothesis that 3 factors are sufficient.
##
## The degrees of freedom for the null model are 21 and the objective function was 5.16 with Chi Square of 6910.24
## The degrees of freedom for the model are 3 and the objective function was 0.08
##
## The root mean square of the residuals (RMSR) is 0.02
## The df corrected root mean square of the residuals is 0.06
##
## The harmonic number of observations is 1344 with the empirical chi square 26.14 with prob < 0.0000089
## The total number of observations was 1344 with Likelihood Chi Square = 100.76 with prob < 0.0000000000000000000011
##
## Tucker Lewis Index of factoring reliability = 0.901
## RMSEA index = 0.156 and the 90 % confidence intervals are 0.13 0.183
## BIC = 79.15
## Fit based upon off diagonal values = 1
## Measures of factor score adequacy
## GLS3 GLS1 GLS2
## Correlation of (regression) scores with factors 0.95 0.96 0.97
## Multiple R square of scores with factors 0.91 0.91 0.95
## Minimum correlation of possible factor scores 0.81 0.83 0.90La librería factanal realiza el Analsis Factorial de Máxima Verosimilitud.
Belts.fa<-factanal(Belts, factors=3, rotation="varimax",scores = "Bartlett")
Belts.fa##
## Call:
## factanal(x = Belts, factors = 3, scores = "Bartlett", rotation = "varimax")
##
## Uniquenesses:
## DriversKilled drivers front rear kms
## 0.197 0.005 0.005 0.227 0.051
## PetrolPrice VanKilled
## 0.660 0.645
##
## Loadings:
## Factor1 Factor2 Factor3
## DriversKilled 0.820 0.264 0.244
## drivers 0.883 0.391 0.249
## front 0.485 0.531 0.691
## rear 0.204 -0.121 0.846
## kms -0.191 -0.903 0.311
## PetrolPrice -0.241 -0.469 -0.249
## VanKilled 0.301 0.507
##
## Factor1 Factor2 Factor3
## SS loadings 1.915 1.813 1.482
## Proportion Var 0.274 0.259 0.212
## Cumulative Var 0.274 0.533 0.744
##
## Test of the hypothesis that 3 factors are sufficient.
## The chi square statistic is 11.54 on 3 degrees of freedom.
## The p-value is 0.00914La libreria rela realiza el Análisis Factorial de Factor o Eje Principal.
library(rela)
res <- paf(as.matrix(Belts))
summary(res) # Calcula automáticamente KMO con MSA, determina el número de factores,## $KMO
## [1] 0.66899
##
## $MSA
## MSA
## DriversKilled 0.75338
## drivers 0.72295
## front 0.65795
## rear 0.40214
## kms 0.53517
## PetrolPrice 0.83413
## VanKilled 0.88197
##
## $Bartlett
## [1] 968.76
##
## $Communalities
## Initial Communalities Final Extraction
## DriversKilled 0.79824 0.66181
## drivers 0.87486 0.85141
## front 0.87225 0.91049
## rear 0.76216 0.69016
## kms 0.67184 0.89761
## PetrolPrice 0.36120 0.29405
## VanKilled 0.36294 0.34590
##
## $Factor.Loadings
## [,1] [,2]
## DriversKilled 0.80934 -0.082307
## drivers 0.92263 -0.012744
## front 0.92638 -0.228709
## rear 0.41852 -0.717642
## kms -0.53335 -0.783039
## PetrolPrice -0.53096 -0.110142
## VanKilled 0.55008 0.208105
##
## $RMS
## [1] 0.050492# calcula chi-cuadrado de la prueba de esfericidad de Bartlett, comunalidades y
# cargas factoriales. Las comunalidades son 1 menos la unicidad.
barplot(res$Eigenvalues[,1]) # Primera columna de valores propios.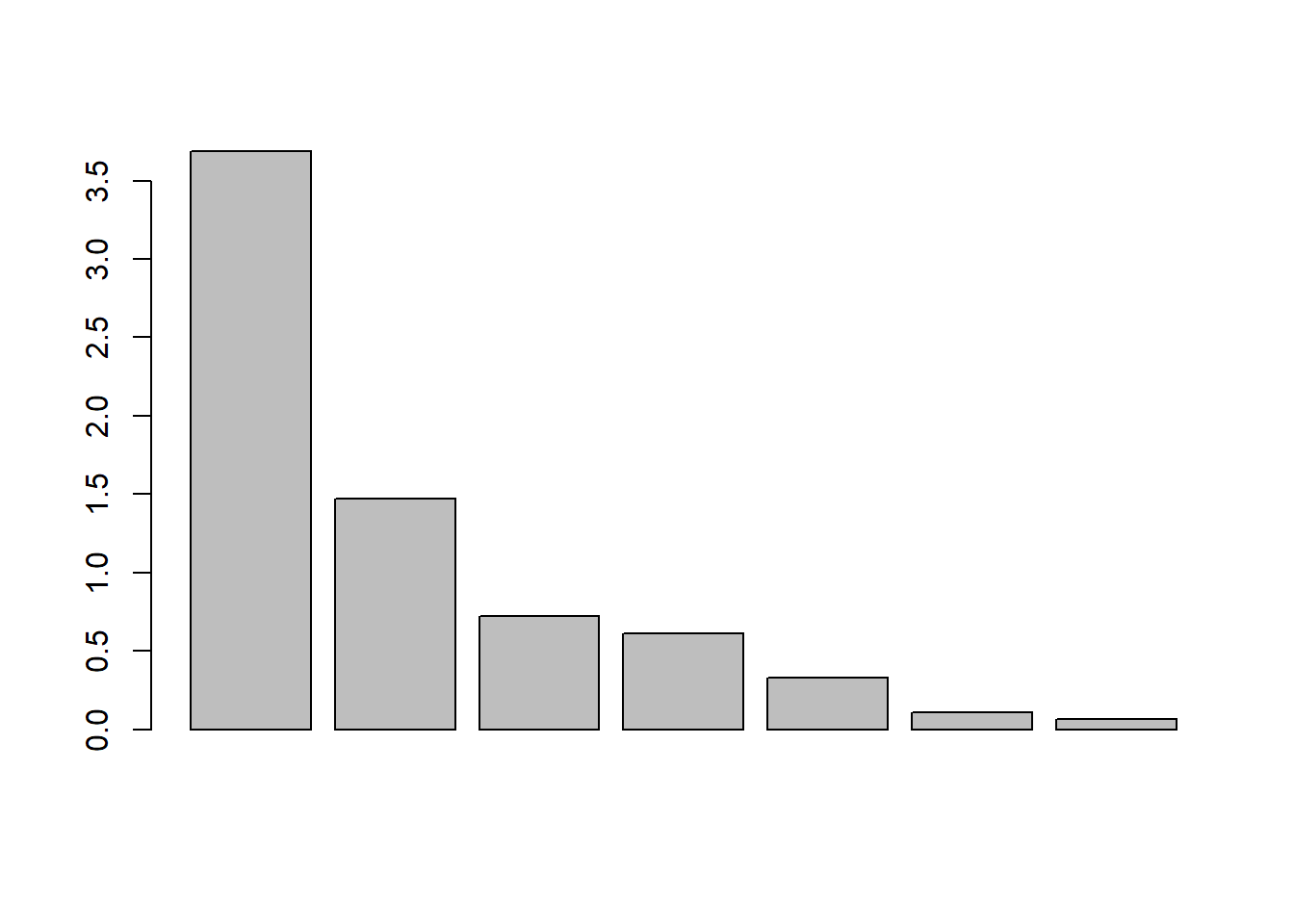
resv <- varimax(res$Factor.Loadings) # La rotación Varimax es posible más tarde.
print(resv)## $loadings
##
## Loadings:
## [,1] [,2]
## DriversKilled 0.773 -0.254
## drivers 0.898 -0.211
## front 0.856 -0.422
## rear 0.255 -0.791
## kms -0.689 -0.650
## PetrolPrice -0.542
## VanKilled 0.582
##
## [,1] [,2]
## SS loadings 3.309 1.343
## Proportion Var 0.473 0.192
## Cumulative Var 0.473 0.664
##
## $rotmat
## [,1] [,2]
## [1,] 0.97667 -0.21474
## [2,] 0.21474 0.97667barplot(sort(colSums(loadings(resv)^2),decreasing=TRUE)) # Gráfico de sedimentación usando las cargas rotadas.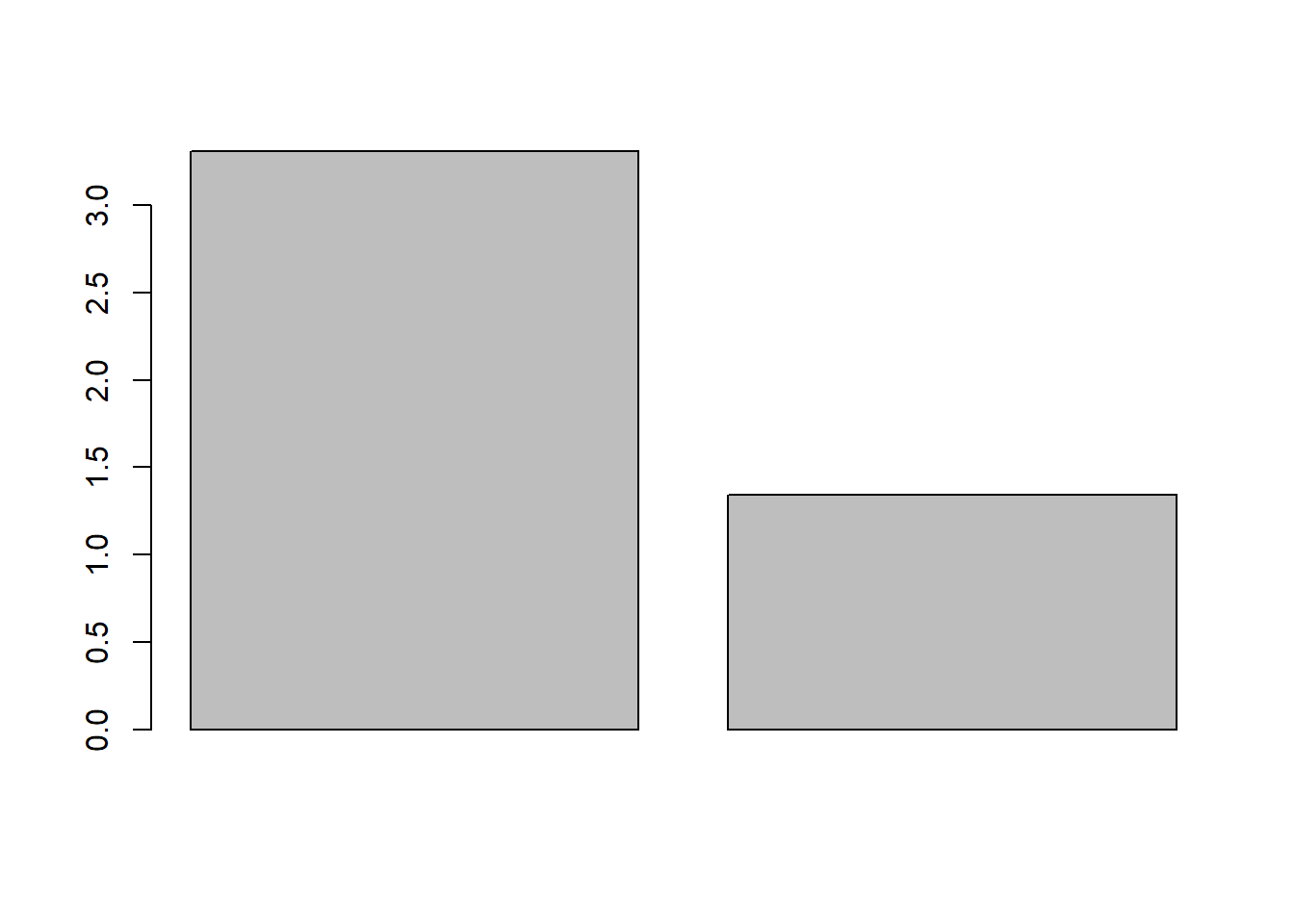
scores <- as.matrix(Belts) %*% as.matrix(resv$loadings) # Obtiene las puntuaciones de una manera sencilla.7.4 Análisis clúster
7.4.1 Introducción
El análisis cluster (AC) es un conjunto de técnicas multivariantes cuyo principal propósito es agrupar objetos basándose en las características que poseen. El AC clasifica los objetos en clases ó conglomerados de tal forma que cada objeto sea parecido a los que hay en el conjunto de su conglomerado. Los conglomerados resultantes tendrán que tener un alto grado de homogeneidad interna (dentro del conglomerado) y de heterogeneidad externa (entre conglomerados).
Los principales objetivos perseguidos por un análisis cluster son:
Elaboración de una tipología o clasificación,
Investigación de esquemas conceptuales útiles para agrupar sujetos,
Generación de hipótesis a través de exploraciones de datos.
Comprobar si las hipótesis generadas a través de otros procedimientos se cumplen en la muestra de datos.
7.4.2 Etapas a seguir en el desarrollo del Análisis Cluster
Podemos distinguir tres pasos básicos para todos los estudios realizados con análisis cluster:
7.4.2.1 Selección de la muestra que se pretende dividir en grupos.
Por ejemplo países de la Unión Europea, compradores de un producto, etc. Pueden ser elegidos individuos, asociaciones, empresas o países. También es posible agrupar variables.
7.4.2.2 Selección de las variables que se van a utilizar para realizar el análisis.
Éste es uno de los pasos más críticos. Dentro de éste paso se pueden distinguir los siguientes puntos:
Número de variables: La elección del mismo es una decisión muy importante que va a condicionar en gran parte el éxito en los resultados de la investigación pero, a su vez, plantea grandes dificultades. Se tiende a pensar que con mayor número de variables se va a conseguir una mayor homogeneidad dentro de cada grupo. Esto es un error, ya que se pueden estar introduciendo variables que estén desvirtuando las semejanzas entre los sujetos al no estar estas relacionadas con el objetivo del estudio.
Utilización de variables transformadas: La decisión aquí reside en si se utilizarán las variables tal cual son obtenidas o si se debe realizar alguna modificación. Una posible modificación en las variables es estandarizarlas, es decir, convertirlas en variables con media igual a cero y varianza igual a uno. Para hacer esto basta con restar a las variables la media y dividir el resultado por la desviación típica.
\[z = \frac {x_i- \bar{x}} {s}\]
donde:
\(\bar{x}\) = Media
\(s\) = Desviación típica
Realizar esta modificación puede reducir las diferencias entre grupos en aquellas variables que pudieran ser el mejor discriminante para las diferencias entre grupos. La estandarización puede suponer una transformación no equivalente entre las variables y podría cambiar las relaciones entre ellas. La decisión de estandarizar o no debe ser, por tanto, una de las primeras decisiones a tomar, y debe tenerse en cuenta que los resultados de la investigación pueden variar en función de que se haya realizado o no dicha estandarización.
La estandarización es útil especialmente en el caso de variables que están medidas en distintas escalas o magnitudes. Por ejemplo, si se quiere estudiar la semejanza entre los distintos países de la UE y se tienen en cuenta variables como el número de televisores por 1.000 habitantes, la renta per cápita, o el porcentaje de usuarios de Internet son variables que están medidas en unidades muy distintas la estandarización puede servir para compararlas entre sí.
Otro tema que se discute es si se pueden ponderar las variables para dar más importancia a alguna de ellas.
7.4.2.3 Cálculo de las similitudes o disimilitudes entre los casos o sujetos y validación de los resultados obtenidos.
Para realizar un AC se necesita una medida de similitud, de correspondencia, o parecido entre objetos que van a ser analizados. Las distintas medidas disponibles, en función de los tipos de datos que estemos analizando, son las enumeradas en el primer apartado de este módulo.
Una vez se tiene una matriz de simulitud calculada, hay que realizar el proceso de partición de los datos, para ello hay que decidir el algoritmo de aglomeración utilizado en la formación de conglomerados, para despues tomar una decisión acerca del número de conglomerados que se van a formar.
Los algoritmos de obtención de conglomerados se subdividen en:
Métodos jerárquicos (encadenamiento simple, encadenamiento completo, encadenamiento médio, método de Ward, método del centroide).
Métodos no jerarquicos (umbral secuencial, umbral paralelo, k-medias),
O una combinación de los dos.
El dendrograma ó gráfico en forma de arbol, es una herramienta visual que ayuda a decidir el número de conglomerados que podrían representar mejor la estructura de los datos.
Para determinar el número final de conglomerados a formar o regla de parada, no hay un procedimiento determinado, ha de decidirlo el investigador en la fase de interpretación de los datos.
7.4.3 Modelos Jerárquicos
En el análisis cluster jerárquico se parte del número de individuos (países, empresas etc.) y posteriormente se van uniendo en función de la mayor o menor proximidad de los individuos entre sí, formando grupos. Éstos a su vez se van uniendo entre sí hasta llegar a un único grupo. Obviamente, las dos decisiones que existen son:
La determinación de la medida de distancia o proximidad a usar: como hemos visto, la opción entre una u otra vendrá determinada por la medida en que los datos estén referidos.
El método que determinará el modo de unión sucesiva de los distintos grupos entre sí. Es decir, el que determinará la distancia existente entre los sucesivos grupos. Entre ellos encontramos los siguientes:
● Vinculación inter-grupos: Según ella se define la distancia entre dos clusters (grupos) como la media de las distancias entre todas las combinaciones posibles dos a dos de los elementos de uno y otro grupo. Por ejemplo, si en primer lugar se han agrupado los individuos 1 y 2 la distancia entre el grupo (cluster) formado por éstos y el grupo 3 vendría dada por la media de las distancias 1-3 y 1-2. Usa pues los pares de distancias.
● Vinculación intra-grupos: combina los grupos (clusters) de manera que la media de las distancias entre todos los pares de sujetos dentro del resultante sea la menor posible.
● Vecino más próximo o distancia mínima: los individuos que se combinan en cada grupo son aquellos que tienen una menor distancia o mayor similitud. Posteriormente se recalcula la distancia del cluster respecto al resto de casos formándose el siguiente mediante el mismo criterio
● Vecino más lejano o distancia máxima: la distancia se calcula a partir de la distancia de los dos puntos más alejados.
● Método de Ward: El objetivo de este método es minimizar la varianza intra-grupos. Su funcionamiento es el siguiente: Se parte de n grupos formados todos ellos por un único punto (todos los individuos). En este momento la suma de las varianzas intra-grupo es cero. A continuación se unirán dos grupos (individuos) en uno sólo. Más concretamente, se unirán aquellos dos puntos que minimicen el incremento en la suma de las varianzas intra-grupo. El proceso continua del mismo modo sucesivamente.
7.4.4 Ejemplos con R
R incluye la función hclust para la realización de clasificaciones jerárquicas.
El investigador debe de suministrar dos opciones básicas a R:
Medida de similitud/disimilitud para calcular la matriz de distancias.
Estrategia de fusión.
Posteriormente, en la interpretación de los datos el investigador deberá decidir el punto de corte y, con ello, el número de grupos.
Se puede usar la función nativa de R dist para calcular la matriz de distancias; por defecto el programa usa la distancia euclídea (euclidean), siendo posible elegir otras con la opción method=“
Las estrategias de fusión más usadas son las siguientes:
●“ward”: la distancia entre dos conglomerados es la suma de los cuadrados entre dos conglomerados sumados para todas las variables. En cada paso del procedimiento de aglomeración se minimiza la suma de cuadrados dentro del conglomerado para todas las particiones. Tiende a combinar los conglomerados con un número reducido de dimensiones.
●“single”: distancia mínima o vecino más próximo, encuentra dos objetos separados por la distancia más corta y los coloca en un primer conglomerado. A continuación se encuentra la distancia más corta, y se une a él un tercer objeto o se forma un nuevo conglomerado de dos miembros. El proceso continúa hasta que todos los objetos están en un conglomerado.
●“complete”: Parecido al “single”(simple) pero utilizando como criterio de agregación la distancia máxima (aproximación al vecino más lejano).
●“average”: comienza igual que los métodos “single” y “complete”, pero el método de aproximación es la distancia media entre todos los individuos de un conglomerado y los de otro.
●“centroid”: la distancia entre dos conglomerados es la distancia (euclídea) entre centroides.
Realizamos un clúster Jerarquico con las tasas de crimen en USA (USArrests), utilizando una medida de similaridad de distancias euclideas y el método de agrupación de encadenamiento medio:
require(graphics)
str(USArrests)## 'data.frame': 50 obs. of 4 variables:
## $ Murder : num 13.2 10 8.1 8.8 9 7.9 3.3 5.9 15.4 17.4 ...
## $ Assault : int 236 263 294 190 276 204 110 238 335 211 ...
## $ UrbanPop: int 58 48 80 50 91 78 77 72 80 60 ...
## $ Rape : num 21.2 44.5 31 19.5 40.6 38.7 11.1 15.8 31.9 25.8 ...hc <- hclust(dist(USArrests), "ave")
plot(hc,cex=0.5)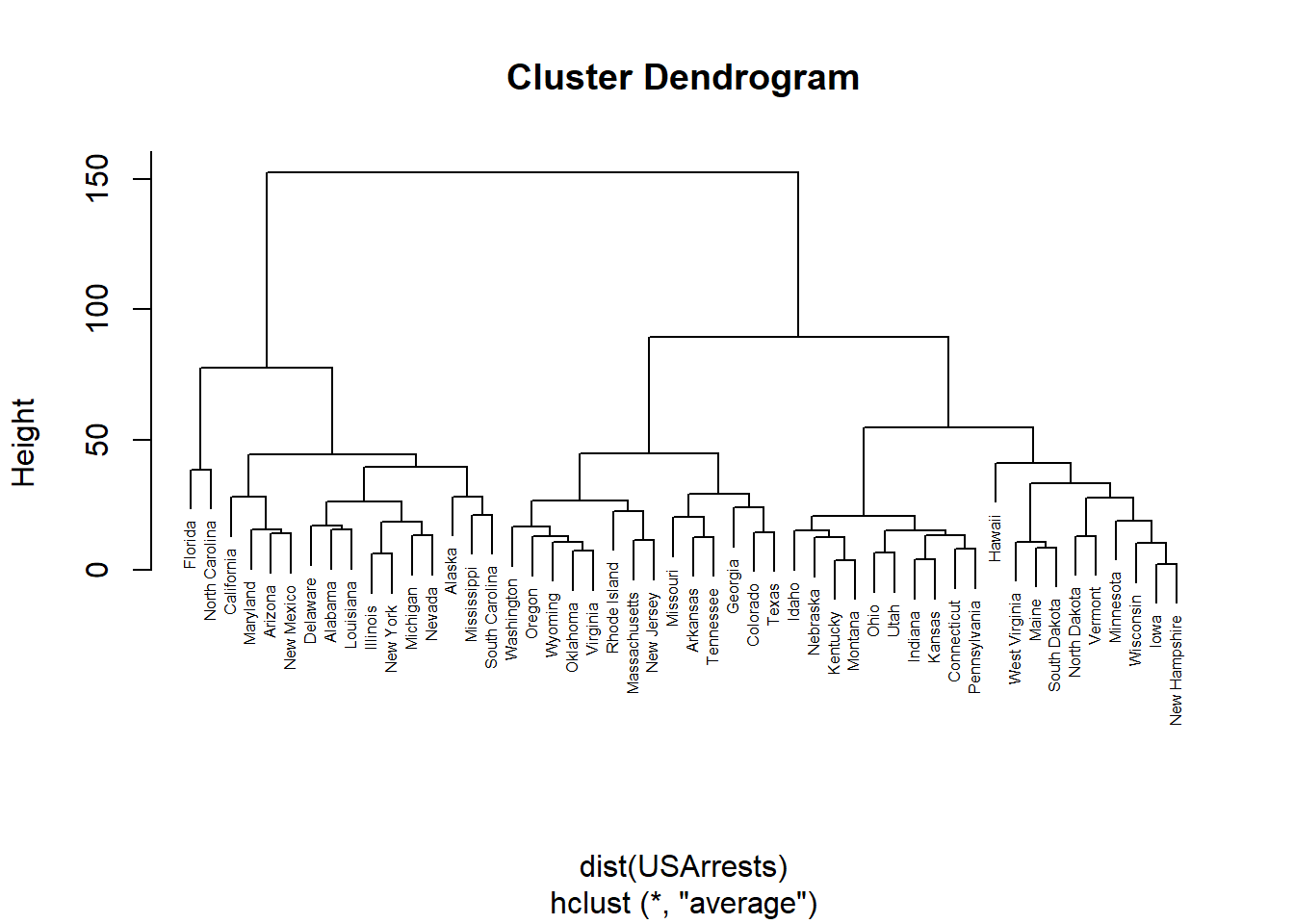
plot(hc, hang = -1,cex=0.5)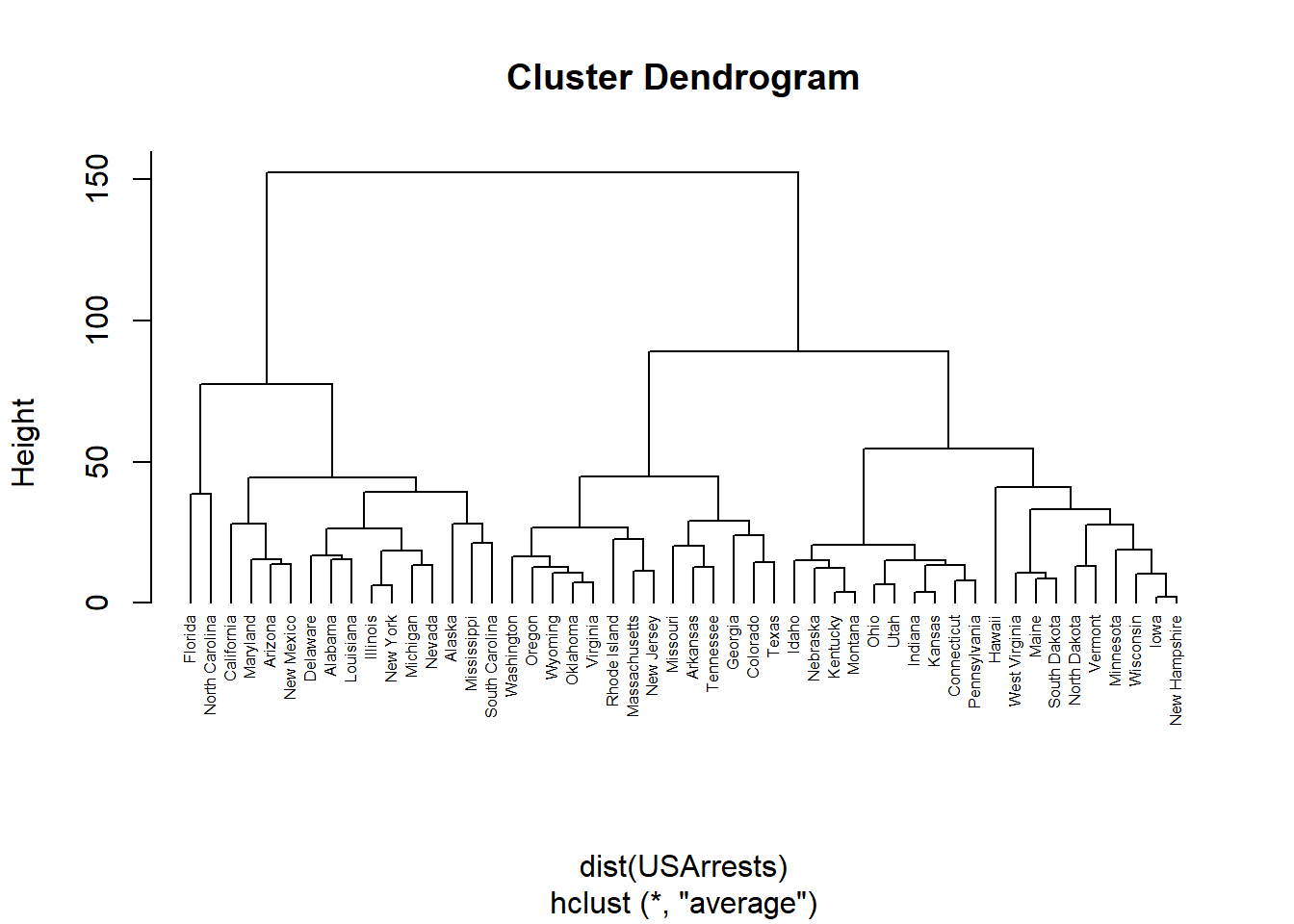
Se realiza el mismo clúster Jerarquico, se establece una parada de 10 clúster (cutree), y se realiza un nuevo clúster con los 10 conglomerados.
hc <- hclust(dist(USArrests)^2, "cen")
memb <- cutree(hc, k = 10)
cent <- NULL
for(k in 1:10){
cent <- rbind(cent, colMeans(USArrests[memb == k, , drop = FALSE]))
}
str(cent)## num [1:10, 1:4] 11.47 13.5 9.95 11.5 5.59 ...
## - attr(*, "dimnames")=List of 2
## ..$ : NULL
## ..$ : chr [1:4] "Murder" "Assault" "UrbanPop" "Rape"hc1 <- hclust(dist(cent)^2, method = "cen", members = table(memb))
opar <- par(mfrow = c(1, 2))
plot(hc, labels = FALSE, hang = -1, main = "árbol Inicial")
plot(hc1, labels = FALSE, hang = -1, main = "Re-estimado con 10 clústers")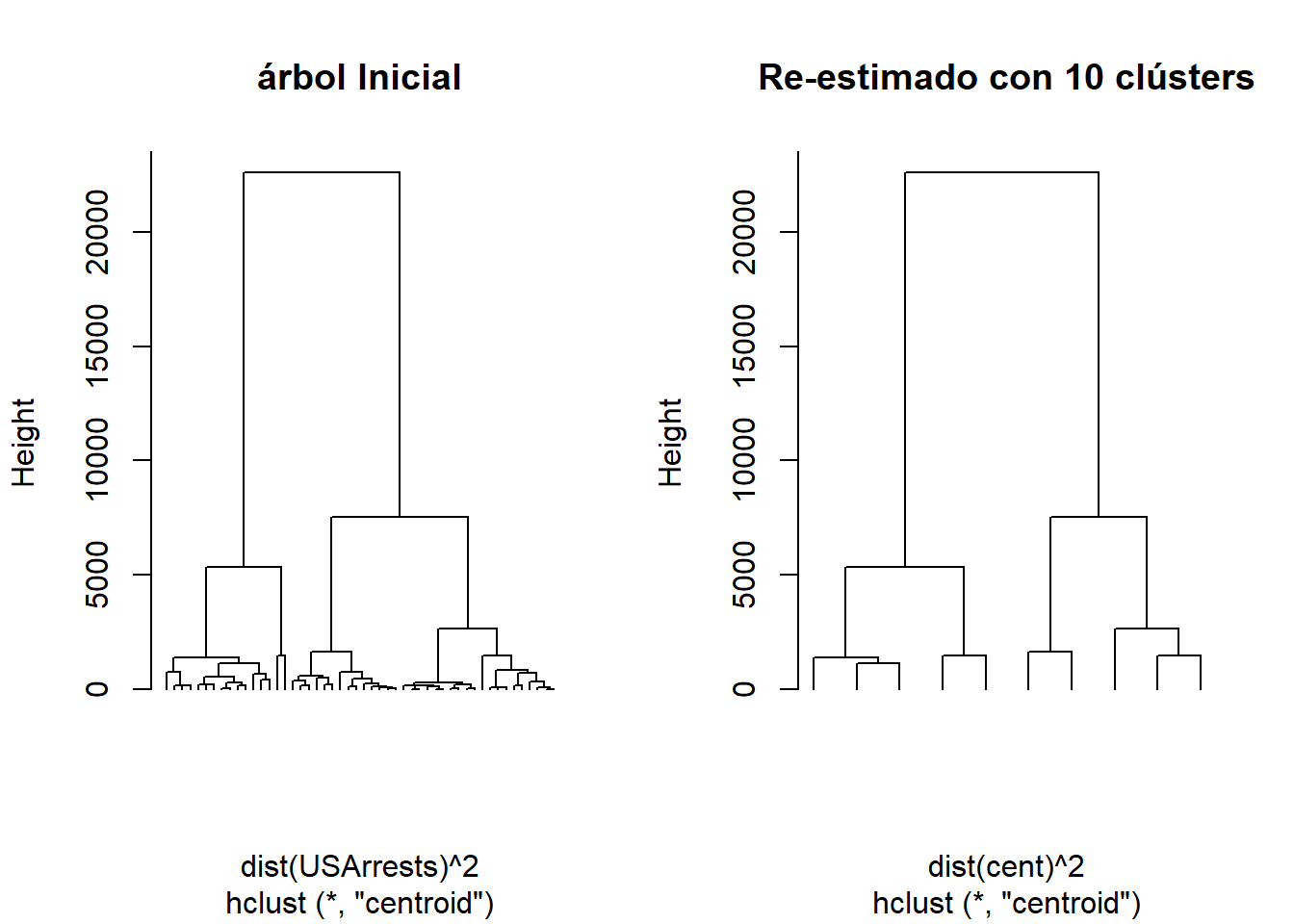
par(opar)7.4.4.1 Determinar el número de clúster con k-means
Determinar el número de clúster o la regla de parada es una de las tareas más sensibles en el AC, una forma de incluir un test para decidir el numero de conglomerados en utilizar la función k-means de R, y representar gráficamente el vector la suma de cuadrados entre conglomerados (withniss), para diferentes agrupamientos.
d=dist(USArrests)^2
# Determinar el numero de clúster
# Fija semilla inicial de numeros pseudoaleatorios
# para obtener misma serie aleatoria en ejecuciones.
set.seed(123)
# Crea vector "Errores", sin datos
# Crea variable "K_Max" con la cant. maxima de k a analizar
Errores <-NULL
K_Max <-10
# Ejecuta kmeans con diferentes clúster, desde 1 hasta 10
# Luego guarda el error de cada ejecucion en el vector "Errores"
for (i in 1:K_Max)
{
Errores[i] <- sum(kmeans(d[-1], centers=i)$withinss)
}
# Grafica el vector "Errores"
plot(1:K_Max, Errores, type="b",
xlab="Cantidad de clúster",
ylab="Suma de error")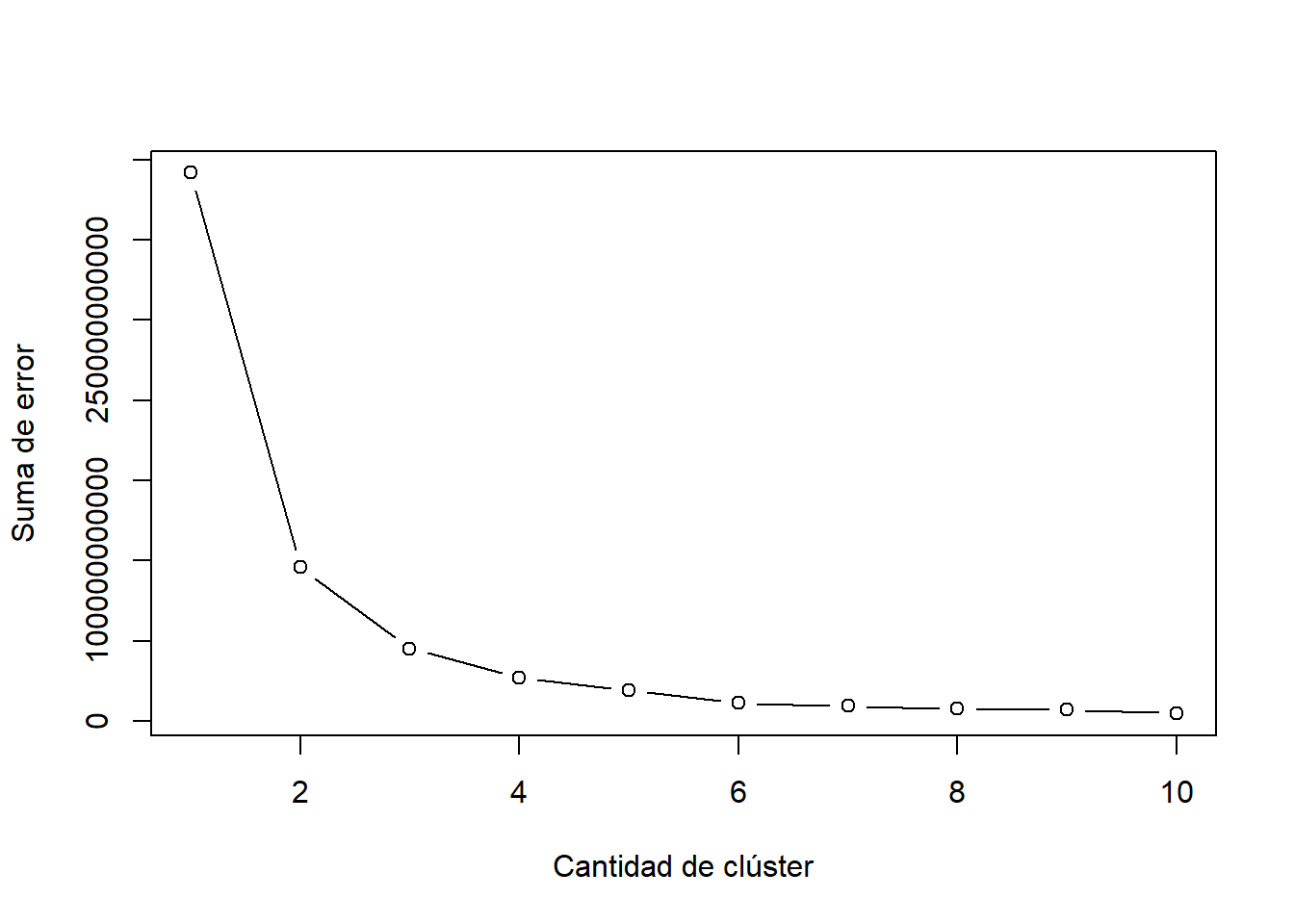
7.4.4.2 Clúster Jerárquico de series temporales con DTW
La agrupación en series temporales consiste, como se señaló en el apartardo anterior, en dividir el data-set de series temporales en grupos basados en similitudes o distancias, de modo que las series temporales de un mismo grupo tengan la misma naturaleza dinámica.
Para la agrupación de series de tiempo, el primer paso es elaborar una métrica de distancia ó similitud apropiada, y luego, en el segundo paso, utilizar técnicas de agrupación existentes, como k-means, clústering jerárquico, clústering basado en densidad o clústering subespacial.
Para encontrar estructuras de agrupamiento, de series temporales una metrica adecuada es la distancia Dynamic Time Warping (DTW), que encuentra la alineación óptima entre dos series temporales.
El DTW es una técnica desarrollada en el ambito de reconocimiento de la voz, cuyo objetivo es comparar dos emisiones vocales aisladas a fin de determinar si corresponden o no a la misma palabra.
De manera resumida, el DTW se diseño para comprobar si existe una sincronización temporal (alineamiento temporal) entre dos grupos fónicos. La falta de alineamiento, por lo general, no obedece a una ley fija (p. e., un retardo constante), sino que se da de forma heterogénea, produciéndose así variaciones localizadas que aumentan o disminuyen la duración del tramo de análisis.
El problema de calcular una función de alineamiento se resuelve en el DTW mediante técnicas de programación dinámica, motivo por el que se conoce a esta técnica como Alineamiento Temporal Dinámico.
En el ejemplo, se utiliza un conjunto de datos de la serie temporal de gráficos de control sintético, que contiene 600 ejemplos de gráficos de control. Cada gráfico de control es una serie de tiempo con 60 valores. Hay seis clases:
1-100 Normal,
101-200 Cíclico,
201-300 Tendencia creciente,
301-400 Tendencia decreciente,
401-500 Cambio hacia arriba y
501-600 Descenso cambio.
Los datos y el script se ha obtenido de :http://www.rdatamining.com/examples/time-series-clústering-classification.
# lectura de datos
sc <- read.table("http://kdd.ics.uci.edu/databases/synthetic_control/synthetic_control.data", header=F, sep="")
# Selección aleatoria de variables
n <- 10
s <- sample(1:100, n)
idx <- c(s, 100+s, 200+s, 300+s, 400+s, 500+s)
sample2 <- sc[idx,]
observedLabels <- c(rep(1,n), rep(2,n), rep(3,n), rep(4,n), rep(5,n), rep(6,n))
# calculo de distancias DTW
library(dtw)## Loading required package: proxy##
## Attaching package: 'proxy'## The following objects are masked from 'package:stats':
##
## as.dist, dist## The following object is masked from 'package:base':
##
## as.matrix## Loaded dtw v1.20-1. See ?dtw for help, citation("dtw") for use in publication.distMatrix <- dist(sample2, method="DTW")
# clúster jerrárquico
hc <- hclust(distMatrix, method="average")
plot(hc, labels=observedLabels, main="",cex=0.5)
7.4.4.3 Clúster Jerárquico con span-tree
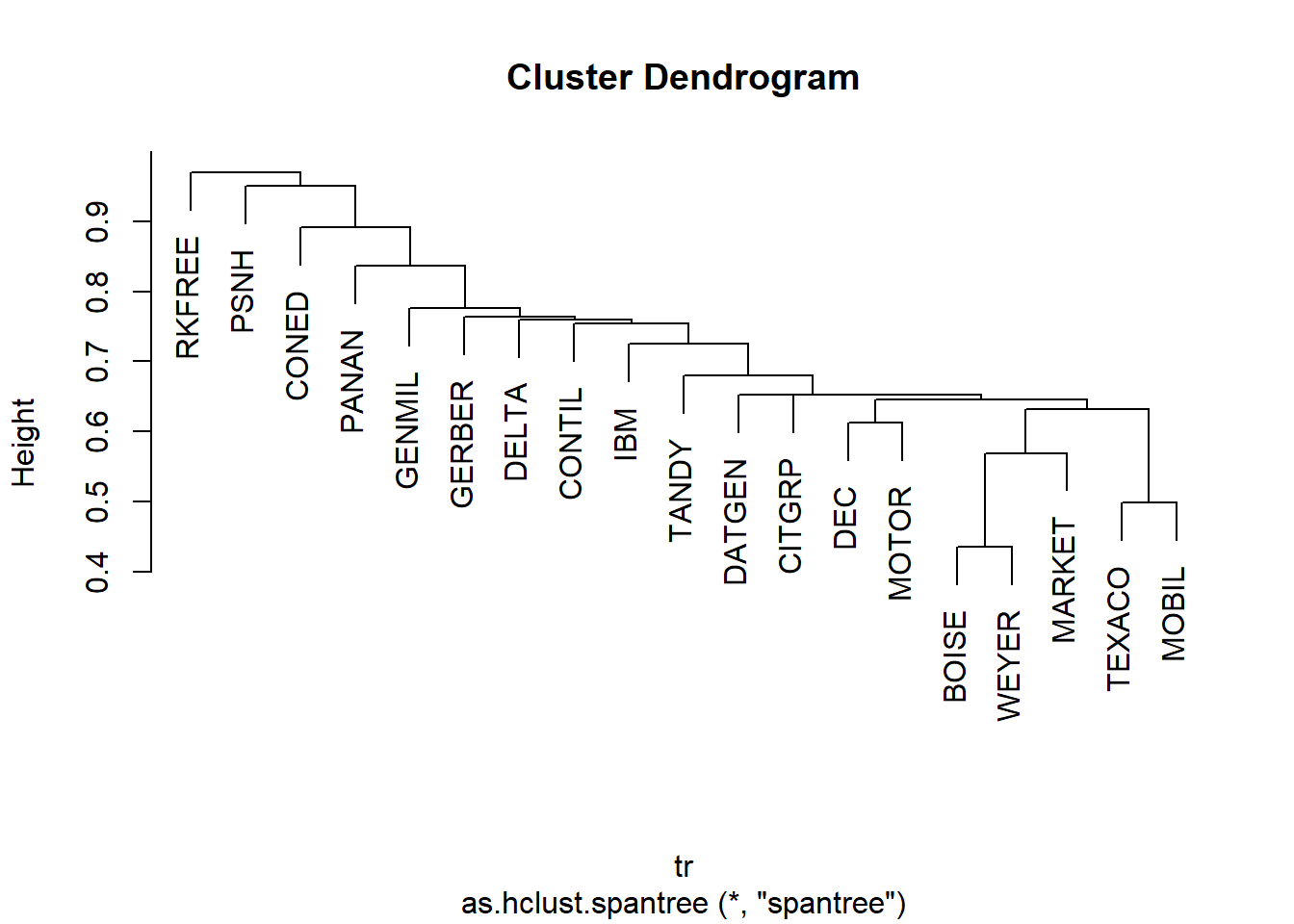
Si al clasificar un conjunto de datos no encontramos una decisión adecuada para establecer una regla de parada, y obtenemos como resultado un conjunto inclasificable, es util combinar la metodología de jerarquía y topología de los árboles de expansión mínima (MST, Minimal Spanning Tree).
Dado un grafo, su árbol mínimo generador (o árbol de peso mínimo o árbol mínimo de expansión) es un árbol que pasa por todos los vértices y que la suma de sus aristas es la de menor peso.
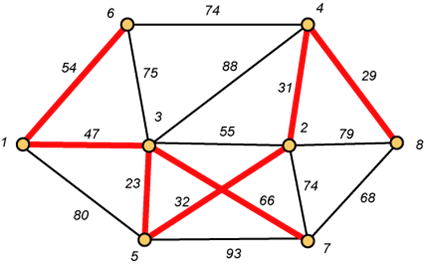
La gráfica siguiente ilustra el proceso, se trata de un árbol de expansión de 7 nodos (acciones), con las medidas de distancia que hay entre ellos. Partiendo de la distancia menor, 29, entre el nodo 8 y 4, se inicia el árbol, que en el nodo 4, encuentra la segunda minima distancia en su enlace con el nodo 2, 31, y en el nodo 2, la menor distancia la encuentra con el nodo 5, operando de esta manera hasta tener enlazados todos los nodos. Como se puede observar en la figura, un nodo puede tener, más de un enlace con otros nodos, tal y como ocurre en el gráfico, nodo 3.
Basandonos en el trabajo pionero de Mantegna (1999) sobre tasas de retornos en los mercados financieros, realizamos un ejercicio clasificatorio con la función span-tree, de la librería vegan, que ordena y establece dependencias entre diversos activos financieros utilizando datos de rendimientos mensuales de activos procedentes de Berndt’s The Practice of Econometrics: http://web.stanford.edu/~clint/berndt/
# Leemos las cotizaciones desde un fichero csv
bolsa.df = load("berndt.RData")
colnames(berndt.df)## [1] "Año" "MOBIL" "TEXACO" "IBM" "DEC" "DATGEN" "CONED"
## [8] "PSNH" "WEYER" "BOISE" "MOTOR" "TANDY" "PANAN" "DELTA"
## [15] "CONTIL" "CITGRP" "GERBER" "GENMIL" "MARKET" "RKFREE"# creamos un objeto de series regulares zoo, ya que se trata de series indexadas en el tiempo
library(zoo)
berndt.z = zooreg(berndt.df[,-1], start=c(1978, 1), end=c(1987,12),frequency=12)
index(berndt.z) = as.yearmon(index(berndt.z))
start(berndt.z)## [1] "ene. 1978"end(berndt.z)## [1] "dic. 1987"nrow(berndt.z)## [1] 120# coredata() es una funcion que extrae datos de objetos zoo
returns.mat = as.matrix(coredata(berndt.z))
# Coeficients de correlación
coef.corr <- cor(returns.mat)
coef.d <- (1-coef.corr^2) # compute distance (Mantegna, 1998)
# clúster jerárquico con hclust
d <- as.dist(as.matrix(coef.d)) # Convierte en matrices de distancia
#La función spantree () encuentra el árbol de expansión mínimo (MTA) que conecta todos los puntos, pero sin tener en cuenta las diferencias que están en o por encima del umbral o NA.
library(vegan)## Loading required package: permute## Loading required package: lattice## This is vegan 2.5-3##
## Attaching package: 'vegan'## The following object is masked from 'package:MCMCpack':
##
## procrustestr <- spantree(d)
## Agregamos al árbol una escala métrica
plot(tr, cmdscale(d), type = "t")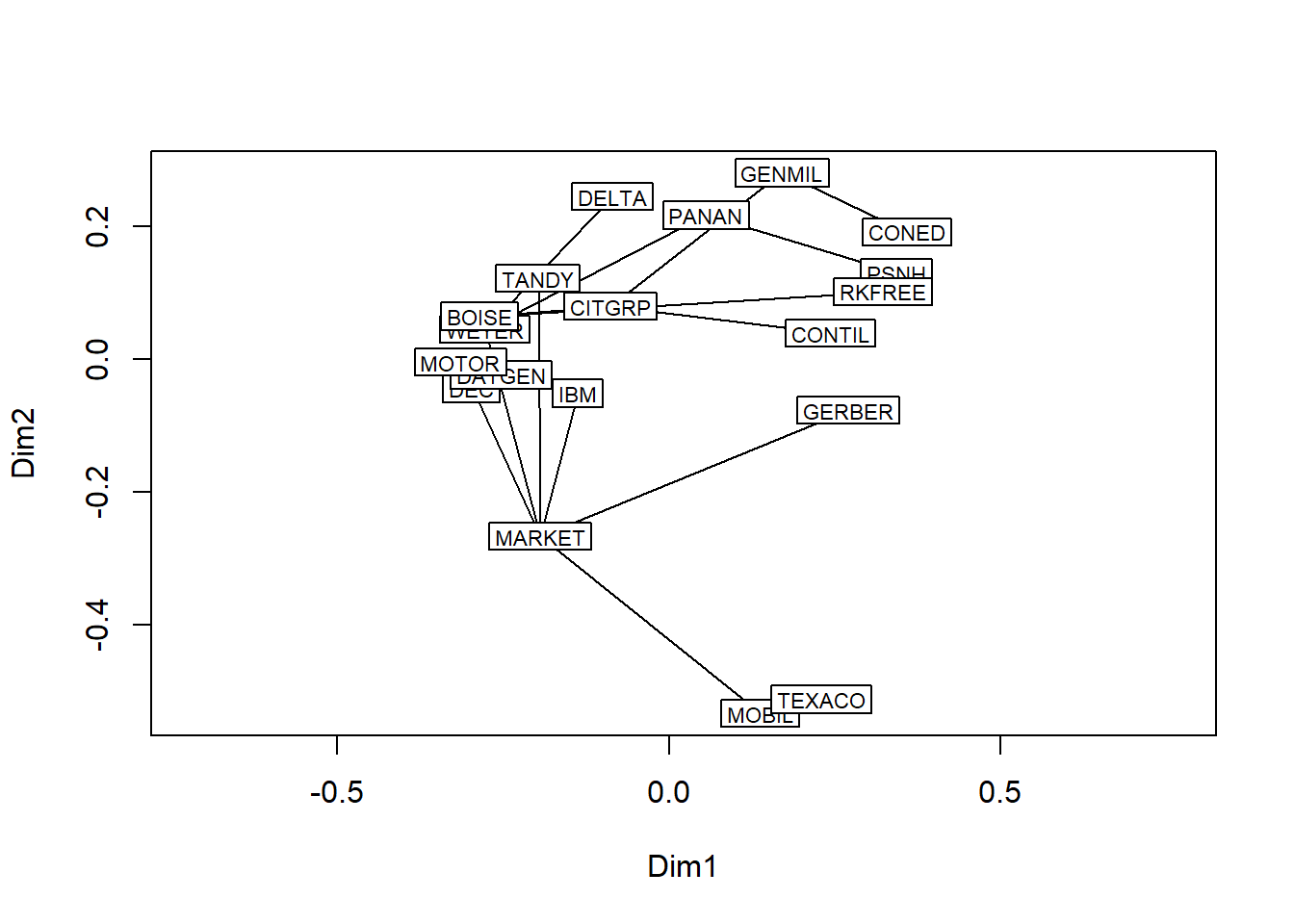
## Buscamos el mejor árbol
plot(tr, type = "t")## Initial stress : 0.10907
## stress after 2 iters: 0.06448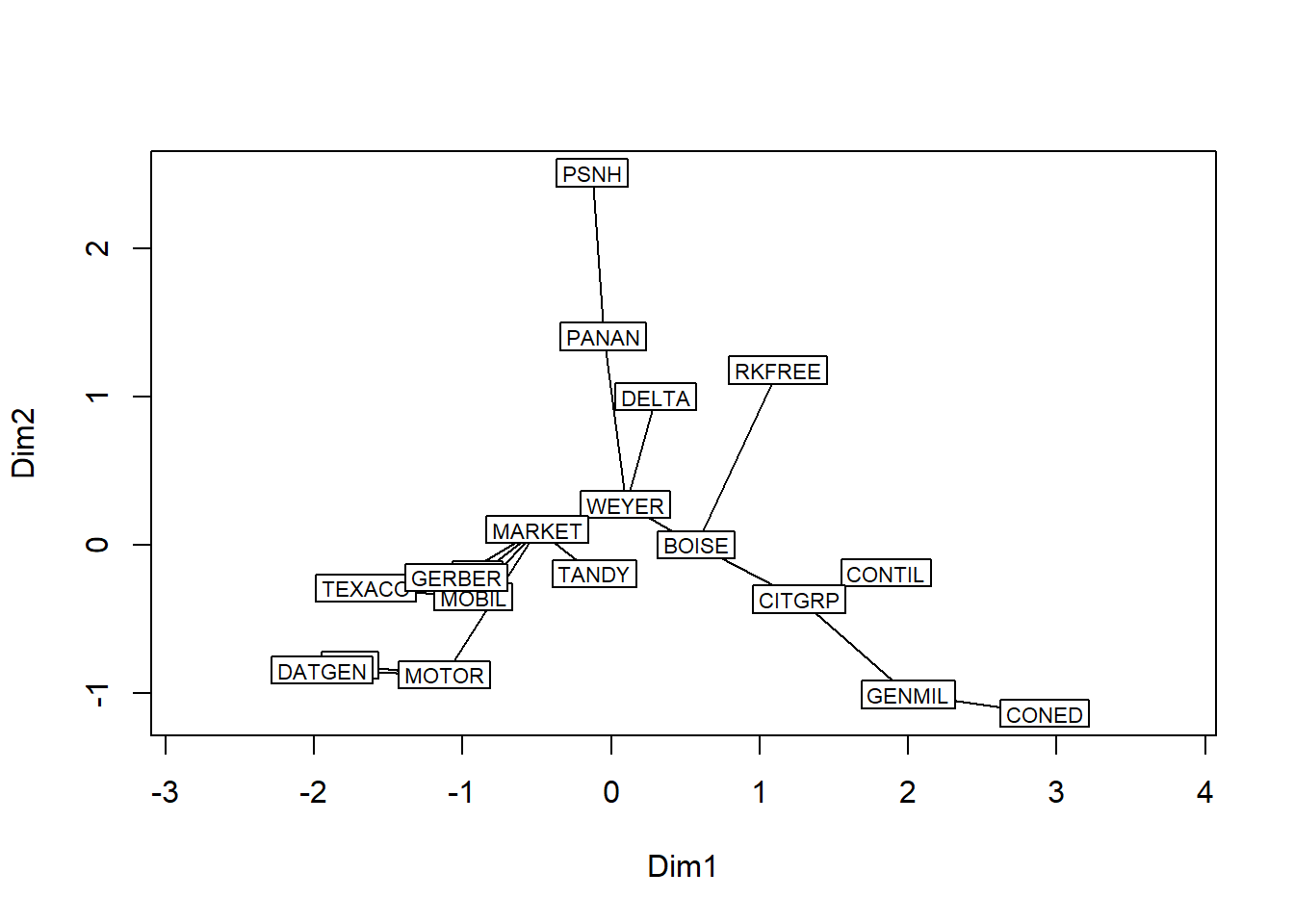
## Profundidad de los nodos
depths <- spandepth(tr)
plot(tr, type = "t", label = depths)## Initial stress : 0.10907
## stress after 2 iters: 0.06448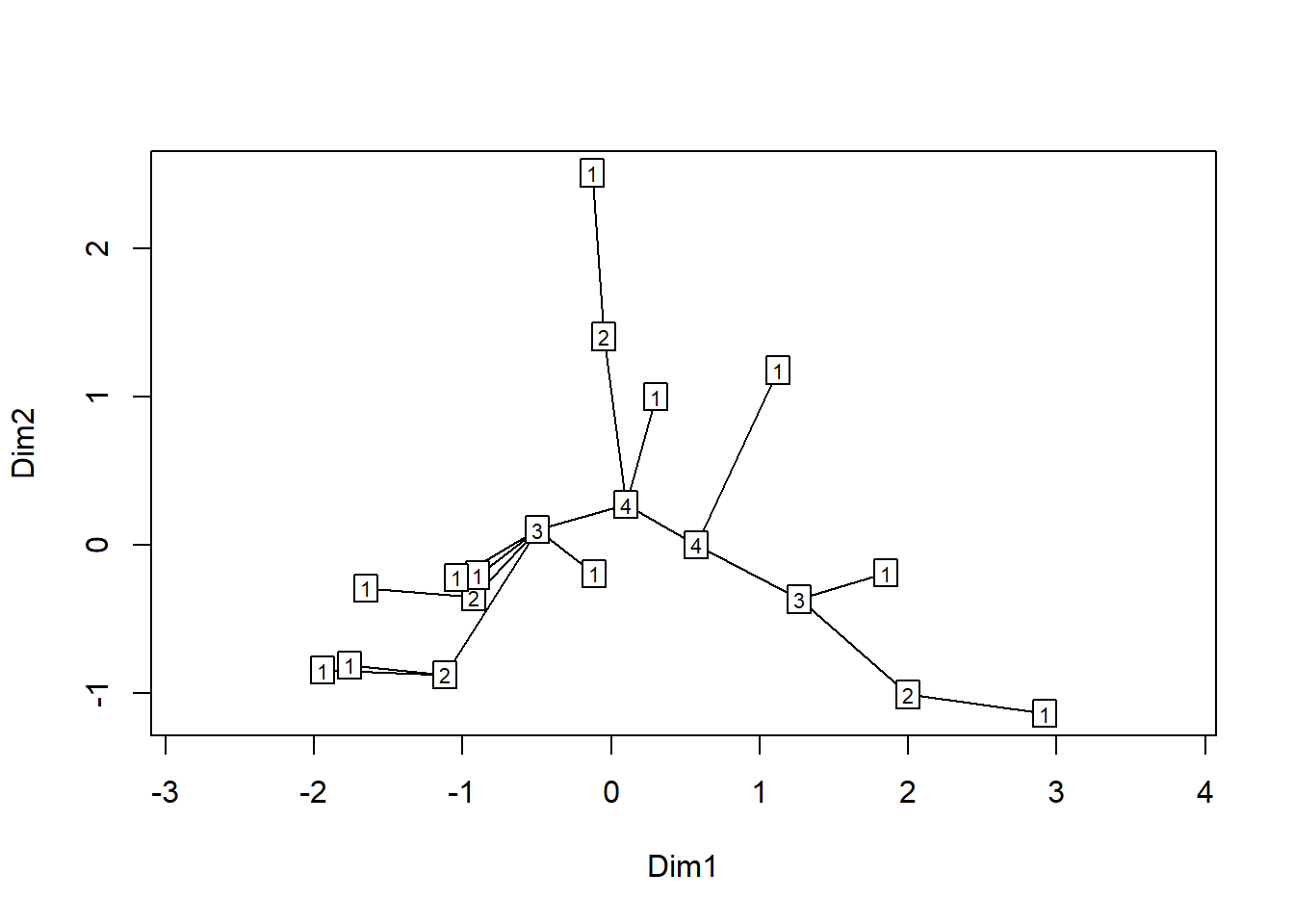
## Grafico del dendograma
cl <- as.hclust(tr)
plot(cl)