Hoofdstuk 6 Datamodellering
6.1 Van processen, over beslissingen, naar data
- Om waarde te creëren voor klanten en andere belanghebbenden van een organisatie, worden bedrijfsprocessen uitgevoerd. Zoals voorheen vermeld, is het belangrijk een goed zicht te hebben op de relevante beslissingen die tijdens deze processen worden genomen. Het al dan niet nemen van een juiste beslissing, bepaalt namelijk mee de performantie van een proces. Om echter een doordachte, goed geïnformeerde beslissing te nemen, is er nood aan kwaliteitsvolle informatie.
- Eigenschappen van kwaliteitsvolle informatie:
- Nauwkeurigheid: komen de gegevens overeen met de werkelijkheid en zijn ze voldoende gedetailleerd?
- Integriteit: verwijzen gegevens van een bepaalde entiteit consistent op dezelfde manier en naar dezelfde entiteit? Bijvoorbeeld: verwijzen de gegevens onder de noemer ‘verkooppunt’ altijd naar de locatie van het eerste klantencontact, of verwijst dit soms ook naar een ander contactpunt? Indien dit laatste het geval is, is deze informatie niet integer.
- Consistentie: zijn definities van gegevens consistent? Een voorbeeld van constistentie tussen gegevensdefinities is dat je verschillende ‘locaties’ telkens op hetzelfde niveau definieert, bv. op stadsniveau. ‘kantoorlocatie’ definiëren op stadsniveau en ‘klantenlocatie’ op straatniveau, is een voorbeeld van inconsistente definiëring van gegevenselementen.
- Volledigheid: zijn alle noodzakelijke gegevens aanwezig?
- Validiteit: vallen de gegevens binnen de verwachte waardes? Bijvoorbeeld, een negatieve waarde bij ‘leeftijd’ is geen valide waarde.
- Tijdigheid: zijn de gegevens beschikbaar op het moment dat ze nodig zijn, of zijn ze pas beschikbaar wanneer de informatiebehoefte reeds voorbij is?
- Toegankelijkheid: Zijn de gegevens toegankelijk, begrijpelijk en bruikbaar?
- Zoals uit de kenmerken van kwaliteitsvolle informatie kan worden opgemaakt, is informatie een product van gegevens, die op een bepaalde manier ter beschikking worden gesteld. Gegevens, oftewel data, zijn de kern van informatie.
- Om te zorgen dat opgeslagen gegevens leiden tot kwaliteitsvolle informatie, is het noodzaak om een goede afstemming te hebben tussen de manier waarop gegevens opgeslagen worden (de gegevensopslag) en de informatiebehoefte.
- Net zoals processen en beslissingen worden gemodelleerd, kan men gegevens modelleren. De manier waarop gegevens opgeslagen worden, met welke structuur en relaties, wordt hierbij ondubbelzinnig vastgelegd.
6.2 Gegevenshiërarchie
- De onderliggende gegevens die vandaag gebruikt worden als informatiebron, zijn hoofdzakelijk gegevens die zijn opgeslagen in informatiesystemen.
- Wanneer een informatiesysteem gegevens opslaat, volgt het hierbij een hiërarchie, zoals je die kan zien in volgende figuur (bron: Figuur 5.1 in Laudon & Laudon, 2015).
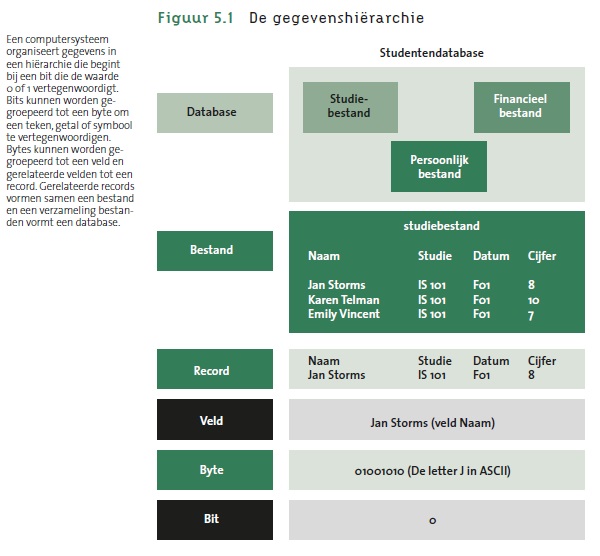
- Gegevens worden opgeslagen in bits (0 of 1), die per 8 een byte vormen. Een combinatie van bytes kan geïnterpreteerd worden als een waarde in een bepaald veld. In het voorbeeld is de naam ‘Jan Storms’ de waarde van het veld ‘Naam’. De waardes van verschillende velden samen, geven een record weer. Het record in het voorbeeld wordt opgemaakt uit de combinatie ‘Jan Storms’, ‘IS 101’, ‘F01’ en ‘8’. Om betekenis aan deze waarden -en dus ook aan het record- te geven, worden de aparte veldnamen (Naam, Studie, Datum en Cijfer) erbij vermeld. Verschillende records samen vormen op hun beurt een bestand, in dit voorbeeld het studiebestand. Het studiebestand, samen met het persoonlijk bestand en het financieel bestand, vormen hier vervolgens een database van studentengegevens.
6.3 Traditionele bestandsomgeving
- Zoals veel aspecten van een organisatie, groeit gegevensopslag organisch. Er wordt kleinschalig gestart met het opslaan van gegevens, om deze vervolgens te verwerken.
- Terugdenkend aan de functionele organisatie van een bedrijf, worden gegevens vaak per departement opgeslagen, met oog op de informatiebehoeften van dat departement.
- Als gevolg hiervan worden verschillende ‘gegevensverzamelingen’ gecreëerd, ieder met eigen definities en linken van gegevens, in verschillende toepassingen, voor verschillende doeleinden.
- Dit leidt hoofdzakelijk tot volgende problemen:
- Dataredundantie: dezelfde gegevens worden meerdere malen opgeslagen op verschillende plaatsen. Denk bijvoorbeeld aan de verkoopsafdeling die de naam en het adres van een klant bijhoudt om een levering naartoe te sturen, evenals de boekhouding die dezelfde informatie zal opslaan om te weten waar de factuur naartoe gestuurd moet worden.
- Data-inconsistentie: dezelfde attributen hebben verschillende waarden. Dit treedt op als bijvoorbeeld een update van gegevens slechts op één locatie wordt doorgevoerd, hoewel dit simultaan op meerdere plaatsen had moeten gebeuren.
- Programmadata-afhankelijkheid: afhankelijk van welk programma gebruikt wordt om de gegevens op te slaan, kunnen de gegevens op verschillende manieren worden opgeslagen. Denk bijvoorbeeld aan de postcode die in het ene programma als een numeriek gegeven wordt herkend (je zou dan hypothetisch postcodes kunnen optellen, hoewel dat natuurlijk een raar idee is), en in het ander programma niet. De koppeling tussen gegevens en programma zorgt ervoor dat veranderingen in de programma’s kunnen leiden tot het aanpassen van gegevens (meer kosten) en beperkt de uitwisselingsmogelijkheden tussen verschillende eindgebruikers (weinig flexibiliteit).
- Deze problemen leiden tot:
- extra kosten voor de organisatie door de vergrote last om gegevens te beheren en accuraat te houden.
- een inferieure informatiekwaliteit, die op haar beurt leidt tot inferieure beslissingen (en uiteindelijk tot minder performante procesuitvoeringen).
6.4 Databasemanagementsystemen
- Om de problemen van de traditionele gegevensopslag (aparte bestanden in aparte programma’s) tegen te gaan, kan een databasebenadering gehanteerd worden.
- Een database is een verzameling van gegevens die op zo een manier wordt opgeslagen, dat verschillende toepassing efficiënt gebruik kunnen maken van deze gegevens. De gegevens worden gecentraliseerd (op één locatie opgeslagen), wat de problemen van dataredundantie en -inconsistentie oplost.
- Om de gegevens op deze manier te organiseren, bestaat specifieke software: databasesmanagementsystemen (DBMS). Deze systemen beschrijven de datastructuren voor het opslaan van gegevens en beheren de opgeslagen gegevens. De meest gekende DBMS-en zijn Microsoft SQL Server, MySQL en Oracle Database.
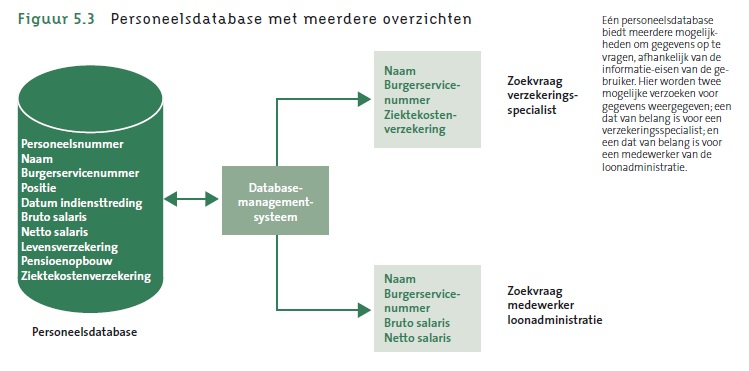
- Het DBMS zorgt ervoor dat, hoewel gegevens op slechts één manier (fysiek) worden opgeslagen en gestructureerd, ze voor verschillende gebruikers op verschillende manieren worden weergegeven (logische weergave). Zie onderstaande figuur voor een visuele weergave van het DBMS-principe (bron: Figuur 5.3 in Laudon & Laudon, 2015).
- Huidige, populaire DBMS-en zijn vaak relationele databasemanagementsystemen.
- Relationele DBMS-en zijn gebaseerd op het relationele model, zoals geformuleerd door de Britse computerwetenschapper Edgar F. (Ted) Codd in 1970. (E.F. Codd, “A Relational Model of Data for Large Shared Databanks”, Communications of the ACM, juni 1970, p. 377-387)
- Het relationele model van Codd is een declaratieve methode voor het structureren van gegevens en zoekopdrachten in databases. (declaratieve methode: beschrijvende methode die uit verschillende elementen (beschrijvingen) bestaat die leiden tot de beschrijving van één (complex) geheel)
6.5 Relaties in het relationele model
- Het relationele model, zoals beschreven door Codd, is gebaseerd op het gebruik van tabellen om relaties in op te slaan.
- Wil een tabel een relatie voorstellen, dan moet het aan een aantal voorwaarden voldoen:
- Rijen bevatten gegevens over een entiteit.
- Kolommen bevatten gegevens over attributen van de entiteit.
- Alle items in een kolom zijn van dezelfde soort.
- Elke kolom heeft een unieke naam.
- Cellen van de tabel bevatten enkelvoudige gegevens.
- De volgorde van de kolommen is niet van belang.
- De volgorde van de rijen is niet van belang.
- Er mogen geen identieke rijen voorkomen.
- Entiteiten kunnen personen zijn, maar ook objecten, plaatsen… Met een entiteit wordt één of ander identificeerbaar ding bedoeld, iets wat de gebruiker wil volgen.
- Met betrekking tot een entiteit, worden karakteristieken opgeslagen die deze entiteit beschrijven, attributen genaamd. (Deze worden in kolommen georganiseerd - zie tweede puntje.)
- In het voorheen getoonde voorbeeld, zijn Naam, Studie, Datum en Cijfer attributen van de entiteit die wordt beschreven in het Studiebestand.
- Volgens de definities van Codd worden de kolommen attributen genoemd, en de rijen tuples. In de praktijk zijn er verschillende sets van termen die door elkaar gebruikt (kunnen) worden.
| Codd | Altern. 1 | Altern. 2 |
|---|---|---|
| Relatie | Tabel | Bestand |
| Attribuut | Kolom | Veld |
| Tuple | Rij | Record |
- Om unieke tuples (rijen) te identificeren in een relatie (tabel), maakt men gebruik van een primaire sleutel -of primary key. Dit is een combinatie van één of meerdere attributen die gebruikt kan worden voor het selecteren van een specifieke rij.
- Indien meerdere kolommen samen de primaire sleutel vormen, noemt men dit een samengestelde sleutel.
- Men kan ook een kunstmatige kolom toevoegen om als primaire sleutel te fungeren. Dat wordt een surrogaatsleutel genomend.
- Wanneer een relatie een attribuut bevat dat in een andere relatie de primaire sleutel is, dan noemt men dit attribuut een externe sleutel -of foreign key.
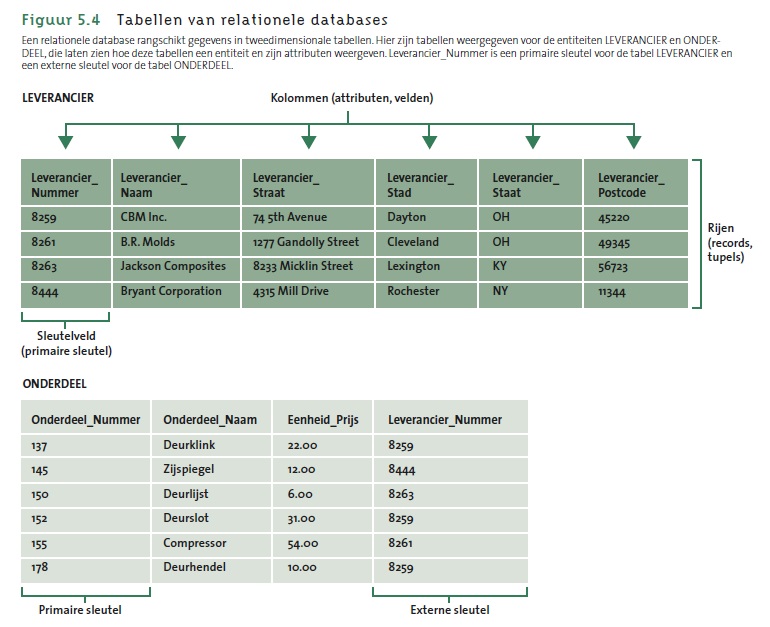
- In onderstaande figuur vind je een voorbeeld van tabellen die relaties voorstellen, inclusief hun primaire en externe sleutel. Merk op dat de primaire sleutel een surrogaatsleutel is. (bron: Figuur 5.4 in Laudon & Laudon, 2015).
6.6 Het Entiteit-Relatie-datamodel
6.6.1 Visuele weergave van entiteiten en attributen
- Een datamodel kan gezien worden als de blauwdruk van een databaseontwerp.
- Verschillende technieken bestaan voor het maken van datamodellen, maar het eniteit-relatiemodel (E-R-model) heeft zich doorheen de jaren tot standaard ontwikkeld.
- Een entiteiten-relatiediagram is een techniek om een datamodel grafisch weer te geven. De basisbeginselen van dit datamodel werden in 1976 ontwikkeld door Peter Chen.
- Het E-R-model visualiseert drie aspecten:
- Entiteiten
- Attributen
- Relaties tussen de entiteiten
- Zoals reeds vermeld, zijn entiteiten iets wat de gebruiker wil volgen. Het is belangrijk het verschil te weten tussen een entiteitenklasse en een instantie van een entiteit. Entiteiten van eenzelfde soort worden gegroepeerd in een entiteitenklasse, vaak kortweg entiteit genoemd. In het voorbeeld van de tabellen (figuur 5.4 van Laudon & Laudon) kunnen we vier instanties van de entiteitenklasse LEVERANCIER zien en 6 instanties van de entiteitenklasse ONDERDEEL.
- Attributen zijn eigenschappen die de entiteit beschrijven.
- Er zijn verschillende manieren om attributen in te delen:
- Enkelvoudige versus samengestelde attributen. Bv.: studentennummer (enkelvoudig), adres (samengesteld uit: straatnaam+huisnr.+postcode+gemeente)
- Eénwaardige versus meerwaardige attributen. Bv.: geslacht (éénwaardig), telefoonnummer (meerdere waarden bijhouden: zakennr en gsm)
- Niet-afgeleide en afgeleide attributen. Bv.: geboortedatum (niet afgeleid), leeftijd (afgeleid van geboortedatum)
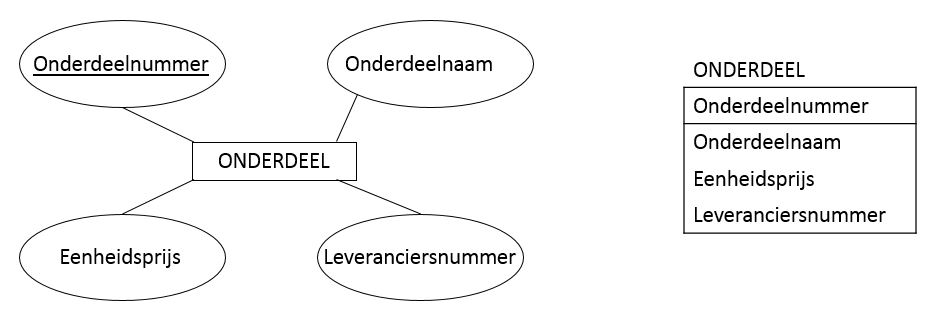
- Volgens de notatie van Chen wordt een entiteit visueel weergegeven door een rechthoek en attributen door een ovaal. De relaties tussen de attributen en de entiteiten worden door lijnen voorgesteld. In onderstaande figuur kan je deze notatie vinden voor de entiteitenklasse ONDERDEEL die we voorheen hebben gezien. De blokstijl, die rechts getoond wordt, is een notatie die momenteel meer gebruikt wordt.
- De verschillende types attributen hebben ook hun eigen notatie:
- De meerwaardige attributen worden voorgesteld door een dubbele ovaal.
- De afgeleide attributen door een gestippelde ovaal.
- In onderstaande figuur kan je een voorbeeld vinden van een entiteit met enkelvoudige, samengestelde, meerwaardige en afgeleide attributen.
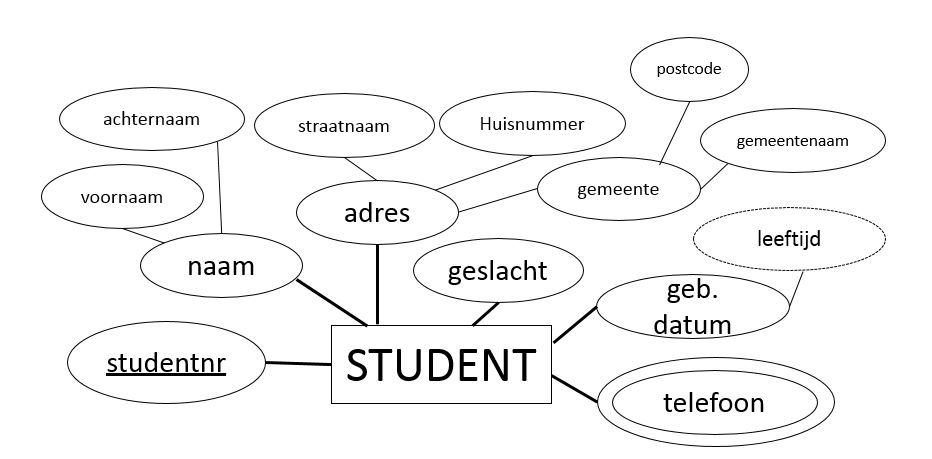
6.6.2 Identifiers
- Om specifieke instanties van entiteiten te identificeren, wordt er in het ER-model gebruik gemaakt van identifiers. In de vorige figuur kon je deze herkennen aan het onderlijnde attribuut in de ovaal, of aan het apart opgelijste attribuut in de blokstructuur (onderdeelnummer).
- Net zoals de primaire sleutels van relatietabellen samengesteld kunnen zijn, bestaan er ook samengestelde identifiers.
- Wat is het verschil tussen sleutel en identifier?
- De term sleutel wordt gebruikt in een databaseontwerp: een tabel (of relatie) heeft sleutels.
- De term identifier wordt gebruikt bij datamodelering: een entiteit heeft identifiers.
- Beiden vervullen ze dezelfde rol en er is bijgevolg een grote overeenkomst.
6.6.3 Relaties
- Entiteitenklassen kunnen met elkaar verbonden zijn via relaties, die worden weergegeven door een ruit in de notatie van Chen.
- Het aantal klassen die in de relatie met elkaar verbonden worden, noemt men de graad.
- In onderstaande figuur vind je een voorbeeld van zowel een relatie van de tweede graad (een binaire relatie), als een relatie van de derde graad (een tertiaire relatie).
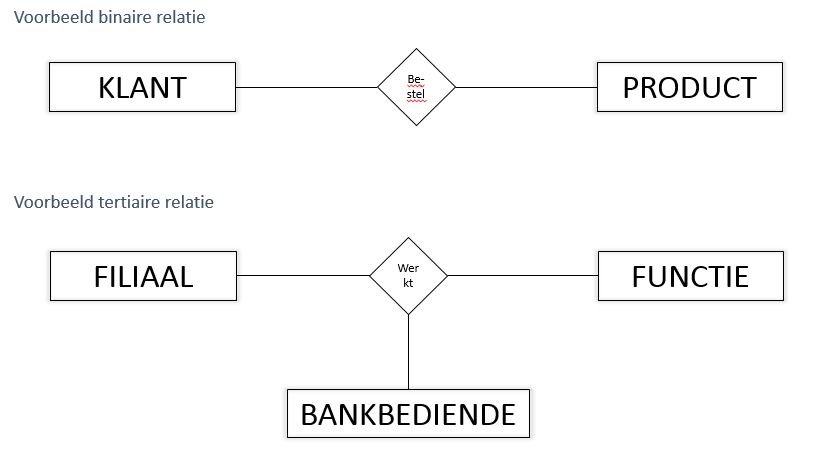
- Naast de graad van een relatie, is de kardinaliteit belangrijk in datamodelering.
- De kardinaliteit van een relatie is het aantal voorkomens van de relatie: 0, 1 of n:
- De minimumkardinaliteit verwijst naar het minimum aantal voorkomens in de relatie.
- Is de relatie optioneel of verplicht? Als de relatie optioneel is, KAN de relatie bestaan en is de minimumkardinaliteit 0; als de relatie verplicht is, MOET de relatie bestaan en is de minimumkardinaliteit 1.
- De maximumkardinaliteit verwijst naar het maximum aantal voorkomens in de relatie.
- De maximumkardinaliteit kan ‘1’ of ‘meer’ zijn. ‘meer’ wordt ook weergegeven door de abstracte n.
- Voor de notatie van de kardinaliteiten maken we gebruik van de ‘Crow’s foot notation’, oftwel het kraaienpootmodel. Bij elke entiteit worden 2 symbolen getekend: 1 symbool voor de aanduiding van de minimumkardinaliteit en 1 symbool voor de aanduiding van de maximumkardinaliteit.
- Optionele relatie (minimumkardinaliteit = 0) wordt aangegeven door een rondje in de relatielijn.
- Kardinaliteit = 1 wordt aangegeven door een kruisstreep (verticaal) in de relatielijn.
- Kardinaliteit = n wordt aangegeven door ee kraaienpoot aan de veel-kant van de relatie.
- Onderstaande figuur vat de verschillende mogelijke relaties samen.

- Om relaties weer te geven, kan men kiezen om de ruitnotatie te blijven hanteren, of dat men de relaties uitschrijft in beide richtingen.
- Opmerking: de entiteiten mogen omgewisseld worden (inclusief hun kardinaliteiten), maar de betekenis van de relaties moet behouden blijven.
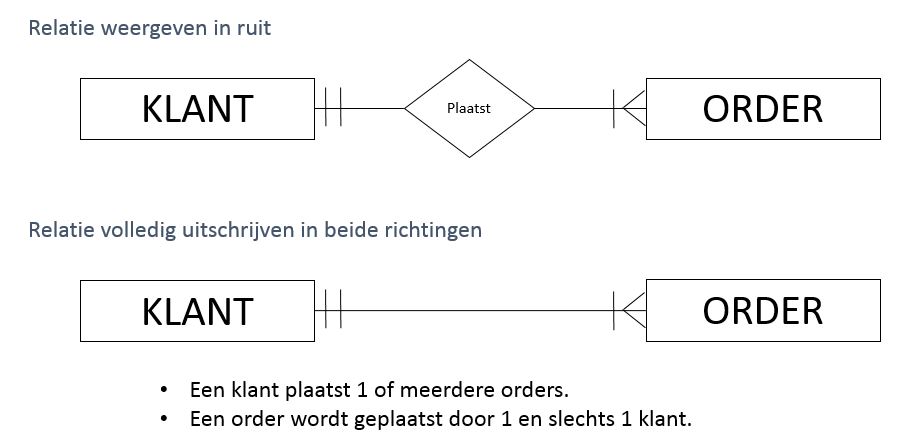
6.6.4 Associatieve entiteiten
- Zoals vermeld worden entiteiten voorgesteld in rechthoeken, en relaties in ruiten. De relaties beschrijven de verhoudingen tussen de entiteiten, en hebben in principe geen andere eigenschappen (attributen).
- Soms zijn er echter ‘relaties’ die ook eigen attributen hebben. Deze relatie is dan eigenlijk een entiteit én een relatie en kan worden weergegeven door een ruit in een rechthoek.
- Van een datamodelerings-standpunt dienen deze relaties geïdentificeerd te worden en opgeslagen als een associatieve entiteit: ze staat voor associaties tussen entiteiten (de relatie) en is zelf een entiteit.
- Neem het volgende voorbeeld:
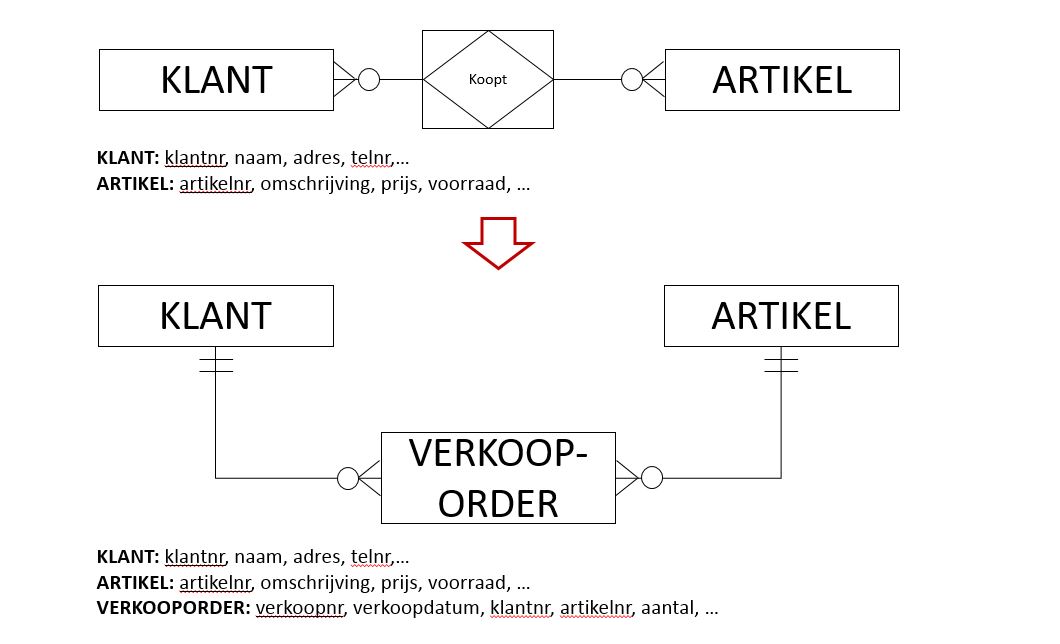
- We hebben 2 entiteiten, die opgeslagen kunnen worden in de relatietabellen:
- KLANT: klantnr, naam, adres, telnr,.
- ARTIKEL: artikelnr, omschrijving, prijs, voorraad,.
- De relatie tussen de 2 entiteiten kan samengevat worden in ‘koopt’, weergegeven in een ruit.
- Relatie klant-artikel: Eén klant KAN (0) één of meerdere artikels kopen. In dit voorbeeld houden we ook gegevens bij van potentiële klanten, die nog geen enkel artikel gekocht hebben. Er KAN bijgevolg een relatie zijn tussen beiden entiteiten. Indien we enkel gegevens zouden bijhouden van klanten die al minstens 1 aankoop hebben gedaan, MOET er (minstens één) relatie zijn tussen beide entiteiten. Het symbool (0) wordt dan vervangen door het symbool (|).
- Relatie artikel-klant: Eén artikel KAN door 0, 1 of meerdere klanten gekocht worden. Het gaat dan niet fysisch om hetzelfde artikel natuurlijk maar om een product met hetzelfde artikelnummer.
- Dit resulteert in een meer-op-meer (of N-op-M) relatie!
- Het probleem met een N-op-M relatie is dat, als we dit in relatietabellen zouden proberen te zetten, we altijd zullen zondigen tegen de principes van het relationele model: enkelvoudige gegevens in 1 cel en 1 record bevat gegevens over 1 unieke entiteit(sinstantie).
- Daarnaast wensen we ook informatie bij te houden over de verkoop zelf, o.a. de datum, het aantal, … Deze verkoopdatum kan niet worden opgeslagen als eigenschap van KLANT noch als eigenschap van ARTIKEL, maar hoort momenteel bij de relatie ‘koopt’, waar we geen attributen van kunnen opslaan.
- De twee vermelde problemen kunnen opgelost worden door de ‘relatie’ te erkennen als een entiteit.
- De ‘relatie’ wordt in dit voorbeeld omgezet in de associatieve entiteit VERKOOPORDER met eigen attributen zoals een verkoopnr, een verkoopdatum, enz. De verkooporder is verbonden met klant en artikel via de relatie-attributen klantnr en artikelnr. De derde (associatieve) entiteit is
- VERKOOPORDER: verkoopnr, verkoopdatum, klantnr, artikelnr, aantal, .
- De N-op-M relatie wordt zo omgezet in twee 1-op-N relaties.
- Volgende beschrijving past bij de nieuwe relaties:
- Een klant kan (0) voorkomen in één of meerdere verkooporders.
- Een verkooporder hoort bij 1 en slechts 1 klant.
- Een artikel kan (0) voorkomen in één of meerdere verkooporders.
- Een verkooporder hoort bij 1 en slechts 1 artikel.
- We hebben 2 entiteiten, die opgeslagen kunnen worden in de relatietabellen:
6.6.5 Afsluitend voorbeeld normalisatie
- Voorbeeld uit het handboek ‘Bedrijfsinformatiesystemen’ van Laudon & Laudon (2015).
- De oorspronkelijke organisatie van data, gerelateerd aan bestellingen, was als volgt.

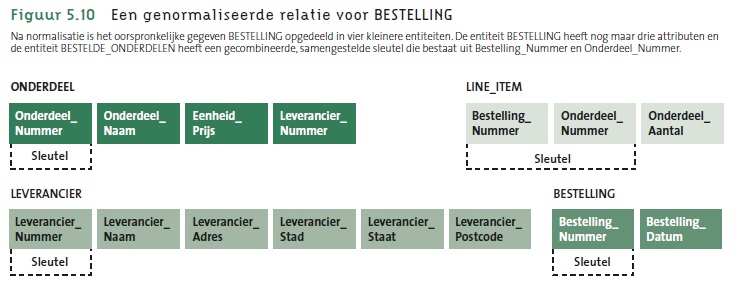
- In de bovenstaande dataset worden in elke bestelling gegevens herhaald, bijvoorbeeld de naam en het adres van de leverancier. Daarnaast kan een bestelling herhalende groepen bevatten omdat er verschillende producten in een bestelling kunnen staan. Dit resulteert in data-redundantie (overtolligheid) en inconsistentie (foutieve waarden bij wijzigingen). Om deze problemen te vermijden, worden de herhalende groepen in aparte tabellen geplaatst. Dit opsplitsen van gegevens in groepen van bij elkaar horende gegevens opdat zo weinig mogelijk problemen veroorzaakt kunnen worden, wordt normalisatie genoemd.
- Na normalisatie is de oorspronkelijke gegevensverzameling opgedeeld in 4 entiteiten.
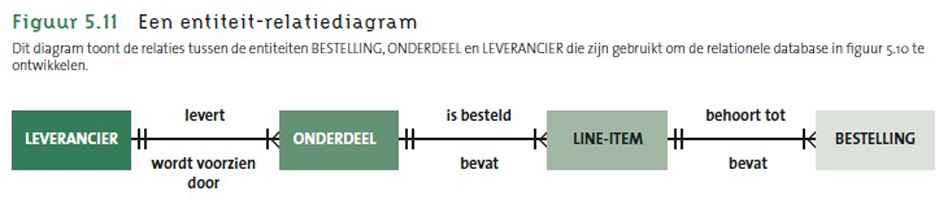
- De relaties tussen de entiteiten kunnen in de onderste figuur teruggevonden worden.
Bronnen
- ‘Bedrijfsinformatiesystemen - 14de editie, Hoofdstuk 5’ van Laudon en Laudon, uitgegeven door Pearson
- ‘Databases - Beginselen, ontwerp en implementatie’ van David M. Kroenke, uitgegeven door Pearson