Ziel: Klassifikation von Variablen gemäß ihrer korrelativen Beziehungen in voneinander unabhängige Gruppen
Dazu wird eine künstliche Variable (= Faktor) ermittelt, die mit den anderen Variablen möglichst hoch korreliert
Allgemeines
Wenn der Einfluss des ersten Faktors aus den Korrelationen der Variablen untereinander entfernt wird, bleibt nur mehr Korrelation übrig, die nicht durch den Faktor erklärt werden kann
Restkorrelation wird durch weiteren Faktor zu erklären versucht
Ergebnis: Wechselseitig voneinander unabhängige Faktoren, die die Zusammenhänge zwischen den Variablen erklären
Je höher die Korrelationen der Variablen untereinander, desto weniger Faktoren nötig
Motivation
Datenreduktion ohne großen Informationsverlust
Generierung von Hypothesen zur Struktur der Merkmale
Bestimmung der Dimensionalität komplexer Merkmale
Überprüfung der (Ein-)Dimensionalität
Vorgehen
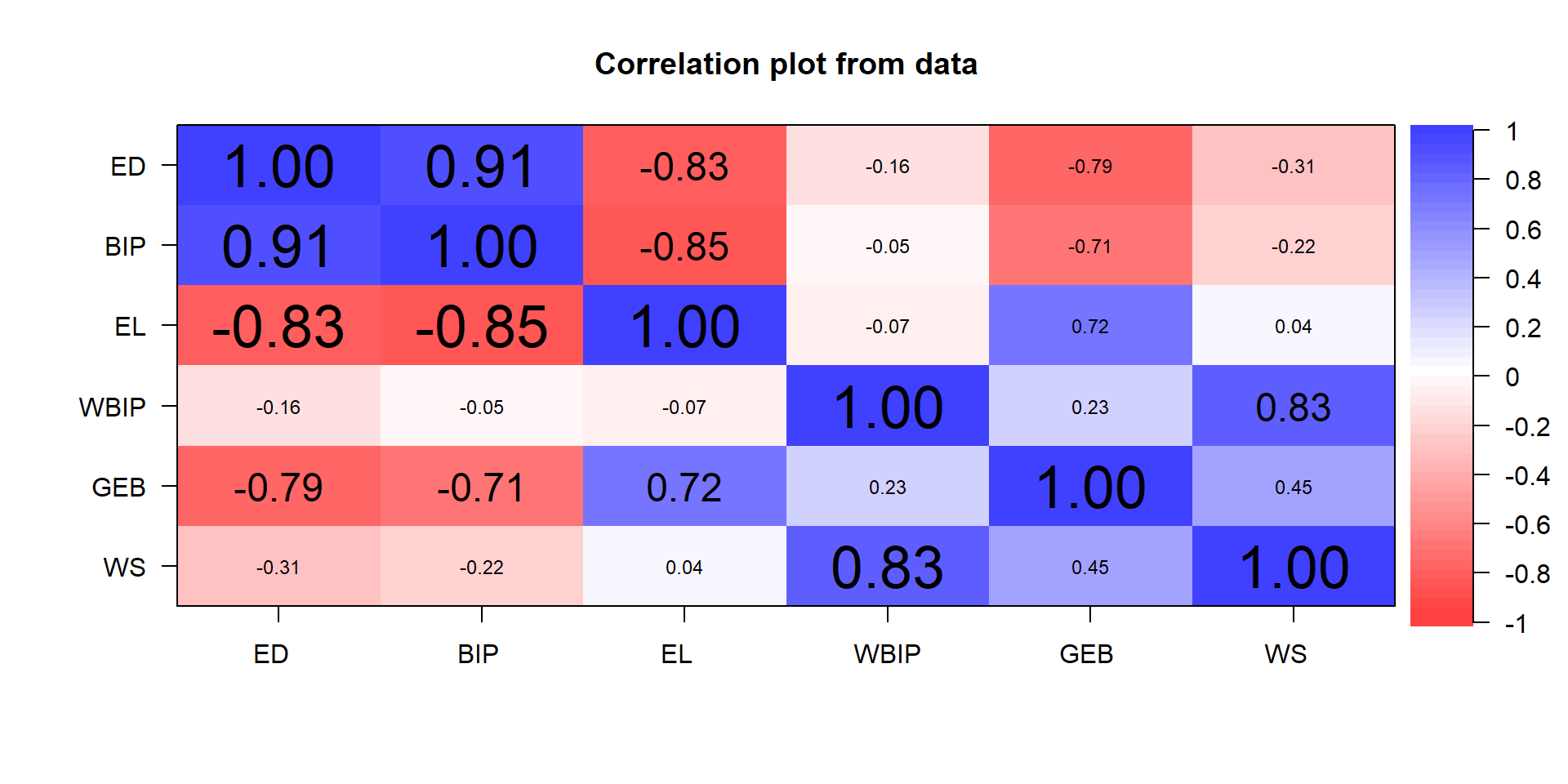
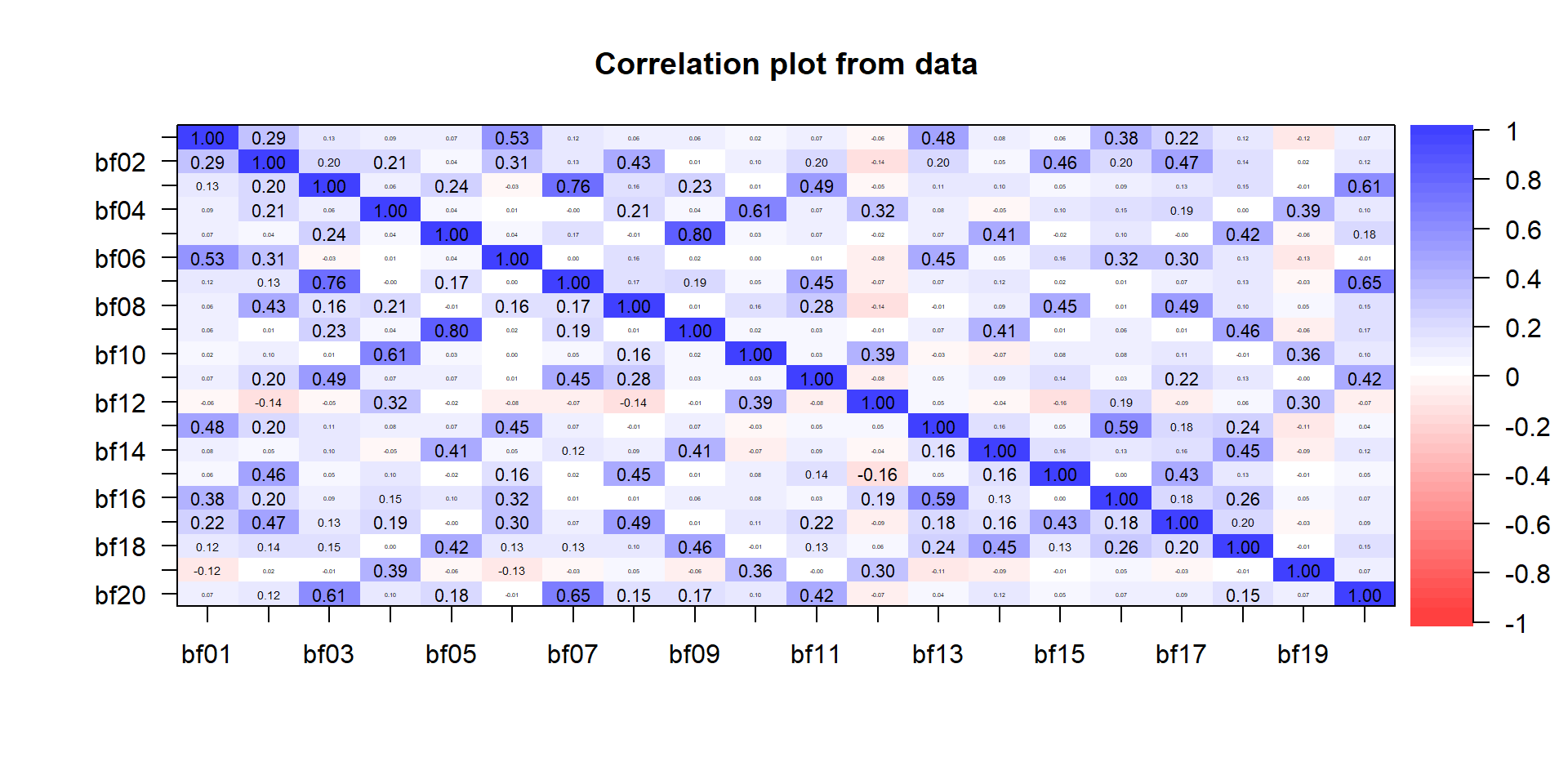
Variablenauswahl und Korrelationsmatrix
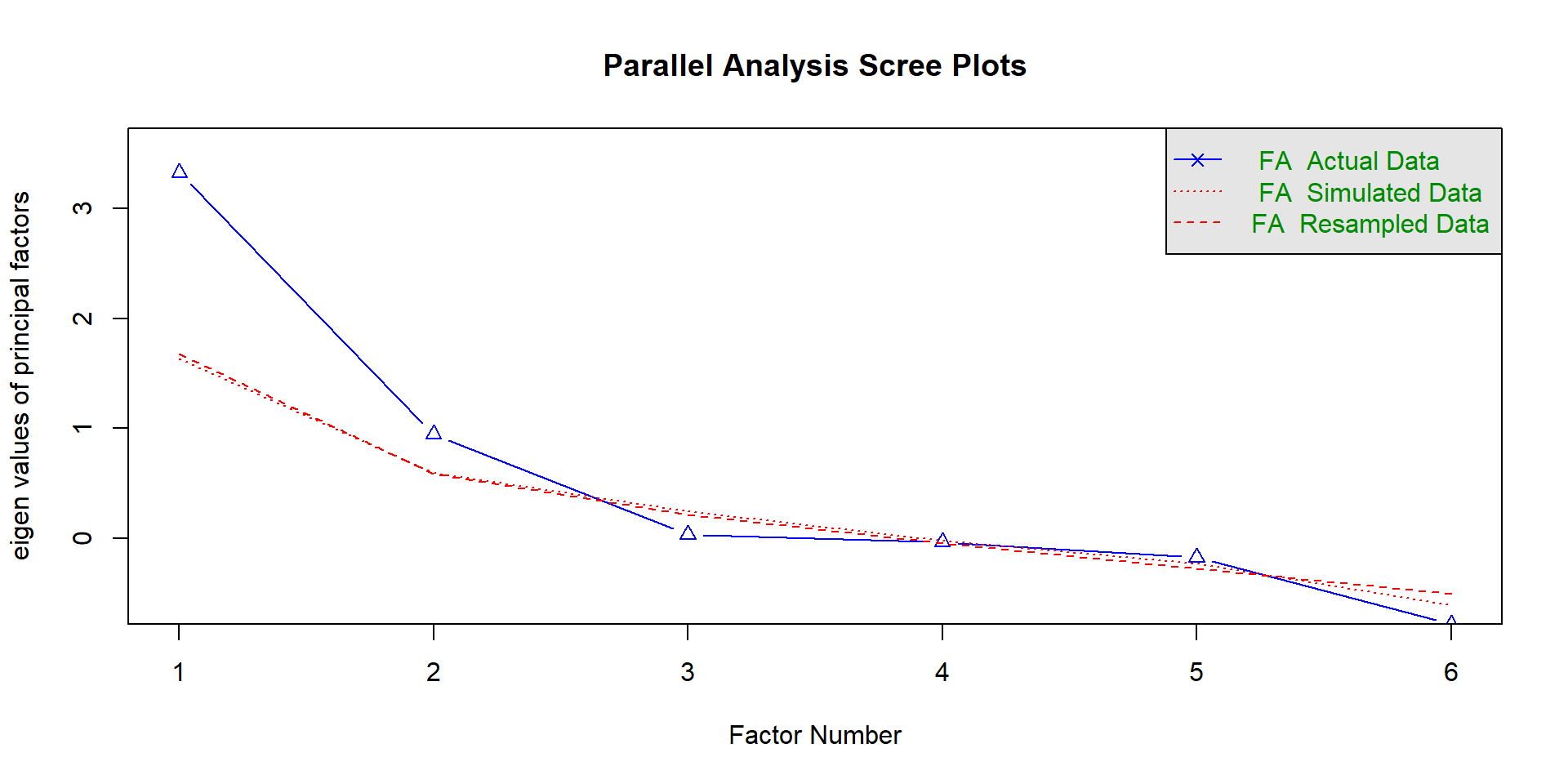
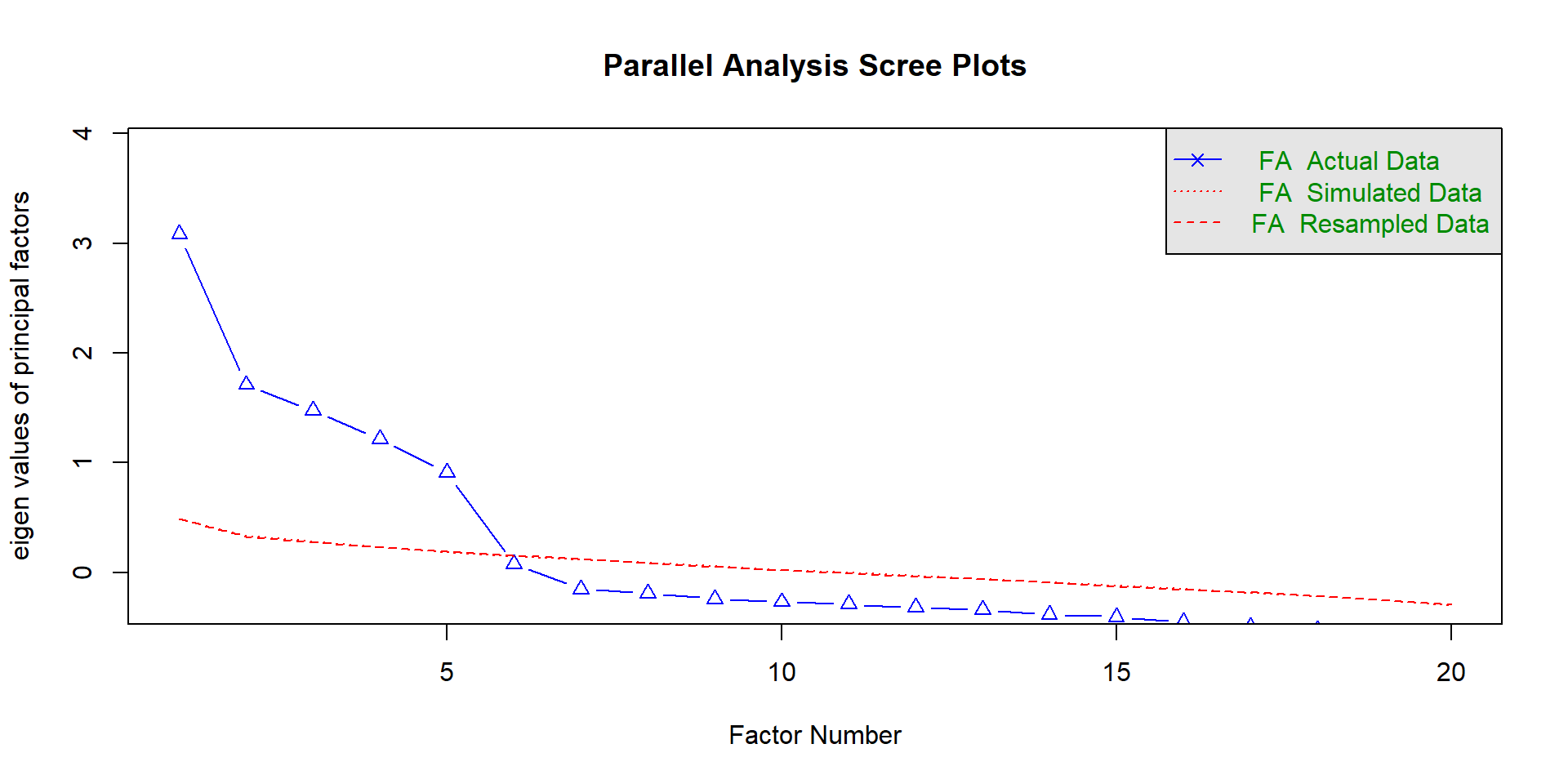
Bestimmung der Zahl der Faktoren (Parallel-Analyse)
Extraktion der Faktoren
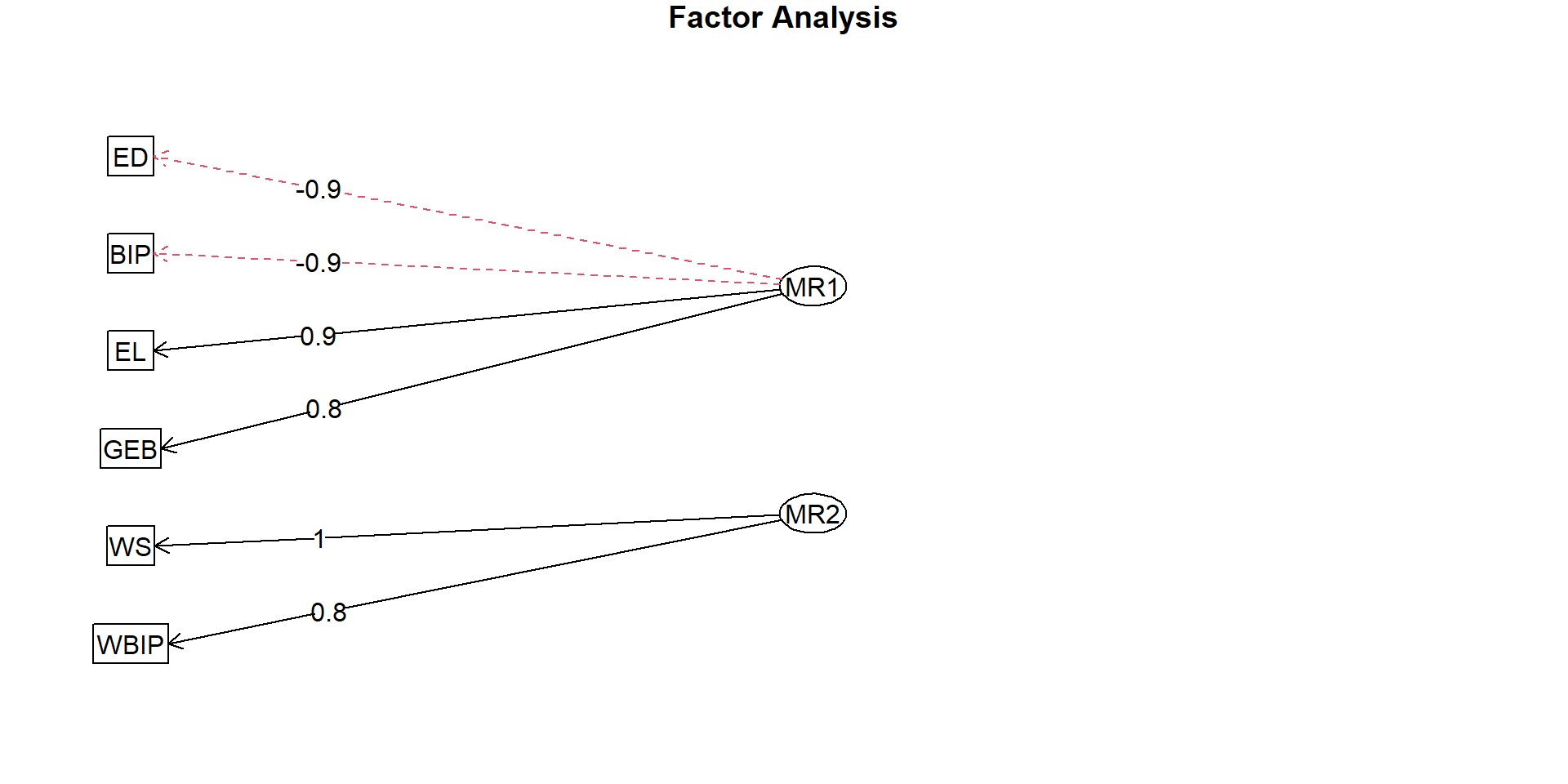
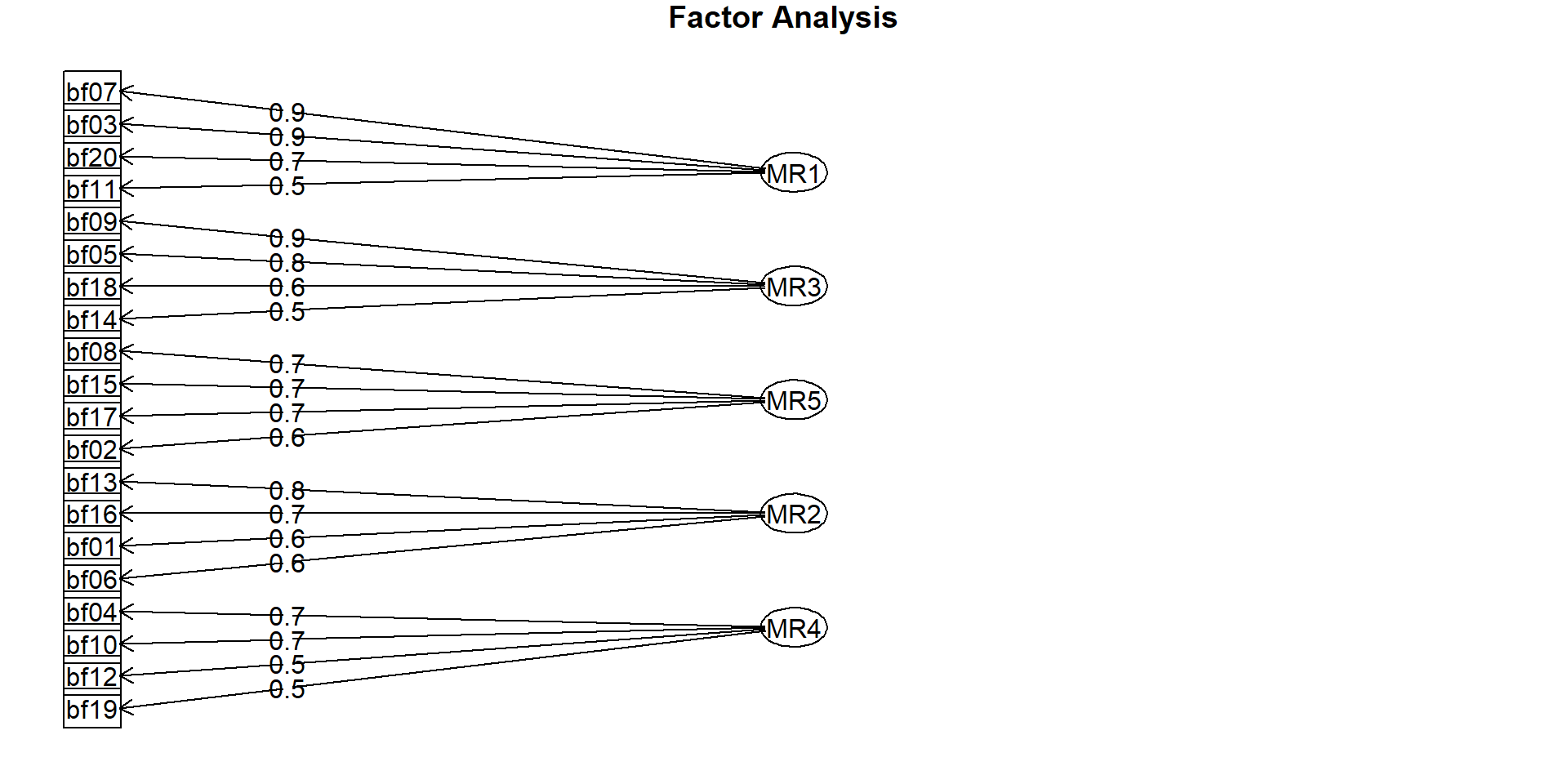
Interpretation der Faktoren (meist nach Rotation)
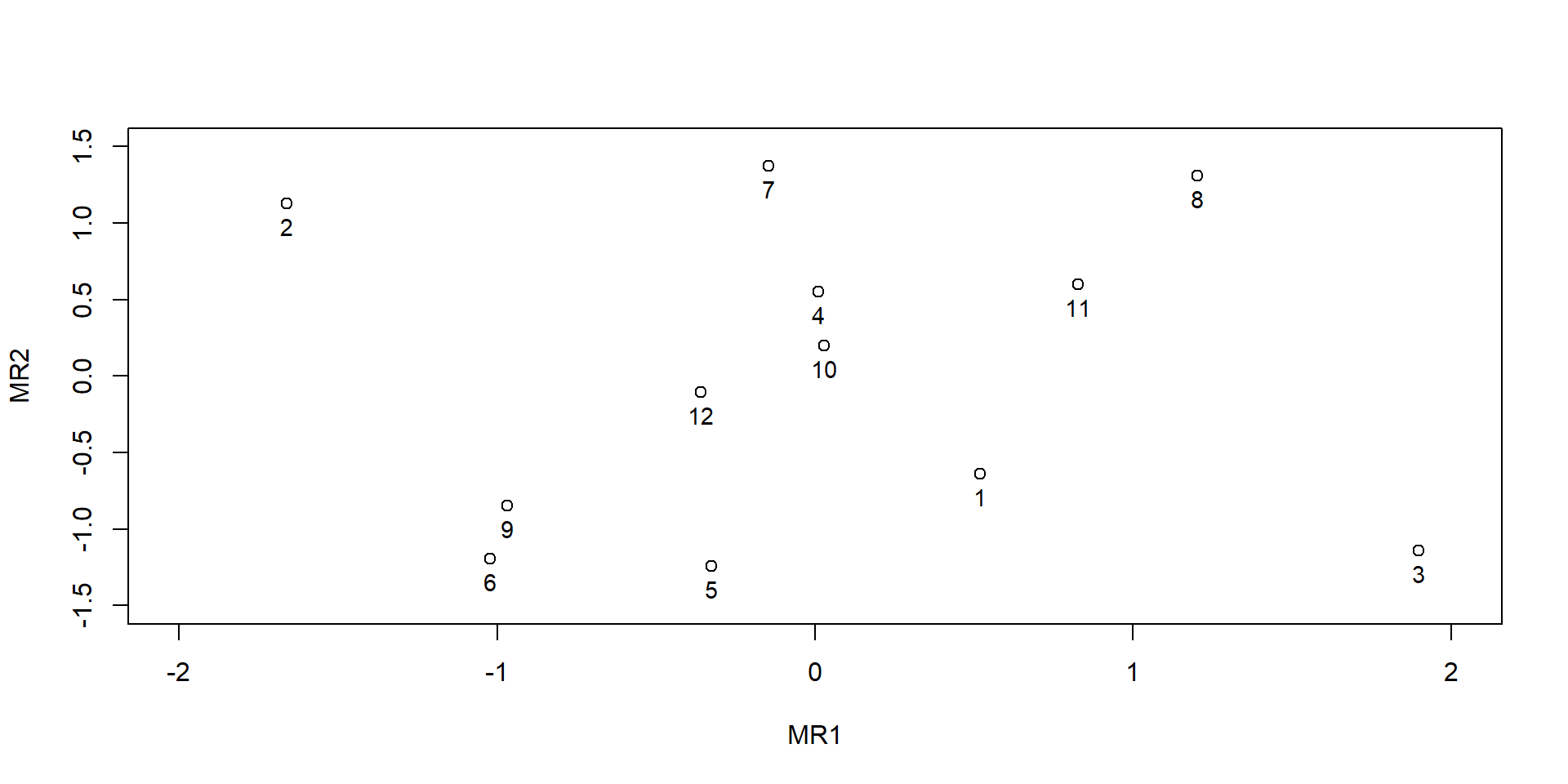
Bestimmung der Faktorwerte
Wichtige Begriffe
Faktorladung
Korrelation Variable - Faktor
Kommunalität
Summe der quadrierten Faktorladungen einer Variablen über alle Faktoren; in welchem Maß wird die Varianz einer Variablen durch die Faktoren erfasst
Eigenwert
Wie viel der Gesamtvarianz aller Variablen erfasst ein bestimmter Faktor
Faktorwerte
Wie stark sind die in einem Faktor zusammengefassten Merkmale bei einem Objekt ausgeprägt: Position des Objekts auf dem Faktor
Umsetzung
Eignung der Korrelationsmatrix
Bartlett-Test: Überprüft die Nullhypothese, dass die Variablen aus einer unkorrelierten Grundgesamtheit stammen
Factor Analysis using method = minres
Call: fa(r = regionen_data, nfactors = 2, rotate = "varimax")
Standardized loadings (pattern matrix) based upon correlation matrix
item MR1 MR2 h2 u2 com
ED 1 -0.95 0.92 0.080 1.1
BIP 2 -0.92 0.86 0.142 1.0
EL 3 0.92 0.86 0.139 1.0
GEB 5 0.78 0.70 0.299 1.3
WS 6 0.99 1.01 -0.009 1.1
WBIP 4 0.83 0.69 0.309 1.0
MR1 MR2
SS loadings 3.25 1.79
Proportion Var 0.54 0.30
Cumulative Var 0.54 0.84
Proportion Explained 0.64 0.36
Cumulative Proportion 0.64 1.00
Mean item complexity = 1.1
Test of the hypothesis that 2 factors are sufficient.
df null model = 15 with the objective function = 5.99 with Chi Square = 48.88
df of the model are 4 and the objective function was 0.25
The root mean square of the residuals (RMSR) is 0.02
The df corrected root mean square of the residuals is 0.04
The harmonic n.obs is 12 with the empirical chi square 0.12 with prob < 1
The total n.obs was 12 with Likelihood Chi Square = 1.72 with prob < 0.79
Tucker Lewis Index of factoring reliability = 1.331
RMSEA index = 0 and the 90 % confidence intervals are 0 0.296
BIC = -8.22
Fit based upon off diagonal values = 1
# Diagramm der Faktorenladungen fa.diagram(efa_result)
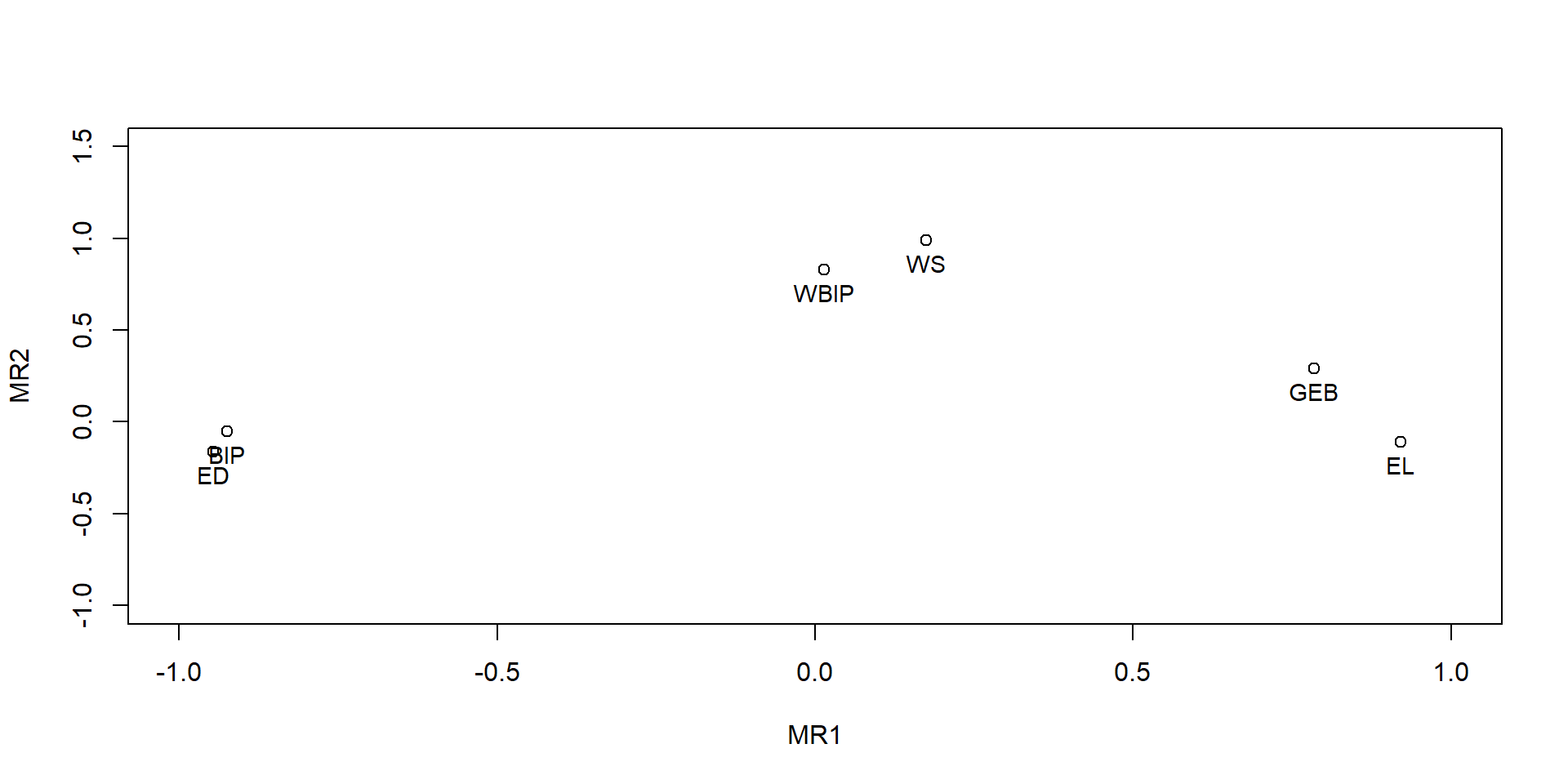
# Weitere Diagramme# Achsen festlegenxlim =c(-2, 2)ylim =c(-1.5, 1.5)# Regionen im Faktorraum (Faktorwerte)plot(factor_scores$scores, xlim=xlim,ylim=ylim)text(factor_scores$scores, labels =c(1:12), cex =0.9, pos =1, font =1, col ="black")
# Achsen festlegenxlim =c(-1, 1)ylim =c(-1, 1.5)# Variablen im Faktorraumplot(efa_result$loadings, xlim=xlim,ylim=ylim)text(efa_result$loadings, labels =colnames(regionen_data), cex =0.9, pos =1, font =1, col ="black")
Beispiel Big Five 🖐
Daten
480 Studierende der FU Berlin
Persönlichkeitsfragebogen zur Erhebung der Big Five
Ziel der Analyse: Prüfung der Dimensionalität einer Skala
Eignung für FA: Bartlett-Test
Blick auf die Korrelationen
# Daten einlesenbigfive.items <-read.csv("./data/bigfive_items.csv")#Liefert die ersten Zeilen des Datensatzeshead(bigfive.items)
… für eine FA nach den Regeln der Kunst. Wenn wir eine EFA nur als Erkundungswerkzeug verwenden, können wir diese Empfehlungen entsprechend entspannen.
Metrisch skalierte Variable
Fallzahl sollte mindestens dreimal so groß wie die Zahl der Variablen sein
Für eine stabile Lösung: n > 250 (Bühner, 2021)
Zur Interpretation nur Faktorladungen > 0,5 verwenden
Faktorenanzahl: Parallel-Analyse, ggf. Kaiser-Kriterium (ungeeignet für viele Variablen)
Rotation: Varimax
Empfehlungen
Bortz & Schuster (2010):
Interpretation eines Faktors, wenn vier Variablen > 0,60 laden