Vollziehen Sie das Beispiel zu den Regionen aus der Vorlesung nach. Die Daten finden Sie hier.
Kopieren Sie schrittweise den Code in ein leeres Quarto-Dokument und bauen Sie das Beispiel so auf.
Aufgabe: Social Media + Gym
Ein Beispiel, das ich von der Seite datatab.de habe: Elf Personen wurden danach gefragt, wie viele Stunden sie in der Woche auf Social-Media-Plattformen und im Fitnessstudio verbringen.
Führen Sie eine Clusterananlyse in folgenden Schritten durch:
Erstellen Sie ein leeres Quarto-Dokument und geben Sie ihm die Dateiendung .qmd.
Lesen Sie die Daten ein (die Sie auch hier finden); Sie können sie aber auch direkt von ihrem Online-Speicherort einlesen. Kopieren Sie dazu die Adresse des Links.
Lassen Sie sich zur Kontrolle die Daten ausgeben. Dazu rufen Sie einfach den Namen der Variablen auf, die auf die Daten verweist.
Erstellen Sie den Code für die folgenden Teilaufgaben. Kopieren Sie dazu den Code aus der Vorlesung und passen Sie ihn an. Lassen Sie sich von ChatGPT helfen.
Überführen Sie die Daten in z-transformierte Werte
Erstellen Sie die Distanz-Matrix
Führen Sie die eigentliche Clusteranalyse durch
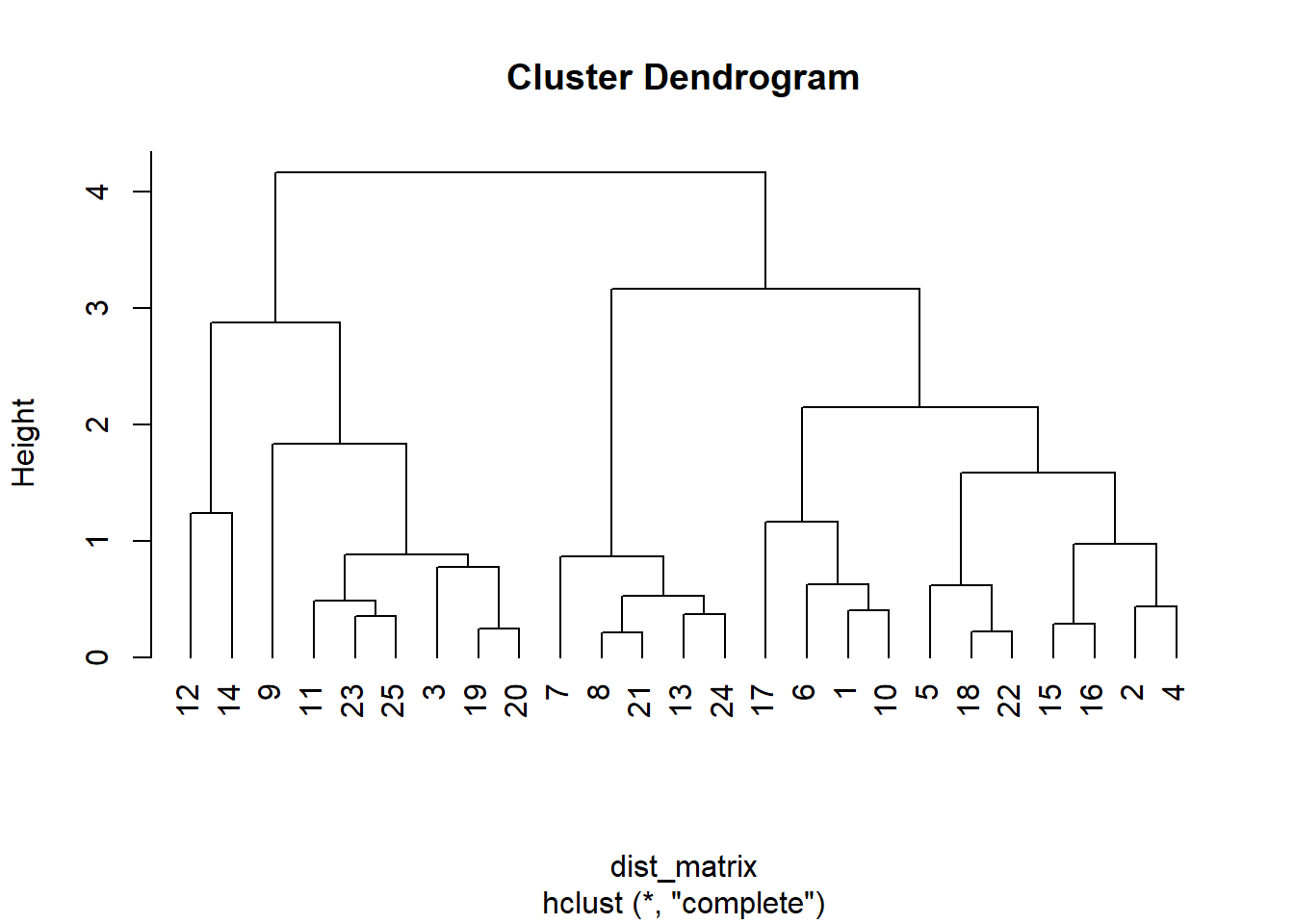
Geben Sie das Dendrogramm aus
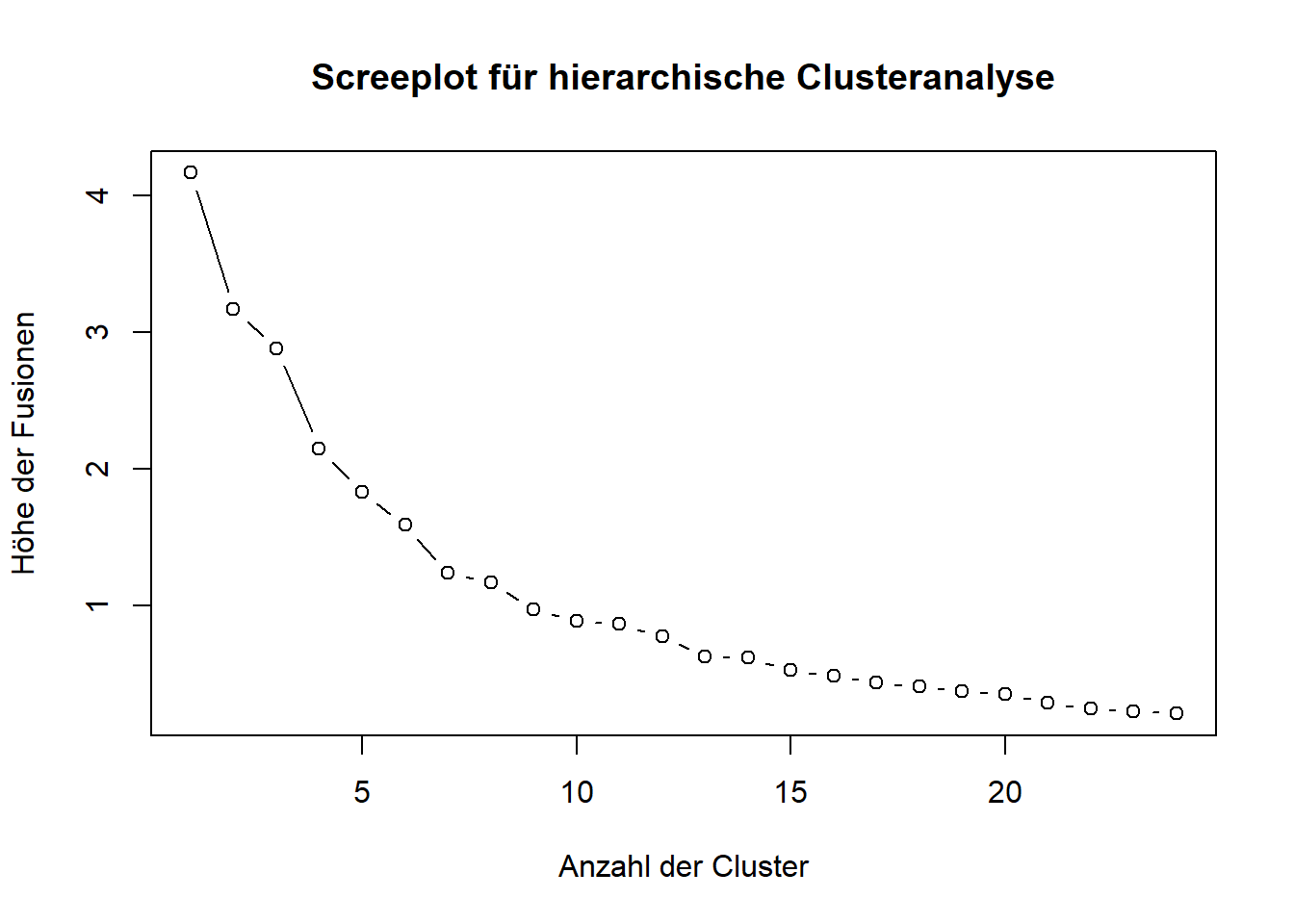
Geben Sie den Screeplot aus
[optional] Identifizieren und entfernen Sie ggf. Ausreißer (bei mir sieht der Code so aus: socmedia_gym_data_z <- socmedia_gym_data_z[-10, ])
[optional] Nun ohne Ausreißer: CA + Dendrogramm + Screeplot
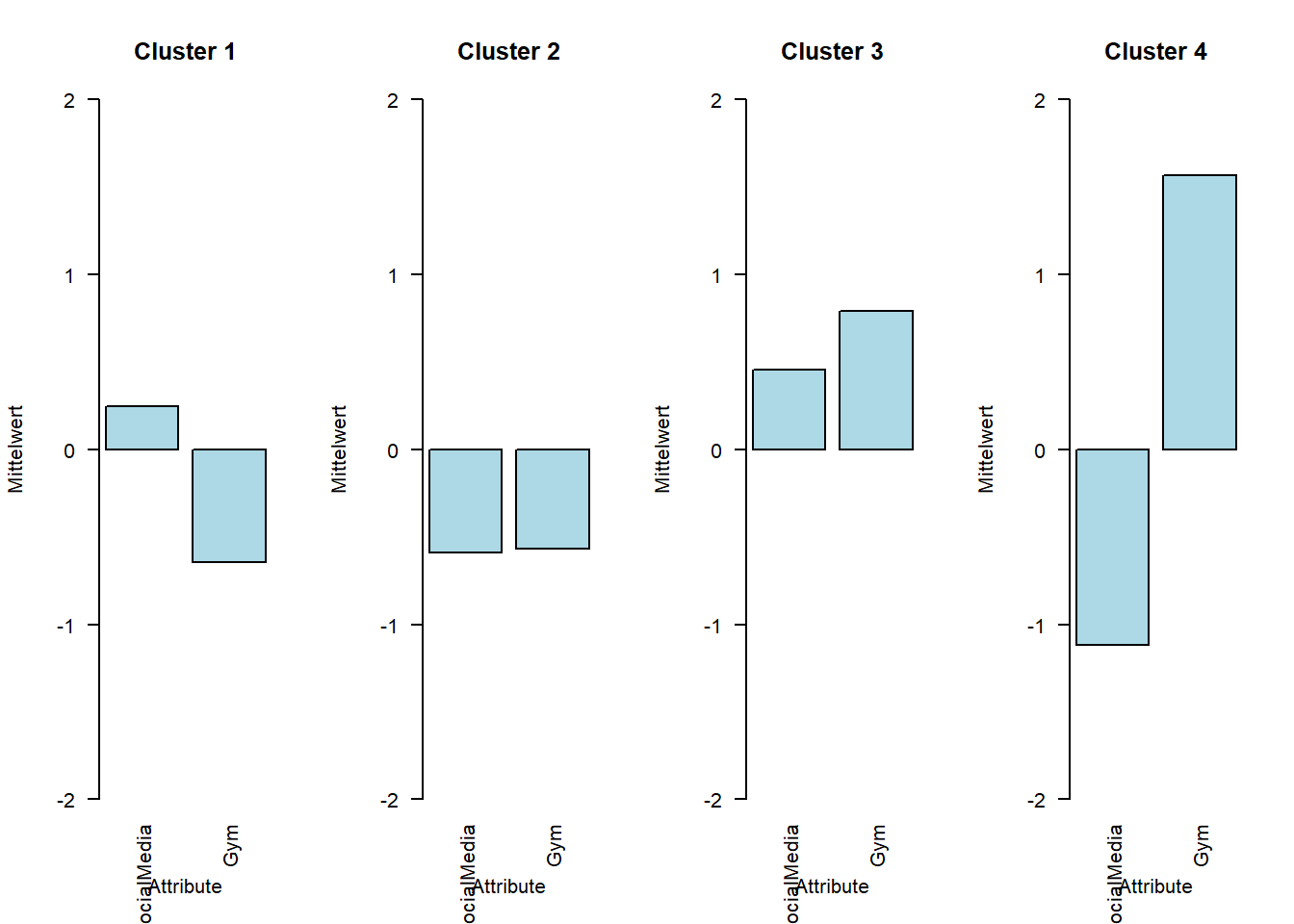
[optional]: Erstellen Sie die Profildiagramme für zwei Cluster.
Beantworten Sie die folgenden Fragen:
In welcher Zeile wird die Anzahl Cluster festgelegt?
Wie heißt die Funktion, die das tut?
Wie heißt die Funktion, die die eigentliche Clusteranayse durchführe? Nach welchem Verfahren?
Was macht die Funktion scale?
Interpretieren Sie die Profildiagramme.
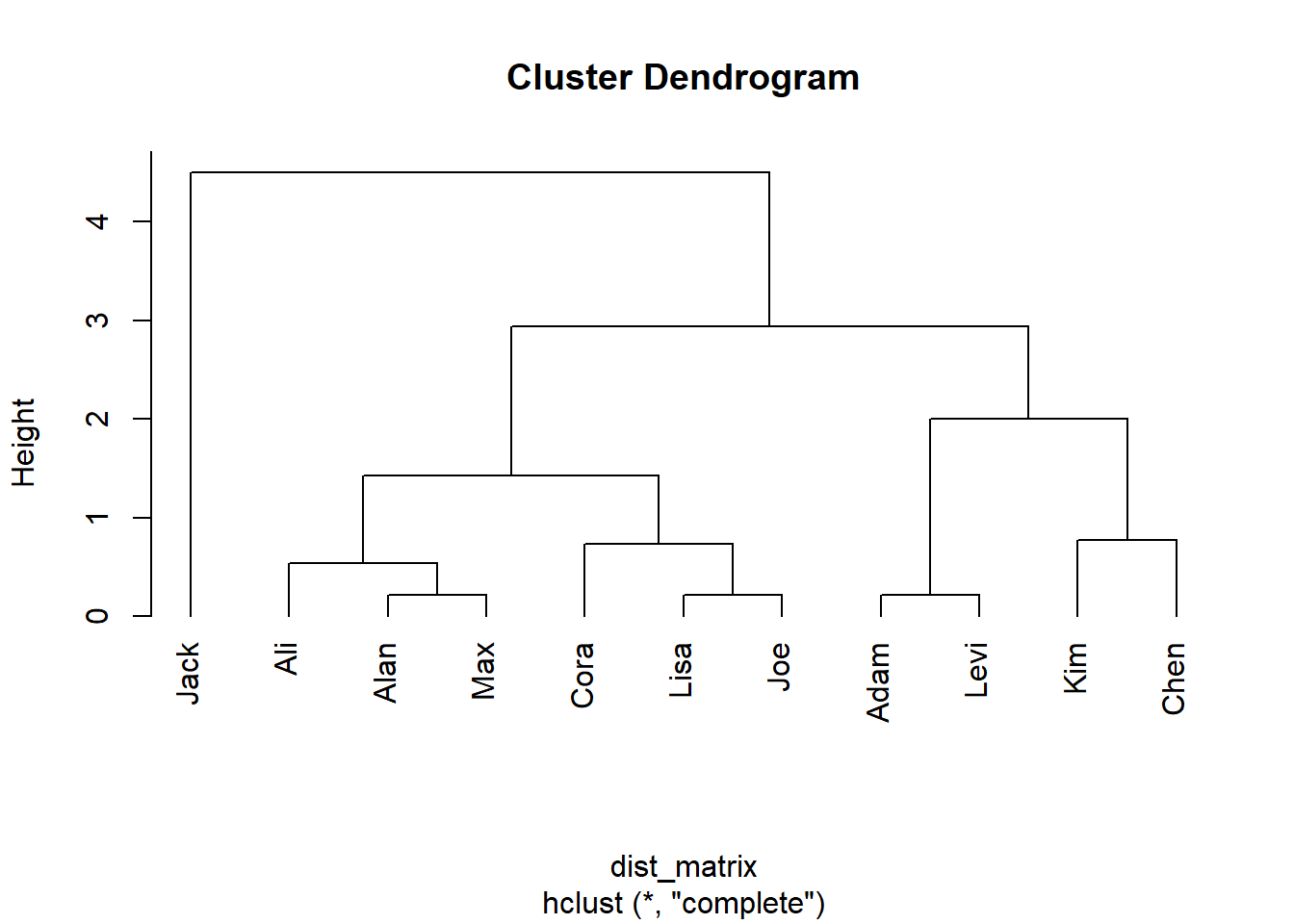
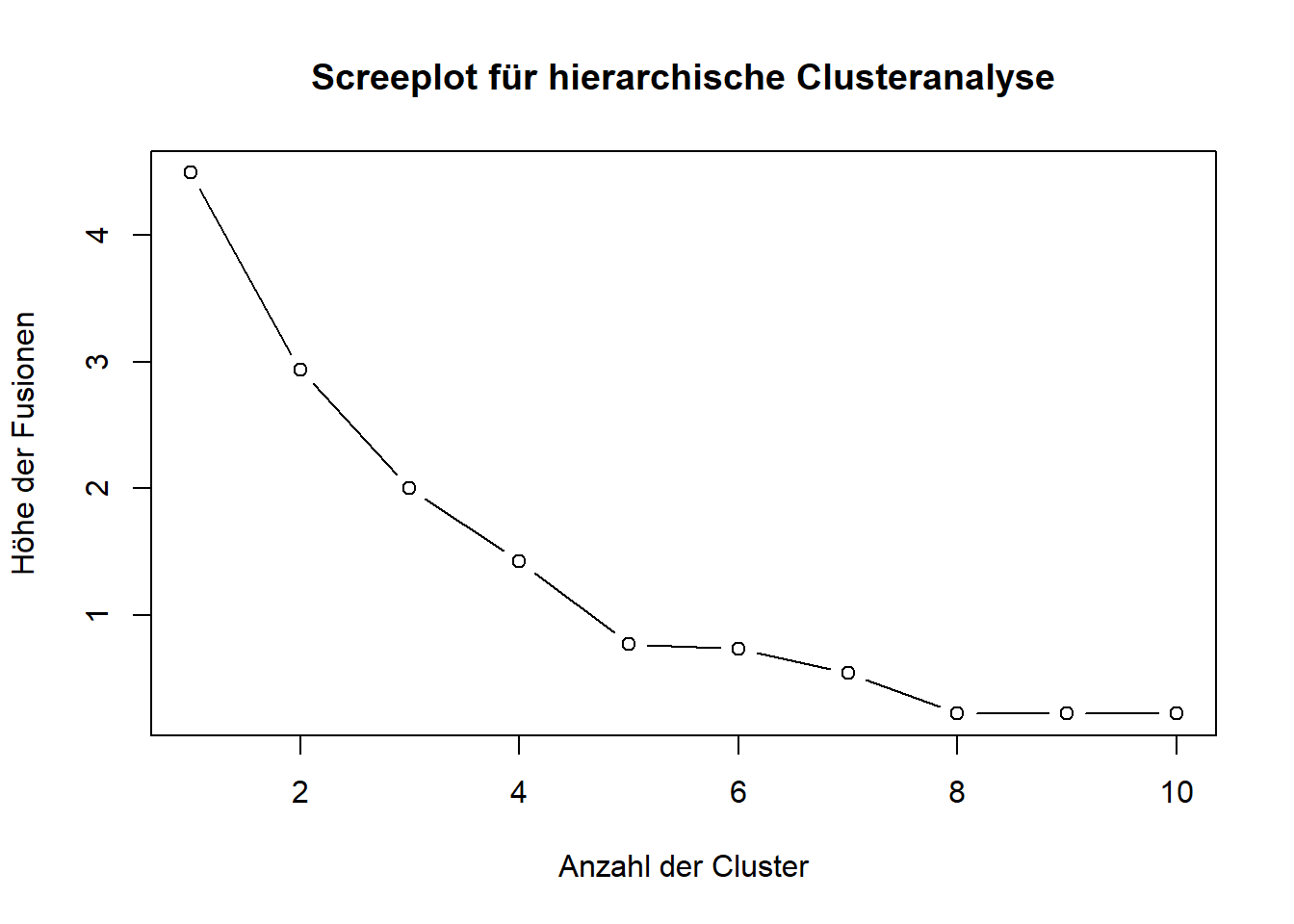
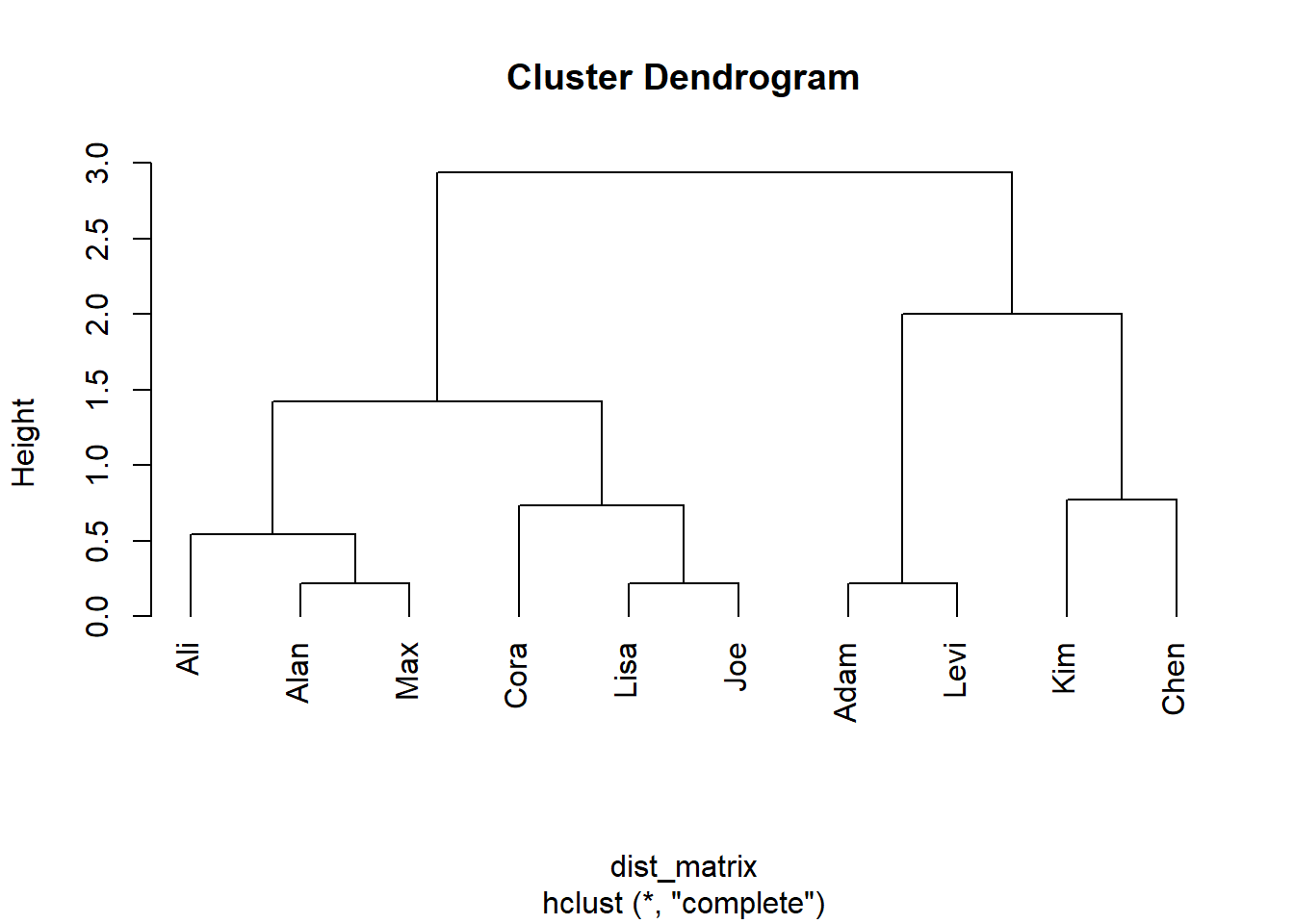
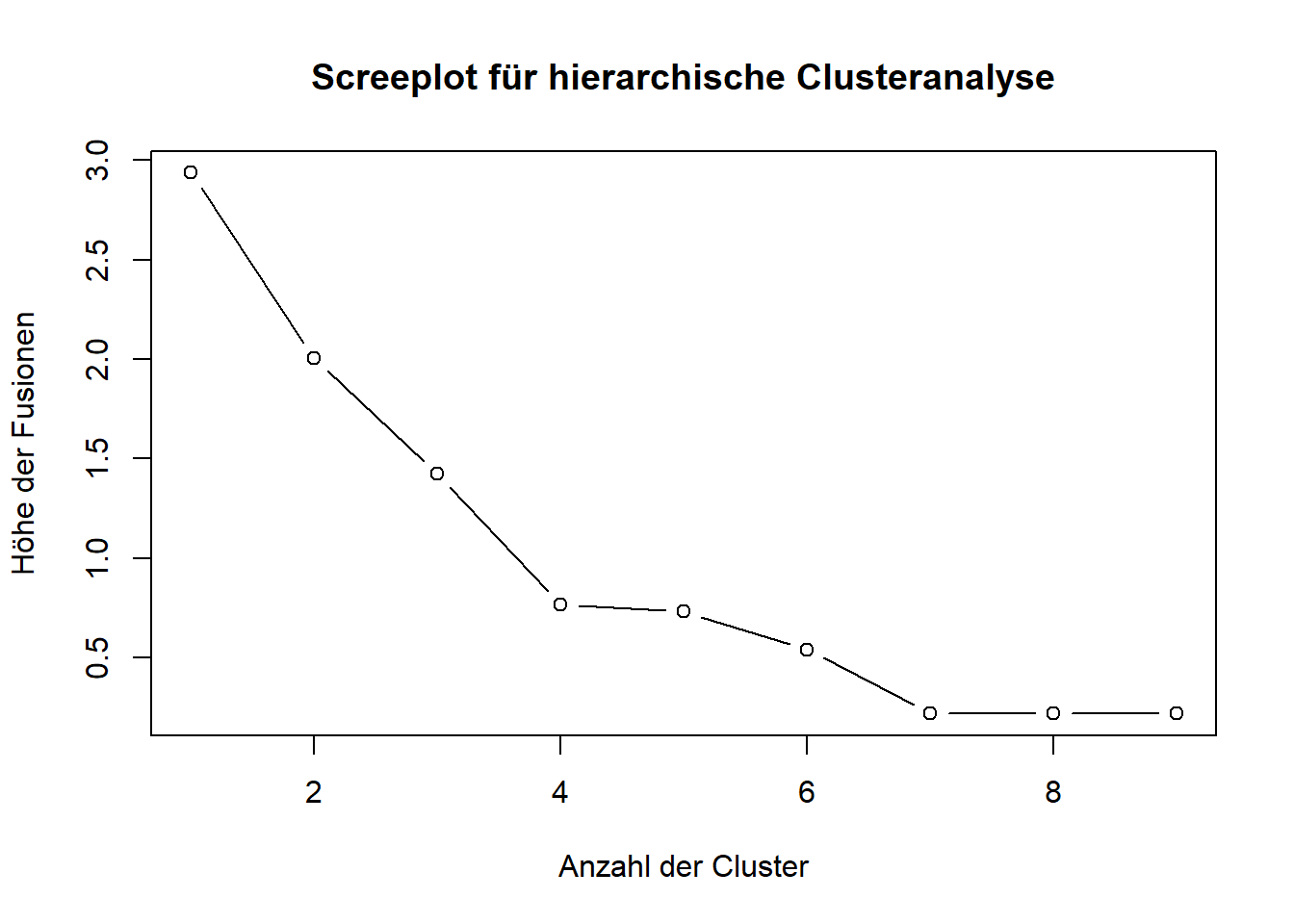
Bei mir sieht der Output dazu wie folgt aus (einmal mit allen Daten und einmal nach Entfernung eines Ausreißers; ich geben Ihnen den Code gleich mit aus):
# Beispiel kommt von hier: # https://datatab.de/statistik-rechner/cluster/hierarchische-clusteranalyse-rechner?example=hierarchische_clusteranalyse# Einlesen der Datensocmedia_gym_data <-read.csv("https://bookdown.org/Armin_E/ca_ex_1/data/ca_ex_socmedia_gym.csv", row.names =1, sep=";")# Ausgeben der Datensocmedia_gym_data
SocialMedia Gym
Alan 7 3
Lisa 5 2
Joe 5 3
Max 7 4
Cora 4 5
Adam 8 9
Kim 2 12
Ali 8 2
Chen 4 14
Jack 14 1
Levi 8 10
# z-Transformation der Datensocmedia_gym_data_z <-scale(socmedia_gym_data) # Erstellen der Distanzmatrixdist_matrix <-dist(socmedia_gym_data_z, method ="euclid")# Durchführen der CA hc_result <-hclust(dist_matrix, method ="complete")# Dendrogramm erstellenplot(hc_result, hang=-1)
# Scree-Plot erstellenplot(1:(length(hc_result$height)), rev(hc_result$height), type ="b",xlab ="Anzahl der Cluster",ylab ="Höhe der Fusionen",main ="Screeplot für hierarchische Clusteranalyse")
# Datensatz Nummer 10 entfernensocmedia_gym_data_z <- socmedia_gym_data_z[-10, ]# Erstellen der Distanzmatrixdist_matrix <-dist(socmedia_gym_data_z, method ="euclid")# Durchführen der CA hc_result <-hclust(dist_matrix, method ="complete")# Dendrogramm erstellenplot(hc_result, hang=-1)
# Scree-Plot erstellenplot(1:(length(hc_result$height)), rev(hc_result$height), type ="b",xlab ="Anzahl der Cluster",ylab ="Höhe der Fusionen",main ="Screeplot für hierarchische Clusteranalyse")
#### Clusterzuordnung# Cluster-Zuordnung für k Clustercluster_assignments <-cutree(hc_result, k =4)# Matrix wird in Dataframe umgewandelt (macht das Spalte-Anhängen leichter)socmedia_gym_data_z <-as.data.frame(socmedia_gym_data_z)# Der Dataframe erhält eine neue Spalte "Cluster"socmedia_gym_data_z$Cluster <-factor(cluster_assignments)# Daten MIT Clustersocmedia_gym_data_z
SocialMedia Gym Cluster
Alan 0.1432200 -0.6426532 1
Lisa -0.4869481 -0.8635652 2
Joe -0.4869481 -0.6426532 2
Max 0.1432200 -0.4217412 1
Cora -0.8020322 -0.2008291 2
Adam 0.4583041 0.6828190 3
Kim -1.4322004 1.3455552 4
Ali 0.4583041 -0.8635652 1
Chen -0.8020322 1.7873792 4
Levi 0.4583041 0.9037311 3
#### Profildiagramme; # Code-Vorlage arbeitet mit "df", daher umbenennendf <- socmedia_gym_data_z#### Code ab hier uninteressant# Mittelwerte für jede Dimension pro Cluster berechnencluster_means <-aggregate(. ~ Cluster, data = df, FUN = mean)# Anzahl der Clusternum_clusters <-length(unique(df$Cluster))# Layout für die Plotspar(mfrow =c(1, num_clusters)) # Layout festlegen für die Anzahl der Cluster# Für jedes Cluster ein Balkendiagramm erstellenfor (i in1:num_clusters) {# Daten für das aktuelle Cluster (ohne Cluster-Spalte) data <-as.numeric(cluster_means[i, -1])# Namen der Attribute für die x-Achsenames(data) <-names(cluster_means)[-1]# Balkendiagramm erstellenbarplot( data,main =paste("Cluster", cluster_means$Cluster[i]), # Titel des Diagrammsylim =c(-2, 2), # Skalierung der y-Achsecol ="lightblue", # Farbe der Balkenxlab ="Attribute", # Bezeichnung der x-Achseylab ="Mittelwert", # Bezeichnung der y-Achselas =2# Dreht die x-Achsenbeschriftungen für bessere Lesbarkeit )}
Aufgabe Soziale Medien: EFA + CA
Erinnern Sie sich an die Aufgabe zu den Sozialen Medien, die wir im Rahmen der Faktorenanalyse besprochen haben. 25 Versuchspersonen haben vier Arten von Fragen zu sieben Sozialen Medien beantwortet. Wir haben neun Variablen ausgewählt, für die wir eine zweifaktorielle Lösung erstellt haben.
Einen Teil der Analyse und des Outputs sehen Sie hier:
Factor Analysis using method = minres
Call: fa(r = soz_med_data, nfactors = 2, rotate = "varimax")
Standardized loadings (pattern matrix) based upon correlation matrix
item MR1 MR2 h2 u2 com
X1.TikTok 2 0.73 0.63 0.37 1.3
X1.Instagram 1 0.71 0.56 0.44 1.2
X2.TikTok 5 0.71 -0.36 0.62 0.38 1.5
X2.Instagram 4 0.68 0.48 0.52 1.0
X1.SnapChat 3 0.59 0.40 0.60 1.3
X2.SnapChat 6 0.57 0.32 0.68 1.0
X3.Instagram 7 0.64 0.41 0.59 1.0
X3.TikTok 8 0.61 0.38 0.62 1.0
X3.SnapChat 9 0.61 0.37 0.63 1.0
MR1 MR2
SS loadings 2.69 1.49
Proportion Var 0.30 0.17
Cumulative Var 0.30 0.46
Proportion Explained 0.64 0.36
Cumulative Proportion 0.64 1.00
Mean item complexity = 1.2
Test of the hypothesis that 2 factors are sufficient.
df null model = 36 with the objective function = 5.15 with Chi Square = 103.95
df of the model are 19 and the objective function was 2.48
The root mean square of the residuals (RMSR) is 0.11
The df corrected root mean square of the residuals is 0.15
The harmonic n.obs is 25 with the empirical chi square 22.73 with prob < 0.25
The total n.obs was 25 with Likelihood Chi Square = 46.79 with prob < 0.00038
Tucker Lewis Index of factoring reliability = 0.138
RMSEA index = 0.238 and the 90 % confidence intervals are 0.158 0.337
BIC = -14.37
Fit based upon off diagonal values = 0.9
Measures of factor score adequacy
MR1 MR2
Correlation of (regression) scores with factors 0.92 0.85
Multiple R square of scores with factors 0.85 0.71
Minimum correlation of possible factor scores 0.69 0.43
# Weitere Diagramme# Achsen festlegenxlim =c(-2, 2)ylim =c(-1.5, 1.5)# Personen im Faktorraumplot(factor_scores$scores, xlim=xlim,ylim=ylim)text(factor_scores$scores, labels =c(1:25), cex =0.9, pos =1, font =1, col ="black")
# Achsen festlegenxlim =c(-1, 1)ylim =c(-1, 1.5)
Unser eigentliches Thema ist ja die Clusteranalyse. Wir könnten nun mit denselben neun Variablen eine Clusteranalyse durchführen. Zum Verständnis: Jede der 25 Personen hätte dann neun Werte, die in die Analyse eingehen.
Wir können aber einen viel eleganteren – und hinsichtlich der erforderlichen Daten sparsameren – Weg gehen: Wir können statt der neun Variablen die zwei Faktorwerte (Factor-Scores) verwenden, die wir aus der EFA erhalten haben (die heißen factor_scores$scores).
Die Faktoren sollten ja die Essenz der Variablen zusammenfassen. Das nutzen wir nun aus. Es ist auch viel einfacher, eine Lösung mit zwei Faktoren als mit neun Variablen zu interpretieren.
############# ClusteranalyseAefa4ca_data <- factor_scores$scoresefa4ca_data_z <-scale(efa4ca_data) dist_matrix <-dist(efa4ca_data_z, method ="euclid")# Durchführen der CA hc_result <-hclust(dist_matrix, method ="complete")# Dendrogramm erstellenplot(hc_result, hang=-1)
# Scree-Plot erstellenplot(1:(length(hc_result$height)), rev(hc_result$height), type ="b",xlab ="Anzahl der Cluster",ylab ="Höhe der Fusionen",main ="Screeplot für hierarchische Clusteranalyse")
#### Clusterzuordnung# Cluster-Zuordnung für k Clustercluster_assignments <-cutree(hc_result, k =4)# Matrix wird in Dataframe umgewandelt (macht das Spalte-Anhängen leichter)efa4ca_data_z <-as.data.frame(efa4ca_data_z)# Der Dataframe erhält eine neue Spalte "Cluster"efa4ca_data_z$Cluster <-factor(cluster_assignments)# Daten MIT Clusterefa4ca_data_z
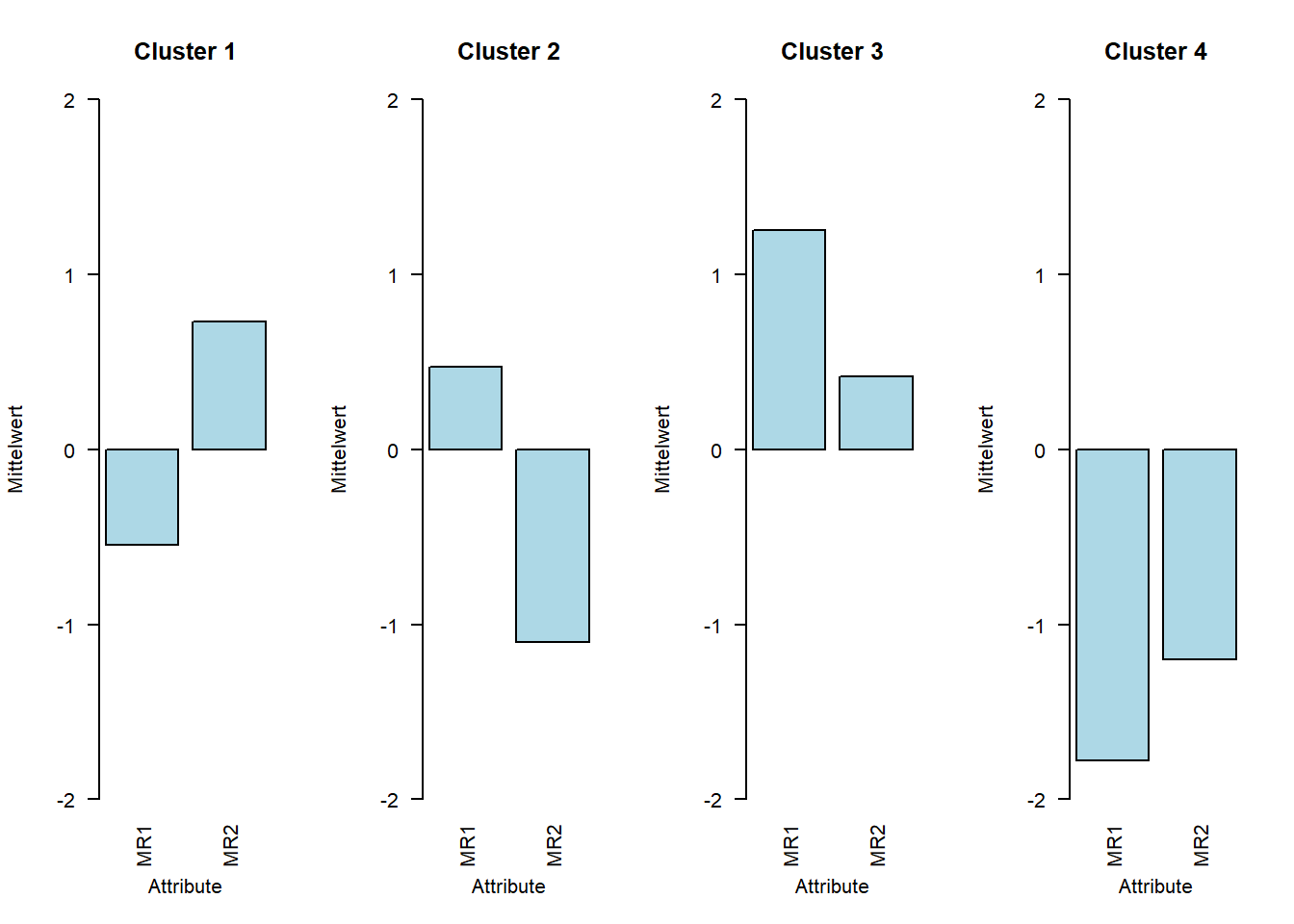
#### Profildiagramme; # Code-Vorlage arbeitet mit "df", daher umbenennendf <- efa4ca_data_z#### Code ab hier uninteressant# Mittelwerte für jede Dimension pro Cluster berechnencluster_means <-aggregate(. ~ Cluster, data = df, FUN = mean)# Anzahl der Clusternum_clusters <-length(unique(df$Cluster))# Layout für die Plotspar(mfrow =c(1, num_clusters)) # Layout festlegen für die Anzahl der Cluster# Für jedes Cluster ein Balkendiagramm erstellenfor (i in1:num_clusters) {# Daten für das aktuelle Cluster (ohne Cluster-Spalte) data <-as.numeric(cluster_means[i, -1])# Namen der Attribute für die x-Achsenames(data) <-names(cluster_means)[-1]# Balkendiagramm erstellenbarplot( data,main =paste("Cluster", cluster_means$Cluster[i]), # Titel des Diagrammsylim =c(-2, 2), # Skalierung der y-Achsecol ="lightblue", # Farbe der Balkenxlab ="Attribute", # Bezeichnung der x-Achseylab ="Mittelwert", # Bezeichnung der y-Achselas =2# Dreht die x-Achsenbeschriftungen für bessere Lesbarkeit )}