Chi²-Vierfeldertest
_Statistik
10.12.2025
Signifikanztest
Freiheitsgrade: \(\textit{df} = (m - 1)(k - 1)\)
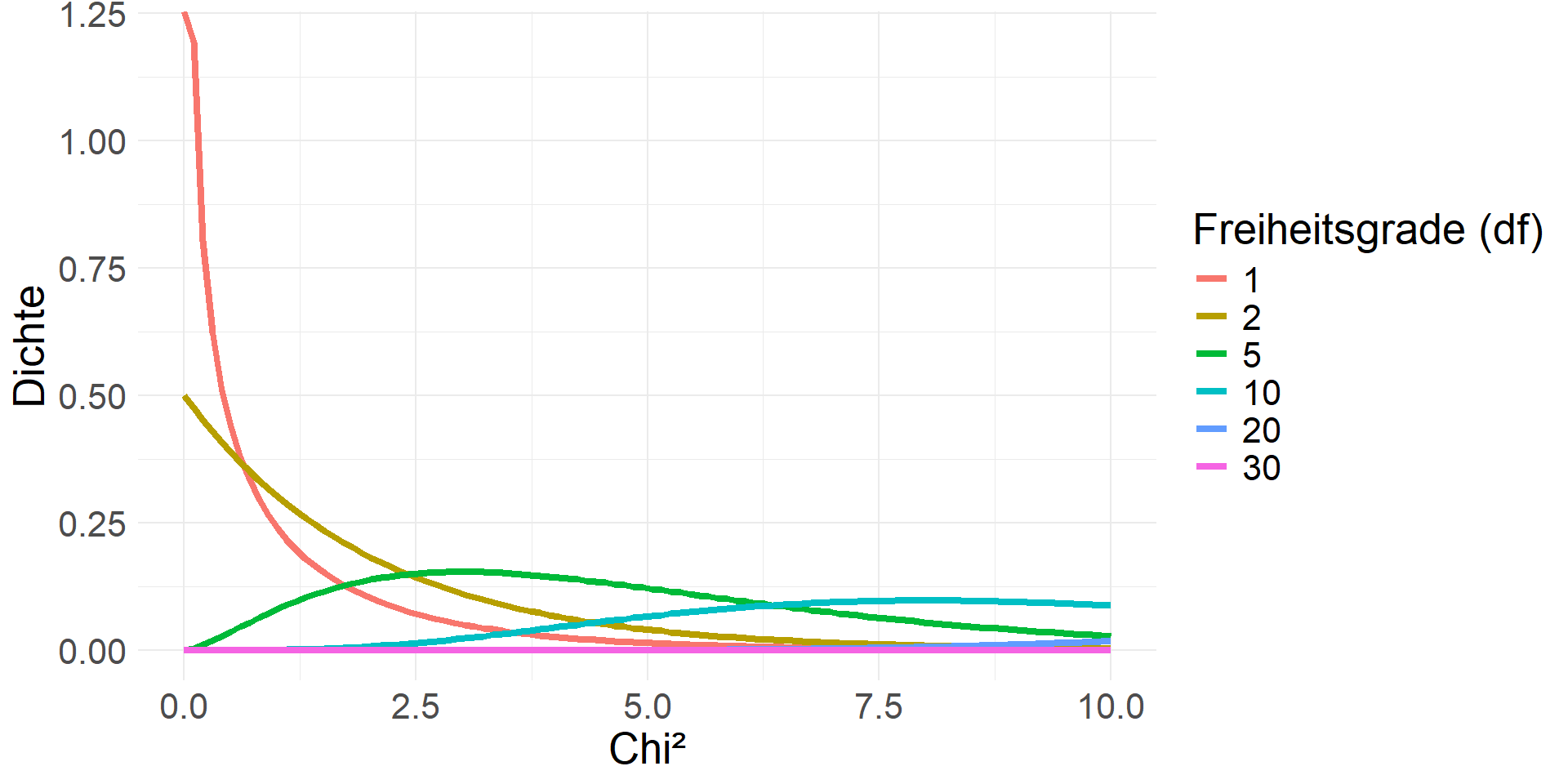
Vierfeldertest: \(\textit{df} = (2-1)(2-1) = 1\)
Entscheidung:
- Vierfeldertest: nicht unabhängig (und damit abhängig), wenn \(\chi^{2}_{emp} > \chi^{2}_{krit}(1) =\) 3.841
- \((i \times j)\)-Felder: nicht unabhängig (und damit abhängig), wenn \(\chi^{2}_{emp} > \chi^{2}_{krit}(\textit{df})\)
Effektstärke: Cramer’s V
\(V = \sqrt{\frac{\chi²}{n(k - 1)}}\),
mit k = min(Kategorienzahl)- Werte von 0 – kein Effekt bis 1 – max. Effekt
- Einordnung: ~0.1 kleiner Effekt, ~0.3 mittlerer Effekt, ab ~0.5 großer Effekt
- Werte von 0 – kein Effekt bis 1 – max. Effekt
\(\chi²\)-Verteilung
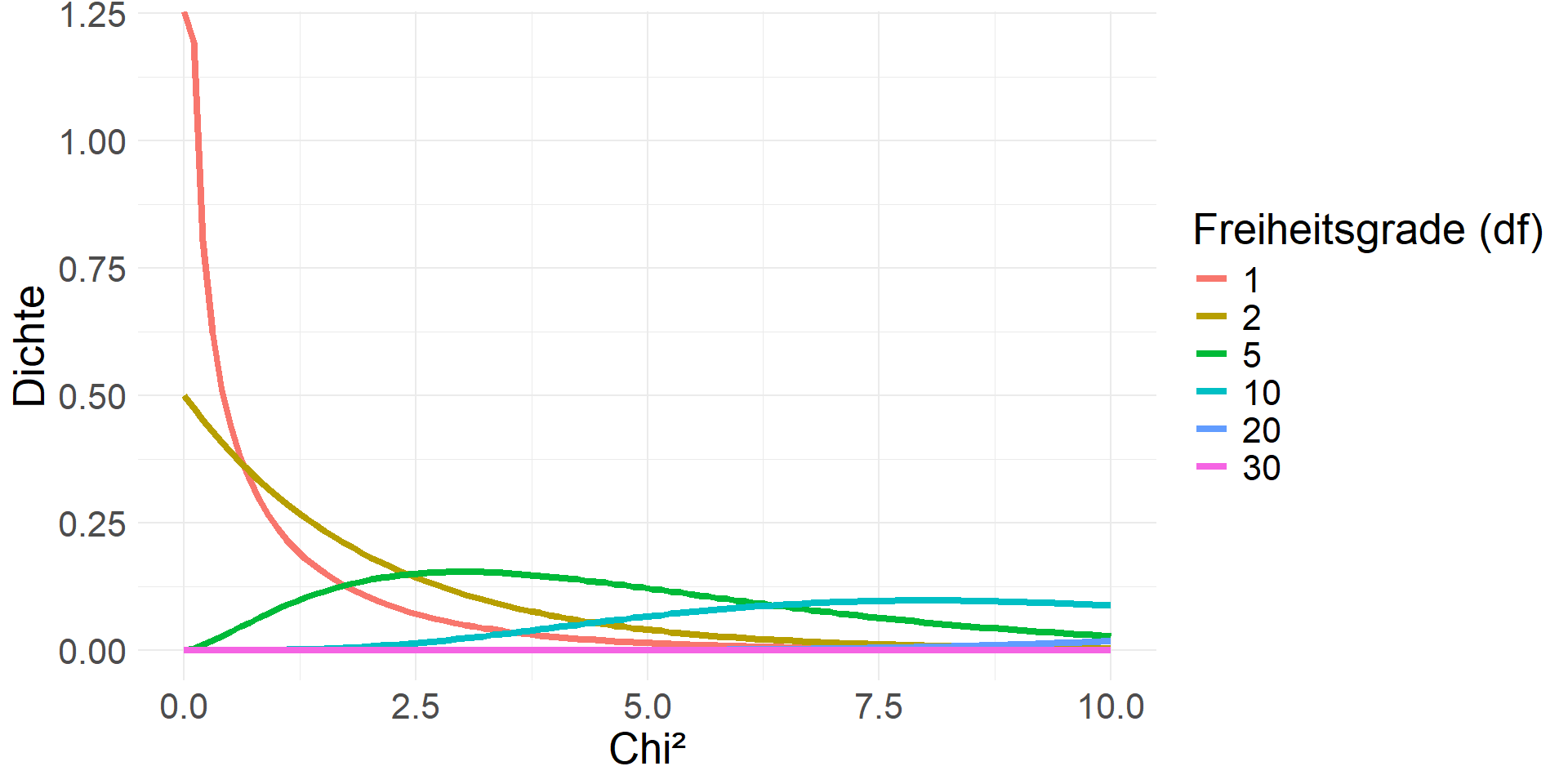
| df | Kritische_Werte |
|---|---|
| 1 | 3.841459 |
| 2 | 5.991465 |
| 3 | 7.814728 |
| 4 | 9.487729 |
| 5 | 11.070498 |
| 6 | 12.591587 |
| 7 | 14.067140 |
| 8 | 15.507313 |
| 9 | 16.918978 |
| 10 | 18.307038 |
| 11 | 19.675138 |
| 12 | 21.026070 |
| 13 | 22.362033 |
| 14 | 23.684791 |
| 15 | 24.995790 |
| 16 | 26.296228 |
| 17 | 27.587112 |
| 18 | 28.869299 |
| 19 | 30.143527 |
| 20 | 31.410433 |
| 21 | 32.670573 |
| 22 | 33.924439 |
| 23 | 35.172462 |
| 24 | 36.415028 |
| 25 | 37.652484 |
| 26 | 38.885139 |
| 27 | 40.113272 |
| 28 | 41.337138 |
| 29 | 42.556968 |
| 30 | 43.772972 |
🚬 Beispiel
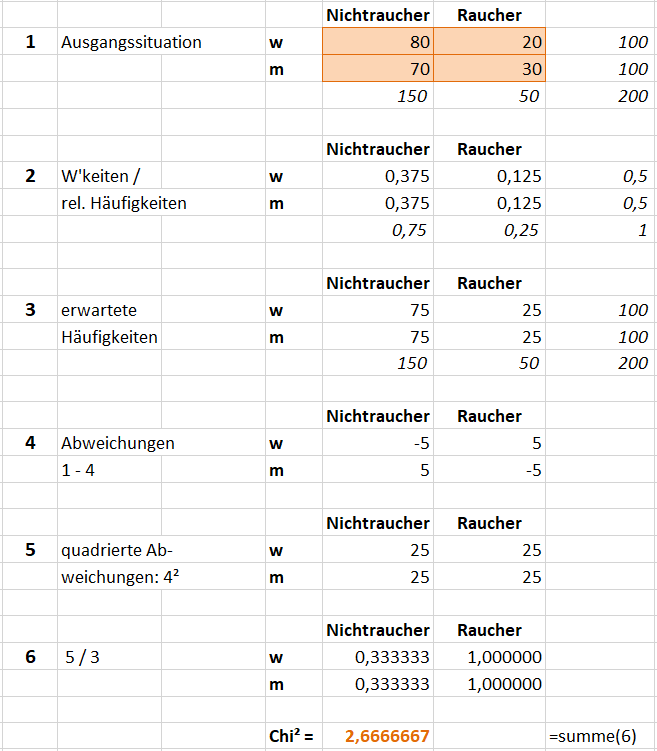
Ausgangszahlen mit Randsummen (Beobachtung)

🚬 Beispiel
Relative Häufigkeiten

🚬 Beispiel
Erwartete Häufigkeiten

🚬 Beispiel
Abweichung Beobachtung - Erwartung

🚬 Beispiel
Quadrierte Abweichung

🚬 Beispiel
Quadrierte Abweichung geteilt durch die Erwartung

🚬 Beispiel
Vorgehen im Überblick
Pearson's Chi-squared test
data: vierfelder
X-squared = 2.6667, df = 1, p-value = 0.1025Cramer V
0.1155